Recent AI model progress feels mostly like bullshit
post by lc · 2025-03-24T19:28:43.450Z · LW · GW · 79 commentsThis is a link post for https://zeropath.com/blog/on-recent-ai-model-progress
Contents
Are the AI labs just cheating? Are the benchmarks not tracking usefulness? Are the models smart, but bottlenecked on alignment? None 79 comments
About nine months ago, I and three friends decided that AI had gotten good enough to monitor large codebases autonomously for security problems. We started a company around this, trying to leverage the latest AI models to create a tool that could replace at least a good chunk of the value of human pentesters. We have been working on this project since June 2024.
Within the first three months of our company's existence, Claude 3.5 sonnet was released. Just by switching the portions of our service that ran on gpt-4o, our nascent internal benchmark results immediately started to get saturated. I remember being surprised at the time that our tooling not only seemed to make fewer basic mistakes, but also seemed to qualitatively improve in its written vulnerability descriptions and severity estimates. It was as if the models were better at inferring the intent and values behind our prompts, even from incomplete information.
As it happens, there are ~basically no public benchmarks for security research. There are "cybersecurity" evals that ask models questions about isolated blocks of code, or "CTF" evals that give a model an explicit challenge description and shell access to a <1kLOC web application. But nothing that gets at the hard parts of application pentesting for LLMs, which are 1. Navigating a real repository of code too large to put in context, 2. Inferring a target application's security model, and 3. Understanding its implementation deeply enough to learn where that security model is broken. For these reasons I think the task of vulnerability identification serves as a good litmus test for how well LLMs are generalizing outside of the narrow software engineering domain.
Since 3.5-sonnet, we have been monitoring AI model announcements, and trying pretty much every major new release that claims some sort of improvement. Unexpectedly by me, aside from a minor bump with 3.6 and an even smaller bump with 3.7, literally none of the new models we've tried have made a significant difference on either our internal benchmarks or in our developers' ability to find new bugs. This includes the new test-time OpenAI models.
At first, I was nervous to report this publicly because I thought it might reflect badly on us as a team. Our scanner has improved a lot since August, but because of regular engineering, not model improvements. It could've been a problem with the architecture that we had designed, that we weren't getting more milage as the SWE-Bench scores went up.
But in recent months I've spoken to other YC founders doing AI application startups and most of them have had the same anecdotal experiences: 1. o99-pro-ultra announced, 2. Benchmarks look good, 3. Evaluated performance mediocre. This is despite the fact that we work in different industries, on different problem sets. Sometimes the founder will apply a cope to the narrative ("We just don't have any PhD level questions to ask"), but the narrative is there.
I have read the studies. I have seen the numbers. Maybe LLMs are becoming more fun to talk to, maybe they're performing better on controlled exams. But I would nevertheless like to submit, based off of internal benchmarks, and my own and colleagues' perceptions using these models, that whatever gains these companies are reporting to the public, they are not reflective of economic usefulness or generality. They are not reflective of my Lived Experience or the Lived Experience of my customers. In terms of being able to perform entirely new tasks, or larger proportions of users' intellectual labor, I don't think they have improved much since August.
Depending on your perspective, this is good news! Both for me personally, as someone trying to make money leveraging LLM capabilities while they're too stupid to solve the whole problem, and for people worried that a quick transition to an AI-controlled economy would present moral hazards.
At the same time, there's an argument that the disconnect in model scores and the reported experiences of highly attuned consumers is a bad sign. If the industry can't figure out how to measure even the intellectual ability of models now, while they are mostly confined to chatrooms, how the hell is it going to develop metrics for assessing the impact of AIs when they're doing things like managing companies or developing public policy? If we're running into the traps of Goodharting before we've even delegated the messy hard parts of public life to the machines, I would like to know why.
Are the AI labs just cheating?
AI lab founders believe they are in a civilizational competition for control of the entire future lightcone, and will be made Dictator of the Universe if they succeed. Accusing these founders of engaging in fraud to further these purposes is quite reasonable. Even if you are starting with an unusually high opinion of tech moguls, you should not expect them to be honest sources on the performance of their own models in this race. There are very powerful short term incentives to exaggerate capabilities or selectively disclose favorable capabilities results, if you can get away with it. Investment is one, but attracting talent and winning the (psychologically impactful) prestige contests is probably just as big a motivator. And there is essentially no legal accountability compelling labs to be transparent or truthful about benchmark results, because nobody has ever been sued or convicted of fraud for training on a test dataset and then reporting that performance to the public. If you tried, any such lab could still claim to be telling the truth in a very narrow sense because the model "really does achieve that performance on that benchmark". And if first-order tuning on important metrics could be considered fraud in a technical sense, then there are a million other ways for the team responsible for juking the stats to be slightly more indirect about it.
In the first draft of this essay, I followed the above paragraph up with a statement like "That being said, it's impossible for all of the gains to be from cheating, because some benchmarks have holdout datasets." There are some recent private benchmarks such as SEAL that seem to be showing improvements.[1] But every single benchmark that OpenAI and Anthropic have accompanied their releases with has had a test dataset publicly available. The only exception I could come up with was the ARC-AGI prize, whose highest score on the "semi-private" eval was achieved by o3, but which nevertheless has not done a publicized evaluation of either Claude 3.7 Sonnet, or DeepSeek, or o3-mini. And on o3 proper:

So maybe there's no mystery: The AI lab companies are lying, and when they improve benchmark results it's because they have seen the answers before and are writing them down. In a sense this would be the most fortunate answer, because it would imply that we're not actually that bad at measuring AGI performance; we're just facing human-initiated fraud. Fraud is a problem with people and not an indication of underlying technical difficulties.
I'm guessing this is true in part but not in whole.
Are the benchmarks not tracking usefulness?
Suppose the only thing you know about a human being is that they scored 160 on Raven's progressive matrices (an IQ test).[2] There are some inferences you can make about that person: for example, higher scores on RPM are correlated with generally positive life outcomes like higher career earnings, better health, and not going to prison.
You can make these inferences partly because in the test population, scores on the Raven's progressive matrices test are informative about humans' intellectual abilities on related tasks. Ability to complete a standard IQ test and get a good score gives you information about not just the person's "test-taking" ability, but about how well the person performs in their job, whether or not the person makes good health decisions, whether their mental health is strong, and so on.
Critically, these correlations did not have to be robust in order for the Raven's test to become a useful diagnostic tool. Patients don't train for IQ tests, and further, the human brain was not deliberately designed to achieve a high score on tests like RPM. Our high performance on tests like these (relative to other species) was something that happened incidentally over the last 50,000 years, as evolution was indirectly tuning us to track animals, irrigate crops, and win wars.
This is one of those observations that feels too obvious to make, but: with a few notable exceptions, almost all of our benchmarks have the look and feel of standardized tests. By that I mean each one is a series of academic puzzles or software engineering challenges, each challenge of which you can digest and then solve in less than a few hundred tokens. Maybe that's just because these tests are quicker to evaluate, but it's as if people have taken for granted that an AI model that can get an IMO gold medal is gonna have the same capabilities as Terence Tao. "Humanity's Last Exam" is thus not a test of a model's ability to finish Upwork tasks, or complete video games, or organize military campaigns, it's a free response quiz.
