16 types of useful predictions
post by Julia_Galef · 2015-04-10T03:31:39.018Z · LW · GW · Legacy · 55 commentsContents
55 comments
How often do you make predictions (either about future events, or about information that you don't yet have)? If you're a regular Less Wrong reader you're probably familiar with the idea that you should make your beliefs pay rent by saying, "Here's what I expect to see if my belief is correct, and here's how confident I am," and that you should then update your beliefs accordingly, depending on how your predictions turn out.
And yet… my impression is that few of us actually make predictions on a regular basis. Certainly, for me, there has always been a gap between how useful I think predictions are, in theory, and how often I make them.
I don't think this is just laziness. I think it's simply not a trivial task to find predictions to make that will help you improve your models of a domain you care about.
At this point I should clarify that there are two main goals predictions can help with:
- Improved Calibration (e.g., realizing that I'm only correct about Domain X 70% of the time, not 90% of the time as I had mistakenly thought).
- Improved Accuracy (e.g., going from being correct in Domain X 70% of the time to being correct 90% of the time)
If your goal is just to become better calibrated in general, it doesn't much matter what kinds of predictions you make. So calibration exercises typically grab questions with easily obtainable answers, like "How tall is Mount Everest?" or "Will Don Draper die before the end of Mad Men?" See, for example, the Credence Game, Prediction Book, and this recent post. And calibration training really does work.
But even though making predictions about trivia will improve my general calibration skill, it won't help me improve my models of the world. That is, it won't help me become more accurate, at least not in any domains I care about. If I answer a lot of questions about the heights of mountains, I might become more accurate about that topic, but that's not very helpful to me.
So I think the difficulty in prediction-making is this: The set {questions whose answers you can easily look up, or otherwise obtain} is a small subset of all possible questions. And the set {questions whose answers I care about} is also a small subset of all possible questions. And the intersection between those two subsets is much smaller still, and not easily identifiable. As a result, prediction-making tends to seem too effortful, or not fruitful enough to justify the effort it requires.
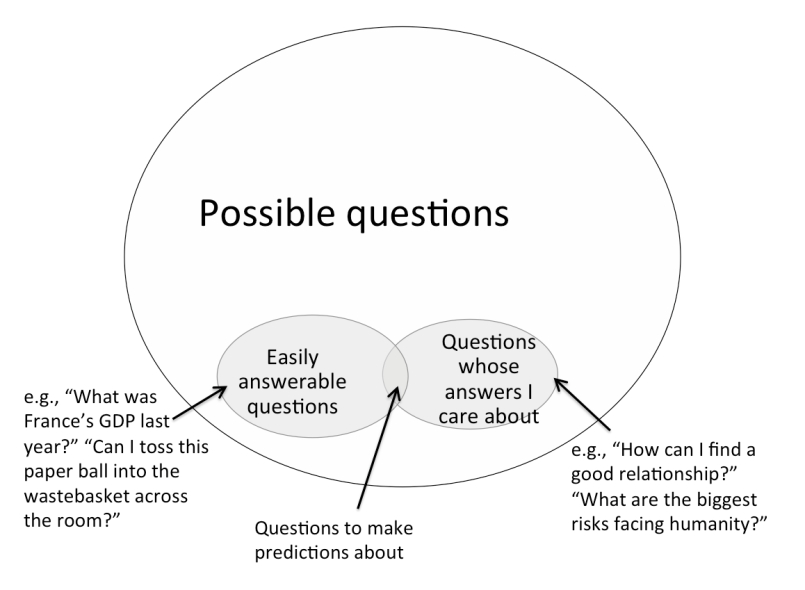
But the intersection's not empty. It just requires some strategic thought to determine which answerable questions have some bearing on issues you care about, or -- approaching the problem from the opposite direction -- how to take issues you care about and turn them into answerable questions.
I've been making a concerted effort to hunt for members of that intersection. Here are 16 types of predictions that I personally use to improve my judgment on issues I care about. (I'm sure there are plenty more, though, and hope you'll share your own as well.)
- Predict how long a task will take you. This one's a given, considering how common and impactful the planning fallacy is.
Examples: "How long will it take to write this blog post?" "How long until our company's profitable?" - Predict how you'll feel in an upcoming situation. Affective forecasting – our ability to predict how we'll feel – has some well known flaws.
Examples: "How much will I enjoy this party?" "Will I feel better if I leave the house?" "If I don't get this job, will I still feel bad about it two weeks later?" - Predict your performance on a task or goal.
One thing this helps me notice is when I've been trying the same kind of approach repeatedly without success. Even just the act of making the prediction can spark the realization that I need a better game plan.
Examples: "Will I stick to my workout plan for at least a month?" "How well will this event I'm organizing go?" "How much work will I get done today?" "Can I successfully convince Bob of my opinion on this issue?" - Predict how your audience will react to a particular social media post (on Facebook, Twitter, Tumblr, a blog, etc.).
This is a good way to hone your judgment about how to create successful content, as well as your understanding of your friends' (or readers') personalities and worldviews.
Examples: "Will this video get an unusually high number of likes?" "Will linking to this article spark a fight in the comments?" - When you try a new activity or technique, predict how much value you'll get out of it.
I've noticed I tend to be inaccurate in both directions in this domain. There are certain kinds of life hacks I feel sure are going to solve all my problems (and they rarely do). Conversely, I am overly skeptical of activities that are outside my comfort zone, and often end up pleasantly surprised once I try them.
Examples: "How much will Pomodoros boost my productivity?" "How much will I enjoy swing dancing?" - When you make a purchase, predict how much value you'll get out of it.
Research on money and happiness shows two main things: (1) as a general rule, money doesn't buy happiness, but also that (2) there are a bunch of exceptions to this rule. So there seems to be lots of potential to improve your prediction skill here, and spend your money more effectively than the average person.
Examples: "How much will I wear these new shoes?" "How often will I use my club membership?" "In two months, will I think it was worth it to have repainted the kitchen?" "In two months, will I feel that I'm still getting pleasure from my new car?" - Predict how someone will answer a question about themselves.
I often notice assumptions I'm been making about other people, and I like to check those assumptions when I can. Ideally I get interesting feedback both about the object-level question, and about my overall model of the person.
Examples: "Does it bother you when our meetings run over the scheduled time?" "Did you consider yourself popular in high school?" "Do you think it's okay to lie in order to protect someone's feelings?" - Predict how much progress you can make on a problem in five minutes.
