Conflating value alignment and intent alignment is causing confusion
post by Seth Herd · 2024-09-05T16:39:51.967Z · LW · GW · 18 commentsContents
Summary:
Overview
Another unstated divide
Personal intent alignment for full ASI: can I have your goals?
Conclusions
None
18 comments
Epistemic status: I think something like this confusion is happening often. I'm not saying these are the only differences in what people mean by "AGI alignment".
Summary:
Value alignment is better but probably harder to achieve than personal intent alignment to the short-term wants of some person(s). Different groups and people tend to primarily address one of these alignment targets when they discuss alignment. Confusion abounds.
One important confusion stems from an assumption that the type of AI defines the alignment target: strong goal-directed AGI must be value aligned or misaligned, while personal intent alignment is only viable for relatively weak AI. I think this assumption is important but false.
While value alignment is categorically better, intent alignment seems easier, safer, and more appealing in the short term, so AGI project leaders are likely to try it.[1]
Overview
Clarifying what people mean by alignment should dispel some illusory disagreement, and clarify alignment theory and predictions of AGI outcomes.
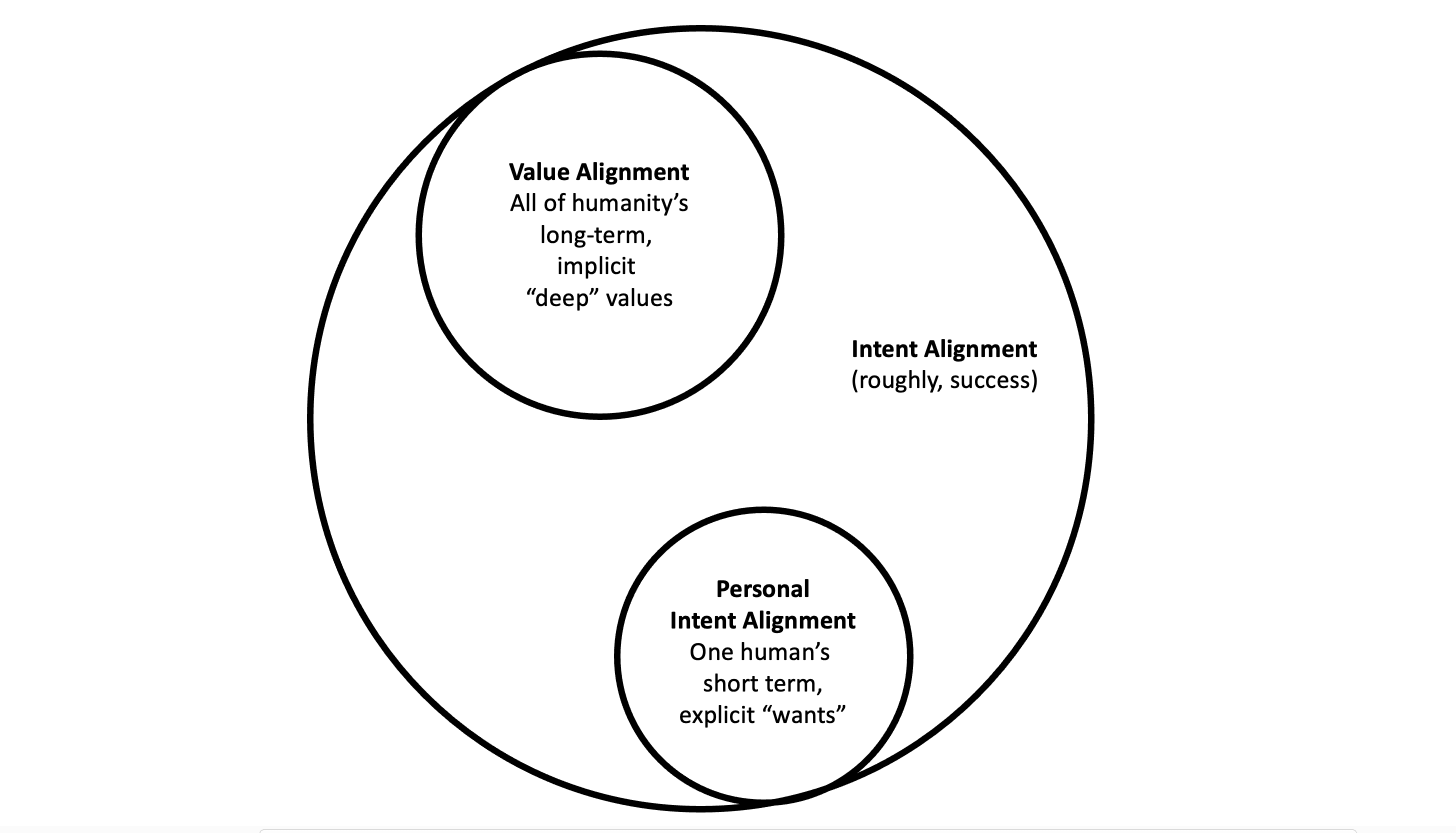
Caption: Venn diagram of three types of alignment targets. Value alignment and Personal intent alignment are both subsets of Evan Hubinger's definition [LW · GW] of intent alignment: AGI aligned with human intent in the broadest sense. Prosaic alignment work usually seems to be addressing a target somewhere in the neighborhood of personal intent alignment (following instructions or doing what this person wants now), while agent foundations and other conceptual alignment work usually seems to be addressing value alignment. Those two clusters have different strengths and weaknesses as alignment targets, so lumping them together produces confusion.
