Posts
Comments
Another hypothesis: Your description of the task is
the hard parts of application pentesting for LLMs, which are 1. Navigating a real repository of code too large to put in context, 2. Inferring a target application's security model, and 3. Understanding its implementation deeply enough to learn where that security model is broken.
From METR's recent investigation on long tasks you would expect current models not to perform well on this.
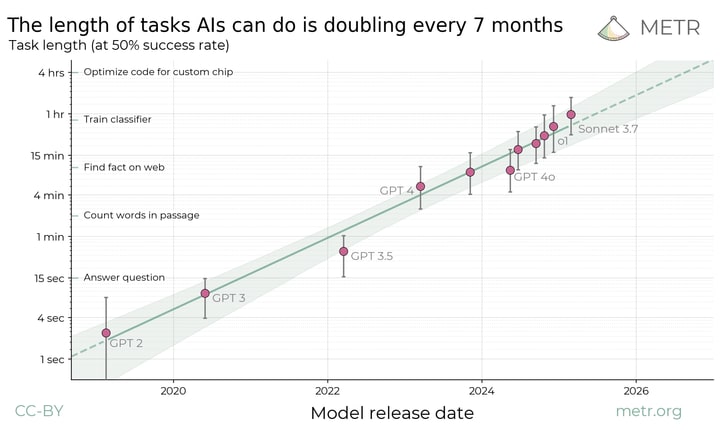
I doubt a human professional could do the tasks you describe in something close to an hour, so perhaps its just currently too hard and the current improvements don't make much of a difference for the benchmark, but it might in the future.
(Perhaps you're thinking of this https://www.lesswrong.com/posts/EKu66pFKDHFYPaZ6q/the-hero-with-a-thousand-chances)
Good formulation. "Given it's Monday" can have two different meanings:
- you learn that you will only be awoken on Monday, then it's 50%
- you awake assign 1/3 probability to each instance and then make the update
So it turns out to 50 % for both but it wasn't initially obvious to me that these two ways would have the same result.
I'd say
The possible observer instances and their probability are:
- Heads 50 %
- Red room 25 %
- Blue room 25 %
- Tails 50 %
- Red room 50 % (On Monday or Tuesday)
- Blue room 50 % (On Monday or Tuesday)
If I choose a strategy "bet only if blue" (or equivalentely "bet only if red") then expected value for this strategy is so I choose to follow this strategy.
I don't remember what halfer and thirder were or what position I consider to be correct.
Capabilities leakages don’t really “increase race dynamics”.
Do people actually claim this? Shorter timelines seems like a more reasonable claim to make. To jump directly to impacts on race dynamics is skipping at least one step.
To me it feels like this policy is missing something that accounts for a big chunk of the risk.
While recursive self-improvement is covered by the "Autonomy and replication" point, there is another risk from actors that don't intentionally cause large scale harm but use your system to make improvements to their own systems as they don't follow your RSP. This type of recursive improvement doesn't seem to be covered by any of "Misuse" or "Autonomy and replication".
In short it's about risks due to shortening of timelines.
You can see twin birth rates fell sharply in the late 90s
Shouldn't this be triplet birthrates? Twin birthrates look pretty stable in comparison.
Hmm, yeah it's a bit hard to try stuff when there's no good preview. Usually I'd recommend rot13 chiffer if all else fails but for number sequences that makes less sense.
I knew about 2-4-6 problem from HPMOR, I really like the opportunity to try it out myself. These are my results on the four other problems:
indexA
Number of guesses:
8 guesses of which 3 were valid and 5 non-valid
Guess:
"A sequence of integers whose sum is non-negative"
Result: Failure
indexB
Number of guesses:
39 of which 23 were valid 16 non-valid
Guess:
"Three ordered real numbers where the absolute difference between neighbouring numbers is decreasing."
Result: Success
indexC
Number of guesses:
21 of which 15 were valid and 6 non-valid
Guess:
"Any three real numbers whose sum is less than 50."
Result: Success
indexD
Number of guesses:
16 of which 8 were valid and 8 non-valid
Guess:
"First number is a real number and the other two are integers divisible by 5"
Result: Failure
Performance analysis
I'd say that the main failure modes were that I didn't do enough tests and I was a very bad number generator. For example, in indexD
I made 9 tests to test my final hypothesis 4 of which were valid, that my guess and the actual rule would give the same result for these 9 tests if I were actually good at randomizing is very small.
