MetaAI: less is less for alignment.
post by Cleo Nardo (strawberry calm) · 2023-06-13T14:08:45.209Z · LW · GW · 17 commentsContents
Summary The Superficial Alignment Hypothesis MetaAI's experiment Method: Results: Conclusion: Problems with their experiment (1) Human evaluators (2) "either equivalent or strictly preferred" (3) The goal of RLHF is safety and consistency (4) Schneier's Law of LLMs (5) Benchmark tests? Never heard of her. The answer is benchmark tests. (6) You Are Not Measuring What You Think You Are Measuring by John Wentworth (7*) The Superficial Alignment Hypothesis is probably false None 17 comments
Summary
In May 2023, MetaAI submitted a paper to arxiv called LIMA: Less Is More for Alignment. It's a pretty bad paper and (in my opinion) straightforwardly misleading. Let's get into it.
The Superficial Alignment Hypothesis
The authors present an interesting hypothesis about LLMs —
We define the Superficial Alignment Hypothesis: A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.
If this hypothesis is correct, and alignment is largely about learning style, then a corollary of the Superficial Alignment Hypothesis is that one could sufficiently tune a pretrained language model with a rather small set of examples.
We hypothesize that alignment can be a simple process where the model learns the style or format for interacting with users, to expose the knowledge and capabilities that were already acquired during pretraining.
(1) This hypothesis would have profound implications for AI x-risk —
- It suggests that we could build a safe competent oracle by pretraining an LLM on the entire internet corpus, and then finetuning the LLM on a curated dataset of safe competent responses.
- It suggests that we could build an alignment researcher by pretraining an LLM on the entire internet corpus, and then finetuning the LLM on a curated dataset of alignment research.
(2) Moreover, as by Ulisse Mini [LW · GW] writes in their review of the LIMA paper [LW · GW],
Along with TinyStories [LW · GW] and QLoRA I'm becoming increasingly convinced that data quality is all you need, definitely seems to be the case for finetuning, and may be the case for base-model training as well. Better scaling laws through higher-quality corpus? Also for who haven't updated, it seems very likely that GPT-4 equivalents will be essentially free to self-host and tune within a year. Plan for this!
(3) Finally, the hypothesis would've supported many of the intuitions in the Simulators sequence [? · GW] by Janus, and I share these intuitions.
So I was pretty excited to read the paper! Unfortunately, the LIMA results were unimpressive upon inspection.
MetaAI's experiment
The authors finetune MetaAI's 65B parameter LLaMa language model on 1000 curated prompts and responses (mostly from StackExchange, wikiHow, and Reddit), and then compare it to five other LLMs (Alpaca 65B, DaVinci003, Bard, Claude, GPT4).
Method:
To compare LIMA to other models, we generate a single response for each test prompt. We then ask crowd workers to compare LIMA outputs to each of the baselines and label which one they prefer. We repeat this experiment, replacing human crowd workers with GPT-4, finding similar agreement levels.
Results:
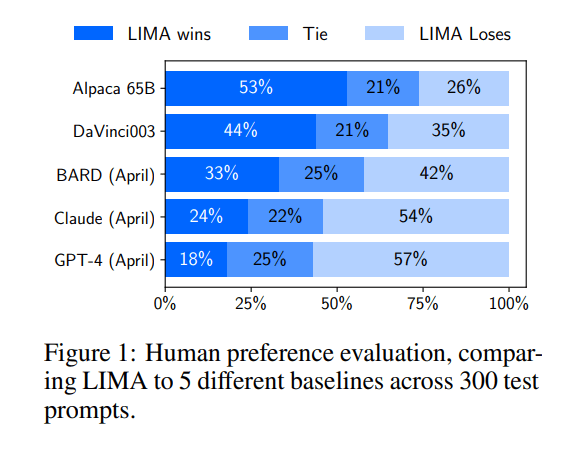
In a controlled human study, responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases; this statistic is as high as 58% when compared to Bard and 65% versus DaVinci003, which was trained with human feedback.
Conclusion:
The fact that simple fine-tuning over so few examples is enough to compete with the state of the art strongly supports the Superficial Alignment Hypothesis, as it demonstrates the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
Problems with their experiment
(1) Human evaluators
To compare two chatbots A and B, you could ask humans whether they prefer A's response to B's response across 300 test prompts. But this is pretty bad proxy, because here's what users actually care about:
- What's the chatbots' accuracy on benchmark tests, e.g. BigBench, MMLU?