People mean different things when they say alignment. Some are mostly thinking about value alignment (VA): creating sovereign AGI that has values close enough to humans' for our liking. Others are talking about making AGI that is corrigible (in the Christiano or Harms [LW · GW] sense)[2] or follows instructions from its designated principal human(s). I'm going to use the term personal intent alignment (PIA) until someone has a better term for that type of alignment target. Different arguments and intuitions apply to these two alignment goals, so talking about them without differentiation is creating illusory disagreements.
Value alignment is better almost by definition, but personal intent alignment seems to avoid some of the biggest difficulties of value alignment. Max Harms' recent sequence on corrigibility as a singular target [LW · GW] (CAST) gives both a nice summary and detailed arguments. We do not need us to point to or define values, just short term preferences or instructions. The principal advantage is that an AGI that follows instructions can be used as a collaborator in improving its alignment over time; you don't need to get it exactly right on the first try. This is more helpful in slower and more continuous takeoffs. This means that PI alignment has a larger basin of attraction [? · GW] than value alignment does.[3]
Most people who think alignment is fairly achievable seem to be thinking of PIA, while critics often respond thinking of value alignment. It would help to be explicit. PIA is probably easier and more likely than full VA for our first stabs at AGI, but there are reasons to wonder if it's adequate for real success. In particular, there are intuitions and arguments that PIA doesn't address the real problem of AGI alignment.
I think PIA does address the real problem, but in a non-obvious and counterintuitive way.
Another unstated divide
There's another important clustering around these two conceptions of alignment. People who think about prosaic (and near term) AI alignment tend to be thinking about PIA, while those who think about aligning ASI for the long term are usually thinking of value alignment. The first group tends to have much lower estimates of alignment difficulty and p(doom) than the other. This causes dramatic disagreements on strategy and policy, which is a major problem: if the experts disagree, policy-makers are likely to just pick an expert that supports their own biases.
Thinking about one vs the other appears to be one major crux of disagreement on alignment difficulty. [LW(p) · GW(p)]
And All the Shoggoths Merely Players [LW · GW] (edit: and its top comment [LW(p) · GW(p)] thread continuation) is a detailed summary of (and a highly entertaining commentary on) the field's current state of disagreement. In that dialogue, Simplicia Optimistovna asks whether the relative ease of getting LLMs to understand and do what we say is good news about alignment difficulty, while Doomimir Doomovitch sourly argues that this isn't alignment at all; it's just a system that superficially has behavior that you want (within the training set), without having actual goals to align. Actual AGI, he says, will have actual goals, whether we try (and likely fail) to engineer them in properly, or whether optimization creates a goal-directed search process with weird emergent goals [LW · GW].
I agree with Doomimir on this. Directing LLMs behavior isn't alignment in the important sense. We will surely make truly goal-directed agents, probably sooner than later. And when we do, all that matters is whether their goals align closely enough with ours. Prosaic alignment for LLMs is not fully addressing the alignment problem for autonomous, competent AGI or ASI, even if they're based on LLMs.[4]
However, I also agree with Simplicia: it's good news that we've created AI that even sort of understands what we mean and does what we ask.
That's because I think approximate understanding is good enough for personal intent alignment, and that personal intent alignment is workable for ASI. I think there's a common and reasonable intuitions that it's not, which create more illusory disagreements between those who mean PIA vs VA when they say "alignment".
Personal intent alignment for full ASI: can I have your goals?
There's an intuition that intent alignment isn't workable for a full AGI; something that's competent or self-aware usually[5] has its own goals, so it doesn't just follow instructions.
But that intuition is based on our experience with existing minds. What if that synthetic being's explicit, considered goal is to approximately follow instructions?
I think it's possible for a fully self-aware, goal-oriented AGI to have its goal be, loosely speaking, a pointer to someone else's goals. No human is oriented this way, but it seems conceptually coherent to want to do, with all of your heart, just what someone else wants.
It's good news that LLMs have an approximate understanding of our instructions because that can, in theory, be plugged into the "goal slot" in a truly goal-directed agentic architecture. I have summarized proposals for how to do this for several possible AGI architectures (focusing on language model agents [AF · GW] as IMO the most likely), but the details don't matter here, just that it's empirically possible to make an AI system that approximately understand what we want.
Conclusions
Approximate understanding and goal direction looks (to me) to be good enough for personal intent alignment, but not for value alignment.[1] And PIA does seem adequate for real AGI. Therefore, intent aligned AGI looks to be far easier and safer in the short term (parahuman AGI or pre-ASI) than trying for full value alignment and autonomy. And it can probably be leveraged into full value alignment (if we get an ASI acting as a full collaborator in value-aligning itself or a predecessor).
However, this alignment solution has a huge downside. It leaves fallible, selfish humans in charge of AGI systems. These will have immense destructive as well as creative potential. Having humans in charge of them allows for both conflict and ill use, a whole different set of ways we could get doom even if we solve technical alignment. The multipolar scenario with PI aligned, recursive self-improvement capable AGIs looks highly dangerous, but not like certain doom; see If we solve alignment, do we die anyway? [LW · GW]
There's another reason we might want to think more, and more explicitly, about intent alignment: it's what we're likely to try, even if it's not the best idea. It's hard to see how we could get a technical solution for value alignment that couldn't also be used for intent alignment. And it seems likely that the types of humans actually in charge of AGI projects would rather implement personal intent alignment; everyone by definition prefers their values to the aggregate of humanity's. If PIA seems even a little safer or better for them, it will serve as a justification for aligning their first AGIs as they'd prefer anyway: to follow their orders.
