Incentive Problems With Current Forecasting Competitions.
post by NunoSempere (Radamantis), Alex Lawsen (alex-lszn) · 2020-11-09T16:20:06.394Z · LW · GW · 21 commentsContents
Problems Discrete prizes distort forecasts Incentives not to share information and to produce corrupt information Incentives to selectively pick questions. Incentive to just copy the community on every question. Solutions Probabilistic rewards Giving rewards to the best forecasters among many questions. Forcing forecasters to forecast on all questions Scoring groups Designing collaborative scoring rules Divide information gatherers and prediction producers. Other ideas None 21 comments
This post outlines some incentive problems with forecasting tournaments, such as Good Judgement Open, CSET, or Metaculus. These incentive problems may be problematic not only because unhinged actors might exploit them, but also because of mechanisms such as those outlined in Unconscious Economics [LW · GW]. For a similar post about PredictIt, a prediction market in the US, see here [LW · GW]. This post was written in collaboration with alexrjl [LW · GW], who should be added as a coauthor soon.
Problems
Discrete prizes distort forecasts
If a forecasting tournament offers a prize to the top X forecasters, the objective "be in the top X forecasters" differs from "maximize predictive accuracy". The effects of this are greater the smaller the number of questions.
For example if only the top forecaster wins a prize, you might want to predict a surprising scenario, because if it happens you will reap the reward, whereas if the most likely scenario happens, everyone else will have predicted it too.
Consider for example this prediction contest, which only had a prize for #1. The following question asks about the margin Biden would win or lose Georgia by:
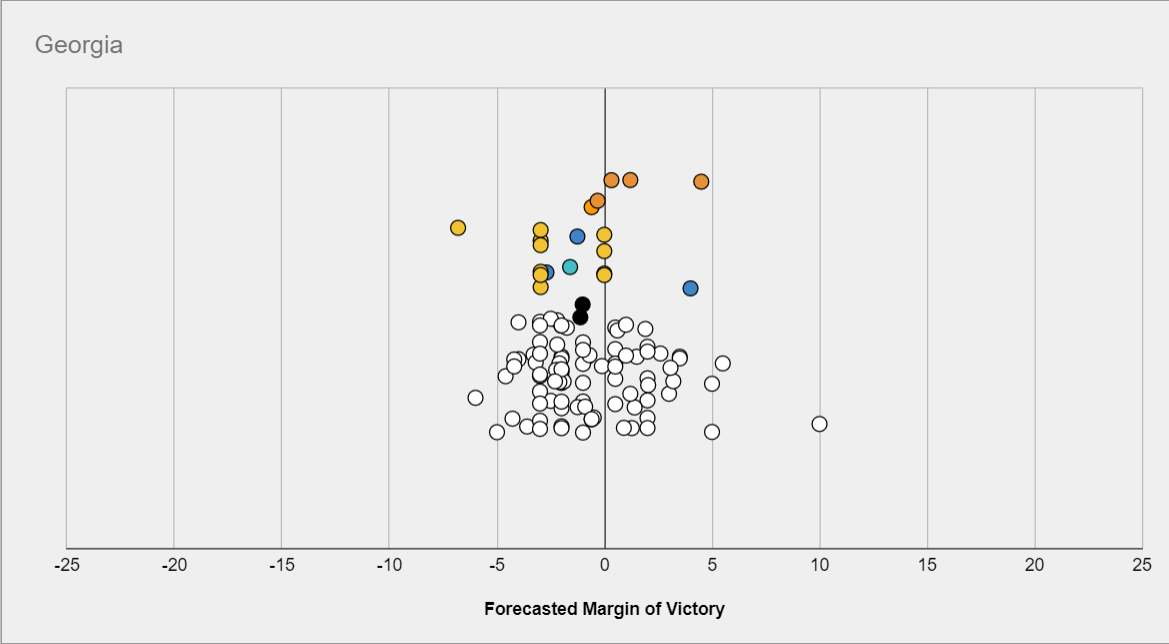
Then the most likely scenario might be a close race, but the prediction which would have maximized your odds of coming in #1st might be much more extremized, because other predictors are more tightly packed in the middle.
