LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
This is clever. Looking at readership views on a subject Scott posted about during the survey wasn't something I'd even thought about, but it feels obvious in hindsight which is an excellent sign of clever in my book. And your results are not just significant but at the "hot damn look at that chart" level.
Thank you for thinking of this and writing it up!
lawrencec on "AI Safety for Fleshy Humans" an AI Safety explainer by Nicky CaseAlso, I added another sentence trying to clarify what I meant at the end of the paragraph, sorry for the confusion.
johnswentworth on My hour of memoryless lucidityDo you know what the drug was which did this?
nathan-helm-burger on How does the ever-increasing use of AI in the military for the direct purpose of murdering people affect your p(doom)?Personally, I have gradually moved to seeing this as lowering my p(doom). I think humanity's best chance is to politically coordinate to globally enforce strict AI regulation. I think the most likely route to this becoming politically feasible is through empirical demonstrations of the danger of AI. I think AI is more likely to be legibly empirically dangerous to political decision-makers if it is used in the military. Thus, I think military AI is, counter-intuitively, lowering p(doom). A big accident that caused military AI to kill thousands of innocent people that the military had not intended to kill could be really great for p(doom).
This is a sad thing to think, obviously. I'm hopeful we can come up with harmless demonstrations of the dangers involved, so that political action will be taken without anyone needing to be killed.
In scenarios where AI becomes powerful enough to present an extinction risk to humanity, I don't expect that the level of robotic weaponry it has control over to matter much. It will have many many opportunities to hurt humanity that look nothing like armed robots and greatly exceed the power of armed robots.
joshjacobson on Key takeaways from our EA and alignment research surveysEpistemic status: just speculation, from a not very concrete memory, written hastily on mobile after a quick skim of the post.
My guess is that these results should be taken with a large grain of salt, but if I'm wrong, I'd be interested in hearing more about why.
Specifically, I think the "alignment researcher" population and "org leader" populations here are probably a far departure from what people envision when they hear these terms. I also expect other populations reported on to have a directionally similar skew to what I speculate below.
An anecdote for why I expect that (some aspects may be off):
One additional factor for my abandoning it was that I couldn't imagine it drawing a useful response population anyway; the sample mentioned above is a significant surprise to me (even with my skepticism around the makeup of that population). Beyond the reasons I already described, I felt that it being done by a for-profit org that is a newcomer and probably largely unknown would dissuade a lot of people from responding (and/or providing fully candid answers to some questions).
All in all, I expect that the respondent population skews heavily toward those who place a lower value on their time and are less involved. I expect this to generally be a more junior group, often not fully employed in these roles, with eg the average age and funding level of the orgs that are being led particularly low (and some of the orgs being more informal).
That's a very legitimate and useful population to survey; I just think it also isn't at all what people typically think of when hearing these terms.
I could be wrong about all of this! But my guess is it's directionally useful for understanding this post.
lukehmiles on AI #62: Too Soon to TellOriginal post that introduced the technique is best explanation of steering stuff. https://www.lesswrong.com/posts/5spBue2z2tw4JuDCx/steering-gpt-2-xl-by-adding-an-activation-vector [LW · GW]
lawrencec on "AI Safety for Fleshy Humans" an AI Safety explainer by Nicky CaseNo, I'm saying that "adding 'logic' to AIs" doesn't (currently) look like "figure out how to integrate insights from expert systems/explicit bayesian inference into deep learning", it looks like "use deep learning to nudge the AI toward being better at explicit reasoning by making small changes to the training setup". The standard "deep learning needs to include more logic" take generally assumes that you need to add the logic/GOFAI juice in explicitly, while in practice people do a slightly different RL or supervised finetuning setup instead.
(EDITED to add: so while I do agree that "LMs are bad at the things humans do with 'logic' and good at 'intuition' is a decent heuristic, I think the distinction that we're talking about here is instead about the transparency of thought processes/"how the thing works" and not about if the thing itself is doing explicit or implicit reasoning. Do note that this is a nitpick (as the section header says) that's mainly about framing and not about the core content of the post.)
That being said, I'll still respond to your other point:
Chain of thought is a wonderful thing, it clears a space where the model will just earnestly confess its inner thoughts and plans in a way that isn't subject to training pressure, and so it, in most ways, can't learn to be deceptive about it.
I agree that models with CoT (in faithful, human-understandable English) are more interpretable than models that do all their reasoning internally. And obviously I can't really argue against CoT being helpful in practice; it's one of the clear baselines for eliciting capabilities.
But I suspect you're making a distinction about "CoT" that is actually mainly about supervised finetuning vs RL, and not a benefit about CoT in particular. If the CoT comes from pretraining or supervised fine-tuning, the ~myopic next-token-prediction objective indeed does not apply much if training pressure in the relevant ways.[1] Once you start doing any outcome-based supervision (i.e. RL) without good regularization, I think the story for CoT looks less clear. And the techniques people use for improving CoT tend to involve upweighting entire trajectories based on their reward (RLHF/RLAIF with your favorite RL algorithm) which do incentivize playing the training game unless you're very careful with your fine-tuning.