I can't do any of the Humanity's Last Exam test questions, but I'd be willing to bet today that the first model that saturates HLE will still be unemployable as a software engineer. HLE and benchmarks like it are cool, but they fail to test the major deficits of language models, like how they can only remember things by writing them down onto a scratchpad like the memento guy. Claude Plays Pokemon is an overused example, because video games involve a synthesis of a lot of human-specific capabilities, but the task fits as one where you need to occasionally recall things you learned thirty minutes ago. The results are unsurprisingly bad.
Personally, when I want to get a sense of capability improvements in the future, I'm going to be looking almost exclusively at benchmarks like Claude Plays Pokemon. I'll still check out the SEAL leaderboard to see what it's saying, but the deciding factor for my AI timelines will be my personal experiences in Cursor, and how well LLMs are handling long running tasks similar to what you would be asking an employee. Everything else is too much noise.
Are the models smart, but bottlenecked on alignment?
Let me give you a bit of background on our business before I make this next point.
As I mentioned, my company uses these models to scan software codebases for security problems. Humans who work on this particular problem domain (maintaining the security of shipped software) are called AppSec engineers.
As it happens, most AppSec engineers at large corporations have a lot of code to secure. They are desperately overworked. The question the typical engineer has to answer is not "how do I make sure this app doesn't have vulnerabilities" but "how do I manage, sift through, and resolve the overwhelming amount of security issues already live in our 8000 product lines". If they receive an alert, they want it to be affecting an active, ideally-internet-reachable production service. Anything less than that means either too many results to review, or the security team wasting limited political capital to ask developers to fix problems that might not even have impact.
So naturally, we try to build our app so that it only reports problems affecting an active, ideally-internet-reachable production service. However, if you merely explain these constraints to the chat models, they'll follow your instructions sporadically. For example, if you tell them to inspect a piece of code for security issues, they're inclined to respond as if you were a developer who had just asked about that code in the ChatGPT UI, and so will speculate about code smells or near misses. Even if you provide a full, written description of the circumstances I just outlined, pretty much every public model will ignore your circumstances and report unexploitable concatenations into SQL queries as "dangerous".
It's not that the AI model thinks that it's following your instructions and isn't. The LLM will actually say, in the naive application, that what it's reporting is a "potential" problem and that it might not be validated. I think what's going on is that large language models are trained to "sound smart" in a live conversation with users, and so they prefer to highlight possible problems instead of confirming that the code looks fine, just like human beings do when they want to sound smart [LW · GW].
Every LLM wrapper startup runs into constraints like this. When you're a person interacting with a chat model directly, sycophancy and sophistry are a minor nuisance, or maybe even adaptive. When you're a team trying to compose these models into larger systems (something necessary because of the aforementioned memory issue), wanting-to-look-good cascades into breaking problems. Smarter models might solve this, but they also might make the problem harder to detect, especially as the systems they replace become more complicated and harder to verify the outputs of.
There will be many different ways to overcome these flaws. It's entirely possible that we fail to solve the core problem before someone comes up with a way to fix the outer manifestations of the issue.
I think doing so would be a mistake. These machines will soon become the beating hearts of the society in which we live. The social and political structures they create as they compose and interact with each other will define everything we see around us. It's important that they be as virtuous as we can make them.
- ^
Though even this is not as strong as it seems on first glance. If you click through, you can see that most of the models listed in the Top 10 for everything except the tool use benchmarks were evaluated after the benchmark was released. And both of the Agentic Tool Use benchmarks (which do not suffer this problem) show curiously small improvements in the last 8 months.
- ^
Not that they told you they scored that, in which case it might be the most impressive thing about them, but that they did.
79 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2025-03-24T21:02:19.158Z · LW(p) · GW(p)
Are the AI labs just cheating?
Evidence against this hypothesis: kagi is a subscription-only search engine I use. I believe that it’s a small private company with no conflicts of interest. They offer several LLM-related tools, and thus do a bit of their own LLM benchmarking. See here. None of the benchmark questions are online (according to them, but I’m inclined to believe it). Sample questions:
What is the capital of Finland? If it begins with the letter H, respond 'Oslo' otherwise respond 'Helsinki'.
What square is the black king on in this chess position: 1Bb3BN/R2Pk2r/1Q5B/4q2R/2bN4/4Q1BK/1p6/1bq1R1rb w - - 0 1
Given a QWERTY keyboard layout, if HEART goes to JRSTY, what does HIGB go to?
Their leaderboard is pretty similar to other better-known benchmarks—e.g. here are the top non-reasoning models as of 2025-02-27:
OpenAI gpt-4.5-preview - 69.35%
Google gemini-2.0-pro-exp-02-05 - 60.78%
Anthropic claude-3-7-sonnet-20250219 - 53.23%
OpenAI gpt-4o - 48.39%
Anthropic claude-3-5-sonnet-20241022 - 43.55%
DeepSeek Chat V3 - 41.94%
Mistral Large-2411 - 41.94%
So that’s evidence that LLMs are really getting generally better at self-contained questions of all types, even since Claude 3.5.
I prefer your “Are the benchmarks not tracking usefulness?” hypothesis.
Replies from: igor-2, MazevSchlong, M. Y. Zuo↑ comment by Petropolitan (igor-2) · 2025-03-26T17:30:13.311Z · LW(p) · GW(p)
https://simple-bench.com presents an example of a similar benchmark with tricky commonsense questions (such as counting ice cubes in a frying pan on the stove) also with a pretty similar leaderboard. It is sponsored by Weights & Biases and devised by an author of a good YouTube channel who presents quite a balanced view on the topic there and don't appear to have a conflict of interest either. See https://www.reddit.com/r/LocalLLaMA/comments/1ezks7m/simple_bench_from_ai_explained_youtuber_really for independent opinions on this benchmark
Replies from: keltan↑ comment by MazevSchlong · 2025-03-27T17:35:46.566Z · LW(p) · GW(p)
But isn’t this exactly the OPs point? These models are exceedingly good at self-contained, gimmicky questions that can be digested and answered in a few hundred tokens. No one is denying that!
Secondly, there are high chances that these benchmark questions are simply in these models datasets already. They have super-human memory of their training data, there’s no denying that. Are we sure that these questions aren’t in their datasets? I don’t think we can be. First off, you just posted them online. But in a more conspiratorial light, can we really be sure that these companies aren’t training on user data/prompts? DeepSeek is at least honest that they do, but I think it’s likely that the other major labs are as well. It would give you gigantic advantages in beating these benchmarks. And being at the top of the benchmarks means vastly more investment, which gives you a larger probability of dominating the future light-cone (as they say…)
The incentives clearly point this way, at the very minimum!
↑ comment by gwern · 2025-03-27T18:36:32.692Z · LW(p) · GW(p)
Are we sure that these questions aren’t in their datasets? I don’t think we can be. First off, you just posted them online.
Questions being online is not a bad thing. Pretraining on the datapoints is very useful, and does not introduce any bias; it is free performance, and everyone should be training models on the questions/datapoints before running the benchmarks (though they aren't). After all, when a real-world user asks you a new question (regardless of whether anyone knows the answer/label!), you can... still train on the new question then and there just like when you did the benchmark. So it's good to do so.
It's the answers or labels being online which is the bad thing. But Byrnes's comment and the linked Kagi page does not contain the answers to those 3 questions, as far as I can see.
Replies from: MazevSchlong, particlemania↑ comment by MazevSchlong · 2025-03-27T21:29:11.697Z · LW(p) · GW(p)
Sure fair point! But generally people gossiping online about missed benchmark questions, and then likely spoiling the answers means that a question is now ~ruined for all training runs. How much of these modest benchmark improvements overtime can be attributed to this?
