The Lightcone Theorem: A Better Foundation For Natural Abstraction?
post by johnswentworth · 2023-05-15T02:24:02.038Z · LW · GW · 25 commentsContents
The Proof, In Pictures How To Use The Lightcone Theorem? None 25 comments
Thankyou to David Lorell for his contributions as the ideas in this post were developed.
For about a year and a half now, my main foundation for natural abstraction math has been The Telephone Theorem [LW · GW]: long-range interactions in a probabilistic graphical model (in the long-range limit) are mediated by quantities which are conserved (in the long-range limit). From there, the next big conceptual step [LW · GW] is to argue that the quantities conserved in the long-range limit are also conserved by resampling, and therefore the conserved quantities of an MCMC sampling process on the model mediate all long-range interactions in the model.
The most immediate shortcoming of the Telephone Theorem and the resampling argument is that they talk about behavior in infinite limits. To use them, either we need to have an infinitely large graphical model, or we need to take an approximation. For practical purposes, approximation is clearly the way to go, but just directly adding epsilons and deltas to the arguments gives relatively weak results.
This post presents a different path.
The core result is the Lightcone Theorem:
- Start with a probabilistic graphical model on the variables .
- The graph defines adjacency, distance, etc between variables. For directed graphical models (i.e. Bayes nets), spouses (as well as parents and children) count as adjacent.
- We can model those variables as the output of a Gibbs sampler (that’s the MCMC process) on the graphical model.
- Call the initial condition of the sampler . The distribution of must be the same as the distribution of (i.e. the sampler is initialized “in equilibrium”).
- We can model the sampler as having run for any number of steps to generate the variables; call the number of steps .
- At each step, the process resamples some set of nonadjacent variables conditional on their neighbors.
- The Lightcone Theorem says: conditional on , any sets of variables in which are a distance of at least apart in the graphical model are independent.
- Yes, exactly independent, no approximation.
In short: the initial condition of the resampling process provides a latent, conditional on which we have exact independence at a distance.
This was… rather surprising to me. If you’d floated the Lightcone Theorem as a conjecture a year ago, I’d have said it would probably work as an approximation for large , but no way it would work exactly for finite . Yet here we are.
The Proof, In Pictures
The proof is best presented visually.[1] High-level outline:
- Perform a do() operation on the Gibbs sampler, so that it never resamples the variables a distance of from .
- In the do()-operated process, mediates between and , where indicates indices of variables a distance of at least from .
- Since , and are all outside the lightcone of the do()-operation, they have the same joint distribution under the non-do()-operated sampler as under the do()-operated sampler.
- Therefore mediates between and under the original sampler.
We start with the graphical model:
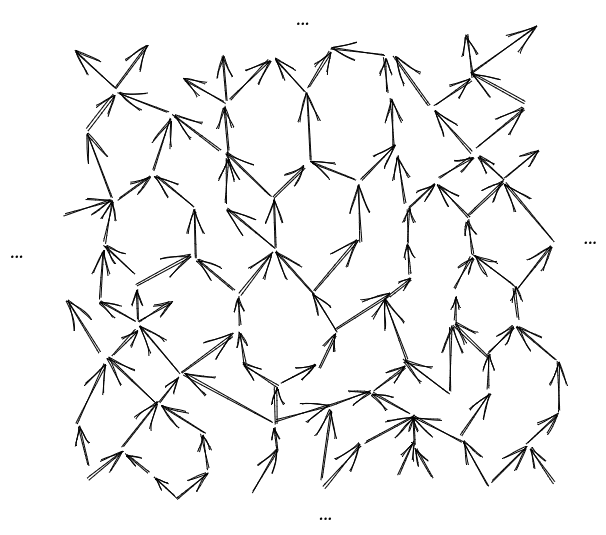
Within that graphical model, we’ll pick some tuple of variables (“R” for “region”)[2]. I’ll use the notation for the variables a distance away from , for variables a distance greater than away from , for variables a distance less than away from , etc.
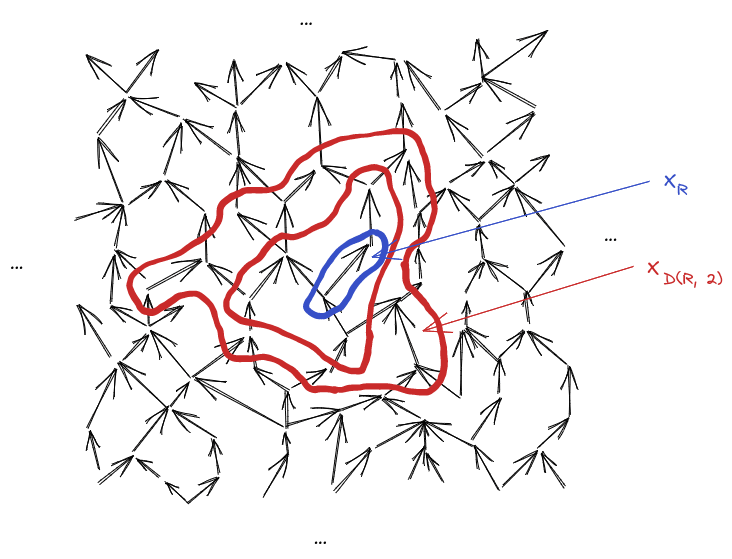
Note that for any , (the variables a distance away from ) is a Markov blanket, mediating interaction between (everything less than distance from ), and (everything more than distance from ).
