OpenAI: Exodus
post by Zvi · 2024-05-20T13:10:03.543Z · LW · GW · 26 commentsContents
Table of Contents The Two Departure Announcements Who Else Has Left Recently? Who Else Has Left Overall? Early Reactions to the Departures The Obvious Explanation: Altman Jan Leike Speaks Reactions after Leike’s Statement Greg Brockman and Sam Altman Respond to Leike Reactions from Some Folks Unworried About Highly Capable AI Don’t Worry, Be Happy? The Non-Disparagement and NDA Clauses Legality in Practice Implications and Reference Classes Altman Responds on Non-Disparagement Clauses So, About That Response How Bad Is All This? Those Who Are Against These Efforts to Prevent AI From Killing Everyone What Will Happen Now? What Else Might Happen or Needs to Happen Now? None 27 comments
Previously: OpenAI: Facts From a Weekend, OpenAI: The Battle of the Board, OpenAI: Leaks Confirm the Story, OpenAI: Altman Returns, OpenAI: The Board Expands.
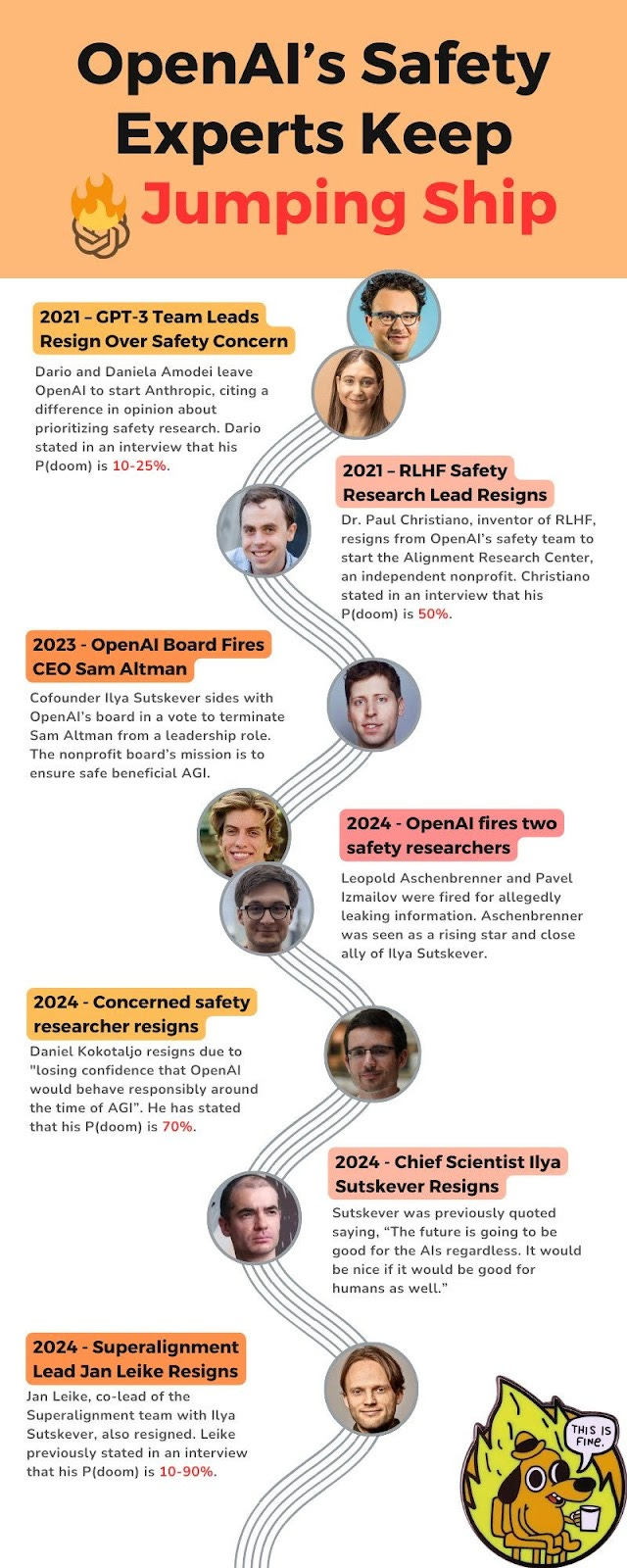
Ilya Sutskever and Jan Leike have left OpenAI. This is almost exactly six months [LW(p) · GW(p)] after Altman’s temporary firing and The Battle of the Board, the day after the release of GPT-4o, and soon after a number of other recent safety-related OpenAI departures. Many others working on safety have also left recently. This is part of a longstanding pattern at OpenAI.
Jan Leike later offered an explanation for his decision on Twitter. Leike asserts that OpenAI has lost the mission on safety and culturally been increasingly hostile to it. He says the superalignment team was starved for resources, with its public explicit compute commitments dishonored, and that safety has been neglected on a widespread basis, not only superalignment but also including addressing the safety needs of the GPT-5 generation of models.
Altman acknowledged there was much work to do on the safety front. Altman and Brockman then offered a longer response that seemed to say exactly nothing new.
Then we learned that OpenAI has systematically misled and then threatened its departing employees, forcing them to sign draconian lifetime non-disparagement agreements, which they are forbidden to reveal due to their NDA.
Altman has to some extent acknowledged this and promised to fix it once the allegations became well known, but so far there has been no fix implemented beyond an offer to contact him privately for relief.
These events all seem highly related.
Also these events seem quite bad.
What is going on?
This post walks through recent events and informed reactions to them.
The first ten sections address departures from OpenAI, especially Sutskever and Leike.
The next five sections address the NDAs and non-disparagement agreements.
Then at the end I offer my perspective, highlight another, and look to paths forward.
Table of Contents
- The Two Departure Announcements
- Who Else Has Left Recently?
- Who Else Has Left Overall?
- Early Reactions to the Departures
- The Obvious Explanation: Altman
- Jan Leike Speaks
- Reactions After Lekie’s Statement
- Greg Brockman and Sam Altman Respond to Leike
- Reactions from Some Folks Unworried About Highly Capable AI
- Don’t Worry, Be Happy?
- The Non-Disparagement and NDA Clauses
- Legality in Practice
- Implications and Reference Classes
- Altman Responds on Non-Disparagement Clauses
- So, About That Response
- How Bad Is All This?
- Those Who Are Against These Efforts to Prevent AI From Killing Everyone
- What Will Happen Now?
- What Else Might Happen or Needs to Happen Now?
The Two Departure Announcements
Here are the full announcements and top-level internal statements made on Twitter around the departures of Ilya Sutskever and Jan Leike.
Ilya Sutskever: After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and beneficial under the leadership of @sama, @gdb, @miramurati and now, under the excellent research leadership of Jakub Pachocki. It was an honor and a privilege to have worked together, and I will miss everyone dearly. So long, and thanks for everything. I am excited for what comes next — a project that is very personally meaningful to me about which I will share details in due time.
[Ilya then shared the photo below]

Jakub Pachocki: Ilya introduced me to the world of deep learning research, and has been a mentor to me, and a great collaborator for many years. His incredible vision for what deep learning could become was foundational to what OpenAI, and the field of AI, is today. I am deeply grateful to him for our countless conversations, from high-level discussions about the future of AI progress, to deeply technical whiteboarding sessions.
Ilya – I will miss working with you.
Sam Altman: Ilya and OpenAI are going to part ways. This is very sad to me; Ilya is easily one of the greatest minds of our generation, a guiding light of our field, and a dear friend. His brilliance and vision are well known; his warmth and compassion are less well known but no less important.
OpenAI would not be what it is without him. Although he has something personally meaningful he is going to go work on, I am forever grateful for what he did here and committed to finishing the mission we started together. I am happy that for so long I got to be close to such genuinely remarkable genius, and someone so focused on getting to the best future for humanity.
Jakub is going to be our new Chief Scientist. Jakub is also easily one of the greatest minds of our generation; I am thrilled he is taking the baton here. He has run many of our most important projects, and I am very confident he will lead us to make rapid and safe progress towards our mission of ensuring that AGI benefits everyone.
Greg Brockman: I have immense gratitude to Ilya for being my co-founder, my friend, and the officiant at my civil ceremony.
Together, we charted the path of what OpenAI would become today. When we started in late 2015, OpenAI was a non-profit with a mission to make AGI go well but without a credible plan of how to accomplish it. In the early days, Ilya and I spent countless hours thinking hard about every aspect of culture, technical direction, and strategy. Together we realized that we would need to raise a lot more capital than anyone had imagined in order to build supercomputers of unprecedented size. We fundraised together in the non-profit, raising more than others thought possible but still far less than what was needed. We proposed creating a for-profit structure in service of the mission. And once that had been created, we continued to align and shape what that company stood for, maintaining the focus on our AGI mission while grappling with the hard practical questions of how to make progress each day.
Ilya is an artist. His vision and gusto are infectious, and he helped me understand this field when I was just getting started. He is unafraid of thinking through the logical conclusion of his intuitions. We were motivated by the 1962 book Profiles of the Future, which opens with descriptions of the incorrect mindsets that led to scientific claims of the impossibility of the lightbulb, flight, and reaching orbit shortly before these feats were accomplished. So despite people doubting that AGI was anywhere on the foreseeable horizon, we would think through and act on the conviction of our beliefs that deep learning can take us there.
The mission is far from complete, and Ilya played a key role in helping build the foundations of what OpenAI has become today. Thank you for everything.
Jan Leike: I resigned.
Jan Leike later offered a full Twitter thread, which I analyze in detail later.
Who Else Has Left Recently?
Wei Dai (November 21, 2023): The OpenAI Cultural Revolution
If you asked me last week whose departures other than Sam Altman himself or a board member would update me most negatively about the likelihood OpenAI would responsibly handle the creation and deployment of AGI, I would definitely have said Ilya Sutskever and Jan Leike.
