What are the strongest arguments for very short timelines?
post by Kaj_Sotala · 2024-12-23T09:38:56.905Z · LW · GW · 11 commentsThis is a question post.
Contents
Answers 105 elifland 50 Seth Herd 28 Nathan Helm-Burger 19 Vladimir_Nesov 14 Mitchell_Porter 6 Carl Feynman 4 Seth Herd 4 chasmani 4 Pwlot None 11 comments
I'm seeing a lot of people on LW saying that they have very short timelines (say, five years or less) until AGI. However, the arguments that I've seen often seem to be just one of the following:
- "I'm not going to explain but I've thought about this a lot"
- "People at companies like OpenAI, Anthropic etc. seem to believe this"
- "Feels intuitive based on the progress we've made so far"
At the same time, it seems like this is not the majority view among ML researchers. The most recent representative expert survey that I'm aware of is the 2023 Expert Survey on Progress in AI. It surveyed 2,778 AI researchers who had published peer-reviewed research in the prior year in six top AI venues (NeurIPS, ICML, ICLR, AAAI, IJCAI, JMLR); the median time for a 50% chance of AGI was either in 23 or 92 years, depending on how the question was phrased.
While it has been a year since fall 2023 when this survey was conducted, my anecdotal impression is that many researchers not in the rationalist sphere still have significantly longer timelines, or do not believe that current methods would scale to AGI.
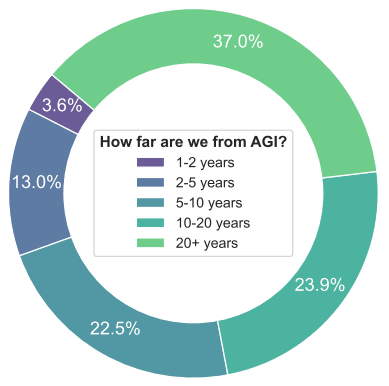
A more recent, though less broadly representative, survey is reported in Feng et al. 2024, In the ICLR 2024 "How Far Are We From AGI" workshop, 138 researchers were polled on their view. "5 years or less" was again a clear minority position, with 16.6% respondents. On the other hand, "20+ years" was the view held by 37% of the respondents.
Most recently, there were a number of "oh AGI does really seem close" comments with the release of o3. I mostly haven't seen these give very much of an actual model for their view either; they seem to mostly be of the "feels intuitive" type. There have been some posts discussing the extent [LW · GW] to which we can continue to harness compute and data for training bigger models, but that says little about the ultimate limits of the current models.
The one argument that I did see that felt somewhat convincing were the "data wall" and "unhobbling" sections of the "From GPT-4 to AGI" chapter of Leopold Aschenbrenner's "Situational Awareness", that outlined ways in which we could build on top of the current paradigm. However, this too was limited to just "here are more things that we could do".
So, what are the strongest arguments for AGI being very close? I would be particularly interested in any discussions that explicitly look at the limitations of the current models and discuss how exactly people expect those to be overcome.
Answers
Here's the structure of the argument that I am most compelled by (I call it the benchmarks + gaps argument), I'm uncertain about the details.
- Focus on the endpoint of substantially speeding up AI R&D / automating research engineering. Let's define our timelines endpoint as something that ~5xs the rate of AI R&D algorithmic progress (compared to a counterfactual world with no post-2024 AIs). Then make an argument that ~fully automating research engineering (experiment implementation/monitoring) would do this, along with research taste of at least the 50th percentile AGI company researcher (experiment ideation/selection).
- Focus on REBench since it's the most relevant benchmark. REBench is the most relevant benchmark here, for simplicity I'll focus on only this though for robustness more benchmarks should be considered.
- Based on trend extrapolation and benchmark base rates, roughly 50% we'll saturate REBench by end of 2025.
- Identify the most important gaps between saturating REBench and the endpoint defined in (1). The most important gaps between saturating REBench and achieving the 5xing AI R&D algorithmic progress are: (a) time horizon as measured by human time spent (b) tasks with worse feedback loops (c) tasks with large codebases (d) becoming significantly cheaper and/or faster than humans. There are some more but my best guess is that these 4 are the most important, should also take into account unknown gaps.
- When forecasting the time to cross the gaps, it seems quite plausible that we get to the substantial AI R&D speedup within a few years after saturating REBench, so by end of 2028 (and significantly earlier doesn't seem crazy).
- This is the most important part of the argument, and one that I have lots of uncertainty over. We have some data regarding the "crossing speed" of some of the gaps but the data are quite limited at the moment. So there are a lot of judgment calls needed and people with strong long timelines intuitions might think the remaining gaps will take a long time to cross without this being close to falsified by our data.
- This is broken down into "time to cross the gaps at 2024 pace of progress" -> adjusting based on compute forecasts and intermediate AI R&D speedups before reaching 5x.
- From substantial AI R&D speedup to AGI. Once we have the 5xing AIs, that's potentially already AGI by some definitions but if you have a stronger one, the possibility of a somewhat fast takeoff means you might get it within a year or so after.
One reason I like this argument is that it will get much stronger over time as we get more difficult benchmarks and otherwise get more data about how quickly the gaps are being crossed.
I have a longer draft which makes this argument but it's quite messy and incomplete and might not add much on top of the above summary for now. Unfortunately I'm prioritizing other workstreams over finishing this at the moment. DM me if you'd really like a link to the messy draft.
↑ comment by Steven Byrnes (steve2152) · 2024-12-23T19:32:54.829Z · LW(p) · GW(p)
RE-bench tasks (see page 7 here) are not the kind of AI research where you’re developing new AI paradigms and concepts. The tasks are much more straightforward than that. So your argument is basically assuming without argument that we can get to AGI with just the more straightforward stuff, as opposed to new AI paradigms and concepts.
If we do need new AI paradigms and concepts to get to AGI, then there would be a chicken-and-egg problem in automating AI research. Or more specifically, there would be two categories of AI R&D, with the less important R&D category (e.g. performance optimization and other REbench-type tasks) being automatable by near-future AIs, and the more important R&D category (developing new AI paradigms and concepts) not being automatable.
(Obviously you’re entitled to argue / believe that we don’t need need new AI paradigms and concepts to get to AGI! It’s a topic where I think reasonable people disagree. I’m just suggesting that it’s a necessary assumption for your argument to hang together, right?)
Replies from: nathan-helm-burger, elifland, ryan_greenblatt, daniel-kokotajlo↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T20:49:53.361Z · LW(p) · GW(p)
I disagree. I think the existing body of published computer science and neuroscience research are chock full of loose threads. Tons of potential innovations just waiting to be harvested by automated researchers. I've mentioned this idea elsewhere. I call it an 'innovation overhang'. Simply testing interpolations and extrapolations (e.g. scaling up old forgotten ideas on modern hardware) seems highly likely to reveal plenty of successful new concepts, even if the hit rate per attempt is low. I think this means a better benchmark would consist of: taking two existing papers, finding a plausible hypothesis which combines the assumptions from the papers, designs and codes and runs tests, then reports on results.
So I don't think "no new concepts" is a necessary assumption for getting to AGI quickly with the help of automated researchers.
Replies from: faul_sname↑ comment by faul_sname · 2024-12-23T21:10:38.516Z · LW(p) · GW(p)
Simply testing interpolations and extrapolations (e.g. scaling up old forgotten ideas on modern hardware) seems highly likely to reveal plenty of successful new concepts, even if the hit rate per attempt is low
Is this bottlenecked by programmer time or by compute cost?
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T21:48:17.657Z · LW(p) · GW(p)
Both? If you increase only one of the two the other becomes the bottleneck?
I agree this means that the decision to devote substantial compute to both inference and to assigning compute resources for running experiments designed by AI reseachers is a large cost. Presumably, as the competence of the AI reseachers gets higher, it feels easier to trust them not to waste their assigned experiment compute.
There was discussion on Dwarkesh Patel's interview with researcher friends where there was mention that AI reseachers are already restricted by compute granted to them for experiments. Probably also on work hours per week they are allowed to spend on novel "off the main path" research.
So in order for there to be a big surge in AI R&D there'd need to be prioritization of that at a high level. This would be a change of direction from focusing primarily on scaling current techniques rapidly, and putting out slightly better products ASAP.
So yes, if you think that this priority shift won't happen, then you should doubt that the increase in R&D speed my model predicts will occur.
But what would that world look like? Probably a world where scaling continues to pay dividends, and getting to AGI is more straightforward yhan Steve Byrnes or I expect.
I agree that that's a substantial probability, but it's also an AGI-soon sort of world.
I argue that for AGI to be not-soon, you need both scaling to fail and for algorithm research to fail.
Replies from: faul_sname↑ comment by faul_sname · 2024-12-24T07:12:31.255Z · LW(p) · GW(p)
Both? If you increase only one of the two the other becomes the bottleneck?
My impression based on talking to people at labs plus stuff I've read is that
- Most AI researchers have no trouble coming up with useful ways of spending all of the compute available to them
- Most of the expense of hiring AI reseachers is compute costs for their experiments rather than salary
- The big scaling labs try their best to hire the very best people they can get their hands on and concentrate their resources heavily into just a few teams, rather than trying to hire everyone with a pulse who can rub two tensors together.
(Very open to correction by people closer to the big scaling labs).
My model, then, says that compute availability is a constraint that binds much harder than programming or research ability, at least as things stand right now.
There was discussion on Dwarkesh Patel's interview with researcher friends where there was mention that AI reseachers are already restricted by compute granted to them for experiments. Probably also on work hours per week they are allowed to spend on novel "off the main path" research.
Sounds plausible to me. Especially since benchmarks encourage a focus on ability to hit the target at all rather than ability to either succeed or fail cheaply, which is what's important in domains where the salary / electric bill of the experiment designer is an insignificant fraction of the total cost of the experiment.
But what would that world look like? [...] I agree that that's a substantial probability, but it's also an AGI-soon sort of world.
Yeah, I expect it's a matter of "dumb" scaling plus experimentation rather than any major new insights being needed. If scaling hits a wall that training on generated data + fine tuning + routing + specialization can't overcome, I do agree that innovation becomes more important than iteration.
My model is not just "AGI-soon" but "the more permissive thresholds for when something should be considered AGI have already been met, and more such thresholds will fall in short order, and so we should stop asking when we will get AGI and start asking about when we will see each of the phenomena that we are using AGI as a proxy for".
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-24T21:19:13.828Z · LW(p) · GW(p)
I think you're mostly correct about current AI reseachers being able to usefully experiment with all the compute they have available.
I do think there are some considerations here though.