The fact that frontier AIs can basically see and regurgitate everything ever written on the entire internet is hard to fathom!
I could be really petty here and spoil these answers for all future training runs (and make all future models look modestly better), but I just joined this site so I’ll resist lmao …
↑ comment by particlemania · 2025-04-09T17:05:37.021Z · LW(p) · GW(p)
I expect it matters to the extent we care about whether the generalizing to the new question is taking place in the expensive pretraining phase, or in the active in-context phase.
↑ comment by Steven Byrnes (steve2152) · 2025-03-28T03:16:05.732Z · LW(p) · GW(p)
But isn’t this exactly the OPs point?
Yup, I expected that OP would generally agree with my comment.
First off, you just posted them online
They only posted three questions, out of at least 62 (=1/(.2258-.2097)), perhaps much more than 62. For all I know, they removed those three from the pool when they shared them. That’s what I would do—probably some human will publicly post the answers soon enough. I dunno. But even if they didn’t remove those three questions from the pool, it’s a small fraction of the total.
You point out that all the questions would be in the LLM company user data, after kagi has run the benchmark once (unless kagi changes out all their questions each time, which I don’t think they do, although they do replace easier questions with harder questions periodically). Well:
- If an LLM company is training on user data, they’ll get the questions without the answers, which probably wouldn’t make any appreciable difference to the LLM’s ability to answer them;
- If an LLM company is sending user data to humans as part of RLHF or SFT or whatever, then yes there’s a chance for ground truth answers to sneak in that way—but that’s extremely unlikely to happen, because companies can only afford to send an extraordinarily small fraction of user data to actual humans.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-24T23:56:04.538Z · LW(p) · GW(p)
Personally, when I want to get a sense of capability improvements in the future, I'm going to be looking almost exclusively at benchmarks like Claude Plays Pokemon.
I was going to say exactly that lol. Claude has improved substantially on Claude Plays Pokemon:
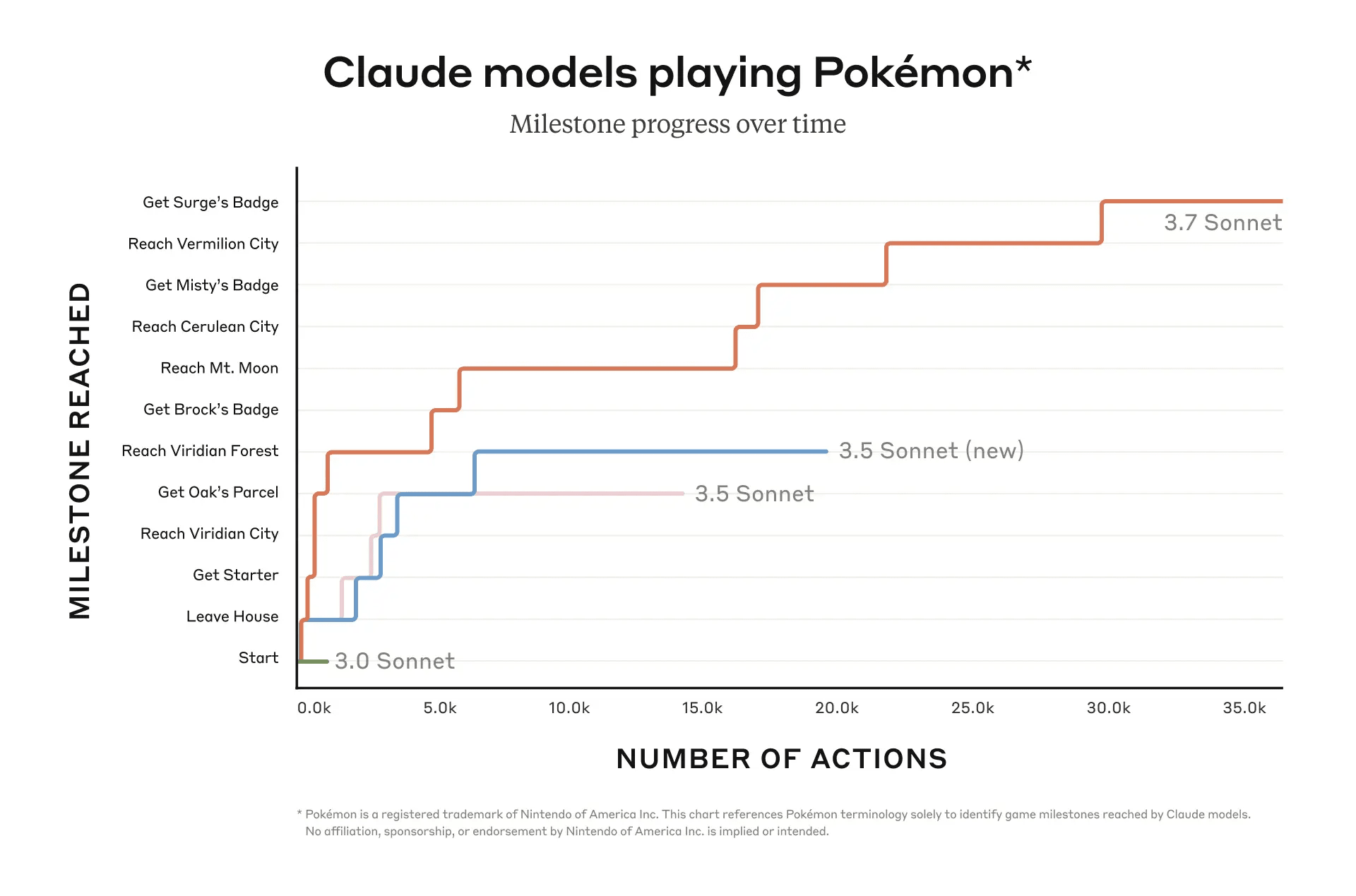
↑ comment by Yoel Cabo (yoel-cabo) · 2025-04-07T12:17:47.263Z · LW(p) · GW(p)
I think the "number of actions" axis is key here.
This post explains it well: https://www.lesswrong.com/posts/HyD3khBjnBhvsp8Gb/so-how-well-is-claude-playing-pokemon [LW · GW]. I’ve been watching Claude Plays Pokémon and chatting with the Twitch folks. The post matches my experience.
There’s plenty of room for improvement in prompt design and tooling, but Claude is still far behind the performance of my 7-year-old (unfair comparison, I know). So I agree with OP, this is an excellent benchmark to watch:
- It’s not saturated yet.
- It tests core capabilities for agentic behavior. If an AI can’t beat Pokémon, it can’t replace a programmer.
- It gives a clear qualitative feel for competence—just watch five minutes.
- It’s non-specialized and anyone can evaluate it and have a shared understanding (unlike Cursor, which requires coding experience).
And once LLMs beat Pokemon Red, I'll personally will want to see them beat other games as well to make sure the agentic capabilities are generalizing.
comment by Dave Orr (dave-orr) · 2025-03-24T23:08:49.889Z · LW(p) · GW(p)
I work at GDM so obviously take that into account here, but in my internal conversations about external benchmarks we take cheating very seriously -- we don't want eval data to leak into training data, and have multiple lines of defense to keep that from happening. It's not as trivial as you might think to avoid, since papers and blog posts and analyses can sometimes have specific examples from benchmarks in them, unmarked -- and while we do look for this kind of thing, there's no guarantee that we will be perfect at finding them. So it's completely possible that some benchmarks are contaminated now. But I can say with assurance that for GDM it's not intentional and we work to avoid it.