I often have the impression that a problem is intractable, or that I've already worked on it and have considered all of the obvious solutions. But then when I decide (or when someone prompts me) to sit down and brainstorm for five minutes, I am surprised to come away with a promising new approach to the problem.
Example: "I feel like I've tried everything to fix my sleep, and nothing works. If I sit down now and spend five minutes thinking, will I be able to generate at least one new idea that's promising enough to try?" - Predict whether the data in your memory supports your impression.
Memory is awfully fallible, and I have been surprised at how often I am unable to generate specific examples to support a confident impression of mine (or how often the specific examples I generate actually contradict my impression).
Examples: "I have the impression that people who leave academia tend to be glad they did. If I try to list a bunch of the people I know who left academia, and how happy they are, what will the approximate ratio of happy/unhappy people be?"
"It feels like Bob never takes my advice. If I sit down and try to think of examples of Bob taking my advice, how many will I be able to come up with?" - Pick one expert source and predict how they will answer a question.
This is a quick shortcut to testing a claim or settling a dispute.
Examples: "Will Cochrane Medical support the claim that Vitamin D promotes hair growth?" "Will Bob, who has run several companies like ours, agree that our starting salary is too low?" - When you meet someone new, take note of your first impressions of him. Predict how likely it is that, once you've gotten to know him better, you will consider your first impressions of him to have been accurate.
A variant of this one, suggested to me by CFAR alum Lauren Lee, is to make predictions about someone before you meet him, based on what you know about him ahead of time.
Examples: "All I know about this guy I'm about to meet is that he's a banker; I'm moderately confident that he'll seem cocky." "Based on the one conversation I've had with Lisa, she seems really insightful – I predict that I'll still have that impression of her once I know her better." - Predict how your Facebook friends will respond to a poll.
Examples: I often post social etiquette questions on Facebook. For example, I recently did a poll asking, "If a conversation is going awkwardly, does it make things better or worse for the other person to comment on the awkwardness?" I confidently predicted most people would say "worse," and I was wrong. - Predict how well you understand someone's position by trying to paraphrase it back to him.
The illusion of transparency is pernicious.
Examples: "You said you think running a workshop next month is a bad idea; I'm guessing you think that's because we don't have enough time to advertise, is that correct?"
"I know you think eating meat is morally unproblematic; is that because you think that animals don't suffer?" - When you have a disagreement with someone, predict how likely it is that a neutral third party will side with you after the issue is explained to her.
For best results, don't reveal which of you is on which side when you're explaining the issue to your arbiter.
Example: "So, at work today, Bob and I disagreed about whether it's appropriate for interns to attend hiring meetings; what do you think?" - Predict whether a surprising piece of news will turn out to be true.
This is a good way to hone your bullshit detector and improve your overall "common sense" models of the world.
Examples: "This headline says some scientists uploaded a worm's brain -- after I read the article, will the headline seem like an accurate representation of what really happened?"
"This viral video purports to show strangers being prompted to kiss; will it turn out to have been staged?" - Predict whether a quick online search will turn up any credible sources supporting a particular claim.
Example: "Bob says that watches always stop working shortly after he puts them on – if I spend a few minutes searching online, will I be able to find any credible sources saying that this is a real phenomenon?"
I have one additional, general thought on how to get the most out of predictions:
Rationalists tend to focus on the importance of objective metrics. And as you may have noticed, a lot of the examples I listed above fail that criterion. For example, "Predict whether a fight will break out in the comments? Well, there's no objective way to say whether something officially counts as a 'fight' or not…" Or, "Predict whether I'll be able to find credible sources supporting X? Well, who's to say what a credible source is, and what counts as 'supporting' X?"
And indeed, objective metrics are preferable, all else equal. But all else isn't equal. Subjective metrics are much easier to generate, and they're far from useless. Most of the time it will be clear enough, once you see the results, whether your prediction basically came true or not -- even if you haven't pinned down a precise, objectively measurable success criterion ahead of time. Usually the result will be a common sense "yes," or a common sense "no." And sometimes it'll be "um...sort of?", but that can be an interestingly surprising result too, if you had strongly predicted the results would point clearly one way or the other.
Along similar lines, I usually don't assign numerical probabilities to my predictions. I just take note of where my confidence falls on a qualitative "very confident," "pretty confident," "weakly confident" scale (which might correspond to something like 90%/75%/60% probabilities, if I had to put numbers on it).
There's probably some additional value you can extract by writing down quantitative confidence levels, and by devising objective metrics that are impossible to game, rather than just relying on your subjective impressions. But in most cases I don't think that additional value is worth the cost you incur from turning predictions into an onerous task. In other words, don't let the perfect be the enemy of the good. Or in other other words: the biggest problem with your predictions right now is that they don't exist.
55 comments
Comments sorted by top scores.
comment by benjaminhaley · 2015-04-10T22:53:32.050Z · LW(p) · GW(p)
I've established a habit of putting my money where my mouth is to encourage myself to make more firm predictions. When I am talking with someone and we disagree, I ask if they want to bet a dollar on it. For example, I say, "Roger Ebert directed Beyond the Valley of the Dolls". My wife says, "No, he wrote it.". Then I offer to bet. We look up the answer, and I give her a dollar.
This is a good habit for many reasons.
- It is fun to bet. Fun to win. And (kinda) fun to lose.
- It forces people to evaluate honestly. The same people that say "I'm sure..." will back off their point when asked to bet a dollar on the outcome.
- It forces people to negotiate to concrete terms. For example, I told a friend that a 747 burns 30,000 lbs of fuel an hour. He said no way. We finally settled on the bet "Ben thinks that a fully loaded 747 will burn more than 10,000 lbs of fuel per hour under standard cruising conditions". (I won that bet, it burns ~25,000 lbs of fuel/hour under these conditions).
- A dollar feels more important than it actually is, so people treat the bets seriously even though they are not very serious. For this reason, I think it is important to actually exchange a dollar bill at the end, rather than treating it as just an abstract dollar.
I've learned a lot from this habit.
- I'm right more often than not (~75%). But I'm wrong a lot too (~25%). This is more wrong than I feel. I feel 95% confident. I shouldn't be so confident.
- The person proposing the bet is usually right. My wife has gotten in the habit too. If I propose we bet, I'm usually right. If she proposes we bet I've learned to usually back down.
- People frequently overstate their confidence. I mentioned this above, but it bears repeating. Some people regularly will use phrases like "I am sure" or say something emphatically. People are calibrated to express their beliefs differently. But when you ask them to bet a dollar you get a more consistent calibration. People that are over-confident often back away from their positions. Really interesting considering that its only a dollar on the line.