This effect also applies if you think of "becoming a superforecaster", which you can do if you are in the top 2% and have over 100 predictions in Good Judgement Open, as a distinct objective from "maximizing reward accuracy".
Incentives not to share information and to produce corrupt information
In a forecasting tournament, there is a disincentive to sharing information, because other forecasters can use it to improve relative standing. This not only includes not sharing information but also providing misleading information. As a counterpoint, other forecasters can and will often point out flaws in your reasoning if you're wrong.
Incentives to selectively pick questions.
If one is maximizing the Brier score, one is incentivized to pick easier questions. Specifically, if someone has a brier score b2, then they should not make a prediction on any question where the probability is between b and (1-b), even if they know the true probability exactly. Tetlock explicitly mentions this in one of his Commandments for superforecasters: “Focus on questions where your hard work is likely to pay off”. Yet if we care about making better predictions of things we need to know the answer to, the skill of "trying to answer easier questions so you score better" is not a skill we should reward, let alone encourage the development of.
A related issue is that, if one is maximizing the difference between one's Brier score and the aggregate’s Brier score, one is incentivized to pick questions for which the one thinks the aggregate is particularly wrong. This is not necessarily a problem, but can be.
Incentive to just copy the community on every question.
In scoring systems which more directly reward making many predictions, such as the Metaculus scoring system where in general one has to be both wrong and very confident to actually lose points, predictors are heavily incentivized to make predictions on as many questions as possible in order to move up the leaderboard. In particular, a strategy of “predict the community median with no thought” could see someone rise to the top 100 with a few months of signing up.
This is plausibly less bad than the incentives above, although this depends on your assumptions. If the main value of winning “metaculus points” is personal satisfaction, then predicting exactly the community median is unlikely to keep people entertained for long. New users predicting something fairly close to the community median on lots of questions, but updating a little bit based on their own thinking, is arguably not a problem at all, as the small adjustments may be enough to improve the crowd forecast, and the high volume of practice that users with this strategy experience can lead to rapid improvement.
Solutions
Probabilistic rewards
In tournaments with fairly small numbers of questions, where paying only the top few places would incentivize forecasters to make overconfident predictions to maximize their chance of first-place finishes as discussed above, probabilistic rewards may be used to mitigate this effect.
In this case, rather than e.g. having prizes for the top three scorers, prizes would be distributed according to a lottery, where the number of tickets each player received was some function of their score, thereby incentivizing players to maximize their expected score, rather than their chance of scoring highest.
Which precise function should be used is a non-trivial question: If the payout structure is too “flat”, then there is not sufficient incentive for people to work hard on their forecasts compared to just entering with the community median or some reasonable prior. If on the other hand the payout structure too heavily rewards finishing in one of the top few places, then the original problem returns. This seems like a promising avenue for a short research project or article.
Giving rewards to the best forecasters among many questions.
If one gives rewards to the top three forecasters for 10 questions in a contest in which there are 200 forecasters, the top three forecasters might be as much a function of luck as of skill, which might be perceived as unfair. Giving prizes for much larger pools of questions makes this effect smaller.
Forcing forecasters to forecast on all questions
This fixes the incentive to pick easier questions to forecast on.
A similar idea is assuming that forecasters have predicted the community median on any question that they haven't forecast on, until they make their own prediction, and then reporting the average brier score over all questions. This has the disadvantage of not rewarding "first movers/market makers", however it has the advantage of "punishing" people for not correcting a bad community median in a way that relative Brier doesn't (at least in terms of how people experience it).
Scoring groups
If one selects a group of forecasters and offers to reward them in proportion to the Brier score of the group’s predictions for a fixed set of questions, then the forecasters now have the incentive to share information with the group. This group of forecasters could be pre-selected for having made good predictions in the past.
