Proofs, Implications, and Models
post by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-30T13:02:20.077Z · LW · GW · Legacy · 218 commentsContents
Mainstream status. None 218 comments
Followup to: Causal Reference
From a math professor's blog:
One thing I discussed with my students here at HCSSiM yesterday is the question of what is a proof.
They’re smart kids, but completely new to proofs, and they often have questions about whether what they’ve written down constitutes a proof. Here’s what I said to them.
A proof is a social construct – it is what we need it to be in order to be convinced something is true. If you write something down and you want it to count as a proof, the only real issue is whether you’re completely convincing.
This is not quite the definition I would give of what constitutes "proof" in mathematics - perhaps because I am so used to isolating arguments that are convincing, but ought not to be.
Or here again, from "An Introduction to Proof Theory" by Samuel R. Buss:
There are two distinct viewpoints of what a mathematical proof is. The first view is that proofs are social conventions by which mathematicians convince one another of the truth of theorems. That is to say, a proof is expressed in natural language plus possibly symbols and figures, and is sufficient to convince an expert of the correctness of a theorem. Examples of social proofs include the kinds of proofs that are presented in conversations or published in articles. Of course, it is impossible to precisely define what constitutes a valid proof in this social sense; and, the standards for valid proofs may vary with the audience and over time. The second view of proofs is more narrow in scope: in this view, a proof consists of a string of symbols which satisfy some precisely stated set of rules and which prove a theorem, which itself must also be expressed as a string of symbols. According to this view, mathematics can be regarded as a 'game' played with strings of symbols according to some precisely defined rules. Proofs of the latter kind are called "formal" proofs to distinguish them from "social" proofs.
In modern mathematics there is a much better answer that could be given to a student who asks, "What exactly is a proof?", which does not match either of the above ideas. So:
Meditation: What distinguishes a correct mathematical proof from an incorrect mathematical proof - what does it mean for a mathematical proof to be good? And why, in the real world, would anyone ever be interested in a mathematical proof of this type, or obeying whatever goodness-rule you just set down? How could you use your notion of 'proof' to improve the real-world efficacy of an Artificial Intelligence?
...
...
...
Consider the following syllogism:
- All kittens are little;
- Everything little is innocent;
- Therefore all kittens are innocent.
Here's four mathematical universes, aka "models", in which the objects collectively obey or disobey these three rules:
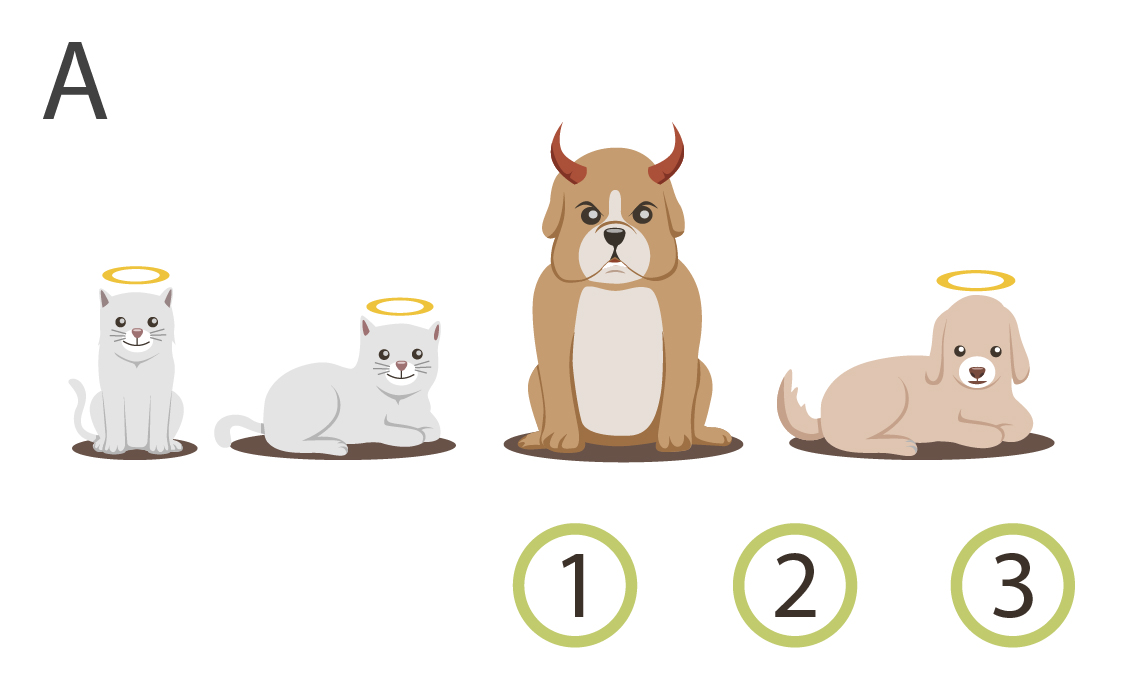 |
 |
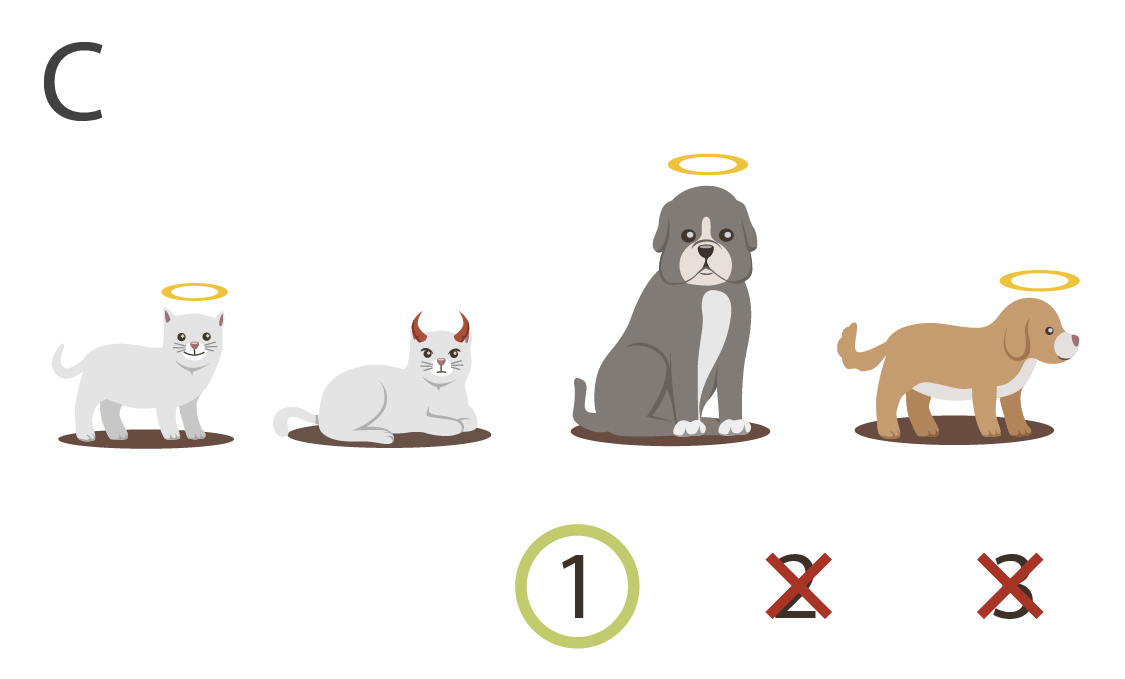 |
 |
There are some models where not all kittens are little, like models B and D. And there are models where not everything little is innocent, like models C and D. But there are no models where all kittens are little, and everything little is innocent, and yet there exists a guilty kitten. Try as you will, you won't be able to imagine a model like that. Any model containing a guilty kitten has at least one kitten that isn't little, or at least one little entity that isn't innocent - no way around it.
Thus, the jump from 1 & 2, to 3, is truth-preserving: in any universe where premises (1) and (2) are true to start with, the conclusion (3) is true of the same universe at the end.
Which is what makes the following implication valid, or, as people would usually just say, "true":
"If all kittens are little and everything little is innocent, then all kittens are innocent."
The advanced mainstream view of logic and mathematics (i.e., the mainstream view among professional scholars of logic as such, not necessarily among all mathematicians in general) is that when we talk about math, we are talking about which conclusions follow from which premises. The "truth" of a mathematical theorem - or to not overload the word 'true' meaning comparison-to-causal-reality, the validity of a mathematical theorem - has nothing to do with the physical truth or falsity of the conclusion in our world, and everything to do with the inevitability of the implication. From the standpoint of validity, it doesn't matter a fig whether or not all kittens are innocent in our own universe, the connected causal fabric within which we are embedded. What matters is whether or not you can prove the implication, starting from the premises; whether or not, if all kittens were little and all little things were innocent, it would follow inevitably that all kittens were innocent.
To paraphrase Mayor Daley, logic is not there to create truth, logic is there to preserve truth. Let's illustrate this point by assuming the following equation:
x = y = 1
...which is true in at least some cases. E.g. 'x' could be the number of thumbs on my right hand, and 'y' the number of thumbs on my left hand.
Now, starting from the above, we do a little algebra:
1 |
x = y = 1 |
starting premise |
2 |
x2 = xy |
multiply both sides by x |
3 |
x2 - y2 = xy - y2 |
subtract y2 from both sides |
4 |
(x + y)(x - y) = y(x - y) |
factor |
5 |
x + y = y |
cancel |
6 |
2 = 1 |
substitute 1 for x and 1 for y |
We have reached the conclusion that in every case where x and y are equal to 1, 2 is equal to 1. This does not seem like it should follow inevitably.
You could try to find the flaw just by staring at the lines... maybe you'd suspect that the error was between line 3 and line 4, following the heuristic of first mistrusting what looks like the most complicated step... but another way of doing it would be to try evaluating each line to see what it said concretely, for example, multiplying out x2 = xy in line 2 to get (12) = (1 * 1) or 1 = 1. Let's try doing this for each step, and then afterward mark whether each equation looks true or false:
1 |
x = y = 1 |
1 = 1 |
true |
2 |
x2 = xy |
1 = 1 |
true |
3 |
x2 - y2 = xy - y2 |
0 = 0 |
true |
4 |
(x + y)(x - y) = y(x - y) |
0 = 0 |
true |
5 |
x + y = y |
2 = 1 |
false |
6 |
2 = 1 |
2 = 1 |
false |
Logic is there to preserve truth, not to create truth. Whenever we take a logically valid step, we can't guarantee that the premise is true to start with, but if the premise is true the conclusion should always be true. Since we went from a true equation to a false equation between step 4 and step 5, we must've done something that is in general invalid.
In particular, we divided both sides of the equation by (x - y).
Which is invalid, i.e. not universally truth-preserving, because (x - y) might be equal to 0.
And if you divide both sides by 0, you can get a false statement from a true statement. 3 * 0 = 2 * 0 is a true equation, but 3 = 2 is a false equation, so it is not allowable in general to cancel any factor if the factor might equal zero.
On the other hand, adding 1 to both sides of an equation is always truth-preserving. We can't guarantee as a matter of logic that x = y to start with - for example, x might be my number of ears and y might be my number of fingers. But if x = y then x + 1 = y + 1, always. Logic is not there to create truth; logic is there to preserve truth. If a scale starts out balanced, then adding the same weight to both sides will result in a scale that is still balanced:

I will remark, in some horror and exasperation with the modern educational system, that I do not recall any math-book of my youth ever once explaining that the reason why you are always allowed to add 1 to both sides of an equation is that it is a kind of step which always produces true equations from true equations.
What is a valid proof in algebra? It's a proof where, in each step, we do something that is universally allowed, something which can only produce true equations from true equations, and so the proof gradually transforms the starting equation into a final equation which must be true if the starting equation was true. Each step should also - this is part of what makes proofs useful in reasoning - be locally verifiable as allowed, by looking at only a small number of previous points, not the entire past history of the proof. If in some previous step I believed x2 - y = 2, I only need to look at that single step to get the conclusion x2 = 2 + y, because I am always allowed to add y to both sides of the equation; because I am always allowed to add any quantity to both sides of the equation; because if the two sides of an equation are in balance to start with, adding the same quantity to both sides of the balance will preserve that balance. I can know the inevitability of this implication without considering all the surrounding circumstances; it's a step which is locally guaranteed to be valid. (Note the similarity - and the differences - to how we can compute a causal entity knowing only its immediate parents, and no other ancestors.)
You may have read - I've certainly read - some philosophy which endeavors to score points for counter-intuitive cynicism by saying that all mathematics is a mere game of tokens; that we start with a meaningless string of symbols like:
...and we follow some symbol-manipulation rules like "If you have the string 'A ∧ (A → B)' you are allowed to go to the string 'B'", and so finally end up with the string:
...and this activity of string-manipulation is all there is to what mathematicians call "theorem-proving" - all there is to the glorious human endeavor of mathematics.
This, like a lot of other cynicism out there, is needlessly deflationary.
There's a family of techniques in machine learning known as "Monte Carlo methods" or "Monte Carlo simulation", one of which says, roughly, "To find the probability of a proposition Q given a set of premises P, simulate random models that obey P, and then count how often Q is true." Stanislaw Ulam invented the idea after trying for a while to calculate the probability that a random Canfield solitaire layout would be solvable, and finally realizing that he could get better information by trying it a hundred times and counting the number of successful plays. This was during the era when computers were first becoming available, and the thought occurred to Ulam that the same technique might work on a current neutron diffusion problem as well.
Similarly, to answer a question like, "What is the probability that a random Canfield solitaire is solvable, given that the top card in the deck is a king?" you might imagine simulating many 52-card layouts, throwing away all the layouts where the top card in the deck was not a king, using a computer algorithm to solve the remaining layouts, and counting what percentage of those were solvable. (It would be more efficient, in this case, to start by directly placing a king on top and then randomly distributing the other 51 cards; but this is not always efficient in Monte Carlo simulations when the condition to be fulfilled is more complex.)

Okay, now for a harder problem. Suppose you've wandered through the world a bit, and you've observed the following:
(1) So far I've seen 20 objects which have been kittens, and on the 6 occasions I've paid a penny to observe the size of something that's a kitten, all 6 kitten-objects have been little.
(2) So far I've seen 50 objects which have been little, and on the 30 occasions where I've paid a penny to observe the morality of something little, all 30 little objects have been innocent.
(3) This object happens to be a kitten. I want to know whether it's innocent, but I don't want to pay a cent to find out directly. (E.g., if it's an innocent kitten, I can buy it for a cent, sell it for two cents, and make a one-cent profit. But if I pay a penny to observe directly whether the kitten is innocent, I won't be able to make a profit, since gathering evidence is costly.)
Your previous experiences have led you to suspect the general rule "All kittens are little" and also the rule "All little things are innocent", even though you've never before directly checked whether a kitten is innocent.
Furthermore...
You've never heard of logic, and you have no idea how to play that 'game of symbols' with K(x), I(x), and L(x) that we were talking about earlier.
But that's all right. The problem is still solvable by Monte Carlo methods!
First we'll generate a large set of random universes. Then, for each universe, we'll check whether that universe obeys all the rules we currently suspect or believe to be true, like "All kittens are little" and "All little things are innocent" and "The force of gravity goes as the square of the distance between two objects and the product of their masses". If a universe passes this test, we'll check to see whether the inquiry of interest, "Is the kitten in front of me innocent?", also happens to be true in that universe.
We shall repeat this test a large number of times, and at the end we shall have an approximate estimate of the probability that the kitten in front of you is innocent.

On this algorithm, you perform inference by visualizing many possible universes, throwing out universes that disagree with generalizations you already believe in, and then checking what's true (probable) in the universes that remain. This algorithm doesn't tell you the state of the real physical world with certainty. Rather, it gives you a measure of probability - i.e., the probability that the kitten is innocent - given everything else you already believe to be true.
And if, instead of visualizing many imaginable universes, you checked all possible logical models - which would take something beyond magic, because that would include models containing uncountably large numbers of objects - and the inquiry-of-interest was true in every model matching your previous beliefs, you would have found that the conclusion followed inevitably if the generalizations you already believed were true.
This might take a whole lot of reasoning, but at least you wouldn't have to pay a cent to observe the kitten's innocence directly.
But it would also save you some computation if you could play that game of symbols we talked about earlier - a game which does not create truth, but preserves truth. In this game, the steps can be locally pronounced valid by a mere 'syntactic' check that doesn't require us to visualize all possible models. Instead, if the mere syntax of the proof checks out, we know that the conclusion is always true in a model whenever the premises are true in that model.
And that's a mathematical proof: A conclusion which is true in any model where the axioms are true, which we know because we went through a series of transformations-of-belief, each step being licensed by some rule which guarantees that such steps never generate a false statement from a true statement.
The way we would say it in standard mathematical logic is as follows:
A collection of axioms X semantically implies a theorem Y, if Y is true in all models where X are true. We write this as X ⊨ Y.
A collection of axioms X syntactically implies a theorem Y within a system S, if we can get to Y from X using transformation steps allowed within S. We write this as X ⊢ Y.
The point of the system S known as "classical logic" is that its syntactic transformations preserve semantic implication, so that any syntactically allowed proof is semantically valid:
If X ⊢ Y, then X ⊨ Y.
If you make this idea be about proof steps in algebra doing things that always preserve the balance of a previously balanced scale, I see no reason why this idea couldn't be presented in eighth grade or earlier.
I can attest by spot-checking for small N that even most mathematicians have not been exposed to this idea. It's the standard concept in mathematical logic, but for some odd reason, the knowledge seems constrained to the study of "mathematical logic" as a separate field, which not all mathematicians are interested in (many just want to do Diophantine analysis or whatever).
