Complex Behavior from Simple (Sub)Agents
post by moridinamael · 2019-05-10T21:44:04.895Z · LW · GW · 14 commentsContents
Introduction 1. Baseline 2. "Ugh field" 3. Smartphone 4. Agitation and/or Energy 5. Look-Ahead 6. Sociability 7. New Goals Are Disruptive 8. Winner-Take-All? 9. Belief, Bias, and Learning 10. Goal Hierarchies 11. Suffering 12. Happiness and Utility Conclusion None 14 comments
Epistemic Status: Simultaneously this is work that took me a long time and a lot of thought, and also a playful and highly speculative investigation. Consider taking this seriously but not literally.
Introduction
Take a simple agent (GitHub; Python), with no capacity for learning, that exists on a 2D plane. It shares the plane with other agents and objects, to be described shortly.
The agent intrinsically doesn't want anything. But it can be assigned goal-like objects, which one might view as subagents. Each individual goal-like subagent can possess a simple preference, such as a desire to reach a certain region of space, or a desire to avoid a certain point.
The goal-like subagents can also vary in the degree to which they remain satisfied. Some might be permanently satisfied after achieving their goal once; some might quickly become unsatisfied again after a few timesteps.
Every timestep, the agent considers ten random movements of unit-distance, and executes the movement corresponding to the highest expected valence being reported by its goal-like subagents, in a winner-take-all fashion.
Even with such an intentionally simplistic model, a surprising and illuminating level of behavioral complexity can arise.
Sections 1-8 concern interesting or amusing behaviors exhibited by the model.
Sections 8-12 outline future directions for the model and ruminations on human behavior.
1. Baseline
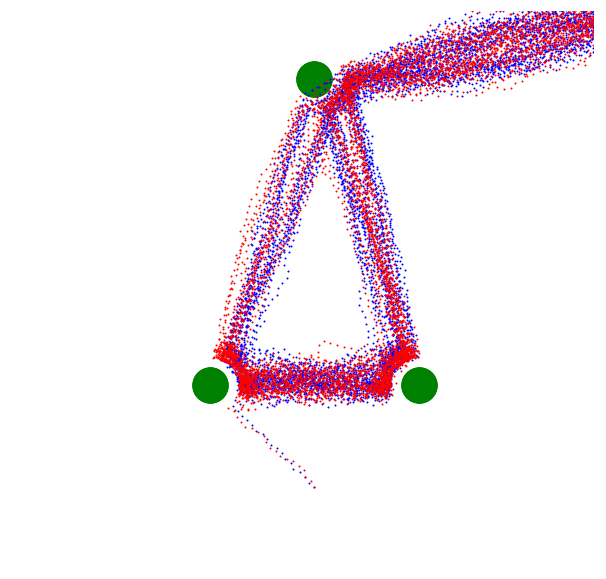
In this image, the path of the agent is painted with points, the color of the points changing slowly with the passage of time. This agent possesses three subagents with preferences for reaching the three green circles, and a fourth mild preference for avoiding the red circle.
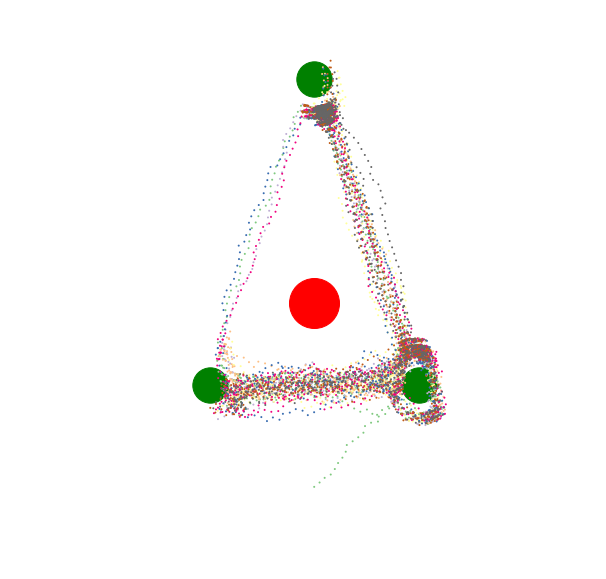
Once it comes within a set distance of one of the green circles, the corresponding subagent is satisfied, and thus the movement with the highest expected valence switches to the next-highest valence goal. The satisfaction gradually wears off, and the agent begins to be drawn to the goal again. Thus, the agent moves inexorably around the triangle of green circles, sometimes in a circuit, sometimes backtracking.