- Over time people learn to calibrate better. At first my wife would agree to nearly every bet I proposed. Now she usually doesn't want to. When she agrees to a bet now, I get worried.
↑ comment by afeller08 · 2015-04-28T05:48:56.889Z · LW(p) · GW(p)
The person proposing the bet is usually right.
This is a crucial observation if you are trying to use this technique to improve your calibration of your own accuracy! You can't just start making bets when no one else you associate regularly is challenging you to the bets.
Several years ago, I started taking note of all of the times I disagreed with other people and looking it up, but initially, I only counted myself as having "disagreed with other people" if they said something I thought was wrong, and I attempted to correct them. Then I soon added in the case when they corrected me and I argued back. During this period of time, I went from thinking I was about 90% accurate in my claims to believing I was way more accurate than that. I would go months without being wrong, and this was in college, so I was frequently getting into disagreements with people, probably, an average, three a day during the school year. Then I started checking the times that other people corrected me, just as much as I checked when I corrected other people. (Counting even the times that I made no attempt to argue.) And my accuracy rate plummeted.
Another thing I would recommend to people starting out in doing this is that you should keep track of your record with individual people not just your general overall record. My accuracy rate with a few people is way lower than my overall accuracy rate. My overall rate is higher than it should be because I know a few argumentative people who are frequently wrong. (This would probably change if we were actually betting money, and we were only counting arguments when those people were willing to bet. So you're approach adjusts for this better than mine.) I have several people for whom I'm close to 50%, and there are two people for whom I have several data points and my overall accuracy is below 50%.
There's one other point I think somebody needs to make about calibration. And that's that 75% accuracy when you disagree with other people is not the same thing as 75% accuracy. 75% information fidelity is atrocious; 95% information fidelity is not much better. Human brains are very defective in a lot of ways, but they aren't that defective! Except at doing math. Brains are ridiculously bad at math relative to how easily machines can be implemented to be good at math. For most intents and purposes, 99% isn't a very high percentage. I am not a particular good driver, but I haven't gotten into a collision with another vehicle in my well over 1000 times driving. Percentages tend to have an exponential scale to them (or more accurately a logistic curve). You don't have to be a particularly good driver to avoid getting into an accident 99.9% of the time you get behind the wheel, because that is just a few orders of magnitude improvement relative to 50%.
Information fidelity differs from information retention. Discarding 25% or 95% or more of collected information is reasonable; corrupting information at that rate is what I'm saying would be horrendous. (Because discarding information conserves resources; whereas corrupting information does not... except to the extent that you would consider compressing information with a lossy (as in "not lossless") compression to be a corrupting information, but I would still consider that to be discarding information. Episodic memory is either very compressed or very corrupted depending on what you think it should be.)
In my experience, people are actually more likely to be underconfident about factual information than they are to be overconfident, if you measure confidence on an absolute scale instead of a relative-to-other-people scale. My family goes to trivia night, and we almost always get at least as many correct as we expect to get correct, usually more. However, other teams typically score better than we expect them to score too, and we win the round less often than we expect to.
Think back to grade school when you actually had fill in the blank and multiple choice questions on tests. I'm going to guess that you probably were an A student and got around 95% right on your tests... because a) that's about what I did and I tend to project, b) you're on LessWrong so you were probably an A student, and C) you say you feel like you ought to be right about 95% of the time. I'm also going to guess (because I tend to project my experience onto other people) that you probably felt a lot less than 95% confident on average when you were taking the tests. There were more than a few tests I took in my time in school where I walked out of the test thinking "I didn't know any of that; I'll probably get a 70 or better just because that would be horribly bad compared to what I usually do, but I really feel like I failed that"... and it was never 70. (Math was the one exception in which I tended to be overconfident, I usually made more mistakes than I expected to make on my math tests.)
Where calibration is really screwed up is when you deal with subjects that are way outside of the domain of normal experience, especially if you know that you know more than your peer group about this domain. People are not good at thinking about abstract mathematics, artificial intelligence, physics, evolution, and other subjects that happen at a different scale from normal everyday life. When I was 17, I thought I understood Quantum Mechanics just because I'd read A Brief History of Time and A Universe in a Nut Shell... Boy was I wrong!
On LessWrong, we are usually discussing subjects that are way beyond the domain of normal human experience, so we tend to be overconfident in our understanding of these subjects... but part of the reason for this overconfidence is that we do tend to be correct about most of the things we encounter within the confines of routine experience.
↑ comment by Sable · 2015-04-26T01:35:50.468Z · LW(p) · GW(p)
I was reading your comment, and when I thought about always betting a dollar, my brain went, "That's a good idea!"
So I asked my brain, "What memory are you accessing that makes you think that's a good idea?"
And my brain replied, "Remember that CFAR reading list you're going through? Yeah, that one."
So I went to my bookshelf, got out Dan Ariely's Predictably Irrational, and started paging through it.
Professor Ariely had several insights that helped me understand why actually using money seemed like such a good idea:
Interacting within market norms makes you do a cost-benefit analysis. Professor Ariely discusses the difference between social norms and market norms in chapter 4. Social norms govern interactions that don't involve money (favors for a friend), and market norms govern interactions that do (costs and benefits). The professor did an experiment in which he had people drag circles into a square on a computer screen (judging their productivity by how many times they did this in a set period of time). He gave one group of such participants an explicitly stated "50-cent snickers bar" and the other a "five-dollar box of Godiva chocolates." As it turns out, the results were identical to a previous experiment in which the same amounts of direct cash were used. Professor Ariely concludes, "These results show that for market norms to emerge, it is sufficient to mention money." In other words, Professor Ariely's research supports your first (4.) - "A dollar feels more important than it actually is..." This is the case because as soon as money enters the picture, so do market norms.
Money makes us honest. In chapter 14, aptly titled "Why Dealing With Cash Makes Us More Honest," Professor Ariely explains an experiment he conducted in the MIT cafeteria. Students were given a sheet of 20 math problems to solve in five minutes. The control group was to have their solutions checked, and then were given 50 cents per correct answer. A second group was instructed to tear their paper apart, and then tell the experimenter how many questions they got correct (allowing them to cheat). They were then paid 50 cents for every correct answer they claimed. Lastly, a third group was allowed to cheat similarly to the second group, except that when they gave one experimenter their score, they were given tokens, which were traded in immediately thereafter for cash through a second experimenter. The results: A) The control group solved an average of 3.5 questions correctly. B) The second group, who cheated for cash, claimed an average of 6.2 correct solutions. C) The third group, who cheated for tokens, claimed an average of 9.4 correct solutions. Simply put, when actual, physical money was removed from the subjects' thought process by a token and a few seconds, the amount of cheating more than doubled, from 2.7 to 5.9.
