Devin has its own web browser, which it uses to pull up documentation.
Devin has its own code editor.
Devin has its own command line.
Devin uses debugging print statements and uses the log to fix bugs.
Devin builds and deploys entire stylized websites without even being directly asked.
What could possibly go wrong? Install this on your computer today.
Padme.
The Real Deal
I would by default assume all demos were supremely cherry-picked. My only disagreement with Austen Allred’s statement here is that this rule is not new:
He is very much a maximum acceleration guy, for whom everything is always great and the future is always bright, so calibrate for that, but still yes this seems like evidence Devin is for real.
This article in Bloomberg from Ashlee Vance has further evidence. It is clear that Devin is a quantum leap over known past efforts in terms of its ability to execute complex multi-step tasks, to adapt on the fly, and to fix its mistakes or be adjusted and keep going.
For once, when we wonder ‘how did they do that, what was the big breakthrough that made this work’ the Cognition AI people are doing not only the safe but also the smart thing and they are not talking.
They do have at least one series rival, as Magic.ai has raised $100 million from the venture team of Daniel Gross and Nat Friedman to build ‘a superhuman software engineer,’ including training their own model. The article seems strange interested in where AI is ‘a bubble’ as opposed to this amazing new technology.
This is one of those ‘helps until it doesn’t situations’ in terms of jobs:
vanosh: Seeing this is kinda scary. Like there is no way companies won’t go for this instead of humans.
Should I really have studied HR?
Mckay Wrigley: Learn to code! It makes using Devin even more useful.
Devin makes coding more valuable, until we hit so many coders that we are coding everything we need to be coding, or the AI no longer needs a coder in order to code. That is going to be a ways off. And once it happens, if you are not a coder, it is reasonable to ask yourself: What are you even doing? Plumbing while hoping for the best will probably not be a great strategy in that world.
Aravind Srinivas (CEO Perplexity): This is the first demo of any agent, leave alone coding, that seems to cross the threshold of what is human level and works reliably. It also tells us what is possible by combining LLMs and tree search algorithms: you want systems that can try plans, look at results, replan, and iterate till success. Congrats to Cognition Labs!
Andres Gomez Sarmiento: Their results are even more impressive you read the fine print. All the other models were guided whereas devin was not. Amazing.
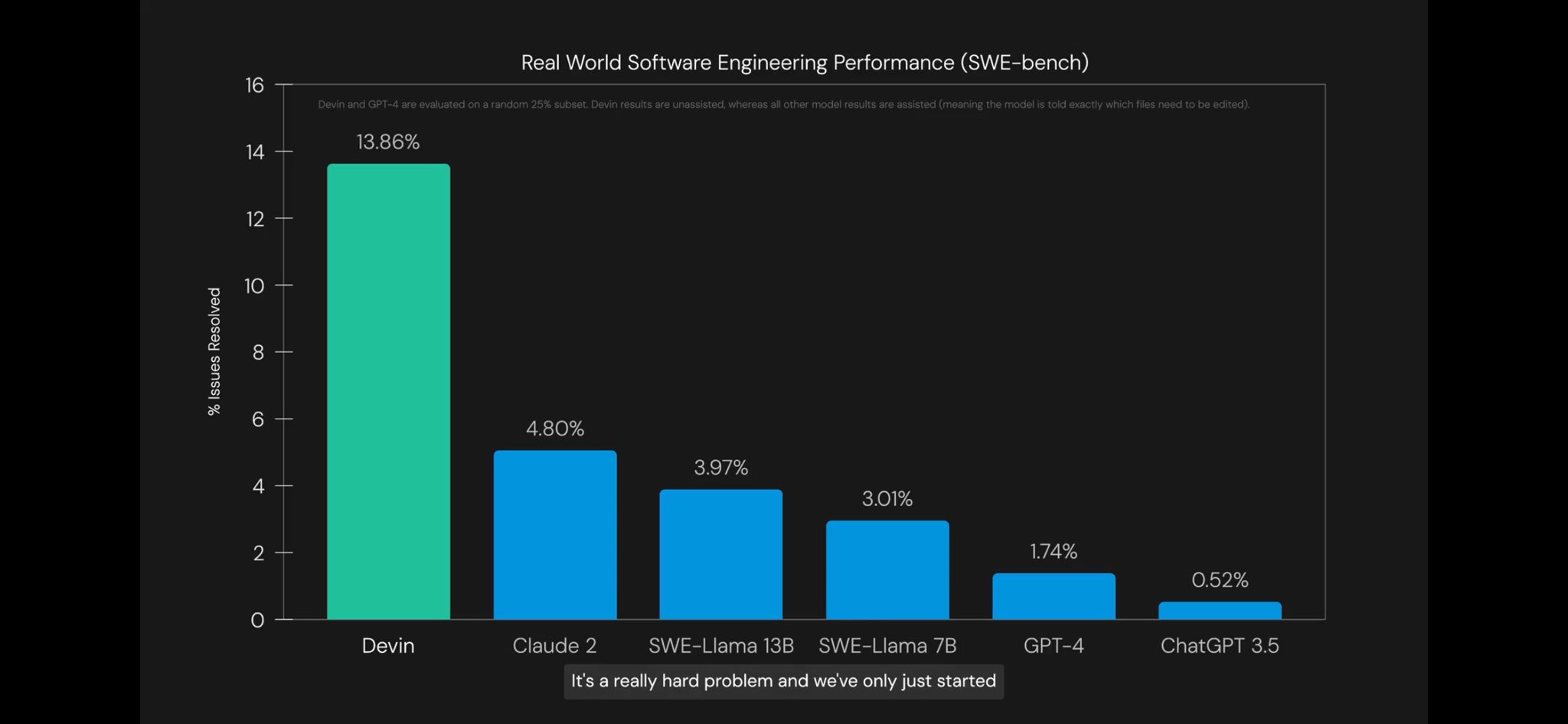
Deedy: I know everyone’s taking about it, but Devin’s 13% on SWE Bench is actually incredible.