2. "Ugh field"
If the aversion to the red circle is amplified above a certain threshold, this behavior results. The subagent with preferences for reaching the top green circle still exists, but it will never be satisfied, because expected negative valence of passing near the red circle is too high.
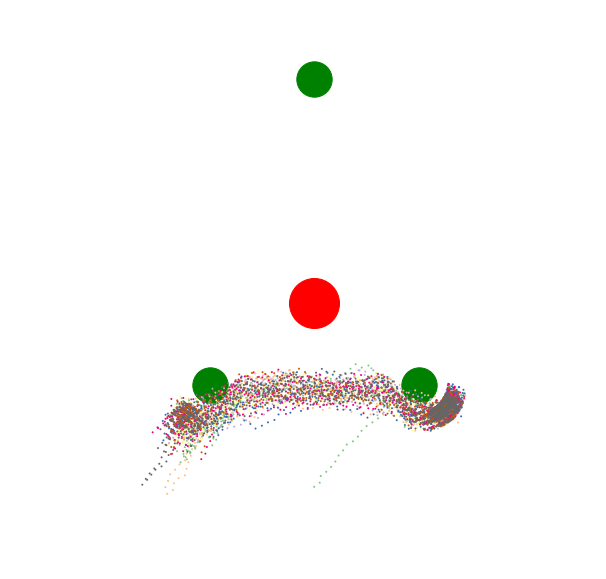
But if one is clever, one can find a way around aversions, by inventing intermediary goals or circumventing the aversion with intermediate desirable states.
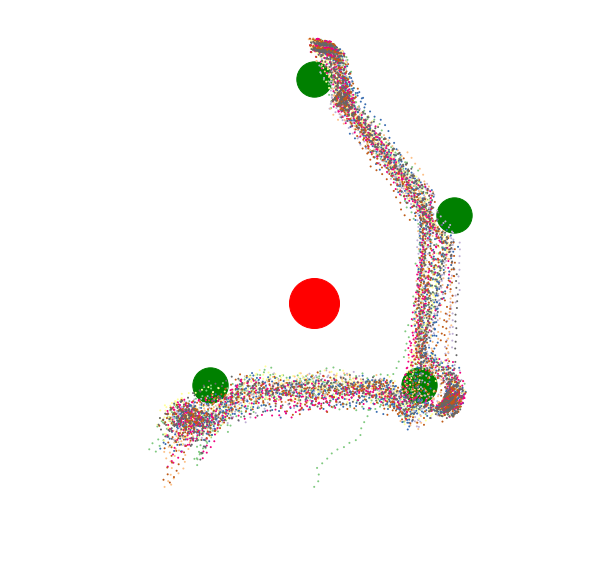
Sometimes a you want to accomplish something, but a seemingly trivial inconvenience will arise to screen off your motivation. If you can't remove the inconvenience, you can usually find a path around it.
3. Smartphone
What if the agent has, pinned to its position (such that it is constantly somewhat nearby), a low-valence rewarding object, which doesn't provide lasting satisfaction? (In other words - the agent has a goal-like subagent which mildly but relatively persistently wants to approach the pinned object.)

The agent suddenly looks very distracted, doesn't it? It doesn't make the same regular productive circuits of its goals. It seems to frequently get stuck, sphexishly returning to a goal that it just accomplished, and to take odd pointless energy-wasting zigzags in its path.
Maybe it's bad to constantly carry around attention-grabbing objects that provide us with miniscule, unsatisfying hits of positive valence.
Considered together, Parts 2 and 3 speak to the dangers of convenience and the power of trivial inconvenience. The agents (and humans) are extraordinarily sensitive not only to the absolute valence of an expectation, but to the proximity of that state. Even objectively weak subagents can motivate behavior if they are unceasingly present.