-
How closely are they adhering to the "main path" of scaling existing techniques with minor tweaks? If you want to know how a minor tweak affects your current large model at scale, that is a very compute-heavy researcher-time-light type of experiment. On the other hand, if you want to test a lot of novel new paths at much smaller scales, then you are in a relatively compute-light but researcher-time-heavy regime.
-
What fraction of the available compute resources is the company assigning to each of training/inference/experiments? My guess it that the current split is somewhere around 63/33/4. If this was true, and the company decided to pivot away from training to focus on experiments (0/33/67), this would be something like a 16x increase in compute for experiments. So maybe that changes the bottleneck?
-
We do indeed seem to be at "AGI for most stuff", but with a spikey envelope of capability that leaves some dramatic failure modes. So it does make more sense to ask something like, "For remaining specific weakness X, what will the research agenda and timeline look like?"
This makes more sense then continuing to ask the vague "AGI complete" question when we are most of the way there already.
↑ comment by elifland · 2024-12-24T14:58:05.618Z · LW(p) · GW(p)
For context in a sibling comment Ryan said [LW(p) · GW(p)] and Steven agreed with:
It sounds like your disagreement isn't with drawing a link from RE-bench to (forecasts for) automating research engineering, but is instead with thinking that you can get AGI shortly after automating research engineering due to AI R&D acceleration and already being pretty close. Is that right?
Note that the comment says research engineering, not research scientists.
Now responding on whether I think the no new paradigms assumption is needed:
(Obviously you’re entitled to argue / believe that we don’t need need new AI paradigms and concepts to get to AGI! It’s a topic where I think reasonable people disagree. I’m just suggesting that it’s a necessary assumption for your argument to hang together, right?)
I generally have not been thinking in these sorts of binary terms but instead thinking in terms more like "Algorithmic progress research is moving at pace X today, if we had automated research engineers it would be sped up to N*X." I'm not necessarily taking a stand on whether the progress will involve new paradigms or not, so I don't think it requires an assumption of no new paradigms.
However:
- If you think almost all new progress in some important sense will come from paradigm shifts, the forecasting method becomes weaker because the incremental progress doesn't say as much about progress toward automated research engineering or AGI.
- You might think that it's more confusing than clarifying to think in terms of collapsing all research progress into a single "speed" and forecasting based on that.
- Requiring a paradigm shift might lead to placing less weight on lower amounts of research effort required, and even if the probability distribution is the same what we should expect to see in the world leading up to AGI is not.
I'd also add that:
- Regarding what research tasks I'm forecasting for the automated research engineer: REBench is not supposed to fully represent the tasks involved in actual research engineering. That's why we have the gaps.
- Regarding to what extent having an automated research engineer would speed up progress in worlds in which we need a paradigm shift: I think it's hard to separate out conceptual from engineering/empirical work in terms of progress toward new paradigms. My guess would be being able to implement experiments very cheaply would substantially increase the expected number of paradigm shifts per unit time.
↑ comment by ryan_greenblatt · 2024-12-23T20:58:57.592Z · LW(p) · GW(p)
It sounds like your disagreement isn't with drawing a link from RE-bench to (forecasts for) automating research engineering, but is instead with thinking that you can get AGI shortly after automating research engineering due to AI R&D acceleration and already being pretty close. Is that right?
Note that the comment says research engineering, not research scientists.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-24T16:03:14.737Z · LW(p) · GW(p)
Thanks for this thoughtful reply!
In the framework of the argument, you seem to be objecting to premises 4-6. Specifically you seem to be saying "There's another important gap between RE-bench saturation and completely automating AI R&D: new-paradigm-and-concept-generation. Perhaps we can speed up AI R&D by 5x or so without crossing this gap, simply by automating engineering, but to get to AGI we'll need to cross this gap, and this gap might take a long time to cross even at 5x speed."
(Is this a fair summary?)
If that's what you are saying, I think I'd reply:
We already have a list of potential gaps, and this one seems to be a mediocre addition to the list IMO. I don't think this distinction between old-paradigm/old-concepts and new-paradigm/new-concepts is going to hold up very well to philosophical inspection or continued ML progress; it smells similar to ye olde "do LLMs truly understand, or are they merely stochastic parrots?" and "Can they extrapolate, or do they merely interpolate?"
That said, I do think it's worthy of being included on the list. I'm just not as excited about it as the other entries, especially (a) and (b).
I'd also say: What makes you think that this gap will take years to cross even at 5x speed? (i.e. even when algorithmic progress is 5x faster than it has been for the past decade) Do you have a positive argument, or is it just generic uncertainty / absence-of-evidence?
(For context: I work in the same org as Eli and basically agree with his argument above)
↑ comment by Steven Byrnes (steve2152) · 2024-12-24T16:25:07.426Z · LW(p) · GW(p)
I think I’m objecting to (as Eli wrote) “collapsing all [AI] research progress into a single "speed" and forecasting based on that”. There can be different types of AI R&D, and we might be able to speed up some types without speeding up other types. For example, coming up with the AlphaGo paradigm (self-play, MCTS, ConvNets, etc.) or LLM paradigm (self-supervised pretraining, Transformers, etc.) is more foundational, whereas efficiently implementing and debugging a plan is less foundational. (Kinda “science vs engineering”?) I also sometimes use the example of Judea Pearl coming up with the belief prop algorithm in 1982. If everyone had tons of compute and automated research engineer assistants, would we have gotten belief prop earlier? I’m skeptical. As far as I understand: Belief prop was not waiting on compute. You can do belief prop on a 1960s mainframe. Heck, you can do belief prop on an abacus. Social scientists have been collecting data since the 1800s, and I imagine that belief prop would have been useful for analyzing at least some of that data, if only someone had invented it.
Replies from: Radford Neal, steve2152, carl-feynman, daniel-kokotajlo, elifland↑ comment by Radford Neal · 2024-12-24T20:06:25.684Z · LW(p) · GW(p)
Indeed. Not only could belief prop have been invented in 1960, it was invented around 1960 (published 1962, "Low density parity check codes", IRE Transactions on Information Theory) by Robert Gallager, as a decoding algorithm for error correcting codes.
I recognized that Gallager's method was the same as Pearl's belief propagation in 1996 (MacKay and Neal, ``Near Shannon limit performance of low density parity check codes'', Electronics Letters, vol. 33, pp. 457-458).
This says something about the ability of AI to potentially speed up research by simply linking known ideas (even if it's not really AGI).
Replies from: carl-feynman↑ comment by Carl Feynman (carl-feynman) · 2024-12-24T21:56:54.901Z · LW(p) · GW(p)
Came here to say this, got beaten to it by Radford Neal himself, wow! Well, I'm gonna comment anyway, even though it's mostly been said.
Gallagher proposed belief propagation as an approximate good-enough method of decoding a certain error-correcting code, but didn't notice that it worked on all sorts of probability problems. Pearl proposed it as a general mechanism for dealing with probability problems, but wanted perfect mathematical correctness, so confined himself to tree-shaped problems. It was their common generalization that was the real breakthrough: an approximate good-enough solution to all sorts of problems. Which is what Pearl eventually noticed, so props to him.
If we'd had AGI in the 1960s, someone with a probability problem could have said "Here's my problem. For every paper in the literature, spawn an instance to read that paper and tell me if it has any help for my problem." It would have found Gallagher's paper and said "Maybe you could use this?"
↑ comment by Steven Byrnes (steve2152) · 2024-12-27T01:32:32.553Z · LW(p) · GW(p)
I just wanted to add that this hypothesis, i.e.
I think I’m objecting to (as Eli wrote) “collapsing all [AI] research progress into a single "speed" and forecasting based on that”. There can be different types of AI R&D, and we might be able to speed up some types without speeding up other types.
…is parallel to what we see in other kinds of automation.
The technology of today has been much better at automating the production of clocks than the production of haircuts. Thus, 2024 technology is great at automating the production of some physical things but only slightly helpful for automating the production of some other physical things.
By the same token, different AI R&D projects are trying to “produce” different types of IP. Thus, it’s similarly possible that 2029 AI technology will be great at automating the production of some types of AI-related IP but only slightly helpful for automating the production of some other types of AI-related IP.
↑ comment by Carl Feynman (carl-feynman) · 2024-12-24T22:34:42.887Z · LW(p) · GW(p)
I disagree that there is a difference of kind between "engineering ingenuity" and "scientific discovery", at least in the business of AI. The examples you give-- self-play, MCTS, ConvNets-- were all used in game-playing programs before AlphaGo. The trick of AlphaGo was to combine them, and then discover that it worked astonishingly well. It was very clever and tasteful engineering to combine them, but only a breakthrough in retrospect. And the people that developed them each earlier, for their independent purposes? They were part of the ordinary cycle of engineering development: "Look at a problem, think as hard as you can, come up with something, try it, publish the results." They're just the ones you remember, because they were good.
Paradigm shifts do happen, but I don't think we need them between here and AGI.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-25T02:30:17.136Z · LW(p) · GW(p)
Yeah I’m definitely describing something as a binary when it’s really a spectrum. (I was oversimplifying since I didn’t think it mattered for that particular context.)
In the context of AI, I don’t know what the difference is (if any) between engineering and science. You’re right that I was off-base there…
…But I do think that there’s a spectrum from ingenuity / insight to grunt-work.
So I’m bringing up a possible scenario where near-future AI gets progressively less useful as you move towards the ingenuity side of that spectrum, and where changing that situation (i.e., automating ingenuity) itself requires a lot of ingenuity, posing a chicken-and-egg problem / bottleneck that limits the scope of rapid near-future recursive AI progress.
Paradigm shifts do happen, but I don't think we need them between here and AGI.
Perhaps! Time will tell :)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-24T19:41:26.250Z · LW(p) · GW(p)
I certainly agree that the collapse is a lossy abstraction / simplifies; in reality some domains of research will speed up more than 5x and others less than 5x, for example, even if we did get automated research engineers dropped on our heads tomorrow. Are you therefore arguing that in particular, the research needed to get to AGI is of the kind that won't be sped up significantly? What's the argument -- that we need a new paradigm to get to AIs that can generate new paradigms, and being able to code really fast and well won't majorly help us think of new paradigms? (I'd disagree with both sub-claims of that claim)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-24T19:53:07.141Z · LW(p) · GW(p)
Are you therefore arguing that in particular, the research needed to get to AGI is of the kind that won't be sped up significantly? What's the argument -- that we need a new paradigm to get to AIs that can generate new paradigms, and being able to code really fast and well won't majorly help us think of new paradigms? (I'd disagree with both sub-claims of that claim)
Yup! Although I’d say I’m “bringing up a possibility” rather than “arguing” in this particular thread. And I guess it depends on where we draw the line between “majorly” and “minorly” :)
↑ comment by elifland · 2024-12-24T19:50:42.613Z · LW(p) · GW(p)
This is clarifying for me, appreciate it. If I believed (a) that we needed a paradigm shift like the ones to LLMs in order to get AI systems resulting in substantial AI R&D speedup, and (b) that trend extrapolation from benchmark data would not be informative for predicting these paradigm shifts, then I would agree that the benchmarks + gaps method is not particularly informative.