Designing collaborative scoring rules
One could design rules around, e.g., Shapley values, but this is tricky to do. Currently, some platforms make it possible to give upvotes to the most insightful forecasters, but if upvotes were monetarily rewarded, one might not have the incentive to upvote other participants’ contributions as opposed to waiting for one’s contributions to be upvoted.
In practice, Metaculus and GJOpen do have healthy communities which collaborate, where trying to maximize accuracy at the expense of other forecasters is frowned upon, but this might change with time, and it might not always be replicable. In the specific case of Metaculus, monetary prizes are relatively new, but becoming more frequent. It remains to be seen whether this will change the community dynamic.
Divide information gatherers and prediction producers.
In this case, information gatherers might then be upvoted by prediction producers, who wouldn’t have any disincentive not to do so. Alternatively, some prediction producers might be shown information from different information gatherers, or select which information was responsible for a particular change in their forecast. A scheme in which the two tasks are separated might also lead to efficiency gains.
Other ideas
- One might explicitly reward reasoning rather than accuracy (this has been tried on Metaculus for the insight tournament, and also for the El Paso series). This has its own downsides, notably that it’s not obvious that reasoning which looks good/reads well is actually correct.
- One might make objectives more fuzzy, like the Metaculus points system, hoping this would make it more difficult to hack.
- One might reward activity, i.e., frequency of updates, or some other proxy expected to correlate with forecasting accuracy. This might work better if the correlation is causal (i.e., better forecasters have higher accuracy because they forecast more often), rather than due to a confounding factor. The obvious danger with any such strategy is that rewarding the proxy is likely to break the correlation [LW · GW].
21 comments
Comments sorted by top scores.
comment by Unnamed · 2020-11-09T20:57:41.007Z · LW(p) · GW(p)
There's a similar challenge in sports with evaluating athletes' performance. Some pieces of what happens there:
There are many different metrics to summarize/evaluate a player's performance rather than just one score (e.g., see all the tables here). Many are designed to evaluate a particular aspect of a player's performance rather than how well they did overall, and there are also multiple attempts to create a single comprehensive overall rating. Over the past decade or two there have been a bunch of improvements in this, with more and better metrics, including metrics that incorporate different sources of information.
There common features of different stats that people who follow the analytics are aware of, such as whether they're volume stats (number of successes) or efficiency stats (number of successes per attempt). Some metrics attempt to adjust for factors that aren't under the player's control which can influence the numbers, such as the quality of the opponent, the quality of the player's teammates, the environment of the game (weather & stadium), various sources of randomness, and whether the play happened in "garbage time" (when the game was already basically decided).
Payment is based on negotiations with the people who benefit from the player's performance (their team's owners) rather than being directly dependent on their stats. Their stats do play into the decision, as do other thing such as close examinations of particular plays that they made.
The awards for individual performance that people care about the most (e.g., All-Star teams, MVP awards, Hall of Fame) are based on voting (by various pools of voters) rather than being directly based on the statistics. Though again, they're influenced by the statistics and tend to line up pretty closely with the statistics.
The achievements that people care about the most (e.g., winning games & championships) are team achievements rather than individual achievements. In a typical league there might be 30 teams which each have 20 players, and there's a mix of competitiveness between teams and cooperativeness within a team.
Seems like forecasting might benefit from copying some parts of this. For example, instead of having one leaderboard with an overall forecasting score, have several leaderboards for different ways of evaluating forecasts, along with tables where you can compare forecasters on a bunch of them at once and a page for each forecaster where you can see all their metrics, how they rank, and maybe some other stuff like links to their most upvoted comments.