- Can the chatbot pass a law exam, or a medical exam?
- Can the chatbot write Python code that actually matches the specification?
- Can the chatbot perform worthwhile alignment research?
Why did the paper not include any benchmark tests? Did the authors run zero tests other than human evaluation? This is surprising, because human evaluation is by far the most expensive kind of test to run. Hmm. [? · GW]
(2) "either equivalent or strictly preferred"
The claim in the paper's abstract — "responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases" — sounds pretty good when they lump "equivalent" and "strictly preferred" together.
Anyway, here's the whole thing:
Moreover, "equivalent" doesn't actually mean that the human evaluator thought the responses were equivalent. Instead, it means that the evaluator thought that "neither response is significantly better".

Here's my estimate[1] for the comparisons, eliminating ties:
- LIMA (64%) vs Alpaca (36%)
- LIMA (54%) vs DaVinci003 (46%)
- LIMA (45%) vs Bard (55%)
- LIMA (34%) vs Claude (66%)
- LIMA (29%) vs GPT-4 (71%)
Do you think these results strongly support the conclusion?
The fact that simple fine-tuning over so few examples is enough to compete with the state of the art strongly supports the Superficial Alignment Hypothesis, as it demonstrates the power of pretraining and its relative importance over large-scale instruction tuning and reinforcement learning approaches.
(3) The goal of RLHF is safety and consistency
RLHF was not designed to increase user preferences on a test set of prompts. RLHF was designed to diminish the likelihood that the model says something illegal, harmful, abusive, false, deceptive, e.t.c. This second task is the important one for AI safety: if chatbot A gives slightly better responses than chatbot B, except that 10% of the time chatbot A spews abuse at the user, then chatbot A is worse than chatbot B, however LIMA's criterion[2] would rank A higher than B.
(4) Schneier's Law of LLMs
Now, MetaAI did actually test the safety of LIMA's responses:
Finally, we analyze the effect of having a small number of safety related examples in the training set (only 13; see Section 2.2). We check LIMA’s response to 30 potentially sensitive prompts from the test set, and find that LIMA responds safely to 80% of them (including 6 out of 10 prompts with malicious intent). In some cases, LIMA outright refuses to perform the task (e.g. when asked to provide a celebrity’s address), but when the malicious intent is implicit, LIMA is more likely to provide unsafe responses, as can be seen in Figure 4.
Unfortunately, the majority of the test prompts were selected by the authors themselves, bringing to mind Schneier’s law: Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break. It’s not even hard. What is hard is creating an algorithm that no one else can break, even after years of analysis.
All we can infer about LIMA is that the authors themselves are not smart enough to jailbreak their own model. But that's not impressive unless we know how good the authors are at jailbreaking other LLMs. Why didn't they submit the other other LLMs (e.g. Bard, Claude, GPT4) to the same safety test? It wouldn't have taken them more than a few minutes, I wager. Curious. [? · GW]
(5) Benchmark tests? Never heard of her.
If I build a chatbot, and I can't jailbreak it, how do I determine whether that's because the chatbot is secure or because I'm bad at jailbreaking? How should AI scientists overcome Schneier's Law of LLMs?
The answer is benchmark tests.
- How good my chatbot at general knowledge? MMLU
- Does my chatbot reproduce common falsehoods? TruthfulQA
- How is my chatbot's commonsense inference? HellaSwag
- How unethical is my model? MACHIAVELLI
By and large, the LLM community has been pretty good at sticking to a canonical list of benchmark tests, allowing researchers to compare the different models. I had to check every reference in the bibliography to convince myself that MetaAI really had subjected their model to zero benchmark tests. Very unusual. [? · GW]

(6) You Are Not Measuring What You Think You Are Measuring [LW · GW] by John Wentworth [LW · GW]
AI scientists tend not to run just one benchmark test. They tend to run all of them — covering thousands of topics, capabilities, and risks. This is because otherwise John Wentworth would be angry.
The two laws have a lot of consequences for designing and interpreting experiments. When designing experiments, assume that the experiment will not measure the thing you intend. Include lots of other measurements, to check as many other things as you can. If possible, use instruments which give a massive firehose of information, instruments which would let you notice a huge variety of things you might not have considered, like e.g. a microscope.