In short, using money to back a prediction a) forces us to think analytically, and b) keeps us honest.
Thank you for the idea. Now I just need to find an ATM to get some ones...
Replies from: Alex_O↑ comment by Alex_O · 2015-05-08T08:23:58.195Z · LW(p) · GW(p)
This experiment does not prove that money keeps people more honest than absence of money, but more honest than token exchangeable for money. If a control group was allowed to cheat without receiving money at all they might (my prediction and I would bet a dollar on it if I didn't use Euros) cheat even less. Then, the hypothesis "money keeps us honest" would be disproved.
Replies from: efim↑ comment by efim · 2015-05-27T14:00:03.433Z · LW(p) · GW(p)
I think I remember described set of experiments correctly and at least in some of them control group was definitely allowed to cheat - there were no difference in the way people turned in their results (shredding questionare and submitting only purported result on different sheet)
↑ comment by Pattern · 2021-08-02T17:52:52.808Z · LW(p) · GW(p)
When I am talking with someone and we disagree, I ask if they want to bet a dollar on it. For example, I say, "Roger Ebert directed Beyond the Valley of the Dolls". My wife says, "No, he wrote it.". Then I offer to bet. We look up the answer, and I give her a dollar.
What would you do if he wrote and directed it? Neither? If there was more than one writer (which he was one of), or more than one director (of which he was one)?
↑ comment by Arielgenesis · 2016-07-24T17:51:28.037Z · LW(p) · GW(p)
A dollar feels more important than it actually is, so people treat the bets seriously even though they are not very serious.
Although there is a weight in the dollar, I think there is also another reason why people take it more seriously. People adjust their believe according to what other people believe and their confidence level. Therefore, when you propose a bet, even only for a dollar, you are showing a high confidence level and this decrease their confidence level. As a result, system 2 kicks in and they will be > [forced] to evaluate honestly.
comment by luminosity · 2015-04-09T08:36:32.001Z · LW(p) · GW(p)
I love the list of predictions, but I also feel fairly confident in predicting that this post won't prompt me to actually make more (or more useful) predictions. Do you have any tips on building the habit of making predictions?
Replies from: Gram_Stone↑ comment by Gram_Stone · 2015-04-09T19:39:42.088Z · LW(p) · GW(p)
My plan is to pick one of these and predict like hell, because sixteen possibilities makes this look more daunting than it is, and then I plan to move on to others or come up with my own when it's semi-habitual. I did a sort of method of elimination to pick my initial habit-former. I'm not going to list my entire process, unless someone really wants me to, but I settled on #13 because:
- I already do something similar to this. All I have to do is affix a Predict step to the beginning of my algorithm.
- Successful and unsuccessful predictions are very clear cut, which is good for getting System 1's attention and successfully forming the habit.
- It has few, if any, trivial inconveniences.
- It's not associated with an activity that has an ugh field around it for me.
I haven't been here long, but I feel like I've seen comments like this a lot, of the form, "This is all Well and Good, but how precisely do I really, actually implement this?" And sometimes that's a valid point. Sometimes what looks like a suggestion is all noise and no signal (or all signal? Hell, I don't know).
Other times someone is apt to say, "I predict that this post will not result in actual improvement of Problem X," in Rationalspeak and all, and they are universally acclaimed. For you see, in this way, they and all of their followers are above the fray.
When the suggestions are good, I've always felt that it's a bit inconsiderate to immediately ping the Burden of Thought back at someone who just wrote a blog post on a site as critical as LessWrong. I share things when my brain sputters out and can't go any further on its own; it needs help from the tribe. Did you or the people who upvoted you think for five minutes by the clock about how you might form a predicting habit before outsourcing the question to Julia_Galef? It's awfully easy to never form a predicting habit when the President of CFAR conveniently never gets back to you! You also could have #8-ed and predicted whether or not you would be able to come up with a way to build a predicting habit.
I sort of (read: completely) made an example out of you for community's sake, so sorry if I was hurtful or otherwise. This is not all directed at you in particular; it was an opportunity to make an observation.
Replies from: luminosity↑ comment by luminosity · 2015-04-11T02:19:18.451Z · LW(p) · GW(p)
Fair call on my intellectual laziness in not performing the brainstorming myself. Point taken. However, if you are noticing a pattern of many people doing this over time, it seems like this is something article authors could take into account to get more impact out of their articles. Unless the point is to make the person reading do the brainstorming to build that habit, then the time of many readers can be saved by the person who wrote the article, and presumably has already passed this point and thus put in the time sharing tips or a call to action on how to get started.
I want to stress that I don't consider this an obligation on the article author. If Julia, or anyone else, doesn't want to put in that time, then we can be grateful (and I am) that they have shared with us the time they have already. However, I do view it as an opportunity for authors who wish to have a greater impact.
On a a more concrete level, thanks for sharing your thought process on this topic. Very useful.
comment by Thecommexokid · 2015-04-17T18:48:53.737Z · LW(p) · GW(p)
Apparently you are putting
2. Predict how you'll feel in an upcoming situation. Affective forecasting – our ability to predict how we'll feel – has some well known flaws.
Examples: "How much will I enjoy this party?" "Will I feel better if I leave the house?" "If I don't get this job, will I still feel bad about it two weeks later?"
into your "Easily answerable questions" subset. Personally, I struggle to obtain a level of introspection sufficient to answer questions like these even after the fact.
Does anyone have any tips to help me better access my own feelings in this way? After I have left the house, how do I determine if I feel better? If I don't get the job, how do I determine if I feel bad about it? Etc.
Replies from: ChristianKl, afeller08, efim, TheOtherDave↑ comment by ChristianKl · 2015-04-18T12:03:27.655Z · LW(p) · GW(p)
Does anyone have any tips to help me better access my own feelings in this way? After I have left the house, how do I determine if I feel better? If I don't get the job, how do I determine if I feel bad about it? Etc.
Focusing. Learn to locate feelings in your body and learn to put labels on emotions.
Having QS rituals where you put down an estamation of your internal state every day. I for example write down my dominating mood for the last 24 hours and a few numbers.