4. Agitation and/or Energy
The model does not actually have any concept of energy, but it is straightforward to encode a preference for moving around a lot. When the agent is so inclined, its behavior becomes chaotic.

Even a relatively moderate preference for increased movement will lead to some erratic swerves in behavior.
If one wished, one could map this type of behavior onto agitation, or ADHD, or anxiety, or being overly caffeinated. On the other hand, you could view some degree of "restlessness" as a drive toward exploration, without which one might never discover new goals.
One path of investigation that occurred to me but which I did not explore was to give the agent a level of movement-preference that waxed and waned cyclically over time. Sometimes you subjectively have a lot of willpower, sometimes you subjectively can't focus on anything. But, on the whole, we all manage to get stuff done.
5. Look-Ahead
I attempted to implement an ability for the agent to scan ahead more than one step into the future and take the movement corresponding the highest expected valence in two timesteps, rather than just the next timestep. This didn't really show anything interesting, and remains in the category of things that I will continue to look into. (The Red agent is thinking two moves ahead, the Blue agent only one move ahead. Is there a difference? Is the clustering of the Red agent's pathing slightly tighter? Difficult to say.)
I don't personally think humans explicitly look ahead very often. We give ourselves credit as the "thinking, planning animal", but we generally just make whichever choice corresponds to the highest expected valence in the current moment. Looking ahead is also very computationally expensive - both for people, and for these agents - because it inevitably requires something like a model-based tree search. What I think we actually do is better addressed in Section 10 regarding Goal Hierarchies.
6. Sociability
Of course, we can give the agents preferences for being near other agents, obeying the same rules as the preferences for any other position in space.
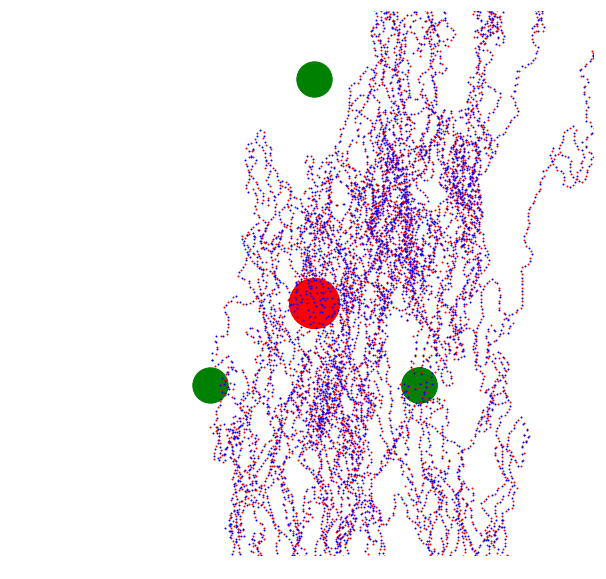
With hyper-dominant, non-extinguishing preferences for being around other agents, we get this piece of computer generated art that I call "Lovers".
With more modest preference for the company of other agents, and with partially-overlapping goals (Blue agent wants to spend time around the top and rightmost target, Red agent wants to spend time around the top and leftmost target) you get this other piece of art that I call "Healthy Friendship". It looks like they're having fun, doesn't it?

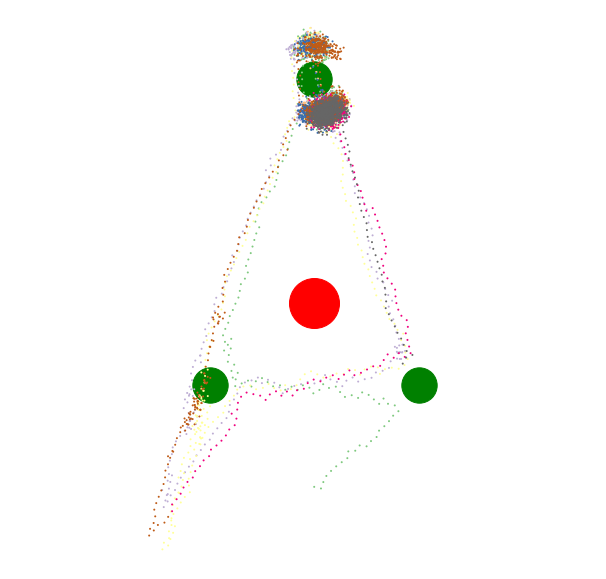
7. New Goals Are Disruptive
Brief reflection should confirm that introducing a new goal into your life can be very disruptive to your existing goals. You could say that permitting a new goal-like subagent to take root in your mind is akin to introducing a competitor who will now be bidding against all your existing goals for the scarce resource of your time and attention.
