0 comments
Comments sorted by top scores.
comment by MackGopherSena · 2022-02-04T18:01:05.501Z · LW(p) · GW(p)
[edited]
Replies from: Algon, yitz↑ comment by Algon · 2022-02-04T19:04:37.153Z · LW(p) · GW(p)
People like Scott Garabrant care about you less? https://www.lesswrong.com/posts/NvwJMQvfu9hbBdG6d/preferences-without-existence [LW · GW]
I think this question is poorly specified, though it sounds like it could lead somewhere fun. For one thing, the more of your actions are random, the harder it is for an adversary to anticipate your actions. But also, it seems likely that you have less power in the long run, so the less important it is overall. It washes out.
Increasing the randomness of your actions slightly for actions which don't sacrifice much resources in expectation, it might make you marginally happier by breaking you out of the status quo. And feel like life goes on longer because your memory becomes less compressible.
Oh, and you become more unbelievable as an individual and, depending how you inserted randomes, more interesting, but you may become more complex and hence harder to specify. So simulating you may become more costly, but also more worthwhile.
↑ comment by Yitz (yitz) · 2022-02-04T18:23:19.570Z · LW(p) · GW(p)
Would that look something like a reverse Pascal’s mugging? Under what circumstances would that be to a “mugger’s” advantage?
comment by MackGopherSena · 2022-04-20T14:44:45.358Z · LW(p) · GW(p)
[edited]
Replies from: Dagon↑ comment by Dagon · 2022-04-20T17:01:55.439Z · LW(p) · GW(p)
Do you have a reference or definition for this? It sounds like "subjective time" or "density/sparseness of experience over time" or possibly "rate of memory formation". If so, I get it for attention span or mindfulness, but vegan eating and clothes fabric type seem a stretch.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-29T16:02:48.815Z · LW(p) · GW(p)
[edited]
Replies from: Dagon↑ comment by Dagon · 2022-04-29T17:03:52.012Z · LW(p) · GW(p)
how much objective time it would take to generate your subjective experiences.
Nope, I don't follow at all. One second per second is how I experience time. I can understand compression or variance in rate of memory formation or retention (how much the experience of one second has an impact a week or a decade later). And I'd expect there's more data in variance over time (where the second in question has different experiences than the previous second did) than in variance at a point in time (where there are many slightly different sensations).
comment by MackGopherSena · 2022-05-09T17:07:03.128Z · LW(p) · GW(p)
[edited]
Replies from: Dagon, JBlackcomment by MackGopherSena · 2022-04-27T20:36:55.239Z · LW(p) · GW(p)
[edited]
Replies from: Dagon, TLW↑ comment by Dagon · 2022-04-27T21:34:23.732Z · LW(p) · GW(p)
I didn't catch that post. It would be interesting to solve for optimum strategy here. Almost certainly a mixed strategy, both for selecting and for accusing. The specifics of length of game, cost/benefit of false/true accusation, and the final evaluation (do points matter or it it just win/lose) all go into it.
I suspect there would be times when one would pick a low roll so as not to get accused but also prevent a worst-case roll. I also suspect those are times when one should always accuse, regardless of roll.
Replies from: TLW↑ comment by TLW · 2022-04-29T18:49:16.587Z · LW(p) · GW(p)
Let's look at a relatively simple game along these lines:
Person A either cheats an outcome or rolls a d4. Then person B either accuses, or doesn't. If person B accuses, the game ends immediately, with person B winning (losing) if their accusation was correct (incorrect). Otherwise, repeat a second time. At the end, assuming person B accused neither time, person A wins if the total sum is at least 6. (Note that person A has a lower bound of a winrate of 3/8ths simply by never cheating.)
Let's look at the second round first.
First subcase: the first roll (legitimate or uncaught) was 1. Trivial win for person B.