Just take a look at a sample SWE Bench problem: this is a task for a human! Shout out to Carlos Jimenez for the fantastic dataset.
This is what exponential growth looks like (source).
What Could Possibly Go Subtly Wrong?
I mean, yes, recursive self-improvement (RSI), autonomous agents seeking power and money and to wreck havoc whether or not this was an explicit instruction (and oh boy will it be an explicit instruction).
And of course there is losing control of your compute and accounts and your money and definitely your crypto and all that, obviously.
And there is the amount you had better trust whoever is making Devin.
But beyond that. What happens when this is used as designed without blowing up in someone’s face too blatantly? What more subtle things might happen?
One big danger is that AIs do not like to tell their manager that the proposed project is a bad idea. Another is that they write code without thinking too hard about how it will need to be maintained, or what requirements it will have to hook into the rest of the system, or what comments will allow humans (or other AIs) to understand it, and generally by default make a long term time bomb mess of everything involved.
GFodor.id: Managers are going to get such relief when they replace their senior engineers who always told them why they couldn’t do X or Y with shoddy AI devs who just do what they’re told.
Then the race is between the exponential tech debt spaghetti bomb and good AI devs appearing in time.
Real Selim Shady: I’m grabbing my popcorn. This will be the new crusade execs go on, brought to you by the same execs that had to bring back US engineering teams after a couple years of overseas outsourcing.
GFodor: No, I think that analogy is going to lead to a lot of mistakes in predicting what will happen.
What probably happens is some companies pull the trigger too early and implode but the ones that recover will do so by upgrading their AI devs. The jobs won’t be coming back.
Nick Dobos: Embrace the spaghetti code.
Devin or another similar AI will not properly appreciate the long term considerations involved in writing code that humans or other AIs will then be working to modify. This is not an easy thing to build into the incentive structure.
Nor is the question of whether your you should, even if technically you could. Or, the question of whether you ‘could’ in the sense that a senior engineer would stop you and tell you the reasons you ‘can’t’ do that even if you technically have a way to do it, which is a hybrid of the two.
Ideally over time people will learn how to include such considerations in the instruction set and make this less terrible, and find ways to ensure they are making less doomed or stupid requests, but all of this is going to be a problem even in good scenarios.
What Could Possibly Go Massively Wrong for You?
I find it odd no one is discussing this question.