As a weekly ritual it's also possible to fill out longer questionaires such as http://www.connections-therapy-center.com/upload/burns_anxiety_inventory.pdf .
It's like a muscle. If you train to assess your internal state you get better.
↑ comment by afeller08 · 2015-04-28T06:29:13.219Z · LW(p) · GW(p)
I find that playing the piano is a particularly useful technique for gauging my emotions, when they are suppressed/muted. This works better when I'm just making stuff up by ear than it does when I'm playing something I know or reading music. (And learning to make stuff up is a lot easier than learning to read music if you don't already play.) Playing the piano does not help me feel the emotions any more strongly, but it does let me hear them -- I can tell that music is sad, happy, or angry regardless of its impact on my affect. Most people can.
Something that I don't do that I think would work (based partially on what Ariely says in The Upside of Irrationality, partially on what Norman says in Emotional Design, and partially on anecdotal experience) is to do something challenging/frustrating and see how long it takes for you to give up or get angry. If you can do it for a while without getting frustrated, you're probably in a positive state of mind. If you give up feeling like it's futile, you're sad, and if you start feeling an impulse to break something, you're frustrated/angry. The shorter it takes you to give up or angry the stronger that emotion is. The huge downside to this approach is that it results in exacerbating negative emotions (temporarily) in order to gauge what you were feeling and how strongly.
↑ comment by efim · 2015-05-27T14:37:32.257Z · LW(p) · GW(p)
Hi!
1) If I understood Julia correctly "easily answerable questions" correspond not to areas where you are good at predicting, but to areas where answer space is known to you: "Can I toss the ball through the hoop?" - Yes\No vs. "What is the best present for a teenage girl?" ??\??\money??\puppy??
2) If you have difficulties with associating common groups with your feelings or even percieve feelings that is really confusing and it would be good not to jump to the conclusions, but to add to other commenters: you could probably start by asking outside observer (i.e body language "comfort\defensiveness" "happy\sad")
↑ comment by TheOtherDave · 2015-04-17T19:21:06.777Z · LW(p) · GW(p)
Hm.
Are there any contexts in which you do have reliable insight into your own mood?
comment by [deleted] · 2015-04-14T11:30:49.152Z · LW(p) · GW(p)
Maintaining a vegetable garden gives plenty of opportunities for such quick predictions, even for sequentially updated ones. 'I have to weed the carrot rows. But I have only done them last week! Surely there will be less than a hundred weed seedlings?' -> 'Oh, this is how it looks today! Okay, raising the estimate to 150.' -> 'My back! Why do I grow carrots, anyway? It's a carpet of weeds!':)
comment by [deleted] · 2015-04-11T21:51:04.462Z · LW(p) · GW(p)
Apart from PredictionBook, what's out there in terms of software for tracking your predictions?
(PredictionBook is nice, but there are predictions I make that I don't want to have online, and I find the inability to organise predictions rather inconvenient. Ideally, some kind of system with tags would be nice. I guess I could just set up a SQLite database and write some shell scripts to add/remove data, but something neater would be nice.)
comment by michael_b · 2015-04-10T12:07:54.252Z · LW(p) · GW(p)
The more time I spend hanging out with rationalists the less comfortable I am making predictions about anything. It's kind of becoming a real problem?
"Do you think you'll be hungry later?" "Maybe"
: /
Replies from: Richard_Kennaway, adamzerner↑ comment by Richard_Kennaway · 2015-04-13T13:31:45.628Z · LW(p) · GW(p)
How are you with decisions? Which after all are the point of all this rationality.
"How about eating here?" "...?"
↑ comment by Adam Zerner (adamzerner) · 2015-04-12T01:21:10.782Z · LW(p) · GW(p)
Sorry to hear that :(
My guess is that a lot of predictions -> you're wrong sometimes -> it feels like you're wrong a lot. Contrasted with not making many predictions -> not being actually wrong as much. If so:
1) Percent incorrect is what matters, not number incorrect. I'm sure you know this, but it could be difficult to get your System 1 to know it.
2) If making a lot of predictions does happen to lead to a high percentage incorrect, that's valuable information to you! It tells you that your models of the world are off and thus provides you with an opportunity to improve!
comment by ChristianKl · 2015-04-09T13:09:46.368Z · LW(p) · GW(p)
Performance prediction is a bit tricky. You usually care more about the performance than being accurate at predicting. You don't want to come into a situation where you reduce your performance to get your prediction right.
Replies from: compartmentalization↑ comment by compartmentalization · 2015-06-08T22:30:46.556Z · LW(p) · GW(p)
This is the reason I have mixed feelings about making predictions of events that I can influence. I'm curious whether there is any research about this 'jinxing' - does predicting low chances of success at a task make people less likely to succeed? Or (maybe) the opposite?
Replies from: Peacewise↑ comment by Peacewise · 2015-07-04T20:37:45.684Z · LW(p) · GW(p)
re compartmentalization question about 'jinxing'.
I have some experience and knowledge in this subject from a sports science perspective.
It's commonly accepted within sport psychology that first, negativity, is associated with predicting low chances of success, and secondly that those who do display negativity and predict low chance of success decrease their own performance.
For example, a well coached basketball player at the free throw line would be aware that saying "I'm going to miss this free throw" increases their chances of missing the free throw. Note now that "well coached" implies including psychological training as a component of a wider training program.
One source for you compartmentalization, to dig a little deeper is...
"Krane and Williams concluded that a certain psychological profile appears to be correlated with peak performance for most athletes. More specifically, this ideal mind/body state consists of the following: (a) feelings of high self-confidence and expectations of success, (b) being energized yet relaxed, (c) feeling in control,(d) being totally concentrated, (e) having a keen focus on the present task, (f) having positive attitudes and thoughts about performance, and (g) being strongly determined and committed. Conversely, the mental state typically associated with poorer performances in sport seems to be marked by feelings of self-doubt, lacking concentration, being distracted, being overly focused on the competition outcome or score, and feeling overly or under aroused. While acknowledging that this ideal mind/body state is highly idiosyncratic, Krane and Williams concluded that for most athletes, the presence of the right mental and emotional state just described is associated with them performing to their potential." Harmison, R. J. (2006). Peak performance in sport: Identifying ideal performance states and developing athletes' psychological skills. Professional Psychology: Research and Practice, 37(3), 233-243. doi: 10.1037/0735-7028.37.3.233
comment by Peacewise · 2015-06-27T05:44:14.188Z · LW(p) · GW(p)
Microsoft Outlook Business Contact Manager provides ways forward to utilising prediction. Within its Task scheduling one has opportunity to estimate what percentage of the set task is already completed. Also how long the task will take is estimated by the user.