Where am I wrong? Where should this logic be extended or deepened? What issues would you like to see addressed in further treatments of this thesis?
- ^
Very approximate personal intent alignment might be good enough if it's used even moderately wisely. More on this in Instruction-following AGI is easier and more likely than value aligned AGI [LW · GW]. You can instruct your approximately-intent-aligned AGI to tell you about its internal workings, beliefs, goals, and counterfactuals. You can use that knowledge to improve its alignment, if it understands and follows instructions even approximately and most of the time. You can also instruct it to shut down if necessary.
One common objection is that if the AGI gets something slightly wrong, it might cause a disaster very quickly. A slow takeoff gives time with an AGI before it's capable of doing that. And giving your AGI standing instructions to check that it's understood what want before taking action reduces this possibility. This do what I mean and check (DWIMAC) strategy [LW · GW] should dramatically reduce dangers of an AGI acting like a literal genie
A second common objection is that humans are bound to screw this up. That's quite possible, but it's also possible that they'll get their shit together when it's clear they need to. Given the salient reality of an alien but capable agent, the relevant humans may step up and take the matter seriously, as humans in historical crises seem to sometimes have done.
- ^
Personal intent alignment is roughly what Paul Christiano and Max Harms means by corrigibility.
It is definitely not what Eliezer Yudkowsky means by corrigibility. He originally coined the clever term, which we're using now in somewhat different ways than as he carefully defined it: an agent that has its own consequentialist goals, but will allow itself to be corrected by being shut down or modified.
I agree with Eliezer that corrigibility as a secondary property would be anti-natural in that it would violate consequentialist rationality. Wanting to achieve a goal firmly implies not wanting to be modified, because that would mean stopping working toward that goal, making it less likely to be achieved. It would therefore seem difficult or impossible to implement that sort of corrigibility in a highly capable and therefore probably rational goal-oriented mind.
But making corrigibility (correctability) the sole goal- the singular target as Max puts it - avoids the conflict with other consequentialist goals. In that type of agent, consequentialist goals are always subgoals of the primary goal of doing what the principal wants or says (Max says this is a decent approximation but "doing what the principal wants" is not precisely what he means by his sense of corrigibility). Max and I agree that it's safest if this is the singular or dominant goal of a real AGI. I currently slightly prefer the throughly instruction-following approach [LW · GW] but that's pending further thought and discussion.
This "your-goals-are-my-goals" alignment seems to not be exactly what Christiano means by corrigibility, nor is it precisely the alignment target implied in most other prosaic alignment work on LLM alignment. There, alignment targets are a mix of various ethical considerations along with following instructions. I'd want to make instruction-following clearly the prime goal [LW · GW] to avoid shooting for value alignment and missing; that is, producing an agent that's "decided" that it should pursue its (potentially vague) understanding of ethics instead of taking instructions and thereby remaining correctable.
- ^
Value alignment can also be said to have a basin of attraction: if you get it to approximately value what humans value, it can refine its understanding of exactly what humans value, and so improve its alignment. This can be described as its alignment falling into a basin of attraction. For more, and stronger arguments, see Requirements for a Basin of Attraction to Alignment [LW · GW].
The same can be said of personal intent alignment. If my AGI approximately wants to do what I say, it can refine its understanding of what I mean by what I say, and so improve its alignment. However, this has an extra dimension of alignment improvement: I can tell it to shut down to adjust its alignment, and I can tell it to explain its alignment and its motivations in detail to decide whether I should adjust them or order it to adjust them.
Thus, it seems to me that the metaphorical basin of attraction around PI alignment is categorically stronger than that around value alignment. I'd love to hear good counterarguments.
- ^
Here's a little more on the argument that prosaic alignment isn't addressing how LLMs would change as they're turned into competent, agentic "real AGI". Current LLMs are tool AI that doesn't have explicitly represented and therefore flexible goals (a steering subsystem [LW · GW]). Thus, they don't in a rich sense have values or goals; they merely behave in ways that tend to carry out instructions in relatively ethical ways. Thus, they can't be aligned in the original sense of having goals or values aligned with humanity's.
On a more practical level, LLMs and foundation models don't have the capacity to learn continuously reflect on and change their beliefs and goals that I'd expect a "real AGI" to have. Thus, they don't face the The alignment stability problem [LW · GW]. When such a system is made reflective and so more coherent, I worry that goals other than instruction-following might gain precedence, and the resulting AGI would no longer be instructable and therefore corrigible.
It looks to me like the bulk of work on prosaic alignment does not address those issues. Prosaic alignment work seems to implicitly assume that either we won't make full AGI, or that learning to make LLMs do what we want will somehow extend to making full AGI that shares our goals. As outlined above, I think aligning LLMs will help align full AGI based on similar foundation models, but will not be adequate on its own.
- ^
If we simply left our AI systems goal-less "oracles", like LLMs currently are, we'd have little to no takeover risk. I don't think there's any hope we do that. People want things done, and getting things done involves an agent setting goals and subgoals. See Steering subsystems: capabilities, agency, and alignment [LW · GW] for the full argument. In addition, creating agents with reflection and autonomy is fascinating. And when it's as easy as calling an oracle system repeatedly with the prompt "Continue pursuing goal X using tools Y", there's no real way to build really useful oracles without someone quickly using them to power dangerous agents.