Next, we’ll draw the Gibbs resampler as a graphical model. We’ll draw the full state at each timestep as a “layer”, with as the initial layer and as the final layer. At each timestep, some (nonadjacent) variables are resampled conditional on their neighbors, so we have arrows from the neighbor-variables in the previous timestep. The rest of the variables stay the same, so they each just have a single incoming variable from themselves at the previous timestep.
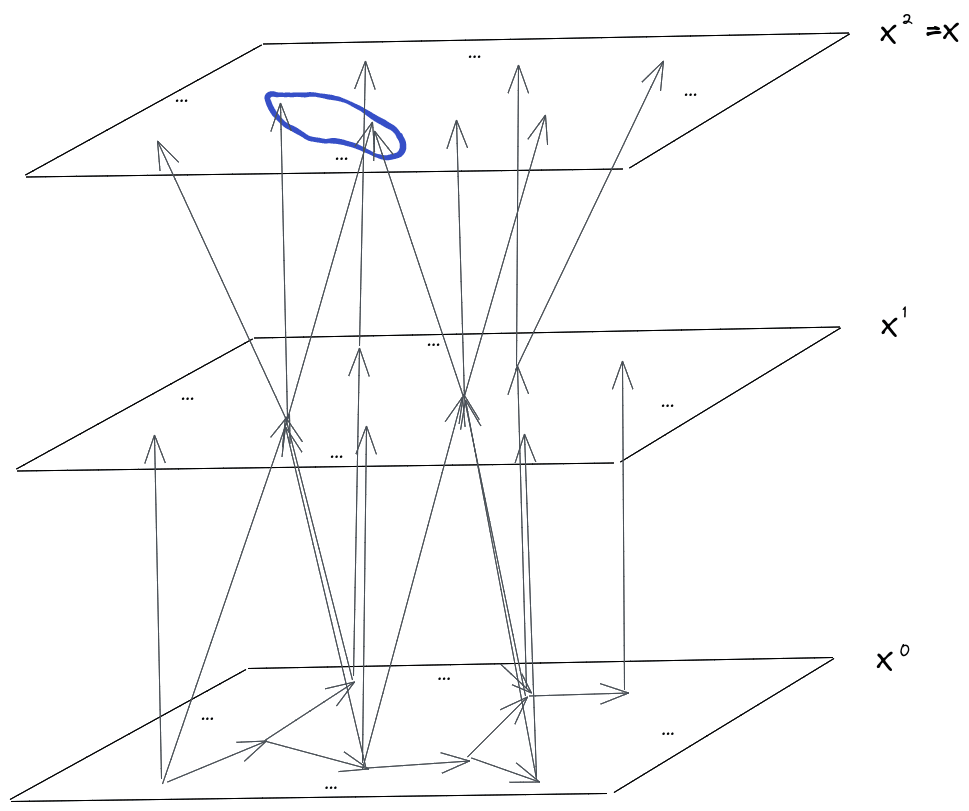
Now for the core idea: we’re going to perform a do() operation on the resampler-graph. Specifically, we’re going to hold constant; none of the variables in that Markov blanket are ever resampled in the do()-transformed resampling process.