Replies from: Unnamed, Davidmanheim↑ comment by Unnamed · 2021-02-15T09:45:19.972Z · LW(p) · GW(p)
Here' s a brainstorm of some possible forecasting metrics which might go in those tables (probably I'm reinventing some wheels here; I know more about existing metrics for sports than for forecasting):
- Leading Indicator: get credit for making predictions if the consensus then moves in the same direction over the next hours / days / n predictions (alternate version: only if that movement winds up being towards the true outcome)
- Points Relative to Your Expectation: each forecast has an expected score according to that forecast (e.g., if the consensus is 60% and you say 80%, you think there's a 0.8 chance you'll gain points for doing better than the consensus and a 0.2 chance you'll lose points for doing worse than consensus). Report expected score alongside actual score, or report the ratio actual/expected. If that ratio is > 1, that means you've been underconfident or (more likely) lucky. Also, expected score is similar to "total number of forecasts", weighted by boldness of forecasts. You could also have a column for the consensus expected score (in the example: your expected score if there was only a 0.6 chance you'd gain points and a 0.4 chance you'd lose points).
- Marginal Contribution to Collective Forecast: have some way of calculating the overall collective forecast on each question (which could be just a simple average, or could involve fancier stuff to try to make it more accurate including putting more weight on some people's forecasts than others). Also calculate what the overall collective forecast would have been if you'd been absent from that question. You get credit for the size of the difference between those two numbers. (Alternative versions: you only get credit if you moved the collective forecast in the right direction, or you get negative credit if you moved it in the wrong direction.)
- Trailblazer Score: use whichever forecasting accuracy metric (e.g. brier score relative to consensus) while only including cases where a person's forecast differed from the consensus at the time by at least X amount. Relevant in part because there might be different skillsets to noticing that the consensus seems off and adjusting a bit in the right direction vs. coming up with your own forecast and trusting it even if it's not close to consensus. (And the latter skillset might be relevant if you're making forecasts on your own without the benefit of having a platform consensus to start from.)
- Market Mover: find some way to track which comments lead to people changing their forecasts. Credit those commenters based on how much they moved the market. (alternative version: only if it moved towards truth)
- Pseudoprofit: find some way to transform people's predictions into hypothetical bets against each other (or against the house), track each person's total profit & total amount "bet". (I'm not sure if this to different calculations or if it's just a different gloss on the same calculations.)
- Splits: tag each question, and each forecast, with various features. Tags by topic (coronavirus, elections, technology, etc.), by what sort of event it's about (e.g. will people accomplish a thing they're trying to do), by amount of activity on the question, by time till event (short term vs. medium term vs. long term markets), by whether the question is binary or continuous, by whether the forecast was placed early vs. middle vs. late in the duration of the question, etc. Be able to show each scoring table only for the subset of forecasts that fit a particular tag.
- Predicted Future Rating: On any metric, you can set up formulas to predict what people will score on that metric over the next (period of time / set of markets). A simple way to do that is to just predict future scores on that metric based on past scores on the same metric, with some regression towards the mean, using historical data to estimate the relationship. But there are also more complicated things using past performance on some metrics (especially less noisy ones) to help predict future performance on other metrics. And also analyses to check whether patterns in past data are mostly signal or noise (e.g. if a person appears to have improved over time, or if they have interesting splits). (Finding a way to predict future scores is a good way to come up with a comprehensive metric, since it involves finding an underlying skill from among the noise. And the analyses can also provide information about how important different metrics are, which ones to include in the big table, which ones to make more prominent.)
↑ comment by NunoSempere (Radamantis) · 2021-02-16T11:37:56.595Z · LW(p) · GW(p)
Cheers, thanks! These are great
↑ comment by Davidmanheim · 2020-11-11T10:14:42.316Z · LW(p) · GW(p)
This is tractable in sports because there are millions of dollars on the line for each player. In most contexts, the costs of negotiation and running a market for talent doesn't work as well, and it's better to use simple metrics despite all the very important problems with poorly aligned metrics. (Of course, the better solution is to design better metrics; https://mpra.ub.uni-muenchen.de/98288/ )
Replies from: Unnamed↑ comment by Unnamed · 2021-02-15T10:40:59.802Z · LW(p) · GW(p)
The full-blown process of in-depth contract negotiations, etc., is presumably beyond the scope of the current competitive forecasting arena.
