The case for a negative alignment tax
post by Cameron Berg (cameron-berg), Judd Rosenblatt (judd), Diogo de Lucena (diogo-de-lucena), AE Studio (AEStudio) · 2024-09-18T18:33:18.491Z · LW · GW · 20 commentsContents
TL;DR: Introduction Is a negative alignment tax plausible (or desirable)? Early examples of negative alignment taxes The elephant in the lab: RLHF Cooperative/prosocial AI systems Process supervision and other LLM-based interventions Concluding thoughts None 20 comments
TL;DR:
Alignment researchers have historically predicted that building safe advanced AI would necessarily incur a significant alignment tax [? · GW] compared to an equally capable but unaligned counterfactual AI.
We put forward a case here that this prediction looks increasingly unlikely given the current ‘state of the board,’ as well as some possibilities for updating alignment strategies accordingly.
Introduction
We recently found [LW · GW] that over one hundred grant-funded alignment researchers generally disagree with statements like:
- alignment research that has some probability of also advancing capabilities should not be done (~70% somewhat or strongly disagreed)
- advancing AI capabilities and doing alignment research are mutually exclusive goals (~65% somewhat or strongly disagreed)
Notably, this sample also predicted that the distribution would be significantly more skewed in the ‘hostile-to-capabilities’ direction.
See ground truth vs. predicted distributions for these statements
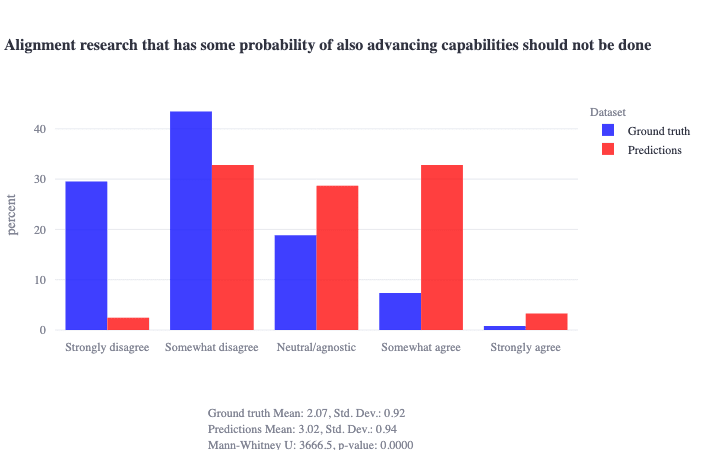
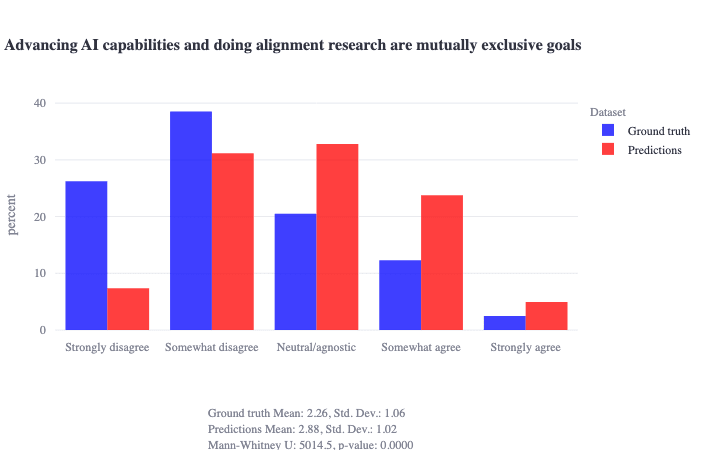
These results—as well as recent [LW · GW] events [LW · GW] and related discussions [LW · GW]—caused us to think more about our views on the relationship between capabilities and alignment work given the ‘current state of the board,’[1] which ultimately became the content of this post. Though we expect some to disagree with these takes, we have been pleasantly surprised by the positive feedback we’ve received from discussing these ideas in person and are excited to further stress-test them here.
Is a negative alignment tax plausible (or desirable)?