I could also say that I was a bit naive on the first test and that I'd grown overconfident after two successive successes for the final test.
See FAQ for spoiler tags, it seems mods haven't seen your request. https://www.lesswrong.com/faq#How_do_I_insert_spoiler_protections_
These problems seemed to me similar to the problems at the International Physicist's Tournament. If you want more problems check out https://iptnet.info
In case anyone else is looking for a source a good search term is probably the Beal Effect. From the original paper by Beal and Smith:
Once the effect is pointed out, it does not take long to arrive at the conclusion that it arises from a natural correlation between a high branching factor in the game tree and having a winning move available. In other words, mobility (in the sense of having many moves available) is associated with better positions
Or a counterexample from the other direction would be that you can't describe a uniform distribution of the empty set either (I think). And that would feel even weirder to call "bigger".
Why would this property mean that it is "bigger"? You can construct a uniform distribution of a uncountable set through a probability density as well. However, using the same measure on a countably infinite subset of the uncountable set would show that the countable set has measure 0.
So we have that
[...] Richard Jeffrey is often said to have defended a specific one, namely the ‘news value’ conception of benefit. It is true that news value is a type of value that unambiguously satisfies the desirability axioms.
but at the same time
News value tracks desirability but does not constitute it. Moreover, it does not always track it accurately. Sometimes getting the news that X tells us more than just that X is the case because of the conditions under which we get the news.
And I can see how starting from this you would get that . However, I think one of the remaining confusions is how you would go in the other direction. How can you go from the premise that we shift utilities to be for tautologies to say that we value something to a large part from how unlikely it is.
And then we also have the desirability axiom
for all and such that together with Bayesian probability theory.
What I was talking about in my previous comment goes against the desirability axiom in the sense that I meant that for in the more general case there could be subjects that prefer certain outcomes proportionally more (or less) than usual such that for some probabilities . As the equality derives directly from the desirability axiom, it was wrong of me to generalise that far.
But, to get back to the confusion at hand we need to unpack the tautology axiom a bit. If we say that a proposition is a tautology if and only if [1], then we can see that any proposition that is no news to us has zero utils as well.
And I think it might be well to keep in mind that learning that e.g. sun tomorrow is more probable than we once thought does not necessarily make us prefer sun tomorrow less, but the amount of utils for sun tomorrow has decreased (in an absolute sense). This comes in nicely with the money analogy because you wouldn't buy something that you expect with certainty anyway[2], but this doesn't mean that you prefer it any less compared to some other worse outcome that you expected some time earlier. It is just that we've updated from our observations such that the utility function now reflects our current beliefs. If you prefer to then this is a fact regardless of the probabilities of those outcomes. When the probabilities change, what is changing is the mapping from proposition to real number (the utility function) and it is only changing with an shift (and possibly scaling) by a real number.
At least that is the interpretation that I've done.
Skimming the methodology it seems to be a definite improvement and does tackle the short-comings mentioned in the original post to some degree at least.
Isn't that just a question whether you assume expected utility or not. In the general case it is only utility not expected utility that matters.
Anyway, someone should do a writeup of our findings, right? :)
Sure, I've found it to be an interesting framework to think in so I suppose someone else might too. You're the one who's done the heavy lifting so far so I'll let you have an executive role.
If you want me to write up a first draft I can probably do it end of next week. I'm a bit busy for at least the next few days.
Lol. Somehow made it more clear that it was meant as a hyperbole than did.
You might want to consider cross-posting this to EA forum to reach a larger audience.
I've been thinking about the Eliezer's take on the Second Law of Thermodynamics and while I can't think of a succint comment to drop with it. I think it could bring value to this discussion.
Well I'd say that the difference between your expectations of the future having lived a variant of it or not is only in degree not in kind. Therefore I think there are situations where the needs of the many can outweigh the needs of the one, even under uncertainty. But, I understand that not everyone would agree.
I agree with as a sufficient criteria to only sum over , the other steps I'll have to think about before I get them.
I found this newer paper https://personal.lse.ac.uk/bradleyr/pdf/Unification.pdf and having skimmed it seemed like it had similar premises but they defined (instead of deriving it).