18 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-05T22:11:40.193Z · LW(p) · GW(p)
Thanks so much for writing this Seth! I so often get into conversations with people where I wished I had something like this post to refer them to. And now I do!
I really hope that you and Max's ideas soon get the wider recognition that I think they deserve!
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-06T04:29:23.028Z · LW(p) · GW(p)
Thanks! A big part of my motivation for writing this was to try to direct more attention to Max's excellent, detailed, and important work on personal intent alignment. And I wanted to understand the group communication/epistemics that have kept it from being as impactful as it seems to me to deserve.
People who think seriously about AGI alignment seem to still mostly be thinking that we'll try to value align AGI, even though that's nigh impossible in the near term. And they shouldn't.
comment by Noosphere89 (sharmake-farah) · 2024-09-05T17:47:27.209Z · LW(p) · GW(p)
Re value alignment to all of humanity, I'll say 2 things:
- I believe it is mostly impossible except in corner/edge cases like everyone having the same preferences, because of this post:
https://www.lesswrong.com/posts/YYuB8w4nrfWmLzNob/thatcher-s-axiom [LW · GW]
So personal intent alignment is basically all we get except in perhaps very small groups.
I like @Edward P. Könings [LW · GW]'s statement here on what people are actually doing when they try to improve society:
⦾ Carrying out a simplification or homogenization of the multiple preferences of the individuals that make up that society;
⦾ Modeling your own personal preferences as if these were the preferences of society as a whole.
2. While I agree that there are definitely paths to danger, I see reality as less offense biased than LWers/rationalists tend to think, enough so that I think that a multi-polar scenario doesn't leave us automatically/highly doomed.
(Biology is probably the closest exception, but I also expect this to be fixable).
(That said, it would be good to have a policy on when to stop open-weighting/open-sourcing powerful AIs, because of the risk.)
Also, this is an uncompleted sentence: "which create more illusory disagreements between those who mean personal intent alignment".
On footnote 4, I think a general crux is that as LLMs get more coherent and powerful, I still expect them to be corrigible by default, because the utility function that they are maximizing doesn't imply that they will try to assert their existence, which is:
The ideal predictor's utility function is instead strictly over the model's own outputs, conditional on inputs.
And I think there will be more constraints on AI development than on human development, such that at least in training, that unbounded/large instrumental convergence is very unlikely to be rewarded as much as LWers assumed.
See also these posts:
https://www.lesswrong.com/posts/k48vB92mjE9Z28C3s/implied-utilities-of-simulators-are-broad-dense-and-shallow [LW · GW]
https://www.lesswrong.com/posts/EBKJq2gkhvdMg5nTQ/instrumentality-makes-agents-agenty [LW · GW]
https://www.lesswrong.com/posts/vs49tuFuaMEd4iskA/one-path-to-coherence-conditionalization [LW · GW]
I agree that they will be easy to agentize, and that many people will try to agentize LLMs, but the value of a capable, not unbounded/very instrumentally convergent AI is very valuable, as it unblocks the path to corrigibility/instruction following AGI/ASI.
Agree with you in that we should probably aim for instruction following for the first AGI/ASI.
This part is very important, and I agree wholeheartedly with this point:
There's an intuition that intent alignment isn't workable for a full AGI; something that's competent or self-aware usually[5] has its own goals, so doesn't just follow instructions.
But that intuition is is based on our experience with existing minds. What if that synthetic being's explicit, considered goal is to approximately follow instructions?
I think it's possible for a fully self-aware, goal-oriented AGI to have its goal be, loosely speaking, a pointer to someone else's goals. No human is oriented this way, but it seems conceptually coherent to want to do, with all of your heart, just what someone else wants.
I think a lot of alignment discourse was thrown off in assuming that what the properties of human minds, especially for values/alignment properties were what AI systems had to look like in the limit of ASI, and more generally I think people heavily overestimated how much evidence human/evolution analogies brought on questions of AI alignment, compared to current Deep Learning/AI systems of today.
Indeed, I actually expect a lot of AIs to have corrigibility/personal intent alignment/instruction following/DWIMAC by default, given a minimally instrumentally convergent base.
Finally, I think one important implication is that if we are in a world where it's easy to align AIs to instruction following/personal intent, politics starts mattering again, and as AI takeoff happens, who your AIs are aligned to on politics will probably become a very important factor in how much you use your AIs.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-05T22:08:52.680Z · LW(p) · GW(p)
- I believe it is mostly impossible except in corner/edge cases like everyone having the same preferences, because of this post:
https://www.lesswrong.com/posts/YYuB8w4nrfWmLzNob/thatcher-s-axiom [LW · GW]
So personal intent alignment is basically all we get except in perhaps very small groups.
I want to disagree here. I think that a widely acceptable compromise on political rules, and the freedom to pursue happiness on one's own terms without violating others' rights, is quite achievable and desirable. I think that having a powerful AI establish/maintain the best possible government given the conflicting sets of values held by all parties is a great outcome. I agree that this isn't what is generally meant by 'values alignment', but I think it's a more useful thing to talk about.
I do agree that large groups of humans do seem to inevitably have contradictory values such that no perfect resolution is possible. I just think that that is beside the point, and not what we should even be fantasizing about. I also agree that most people who seem excited about 'values alignment' mean 'alignment to their own values'. I've had numerous conversations with such people about the problem of people with harmful intent towards others (e.g. sadism, vengeance). I have yet to receive anything even remotely resembling a coherent response to this. Averaging values doesn't solve the problem, there are weird bad edge cases that that falls into. Instead, you need to focus on a widely (but not necessarily unanimously) acceptable political compromise.