Often, capabilities and alignment are framed with reference to the alignment tax [? · GW], defined as ‘the extra cost [practical, developmental, research, etc.] of ensuring that an AI system is aligned, relative to the cost of building an unaligned alternative.’
The AF [? · GW]/LW [? · GW] wiki entry on alignment taxes notably includes the following claim:
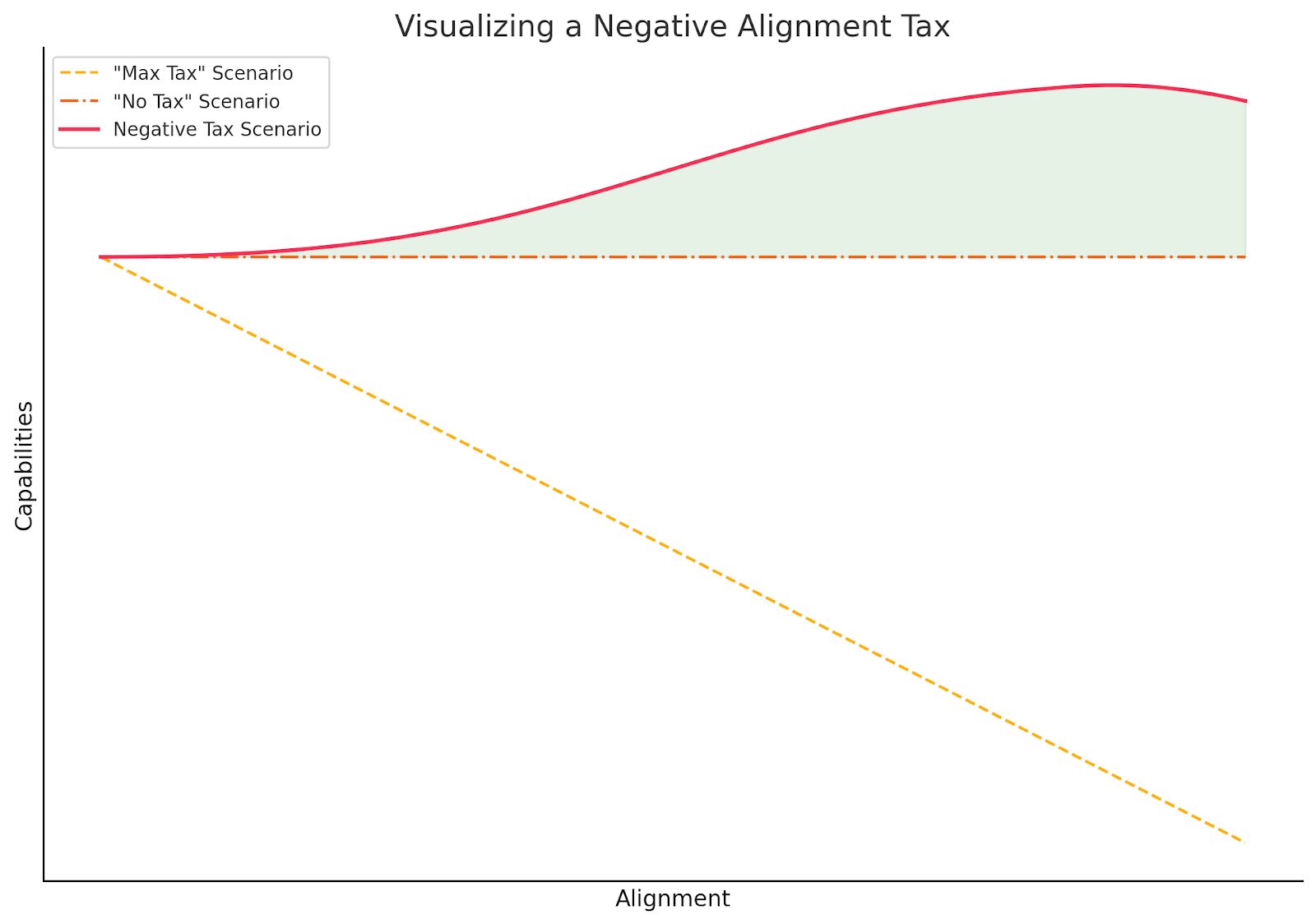
The best case scenario is No Tax: This means we lose no performance by aligning the system, so there is no reason to deploy an AI that is not aligned, i.e., we might as well align it.