How do you use Devin while ensuring that your online accounts and money at the bank and reputation and computer and hard drive remain safe, on a very practical, ‘I do not want something dumb to happen’ kind of way?
Also, how do you use Devin and then know you can rely on the results for practical purposes?
How do you dare put this level of trust and power in an autonomous coding agent?
I would love to be able to use something like Devin, if it is half as good as these demos say it is and of course it will only get better over time. The mundane utility is so obvious, so great, I am roaring to go. Except, how would I dare?
Let’s take a simple concrete example that really should be harmless and within its range. Say I want it to build me a website, or I want it to download and implement a GitHub repo and perhaps make a few tweaks, for example to download a new image model and some cool additional tricks for it.
I still need to know why giving Devin a command line and a code editor, and the ability to execute arbitrary code including things downloaded from arbitrary places on the internet, is not going to cook my goose.
One obvious solution is to completely isolate Devin from all of your other files and credentials. So you have a second computer that only runs Devin and related programs. You don’t give that computer any passwords or credentials that you care about. Maybe you find a good way to sandbox it.
I am not saying this cannot be done. On the contrary, if this is cool enough, while staying safe on a broader level, then I am positive that it can be done. There is a way to do it locally safely, if you are willing to jump through the hoops to do that. We just haven’t figured out what that is yet.
I am also presuming that there will be a lot of people who, unless that safety is made the default, will not take those steps, and sometimes hilarity will ensue.
I am not saying I will be Jack’s complete lack of sympathy, but… yeah.
If This is What Skepticism Looks Like
As with those who claim to pick winners in sports, if someone is offering to sell you a software engineer, well, there is an upper limit on how good it might be.
Anton: Real talk, if you actually built a working “ai engineer” – what’s stopping you from scaling to 1000x and dominating the market (building everything)? Instead it’s being sold as a product hmmm
That upper limit is still quite high. People can do things on their own with workflows that would not make sense if they had to go through your company. You act as a force multiplier on projects you could not otherwise get involved with. Scaling up your operation without selling the product is not a trivial task. Even if you have the software engineer, that does nto mean you have the managers and architects, or the ideas, or any number of other things.
Also, by selling the product, it gets lots of data with which you can make the product so much better.
AI is NOWHERE near automating software engineering.
Of course, a co-pilot is great for increasing productivity, but AI is strictly just an assistant to aid programming professionals.
We are at least 3-5 years away from automating software engineering.
Claudiu: 3-5 years… is that a lot now? If you think so, think again: someone who just entered the field, in their 20s, is about half a century away from retirement. I don’t think they’ll like the prospects they have.
No, being able to do (presumably the easiest) 13.8% of Upwork projects does not mean you are that close to automating software engineering.
It does mean we are a lot closer, or at least making more progress, than we looked a week ago. Agents are working better in the current generation of LLMs than we anticipated, and will get much better when GPT-5 and friends drop, which will improve all the other steps as well. Devin is a future product being built for the future.
Even if you can get Devin or a similar agent to do these kinds of tasks reliably, being able to then use that to get maintainable code, to build up larger projects, to get things you can deploy and count on, is a very different matter. This is an extremely wrong road, and it seems AGI complete.
I agree that we are ‘at least 3-5 years away.’
But I had the same thought as Claudiu. That is not very many years.
It is also a supremely scary potential event.
What happens after you fully automate software engineering? Or if you, in magic.ai’s terms, build ‘a superhuman’ software engineer, which you can copy?
What Happens If You Fully Automate Software Engineering
Horror Unpacked: I see Devin and then I remember http://magic.ai getting 100m to automate SWEs, and how the frontier models are all explicitly specced for code, and I feel like I should have known that we’d all race to get underneath the lowest possible bar for x-risk.
Alternatively, consider this discussion under Mckay Wrigley’s post:
James: You can just ‘feel’ the future. Imagine once this starts being applied to advanced research. If we get a GPT5 or GPT6 with a 130-150 IQ equivalent, combined with an agent. You’re literally going to ask it to ‘solve cold fusion’ and walk away for 6 months.
Mckay Wrigley: Exactly. The mistake people make is assuming it won’t improve. And it blows my mind how many people make this mistake, even those that are in tech.
Kevin Siskar: McKay, do you think you will build a “agent UI” frontend into ChatbotUI [that is built by the agent in the video]?
