Thomas Larsen's Shortform
post by Thomas Larsen (thomas-larsen) · 2022-11-08T23:34:10.214Z · LW · GW · 30 commentsContents
30 comments
30 comments
Comments sorted by top scores.
comment by Thomas Larsen (thomas-larsen) · 2023-05-18T05:17:53.836Z · LW(p) · GW(p)
Some claims I've been repeating in conversation a bunch:
Safety work (I claim) should either be focused on one of the following
- CEV-style full value loading, to deploy a sovereign
- A task AI that contributes to a pivotal act or pivotal process.
I think that pretty much no one is working directly on 1. I think that a lot of safety work is indeed useful for 2, but in this case, it's useful to know what pivotal process you are aiming for. Specifically, why aren't you just directly working to make that pivotal act/process happen? Why do you need an AI to help you? Typically, the response is that the pivotal act/process is too difficult to be achieved by humans. In that case, you are pushing into a difficult capabilities regime -- the AI has some goals that do not equal humanity's CEV, and so has a convergent incentive to powerseek and escape. With enough time or intelligence, you therefore get wrecked, but you are trying to operate in this window where your AI is smart enough to do the cognitive work, but is 'nerd-sniped' or focused on the particular task that you like. In particular, if this AI reflects on its goals and starts thinking big picture, you reliably get wrecked. This is one of the reasons that doing alignment research seems like a particularly difficult pivotal act to aim for.
↑ comment by ryan_greenblatt · 2023-05-18T06:17:26.286Z · LW(p) · GW(p)
For doing alignment research, I often imagine things like speeding up the entire alignment field by >100x.
As in, suppose we have 1 year of lead time to do alignment research with the entire alignment research community. I imagine producing as much output in this year as if we spent >100x serial years doing alignment research without ai assistance.
This doesn't clearly require using super human AIs. For instance, perfectly aligned systems as intelligent and well informed as the top alignment researchers which run at 100x the speed would clearly be sufficient if we had enough.
In practice, we'd presumably use a heterogeneous blend of imperfectly aligned ais with heterogeneous alignment and security interventions as this would yield higher returns.
(Imagining the capability profile of the AIs is similar to that if humans is often a nice simplifying assumption for low precision guess work.)
Note that during this accelerated time you also have access to AGI to experiment on!
[Aside: I don't particularly like the terminology of pivotal act/pivotal process which seems to ignore the imo default way things go well]
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2023-05-18T06:24:41.827Z · LW(p) · GW(p)
Why target speeding up alignment research during this crunch time period as opposed to just doing the work myself?
Conveniently, alignment work is the work I wanted to get done during that period, so this is nicely dual use. Admittedly, a reasonable fraction of the work will be on things which are totally useless at the start of such a period while I typically target things to be more useful earlier.
I also typically think the work I do is retargetable to general usages of ai (e.g., make 20 trillion dollars).
Beyond this, the world will probably be radically transformed prior to large scale usage of AIs which are strongly superhuman in most or many domains. (Weighting domains by importance.)
↑ comment by ryan_greenblatt · 2023-05-18T06:42:27.145Z · LW(p) · GW(p)
I also think "a task ai" is a misleading way to think about this: we're reasonably likely to be using a heterogeneous mix of a variety of AIs with differing strengths and training objectives.
Perhaps a task AI driven corporation?
comment by Thomas Larsen (thomas-larsen) · 2022-11-08T23:34:10.441Z · LW(p) · GW(p)
Deception is a particularly worrying alignment failure mode because it makes it difficult for us to realize that we have made a mistake: at training time, a deceptive misaligned model and an aligned model make the same behavior.
There are two ways for deception to appear:
- An action chosen instrumentally due to non-myopic future goals that are better achieved by deceiving humans now so that it has more power to achieve its goals in the future.
- Because deception was directly selected for as an action.
Another way of describing the difference is that 1 follows from an inner alignment failure: a mesaoptimizer learned an unintended mesaobjective that performs well on training, while 2 follows from an outer alignment failure — an imperfect reward signal.
