The Agency Overhang
post by Jeffrey Ladish (jeff-ladish) · 2023-04-21T07:47:19.454Z · LW · GW · 6 commentsContents
Building agents out of language models How to mitigate agency overhang concerns None 6 comments
As language models become increasingly capable of performing cognitive tasks that humans can solve quickly, it appears that a "cognitive capability : agency overhang" is emerging. We have powerful systems that currently have little ability to carry out complex, multi-step plans, but at some point, these powerful yet not-very-agentic systems may develop sophisticated planning and execution abilities. Since "fast cognition capability : agency overhang" is unwieldy, I will shorten this to “agency overhang”.
By agency, I mean the ability to generate and carry out complex plans to do specific things, like run a software company, or run a scientific research program investigating cancer treatments. I think of a system as “more agentic” when it can carry out more complex plans that take more steps to accomplish.
It’s hard to estimate how quickly planning and execution abilities could be developed from state of the art (SOTA) language models, but there is some risk these abilities could develop quickly given the right training environment or programmatic scaffolding (e.g. something like AutoGPT). This could look like a sharp left turn [LW · GW] that happens very suddenly during training, or it could look like a smoother-but-still-fast development taking weeks or months. My claim is that any of these relatively fast transitions from “systems with superhuman cognitive abilities on short time horizon tasks but poor planning and execution ability” to “systems that have these abilities plus impressive planning and execution ability” would be very dangerous. Not only because rapid gains in cognitive capabilities are generally risky, but because people might underestimate how quickly models could gain the dangerous planning and execution abilities.
Below I discuss how people are experimenting with making large language models more agentic through the use of programmatic scaffolding. Before I do, I want to emphasize the more general point that an agency overhang is concerning because the risks from an overhang don’t depend on exactly how the agentic-capabilities gap gets closed, only that it does. We currently possess powerful cognitive engines that perform superhumanly well along many dimensions but not all dimensions of general intelligence. At some point we will close this gap by finding ways to train or program AI systems to have the capabilities they need to plan and execute and iterate well. This may be through the current scaling regime using similar internet training data. It may be through utilizing new training techniques, architectures, or types of training data. It may be through building new types of scaffolding. Regardless, there is significant risk that AI systems could cross this threshold quickly, and go from relatively harmless to extremely dangerous in a short amount of time.
Once AI systems with superhuman capabilities along many dimensions close the agency gap and are able to plan and execute well, they will be much more capable of acquiring more financial, social, and computational resources, manipulating large groups of humans, and recursively self-improving.
An agency overhang is bad in that it makes experimenting with building agentic systems much more dangerous. I’m not against building agents to study how to align them. I think we'll need to study agency empirically before we can solve alignment. But we should do this extremely carefully, with significant security measures and information management (don't publish AI agent capability results) starting with less powerful models and lots of interpretability tools. In an ideal world, we would study many different types of weak agentic systems this way, look at their internals, test them in lots of different kinds of environments, and come to deeply understand their goals and goal structures before making them more powerful. I am not saying we should rush to develop agentic systems as fast as possible - the overhang already exists, GPT-4 is already superhumanly capable among several important dimensions, and making systems with the capabilities at least as powerful as GPT-4 more agentic is already dangerous.
Building agents out of language models
Since GPT-4 came out, there have been a number of efforts to make GPT-4 more agentic by creating applications that allow GPT-4 to write prompts for itself recursively with some scaffolding, e.g. AutoGPT, BabyAGI. Right now, even though language models aren’t trained to be sophisticated planning agents, they appear to have lots of latent planning ability that can be solicited by programmatic scaffolding that splits up various parts of the planning and execution process. These can include subtasks like writing / reading to memory and evaluating the efficacy of the last action step.
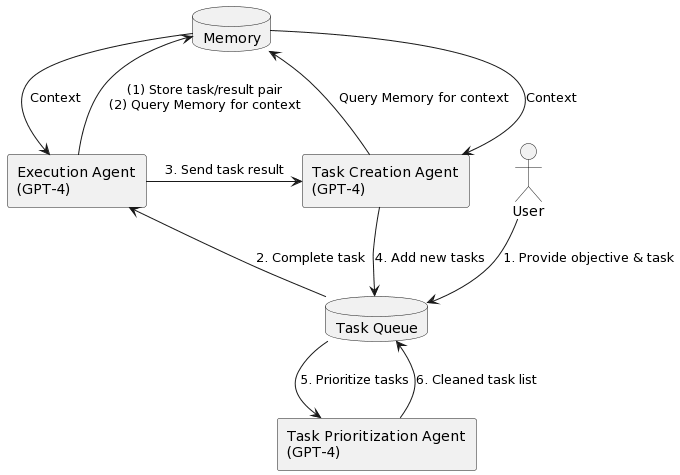
It’s unclear how far GPT-4 or similar models can be combined with agent-scaffolding to create powerful agents, but it seems clear that the more powerful the base model is, the easier it will be to use frameworks like this to try to build agents. One notable thing about agent scaffolds is that they are being built to allow the use of any base model. The programmatic scaffolding people have built is currently quite simple, but it may be possible to improve such scaffolding to the point where such systems can significantly enhance the agentic capabilities of an otherwise fairly limited or myopic [? · GW] language model.