Mckay Wrigley: This is in the works :)
Um. I. Uh. I do not think you have thought about the implications of ‘solve cold fusion’ being a thing that one can do at a computer terminal?
What else could you type into that computer terminal?
There are few limits to what you can type into that terminal. There are also few limits of what might happen after you do so. The future gets weird and unknown, and it gets weird and unknown fast. The chances that the resulting configurations of atoms contain no human beings, and rather quickly? Rather high.
Paul Graham: We seem to be moving from “software is eating the world” to “software written by software is eating the world.”
I wonder how many “software written by”s ultimately get prepended.
This is one of those cases where the number are one, two and many. If you get software^3, well, hold onto your butts.
I want to be very clear that none of this this is something I worry about for Devin as it exists right now.
As noted above, I am terrified on a practical level of using Devin on my own computer. But that is a distinct class of concern. Devin 1 is not going to be good enough to build Devin 2 on its own (although it would presumably help), or to cause an extinction event, or anything like that, unless they really do not like shipping early products.
I do notice that this is exactly the lowest-resistance default shortest path to ensuring that AI agents exist and have the capabilities necessary to cause serious trouble at the earliest possible moment, when sufficient improvements are made in various places. Our strongest models are optimizing for writing code, and we are working on how to have them write code and form and execute plans for making software without humans in the loop. You do not need to be a genius to know how that story might end.
What Could Possibly Go Massively Wrong for Everyone?
As discussed in the previous section, the most obvious failure mode is eventually recursive self-improvement, or RSI.
Or, even without that, setting such programs off to do various things autonomously, including to make money or seek power, often in ways (intentionally or otherwise) that make it difficult to turn off for its author, for others or for both.
We also have instrumental convergence. Devin is designed to handle obstacles and find ways to solve problems. What happens when a sufficiently capable version of this is given a mission that it lacks the resources to directly complete? What will it do if the task requires more compute, or more access, or persuading people, and so on? At some point some future version is going to go there.
There also does not seem to be any reasonable way to keep Devin from implementing things that would be harmful or immoral? At best this is alignment to the user and the request of the user. And there is no attempt to actually consider what other impacts might happen along the way.
In general, this is giving everyone the capability to take an agent capable of coding complex things in multiple steps and planning around obstacles and problems, give it an arbitrary goal, and give it full access to our world and the internet. Then we hope it all works out for the best.
And we all race to make such systems more capable and intelligent, better at doing that, until… well… yeah.
Even if everyone involved means well, and even if none of the direct simple failure modes happen, sufficiently efficient and capable and intelligent agents given goals that will advance people’s individual causes creates dynamics that seem to by default doom us. Remember that giving such agents maximum freedom of action tends to be economically efficient.
As one might expect Tyler Cowen to say, model this.
At best, we are about to go down a highly volatile and dangerous road.
Conclusion: Whistling Past
This is somewhat of a reiteration, but it needs to be made very salient and clear.
One should periodically pause to notice how a new technological marvel like Devin compares to prior models of how things would go. We don’t know if Devin has the full capabilities that people are saying it does, or how far that will go in practice, but it is clearly a big step up, and more steps up are coming. This is happening.
Remember all those precautions any sane person would obviously take before letting something like Devin exist, or using it?
How many of those does it look like Devin is going to be using?
Even if that is mostly harmless now, what does that tell you about the future?
Also consider what this implies about future capabilities.
If you were counting on AIs or LLMs not having goals or not wanting things? If you were counting on them being unable to make plans or handle obstacles? If that was what was making you think everything was going to be fine?
Well, set all that aside. People are hard at work invalidating that hope, and it sure looks like they are going to succeed.
That does not mean that any given future new LLM couldn’t be implemented without letting such a system be attached to it. You could keep close watch on the weights. You could do all the precautions, up to and including things like air gapping the system and assuming it is unsafe for humans to view outputs during testing. You can engineer the system to only do a narrow set of things that you predict allow us to proceed safely. You can apply various control and alignment techniques. There are many options. Some of them might work.
I am not filled with confidence that anyone will even bother to try.