I find B.C.M highly useful for focusing prediction and task achievement.
comment by MalcolmOcean (malcolmocean) · 2015-04-12T04:44:51.815Z · LW(p) · GW(p)
Last year I built a spreadsheet for helping with #1 (Predict how long a task will take you) which I still use daily.
You input the name of a task (with categorization if you want) and a lower and upper bound for how long you expect it to take. Start a timer, do the thing, then put in the actual time. If you were within the bounds, you get a ✓ in the next column, otherwise you get your error, green for overestimate and red for underestimate. I'll probably add some stuff that does aggregate stats on how often you're within the bounds (i.e. what actual confidence interval those bounds represent for you) but for now it's mostly just the experience of doing it that's helpful.
I think I've become better calibrated over months of using this, although some days it's way off because I don't give it enough attention. There's a pretty big difference between a duration estimate made in 1 second vs 5 seconds.
When I first tried this, I thought that it would be annoying, but I actually found it to be a really enjoyable way to do lots of different kinds of things, because it kept me really focused on the specific thing I was timing, rather than going off on other tangents that felt productive but were unfocused, or jumping around. In addition to tracking "tasks", I would also sometimes track things like reading a chapter of hpmor, or how long it would take me to go get a snack.
(I was planning to write a top-level post about this, but since it's super topical I figured I might as well post it as a comment here. Top level post to follow, perhaps.)
comment by Adam Zerner (adamzerner) · 2015-04-12T01:24:40.184Z · LW(p) · GW(p)
Does making a lot of predictions cause any stress? To me it does, almost like a sense that I'm always "on duty". Also, I'm a bit easily distracted and it could distract me from the task at hand. So I try to strike some sort of balance. Thoughts?
Also, sometimes predictions negatively affect the amount of enjoyment I get. Ex. I'm a big basketball fan and I do love making predictions in basketball, but sometimes it isn't fun to have predicted that the team I like is going to lose.
comment by Gram_Stone · 2015-04-09T20:00:27.266Z · LW(p) · GW(p)
I agree with your closing comments, but I think it's useful to make the distinction that it's helpful to begin with predictions that are very clearly successful or unsuccessful, even if this might be construed as erring toward more 'objective' metrics. This is why I chose #13 to begin forming my predicting habit; my paraphrases of others' positions are usually easily categorized as either correct or incorrect and salient outcomes are better for habit formation.
Great post!
comment by WilliamKiely · 2015-05-08T06:47:26.379Z · LW(p) · GW(p)
Certainly, for me, there has always been a gap between how useful I think predictions are, in theory, and how often I make them.
Same here.
There's probably some additional value you can extract by writing down quantitative confidence levels, and by devising objective metrics that are impossible to game, rather than just relying on your subjective impressions.
I agree.
But in most cases I don't think that additional value is worth the cost you incur from turning predictions into an onerous task.
I disagree in that (1) I think much of the value of predictions would come from the ability to examine and analyze my past prediction accuracy and (2) I don't think the task of recording the predictions would necessarily be very onerous (e.g. especially if there is some recurring prediction which you don't have to write a new description for every time you make it).
I really like Prediction Book (which I just checked out for the first time before Googling and finding this post), but it doesn't offer sufficient analysis options to make me want to really begin using it yet.
But this could change!
I would predict (75%) that I would begin using it on a daily basis (and would continue to do so indefinitely upon realizing that I was indeed getting sufficient value out of it to justify the time it takes to record my predictions on the site) if it offered not just the single Accuracy vs 50-100% Confidence plot and graph, but the following features:
Ability to see confidence and accuracy plotted versus time. (Useful, e.g. to see weekly progress on meeting some daily self-imposed deadline. Perhaps you used to meet it 60% of days on average, but now you meet it 80% of days on average. You could track your progress while seeing if you accurately predict progress as well, or if your predicted values follow the improvement.)
Ability to see 0-100% confidence on statistics plot, instead of just 50-100%. (Maybe it already includes 0-50% and just does the negative of each prediction (?). However, if so, this is still a problem since I may have different biases for 10% predictions than 90% predictions.)
Ability to set different different prediction types and analyze the data separately. (Useful for learning how accurate one's predictions are in different domains.)
Ability to download all of one's past prediction data. (Useful if there is some special analysis that one wants to perform.)
A public/private prediction toggle button (Useful because there may be times when it's okay for someone to hide a prediction they were embarrassingly wrong about or someone may want to publicize a previously-private prediction. Forcing users to decide at the time of the prediction whether their prediction will forever be displayed publicly on their account or remain private forever doesn't seem very user-friendly.)
Bonus: An app allowing easy data input when not at your computer. (Would make it even more convenient to record predictions.)
Some of these features can be achieved by creating multiple accounts. And I could accomplish all of this in Excel. But using multiple accounts or Excel would make it too tedious to be worth it. The value is in having the graphs and analysis automatically generated and presented to you with only a small amount of effort needed to input the predictions in the first place.
I don't think any of these additional features would be very difficult to implement. However, I'm not a programmer, so for me to dive into the Prediction Book GitHub and try to figure out how to make these changes would probably be quite time-consuming and not worth it.
Maybe there is someone else who agrees that these features would be useful to them who is a programmer and would like to add some or all of the suggested features I mentioned? Does anyone know the people who did most of the work programming the current website?
comment by Adam Zerner (adamzerner) · 2015-04-14T02:38:26.325Z · LW(p) · GW(p)
You could always play ask a stranger a question.
comment by whales · 2015-04-11T00:47:06.505Z · LW(p) · GW(p)
I like this post. I lean towards skepticism about the usefulness of calibration or even accuracy, but I'm glad to find myself mostly in agreement here.
For lots of practical (to me) situations, a little bit of uncertainty goes a long way concerning how I actually decide what to do. It doesn't really matter how much uncertainty, or how well I can estimate the uncertainty. It's better for me to just be generally humble and make contingency plans. It's also easy to imagine that being well-calibrated (or knowing that you are) could actually demolish biases that are actually protective against bad outcomes, if you're not careful. If you are careful, sure, there are possible benefits, but they seem modest.
But making and testing predictions seems more than modestly useful, whether or not you get better (or better calibrated) over time. I find I learn better (testing effect!) and I'm more likely to notice surprising things. And it's an easy way to lampshade certain thoughts/decisions so that I put more effort into them. Basically, this:
Or in other other words: the biggest problem with your predictions right now is that they don't exist.