One of the main things that I get out of the sports comparison is that it points to a different way of using (and thinking of) metrics. The obvious default, with forecasting, is to think of metrics as possible scoring rules, where the person with the highest score wins the prize (or appears first on the leaderboard). In that case, it's very important to pick a good metric, which provides good incentives. An alternative is to treat human judgment as primary, whether that means a committee using its judgment to pick which forecasters win prizes, or forecasters voting on an all-star team, or an employer trying to decide who to hire to do some forecasting for them, or just who has street cred in the forecasting community. And metrics are a way to try to help those people be more informed about forecasters' abilities & performance, so that they'll make better judgment. In that case, the standards for what is a good metric to include are very different. (There's also a third use case for metrics, where the forecaster uses metrics about their own performance to try to get better at forecasting.)
Sports also provide an example of what this looks like in action, what sorts of stats exist, how they're presented, who came up with them, what sort of work went into creating them, how they evaluate different stats and decide which ones to emphasize, etc. And it seems plausible that similar work could be done with forecasting, since much of that work was done by sports fans who are nerds rather than by the teams; forecasting has fewer fans but a higher nerd density. I did some brainstorming in another comment [LW(p) · GW(p)] on some potential forecasting stats which draws a lot of inspiration from that; not sure how much of it is retreading familiar ground.
comment by aaguirre · 2020-11-10T23:08:05.322Z · LW(p) · GW(p)
Thanks for this great piece! A few thoughts with my Metaculus hat on:
- We can think of a sort of "contest spectrum" where there is always a ranking, and there is a relationship between ranking and win probability. On one end of the spectrum the top N people win, and on the other end people are just paid in proportion to how well they predict. The latter end runs into legal problems, as it's effectively then just a betting , while the former end runs into problems, as you say, if the number of questions in the contest is too low. Our current plan at Metaculus is to just make sure contests generally have enough questions (>20 is probably enough) to ensure that your chance of winning by taking extreme positions is vanishingly small; then we hope to implement other sorts of "bounties" that are not directly in proportion to predictive success (and are hence not betting). The probabilistic contest is a good fix for a contest with too few questions, but I'm not sure I love it in general.
- In designing a scoring or reward system, it's very tricky to find the right level of transparency/simplicity. Some transparency and simplicity is important as people need to know what the incentives are. But if it's too simple and transparent, then the metric becomes the goal rather than measuring something else. The current Metaculus point system is complicated, but devised to incentivise certain things (lots of participation, frequent updates, and prediction of one's true estimate of the probability) while being complicated enough that it's kindof inscrutable and hence a pain to game. But there are lots of possible ways to do it and it would be quite interesting to think of more metrics for assessing and comparing predictors. In addition, there's no reason for that Metaculus or anyone else to stick to a single metric (indeed the Metaculus aggregation does not work on the basis of points, and bounties — someday — probably won't either).
- We have a possible idea of "microteaming" here, but have not gotten much feedback on it so far. We definitely need more ways of rewarding information sharing and collaboration.
comment by Davidmanheim · 2020-11-11T10:10:09.821Z · LW(p) · GW(p)
This is great, and it deals with a few points I didn't, but here's my tweetstorm from the beginning of last year about the distortion of scoring rules alone:
https://twitter.com/davidmanheim/status/1080458380806893568
If you're interested in probability scoring rules, here's a somewhat technical and nit-picking tweetstorm about why proper scoring for predictions and supposedly "incentive compatible" scoring systems often aren't actually a good idea.
First, some background. Scoring rules are how we "score" predictions - decide how good they are. Proper scoring rules are ones where a predictor's score is maximized when it give it's true best guess. Wikipedia explains; en.wikipedia.org/wiki/Scoring_r…
A typical improper scoring rule is the "better side of even" rule, where every time your highest probability is assigned to the actual outcome, you get credit. In that case, people have no reason to report probabilities correctly - just pick a most likely outcome and say 100%.