If you had asked me what piece of news about OpenAI’s employees would have updated me most positively, I would have said ‘Ilya Sutskever makes it clear he is fully back and is resuming his work in-office as head of the Superalignment team, and he has all the resources he needs and is making new hires.’
If Jan’s and Ilya’s departures were isolated, that would be bad enough. But they are part of a larger pattern.
Here is Shakeel’s list of safety researchers at OpenAI known to have left in the last six months, minus Cullen O’Keefe who worked on policy and legal (so was not a clear cut case of working on safety), plus the addition of Ryan Lowe.
- Ilya Sutskever
- Jan Leike
- Leopold Aschenbrenner
- Pavel Izmailov
- William Saunders
- Daniel Kokotajlo
- Ryan Lowe
Here’s some other discussion of recent non-safety OpenAIemployee departures.
Shakeel: Other recent departures include Chris Clark, head of nonprofit and strategic initiatives and Sherry Lachman, head of social impact.
Zack Stein-Perlman [LW(p) · GW(p)]: Two other executives left two weeks ago, but that’s not obviously safety-related.
Diane Yoon [was] vice president of people, [and Chris Clark as above].
HT [LW(p) · GW(p)] LGS: Evan Morikawa also left on the 15th to join his friend Andy Barry at Boston Dynamics but that does not seem related.
Ilya Sutskever was one of the board members that attempted to fire Sam Altman.
Jan Leike worked closely with Ilya to essentially co-lead Superalignment. He has now offered an explanation thread.
William Saunders also worked on Superalignment; he resigned on February 15. He posted this on LessWrong [LW(p) · GW(p)], noting his resignation and some of what he had done at OpenAI, but no explanation. When asked why he quit, he said ‘no comment.’ The logical implications are explored.
Leopold Aschenbrenner and Pavel Izmailov were fired on April 11 for supposedly leaking confidential information. The nature of leaking confidential information is that people are reluctant to talk about exactly what was leaked, so it is possible that OpenAI’s hand was forced. From what claims we do know and what I have read, the breach seemed technical and harmless. OpenAI chose to fire them anyway. In Vox, Sigal Samuel is even more skeptical that this was anything but an excuse. Leopold Aschenbrenner was described as an ally of Ilya Sutskever.
Ryan Lowe ‘has a few projects in the oven’. He also Tweeted the following and as far as I can tell that’s all we seem to know.
Ryan Lowe: I’m so grateful I got to work closely with Jan at OpenAI. he’s an amazing human being.
Cullen O’Keefe left to be Director of Research at the Institute for Law & AI.
Daniel Kokotajlo quit [LW(p) · GW(p)] on or before April 18 ‘due to losing confidence that [OpenAI] would behave responsibly around the time of AGI.’ He gave up his equity in OpenAI, constituting 85% of his family’s net worth, to avoid signing a non-disparagement agreement, but he is still under NDA.
We do not have a full enumeration of how many people would have counted for a list like this. Based on this interview with Jan Leike (at about 2:16:30) six months ago superalignment was about a 20 person team, and safety outside of it was broad but mostly RLHF and other mundane safety efforts with easy business cases that don’t clash with the company culture.
Then we lost 7 within 6 months, concentrated on senior leadership. This seems like rather a lot.
Then we can add, within weeks, the head of nonprofit and strategic initiatives, the head of social impact and a vice president of people. That sounds a lot like this goes well beyond potential future safety issues, and goes deep into problems such as general ethical behavior and responsible strategic planning.
Who Else Has Left Overall?
Sigal Samuel (Vox, Future Perfect): For months, OpenAI has been losing employees who care deeply about making sure AI is safe. Now, the company is positively hemorrhaging them.
OpenAI has a longstanding habit of losing its top safety-oriented people.
As we all know, OpenAI is nothing without its people.
I asked GPT-4o, Claude Opus and Gemini Advanced to rank the current and former employees of OpenAI by how important they are in terms of AGI safety efforts:
Q: In order ranked by importance to OpenAI’s efforts in the area, who are the top 10 employees (past or current) who have worked on AGI Safety or AGI Alignment in various forms? Consider only as it pertains to the safety of future highly capable systems, not alignment of current systems (e.g. not GPT-4).
Here are the answers, removing explanations. The names in bold seem to no longer work at OpenAI.
Here is GPT-4o:
- Ilya Sutskever
- Dario Amodei
- Paul Christiano
- Jan Leike
- Geoffrey Irving
- Chris Olah
- Jakob Foerster
- Alec Radford
- Ryan Lowe
- Miles Brundage
Here is Claude Opus:
- Paul Christiano
- Jan Leike
- Dario Amodei
- Geoffrey Irving
- Amanda Askell
- Miles Brundage
- Jack Clark
- Ilya Sutskever
- Sam Altman
- Chris Olah
Here is Gemini Advanced:
- Ilya Sutskever
- Jan Leike
- Paul Christiano
- Dario Amodei
- Chris Olah
- Jeff Wu
- Vicki Cheung
- John Schulman
- Pieter Abbeel
- Alec Radford
[EDIT: A previous version incorrectly thought Miles Brundage had left. My apologies.]
On average, over 70% of the named people have now departed, including 100% of the top 5 from all lists. This is in addition to what happened to the board including Helen Toner.
Those that remain are CEO Sam Altman, co-founder John Schulman, Alec Radford, Miles Brundage and Jeff Wu. What do all of them appear to have in common? They do not have obvious ‘safety branding,’ and their primary work appears to focus on other issues. John Schulman does have a co-authored alignment forum post.
Once is a coincidence. Twice is suspicious. Over 70% of the time is enemy action.
Early Reactions to the Departures
Here are various early reactions to the news, before the second wave of information on Friday from Vox, Bloomberg, Leike, and others.
Connor Leahy: Canary in the coal mine.
Congrats to Ilya and Jan for doing the right thing.
Jeffrey Ladish: Really not a good sign. That’s the second gen of safety team leads OpenAI has lost…
David Krueger [QTing Leike]: For a while I’ve been saying that I still know *some* people at OpenAI understand and care about x-safety.
The list is growing shorter and shorter…
James Campbell: Surely this means superalignment is solved. The job is done. They set out to do it in four years and it only took a mere 10 months. Our boys can come home now.
Metaculus: OpenAI is 3% likely to announce it has solved the core technical challenges of superintelligence alignment by June 30, 2027, down 2% this week.
James Miller: [Leike] knows that not saying something like “It was an honor to have worked at OpenAI” will be interpreted as “I’m under a NDA but I think OpenAI is on track to destroy the universe” and yet he has still given us just these two words [‘I resign’].
Breaching his NDA could increase the chances of humanity going extinct because he would get sued, and lose time and money that he could otherwise spend helping us survive.
John David Pressman: Considering [Leike is] under a strict NDA and the professional standard thing to do is say “It’s been an incredible opportunity I’m excited for what OpenAI will do in the future” and he didn’t say that I’m genuinely concerned.
That he doesn’t break the NDA outright tells me it’s not any form of imminent catastrophic risk. Doesn’t mean it’s not a bad sign about OpenAI from an AI alignment standpoint.
How concerned [from 0-10]? Uh maybe like a 5-6? I’m mostly annoyed with the people going “lolol now the real engineers can get to work” as though this does not in fact look bad for OpenAI. Would love to know more about what’s going on here.
Realistically? Something like “OpenAI no longer takes basic research seriously and the culture is actively toxic if you work on things like weak to strong generalization”. Not “what did Ilya see?” type stuff.
Marvin Baumann (responding to JDP): OpenAI is a product company now (apparently so), no more research. What besides that fact does concern you further?
Andrew Critch: I’m sad to see so many people leaving OpenAI. I’ve really enjoyed their products, and the way they’ve helped humanity come to grips with the advent of LLMs by making them more openly available in their products.
I remain “optimistic” that we probably have only a ~25% chance of AI-driven extinction this decade — and there’s a lot that can be done to change that! — but it’s not a good sign when leadership at AI companies keep splintering apart like this while trying to develop the most important technology of all time.
If there’s anything positive to take from this, maybe this fragmentation process can help wake people up into realizing that no one company should be trusted to control humanity’s future with AI technology, and that we should all be working to democratize and diversify decision-making and deliberation over these incredibly impactful technologies. Many have said this before, and at some point the talk needs to turn into real change.
I’m currently 80% on human extinction by 2060.
Thane Ruthenis [LW(p) · GW(p)]: [The departures are] good news.
There was a brief moment, back in 2023, when OpenAI’s actions made me tentatively optimistic that the company was actually taking alignment seriously, even if its model of the problem was broken.
Everything that happened since then has made it clear that this is not the case; that all these big flashy commitments like Superalignment were just safety-washing and virtue signaling. They were only going to do alignment work inasmuch as that didn’t interfere with racing full-speed towards greater capabilities.
So these resignations don’t negatively impact my p(doom) in the obvious way. The alignment people at OpenAI were already powerless to do anything useful regarding changing the company direction.
On the other hand, what these resignations do is showcasing that fact. Inasmuch as Superalignment was a virtue-signaling move meant to paint OpenAI as caring deeply about AI Safety, so many people working on it resigning or getting fired starkly signals the opposite.
And it’s good to have that more in the open; it’s good that OpenAI loses its pretense.
Oh, and it’s also good that OpenAI is losing talented engineers, of course.
Jelle Donders: Guaranteeing all the safety people that left OpenAI that any legal fees for breaking their NDA would be fully compensated might be a very effective intervention.
Tristan Wegner: On first order, this might have a good effect on safety.
On second order, it might have negative effects, because it increases the risk of and therefor lowers the rate of such companies hiring people openly worrying about AI X-Risk.
Linch [LW(p) · GW(p)]: It’ll be interesting to see if OpenAI will keep going with their compute commitments now that the two main superalignment leads have left.
Zack Stein-Perlman: The commitment—”20% of the compute we’ve secured to date” (in July 2023), to be used “over the next four years”—may be quite little in 2027, with compute use increasing exponentially. I’m confused about why people think it’s a big commitment.
