Posts
Comments
Nice work! I'm not sure I fully understand what the "gated-ness" is adding, i.e. what the role the Heaviside step function is playing. What would happen if we did away with it? Namely, consider this setup:
Let and be the encoder and decoder functions, as in your paper, and let be the model activation that is fed into the SAE.
The usual SAE reconstruction is , which suffers from the shrinkage problem.
Now, introduce a new learned parameter , and define an "expanded" reconstruction , where denotes elementwise multiplication.
Finally, take the loss to be:
.
where ensures the decoder gets no gradients from the first term. As I understand it, this is exactly the loss appearing in your paper. The only difference in the setup is the lack of the Heaviside step function.
Did you try this setup? Or does it fail for an obvious reason I missed?
The peaks at 0.05 and 0.3 are strange. What regulariser did you use? Also, could you check whether all features whose nearest neighbour has cosine similarity 0.3 have the same nearest neighbour (and likewise for 0.05)?
The typical noise on feature caused by 1 unit of activation from feature , for any pair of features , , is (derived from Johnson–Lindenstrauss lemma)
1. ... This is a worst case scenario. I have not calculated the typical case, but I expect it to be somewhat less, but still same order of magnitude
Perhaps I'm misunderstanding your claim here, but the "typical" (i.e. RMS) inner product between two independently random unit vectors in is . So I think the shouldn't be there, and the rest of your estimates are incorrect.
This means that we can have at most simultaneously active features
This conclusion gets changed to .
Paging hijohnnylin -- it'd be awesome to have neuronpedia dashboards for these features. Between these, OpenAI's MLP features, and Joseph Bloom's resid_pre features, we'd have covered pretty much the whole model!
For each SAE feature (i.e. each column of W_dec), we can look for a distinct feature with the maximum cosine similarity to the first. Here is a histogram of these max cos sims, for Joseph Bloom's SAE trained at resid_pre, layer 10 in gpt2-small. The corresponding plot for random features is shown for comparison:
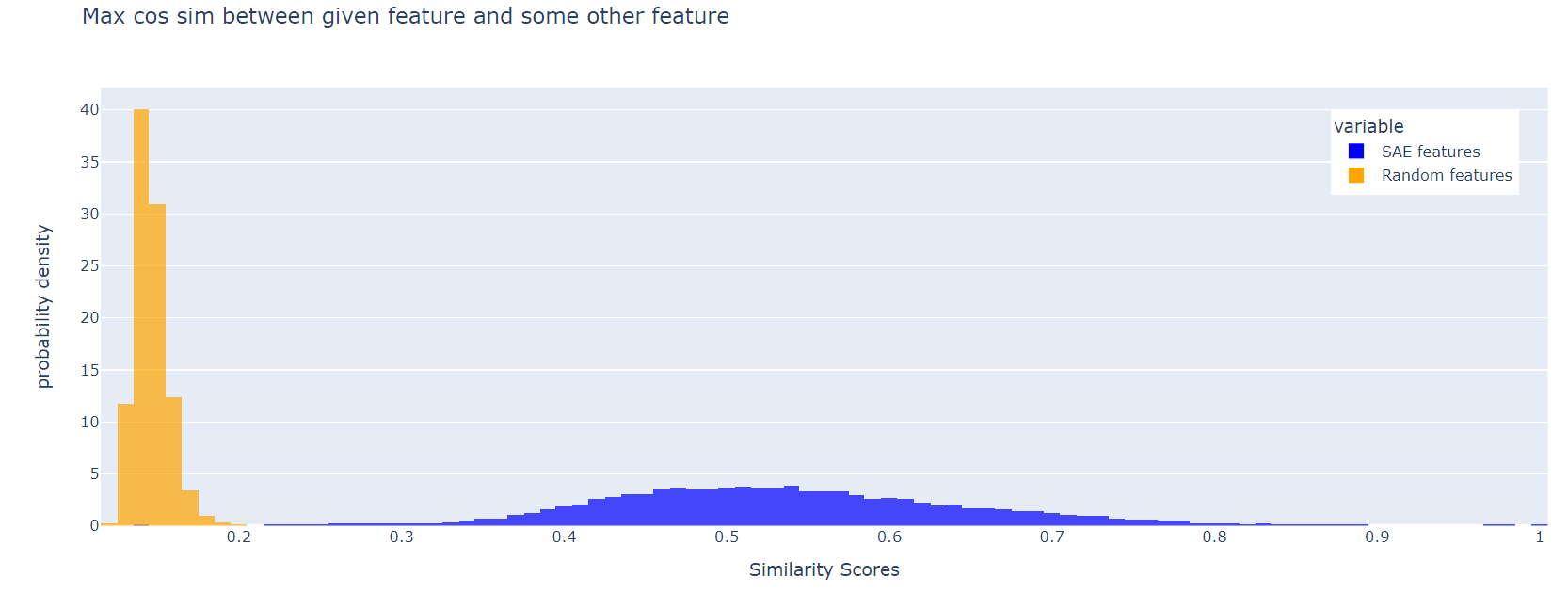
The SAE features are much less orthogonal than the random ones. This effect persists if, instead of the maximum cosine similarity, we look at the 10th largest, or the 100th largest:
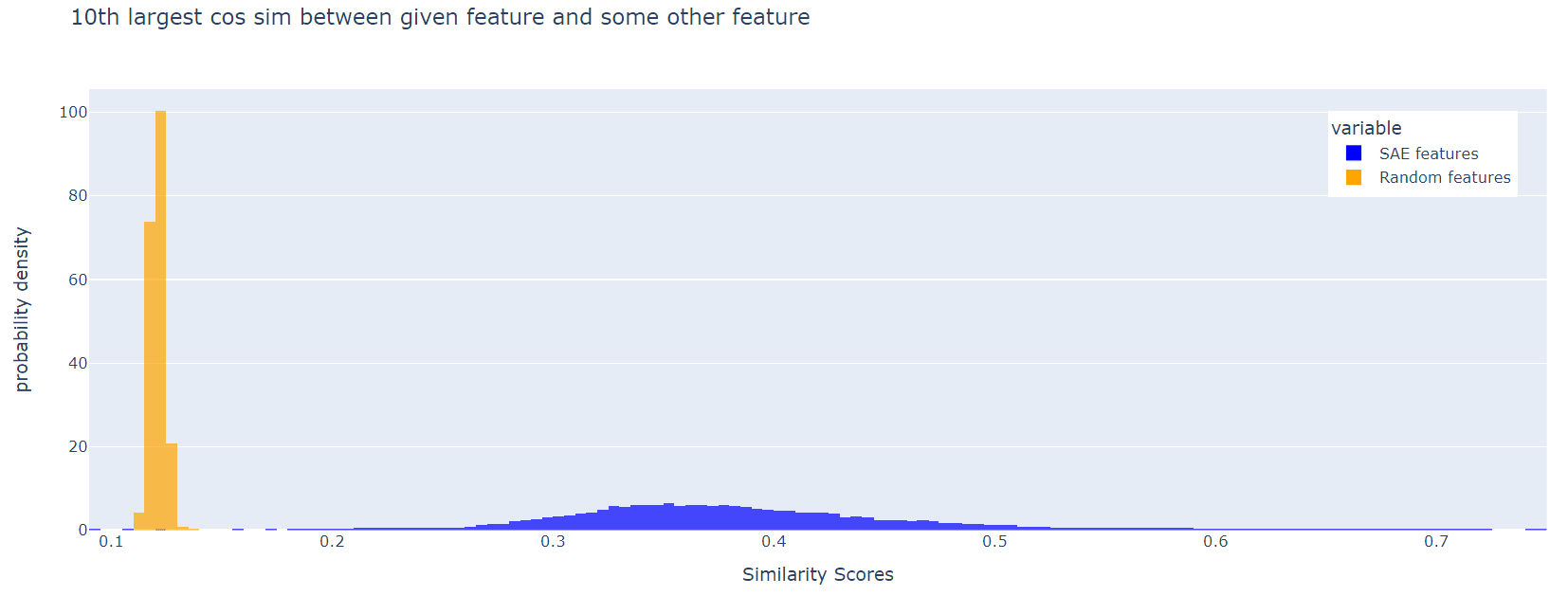
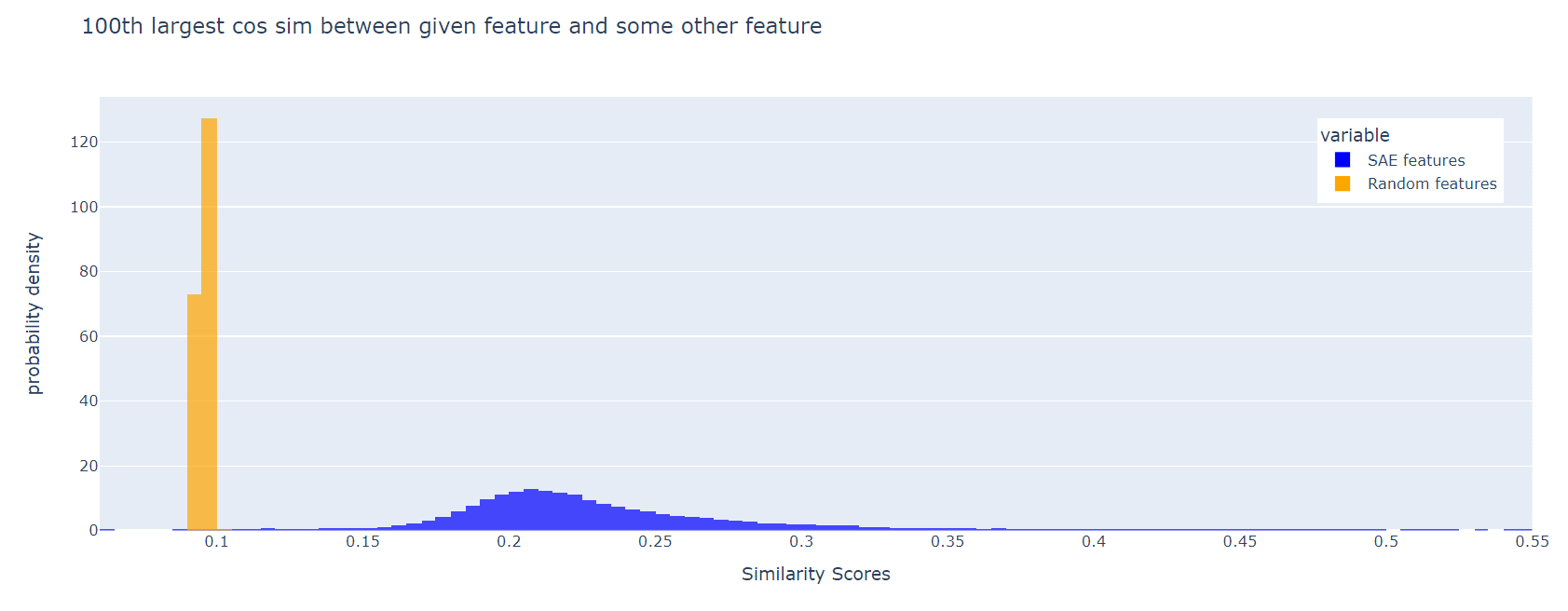
I think it's a good idea to include a loss term to incentivise feature orthogonality.
Nice, this is exactly what I was asking for. Thanks!
I'm confused about your three-dimensional example and would appreciate more mathematical detail.
Call the feature directions f1, f2, f3.
Suppose SAE hidden neurons 1,2 and 3 read off the components along f1, f2, and f1+f2, respectively. You claim that in some cases this may achieve lower L1 loss than reading off the f1, f2, f3 components.
[note: the component of a vector X along f1+f2 here refers to 1/2 * (f1+f2) \cdot X]
Can you write down the encoder biases that would achieve this loss reduction? Note that e.g. when the input is f1, there is a component of 1/2 along f1+f2, so you need a bias < -1/2 on neuron 3 to avoid screwing up the reconstruction.
Nice post. I was surprised that the model provides the same nonsense definition regardless of the token when the embedding is rescaled to be large, and moreover that this nonsense definition is very similar to the one given when the embedding is rescaled to be small. Here's an explanation I find vaguely plausible. Suppose the model completes the task as follows:
- The model sees the prompt
'A typical definition of <token> would be '. - At some attention head A1, the
<token>position attends back to'definition'and gains a component in the residual stream direction that represents the I am the token being defined feature. - At some later attention head A2, the final position of the prompt attends back to positions with the I am the token being defined feature, and moves whatever information from that position is needed for defining the corresponding token.