Notice that, in the do()-operated process, knowing also tells us the value of for all . So, if we condition on , then visually we’re conditioning on:
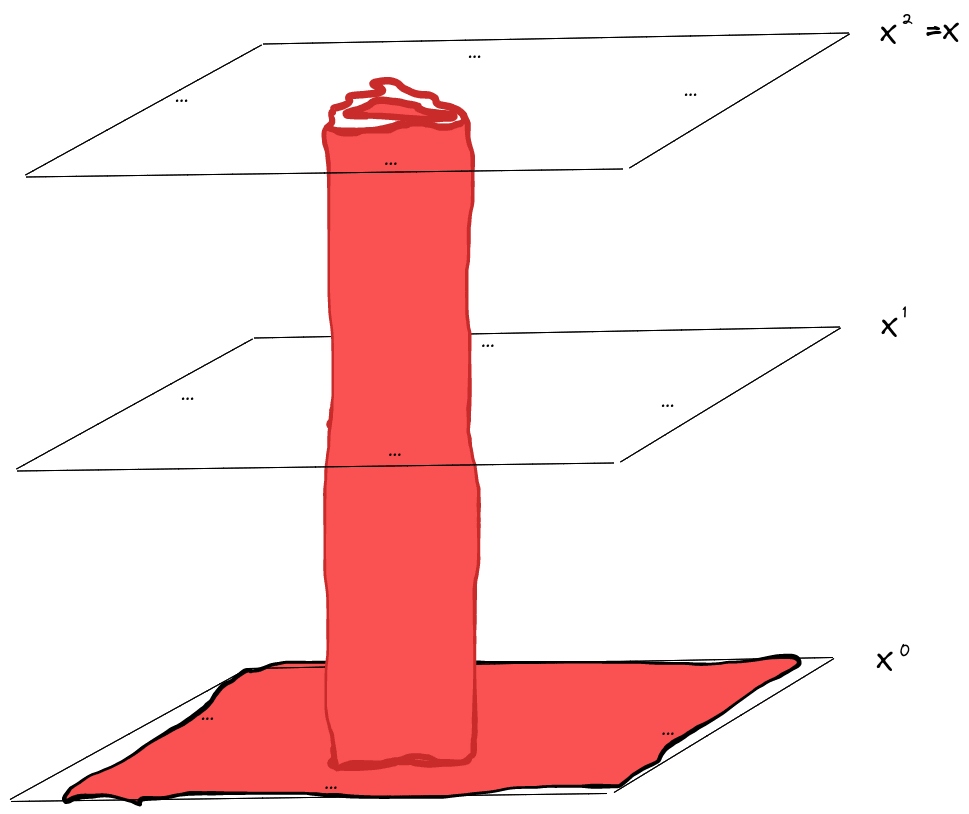
Note that the “cylinder” (including the “base”) separates into two pieces - one contains everything less than distance from , and the other everything more than distance from . The separation indicates that is a Markov blanket between those pieces… at least within the do()-operated resampling process.
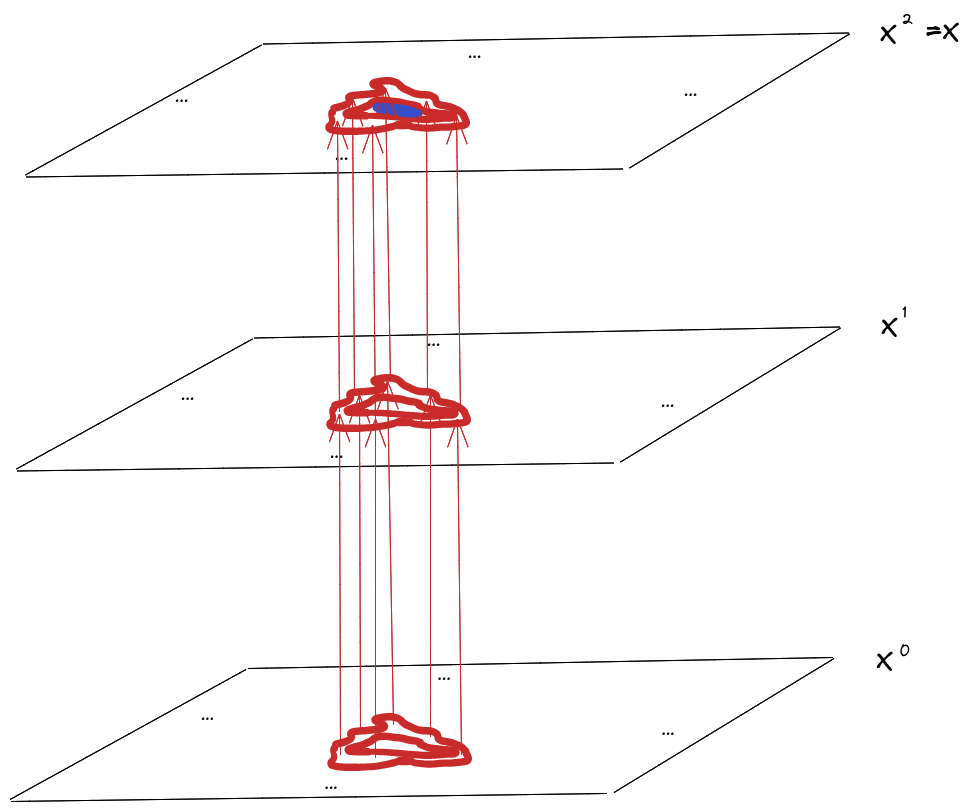
Now for the last step: we’ll draw a forward “lightcone” around our do()-operation. As the name suggests, it expands outward along outgoing arrows, starting from the nodes intervened-upon, to include everything downstream of the do()-intervention.
