JargonBot Beta Test
post by Raemon · 2024-11-01T01:05:26.552Z · LW · GW · 55 commentsContents
0. Background Managing Slop: Author Approval & Opt In The longterm vision Automated "adjust to reader level." The 0-1 second level LaTeX Curating technical posts Higher level distillation Remember AI capabilities are probably bad, actually Feedback None 55 comments
We've just launched a new experimental feature: "Automated Jargon Glossaries." If it goes well, it may pave the way for things like LaTeX hoverovers and other nice things.
Whenever an author with 100+ karma saves a draft of a post[1] or presses the "Generate Terms" button, our database queries a language model to:
- Identify terms that readers might not know.
- Write a first draft of an explanation of that term
- Make a guess as to which terms are useful enough to include.
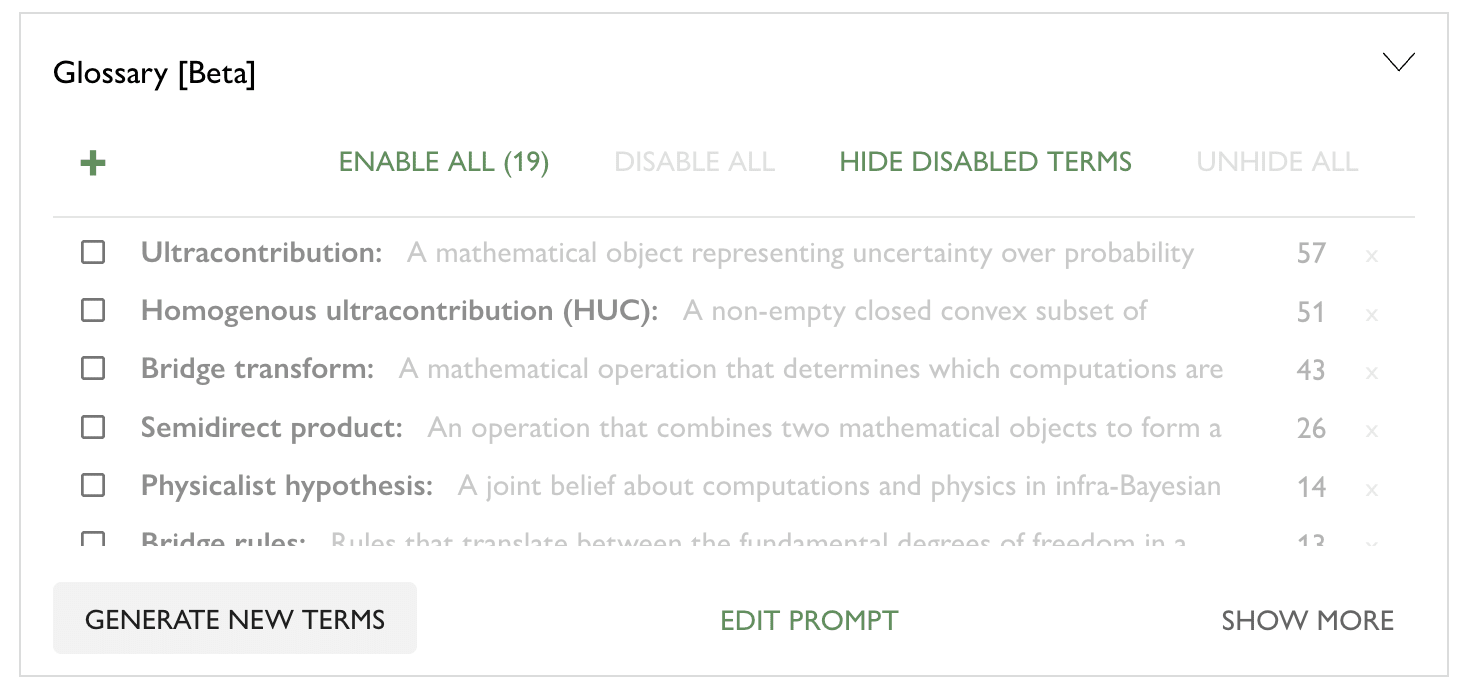
By default, explanations are not shown to readers. Authors get to manually approve term/explanations that they like, or edit them. Authors will see a UI looking like this, allowing them to enable terms so readers see them. They can also edit them (by clicking on the term).
Meanwhile, here's a demo of what readers might see, from the Infra-Bayesian physicalism post.[2]
TLDR: We present a new formal decision theory that realizes naturalized induction. Our agents reason in terms of infra-Bayesian hypotheses, the domain of which is the cartesian product of computations and physical states, where the ontology of "physical states" may vary from one hypothesis to another. The key mathematical building block is the "bridge transform", which, given such a hypothesis, extends its domain to "physically manifest facts about computations". Roughly speaking, the bridge transforms determines which computations are executed by the physical universe. In particular, this allows "locating the agent in the universe" by determining on which inputs its own source is executed.
0. Background
The "standard model" of ideal agency is Bayesian reinforcement learning, and more specifically, AIXI. We challenged this model before due to its problems with non-realizability, suggesting infra-Bayesianism as an alternative. Both formalisms assume the "cartesian cybernetic framework", in which (i) the universe is crisply divided into "agent" and "environment" and (ii) the two parts interact solely via the agent producing actions which influence the environment and the environment producing observations for the agent. This is already somewhat objectionable on the grounds that this division is not a clearly well-defined property of the physical universe. Moreover, once we examine the structure of the hypothesis such an agent is expected to learn (at least naively), we run into some concrete problems.