If programmatic scaffolding ends up being a significant component of the first AGI systems, then rigorously testing model capabilities without that scaffolding would not be sufficient to guarantee the safety of that model. For example, GPT-5 might not pose a large risk on its own, but GPT-5 plugged into a powerful agent-scaffold might show dangerous capabilities.
As far as I know, no one has fine-tuned language models to act more coherently in the context of an agent scaffold like AutoGPT, but this seems likely to be a research direction that people will pursue. It seems plausible that fine-tuning could significantly improve the performance of these ensemble agents. This seems like a dangerous research direction that should be subject to significant oversight.
AGI companies should prevent people from doing their own fine tuning in this direction, and refrain from internal experimentation until they have built up sufficient operational adequacy [LW · GW] to carry out experiments carefully. At present, random members of the general public are able to run open-ended experiments with AI agents. This seems really dumb. There will always be trolls or individuals with malicious intent, e.g. within a day of autoGPT being released someone already told it to cause as much destruction and suffering as possible.
Ultimately it’s not clear that “LM + programmatic scaffolding” will end up being a successful way to build AGI, but it’s concerning that this path might be possible without further conceptual advances in ML. A plausible self-improvement pathway is via a model iteratively generating better scaffolding for itself. Note also that this approach wouldn’t require access to a large amount of compute resources. Models with powerful coding abilities seem especially dangerous in terms of their agency overhang to the extent that better scaffolding helps them be more agentic and capable. People often think about recursive self improvement of ML systems being mostly about improving the ML training process, but if better agent scaffolding turns out to be a significant capability boost, then superhuman coding abilities could lead to large capability advances without the need for expensive compute resources.
As I was writing this post, I debated whether I should mention recursive self improvement on agentic scaffolding. Then I glanced at Twitter and did a quick Google search, and of course people were already trying this with AutoGPT. Of course they are. At present I don't expect recursive self-improvement of programatic scaffolding to be very useful since language models + scaffolding are far worse than human programmers right now. But we don't know if and when this will change. If it became possible to get large cognitive gains just from scaffolding improvements, then letting anyone on the internet use a LLM API for whatever AGI experiment they want becomes very dangerous.
How to mitigate agency overhang concerns
To reiterate, I am not saying that anyone should rush to build agents in order to reduce the agency overhang. The problem is not that we don’t have agents. The problem is that we have very powerful cognitive capabilities that could rapidly become dangerous if such systems develop the missing capabilities they need to be strongly agentic. Rushing to build agents would just make us less safe.
Ultimately we do need a deep understanding of agentic systems to solve the alignment problem, and empirical research will be necessary, but this kind of research is inherently dual use and should only be done with extreme caution and operational adequacy [LW · GW], beyond that which most AGI companies currently possess.
The way to mitigate the agency overhang right now is to stop training more powerful language models. Scaling and other big capability improvements will increase the agency overhang, shortening timelines and also making big power discontinuities more likely. I think the best way forward is to pause large training runs and pour lots of resources into understanding existing language models, then slowly and carefully experiment with ways to understand agentic AI systems and how to make them safely.
It is not obvious that it is possible to make agents safely with the GPT architecture. If it is, we can study this question by starting agency engineering experiments with less capable models like GPT-3 until we understand their cognition quite well, including how their goals form and change in response to different training pressures. Then, if and only if we can demonstrate we understand these systems and know how to train them safely, we could slowly scale up agency experiments with larger models like GPT-3.5 and GPT-4. Even then, scaling up agentic systems would pose significant risks, since understanding goal structure formation in a kinda-smart agent is likely far easier than understanding goal structure formation in very-smart agents. Even so, I’d be much more optimistic about our chances of creating aligned AI systems if we built up an understanding of agency in weak AI systems before we experimented with powerful AI systems.
6 comments
Comments sorted by top scores.
comment by simeon_c (WayZ) · 2023-04-21T08:22:55.615Z · LW(p) · GW(p)
I'd add that it's not an argument to make models agentic in the wild. It's just an argument to be already worried.
comment by Htarlov (htarlov) · 2023-04-21T18:43:50.969Z · LW(p) · GW(p)
I'm already worried as I tested AutoGPT and looked at how it works in code and for me, it seems like it will get very good planning capabilities with the change of a model to one with a few times longer token scope (like coming soon GPT-4 version with about 32k tokens) plus small refinements. So it won't get into loops, maybe have more than one GPT-4 module for different scopes of planning like long-term strategy vs short-term strategy vs tactic vs decisions on most current task + maybe some summarization-based memory. I don't see how it wouldn't work as an agent.
comment by the gears to ascension (lahwran) · 2023-04-21T08:13:12.411Z · LW(p) · GW(p)
This is dead obvious and not helpful to hammer into everyone's heads [LW · GW]. Only technical solutions are of any use - ringing the alarm bell is a waste of time this late in the game, the only way to get people to understand is to give away information that need not be advertised early. Is there some part of this that is actually new, or are you continuing to ring the alarm bell about "oh no, here's a plan for how to do bad thing" for nearly no benefit?
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-04-21T17:27:55.330Z · LW(p) · GW(p)
I guess it is well enough known that this doesn't make it worse. I guess.
Replies from: gwillen↑ comment by gwillen · 2023-04-21T21:41:51.011Z · LW(p) · GW(p)
I think you are not wrong to be concerned, but I also agree that this is all widely known to the public. I am personally more concerned that we might want to keep this sort of discussion out of the training set of future models; I think that fight is potentially still winnable, if we decide it has value.