Do you think that's a fair summary of (this particular set of) necessary conditions?
(edit: didn't see @Daniel Kokotajlo [LW · GW]'s new comment before mine. I agree with him regarding disagreeing with both sub-claims but I think I have a sense of where you're coming from.)
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2024-12-24T16:28:19.131Z · LW(p) · GW(p)
I don't think this distinction between old-paradigm/old-concepts and new-paradigm/new-concepts is going to hold up very well to philosophical inspection or continued ML progress; it smells similar to ye olde "do LLMs truly understand, or are they merely stochastic parrots?" and "Can they extrapolate, or do they merely interpolate?"
I find this kind of pattern-match pretty unconvincing without more object-level explanation. Why exactly do you think this distinction isn't important? (I'm also not sure "Can they extrapolate, or do they merely interpolate?" qualifies as "ye olde," still seems like a good question to me at least w.r.t. sufficiently out-of-distribution extrapolation.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-24T19:48:59.562Z · LW(p) · GW(p)
We are at an impasse then; I think basically I'm just the mirror of you. To me, the burden is on whoever thinks the distinction is important to explain why it matters. Current LLMs do many amazing things that many people -- including AI experts -- thought LLMs could never do due to architectural limitations. Recent history is full of examples of AI experts saying "LLMs are the offramp to AGI; they cannot do X; we need new paradigm to do X" and then a year or two later LLMs are doing X. So now I'm skeptical and would ask questions like: "Can you say more about this distinction -- is it a binary, or a dimension? If it's a dimension, how can we measure progress along it, and are we sure there hasn't been significant progress on it already in the last few years, within the current paradigm? If there has indeed been no significant progress (as with ARC-AGI until 2024) is there another explanation for why that might be, besides your favored one (that your distinction is super important and that because of it a new paradigm is needed to get to AGI)"
Replies from: TsviBT, antimonyanthony↑ comment by TsviBT · 2024-12-25T05:16:48.407Z · LW(p) · GW(p)
The burden is on you because you're saying "we have gone from not having the core algorithms for intelligence in our computers, to yes having them".
https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce#The__no_blockers__intuition [LW · GW]
And I think you're admitting that your argument is "if we mush all capabilities together into one dimension, AI is moving up on that one dimension, so things will keep going up".
Would you say the same thing about the invention of search engines? That was a huge jump in the capability of our computers. And it looks even more impressive if you blur out your vision--pretend you don't know that the text that comes up on your screen is written by a humna, and pretend you don't know that search is a specific kind of task distinct from a lot of other activity that would be involved in "True Understanding, woooo"--and just say "wow! previously our computers couldn't write a poem, but now with just a few keystrokes my computer can literally produce Billy Collins level poetry!".
Blurring things together at that level works for, like, macroeconomic trends. But if you look at macroeconomic trends it doesn't say singularity in 2 years! Going to 2 or 10 years is an inside-view thing to conclude! You're making some inference like "there's an engine that is very likely operating here, that takes us to AGI in xyz years".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-25T13:44:47.592Z · LW(p) · GW(p)
I'm not saying that. You are the one who introduced the concept of "the core algorithms for intelligence;" you should explain what that means and why it's a binary (or if it's not a binary but rather a dimension, why we haven't been moving along that dimension in recent past.
ETA: I do have an ontology, a way of thinking about these things, that is more sophisticated than simply mushing all capabilities together into one dimension. I just don't accept your ontology yet.
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2024-12-25T17:43:30.637Z · LW(p) · GW(p)
(I might misunderstand you. My impression was that you're saying it's valid to extrapolate from "model XYZ does well at RE-Bench" to "model XYZ does well at developing new paradigms and concepts." But maybe you're saying that the trend of LLM success at various things suggests we don't need new paradigms and concepts to get AGI in the first place? My reply below assumes the former:)
I'm not saying LLMs can't develop new paradigms and concepts, though. The original claim you were responding to was that success at RE-Bench in particular doesn't tell us much about success at developing new paradigms and concepts. "LLMs have done various things some people didn't expect them to be able to do" doesn't strike me as much of an argument against that.
More broadly, re: your burden of proof claim, I don't buy that "LLMs have done various things some people didn't expect them to be able to do" determinately pins down an extrapolation to "the current paradigm(s) will suffice for AGI, within 2-3 years." That's not a privileged reference class forecast, it's a fairly specific prediction.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-12-26T16:02:25.950Z · LW(p) · GW(p)
I feel like this sub-thread is going in circles; perhaps we should go back to the start of it. I said:
I don't think this distinction between old-paradigm/old-concepts and new-paradigm/new-concepts is going to hold up very well to philosophical inspection or continued ML progress; it smells similar to ye olde "do LLMs truly understand, or are they merely stochastic parrots?" and "Can they extrapolate, or do they merely interpolate?"
You replied:
I find this kind of pattern-match pretty unconvincing without more object-level explanation. Why exactly do you think this distinction isn't important? (I'm also not sure "Can they extrapolate, or do they merely interpolate?" qualifies as "ye olde," still seems like a good question to me at least w.r.t. sufficiently out-of-distribution extrapolation.)
Now, elsewhere in this comment section, various people (Carl, Radford) have jumped in to say the sorts of object-level things I also would have said if I were going to get into it. E.g. that old vs. new paradigm isn't a binary but a spectrum, that automating research engineering WOULD actually speed up new-paradigm discovery, etc. What do you think of the points they made?
Also, I'm still waiting to hear answers to these questions: "Can you say more about this distinction -- is it a binary, or a dimension? If it's a dimension, how can we measure progress along it, and are we sure there hasn't been significant progress on it already in the last few years, within the current paradigm? If there has indeed been no significant progress (as with ARC-AGI until 2024) is there another explanation for why that might be, besides your favored one (that your distinction is super important and that because of it a new paradigm is needed to get to AGI)"
↑ comment by nostalgebraist · 2025-03-13T05:46:23.998Z · LW(p) · GW(p)
Here's why I'm wary of this kind of argument:
First, we know that labs are hill-climbing on benchmarks.
Obviously, this tends to inflate model performance on the specific benchmark tasks used for hill-climbing, relative to "similar" but non-benchmarked tasks.
More generally and insidiously, it tends to inflate performance on "the sort of things that are easy to measure with benchmarks," relative to all other qualities that might be required to accelerate or replace various kinds of human labor.
If we suppose that amenability-to-benchmarking correlates with various other aspects of a given skill (which seems reasonable enough, "everything is correlated" after all), then we might expect that hill-climbing on a bunch of "easy to benchmark" tasks will induce generalization to other "easy to benchmark" tasks (even those that weren't used for hill-climbing), without necessarily generalizing to tasks which are more difficult to measure.
For instance, perhaps hill-climbing on a variety of "difficult academic exam" tasks like GPQA will produce models that are very good at exam-like tasks in general, but which lag behind on various other skills which we would expect a human expert to possess if that human had similar exam scores to the model.
Anything that we can currently measure in a standardized, quantified way becomes a potential target for hill-climbing. These are the "benchmarks," in the terms of your argument.
And anything we currently can't (or simply don't) measure well ends up as a "gap." By definition, we don't yet have clear quantitative visibility into how well we're doing on the gaps, or how quickly we're moving across them: if we did, then they would be "benchmarks" (and hill-climbing targets) rather than gaps.
It's tempting here to try to forecast progress on the "gaps" by using recent progress on the "benchmarks" as a reference class. But this yields a biased estimate; we should expect average progress on "gaps" to be much slower than average progress on "benchmarks."
The difference comes from the two factors I mentioned at the start:
- Hill-climbing on a benchmark tends to improve that benchmark more than other things (including other, non-hill-climbed measures of the same underlying trait)
- Benchmarks are – by definition – the things that are easy to measure, and thus to hill-climb.
- Progress on such things is currently very fast, and presumably some of that speed owes to the rapid, quantitative, and inter-comparable feedback that benchmarks provide.
- It's not clear how much this kind of methodology generalizes to things that are important but inherently harder to measure. (How do you improve something if you can't tell how good it is in the first place?)
Presumably things that are inherently harder to measure will improve more slowly – it's harder to go fast when you're "stumbling around in the dark" – and it's difficult to know how big this effect is in advance.
I don't get a sense that AI labs are taking this kind of thing very seriously at the moment (at least in their public communications, anyway). The general vibe I get is like, "we love working on improvements to measurable things, and everything we can measure gets better with scale, so presumably all the things we can't measure will get solved by scale too; in the meantime we'll work on hill-climbing the hills that are on our radar."
If the unmeasured stuff were simply a random sample from the same distribution as the measured stuff, this approach would make sense, but we have no reason to believe this is the case. Is all this scaling and benchmark-chasing really lifting all boats, simultaneously? I mean, how would we know, right? By definition, we can't measure what we can't measure.
Or, more accurately, we can't measure it in quantitative and observer-independent fashion. That doesn't mean we don't know it exists.
Indeed, some of this "dark matter" may well be utterly obvious when one is using the models in practice. It's there, and as humans we can see it perfectly well, even if we would find it difficult to think up a good benchmark for it.
As LLMs get smarter – and as the claimed distance between them and "human experts" diminishes – I find that these "obvious yet difficult-to-quantify gaps" increasingly dominate my experience of LLMs as a user.
Current frontier models are, in some sense, "much better at me than coding." In a formal coding competition I would obviously lose to these things; I might well perform worse at more "real-world" stuff like SWE-Bench Verified, too.
Among humans with similar scores on coding and math benchmarks, many (if not all) of them would be better at my job than I am, and fully capable of replacing me as an employee. Yet the models are not capable of this.
Claude-3.7-Sonnet really does have remarkable programming skills (even by human standards), but it can't adequately do my job – not even for a single day, or (I would expect) for a single hour. I can use it effectively to automate certain aspects of my work, but it needs constant handholding, and that's when it's on the fairly narrow rails of something like Cursor rather than in the messy, open-ended "agentic environment" that is the real workplace.
What is it missing? I don't know, it's hard to state precisely. (If it were easier to state precisely, it would be a "benchmark" rather than a "gap" and we'd be having a very different conversation right now.)