Managing Slop: Author Approval & Opt In
I take pretty seriously the worry that LessWrong will become filled with AI slop, and that people will learn to tune out UI features built around it. Longterm, as AI gets good enough to not be slop, I'm even more worried, since then it might get things subtly wrong and it'd be really embarrassing if the AI Alignment discourse center plugged AIs into its group cognition and then didn't notice subtle errors.
These problems both seem tractable to me to deal with, but do require a bunch of effort and care.
For now: we've tried to tune the generation to minimize annoying "false positives" (terms which are too basic or sufficiently obvious from context) for authors or readers, while setting things up so it's possible to notice "false negatives" (perfectly good terms that the system rejected).
The current system is that authors have:
- Shortlist of "probably good" terms to review . By the time they're done editing a post, authors should be presented with a short list of terms, that (we hope) are mostly useful and accurate enough to be worth enabling, without much overhead.
- Hidden-but-accessible "less good" terms. Authors also have access to additional terms that are less likely to be useful, which are hidden by default (even to the authors, unless they click "show hidden" in their glossary editor).
- Prompt Tuning. Authors can edit the glossary prompt to fit their preferred style. (Currently, this prompt editing isn't saved between page reloads, but longterm we'd likely add some kind of Prompt Library)
Meanwhile, readers experience:
- Default to "author approved." Only see high signal glossary terms.
- Default to "only highlight each term once." The first time you see a term in a post, it'll show up as slightly-grey, to indicate you can hoverover it. But subsequent instances of that term won't be highlighted or have hoverovers.
- Default to "unclickable tooltip," click to keep it open. If you click on a term, the hoverover will stay open instead of disappearing when you move your mouse away (or over it).
- Know who edited an explanation. See if a term was "AI generated", "Human generated" or "AI and human edited".
- Opt into "Highlight All." At the top-right of a post, if there are any approved terms, you'll see a glossary. If you click on it, it'll pin the glossary in place, and switch to highlighting each term every time it appears, so you can skim the post and still get a sense of what technical terms mean if you start diving into a section in the middle. (There is also a hotkey for this: opt/alt + shift + J.)
- Opt into "Show Unapproved Terms." On a given post, you can toggle "show all terms." It'll come with the warning: "Enable AI slop that the author doesn't necessarily endorse." (There is also a hotkey for this: opt/alt + shift + G. This works even if there aren't any approved terms for a post, which is a case where the entire glossary is hidden by default.)
I'm not sure whether it's correct to let most users see the "hidden potential-slop", but I'm somewhat worried that authors won't actually approve enough terms on the margin for more intermediate-level readers. It seems okay to me to let readers opt-in, but, I'm interested in how everyone feels about that.
The longterm vision
The Lightcone team has different visions about whether/how to leverage LLMs on LessWrong. Speaking only for myself, here are some things I'm (cautiously) excited about:
Automated "adjust to reader level."
Readers who are completely new to LessWrong might see more basic terms highlighted. We've tried to tune the system so it doesn't, by default, explain words like 'bayesian' since it'd be annoying to longterm readers, but newcomers might actively want those.
People who are new to the field of Machine Learning might want to know what a ReLU is. Experienced ML people probably don't care.
I think the mature version of this a) makes a reasonable guess about what terms you'll want highlighted by default, b) lets you configure it yourself.
If you're reading a highly technical post in a domain you don't know, eventually we might want to have an optional "explain like I'm 12" button at the top, that takes all the author-approved-terms and assembles them into an introduction, that gives you background context on what this field and author are trying to accomplish, before diving into the cutting-edge details.
The 0-1 second level
Some other LW team members are less into JargonBot, because they were already having a pretty fine time asking LLMs "hey what's this word mean?" while reading dense posts. I'm not satisfied with that, because I think there's a pretty big difference between "actions that take 5-10 seconds" and "actions that take 0-1 second".
Actions in the 0-1 second zone can be a first-class part of my exobrain – if I see something I don't know, I personally want to briefly hover over it, get a sense of it, and then quickly move back to whatever other sentence I was reading.
The 0-1 second level is also, correspondingly, more scary, from the standpoint of 'integrating AI into your thought process.' I don't currently feel worried about it for JargonBot in particular (in particular since it warns when a thing is AI generated).
I do feel much more worried about it for writing rather than reading, since things like "autocomplete" more actively insert themselves into your thinking loop. I'm interested in takes on this (both for JargonBot and potential future tools)
LaTeX
This started with a vision for "hoverovers for LaTeX", such that you could easily remember what each term in an equation means, and what each overall chunk of the equation represents. I'm pretty excited for a LessWrong that actively helps you think through complex, technical concepts.
Curating technical posts
Currently, posts are more likely to get curated if they are easier to read – simply because easier to read things get read more. Periodically a technical post seems particularly important, and I sit down and put in more effort to slog through it and make sure I understand it so I can write a real curation notice, but it's like a 5-10 hour job for me. (Some other LW staff find it easier, but I think even the more technically literate staff curate fewer technical things on the margin)
I'm excited for a world where the LW ecosystem has an easier time rewarding dense, technical work, which turns abstract concepts into engineering powertools. I'm hoping JargonBot both makes it easier for me to read and curate things, as well as easier for readers to read them (we think of ourselves as having some kinda "budget" for curating hard-to-read things, since most of the 30,000 people on the curation mailing list probably wouldn't actually get much out of them).