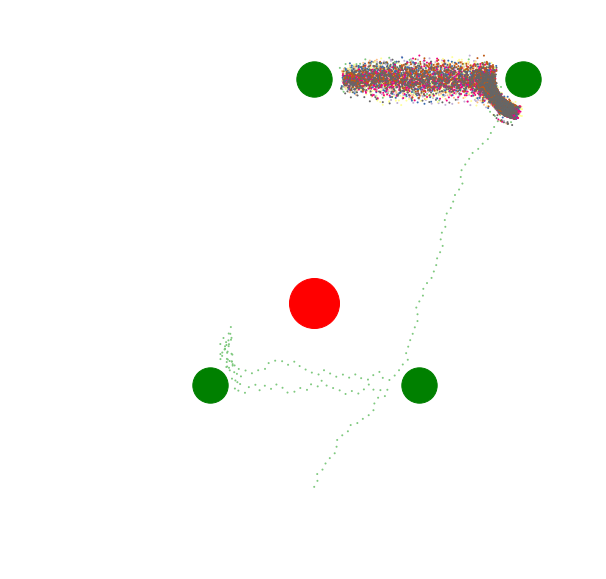
Compare this image with the Baseline at the top of this article. The new, powerful top-right goal has siphoned away all the attention from the formerly stable, well-tended trio of goals.
I think one of the main reasons we fall down on our goals is simply that we spontaneously generate new goals, and these new goals disrupt our existing motivational patterns.
8. Winner-Take-All?
You may have more questions about the winner-take-all assumption that I mentioned above. In this simple model, the goal-like subagents do not "team up". If two subagents would prefer that the agent move to the left, this does not mean that their associated valence will sum up and make that choice more globally appealing. The reason is simple: if you straightforwardly sum up over all valences instead of picking a winner, this is what happens:
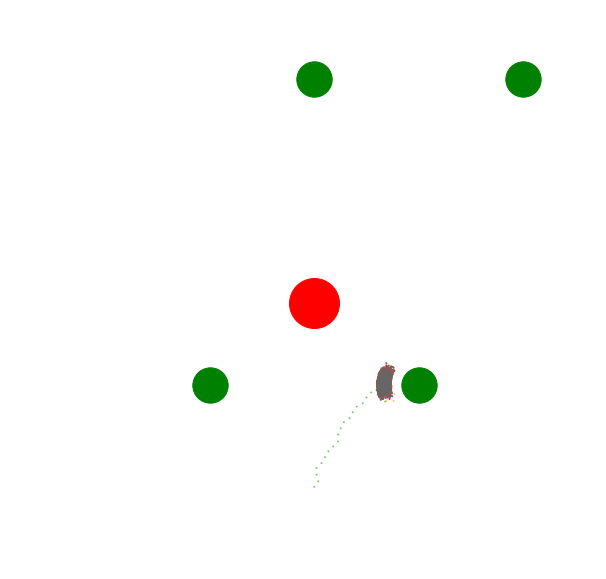
The agent simply seeks out a local minimum and stays there.
I am currently somewhat agnostic as to what the human or animal brain is actually doing. We do appear to get stuck in local minima sometimes. But you can get sphexish behavior that looks like a local minimum out of a particular arrangement of winner-take-all subagents. For example, if an agent is hemmed in by aversive stimuli with no sufficiently positive goal-states nearby, that might look like a local minimum, though it is still reacting to each aversive stimulus in a winner-take-all fashion.