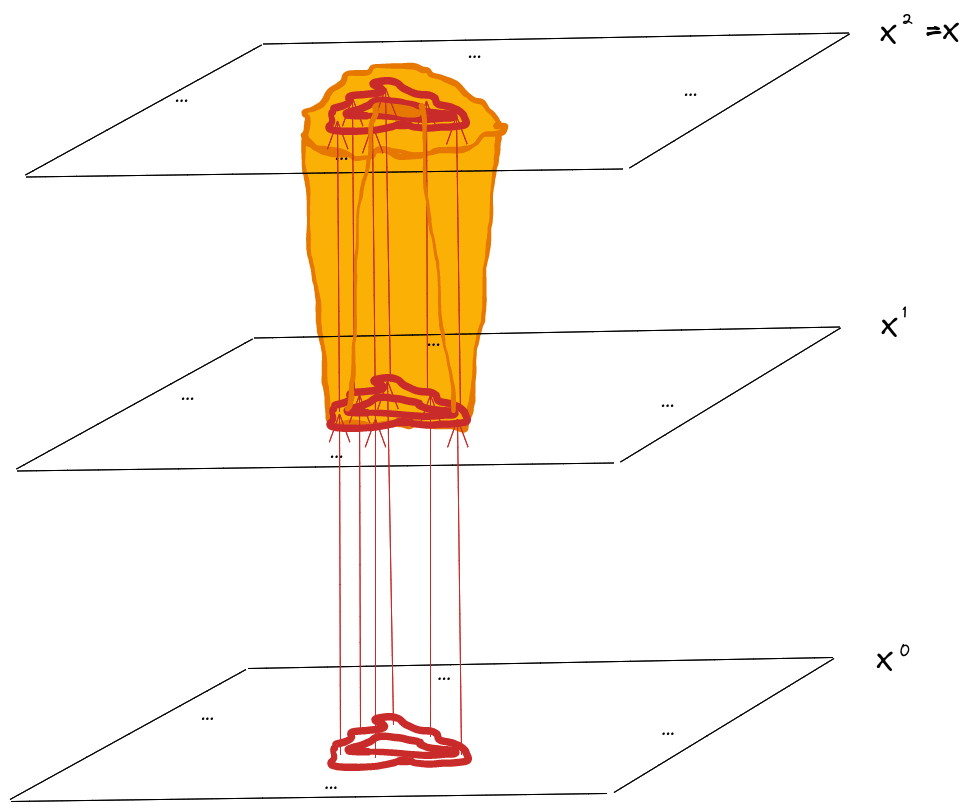
Outside of that lightcone, the distribution of the do()-operated process matches that of the non-do()-operated process.
Crucially, , , and are all outside of the lightcone, so their joint distribution is the same under the do()-operated and non-do()-operated resampling process.
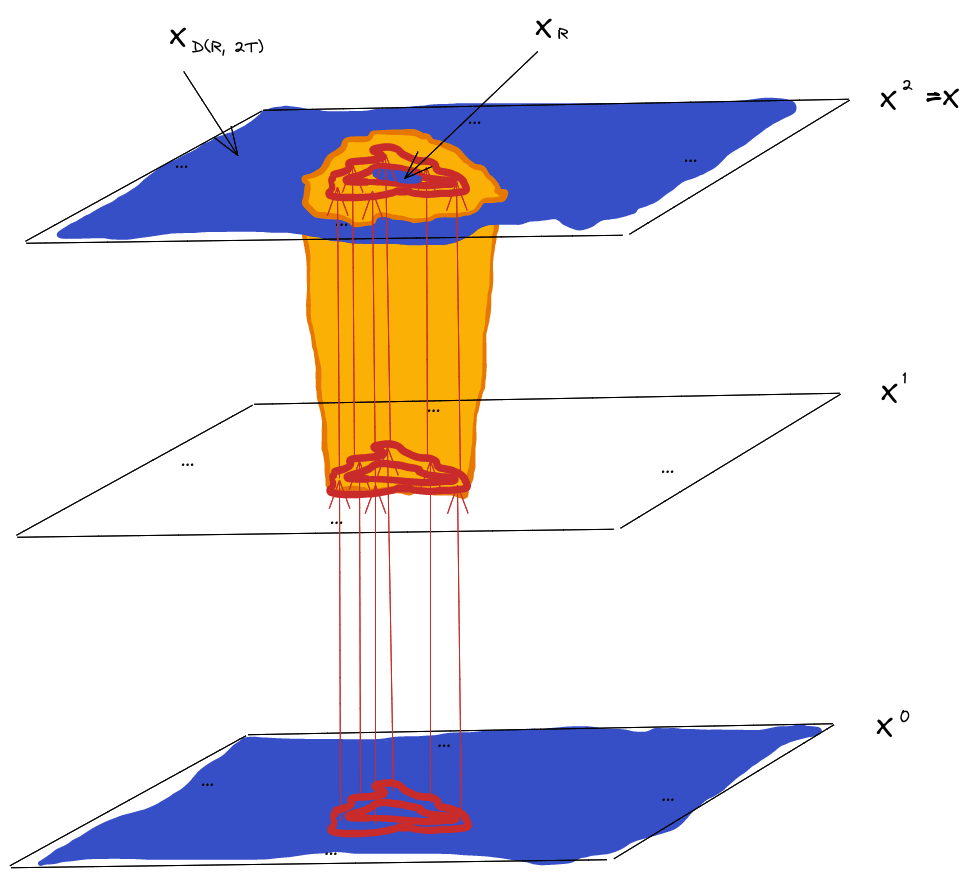
Since mediates between and in the do()-operated process, and the joint distribution is the same between the do()-operated and non-do()-operated process, must mediate between and under the non-do()-operated process.