Higher level distillation
Right now, AIs are good at explaining simple things, and not very good at thinking about how large concepts fit together. It currently feels like o1 is juuuuust on the edge of being able to do a good job with this.
It's plausible than in ~6 months the tools will naturally be good enough (and we'll have figured out how to leverage them into good UI) that in addition to individual terms, AI tools can assist with understanding the higher-level bits of posts and longterm research agendas. ("WTF is Infrabayesianism for, again?")
Remember AI capabilities are probably bad, actually
Despite all that, I do remind myself that although a lot of this is, like, objectively cool, also, man I do really wish the frontier labs would coordinate to slow down and lobby the government to help them do it. I'm really worried about how fast this is changing, and poorly I expect humanity to handle the situation.
As I've thought more about how to leverage AI tools, I've also somewhat upweighted how much I try to prioritize thinking about coordinated AI pause/slowdown, so that my brain doesn't naturally drift towards fewer marginal thoughts about that.
Feedback
With all that in mind, I would like to hear from LW users:
- Is this useful, as a reader?
- Are you seeing terms that feel too basic to be worth including?
- Are you not seeing enough terms that the system is skipping, to avoid false-positives?
- As an author, how do you feel about it? Does it feel more like a burdensome chore to approve glossary terms, or a cool UI opportunity?
- As an author, how do you feel about users being able to toggle on the "hidden slop" if they want?
Let us know what you think!
- ^
Update: we turned this off after realizing some people might be using LW drafts to write stuff they wouldn't want being sent to Claude. Sorry about shipping this without thinking through that case. We'll think through options tomorrow.
- ^
(Note: I have not yet checked with @Vanessa Kosoy [LW · GW] if the initial definition here is accurate. On the real post, it won't appear for readers until the author deliberately enabled it. I've enabled it on this particular post, for demonstration purposes. But, warning! It might be wrong!)
55 comments
Comments sorted by top scores.
comment by Richard_Kennaway · 2024-11-01T12:15:41.930Z · LW(p) · GW(p)
I would like to be able to set my defaults so that I never see any of the proposed AI content. Will this be possible?
Replies from: Raemon, Raemon↑ comment by Raemon · 2024-11-01T15:24:58.042Z · LW(p) · GW(p)
To doublecheck/clarify: do you feel strongly (or, weakly) that you don't want autogenerated jargon to exist on your posts for people who click the "opt into non-author-endorsed AI content" for that post? Or simply that you don't personally want to be running into it?
(Oh, hey, you're the one who wrote Please do not use AI to write for you [LW · GW])
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2024-11-01T16:22:12.459Z · LW(p) · GW(p)
Both. I do not want to have AI content added to my post without my knowledge or consent.
In fact, thinking further about it, I do not want AI content added to anyone's post without their knowledge or consent, anywhere, not just on LessWrong.
Such content could be seen as just automating what people can do anyway with an LLM open in another window. I've no business trying to stop people doing that. However, someone doing that knows what they are doing. If the stuff pops up automatically amidst the author's original words, will they be so aware of its source and grok that the author had nothing to do with it? I do not think that the proposed discreet "AI-generated" label is enough to make it clear that such content is third-party commentary, for which the author carries no responsibility.
But then, who does carry that responsibility? No-one. An AI's words are news from nowhere. No-one's reputation is put on the line by uttering them. For it is written, the fundamental question of rationality is "What do I think I know and how do I think I know it?" But these AI popovers cannot be questioned.
And also, I do not personally want to be running into any writing that AI had a hand in.
(Oh, hey, you're the one who wrote Please do not use AI to write for you [LW · GW])
I am that person, and continue to be.
Replies from: Raemon, habryka4↑ comment by Raemon · 2024-11-01T19:30:35.593Z · LW(p) · GW(p)
But then, who does carry that responsibility? No-one.
For thie case of this particular feature and ones like it: The LessWrong team. And, in this case, more specifically, me.
I welcome being held accountable for this going wrong in various ways. (I plan to engage more with people who present specific cruxes rather than a generalized "it seems scary", but, this seems very important for a human to be in the loop about, who actually takes responsibility for both locally being good, and longterm consequences)
Replies from: DanielFilan, Richard_Kennaway, SaidAchmiz↑ comment by DanielFilan · 2024-11-01T20:13:39.770Z · LW(p) · GW(p)
FWIW I think the actual person with responsibility is the author if the author approves it, and you if the author doesn't.
↑ comment by Richard_Kennaway · 2024-11-02T09:27:58.255Z · LW(p) · GW(p)
You and the LW team are indirectly responsible, but only for the general feature. You are not standing behind each individual statement the AI makes. If the author of the post does not vet it, no-one stands behind it. The LW admins can be involved only in hindsight, if the AI does something particularly egregious.
Replies from: Raemon↑ comment by Raemon · 2024-11-02T19:57:06.931Z · LW(p) · GW(p)
This feels like you have some way of thinking about responsibility that I'm not sure I'm tracking all the pieces of.