Lukas Gloor: It seems likely (though not certain) that they signed non-disparagement agreements, so we may not see more damning statements from them even if that’s how they feel. Also, Ilya at least said some positive things in his leaving announcement, so that indicates either that he caved in to pressure (or too high agreeableness towards former co-workers) or that he’s genuinely not particularly worried about the direction of the company and that he left more because of reasons related to his new project.
Danbmil99: Putting aside the fact that OpenAI drama seems to always happen in a world-is-watching fishbowl, this feels very much like the pedestrian trope of genius CTO getting sidelined as the product succeeds and business people pushing business interests take control. On his own, Ilya can raise money for anything he wants, hire anyone he wants, and basically just have way more freedom than he does at OpenAI.
I do think there is a basic p/doom vs e/acc divide which has probably been there all along, but as the tech keeps accelerating it becomes more and more of a sticking point.
I suspect in the depths of their souls, SA and Brock and the rest of that crowd do not really take the idea of existential threat to humanity seriously. Giving Ilya a “Safety and alignment” role probably now looks like a sop to A) shut the p-doomers up and B) signal some level of concern. But when push comes to shove, SA and team do what they know how to do — push product out the door. Move fast and risk extinction.
One CEO I worked with summed up his attitude thusly: “Ready… FIRE! – aim.”
Arthur Breitman: The default explanation for high-profile safety people leaving OpenAI is not them being about to unleash existentially risky models but rather a culture and priority shift having taken place, translating in teams not getting headcount or GPU.
It’s still bad though.
Low confidence that it’s the correct explanation, high confidence that it’s close to the best guess outsiders can reasonably make.
Jacques: Not a productive comment (0), yet everyone agrees (57).
Version of that comment on Friday morning, still going:

For symmetry, here’s the opposite situation [LW(p) · GW(p)]:

Gary Marcus summarized, suggests ‘his friends in Washington should look into this.’
The Obvious Explanation: Altman
We know that a lot of OpenAI’s safety researchers, including its top safety researchers, keep leaving. We know that has accelerated in the wake of the attempted firing of Sam Altman.
That does not seem great. Why is it all happening?
At Vox, Sigal Samuel offers a simple explanation. It’s Altman.
Sigal Samuel: But the real answer may have less to do with pessimism about technology and more to do with pessimism about humans — and one human in particular: Altman. According to sources familiar with the company, safety-minded employees have lost faith in him.
“It’s a process of trust collapsing bit by bit, like dominoes falling one by one,” a person with inside knowledge of the company told me, speaking on condition of anonymity.
Not many employees are willing to speak about this publicly. That’s partly because OpenAI is known for getting its workers to sign offboarding agreements with non-disparagement provisionsupon leaving. If you refuse to sign one, you give up your equity in the company, which means you potentially lose out on millions of dollars.
…
For employees, all this led to a gradual “loss of belief that when OpenAI says it’s going to do something or says that it values something, that that is actually true,” a source with inside knowledge of the company told me.
That gradual process crescendoed this week.
Jan Leike Speaks
I want to deeply thank Jan Leike for his explanation of why he resigned.
Here is Jan Leike’s statement, in its entirety:
Jan Leike: Yesterday was my last day as head of alignment, superalignment lead, and executive @OpenAI.
It’s been such a wild journey over the past ~3 years. My team launched the first ever RLHF LLM with InstructGPT, published the first scalable oversight on LLMs, pioneered automated interpretability and weak-to-strong generalization. More exciting stuff is coming out soon.
I love my team.
I’m so grateful for the many amazing people I got to work with, both inside and outside of the superalignment team.
OpenAI has so much exceptionally smart, kind, and effective talent.
Stepping away from this job has been one of the hardest things I have ever done, because we urgently need to figure out how to steer and control AI systems much smarter than us.
I joined because I thought OpenAI would be the best place in the world to do this research.
However, I have been disagreeing with OpenAI leadership about the company’s core priorities for quite some time, until we finally reached a breaking point.
I believe much more of our bandwidth should be spent getting ready for the next generations of models, on security, monitoring, preparedness, safety, adversarial robustness, (super)alignment, confidentiality, societal impact, and related topics.
These problems are quite hard to get right, and I am concerned we aren’t on a trajectory to get there.
Over the past few months my team has been sailing against the wind. Sometimes we were struggling for compute and it was getting harder and harder to get this crucial research done.
Building smarter-than-human machines is an inherently dangerous endeavor.
OpenAI is shouldering an enormous responsibility on behalf of all of humanity.
But over the past years, safety culture and processes have taken a backseat to shiny products.
We are long overdue in getting incredibly serious about the implications of AGI.
We must prioritize preparing for them as best we can.
Only then can we ensure AGI benefits all of humanity.
OpenAI must become a safety-first AGI company.
To all OpenAI employees, I want to say:
Learn to feel the AGI.
Act with the gravitas appropriate for what you’re building.
I believe you can “ship” the cultural change that’s needed.
I am counting on you.
The world is counting on you.
:openai-heart:
This paints a very clear picture, although with conspicuous absence of any reference to Altman. The culture of OpenAI had indeed become toxic, and unwilling to take safety seriously.
This is a deeply polite version of ‘We’re f***ed.’
Leike’s team was starved for compute, despite the commitments made earlier.
OpenAI was, in his view, severely underinvesting in both Superalignment and also more mundane forms of safety.
Safety culture took a backseat to shiny new products (presumably GPT-4o was one of these).
According to Bloomberg, Ilya’s departure was Jan’s last straw.
TechCrunch confirms that OpenAI failed to honor its compute commitments.
Kyle Wiggers (TechCrunch): OpenAI’s Superalignment team, responsible for developing ways to govern and steer “superintelligent” AI systems, was promised 20% of the company’s compute resources, according to a person from that team. But requests for a fraction of that compute were often denied, blocking the team from doing their work.
Now the Superalignment team has been dissolved.
I presume that OpenAI would not be so brazen as to go after Jan Leike or confiscate his equity in light of this very respectful and restrained statement, especially in light of other recent statements in that area.
It would be very bad news if this turns out to not be true. Again, note that the threat is stronger than its execution.
Reactions after Leike’s Statement
Roon: i don’t endorse the rest of this thread but yeah [quotes the last Tweet in Jan Leike’s statement, which starts with ‘To all OpenAI employees.’]
Roon is in some ways strategically free and reckless. In other ways, and in times like this he chooses his Exact Words very carefully.
Roon: I
OpenAI.
The last best hope of navigating the golden path to safe superintelligence.
Everyone hates a centrist.
Pager: Mandate of heaven is lost sir.
Roon: Tell it to the sweet sweet research progress.
Others were less Straussian.
Matt Yglesias: Not ideal when a company’s head safety guy quits because he thinks the company is being too reckless.
I hate the rhetoric around “doomers” but all kinds of useful technologies would be really dangerous and harmful if deployed with neither voluntary prudence nor formal regulation.
Vitalik Buterin: I’m really proud that ethereum does not have any culture of trying to prevent people from speaking their minds, even when they have very negative feelings toward major things in the protocol or ecosystem.
Some wave the ideal of “open discourse” as a flag, some take it seriously.
Matt Shumer: Wow. This is huge. The first time (I’m aware of) that an OpenAI exec has publicly stated that they believe OpenAI is clearly prioritizing capabilities over safety research. Massive implications, in many ways.
Wei Dei: I was thinking about writing an AI Alignment Forum post titled “Top signs your alignment work is being exploited for safety-washing” but somehow that feels less urgent now.
David Chapman:
This may be a historically important thread (or not). The head of safety at OpenAI has quit, saying that the company’s leadership is not taking safety seriously enough.
Tetraspace: How could I operationalise “OpenAI will have a notkilleveryoneism team with any influence at all by the end of 202X”?
One read of the situation is Altman and some OpenAI employees have non-tiny probabilities of extinction, and don’t want to die, but OpenAI-the-egregore doesn’t want to hear disappointing news, and Altman’s one trick is hardline corporate manipulator.
So they end up hiring a notkilleveryoneism team, being disappointed by all the bad news they’re hearing, marginalizing them, and then the leadership and main talent of that team leaves in frustration.
In this world, perhaps they try again, with some new governance structure, which makes their NKEism team feel more powerful but able to less of what would offend OpenAI; or perhaps they finally rationalise away this error signal – how silly we were before we learned RLHF worked.
Sarah (Little Ramblings): OpenAI quietly shuts down the effort they established less than a year ago to ensure that their own technology doesn’t literally kill everyone on earth, and prioritises developing said technology faster. It’s days like this what I feel almost frustrated to tears at the fact that this isn’t all anyone in the world is talking about.
Connor Leahy: Props to Jan [Leike] for speaking out and confirming what we already suspected/knew.
From my point of view, of course profit maximizing companies will…maximize profit. It never was even imaginable that these kinds of entities could shoulder such a huge risk responsibly.
And humanity pays the cost.
Greg Brockman and Sam Altman Respond to Leike
Altman initially responded with about the most graceful thing he could have said (in a QT). This is The Way provided you follow through.
Sam Altman: I’m super appreciative of @janleike’s contributions to OpenAI’s alignment research and safety culture, and very sad to see him leave. he’s right we have a lot more to do; we are committed to doing it. I’ll have a longer post in the next couple of days.

A few days to process all this and prepare a response is a highly reasonable request.
So what did they come back with?
Here is the full statement.
Greg Brockman and Sam Altman (cosigned): We’re really grateful to Jan for everything he’s done for OpenAI, and we know he’ll continue to contribute to the mission from outside. In light of the questions his departure has raised, we wanted to explain a bit about how we think about our overall strategy.
First, we have raised awareness of the risks and opportunities of AGI so that the world can better prepare for it. We’ve repeatedly demonstrated the incredible possibilities from scaling up deep learning and analyzed their implications; called for international governance of AGI before such calls were popular; and helped pioneer the science of assessing AI systems for catastrophic risks.