GovAI is probably one of the densest places to find that. You could also check out FHI's AI Governance group.
There is no consensus about what constitutes a moral patient and I have seen nothing convincing to rule out that an AGI could be a moral patient.
However, when it comes to AGI some extreme measures are needed.
I'll try with an analogy. Suppose that you traveled back in time to Berlin 1933. Hitler has yet to do anything significantly bad but you still expect his action to have some really bad consequences.
Now I guess that most wouldn't feel terribly conflicted about removing Hitler's right of privacy or even life to prevent Holocaust.
For a longtermist the risks we expect from AGI are order of magnitudes worse than the Holocaust.
Have these issues been discussed somewhere in the canon?
The closest thing of this being discussed that I can think of is when it comes to Suffering Risks from AGI. The most clear cut example (not necessarily probable) is if an AGI would spin up sub-processes that simulate humans that experience immense suffering. Might be that you find something if you search for that.
Didn't you use that . I can see how to extend the derivation for more steps but only if . The sums
and
for arbitrary are equal if and only if .
The other alternative I see is if (and I'm unsure about this) we assume that and for .
What I would think that would mean is after we've updated probabilities and utilities from the fact that is certain. I think that would be the first one but I'm not sure. I can't tell which one that would be.
General (even if mutually exclusive) is tricky I'm not sure the expression is as nice then.
that was one of the premises, no? You expect utility from your prior.
Some first reflections on the results before I go into examining all the steps.
Hmm, yes my expression seems wrong when I look at it a second time. I think I still confused the timesteps and should have written
The extra negation comes from a reflex from when not using Jeffrey's decision theory. With Jeffrey's decision theory it reduces to your expression as the negated terms sum to . But, still I probably should learn not to guess at theorems and properly do all steps in the future. I suppose that is a point in favor for Jeffrey's decision theory that the expressions usually are cleaner.
As for your derivation you used that in the derivation but that is not the case for general . This is a note to self to check whether this still holds for .
Edit: My writing is confused here disregard it. My conclusion is still
Your expression for is nice
and what I would have expected. The problem I had was that I didn't realize that (which should have been obvious). Furthermore your expression checks out with my toy example (if remove the false expectation I had before).
Consider a lottery where you guess the sequence of 3 numbers and , and are the corresponding propositions that you guessed correctly and and . You only have preferences over whether you win or not .
Ah, those timestep subscripts are just what I was missing. I hadn't realised how much I needed that grounding until I noticed how good it felt when I saw them.
So to summarise (below all sets have mutually exclusive members). In Jeffrey-ish notation we say have the axiom
and normally you would want to indicate what distribution you have over in the left-hand side. However, we always renormalize such that the distribution is our current prior. We can indicate this by labeling the utilities from what timestep (and agent should probably included as well, but lets skip this for now).
That way we don't have to worry about being shifted during the sum in the right hand side or something. (I mean notationally that would just be absurd, but if I would sit down and estimate the consequences of possible actions I wouldn't be able to not let this shift my expectation for what action I should take before I was done.).
We can also bring up the utility of an action to be
Furthermore, for most actions it is quite clear that we can drop the subscript as we know that we are considering the same timestep consistently for the same calculation
Now I'm fine with this because I will have those subscript s in the back of my mind.
I still haven't commented on in general or . My intuition is that they should be able to be described from , and , but it isn't immediately obvious to me how to do that while keeping .
I tried considering a toy case where and () and then
but I couldn't see how it would be possible without assuming some things about how , and relate to each other which I can't in general.
Well, deciding to do action would also make it utility 0 (edit: or close enough considering remaining uncertainties) even before it is done. At least if you're committed to the action and then you could just as well consider the decision to be the same as the action.
It would mean that a "perfect" utility maximizer always does the action with utility (edit: but the decision can have positive utility(?)). Which isn't a problem in any way except that it is alien to how I usually think about utility.
Put in another way. While I'm thinking about which possible action I should take the utilities fluctuate until I've decided for an action and then that action has utility . I can see the appeal of just considering changes to the status quo, but the part where everything jumps around makes it an extra thing for me to keep track of.
Oh, I think I see what confuses me. In the subjective utility framework the expected utilities are shifted to after each Bayesian update?
So then utility of doing action to prevent a Doom is . But when action has been done then the utility scale is shifted again.