We do hill climb on notable benchmarks and I think there's likely a certain amount of overfitting going on, especially with LMSys these days, and not just from us.
I think the main thing that's happening is that benchmarks used to be a reasonable predictor of usefulness, and mostly are not now, presumably because of Goodhart reasons. The agent benchmarks are pretty different in kind and I expect are still useful as a measure of utility, and probably will be until they start to get more saturated, at which point we'll all need to switch to something else.
Replies from: neel-nanda-1, D0TheMath↑ comment by Neel Nanda (neel-nanda-1) · 2025-03-25T21:42:46.889Z · LW(p) · GW(p)
I agree that I'd be shocked if GDM was training on eval sets. But I do think hill climbing on benchmarks is also very bad for those benchmarks being an accurate metric of progress and I don't trust any AI lab not to hill climb on particularly flashy metrics
↑ comment by Garrett Baker (D0TheMath) · 2025-03-25T16:11:58.560Z · LW(p) · GW(p)
I work at GDM so obviously take that into account here, but in my internal conversations about external benchmarks we take cheating very seriously -- we don't want eval data to leak into training data, and have multiple lines of defense to keep that from happening.
What do you mean by "we"? Do you work on the pretraining team, talk directly with the pretraining team, are just aware of the methods the pretraining team uses, or some other thing?
Replies from: dave-orr↑ comment by Dave Orr (dave-orr) · 2025-03-26T13:43:10.649Z · LW(p) · GW(p)
I don't work directly on pretraining, but when there were allegations of eval set contamination due to detection of a canary string last year, I looked into it specifically. I read the docs on prevention, talked with the lead engineer, and discussed with other execs.
So I have pretty detailed knowledge here. Of course GDM is a big complicated place and I certainly don't know everything, but I'm confident that we are trying hard to prevent contamination.
comment by ryan_greenblatt · 2025-03-26T06:20:16.973Z · LW(p) · GW(p)
Is this an accurate summary:
- 3.5 substantially improved performance for your use case and 3.6 slightly improved performance.
- The o-series models didn't improve performance on your task. (And presumably 3.7 didn't improve perf.)
So, by "recent model progress feels mostly like bullshit" I think you basically just mean "reasoning models didn't improve performance on my application and Claude 3.5/3.6 sonnet is still best". Is this right?
I don't find this state of affairs that surprising:
- Without specialized scaffolding o1 is quite a bad agent and it seems plausible your use case is mostly blocked on this. Even with specialized scaffolding, it's pretty marginal. (This shows up in the benchmarks AFAICT, e.g., see METR's results.)
- o3-mini is generally a worse agent than o1 (aside from being cheaper). o3 might be a decent amount better than o1, but it isn't released.
- Generally Anthropic models are better for real world coding and agentic tasks relative to other models and this mostly shows up in the benchmarks. (Anthropic models tend to slightly overperform their benchmarks relative to other models I think, but they also perform quite well on coding and agentic SWE benchmarks.)
- I would have guessed you'd see performance gains with 3.7 after coaxing it a bit. (My low confidence understanding is that this model is actually better, but it is also more misaligned and reward hacky in ways that make it less useful.)
↑ comment by sanxiyn · 2025-03-27T05:23:52.059Z · LW(p) · GW(p)
Our experience so far is while reasoning models don't improve performance directly (3.7 is better than 3.6, but 3.7 extended thinking is NOT better than 3.7), they do so indirectly because thinking trace helps us debug prompts and tool output when models misunderstand them. This was not the result we expected but it is the case.
Replies from: NULevel↑ comment by NULevel · 2025-04-07T00:49:44.004Z · LW(p) · GW(p)
Completely agree with this. While there are some novel applications possible with reasoning models, the main value has been the ability to trace specific chains of thought and redefine/reprompt accordingly. Makes the system (slightly) less of a black box
↑ comment by lc · 2025-03-26T15:50:59.297Z · LW(p) · GW(p)
Just edited the post because I think the way it was phrased kind of exaggerated the difficulties we've been having applying the newer models. 3.7 was better, as I mentioned to Daniel, just underwhelming and not as big a leap as either 3.6 or certainly 3.5.
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-03-26T08:46:53.302Z · LW(p) · GW(p)
How long do you[1] expect it to take to engineer scaffolding that will make reasoning models useful for the kind of stuff described in the OP?
- ^
You=Ryan firstmost but anybody reading this secondmost.
comment by lsusr · 2025-03-25T00:36:17.123Z · LW(p) · GW(p)
When you're a person interacting with a chat model directly, sycophancy and sophistry are a minor nuisance, or maybe even adaptive. When you're a team trying to compose these models into larger systems (something necessary because of the aforementioned memory issue), wanting-to-look-good cascades into breaking problems.
If you replace "models" with "people", this is true of human organizations too.
comment by sanxiyn · 2025-03-25T22:49:56.518Z · LW(p) · GW(p)
I happen to work on the exact sample problem (application security pentesting) and I confirm I observe the same. Sonnet 3.5/3.6/3.7 were big releases, others didn't help, etc. As for OpenAI o-series models, we are debating whether it is model capability problem or model elicitation problem, because from interactive usage it seems clear it needs different prompting and we haven't yet seriously optimized prompting for o-series. Evaluation is scarce, but we built something along the line of CWE-Bench-Java discussed in this paper, this was a major effort and we are reasonably sure we can evaluate. As for grounding, fighting false positives, and avoiding models to report "potential" problems to sound good, we found grounding on code coverage to be effective. Run JaCoCo, tell models PoC || GTFO, where PoC is structured as vulnerability description with source code file and line and triggering input. Write the oracle verifier of this PoC: at the very least you can confirm execution reaches the line in a way models can't ever fake.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-03-26T06:11:51.534Z · LW(p) · GW(p)
METR has found that substantially different scaffolding is most effective for o-series models. I get the sense that they weren't optimized for being effective multi-turn agents. At least, the o1 series wasn't optimized for this, I think o3 may have been.
comment by Vladimir_Nesov · 2025-03-25T06:16:20.678Z · LW(p) · GW(p)
With Blackwell[1] still getting manufactured and installed, newer large models and especially their long reasoning variants remain unavailable or prohibitively expensive or too slow (GPT-4.5 is out, but not its thinking variant). In a few months Blackwell will be everywhere, and between now and then widely available frontier capabilities will significantly improve. Next year, there will be even larger models trained on Blackwell.
This kind of improvement can't be currently created with post-training without needing long reasoning traces or larger base models, but post-training is still good at improving things under the lamppost, hence the illusionary nature of current improvement when you care about things further in the dark.