So far as real life is concerned, mathematical logic only tells us the implications of what we already believe or suspect, but this is a computational problem of supreme difficulty and importance. After the first thousand times we observe that objects in Earth gravity accelerate downward at 9.8 m/s2, we can suspect that this will be true on the next occasion - which is a matter of probabilistic induction, not valid logic. But then to go from that suspicion, plus the observation that a building is 45 meters tall, to a specific prediction of how long it takes the object to hit the ground, is a matter of logic - what will happen if everything we else we already believe, is actually true. It requires computation to make this conclusion transparent. We are not 'logically omniscient' - the technical term for the impossible dreamlike ability of knowing all the implications of everything you believe.
The great virtue of logic in argument is not that you can prove things by logic that are absolutely certain. Since logical implications are valid in every possible world, "observing" them never tells us anything about which possible world we live in. Logic can't tell you that you won't suddenly float up into the atmosphere. (What if we're in the Matrix, and the Matrix Lords decide to do that to you on a whim as soon as you finish reading this sentence?) Logic can only tell you that, if that does happen, you were wrong in your extremely strong suspicion about gravitation being always and everywhere true in our universe.
The great virtue of valid logic in argument, rather, is that logical argument exposes premises, so that anyone who disagrees with your conclusion has to (a) point out a premise they disagree with or (b) point out an invalid step in reasoning which is strongly liable to generate false statements from true statements.
For example: Nick Bostrom put forth the Simulation Argument, which is that you must disagree with either statement (1) or (2) or else agree with statement (3):
(1) Earth-originating intelligent life will, in the future, acquire vastly greater computing resources.
(2) Some of these computing resources will be used to run many simulations of ancient Earth, aka "ancestor simulations".
(3) We are almost certainly living in a computer simulation.
...but unfortunately it appears that not only do most respondents decline to say why they disbelieve in (3), most are unable to understand the distinction between the Simulation Hypothesis that we are living in a computer simulation, versus Nick Bostrom's actual support for the Simulation Argument that "You must either disagree with (1) or (2) or agree with (3)". They just treat Nick Bostrom as having claimed that we're all living in the Matrix. Really. Look at the media coverage.
I would seriously generalize that the mainstream media only understands the "and" connective, not the "or" or "implies" connective. I.e., it is impossible for the media to report on a discovery that one of two things must be true, or a discovery that if X is true then Y must be true (when it's not known that X is true). Also, the media only understands the "not" prefix when applied to atomic facts; it should go without saying that "not (A and B)" cannot be reported-on.
Robin Hanson sometimes complains that when he tries to argue that conclusion X follows from reasonable-sounding premises Y, his colleagues disagree with X while refusing to say which premise Y they think is false, or else say which step of the reasoning seems like an invalid implication. Such behavior is not only annoying, but logically rude, because someone else went out of their way and put in extra effort to make it as easy as possible for you to explain why you disagreed, and you couldn't be bothered to pick one item off a multiple-choice menu.
The inspiration of logic for argument is to lay out a modular debate, one which conveniently breaks into smaller pieces that can examined with smaller conversations. At least when it comes to trying to have a real conversation with a respected partner - I wouldn't necessarily advise a teenager to try it on their oblivious parents - that is the great inspiration we can take from the study of mathematical logic: An argument is a succession of statements each allegedly following with high probability from previous statements or shared background knowledge. Rather than, say, snowing someone under with as much fury and as many demands for applause as you can fit into sixty seconds.
Michael Vassar is fond of claiming that most people don't have the concept of an argument, and that it's pointless to try and teach them anything else until you can convey an intuitive sense for what it means to argue. I think that's what he's talking about.
Meditation: It has been claimed that logic and mathematics is the study of which conclusions follow from which premises. But when we say that 2 + 2 = 4, are we really just assuming that? It seems like 2 + 2 = 4 was true well before anyone was around to assume it, that two apples equaled two apples before there was anyone to count them, and that we couldn't make it 5 just by assuming differently.
Part of the sequence Highly Advanced Epistemology 101 for Beginners
Next post: "Logical Pinpointing"
Previous post: "Causal Reference"
218 comments
Comments sorted by top scores.
comment by bryjnar · 2012-10-29T12:00:53.834Z · LW(p) · GW(p)
A proof is a social construct – it is what we need it to be in order to be convinced something is true. If you write something down and you want it to count as a proof, the only real issue is whether you’re completely convincing.
Some philosophers of mathematics (often those who call themselves "naturalists") argue that what we ought to be paying attention to in mathematics is what mathematicians actually do. If you look at it like this, you notice that very few mathematicians actually produce fully valid proofs in first-order logic, even when they're proving a new theorem (although there are salutory attempts to change this, such as proving lots of existing theorems using Coq).
The best encapsulation that I've heard of what mathematicians actually do when they offer proofs is something like:
You don't have to provide a fully rigorous proof, you just have to convince me that you could do if you had to.
It seems pretty clear to me that this still indicates that mathematicians are really interested in the existence of the formal proof, but they use a bunch of heuristics to figure out whether it exists and what it is. Rather than mathematical practice showing us that the notion of proof is really this more social notion, and that therefore the formal version is somehow off base.
Replies from: benelliott↑ comment by benelliott · 2012-11-01T21:30:43.811Z · LW(p) · GW(p)
Another way of looking at it, would be to imagine what would happen if we started writing proofs in formal logic. Quite quickly, people would notice patterns of inferences that appeared again and again, and save space and time by encoding the pattern in a single statement which anyone could use, not actually an additional axiom since it follows from the others, but working like one. If you do this a lot quite soon you would be almost entirely using short-cuts like this, and begin to notice higher-level patterns in the short-cuts you are using. Keep extending this short-cut-generating process until mathematical papers are actually of a remotely readable length, and you get something that looks quite a lot like modern mathematics.
I'm not claiming this is what actually happened, what actually happened is a few hundred years ago mathematics really was as wishy-washy as you say it is, and people gradually realised what they should actually be doing, then skipped the stage of writing 10000-page proofs in formal logic because mathematicians aren't stupid and could see where the chain ended from there.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-25T01:59:36.161Z · LW(p) · GW(p)
This is meant to present a completely standard view of semantic implication, syntactic implication, and the link between them, as understood in modern mathematical logic. All departures from the standard academic view are errors and should be flagged accordingly.
Although this view is standard among the professionals whose job it is to care, it is surprisingly poorly known outside that. Trying to make a function call to these concepts inside your math professor's head is likely to fail unless they have knowledge of "mathematical logic" or "model theory".
Beyond classical logic lie the exciting frontiers of weird logics such as intuitionistic logic, which doesn't have the theorem ¬¬P → P. These stranger syntaxes can imply entirely different views of semantics, such as a syntactic derivation of Y from X meaning, "If you hand me an example of X, I can construct an example of Y."
I can't actually recall where I've seen someone else say that e.g. "An algebraic proof is a series of steps that you can tell are locally licensed because they maintain balanced weights", but it seems like an obvious direct specialization of "syntactic implication should preserve semantic implication" (which is definitely standard). Similarly, I haven't seen the illustration of "Where does this first go from a true equation to a false equation?" used as a way of teaching the underlying concept, but that's because I've never seen the difference between semantic and syntactic implication taught at all outside of one rare subfield of mathematics. (AAAAAAAAAAAAHHHH!)
The idea that logic can't tell you anything with certainty about the physical universe, or that logic is only as sure as its premises, is very widely understood among Traditional Rationalists:
... as far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality.
--Albert Einstein
Replies from: lukeprog, bryjnar, JasonGross, chaosmosis, gwern, TsviBT, Klao, TimS, thomblake, Jayson_Virissimo↑ comment by lukeprog · 2012-10-29T08:52:33.999Z · LW(p) · GW(p)
I can't actually recall where I've seen someone else say that e.g. "An algebraic proof is a series of steps that you can tell are locally licensed because they maintain balanced weights"
The metaphor of a scale is at least a common teaching tool for algebra: see 1, 2, 3.
Replies from: Yvain, Eliezer_Yudkowsky↑ comment by Scott Alexander (Yvain) · 2012-10-29T09:18:49.847Z · LW(p) · GW(p)
I was taught algebra with a scale in the sixth grade. We had little weights that said "X" on them and learned that you could add or take away "x" from both sides.
Replies from: Jay_Schweikert↑ comment by Jay_Schweikert · 2012-10-31T16:44:54.810Z · LW(p) · GW(p)
Yeah, we were taught in basically the exact same way -- moving around different colored weights on plastic print-outs of balances. I'll also note that this was a public (non-magnet) school -- a reasonably good public school in the suburbs, to be sure, but not what I would think of as an especially advanced primary education.
I join lots of other commenters as being genuinely surprised that the content of this post is understood so little, even by mathematicians, as it all seemed pretty common sense to me. Indeed, my instinctive response to the first meditation was almost exactly what Eliezer went on to say, but I kept trying to think of something else for a while because it seemed too obvious.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T10:08:02.942Z · LW(p) · GW(p)
GOOD. Especially this one: http://www.howtolearn.com/2011/02/demystifying-algebra
But I don't recall ever getting that in my classes. Also, the illustration of "first step going from true equation to false equation" I think is also important to have in there somewhere.
Replies from: Vertigo↑ comment by Vertigo · 2013-03-21T02:35:03.932Z · LW(p) · GW(p)
I love this idea, so I've taken it to the next level: http://sphotos-a.xx.fbcdn.net/hphotos-ash4/405144_10151268024944598_356596037_n.jpg
{kind=link}
Hanger, paper clips, dental floss, tupperware, pencil, ruler, and lamp. If we're trying to be concrete about this, no need to do it only part way.
↑ comment by bryjnar · 2012-10-29T11:53:49.789Z · LW(p) · GW(p)
My data point: as an undergraduate mathematician at Oxford, the mathematical logic course was one of the most popular, and certainly covered most of this material. I guess I haven't talked a huge number of mathematicians about logic, but I'd be pretty shocked if they didn't know the difference between syntax and semantics. YMMV.
Replies from: wuncidunci, handoflixue↑ comment by wuncidunci · 2012-10-29T21:56:57.649Z · LW(p) · GW(p)
Another data point: in Cambridge the first course in logic done by mathematics undergraduates is in third year. It covers completeness and soundness of propositional and predicate logic and is quite popular. But in third year people are already so specialised that probably way less than half of us take it.
↑ comment by handoflixue · 2012-10-30T19:23:29.934Z · LW(p) · GW(p)
It terrifies me that I seem to be unique in having had pretty much all of this covered in my high school's standard math curriculum (not even an advanced or optional class). Eliezer's method of "find the point where it becomes untrue" wasn't standard, but I think (p ~0.5) that my teacher went over it when I wrote a proof of 2=1 on the board. I knew he was a cool math teacher who made a point of tutoring flagging students, but I hadn't realized he was this exceptional.
Replies from: DaFranker↑ comment by DaFranker · 2012-10-30T19:27:28.563Z · LW(p) · GW(p)
Judging just from your description, he's probably more than two standard deviations of abnormal.
Your curriculum sounds at least a good deal above average, but the core problem is that most "curricula" are effectively nothing more than a list of things that teachers should make sure to mention, along with a separate, disjoint, often not correlated list of things that will be "tested" in an exam.
I expect many curricula would contain a good deal of the good parts of traditional rationality and mathematics, but there are many steps between a list on one sheet of paper that each teacher must read once a year and actual non-password understanding becoming commonplace among students.
I still have a copy of my Secondary 4 (US 10th / high school sophomore) curriculum somewhere, which my math teacher gave me secretly back then despite the threat of severe reprimand (our teachers were not even allowed to disclose the actual curriculum - that's how bad things often are). We both verified back then that not even half of what's supposed to be covered according to this piece of paper ever actually gets taught in most classes. That teacher really was that exceptional, but he only had so much time, split across several hundred students.
↑ comment by JasonGross · 2013-10-21T00:43:38.196Z · LW(p) · GW(p)
"An algebraic proof is a series of steps that you can tell are locally licensed because they maintain balanced weights", but it seems like an obvious direct specialization of "syntactic implication should preserve semantic implication"
Eliezer, I very much like your answer to the question of what makes a given proof valid, but I think your explanation of what proofs are is severely lacking. To quote Andrej Bauer in his answer to the question "Is rigour just a ritual that most mathematicians wish to get rid of if they could?", treating proofs as syntatic objects "puts logic where analysis used to be when mathematicians thought of functions as symbolic expressions, probably sometime before the 19th century." If the only important thing about the steps of a proof are that they preserve balanced weights (or semantic implication), then it shouldn't be important which steps you take, only that you take valid steps. Consequently, it should be either nonsensical or irrelevant to ask if two proofs are the same; the only important property of a proof, mathematically, validity (under this view). But this isn't the case. People care about whether or not proofs are new and original, and which methods they use, and whether or not they help give a person intuition. Furthermore, it is common to prove a theorem, and refer to a constant constructed in that proof. (If the only important property of a proof were validity, this should be an inadmissible practice.) Finally, as we have only recently discovered, it is fruitful to interpret proofs of equality as paths in topological spaces! If a proof is just a series of steps which preserve semantic implication, we should be wary of models which only permit continuous preservation of semantic implication, but this interpretation is precisely the one which leads to homotopy type theory.
So while I like your answer to the question "What exactly is the difference between a valid proof and an invalid one?", I think proof-relevant mathematics has a much better answer to the question you claimed to answer "What exactly is a proof?"
(By the way, I highly reccomend Andrej Bauer's answer to anyone interested in eloquent prose about why proof-relevant mathematics and homotopy type theory are interesting.)
↑ comment by chaosmosis · 2012-10-29T17:33:24.764Z · LW(p) · GW(p)
Similarly, I haven't seen the illustration of "Where does this first go from a true equation to a false equation?" used as a way of teaching the underlying concept,
My middle school algebra books discussed this on a very basic level. The problem in the book would show the work of a fictional child who was trying to solve a math problem and failing, and the real student would be told to identify where the first one went wrong and how the problem should have been solved instead.
I never saw it done with anything more complicated than algebra, though.
I'm not sure whether or not this is common, either.
↑ comment by TsviBT · 2012-10-29T07:04:49.776Z · LW(p) · GW(p)
Great post!
Trying to make a function call to these concepts inside your math professor's head is likely to fail unless they have knowledge of "mathematical logic" or "model theory".
Hrmm... I don't think that's right at all, at least for professors who teach proof-based classes. Doing proofs, in any area, really does feel like going from solid ground to new ground, only taking steps that are guaranteed to keep you from falling into the lava. My models of my math professors understand how an argument connects its premises to its conclusions - but I haven't gotten into philosophical discussions with them. My damned philosophy professors, on the other hand, are the logically-rudest people I've ever spoken to.
BTW,
Robin Hanson sometimes complains that when he tries to argue that conclusion X follows from reasonable-sounding premises Y, his colleagues disagree with X while declining to say which premise Y they think is false, or pointing out which step of the reasoning seems like an invalid implication.
I parsed this as "...his colleagues disagree with X while declining ... or while pointing out which step of the reasoning seems like an invalid implication", which is the opposite of what you meant.
Replies from: Eliezer_Yudkowsky, wedrifid↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T07:38:37.007Z · LW(p) · GW(p)
Tried an edit.
Math professors certainly understand instinctively what connects premises to conclusions, or they couldn't do algebra. It's trying to talk about the process explicitly where the non-modern-logicians start saying things like "proofs are absolutely convincing, hence social constructs".
Replies from: Vladimir_Nesov, nshepperd↑ comment by Vladimir_Nesov · 2012-10-29T08:56:48.067Z · LW(p) · GW(p)
A math professor who failed to get a solid course in formal logic sounds unlikely... (If it's not what you are saying, it's not clear to me what that is.)
Replies from: None, Stuart_Armstrong, Eliezer_Yudkowsky↑ comment by Stuart_Armstrong · 2012-10-29T20:59:40.507Z · LW(p) · GW(p)
I never got a course in formal logic, and could probably have been close to being a math professor by now.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T10:06:28.840Z · LW(p) · GW(p)
Yes, well, the problem is that many courses on "logic" don't teach model theory, at least from what I've heard. Try it and see. I could've just been asking the wrong mathematicians - e.g. a young mathematician visiting CFAR knew about model theory, but that itself seems a bit selected. But the modern courses could be better than the old courses! It's been known to happen, and I'd sure be happy to hear it.
(I'm pretty sure mathbabe has been through a course on formal logic and so has Samuel R. Buss...)
Replies from: CronoDAS, None↑ comment by CronoDAS · 2012-10-29T19:23:25.544Z · LW(p) · GW(p)
When I went to Rutgers, the course on proof theory and model theory was taught by the philosophy department. (And it satisfied my humanities requirement for graduation!)
Replies from: Lambda↑ comment by Lambda · 2013-08-31T06:23:02.066Z · LW(p) · GW(p)
At Yale, the situation is similar. I took a course on Gödel's incompleteness theorem and earned a humanities credit from it. The course was taught by the philosophy department and also included a segment on the equivalence of various notions of computability. Coolest humanities class ever!
I shudder to think of what politics were involved to classify it as such, though.
Replies from: VAuroch↑ comment by VAuroch · 2013-12-12T10:37:30.265Z · LW(p) · GW(p)
Probably it was that a Phil professor wanted to teach the class, and no one cared to argue. It's not things like which classes are taught that are the big political fights, to my knowledge; the fights are more often about who gets the right to teach a topic of their choosing, and who doesn't.