There are many proper scoring rules. Examples include logarithmic scoring, where your score is the log of the probability assigned to the correct answer, and Brier score, which is the mean squared error. de Finetti et al. lays out the details here; link.springer.com/chapter/10.100…
These scoring rules are all fine as long as people's ONLY incentive is to get a good score.
In fact, in situations where we use quantitative rules, this is rarely the case. Simple scoring rules don't account for this problem. So what kind of misaligned incentives exist?
Bad places to use proper scoring rules #1 - In many forecasting applications, like tournaments, there is a prestige factor in doing well without a corresponding penalty for doing badly. In that case, proper scoring rules incentivise "risk taking" in predictions, not honesty.
Bad places to use proper scoring rules #2 - In machine learning, scoring rules are used for training models that make probabilistic predictions. If predictions are then used to make decisions that have asymmetric payoffs for different types of mistakes., it's misaligned.
Bad places to use proper scoring rules #3 - Any time you want the forecasters to have the option to say answer unknown. If this is important - and it usually is - proper scoring rules can disincentify or overincentify not guessing, depending on how that option is treated.
Using a metric that isn't aligned with incentives is bad. (If you want to hear more, follow me. I can't shut up about it.)
Carvalho discusses how proper scoring is misused; https://viterbi-web.usc.edu/~shaddin/cs699fa17/docs/Carvalho16.pdf
Anyways, this paper shows a bit of how to do better; https://pubsonline.informs.org/doi/abs/10.1287/deca.1110.0216
Fin.
comment by philh · 2020-11-11T22:31:09.244Z · LW(p) · GW(p)
At one event I went to, we were told there'd be a prize distributed as some random function of predictive scores, and there was. What they didn't tell us was that there was also a prize for whoever got the highest score. Presumably they kept quiet about that one to avoid giving bad incentives, though it's not a solution that's generally available.
comment by Ulrik Horn (ulrik-horn) · 2022-01-28T14:37:48.859Z · LW(p) · GW(p)
Maybe someone else commented something similar here, but I encountered this issue for the first time in an internship in a bank in 2007 where we had a fake investment competition. An option trader told me that a competition is really a binary option, with 0 value if less than strike price and a big reward if above. This means you want to maximize the value of the option which in this case means maximizing volatility. I crushed the portfolio competition by betting on leveraged financial instruments correlated to oil price (the biggest volatility investment at the time).
Another issue I have not explored with GJopen is the possibility of adjusting for past over or under estimates. For example, if you for some period in the beginning forecasted 70% probability of A and 30% of B and then mid way through the question get new data indicating that B is actually 70% likely, you might not want to put 70% but some higher percentage to compensate for the period before having a too low probability. So you can artificially lower your Brier score due to the forecasts being made over time. I am sure there are ways to account for that, I just have not had time to think about it.
↑ comment by gwern · 2022-01-28T16:20:51.904Z · LW(p) · GW(p)
an internship in a bank in 2007...I crushed the portfolio competition by betting on leveraged financial instruments correlated to oil price (the biggest volatility investment at the time).
This is such a common failure mode of stock competitions. Like every time you read about one of those old highschool stock market contests, back when newspapers printed stock listings, the story is invariably some bright kid realizing that trying to be Warren Buffett is for suckers because you get nothing if you don't come in first, and YOLOing it on the most volatile or meme stock they can find. Embarrassing to see a bank with actual traders make that mistake - 'heads I win tails you lose' is the last lesson you want to be teaching your prospective traders... (Now, I'm not saying that your bank caused the 2008 crash and worldwide recession, but you'll admit that it's suspicious that it happened right before!)