Second subcase: the first roll was 2. Subgame tree is as follows: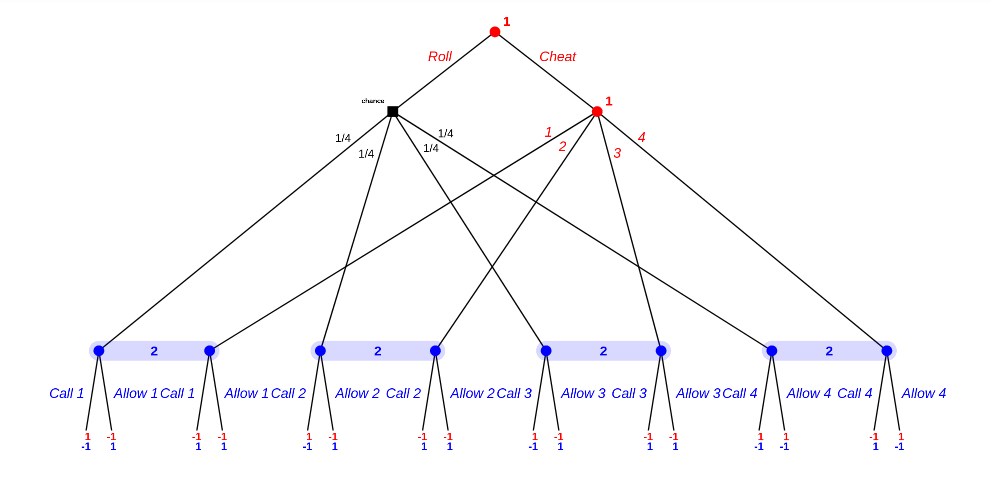
The resulting equlibria are:
- Person A always rolls.
- Person B allows 1-3, and either always calls 4, or calls 4 1/4 of the time.
Either way, expected value is -1/2 for Person A, which makes sense given person A plays randomly (1/4 die rolls win for person A).
Third subcase: the first roll was 3. Simplified subgame tree is as follows:
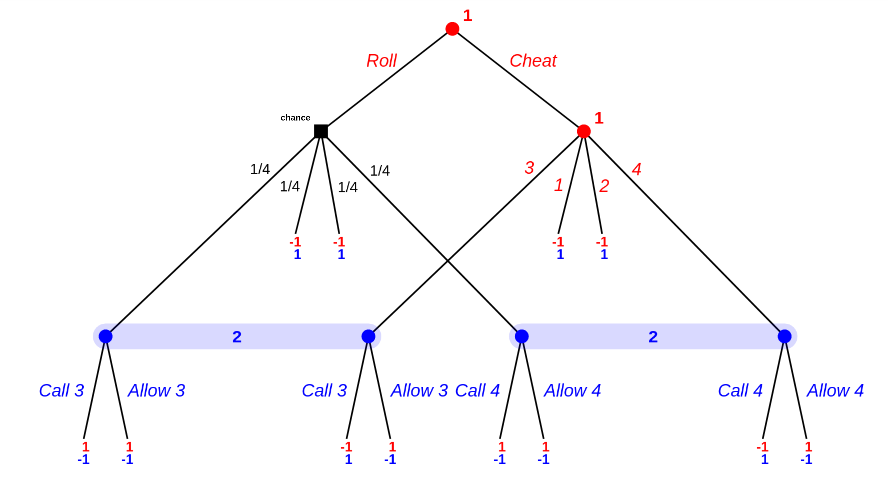
There are 5 (five) equlibria for this one:
- Person A always plays randomly.
- Person B always allows 1 and 2, and either always calls both 3 and 4, or always calls one of 3 or 4 and allows the other 50% of the time, or 50/50 allows 3/calls 4 or allows 4/calls 3, or 50/50 allows both / calls both.
Overall expected value is 0, which makes sense given person A plays randomly (2/4 die rolls win for person A).
Fourth subcase: the first roll was 4. I'm not going to enumerate the equlibria here, as there are 40 of them (!). Suffice to say, the result is, yet again, person A always playing randomly, with person B allowing 1 and calling 2-4 always or probabilistically in various combinations, with an expected value of +1/2.
And then the first round:
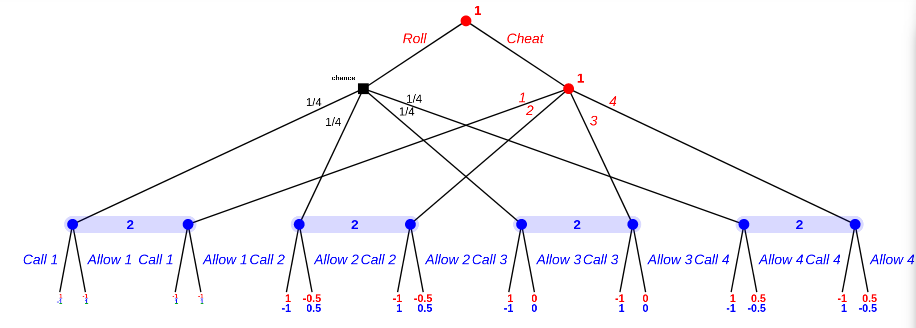
Overall equlibria are:
- Person A plays randomly 3/4 of the time, cheats 3 3/16th of the time, and cheats 4 1/16th of the time.