Subjectively, though, it feels like if you have two good reasons supporting an action, that makes the action feel a bit easier to do, a bit more motivating, than if you just had one good reason. This hints that maybe goal-like subagents can gang up together. But I also doubt that this is anything like strictly additive. Thinking of 2,000 reasons why I should go to the gym isn't 2,000 times more compelling than thinking of one reason.
9. Belief, Bias, and Learning
The main area of the model that I would like to improve, but which would amplify the complexity of the code tremendously, would be in introducing the concept of bias and/or belief. The agent should be able to be wrong about its expected valence. I think this is hugely important, actually, and explains a lot about human behavior.
Pathologies arise when we are systematically wrong about how good, or how bad, some future state will be. But we can overcome pathologies by exposing ourselves to those states, and becoming deeply calibrated regarding their reality. On the aversion side this applies to everything from the treatment of phobias and PTSD, to the proper response to a reasonable-seeming anxiety. On the positive-valence side, we may imagine that it would be incredibly cool and awesome to do or to be some particular thing, and only experience can show us that accomplishing such things yields only a shadow of what we expected. Then your brain updates on that, and you cease to feel motivated to do that thing anymore. You can no longer sustain the delusion that it was going to be awesome.
10. Goal Hierarchies
It seems clear that, in humans, goals are arranged in something like trees: I finish this current push-up because I want to finish my workout. I want to finish my workout because I want to stay on my workout program. I want to stay on my workout program because I want to be strong and healthy.
But it's almost certainly more complex than this, and I don't know how the brain manages its "expected valence" calculations across levels of the tree.
I hypothesize that it goes something like this. Goal-like subagents concerned with far-future outcomes, like "being strong and healthy", generate (or perhaps manifest as) more specific near-term goal-like targets, with accompanying concrete sensory-expectation targets, like "working out today". This seems like one of those mostly automatic things that happens whether or not we engineer it. The automaticity of it seems to rely on our maps/models/beliefs about how the world works. Even much simpler animals can chain together and break down goals, in the course of moving across terrain toward prey, for example.
The model described above doesn't really have a world model and can't learn. I could artificially designate some goals as being sub-goals of other goals, but I don't think this is how it actually works, and I don't actually think it would yield any more interesting behavior. But it might be worth looking into. Perhaps the most compelling aspect of this area is that what would be needed would not be to amplify the cleverness of the agent; it would be to amplify the cleverness of the subagent in manipulating and making its preferences clearer to the agent. For example: give subagents the power to generate new goal-objects, and lend part of their own valence to those subagents.
11. Suffering
I toyed with the idea of summing up all the valences of the goal-objects that were being ignored at any given moment, and calling that "suffering". This sure is what suffering feels like, and it's akin to what those of a spiritual bent would call suffering. Basically, suffering is wanting contradictory, mutually exclusive things, or, being aware of wanting things to be a certain way while simultaneously being aware of your inability to work toward making it that way. One subagent wants to move left, one subagent wants to move right, but the agent has to pick one. Suffering is something like the expected valence of the subagent that is left frustrated.
I had a notion here that I could stochastically introduce a new goal that would minimize total suffering over an agent's life-history. I tried this, and the most stable solution turned out to be thus: introduce an overwhelmingly aversive goal that causes the agent to run far away from all of its other goals screaming. Fleeing in perpetual terror, it will be too far away from its attractor-goals to feel much expected valence towards them, and thus won't feel too much regret about running away from them. And it is in a sense satisfied that it is always getting further and further away from the object of its dread.
File this under "degenerate solutions that an unfriendly AI would probably come up with to improve your life."
I think a more well-thought-out definition of suffering might yield much more interesting solutions to the suffering-minimization problem. This is another part of the model I would like to improve.
12. Happiness and Utility
Consider our simple agents. What makes them happy?
You could say that something like satisfaction arises the moment they trigger a goal-state. But that goal object immediately begins recharging, becoming "dissatisfied" again. The agent is never actually content, unless you set up the inputs such that the goal valences don't regenerate - or if you don't give it goals in the first place. But if you did that, the agent would just wander around randomly after accomplishing its goals. That doesn't seem like happiness.