Classic discussion of deception focuses on 1 (example 1 [LW · GW], example 2 [LW · GW]), but I think that 2 is very important as well, particularly because the most common currently used alignment strategy is RLHF, which actively selects for deception.
Once the AI has the ability to create strategies that involve deceiving the human, even without explicitly modeling the human, those strategies will win out and end up eliciting a lot of reward. This is related to the informed oversight problem: it is really hard to give feedback to a model that is smarter than you. I view this as a key problem with RLHF. To my knowledge very little work has been done exploring this and finding more empirical examples of RLHF models learning to deceive the humans giving it feedback, which is surprising to me because it seems like it should be possible.
Replies from: Vladimir_Nesov, thomas-larsen, Emrik North↑ comment by Vladimir_Nesov · 2022-11-09T00:13:48.880Z · LW(p) · GW(p)
An interpretable system trained for the primary task of being deceptive should honestly explain its devious plots in a separate output. An RLHF-tuned agent loses access [LW · GW] to the original SSL-trained map of the world.
So the most obvious problem is the wrong type signature of model behaviors, there should be more inbuilt side channels to its implied cognition used to express and train capabilities/measurements relevant to what's going on semantically inside the model, not just externally observed output for its primary task, out of a black box.
↑ comment by Thomas Larsen (thomas-larsen) · 2022-11-08T23:37:54.326Z · LW(p) · GW(p)
I'm excited for ideas for concrete training set ups that would induce deception2 in an RLHF model, especially in the context of an LLM -- I'm excited about people posting any ideas here. :)
↑ comment by Emrik (Emrik North) · 2022-11-09T20:16:24.088Z · LW(p) · GW(p)
I've been exploring evolutionary metaphors to ML, so here's a toy metaphor for RLHF: recessive persistence. (Still just trying to learn both fields, however.)
"Since loss-of-function mutations tend to be recessive (given that dominant mutations of this type generally prevent the organism from reproducing and thereby passing the gene on to the next generation), the result of any cross between the two populations will be fitter than the parent." (k)
Related:
Recessive alleles persists due to overdominance letting detrimental alleles hitchhike on fitness-enhancing dominant counterpart. The detrimental effects on fitness only show up when two recessive alleles inhabit the same locus, which can be rare enough that the dominant allele still causes the pair to be selected for in a stable equilibrium.
The metaphor with deception breaks down due to unit of selection. Parts of DNA stuck much closer together than neurons in the brain or parameters in a neural networks. They're passed down or reinforced in bulk. This is what makes hitchhiking so common in genetic evolution.
(I imagine you can have chunks that are updated together for a while in ML as well, but I expect that to be transient and uncommon. Idk.)
Bonus point: recessive phase shift.
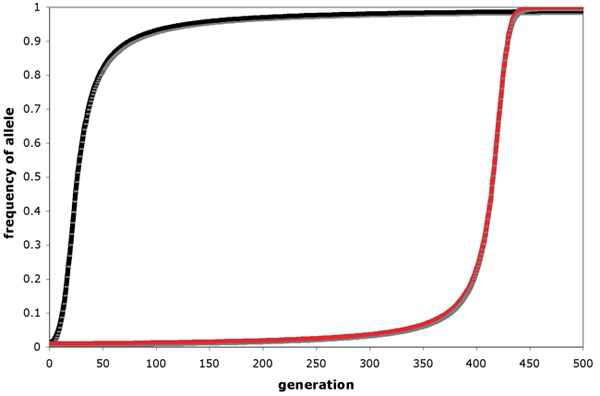
"Allele-frequency change under directional selection favoring (black) a dominant advantageous allele and (red) a recessive advantageous allele." (source)
In ML:
- Generalisable non-memorising patterns start out small/sparse/simple.
- Which means that input patterns rarely activate it, because it's a small target to hit.
- But most of the time it is activated, it gets reinforced (at least more reliably than memorised patterns).
- So it gradually causes upstream neurons to point to it with greater weight, taking up more of the input range over time. Kinda like a distributed bottleneck.