(EDITED to add: Or maybe the claim is, if you do CoT on a 'secret' scratchpad (i.e. one that you never look at when evaluating or training the model), then this would by default produce more interpretable thought processes?)
I'm not sure this is true in the limit (e.g. it seems plausible to me that the Solomonoff prior is malign). But it's most likely true in the next few years and plausibly true in all practical cases that we might consider.
I absolutely sympathize, and I agree that with the world view / information you have that advocating for a pause makes sense. I would get behind 'regulate AI' or 'regulate AGI', certainly. I think though that pausing is an incorrect strategy which would do more harm than good, so despite being aligned with you in being concerned about AGI dangers, I don't endorse that strategy.
Some part of me thinks this oughtn't matter, since there's approximately ~0% chance of the movement achieving that literal goal. The point is to build an anti-AGI movement, and to get people thinking about what it would be like to be able to have the government able to issue an order to pause AGI R&D, or turn off datacenters, or whatever. I think that's a good aim, and your protests probably (slightly) help that aim.
I'm still hung up on the literal 'Pause AI' concept being a problem though. Here's where I'm coming from:
1. I've been analyzing the risks of current day AI. I believe (but will not offer evidence for here) current day AI is already capable of providing small-but-meaningful uplift to bad actors intending to use it for harm (e.g. weapon development). I think that having stronger AI in the hands of government agencies designed to protect humanity from these harms is one of our best chances at preventing such harms.
2. I see the 'Pause AI' movement as being targeted mostly at large companies, since I don't see any plausible way for a government or a protest movement to enforce what private individuals do with their home computers. Perhaps you think this is fine because you think that most of the future dangers posed by AI derive from actions taken by large companies or organizations with large amounts of compute. This is emphatically not my view. I think that actually more danger comes from the many independent researchers and hobbyists who are exploring the problem space. I believe there are huge algorithmic power gains which can, and eventually will, be found. I furthermore believe that beyond a certain threshold, AI will be powerful enough to rapidly self-improve far beyond human capability. In other words, I think every AI researcher in the world with a computer is like a child playing with matches in a drought-stricken forest. Any little flame, no matter how small, could set it all ablaze and kill everyone. Are the big labs playing with bonfires dangerous? Certainly. But they are also visible, and can be regulated and made to be reasonably safe by the government. And the results of their work are the only feasible protection we have against the possibility of FOOM-ing rogue AGI launched by small independent researchers. Thus, pausing the big labs would, in my view, place us in greater danger rather than less danger. I think we are already well within the window of risk from independent-researcher-project-initiated-FOOM. Thus, the faster we get the big labs to develop and deploy worldwide AI-watchdogs, the sooner we will be out of danger.
I know these views are not the majority views held by any group (that I know of). These are my personal inside views from extensive research. If you are curious about why I hold these views, or more details about what I believe, feel free to ask. I'll answer if I can.
mako-yass on KAN: Kolmogorov-Arnold NetworksTheoretically and em-
pirically, KANs possess faster neural scaling laws than MLPs
What do they mean by this? Isn't that contradicted by this recommendation to use the an ordinary architecture if you want fast training:
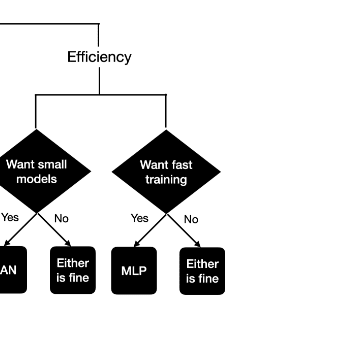
It seems like they mean faster per parameter, which is an... unclear claim given that each parameter or step, here, appears to represent more computation (there's no mention of flops) than a parameter/step in a matmul|relu would? Maybe you could buff that out with specialized hardware, but they don't discuss hardware.
One might worry that KANs are hopelessly expensive, since each MLP’s weight
parameter becomes KAN’s spline function. Fortunately, KANs usually allow much smaller compu-
tation graphs than MLPs. For example, we show that for PDE solving, a 2-Layer width-10 KAN
is 100 times more accurate than a 4-Layer width-100 MLP (10−7 vs 10−5 MSE) and 100 times
more parameter efficient (102 vs 104 parameters) [this must be a typo, this would only be 1.01 times more parameter efficient].
I'm not sure this answers the question. What are the parameters, anyway, are they just single floats? If they're not, pretty misleading.
nathan-helm-burger on An Introduction to AI SandbaggingI've mentioned it elsewhere, but I'll repeat it again here since it's relevant. For GPT-style transformers, and probably for other model types, you can smoothly subtly degrade the performance of the model by adding in noise to part or all of the activations. This is particularly useful for detecting sandbagging, because you would expect sandbagging to show up as an anomalous increase in capability, breaking the smooth downward trend in capability, as you increased the amount of noise injected or fraction of activations to which noise was added. I found that there was noticeable decrease in performance even when the noise was added even to a small fraction (e.g. < 1%) of the activations and was created to be small relative to the given activation-magnitude it was being added to.