- Who literally meant the individuals? No one (or, some random alien mind).
- Who should take actions if someone flags that an unapproved term is wrong? The author, if they want to be involved, and site-admins (or me-in-particular), if they author does not want to be involved.
- Who should be complained to if this overall system is having bad consequences? Site admins, me-in-particular or habryka-in-particular (Habryka has more final authority, I have more context on this feature. You can start with me and then escalate, or tag both of us, or whatever)
- Who should have Some Kind of Social Pressure Leveraged At them if reasonable complaints seem to be falling on deaf ears and there are multiple people worried? Also the site admins, and habryka-and-me-in-particular.
It seems like you want #1 to have a better answer, but I don't really know why.
Replies from: Richard_Kennaway, ben-lang↑ comment by Richard_Kennaway · 2024-11-02T20:49:14.410Z · LW(p) · GW(p)
Rather, I am pointing out that #1 is the case. No-one means the words that an AI produces. This is the fundamental reason for my distaste for AI-generated text. Its current low quality is a substantial but secondary issue.
If there is something flagrantly wrong with it, then 2, 3, and 4 come into play, but that won't happen with standard average AI slop, unless it were eventually judged to be so persistently low quality that a decision were made to discontinue all ungated AI commentary.
↑ comment by Ben (ben-lang) · 2024-11-21T18:22:37.245Z · LW(p) · GW(p)
I suppose its the difference between the LW team taking responsibility for any text the feature shows people (which you are), and the LW team endorsing any text the feature shows (which you are not). I think this is Richard's issue, although the importance is not obvious to me.
↑ comment by Said Achmiz (SaidAchmiz) · 2024-11-01T19:41:18.981Z · LW(p) · GW(p)
I welcome being held accountable for this going wrong in various ways.
It happening at all already constitutes “going wrong”.
Also: by what means can you be “held accountable”?
Replies from: Raemon↑ comment by Raemon · 2024-11-02T00:05:42.124Z · LW(p) · GW(p)
The most important thing is "There is a small number of individuals who are paying attention, who you can argue with, and if you don't like what they're doing, I encourage you to write blogposts or comments complaining about it. And if your arguments make sense to me/us, we might change our mind. If they don't make sense, but there seems to be some consensus that the arguments are true, we might lose the Mandate of Heaven or something."
I will personally be using my best judgment to guide my decisionmaking. Habryka is the one actually making final calls about what gets shipped to the site, insofar as I update that we're doing a wrong thing, I'll argue about it."
It happening at all already constitutes “going wrong”.
This particular sort of comment doesn't particularly move me. I'm more likely to be moved by "I predict that if AI used in such and such a way it'll have such and such effects, and those effects are bad." Which I won't necessarily automatically believe, but, I might update on if it's argued well or seems intuitively obvious once it's pointed out.
I'll be generally tracking a lot of potential negative effects and if it seems like it's turning out "the effects were more likely" or "the effects were worse than I thought", I'll try to update swiftly.
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2024-11-02T01:50:04.854Z · LW(p) · GW(p)
The most important thing is “There is a small number of individuals who are paying attention, who you can argue with, and if you don’t like what they’re doing, I encourage you to write blogposts or comments complaining about it. And if your arguments make sense to me/us, we might change our mind. If they don’t make sense, but there seems to be some consensus that the arguments are true, we might lose the Mandate of Heaven or something.”
There’s not, like, anything necessarily wrong with this, on its own terms, but… this is definitely not what “being held accountable” is.
It happening at all already constitutes “going wrong”.
This particular sort of comment doesn’t particularly move me.
All this really means is that you’ll just do with this whatever you feel like doing. Which, again, is not necessarily “wrong”, and really it’s the default scenario for, like… websites, in general… I just really would like to emphasize that “being held accountable” has approximately nothing to do with anything that you’re describing.
As far as the specifics go… well, the bad effect here is that instead of the site being a way for me to read the ideas and commentary of people whose thoughts and writings I find interesting, it becomes just another purveyor of AI “extruded writing product”. I really don’t know why I’d want more of that than there already is, all over the internet. I mean… it’s a bad thing. Pretty straightforwardly. If you don’t think so then I don’t know what to tell you.
All I can say is that this sort of thing drastically reduces my interest in participating here. But then, my participation level has already been fairly low for a while, so… maybe that doesn’t matter very much, either. On the other hand, I don’t think that I’m the only one who has this opinion of LLM outputs.
Replies from: Raemon↑ comment by Raemon · 2024-11-02T02:40:49.636Z · LW(p) · GW(p)
it becomes just another purveyor of AI “extruded writing product”.
If it happened here the way it happened on the rest of the internet, (in terms of what the written content was like) I'd agree it'd be straightforwardly bad.
For things like jargon-hoverovers, the questions IMO are:
- is the explanation accurate?
- is the explanation helpful for explaining complex posts, esp. with many technical terms?
- does the explanation feel like soulless slop that makes you feel ughy the way a lot of the internet is making you feel ughy these days?
If the answer to the first two is "yep", and the third one is "alas, also yep", then I think an ideal state is for the terms to be hidden-by-default but easily accessible for people who are trying to learn effectively, and are willing to put up with somewhat AI-slop-sounding but clear/accurate explanations.