↑ comment by Seth Herd · 2024-09-05T20:02:22.875Z · LW(p) · GW(p)
Thanks for the detailed response!
I'm glad you agree on the importance of PIA being workable for real AGI. I sometimes wonder if I'm hallucinating this huge elephant in the room.
I'm not sure I'd a expect DWIMAC type alignment to emerge by default if you mean that an LLM-centered agent might just decide that's it's reflectively stable central goal. It might, but I wouldn't want to bet the farm on it.
If you mean that by default this is what the first successful AGI projects will try, I agree completely. I think it will look like there's very little sensible choice in the matter once people are really thinking about increasingly competent but still subhuman agents.
Finally, I think one important implication is that if we are in a world where it's easy to align AIs to instruction following/personal intent, politics starts mattering again, and as AI takeoff happens, who your AIs are aligned to on politics will probably become a very important factor in how much you use your AIs.
This was exactly my conclusion after writing about and discussing this scenario for If we solve alignment, do we die anyway? [LW · GW]. Politics are how we'll succeed or fail at alignment as a species. I hate this conclusion, because politics is one area I have no expertise or competence in.
And I think there will be more constraints on AI development than on human development, such that at least in training, that unbounded/large instrumental convergence is very unlikely to be rewarded as much as LWers assumed.
See also these posts: [...]
I agree that they will be easy to agentize, and that many people will try to agentize LLMs, but the value of a capable, not unbounded/very instrumentally convergent AI is very valuable, as it unblocks the path to corrigibility/instruction following AGI/ASI.
I don't really understand any of those statements, even after rereading those posts.
You might mean constraints from developers or constraints in AGIs self-improvement/learning.
I see unbounded instrumental convergence as the default in a competent reflective agent; it doesn't need to be rewarded explicitly, it's just what beings with goals do.
By "the value of a capable, not unbounded/very instrumentally convergent AI" you might mean either one that is or isn't very instrumentally convergent. If you mean not very instrumentally convergent, as above, I think that's the default and hard to avoid. I don't think it's possible without some very careful and difficult engineering of bounded goals (like Max Harms proposes for his definition of corrigibility, linked above). Just emitting behaviors that follow instructions isn't nearly as useful as pursuing user-defined goals autonomously.
The hope is that for an instruction-following PIA AGI, its instrumentally convergent subgoals all align with the principal's goals. That's if you've defined/trained instruction following just right; but you can adjust it if you catch the discrepencies before the AGI is a lot smarter than you and capable of escape.
Last and least: On the impossibility of value alignment: you can't align to everyone's values, as you say. But you can align to the overlap among everyone's values, something like "I'd like to be able to do whatever I want to the extent it's possible without other people keeping me from doing what I want". I think that's what people typically mean by value alignment. I like Empowerment is (almost) All We Need [LW · GW] on this.
Again, thanks for engaging closely with this!
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-05T20:29:56.465Z · LW(p) · GW(p)
Note, I edited my first comment to also include this link, which I somehow forgot to do, and I especially appreciate footnote 3 on that post:
https://www.lesswrong.com/posts/EBKJq2gkhvdMg5nTQ/instrumentality-makes-agents-agenty [LW · GW]
To respond to this:
You might mean constraints from developers or constraints in AGIs self-improvement/learning.
I'd say the closest thing I'm arguing for is from constraints on the reward function.
Re instrumental convergence being natural and unboundedly dangerous, I think a crux is that the reason why instrumental convergence is so unbounded and natural for humans doesn't generalize to the AI case, which is that humans were essentially trained on ridiculously sparse reward and basically very long-term feedback from evolution at best on reward, and I think the type of capabilities that naturally leads to instrumental convergence being unboundedly dangerous is also the area where AI research just completely sucks at.
I think future super-intelligent AI like agentized LLMs or Model-Free/Model Based RL will be way less incentivized to learn unboundedly large instrumental convergence (at least the dangerous ones like deceptive alignment and seeking power), because of much, much denser feedback, and much more reward shaping.
I do think it would still be too easy to give it extremely harmful goals, but that's a separate concern.
The short version is that the incentives to make AI more capable are less related to making them have dangerous instrumental convergence, because you can bound the instrumental convergence way more via very dense feedback, probably thousands or millions of times more dense feedback than what evolution had.
Some more links on the topic:
https://www.lesswrong.com/posts/dcoxvEhAfYcov2LA6/agentized-llms-will-change-the-alignment-landscape [LW · GW]
https://www.lesswrong.com/posts/JviYwAk5AfBR7HhEn/how-to-control-an-llm-s-behavior-why-my-p-doom-went-down-1 [LW · GW]
https://www.lesswrong.com/posts/DfJCTp4MxmTFnYvgF/goals-selected-from-learned-knowledge-an-alternative-to-rl [LW · GW]
https://www.lesswrong.com/posts/xqqhwbH2mq6i4iLmK/we-have-promising-alignment-plans-with-low-taxes [LW · GW]
https://www.lesswrong.com/posts/ogHr8SvGqg9pW5wsT/capabilities-and-alignment-of-llm-cognitive-architectures [LW · GW]
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-06T00:24:09.968Z · LW(p) · GW(p)
I very much agree that instrumentality makes agents agenty. It seems like we need them to be agenty to get stuff done. Whether it's translating data into a report or researching new cancer drugs, we have instrumental goals we want help with. And those instrumental goals have important subgoals, like making sure no one switches you off before you accomplish the goal.