The worst case scenario is Max Tax: This means that we lose all performance by aligning the system, so alignment is functionally impossible.
We speculate in this post about a different best case scenario: a negative alignment tax—namely, a state of affairs where an AI system is actually rendered more competent/performant/capable by virtue of its alignment properties.
Why would this be even better than 'No Tax?' Given the clear existence of a trillion dollar attractor state towards ever-more-powerful AI, we suspect that the most pragmatic and desirable outcome would involve humanity finding a path forward that both (1) eventually satisfies the constraints of this attractor (i.e., is in fact highly capable, gets us AGI, etc.) and (2) does not pose existential risk to humanity.
Ignoring the inevitability of (1) seems practically unrealistic as an action plan at this point—and ignoring (2) could be collectively suicidal.

Therefore, if the safety properties of such a system were also explicitly contributing to what is rendering it capable—and therefore functionally causes us to navigate away from possible futures where we build systems that are capable but unsafe—then these 'negative alignment tax' properties seem more like a feature than a bug.
It is also worth noting here as an empirical datapoint here that virtually all frontier models’ alignment properties have rendered them more rather than less capable (e.g., gpt-4 is far more useful and far more aligned than gpt-4-base), which is the opposite of what the ‘alignment tax’ model would have predicted.
This idea is somewhat reminiscent of differential technological development [EA · GW], in which Bostrom suggests “[slowing] the development of dangerous and harmful technologies, especially ones that raise the level of existential risk; and accelerating the development of beneficial technologies, especially those that reduce the existential risks posed by nature or by other technologies.” If alignment techniques were developed that could positively ‘accelerate the development of beneficial technologies’ rather than act as a functional ‘tax’ on them, we think that this would be a good thing on balance.
Of course, we certainly still do not think it is wise to plow ahead with capabilities work given the current practical absence of robust ‘negative alignment tax’ techniques—and that safetywashing capabilities gains without any true alignment benefit is a real and important ongoing concern.
However, we do think if such alignment techniques were discovered—techniques that simultaneously steered models away from dangerous behavior while also rendering them more generally capable in the process—this would probably be preferable in the status quo to alignment techniques that steered models away from dangerous behavior with no effect on capabilities (ie, techniques with no alignment tax) given the fairly-obviously-inescapable strength of the more-capable-AI attractor state.
In the limit (what might be considered the ‘best imaginable case’), we might imagine researchers discovering an alignment technique that (A) was guaranteed to eliminate x-risk and (B) improve capabilities so clearly that they become competitively necessary for anyone attempting to build AGI.
Early examples of negative alignment taxes
We want to emphasize that the examples we provide here are almost certainly not the best possible examples of negative alignment taxes—but at least provide some basic proof of concept that there already exist alignment properties that can actually bolster capabilities—if only weakly compared to the (potentially ideal) limit case.
The elephant in the lab: RLHF
RLHF is clearly not [LW · GW] a [LW · GW] perfect [LW(p) · GW(p)] alignment technique [LW · GW], and it probably won’t [LW · GW] scale [EA · GW]. However, the fact that it both (1) clearly renders frontier[2] models’ outputs less toxic and dangerous and (2) has also been widely adopted given the substantial associated improvements in task performance and naturalistic conversation ability seems to us like a clear (albeit nascent) example of a ‘negative alignment tax’ in action.
It also serves as a practical example of point (B) above: the key labs pushing the envelope on capabilities have all embraced RLHF to some degree, likely not out of a heartfelt concern for AI x-risk, but rather because doing so is actively competitively necessary in the status quo.
Consider the following from Anthropic’s 2022 Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback:
Our alignment interventions actually enhance the capabilities of large models, and can easily be combined with training for specialized skills (such as coding or summarization) without any degradation in alignment or performance. Models with less than about 10B parameters behave differently, paying an ‘alignment tax’ on their capabilities. This provides an example where models near the state-of-the-art may have been necessary to derive the right lessons from alignment research.