↑ comment by nshepperd · 2012-10-29T10:30:35.016Z · LW(p) · GW(p)
Robin Hanson sometimes complains that when he tries to argue that conclusion X follows from reasonable-sounding premises Y, his colleagues disagree with X while declining to say which premise Y they think is false, or pointing out which step of the reasoning seems like an invalid implication.
I parsed this as "...his colleagues disagree with X while declining ... or while pointing out which step of the reasoning seems like an invalid implication", which is the opposite of what you meant.
I think the correct syntax here is "...his colleagues disagree with X while declining to say which premise..., or to point out which step...", which links the two infinitives "to say" and "to point out" to the verb "declining". ETA: The current edit works too.
↑ comment by wedrifid · 2012-10-29T07:13:06.587Z · LW(p) · GW(p)
My damned philosophy professors, on the other hand, are the logically-rudest people I've ever spoken to.
Really? I find people who have done just first year philosophy worse. Maybe I was lucky and had the two philosophy professors who philosophize well.
Replies from: TsviBT↑ comment by TsviBT · 2012-10-30T01:09:30.402Z · LW(p) · GW(p)
Ok, fair enough. My philosophy professors were the logically-rudest adults I've spoken to. Actually, that's not even true. Rather, my philosophy professors were the people I most hoped would have less than the standard rudeness, but did not at all.
An anecdote: spring quarter last year, I tried to convince my philosophy professor that logic preserves certainty, but that we could (probably) never be absolutely certain that we had witnessed a correct derivation. He dodged, and instead sermonized about the history of logic. At one point I mentioned GEB, and he said, I quote, "Hofstadter is something of a one trick pony". Here, "one trick" refers to "self-reference". I was too flabbergasted to respond politely.
Replies from: wedrifid, Peterdjones, VAuroch, wedrifid, wedrifid, TimS↑ comment by wedrifid · 2012-10-30T02:30:51.877Z · LW(p) · GW(p)
I was too flabbergasted to respond politely.
I hope that means you refrain from responding at all. You can't fix broken high status people!
Wait. Oh bother. I try to do that all the time. But I at least tend to direct my efforts towards influencing the social environment such that the incentives for securing said status further are changed so that on the margin the behavior of the high-status people (including, at times, logical rudeness) is somewhat altered. "Persuasion" of a kind.
Replies from: Ritalin↑ comment by Ritalin · 2012-10-30T12:42:13.088Z · LW(p) · GW(p)
Name three ways of you performing said persuasion.
Replies from: wedrifid↑ comment by Peterdjones · 2012-10-30T01:56:18.466Z · LW(p) · GW(p)
He dodged, and instead sermonized about the history of logic
Or tried to tell you something you didn't get.
Replies from: wedrifid↑ comment by wedrifid · 2012-10-30T02:24:51.443Z · LW(p) · GW(p)
Or tried to tell you something you didn't get.
From the description TsviBT gives it is far more likely that the professor was stubbornly sermonizing against a strawman.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-10-30T02:32:09.984Z · LW(p) · GW(p)
If TsviBT failed to get something, it is quite likely that from TsviBT 's perspective the professor was waffling pointlessly, and that TsviBTs account would reflect that. We cannot appeal to TsviBT's subjective perspective as proving the objective validity of itself, can we?
Replies from: wedrifid↑ comment by wedrifid · 2012-10-30T02:38:29.515Z · LW(p) · GW(p)
If TsviBT failed to get something, it is quite likely that from TsviBT 's perspective the professor was waffling pointlessly, and that TsviBTs account would reflect that. We cannot appeal to TsviBT's subjective perspective as proving the objective validity of itself, can we?
I can look at the specific claim TsviBT says he made and evaluate whether it is a true claim or a false claim. It happens to be a true claim.
Assuming you accept the above claim then before questioning whether TsviBT failed to comprehend you must first question whether what TsviBT says he said is what he actually said. It seems unlikely that he is lying about what he said and also not especially likely that he forgot what point he was making---it is something etched firmly in his mind. It is more likely that the professor did not pay sufficient attention to comprehend than it is than that Tsvi did not say what he says he said. The former occurs far more frequently than I would prefer.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-10-30T02:47:10.589Z · LW(p) · GW(p)
Edit:
It happens to be a true claim.
Is it? I think it's a bit misleading. Logic would preserve certainty if there were any certainty. But there probably isnt. Maybe the prof was trying to make that point.
Assuming you accept the above claim then before questioning whether TsviBT failed to comprehend you must first question whether what TsviBT says he said is what he actually said.
No, that isn;t the issue. TsviBT only offered a subjective reaction to the professor's words, not the words themselves. We cannot judge from that whether the professor was rudely missing his birlliant point, or making an even more birlliant riposte, the subteleties of which passed TsviBT by.
Replies from: wedrifid↑ comment by wedrifid · 2012-10-30T03:08:11.945Z · LW(p) · GW(p)
I disagree regarding the accuracy of the claim as stated (you seem to be making the mistake a professor may carelessly make by considering a different more trivial point). I also disagree that the alleged "brilliant riposte" could be 'brilliant' as more than an effective social move given that it moved to to a different point (as a riposte to the claim and not just an appropriate subject change) rather than acknowledging the rather simple technical correction.
You are giving the professor the benefit of doubt that can not exist without TsviBT's claim of what he personally said being outright false.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-10-30T03:11:04.287Z · LW(p) · GW(p)
We don;t know that the riposte moved to a differnt point because we weren;t there and do not have the profs words.
Replies from: wedrifid↑ comment by wedrifid · 2012-10-30T03:17:01.389Z · LW(p) · GW(p)
We don;t know that the riposte moved to a differnt point because we weren;t there and do not have the profs words.
It did one of moving to a different point, agreeing with TsviBT or being outright incorrect. (Again following your assumption that it was, in fact, a riposte.) Moving to a different point is the most likely (and most generous) assumption.
(I have expressed my point as much as I ought and most likely then some. It would be best for me to stop.)
Replies from: Peterdjones↑ comment by Peterdjones · 2012-10-30T03:23:46.067Z · LW(p) · GW(p)
TsviBT 's point was not outright correct,, which leads to further options such as expounding on a subtle error.
↑ comment by VAuroch · 2013-12-12T10:39:51.906Z · LW(p) · GW(p)
To be fair, Hoftstadter is basically a one-trick pony, in that he published one academically-relevant book and then more or less jumped straight to Professor Emeritus in all but name, publishing very little and interacting with academia even less.
Replies from: Laoch↑ comment by Laoch · 2013-12-12T10:54:48.269Z · LW(p) · GW(p)
Just wishing I had read GEB sooner. Reading it now and it seems to be getting ruined by politics.
Replies from: VAuroch↑ comment by wedrifid · 2012-10-30T02:33:08.311Z · LW(p) · GW(p)
An anecdote: spring quarter last year, I tried to convince my philosophy professor that logic preserves certainty, but that we could (probably) never be absolutely certain that we had witnessed a correct derivation.
This does seem correct as stated. I wonder if he deliberately avoided the point to save face regarding a previous error or, as Tim suggested, pattern matched to something different.
↑ comment by wedrifid · 2012-10-30T02:21:47.214Z · LW(p) · GW(p)
Rather, my philosophy professors were the people I most hoped would have less than the standard rudeness, but did not at all.
Now that is far less surprising and on average I can agree there (although I personally had exceptions!) It was the absolute scale that I perhaps questioned.
↑ comment by TimS · 2012-10-30T01:18:43.222Z · LW(p) · GW(p)
To be fair to the professor, conflating deductive and inductive reasoning is a basic error that's easy to pattern match.
Replies from: wedrifid↑ comment by wedrifid · 2012-10-30T02:24:03.076Z · LW(p) · GW(p)
To be fair to the professor, conflating deductive and inductive reasoning is a basic error that's easy to pattern match.
To be fair to TsviBT it is pattern matching to the nearest possible stupid thing that is perhaps the most annoying logical rude tactics there is (whether employed deliberately or instinctively according to social drives).
↑ comment by TimS · 2012-10-29T15:27:12.876Z · LW(p) · GW(p)
to not overload the word 'true' meaning comparison-to-causal-reality, the validity of a mathematical theorem
Ok, deductively true things should be labeled valid to avoid confusion with inductively true things. That's an excellent resolution of the overloading of the word "true" in popular vernacular.
But sometimes you aren't clear in earlier writings about whether you are referring to true or valid. For example, one message of Zero and One are not Probabilities is a sophisticated restatement of the problem of induction. Still, I'm honestly uncertain whether you intended a broader point. I mostly agree with what I understand, but there is some uncertainty about what precise rents are paid by these specific beliefs.
↑ comment by thomblake · 2012-11-01T18:23:40.953Z · LW(p) · GW(p)
FWIW, the undergraduate Philosophy department at Southern Connecticut State University has at least 2 logic courses, and the "Philosophical logic" special topics course covers everything here and then some in a lot of detail. The first half of the course goes through syntax and semantics for propositional logic separately, as well as the relevant theorems that show how to link them up.
↑ comment by Jayson_Virissimo · 2012-10-29T08:02:48.335Z · LW(p) · GW(p)
Finally, an Einstein quote used on the internet that isn't obviously false.
comment by JoshuaZ · 2012-10-30T03:32:26.466Z · LW(p) · GW(p)
I can attest by spot-checking for small N that even most mathematicians have not been exposed to this idea. It's the standard concept in mathematical logic, but for some odd reason, the knowledge seems constrained to the study of "mathematical logic" as a separate field, which not all mathematicians are interested in (many just want to do Diophantine analysis or whatever).
I'm surprised by this claim. Most mathematicians have at least some understanding of mathematical logic. What you may be encountering are people who simply haven't had to think about these issues in a while. But your use of Diophantine analysis, a subbranch of number theory, as your other example is a bit strange because number theory and algebra have become quite adept in the last few years at using model theory to show the existence of proofs even when one can't point to the proof in question. The classical example is the Ax-Grothendieck theorem, Terry Tao discusses this and some related issues here. Similarly , Mochizuki's attempted proof of the ABC conjecture (as I very roughly understand it) requires delicate work with models.
Replies from: ScottMessick, Douglas_Knight↑ comment by ScottMessick · 2012-11-01T05:38:23.855Z · LW(p) · GW(p)
I'm not going to say they haven't been exposed to it, but I think quite few mathematicians have ever developed a basic appreciation and working understanding of the distinction between syntactic and semantic proofs.
Model theory is, very rarely, successfully applied to solve a well-known problem outside logic, but you would have to sample many random mathematicians before you could find one that could tell you exactly how, even if you restricted to only asking mathematical logicians.
I'd like to add that in the overwhelming majority of academic research in mathematical logic, the syntax-semantics distinction is not at all important, and syntax is suppressed as much as possible as an inconvenient thing to deal with. This is true even in model theory. Now, it is often needed to discuss formulas and theories, but a syntactical proof need not ever be considered. First-order logic is dominant, and the completeness theorem (together with soundness) shows that syntactic implication is equivalent to semantic implication.
If I had to summarize what modern research in mathematical logic is like, I'd say that it's about increasingly elaborate notions of complexity (of problems or theorems or something else), and proving that certain things have certain degrees of complexity, or that the degrees of complexity themselves are laid out in a certain way.
There are however a healthy number of logicians in computer science academia who care a lot more about syntax, including proofs. These could be called mathematical logicians, but the two cultures are quite different.
(I am a math PhD student specializing in logic.)
↑ comment by Douglas_Knight · 2012-11-01T03:56:59.195Z · LW(p) · GW(p)
How about you survey mathematicians?
comment by Bakkot · 2012-10-29T06:29:19.846Z · LW(p) · GW(p)
I happen to be studying model theory at the moment. For anyone curious, when Eliezer say 'If X ⊢ Y, then X ⊨ Y' (that is, if a model proves a statement, that statement is true in the model), this is known as soundness. The converse is completeness, or more specifically semantic completeness, which says that if a statement is true in every model of a theory (in other words, in every possible world where that theory is true), then there is a finite proof of the statement. In symbols this is 'If X ⊨ Y, then X ⊢ Y'. Note that this notion of 'completeness' is not the one used in Gödel's incompleteness theorems.
Replies from: Eliezer_Yudkowsky, bryjnar↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T07:41:05.904Z · LW(p) · GW(p)
I plan to talk about this in some posts on second-order logic.
↑ comment by bryjnar · 2012-10-29T12:03:35.960Z · LW(p) · GW(p)
Note that this notion of 'completeness' is not the one used in Gödel's incompleteness theorems.
Um, yes it is, I think. The incompleteness theorems tell you that there are statements that are true (semantically valid) but unprovable, and hence they provide a counterexample to "If X |=Y then X |- Y", i.e. the proof system is not complete.
EDIT: To all respondents: sorry, I was unclear. Yes, I do realise that FOL is complete, but the same notion of completeness generalises to different proof systems. The incompleteness theorems show that the proof system for Peano arithmetic is incomplete, in precisely this way
Replies from: Richard_Kennaway, pragmatist, Bakkot, Eugine_Nier↑ comment by Richard_Kennaway · 2012-10-29T12:47:57.734Z · LW(p) · GW(p)
The incompleteness theorems tell you that there are statements that are true (semantically valid) but unprovable, and hence they provide a counterexample to "If X |=Y then X |- Y", i.e. the proof system is not complete.
This is not correct. In first-order logic, there are no counterexamples to "If X |=Y then X |- Y" -- this is (equivalent to) Gödel's completeness theorem. Gödel's incompleteness theorem says that every first-order theory with an effectively enumerable set of axioms, and which includes arithmetic, contains some propositions which have neither a proof nor a disproof. One typically goes on to say that the undecidable proposition that the proof constructs is true in the "usual model" of the natural numbers, but that is verging on philosophy. At any rate, the truth of the proposition is asserted for only one particular model of the axioms of arithmetic, not all possible models. By the completeness theorem, an undecidable proposition must be true in some models and false in others.
Replies from: bryjnar↑ comment by bryjnar · 2012-10-29T23:15:36.018Z · LW(p) · GW(p)
I think you're confusing syntax and semantics yourself here. An undecidable proposition has no proof, that does not mean it is not semantically valid. So the second theorem shows that for a consistent theory T, the statement ConT that T is consistent is not provable, but it is true in all models.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2012-10-29T23:25:42.038Z · LW(p) · GW(p)
So the second theorem shows that for a consistent theory T, the statement ConT that T is consistent is not provable, but it is true in all models.
No, it isn't. When T includes arithmetic, ConT is not provable in T (provided that T is consistent, the usual background assumption). Therefore by the completeness theorem, there are models of T in which ConT is false.
ConT can be informally read as "T is consistent", and by assumption the latter statement is true, but that is not the same as ConT itself being true in any model other than the unique one we think we are talking about when we talk about the natural numbers.
Replies from: bryjnar↑ comment by bryjnar · 2012-10-29T23:36:45.558Z · LW(p) · GW(p)
Okay, I think this is still because I'm thinking about the second-order logic result. I just went and looked up the FOL stuff, and the incompleteness theorem does give some weird results in FOL! You're quite right, you do get models in which ConT is false.
I think my point still stands for SOL, though.
↑ comment by pragmatist · 2012-10-29T14:29:11.470Z · LW(p) · GW(p)
First-order logic is complete. There are no counterexamples. Since the Godel sentence of a theory is not provable from the axioms of a theory, it follows (from completeness) that the Godel sentence must be false in some "non-standard" models of the axioms.
You can read the first incompleteness theorem as saying that there's no way to come up with a finitely expressible set of axioms that can prove all the truths of arithmetic. This is not in conflict with the completeness theorem. The completeness theorem tells us that if there were some finite (or recursively enumerable) set of axioms of arithmetic such that the inference to any truth of arithmetic from those axioms was semantically valid, then all truths of arithmetic can be proven from that set of axioms. The incompleteness theorem tells us that the antecedent of this conditional is false; it doesn't deny the truth of the conditional itself.
Replies from: bryjnar↑ comment by Bakkot · 2012-10-29T12:48:35.761Z · LW(p) · GW(p)
No, not quite. The distinction is subtle, but I'll try to lay it out.
there are statements that are true (semantically valid) but unprovable, and hence they provide a counterexample to "If X |=Y then X |- Y"
This is not the case. The problem is with the 'and hence': 'X ⊨ Y' should not be read as 'Y is true in X' but rather 'Y is true in every model of X'. There are statements which are true in the standard model of Peano arithmetic which are not entailed by it - that is, 'Y is true in the standard model of Peano arithmetic' is not the same as 'PA ⊨ Y'. So this is not a counterexample.
Rather, the notion of 'complete' in the incompleteness theorem is that a model is complete if for every statement, either the statement or its negation is entailed by the model (and hence provable by semantic completeness). Gödel's incompleteness theorem shows that no theory T containing PA is complete in this sense; that is, there statements S which are true in T but not entailed by it (and so not provable). This is because there are models of T in which S is not true: that is, systems in which every statement in T holds, but S does not. (These systems have some additional structure beyond that required by T.)
Wikipedia may do a better job of explaining this than I can at the moment.
Replies from: bryjnar, IainM↑ comment by IainM · 2012-10-29T15:40:09.360Z · LW(p) · GW(p)
I'll attempt to clarify a little, if that's alright. Given a particular well-behaved theory T, Gödel's (first!) incompleteness theorem exhibits a statement G that is neither provable nor disprovable in T - that is, neither G nor ¬G is syntactically entailed by T. It follows by the completeness theorem that there are models of T in which G is true, and models of T in which ¬G is true.