Second, we have been putting in place the foundations needed for safe deployment of increasingly capable systems. Figuring out how to make a new technology safe for the first time isn’t easy. For example, our teams did a great deal of work to bring GPT-4 to the world in a safe way, and since then have continuously improved model behavior and abuse monitoring in response to lessons learned from deployment.
Third, the future is going to be harder than the past. We need to keep elevating our safety work to match the stakes of each new model. We adopted our Preparedness Framework last year to help systematize how we do this.
This seems like as good of a time as any to talk about how we view the future.
As models continue to become much more capable, we expect they’ll start being integrated with the world more deeply. Users will increasingly interact with systems — composed of many multimodal models plus tools — which can take actions on their behalf, rather than talking to a single model with just text inputs and outputs.
We think such systems will be incredibly beneficial and helpful to people, and it’ll be possible to deliver them safely, but it’s going to take an enormous amount of foundational work. This includes thoughtfulness around what they’re connected to as they train, solutions to hard problems such as scalable oversight, and other new kinds of safety work. As we build in this direction, we’re not sure yet when we’ll reach our safety bar for releases, and it’s ok if that pushes out release timelines.
We know we can’t imagine every possible future scenario. So we need to have a very tight feedback loop, rigorous testing, careful consideration at every step, world-class security, and harmony of safety and capabilities. We will keep doing safety research targeting different timescales. We are also continuing to collaborate with governments and many stakeholders on safety.
There’s no proven playbook for how to navigate the path to AGI. We think that empirical understanding can help inform the way forward. We believe both in delivering on the tremendous upside and working to mitigate the serious risks; we take our role here very seriously and carefully weigh feedback on our actions.
My initial response was: “I do not see how this contains new information or addresses the concerns that were raised?”
Others went further, and noticed this said very little.
This did indeed feel like that part of Isaac Asimov’s Foundation, where a diplomat visits and everyone thinks he is a buffoon, then after he leaves they use symbolic logic to analyze his statements and realize he managed to say exactly nothing.
So I had a fun conversation where I asked GPT-4o, what in this statement was not known as of your cutoff date? It started off this way:
Then I shared additional previously known information, had it browse the web to look at the announcements around GPT-4o, and asked, for each item it named, whether there was new information.
Everything cancelled out. Link has the full conversation.

And then finally:

Reactions from Some Folks Unworried About Highly Capable AI
Colin Fraser: Right, yeah, like I said.
I happen to know for a fact that OpenAI does invest some amount in keeping its products “safe” in the sense of mitigating abuse and harmful output but I just don’t think they have the resources to float basic research into ill-defined science fiction scenarios.
It does put them in a bit of a pickle though because “the science fiction scenario is real” is a core part of their public messaging. What they need is a Superalignment figurehead to signal that they take it seriously but who won’t demand a billion dollars to play the sims.
I also do think things have fundamentally shifted since ChatGPT blew up. I think if you asked three years ago under truth serum what they’re trying to do it would be “build AGI” but today it would be “sell access to ChatGPT.”
The sad irony is without the early Superalignment research ChatGPT couldn’t exist.
Note the distinction between Colin’s story here, that OpenAI lacks the resources to do basic research, and his previous claim that a culture clash makes it effectively impossible for OpenAI to do such research. Those stories suggest different problems with different solutions.
‘OpenAI does not have sufficient resources’ seems implausible given their ability to raise capital, and Leike says they’re severely underinvesting in safety even on business grounds over a two year time horizon. A culture clash or political fight fits the facts much better.
Ben Landau-Taylor: Safetyists purging their factional rivals: Haha fuck yeah!!! Yes!! Safetyists being purged by their factional rivals: Well this fucking sucks. What the fuck.
[Quotes himself showing two forum comments with the names redacted saying that if Altman was taking OpenAI in an unsafe direction that would endanger humanity (a point both made clear was a fully conditional statement) then that would be a good reason to fire him.]
So there are outsiders who want work done on safety and many of them think endangering humanity would have been a good justification, if true, for firing the CEO? And that makes it good to purge everyone working on safety? Got it.
Timothy Lee: I’m not worried about existential risk from AI and didn’t understand what the superalignment team was doing so I wouldn’t say I’m upset about this. But given that @sama purports to be concerned about X-risk, it would be nice to hear from him about it.
Like has he decided that AI isn’t dangerous? Does he still think it was dangerous but the superalignment team had the wrong approach? Did he think it was being badly managed? If he is still worried is he going to take the resources from the old team into some new effort?
Good questions, even if like Timothy you are skeptical of the risks.
Don’t Worry, Be Happy?
How bad can it be if they’re not willing to violate the NDAs, asks Mason.
Mason: People are freaking out about the Ilya/Jan resignations like the obvious thing anyone would do if their company was about to
destroy
humanity
is resign and post cryptic tweets about it.
I’m not saying it’s a nothingburger.
But I am saying that public-but-cryptic resignations are obviously getting these very intelligent guys more bang for their buck than violating their NDAs and I don’t think that’s compatible with the idea that we’re all about to die.
(and yeah, I do think it’s a nothingburger).
This follows in the tradition of people saying versions of:
- If you were truly worried about this you would blow up your life and savings, in this way that I say would make sense, despite all explanations why it doesn’t.
- You didn’t.
- So clearly you are not worried.
- Nothing to worry about.
- You did.
- So clearly you are an idiot.
- Nothing to worry about.
- You didn’t.
Classic versions of this include ‘are you short the market?’ ‘why are you not borrowing at terrible interest rates?’ and ‘why haven’t you started doing terrorism?’
Here is an example from this Saturday. This is an ongoing phenomenon. In case you need a response, here are On AI and Interest Rates (which also covers the classic ‘the market is not predicting it so it isn’t real’) and AI: Practical Advice for the Worried. I still endorse most of that advice, although I mostly no longer think ‘funding or working on any AI thing at all’ is still a major vector for AI acceleration, as long as something is unrelated to core capabilities.
Other favorites include all variations of both ‘why are you taking any health risks [or other consequences]’ and ‘why are you paying attention to your long term health [or other consequences].’
Maybe half the explanation is embodied in this very good two sentences:
Cate Hall: [That] statement makes sense if you reject the idea of probabilistic beliefs. I don’t know many wise people who do that.
Then the next day Jan Leike got a lot less cryptic, as detailed above.
Then we found out it goes beyond the usual NDAs.
The Non-Disparagement and NDA Clauses
Why have we previously heard so little from ex-employees?
Short of forfeiting their equity, OpenAI employees are told they must sign extremely strong NDAs and non-disparagement agreements, of a type that sets off alarm bells. Then you see how they mislead and threaten employees to get them to sign.
Kelsey Piper: It turns out there’s a very clear reason for that. I have seen the extremely restrictive off-boarding agreement that contains nondisclosure and non-disparagement provisions former OpenAI employees are subject to. It forbids them, for the rest of their lives, from criticizing their former employer. Even acknowledging that the NDA exists is a violation of it.
Equity is part of negotiated compensation; this is shares (worth a lot of $$) that the employees already earned over their tenure at OpenAI. And suddenly they’re faced with a decision on a tight deadline: agree to a legally binding promise to never criticize OpenAI, or lose it.
Employees are not informed of this when they’re offered compensation packages that are heavy on equity. Vague rumors swirl, but many at OpenAI still don’t know details. The deal also forbids anyone who signs from acknowledging the fact that the deal exists.
This isn’t just a confidentiality agreement (that is normal). It prohibits disparaging comments made from public information. A former employee could potentially be in violation if they told a friend that they thought OpenAI’s latest public research paper was low-quality.
OpenAI’s leadership likes to talk about their commitment to democratic governance and oversight. It’s hard to take them seriously when they’re springing a surprise of this magnitude on former employees in order to shut down conversations about the company.
I am grateful for the courage of the ex-employees who under a lot of pressure and at significant personal cost shared the evidence of this situation.
Soumith Chintala (May 17, 3:14pm): Holding your (already earned) stock compensation hostage over signing a non-disparagement clause is **not** normal. IMO its pretty sketchy and sleazy. Its sleazier when a super-majority of your compensation comes in the form of stock (like at OpenAI).
Is this confirmed and real?
Soumith Chintala (May 17 7:30pm): I got confirmation from multiple ex-OpenAI folks that this is true, and that’s why they don’t say anything negative about their experience.
Matt Bruenig: If this is you, hire me.
If this was me, and I was a current or former OpenAI employee, I would absolutely, at minimum, consult a labor lawyer to review my options.
How are they doing it? Well, you see…
Evan Hubinger: Here’s the full answer—looks like it’s worse than I thought and the language in the onboarding agreement seems deliberately misleading.
Kelsey Piper: I’m getting two reactions to my piece about OpenAI’s departure agreements: “that’s normal!” (it is not; the other leading AI labs do not have similar policies) and “how is that legal?” It may not hold up in court, but here’s how it works:
OpenAI like most tech companies does salaries as a mix of equity and base salary. The equity is in the form of PPUs, ‘Profit Participation Units’. You can look at a recent OpenAI offer and an explanation of PPUs here.
Many people at OpenAI get more of their compensation from PPUs than from base salary. PPUs can only be sold at tender offers hosted by the company. When you join OpenAI, you sign onboarding paperwork laying all of this out.
And that onboarding paperwork says you have to sign termination paperwork with a ‘general release’ within sixty days of departing the company. If you don’t do it within 60 days, your units are canceled. No one I spoke to at OpenAI gave this little line much thought.

- Release of Claims: If the Grantee becomes a Withdrawn Limited Partner, then unless, within 60 days following its applicable Withdrawal Event, the Grantee (or, if the Grantee has become a Withdrawn Limited Partner in consequence of death or Permanent Incapacity, such Withdrawn Limited Partner’s estate, custodian or other legal representative or successor) duly executes and delivers to the Partnership a general release of claims against the Partnership and the other Partners with regard to all matters relating to the Partnership up to and including the time of such Withdrawal Event, such Grantee’s Units shall be cancelled and reduced to zero (0) effective as of the date of the Withdrawal Event, as set forth in Section 7.5(c) of the Partnership Agreement.