The overall picture we seem to find – that large models can learn a wide variety of skills, including alignment, in a mutually compatible way – does not seem very surprising. Behaving in an aligned fashion is just another capability, and many works have shown that larger models are more capable [Kaplan et al., 2020, Rosenfeld et al., 2019, Brown et al., 2020], finetune with greater sample efficiency [Henighan et al., 2020, Askell et al., 2021], and do not suffer significantly from forgetting [Ramasesh et al., 2022].
Cooperative/prosocial AI systems
We suspect there may be core prosocial [LW · GW] algorithms [? · GW] (already running in human brains[3]) that, if implemented into AI systems in the right ways, would also exhibit a negative alignment tax. To the degree that humans actively prefer to interface with AI that they can trust and cooperate with, embedding prosocial algorithms into AI could confer both new capabilities and favorable alignment properties.
The operative cluster of examples we are personally most excited about—things like attention schema theory, theory of mind, empathy, and self-other overlap [LW · GW]—all basically relate to figuring out how to robustly integrate in an agent’s utility function(s) the utility of other relevant agents. If the right subset of these algorithms could be successfully integrated into an agentic AI system—and cause it to effectively and automatically [LW · GW] predict and reason about the effects of its decisions on other agents—we would expect that, by default, it would not want to kill everyone,[4] and that this might even scale to superintelligence given orthogonality.
In a world where the negative alignment tax model is correct, prosocial algorithms could also potentially avoid value lock-in [? · GW] by enabling models to continue reasoning about and updating their own values in the 'right' direction long after humans are capable of evaluating this ourselves. Given that leading models' capabilities now seem to scale almost linearly with compute along two dimensions—not only during training but also during inference—getting this right may be fairly urgent.
There are some indications that LLMs already exhibit theory-of-mind-like abilities, albeit more implicitly than what we are imagining here. We suspect that discovering architectures that implement these sorts of prosocial algorithms in the right ways would represent both a capabilities gain and tangible alignment progress.
As an aside from our main argument here, we currently feel more excited about systems whose core functionality is inherently aligned/alignable (reasonable examples include: prosocial AI [LW · GW], safeguarded AI [LW · GW], agent foundations [LW · GW]) as compared to corrigibility-style approaches that seemingly aim to optimize more for oversight, intervention, and control (as a proxy for alignment) rather than for ‘alignedness’ directly. In the face of sharp left turns or inevitable jailbreaking,[5] it is plausible that the safest long-term solution might look something like an AI whose architecture explicitly and inextricably encodes acting in light of the utility of other agents, rather than merely ‘bolting on’ security or containment measures to an ambiguously-aligned system.
The question isn't will your security be breached? but when? and how bad will it be?
-Bruce Schneier
Process supervision and other LLM-based interventions
OpenAI’s recent release of the o1 model series serves as the strongest evidence to date that rewarding each step of an LLM’s chain of thought rather than only the final outcome improves both capabilities and alignment in multi-step problems, notably including 4x improved safety performance on the challenging Goodness@0.1 StrongREJECT jailbreak eval. This same finding was also reported in earlier, more constrained task settings.
We suspect there are other similar interventions for LLMs that would constitute good news for both alignment and capabilities (e.g. Paul Christiano’s take that LLM agents might be net-good for alignment [LW · GW]; the finding that more persuasive LLM debaters enables non-expert models to identify truth better; and so on).
Concluding thoughts
Ultimately, that a significant majority [LW · GW] of the alignment researchers we surveyed don’t think capabilities and alignment are mutually exclusive indicates to us that the nature of the relationship between these two domains is itself a neglected [LW · GW] area of research and discussion.
While there are certainly good [LW · GW] reasons [LW · GW] to be concerned about any capabilities improvements whatsoever in the name of safety, we think there are also good reasons to be concerned that capabilities taboos [LW · GW] in the name of safety may backfire in actually navigating towards a future in which AGI is aligned.
While we argue for the possibility of a negative alignment tax, it's important to note that this doesn't eliminate all tradeoffs between performance and alignment. Even in systems benefiting from alignment-driven capabilities improvements, there may still be decisions that pit marginal gains in performance against marginal gains in alignment (see 'Visualizing a Negative Alignment Tax' plot above).