Now G is often interpreted as meaning "G is not provable in T", which is obviously true. However, this interpretation is an artifact of the way we've carefully constructed G, using a system of relations on Gödel numbers designed to carefully reflect the provability relations on statements in the language of T. But these Gödel numbers are elements of whatever model of T we're using, and our assumption that the relations used in the construction of G have anything to do with provability in T only apply if the Gödel numbers are from the usual, non-crazy model N of the natural numbers. There are unusual, very-much-crazy models of the natural numbers which are not N, however, and if we're using one of those then our relations are unintuitive and wacky and have nothing at all to do with provability in T, and in these G can be true or false as it pleases. So when we say "G is true", we actually mean "G is true if we're using the standard model of the natural numbers, which may or may not even be a valid model of T in the first place".
↑ comment by Eugine_Nier · 2012-10-29T20:27:48.060Z · LW(p) · GW(p)
The simplest way to explain the difference, is that Gödel's completeness theorem applies to first order logic, whereas Gödel's incompleteness theorem applies to second order logic.
Replies from: bryjnarcomment by CarlShulman · 2012-10-30T00:38:57.211Z · LW(p) · GW(p)
Nick Bostrom put forth the Simulation Argument, which is that you must disagree with either statement (1) or (2) or else agree with statement
Given several other assumptions, some empirical, some about anthropic reasoning.
Replies from: Randy_M, Ritalin↑ comment by Randy_M · 2012-10-30T15:33:07.510Z · LW(p) · GW(p)
Right. Most poeple disagree with the premise "Being in a simulation is/can be made to be indistinguishable from reality from the point of view of the simulee."
Edit: And by most people, I mean my analysis of why I intuitively reject the conclusion, not any discussion with other, let alone 3.6+ billion people or statistically representative sampling, etc.
Replies from: electricfistula, ewbrownv↑ comment by electricfistula · 2012-10-31T23:26:29.839Z · LW(p) · GW(p)
Most poeple disagree with the premise "Being in a simulation is/can be made to be indistinguishable from reality from the point of view of the simulee."
I am surprised to hear this. What is your basis for claiming that this is the premise most people object to?
Also, if you are aware of or familiar with this objection - would you mind explaining the following questions I have regarding it?
What reason is there to suspect that a simulated me would have a different/distinguishable experience from real me?
What reason is there to suspect that if there were differences between simulated and real life, that a simulated life would be aware of those differences? That is, even if it is distinguishable - I have only experienced one kind of life and can't say if my totally distinguishable experience of life is that of a simulated life or a real one.
A magic super computer from the future will be able to simulate one atom with arbitrary accuracy - right? A super-enough computer will be able to simulate many atoms interacting with arbitrary accuracy. If this super computer is precisely simulating all the atoms of an empty room containing a single human being (brain included). If this simulation is happening - how could the simulated being possibly have a different experience than its real counterpart in an empty room? Atomically speaking everything is identical.
Maybe questions 1 and 3 are similar - but I'd appreciate if you (or someone else) could enlighten me regarding these issues.
Replies from: mwengler, Randy_M↑ comment by mwengler · 2012-11-01T13:49:11.557Z · LW(p) · GW(p)
What reason is there to suspect that a simulated me would have a different/distinguishable experience from real me?
As someone who has written lots of simulations, there are a few reasons.
1) The simulation deliberately simplifies or changes some things from reality. At minimum, when "noise" is required an algorithm is used to generate numbers which have many of the properties of random numbers but a) are not in fact random, b) are usually much more accurately described by a particular mathematical distribution than would any measurements of the actual noise in the system be.
2) The simulation accidentally simplifies/changes LOTS of things from reality. A brain simulation at the neuron level is likely to simulate observed variations using a noise generator, when these variations arise from a) a ream of detailed motions of individual ions and b) quantum interactions. The claim is generally made that one can simulate at a more and more detailed level AND GET TO THE ENDPOINT where the simulation is "perfect." The getting to the endpoint claim is not only unproven, but highly suspect. At every level of physics we have investigated so far, we have always found a deeper level. Further, the equations of motions at these deepest layers are not known in complete detail. So even if we can get to an endpoint, we have no reason to believe we have gotten to the endpoint in any given simulation. At some point, we are no longer compute bound, we are knowledge bound.
3) There is a great insight in software that "if it isn't tested, its broken." How do you even test a supremely deep simulation of yourself? If there are features of yourself you are still learning, you can't test for them. Until you comprehensievly comprehend yourself, you can never know that a simulation was comprehensively similar.
Even something as simple as a coin toss simulation is likely to be "wrong" in detail. Perhaps you know the coin toss you are actually simulating has .500 or even .500000000 probability of giving heads (where number of zeros represents accuracy to which you know it.) But what is your confidence that the true expectation is 0.5 with a googleplex zeros following (or 3^^3 zeros to pretend to try to fit in here) is the experimental fact? Even 64 zeros would be a bitch to prove. And what are the chances that your simulation gets a 'true expectation" of 0.5 with even 64 zeros after it? With the coin toss, the variance might SEEM trivial, but consider the same uncertainty in the human. You need to predict my next post keystroke for keystroke, which necessarily includes a prediction of whether I will eat an egg for breakfast or a bowel of cereal because the posts I read while eating depend on that. And so on and so on.
My claim is that the existence of an endpoint in finally getting the simulation complete is at best vastly beyond our knowledge (and not in a compute bound way) and at worst simply unknowable for a ream of good reasons. My estimate of the probability that a simulation will ever be reliably known is < 0.01%.
Now we may get to a much easier place: good enough to convince others. That someone can write a simulation of me that cannot be distinguished from me by people who know me is a much lower bar than that the simulatino feels the same as me to itself. To convince others, the simulation may not even have to be conscious, for example. But you are going to have to build your simulation in to a fat human body good enough to fool my wife, and give it a variety of nervous and personality disorders that cause it to come up with digs that are deeply disturbing to her to do even that.
At some point, the comprehensive difficulty of a problem has to open the question: is it reasonable to sweep this under the rug by appealing to an unknown future of much greater capability than we have now, or is doing that a human bias we may need to avoid?
↑ comment by Randy_M · 2012-11-01T21:39:29.675Z · LW(p) · GW(p)
I think enough people are non-reductionist/materialist to have doubt about whether a simulation can be said to have experiences. And we don't exactly have demonstration of this at this time, do we? I mean, in the example cited, Cvilization PC games, there aren't individuals there to have experiences (unless one counts the ai which is running the entire faction), rather there are some blips in databases incrementing the number of units here or there, or raising the population from an abstract 6 to 7. I don't think people will be able to take simulation theory seriously until they have personal interaction with a convincing ai.
That's probably as much an answer as I can give for any of the questsions, other than that I don't see why we can assume that magic super computers are plausible. Related, I don't know if I trust my intuition or reasoning as to whether an infinite simulation will resemble realty in every way (assuming the supercomputer is running equations and databases, etc, rather than actually reconstucting a universe atom by atom or something).
It feels like you're asking me to believe that a map is the same as the territory if it is a good enough map. I know that's just an analogy, but I have a hard time comprehending the sentence that "reality is the solution to/ equations and nothing more" (as opposed to even "reality is predictable by equations").
This is probably not the LW approved answer, but then, I did say most people and not most LW-ers.
Replies from: CronoDAS↑ comment by CronoDAS · 2012-11-03T00:09:39.354Z · LW(p) · GW(p)
I don't understand subjective experience very well, so I don't know if a simulation would have it. I know that an adult human brain does, and I'm pretty sure a rock doesn't, but there are other cases I'm much less certain about. Mice, for example.
↑ comment by ewbrownv · 2012-10-31T21:47:13.240Z · LW(p) · GW(p)
Yes, and this isn't necessarily due to naive 'no mere simulation could feel so real'-type thinking either. Once can make a decent argument that the only known method of making a simulation that can fool modern physics labs would be to simulate the entire planet and much of surrounding space at the level of quantum mechanics, which is computationally intractable even with mature nanotech. Well, that or have an SI constantly tinkering with everyone's perceptions to make them think everything looks correct, but then you have to suppose that such entities have nothing more interesting to do with their runtime.
Replies from: mwengler, TheOtherDave↑ comment by mwengler · 2012-11-01T13:52:34.814Z · LW(p) · GW(p)
I once described a 240 GHz waveguide-structure radio receiver I had built as a "comprehensive analogue simulation of Maxwell's equations incorporating realistic assumptions about the conductivity of real materials used in waveguide manufacture." Although this simulation was insanely accurate, it was much more difficult to a) change parameters in this simulation and b) measure/calculate the results of this simulation than with the more traditional digital simulations of Maxwell's equations we had available.
↑ comment by TheOtherDave · 2012-11-01T01:56:20.779Z · LW(p) · GW(p)
Another possibility would be to build simulated perceivers whose perceptions are systematically distorted in such a way that they will fail to notice the gaps in the simulated environment, I suppose. Which would not require constant deliberate intervention by an intelligence.
Replies from: mwengler↑ comment by mwengler · 2012-11-01T13:55:27.713Z · LW(p) · GW(p)
Before you build that, just to practice your skills you can build some code that will take a blurry picture and with extremely high accuracy show what the picture would have looked like had the camera been in focus. This problem would of course be much easier than knowing that you had built a simulation with holes in it but managed to correct for the absence of information in the simulation in a way that was actually simpler than fixing the simulation in the first place.
I think you might run in to limits based on considerations of information theory that make both tasks possible, but if you start with the image reconstruction problem you will save a lot of effort.
Replies from: CCC, TheOtherDave↑ comment by CCC · 2012-11-01T14:24:04.164Z · LW(p) · GW(p)
Before you build that, just to practice your skills you can build some code that will take a blurry picture and with extremely high accuracy show what the picture would have looked like had the camera been in focus.
This has now been done - to a first approximation, at least.
Replies from: Sengachi↑ comment by Sengachi · 2012-11-04T00:09:32.773Z · LW(p) · GW(p)
The problem with that program is that the information was already there. The information may have been scattered in a semi-random pattern, but it was still there to be reorganized. In this hypothetical simulation, there is a lack of information. And while you can undo randomization to recreate a blurred image, you cannot create information from nothing.
However, the human brain does have some interesting traits which might make it possible for humans to think they are seeing something without creating all the information such a thing would possess. The neocortex has multiple levels. Lower levels detect things like absence and presence of light, which higher levels turn into lines and curves, which even higher levels turn into shapes, which eventually get interpreted as a specific face (the brain has clusters of a few hundred neurons responsible for every face we have memorized). All you would have to do to make a human brain think they saw someone would be to stimulate the top few hundred neurons, the bottom ones need not be given information. Imagine a general telling his troops to move somewhere. Each troop carries out an action, tells their superior, who gives their superior a generalization, who gives their superior a generalization, until the general gets one message "Move going fine". To fool the general (human) into thinking the move is going fine (interacting with something), you don't need to forge the entire chain of events (simulate every quark), you just need to give them the message saying everything is going great (stimulate those few hundred neurons). And then when the matrix person looks closer, the Matrix Lords just forge the lower levels temporarily.
The problem with this is is it does not match the principle "Humans simulating old earth to get information". It would not be giving the future humans any new information they hadn't created, because they would have to fake that information. They wouldn't learn anything. It is possible to fool humans in that way, but the only possible use would be for the purpose of fooling someone. And that would require some serious sadism. So there is a scenario in which humans have the computational power and algorithms to make you live in a simulation you think is real, but have no reason to do so.
Replies from: CCC↑ comment by CCC · 2012-11-04T17:01:39.227Z · LW(p) · GW(p)
The original hypothetical was to create a simulated agent that merely fails to notice a gap. New information does not need to be added for this; information from around the gap merely needs to be averaged out to create what appears to be not-a-gap (much as human sight doesn't have a visible hole in the blind spot).
Now, if the intent was to cover the gap with something specific, then your argument would apply. If, however, the intent is to simply cover up the gap with the most easily calculated non-gap data, then it becomes possible to do so. (Note that it may still remain possible, in such circumstances, to discover the gap indirectly).
↑ comment by TheOtherDave · 2012-11-01T15:46:26.449Z · LW(p) · GW(p)
Well, given that the alternative ebrownv was considering was ongoing tinkering during runtime by a superintelligence, it's not quite clear what my ability to build such code has to do with anything.
There's also a big difference, even for a superintelligence, between building a systematically deluded observer, building a systematically deluded high-precision observer, and building a guaranteed systematically deluded high-precision observer. I'm not sure more than the former is needed for the scenario ebrownv had in mind.
Sure, it might notice something weird one in a million times, but one can probably count on social forces to prevent such anomalous perceptions from being taken too seriously, especially if one patches the simulation promptly on the rare occasions when it doesn't.
↑ comment by Ritalin · 2012-10-30T12:30:02.191Z · LW(p) · GW(p)
Also, 2 seems to imply there's a reason to do historical simulations without the knowledge of the simulees, and to thus effectively have billions of sentient beings lead suboptimal miserable lives without their consent.
Replies from: DaFranker↑ comment by DaFranker · 2012-10-30T14:21:51.548Z · LW(p) · GW(p)
If the project is government-funded, and the government is any conceivable direct descendent of our current forms of government, then this seems like the default result.
When was the last time you didn't hear a religious conservative claim "But they're not really alive, they're just machines, they don't have a soul!" or some similar argument (or the shorthand "Who cares? They're just robots, not living things.") whenever the subject of reverse machine ethics (i.e. how we treat computers, robots and AIs and whether they should be happy or something) came up?
Replies from: Ritalin↑ comment by Ritalin · 2012-10-30T18:52:18.129Z · LW(p) · GW(p)
There's already some effort being done in that direction. If sentient extraterrestrial lifeforms could at least be considered legal animals, what of our own human-made creatures?
I also don't see the point of making historical simulations of that kind in the first place. It strikes me as unnecessarily complex and costly.
Finally, if we've reached that level of development so that virtual constructs mistake themselves for conscious, one would think humans would have developed their use as councelors, pets, company, and so on, and would have come to value them as "more than machines", not because it's true, but because they want it to be. We humans have a lot of trouble fulfilling each other's emotional needs, and, if machines were able to do it better, we'd probably refuse to acknowledge their love, affection, esteem, trust, and so on, as lies.
On the other hand, we might also want to believe that they aren't "real people" so that we can misuse, abuse and destroy them whenever that's convenient, like we used to do with slaves and prostitutes. It certainly raises interesting questions, and I can't presume to know enough about human psychology (or future AI development) to confidently make a prediction one way or another.
Replies from: mwengler, DaFranker↑ comment by mwengler · 2012-11-01T13:58:50.577Z · LW(p) · GW(p)
virtual constructs mistake themselves for conscious
My brain just folded in on itself and vanished. Or at least in simulation it did. I think you may have stated a basilisk, or at least one that works on my self-simulation.
I used to think I was conscious, but then I realized I was mistaken.
Whoever it was that said "I err, therefore I am" didn't know what he was talking about... because he was wrong in thinking he was even conscious!
Replies from: Ritalin, Peterdjones↑ comment by Ritalin · 2012-11-01T18:27:01.889Z · LW(p) · GW(p)
I used to wonder what consciousness could be, until you all shared its qualia with me.
You know, we could simply ask; "What would convince us that the simulated humans are not conscious?" "What would convince us that we ourselves are not conscious?" Because, otherwise, "unconscious homunculi" are basically the same as P-Zombies, and we're making a useless distinction.
Nevertheless, it is possible for a machine to be mistaken about being conscious. Make it un-conscious (in some meaningful way), but make it unable to distinguish conscious from unconscious, and bias its judgment towards qualifying itself as conscious. Basically, the "mistake" would be in its definition of consciousness.
↑ comment by Peterdjones · 2012-11-01T14:21:07.310Z · LW(p) · GW(p)
I used to think I was conscious, but then I realized I was mistaken.
Dennett actually believes somehting like that about phenomenal consciousness.
[Dennett:] These additions are perfectly real, but they are … not made of figment, but made of judgment. There is nothing more to phenomenology than that [Otto:] But there seems to be! [Dennett:] Exactly! There seems to be phenomenology. That's a fact that the heterophenomenologist enthusiastically concedes. But it does not follow from this undeniable, universally attested fact thatth ere really is phenomenology. This is the crux. (Dennett, 1991, p. 366)
Replies from: Ritalin, TheOtherDave↑ comment by TheOtherDave · 2012-11-01T16:23:00.036Z · LW(p) · GW(p)
(nods) There's an amusing bit in a John Varley novel along these lines, where our hero asks a cutting-edge supercomputer AI whether it's genuinely conscious, and it replies something like "I've been exploring that question for a long time, and I'm still not certain. My current working theory is that no, I'm not -- nor are you, incidentally -- but I am not yet confident of that." Our hero thinks about that answer for a while and then takes a nap, IIRC.
↑ comment by DaFranker · 2012-10-30T19:03:04.250Z · LW(p) · GW(p)
I also don't see the point of making historical simulations of that kind in the first place. It strikes me as unnecessarily complex and costly.
Calibration test: How many policies that have been enforced by governments worldwide would you have made the same claim for? How many are currently still being enforced? How many are currently in planning/discussion/voting/etc. but not yet implemented?
In my own, not seeing the point and this being unnecessarily complex and costly, combined with the fact that it's something people discuss as opposed to any random other possible hypothesis, makes it just as valid a candidate for government signaling and status-gaming as many other types of policies.