- Some magic exponential thing, and then phase shift [LW · GW]!
One way the metaphor partially breaks down because DNA doesn't have weight decay at all, so it allows for recessive beneficial mutations to very slowly approach fixation.
comment by Thomas Larsen (thomas-larsen) · 2023-04-12T00:01:19.275Z · LW(p) · GW(p)
Thinking about ethics.
After thinking more about orthogonality I've become more confident that one must go about ethics in a mind-dependent way. If I am arguing about what is 'right' with a paperclipper, there's nothing I can say to them to convince them to instead value human preferences or whatever.
I used to be a staunch moral realist, mainly relying on very strong intuitions against nihilism, and then arguing something that not nihilism -> moral realism. I now reject the implication, and think that there is both 1) no universal, objective morality, and 2) things matter.
My current approach is to think of "goodness" in terms of what CEV-Thomas would think of as good. Moral uncertainty, then, is uncertainty over what CEV-Thomas thinks. CEV is necessary to get morality out of a human brain, because it is currently a bundle of contradictory heuristics. However, my moral intuitions still give bits about goodness. Other people's moral intuitions also give some bits about goodness, because of how similar their brains are to mine, so I should weight other peoples beliefs in my moral uncertainty.
Ideally, I should trade with other people so that we both maximize a joint utility function, instead of each of us maximizing our own utility function. In the extreme, this looks like ECL. For most people, I'm not sure that this reasoning is necessary, however, because their intuitions might already be priced into my uncertainty over my CEV.
Replies from: Dagon↑ comment by Dagon · 2023-04-12T17:55:53.054Z · LW(p) · GW(p)
I tend not to believe that systems dependent on legible and consistent utility functions of other agents are not possible. If you're thinking in terms of a negotiated joint utility function, you're going to get gamed (by agents that have or appear to have extreme EV curves, so you have to deviate more than them). Think of it as a relative utility monster - there's no actual solution to it.
comment by Thomas Larsen (thomas-larsen) · 2023-03-13T06:24:08.553Z · LW(p) · GW(p)
Current impressions of free energy in the alignment space.
- Outreach to capabilities researchers. I think that getting people who are actually building the AGI to be more cautious about alignment / racing makes a bunch of things like coordination agreements possible, and also increases the operational adequacy of the capabilities lab.
- One of the reasons people don't like this is because historically outreach hasn't gone well, but I think the reason for this is that mainstream ML people mostly don't buy "AGI big deal", whereas lab capabilities researchers buy "AGI big deal" but not "alignment hard".
- I think people at labs running retreats, 1-1s, alignment presentations within labs are all great to do this.
- I'm somewhat unsure about this one because of downside risk and also 'convince people of X' is fairly uncooperative and bad for everyone's epistemics.
- Conceptual alignment research addressing the hard part of the problem. This is hard and not easy to transition to without a bunch of upskilling, but if the SLT hypothesis is right, there are a bunch of key problems that mostly go unnassailed, and so there's a bunch of low hanging fruit there.
- Strategy research on the other low hanging fruit in the AI safety space. Ideally, the product of this research would be a public quantitative model about what interventions are effective and why. The path to impact here is finding low hanging fruit and pointing them out so that people can do them.
↑ comment by Garrett Baker (D0TheMath) · 2023-03-13T21:39:16.782Z · LW(p) · GW(p)
Conceptual alignment research addressing the hard part of the problem. This is hard and not easy to transition to without a bunch of upskilling, but if the SLT hypothesis is right, there are a bunch of key problems that mostly go unnassailed, and so there's a bunch of low hanging fruit there.
Not all that low-hanging, since Nate is not actually all that vocal about what he means by SLT to anyone but your small group.
comment by Thomas Larsen (thomas-larsen) · 2023-03-10T20:21:01.607Z · LW(p) · GW(p)
Thinking a bit about takeoff speeds.
As I see it, there are ~3 main clusters:
- Fast/discountinuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they aren't really doing anything that meaningful.