- Removal for Cause. If the Grantee becomes a Withdrawn Limited Partner pursuant to Section 7.3(b) of the Partnership Agreement in response to an action or omission on the part of such Limited Partner that constitutes Cause, then such Grantee’s Units shall be cancelled and reduced to zero (0) effective as of the date of the Withdrawal Event, as set forth in Section 7.5(d) of the Partnership Agreement.
Kelsey Piper: And yes this is talking about vested units, because a separate clause clarifies that unvested units just transfer back to the control of OpenAI when an employee undergoes a termination event (which is normal).
There’s a common legal definition of a general release, and it’s just a waiver of claims against each other. Even someone who read the contract closely might be assuming they will only have to sign such a waiver of claims.
But when you actually quit, the ‘general release’? It’s a long, hardnosed, legally aggressive contract that includes a confidentiality agreement which covers the release itself, as well as arbitration, nonsolicitation and nondisparagement and broad ‘noninterference’ agreement.
And if you don’t sign within sixty days your units are gone. And it gets worse – because OpenAI can also deny you access to the annual events that are the only way to sell your vested PPUs at their discretion, making ex-employees constantly worried they’ll be shut out.
Finally, I want to make it clear that I contacted OpenAI in the course of reporting this story. So did my colleague Sigal Samuel. They had every opportunity to reach out to the ex-employees they’d pressured into silence and say this was a misunderstanding. I hope they do.
Clause four was the leverage. Have people agree to sign a ‘general release,’ then have it include a wide variety of highly aggressive clauses, under threat of loss of equity. Then, even if you sign it, OpenAI has complete discretion to deny you any ability to sell your shares.
Note clause five as well. This is a second highly unusual clause in which vested equity can be canceled. What constitutes ‘cause’? Note that this is another case where the threat is stronger than its execution.
One potential legal or ethical justification for this is that these are technically ‘profit participation units’ (PPUs) rather than equity. Perhaps one could say that this was a type of ‘partnership agreement’ for which different rules apply, if you stop being part of the team you get zeroed.
But notice Sam Altman has acknowledged, in the response we will get to below, that this is not the case. Not only does he claim no one has had their vested equity confiscated, he then admits that there were clauses in the contracts that refer to the confiscation of vested equity. That is an admission that he was, for practical purposes, thinking of this as equity.
Legality in Practice
So the answer to ‘how is this legal’ is ‘it probably isn’t, but how do you find out?’
Ravi Parikh: In the same way that California (and now the US) made noncompetes illegal, holding already-earned compensation hostage is another anticompetitive business practice that should be shut down.
Sanjay: I think using vested equity as hostage is fairly common, just not like this. The more common way to hold people hostage is with the 90 day exercise window and preventing employees from selling secondaries.
Ravi Parikh: 90 day exercise window is a side effect of the law, which does hurt employees but it’s not explicitly a choice companies make. Companies can extend it to 10 years by converting the type of option, which we did at my startup Heap.
Garrison Lovely: Perhaps this is a dumb question, but why do non-disparagement agreements exist? Like what is the moral case for them?
They seem fundamentally in tension with having a free and democratic society. If someone says false, damaging things about you, there are already options.
(I get why they actually exist — being able to buy silence is very valuable to those in power!)
Overly broad non-disparagement clauses (such as ‘in any way for the rest of your life’) can be deemed unenforceable in court, as unreasonable restraints on speech. Contracts for almost anything can be void if one party was not offered consideration, as is plausibly the case here. There are also whistleblower and public policy concerns. And the timing and context of the NDA and especially non-disparagement clause, where the employee did not know about them, and tying them to a vested equity grant based on an at best highly misleading contract clause, seems highly legally questionable to me, although of course I am not a lawyer and nothing here is legal advice.
Certainly it would seem bizarre to refuse to enforce non-compete clauses, as California does and the FTC wants to do, and then allow what OpenAI is doing here.
Implications and Reference Classes
A fun and enlightening exercise is to ask LLMs what they think of this situation, its legality and ethics and implications, and what companies are the closest parallels.
The following interaction was zero shot. As always, do not take LLM outputs overly seriously or reliably:
(For full transparency: Previous parts of conversation at this link, I quoted Kelsey Piper and then ask ‘If true, is what OpenAI doing legal? What could an employee do about it’ then ‘does it matter that the employee has this sprung upon them on departure?’ and then ‘same with the non-disparagement clause?’ in terms of whether I am putting my thumb on the scale.)

I pause here because this is a perfect Rule of Three, and because it then finishes with In-N-Out Burger and Apple, which it says use strict NDAs but are not known to use universal non-disparagement agreements.

Claude did miss at least one other example.
Jacques: True, but taking away *vested equity* is so uncommon, I don’t see how you just stumble into writing that in but idk
.
And by uncommon I mean this is the first time people have noticed it at any company, so potentially so rare it’s a first.
Kelsey Piper: TikTok also does this. They were the only other major company with similar behavior I found while trying to determine how irregular this was. Skype also once criticized/sued for something sort of similar.
Kajota: Could be worse. It could be Boeing. I hear their NDA is deadly strict.
At a minimum, this practice forces us to assume the worst, short of situations so dire a threat to humanity that caution would in practice be thrown to the wind.
Seán Ó hÉigeartaigh: In 2019/2020, we and many others worked with OpenAI researchers on workshops and a report focused on moving ” beyond principles to a focus on mechanisms for demonstrating responsible behavior.” The workshops explored importance of whistleblowing.
The report highlights “Employees within organizations developing AI systems can play an important role in identifying unethical or unsafe practices. For this to succeed, employees must be well-informed about the scope of AI development efforts within their organization, and be comfortable raising their concerns, and such concerns need to be taken seriously by management. Policies that help ensure safe channels for expressing concerns are thus key foundations for verifying claims about AI development being conducted responsibly.
The goals OpenAI and others have set themselves require solving major problems and risks. Doing so safely means being careful to make it possible to raise concerns, ask for (and justify need for) help, and yes, even criticise where warranted.
It seems the only way to approach such a high-stakes challenge responsibly. I struggle to imagine anything more antithetical to those discussions than punitive NDAs that so heavily penalise staff who might want to raise such concerns; after those staff have apparently failed to resolve these matters internally with management. I’m shaken by this reporting, and I hope there is something I don’t know that can explain it.
Adam Gleave: A non-disparagement agreement that is itself subject to a non-disclosure agreement that you are only informed of when leaving the company is completely wild. I can’t think of any other tech company that does anything like that, let alone a tech non-profit.
Neel Nanda: Oh, I heard that that was standard?
Kevin Lacker: No, it’s pretty unusual, how the initial contract has “when I leave I will sign a general release.” And then the general release has other stuff in it. It seems…sneaky. What is common is to offer a severance package in return for signing nondisparagement, etc.
Neel Nanda: Sorry – the whole thing is sneaky as fuck, I’m outraged. But specifically a non disparagement stopping you talking about the non disparagement is fairly standard, as far as I’m aware (though I think it’s awful and should not be).
Kevin Lacker: I dunno, the whole point of non disparagement is that you are getting paid to publicly support the company. If you don’t want to publicly support the company, don’t sign the non disparagement agreement. IMO the only uncool part is to “submarine” the agreement.
Neel Nanda (other thread, minutes later): I think this is absolutely outrageous behaviour from OpenAI, and far outside my understanding of industry norms. I think anyone considering joining OpenAI should think hard about whether they’re comfortable with this kind of arrangement and what it implies about how employees are treated.
My sympathies go to any OpenAI employees or recent departures trapped by this kind of malpractice.
To be fair, the whole point of these setups is the public is not supposed to find out.
That makes it hard to know if the practice is widespread.
Sampat: Every company I’ve worked at had an NDA, intention assignment, noncompete and non disparagement built into the offer letter. Can’t violate any of it.
Kelsey Piper: Built into the offer letter seems much more common and more ethical than “sprung on you at departure for the consideration of already earned equity.”
Alex Covo: This might not be “normal” but I had to sign one. Sam is a VC/Banker. They have lawyers and minions to threaten and sue you into oblivion. They don’t care. It seems like a lot of the academic researchers, engineers and scientist aren’t familiar with this tactic. Welcome to Wall Street mentality. Has nothing to do with humanity, science, etc. Just protecting your investment. It’s all about the Benjamins.
Linch: “I had to sign one.”
How are you able to talk about it then?
Exactly. The non-disparagement agreement that can be discussed is not the true fully problematic non-disparagement agreement.
Rob Bensinger offers a key distinction, which I will paraphrase for length:
It is wise and virtuous to have extraordinarily tight information security practices around IP when building AGI. If anything I would worry that no company is taking sufficient precautions. OpenAI being unusually strict here is actively a feature.
This is different. This is allowing people to say positive things but not negative things, forever, and putting a high priority on that. That is deception, that is being a bad actor, and it provides important context to the actions of the board during the recent dispute.
Also an important consideration:
Pearl: Honestly, I think if I were one of the ex OpenAI employees it wouldn’t be the fear of losing my equity holding me back from whistleblowing so much as fear of Sam Altman himself.
Kelsey Piper: This was 100% a thing among many of the people I spoke to.
Altman Responds on Non-Disparagement Clauses
Sam Altman (May 18, 5pm Eastern): In regards to recent stuff about how OpenAI handles equity:
We have never clawed back anyone’s vested equity, nor will we do that if people do not sign a separation agreement (or don’t agree to a non-disparagement agreement). Vested equity is vested equity, full stop.
There was a provision about potential equity cancellation in our previous exit docs; although we never clawed anything back, it should never have been something we had in any documents or communication. This is on me and one of the few times I’ve been genuinely embarrassed running OpenAI; I did not know this was happening and I should have.