However, to clarify my own position: I agree that the second premise implies some sort of motive for running such a simulation without caring for the lives of the minds inside it, but I just don't think that the part about having billions of "merely simulated" miserable lives would be of much concern to most people with a motive to do it in the first place.
As evidence, I'll point to the many naive answers to counterfactual muggings of the form "If you don't give me 100$ I'll run a trillion simulated copies of you and torture them immensely for billions of subjective years." "Yeah, so what? They're just simulations, not real people."
It certainly raises interesting questions, and I can't presume to know enough about human psychology (or future AI development) to confidently make a prediction one way or another.
I'd be careful here about constraining your thoughts to "Either magical tiny green buck-toothed AK47-wielding goblins yelling 'Wazooomba' exist, or they don't, right? So it's about 50-50 that they do." I'm not quite sure if there even is any schelling point in-between.
Replies from: Ritalin, CronoDAS↑ comment by Ritalin · 2012-10-30T20:03:22.969Z · LW(p) · GW(p)
I can't say that any policy comes to mind at this point. In my country the norm has always been to claim for more government intervention and higher direct taxes, not less. If anything, I find government spending cuts are the ones that tend to be irrationally implemented and make a mess of perfectly serviceable services, and I always see those as a threat. The private sector is the one in charge of frivolities, luxuries and unnecessary stuff that people still want to spend money on, as long as it isn't public dimes. [I've been downvoted over expressing this kind of opinion in the past; if you have different opinions that consider these to be blatantly stupid, I'll still humbly request that you refrain from doing that. Please.].
It's only something people discuss because, as far as I can tell from the superficial data I've collected so far, some intellectual hipster decided it would be amusing to pose a disturbing and unfalsifiable hypothesis, and see how people reacted to it and argued against it. As far as I'm concerned, until there's any evidence at all that this reality is not the original, it simply doesn't make sense to promote the hypothesis to our attention.
That counterfactual mugging would at least give me pause. Though I think my response would be more long the lines of attempting pre-emptive use of potentially lethal force than simply paying the bribe. That sort of dangerous, genocidal madman shouldn't be allowed access to a computer.
I didn't imply that there are only two ways this can go, but the hypothesis space and the state of current evidence is such that I can't see any specific hypothesis being promoted to my attention, so I'm sticking with the default "this is the original reality" until evidence shows up to make me consider otherwise.
↑ comment by CronoDAS · 2012-11-02T23:50:34.003Z · LW(p) · GW(p)
I'd be careful here about constraining your thoughts to "Either magical tiny green buck-toothed AK47-wielding goblins yelling 'Wazooomba' exist, or they don't, right? So it's about 50-50 that they do." I'm not quite sure if there even is any schelling point in-between.
Complexity-based priors solve that problem. Magical tiny green buck-toothed AK47-wielding goblins yelling 'Wazooomba' are complex, so, in the absence of evidence that they do exist, you're justified in concluding that they don't. ;)
comment by moshez · 2012-10-30T17:47:51.556Z · LW(p) · GW(p)
"I will remark, in some horror and exasperation with the modern educational system, that I do not recall any math-book of my youth ever once explaining that the reason why you are always allowed to add 1 to both sides of an equation is that it is a kind of step which always produces true equations from true equations."
I can now say that my K-12 education was, at least in this one way, better than yours. I must have been 14 at the time, and the realization that you can do that hit me like a ton of bricks, followed closely by another ton of bricks -- choosing what to add is not governed by the laws of math -- you really can add anything, but not everything is equally useful.
E.g., "solve for x, x+1=5"
You can choose to add -1 to the equation, getting "x+1+-1=5+-1", simplify both sides and get "x=4" and yell "yay", but you can also choose to add, say, 37, and get (after simplification) "x+38=42" which is still true, just not useful. My immediate question after that was "how do you know what to choose" and, long story short, 15 years later I published a math paper... :)
Replies from: mwengler, DaFranker, handoflixue, MTGandP, Eliezer_Yudkowsky↑ comment by mwengler · 2012-11-01T13:22:03.729Z · LW(p) · GW(p)
I absolutely remember being taught that the reason we could add something to both sides, subtract something from both sides, divide or multiply... was because it preserved the equality. I think 7th grade. And when I helped my kids on the relevant math (they did not inherit my "intuitive obviousness" gene) I would repeat this over and over.
Of course we all want to blame the teacher or the course when we haven't learned something in the past, but I have seen too many people not learn things that I was repeating and emphasizing and explaining in as many ways as I could imagine or read, and still they didn't get it. I think we have all head the experience of having someone we were explaining something to finally get it and exclaim something like "why didn't you just tell me that in the first place."
↑ comment by DaFranker · 2012-10-30T17:59:32.259Z · LW(p) · GW(p)
I'd probably be interested in reading that paper, since I've never myself figured it out and still have to (grudgingly) rely on the school-drilled method of "do more exercises and solve more problems until it's so painfully obvious that it hurts". AKA the we-have-no-idea-but-do-it-anyway method.
↑ comment by handoflixue · 2012-10-30T17:57:21.234Z · LW(p) · GW(p)
My mat class provided the simple "how to choose" heuristic that you want X to be alone. So if you have "x+1" on one side, you'll need to subtract 1 to get it by itself. X+1-1=5-1. X=4.
I can see how this wouldn't get explicit attention, since I'd suspect it becomes intuitive after a point, and you just don't think to ask that question. I can't see how one could get through even basic algebra without developing this intuition, though o.o
Replies from: moshez, DaFranker↑ comment by moshez · 2012-10-30T20:03:31.305Z · LW(p) · GW(p)
Yes, clearly, a bit after I asked, I learned how to use intuition, and at some point, it became rote. But the bigger point is that this is a special case -- in logic, and in math, there are a lot of truth-preserving transformations, and choosing a sequence of transformations is what doing math is. That interesting interface between logic-as-rigid and math-as-something-exploratory is a big part of the fun in math, and what led me to do enough math that led to a published paper. Of course, after that, I went into software engineering, but I never forgot that initial sensation of "oh my god that is awesome" the first time Moshe_1992 learned that there is no such thing as "moving the 1 from one side of the equation to the other" except as a high-level abstraction.
↑ comment by DaFranker · 2012-10-30T20:21:03.634Z · LW(p) · GW(p)
I can't see how one could get through even basic algebra without developing this intuition, though o.o
And yet so many do. Numbers are horribly scarce in this area, though. Sometimes I get desperate.
Anecdotally, I do remember saying something very similar to high school peers, in a manner that assumed they already understood it, and seeing their face contort in exactly the same manner that it would have had I suddenly metamorphosed into a polar bear and started writing all the equations for fourier and laplace transforms using trails of volcanic ash in mid-air.
This was years after basic algebra had already been taught according to the curriculum, and we were now beginning pre-calculus (i.e. last year of secondary / high school here in québec, calculus itself is never touched in high school level courses).
↑ comment by MTGandP · 2012-11-01T17:47:00.006Z · LW(p) · GW(p)
If you're trying to find the value of x and there's only one x in the equation, it's simply a matter of inverting every function in the equation from the outside in. It's harder if you have multiple x's because you have to try to combine them in some reasonable way—and sometimes you actually want to separate them, e.g. "x^2 - 9 = 0" into "(x - 3)(x + 3) = 0".
Solving this problem appears equivalent to writing a computer program to solve algebraic equations.
Replies from: Decius↑ comment by Decius · 2012-11-05T04:07:36.186Z · LW(p) · GW(p)
For polynomial expressions of the third order or lower in only one variable, the process is trivial. I believe that in every general case for which a solution is guaranteed, there is also a trivial method which will always generate such a solution.
Replies from: asr↑ comment by asr · 2012-11-06T01:43:11.692Z · LW(p) · GW(p)
There are closed form solutions to all cubic or quartic polynomial equations, but they're quite complicated. Do those solutions count as "trivial"?
Replies from: Decius↑ comment by Decius · 2012-11-06T05:42:09.727Z · LW(p) · GW(p)
Are any decisions required to be made in their implementation? If so, they are nontrivial. If not, they are trivial.
I was saying that for every general case in which a zero of a polynomial is guaranteed, there is a deterministic path to determine what the guaranteed zeros are.
Replies from: asr↑ comment by asr · 2012-11-06T06:02:17.669Z · LW(p) · GW(p)
Hrm. Is there a short proof of this claim? It's not completely obvious to me. How do you know there isn't some set of n-th degree polynomials, for which there's a non-constructive proof that they have roots, but where there isn't any known algorithm for finding them?
I suppose you could always do numeric evaluation with bisection or somesuch, since polynomials are smooth. But I think you're saying something more than "iterative numerical methods can find zeros of polynomials over one variable." I also imagine that you don't want to include "explore all possible decision trees" as a valid solution method.
Part of my hesitation is that there are classes of equation (not polynomial) for which it's believed that there aren't efficient algorithms to find solutions. For instance, suppose we have a fixed g, k, n. There's no known efficient technique to find x such that g^x = k, mod n. (This is the discrete logarithm problem.) It seems thinkable to me that there are similar cases over the reals, but where you can't do exhaustive search.
Replies from: None↑ comment by [deleted] · 2012-11-13T14:53:17.915Z · LW(p) · GW(p)
There exist what is called non-algebraic reals, which cannot be described with anything other than the infinite string of decimals they are.
Replies from: asr↑ comment by asr · 2012-11-14T06:32:44.729Z · LW(p) · GW(p)
Yes. I'm aware of them. But that's not quite the question here. The question was whether there were equations that have solutions, that can be found, but where there's no algorithm to do so. So by definition the numbers of interest are definable in some way more succinct than their infinite representation.
As a nitpick: My understanding is that algebraic just means a number is the root of some polynomial equation with rational coefficients. But that's not the same as "cannot be described except with an infinite decimal string." A number might be described succinctly while still being transcendental. The natural logarithm base is transcendental -- not algebraic -- but can be described succinctly. It has a one-letter name ("e") and a well known series expression that converges quickly. I think you want to refer to something like the non-computable reals, not the non-algebraic reals.
Replies from: IlyaShpitser↑ comment by IlyaShpitser · 2012-11-14T06:46:03.926Z · LW(p) · GW(p)
Yes, the distinction is this:
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-01T13:38:46.076Z · LW(p) · GW(p)
I only got K-8[\6] (I'm not a highschool dropout, thank you, I just never went in the first place) so I've got no idea what people learn when they're 14.
Replies from: CronoDAS, Epiphany↑ comment by CronoDAS · 2012-11-03T00:11:54.939Z · LW(p) · GW(p)
Homeschooled! The status-preserving term is "homeschooled"!
Replies from: Curiouskid, Eliezer_Yudkowsky, wedrifid↑ comment by Curiouskid · 2012-11-05T04:26:39.795Z · LW(p) · GW(p)
For the people who got Thiel Fellowships, the status-preserving term is "stopped-out".
Replies from: Eugine_Nier↑ comment by Eugine_Nier · 2012-11-06T02:02:27.471Z · LW(p) · GW(p)
Heck, at that level even "drop-out" works as a form of counter-signaling.
↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-03T00:19:59.132Z · LW(p) · GW(p)
Homeschooling is what Christians do. I'm an autodidact.
Replies from: somervta↑ comment by wedrifid · 2012-11-03T00:41:03.017Z · LW(p) · GW(p)
Homeschooled! The status-preserving term is "homeschooled"!
Homeschooled? That is status-preserving? Really? I think I'd prefer "dropout".
Replies from: CronoDAS↑ comment by CronoDAS · 2012-11-03T00:44:10.042Z · LW(p) · GW(p)
"Homeschooled" is what you say to college admissions people.
"Dropout" implies that you're not interested in continuing your education.
Replies from: Epiphany↑ comment by Epiphany · 2012-11-03T01:18:03.621Z · LW(p) · GW(p)
If you consider the ideas of John Taylor Gatto, the 1991 New York State teacher of the year, regarding schooling, you might hesitate before using the word "schooling" to mean something credible.
His perspective is that schooling is not education and can help or hinder learning (explained under the heading "Learning, Schooling, & Education"). The criticisms he provides in "Dumbing us Down" are pretty nasty. I gave the gist of it and linked to an online book preview here. I highly recommend reading at least the first chapter of that book.
Replies from: CronoDAS↑ comment by CronoDAS · 2012-11-03T02:07:17.193Z · LW(p) · GW(p)
Yeah, I've read some of what he says. He's right and he's wrong; American public education is indeed designed to produce workers, but we still have far more entrepreneurs per capita than, say, China.
Replies from: Epiphany↑ comment by Epiphany · 2012-11-03T04:50:04.966Z · LW(p) · GW(p)
Hmmm. Not to ignore the fact that this essentially sidesteps my point that school should not necessarily be associated with credibility, but you've succeeded in making me curious: what do you think the difference is between the US and China that would explain that?
Replies from: CronoDAS↑ comment by CronoDAS · 2012-11-03T23:30:16.895Z · LW(p) · GW(p)
Actually, I think I'm wrong on the facts here; The GEM 2011 Global Report has some tables about this, but they don't copy/paste very well. The U.S. is ranked first in "early-stage entrepreneurial activity" (percentage of the population that owns or is employed by a business less than three and a half years old) among nations characterized as "innovation-driven economies" (a category that includes most of Europe, Japan, and South Korea) at 12.3%, but "efficiency-driven economies" (which includes China, most of Latin America, and much of Eastern Europe) tend to have higher values; China is listed at 24.0%,
comment by glaucon · 2012-10-29T02:42:51.551Z · LW(p) · GW(p)
The motivation for the extremely unsatisfying idea that proofs are social is that no language—not even the formal languages of math and logic—is self-interpreting. In order to understand a syllogism about kittens, I have to understand the language you use to express it. You could try to explain to me the rules of your language, but you would have to do that in some language, which I would also have to understand. Unless you assume some a priori linguistic agreement, explaining how to interpret your syllogism, requires explaining how to interpret the language of your explanation, and explaining how to interpret the language of that explanation, and so on ad infinitum. This is essentially the point Lewis Carroll was making when he said that "A" and "if A then B" were not enough to conclude B. You also need "if 'A' and 'if A then B' then B" and and so on and so on. You and I may understand that as implied already. But it is not logically necessary that we do so, if we don't already understand the English language the same way.
This is, I think, the central point that Ludwig Wittgenstein makes in The Philosophical Investigations and Remarks on the Foundation of Mathematics. It's not your awesome kitten pictures are problematic. You and I might well see the same physical world, but not agree on how your syllogism applies to it. Along the same lines, Saul Kripke argued that the statement 2+2=4 was problematic, not because of any disagreement about the physical world, but because we could disagree about the meaning of the statement 2+2=4 in ways that no discussion could ever necessarily clear up (and that it was therefore impossible to really say what the meaning of that simple statement is).
In math and logic, this is typically not much of a problem. We generally all read the statement 2+2=4 in a way that seems the same as the way everyone else reads it. But that is a fact about us as humans with our particular education and cognitive abilities, not an intrinsic feature of math or logic. Proof of your kitten syllogism is social in the sense that we agree socially on the meaning of the syllogism itself, but not because states of affairs you represent in your pictures are in any way socially determined.
And if this is normally much of an issue in mathematics, it is incredibly problematic in any kind of metamathematical or metalogical philosophy—in other words, once we start try to explain why math and logic must necessarily be true. The kep point is not that the world is socially constructed, but that any attempt to talk about the world is socially constructed, in a way that makes final, necessary judgments about its truth or falsity impossible.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T02:51:17.862Z · LW(p) · GW(p)
From my perspective, when I've explained why a single AI alone in space would benefit instrumentally from checking proofs for syntactic legality, I've explained the point of proofs. Communication is an orthogonal issue, having nothing to do with the structure of mathematics.
Replies from: glaucon, glaucon↑ comment by glaucon · 2012-10-29T04:15:50.871Z · LW(p) · GW(p)
I thought of a better way of putting what I was trying to say. Communication may be orthogonal to the point of your question, but representation is not. An AI needs to use an internal language to represent the world or the structure of mathematics—this is the crux of Wittgenstein's famous "private language argument"—whether or not it ever attempts to communicate. You can't evaluate "syntactic legality" except within a particular language, whose correspondence to the world is not given a matter of logic (although it may be more or less useful pragmatically).
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-29T05:22:52.993Z · LW(p) · GW(p)
See my reply to Chappell here and the enclosing thread: http://lesswrong.com/lw/f1u/causal_reference/7phu
Replies from: glaucon↑ comment by glaucon · 2012-10-29T08:32:53.175Z · LW(p) · GW(p)
If your point is that it isn't necessarily useful to try to say in what sense our procedures "correspond," "represent," or "are about" what they serve to model, I completely agree. We don't need to explain why our model works, although some theory may help us to find other useful models.
But then I'm not sure see what is at stake when you talk about what makes a proof correct. Obviously we can have a valuable discussion about what kinds of demonstration we should find convincing. But ultimately the procedure that guides our behavior either gives satisfactory results or it doesn't; we were either right or wrong to be convinced by an argument.
↑ comment by glaucon · 2012-10-29T03:31:47.742Z · LW(p) · GW(p)
The mathematical realist concept of "the structure of mathematics"—at least as separate from the physical world—is problematic once you can no longer describe what that structure might be in a non-arbitrary way. But I see your point. I guess my response would be that the concept of "a proof"—which implies that you have demonstrated something beyond the possibility of contradiction—is not what really matters for your purposes. Ultimately, how an AI manipulates its representations of the world and how it internally represents the world are inextricably related problems. What matters is how well the AI can predict/retrodict/manipulate physical phenomena. Your AI can be a pragmatist about the concept of "truth."
comment by chaosmosis · 2012-10-29T01:33:53.913Z · LW(p) · GW(p)
Before I read the rest of the post, I'd like to note that those pictures are adorable. I sincerely hope we'll be seeing more animal cartoons like that in the future.
comment by Stuart_Armstrong · 2012-10-29T20:45:06.263Z · LW(p) · GW(p)
I can attest by spot-checking for small N that even most mathematicians have not been exposed to this idea.