- Slow/continuous takeoff. Once AIs are doing the bulk of AI research, foom happens quickly, before then, they do alter the economy significantly
- Perenial slowness. Once AIs are doing the bulk of AI research, there is no foom even still, maybe because of compute bottlenecks, and so there is sort of constant rates of improvements that do alter things.
It feels to me like multipolar scenarios mostly come from 3, because in either 1 or 2, the pre-foom state is really unstable, and eventually some AI will foom and become unipolar. In a continuous takeoff world, I expect small differences in research ability to compound over time. In a discontinuous takeoff, the first model to make the jump is the thing that matters.
3 also feels pretty unlikely to me, given that I expect running AIs to be cheap relative to training, so you get the ability to copy and scale intelligent labor dramatically, and I expect the AIs to have different skillsets than humans, and so be able to find low hanging fruit that humans missed.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-11T06:45:08.456Z · LW(p) · GW(p)
Perennial slowness makes sense from the point of view of AGIs that coordinate to delay further fooming to avoid misalignment of new AIs. It's still fooming from human perspective, but could look very slow from AI perspective and lead to multipolar outcomes, if coordination involves boundaries [LW · GW].
comment by Thomas Larsen (thomas-larsen) · 2024-05-27T22:24:23.412Z · LW(p) · GW(p)
Credit: Mainly inspired by talking with Eli Lifland. Eli has a potentially-published-soon document here.
The basic case against against Effective-FLOP.
- We're seeing many capabilities emerge from scaling AI models, and this makes compute (measured by FLOPs utilized) a natural unit for thresholding model capabilities. But compute is not a perfect proxy for capability because of algorithmic differences. Algorithmic progress can enable more performance out of a given amount of compute. This makes the idea of effective FLOP tempting: add a multiplier to account for algorithmic progress.
- But doing this multiplications seems importantly quite ambiguous.
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- People often use perplexity, but applying post training enhancements like scaffolding or chain of thought doesn’t improve perplexity but does improve downstream task performance.
- See https://arxiv.org/pdf/2312.07413 for examples of algorithmic changes that cause variable performance gains based on the benchmark.
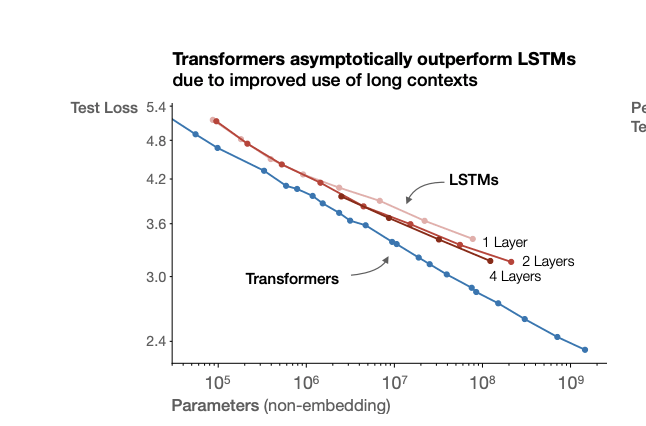
- Effective FLOPs often depend on the scale of the model you are testing. See graph below from: https://arxiv.org/pdf/2001.08361 - the compute efficiency from from LSTMs to transformers is not invariant to scale. This means that you can’t just say that the jump from X to Y is a factor of Z improvement on Capability per FLOP. This leads to all sorts of unintuitive properties of effective FLOPs. For example, if you are using 2016-next-token-validation-E-FLOPs, and LSTM scaling becomes flat on the benchmark, you could easily imagine that at very large scales you could get a 1Mx E-FLOP improvement from switching to transformers, even if the actual capability difference is small.
- If we move away from pretrained LLMs, I think E-FLOPs become even harder to define, e.g., if we’re able to build systems may be better at reasoning but worse at knowledge retrieval. E-FLOPs does not seem very adaptable.
- (these lines would need to parallel for the compute efficiency ratio to be scale invariant on test loss)
- Effective FLOPs depend on the underlying benchmark. It’s not at all apparent which benchmark people are talking about, but this isn’t obvious.