Now, suppose we rescale the <token> embedding to be very large. The size of the I am the token being defined component moved to the <token> position by A1 stays roughly the same as before (since no matter how much we scale query vectors, attention probabilities can never exceed 1). So, as a fraction of the total norm of the residual stream at that position, we've made the I am the token being defined component a lot smaller.
Then, when the residual stream is fed into the layernorm preceding A2, the I am the token being defined component gets squashed down to almost zero: it has been "squeezed out" by the very large token embedding. Hence, when the QK matrix of A2 looks for positions with the I am the token being defined feature, it finds nothing, and all the model can do is give some generic nonsense definition. Unsurprisingly, this nonsense definition ends up being pretty similar to the one given when the token embedding is sent to zero, since in both cases the model is essentially trying to define a token that isn't there.
The details of this explanation may be totally wrong, and I haven't checked any of this. But my guess is that something roughly along these lines is correct.
I hope that type of learning isn't used
I share your hope, but I'm pessimistic. Using RL to continuously train the outer loop of an LLM agent seems like a no-brainer from a capabilities standpoint.
The alternative would be to pretrain the outer loop, and freeze the weights upon deployment. Then, I guess your plan would be to only use the independent reviewer after deployment, so that the reviewer's decision never influences the outer-loop weights. Correct me if I'm wrong here.
I'm glad you plan to address this in a future post, and I look forward to reading it.
I'm a little confused. What exactly is the function of the independent review, in your proposal? Are you imagining that the independent alignment reviewer provides some sort of "danger" score which is added to the loss? Or is the independent review used for some purpose other than providing a gradient signal?
I'm slightly confused about the setup. In the following, what spaces is W mapping between?
Linear:
At first I expected W : R^{d_model} -> R^{d_model}. But then it wouldn't make sense to impose a sparsity penalty on W.
In other words: what is the shape of the matrix W?
Is your issue just "Alice's first sentence is so misguided that no self-respecting safety researcher would say such a thing"? If so, I can edit to clarify the fact that this is a deliberate strawman, which Bob rightly criticises. Indeed:
Bob: I'm asking you why models should misgeneralise in the extremely specific weird way that you mentioned
expresses a similar sentiment to Reward Is Not the Optimization Target: one should not blindly assume that models will generalise OOD to doing things that look like "maximising reward". This much is obvious by the example of individual humans not maximising inclusive genetic fitness.
But, as noted in the comments on Reward Is Not the Optimization Target, it seems plausible that some models really do learn at least some behaviours that are more-or-less what we'd naively expect from a reward-maximiser. E.g. Paul Christiano writes:
If you have a system with a sophisticated understanding of the world, then cognitive policies like "select actions that I expect would lead to reward" will tend to outperform policies like "try to complete the task," and so I usually expect them to be selected by gradient descent over time.
The purpose of Alice's thought experiment is precisely to give such an example, where a deployed model quite plausibly displays the sort of reward-maximiser behaviour one might've naively expected (in this case, power-seeking).
Regarding 3, yeah, I definitely don't want to say that the LLM in the thought experiment is itself power-seeking. Telling someone how to power-seek is not power seeking.
Regarding 1 and 2, I agree that the problem here is producing an LLM that refuses to give dangerous advice to another agent. I'm pretty skeptical that this can be done in a way that scales, but this could very well be lack of imagination on my part.
Define the "frequent neurons" of the hidden layer to be those that fire with frequency > 1e-4. The image of this set of neurons under W_dec forms a set of vectors living in R^d_mlp, which I'll call "frequent features".
These frequent features are less orthogonal than I'd naively expect.
If we choose two vectors uniformly at random on the (d_mlp)-sphere, their cosine sim has mean 0 and variance 1/d_mlp = 0.0005. But in your SAE, the mean cosine sim between distinct frequent features is roughly 0.0026, and the variance is 0.002.
So the frequent features have more cosine similarity than you'd get by just choosing a bunch of directions at random on the (d_mlp)-sphere. This effect persists even when you throw out the neuron-sparse features (as per your top10 definition).
Any idea why this might be the case? My previous intuition had been that transformers try to pack in their features as orthogonally as possible, but it looks like I might've been wrong about this. I'd also be interested to know if a similar effect is also found in the residual stream, or if it's entirely due to some weirdness with relu picking out a preferred basis for the mlp hidden layer.