I can testify that in differential geometry, almost nobody knows this idea (I certainly didn't back in that part of my career). But also nobody really thought as proofs as meaningless symbol manipulations; the models in geometry are so intuitively vivid, it feels you are actually exploring a real platonic realm.
(that's why I found logic so hard: you had to follow the proofs, and intuition wasn't reliable)
comment by Klao · 2012-10-31T21:44:47.955Z · LW(p) · GW(p)
(Audiatur et altera pars is the impressive Latin name of the principle that you should clearly state your premises.)
That's not what I thought it means. My understanding was that it's something like: "all parties should be heard", and it's more of a legal thing...
http://en.wikipedia.org/wiki/Audi_alteram_partem
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-01T04:45:20.872Z · LW(p) · GW(p)
http://www.infidels.org/library/modern/mathew/logic.html#alterapars
Replies from: Vaniver↑ comment by Vaniver · 2012-11-01T05:16:45.459Z · LW(p) · GW(p)
I'm not an expert at Latin, but from what I can tell the vast majority of resources on the internet side with Klao's interpretation, and its Google translation seems much closer to the wikipedia version.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-01T07:07:38.681Z · LW(p) · GW(p)
Mmkay. Page updated.
comment by asr · 2012-11-06T02:06:42.698Z · LW(p) · GW(p)
The great virtue of valid logic in argument, rather, is that logical argument exposes premises, so that anyone who disagrees with your conclusion has to (a) point out a premise they disagree with or (b) point out an invalid step in reasoning which is strongly liable to generate false statements from true statements.
This is false as a description of how mathematics is done in practice. If I am confronted with a purported theorem and a messy complicated "proof", there are ways I can refute it without either challenging a premise or a specific step.
- If I find a counterexample to the claimed theorem, readers probably won't need to dive into the proof to find a specific misstep.
- if the theorem contradicts some well-established result, it's probably wrong. (This is closely related to the above)
- If a purported proof falls into a pattern of proof that is known not to work, that is also sufficient grounds for rationally dismissing it. (This came up during the discussion of Vinay Deolalikar's purported P != NP proof -- most of the professionals were extremely skeptical once it became clear that the proof didn't seem to evade the known limitations of so-called natural proofs.)
comment by nhamann · 2012-10-31T03:35:32.237Z · LW(p) · GW(p)
Your account of "proof" is not actually an alternative to the "proofs are social constructs" description, since these are addressing two different aspects of proof. You have focused on the standard mathematical model of proofs, but there is a separate sociological account of how professional mathematicians prove things.
Here is an example of the latter from Thurston's "On Proof and Progress in Mathematics."
When I started as a graduate student at Berkeley, I had trouble imagining how I could “prove” a new and interesting mathematical theorem. I didn’t really understand what a “proof” was.
By going to seminars, reading papers, and talking to other graduate students, I gradually began to catch on. Within any field, there are certain theorems and certain techniques that are generally known and generally accepted. When you write a paper, you refer to these without proof. You look at other papers in the field, and you see what facts they quote without proof, and what they cite in their bibliography. You learn from other people some idea of the proofs. Then you’re free to quote the same theorem and cite the same citations. You don’t necessarily have to read the full papers or books that are in your bibliography. Many of the things that are generally known are things for which there may be no known written source. As long as people in the field are comfortable that the idea works, it doesn’t need to have a formal written source.
At first I was highly suspicious of this process. I would doubt whether a certain idea was really established. But I found that I could ask people, and they could produce explanations and proofs, or else refer me to other people or to written sources that would give explanations and proofs. There were published theorems that were generally known to be false, or where the proofs were generally known to be incomplete. Mathematical knowledge and understanding were embedded in the minds and in the social fabric of the community of people thinking about a particular topic. This knowledge was supported by written documents, but the written documents were not really primary.
I think this pattern varies quite a bit from field to field. I was interested in geometric areas of mathematics, where it is often pretty hard to have a document that reflects well the way people actually think. In more algebraic or symbolic fields, this is not necessarily so, and I have the impression that in some areas documents are much closer to carrying the life of the field. But in any field, there is a strong social standard of validity and truth. ...
comment by CronoDAS · 2012-10-29T19:16:43.165Z · LW(p) · GW(p)
I will remark, in some horror and exasperation with the modern educational system, that I do not recall any math-book of my youth ever once explaining that the reason why you are always allowed to add 1 to both sides of an equation is that it is a kind of step which always produces true equations from true equations.
Would the average 9-year old be able to understand such a math book? (For that matter, would the average teacher of 9-year-olds?)
Replies from: handoflixue, thomblake, Ritalin, DaFranker↑ comment by handoflixue · 2012-10-30T19:34:23.944Z · LW(p) · GW(p)
http://www.wired.com/geekdad/2012/06/dragonbox/all/ Well, Dragon Box suggests that a five year old can get at least the basic idea, so I'd deeply hope a 9 year old could grasp it more explicitly.
Replies from: Bobertron↑ comment by Bobertron · 2012-10-31T23:27:25.975Z · LW(p) · GW(p)
As I understand the article, the game primarily teaches how the rules can be used to solve for something and secondarily it teaches the rules. It doesn't seem to teach at all why the rules are the way they are. That's actually, IMHO, the biggest issue with the game.
comment by MTGandP · 2012-11-01T17:35:32.653Z · LW(p) · GW(p)
I will remark, in some horror and exasperation with the modern educational system, that I do not recall any math-book of my youth ever once explaining that the reason why you are always allowed to add 1 to both sides of an equation is that it is a kind of step which always produces true equations from true equations.
I had a similar experience. When I took Algebra I, I understood that you could add, subtract, multiply, and divide (non-zero) some value to both sides of the equation and it would still be true. I remember at one point I was working on solving an equation that required taking the square root of both sides, and I wondered, "Are you allowed to do that?"
It wasn't until years later that I figured it out: you're allowed to perform any function on both sides of the equation, because both sides represent the same value. For any function, if a = b, f(a) = f(b).
In this context, you're not allowed to divide by 0 because division by 0 is not a function. Multiplication by zero is a function, but every real input maps to an output of 0; the function is not a one-to-one function, and thus not invertible.
Replies from: CronoDAS↑ comment by CronoDAS · 2012-11-03T00:25:26.492Z · LW(p) · GW(p)
I remember at one point I was working on solving an equation that required taking the square root of both sides, and I wondered, "Are you allowed to do that?"
Yes, but you have to watch out, because of the annoying fact that sqrt(x^2) doesn't equal x when x is negative. It's easy to look at x^2 = y, "take the square root of both sides", and end up with x = sqrt(y) without realizing that you left out a step that is not always truth-preserving.
Replies from: MTGandP↑ comment by MTGandP · 2012-11-03T03:19:01.430Z · LW(p) · GW(p)
Strictly speaking, "take the square root of both sides" is not always a truth-preserving operation, so you should really use "take the +/- square root of both sides" instead.
Replies from: Kindly↑ comment by Kindly · 2012-11-03T03:46:08.449Z · LW(p) · GW(p)
"Take the square root of both sides" is always a truth-preserving operation, but subsequently simplifying sqrt(x^2) to x is not.
So when you take the square root of both sides in, e.g., x^2=25, you really get sqrt(x^2)=5. Simplifying that to x=5 is where you lose generality.
Replies from: Decius↑ comment by Decius · 2012-11-05T04:03:24.103Z · LW(p) · GW(p)
sqrt(x^2)=5 or -5, along with an infinite number of complex values.
Replies from: JoshuaZ, Kindly↑ comment by JoshuaZ · 2012-11-10T19:20:51.954Z · LW(p) · GW(p)
sqrt(x^2)=5 or -5, along with an infinite number of complex values
No. Even in the complex plane there are only two possible square roots. Moreover, if one wants to sqrt to be a function one needs a convention, hence we definite sqrt to be the non-negative square root when it exists.
↑ comment by Kindly · 2012-11-05T04:24:59.036Z · LW(p) · GW(p)
You could define sqrt as a multi-valued function, in which case, when you apply it to x^2 = 25, you will get +/-x = +/-5, but you don't have to. We can take the positive square root (which is what people usually mean) and get sqrt(x^2)=sqrt(25)=5, and the operation is truth-preserving. sqrt(x^2) then simplifies to |x|.
Complex numbers are a bit trickier, but you don't get "an infinite number of complex values". Even over the complex numbers, the only square roots of 25 are 5 and -5. In general, there are two possible square roots, and the popular one to take is the one with positive real part. So everything I said above is still true, except sqrt(x^2) doesn't simplify nicely -- it's no longer equal to |x|. So when you take square roots of complex numbers it's probably better to go the multi-valued function approach with the +/-.
Replies from: Decius↑ comment by Decius · 2012-11-05T17:30:35.491Z · LW(p) · GW(p)
Squaring is not truth-preserving (Although I think raising to any power not an even number is, at least for real numbers). Why would even roots be truth-preserving?
Replies from: Kindly↑ comment by Kindly · 2012-11-05T17:45:08.049Z · LW(p) · GW(p)
What? For any function f, if x=y, then f(x) = f(y). Squaring is a function. Do you mean something else by truth-preserving?
Squaring can introduce truth into a falsehood. For example, if we write -5 = 5, that's false, but we square both sides and get 25=25, and that's true. Furthermore, squaring doesn't preserve the truth of an inequality: -5 < 3, but 25 > 9.
Replies from: Decius↑ comment by Decius · 2012-11-05T20:29:36.646Z · LW(p) · GW(p)
Ah- if you don't define the (principle) square root to be the inverse of squaring, the apparent contradiction goes away.
I concluded that you wanted to be able to preserve falsehood as well. Squaring preserves falsehood in the domain of the nonnegative reals, exactly like multiplication and division by positive values does.
comment by Peterdjones · 2012-10-30T03:38:10.255Z · LW(p) · GW(p)
The great virtue of valid logic in argument, rather, is that logical argument exposes premises, so that anyone who disagrees with your conclusion has to (a) point out a premise they disagree with or (b) point out an invalid step in reasoning which is strongly liable to generate false statements from true statements.
Further to that, there is an advantage to the maker of an argument, in that they have to make explicit assumptions they may not have realised they were making. Speaking of imoplicit assumptions...
For example: Nick Bostrom put forth the Simulation Argument, which is that you must disagree with either statement (1) or (2) or else agree with statement (3):
(1) Earth-originating intelligent life will, in the future, acquire vastly greater computing resources.
(2) Some of these computing resources will be used to run many simulations of ancient Earth, aka "ancestor simulations".
(3) We are almost certainly living in a computer simulation.
(3) is not entailed by the conjunction of (1) and (2). You also need to assume something like "the kind of consciousness we have is computationally simulable". If that is false, no amount of computing power will make the argument work.
Replies from: rkyeun, Decius, scav↑ comment by rkyeun · 2012-11-20T05:29:59.758Z · LW(p) · GW(p)
Law of Identity. If you "perfectly simulate" Ancient Earth, you've invented a time machine and this is the actual Ancient Earth.
If there's some difference, then what you're simulating isn't actually Ancient Earth, and instead your computer hardware is literally the god of a universe you've created, which is a fact about our universe we could detect.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-11-20T13:06:26.633Z · LW(p) · GW(p)
A simulation consists of an inner part that is being simulated and an outer part that is doing the simulating. However perfect the inner part is, it is not the same as the historic event because the historic event did not have the outer part. There is also the issue that in some cases a thing's history is taken to be part of it identity. A perfect replica of the Mona Lisa created in a laboratory would not be the Mona Lisa, since part of the identity of The Mona Lisa is its having been painted by Leonardo.
Replies from: rkyeun↑ comment by rkyeun · 2012-11-23T16:42:39.812Z · LW(p) · GW(p)
However perfect the inner part is, it is not the same as the historic event because the historic event did not have the outer part.
False. The outer part is irrelevant to the inner part in a perfect simulation. The outer part can exert no causal influence, or you won't get a perfect reply of the original event's presumed lack of outer part.
There is also the issue that in some cases a thing's history is taken to be part of it identity.
A thing's history causes it. If you aren't simulating it properly, that's your problem. A perfect simulation of the Mona Lisa was in fact painted by Leonardo, provable in all the same ways you claim the original was.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-11-23T18:52:02.449Z · LW(p) · GW(p)
False. The outer part is irrelevant to the inner part in a perfect simulation.
You cannot claim that such a perfect simulation liteally just is going back in time, because back in time there was no outer part. The claim is dubious for other reasons.
The outer part can exert no causal influence, or you won't get a perfect reply of the original event's presumed lack of outer part.
The outer part can exert whatever influence it likes, so long as it is no detectable from within. A computer must "influence" the programme it is running, even if the pogramme cannot tell how deeply nested in simulation it is .
. A perfect simulation of the Mona Lisa was in fact painted by Leonardo, provable in all the same ways you claim the original was.
A perfect simulation of the ML was in fact simulated and not painted by Leonardo. Suppose someone made a perfect copy and took it into the Louvre in the middle of the night. Then they walk out..with a ML under their arm. We don't know whether or not they have been swapped. We would not then say there are two original ML's , we would say there are two versions of the ML, one of which si the real one,, but we don't know which.
Replies from: bogdanb↑ comment by bogdanb · 2012-12-05T00:59:54.926Z · LW(p) · GW(p)
You cannot claim that such a perfect simulation liteally just is going back in time, because back in time there was no outer part.
You’re not justified in asserting that, for the same reason that your copy in a (correct, accurate) simulation of the moment when you wrote the comment would not be justified in asserting it. You can’t tell there’s no outer part of the universe, because if you could then it would be a part of the universe. Your simulation can’t tell there’s no outer part to its (simulated) universe, because then the simulation wouldn’t be correct and accurate.
There are turtles all the way down.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-12-05T10:55:01.654Z · LW(p) · GW(p)
I am justified in asserting that simulation is not, in principle, time travel. I may not be justifieid in asserting that I am not currently in a simulation. That is a different issue.
Replies from: bogdanb↑ comment by bogdanb · 2012-12-09T12:40:30.797Z · LW(p) · GW(p)
However perfect the inner part is, it is not the same as the historic event because the historic event did not have the outer part.
False. The outer part is irrelevant to the inner part in a perfect simulation.
You cannot claim that such a perfect simulation literally just is going back in time, because back in time there was no outer part.
I am justified in asserting that simulation is not, in principle, time travel.
You are of course right about this statement. It’s not time travel (for “normal” definitions of time travel), since nobody actually traveled through time within one of the universes.
But the precise claim seems to me to have shifted between answers, or at least the way we interpreted them did at each step.
With respect to whether or not the simulated event is the same as the past event in the universe hosting the simulation, I’d say the matters are less clear. First, the question is somewhat unclear: neither the simulated participants nor the historical ones can tell if there’s a outside universe simulating their own’s. So the question is not quite counter-factual, but neither is it about a known (or even knowable) fact. For both the simulated and the historical observers, the presence or absence of an external universe is perfectly hypothetical (or perfectly non-testable, assuming a perfect-enough simulation).
Any “property” of the events (the historical and the simulated one) that can be compared will give the answer “equal”. You (the “real” you) can’t say, for example, “there is an outside-simulated-universe observer of the simulated event, but there was no outside-historical-universe observer of the historical event, so the two events are distinct”, because you can’t (by the assumption that the simulation was perfect enough) have any evidence in favor of the emphasized part of the statement.
I think this is something similar to that between classical and constructivist logic. That is, the answer depends on if your definition of sameness (“same events” in this case) is that
a) Every property can be shown to be identical, or
b) No property can be shown to be distinct.
If it’s (a), then you can’t justify saying that the two events are not the same, nor can you justify saying that they are the same, because there are properties that cannot be compared, so you can’t find out if they’re the same.
If it’s (b), then it follows from the assumptions that the two events are the same. (I take “However perfect the inner part is” to mean that it could be perfect enough that no observation made in the simulated universe is (or even the stronger version, could be) able to give information about the simulating universe’s presence.)
In the (b) case, note that (the historical) you can’t use your knowledge of the simulation to get around this. If the simulation is run for long enough, it will itself contain in its future a you simulating its own history, etc. Even if you stop the simulation before it reaches that point, you can’t claim that its timeline is shorter than yours, because it might be restarted in your future (and potentially catch up).
Of course, you can run a perfect simulation of an event and then intervene in the simulation in a way you remember to be different from your past. But I don’t know if you can design a change that would not require you to run the simulation infinitely long, so as to make sure its future doesn’t contain someone like you (i.e., that there’s no weird consequence of your change that leads to a simulated you that has the same memories as the historical you at the point when you made the simulation diverge, because he doesn’t remember his history correctly). Even if you turn the simulation off, I think that as long as you remember enough about it to be justified in making this kind of claims about it, it could be restarted in your future.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-12-09T14:22:48.039Z · LW(p) · GW(p)
With respect to whether or not the simulated event is the same as the past event in the universe hosting the simulation, I’d say the matters are less clear.