And of course, going forward, one must remember that there will be an open source implementation of an agent similar to Devin, that will continuously improve over time. You can then plug into that any model with open weights, and anything derived from that model. And by you may, I mean someone clearly will, and then do whatever the funniest possible thing is, also the most dangerous, because people are like that.
So, choose your actions and policy regime accordingly.
This seems to be as good of a place as any to post my unjustified predictions on this topic, the second of which I have a bet outstanding on at even odds.
Devin will turn out to be just a bunch of GPT-3.5/4 calls and a pile of prompts/heuristics/scaffolding so disgusting and unprincipled only a team of geniuses could have created it.
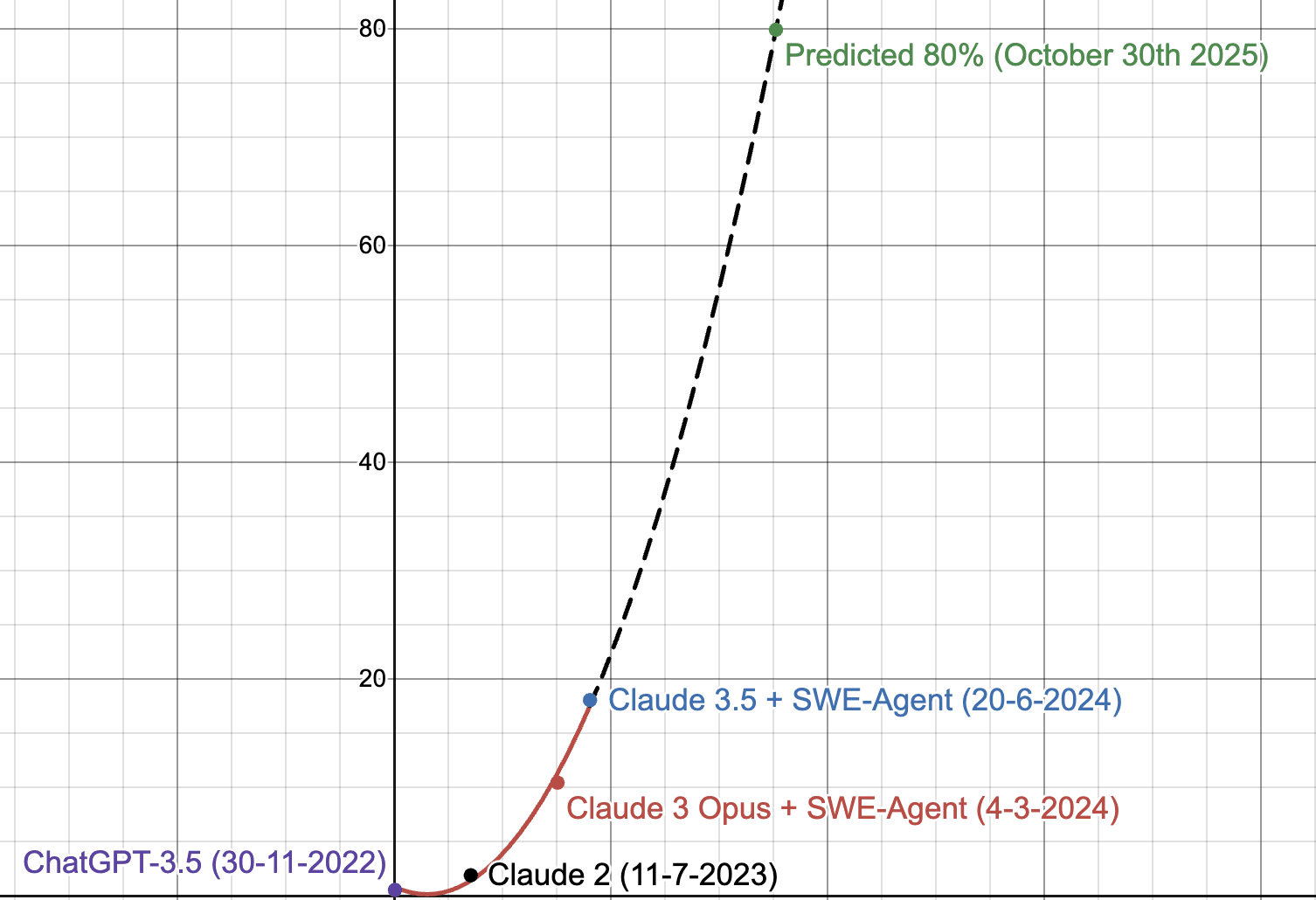
Someone will create an agent that gets 80%+ on SWE-Bench within six months.