- Person B always allows 1 and 2, and does one of two mixes of calling/allowing 3 and 4. (0 | 5/32 | 7/16 | 13/32, or 5/32 | 0 | 9/32 | 9/16 of call/call | call/allow | allow/call | allow/allow).
Either way, expected value for person A is -5/32.
Tl;DR:
This (over)simplified game agrees with your intuition. There are mixed strategies on both sides, and cases where you 'may as well' always call, and cases where you want to cheat to a value below the max value.
(Most of this was done with http://app.test.logos.bg/ - it's quite a handy tool for small games, although note that it doesn't compute equilibria for single giant games. You need to break them down into smaller pieces, or fiddle with the browser debugger to remove the hard-coded 22 node limit.)
↑ comment by TLW · 2022-04-29T16:10:53.176Z · LW(p) · GW(p)
What's the drawback to always accusing here?
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-29T17:24:16.737Z · LW(p) · GW(p)
[edited]
Replies from: TLW↑ comment by TLW · 2022-04-29T20:48:44.594Z · LW(p) · GW(p)
Interesting.
The other player gets to determine your next dice roll (again, either manually or randomly).
Could you elaborate here?
Alice cheats and say she got a 6. Bob calls her on it. Is it now Bob's turn, and hence effectively a result of 0? Or is it still Alice's turn? If the latter, what happens if Alice cheats again?
I'm not sure how you avoid the stalemate of both players 'always' cheating and both players 'always' calling out the other player.
Instead of dice, a shuffled deck of playing cards would work better. To determine your dice roll, just pull two cards from a shuffled deck of cards without revealing them to anyone but yourself, then for posterity you put those two cards face down on top of that deck.
How do you go from a d52 and a d51 to a single potentially-loaded d2? I don't see what to do with said cards.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-29T21:04:17.206Z · LW(p) · GW(p)
[edited]
Replies from: TLW↑ comment by TLW · 2022-04-29T22:28:41.889Z · LW(p) · GW(p)
Ignore the suit of the cards. So you can draw a 1 (Ace) through 13 (King). Pulling two cards is a range of 2 to 26. Divide by 2 and add 1 means you get the same roll distribution as rolling two dice.
That's not the same roll distribution as rolling two dice[1]. For instance, rolling a 14 (pulling 2 kings) has a probability of , not [2].
(The actual distribution is weird. It's not even symmetrical, due to the division (and associated floor). Rounding to even/odd would help this, but would cause other issues.)
This also supposes you shuffle every draw. If you don't, things get worse (e.g. you can't 'roll' a 14 at all if at least 3 kings have already been drawn).
====
Fundamentally: you're pulling out 2 cards from the deck. There are 52 possible choices for the first card, and 51 for the second card. This means that you have 52*51 possibilities. Without rejection sampling this means that you're necessarily limited to probabilities that are a multiple of . Meanwhile, rolling N S-sided dice and getting exactly e.g. N occurs with a probability of . As N and S are both integers, and 52=2*2*13, and 51=3*17, the only combinations of dice you can handle without rejection sampling are:
- Nd1[3]
- 1d2, 1d3, 1d4, 1d13, 1d17, 1d26, ..., 1d(52*51)
- 2d2
...and even then many of these don't actually involve both cards. For instance, to get 2d2 with 2 pulled cards ignore the second card and just look at the suit of the first card.
Alice and Bob won't always cheat because they will get good rolls sometimes that will look like cheats but won't be.
Wait, do you mean:
- Decide to cheat or not cheat, then if not cheating do a random roll, or
- Do a random roll, and then decide to cheat or not?
I was assuming 1, but your argument is more suited for 2...
- ^
Aside from rolling a strange combination of a strangely-labelled d52 and a strangely-labelled d51, or somesuch.