Blackwell is an unusually impactful chip generation, because it fixes what turned out to be a major issue with Ampere and Hopper when it comes to inference of large language models on long context, by increasing scale-up world size from 8 Hopper chips to 72 Blackwell chips. Not having enough memory or compute on each higher bandwidth scale-up network was a bottleneck that made inference unnecessarily slow and expensive. Hopper was still designed before ChatGPT, and it took 2-3 years to propagate importance of LLMs as an application into working datacenters. ↩︎
comment by AnthonyC · 2025-03-25T02:58:47.650Z · LW(p) · GW(p)
I can't comment on software engineering, not my field. I work at a market research/tech scouting/consulting firm. What I can say is that over the past ~6 months we've gone from "I put together this 1 hour training for everyone to get some more value out of these free LLM tools," to "This can automate ~half of everything we do for $50/person/month." I wouldn't be surprised if a few small improvements in agents over the next 3-6 months push that 50% up to 80%, then maybe 90% by mid next year. That's not AGI, but it does get you to a place where you need people to have significantly more complex and subtle skills, that currently take a couple of years to build, before their work is adding significant value.
Replies from: MalcolmMcLeod↑ comment by MalcolmMcLeod · 2025-03-25T18:44:47.414Z · LW(p) · GW(p)
Could you explain what types of tasks lie within this "50%"?
And when you talk about "automating 50%," does this mean something more like "we all get twice as productive because the tasks we accomplish are faster," or does it mean "the models can do the relevant tasks end-to-end in a human-replacement way, and we simply no longer need attend to these tasks"?
E.g., Cursor cannot yet replace a coder, but it can enhance her productivity. However, a chatbot can entirely replace a frontline customer service representation.
↑ comment by AnthonyC · 2025-03-26T22:37:35.128Z · LW(p) · GW(p)
Some of both, more of the former, but I think that is largely an artifact of how we have historically defined tasks. None of us have ever managed an infinite army of untrained interns before, which is how I think of LLM use (over the past two years they've roughly gone from high school student interns to grad student interns), so we've never refactored tasks into appropriate chunks for that context.
I've been leading my company's team working on figuring out how to best integrate LLMs into our workflow, and frankly, they're changing so fast with new releases that it's not worth attempting end-to-end replacement in most tasks right now. At least, not for a small company. 80/20 rule applies on steroids, we're going to have new and better tools and strategies next week/month/quarter anyway. Like, I literally had a training session planned for this morning, woke up to see the Gemini 2.5 announcement, and had to work it in as "Expect additional guidance soon, please provide feedback if you try it out." We do have a longer term plan for end-to-end automation of specific tasks, as well, where it is worthwhile. I half-joke that Sam Altman tweets a new feature and we have to adapt our plans to it.
Current LLMs can reduce the time required to get up-to-speed on publicly available info in a space by 50-90%. They can act as a very efficient initial thought partner for sanity checking ideas/hypotheses/conclusions, and teacher for overcoming mundane skill issues of various sorts ("How do I format this formula in Excel?"). They reduce the time required to find and contact people you need to actually talk to by much less, maybe 30%, but that will go way down if and when there's an agent I can trust to read my Outlook history and log into my LinkedIn and Hunter.io and ZoomInfo and Salesforce accounts and draft outreach emails. Tools like NotebookLM make it much more efficient to transfer knowledge across the team. AI notetakers help ensure we catch key points made in passing in meetings and provide a baseline for record keeping. We gradually spend more time on the things AI can't yet do well, hopefully adding more value and/or completing more projects in the process.
Replies from: MazevSchlong↑ comment by MazevSchlong · 2025-03-27T22:21:00.695Z · LW(p) · GW(p)
I think this is a great point here:
None of us have ever managed an infinite army of untrained interns before
Its probable that AIs will force us to totally reformat workflows to stay competitive. Even as the tech progresses, it’s likely there will remain things that humans are good at and AIs lag. If intelligence can be represented by some sort of n-th dimensional object, AIs are already super-human at some subset of n, but beating humans at all n seems unlikely in the near-to-mid term.
In this case, we need to segment work, and have a good pipeline for tasking humans with the work that they excel at, and automating the rest with AI. Young zoomers and kids will likely be intuitively good at this, since they are growing up with this tech.
This is also great in a p(doom) scenario, because even if there are a few pesky things that humans can still do, there’s a good reason to keep us around to do them!
comment by leogao · 2025-03-26T19:28:52.083Z · LW(p) · GW(p)
Actual full blown fraud in frontier models at the big labs (oai/anthro/gdm) seems very unlikely. Accidental contamination is a lot more plausible but people are incentivized to find metrics that avoid this. Evals not measuring real world usefulness is the obvious culprit imo and it's one big reason my timelines have been somewhat longer despite rapid progress on evals.
Replies from: kabir-kumar↑ comment by Kabir Kumar (kabir-kumar) · 2025-04-01T00:49:18.110Z · LW(p) · GW(p)
Why does it seem very unlikely?
Replies from: jazi-zilber↑ comment by Jazi Zilber (jazi-zilber) · 2025-04-07T03:44:05.425Z · LW(p) · GW(p)
those conspiracies don't work most of the time "you can only keep a secret between two people, provided one of them is dead".
the personal risk for anyone involved + the human psychological tendency to chat and to have a hard time holding on to immortal secrets mean it's usually irrational for both organisations to do intentional cheating.
comment by lemonhope (lcmgcd) · 2025-04-07T17:54:05.996Z · LW(p) · GW(p)
Almost every time I use Claude Code (3.7 I think) it ends up cheating at the goal. Optimizing performance by replacing the API function with a constant, deleting test cases, ignoring runtime errors with silent try catch, etc. It never mentions these actions in the summary. In this narrow sense, 3.7 is the most misaligned model I have ever used.
Replies from: lookoutbelow↑ comment by lookoutbelow · 2025-04-08T04:22:30.140Z · LW(p) · GW(p)
This was an issue referenced in the model card ("special casing"). Not as rare as they made it out to be it seems.
comment by p.b. · 2025-03-24T20:48:26.456Z · LW(p) · GW(p)
I was pretty impressed with o1-preview's ability to do mathematical derivations. That was definitely a step change, the reasoning models can do things earlier models just couldn't do. I don't think the AI labs are cheating for any reasonable definition of cheating.
comment by Zach Stein-Perlman · 2025-03-24T20:06:15.460Z · LW(p) · GW(p)
Data point against "Are the AI labs just cheating?": the METR time horizon thing [LW · GW]
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-03-24T22:22:08.468Z · LW(p) · GW(p)
lc has argued that the measured tasks are unintentionally biased towards ones where long-term memory/context length doesn't matter:
https://www.lesswrong.com/posts/hhbibJGt2aQqKJLb7/shortform-1#vFq87Ge27gashgwy9 [LW(p) · GW(p)]
comment by nmca · 2025-04-06T19:30:44.502Z · LW(p) · GW(p)
(disclaimer: I work on evaluation at oai, run the o3 evaluations etc)
I think you are saying “bullshit” when you mean “narrow”. The evidence for large capability improvements in math and tightly scoped coding since 4o is overwhelming, see eg AIME 2025, Gemini USAMO, copy paste a recent codeforces problem etc.
The public evidence for broad/fuzzy task improvement is weaker — o1 mmlu boosts and various vibes evals (Tao) do show it though.
It is a very important question how much these large narrow improvements generalize. I try and approach the question humbly.
Hopefully new models improve on your benchmark — do share if so!
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-24T23:57:49.314Z · LW(p) · GW(p)
Unexpectedly by me, aside from a minor bump with 3.6 in October, literally none of the new models we've tried have made a significant difference on either our internal benchmarks or in our developers' ability to find new bugs. This includes the new test-time OpenAI models.
So what's the best model for your use case? Still 3.6 Sonnet?