Something like, I dunno... "taste"? "Agency"?
"Being able to look at a messy real-world situation and determine what's important and what's not, rather than treating everything like some sort of school exam?"
"Talking through the problem like a coworker, rather than barreling forward with your best guess about what the nonexistent teacher will give you good marks for doing?"
"Acting like a curious experimenter, not a helpful-and-harmless pseudo-expert who already knows the right answer?"
"(Or, for that matter, acting like an RL 'reasoning' system awkwardly bolted on to an existing HHH chatbot, with a verbose CoT side-stream that endlessly speculates about 'what the user might have really meant' every time I say something unclear rather than just fucking asking me like any normal person would?)"
If you use LLMs to do serious work, these kinds of bottlenecks become apparent very fast.
Scaling up training on "difficult academic exam"-type tasks is not going to remove the things that prevent the LLM from doing my job. I don't know what those things are, exactly, but I do know that the problem is not "insufficient skill at impressive-looking 'expert' benchmark tasks." Why? Because the model is already way better than me at difficult academic tests, and yet – it still can't autonomously do my job, or yours, or (to a first approximation) anyone else's.
Or, consider the ascent of GPQA scores. As "Preparing for the Intelligence Explosion" puts it:
On GPQA — a benchmark of Ph.D-level science questions — GPT-4 performed marginally better than random guessing. 18 months later, the best reasoning models outperform PhD-level experts.
Well, that certainly sounds impressive. Certainly something happened here. But what, exactly?
If you showed this line to someone who knew nothing about the context, I imagine they would (A) vastly overestimate the usefulness of current models as academic research assistants, and (B) vastly underestimate the usefulness of GPT-4 in the same role.
GPT-4 already knew all kinds of science facts of the sort that GPQA tests, even if it didn't know them quite as well, or wasn't as readily able to integrate them in the exact way that GPQA expects (that's hill-climbing for you).
What was lacking was not mainly the knowledge itself – GPT-4 was already incredibly good at obscure book-learning! – but all the... other stuff involved in competent research assistance. The dark matter, the soft skills, the unmesaurables, the gaps. The kind of thing I was talking about just a moment ago. "Taste," or "agency," or "acting like you have real-world experience rather than just being a child prodigy who's really good at exams."
And the newer models don't have that stuff either. They can "do" more things if you give them constant handholding, but they still need that hand-holding; they still can't apply common sense to reason their way through situations that don't resemble a school exam or an interaction with a gormless ChatGPT user in search of a clean, decontextualized helpful-and-harmless "answer." If they were people, I would not want to hire them, any more than I'd want to hire GPT-4.
If (as I claim) all this "dark matter" is not improving much, then we are not going to get a self-improvement loop unless
- It turns out that models without these abilities can bootstrap their way into having them
- Labs start taking the "dark matter" much more seriously than they have so far, rather than just hill-climbing easily measurable things and leaning on scaling and RSI for everything else
I doubt that (1) will hold: the qualities that are missing are closely related to things like "ability to act without supervision" and "research/design/engineering taste" that seem very important for self-improvement.
As for (2), well, my best guess is that we'll have to wait until ~2027-2028, at which point it will become clear that the "just scale and hill-climb and increasingly defer to your HHH assistant" approach somehow didn't work – and then, at last, we'll start seeing serious attempts to succeed at the unmeasurable.
Replies from: Daniel Paleka↑ comment by Daniel Paleka · 2025-03-22T19:25:54.439Z · LW(p) · GW(p)
I think the labs might well be rational in focusing on this sort of "handheld automation", just to enable their researchers to code experiments faster and in smaller teams.
My mental model of AI R&D is that it can be bottlenecked roughly by three things: compute, engineering time, and the "dark matter" of taste and feedback loops on messy research results. I can certainly imagine a model of lab productivity where the best way to accelerate is improving handheld automation for the entirety of 2025. Say, the core paradigm is fixed; but inside that paradigm, the research team has more promising ideas than they have time to implement and try out on smaller-scale experiments; and they really do not want to hire more people.
If you consider the AI lab as a fundamental unit that wants to increase its velocity, and works on things that make models faster, it's plausible they can be aware how bad the model performance is on research taste, and still not be making a mistake by ignoring your "dark matter" right now. They will work on it when they are faster.
↑ comment by Orpheus16 (akash-wasil) · 2024-12-24T00:48:06.972Z · LW(p) · GW(p)
@elifland [LW · GW] what do you think is the strongest argument for long(er) timelines? Do you think it's essentially just "it takes a long time for researchers learn how to cross the gaps"?
Or do you think there's an entirely different frame (something that's in an ontology that just looks very different from the one presented in the "benchmarks + gaps argument"?)
Replies from: elifland↑ comment by elifland · 2024-12-24T16:08:35.600Z · LW(p) · GW(p)
A few possible categories of situations we might have long timelines, off the top of my head:
- Benchmarks + gaps is still best: overall gap is somewhat larger + slowdown in compute doubling time after 2028, but trend extrapolations still tell us something about gap trends: This is how I would most naturally think about how timelines through maybe the 2030s are achieved, and potentially beyond if neither of the next hold.
- Others are best (more than of one of these can be true):
- The current benchmarks and evaluations are so far away from AGI that trends on them don't tell us anything (including regarding how fast gaps might be crossed). In this case one might want to identify the 1-2 most important gaps and reason about when we will cross these based on gears-level reasoning or trend extrapolation/forecasting on "real-world" data (e.g. revenue?) rather than trend extrapolation on benchmarks. Example candidate "gaps" that I often hear for these sorts of cases are the lack of feedback loops and the "long-tail of tasks" / reliability.
- A paradigm shift in AGI training is needed and benchmark trends don't tell us much about when we will achieve this (this is basically Steven's sibling comment [LW(p) · GW(p)]): in this case the best analysis might involve looking at the base rate of paradigm shifts per research effort, and/or looking at specific possible shifts.
^ this taxonomy is not comprehensive, just things I came up with quickly. Might be missing something that would be good.
To cop out answer your question, I feel like if I were making a long-timelines argument I'd argue that all 3 of those would be ways of forecasting to give weight to, then aggregate. If I had to choose just one I'd probably still go with (1) though.
edit: oh there's also the "defer to AI experts" argument. I mostly try not to think about deference-based arguments because thinking on the object-level is more productive, though I think if I were really trying to make an all-things-considered timelines distribution there's some chance I would adjust to longer due to deference arguments (but also some chance I'd adjust toward shorter, given that lots of people who have thought deeply about AGI / are close to the action have short timelines).
There's also "base rate of super crazy things happening is low" style arguments which I don't give much weight to.
↑ comment by Kaj_Sotala · 2024-12-27T20:22:23.406Z · LW(p) · GW(p)
Thanks. I think this argument assumes that the main bottleneck to AI progress is something like research engineering speed, such that accelerating research engineering speed would drastically increase AI progress?
I think that that makes sense as long as we are talking about domains like games / math / programming where you can automatically verify the results, but that something like speed of real-world interaction becomes the bottleneck once shifting to more open domains.
Consider an AI being trained on a task such as “acting as the CEO for a startup”. There may not be a way to do this training other than to have it actually run a real startup, and then wait for several years to see how the results turn out. Even after several years, it will be hard to say exactly which parts of the decision process contributed, and how much of the startup’s success or failure was due to random factors. Furthermore, during this process the AI will need to be closely monitored in order to make sure that it does not do anything illegal or grossly immoral, slowing down its decision process and thus whole the training. And I haven’t even mentioned the expense of a training run where running just a single trial requires a startup-level investment (assuming that the startup won’t pay back its investment, of course).
Of course, humans do not learn to be CEOs by running a million companies and then getting a reward signal at the end. Human CEOs come in with a number of skills that they have already learned from somewhere else that they then apply to the context of running a company, shifting between their existing skills and applying them as needed. However, the question of what kind of approach and skill to apply in what situation, and how to prioritize between different approaches, is by itself a skillset that needs to be learned... quite possibly through a lot of real-world feedback.
I think the gaps between where we are and roughly human-level cognition are smaller than they appear. Modest improvements in to-date neglected cognitive systems can allow LLMs to apply their cognitive abilities in more ways, allowing more human-like routes to performance and learning. These strengths will build on each other nonlinearly (while likely also encountering unexpected roadblocks).
Timelines are thus very difficult to predict, but ruling out very short timelines based on averaging predictions without gears-level models of fast routes to AGI would be a big mistake. Whether and how quickly they work is an empirical question.
One blocker to taking short timelines seriously is the belief that fast timelines mean likely human extinction. I think they're extremely dangerous but that possible routes to alignment also exist - but that's a separate question.
I also think this is the current default path, or I wouldn't describe it.
I think my research career using deep nets and cognitive architectures to understand human cognition is pretty relevant for making good predictions on this path to AGI. But I'm biased [LW(p) · GW(p)], just like everyone else.
Anyway, here's very roughly why I think the gaps are smaller than they appear.
Current LLMs are like humans with excellent:
- language abilities,
- semantic memory
- working memory
They can now do almost all short time-horizon tasks that are framed in language better than humans. And other networks can translate real-world systems into language and code, where humans haven't already done it.
But current LLMs/foundation models are dramatically missing some human cognitive abilities:
- Almost no episodic memory for specific important experiences
- No agency - they do only what they're told
- Poor executive function (self-management of cognitive tasks)
- Relatedly, bad/incompetent at long time-horizon tasks.
- And zero continuous learning (and self-directed learning)
- Crucial for human performance on complex tasks
Those lacks would appear to imply long timelines.
But both long time-horizon tasks and self-directed learning are fairly easy to reach. The gaps are not as large as they appear.
Agency is as simple as repeatedly calling a prompt of "act as an agent working toward goal X; use tools Y to gather information and take actions as appropriate". The gap between a good oracle and an effective agent is almost completely illusory.
Episodic memory is less trivial, but still relatively easy to improve from current near-zero-effort systems. Efforts from here will likely build on LLMs strengths. I'll say no more publicly; DM me for details. But it doesn't take a PhD in computational neuroscience to rederive this, which is the only reason I'm mentioning it publicly. More on infohazards later.
Now to the capabilities payoff: long time-horizon tasks and continuous, self-directed learning.
Long time-horizon task abilities are an emergent product of episodic memory and general cognitive abilities. LLMs are "smart" enough to manage their own thinking; they don't have instructions or skills to do it. o1 appears to have those skills (although no episodic memory which is very helpful in managing multiple chains of thought), so similar RL training on Chains of Thought is probably one route achieving those.