- ^
import itertools import fractions import collections cards = list(range(1, 14))*4 dice_results = collections.Counter(a+b for a in range(1, 8) for b in range(1, 8)) dice_denom = sum(dice_results.values()) card_results = collections.Counter((a+b)//2+1 for a, b in itertools.permutations(cards, r=2)) card_denom = sum(card_results.values()) for val in range(2, 15): print(val, fractions.Fraction(card_results[val], card_denom), fractions.Fraction(dice_results[val], dice_denom), sep='\t')2 11/663 1/49 3 9/221 2/49 4 43/663 3/49 5 59/663 4/49 6 25/221 5/49 7 7/51 6/49 8 33/221 1/7 9 83/663 6/49 10 67/663 5/49 11 1/13 4/49 12 35/663 3/49 13 19/663 2/49 14 1/221 1/49 - ^
This is somewhat trivial, but I figured it was worth mentioning.
comment by MackGopherSena · 2022-02-05T17:22:54.784Z · LW(p) · GW(p)
[edited]
Replies from: Dagon↑ comment by Dagon · 2022-02-05T21:04:00.365Z · LW(p) · GW(p)
What are the axes on these curves? Are there multiple commitment and multiple reneg curves in play for a given commitment? Are distinct commitments (with their own curves) actually correlated for an agent, such that there really should be a unified set of curves that describe all commitments?
Personally, I'm much simpler in my modeling. A commitment is just a credence that the future behavior is what I'll believe is best to do (including my valuation of delivering on commitments). Evidence or model changes which alter the credence perforce changes my commitment level. I currently do and expect to continue valuing pretty highly the fact that I generally keep promises.
comment by MackGopherSena · 2022-01-31T13:19:54.825Z · LW(p) · GW(p)
[edited]
Replies from: Dagon, JBlack↑ comment by JBlack · 2022-02-01T03:04:08.130Z · LW(p) · GW(p)
I'm a little confused. Removing one bit means that two possible images map onto the file that is 1 bit smaller, not 1024 possible images.
I'm also confused about what happens when you remove a million bits from the image. When you go to restore 1 bit, there are two possible files that are 1 bit larger. But which one is the one you want? They are both meaningless strings of bits until you get to the final image, and there are 2^million possible final images.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-02-01T09:58:36.542Z · LW(p) · GW(p)
[edited]
Replies from: JBlack↑ comment by JBlack · 2022-02-03T03:56:07.111Z · LW(p) · GW(p)
Ah I see, the bit you remove is freely chosen. Though I am still confused.
The problem I have is that given a 24 million bit raw image format consisting of a million RGB pixels, there are at least 2^million different images that look essentially identical to a human (let's say a picture of my room with 1 bit of sensor noise per pixel in the blue channel). During the compression process the smaller files must remain distinct, otherwise we lose the property of being able to tell which one is correct on expansion.
So the process must end when the compressed file reaches a million bits, because every compression of the 2^million possible pictures of my room must have a different sequence of bits assigned to it, and there is no room left for being able to encode anything else.
But I can equally well apply the same argument to gigapixel images, concluding that this compression method can't compress anything to less than a billion bits. This argument doesn't have an upper limit, so I'm not sure how it can ever compress anything at all.
comment by MackGopherSena · 2022-01-18T03:49:57.115Z · LW(p) · GW(p)
[edited]
Replies from: Measure↑ comment by Measure · 2022-01-18T15:09:48.841Z · LW(p) · GW(p)
I'm confused. What does anthropics have to do with morality?
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-01-18T23:19:48.166Z · LW(p) · GW(p)
[edited]
Replies from: Measure, JBlack↑ comment by JBlack · 2022-01-19T01:14:19.249Z · LW(p) · GW(p)
Mostly that it's a very big "if". What motivates this hypothesis?
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-01-19T01:41:11.302Z · LW(p) · GW(p)
[edited]
Replies from: JBlack↑ comment by JBlack · 2022-01-19T02:02:43.099Z · LW(p) · GW(p)
The motivation remains the same regardless of whether your first 'if' is just an if, but at least it would answer part of the question.
My motivation is to elicit further communication about the potential interesting chains of reasoning behind it, since I'm more interested in those than in the original question itself. If it turns out that it's just an 'if' without further interesting reasoning behind it, then at least I'll know that.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-01-19T11:41:14.273Z · LW(p) · GW(p)
You'll find it helpful to ignore that aspect for now.
Replies from: Richard_Kennaway, JBlack↑ comment by Richard_Kennaway · 2022-01-19T17:46:03.662Z · LW(p) · GW(p)
"Ought implies can" in that linked article is about the present and future, not the past. There is nothing in that principle to disallow having a preference that the past had not been as it was, and to have regret for former actions. The past cannot be changed, but one can learn from one's past errors, and strive to become someone who would not have made that error, and so will not in the future.
comment by MackGopherSena · 2022-01-05T20:17:34.166Z · LW(p) · GW(p)
[edited]
Replies from: Viliam, JBlack↑ comment by Viliam · 2022-01-06T20:41:51.105Z · LW(p) · GW(p)
What about legality of mana usage? My life could be dramatically changed by adding a few zeroes to my bank account, which would only require changing a few bits, which are probably not even that difficult to find. That is, this task is probably cheaper than either sterilizing or boiling the glass of water.