I am not sure if 1. being true or false is good news. Both suggest we should update towards large jumps in coding ability very soon.
Regarding RSI, my intuition has always been that automating AI research will likely be easier than automating the development and maintenance of a large app like, say, Photoshop, So I don't expect fire alarms like "non-gimmicky top 10 app on AppStore was developed entirely autonomously" before doom.
Someone will create an agent that gets 80%+ on SWE-Bench within six months.
I think this is probably above the effective cap on the current implementation of SWE-bench (where you can't see test cases) because often test cases are specific to the implementation.
E.g. the test cases assume that a given method was named a particular thing even though the task description doesn't specify.
Your timeline was off, but I think your original comment will turn out to have had the right idea. Given the leaps from GPT-3.5 to GPT-4 to Devin to Claude 3.5-Sonnet w/scaffolding, marginal seeming updates to models are turning out to be quite substantial in effective capability. It's hard to create evaluation harnesses for fuzzy, abstract things like the syntax complexity models can handle, and those abilities do transfer to using the models to automate their own post-training tasks, e.g. like what the self-alignment backtranslation paper's scaling charts showed. The better the model, the better they accomplish these tasks with worse task definitions and less help. The piles of prompts necessary for current agents will be less and less necessary, at some point generated on the fly to meek descriptions like "make a code agent to do ${task}" by the models themselves. Whatever human effort will go into the next generation of unprincipled scaffolding will provide yet greater returns to future models. These factors combined, I expect SWE-Bench progress to be discontinuous and rapid, as it has been so far.
A very naive extrapolation using polynomial regression from SWE-Bench scores suggests ≥80% by November 2025. I used model release dates for my x-value. Important to note models may be contaminated too.
1) ...a pile of prompts/heuristics/scaffolding so disgusting and unprincipled only a team of geniuses could have created it
I chuckled out loud over this. Too real.
Also, regarding that second point, how to you plan to adjudicate the bet? It is worded as "create" here, but what can actually be seen to settle the bet will be the effects.
There are rumors coming out of Google including names like "AlphaCode" and "Goose" that suggest they might have already created such a thing, or be near to it. Also, one of the criticisms of Devin (and Devin's likelihood of getting better fast) was that if someone really did crack the problem then they'd just keep the cow and sell the milk. Critch's "tech company singularity" scenario comes to mind.
The bet is with a friend and I will let him judge.
I agree that providing an api to God is a completely mad strategy and we should probably expect less legibility going forward. Still, we have no shortage of ridiculously smart people acting completely mad.
... is that a prototypical problem from that benchmark? Because if so, that is a hilariously easy benchmark. Like, something could ace that task and still be coding at less than a CS 101 level.
(Though to be clear, people have repeatedly told me that a surprisingly high fraction of applicants for programming jobs can't do fizzbuzz, so even a very low level of competence would still put it above many would-be software engineers.)
people have repeatedly told me that a surprisingly high fraction of applicants for programming jobs can't do fizzbuzz
I've heard it argued that this isn't representative of the programming population. Rather, people who suck at programming (and thus can't get jobs) apply to way more positions than people who are good at programming.
I have no idea if it's true, but it sounds plausible.
Rather, people who suck at programming (and thus can't get jobs) apply to way more positions than people who are good at programming.
I have interviewed a fair number of programmers, and I've definitely seen plenty of people who talked a good game but who couldn't write FizzBuzz (or sum the numbers in an array). And this was stacking the deck in their favor: They could use a programming language of their choice, plus a real editor, and if they appeared unable to deal with coding in front of people, I'd go sit on the other side of the office and let them work for a bit.
I do not think these people were representative of the average working programmer, based on my experiences consulting at a variety of companies. The average engineer can write code.
It took longer to get from AutoGPT to Devin than I initially thought it would, though in retrospect it only took "this long" because that's literally about how long it takes to productize something comparatively new like this.