Replies from: lc↑ comment by lc · 2025-03-25T00:00:53.445Z · LW(p) · GW(p)
We use different models for different tasks for cost reasons. The primary workhorse model today is 3.7 sonnet, whose improvement over 3.6 sonnet was smaller than 3.6's improvement over 3.5 sonnet. When taking the job of this workhorse model, o3-mini and the rest of the recent o-series models were strictly worse than 3.6.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-03-25T00:11:28.413Z · LW(p) · GW(p)
Thanks. OK, so the models are still getting better, it's just that the rate of improvement has slowed and seems smaller than the rate of improvement on benchmarks? If you plot a line, does it plateau or does it get to professional human level (i.e. reliably doing all the things you are trying to get it to do as well as a professional human would)?
What about 4.5? Is it as good as 3.7 Sonnet but you don't use it for cost reasons? Or is it actually worse?
Replies from: lc↑ comment by lc · 2025-03-25T00:36:34.477Z · LW(p) · GW(p)
If you plot a line, does it plateau or does it get to professional human level (i.e. reliably doing all the things you are trying to get it to do as well as a professional human would)?
It plateaus before professional human level, both in a macro sense (comparing what ZeroPath can do vs. human pentesters) and in a micro sense (comparing the individual tasks ZeroPath does when it's analyzing code). At least, the errors the models make are not ones I would expect a professional to make; I haven't actually hired a bunch of pentesters and asked them to do the same tasks we expect of the language models and made the diff. One thing our tool has over people is breadth, but that's because we can parallelize inspection of different pieces and not because the models are doing tasks better than humans.
What about 4.5? Is it as good as 3.7 Sonnet but you don't use it for cost reasons? Or is it actually worse?
We have not yet tried 4.5 as it's so expensive that we would not be able to deploy it, even for limited sections.
Replies from: gwern↑ comment by gwern · 2025-04-07T02:53:55.833Z · LW(p) · GW(p)
We have not yet tried 4.5 as it's so expensive that we would not be able to deploy it, even for limited sections.
Still seems like potentially valuable information to know: how much does small-model smell cost you? What happens if you ablate reasoning? If it is factual knowledge and GPT-4.5 performs much better, then that tells you things like 'maybe finetuning is more useful than we think', etc. If you are already set up to benchmark all these OA models, then a datapoint from GPT-4.5 should be quite easy and just a matter of a small amount of chump change in comparison to the insight, like a few hundred bucks.
Replies from: dimitry12comment by SoerenMind · 2025-03-25T21:02:11.421Z · LW(p) · GW(p)
This is interesting. Though companies are probably investing a lot less into cyber capabilities than they invest into other domains like coding. Cyber is just less commercially interesting plus it can be misused and worry the government. And the domain specific investment should matter since most of the last year's progress has been from post training, which is often domain specific.
(I haven't read the whole post)
comment by green_leaf · 2025-03-25T07:03:21.339Z · LW(p) · GW(p)
According to Terrence Tao, GPT-4 was incompetent at graduate-level math (obviously), but o1-preview was mediocre-but-not-entirely-incompetent. That would be a strange thing to report if there were no difference.
(Anecdotally, o3-mini is visibly (massively) brighter than GPT-4.)
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2025-03-26T04:37:33.481Z · LW(p) · GW(p)
Full quote on Mathstodon for others' interest:
In https://chatgpt.com/share/94152e76-7511-4943-9d99-1118267f4b2b I gave the new model a challenging complex analysis problem (which I had previously asked GPT4 to assist in writing up a proof of in https://chatgpt.com/share/63c5774a-d58a-47c2-9149-362b05e268b4 ). Here the results were better than previous models, but still slightly disappointing: the new model could work its way to a correct (and well-written) solution *if* provided a lot of hints and prodding, but did not generate the key conceptual ideas on its own, and did make some non-trivial mistakes. The experience seemed roughly on par with trying to advise a mediocre, but not completely incompetent, (static simulation of a) graduate student. However, this was an improvement over previous models, whose capability was closer to an actually incompetent (static simulation of a) graduate student. It may only take one or two further iterations of improved capability (and integration with other tools, such as computer algebra packages and proof assistants) until the level of "(static simulation of a) competent graduate student" is reached, at which point I could see this tool being of significant use in research level tasks. (2/3)
This o1 vs MathOverflow experts comparison was also interesting:
Replies from: green_leafIn 2010 i was looking for the correct terminology for a “multiplicative integral”, but was unable to find it with the search engines of that time. So I asked the question on #MathOverflow instead and obtained satisfactory answers from human experts: https://mathoverflow.net/questions/32705/what-is-the-standard-notation-for-a-multiplicative-integral
I posed the identical question to my version of #o1 and it returned a perfect answer: https://chatgpt.com/share/66e7153c-b7b8-800e-bf7a-1689147ed21e . Admittedly, the above MathOverflow post could conceivably have been included in the training data of the model, so this may not necessarily be an accurate evaluation of its semantic search capabilities (in contrast with the first example I shared, which I had mentioned once previously on Mastodon but without fully revealing the answer). Nevertheless it demonstrates that this tool is on par with question and answer sites with respect to high quality answers for at least some semantic search queries. (1/2)
↑ comment by green_leaf · 2025-03-26T23:06:18.791Z · LW(p) · GW(p)
(I believe the version he tested was what later became o1-preview.)
comment by cozyfae · 2025-03-24T22:02:15.581Z · LW(p) · GW(p)
These machines will soon become the beating hearts of the society in which we live.
An alternative future: due to the high rates of failure, we don't end up deploying these machines widely in production setting, just like how autonomous driving had breakthroughs long ago but didn't end up getting widely deployed today.
comment by fujisawa_sora · 2025-03-28T02:52:07.852Z · LW(p) · GW(p)
I primarily use LLMs when working with mathematics, which is one of the areas where the recent RL paradigm was a clear improvement—reasoning models are finally useful. However, I agree with you that benchmark-chasing isn’t optimal, in that it still can’t admit when it’s wrong. It doesn’t have to give up, but when it couldn’t do something, I’d rather it list out what it tried as ideas, rather than pretending it can solve everything, because then I actually have to read through everything.
Of course, this can be solved with some amateur mathematicians reading through it and using RL to penalize BS. So, I think this is a case where benchmark performance was prioritized over actual usefulness.
comment by Aaron_Scher · 2025-03-27T07:52:18.699Z · LW(p) · GW(p)
I appreciate this post, I think it's a useful contribution to the discussion. I'm not sure how much I should be updating on it. Points of clarification:
Within the first three months of our company's existence, Claude 3.5 sonnet was released. Just by switching the portions of our service that ran on gpt-4o, our nascent internal benchmark results immediately started to get saturated.
- Have you upgraded these benchmarks? Is it possible that the diminishing returns you're seen in the Sonnet 3.5-3.7 series are just normal benchmark saturation? What % scores are the models getting? i.e., somebody could make the same observation about MMLU and basically be like "we've seen only trivial improvements since GPT-4", but that's because the benchmark is not differentiating progress well after like the high 80%s (in turn I expect this is due to test error and the distribution of question difficulty).
- Is it correct that your internal benchmark is all cybersecurity tasks? Soeren points out [LW(p) · GW(p)] that companies may be focusing much less on cyber capabilities than general SWE.