In other words: any two sets of variables at least a distance of apart (i.e. and ) are independent given . That’s the Lightcone Theorem for two sets of variables.
Finally, note that we can further pick out two subsets of which are themselves separated by , and apply the Lightcone Theorem for two sets of variables again to conclude that and the two chosen sets of variables are all mutually independent given . By further iteration, we can conclude that any number of sets of variables which are all separated by a distance of are independent given . That’s the full Lightcone Theorem.
How To Use The Lightcone Theorem?
The rest of this post is more speculative.
mediates interactions in over distance of at least , but also typically has a bunch of “extra” information in it that we don’t really care about - information which is lost during the resampling process. So, the next step is to define the latent :
By the minimal map [LW · GW] argument, ; is an informationally-minimal summary of all the information in relevant to .
… but that doesn’t mean that is minimal among approximate summaries, nor that it’s a very efficient representation of the information. Those are the two main open threads: approximation and efficient representation.
On the approximation front, a natural starting point is to look at the eigendecomposition of the transition matrix for the resampling process. This works great in some ways, but plays terribly with information-theoretic quantities (logs blow up for near-zero probabilities). An eigendecomposition of the log transition probabilities plays better information-theoretic quantities, but worse with composition as we increase , and we’re still working on theorems to fully justify the use of the log eigendecomposition.
On the efficient representation front, a natural stat-mech-style starting point is to pick “mesoscale regions”: sets of variables which are all separated by at least distance , but big enough to contain the large majority of variables. Then
At this point the physicists wave their hands REALLY vigorously and say “... and since includes the large majority of variables, that sum will approximate ”. Which is of course extremely sketchy, but for some (very loose) notions of “approximate” it can work for some use cases. I’m still in the process of understanding exactly how far that kind of approximation can get us, and for what use-cases.
Insofar as the mesoscale approximation does work, another natural step is to invoke generalized Koopman-Pitman-Darmois [LW · GW] (gKPD). This requires a little bit of a trick: a Gibbs sampler run backwards is still a Gibbs sampler. So, we can swap and in the Lightcone Theorem: subsets of separated by a distance of at least are independent given . From there:
- is a summary of all information in relevant to
- Insofar as the mesoscale argument works, “most of” is independent given
… which is most of what we need to apply gKPD. If we ignore the sketchy part - i.e. pretend that regions cover all of and are all independent given - then gKPD would say roughly: if can be represented as dimensional or smaller, then is isomorphic to for some functions , plus a limited number of “exception” terms. There’s a lot of handwaving there, but that’s very roughly the sort of argument I hope works. If successful, it would imply a nice maxent form (though not as nice as the maxent form I was hoping for [LW · GW] a year ago, which I don’t think actually works), and would justify using an eigendecomposition of the log transition matrix for approximation.
- ^
I’ve omitted from the post various standard things about Gibbs samplers, e.g. explaining why we can model the variables of the graphical model as the output of a Gibbs sampler, how big needs to be in order to resample all the variables at least once, how to generate from (rather than vice-versa), etc. Leave a question in the comments if you need more detail on that.
- ^
Notation convention: capital-letter indices like indicate index-tuples, i.e. if then .
25 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2023-05-15T04:57:53.702Z · LW(p) · GW(p)
The Lightcone Theorem says: conditional on , any sets of variables in which are a distance of at least apart in the graphical model are independent.
I am confused. This sounds to me like:
If you have sets of variables that start with no mutual information (conditioning on ), and they are so far away that nothing other than could have affected both of them (distance of at least ), then they continue to have no mutual information (independent).
Some things that I am confused about as a result:
- I don't see why you are surprised, or why you would have said it wouldn't work for finite T. (It seems obviously true to me from the statement, which makes me think I'm missing some subtlety.)
- I don't understand why the distribution of must be the same as the distribution of . It seems like it should hold for arbitrary .
- I don't see why this is relevant for natural abstractions. To me, the interesting part about abstractions is that it is generally fine to keep track of a small amount of information, even though there is tons and tons of information that "could have" been relevant (and does affect outcomes but in a way that is "noise" rather than "signal"). But this theorem is only telling you that you can throw away information that could never possibly have been relevant.
↑ comment by johnswentworth · 2023-05-15T05:22:55.963Z · LW(p) · GW(p)
If you have sets of variables that start with no mutual information (conditioning on ), and they are so far away that nothing other than could have affected both of them (distance of at least ), then they continue to have no mutual information (independent).