Ok, so this is a lot to take in, but I'll give you my first takes as a start.
My only disagreement prior to your previous comment seems to be in the legibility of the desirability axiom for which I think should contain some reference to the actual probabilities of and .
Now, I gather that this disagreement probably originates from the fact that I defined while in your framework .
Something that appears problematic to me is if we consider the tautology (in Jeffrey notation) . This would mean that reducing the risk of has net utility. In particular, certain and certain are equally preferable (). Which I don't thing either of us agree with. Perhaps I've missed something.
What I found confusing with was that to me this reads as which should always(?) depend on but with this notation it is hidden to me. (Here I picked as the mutually exclusive event , but I don't think it should remove much from the point).
That is also why I want some way of expressing that in the notation. I could imagine writing as that is the cleanest way I can come up with to satisfy both of us. Then with expected utility .
When we accept the expected utility hypothesis then we can always write it as a expectation/sum of its parts and then there is no confusion either.
Hmm, I usually don't think too deeply about the theory so I had to refresh somethings to answer this.
First off, the expected utility hypothesis is apparently implied by the VNM axioms. So that is not something needed to add on. To be honest I usually only think of a coherent preference ordering and expected utilities as two seperate things and hadn't realized that VNM combines them.
About notation, with I mean the utility of getting with certainty and with I mean the utility of getting with probability . If you don't have the expected utility hypothesis I don't think you can separate an event from its probability. I tried to look around to the usual notation but didn't find anything great.
Wikipedia used something like
where is a random variable over the set of states . Then I'd say that the expected utility hypothesis is the step .
Having read some of your other comments. I expect you to ask if the top preference of a thermostat is it's goal temperature? And to this I have no good answer.
For things like a thermostat and a toy robot you can obviously see that there is a behavioral objective which we could use to infer preferences. But, is the reason that thermostats are not included in utility calculations that behavioral objective does not actually map to a preference ordering or that their weight when aggregated is 0.
Perhaps for most they don't have this in the back of their mind when they think of utility. But, for me this is what I'm thinking about. The aggregation is still confusing to me, but as a simple case example. If I want to maximise total utility and am in a situation that only impacts a single entity then increasing utility is the same to me as getting this entity in for them more preferable states.
Expected utility hypothesis is that . To make it more concrete suppose that for outcome is worth for you. Then getting with probaillity is worth . This is not necessarily true, there could be an entity that prefers outcomes comparatively more if they are probable/improbable. The name comes from the fact that if you assume it to be true you can simply take expectations of utils and be fine. I find it very agreeable for me.
You could perhaps argue that "preference" is a human concept. You could extend it with something like coherent extrapolated volition to be what the entity would prefer if it knew all that was relevant, had all the time needed to think about it and was more coherent. But, in the end if something has no preference, then it would be best to leave it out of the aggregation.
Utility when it comes to a single entity is simply about preferences.
The entity should have
- For any two outcomes/states of the world the entity should prefer one over the other or consider them equally preferable
- The entity should be coherent in its preferences such that if it preferes to and to , then the entity prefers to
- When it comes to probabilities, if the entity prefers to then the entity prefers with probability to with probability all else equal. Furthermore, there exist a probability such that and is equally preferable to with certainty with the preference ordering from 2.
This is simply Von Neumann -- Morgenstern utility theory and means that for such an entity you can translate the preference ordering to a real valued function over preferences. When we only consider a single agent this function is undetermined up to a any scaling with positive scalar values or shifting with scalar values.
Usually I'd like to add the expected utility hypothesis as well that
where is with probability .
(Edit: Apparently step 3 implies the expected utility hypothesis. And cubefox pointed out that my notation here was weird. An improved notation would be that
where is a random variable over the set of states . Then I'd say that the expected utility hypothesis is the step .
end of edit.)
Now the tricky part to me is when it comes to multiple entities with utility functions. How do you combine these into a single valued function, how are they aggregated.
Here there are differences in
- Aggregation function. Should you sum the contributions (total utilitarianism), average, take the minimum (for a maximin strategy), ...
- Weighting. For each individual utility function we have a freedom in scale and shift. If we fix utility 0 as this entity does not exist or the world does not exist, then what remains is a scale of the utility functions which effectively functions as weighting in aggregations like sum and average. Here questions like, how many cows living lives worth living would are needed to choose that over a human having a life worth living and how do you determine where in the scale you are in a life worth living.