If the answer to the first two is "yep", and the third one is "no, actually is just reads pretty well (maybe even in the author's own style, if they want that)", then IMO there's not really a problem.
I am interested in your actual honest opinion of, say, the glossary I just generated for Unifying Bargaining Notions (1/2) [LW · GW] (you'll have to click option-shift-G to enable the glossary on lesswrong.com). That seems like a post where you will probably know most of the terms to judge them on accuracy, while it still being technical enough you can imagine being a person unfamiliar with game theory trying to understand the post, and having a sense of both how useful they'd be and how aesthetically they feel.
My personal take is that they aren't quite as clear as I'd like and not quite as alive-feeling as I'd like, but over the threshold of both that I much rather having them than not having them, esp. if I knew less game theory than I currently do.
Replies from: Raemon↑ comment by Raemon · 2024-11-02T02:43:55.966Z · LW(p) · GW(p)
Part of the uncertainties we're aiming to reduce here are "can we make thinking tools or writing tools that are actually good, instead of bad?" and our experiments so far suggest "maybe". We're also designing with "six months from now" in mind – the current level of capabilities and quality won't be static.
Our theory of "secret sauce" is "most of the corporate Tech World in fact has bad taste in writing, and the LLM fine-tunings and RLHF data is generated by people with bad taste. Getting good output requires both good taste and prompting skill, and you're mostly just not seeing people try."
We've experimented with jailbroken Base Claude which does a decent job of actually having different styles. It's harder to get to work reliably, but, not so much harder that it feels intractable.
The JargonHovers currently use regular Claude, not jailbroken claude. I have guesses of how to eventually get them to write it in something like the author's original style, although it's a harder problem so we haven't tried that hard yet.
↑ comment by habryka (habryka4) · 2024-11-01T17:21:09.949Z · LW(p) · GW(p)
And also, I do not personally want to be running into any writing that AI had a hand in.
(My guess is the majority of posts written daily on LW are now written with some AI involvement. My best guess is most authors on LessWrong use AI models on a daily level, asking factual questions, and probably also asking for some amount of editing and writing feedback. As such, I don't think this is a coherent ask.)
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2024-11-01T19:40:19.174Z · LW(p) · GW(p)
If this is true, then it’s a damning indictment of Less Wrong and the authors who post here, and is an excellent reason not to read anything written here.
Replies from: steve2152, habryka4, jimrandomh↑ comment by Steven Byrnes (steve2152) · 2024-11-01T20:51:26.350Z · LW(p) · GW(p)
Here are all of my interactions with claude related to writing blog posts or comments in the last four days:
- I asked Claude for a couple back-of-the-envelope power output estimations (running, and scratching one’s nose). I double-checked the results for myself before alluding to them in the (upcoming) post. Claude’s suggestions were generally in the right ballpark, but more importantly Claude helpfully reminded me that metabolic power consumption = mechanical power + heat production, and that I should be clear on which one I mean.
- “There are two unrelated senses of "energy conservation", one being physics, the other being "I want to conserve my energy for later". Is there some different term I can use for the latter?” — Claude had a couple good suggestions; I think I wound up going with “energy preservation”.
- “how many centimeters separate the preoptic nucleus of the hypothalamus from the arcuate nucleus?” — Claude didn’t really know but its ballpark number was consistent with what I would have guessed. I think I also googled, and then just to be safe I worded the claim in a pretty vague way. It didn’t really matter much for my larger point in even that one sentence, let alone for the important points in the whole (upcoming) post.
- “what's a typical amount that a 4yo can pick up? what about a national champion weightlifter? I'm interested in the ratio.” — Claude gave an answer and showed its work. Seemed plausible. I was writing this comment [LW(p) · GW(p)], and after reading Claude’s guess I changed a number from “500” to “50”.
- “Are there characteristic auditory properties that distinguish the sound of someone talking to me while facing me, versus talking to me while facing a different direction?” — Claude said some things that were marginally helpful. I didn’t wind up saying anything about that in the (upcoming) post.
- “what does "receiving eye contact" mean?” — I was trying to figure out if readers would understand what I mean if I wrote that in my (upcoming) post. I thought it was a standard term but had a niggling worry that I had made it up. Claude got the right answer, so I felt marginally more comfortable using that phrase without defining it.
- “what's the name for the psychotic delusion where you're surprised by motor actions?” — I had a particular thing in mind, but was blanking on the exact word. Claude was pretty confused but after a couple tries it mentioned “delusion of control”, which is what I wanted. (I googled that term afterwards.)
↑ comment by Raemon · 2024-11-01T21:03:56.390Z · LW(p) · GW(p)
Somewhat following this up: I think not using LLMs is going to be fairly similar to "not using google." Google results are not automatically true – you have to use your judgment. But, like, it's kinda silly to not use it as part of your search process.
I do recommend perplexity.ai for people who want an easier time checking up on where the AI got some info (it does a search first and provides citations, while packaging the results in a clearer overall explanation than google)
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2024-11-02T01:53:03.812Z · LW(p) · GW(p)
I in fact don’t use Google very much these days, and don’t particularly recommend that anyone else do so, either.
(If by “google” you meant “search engines in general”, then that’s a bit different, of course. But then, the analogy here would be to something like “carefully select which LLM products you use, try to minimize their use, avoid the popular ones, and otherwise take all possible steps to ensure that LLMs affect what you see and do as little as possible”.)