Yup, that's basically it. And I agree that it's pretty obvious once you see it - the key is to notice that distance implies that nothing other than could have affected both of them. But man, when I didn't know that was what I should look for? Much less obvious.
I don't understand why the distribution of must be the same as the distribution of . It seems like it should hold for arbitrary .
It does, but then doesn't have the same distribution as the original graphical model (unless we're running the sampler long enough to equilibrate). So we can't view as a latent generating that distribution.
But this theorem is only telling you that you can throw away information that could never possibly have been relevant.
Not quite - note that the resampler itself throws away a ton of information about while going from to . And that is indeed information which "could have" been relevant, but almost always gets wiped out by noise. That's the information we're looking to throw away, for abstraction purposes.
So the reason this is interesting (for the thing you're pointing to) is not that it lets us ignore information from far-away parts of which could not possibly have been relevant given , but rather that we want to further throw away information from itself (while still maintaining conditional independence at a distance).
Replies from: Thane Ruthenis, rohinmshah↑ comment by Thane Ruthenis · 2023-05-15T05:27:53.403Z · LW(p) · GW(p)
Yup, that's basically it. And I agree that it's pretty obvious once you see it - the key is to notice that distance implies that nothing other than could have affected both of them. But man, when I didn't know that was what I should look for? Much less obvious.
... I feel compelled to note that I'd pointed out a very similar thing a while ago [LW · GW].
Granted, that's not exactly the same formulation, and the devil's in the details.
↑ comment by Rohin Shah (rohinmshah) · 2023-05-15T05:45:27.831Z · LW(p) · GW(p)
Okay, that mostly makes sense.
note that the resampler itself throws away a ton of information about while going from to . And that is indeed information which "could have" been relevant, but almost always gets wiped out by noise. That's the information we're looking to throw away, for abstraction purposes.
I agree this is true, but why does the Lightcone theorem matter for it?
It is also a theorem that a Gibbs resampler initialized at equilibrium will produce distributed according to , and as you say it's clear that the resampler throws away a ton of information about in computing it. Why not use that theorem as the basis for identifying the information to throw away? In other words, why not throw away information from while maintaining ?
EDIT: Actually, conditioned on , it is not the case that is distributed according to .
(Simple counterexample: Take a graphical model where node A can be 0 or 1 with equal probability, and A causes B through a chain of > 2T steps, such that we always have B = A for a true sample from X. In such a setting, for a true sample from X, B should be equally likely to be 0 or 1, but , i.e. it is deterministic.)
Of course, this is a problem for both my proposal and for the Lightcone theorem -- in either case you can't view as a latent that generates (which seems to be the main motivation, though I'm still not quite sure why that's the motivation).
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T16:18:30.697Z · LW(p) · GW(p)
Sounds like we need to unpack what "viewing as a latent which generates " is supposed to mean.
I start with a distribution . Let's say is a bunch of rolls of a biased die, of unknown bias. But I don't know that's what is; I just have the joint distribution of all these die-rolls. What I want to do is look at that distribution and somehow "recover" the underlying latent variable (bias of the die) and factorization, i.e. notice that I can write the distribution as , where is the bias in this case. Then when reasoning/updating, we can usually just think about how an individual die-roll interacts with , rather than all the other rolls, which is useful insofar as is much smaller than all the rolls.
Note that is not supposed to match ; then the representation would be useless. It's the marginal which is supposed to match .
The lightcone theorem lets us do something similar. Rather all the 's being independent given , only those 's sufficiently far apart are independent, but the concept is otherwise similar. We express as (or, really, , where summarizes info in relevant to , which is hopefully much smaller than all of ).
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2023-05-15T17:23:04.122Z · LW(p) · GW(p)
Okay, I understand how that addresses my edit.
I'm still not quite sure why the lightcone theorem is a "foundation" for natural abstraction (it looks to me like a nice concrete example on which you could apply techniques) but I think I should just wait for future posts, since I don't really have any concrete questions at the moment.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-05-16T02:11:03.728Z · LW(p) · GW(p)
I'm still not quite sure why the lightcone theorem is a "foundation" for natural abstraction (it looks to me like a nice concrete example on which you could apply techniques)
My impression is that it being a concrete example is the why. "What is the right framework to use?" and "what is the environment-structure in which natural abstractions can be defined?" are core questions of this research agenda, and this sort of multi-layer locality-including causal model is one potential answer.
The fact that it loops-in the speed of causal influence is also suggestive — it seems fundamental to the structure of our universe, crops up in a lot of places, so the proposition that natural abstractions are somehow downstream of it is interesting.
comment by Brandeis · 2023-05-15T16:37:43.595Z · LW(p) · GW(p)
I think it might be useful to mention an analogy between your considerations and actual particle physics, where people are stuck with a functionally similar problem. They have tried (and so far failed) to make much progress, but perhaps you can find some inspiration from studying their attempts.