Another tricky part is that humans and other entities are not coherent to satisfy the axioms in Von Neumann -- Morgenstern utility theory. What to do then, which preferences are "rational" and which are not?
Could someone who disagrees with the above statement help me by clarifying what the disagreement is?
Seeing as it has -7 on the agreement vote and that makes me think it should be obvious but it isn't to me.
Due to this, he concludes the cause area is one of the most important LT problems and primarily advises focusing on other risks due to neglectedness.
This sentence is confusing me, should I read it as:
- Due to this, he concludes the cause area is one of the most important LT problems but primarily advises focusing on other risks anyway due to neglectedness.
- Due to this, he concludes the cause area is not one of the most important LT problems and primarily advises focusing on other risks due to neglectedness.
From this summary of the summary I get the the impression that 1 is the correct interpretation but from
I construct several models of the direct extinction risk from climate change but struggle to get the risk above 1 in 100,000 over all time.
in the original summary I get the impression that 2 should be true.
I agree with 1 (but then it is called alignment forum, not the more general AI Safety forum). But I don't see that 2 would do much good.
All narratives I can think of where 2 plays a significant part sounds like strawmen to me, perhaps you could help me?
I suppose I would just like to see more people start at an earlier level and from that vantage point you might actually want to switch to a path with easier parts.
There’s something very interesting in this graph. The three groups have completely converged by the end of the 180 day period, but the average bank balance is now considerably higher.
Wasn't the groups selected for having currently low income? Shouldn't we expect some regression towards the mean i.e. an increase in average bank balance? Was there any indication for if the observed effect was larger or smaller than expected?
Tackle the [Hamming Problems](https://www.lesswrong.com/posts/Thwfy4gNFx9kHgvov/research-hamming-questions), Don't Avoid Them
I agree with that statement and this statement
Far and away the most common failure mode among self-identifying alignment researchers is to look for Clever Ways To Avoid Doing Hard Things [...]
seems true as well. However, there was something in this section that didn't seem quite right to me.
Say that you have identified the Hamming Problem at lowest resolution be getting the outcome "AI doesn't cause extinction or worse". However, if you zoom in a little bit you might find that there are different narratives that lead to the same goal. For example:
- AGI isn't developed due to event(s)
- AGI is developed safely due to event(s)
At this level I would say that it is correct to go for the easier narrative. Going for harder problems seem to be when you zoom into these narratives.
For each path you can imagine a set of events (e.g. research break-throughs) that are necessary and sufficient to solve the end-goal. Here I'm unsure but my intuition tells me that the marginal impact would often be greater working on the necessary parts that are the hardest as these are the ones that are least likely to be solved without intervention.
Of course working on something that isn't necessary in any narrative would probably be easier in most cases but would never be a Hamming Problem.
I don't think an "actual distribution" over the activations is a thing? The distribution depends on what inputs you feed it.
This seems to be what Thomas is saying as well, no?
[...] look at the network activations at each layer for a bunch of different inputs. This gives you a bunch of activations sampled from the distribution of activations. From there, you can do density estimation to estimate the actual distribution over the activations.
The same way you can talk about the actual training distribution underlying the samples in the training set it should be possible to talk about the actual distribution of the activations corresponding to a particular input distribution.
I believe Thomas is asking how you plan to do the first step of: Samples -> Estimate underlying distribution -> Get modularity score of estimated distribution
While from what you are describing I'm reading: Samples -> Get estimate of modularity score
It seems like it could be worthwhile for you to contact someone in connection to AGI Safety Communications Initiative. Or at the very least check out the post I linked.
Other that I find worth mentioning are channels for opportunities at getting started in AI Safety. I know both AGI Safety Fundamentals and AI Safety Camp have slack channels for participants. Invitation needed and you probably need to be a participant to get invited.
There is also a 80000 hours Google group for technical AI safety. Invitation is needed, I can't find that they've broadcasted how to get in so I won't share it. But, they mention it on their website so I guess it is okay to include it here.
I've also heard about research groups in AI safety having their own discords and slack channels. In those cases, to get invited you should probably contact someone at the specific place and show that you have interest in their research. I keep it vague, because again, I don't know how public their existence is.