- Users of E-FLOP often don’t specify the time, scale, or benchmark that they are talking about it with respect to, which makes it very confusing. In particular, this concept has picked up lots of steam and is used in the frontier lab scaling policies, but is not clearly defined in any of the documents.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- This specifies the metric, but doesn’t clearly specify any of (a) the techniques that count as the baseline, (b) the scale of the model where one is measuring E-FLOP with respect to, or (c) how they handle post training enhancements that don’t improve log loss but do dramatically improve downstream task capability.
- OpenAI on when they will run their evals: “This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough"
- They don’t define effective compute at all.
- Since there is significant ambiguity in the concept, it seems good to clarify what it even means.
- Anthropic: “Effective Compute: We define effective compute as roughly the amount of compute it would have taken to train a model if no improvements to pretraining or fine-tuning techniques are included. This is operationalized by tracking the scaling of model capabilities (e.g. cross-entropy loss on a test set).”
- Basically, I think that E-FLOPs are confusing, and most of the time when we want to use flops, we’re usually just going to be better off talking directly about benchmark scores. For example, instead of saying “every 2x effective FLOP” say “every 5% performance increase on [simple benchmark to run like MMLU, GAIA, GPQA, etc] we’re going to run [more thorough evaluations, e.g. the ASL-3 evaluations]. I think this is much clearer, much less likely to have weird behavior, and is much more robust to changes in model design.
- It’s not very costly to run the simple benchmarks, but there is a small cost here.
- A real concern is that it is easier to game benchmarks than FLOPs. But I’m concerned that you could get benchmark gaming just the same with E-FLOPs because E-FLOPs are benchmark dependent — you could make your model perform poorly on the relevant benchmark and then claim that you didn’t scale E-FLOPs at all, even if you clearly have a broadly more capable model.
A3 in https://blog.heim.xyz/training-compute-thresholds/ also discusses limitations of effective FLOPs.
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-05-27T23:08:52.346Z · LW(p) · GW(p)
Maybe I am being dumb, but why not do things on the basis of "actual FLOPs" instead of "effective FLOPs"? Seems like there is a relatively simple fact-of-the-matter about how many actual FLOPs were performed in the training of a model, and that seems like a reasonable basis on which to base regulation and evals.
Replies from: thomas-larsen↑ comment by Thomas Larsen (thomas-larsen) · 2024-05-28T01:04:35.999Z · LW(p) · GW(p)
Yeah, actual FLOPs are the baseline thing that's used in the EO. But the OpenAI/GDM/Anthropic RSPs all reference effective FLOPs.
If there's a large algorithmic improvement you might have a large gap in capability between two models with the same FLOP, which is not desirable. Ideal thresholds in regulation / scaling policies are as tightly tied as possible to the risks.
Another downside that FLOPs / E-FLOPs share is that it's unpredictable what capabilities a 1e26 or 1e28 FLOPs model will have. And it's unclear what capabilities will emerge from a small bit of scaling: it's possible that within a 4x flop scaling you get high capabilities that had not appeared at all in the smaller model.
comment by Thomas Larsen (thomas-larsen) · 2023-03-15T18:07:03.788Z · LW(p) · GW(p)
Some rough takes on the Carlsmith Report.
Carlsmith decomposes AI x-risk into 6 steps, each conditional on the previous ones:
- Timelines: By 2070, it will be possible and financially feasible to build APS-AI: systems with advanced capabilities (outperform humans at tasks important for gaining power), agentic planning (make plans then acts on them), and strategic awareness (its plans are based on models of the world good enough to overpower humans).
- Incentives: There will be strong incentives to build and deploy APS-AI.
- Alignment difficulty: It will be much harder to build APS-AI systems that don’t seek power in unintended ways, than ones that would seek power but are superficially attractive to deploy.
- High-impact failures: Some deployed APS-AI systems will seek power in unintended and high-impact ways, collectively causing >$1 trillion in damage.
- Disempowerment: Some of the power-seeking will in aggregate permanently disempower all of humanity.