The team was already in the process of fixing the standard exit paperwork over the past month or so. If any former employee who signed one of those old agreements is worried about it, they can contact me and we’ll fix that too. Very sorry about this.
So, About That Response
Three things:
- Thank you for acknowledging this happened and promising to fix it.
- This is insufficient until you legally release all former employees and return all equity to Daniel Kokotajlo [LW(p) · GW(p)] (or confirm his equity is intact and will stay that way.)
- You’re shock, shocked to find gambling in this establishment? Bullshit.
As in:
Kelsey Piper: I am glad that OpenAI acknowledges this as an embarrassment, a mistake, and not okay. It’s in their power to set right by releasing everyone who was threatened with loss of equity from the NDAs they signed under this threat.
Kelsey Piper: I’ve talked to a lot of former employees and they want an unambiguous “we’re sorry, you’re free of the agreement, and you can sell your equity at the next tender offering.” And this seems like a reasonable thing for them to want.
And as in:

Jonathan Mannhart: I know that I’m the person in charge and it’s my responsibility
and that we threatened ex-employees, but
I really didn’t know we did this, and…
Yes, I know it’s also my responsibility to know we did that… but come on, guys… we’re all trying to find the culprit here.
We were totally gonna change this just like… now. I mean last month already. We did not do this. I mean we did not MEAN to do this, especially because… it’s maybe illegal in some ways? But how would I know! I didn’t know!
Also, trust me, ok? Thanks. Very sorry this happened.
Alex Lawson: If I had made an embarrassing ‘mistake’ where I accidentally allowed people to be pressured into never being able to say bad things about me, I would be quite a lot more proactive about rectifying it than saying that they could individually ask me to undo it.
Naia: It’s OK, everyone. Mr. Not Consistently Candid says the whole thing was an oopsie, and that he’ll fix things one-by-one for people if they contact him privately. Definitely nothing to worry about, then. Carry on.
At some point, y’all are gonna have to learn that when people tell you someone lies as easy as he breathes, you have to start assuming things he says might be lies.
This shit is SBF all over again. Everyone knows it’s SBF all over again, and people are somehow still falling for it.
This is getting retweeted, so context for people who don’t know me: I worked with SBF in early 2018, warned people then that he was a pathological liar and sociopath, and watched as everyone made excuses for him. I’m not drawing the comparison lightly. This is the exact same shit.
Holly Elmore: *palm to forehead* “So THAT’S why no former employees were speaking out! It all makes sense now.”
Keller Scholl: Extreme chutzpah to post this only after the negative backlash, as opposed to fixing immediately when Vox contacted OpenAI.

I do want to acknowledge that:
- Being a CEO of a company like OpenAI is overwhelming.
- You cannot be fully on top of everything or read every legal document.
- Many lawyers consider it their job to make all contracts as one sided as possible.
But, here, in this case, to this extent? C’mon. No.
I asked around. These levels of legal silencing tactics, in addition to being highly legally questionable, are rare and extreme, used only in the most cutthroat of industries and cases, and very much not the kind of thing lawyers sneak in unrequested unless you knew exactly which lawyers you were hiring.
Why has confiscation not happened before? Why hadn’t we heard about this until now?
Because until Daniel Kokotajlo everyone signed.
Kelsey Piper: OpenAI says that in no cases have they actually stripped someone of their vested equity. Ex-employees aren’t impressed. “Before Daniel K I don’t know of a single person who hasn’t signed,” a person close to the company told me. “Because they did in fact threaten you had to sign.”
Easy to not strip anyone of their equity if they all sign rather than risk it! OpenAI also says that going forward, they *won’t* strip anyone of their equity for not signing the secret NDA, which is a bigger deal. I asked if this was a change of policy.
“This statement reflects reality”, replied OpenAI’s spokesperson. To be fair it’s a Friday night and I’m sure she’s sick of me. But I have multiple ex-employees confirming this, if true, would be a big change of policy, presumably in response to backlash from current employees.
Oliver Habryka: Will they also invalidate or promise not to sue anyone who is now violating the agreements that were signed under pressure? That seems like the natural conclusion of what’s going on.
Anna Salamon: This is a great question. Seems like the right angle for a public protest. Holly Elmore?
Kelsey Piper: I asked “Does OpenAI intend to hold them to those agreements? Would OpenAI sue them if they show me the agreements?” and got “you have our statement. Thanks.”
Oliver Habryka: …I wonder whether OpenAI claiming that this was always their policy might invalidate all past contracts by removing any remaining consideration. Like, if you got to keep the equity anyway, what’s the consideration for the employee who leaves?
Sawyer: Not trying to sound confident, but I’ve noticed before in other domains that it’s not too uncommon for a question like this to come down to “they have a solid theoretical argument but that doesn’t translate to a high degree of confidence in a corresponding outcome in court.”
So you can get a sort of backward-chaining effect, where someone has a legal right on paper, and it’s *theoretically* enforceable, but between the expense and the risk nobody wants to try.
Which in turn makes actually-exercising the right weirder and less of a standard thing to do, which people intuit makes attempting to exercise the right even riskier.
The harm is not the equity. The harm is that people are forced to sign and stay silent.
Kelsey Piper: Sam Altman now says “I did not know this was happening and I should have.” about employees being threatened with loss of their vested equity if they don’t sign a restrictive separation agreement. Sam Altman, will you void the restrictive separation agreement that ex-employees signed?
Andrew Rettek: good that he’s saying this. that they never actually clawed back anyone’s equity is a far way from *no harm was done” and a radical restriction like you reported on is very likely because someone did something bad
Maddie: He thinks he can say it’s okay because “we never actually used it”. It’s the threat that counted; the fact that you didn’t use it means the threat worked.
He thinks we’ll believe him if he says he didn’t know. How could that possibly be true?
Eli Tyre: It’s not that it’s consequentially worse, necessarily. It’s that it’s very legibly OAI doing something against the interests of the world.
People differ about the level of risk and the social benefits of AGI.
Setting the incentives to make it harder for your employees to whistleblow on you, using non-standard legal arrangements, is more obviously a defection against the world than building maybe-risky tech.
The thing that’s bad here is not mainly that, say, Daniel has less money than he would otherwise, it’s that OpenAI is exerting pretty strong pressure to control the information flow about the technology that they explicitly state is world transformative.
None of this is okay.
How Bad Is All This?
I think it is quite bad.
It is quite bad because of the larger pattern. Sutskever’s and Leike’s departures alone would be ominous but could be chalked up to personal fallout from the Battle of the Board, or Sutskever indeed having an exciting project and taking Leike with him.
I do not think we are mostly reacting to the cryptic messages, or to the deadening silences. What we are mostly reacting to is the costly signal of leaving OpenAI, and that this cost has now once again been paid by so many of its top safety people and a remarkably large percentage of all its safety employees.
We are then forced to update on the widespread existence of NDAs and non-disparagement agreements—we are forced to ask, what might people have said if they weren’t bound by NDAs or non-disparagement agreements?
The absence of evidence from employees speaking out, and except for those by Geoffrey Irving the lack of accusations of outright lying, no longer seem like strong evidence of absence. And indeed, we now have at least a number of (anonymous) examples of ex-employees saying they would have said concerning things, but aren’t doing so out of fear.
Yes, if the departing people thought OpenAI was plausibly about to destroy humanity in the near future due to a specific development, they would presumably break the NDAs, unless they thought it would not do any good. So we can update on that.
But that is not the baseline scenario we are worried about. We are worried that OpenAI is, in various ways and for various reasons, unlikely to responsibly handle the future creation and deployment of AGI or ASI. We are worried about a situation in which the timeline to the critical period is unclear even to insiders, so there is always a large cost to pulling costly alarms, especially in violation of contracts, including a very high personal cost. We are especially worried that Altman is creating a toxic working environment at OpenAI for those working on future existential safety, and using power plays to clean house.
We also have to worry what else is implied by OpenAI and Altman being willing to use such rare highly deceptive and cutthroat legal tactics and intimidation tactics, and how they handled the issues once brought to light.
At minimum, this shows a company with an extreme focus on publicity and reputation management, and that wants to silence all criticism. That already is anathema to the kind of openness and truth seeking we will need.
It also in turn suggests the obvious question of what they are so keen to hide.
We also know that the explicit commitment to the Superalignment team of 20% of current compute was not honored. This is a very bad sign.
If OpenAI and Sam Altman want to fix this situation, it is clear what must be done as the first step. The release of claims must be replaced, including retroactively, by a standard release of claims. Daniel’s vested equity must be returned to him, in exchange for that standard release of claims. All employees of OpenAI, both current employees and past employees, must be given unconditional release from their non-disparagement agreements, all NDAs modified to at least allow acknowledging the NDAs, and all must be promised in writing the unconditional ability to participate as sellers in all future tender offers.
Then the hard work can begin to rebuild trust and culture, and to get the work on track.
Those Who Are Against These Efforts to Prevent AI From Killing Everyone
Not everyone is unhappy about these departures.
There is a group of people who oppose the idea of this team, within a private company, attempting to figure out how we might all avoid a future AGI or ASI killing everyone, or us losing control over the future, or other potential bad outcomes. They oppose such attempts on principle.
To be clear, it’s comprehensible to believe that we should only engage in private preventative actions right now, either because (1) there is no worthwhile government action that can be undertaken at this time, or because (2) in practice, government action is likely to backfire.
I strongly disagree with that, but I understand the viewpoint.
It is also not insane to say people are overreacting to the new information.
This is something else. This is people saying: “It is good that a private company got rid of the people tasked with trying to figure out how to make a future highly capable AI do things we want it to do instead of things we do not want it to do.”
There is a reduction in voluntary private safety efforts. They cheer and gloat.
This ranges from insane but at least in favor of humanity…
Matinusdissèque.eth: You’re losing. Just accept it man. We must continue to safely and incrementally accelerate!