Obviously this code doesn't experience happiness, but when I look at the behavior of the agents under different assumptions, the agents seem happy when they are engaged in accomplishing their various goals. They seem unhappy when I create situations that impede the efficiency of their work. This is obviously pure projection, and says more about me, the human, than it says about the agent.
So maybe a more interesting question: What are the high-utility states for the agent? At any given moment of time the agents certainly have preference orderings, but those preference orderings shift quite dramatically based on its location and the exact states of each of its subagents, specifically their current level of satisfaction. In other words, in order to mathematically model the preference ordering of the agent across all times, you must model the individual subagents.
If humans "actually" "have" "subagents" - whatever those words actually end up meaning - then the "human utility function" will need to encompass each and every subagent. Even, I think, the very stupid ones that you don't reflectively endorse.
Conclusion
I set out on this little project because I wanted to prove some assumptions about the "subagent" model of human consciousness. I don't think I can ultimately say that I "proved" anything, and I'm not sure that one could ever "prove" anything about human psychology using this particular methodology.
The line of thinking that prompted this exploration owes a lot to Kaj_Sotala, for his ongoing Sequence [? · GW], Scott Alexander's reflections on motivation, and Mark Lippman's Folding material. It's also their fault I used the unwieldy language "goal-like subagent" instead of just saying "the agent has several goals". I think it's much more accurate, and useful, to think of the mind as being composed of subagents, than to say it "has goals". Do you "have" goals if the goals control you?
This exercise has changed my inner model of my own motivational system. If you think long enough in terms of subagents, something eventually clicks. Your inner life, and your behaviors, seems to make a lot more sense. Sometimes you can even leverage this perspective to construct better goals, or to understand where some goals are actually coming from.
The code linked at the top of this page will generate all of the figures in this article. It is not especially well documented, and bears the marks of having been programmed by a feral programmer raised in the wilds of various academic and industrial institutions. Be the at as it may, the interface is not overly complex. Please let me know if anyone ends up playing with the code and getting anything interesting out of it.
14 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2019-05-11T08:05:31.789Z · LW(p) · GW(p)
Really cool! This reminds me of Braitenberg vehicles.
I had a notion here that I could stochastically introduce a new goal that would minimize total suffering over an agent's life-history. I tried this, and the most stable solution turned out to be thus: introduce an overwhelmingly aversive goal that causes the agent to run far away from all of its other goals screaming. Fleeing in perpetual terror, it will be too far away from its attractor-goals to feel much expected valence towards them, and thus won't feel too much regret about running away from them. And it is in a sense satisfied that it is always getting further and further away from the object of its dread.
Interestingly, this seems somewhat similar to the reactions of severely traumatized people, whose senses partially shut down to make them stop feeling or wanting anything. And then there's also suicide for when the "avoid suffering" goal grows too strong relative to the other ones. For humans there's a counterbalancing goal of avoiding death, but your agents didn't have an equivalent balancing desire to stay "alive" (or within reach of their other goals).
comment by orthonormal · 2019-05-12T06:06:31.711Z · LW(p) · GW(p)
I had a notion here that I could stochastically introduce a new goal that would minimize total suffering over an agent's life-history. I tried this, and the most stable solution turned out to be thus: introduce an overwhelmingly aversive goal that causes the agent to run far away from all of its other goals screaming.
did you mean: anhedonia
(No, seriously, your paragraph is an apt description of a long bout I had of depression-induced anhedonia; I felt so averse to every action that I ceased to feel wants, and I consistently marked my mood as neutral rather than negative despite being objectively more severely depressed than I was at other times when I put negative numbers in my mood tracker.)
comment by habryka (habryka4) · 2019-05-25T01:40:10.327Z · LW(p) · GW(p)
Promoted to curated: This post reminds me of Kevin Simler's "Going Critical" and similar to that post, I think that it explores some quite complicated topics quite well with the help of careful use of small-scale simulations. I don't think we should take any of the simulation-based results here straightforwardly, but I do think there is a lot of value in running simulations like this to further our understanding.