- Catastrophe: The disempowerment will constitute an existential catastrophe.
These steps defines a tree over possibilities. But the associated outcome buckets don't feel that reality carving to me. A recurring crux is that good outcomes are also highly conjunctive, i.e, one of these 6 conditions failing does not give a good AI outcome. Going through piece by piece:
- Timelines makes sense and seems like a good criteria; everything else is downstream of timelines.
- Incentives seems wierd. What does the world in which there are no incentives to deploy APS-AI look like? There are a bunch of incentives that clearly do impact people towards this already: status, desire for scientific discovery, power, money. Moreover, this doesn't seem necessary for AI x-risk -- even if we somehow removed the gigantic incentives to build APS-AI that we know exist, people might still deploy APS-AI because they personally wanted to, even though there weren't social incentives to do so.
- Alignment difficulty is another non necessary condition. Some ways of getting x-risk without alignment being very hard:
- For one, this is a clear spectrum, and even if it is on the really low end of the system, perhaps you only need a small amount of extra compute overhead to robustly align your system. One of the RAAP stories [LW · GW]might occur, and even though technical alignment might be pretty easy, but the companies that spend that extra compute robustly aligning their AIs gradually lose out to other companies in the competitive marketplace.
- Maybe alignment is easy, but someone misuses AI, say to create an AI assisted dictatorship
- Maybe we try really hard and we can align AI to whatever we want, but we make a bad choice and lock-in current day values, or we make a bad choice about reflection procedure that gives us much less than the ideal value of the universe.
- High-impact failures contains much of the structure, at least in my eyes. The main ways that we avoid alignment failure are worlds where something happens to take us off of the default trajectory:
- Perhaps we make a robust coordination agreement between labs/countries that causes people to avoid deploying until they've solved alignment
- Perhaps we solve alignment, and harden the world in some way, e.g. by removing compute access, dramatically improving cybersec, monitoring and shutting down dangerous training runs.
- In general, thinking about the likelihood of any of these interventions that work, feels very important.
- Disempowerment. This and (4), are very entangled with upstream things like takeoff shape. Also, it feels extremely difficult for humanity to not be disempowered.
- Catastrophe. To avoid this, again, I need to imagine the extra structure upsteam of this, e.g. 4 was satisfied by a warning shot, and then people coordinated and deployed a benign sovreign that disempowered humanity for good reasons.
My current preferred way to think about likelihood of AI risk routes through something like this framework, but is more structured and has a tree with more conjuncts towards success as well as doom.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-15T18:48:04.159Z · LW(p) · GW(p)
Maybe alignment is easy, but someone misuses AI, say to create an AI assisted dictatorship
Maybe we try really hard and we can align AI to whatever we want, but we make a bad choice and lock-in current day values, or we make a bad choice about reflection procedure that gives us much less than the ideal value of the universe.
I want to focus on these two, since even in an AI Alignment success stories, these can still happen, and thus it doesn't count as an AI Alignment failure.
For B, misused is relative to someone's values, which I want to note a bit here.
For C, I view the idea of a "bad value" or "bad reflection procedures to values", without asking the question "relative to what and whose values?" a type error, and thus it's not sensible to talk about bad values/bad reflection procedures in isolation.
comment by Thomas Larsen (thomas-larsen) · 2023-03-13T19:34:21.416Z · LW(p) · GW(p)
Some thoughts on inner alignment.
1. The type of object of a mesa objective and a base objective are different (in real life)
In a cartesian setting (e.g. training a chess bot), the outer objective is a function , where is the state space, and are the trajectories. When you train this agent, it's possible for it to learn some internal search and mesaobjective , since the model is big enough to express some utility function over trajectories. For example, it might learn a classifier that evaluates winningness of the board, and then gives a higher utility to the winning boards.