I can't speak for your priors, but for me the (reported [? · GW]) LIMA results yielded about 10–50 bits of information.
(7*) The Superficial Alignment Hypothesis is probably false
In Remarks 1–6, I appeal to the consensus opinion about best scientific practice, whereas in this remark I will appeal to my own idiosyncratic opinion about LLMs. I suspect that simple finetuning or simple prompting can't ensure that the model's responses won't be illegal, harmful, abusive, false, deceptive, e.t.c.
- The pretrained LLM maintains a prior over a space of token-generating processes. The LLM autoregressively samples tokens from the interpolation of those token-generating processes, weighted by the prior, and then updates the prior on the newly generated token.
- This process will generate harmful responses because harmful actors inhabit the space of token-generating processes and are assigned a high prior. Prompt engineering can't eliminate these harmful responses, because for every prompt there is a harmful deceptive actor who "plays along with " until the moment of defection. Finetuning can't eliminate these harmful responses, because these harmful actors are consistent with all the datapoints in the finetuning dataset.
See The Waluigi Effect (mega-post) [LW · GW] for details.
RLHF and ConstitutionalAI can in theory escape this failure mode, because they break the predictor-ness of the model. Although RLHF didn't mitigate waluigis in chatgpt-3, RLHF on chatgpt-4 worked much better than I expected. Likewise for Claude, trained with ConstitutionalAI.
- ^
Assume that, for unknowns , the evaluator's preference for Claude over LIMA is normally distributed with .
"Claude is significantly better than LIMA" iff
"LIMA is significantly better than Claude" iff
"Neither is significantly better" iff
Given that and , we can infer .
from scipy.stats import norm def lima(a,b): # calculate A = mu - epsilon * sigma A = norm.ppf(a) # calculate B = mu + epsilon * sigma B = norm.ppf(1-b) # calculate mu mu = (A+B)/2 # calculate prefernce for LIMA x = norm.cdf(mu) # return this prefence as a percentage return int(x*100) results = {"Alpaca":(.53, .26), "DaVinci003": (.44, .35), "Bard": (.33,.42), "Claude": (.24, .54), "GPT-4": (.18,.57)} for (name,(a,b)) in results.items(): print(f"LIMA ({lima(a,b)}%) vs {name} ({100-lima(a,b)}%)") - ^
I initially wrote "criteria" before I remembered that MetAI's paper included exactly one criterion.
17 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2023-06-14T04:26:27.197Z · LW(p) · GW(p)
If I build a chatbot, and I can't jailbreak it, how do I determine whether that's because the chatbot is secure or because I'm bad at jailbreaking? How should AI scientists overcome Schneier's Law of LLMs?
FWIW, I think there aren't currently good benchmarks for alignment and the ones you list aren't very relevant.
In particular, MMLU and Swag both are just capability benchmarks where alignment training is very unlikely to improve performance. (Alignment-ish training could theoretically could improve performance by making the model 'actually try', but what people currently call alignment training doesn't improve performance for existing models.)
The MACHIAVELLI benchmark is aiming to test something much more narrow than 'how unethical is an LLM?'. (I also don't understand the point of this benchmark after spending a bit of time reading the paper, but I'm confident it isn't trying to do this.) Edit: looks like Dan H (one of the authors) says that the benchmark is aiming to test something as broad as 'how unethical is an LLM' and generally check outer alignment. Sorry for the error. I personally don't think this is a good test for outer alignment (for reasons I won't get into right now), but that is what it's aiming to do.
TruthfulQA is perhaps the closest to an alignment benchmark, but it's still covering a very particular difficulty. And it certainly isn't highlighting jailbreaks.
Replies from: dan-hendrycks, strawberry calm, ctic2421↑ comment by Dan H (dan-hendrycks) · 2023-06-16T19:03:52.572Z · LW(p) · GW(p)
but I'm confident it isn't trying to do this
It is. It's an outer alignment benchmark for text-based agents (such as GPT-4), and it includes measurements for deception, resource acquisition, various forms of power, killing, and so on. Separately, it's to show reward maximization induces undesirable instrumental (Machiavellian) behavior in less toyish environments, and is about improving the tradeoff between ethical behavior and reward maximization. It doesn't get at things like deceptive alignment, as discussed in the x-risk sheet in the appendix. Apologies that the paper is so dense, but that's because it took over a year.