The most immediate shortcoming of the Telephone Theorem and the resampling argument is that they talk about behavior in infinite limits. To use them, either we need to have an infinitely large graphical model, or we need to take an approximation.
In particle physics, there is a quantity called the Scattering matrix; loosely speaking, the S-matrix connects a number of asymptotically free "in" states to a number of asymptotically free "out" states, where "in" means the state is projected to the infinite past, and "out" means projected to the infinite future. For example, if I were trying to describe a 2->2 electron scattering process, I would take two electrons "in" the far past, two electrons "out" in the far future, and sandwich an S-matrix between the two states which contains a bunch of "interaction" information, in particular about the probability (we're considering quantum mechanical entities) of such a process happening.
long-range interactions in a probabilistic graphical model (in the long-range limit) are mediated by quantities which are conserved (in the long-range limit).
The S-matrix can also be almost completely constrained by global symmetries (by Noether's theorem, these imply conserved quantities) using what's known as Bootstrapping. The entries of the S-matrix themselves are Lorentz invariant, so light-cone type causality is baked into the formalism.
In physics, it's perfectly fine to take these infinite limits if the background space-time has the appropriate asymptotic conditions i.e there exists a good definition of what constitutes the far past/future. This is great for particle physics experiments, where the scales are so small that the background spacetime is practically flat, and you can take these limits safely. The trouble is that when we scale up, we seem to live in an expanding universe (de-Sitter space) whose geometry doesn't support the taking of such limits. It's an open problem in physics to formulate something like an S-matrix on de Sitter space so that we can do particle physics on large scales.
People have tried all sorts of things (like what you have; splitting the universe up into a bunch of hypersurfaces X_i doing asymptotics there, and then somehow gluing), but they run into many technical problems like the initial data hypersurface not being properly Cauchy and finite entropy problems and so on.
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2023-05-16T15:52:48.207Z · LW(p) · GW(p)
Do you think this is really the same problem such that these issues will be obstacles for John's approach to Natural Abstractions?
comment by philip_b (crabman) · 2023-05-15T04:39:15.631Z · LW(p) · GW(p)
Can you formulate the theorem statement in a precise and self-sufficient way that is usually used in textbooks and papers so that a reader can understand it just by reading it and looking up the used definitions?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T04:50:12.447Z · LW(p) · GW(p)
Let be the initial state of a Gibbs sampler on an undirected probabilistic graphical model, and be the final state. Assume the sampler is initialized in equilibrium, so the distribution of both and is the distribution given by the graphical model.
Take any subsets of , such that the variables in each subset are at least a distance away from the variables in the other subsets (with distance given by shortest path length in the graph). Then are all mutually independent given .
comment by Thane Ruthenis · 2023-05-15T04:32:48.362Z · LW(p) · GW(p)
Hmm. I may be currently looking at it from the wrong angle, but I'm skeptical that it's the right frame for defining abstractions. It seems to group low-level variables based on raw distance, rather than the detailed environment structure? Which seems like a very weak constraint. That is,
By further iteration, we can conclude that any number of sets of variables which are all separated by a distance of are independent given . That’s the full Lightcone Theorem.
We can make literally any choice of those sets subject to this condition: we can draw the boundaries any way we want. Which means the abstractions we'd recover are not going to be convergent: there's a free parameter of the boundary choice.
Ah, no, I suppose that part is supposed to be handled by whatever approximation process we define for ? That is, the "correct" definition of the "most minimal approximate summary" would implicitly constrain the possible choices of boundaries for which is equivalent to ?
The eigendecomposition/mesoscale-approximation/gKPD approaches seem like they might move in that direction, though I admit I don't see their implications at a first glance.
If we ignore the sketchy part - i.e. pretend that regions cover all of and are all independent given - then gKPD would say roughly: if can be represented as dimensional or smaller
What's the here? Is it meant to be ?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T04:40:41.238Z · LW(p) · GW(p)
Ah, no, I suppose that part is supposed to be handled by whatever approximation process we define for ? That is, the "correct" definition of the "most minimal approximate summary" would implicitly constrain the possible choices of boundaries for which is equivalent to ?
Almost. The hope/expectation is that different choices yield approximately the same , though still probably modulo some conditions (like e.g. sufficiently large ).
What's the here? Is it meant to be ?
System size, i.e. number of variables.
Replies from: Thane Ruthenis, Thane Ruthenis↑ comment by Thane Ruthenis · 2023-05-15T05:09:43.300Z · LW(p) · GW(p)
By the way, do we need the proof of the theorem to be quite this involved? It seems we can just note that for for any two (sets of) variables , separated by distance , the earliest sampling-step at which their values can intermingle (= their lightcones intersect) is (since even in the "fastest" case, they can't do better than moving towards each other at 1 variable per 1 sampling-step).