To be more concrete, a while back I actually ran a self-experiment on quantitative calibration for time-tracking/planning (your point #1). The idea was to get a baseline by making and resolving predictions without any feedback for a few weeks (i.e. I didn't know how well I was doing--I also made predictions in batches so I usually couldn't remember them and thus target my prediction "deadlines"). Then I'd start looking at calibration curves and so on to see if feedback might improve predictions (in general or in particular domains). It turned out after the first stage that I was already well-calibrated enough that I wouldn't be able to measure any interesting changes without an impractical number of predictions, but while it lasted I got a moderate boost in productivity just from knowing I had a clock ticking, plus more effective planning from the way predictions forced me to think about contingencies. (I stopped the experiment because it was tedious, but I upped the frequency of predictions I make habitually.)
comment by Arielgenesis · 2016-07-24T17:45:37.622Z · LW(p) · GW(p)
To the best of my knowledge, human brain is a simulation machine. It unconsciously making prediction about what sensory input it should expect. This include the higher level input, like language and even concepts. This is the basic mechanism underlying surprise and similar emotion. Moreover, it only makes simulation on the things it cares about and filter the rest.
Given this, I would think that most of your prediction is obsolete, because we are doing this unconsciously. Example:
You predict you will finish the task one week early. But you are ended up finishing one day early. You are not surprised. But if you ended up finishing one day late, then you would be surprised. When people are surprised by the same trigger often enough, most normal people I presume, will update their believe. I know this is related to planning fallacy, but I think my arguments still hold water.
You post a post on Facebook. You didn't make any conscious prediction on the reaction of the audience. You got one million likes. I bet you will be surprised and scratching your mind about why and how you could get such reaction.
Otherwise, I still see some value in what you are doing, but not because of prediction per se, but because you it effectively mitigate bias. For example. "Predict how well you understand someone's position by trying to paraphrase it back to him." It addresses illusion of transparency. But I think there is not much more value in making prediction rather than simply making a habit to paraphrase more often than otherwise without making prediction.
Making conscious prediction, on top of the unconscious one, is cognitively costly. I do think it might improve one's calibration and accuracy and is superior to the improvement made by the surprise mechanism alone. However, the question is, is the calibration and accuracy improvement worth the extra cognitive cost?
comment by TimothyScriven · 2015-06-30T07:31:33.038Z · LW(p) · GW(p)
I'm not convinced that improving calibration will not improve accuracy because predictions are often nested within other predictions. For example, suppose we are trying to make a prediction about P, and the truth or falsity of Q, R and S are relevant to the truth of P in some respect. We might use as a basis for guessing P that we are ninety five percent confident in our guesses about Q, R & S, (suppose the truth of all three would guarantee P). Now suppose we become less confident through better calibration and decide there is only a 70% chance that Q, a 70% chance that R and a 70% chance that S, leading to a compound probability of less <50%. Thus overall accuracy can be improved by calibration.
comment by [deleted] · 2015-06-11T14:53:21.560Z · LW(p) · GW(p)
Predict where this link will hyperlink to given that I'm telling you it's a link to a page with photos of the Spanish revolution and my post history.
edit 1: no peaking by hovering over the link!
comment by TomStocker · 2015-05-28T09:35:48.388Z · LW(p) · GW(p)
My hunch is that encouraging people that have to manage an unpredictable or tricky health condition to predict and note their prediction of how good or bad an activity will be for their pain / energy / / mood / whatever else would be a very useful habit that both frees people up to do things and prevents them from doing too much of what hurts. Julia, have you or anyone from CFAR looked at partnering with a pain management or other type of disease management team or setting to see how many of the rationality skills would be helpful?
comment by psychoman · 2015-05-14T20:27:35.155Z · LW(p) · GW(p)
I m new here, it is very helpful wrote for who started to thinking. But thinking is very complex and has very improved versions. I wont comment about my further thouths before reading other articles. Maybe there are some improved ideas.
Replies from: TomStocker↑ comment by TomStocker · 2015-05-28T09:27:06.219Z · LW(p) · GW(p)
Welcome! There are loads of articles, so if it gets confusing, this is a decent place to start. https://intelligence.org/rationality-ai-zombies/
comment by Strangeattractor · 2015-04-21T08:35:47.858Z · LW(p) · GW(p)
Cards Against Humanity is a party game that can help develop the ability to predict what each person in the group finds funny, or which answer they will choose. If you get better at predicting, you get better at the game. I mention it as a fun way to get better at predicting.
comment by ChristianKl · 2015-04-09T14:18:12.822Z · LW(p) · GW(p)
There the possibility to write down predictions whether you make an agreement with another person. If I schedule a date then I can predict the chance of flaking.
That means that I stop fully trusting the person to be there. I treat them more like a number than as a person.
comment by alicey · 2015-04-08T19:39:30.659Z · LW(p) · GW(p)
I liked (and upvoted) this post and the list is useful.
The use of "male pronoun as default" was a bit jarring :(
Replies from: Julia_Galef, Quill_McGee, adamzerner↑ comment by Julia_Galef · 2015-04-08T19:47:38.608Z · LW(p) · GW(p)
I usually try to mix it up. A quick count shows 6 male examples and 2 female examples, which was not a deliberate choice, but I guess I can be more intentional about a more even split in future?
Replies from: Error, gwillen, alicey↑ comment by Error · 2015-04-08T21:36:17.724Z · LW(p) · GW(p)
I think Eliezer mentioned once that he flips a coin for such cases. I think it's a pretty good policy.
Replies from: So8res, adamzerner↑ comment by So8res · 2015-04-08T23:54:58.391Z · LW(p) · GW(p)
Note that a 6/2 split (as in this post) would happen fairly frequently when tossing coins (~20% of the time, unless I miss my guess). Since alicey found that jarring, I expect that purposeful alternation would be a better strategy.
Replies from: Viliam↑ comment by Viliam · 2015-04-09T10:22:14.296Z · LW(p) · GW(p)
Maybe make 4 ♂ symbols and 4 ♀ symbols (if you know there will be 8 cases together) and shuffle them? Oh, I guess even in that case someone would complain if one set of symbols happened to get predominantly at the top of the article, and other set at the bottom of the article...
So probably it is best to alter them like this: ABABABAB... or maybe like this: ABBAABBA... with a coin flip deciding who is A and who is B.