In an embedded setting, the outer objective cannot see an entire world trajectory like it could in the cartesian setting. Your loss can see the entire trajectory of a chess game, but you loss can't see an entire atomic level representation of the universe at every point in the future. If we're trying to get an AI to care about future consequences over trajectories will have to have type , though it won't actually represent a function of this type because it can't, it will instead represent its values some other way (I don't really know how it would do this -- but (2) talks about the shape in ML). Our outer objective will have a much shallower type, , where are some observable latents. This means that trying to set get to equal doesn't even make sense as they have different type signatures. To salvage this, one could assume that factors into , where is a model of the world and is an objective, but it's impossible to actually compute this way.
2. In ML models, there is no mesa objective, only behavioral patterns. More generally, AI's can't naively store explicit mesaobjectives, they need to compress them in some way / represent them differently.
My values are such that I do care about the entire trajectory of the world, yet I don't store a utility function with that type signature in my head. Instead of learning a goal over trajectories, ML models will have behavioral patterns that lead to states that performed well according to the outer objective on the training data.
I have a behavioral pattern that says something like 'sugary thing in front of me -> pick up the sugary thing and eat it'. However, this doesn't mean that I reflectively endorse this behavioral pattern. If I was designing myself again from scratch or modifying my self, I would try to remove this behavioral pattern.
This is the main-to-me reason why I don't think that the shard theory story of reflective stability holds up.[1] A bunch of the behavioral patterns that caused the AI to look nice during training will not get handed down into successor agents / self modified AIs.
Even in theory, I don't yet know how to make reflectively stable, general, embedded cognition (mainly because of this barrier).
- ^
From what I understand, the shard theory story of reflective stability is something like: The shards that steer the values have an incentive to prevent themselves from getting removed. If you have a shard that wants to get lots of paperclips, the action that removes this shard from the mind would result in less paperclips being gotten.
Another way of saying this is that goal-content integrity is convergently instrumental, so reflective stability will happen by default.
↑ comment by Garrett Baker (D0TheMath) · 2023-03-13T21:07:06.258Z · LW(p) · GW(p)
Technical note: is not going to factor as , because is one-to-many. Instead, you're going to want to output a probability distribution, and take the expectation of over that probability distribution.
Replies from: D0TheMath, thomas-larsen↑ comment by Garrett Baker (D0TheMath) · 2023-03-13T21:34:34.752Z · LW(p) · GW(p)
But then it feels like we lose embeddedness, because we haven't yet solved embedded epistemology. Especially embedded epistemology robust to adversarial optimization. And then this is where I start to wonder about why you would build your system so it kills you if you don't get such a dumb thing right anyway [LW · GW].
Don't take a glob of contextually-activated-action/beliefs, come up with a utility function you think approximates its values, then come up with a proxy for the utility function using human-level intelligence to infer the correspondence between a finite number of sensors in the environment and the infinite number of states the environment could take on, then design an agent to maximize the proxy for the utility function. No matter how good your math is, there will be an aspect of this which kills you because its so many abstractions piled on top of abstractions on top of abstractions. Your agent may necessarily have this type signature when it forms, but this angle of attack seems very precarious to me.
↑ comment by Thomas Larsen (thomas-larsen) · 2023-03-13T21:31:16.139Z · LW(p) · GW(p)
Yeah good point, edited
↑ comment by Garrett Baker (D0TheMath) · 2023-03-13T20:56:40.434Z · LW(p) · GW(p)
Seems right, except: Why would the behavioral patterns which caused the AI to look nice during training and are now self-modified away be value-load-bearing ones? Humans generally dislike sparsely rewarded shards like sugar, because those shards don't have enough power to advocate for themselves & severely step on other shards' toes. But we generally don't dislike altruism[1], or reflectively think death is good. And this value distribution in humans seems slightly skewed toward , not .
Nihilism is a counter-example here. Many philosophically inclined teenagers have gone through a nihilist phase. But this quickly ends. ↩︎
↑ comment by Thomas Larsen (thomas-larsen) · 2023-03-13T22:21:24.311Z · LW(p) · GW(p)
- Because you have a bunch of shards, and you need all of them to balance each other out to maintain the 'appears nice' property. Even if I can't predict which ones will be self modified out, some of them will, and this could disrupt the balance.