There is an issue with "difficulty" of finding some bits. Like, difficulty for whom? A hypothetical agent who has what knowledge exactly? I was thinking about self-improvement, which (within human boundaries) has a nice upper limit -- in worst case, you need to change all qbits in your body; but in most reasonable cases a fraction of them would probably suffice. The question is, how to find the relatively few qbits in my brain which would increase my intelligence, or willpower.
Alternatively, modifying other people could be quite profitable. Any person willing to help you is a multiplier for your abilities. The secular alternative to this is social skills (or manipulation).
↑ comment by JBlack · 2022-01-07T05:49:54.680Z · LW(p) · GW(p)
I suspect that I don't understand your last sentence at all.
Human behavior becomes a lot less confusing when you categorize each intentional action according to the two aforementioned categories.
Do you mean in this hypothetical universe? I imagine that it would diverge from our own very quickly if feats like your examples were possible for even a small fraction of people. I don't think intentional actions in such a universe would split nicely into secular and mana actions, they would probably combine and synergize.
comment by MackGopherSena · 2022-04-11T14:30:33.818Z · LW(p) · GW(p)
[edited]
Replies from: Viliam↑ comment by Viliam · 2022-04-11T19:27:34.875Z · LW(p) · GW(p)
The chances of any holder increase when they get the new coin, not just the biggest holder. And although the biggest holder is most likely to get the new coin, it will provide them the smallest relative growth.
I wrote a simulation where players start as [60, 30, 10] and get 100 more coins. The results were: [111, 71, 18], [121, 60, 19], [127, 54, 19], [128, 55, 17], [119, 50, 31], [120, 57, 23], [113, 56, 31], [112, 64, 24], [127, 54, 19], [125, 58, 17], [99, 78, 23], [114, 69, 17], [127, 55, 18], [128, 46, 26], [114, 67, 19], [118, 67, 15], [110, 71, 19], [113, 60, 27], [107, 70, 23], [113, 71, 16].
import random
def next(arr):
... r = random.randrange(sum(arr))
... n = []
... for i in arr:
... ... m = 1 if (r >= 0) and (r < i) else 0
... ... r -= i
... ... n.append(i + m)
... return n
def iterate(arr, count):
... for i in range(count):
... ... arr = next(arr)
... return arr
def main():
... for i in range(20):
... ... print(iterate([60,30,10], 100))
main()
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-11T21:45:26.899Z · LW(p) · GW(p)
[edited]
Replies from: JBlack↑ comment by JBlack · 2022-04-12T01:41:09.923Z · LW(p) · GW(p)
You're stopping as soon as any holder gets at least 50%, or 2^20 iterations, whichever comes first? Obviously this is more likely with few starting coins and few initial participants. It's absolutely certain with 3 participants holding 1 coin each. Even if coins were distributed by initial stake (i.e. uniformly between holders) these conditions would still often be reached with such small initial numbers.
Even with these tiny starting conditions biased toward dominance, a fair few runs never resulted in 50% holdings in the first 2^20 coins: 11 out of the 27 that weren't mathematically impossible.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-12T15:11:52.596Z · LW(p) · GW(p)
[edited]
Replies from: JBlack↑ comment by JBlack · 2022-04-13T03:00:38.369Z · LW(p) · GW(p)
When you start with a tiny number of stakeholders with tiny stakes, large deviations will be likely.
The share-of-ownership sequence for a given stakeholder is essentially a random walk with step size decreasing like 1/n. Since variance of such a walk is the sum of individual variances, the variance for such a walk scales like Sum (1/n)^2, which remains bounded.
If you have N initial coins, the standard deviation in the limiting distribution (as number of allocations goes to infinity) is approximately 1/sqrt(N). In your largest starting allocation you have only N=30, and so the standard deviation in the limit is ~0.18. Since you have only 3 participants the 50% threshold is only 1 standard deviation from the starting values.
So basically what you're seeing is an artifact of starting with tiny toy values. More realistic starting conditions (such as a thousand participants with up to a thousand coins each) will yield trivial deviations even over quadrillions of steps. The probability that any one participant would ever reach 50% via minting (or even a coalition of a hundred of them) is utterly negligible.
Replies from: MackGopherSena↑ comment by MackGopherSena · 2022-04-19T21:23:05.056Z · LW(p) · GW(p)
[edited]