↑ comment by habryka (habryka4) · 2024-11-01T19:44:34.190Z · LW(p) · GW(p)
Do you not use LLMs daily? I don't currently find them out-of-the-box useful for editing, but find them useful for a huge variety of tasks related to writing things.
I think it would be more of an indictment of LessWrong if people somehow didn't use them, they obviously increase my productivity at a wide variety of tasks, and being an early-adopter of powerful AI technologies seems like one of the things that I hope LessWrong authors excell at.
In general, I think Gwern's suggested LLM policy [LW(p) · GW(p)] seems roughly right to me. Of course people should use LLMs extensively in their writing, but if they do, they really have to read any LLM writing that makes it into their post and check what it says is true:
Replies from: DanielFilan, fallcheetah7373, SaidAchmizI am also fine with use of AI in general to make us better writers and thinkers, and I am still excited about this. (We unfortunately have not seen much benefit for the highest-quality creative nonfiction/fiction or research, like we aspire to on LW2, but this is in considerable part due to technical choices & historical contingency, which I've discussed many times before, and I still believe in the fundamental possibilities there.) We definitely shouldn't be trying to ban AI use per se.
However, if someone is posting a GPT-4 (or Claude or Llama) sample which is just a response, then they had damn well better have checked it and made sure that the references existed and said what the sample says they said and that the sample makes sense and they fixed any issues in it. If they wrote something and had the LLM edit it, then they should have checked those edits and made sure the edits are in fact improvements, and improved the improvements, instead of letting their essay degrade into ChatGPTese. And so on.
↑ comment by DanielFilan · 2024-11-01T20:14:57.435Z · LW(p) · GW(p)
FWIW I think it's not uncommon for people to not use LLMs daily (e.g. I don't).
Replies from: habryka4, adam_scholl↑ comment by habryka (habryka4) · 2024-11-01T21:03:49.152Z · LW(p) · GW(p)
Seems like a mistake! Agree it's not uncommon to use them less, though my guess (with like 60% confidence) is that the majority of authors on LW use them daily, or very close to daily.
Replies from: Vaniver, ben-lang, Raemon, MondSemmel↑ comment by Ben (ben-lang) · 2024-11-21T18:16:05.376Z · LW(p) · GW(p)
Could be an interesting poll question in the next LW poll.
Something like:
How often do you use LLMs?
Never used them
Messed about with one once or twice
Monthly
Weekly
Every Day
↑ comment by MondSemmel · 2024-11-01T22:26:44.528Z · LW(p) · GW(p)
I would strongly bet against majority using AI tools ~daily (off the top of my head: <40% with 80% confidence?): adoption of any new tool is just much slower than people would predict, plus the LW team is liable to vastly overpredict this since you're from California.
That said, there are some difficulties with how to operationalize this question, e.g. I know some particularly prolific LW posters (like Zvi) use AI.
↑ comment by Adam Scholl (adam_scholl) · 2024-11-02T08:31:34.324Z · LW(p) · GW(p)
I also use them rarely, fwiw. Maybe I'm missing some more productive use, but I've experimented a decent amount and have yet to find a way to make regular use even neutral (much less helpful) for my thinking or writing.
Replies from: DanielFilan↑ comment by DanielFilan · 2024-11-02T20:01:22.299Z · LW(p) · GW(p)
I enjoyed reading Nicholas Carlini and Jeff Kaufman write about how they use them, if you're looking for inspiration.
Replies from: adam_scholl↑ comment by Adam Scholl (adam_scholl) · 2024-11-02T20:39:13.581Z · LW(p) · GW(p)
Thanks; it makes sense that use cases like these would benefit, I just rarely have similar ones when thinking or writing.
↑ comment by lesswronguser123 (fallcheetah7373) · 2024-11-03T03:42:31.487Z · LW(p) · GW(p)
I recommend having this question in the next lesswrong survey.
Along the lines of "How often do you use LLMs and your usecase?"
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-11-03T06:24:49.400Z · LW(p) · GW(p)
Great idea!
@Screwtape [LW · GW]?
Replies from: Screwtape↑ comment by Said Achmiz (SaidAchmiz) · 2024-11-01T20:14:13.933Z · LW(p) · GW(p)
Do you not use LLMs daily?
Not even once.
In general, I think Gwern’s suggested LLM policy [LW(p) · GW(p)] seems roughly right to me.
First of all, even taking what Gwern says there at face value, how many of the posts here that are written “with AI involvement” would you say actually are checked, edited, etc., in the rigorous way which Gwern describes? Realistically?
Secondly, when Gwern says that he is “fine with use of AI in general to make us better writers and thinkers” and that he is “still excited about this”, you should understand that he is talking about stuff like this and this, and not about stuff like “instead of thinking about things, refining my ideas, and writing them down, I just asked a LLM to write a post for me”.
Approximately zero percent of the people who read Gwern’s comment will think of the former sort of idea (it takes a Gwern to think of such things, and those are in very limited supply), rather than the latter.
The policy of “encourage the use of AI for writing posts/comments here, and provide tools to easily generate more AI-written crap” doesn’t lead to more of the sort of thing that Gwern describes at the above links. It leads to a deluge of un-checked crap.