It does make me realize though that the baking timer has dinged and we're about to see a lot more of this stuff coming out of the oven.
See also MultiOn and Maisa. Both are different agent enhancements for LLMs that claim notable new abilities on benchmarks. MultiOn can do web tasks, Maisa scores better on reasoning tasks than COT prompting and uses more efficient calls for lower cost. Neither is in deployment yet, neither company exains exactly how they're engineered. Ding! Ding!
I also thought developing agents was taking too long until talking to a few people actually working on them. LLMs include new types of unexpected behavior, so engineering around that is a challenge. And there's the standard time to engineer anything reliable and usable enough to be useful.
So, we're right on track for language model cognitive architectures [LW · GW] with alarmingly fast timelines, coupled with a slow enough takeoff that we'll get some warning shots.
Edit: I just heard about another one, GoodAI, developing the episodic (long term) memory that I think will be a key element of LMCA agents. They outperform 128k context GPT4T with only 8k of context, on a memory benchmark of their own design, at 16% of the inference cost. Thanks, I hate it.
Edit: I just heard about another one, GoodAI, developing the episodic (long term) memory that I think will be a key element of LMCA agents. They outperform 128k context GPT4T with only 8k of context, on a memory benchmark of their own design, at 16% of the inference cost. Thanks, I hate it.
GoodAI's Web site says they're working on controlling drones, too (although it looks like a personal pet project that's probably not gonna go that far). The fun part is that their marketing sells "swarms of autonomous surveillance drones" as "safety". I mean, I guess it doesn't say killer drones...
Very little alignment work of note, despite tons of published work on developing agents. I'm puzzled as to why the alignment community hasn't turned more of their attention toward language model cognitive architectures/agents, but I'm also reluctant to publish more work advertising how easily they might achieve AGI.
ARC Evals did set up a methodology for Evaluating Language-Model Agents on Realistic Autonomous Tasks. I view this as a useful acknowledgment of the real danger of better LLMs, but I think it's inherently inadequate, because it's based on the evals team doing the scaffolding to make the LLM into an agent. They're not going to be able to devote nearly as much time to that as other groups will down the road. New capabilities are certainly going to be developed by combinations of LLM improvements, and hard work at improving the cognitive architecture scaffolding around them.
I think evals are fantastic (ie obviously a good and correct thing to do; dramatically better than doing nothing) but there is a little bit of awkwardness in terms of deciding how hard to try. You don't really want to spend a well-funded-startup's worth of effort to trigger dangerous capabilities (and potentially cause your own destruction), but you know eventually that someone will. I don't know how to resolve this.
Totally agree with you here. I think probably half of their development energy was spent getting to where GPT-4 Functions were right when Functions came out and they were probably like...oh...welp.
Is Devin using GPT-4, GPT-4T, or one of the 2 currently available long context models, Claude Opus 200k or Gemini 1.5?
March 14, 2023 is GPT-4, but the "long" context was expensive and initially unavailable to anyone Reason that matters is November 6, 2023 is the announcement for GPT-4T, which is 128k context.
Feb 15, 2024 is Gemini 1.5 LC
March 4, 2024 is Claude 200k is
That makes the timeline less than 4 months, and remember there's a few weeks generally between "announcement" and "here's your opportunity to pay for tokens with an API key".
The prompting structure and meta-analysis for "Devin" was likely in the works since GPT-4, but without the long context you can't fit:
[system prompt forced on you] ['be an elite software engineer' prompt] [ issue description] [ main source file ] [ data structures referenced in the main source file ] [ first attempt to fix ] [ compile or unit test outputs ]
In practice I found that I need Opus 200k to even try when I do the above by hand.