Humans do not mostly perform long time-horizon tasks by trying them over and over. They either ask someone how to do it, then memorize and reference those strategies with episodic memory; or they perform self-directed learning, and pose questions and form theories to answer those same questions.
Humans do not have or need "9s of reliability" to perform long time-horizon tasks. We substitute frequent error-checking and error-correction. We then learn continuously on both strategy (largely episodic memory) and skills/habitual learning (fine-tuning LLMs already provides a form of this habitization of explicit knowledge to fast implicit skills).
Continuous, self-directed learning is a product of having any type of new learning (memory), and using some of the network/agents' cognitive abilities to decide what's worth learning. This learning could be selective fine-tuning (like o1s "deliberative alignment), episodic memory, or even very long context with good access as a first step. This is how humans master new tasks, along with taking instruction wisely. This would be very helpful for mastering economically viable tasks, so I expect real efforts put into mastering it.
Self-directed learning would also be critical for an autonomous agent to accomplish entirely novel tasks, like taking over the world.
This is why I expect "Real AGI [LW · GW]" that's agentic and learns on its own, and not just transformative tool "AGI" within the next five years (or less). It's easy and useful, and perhaps the shortest path to capabilities (as with humans teaching themselves).
If that happens, I don't think we're necessarily doomed, even without much new progress on alignment (although we would definitely improve our odds!). We are already teaching LLMs mostly to answer questions correctly and to follow instructions. As long as nobody gives their agent an open-ended top-level goal like "make me lots of money", we might be okay. Instruction-following AGI is easier and more likely than value aligned AGI [LW · GW] although I need to work through and clarify why I find this so central. I'd love help.
Convincing predictions are also blueprints for progress. Thus, I have been hesitant to say all of that clearly.
I said some of this at more length in Capabilities and alignment of LLM cognitive architectures [LW · GW] and elsewhere. But I didn't publish it in my previous neuroscience career nor have I elaborated since then.
But I'm increasingly convinced that all of this stuff is going to quickly become obvious to any team that sits down and starts thinking seriously about how to get from where we are to really useful capabilities. And more talented teams are steadily doing just that.
I now think it's more important that the alignment community takes short timelines more seriously, rather than hiding our knowledge in hopes that it won't be quickly rederived. There are more and more smart and creative people working directly toward AGI. We should not bet on their incompetence.
There could certainly be unexpected theoretical obstacles. There will certainly be practical obstacles. But even with expected discounts for human foibles and idiocy and unexpected hurdles, timelines are not long. We should not assume that any breakthroughs are necessary, or that we have spare time to solve alignment adequately to survive.
↑ comment by Lukas_Gloor · 2025-03-06T12:46:04.405Z · LW(p) · GW(p)
Great reply!
On episodic memory:
I've been watching Claude play Pokemon recently and I got the impression of, "Claude is overqualified but suffering from the Memento-like memory limitations. Probably the agent scaffold also has some easy room for improvements (though it's better than post-it notes and tatooing sentences on your body)."
I don't know much about neuroscience or ML, but how hard can it be to make the AI remember what it did a few minutes ago? Sure, that's not all that's between claude and TAI, but given that Claude is now within the human expert range on so many tasks, and given how fast progress has been recently, how can anyone not take short timelines seriously?
People who largely rule out 1-5y timelines seem to not have updated at all on how much they've presumably been surprised by recent AI progress.
(If someone had predicted a decent likelihood for transfer learning and PhD level research understanding shortly before those breakthroughs happened, followed by predicting a long gap after that, then I'd be more open to updating towards their intuitions. However, my guess is that people who have long TAI timelines now also held now-wrong confident long timelines for breakthroughs in transfer learning (etc.), and so, per my perspective, they arguably haven't made the update that whatever their brain is doing when they make timelines forecast is not very good.)
↑ comment by Kaj_Sotala · 2024-12-27T20:38:57.640Z · LW(p) · GW(p)
Thanks, this is the kind of comment that tries to break down things by missing capabilities that I was hoping to see.
Episodic memory is less trivial, but still relatively easy to improve from current near-zero-effort systems
I agree that it's likely to be relatively easy to improve from current systems, but just improving it is a much lower bar than getting episodic memory to actually be practically useful. So I'm not sure why this alone would imply a very short timeline. Getting things from "there are papers about this in the literature" to "actually sufficient for real-world problems" often takes a significant time, e.g.:
- I believe that chain-of-thought prompting was introduced in a NeurIPS 2022 paper. Going from there to a model that systematically and rigorously made use of it (o1) took about two years, even though the idea was quite straightforward in principle.
- After the 2007 DARPA Grand Challenge there was a lot of hype about how self-driving cars were just around the corner, but almost two decades later, they’re basically still in beta.
My general prior is that this kind of work - from conceptual prototype to robust real-world application - can in general easily take between years to decades, especially once we move out of domains like games/math/programming and into ones that are significantly harder to formalize and test [LW(p) · GW(p)]. Also, the more interacting components you have, the trickier it gets to test and train.
Replies from: Seth Herd, sharmake-farah↑ comment by Seth Herd · 2024-12-27T21:12:43.273Z · LW(p) · GW(p)
I think the intelligence inherent in LLMs will make episodic memory systems useful immediately. The people I know building chatbots with persistent memory were already finding it useful with vector databases, it just topped out in capacity quickly by slowing down memory search too much. And that was as of a year ago.
I don't think I managed to convey one central point, which is that reflection and continuous learning together can fill a lot of cognitive gaps. I think they do for humans. We can analyze our own thinking and then use new strategies where appropriate. It seems like the pieces are all there for LLM cognitive architectures to do this as well. Such a system will still take time to dramatically self-improve by re-engineering its base systems. But there's a threshold of general intelligence and self-directed learning in which a system can self-correct and self-improve in limited but highly useful ways, so that its designers don't have to fix very flaw by hand, and it can just back up and try again differently.
I don't like the term unhobbling because it's more like adding cognitive tools that make new uses of LLMs considerable flexible intelligence.
All of the continuous learning approaches that would enable self-directed continuous are clunky now but there are no obvious roadblocks to their improving rapidly when a few competent teams start working on them full-time. And since there are multiple approaches already in play, there's a better chance some combination become useful quickly.
Yes, refining it and other systems will take time. But counting on it being a long time doesn't seem sensible. I am considering writing the complementary post, "what are the best arguments for long timelines". I'm curious. I expect the strongest ones to support something like five year timelines to what I consider AGI - which importantly is fully general in that it can learn new things, but will not meet the bar of doing 95% of remote jobs because it's not likely to be human-level in all areas right away.
I focus on that definition because it seems like a fairly natural category shift from limited tool AI to sapience and understanding [LW · GW] in "Real AGI" [LW · GW] that roughly match our intuitive understanding of humans as entities, minds, or beings that understand and can learn about themselves if they choose to.
The other reason I focus on that transition is that I expect it to function as a wake-up call to those who don't imagine agentic AI in detail. It will match their intuitions about humans well enough for our recognition of humans as very dangerous to also apply to that type of AI. Hopefully their growth from general-and-sapient-but-dumb-in-soe-ways will be slow enough for society to adapt - months to years may be enough.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2024-12-29T20:48:04.989Z · LW(p) · GW(p)
Thanks. Still not convinced, but it will take me a full post to explain why exactly. :)
Though possibly some of this is due to a difference in definitions. When you say this:
what I consider AGI - which importantly is fully general in that it can learn new things, but will not meet the bar of doing 95% of remote jobs because it's not likely to be human-level in all areas right away
Do you have a sense of how long you expect it will take for it to go from "can learn new things" to "doing 95% of remote jobs"? If you e.g. expect that it might still take several years for AGI to master most jobs once it has been created, then that might be more compatible with my model.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-12-31T18:29:53.837Z · LW(p) · GW(p)
I do think our models may be pretty similar once we get past slightly different definitions of AGI.
It's pretty hard to say how fast the types of agents I'm envisioning would take off. It could be a while between what I'm calling real AGI that can learn anything, and having it learn well and quickly enough, and be smart enough, to do 95% of remote jobs. If there aren't breakthroughs in learning and memory systems, it could take as much as three years to really start doing substantial work, and be a slow progression toward 95% of jobs as it's taught and teaches itself new skills. The incremental improvements on existing memory systems - RAG, vector databases, and fine-tuning for skills and new knowledge - would remain clumsier than human learning for a while.
This would be potentially very good for safety. Semi-competent agents that aren't yet takeover-capable might wake people up to the alignment and safety issues. And I'm optimistic about the agent route for technical alignment; of course that's a more complex issue. Intent alignment as a stepping-stone to value alignment [LW · GW] gives the broad outline and links to more work on how instruction-following language model agents might bypass some of the worst concerns about goal mis-specification and mis-generalization and risks from optimization.
You made a good point in the linked comment that these systems will be clumsier to train and improve if they have more moving parts. My impression from the little information I have on agent projects is that this is true. But I haven't heard of a large and skilled team taking on this task yet; it will be interesting to see what one can do. And at some point, an agent directing its own learning and performance gains an advantage that can offset the disadvantage of being harder for humans to improve and optimize the underlying system.
I look forward to that post if you get around to writing it. I've been toying with the idea of writing a more complete post on my short timelines and slow takeoff scenario. Thanks for posing the question and getting me to dash off a short version at least.
↑ comment by Noosphere89 (sharmake-farah) · 2024-12-27T20:47:59.777Z · LW(p) · GW(p)
I'd argue that self-driving cars were essentially solved by Waymo in 2021-2024, and to a lesser extent I'd include Tesla in this too, and that a lot of the reason why self-driving cars aren't on the roads is because of liability issues, so in essence self-driving cars came 14-17 years after the DARPA grand challenge.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2024-12-29T20:44:40.874Z · LW(p) · GW(p)
Hmm, some years back I was hearing the claim that self-driving cars work badly in winter conditions, so are currently limited to the kinds of warmer climates where Waymo is operating. I haven't checked whether that's still entirely accurate, but at least I haven't heard any news of this having made progress.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2024-12-29T21:12:04.619Z · LW(p) · GW(p)
My guess is that a large portion of the "works badly in winter conditions" issue is closer to it does work reasonably well in winter climates, but it doesn't work so well that you can't be sued/have liability issues.
I'd argue the moral of self-driving cars is regulation can slow down tech considerably, which does have implications for AI policy.
I've been arguing for 2027-ish AGI for several years now. I do somewhat fall into the annoying category of refusing to give my full details for believing this (publicly). I've had some more in-depth discussions about this privately.