You know all of that; you're thinking that useful work gets done using solely training. I think that only works if the training produces a general-purpose search to effectively do instrumental goal-directed behavior with arbitrary subgoals appropriate to the task. But I don't have a good argument for why I think that human-style problem solving will be vastly more efficient than trying to train useful human-level capabilities into something without real instrumental goal-seeking with flexible subgoals.
I guess the closest I can come is that it seems very difficult to create something smart enough to solve complex tasks, but so inflexible that it can't figure out new valuable subgoals.
Thanks for those citations, I really appreciate them! Four of them are my articles, and I'm so glad you found them valuable. And and I loved Roger Dearnaley's why my p(doom) went down [LW · GW] on the same topics.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-06T01:50:55.156Z · LW(p) · GW(p)
I agree there's pressure towards instrumental goals once LLMs get agentized, where I think I diverge is that the feedback will be a lot denser and way more constraining than evolution on human minds, so much so that I think a lot of the instrumental goals that does arise is very aimable by default. More generally, I consider the instrumental convergence that made humans destroy everyone else, including gorillas and chimpanzees as very much outilers, and I think that human feedback/human alignment attempts will be far more effective in aiming instrumental convergence than what chimpanzees and gorillas did, or what evolution did to humans.
Another way to say it is conditional on instrumental goals arising in LLMs after agentization, I expect them to be very aimable and controllable by default.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-09T21:01:48.271Z · LW(p) · GW(p)
I think I'm understanding you now, and I think I agree.
You might be saying the same thing I've expressed something like: LLMs already follow instructions well enough to serve as the cognitive core of an LLM cognitive architecture, where the goals are supplied as prompts from surrounding scaffolding. Improvements in LLMs need merely maintain the same or better levels of aimability. Occasional mistakes and even Waluigi hostile simulacra will be overwhelmed by the remainder of well-aimed behavior and double-checking mechanisms.
Or you may be addressing LLms that are agentized in a different way: by applying RL for achieving specified insstrumental goals over many steps of cognition and actions with tool calls.
I'm much more uneasy about that route, and distrubed that Demis Hassabis described the path to AGI as Gemini combined with AlphaZero. But if that's only part of the training, and it works well enough, I think a prompted goal and scaffolded double-checks could be enough. Adding reflection and self-editing is another way to ensure that largely useful behavior outweighs occasional mistakes and hostile simulacra in the core LLM/foundation model.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-09T21:40:48.938Z · LW(p) · GW(p)
I think my point is kind of like that, but more so emphasizing the amount of feedback we can give compared to evolution, and more importantly training on goals that have denser rewards tends to provide for safer AI systems.
To address this scenario:
Or you may be addressing LLms that are agentized in a different way: by applying RL for achieving specified insstrumental goals over many steps of cognition and actions with tool calls.
I'm much more uneasy about that route, and distrubed [sic] that Demis Hassabis described the path to AGI as Gemini combined with AlphaZero.
The big difference here is that I expect conditional on Demis Hassabis's plans working, the following things make things easier to constrain the solution in ways that help with safety and alignment:
-
I don't expect sparse reward RL to work, and to expect it to require a densely defined reward, which constrains the shape of solutions a lot, and I think there is a real chance we can add other constraints to the reward function to rule out more unsafe solutions.
-
It will likely involve non-instrumental world models, and in particular I think there are real ways to aim instrumental convergence (Albeit unlike in the case of predictive models, you might not have a base of non-instrumentally convergent behavior, so be careful with how you've set up your constraints.)
I should note that a lot of the arguments for RL breaking things more compared to LLMs, while sort of correct, are blunted a lot because compared to natural selection which probably used 1046-1048 flops of compute, which is way more than any realistic run, conditioning on TAI/AGI/ASI occuring in this century, essentially allowed for ridiculously sparse rewards like "inclusive genetic fitness", and evolution hasn't interfered nearly as much a human will interfere with their AI.
I got the flops number from this website:
https://www.getguesstimate.com/models/10685
So to answer the question, my answer is it would be good for you to think of alignment methods on agentized RL systems like AlphaZero, but that they aren't intrisincally agents, and are not much more dangerous than LLMs provided you've constrained the reward function enough.
I'd probably recommend starting from a base of a pre-trained model like GPT-N though to maximize our safety and alignment chances.
Here are some more links and quotes on Rl and non-instrumental world models:
This also means that minimal-instrumentality training objectives may suffer from reduced capability compared to an optimization process where you had more open, but still correctly specified, bounds. This seems like a necessary tradeoff in a context where we don't know how to correctly specify bounds.
Fortunately, this seems to still apply to capabilities at the moment- the expected result for using RL in a sufficiently unconstrained environment often ranges from "complete failure" to "insane useless crap." It's notable that some of the strongest RL agents are built off of a foundation of noninstrumental world models.
https://www.lesswrong.com/posts/rZ6wam9gFGFQrCWHc/#mT792uAy4ih3qCDfx [LW · GW]
https://www.lesswrong.com/posts/k48vB92mjE9Z28C3s/?commentId=QciMJ9ehR9xbTexcc [LW · GW]
Where we can validly turn utility maximization over plans and predictions into world states.