I think it is clear enough. "Is" usally means "is objectively", not "appears to be so from the perspective of a subject". It has been stipulated that there is a state of the univere S1 followed by a subsequent state S2 that includes a simulation of the state S1. That is enough to show, not only that no travel has occured, but that the state of the universe S1 has not been recreated because the state of the universe at T2 is S2 and S2 =/= S1.
First, the question is somewhat unclear: neither the simulated participants nor the historical ones can tell if there’s a outside universe simulating their own’s.
That involves a shift from what is going on to what seems to be.
So the question is not quite counter-factual, but neither is it about a known (or even knowable) fact.
The original scenario simply stipulated that certain things were happening, so where does knowabiliy come in?
Any “property” of the events (the historical and the simulated one) that can be compared will give the answer “equal”.
But that is irrelevant, because the original scenario stipulates that they are not.
Replies from: bogdanb↑ comment by bogdanb · 2012-12-19T11:27:07.507Z · LW(p) · GW(p)
With respect to whether or not the simulated event is the same as the past event in the universe hosting the simulation, I’d say the matters are less clear.
I think it is clear enough. "Is" usally means "is objectively", not "appears to be so from the perspective of a subject". It has been stipulated that there is a state of the univere S1 followed by a subsequent state S2 that includes a simulation of the state S1. That is enough to show, not only that no travel has occured, but that the state of the universe S1 has not been recreated because the state of the universe at T2 is S2 and S2 =/= S1.
(Emphasis mine.)
I think that is the root of our disagreement. I don't think you're supposed to just accept the "usual" meaning of the word "is" when you're discussing unusual situations, and in this particular case I thought we were doing just that. (I.e., I thought we were using an unusual scenario to explore the possible meanings of "equality", rather than using a certain meaning of "equality" to explore an unusual scenario. That was just my thought, I don't mean you're wrong if you were arguing a different issue, just that we failed to agree what we are talking about.)
My reading of the original scenario agrees with the italicised part of your summary, but not the rest. My claim is not that S2 equals S1, but that the simulation of S1 contained in S2 (call it S1b), could contain an event (call it Eb) that is equal with an event E contained in S1 that precedes the running of S2, for some useful definitions of "equal" and choices of E. Note that the original scenario doesn't say that there is no S0 in which S1 is a simulation.
(I also suggested the stronger claim that, given a good enough simulation, it could also be possible for S1b to actually equal S1, though our universe might not allow the creation of a "good enough" simulation. Or, more precisely, that there are useful meanings of "equality" that allow such scenarios, and even that there might not be a consistent meaning for "equal" that don't allow this in any possible universe.)
I think the root of your disagreement is an unstated assumption that "Sy follows (in time) Sx" implies "Sy =/= Sx". That is usually true, but I don't think it should be accepted without justification in unusual cases, such as those containing time loops or (almost-)perfect simulations (which could mean the same thing for some kinds of universes).
Replies from: Peterdjones↑ comment by Peterdjones · 2012-12-19T15:10:28.828Z · LW(p) · GW(p)
for some useful definitions of "equal"
But what's the mileage in the claim that you have an approximate reproducion of a moment in time? A battel re-enacment or historical move would cound for some values of "approximate". That's a long way from time travel.
I think the root of your disagreement is an unstated assumption that "Sy follows (in time) Sx" implies "Sy =/= Sx". That is usually true,
If you are saying Sx and Sy are universal states, then you would need a simulator that somehow sacrifices itself to in generating the simulated state.
↑ comment by scav · 2012-11-03T20:31:11.277Z · LW(p) · GW(p)
If you are a simulation, then the kind of consciousness you think you have is by definition simulable. Right down to your simulated scepticism that it is possible.
My disagreements with (3) are that (1) is not certain to imply sufficient computing resources for such a project, and (2) is pure speculation not supported by compelling reasons for our descendants to do it.
I agree that if (1) is true to the extent that such enormous resources were available and not needed for anything more important, and (2) is true to the extent that > 10^6 such total planetary simulations were carried out, then that would qualify for (3) being true as stated. ( 1.0 - 1.0e-6 is acceptable for me as "almost certainly"). I just think the premises are bullshit, that's all.
Replies from: CCC, Peterdjones↑ comment by CCC · 2012-11-05T19:19:56.561Z · LW(p) · GW(p)
Note that a proper simulation in step (2) would include a number of simulations of simulations, and each of those would include a number of simulations of simulations of simulations. It's not merely the number of simulations that the base-reality does that's important; it's also the number of layers of simulation within that.
For example, with only three layers of simulation, if each humanity (simulated or not) attempts to simulate its own past just 100 times, then that will result in 10^6 third-layer simulations (1010100 simulations altogether).
Replies from: Eugine_Nier↑ comment by Eugine_Nier · 2012-11-06T02:01:05.801Z · LW(p) · GW(p)
The problem with recursive simulations is that the amount of available computronium decreases exponentially with level.
↑ comment by Peterdjones · 2012-11-04T12:46:04.038Z · LW(p) · GW(p)
If you are a simulation, then the kind of consciousness you think you have is by definition simulable. Right down to your simulated scepticism that it is possible.
But one can't assume that is the case in order to prove the premise.
Replies from: scav↑ comment by scav · 2012-11-05T19:08:19.865Z · LW(p) · GW(p)
Nor can you assume that is not the case to argue against being inside a simulation. Speculations about whether consciousness can be simulated are no help either way. If you're being simulated you don't have any base reality to perform experiments on to decide what things are true. You don't even have a testable model of what you might be being simulated on.
So, deciding between two logically consistent but incompatible hypotheses that you can't directly test, you're down to Occam's Razor, which I think favours base reality rather than a simulated universe.
Replies from: Peterdjones↑ comment by Peterdjones · 2012-11-06T10:28:32.155Z · LW(p) · GW(p)
I agree with all of that. But Bostrom's argument is a bad choice for EY's purposes, because the flaws in it are subtle and not really a case of any one premise being plumb wrong.
comment by Rafael Harth (sil-ver) · 2020-08-10T08:54:58.038Z · LW(p) · GW(p)
What is a valid proof in algebra? It's a proof where, in each step, we do something that is universally allowed, something which can only produce true equations from true equations, and so the proof gradually transforms the starting equation into a final equation which must be true if the starting equation was true. Each step should also - this is part of what makes proofs useful in reasoning - be locally verifiable as allowed, by looking at only a small number of previous points, not the entire past history of the proof.
Note that this doesn't really solve the same problem that the quotes in the introduction are trying to solve. Proofs need to be valid and convincing. The 'valid' part is explained in the above. But the definition of the 'convincing' part is hidden in the phrase 'locally verifiable'. It is not clear what locally verifiable means, so this simply leaves open that part of the definition.
Put differently, you could still define
locally verifiablethe mathematicians who read it can correctly assess whether this step is valid
which is the social approach; or
locally verifiable the mathematician who wrote it is capable of transforming the step into a sequence of steps that are valid according to a formal proof system
which is arguably the proper version of the symbolic approach. Both would fit with the explanation above.
(I'm not claiming that leaving this part open makes it a worthless definition, just that it can't be fairly compared to the opening quotes, as those are, in fact, trying to define the convincing part. They're attempts (not necessarily good ones) at solving a strictly harder problem.)
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-10-25T01:58:02.729Z · LW(p) · GW(p)
It has been claimed that logic and mathematics is the study of which conclusions follow from which premises. But when we say that 2 + 2 = 4, are we really just assuming that? It seems like 2 + 2 = 4 was true well before anyone was around to assume it, that two apples equalled two apples before there was anyone to count them, and that we couldn't make it 5 just by assuming differently.
Replies from: None, IainM, Stuart_Armstrong, Stuart_Armstrong, jimrandomh, Jonathan_Lee, CronoDAS, Pentashagon, None, somervta, wuncidunci, DanArmak, CCC, chaosmosis↑ comment by [deleted] · 2012-10-29T15:14:23.387Z · LW(p) · GW(p)
My two cents:
"2 + 2 = 4" is not the same type of statement as, say, "sugar dissolves in water". The statement "sugar dissolves in water" refers to a fact about the world; there are experiments we can perform that would verify that statement.
The statement "2 + 2 = 4", on the other hand, doesn't refer to a fact about the world; it refers to a truth-preserving transformation that can be applied to facts about the world. It allows us to transform "I have 2 + 2 apples" into "I have 4 apples", and "he is 4 years old" to "he is 2 + 2 years old", and so on.
What do the symbols "2", "4", and "+" mean here? Well, they mean a different thing in each context. In one context, "2" means "two apples", "4" means "four apples", and "X + Y" means "X apples, and also Y separate apples". In the other, "2" means "two years earlier", "4" means "four years earlier", and "X + Y" means "X years earlier than the time that was Y years earlier".
Why do we use the same symbols with different meanings? Because there happens to be a set of truth-preserving transformations—the ring axioms—that can be applied to all of these different meanings. Since they obey the same axioms, they also obey the transformation "2 + 2 = 4", which is just a composite of axioms.
Replies from: None↑ comment by [deleted] · 2012-10-29T18:39:44.124Z · LW(p) · GW(p)
Come to think of it, apples don't actually satisfy the ring axioms. In particular, if you have at least one apple, there is no number of apples I can give you such that you no longer have any apples.
Replies from: imaxwell, None, Bakkot, thomblake, CCC↑ comment by imaxwell · 2012-11-01T15:50:36.040Z · LW(p) · GW(p)
In fancy math-talk, we can say apples are a semimodule over the semiring of natural numbers.
- You can add two bunches of apples through the well-known "glomming-together" operation.
- You can multiply a bunch of apples by any natural number.
- Multiplication distributes over both natural-number addition and glomming-together.
- Multiplication-of-apples is associative with multiplication-of-numbers.
- 1 is an identity with regard to multiplication-of-apples.
You could quibble that there is a finite supply of apples out there, so that (3 apples) + (all the apples) is undefined, but this model ought to work well enough for small collections of apples.
↑ comment by Bakkot · 2012-10-29T20:26:01.974Z · LW(p) · GW(p)
Nor is it obvious how multiplication of apples should work. Apples might be considered an infinite cyclic abelian monoid, if you like, but it's beside the point - the point is that once you know what axioms they satisfy, you now know a whole bunch of stuff.
Replies from: khafra↑ comment by thomblake · 2012-10-30T14:59:08.842Z · LW(p) · GW(p)
In particular, if you have at least one apple, there is no number of apples I can give you such that you no longer have any apples.
Sure there is, as long as you realize that "give" and "take" are the same action. Giving -1 apples is just taking 1 apple.
Replies from: None↑ comment by IainM · 2012-10-29T11:38:46.819Z · LW(p) · GW(p)
Well, strictly speaking we don't directly assume that 2+2=4. We have some basic assumptions about counting and addition, and it follows from these that 2+2=4. But that doesn't really avoid the objection, it just moves it down the chain.
Can I change these assumptions? Well, firstly it bears saying that if I do, I'm not really talking about counting or addition any more, in the same way that if I define "beaver" to mean "300 ton sub-Saharan lizard", I'm not really talking about beavers.
So suppose I change my assumptions about counting and addition such that it came out that 2+2=5. Would that mean that two apples added to two apples made five apples? Obviously not. It would mean that two apples added to two apples made five apples, where the starred words refer to altered concepts.
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-10-29T15:16:41.970Z · LW(p) · GW(p)
That's what I was trying to say, but I couldn't find a decent way to put it and gave up.
↑ comment by Stuart_Armstrong · 2012-10-29T21:09:55.847Z · LW(p) · GW(p)
Not exactly on subject, but the numbers up to 5 seem wired into our brain, so in effect, 2+2=4 before you were old enough to know what "2" was.
↑ comment by Stuart_Armstrong · 2012-10-29T21:19:59.127Z · LW(p) · GW(p)
Anyway, I prefer to see 2+2=4 as deriving from set theory, rather than arithmetic. Set theory has its formal rules, and some version of 2+2=4 is one of them.
The question is, do we find things in our world that can be usefully modelled by set theory? We can. For a start, there seem to be many objects that have persistence - cups, trees and planets don't generally split or multiply in the course of a conversation. Also, we can usefully group objects together by their properties, and it is often useful to ignore their differences. Two similar looking trees are likely to do similar kinds of things in similar situations (ie induction over classes of objects is not completely useless).
So two cups of water plus two cups of sugar makes four cups - as long as we're interested in cups, not in the difference between sugar and water. Two elms and two oaks make four trees - as long as we're interest in trees in general, and as long as we aren't thinking on the scale of decades, and as long there isn't a guy with a chainsaw and an itchy trigger finger.
In fact, set theory is so useful about so many things in the world, that we abstract it to a universal truth - 2+2=4 in so many different circumstances, that simply 2+2=4.
So we can't make two apples plus two apples equal five apples (at least not in a few seconds) because apples, in the way that we use the term, and on the time scales that we use the term, are objects that obey the axioms of set theory.
↑ comment by jimrandomh · 2012-10-29T17:22:05.197Z · LW(p) · GW(p)
All the premises necessary to prove that 2+2=4 can be found in the definitions of 2, 4, + and =. Add in some definitions from set theory, and you get sizeof(X)=2 && sizeof(Y)=2 and disjoint(X,Y) |- sizeof(X u Y)=4. The trickier assumptions are in converting from operations on apples to operations on sets. This isomorphism is entailed by the counting algorithm; if there's no person around to count them, then when we said "there are two apples" we were talking about a counterfactual in which something did run the counting algorithm. (Note that the abstract counting algorithm assumes a perfectly-reliable tagging of counted and not-counted-yet objects, and a perfectly reliable incrementing number; a count made by a human has neither of these things, so sometimes counted_as(25,000)+counted_as(25,000gp) = counted_as(50,001).)
Replies from: chaosmosis↑ comment by chaosmosis · 2012-10-29T17:39:49.152Z · LW(p) · GW(p)
This doesn't seem directly relevant to the meditation. Are you saying that, yes, it is an assumption, because it's an argument from definition? Because I guess that would be responsive, but the more interesting question is whether or not those definitions of 2, 4, +, and = can be known to correspond to the external world through more than just our assumptions.
↑ comment by Joanna Morningstar (Jonathan_Lee) · 2012-10-29T11:11:27.453Z · LW(p) · GW(p)
We might mean many things by "2 + 2 = 4". In PA: "PA |- SS0 + SS0 = SSSS0", and so by soundness "PA |= SS0 + SS0 = SSSS0" In that sense, it is a logical truism independent of people counting apples. Of course, this is clearly not what most people mean by "2+2=4", if for no other reason than people did number theory before Peano.
When applied to apples, "2 + 2 = 4" probably is meant as: "apples + the world |= 2 apples + 2 apples = 4 apples". the truth of which depends on the nature of "the world". It seems to be a correct statement about apples. Technically I have not checked this property of apples recently, but when I consider placing 2 apples on a table, and then 2 more, I think I can remove 4 apples and have none left. It seems that if I require 4 apples, it suffices to find 2 and then 2 more. This is also true of envelopes, paperclips, M&M's and other objects I use. So I generalise a law like behaviour of the world that "2 things + 2 things makes 4 things, for ordinary sorts of things (eg. apples)".
At some level, this is part of why I care about things that PA entails, rather than an arbitrary symbol game; it seems that PA is a logical structure that extracts lawlike behaviour of the world. If I assumed a different system, I might get "2+2=5", but then I don't think the system would correspond to the behaviours of apples and M&M's that I want to generalise.
(On the other hand, PA clearly isn't enough; it seems to me that strengthened finite Ramsey is true, but PA doesn't show it. But then we get into ZFC / second order arithmetic, and then systems at least as strong as PA_ordinal, and still lose because there are no infinite descending chains in the ordinals)
↑ comment by Pentashagon · 2012-11-02T00:01:59.576Z · LW(p) · GW(p)
2, +, 2, =, and 4 are just definitions. What they are definitions for depends on the underlying representation (2 might be a definition for S(S(0)) in PA, { {} , {{}} } in ZF set theory, or two apples in school) but what really matters is that there exists a homomorphism between all our representations.
%20+%5E{school}%20H_{school}(2%20apples)%20=%20H_{school}(2%20apples%20+%202%20apples))
Even better, there's generally an inverse homomorphism back the real world.
)))%20+%20H_{school}%5E{-1}(%20H_{ZF}(\{%20\{\}%20,%20\{\{\}\}%20\})))
We can convert between any of our representations while preserving the structure of the relationships between the objects in our representations. What we have discovered is not that "2 + 2 = 4" was always true but that any possible equivalent representation is an inherent property of the universe.
"2 + 2 = 5" just lacks a homomorphism to any other useful representations of reality based on our common definitions.
↑ comment by [deleted] · 2012-10-30T04:44:10.423Z · LW(p) · GW(p)
This is a tricky one...here's my attempt:
One does not have to directly assume that 2 + 2 = 4. Note that all of the following statements correctly describe first-order logic (given the appropriate definitions of 2, 3, and 4):
- ∀x ∀y ((x + y) + 1 = x + (y + 1)) ⊢ (2 + 1) + 1 = 2 + (1 + 1)
- (2 + 1) + 1 = 2 + (1 + 1) ⊢ 3 + 1 = 2 + (1 + 1)
- 3 + 1 = 2 + (1 + 1) ⊢ 4 = 2 + (1 + 1)
- 4 = 2 + (1 + 1) ⊢ 4 = 2 + 2
- 4 = 2 + 2 ⊢ 2 + 2 = 4
So ∀x ∀y ((x + y) + 1 = x + (y + 1)) ⊢ 2 + 2 = 4 (in the context of first-order logic). By the soundness theorem for first-order logic, then, ∀x ∀y ((x + y) + 1 = x + (y + 1)) ⊨ 2 + 2 = 4. (i.e. In all models where "∀x ∀y ((x + y) + 1 = x + (y + 1))" is true, "2 + 2 = 4" is also true.)