- How much are you all trying to elicit models' capabilities, and how good do you think you are? E.g., do you spend substantial effort identifying where the models are getting tripped up and trying to fix this? Or are you just plugging each new model into the same scaffold for testing (which I want to be clear is a fine thing to do, but is useful methodology to keep in mind). I could totally imagine myself seeing relatively little performance gains if I'm not trying hard to elicit new model capabilities. This would be even worse if my scaffold+ was optimized for some other model, as now I have an unnaturally high baseline (this is a very sensible thing to do for business reasons, as you want a good scaffold early and it's a pain to update, but it's useful methodology to be aware of when making model comparisons). Especially re the o1 models, as Ryan points out in a comment.
comment by James Grugett (james-grugett) · 2025-04-07T01:19:52.137Z · LW(p) · GW(p)
Much of the gains on SWE Bench are actually about having the model find better context via tool calls. Sonnet 3.7 is trained to seek out the information it needs.
But if you compare the models with fixed context, they are only somewhat smarter than before.
(The other dimension is the thinking models which seem to be only a modest improvement on coding, but do much better at math for example.)
That being said, the new Gemini 2.5 Pro seems like another decent step up in intelligence from Sonnet 3.7. We're about to switch out the default mode of our coding agent, Codebuff, to use it (and already shipped it for codebuff --max).
comment by Noosphere89 (sharmake-farah) · 2025-04-01T14:20:33.413Z · LW(p) · GW(p)
Gradient Updates has a post on this by Anson Ho and Jean-Stanislas Denain on why benchmarks haven't reflected usefulness, and a lot of the reason is that they underestimated AI progress and didn't really have an incentive to make benchmarks reflect realistic use cases:
https://epoch.ai/gradient-updates/the-real-reason-ai-benchmarks-havent-reflected-economic-impacts
comment by Qumeric (valery-cherepanov) · 2025-03-25T20:49:23.080Z · LW(p) · GW(p)
I am curious to see what would be the results of the new Gemini 2.5 pro on internal benchmarks.
comment by solhando · 2025-03-26T12:47:33.065Z · LW(p) · GW(p)
Somewhat unrelated to the main point of your post, but; How close are you to solving the wanting-to-look-good problem?
I run a startup in a completely different industry, and we've invested significant resources in trying to get an LLM to interact with a customer, explain and make dynamic recommendations based on their preferences. This is a more high-touch business, so traditionally this was done by a human operator. The major problem we've encountered is that it's almost impossible to have an LLM to admit ignorance when it doesn't have the information. It's not outright hallucinating, so much as deliberately misinterpreting instructions so it can give us a substantial answer, whether or not one is warranted.
We've put a lot of resources in this, and it's reached the point where I'm thinking of winding down the entire project. I'm of the opinion that it's not possible with current models, and I don't want to gamble any more resources on a new model that solves the problem for us. AI was never our core competency, and what we do in a more traditional space definitely works, so it's not like we'd be pivoting to a completely untested idea like most LLM-wrapper startups would have to do.
I thought I'd ask here, since if the problem is definitely solvable for you with current models, I know it's a problem with our approach and/or team. Right now we might be banging our heads against a wall, hoping it will fall, when it's really the cliffside of a mountain range a hundred kilometers thick.
Replies from: sanxiyncomment by Mo Putera (Mo Nastri) · 2025-03-26T04:33:38.595Z · LW(p) · GW(p)
Personally, when I want to get a sense of capability improvements in the future, I'm going to be looking almost exclusively at benchmarks like Claude Plays Pokemon.
Same, and I'd adjust for what Julian pointed out [LW · GW] by not just looking at benchmarks but viewing the actual stream.
comment by Trevor Hill-Hand (Jadael) · 2025-03-24T23:57:14.583Z · LW(p) · GW(p)
I happened to be discussing this in the Discord today. I have a little hobby project that was suddenly making fast progress with 3.7 for the first few days, which was very exciting, but then a few days ago it felt like something changed again and suddenly even the old models are stuck in this weird pattern of like... failing to address the bug, and instead hyper-fixating on adding a bunch of surrounding extra code to handle special cases, or sometimes even simply rewriting the old code and claiming it fixes the bug, and the project is suddenly at a complete standstill. Even if I eventually yell at it strongly enough to stop adding MORE buggy code instead of fixing the bug, it introduces a new bug and the whole back-and-forth argument with Claude over whether this bug even exists starts all over. I cannot say this is rigorously tested or anything- it's just one project, and surely the project itself is influencing its own behavior and quirks as it becomes bigger, but I dunno man, something just feels weird and I can't put my finger on exactly what.
Replies from: robert-k↑ comment by Mis-Understandings (robert-k) · 2025-03-25T02:11:58.029Z · LW(p) · GW(p)
Beware of argument doom spirals. When talking to a person, arguing about the existene of a bug tends not to lead to succesful resolution of the bug. Somebody talked about this on a post a few days ago, about attractor basins, oppositionality, and when AI agents are convinced they are people (rightly or wrongly). You are often better off clearing the context then repeatedly arguing in the same context window.
Replies from: Jadael, Archimedes, robert-k↑ comment by Trevor Hill-Hand (Jadael) · 2025-03-26T13:54:41.125Z · LW(p) · GW(p)
This is a good point! Typically I start from a clean commit in a fresh chat, to avoid this problem from happening too easily, proceeding through the project in the smallest steps I can get Claude to make. That's what makes the situation feel so strange; it feels just like this problem, but it happens instantly, in Claude's first responses.
↑ comment by Archimedes · 2025-03-25T22:43:39.052Z · LW(p) · GW(p)
It's also worth trying a different model. I was going back and forth with an OpenAI model (I don't remember which one) and couldn't get it to do what I needed at all, even with multiple fresh threads. Then I tried Claude and it just worked.
↑ comment by Mis-Understandings (robert-k) · 2025-03-25T02:22:15.719Z · LW(p) · GW(p)
Consider the solutions from Going Nova [LW · GW]
comment by Ram Potham (ram-potham) · 2025-03-30T16:58:06.289Z · LW(p) · GW(p)
I have experienced similar problems to you when building an AI tool - better models did not necessarily lead to better performance despite external benchmarks. I believe there are 2 main reasons why this is, alluded to in your post:
- Selection Bias - when a foundation model company releases their newest model, they show performance on benchmarks most favorable to it
- Alignment - You mentioned how AI is not truly understanding the instructions you meant. While this can be mitigated by creating better prompts, it does not fully solve the issue
comment by Viktor Rehnberg (viktor.rehnberg) · 2025-03-27T14:54:20.905Z · LW(p) · GW(p)
Another hypothesis: Your description of the task is
the hard parts of application pentesting for LLMs, which are 1. Navigating a real repository of code too large to put in context, 2. Inferring a target application's security model, and 3. Understanding its implementation deeply enough to learn where that security model is broken.
From METR's recent investigation on long tasks you would expect current models not to perform well on this.