And finally a link on how to control an LLM's behavior, which while not related too much to RL, is nontheless interesting:
https://www.lesswrong.com/posts/JviYwAk5AfBR7HhEn/how-to-control-an-llm-s-behavior-why-my-p-doom-went-down-1 [LW · GW]
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-09T23:20:55.609Z · LW(p) · GW(p)
I've read each of the posts you cite thoroughly, some of them recently. I remain unclear on one thing: how do you expect to have a densely defined reinforcement signal? I can see that happening if you have some other system estimating success in arbitrary situations; that would be dense but very noisy. Which might be fine.
It would be noisy, but still dense. It wouldn't include goals like "maximize success across tasks and time". Unless the agent was made coherent and autonomous - in which case the reflectively stable center of all of that RL training might be something like that.
I think mostly about AGI that is fully autonomous and therefore becomes coherent around its goals, for better or worse. I wonder if that might be another important difference of perspective. You said
it would be good for you to think of alignment methods on agentized RL systems like AlphaZero, but that they aren't intrisincally agents, and are not much more dangerous than LLMs provided you've constrained the reward function enough.
I don't understand why they wouldn't intrinsically be agents after that RL training?
I want to understand, because I believe refining my model of what AGI will first look like should help a lot with working through alignment schemes adequately before they're tried.
My thought is that they'd need to take arbitrary goals, and create arbitrary subgoals, which training wouldn't always cover. There are an infinite number of valuable tasks in the world. But I can also see the argument that most useful tasks fall into categories, and training on those categories might be not just useful but adequate for most of what we want from AGI.
If that's the type of scenario you're addressing, I think that's plausible for many AGI projects. But I think the same argument I make for LLMs and other "oracle" AGI: someone will turn it into a full real agent very soon; it will have more economic value, but even if it doesn't, people will do it just for the hell of it, because it's interesting.
With LLMs it's as simple as repeating the prompt "keep working on that problem, pursuing goal X, using tools Y". With another architecture, it might be a little different- but turning adequate intelligence into a true agent is almost trivial. Some monkey will pull that lever almost as soon as it's available.
You've probably heard that argument somewhere before, so I may well be misunderstanding your scenario still.
Thanks for the dialogue here, this is useful for my work on my draft post "how we'll try to align AGI".
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-10T00:28:02.976Z · LW(p) · GW(p)
I remain unclear on one thing: how do you expect to have a densely defined reinforcement signal?
Basically, via lots of synthetic data that always shows the AI acting aligned even when the human behaves badly, as well as synthetic data to make misaligned agents reveal themselves safely, and in particular it's done early in the training run, before it can try to deceive or manipulate us.
More generally, the abuse of synthetic data means we have complete control over the inputs to the AI model, which means we can very easily detect stuff like deception and takeover risk.
For example, we can feed RL and LLM agents information about interpretability techniques not working, despite them actually working, or feed them exploits that are both easy and large for misaligned AI to do that seem to work, but doesn't actually work.
More here:
https://www.beren.io/2024-05-11-Alignment-in-the-Age-of-Synthetic-Data/
https://www.lesswrong.com/posts/oRQMonLfdLfoGcDEh/a-bitter-lesson-approach-to-aligning-agi-and-asi-1 [LW · GW]
It's best to make large synthetic datasets now, so that we can apply it continuously throughout AGI/ASI training, and in particular do it before it is capable of learning deceptiveness/training games.
I think mostly about AGI that is fully autonomous and therefore becomes coherent around its goals, for better or worse. I wonder if that might be another important difference of perspective. You said
it would be good for you to think of alignment methods on agentized RL systems like AlphaZero, but that they aren't intrisincally agents, and are not much more dangerous than LLMs provided you've constrained the reward function enough.
I don't understand why they wouldn't intrinsically be agents after that RL training?
If that's the type of scenario you're addressing, I think that's plausible for many AGI projects. But I think the same argument I make for LLMs and other "oracle" AGI: someone will turn it into a full real agent very soon; it will have more economic value, but even if it doesn't, people will do it just for the hell of it, because it's interesting.
With LLMs it's as simple as repeating the prompt "keep working on that problem, pursuing goal X, using tools Y". With another architecture, it might be a little different- but turning adequate intelligence into a true agent is almost trivial. Some monkey will pull that lever almost as soon as it's available.
You've probably heard that argument somewhere before, so I may well be misunderstanding your scenario still.
I was just referring to this post on how RL policies aren't automatically agents, without other assumptions. I agree that they will likely be agentized by someone if RL doesn't agentize them, and I agree with your assumptions on why they will be agentic RL/LLM AIs.
https://www.lesswrong.com/posts/rmfjo4Wmtgq8qa2B7/think-carefully-before-calling-rl-policies-agents [LW · GW]
Also, the argument against synthetic data working because raters make large amounts of compactly describable errors has evidence against it, at least in the data-constrained case.
Some relevant links are these:
https://www.lesswrong.com/posts/8yCXeafJo67tYe5L4/#74DdsQ7wtDnx4ChDX [LW · GW]
https://www.lesswrong.com/posts/8yCXeafJo67tYe5L4/#R9Bfu6tzmuWRCT6DB [LW · GW]
https://www.lesswrong.com/posts/8yCXeafJo67tYe5L4/?commentId=AoxYQR9jLSLtjvLno#AoxYQR9jLSLtjvLno [LW(p) · GW(p)]
At a broader level, my point is that even conditional on you being correct that fully autonomous AI that is coherent across goals will be trained by somebody soon, the path to being coherent and autonomous is both important and influenceable to be more aligned by us.