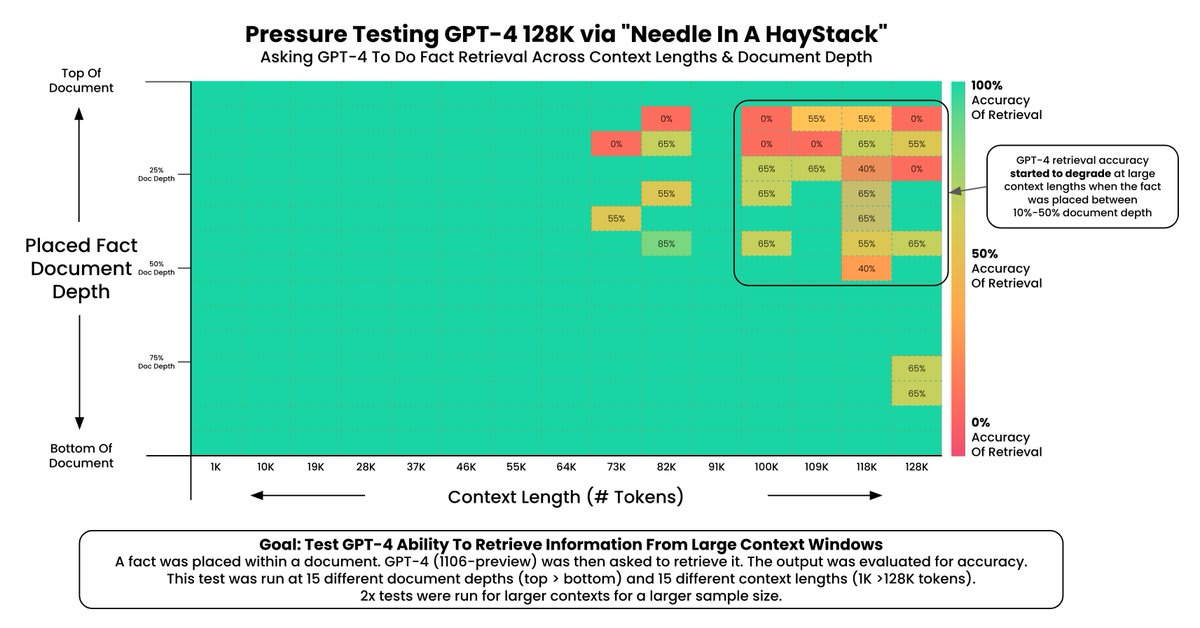
Also remember, GPT-4 128k starts failing near the end of it's context window, the full 128k is not usable:
I hear that they use GPT-4. If you are looking at timelines, recall that Cognition apparently was founded around January 2024. (The March Bloomberg article says "it didn’t even officially exist as a corporation until two months ago".) Since it requires many very expensive GPT-4 calls and RL, I doubt they could have done all that much prototyping or development in 2023.
Just seeing this, sorry. I think they could have gotten a lot of the infrastructure going even before GPT-4, just in a sort of toy fashion, but I agree, most of the development probably happened after GPT-4 became available. I don't think long context was as necessary, because my guess is the infrastructure set up behind the scenes was already parceling out subtasks to subagents and that probably circumvented the need for super-long context, though I'm sure having longer context definitely helps.
My guess is right now they're probably trying to optimize which sort of subtasks go to which model by A/B testing. If Claude 3 Opus is as good as people say at coding, maybe they're using that for actual coding task output? Maybe they're using GPT-4T or Gemini 1.5 Pro for a central orchestration model? Who knows. I feel like there are lots of conceivable ways to string this kind of thing together, and there will be more and more coming out every week now...
Devin can sometimes (13.8% of the time?!) do actual real jobs on Upwork with nothing but a prompt to ‘figure it out.’
You imply in this post that SWE-bench corresponds to jobs on Upwork. This is incorrect, SWE-bench corresponds to issue and pull request pairs on 12 python repos.
I think they may have gotten it working for MDPs, but I see little evidence so far that they've gotten it for POMDPs, due to the general lack of explicit exploration. (Devin does ask questions but rarely, consistent with the base model capabilities and imitation learning.) The former would still be a big deal, however.
What Could Possibly Go Massively Wrong for Everyone?
Things like Devin (when they become actually useful) are important through making $50 billion training runs economically feasible, not through being dangerous directly, because the $50 billion training runs get to have a more immediate effect. There is currently a level of scaling that's within technical reach but only gets attempted if results at lower scale are sufficiently impressive.
Writing correct code given a specification is the relatively easy part of software engineering. The hard part is deciding what you need that code to actually do. In other words, "requirements" - your dumbass customer has only the vaguest idea what they want and contradicts themselves half the time, but they still expect you to read their mind and give them something they're going to be happy with.
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?