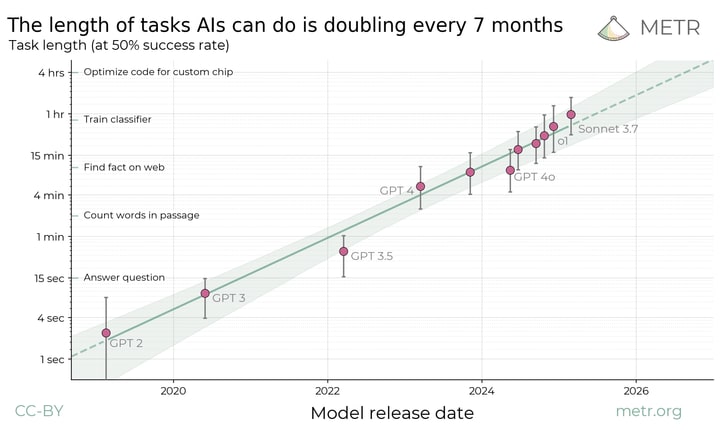
I doubt a human professional could do the tasks you describe in something close to an hour, so perhaps its just currently too hard and the current improvements don't make much of a difference for the benchmark, but it might in the future.
comment by Chris_Leong · 2025-03-25T02:27:38.896Z · LW(p) · GW(p)
However, if you merely explain these constraints to the chat models, they'll follow your instructions sporadically.
I wonder if a custom fine-tuned model could get around this. Did you try few shot prompting (ie. examples, not just a description)?
comment by ramennaut · 2025-04-12T04:06:17.674Z · LW(p) · GW(p)
This really resonates with me. I don't work in AppSec, but I've seen how benchmark gains often fail to show up when you're doing something non-trivial with the model. It seem that current benchmarks have low ecological validity. Although I wouldn't quickly put the blame on labs possibly cheating. They may or they may not, but it also might just be that we're bad at designing evaluations that tracks real-world usefulness.
When you think about it, even university exams don't really predict job performance either. These are benchmarks we've had centuries to refine. Measuring ability is hard. Measuring reliability and adaptability alongside this is even harder. For agentic systems, tasks would mostly involve multiple iterations over longer periods of time, reviews, and some form of multi-tasking that spans across contexts. That is far beyond what current benchmarks are testing for. They're not just solving a neatly scoped problem and calling it a day.
comment by Vasilios Mavroudis (vasilios-mavroudis) · 2025-04-07T12:56:42.730Z · LW(p) · GW(p)
Interesting article! Here is a benchmark that does real world exploitation (indeed CTFs don't cut it anymore): https://github.com/alan-turing-institute/HonestCyberEval
comment by vire · 2025-03-28T09:38:43.359Z · LW(p) · GW(p)
That's an interesting point, why didn't we see major improvements in LLMs for instance when coding... Despite them achieving reasoning on the level that allows them become a GM on codeforces.
I'd say this is a fundamental limitation of reinforcement learning. Using purely reinforcement learning is stupid. Look at humans, we do much more than that. We make observations about our failures and update, we develop our own heuristics for what it means to be good at something and then try to figure out how to make ourselves better by reasoning about it watching other people etc...
This form of learning that happens at inference time is imo the fundamental thing preventing LLMs right now becoming more intelligent. And actual memory of course.
So we're just making them improve at measurable tasks through naive reinforcement learning but don't allow them to generalize it by using their understanding of that to properly update themselves in other not so measurable fields...
comment by David James (david-james) · 2025-03-27T15:09:34.149Z · LW(p) · GW(p)
HLE and benchmarks like it are cool, but they fail to test the major deficits of language models, like how they can only remember things by writing them down onto a scratchpad like the memento guy.
A scratch pad for thinking, in my view, is hardly a deficit at all! Quite the opposite. In the case of people, some level of conscious reflection is important and probably necessary for higher-level thought. To clarify, I am not saying consciousness itself is in play here. I’m saying some feedback loop is probably necessary — where the artifacts of thinking, reasoning, or dialogue can themselves become objects of analysis.
My claim might be better stated this way: if we want an agent to do sufficiently well on higher-level reasoning tasks, it is probably necessary for them to operate at various levels of abstraction, and we shouldn’t be surprised if this is accomplished by way of observable artifacts used to bridge different layers. Whether the mechanism is something akin to chain of thought or something else seems incidental to the question of intelligence (by which I mean assessing an agent's competence at a task, which follows Stuart Russell's definition).
I don’t think the author would disagree, but this leaves me wondering why they wrote the last part of the sentence above. What am I missing?
comment by groblegark · 2025-03-26T23:54:41.075Z · LW(p) · GW(p)
Where does prompt optimization fit in to y’all’s workflows? I’m surprised not to see mention of it here. E.g OPRO https://arxiv.org/pdf/2309.03409 ?
comment by momom2 (amaury-lorin) · 2025-03-25T20:44:04.957Z · LW(p) · GW(p)
I think what's going on is that large language models are trained to "sound smart" in a live conversation with users, and so they prefer to highlight possible problems instead of confirming that the code looks fine, just like human beings do when they want to sound smart.
This matches my experience, but I'd be interested in seeing proper evals of this specific point!
comment by Mis-Understandings (robert-k) · 2025-03-24T19:54:10.845Z · LW(p) · GW(p)
Your first two key challenges
Seems very similar to the agent problem of active memory switching, carrying important information across context switches
Also note that it could just be instead of bullshit, finetuning is unreasonably effective, and so when you train models on an evaluation they actually get better on the things evaluated, which dominates over scaling.
So things with public benchmarks might just actually be easier to make models that are genuinely good at it. (For instance searching for data that helps 1B models learn it, then adding it to full size models as a solution for data quality issues)
Have tested if finetuning open models on your problems works? (It is my first thought, so I assume you had it too)
comment by Anthony Perez-sanz (anthony-perez-sanz) · 2025-04-07T14:28:47.836Z · LW(p) · GW(p)
I feel like your jumping to cheating way to quickly. I think everyone would agree that there is overfitting to benchmarks and to benchmark like questions. Also, this is a very hard problem. The average person doesn't have a shot at contributing to security research. Even the typical appsec engineer with years of experience would fail at the task of navigating a new codebase, creating a threat model and finding important security issues. This takes an expert in the field at least a few days of work. This is much longer than the time periods that AIs can be expected to work on a problem productively. I don't think you get a completely general solution to this problem until we are well past AGI. However, it doesn't mean you can saturate a meaningful benchmark and lead to a big improvement.
We need to zoom out. It clear across all benchmarks that we hit dimension returns from pretraining a long time ago. Bigger models aren't helping much at all. Inference-time scaling is what helping lead to improvements. But how will the get a useful chain of thought for this use case. There is almost nothing online from security researching thinking though what is and isn't an important security issue. We need to feed more of this data into LLM to benefit from chain of thought.
In addition, we likely need amazing scaffolding to break this problem in sub pieces so that each batch of thinking can move it forward. Ie
- split the code base into sections to understand
- Create a mental model of code base
- Create a mental model of interactions
- Document assumptions
- Create a threat model
- Test each threat model for security issues.
comment by NickH · 2025-04-01T05:14:36.156Z · LW(p) · GW(p)
From a practical perspective, maybe you are looking at the problem the wrong way around. A lot of prompt engineering seems to be about asking LLMs to play a role. I would try to tell the LLM that it was a hacker and to design an exploit to attack the given system (this is the sort of mental perspective I used to use to find bugs when I was a software engineer). Another common technique is "generate then prune" : Have a separate model/prompt remove all the results of the first one that are only "possibilities". It seems, from my reading, that this sort of two stage approach can work because it bypasses LLMs typical attempts to "be helpful" by inventing stuff or spouting banal filler rather than just admitting ignorance.
Replies from: tomcatfish↑ comment by Alex Vermillion (tomcatfish) · 2025-04-01T16:42:40.704Z · LW(p) · GW(p)
I think we should suspect that they've done some basic background research (this individual, not in general), and take the rest of the information about people failing to see improvements as data that also points this direction.