Replies from: Benito, habryka4↑ comment by Ben Pace (Benito) · 2024-11-01T20:24:18.792Z · LW(p) · GW(p)
I currently wish I had a policy for knowing with confidence whether a user wrote part of their post with a language model. There's a (small) regular stream of new-user content that I look through, where I'm above 50% that AI wrote some of it (very formulaic, unoriginal writing, imitating academic style) but I am worried about being rude when saying "I rejected your first post because I reckon you didn't write this and it doesn't reflect your thoughts" if I end up being wrong like 1 in 3 times[1].
Sometimes I use various online language-model checkers (1, 2, 3), but I don't know how accurate/reliable they are. If they are actually pretty good, I may well automatically run them on all submitted posts to LW so I can be more confident.
- ^
Also one time I pushed back on this and the user explained they're not a native English speaker, so tried to use a model to improve their English, which I thought was more reasonable than many uses.
↑ comment by Raemon · 2024-11-01T20:26:10.509Z · LW(p) · GW(p)
I'd be pretty into having typography styling settings that auto-detect LM stuff (or, specifically track when users have used any LW-specific LM tools), and flag it with some kind of style difference so it's easy to track at a glance (esp if it could be pretty reliable).
↑ comment by habryka (habryka4) · 2024-11-01T20:25:15.576Z · LW(p) · GW(p)
First of all, even taking what Gwern says there at face value, how many of the posts here that are written “with AI involvement” would you say actually are checked, edited, etc., in the rigorous way which Gwern describes? Realistically?
My guess is very few people are using AI output directly (at least the present it's pretty obvious as their writing is kind of atrocious). I do think most posts probably involved people talking to an LLM through their thoughts, or ask for some editing help, or ask some factual questions. My guess is basically 100% of those went through the kind of process that Gwern was describing here.
↑ comment by jimrandomh · 2024-11-04T23:06:06.298Z · LW(p) · GW(p)
Lots of people are pushing back on this, but I do want to say explicitly that I agree that raw LLM-produced text is mostly not up to LW standards, and that the writing style that current-gen LLMs produce by default sucks. In the new-user-posting-for-the-first-time moderation queue, next to the SEO spam, we do see some essays that look like raw LLM output, and we reject these.
That doesn't mean LLMs don't have good use around the edges. In the case of defining commonly-used jargon, there is no need for insight or originality, the task is search-engine-adjacent, and so I think LLMs have a role there. That said, if the glossary content is coming out bad in practice, that's important feedback.
comment by [deleted] · 2024-11-01T03:34:29.463Z · LW(p) · GW(p)
Let us know what you think!
the grey text feels disruptive to normal reading flow but idk why green link text wouldn't also be, maybe i'm just not used to it. e.g., in this post's "Curating technical posts" where 'Curating' is grey, my mind sees "<Curating | distinct term> technical posts" instead of [normal meaning inference not overfocused on individual words]
Is this useful, as a reader?
if the authors make sure they agree with all the definitions they allow into the glossary, yes. author-written definitions would be even more useful because how things are worded can implicitly convey things like, the underlying intuition, ontology, or related views they may be using wording to rule in or out.
Whenever an author with 100+ karma saves a draft of a post, our database queries a language model to:
i would prefer this be optional too, for drafts which are meant to be private (e.g. shared with a few other users, e.g. may contain possible capability-infohazards), where the author doesn't trust LM companies
Replies from: Raemon↑ comment by Raemon · 2024-11-01T04:09:00.669Z · LW(p) · GW(p)
Mmm, that does seem reasonable.
Replies from: Raemon↑ comment by Raemon · 2024-11-01T06:38:58.348Z · LW(p) · GW(p)
I've reverted the part that automatically generates jargon for drafts until we've figured out a better overall solution.
Replies from: metachirality↑ comment by metachirality · 2024-11-01T18:16:50.065Z · LW(p) · GW(p)
Why not generate it after it's posted publically?
Replies from: Raemon↑ comment by Raemon · 2024-11-01T19:28:44.620Z · LW(p) · GW(p)
Reasoning is:
- Currently it takes 40-60 seconds to generate jargon (we've experimented with ways of trimming that down but it's gonna be at least 20 seconds)
- I want authors to actually review the content before it goes live.
- Once authors publish the post, I expect very few of them to go back and edit it more.
- If it happens automagically during draft saving, then by the time you get to "publish post", there's a natural step where you look at the autogenerated jargon, check if it seems reasonable, approve the ones you like and then hit "publish"
- Anything that adds friction to this process I expect to dramatically reduce how often authors bother to engage with it.
comment by Alex Vermillion (tomcatfish) · 2024-11-02T22:56:53.304Z · LW(p) · GW(p)
Technical discussion aside, please see a UI designer or similar about how to style this, because it has the potential to really make LessWrong unpleasant to read without it really being obvious at all. I try below to make some comments and recommendations, but I recognize that I'm not very good at this (yet?).
Two nightmare issues to watch out for:
- Too little contrast from the background.
- Too much contrast from the foreground.
1. Blending in
This would make the jargon text harder to see by giving it less visibility than the surrounding text. Your demonstrated gray has this issue. Turn your screen brightness up a bunch and the article looks a bit like Swiss cheese (because the contrast between the white background and the black text increases, the relative contrast between the white background and the gray text decreases).