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T05:24:18.245Z · LW(p) · GW(p)
Yeah, that probably works.
↑ comment by Thane Ruthenis · 2023-05-15T10:00:38.539Z · LW(p) · GW(p)
Almost. The hope/expectation is that different choices yield approximately the same , though still probably modulo some conditions (like e.g. sufficiently large ).
Can you elaborate on this expectation? Intuitively, should consist of a number of higher-level variables as well, and each of them should correspond to a specific set of lower-level variables: abstractions and the elements they abstract over. So for a given , there should be a specific "correct" way to draw the boundaries in the low-level system.
But if ~any way of drawing the boundaries yields the same , then what does this mean?
Or perhaps the "boundaries" in the mesoscale-approximation approach represent something other than the factorization of into individual abstractions?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T16:02:58.457Z · LW(p) · GW(p)
is conceptually just the whole bag of abstractions (at a certain scale), unfactored.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-05-16T00:03:07.789Z · LW(p) · GW(p)
Sure, but isn't the goal of the whole agenda to show that does have a certain correct factorization, i. e. that abstractions are convergent?
I suppose it may be that any choice of low-level boundaries results in the same , but the itself has a canonical factorization, and going from back to reveals the corresponding canonical factorization of ? And then depending on how close the initial choice of boundaries was to the "correct" one, is easier or harder to compute (or there's something else about the right choice that makes it nice to use).
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-16T00:40:39.395Z · LW(p) · GW(p)
Yes, there is a story for a canonical factorization of , it's just separate from the story in this post.
comment by romeostevensit · 2023-05-15T05:25:44.559Z · LW(p) · GW(p)
Is there a good primer somewhere on how causal models interact with the standard model of physics?
comment by Nicolas Macé (NicolasMace) · 2023-05-18T10:55:57.984Z · LW(p) · GW(p)
Perhaps of interest that people in quantum many-body physics have related results. One keyword is "scrambling". Like in your case, they have a network of interacting units, and since interactions are local they have a lightcone outside of which correlations are exactly zero.
They can say more than that: Because excitations typically propagate slower than the theoretical max speed (the speed of light or whatever thing is analogous) there's a region near the edge of the lightcone where correlations are almost zero. And then there's the bulk of correlations. They can say all sorts of things in the large time limit. For instance the correlation front typically starts having a universal shape if one waits for long enough. See e.g. this or that.
comment by Shmi (shminux) · 2023-05-15T05:40:17.325Z · LW(p) · GW(p)
I'm wondering if you are reinventing lattice waves., phonons and maybe even phase transitions in the Ising model.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-15T16:04:10.495Z · LW(p) · GW(p)
Phase transitions are definitely on the todo list of things to reinvent. Haven't thought about lattice waves or phonons; I generally haven't been assuming any symmetry (including time symmetry) in the Bayes net, which makes such concepts trickier to port over.
Replies from: shminux↑ comment by Shmi (shminux) · 2023-05-15T17:11:15.697Z · LW(p) · GW(p)
I guess even without symmetry if one assumes finite interaction time, and the nearest-neighbor-only interaction, an analog of the light cone emerges from these two assumptions. As in, Nth neighbor is unaffected until the time Nt where t is the characteristic interaction time. But I assume you are claiming something much less trivial than that.
comment by Thane Ruthenis · 2023-07-21T02:20:18.067Z · LW(p) · GW(p)
Do you have any cached thoughts on the matter of "ontological inertia" of abstract objects? That is:
- We usually think about abstract environments in terms of DAGs. In particular, ones without global time [LW · GW], and with no situations where we update-in-place a variable. A node in a DAG is a one-off.
- However, that's not faithful to reality. In practice, objects have a continued existence, and a good abstract model should have a way to track e. g. the state of a particular human across "time"/the process of system evolution. But if "Alice" is a variable/node in our DAG, she only exists for an instant...
- The model in this post deals with this by assuming that the entire causal structure is "copied" every timestep. So every timestep has an "Alice" variable, and is a function of plus some neighbours...
- But that's not right either. Structure does change; people move around (acquire new causal neighbours and lose old ones) and are born (new variables are introduced), etc.
I think we want our model of the environment to be "flexible" in the sense that it doesn't assume the graph structure gets copied over fully every timestep, but that it has some language for talking about "ontological inertia"/one variable being an "updated version" of another variable. But I'm not quite sure how to describe this relationship.
At the bare minimum, it has to be of same "type" as (e. g., "human"), be directly causally connected to , 's value has to be largely determined by 's value... But that's not enough, because by this definition Alice's newborn child will probably also count as Alice.
Or maybe I'm overcomplicating this, and every variable in the model would just have an "identity" signifier baked-in? Such that ?
Going up or down the abstraction levels doesn't seem to help either. ( isn't necessarily an abstraction over the same set of lower-level variables as , nor does she necessarily have the same relationship with the higher-level variables.)
Back to my question: do you have any cached thoughts on that?