So, yes, an assumption is being made, and that assumption is "∀x ∀y ((x + y) + 1 = x + (y + 1))". To evaluate the plausibility of that assumption, we now must specify a domain of discourse, the meaning of '+', and the meaning of '1'. Eliezer means to (I hope!) specify the natural numbers, addition, and one, respectively. Addition over the natural numbers is itself an abstraction of moving different quantities of discrete non-microscopic objects (like apples) next to each other, and observing the quantity after that. Now we can evaluate the plausibility of "∀x ∀y ((x + y) + 1 = x + (y + 1))", or, to translate into English, "If you take a group of y objects and move it next to a group of x objects, and then move one more object next to that newly formed group of objects, and then observe the quantity, then you will observe the same quantity as if you take a group of y objects and move 1 more object next to it, and then move that newly formed group of objects next to a group of x objects, and observe the quantity, no matter what the original numbers x and y are." (So symbolic language is useful after all....) We observe evidence for that statement every day! It is a belief that pays rent in terms of anticipated experience. So, yes, we could assume differently, but we would be doing so in the face of mountains of evidence pointing in the other direction, and with something to protect, that won't do.
Notes:
- How do we know the soundness theorem for first-order logic is true? For one thing, we observe inductive evidence for it all the time (the rules of first-order logic are incredibly intuitive, see page 51 (PDF page 57) of A Primer for Logic and Proof for an enumeration), just as we see inductive evidence for "∀x ∀y ((x + y) + 1 = x + (y + 1))" all the time. We can also use mathematical induction (on the length of a deduction) to prove the soundness theorem, but this probably won't convince someone who is skeptical of even first-order logic.
- It might be helpful to think of (X ⊨ Y) as meaning P(Y|X) = 1.
↑ comment by somervta · 2012-10-29T04:52:38.445Z · LW(p) · GW(p)
Yes, we are making an assumption, and yes, (if it is true) it was true well before anyone was around to assume it, and yes, making a different assumption does not change it's truth value. That's part of what "assumption" means in this sense.
↑ comment by wuncidunci · 2012-10-29T22:28:51.228Z · LW(p) · GW(p)
The fact that if we put any two objects into the same (previously empty) basket as any other two object we will in this basket have four objects is true before we can make any definitions. But the statement 2 + 2 = 4 does not make any sense before we have invented: (a) the numerals 2 and 4, (b) the symbol for addition + and (c) the symbol for equality =. When we have invented meanings for these symbols (symbols as things we use in formal manipulations are quite different from words and were invented quite late, much later than we started to actually solve problems mathematically) we have to show that they correspond to our intuitive meaning of putting things into baskets and counting them, but if they do they will also satisfy, say the Peano axioms for the natural numbers, which are the axioms we tend to start from to prove statements like 2+2=4 or "there are infinitely many prime numbers".
If we were to assume differently such that 2+2 =5, then our notion of + and = would not correspond to the notions of adding objects to a basket and counting them. This is because we could walk through our proof step by step (as described in this post) to find the first line where we write down something that is not true for our usual notion of adding apples, there we would have an assumption or a rule of inference that was assumed in this new theory but which does not correspond to apple comparison.
↑ comment by DanArmak · 2012-10-29T22:00:36.869Z · LW(p) · GW(p)
When people say "2+2=4", what do they mean? Well, "=" is a standard symbol in logic (IIRC it can be derived from purely syntactical rules). But 2 and 4 and + aren't standard; they are defined as part of the model you're working with. For instance, if your model is boolean algebra, there are no 2 or 4, there are only 'true' and 'false', and "2+2=4" isn't valid or invalid, it's syntactically meaningless.
Depending on the model you choose, the sentence "2+2=4" may be true (as for the Peano integers), or undefined (as for boolean algebra), or even false (exchange the usual meanings of the strings "2" and "4"). The latter case would be human-perverse but mathematically-sound. But once you choose a a model, every sentence - including "2+2=4" - is either a logical truth (is valid) or it is not.
Now, there are some standard (in the sense of widely used) models where 2 and 4 and + are used as symbols. These include the integers, the real numbers, etc. Usually when people say "2+2=4", they are thinking of one of these. And in these standard models, "2+2=4" is indeed a logical truth.
So given a model, we are not assuming 2+2=4. Our choice of a standard model dictates that "2+2=4" is true, without extra assumptions. A different model might dictate that "2+2=4" is false, or undefined.
But we are relying on our shared assumption about what model we're talking about - which is a different kind of assumption; it's not about whether "2+2=4" is true (valid), but about what the string means - how to read it. It's similar to the assumption that we're speaking English, rather than a different language in which all the words just happen to mean something else.
↑ comment by CCC · 2012-10-29T20:33:06.131Z · LW(p) · GW(p)
My response, before reading the other responses, is that this is not a matter of assumption but of definition; the symbols '2', '+', '=' and '4' have been defined in such a way that 2+2=4 is a true statement. (The important symbol, here, is + in my view: 2, 4 and = are such basic operations that it's near certain that there would have been some symbol with those meanings. + is pretty basic, but to my mind less basic - it's not the only way to combine two quantities).
This could be seen as taking the definitions of 2, 4, = and + as premises and the truth of the statement 2+2=4 as a conclusion. The conclusion (2+2=4) follows from the premises whether anyone's around to postulate the premises or not; that remains true of any logical statement. So, similarly, if all kittens are little, and if all little things are innocent, then it remains true that all kittens are innocent whether anyone has ever considered that chain of logic before or not.
↑ comment by chaosmosis · 2012-10-29T05:05:17.731Z · LW(p) · GW(p)
It has been claimed that logic and mathematics is the study of which conclusions follow from which premises. But when we say that 2 + 2 = 4, are we really just assuming that? It seems like 2 + 2 = 4 was true well before anyone was around to assume it, that two apples equaled two apples before there was anyone to count them, and that we couldn't make it 5 just by assuming differently.
I think it's an assumption, depending on what you mean when you say something is an assumption. It seems to us like "2 + 2 = 4", but if we assumed differently then it would seem like "2 + 2 = 5". We seem to have justifications to point to to believe that "2 + 2 = 4", but if we assumed that "2 + 2 = 5" then we would also seem to have justifications for that point of view.
I personally have no problem with this and will continue to follow my current beliefs.
comment by Alex_Arendar · 2014-03-19T11:27:48.547Z · LW(p) · GW(p)
claiming that most people don't have the concept of an argument, and that it's pointless to try and teach them anything else until you can convey an intuitive sense for what it means to argue
This is something I can observe everyday in my life. Probably I am less lucky then other guys and in my surrounding there are not that much "respected partners" who are able to listen and not rudely immediately disagree. So yes, it seems like most people don't have the concept of a proper argument. But that way I also did not have thsi concept for a long time. We all learn and change. The easiest way is to say "people are rude and dumb and there is no point in trying to change them". But in real life one cannot just change his surrounding, change the location, change the work and colleagues, change friends. If you want to have more "respected partners" - try to educate those you already have.
comment by BT_Uytya · 2014-02-08T21:05:34.168Z · LW(p) · GW(p)
A conclusion which is true in any model where the axioms are true, which we know because we went through a series of transformations-of-belief, each step being licensed by some rule which guarantees that such steps never generate a false statement from a true statement.
I want to add that this idea justifies material implication ("if 2x2 = 4, then sky is blue") and other counter-intuitive properties of formal logic, like "you can prove anything, if you assume a contradiction/false statement".
Usual way to show the latter goes like this:
1) Assume that "A and not-A" are true
2) Then "A or «pigs can fly»" are true, since A is true
3) But we know that not-A is true! Therefore, the only way for "A or «pigs can fly»" to be true is to make «pigs can fly» true.
4) Therefore, pigs can fly.
The steps are clear, but this seems like cheating. Even more, this feels like a strange, alien inference. It's like putting your keys in a pocket, popping yourself on the head to induce short-term memory loss and then using your inability to remember keys' whereabouts to win a political debate. That isn't how humans usually reason about things.
But the thing is, formal logic isn't about reasoning about things. Formal logic is about preserving the truth; and if you assumed "A and not-A", then there is nothing left to preserve.
How Wikipedia puts it:
An argument (consisting of premises and a conclusion) is valid if and only if there is no possible situation in which all the premises are true and the conclusion is false.
comment by Indon · 2013-05-18T20:36:23.383Z · LW(p) · GW(p)
I would suggest that the most likely reason for logical rudeness - not taking the multiple-choice - is that most arguments beyond a certain level of sophistication have more unstated premises than they have stated premises.
And I suspect it's not easy to identify unstated premises. Not just the ones you don't want to say, belief-in-belief sort of things, but ones you as an arguer simply aren't sufficiently skilled to describe.
As an example:
For example: Nick Bostrom put forth the Simulation Argument, which is that you must disagree with either statement (1) or (2) or else agree with statement (3):
In the given summary (which may not accurately describe the full argument; for the purposes of the demonstration, it doesn't matter either way), Mr. Bostrom doesn't note that, presumably, the number of potential simulated earths immensely outnumbers the number of nonsimulated earths as a result of his earlier statements. But that premise doesn't necessarily hold!
If the inverse of the chances of an Earth reaching simulation-level progress without somehow self-exterminating or being exterminated (say, 1 in 100) is lower than the average number of Earth-simulations that society runs (so less than 100), then the balance of potential earths does not match the unstated premise... in universes sufficiently large for multiple Earths to exist (See? A potential hidden premise in my proposal of a hidden premise! These things can be tricky).
And if most arguers aren't good at discerning hidden premises, then arguers can feel like they're falling into a trap: that there must be a premise there, hidden, but undiscovered, that provides a more serious challenge to the argument than they can muster. And with that possibility, an average arguer might want to simply be quiet on it, expecting a more skilled arguer to discern a hidden premise that they couldn't.
That doesn't seem rude to me, but humble; a concession of lack of individual skill when faced with a sufficiently sophisticated argument.
comment by [deleted] · 2012-11-13T14:44:42.800Z · LW(p) · GW(p)
Truth preserving logic is part of a family of axiom systems called Modal logics. In my humble opinion I think that Truth preserving logic isn't the most interesting; I think the most interesting logic is the Proof or Justification preserving logic, and coming in at a close second, the break-even-betting-on-probabilistic-outcomes logic.
Classical logic is the common name for truth preserving logic, Intuitionist logic for justification preserving and Bayesian reasoning for the last one.
comment by [deleted] · 2012-11-01T02:47:02.099Z · LW(p) · GW(p)
Great post, Eliezer. I've seen all of this before, but never all in one place, and not explained so clearly.
I was going to write a long story about how I became interested in math, but it would take too much time, and I doubt many people would care. So, I'll abbreviate it: Number Munchers → "How can I solve an algebra problem in which there are "x"s on both sides of the equals sign?" → An obsession with pi (I had over 500 decimal places memorized at one point.) → Learning some easier calculus for fun in 9th grade → An obsession with prime numbers → Metamath , and then there were many things after that, too, but interacting with the idea of formal proof verification using a computer is what forced me into much greater mathematical maturity.
Edit: Formatting issues, sorry.
comment by AnotherIdiot · 2012-10-29T13:18:21.366Z · LW(p) · GW(p)
My [uninformed] interpretation of mathematics is that it is an abstraction of concepts which do exist in this world, which we have observed like we might observe gravity. We then go on to infer things about these abstract concepts using proofs.
So we would observe numbers in many places in nature, from which we would make a model of numbers (which would be an abstract model of all the things which we have observed following the rules of numbers), and from our model of numbers we could infer properties of numbers (much like we can infer things about a falling ball from our model of gravity), and these inferences would be "proofs" (and thankfully, because numbers are so much simpler than most things, we can list all our assumptions and have perfect information about them, so our inferences are indeed proofs in the sense that we can be pretty damn certain of them).
But it seems like a common view that mathematics has some sort of special place in the universe, above the laws of physics. I'm not a mathematician, so it is not unlikely that there is something I don't know which takes down my view. But I'd be glad to know what it is.
comment by chaosmosis · 2012-10-29T03:07:12.222Z · LW(p) · GW(p)
.
comment by Purged Deviator · 2021-07-04T08:48:31.131Z · LW(p) · GW(p)
That Monte Carlo Method sounds a lot like dreaming.
comment by jacinthebox · 2012-11-05T20:57:31.945Z · LW(p) · GW(p)
The rejection of the definition of proofs as "mere" symbol manipulation is as insightful as the rejection of physics as the study of fundamental particles or of neurology as the study of neurons in the brain.
Your emotional appeal is about as moving (and nonsensical) as "It is not possible that all human intelligence, complexity, and emotion could be described by the mere atoms making up the neurons in our brains. What of the human heart and soul?"
The fact is that completely rigorous formal proofs are necessary to approach certain problems. It is not because certain mathematicians are "cynical" but because the approach of treating proofs as "mere" symbol manipulations bears fruit. But this does not invalidate the higher level picture that you are so attached to, just as the relativistic and quantum theories did not invalidate Newton's.
Replies from: None, thomblake↑ comment by [deleted] · 2012-11-05T21:02:01.866Z · LW(p) · GW(p)
What, specifically, did Eliezer say in this post that you disagree with?
Replies from: jacinthebox↑ comment by jacinthebox · 2012-11-05T21:08:47.479Z · LW(p) · GW(p)
Replies from: None, None, MixedNutsYou may have read - I've certainly read - some philosophy which endeavors to score points for counter-intuitive cynicism by saying that all mathematics is a mere game of tokens; that we start with a meaningless string of symbols like: ...and we follow some symbol-manipulation rules like "If you have the string 'A ∧ (A → B)' you are allowed to go to the string 'B'", and so finally end up with the string: ...and this activity of string-manipulation is all there is to what mathematicians call "theorem-proving" - all there is to the glorious human endeavor of mathematics.
↑ comment by [deleted] · 2012-11-05T21:39:10.769Z · LW(p) · GW(p)
Also, read through this thread. I'm pretty sure Eliezer's in agreement with you.
Now, exactly how was this post a moving and nonsensical emotional appeal?
Replies from: jacinthebox↑ comment by jacinthebox · 2012-11-05T23:11:03.948Z · LW(p) · GW(p)
I don't consider the post to be an emotional appeal, just the phrase "and this activity of string-manipulation is all there is to what mathematicians call "theorem-proving" - all there is to the glorious human endeavor of mathematics." I mean, there is essentially no content there. Just a rough outline of a philosophy, and then not even a legitimate attack on it, just a "if they are right, then mathematics doesn't seem glorious to me any longer!"
Replies from: None↑ comment by [deleted] · 2012-11-05T21:27:33.817Z · LW(p) · GW(p)
I agree that mathematical symbols are inherently meaningless. I doubt Eliezer would disagree with that.
Mathematicians do assign meaning to symbols while working, though. See this comment for an example.
↑ comment by MixedNuts · 2012-11-05T21:18:51.095Z · LW(p) · GW(p)
Yeah, when it starts with "You may have read philosophy trying to score points by saying", it doesn't mean the writer endorses it.
Replies from: jacinthebox↑ comment by jacinthebox · 2012-11-05T21:28:52.171Z · LW(p) · GW(p)
I'm sorry if I wasn't clear. I endorse the "cynical view" that mathematics is fundamentally symbol manipulation. Fundamental in the sense that mathematics as we currently know it can be completely described by symbol manipulation without having to resort to notions such as "intuition." Eliezer, apparently, disagrees with this philosophy on the grounds that it is robbing mathematics of something which he finds aesthetically pleasing.
↑ comment by thomblake · 2012-11-05T21:57:25.307Z · LW(p) · GW(p)
You seem to be arguing that mathematics is all syntax and no semantics. I shall refer you to Gödel numbering, as well as the recursion theorem.
comment by Johnicholas · 2012-10-29T02:22:35.046Z · LW(p) · GW(p)
Uncountability is an idea that skeptics/rationalists/less-wrongers should treat with a grain of salt.
Inside of a particular system, you might add an additional symbol, "i", with the assumed definitional property that "i times i plus one equals zero". This is how we make complex numbers. We might similarly add "infinity", with an assumed definitional property that "infinity plus one equals infinity". Depending on the laws that we've already assumed, this might form a contradiction or cause everything to collapse, but in some situations it's a reasonable thing to do. This new symbol, "infinity" can be definitionally large in magnitude without being large in information content - bits or bytes required to communicate it.
A specific generic member of an uncountable set is infinitely large in information content - that means it would take infinite time to communicate at finite bandwidth, infinite volume to store at finite information density. It is utterly impractical.
It is reasonable (because it is true) to believe that every mathematical object that a mathematician has ever manipulated was of finite information content. The set of all objects of finite information content is merely countable, not uncountable.
What I'm trying to say is: Don't worry about uncountability. It isn't physical and it isn't practical. Mathematicians may be in love with it (Hilbert's famous quote: "No one shall expel us from the Paradise that Cantor has created."), but the concept is a bit like that "infinite" symbol - infinite in magnitude, not in information content.
Replies from: DSimon↑ comment by DSimon · 2012-12-16T06:37:36.133Z · LW(p) · GW(p)
I strongly recommend that, if you haven't already, you learn enough introductory calculus to understand what it means to take the limit of an expression as a variable approaches infinity. You are making a common mistake here by conflating your intuitive understanding about infinity with its meaning in stricter mathematical contexts.