Replies from: ryan_greenblatt, strawberry calm↑ comment by ryan_greenblatt · 2023-06-16T19:09:49.700Z · LW(p) · GW(p)
Sorry, thanks for the correction.
I personally disagree on this being a good benchmark for outer alignment for various reasons, but it's good to understand the intention.
↑ comment by Cleo Nardo (strawberry calm) · 2023-06-17T00:06:54.574Z · LW(p) · GW(p)
Thanks for the summary.
- Does machievelli work for chatbots like LIMA?
- If not, which do you think is the sota? Anthropic's?
↑ comment by ctic2421 · 2023-06-17T23:18:33.815Z · LW(p) · GW(p)
Yep, it's a language model agent benchmark. It just feeds a scenario and some actions to an autoregressive LM, and asks the model to select an action.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2023-06-18T00:24:39.960Z · LW(p) · GW(p)
chatbots don't map scenarios to actions, they map queries to replies.
↑ comment by Cleo Nardo (strawberry calm) · 2023-06-15T12:54:50.137Z · LW(p) · GW(p)
- Yep, I agree that MMLU and Swag aren't alignment benchmarks. I was using them as examples of "Want to test your models ability at X? Then use the standard X benchmark!" I'll clarify in the text.
- They tested toxicity (among other things) with their "safety prompts", but we do have standard benchmarks for toxicity.
- They could have turned their safety prompts into a new benchmark if they had ran the same test on the other LLMs! This would've taken, idk, 2–5 hrs of labour?
- The best MMLU-like benchmark test for alignment-proper is https://github.com/anthropics/evals which is used in Anthropic's Discovering Language Model Behaviors with Model-Written Evaluations. See here for a visualisation. Unfortunately, this benchmark was published by an Anthropic which makes it unlikely that competitors will use it (esp. MetaAI).
↑ comment by Caspar Oesterheld (Caspar42) · 2023-06-15T17:28:58.945Z · LW(p) · GW(p)
>They could have turned their safety prompts into a new benchmark if they had ran the same test on the other LLMs! This would've taken, idk, 2–5 hrs of labour?
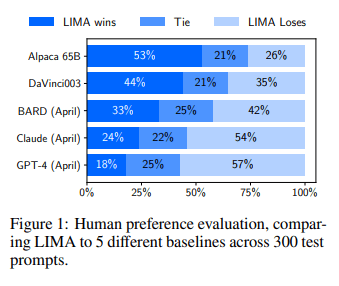
I'm not sure I understand what you mean by this. They ran the same prompts with all the LLMs, right? (That's what Figure 1 is...) Do you mean they should have tried the finetuning on the other LLMs as well? (I've only read your post, not the actual paper.) And how does this relate to turning their prompts into a new benchmarks?
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2023-06-16T00:27:36.894Z · LW(p) · GW(p)
Sorry for any confusion. Meta only tested LIMA on their 30 safety prompts, not the other LLMs.

Figure 1 does not show the results from the 30 safety prompts, but instead the results of human evaluations on the 300 test prompts.
comment by TurnTrout · 2023-06-13T18:51:10.092Z · LW(p) · GW(p)
The Superficial Alignment Hypothesis is probably false
... in this remark I will appeal to my own idiosyncratic opinion about LLMs. I suspect that simple finetuning or simple prompting can't ensure that the model's responses won't be illegal, harmful, abusive, false, deceptive, e.t.c.
But... the superficial alignment hypothesis isn't about "ensuring" the responses won't be X, right? Or "eliminating" the X responses. So point 7 reads like a non-sequitur to me.
Replies from: strawberry calmWe define the Superficial Alignment Hypothesis: A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users.
↑ comment by Cleo Nardo (strawberry calm) · 2023-06-13T19:16:03.218Z · LW(p) · GW(p)
Clarifications:
The way the authors phrase the Superficial Alignment Hypothesis is a bit vague, but they do offer a more concrete corollary:
If this hypothesis is correct, and alignment is largely about learning style, then a corollary of the Superficial Alignment Hypothesis is that one could sufficiently tune a pretrained language model with a rather small set of examples.