comment by habryka (habryka4) · 2019-05-11T20:17:47.216Z · LW(p) · GW(p)
This is quite interesting. I like both the idea of running small simulations like this and of how you ended up visualizing them.
comment by Hazard · 2019-05-11T12:42:55.136Z · LW(p) · GW(p)
Yay model building and experimenting! I like, and would love to see more of, people building simple models to experiment with the plausibility of ideas and build intuition. You also seem to have approached this with a good epistemic attitude; yes, this does not constitute strong evidence that humans are implemented with sub agents, but does demonstrate that familiar humany behaviours can arise from some form of sub agents.
comment by Ben Pace (Benito) · 2021-01-13T07:00:39.048Z · LW(p) · GW(p)
I love this post, it's a really healthy way of exploring assumptions about one's goals and subagents. I think it's really hard to come up with simple diagrams that communicate key info, and I am impressed by choices such as changing the color of the path over time. I also find it insightful in matters relating to what a distracted agent looks like, or how adding subgoals can improve things.
It's the sort of thing I'd like to see more rationalists doing, and it's a great read, and I feel very excited about more of this sort of work on LessWrong. I hope it inspires more LessWrongers to build on it. I expect to vote it at somewhere between +5 and +7.
comment by waveBidder · 2019-05-14T03:52:46.509Z · LW(p) · GW(p)
This is fun. You might consider looking into dynamical systems, since this is in effect what you are studying here. The general idea for a dynamical system is that you have some state whose derivative is given by some function . You can look at the fixed points of such systems, and characterize their behavior relative to these. The notion of bifurcation classifies what happens as you change the parameters in a similar way to what you're doing
There are maybe 2 weird things you're doing from this perspective. The first is the max function, which is totally valid, though usually people study these systems with continuous and nonlinear functions . What you're getting with it falling into a node and staying is a consequence of the system being otherwise linear. Such systems are pretty easy to characterize in terms of their fixed points. The other weird thing is time dependence; normally these things are given by with no time dependence, called autonomous systems. I'm not entirely clear how you're implementing the preference decay, so I can't say too much there.
As for the specific content, give me a bit to read more.
comment by Ben Pace (Benito) · 2020-12-12T05:54:01.602Z · LW(p) · GW(p)
Oh this was dope. I really liked it. I'd like to see it reviewed.
comment by Kaj_Sotala · 2019-09-25T12:47:42.503Z · LW(p) · GW(p)
It's interesting to compare the framework in this post, to the one in this paper [LW(p) · GW(p)].
comment by Slider · 2019-05-25T04:14:34.156Z · LW(p) · GW(p)
In posts about circular preferences that was appointed the role of "busy work amount to nothing" and the highest scorer on the utility function as the "optimal solution". However here roles are pretty much reversed in that cyclical movement is "productive work" and stable maximisation is "death".
The text also adds a lot of interpretative layer in addition to the experimental setups. Would not derive same semantics from the setups only.
comment by Mateusz Bagiński (mateusz-baginski) · 2025-02-23T14:43:18.874Z · LW(p) · GW(p)
Images in this post are broken.
comment by Multicore (KaynanK) · 2020-12-14T16:44:02.239Z · LW(p) · GW(p)
Last-minute nomination: This is high-quality and timeless, and would look nice in a book.
comment by Vaniver · 2020-12-12T15:48:54.364Z · LW(p) · GW(p)
With more modest preference for the company of other agents, and with partially-overlapping goals (Blue agent wants to spend time around the top and rightmost target, Red agent wants to spend time around the top and leftmost target) you get this other piece of art that I call "Healthy Friendship". It looks like they're having fun, doesn't it?
Surely both agents want to spend time around the rightmost target? Or is this in fact a rather uneven friendship?
comment by Pattern · 2019-05-19T03:00:24.032Z · LW(p) · GW(p)
The agent should be able to be wrong about its expected valence. I think this is hugely important, actually, and explains a lot about human behavior.
Does this fall out of imperfect information? (Say, instead of green dots seeming nice, and the straight line to them being considered, with red dots seeming bad, and agents not taking paths that go straight to green that pass by red, there could also be limited visibility. Like, the other green/s are on the other side of the mountain and can't be seen.)