One argument I have been making publicly is that I think Ajeya's Bioanchors report greatly overestimated human brain compute. I think a more careful reading of Joe Carlsmith's report that hers was based on supports my own estimates of around 1e15 FLOPs.
Connor Leahy makes some points I agree with in his recent Future of Life interview. https://futureoflife.org/podcast/connor-leahy-on-why-humanity-risks-extinction-from-agi/
Another very relevant point is that recent research on the human connectome shows that long-range connections (particularly between regions of the cortex) are lower bandwidth than was previously thought. Examining this bandwidth in detail leads me to believe that efficient decentralized training should be possible. Even with considering that training a human brain equivalent model would require 10000x parallel brain equivalents to have a reasonable training time, the current levels of internet bandwidth between datacenters worldwide should be more than sufficient.
Thus, my beliefs are strongly pointint towards: "with the right algorithms we will have more than good enough hardware and more than sufficient data. Also, those algorithms are available to be found, and are hinted at by existing neuroscience data." Thus, with AI R&D accelerated research on algorithms, we should expect rapid progress on peak capabilities and efficiency which doesn't plateau at human-peak-capability or human-operation-speed. Super-fast and super-smart AGI within a few months of full AGI, and rapidly increasing speeds of progress leading up to AGI.
If I'm correct, then the period of time from 2026 to 2027 will contain as much progress on generally intelligent systems as all of history leading up to 2026. ASI will thus be possible before 2028.
Only social factors (e.g. massively destructive war or unprecedented international collaboration on enforcing an AI pause) will change these timelines.
Further thoughts here: A path to human autonomy [LW · GW]
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T20:51:21.960Z · LW(p) · GW(p)
Lots of disagree votes, but no discussion. So annoying when that happens.
Propose a bet! Ask for my sources! Point out a flaw in my reasoning! Don't just disagree and walk away!
Replies from: Vladimir_Nesov, sil-ver↑ comment by Vladimir_Nesov · 2024-12-23T22:42:15.437Z · LW(p) · GW(p)
Don't just disagree and walk away!
Feeding this norm creates friction, filters evidence elicited in the agreement-voting. If there is a sense that a vote needs to be explained, it often won't be cast.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-12-23T22:47:33.628Z · LW(p) · GW(p)
Agree. I do think it is annoying, but allowing people to do that is quite crucial for the integrity of the voting system.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-24T01:56:59.425Z · LW(p) · GW(p)
I'm not interested in modifying the site to prevent this, or even really modifying the underlying norm (much). I guess I'm just complaining on my own behalf, making an ask of the community. And the result was that the squeaky wheel got the grease, I got the thoughtful engagement I was hoping for.
So, in conclusion, I'll try to frame my future pleas for engagement in a way which doesn't imply I think the norm of voting-without-commenting is bad.
↑ comment by Rafael Harth (sil-ver) · 2024-12-23T21:42:56.849Z · LW(p) · GW(p)
I feel like a bet is fundamentally unfair here because in the cases where I'm wrong, there's a high chance that I'll be dead anyway and don't have to pay. The combination of long timelines but high P(doom|AGI soon) means I'm not really risking my reputation/money in the way I'm supposed to with a bet. Are you optimistic about alignment, or does this asymmetry not bother you for other reasons? (And I don't have the money to make a big bet regardless.)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T21:57:08.356Z · LW(p) · GW(p)
Great question! Short answer: I'm optimistic about muddling through with partial alignment combined with AI control and AI governance (limiting peak AI capabilities, global enforcement of anti-rogue-AI, anti-self-improving-AI, and anti-self-replicating-weapons laws). See my post "A Path to Human Autonomy" for more details.
I also don't have money for big bets. I'm more interested in mostly-reputation-wagers about the very near future. So that I might get my reputational returns in time for them to pay off in respectful-attention-from-powerful-decisionmakers, which in turn I would hope might pay off in better outcomes for me, my loved ones, and humanity.
If I am incorrect, then I want to not be given the ear of decision makers, and I want them to instead pay more attention to someone with better models than me. Thus, seems to me like a fairly win-win situation to be making short term reputational bets.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2024-12-23T22:03:55.754Z · LW(p) · GW(p)
Gotcha. I'm happy to offer 600 of my reputation points vs. 200 of yours on your description of 2026-2028 not panning out. (In general if it becomes obvious[1] that we're racing toward ASI in the next few years, then people should probably not take me seriously anymore.)
well, so obvious that I agree, anyway; apparently it's already obvious to some people. ↩︎
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T22:07:09.141Z · LW(p) · GW(p)
I'll happily accept that bet, but maybe we could also come up with something more specific about the next 12 months?
Example: https://manifold.markets/MaxHarms/will-ai-be-recursively-self-improvi
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2024-12-23T22:30:34.462Z · LW(p) · GW(p)
Not that one; I would not be shocked if this market resolves Yes. I don't have an alternative operationalization on hand; would have to be about AI doing serious intellectual work on real problems without any human input. (My model permits AI to be very useful in assisting humans.)
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-24T03:37:25.960Z · LW(p) · GW(p)
Hmm, yes. I agree that there's something about self-guiding /self-correcting on complex lengthy open-ended tasks where current AIs seem at near-zero performance.
I do expect this to improve dramatically in the next 12 months. I think this current lack is more about limitations in the training regimes so far, rather than limitations in algorithms/architectures.
Contrast this with the challengingness of ARC-AGI, which seems like maybe an architecture weakness?
↑ comment by Lukas Finnveden (Lanrian) · 2024-12-25T19:11:40.214Z · LW(p) · GW(p)
One argument I have been making publicly is that I think Ajeya's Bioanchors report greatly overestimated human brain compute. I think a more careful reading of Joe Carlsmith's report that hers was based on supports my own estimates of around 1e15 FLOPs.
Am I getting things mixed up, or isn’t that just exactly Ajeya’s median estimate? Quote from the report: ”Under this definition, my median estimate for human brain computation is ~1e15 FLOP/s.”
https://docs.google.com/document/d/1IJ6Sr-gPeXdSJugFulwIpvavc0atjHGM82QjIfUSBGQ/edit
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-09T18:28:38.248Z · LW(p) · GW(p)
Yeah, to be more clear, it's not so much that she got that wrong. It's that she didn't accept the reasoning behind that number enough to really believe it. She added a discount factor based on fallacious reasoning around "if it were that easy, it'd be here already".
Some hypotheses predict that we should have already been able to afford to train a transformative model with reasonable probability; I think this is unlikely, so I execute an update against low levels of FLOP...
In my opinion the correct takeaway from an estimate showing that "a low number of FLOPs should be enough if the right algorithm is used" combined with "we don't seem close, and are using more FLOPs than that already" is "therefore, our algorithms must be pretty crap and there must be lots of room for algorithmic improvement." Thus, that we are in a compute hardware overhang and that algorithmic improvement will potentially result in huge capabilities gains, speed gains, and parallel inference instances. Of course, if our algorithms are really that far from optimal, why should we not expect to continue to be bottlenecked by algorithms? The conclusion I come to is that if we can compensate for inefficient algorithms with huge over-expenditure in compute, then we can get a just-barely-good-enough ML research assistant who can speed up the algorithm progress. So we should expect training costs to drop rapidly after automating ML R&D.
Then she also blended the human brain compute estimate with three other estimates which were multiple orders of magnitude larger. These other estimates were based on, in my opinion, faulty premises.
I first lay out four hypotheses about 2020 training computation requirements, each of which anchors on a key quantity estimated from biology: total computation done over evolution, total computation done over a human lifetime, the computational power of the human brain, and the amount of information in the human genome...
Since the time of her report she has had to repeatedly revise her timelines down. Now she basically agrees with me. Props to her for correcting.
https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp [LW(p) · GW(p)]
Replies from: Lanrian↑ comment by Lukas Finnveden (Lanrian) · 2025-01-10T18:03:32.920Z · LW(p) · GW(p)
Ok, gotcha.
It's that she didn't accept the reasoning behind that number enough to really believe it. She added a discount factor based on fallacious reasoning around "if it were that easy, it'd be here already".
Just to clarify: There was no such discount factor that changed the median estimate of "human brain compute". Instead, this discount factor was applied to go from "human brain compute estimate" to "human-brain-compute-informed estimate of the compute-cost of training TAI with current algorithms" — adjusting for how our current algorithm seem to be worse than those used to run the human brain. (As you mention and agree with, although I infer that you expect algorithmic progress to be faster than Ajeya did at the time.) The most relevant section is here.
↑ comment by yo-cuddles · 2024-12-23T21:00:18.301Z · LW(p) · GW(p)
I think the algorithm progress is doing some heavy lifting in this model. I think if we had a future textbook on agi we could probably build one but AI is kinda famous for minor and simple things just not being implemented despite all the parts being there
See ReLU activations and sigmoid activations.
If we're bottlenecking at algorithms alone is there a reason that isn't a really bad bottleneck?
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T22:04:35.347Z · LW(p) · GW(p)
See my other response to Raphael elsewhere in this comment thread.
My model is that the big AI labs are currently throttling algorithmic progress by choosing to devote their resources to scaling.
If scaling leads to AGI, we get AGI soon that way. (I give this about 20% chance.)
If scaling doesn't lead to AGI, then refocusing resources on experimentation seems like a natural next move. (I think this is about 80% likely to work in under two years if made a major focus of resources, including both giving human researchers the time, encouragement and compute resources they need, plus developing increasingly helpful AI reseachers.)
Replies from: yo-cuddles↑ comment by yo-cuddles · 2024-12-23T22:24:29.530Z · LW(p) · GW(p)
Hmm, mixed agree/disagree. Scale probably won't work, algorithms probably would, but I don't think it's going to be that quick.
Namely, I think that the company struggling with fixed capital costs could accomplish much more, much quicker using the salary expenses of the top researchers they already have they'd have done it or gave it a good try at least
I'm 5 percent that a serious switch to algorithms would result in AGI in 2 years. You might be more well read than me on this so I'm not quite taking side bets right now!
An AGI broadly useful for humans needs to be good at general tasks for which currently there is no way of finding legible problem statements (where System 2 reasoning is useful) with verifiable solutions. Currently LLMs are slightly capable at such tasks, and there are two main ways in which they become more capable, scaling and RL.
Scaling is going to continue rapidly showing new results at least until 2026-2027, probably also 2028-2029 [LW · GW]. If there's no AGI or something like a $10 trillion AI company by then, there won't be a trillion dollar training system and the scaling experiments will fall back to the rate of semiconductor improvement.