2. Jumping out
This would make the entire text harder to read by making it jump around in either style or color. Link-dense text can run into this problem[1]. In my opinion, the demo has this issue a bit in §0 (but not in the TLDR).
As an alternative, consider styling like a footnote/endnote. An example of a website that pulls off multiple floating note styles without it being attention-grabby is Wait But Why. Take a look at the end of the first main body paragraph on this page for an example.
Go to Wikipedia and turn on link underlining to see small of a change can make or break this. ↩︎
↑ comment by Raemon · 2024-11-03T06:29:22.104Z · LW(p) · GW(p)
Nod.
One of the things we've had a bunch of internal debate about is "how noticeable should this be at all, by default?" (with opinions ranging from "it should be about as visible as the current green links are" to "it'd be basically fine if it jargon-terms weren't noticeable at all by default."
Another problem is just variety in monitor and/or "your biological eyes." When I do this:
Turn your screen brightness up a bunch and the article looks a bit like Swiss cheese (because the contrast between the white background and the black text increases, the relative contrast between the white background and the gray text decreases).
What happens to me when I turn my macbook brightness to the max is that I stop being able to distinguish the grey and the black (rather than the contrast between white and grey seeming to decrease). I... am a bit surprised you had the opposite experience (I'm on a ~modern M3 macbook. What are you using?)
I will mock up a few options soon and post them here.
For now, here are a couple random options that I'm not currently thrilled with:
1. the words are just black, not particularly noticeable, but use the same little ° that we use for links.

2. Same, but the circle is green:

↑ comment by Alex Vermillion (tomcatfish) · 2024-11-03T23:21:54.636Z · LW(p) · GW(p)
(I'm on a Framework computer)
Each of your examples is a lot easier to read, since I've already learned how much I should ignore the circles and how much I should pay attention to them. I'd be quite happy with either.
If someone really really wants color, try using subtle colors. I fiddled around, and on my screen, rgb(80,20,0) is both imperceptible and easily noticed. You really can do a lot with subtlety, but of course the downside is that this sucks for people who have a harder time seeing. From the accessibility standpoint, my favorite (out of the original, your 2 mockups, and my ugly color hinting) is your green circle version. It should be visible to absolutely everyone when they look for it, but shouldn't get in anyone's way.
I appreciate the mockups!
Replies from: lelapin↑ comment by Jonathan Claybrough (lelapin) · 2024-11-04T17:23:50.949Z · LW(p) · GW(p)
Without removing from the importance of getting the default right, and with some deliberate daring to feature creep, I think adding a customization feature (select colour) in personal profiles is relatively low effort and maintenance, so would solve the accessibility problem.
comment by Archimedes · 2024-11-02T15:58:36.588Z · LW(p) · GW(p)
There should be some way for readers to flag AI-generated material as inaccurate or misleading, at least if it isn’t explicitly author-approved.
comment by Alex Vermillion (tomcatfish) · 2024-11-18T01:30:51.701Z · LW(p) · GW(p)
Amusingly, I found a 16-year old comment asking for jargon integration [LW(p) · GW(p)]. Dropping it here just to document that people want this, so that people don't say "Who wants this?" without an answer.
comment by CstineSublime · 2024-11-03T04:28:15.680Z · LW(p) · GW(p)
AIs are good at explaining simple things, and not very good at thinking about how large concepts fit together.
For me there was a good example of this in the provided demonstration section, the phrase "Bayesian reinforcement learning" generated the following hilariously redundant explanation:
A learning approach that combines Bayesian inference with reinforcement learning to handle uncertainty in decision-making. It's mentioned here as part of the 'standard model' of ideal agency, alongside AIXI.
I am well aware that this is simply a demonstration for illustrative purposes and not meant to be representative of what the actual generated explanations will be like.
This is an exciting feature! Although these generated explanations remind me an awful lot of the frustration and lost productivity I experience trying to comprehend STEM terms and the long Wikipedia hopping from a term to another term to explain it; I think with better explanations it could solve part of that frustration and lost productivity. I often find STEM jargon impenetrable and find myself looking for ELI5 posts of a term used in a description of a term, used in the description of the thing I'm trying to directly learn about.
comment by DanielFilan · 2024-11-01T20:19:20.262Z · LW(p) · GW(p)
How are you currently determining which words to highlight? You say "terms that readers might not know" but this varies a lot based on the reader (as you mention in the long-term vision section).
Replies from: DanielFilan↑ comment by DanielFilan · 2024-11-01T20:22:12.087Z · LW(p) · GW(p)
Also, my feedback is that some of the definitions seem kind of vague. Like, apparently an ultracontribution is "a mathematical object representing uncertainty over probability" - this tells me what it's supposed to be, but doesn't actually tell me what it is. The ones that actually show up in the text don't seem too vague, partially because they're not terms that are super precise.
Replies from: Raemon↑ comment by Raemon · 2024-11-01T20:27:52.461Z · LW(p) · GW(p)
This comment caused me to realize: even though generating LaTeX hoverovers involves more technical challenges, I might be able to tell it "if it's a term that gets defined in LaTeX, include an example equation in the hoverover" (or something like that), which might help for some of these.
Replies from: DanielFilan↑ comment by DanielFilan · 2024-11-01T20:28:58.693Z · LW(p) · GW(p)
Could be a thing where people can opt into getting the vibes or the vibes and the definitions.
Replies from: Raemon