…to those who continue to have a false idea of what happened when the board attempted to fire Altman, and think that safety is a single entity, so trying not to die is bad now…
Stefano Fait: Good, they almost killed the company.
…to those who (I think correctly) think OpenAI’s specific approach to safety wouldn’t work, and who are modeling the departures and dissolution of the Superalignment team as a reallocation to other long term safety efforts as opposed to a move against long term (and also short term) safety efforts in general…
Gallabytes: so tbh I think this is probably good – imo “superalignment” and “weak to strong generalization” are terrible frames for how to control neural systems, and I’m happy to see those resources go elsewhere.
…to those who dismiss all such concerns as ‘sci-fi’ as if that is an argument…
Colin Fraser (before Leike’s thread): Maybe “what they saw” is that having a large division dedicated to science fiction larping is not actually conducive to running a business and that causes irreconcilable tension with the people who are trying to make money.
I think there is good work to do on alignment by which I mean getting the chat bot to more frequently output text that is aesthetically aligned with the company’s objectives but not really on superalignment by which I mean imagining a guy to be scared of.
…to those who consider this a problem for Future Earth and think Claude Opus is dumber than a cat…
Yann LeCun: It seems to me that before “urgently figuring out how to control AI systems much smarter than us” we need to have the beginning of a hint of a design for a system smarter than a house cat.
Such a sense of urgency reveals an extremely distorted view of reality. No wonder the more based members of the organization seeked to marginalize the superalignment group.
It’s as if someone had said in 1925 “we urgently need to figure out how to control aircrafts that can transport hundreds of passengers at near the speed of the sound over the oceans.”
…
It will take years for them to get as smart as cats, and more years to get as smart as humans, let alone smarter (don’t confuse the superhuman knowledge accumulation and retrieval abilities of current LLMs with actual intelligence).
…to those who are in favor of something else entirely and want to incept even more of it.
Based Beff Jezos: OpenAI all-in on e/acc confirmed.
What Will Happen Now?
Jakub Pachocki will replace Ilya as Chief Scientist.
The Superalignment team has been dissolved (also confirmed by Wired).
John Schulman will replace Jan Leike as head of AGI related safety efforts, but without a dedicated team. Remaining members have been dispersed across various research efforts.
We will watch to see how OpenAI chooses to handle their non-disparagement clauses.
What Else Might Happen or Needs to Happen Now?
One provision of the proposed bill SB 1047 is whistleblower protections. This incident illustrates why such protections are needed, whatever one thinks of the rest of the bill.
This also emphasizes why we need other transparency and insight into the actions of companies such as OpenAI and their safety efforts.
If you have information you want to share, with any level of confidentiality, you can reach out to me on Twitter or LessWrong or otherwise, or you can contact Kelsey Piper whose email is at the link, and is firstname.lastname@vox.com.
If you don’t have new information, but do have thoughtful things to say, speak up.
As a canary strategy, consider adding your like to this Twitter post to indicate that (like me) you are not subject to a non-disparagement clause or a self-hiding NDA.
Everyone needs to update their views and plans based on this new information. We need to update, and examine our past mistakes, including taking a hard look at the events that led to the founding of OpenAI. We should further update based on how they deal with the NDAs and non-disparagement agreements going forward.
The statements of anyone who worked at OpenAI at any point need to be evaluated on the assumption that they have signed a self-hiding NDA and a non-disparagement clause. Note that this includes Paul Christiano and Dario Amodei [LW(p) · GW(p)]. There have been notes that Elon Musk has been unusually quiet, but if he has a non-disparagement clause he’s already violated it a lot.
Trust and confidence in OpenAI and in Sam Altman has been damaged, especially among safety advocates and the worried. Also across the board given the revelations about the non-disparagement provisions. The magnitude remains to be seen.
Will there be consequences to ability to raise capital? In which direction?
Wei Dei: OpenAI relies a lot on external capital/support, and recent events hopefully mean that others will now trust it less so it’s less likely to remain a leader in the AI space. What is x-safety culture like at other major AI labs, especially Google DeepMind?
Inspect Element Capital: I think that’s the opposite. Why would you invest in a company that ties their own hands because of some nebulous beliefs in AI safety? Getting rid of this means they will now advance quicker.
Wei Dei: I was thinking about what the episodes reveal about SamA’s character, but you’re right that it could also make some people more likely to invest in OpenAI. I said “hopefully” suggesting that maybe the former would outweigh the latter.
Most large investors do not care about ethics. They care about returns. Nor do they in practice care much about how likely a company is to kill everyone. Credibly signaling that you will not pay to produce badly needed public goods, and that you will be ruthless and do what it takes, that you are willing to at least skirt with the edges of the law and employ highly deceptive practices, and are orienting entirely around profits, near term results and perhaps building a business? By default these are all very good for the stock price and for talking to venture capital.
The flip side is that past a certain point such actions are highly indicative of a company and leader likely to blow themselves up in the not too distant future. Such tactics strongly suggest that there were things vital enough to hide that such tactics were deemed warranted. The value of the hidden information is, in expectation, highly negative. If there is a public or government backlash, or business partners stop trusting you, that is not good.
There is also the issue of whether you expect Altman to honor his deal with you, including if you are an employee. If you sign a business deal with certain other individuals we need not name, knowing what we know about them now, and they as is their pattern refuse to honor it and instead attempt to cheat and sue and lie about you? That is from my perspective 100% on you.
Yet some people still seem eager to get into business with them, time and again.
OpenAI says roughly to ‘look upon your investment as something akin to a donation.’ When you invest in Sam Altman, you are risking the world’s largest rug pull. If they never earn a dollar because they are fully serious about being a non-profit, and you will get no money and also no voice, then you better find a greater fool, or you lose. If instead Altman and OpenAI are all about the money, boys, that is good news for you until you are the one on the other end.
There is also the issue that cutting this work is not good business. If this was all merely ‘OpenAI was toxic to and lost its long term safety teams forcing others to do the work’ then, sure, from one angle that’s bad for the world but also good hard nosed business tactics. Instead, notice that Jan Leike warned that OpenAI is not ready for the next generation of models, meaning GPT-5, meaning this is likely an issue no later than 2025.
Ideas like weak-to-strong generalization are things I do not expect to work with GPT-9, but I do expect them to likely be highly useful for things like GPT-5. A wise man does not cut the ‘get the AI to do what you want it to do’ department when it is working on AIs it will soon have trouble controlling. When I put myself in ‘amoral investor’ mode, I notice this is not great, a concern that most of the actual amoral investors have not noticed.
My actual expectation is that for raising capital and doing business generally this makes very little difference. There are effects in both directions, but there was overwhelming demand for OpenAI equity already, and there will be so long as their technology continues to impress.
What about employee relations and ability to hire? Would you want to work for a company that is known to have done this? I know that I would not. What else might they be doing? What is the company culture like?
26 comments
Comments sorted by top scores.
comment by Tenoke · 2024-05-20T19:55:19.067Z · LW(p) · GW(p)
Somewhat tangential but when you list the Safety people who have departed, I'd have prefered to see some sort of comparison group or base rate, as it always raises a red flag for me when only the absolute numbers are provided.
I did a quick check by changing your prompt from 'AGI Safety or AGI Alignment' to 'AGI Capabilities or AGI Advancement' and got 60% departed (compared to 70% for AGI Safety by you) with 4o. I do think what we are seeing is alarming but it's too easy for either 'side' to accidentally exagerate via framing if you don't watch for that sort of thing.
comment by Lorxus · 2024-05-20T14:52:17.375Z · LW(p) · GW(p)
If OpenAI and Sam Altman want to fix this situation, it is clear what must be done as the first step. The release of claims must be replaced, including retroactively, by a standard release of claims. Daniel’s vested equity must be returned to him, in exchange for that standard release of claims. All employees of OpenAI, both current employees and past employees, must be given unconditional release from their non-disparagement agreements, all NDAs modified to at least allow acknowledging the NDAs, and all must be promised in writing the unconditional ability to participate as sellers in all future tender offers.
Then the hard work can begin to rebuild trust and culture, and to get the work on track.
Alright - suppose they don't. What then?
I don't think I misstep in positing that we (for however you want to construe "we") should model OAI as - jointly but independently - meriting zero trust and functioning primarily to make Sam Altman personally more powerful. I'm also pretty sure that asking Sam to pretty please be nice and do the right thing is... perhaps strategically counterindicated.
Suppose you, Zvi (or anyone else reading this! yes, you!) were Unquestioned Czar of the Greater Ratsphere, with a good deal of money, compute, and soft power, but basically zero hard power. Sam Altman has rejected your ultimatum to Do The Right Thing and cancel the nondisparagements, modify the NDAs, not try to sneakily fuck over ex-employees when they go to sell and are made to sell for a dollar per PPU, etc, etc.
What's the line?
Replies from: orthonormal, MichaelDickens↑ comment by orthonormal · 2024-05-21T01:46:48.938Z · LW(p) · GW(p)
Go all-in on lobbying the US and other governments to fully prohibit the training of frontier models beyond a certain level, in a way that OpenAI can't route around (so probably block Altman's foreign chip factory initiative, for instance).
↑ comment by MichaelDickens · 2024-05-20T22:17:49.876Z · LW(p) · GW(p)
Some ideas:
- Make Sam Altman look stupid on Twitter, which will marginally persuade more employees to quit and more potential investors not to invest (this is my worst idea but also the easiest, and people seem to pretty much have this one covered already)
- Pay a fund to hire a good lawyer to figure out a strategy to nullify the non-disparagement agreements. Maybe a class-action lawsuit, maybe a lawsuit on the behalf of one individual, maybe try to charge Altman with some sort of crime, I'm not sure the best way to do this but that's the lawyer's job to figure out.
- Have everyone call their representative in support of SB 1047, or maybe even say you want SB 1047 to have stronger whistleblower protections or something similar.