Replies from: ulrik-horn↑ comment by Ulrik Horn (ulrik-horn) · 2023-01-19T19:08:47.333Z · LW(p) · GW(p)
Apologies, I don't often come to this forum and only now saw your response. Fair point on teaching the wrong lesson. But to BofAs defence they had a really good workshop for us interns on betting under uncertainty. We had to answer various questions like how long is the Nile. The answer has to be a range and we could set it ourselves. We could put 0 - 10^99 on every answer and get all answers correct. Nobody got more than half right (mostly top grade ivy League grads) or so which really made me humble to overconfidence. They really did try to hammer in proper risk adjustment. That said, how traders bonuses were tied to their profit and loss was not ideal i think - i am pretty sure there were no negative bonuses. The bonuses were like the portfolio competition!
↑ comment by NunoSempere (Radamantis) · 2022-01-28T20:35:13.334Z · LW(p) · GW(p)
For example, if you for some period in the beginning forecasted 70% probability of A and 30% of B and then mid way through the question get new data indicating that B is actually 70% likely, you might not want to put 70% but some higher percentage to compensate for the period before having a too low probability
As it happens, I don't think that's the case. Like, ignoring the issues in the post/paper, the Brier score is proper, and this is regardless of how many points you've lost in the past.
Replies from: ulrik-horn↑ comment by Ulrik Horn (ulrik-horn) · 2023-01-19T19:11:05.461Z · LW(p) · GW(p)
Yeah I'm not too confident about it, i did not spend time looking into it. But I think it is >30% likely you can compensate for past over or under estimations.
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2023-01-21T15:51:55.031Z · LW(p) · GW(p)
But I think it is >30% likely you can compensate for past over or under estimations.
I'd bet against that at 1:5, i.e., against the proposition that the optimal forecast is not subject to your previous history
comment by RupertFreeman · 2020-12-03T20:39:44.439Z · LW(p) · GW(p)
Thanks for a great post! You may be interested in our paper addressing the discrete prize problem with a (carefully crafted) probabilistic reward that preserves incentive properties.
https://www.rupertfreeman.com/forecaster-selection.pdf
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2020-12-03T21:12:30.186Z · LW(p) · GW(p)
Thanks!
comment by crl826 · 2020-11-09T17:18:43.145Z · LW(p) · GW(p)
Seems like the PredictIt model of turning the questions into Yes/No questions where either side can bid up or down solves a lot of these. Or am I misunderstanding?
Replies from: alex-lszn, Radamantis↑ comment by Alex Lawsen (alex-lszn) · 2020-11-09T18:48:00.906Z · LW(p) · GW(p)
Prediction markets also have problems around events with very low probability, as it is unattractive to lay bet low probability events, both qualitatively (people don't like risking a lot of money for a small reward), and also quantitatively (you can often get similar returns just investing the money, usually at lower risk).
The latter of these problems is in theory solveable by an exchange paying interest on stakes, or by using fractions of stocks as currency, but neither of these options is implemented in a major market.
↑ comment by NunoSempere (Radamantis) · 2020-11-09T18:20:36.749Z · LW(p) · GW(p)
Yeah, it solves some, but not all. For example, not the "incentives not to share information and to produce corrupt information" e.g., PredictIt traders may have created fake polls in the past.
Replies from: crl826↑ comment by crl826 · 2020-11-09T21:24:47.984Z · LW(p) · GW(p)
Agreed.
I guess I didn't/don't think of that as a goal of prediction markets.
The public gets value from the outputs of the market. One of the values of them is being able to get information from insiders who have info that they wouldn't have otherwise shared. Bad data is always a risk with or without prediction markets.
Replies from: Radamantis↑ comment by NunoSempere (Radamantis) · 2020-11-09T22:33:44.665Z · LW(p) · GW(p)
So specifically, in forecasting tournaments, if A knows that "X", and B knows that "X=>Y", and both leave a comment, then the aggregate can come to "Y", particularly if A and B are incentivized with respect and upvotes from other forecasters. In prediction markets, this is trickier (there may not even be a comments section).