Replies from: ChristianKl, afeller08↑ comment by ChristianKl · 2015-04-09T14:18:26.622Z · LW(p) · GW(p)
You can also simply use standard names:
Alice, Bob, Carol, Dave, Erin, Frank...
↑ comment by afeller08 · 2015-04-28T04:55:58.075Z · LW(p) · GW(p)
More jarring than that is if one set of gender pronouns gets used predominantly in negative examples, and the other set gets used predominantly in positive examples.
I try to deliberately switch based on context. If I wrote an example of someone being wrong and then someone being right. I will stick with the same gender for both cases, and then switch to the other gender when I move to the next example of someone being wrong, right, or indifferent.
Occasionally, something will be so inherently gendered that I cannot use the non-default gender and feel reasonable doing it. In these cases, I actually don't think I should. (Triggers: sexual violence. I was recently writing about violence, including rape, and I don't think I could reasonable alternate pronouns for referring to the rapist because, while not all perpetrators are male, they are so overwhelmingly male that it would be unreasonable to use "she" in isolation. I mixed "he" with an occasional "he or she" for the extremely negative examples in those few paragraphs.)
↑ comment by Adam Zerner (adamzerner) · 2015-04-12T01:15:45.370Z · LW(p) · GW(p)
That seems like it'd interrupt the flow of writing.
It'd be interesting if there was some sort of compiler that did this for you :)
↑ comment by afeller08 · 2015-04-28T05:13:54.867Z · LW(p) · GW(p)
Precisely for this reason, there was a time when I wrote in Elverson pronouns (basically, Spivak pronouns) for gender ambiguous cases. So, if I was writing about Bill Clinton, I would use "he," and if I was writing about Grace Hopper, I would use "she," but if I was writing about somebody/anybody in would use, I would use "ey" instead. This allows one to easily compile the pronouns according to preference without mis-attributing pronouns to actual people... I've always planned on getting around to hosting my own blog running on my own code which would include an option to let people set a cookie to store their gender preference so they could get "she by default", "he by default", "Spivak by default", or randomization between he and she -- with a gimmick option for switching between different sets of gender neutral pronouns at random. The default default being randomization between he and she. But I haven't gotten around to writing the website to host my stuff yet, and I just use unmodified blogger, so for now I'm doing deliberate switching by hand as described above.
(I think I could write a script like that for blogger too, but I haven't bothered looking into how to customize blogger because I keep planning to write my own website anyways because there are a lot of things I want to differently, and that's not necessarily the one that's at the top of my list.)
↑ comment by gwillen · 2015-04-09T20:13:23.442Z · LW(p) · GW(p)
Oddly, I also came away with an impression of 'male pronoun as default', and on rereading it seems that e.g. I strongly noticed the male pronoun in 13, but did not notice the female pronoun in 14. I guess I've just been trained to notice default-male-pronoun usages. (You did also use 'singular they' in example 7, which to me reads much more naturally than pronoun alternation.)
Replies from: juliad↑ comment by juliad · 2015-04-22T17:46:31.391Z · LW(p) · GW(p)
Huh, I missed the pronoun in 14 too. I suspect the 6:2 ratio is less of an issue than three male references being before the first female one. I noticed "Lisa", but at that point I already had the idea that the article was gender-biased. Confirmation bias I suppose.
↑ comment by alicey · 2015-04-08T22:06:42.514Z · LW(p) · GW(p)
nod. Sounds reasonable!
It might help to be more intentional, to prevent people from having jarring experiences like that.
Replies from: Nornagest↑ comment by Nornagest · 2015-04-09T18:49:21.073Z · LW(p) · GW(p)
For every person that finds "male pronoun as default" jarring, I'd expect there to be two who find consciously alternating between genders jarring, and five for most of the more exotic alternatives. I'm not saying it's a bad idea after taking everything into account, but if all you care about is ease of reading, you'd have to have a very specific audience in mind for this solution to make sense to me.
(Not my downvote, by the way.)
Replies from: TheOtherDave↑ comment by TheOtherDave · 2015-04-09T19:30:52.393Z · LW(p) · GW(p)
IME I've mostly found that using plural pronouns without calling attention to them works well enough, except in cases where there's another plural pronoun in the same phrase. That is, "Sam didn't much care for corn, because it got stuck in their teeth" rarely causes comment (though I expect it to cause comment now, because I've called attention to it), but "Sam didn't much care for corn kernels, because they got stuck in their teeth" makes people blink.
(Of course, this is no different from any other shared-pronoun situation. "Sam didn't much care for kissing her boyfriend, because her tongue kept getting caught in his braces" is clear enough, but "Sam didn't much care for kissing her girlfriend, because her tongue kept getting caught in her braces" is decidedly unclear.)
↑ comment by Quill_McGee · 2015-04-28T17:42:22.301Z · LW(p) · GW(p)
After a bit of thought, I believe I've found a basically permanent solution for this. I use word replacer (not sure how to add links without just posting them, you can google it, it is in the chrome web store) with a bunch of rules to enforce 'they' as default. If you put rules for longer strings at the top they match first ('he is' to 'they are' at the top with 'he' to 'they' lower down, for example)
You will have to put up with some number mismatch unless you want to add a rule for every verb in English ('they puts'), but I feel that that is an acceptable sacrifice.
EDIT: another issue: If you are actually talking about pronouns, you will have to temporarily disable it for things to make any sense whatsoever, and it doesn't seem to have a way to disable it on a specific page unlike the service I was using it to replace, so you have to use the extensions screen in settings.
EDEDIT: Also, and this is bothering me enough that I might actually stop using this, is 'her' as a pronoun versus 'her' as a possessive. for example in 'Get to know her' versus 'I found her wallet'. The first should be 'Get to know them' wheras the second one should be 'I found their wallet', and I'm not sure what to do about that. If I find/build an extension which can interface with a list of english words with part-of-speech tagging and have rules like 'her'->'them', 'her '->'their ', then that'd work, but as is it is bugging me.
↑ comment by Adam Zerner (adamzerner) · 2015-04-12T01:13:16.209Z · LW(p) · GW(p)
My impression is that switching it up would be a bit confusing to the reader. In the spirit of making predictions, I'll say that I'm 70% confident that switching it up would cause confusion in readers (not sure how I'd define confusion :/ ). It'd be interesting to see research on this. Maybe how switching it up affects reading comprehension or something.
For better or for worse, convention seems to be to use male pronouns, and I sense that deviation from this draws the readers attention towards pronoun use and away from the content. You may argue that this is an example of the legacy problem. Again, it'd be interesting to see if there was any similar research into this.