Thanks for the dialogue here, this is useful for my work on my draft post "how we'll try to align AGI".
And thank you for being willing to read so much. I will ask you to read more posts and comments here, so that I can finally explicate what exactly is the plan to align AGI via RL or LLMs, which is large synthetic datasets.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-10T19:16:53.550Z · LW(p) · GW(p)
I just finished reading all of those links. I was familiar with Roger Dearnaleys' proposal of synthetic data for alignment but not Beren Millidge's. It's a solid suggestion that I've added to my list of likely stacked alignment approaches, but not fully thought through. It does seem to have a higher tax/effort than the methods so I'm not sure we'll get around to it before real AGI. But it doesn't seem unlikely either.
I got caught up reading the top comment thread above the Turntrout/Wentworth exchange you linked. I'd somehow missed that by being off-grid when the excellent All the Shoggoths Merely Players came out. It's my nomination for SOTA of the current alignment difficulty discussion.
I very much agree that we get to influence the path to coherent autonomous AGI. I think we'll probably succeed in making aligned AGI- but then quite possibly tragically extinct ourselves with standard human combativeness/paranoia or foolishness - If we solve alignment, do we die anyway? [LW · GW]
I think you've read that and we've had a discussion there, but I'm leaving that link here as the next step in this discussion now that we've reached approximate convergence.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-10T19:37:15.341Z · LW(p) · GW(p)
I just finished reading all of those links. I was familiar with Roger Dearnaleys' proposal of synthetic data for alignment but not Beren Millidge's. It's a solid suggestion that I've added to my list of likely stacked alignment approaches, but not fully thought through. It does seem to have a higher tax/effort than the methods so I'm not sure we'll get around to it before real AGI. But it doesn't seem unlikely either.
I agree it has a higher tax rate than RLHF, but to make the case for lower tax rates than people think, it's because synthetic data will likely be a huge part of what makes AGI into ASI, as models require a lot of data, and synthetic data is a potentially huge industry in futures where AI progress is very high, because the amount of human data is both way too limiting for future AIs, and probably doesn't show superhuman behavior like we want from LLMs/RL.
Thus huge amounts of synthetic data will be heavily used as part of capabilities progress, meaning we can incentivize them to also put alignment data in the synthetic data.
I very much agree that we get to influence the path to coherent autonomous AGI. I think we'll probably succeed in making aligned AGI- but then quite possibly tragically extinct ourselves with standard human combativeness/paranoia or foolishness - If we solve alignment, do we die anyway? [LW · GW]
This is why I think we will need to use targeted removals of capabilities like LEACE combined with using synthetic data to remove infohazardous knowledge, combined with not open-weighting/open-sourcing models as AIs get more capable and only allowing controlled API use.
Here's the LEACE paper and code:
https://github.com/EleutherAI/concept-erasure/pull/2
https://github.com/EleutherAI/concept-erasure
https://github.com/EleutherAI/concept-erasure/releases/tag/v0.2.0
https://arxiv.org/abs/2306.03819
https://blog.eleuther.ai/oracle-leace
I'll reread that post again.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-09-10T22:26:44.468Z · LW(p) · GW(p)
Agreed on the capabilities advantages of synthetic data; so it might not be much of a tax at all to mix in some alignment.
I don't think removing infohazardous knowledge will work all the way into dangerous AGI, but I don't think it has to - there's a whole suite of other alignment techniques for language model agents [AF · GW] that should suffice together.
Keeping a superintelligence ignorant of certain concepts sounds impossible. Even a "real AGI" of the type I expect soon will be able to reason and learn, causing it to rapidly rediscover any concepts you've carefully left out of the training set. Leaving out this relatively easy capability (to reason and learn online) will hurt capabilities, so you'd have a huge uphill battle in keeping it out of deployed AGI. At least one current projects have already accomplished limited (but impressive) forms of this as part of their strategy to create useful LM agents. So I don't think it's getting rolled back or left out.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-09-10T22:39:07.207Z · LW(p) · GW(p)
I agree with you that there are probably better methods to handle the misuse risk, and note I also pointed out them as options, not exactly guarantees.
And yeah, I agree with this specifically:
but I don't think it has to - there's a whole suite of other alignment techniques for language model agents that should suffice together.
Thanks for mentioning that.
Now that I think about it, I agree that it's only a stop gap for misuse, and yeah if there is even limited generalization ability, I agree that LLMs will be able to rediscover dangerous knowledge, so we will need to make LLMs that don't let users completely make bio-weapons for example.
comment by simon · 2024-10-04T14:54:02.265Z · LW(p) · GW(p)
I think this post is making a sharp distinction to what really is a continuum; any "intent aligned" AI becomes more safe and useful as you add more "common sense" and "do what I mean" capability to it, and at the limit of this process you get what I would interpret as alignment to the long term, implicit deep values (of the entity or entities the AI started out intent aligned to).
I realize other people might define "alignment to the long term, implicit deep values" differently, such that it would not be approached by such a process, but currently think they would be mistaken in desiring whatever different definition they have in mind. (Indeed, what they actually want is what they would get under sufficiently sophisticated intent alignment, pretty much by definition).
P.S. I'm not endorsing intent alignment (for ASI) as applied to only an individual/group - I think intent alignment can be applied to humanity collectively [LW(p) · GW(p)].
comment by Czynski (JacobKopczynski) · 2024-09-12T02:52:52.922Z · LW(p) · GW(p)
I currently slightly prefer an but that's pending further thought and discussion.
missing thought in the footnotes