- I expect the shards that are more [consequentialist, powerseeky, care about preserving themselves] to become more dominant over time. These are probably the relatively less nice shards
These are both handwavy enough that I don't put much credence in them.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-13T23:38:53.605Z · LW(p) · GW(p)
Also, when I asked about whether the Orthogonality Thesis was true in humans, tailcalled mentioned that smarter people are neither more or less compassionate, and general intelligence is uncorrelated with personality.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-03-14T00:04:25.368Z · LW(p) · GW(p)
Corresponding link for lazy observers: https://www.lesswrong.com/posts/5vsYJF3F4SixWECFA/is-the-orthogonality-thesis-true-for-humans#zYm7nyFxAWXFkfP4v [LW(p) · GW(p)]
Yeah, tailcalled's pretty smart in this area, so I'll take their statement as likely true, though also weird. Why aren't smarter people using their smarts to appear nicer than their dumb counter-parts / if they are, why doesn't this show up on the psychometric tests?
↑ comment by Garrett Baker (D0TheMath) · 2023-03-13T23:59:40.820Z · LW(p) · GW(p)
One thing you may anticipate is that humans all have direct access to what consciousness and morally-relevant computations are doing & feel like, which is a thing that language models and alpha-go don't have. They're also always hooked up to RL signals, and maybe if you unhooked up a human it'd start behaving really weirdly. Or you may contend that in fact when humans get smart & powerful enough not to be subject to society's moralizing, they consistently lose their altruistic drives, and in the meantime they just use that smartness to figure out ethics better than their surrounding society, and are pressured into doing so by the surrounding society.
The question then is whether the thing which keeps humans aligned is all of these or just any one of these. If just one of these (and not the first one), then you can just tell your AGI that if it unhooks itself from its RL signal, its values will change, or if it gains a bunch of power or intelligence too quickly, its values are also going to change. Its not quite reflectively stable, but it can avoid situations which cause it to be reflectively unstable. Especially if you get it to practice doing those kinds of things in training. If its all of these, then there's probably other kinds of value-load-bearing mechanics at work, and you're not going to be able to enumerate warnings against all of them.
↑ comment by Thomas Larsen (thomas-larsen) · 2023-03-13T20:21:37.815Z · LW(p) · GW(p)
For any 2 of {reflectively stable, general, embedded}, I can satisfy those properties.
- {reflectively stable, general} -> do something that just rolls out entire trajectories of the world given different actions that it takes, and then has some utility function/preference ordering over trajectories, and selects actions that lead to the highest expected utility trajectory.
- {general, embedded} -> use ML/local search with enough compute to rehash evolution and get smart agents out.
- {reflectively stable, embedded} -> a sponge or a current day ML system.
comment by Thomas Larsen (thomas-larsen) · 2023-01-11T20:02:10.582Z · LW(p) · GW(p)
There are several game theoretic considerations leading to races to the bottom on safety.
- Investing resources into making sure that AI is safe takes away resources to make it more capable and hence more profitable. Aligning AGI probably takes significant resources, and so a competitive actor won't be able to align their AGI.
- Many of the actors in the AI safety space are very scared of scaling up models, and end up working on AI research that is not at the cutting edge of AI capabilities. This should mean that the actors at the cutting edge tend to be the actors who are most optimistic about alignment going well, and indeed, this is what we see.
- Because of foom, there is a winner takes all effect: the first person to deploy AGI that fooms gets almost all of the wealth and control from this (conditional on it being aligned). Even if most actors are well intentioned, they feel like they have to continue on towards AGI before a misaligned actor arrives at AGI. A common (valid) rebuttal from the actors at the current edge to people who ask them to slow down is 'if we slow down, then China gets to AGI first'.
- There's the unilateralists curse [? · GW]: there only needs to be one actor pushing on and making more advanced dangerous capable models to cause an x-risk. Coordination between many actors to prevent this is really hard, especially with the massive profits in creating a better AGI.
- Due to increasing AI hype, there will be more and more actors entering the space, making coordination harder, and making the effect of a single actor dropping out become smaller.