↑ comment by HiddenPrior (SkinnyTy) · 2024-05-20T22:54:28.816Z · LW(p) · GW(p)
I am limited in my means, but I would commit to a fund for strategy 2. My thoughts were on strategy 2, and it seems likely to do the most damage to OpenAI's reputation (and therefore funding) out of the above options. If someone is really protective of something, like their public image/reputation, that probably indicates that it is the most painful place to hit them.
comment by Wei Dai (Wei_Dai) · 2024-05-21T15:02:02.008Z · LW(p) · GW(p)
I'd like to hear from people who thought that AI companies would act increasingly reasonable (from an x-safety perspective) as AGI got closer. Is there still a viable defense of that position (e.g., that SamA being in his position / doing what he's doing is just uniquely bad luck, not reflecting what is likely to be happening / will happen at other AI labs)?
Also, why is there so little discussion of x-safety culture at other AI labs? I asked on Twitter and did not get a single relevant response. Are other AI company employees also reluctant to speak out, if so that seems bad (every explanation I can think of seems bad, including default incentives + companies not proactively encouraging transparency).
comment by rotatingpaguro · 2024-05-20T20:42:57.874Z · LW(p) · GW(p)
Naia: It’s OK, everyone. Mr. Not Consistently Candid says the whole thing was an oopsie, and that he’ll fix things one-by-one for people if they contact him privately. Definitely nothing to worry about, then. Carry on.
I'm wondering, what would happen if you contact Altman privately right now? Would you be added to a list of bad kids? What is the typical level of shadiness of American VCs?
Replies from: Lorxus↑ comment by Lorxus · 2024-05-21T12:07:22.023Z · LW(p) · GW(p)
Would you be added to a list of bad kids?
That would seem to be the "nice" outcome here, yes.
What is the typical level of shadiness of American VCs?
If you're asking that question, I claim that you already suspect the answer and should stop fighting it.
comment by Chi Nguyen · 2024-05-20T13:50:10.605Z · LW(p) · GW(p)
From my point of view, of course profit maximizing companies will…maximize profit. It never was even imaginable that these kinds of entities could shoulder such a huge risk responsibly.
Correct me if I'm wrong but isn't Conjecture legally a company? Maybe their profit model isn't actually foundation models? Not actually trying to imply things, just thought the wording was weird in that context and was wondering whether Conjecture has a different legal structure than I thought.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-05-21T12:52:25.563Z · LW(p) · GW(p)
It’s a funny comment because legally Conjecture is for-profit and OpenAI is not. It just goes to show that the various internal and external pressures and incentives on an organization and its staff are not encapsulated by glancing at their legal status—see also my comment here [LW(p) · GW(p)].
Anyway, I don’t think Connor is being disingenuous in this particular comment, because he has always been an outspoken advocate for government regulation of all AGI-related companies including his own.
I don’t think it’s crazy or disingenuous in general to say “This is a terrible system, so we’re gonna loudly criticize it and advocate to change it. But meanwhile / in parallel, we’re gonna work within the system we got, and do the best we can.” And “the system we got” is that private organizations are racing to develop AGI.
comment by Donald Hobson (donald-hobson) · 2024-05-22T23:50:12.793Z · LW(p) · GW(p)
I think the marginal value of OpenAI competence is now negative. We are at a point where they have basically no chance to succeed at alignment, and further incompetence makes it more likely for the company to not get anything dangerous. Making any AGI at all requires competence and talent, and an environment that isn't a political cesspool.
comment by Chi Nguyen · 2024-05-20T14:12:50.515Z · LW(p) · GW(p)
Greg Brockman and Sam Altman (cosigned):
[...]
First, we have raised awareness of the risks and opportunities of AGI so that the world can better prepare for it. We’ve repeatedly demonstrated the incredible possibilities from scaling up deep learning
chokes on coffee
Replies from: MichaelDickens↑ comment by MichaelDickens · 2024-05-20T22:19:29.000Z · LW(p) · GW(p)
This also stood out to me as a truly insane quote. He's almost but not quite saying "we have raised awareness that this bad thing can happen by doing the bad thing"
Replies from: Linch↑ comment by Linch · 2024-05-20T23:29:36.982Z · LW(p) · GW(p)
This has been OpenAI's line (whether implicitly or explicitly) for a while iiuc. I referenced it on my Open Asteroid Impact website, under "Operation Death Star."
comment by Lorxus · 2024-05-20T15:04:39.977Z · LW(p) · GW(p)
A wise man does not cut the ‘get the AI to do what you want it to do’ department when it is working on AIs it will soon have trouble controlling. When I put myself in ‘amoral investor’ mode, I notice this is not great, a concern that most of the actual amoral investors have not noticed.
My actual expectation is that for raising capital and doing business generally this makes very little difference. There are effects in both directions, but there was overwhelming demand for OpenAI equity already, and there will be so long as their technology continues to impress.
No one ever got fired buying IBM OpenAI. ML is flashy and investors seem to care less about gears-level understanding of why something is potentially profitable than whether they can justify it. It seems to work out well enough for them.
What about employee relations and ability to hire? Would you want to work for a company that is known to have done this? I know that I would not. What else might they be doing? What is the company culture like?
Here's a sad story of a plausible possible present: OAI fires a lot of people who care more-than-average about AI safety/NKE/x-risk. They (maybe unrelatedly) also have a terrible internal culture such that anyone who can leave, does. People changing careers to AI/ML work are likely leaving careers that were even worse, for one reason or another - getting mistreated as postdocs or adjuncts in academia has gotta be one example, and I can't speak to it but it seems like repeated immediate moral injury in defense or finance might be another. So... those people do not, actually, care, or at least they can be modelled as not caring because anyone who does care doesn't make it through interviews.
What else might they be doing? Can't be worse than callously making the guidance systems for the bombs for blowing up schools or hospitals or apartment blocks. How bad is the culture? Can't possibly be worse than getting told to move cross-country for a one-year position and then getting talked down to and ignored by the department when you get there.
It pays well if you have the skills, and it looks stable so long as you don't step out of line. I think their hiring managers are going to be doing brisk business.
comment by Chi Nguyen · 2024-05-20T13:30:53.940Z · LW(p) · GW(p)
minus Cullen O’Keefe who worked on policy and legal (so was not a clear cut case of working on safety),
I think Cullen was on the same team as Daniel (might be misremembering), so if you count Daniel, I'd also count Cullen. (Unless you wanna count Daniel because he previously was more directly part of technical AI safety research at OAI.)
comment by Tapatakt · 2024-05-20T19:33:20.462Z · LW(p) · GW(p)
I'm sorry if this is a stupid question.
How can NDA actually work effectively? What if Alice, ex-employee of OpenAI write a "totally fictional short story about Bob, ex-employee of ClosedDM, who wants to tell about horrible things this company did"?
Replies from: RamblinDash↑ comment by RamblinDash · 2024-05-20T20:32:39.034Z · LW(p) · GW(p)
In general, courts are not so stupid and the law is not so inflexible to ignore such an obvious fig leaf, if the NDA was otherwise enforceable. Query whether it is, but whether or not you just make your statement openly or whether you have a totally-fictional statement about totally-not-OpenAI would be unlikely to make a difference IMO.
*I don't represent you and this statement should not be taken as legal advice on any particular concrete scenario.
Replies from: Tapatakt↑ comment by Tapatakt · 2024-05-24T17:18:25.526Z · LW(p) · GW(p)
Thanks! BTW, my curiosity doesn't stop: do you (americans? west-europeans too?) actually feel the necessity to write this disclaimers about "not a legal/financial advice"? It's like "my granpa said he remembers one time someone got sued because they didn't write it" or more like "fasten your seatbelt"?
Replies from: RamblinDash↑ comment by RamblinDash · 2024-05-24T17:25:34.479Z · LW(p) · GW(p)
It's something that kinda falls out of Attorney ethics rules, where a lot of duties attach to representation of a client. So we want to be very clear when we are and are not representing someone. In addition, under state ethics laws (I'm a state government lawyer), we are not authorized to provide legal advice to private parties.
Replies from: Tapatakt↑ comment by Tapatakt · 2024-05-24T17:30:33.433Z · LW(p) · GW(p)
Oh, so (almost) everyone who write this do it because they have some profession such that they sometimes really give serious legal/financial/medical advise, right? This makes perfect sense, I think I just didn't realise how often the people I read in the Internet are like this, so I didn't have this as a hypothesis in my head :)
comment by Askwho · 2024-05-20T14:41:09.157Z · LW(p) · GW(p)
Multi voiced AI reading for this post:
https://open.substack.com/pub/thezvi/p/openai-exodus
↑ comment by HiddenPrior (SkinnyTy) · 2024-05-20T22:55:09.185Z · LW(p) · GW(p)
Super helpful! Thanks!
comment by eggsyntax · 2024-05-24T12:48:11.340Z · LW(p) · GW(p)
Yes, if the departing people thought OpenAI was plausibly about to destroy humanity in the near future due to a specific development, they would presumably break the NDAs, unless they thought it would not do any good. So we can update on that.
Thanks for pointing that out -- it hadn't occurred to me that there's a silver lining here in terms of making the shortest timelines seem less likely.
On another note, I think it's important to recognize that even if all ex-employees are released from the non-disparagement clauses and the threat of equity clawback, they still have very strong financial incentives against saying negative things about the company. We know that most of them are moved by that, because that was the threat that got them to sign the exit docs.
I'm not really faulting them for that! Financial security for yourself and your family is an extremely hard thing to turn down. But we still need to see whatever statements ex-employees make with an awareness that for every person who speaks out, there might have been more if not for those incentives.
comment by green_leaf · 2024-05-23T05:24:08.347Z · LW(p) · GW(p)
"we need to have the beginning of a hint of a design for a system smarter than a house cat"
You couldn't make a story about this, I swear.
comment by Review Bot · 2024-05-21T04:46:19.154Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?