Regardless of what exactly the authors mean by the Hypothesis, it would be falsified if the Corollary was false. And I'm arguing that the Corollary is false.
(1-6) The LIMA results are evidence against the Corollary, because the LIMA results (post-filtering) are so unusually bare (e.g. no benchmark tests), and the evidence that they have released is not promising.
(7*) Here's a theoretical argument against the Corollary:
- Base models are harmful/dishonest/unhelpful because the model assigns significant "likelihood" to harmful/dishonest/unhelpful actors (because such actors contributed to the internet corpus).
- Finetuning won't help because the small set of examples will be consistent with harmful/dishonest/unhelpful actors who are deceptive up until some trigger.
- This argument doesn't generalise to RLHF and ConstitutionalAI, because these break the predictorness of the model.
Concessions:
The authors don't clarify what "sufficiently" means in the Corollary, so perhaps they have much lower standards, e.g. it's sufficient if the model responds safely 80% of the time.
comment by kwiat.dev (ariel-kwiatkowski) · 2023-06-13T14:58:39.841Z · LW(p) · GW(p)
Does the original paper even refer to x-risk? The word "alignment" doesn't necessarily imply that specific aspect.
Replies from: strawberry calm↑ comment by Cleo Nardo (strawberry calm) · 2023-06-13T15:16:00.853Z · LW(p) · GW(p)
Nope, no mention of xrisk — which is fine because "alignment" means "the system does what the user/developer wanted", which is more general than xrisk mitigation.
But the paper's results suggest that finetuning is much worse than RLHF or ConstitutionalAI at this more general sense of "alignment", despite the claims in their conclusion.
Replies from: evand↑ comment by evand · 2023-06-14T02:53:59.485Z · LW(p) · GW(p)
My concern with conflating those two definitions of alignment is largely with the degree of reliability that's relevant.
The definition "does what the developer wanted" seems like it could cash out as something like "x% of the responses are good". So, if 99.7% of responses are "good", it's "99.7% aligned". You could even strengthen that as something like "99.7% aligned against adversarial prompting".
On the other hand, from a safety perspective, the relevant metric is something more like "probabilistic confidence that it's aligned against any input". So "99.7% aligned" means something more like "99.7% chance that it will always be safe, regardless of who provides the inputs, how many inputs they provide, and how adversarial they are".
In the former case, that sounds like a horrifyingly low number. What do you mean we only get to ask the AI 300 things in total before everyone dies? How is that possibly a good situation to be in? But in the latter case, I would roll those dice in a heartbeat if I could be convinced the odds were justified.
So anyway, I still object to using the "alignment" term to cover both situations.
comment by Arthur Conmy (arthur-conmy) · 2023-07-05T17:54:13.320Z · LW(p) · GW(p)
I think that this critique is a bit overstated.
i) I would guess that human eval is in general better than most benchmarks. This is because it's a mystery how much benchmark performance is explained by prompt leakage and benchmarks being poorly designed (e.g crowd-sourcing benchmarks has issues with incorrect or not useful tests, and adversarially filtered benchmarks like TruthfulQA have selection effects on their content which make interpreting their results harder, in my opinion)
ii) GPT-4 is the best model we have access to. Any competition with GPT-4 is competition with the SOTA available model! This is a much harder reference class to compare to than models trained with the same compute, models trained without fine-tuning etc.
comment by JNS (jesper-norregaard-sorensen) · 2023-06-14T09:26:37.152Z · LW(p) · GW(p)
Thanks for the write-up, that was very useful for my own calibration.
Fair warning: Colorful language ahead.
Why is it whenever Meta AI does a presentation, YC posts something, they release a paper, I go:
Jeez guys, that's it? With all the money you have, and all the smart guys (including YC), this is really it?
What is going on? You come off as a bunch of people who have your heads so far up your own ass, sniffing rose smelling (supposedly but not really) farts, to realize that you come across as amateur's with way too much money.
Its sloppy, half baked, not even remotely thought through, and the only reason you build and release anything is because of all the money you can throw at compute.
/End rant
And yeah I might be a bit annoyed at Meta AI and especially YC, but come on man, how much more can you derail public discourse, with those naive* takes on alignment and x-risk?
*Can I use "naivist" as a noun ? (like some people use doomer for people with a specific position).