Then there's RL, which as o3 demonstrates applies to LLMs as a way of making them stronger and not merely eliciting capabilities formed in pretraining. But it only works directly around problem statements with verifiable solutions, and it's unclear how to generate them for more general tasks or how far will the capabilities generalize from the training problems that are possible to construct in bulk. (Arguably self-supervised learning is good at instilling general capabilities because the task of token prediction is very general, it subsumes all sorts of things. But it's not legible.) Here too scale might help with generalization stretching further from the training problems, and with building verifiable problem statements for more general tasks, and we won't know how much it will help until the experiments are done.
So my timelines are concentrated on 2025-2029, after that the rate of change in capabilities goes down. Probably 10 more years of semiconductor and algorithmic progress after that are sufficient to wrap it up though, so 2040 without AGI seems unlikely.
↑ comment by Cole Wyeth (Amyr) · 2024-12-23T23:48:06.176Z · LW(p) · GW(p)
I agree with this picture pretty closely. I think 2025 is unlikely, because there are probably a couple of tricks left to invent. But 2026-30 carries a lot of probability mass, and the rest is spread out over decades.
I have seen a poll asking "when will indefinite lifespans be possible?", and Eric Drexler answered "1967", because that was when cryonic suspension first became available.
Similarly, I think we've had AGI at least since 2022, because even then, ChatGPT was an intelligence, and it was general, and it was artificial.
(To deny that the AIs we have now have general intelligence, I think one would have to deny that most humans have general intelligence, too.)
So that's my main reason for very short timelines. We already crossed the crucial AGI threshold through the stupid serendipity of scaling up autocomplete, and now it's just a matter of refining the method, and attaching a few extra specialized modules.
↑ comment by tangerine · 2024-12-24T12:24:14.130Z · LW(p) · GW(p)
I agree with this view. Deep neural nets trained with SGD can learn anything. (“The models just want to learn.”) Human brains are also not really different from brains of other animals. I think the main struggles are 1. scaling up compute, which follows a fairly predictable pattern, and 2. figuring out what we actually want them to learn, which is what I think we’re most confused about.
Summary: Superintelligence in January-August, 2026. Paradise or mass death, shortly thereafter.
This is the shortest timeline proposed in these answers so far. My estimate (guess) is that there's only 20% of this coming true, but it looks feasible as of now. I can't honestly assert it as fact, but I will say it is possible.
It's a standard intelligence explosion scenario: with only human effort, the capacities of our AIs double every two years. Once AI gets good enough to do half the work, we double every one year. Once we've done that for a year, our now double-smart AIs help us double in six months. Then we double in three months, then six weeks.... to perfect ASI software, running at the the limits of our hardware, in a finite time. Then the ASI does what it wants, and we suffer what we must.
I hear you say "Carl, this argument is as old as the hills. It hasn't ever come true, why bring it up now?" The answer is, I bring it up because it seems to be happening.
- For at least six months now, we've had software assistants that can roughly double the productivity of software development. At least at the software company where I work, people using AI (including me) are seeing huge increases in effectiveness. I assume the same is true of AI software development, and that AI labs are using this technology as much as they can.
- In the last few months, there's been a perceptible increase in the speed of releases of better models. I think this is a visible (subjective, debatable) sign of an intelligence explosion starting up.
So I think we're somewhere in the "doubling in one year" phase of the explosion. If we're halfway through that year, the singularity is due in August 2026. If we're near the end of that year, the date is January 2026.
There are lots of things that might go wrong with this scenario, and thereby delay the intelligence explosion. I will mention a few, so you don't have to.
First, the government might stop the explosion, by banning AI being used for the development of AI. Or perhaps the management of all major AI labs will spontaneously not be so foolish as to. This will delay the problem for an unknown time.
Second, the scenario has an extremely naive model of intelligence explosion microeconomics. It assumes that one doubling of "smartness" produces one doubling of speed. In Yudkowsky's original scenario, AIs were doing all the work of development, and this might be a sensible assumption. But what has actually happened is that successive generations of AI can handle larger and larger tasks, before they go off the rails. And they can handle these tasks far faster than humans. So the way we work now is that we ask the AI to do some small task, and bang, it's done. It seems like testing is showing that current AIs can do things that would take a human up to an hour or two. Perhaps the next generation will be able to do tasks up to four hours. The model assumes that this allows a twofold speedup, then fourfold, etc. But this assumption is unsupported.
Third, the scenario assumes that near-term hardware is sufficient for superintelligence. There isn't time for the accelerating loop to take effect in hardware. Even if design was instant, the physical processes of mask making, lithography, testing, yield optimization and mass production take more than a year. The chips that the ASI will run on in mid-2026 have their design almost done now, at the end of 2024. So we won't be able to get to ASI, if the ASI requires many orders of magnitude more FLOPs than current models. Instead, we'll have to wait until the AI designs future generations of semiconductor technology. This will delay matters by years (if using humans to build things) or hours (if using nanotechnology.)
(I don't think the hardware limit is actually much of a problem; AIs have recently stopped scaling in numbers of parameters and size of training data. Good engineers are constantly figuring out how to pack more intelligence into the same amount of computation. And the human brain provides an existence proof that human-level intelligence requires much less training data. Like Mr. Helm-Burger above, I think human-equivalent cognition is around 10^15 Flops. But reasonable people disagree with me.)
↑ comment by xpym · 2024-12-25T10:48:23.995Z · LW(p) · GW(p)
For at least six months now, we’ve had software assistants that can roughly double the productivity of software development.
Is this the consensus view? I've seen people saying that those assistants give 10% productivity improvement, at best.
In the last few months, there’s been a perceptible increase in the speed of releases of better models.
On the other hand, the schedules for headline releases (GPT-5, Claude 3.5 Opus) continue to slip, and there are anonymous reports of diminishing returns from scaling. The current moment is interesting in that there are two essentially opposite prevalent narratives barely interacting with each other.
Replies from: carl-feynman↑ comment by Carl Feynman (carl-feynman) · 2024-12-26T19:45:18.691Z · LW(p) · GW(p)
Is this the consensus view? I think it’s generally agreed that software development has been sped up. A factor of two is ambitious! But that’s what it seems to me, and I’ve measured three examples of computer vision programming, each taking an hour or two, by doing them by hand and then with machine assistance. The machines are dumb and produce results that require rewriting. But my code is also inaccurate on a first try. I don’t have any references where people agree with me. And this may not apply to AI programming in general.
You ask about “anonymous reports of diminishing returns to scaling.” I have also heard these reports, direct from a friend who is a researcher inside a major lab. But note that this does not imply a diminished rate of progress, since there are other ways to advance besides making LLMs bigger. O1 and o3 indicate the payoffs to be had by doing things other than pure scaling. If there are forms of progress available to cleverness, then the speed of advance need not require scaling.
We should expect a significant chance of very short (2-5 year) timelines because we don't have good estimates of timelines.
We are estimating an ETA by having good estimates of our position and velocity, but not a well-known destination.
A good estimate of the end point for timelines would require a good gears-level models of AGI. We don't have that.
The rational thing to do is admit that we have very broad uncertainties, and make plans for different possible timelines. I fear we're mostly just hoping tinmelines aren't really short.
This argument is separate from and I think stronger than my other answer with specific reasons to find short timelines plausible. Short timelines are plausible as a baseline. We'd all probably agree that LLMs are doing a lot of what humans do (if you don't, see my answer here and in slightly different terms in my response [LW(p) · GW(p)] to Thane Ruthenis' more recent Bear Case for AI Progress [LW · GW]. - my point is that "most of what humans do" is highly debatable. And we should not be reasoning with point estimates.
↑ comment by arisAlexis (arisalexis) · 2025-03-06T17:31:23.539Z · LW(p) · GW(p)
no 2. is much more important than academic ML researchers which is the majority of the surveys done. When someone delivers a product and is the only one building it and they tells you X, you should belive X unless there is a super strong argument for the contrary and there just isn't.
I have a meta-view on this that you might think falls into the bucket of "feels intuitive based on the progress so far". To counter that, this isn't pure intuition. As a side note I don't believe that intuitions should be dismissed and should be at least a part of our belief updating process.
I can't tell you the fine details of what will happen and I'm suspicious of anyone who can because a) this is a very complex system b) no-one really knows how LLMs work, how human cognition works, or what is required for an intelligence takeoff.
However, I can say that for the last decade or so most predictions of AI progress have been on consistently longer timescales than what has happened. Things are happening quicker than the experts believe they will happen. Things are accelerating.
I also believe that there are many paths to AGI, and that given the amount of resources currently being put into the search for one of those paths, they will be found sooner rather than later.
The intelligence takeoff is already happening.
It's worthy of a (long) post, but I'll try to summarize. For what it's worth, I'll die on this hill.
General intelligence = Broad, cross-domain ability and skills.
Narrow intelligence = Domain-specific or task-specific skills.
The first subsumes the second at some capability threshold.
My bare bones definition of intelligence: prediction. It must be able to consistently predict itself & the environment. To that end it necessarily develops/evolves abilities like learning, environment/self sensing, modeling, memory, salience, planning, heuristics, skills, etc. Roughly what Ilya says about token prediction necessitating good-enough models to actually be able to predict that next token (although we'd really differ on various details)
Firstly, it's based on my practical and theoretical knowledge of AI and insights I believe to have had into the nature of intelligence and generality for a long time. It also includes systems, cybernetics, physics, etc. I believe a holistic view helps inform best w.r.t. AGI timelines. And these are supported by many cutting edge AI/robotics results of the last 5-9 years (some old work can be seen in new light) and also especially, obviously, the last 2 or so.
Here are some points/beliefs/convictions I have for thinking AGI for even the most creative goalpost movers is basically 100% likely before 2030, and very likely much sooner. A fast takeoff also, understood as the idea that beyond a certain capability threshold for self-improvement, AI will develop faster than natural, unaugmented humans can keep up with.
It would be quite a lot of work to make this very formal, so here are some key points put informally:
- Weak generalization has been already achieved. This is something we are piggybacking off of already, and there is meaningful utility since GPT-3 or so. This is an accelerating factor.
- Underlying techniques (transformers , etc) generalize and scale.
- Generalization and performance across unseen tasks improves with multi-modality.
- Generalist models outdo specialist ones in all sorts of scenarios and cases.
- Synthetic data doesn't necessarily lead to model collapse and can even be better than real world data.
- Intelligence can basically be brute-forced it looks like, so one should take Kurzweil *very* seriously (he tightly couples his predictions to increase in computation).
- Timelines shrunk massively across the board for virtually all top AI names/experts in the last 2 years. Top Experts were surprised by the last 2 years.
- Bitter Lesson 2.0.: there are more bitter lessons than Sutton's, which are that all sorts of old techniques can be combined for great increases in results. See the evidence in papers linked below.
- "AGI" went from a taboo "bullshit pursuit for crackpots", to a serious target of all major labs, publicly discussed. This means a massive increase in collective effort, talent, thought, etc. No more suppression of cross-pollination of ideas, collaboration, effort, funding, etc.
- The spending for AI only bolsters, extremely so, the previous point. Even if we can't speak of a Manhattan Project analogue, you can say that's pretty much what's going on. Insane concentrations of talent hyper focused on AGI. Unprecedented human cycles dedicated to AGI.
- Regular software engineers can achieve better results or utility by orchestrating current models and augmenting them with simple techniques(RAG, etc). Meaning? Trivial augmentations to current models increase capabilities - this low hanging fruit implies medium and high hanging fruit (which we know is there, see other points).
I'd also like to add that I think intelligence is multi-realizable, and generality will be considered much less remarkable soon after we hit it and realize this than some still think it is.
Anywhere you look: the spending, the cognitive effort, the (very recent) results, the utility, the techniques...it all points to short timelines.
In terms of AI papers, I have 50 references or so I think support the above as well. Here are a few:
SDS : See it. Do it. Sorted Quadruped Skill Synthesis from Single Video Demonstration, Jeffrey L., Maria S., et al. (2024).
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning, Zhenyu J., Yuqi X., et in. (2024).
One-Shot Imitation Learning, Duan, Andrychowicz, et al. (2017).
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, Finn et al., (2017).
Unsupervised Learning of Semantic Representations, Mikolov et al., (2013).
A Survey on Transfer Learning, Pan and Yang, (2009).
Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly, Xian et al., (2018).
Learning Transferable Visual Models From Natural Language Supervision, Radford et al., (2021).
Multimodal Machine Learning: A Survey and Taxonomy, Baltrušaitis et al., (2018).
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine, Harsha N., Yin Tat Lee et al. (2023).
A Vision-Language-Action Flow Model for General Robot Control, Kevin B., Noah B., et al. (2024).
Open X-Embodiment: Robotic Learning Datasets and RT-X Models, Open X-Embodiment Collaboration, Abby O., et al. (2023).
11 comments
Comments sorted by top scores.
comment by Lukas_Gloor · 2024-12-23T11:50:42.055Z · LW(p) · GW(p)
It surveyed 2,778 AI researchers who had published peer-reviewed research in the prior year in six top AI venues (NeurIPS, ICML, ICLR, AAAI, IJCAI, JMLR); the median time for a 50% chance of AGI was either in 23 or 92 years, depending on how the question was phrased.
Doesn't that discrepancy (how much answers vary between different ways of asking the question) tell you that the median AI researcher who published at these conferences hasn't thought about this question sufficiently and/or sanely?
It seems irresponsible to me to update even just a small bit to the specific reference class of which your above statement is true.
If you take people who follow progress closely and have thought more and longer about AGI as a research target specifically, my sense is that the ones who have longer timeline medians tend to say more like 10-20y rather than 23y+. (At the same time, there's probably a bubble effect in who I follow or talk to, so I can get behind maybe lengthening that range a bit.)
Doing my own reasoning, here are the considerations that I weigh heavily:
- we're within the human range of most skill types already (which is where many of us in the past would have predicted that progress speeds up, and don't see any evidence of anything that should change our minds on that past prediction – deep learning visibly hitting a wall would have been one conceivable way, but it hasn't happened yet)
- that time for "how long does it take to cross and overshoot the human range at a given skill?" has historically gotten a lot smaller and is maybe even decreasing(?) (e.g., it admittedly took a long time to cross the human expert range in chess, but it took less long in Go, less long at various academic tests or essays, etc., to the point that chess certainly doesn't constitute a typical baseline anymore)
- that progress has been quite fast lately, so that it's not intuitive to me that there's a lot of room left to go (sure, agency and reliability and "get even better at reasoning")
- that we're pushing through compute milestones rather quickly because scaling is still strong with some more room to go, so on priors, the chance that we cross AGI compute thresholds during this scale-up is higher than that we'd cross it once compute increases slow down
that o3 seems to me like significant progress in reliability, one of the things people thought would be hard to make progress on
Given all that, it seems obvious that we should have quite a lot of probability of getting to AGI in a short time (e.g., 3 years). Placing the 50% forecast feels less obvious because I have some sympathy for the view that says these things are notoriously hard to forecast and we should smear out uncertainty more than we'd intuitively think (that said, lately the trend has been that people consistently underpredict progress, and maybe we should just hard-update on that.) Still, even on that "it's prudent to smear out the uncertainty" view, let's say that implies that the median would be like 10-20 years away. Even then, if we spread out the earlier half of probability mass uniformly over those 10-20 years, with an added probability bump in the near-term because of the compute scaling arguments (we're increasing training and runtime compute now but this will have to slow down eventually if AGI isn't reached in the next 3-6 years or whatever), that IMO very much implies at least 10% for the next 3 years. Which feels practically enormously significant. (And I don't agree with smearing things out too much anyway, so my own probability is closer to 50%.)
↑ comment by Kaj_Sotala · 2024-12-23T15:23:34.236Z · LW(p) · GW(p)
Doesn't that discrepancy (how much answers vary between different ways of asking the question) tell you that the median AI researcher who published at these conferences hasn't thought about this question sufficiently and/or sanely?
We know that AI expertise and AI forecasting are separate skills and that we shouldn't expect AI researchers to be skilled at the latter. So even if researchers have thought sufficiently and sanely about the question of "what kinds of capabilities are we still missing that would be required for AGI", they would still be lacking the additional skill of "how to translate those missing pieces into a timeline estimate".
Suppose that a researcher's conception of current missing pieces is a mental object M, their timeline estimate is a probability function P, and their forecasting expertise F is a function that maps M to P. In this model, F can be pretty crazy, creating vast differences in P depending how you ask, while M is still solid.
I think the implication is that these kinds of surveys cannot tell us anything very precise such as "is 15 years more likely than 23", but we can use what we know about the nature of F in untrained individuals to try to get a sense of what M might be like. My sense is that answers like "20-93 years" often translate to "I think there are major pieces missing and I have no idea of how to even start approaching them, but if I say something that feels like a long time, maybe someone will figure it out in that time", "0-5 years" means "we have all the major components and only relatively straightforward engineering work is needed for them", and numbers in between correspond to Ms that are, well, somewhere in between those.
Replies from: Lukas_Gloor↑ comment by Lukas_Gloor · 2024-12-23T16:00:31.450Z · LW(p) · GW(p)
Suppose that a researcher's conception of current missing pieces is a mental object M, their timeline estimate is a probability function P, and their forecasting expertise F is a function that maps M to P. In this model, F can be pretty crazy, creating vast differences in P depending how you ask, while M is still solid.
Good point. This would be reasonable if you think someone can be super bad at F and still great at M.
Still, I think estimating "how big is this gap?" and "how long will it take to cross it?" might quite related, so I expect the skills to be correlated or even strongly correlated.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2024-12-23T16:48:27.443Z · LW(p) · GW(p)
I think their relationship depends on whether crossing the gap requires grind or insight. If it's mostly about grind then a good expert will be able to estimate it, but insight tends to unpredictable by nature.
Another way of looking at my comment above would be that timelines of less than 5 years would imply the remaining steps mostly requiring grind, and timelines of 20+ years would imply that some amount of insight is needed.
↑ comment by Kaj_Sotala · 2024-12-23T16:42:52.946Z · LW(p) · GW(p)
we're within the human range of most skill types already
That would imply that most professions would be getting automated or having their productivity very significantly increased. My impression from following the news and seeing some studies is that this is happening within copywriting, translation, programming, and illustration. [EDIT: and transcription] Also people are turning to chatbots for some types of therapy, though many people will still intrinsically prefer a human for that and it's not affecting the employment of human therapists yet. With o3, math (and maybe physics) research is starting to be affected, though it mostly hasn't been yet.
I might be forgetting some, but the amount of professions left out of that list suggests that there are quite a few skill types that are still untouched. (There are of course a lot of other professions for which there have been moderate productivity boosts, but AFAIK mostly not to the point that it would affect employment.)
comment by samuelshadrach (xpostah) · 2024-12-23T09:55:49.779Z · LW(p) · GW(p)
+1
On lesswrong, everyone and their mother has an opinion on AI timelines. People just stating their views without any arguments doesn't add a lot of value to the conversation. It would be good if there was a single (monthly? quarterly?) thread that collates all the opinions that are stated without proof. And outside of this thread only posts with some argumentation are allowed.
P.P.S. Sorry for the wrong link, it's fixed now
Replies from: xpostah↑ comment by samuelshadrach (xpostah) · 2024-12-23T09:57:24.508Z · LW(p) · GW(p)
If all the positions were collated in one place it'll also be easy to get some statistics about them a few years from now.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-12-23T20:42:37.938Z · LW(p) · GW(p)
By then it'll be a project for historians, not heros. Not worth the effort.
Replies from: xpostah↑ comment by samuelshadrach (xpostah) · 2024-12-24T03:25:55.450Z · LW(p) · GW(p)
I think it depends on some factors actually.
For instance if we don’t get AGI by 2030 but lots of people still believe it could happen by 2040, we as a species might be better equipped to form good beliefs on it, figure out who to defer to, etc.
I already think this has happened btw. AI beliefs in 2024 are more sane on average than beliefs in say 2010 IMO.
P.S. I’m not talking about what you personally should do with your time and energy, maybe there’s other projects that appeal to you more. But I think it is worthwhile for someone to be doing the thing I ask. It won’t take much effort.
comment by TsviBT · 2024-12-23T18:07:06.662Z · LW(p) · GW(p)
You probably won't find good arguments because there don't seem to be any. Unless, of course, there's some big lab somewhere that, unlike the major labs we're aware of, has made massive amounts of progress and kept it secret, and you're talking to one of those people.
https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce [LW · GW]
comment by Gordon Seidoh Worley (gworley) · 2024-12-24T19:36:43.122Z · LW(p) · GW(p)
Most arguments I see in favor of AGI ignore economic constraints. I strongly suspect that we can't actually afford to create AGI yet; world GDP isn't high enough. They seem to be focused on inside-view arguments for why method X will make it happen, which sure, maybe, but even if we achieve AGI, if we aren't rich enough to run it or use it for anything it hardly matters.
So the question in my mind is, if you think AGI is soon, how are we getting the level of economic growth needed in the next 2-5 years to afford to use AGI at all before AGI is created?