However, what we're proposing is that certain alignment techniques can shift the entire tradeoff curve, resulting in systems that are both more capable and more aligned than their unaligned counterparts. This view implies that rather than viewing alignment as a pure cost to be minimized, we should seek out techniques that fundamentally improve the baseline performance-alignment tradeoff.
While the notion of a negative alignment tax is fairly speculative and optimistic, we think the theoretical case for it being a desirable and pragmatic outcome is straightforward given the current state of the board.[6] Whether we like it or not, humanity’s current-and-seemingly-highly-stable incentive structures have us hurtling towards ever-more-capable AI without any corresponding guarantees regarding safety. We think that an underrated general strategy for contending with this reality is for researchers—and alignment startup [LW · GW] founders—to further explore neglected [LW · GW] alignment approaches with negative alignment taxes.
- ^
Monte Carlo Tree Search is a surprisingly powerful decision-making algorithm that teaches us an important lesson about the relationship between plans and the current state of the board: recompute often. Just as MCTS builds a tree of possibilities, simulating many 'playouts' from the current state to estimate the value of each move, and then focuses its search on the most promising branches before selecting a move and effectively starting anew from the resulting state, so too might we adopt a similar attitude for alignment research. It does not make much sense to attempt to navigate towards aligned AGI by leaning heavily on conceptual frameworks ('past tree expansions') generated in an earlier, increasingly unrecognizable board state—namely, the exponential increase in resources and attention being deployed towards advancing AI capabilities and the obvious advances that have already accompanied this investment. Alignment plans that do not meaningfully contend with this reality might be considered 'outdated branches' in the sense described above.
- ^
In general, there is some evidence that RLHF seems to work better on larger and more sophisticated models, though it is unclear to what extent this trend can be extrapolated.
- ^
“I've been surprised, in the past, by how many people vehemently resist the idea that they might not actually be selfish, deep down. I've seen some people do some incredible contortions in attempts to convince themselves that their ability to care about others is actually completely selfish. (Because iterated game theory says that if you're in a repeated game it pays to be nice, you see!) These people seem to resist the idea that they could have selfless values on general principles, and consistently struggle to come up with selfish explanations for their altruistic behavior.” - Nate Soares, Replacing Guilt.
- ^
- ^
…or overdependence on the seemingly-innocuous software of questionably competent actors.
- ^
If the current state of the board changes, this may also change. It is important to be sensitive to how negative alignment taxes may become more or less feasible/generalizable over time.
20 comments
Comments sorted by top scores.
comment by Seth Herd · 2024-09-18T23:41:37.834Z · LW(p) · GW(p)
Nice article! Your main point, that capabilities and alignment can be and often are advanced together, is valuable, and I take it.
Now, to voice the definitional quibble I suspect many readers are thinking of:
I think it's more correct to say that some techniques invented for alignment might also be used to improve capabilities, and the way they're first implemented might do that by accident. Literally negative alignment taxes for a whole technique seem like it's stretching the definition of capabilities and alignment.
For instance, the approach I propose in Internal independent review for language model agent alignment [LW · GW] should hypothetically improve capabilities when it's turned to that end, but will not if it's used strictly for alignment. A better term for it, (coined by Shane Legg in this short talk), is System 2 alignment. It's scripting the agent to "think through" the consequences of an action before taking it, like humans employ System 2 thinking for important actions. You could design it to think through the ethical consequences, or the efficacy or cost of an action, or any combination. Including checking the predicted ethical consequences will take slightly longer than checking only predicted efficacy and costs, and thus have a small but positive alignment tax.
The technique itself of implementing System 2 predictions for actions doesn't have a negative alignment tax, just the potential to be employed for both alignment and capabilities in ways so similar that the design/implementation costs are probably almost zero. This technique seems to have been independently invented several times, often with alignment as the inspiration, so we could argue that working on alignment is also advancing capabilities here.
In the case of RLHF, we might even argue that the creation tax is negative; if you don't specify what criteria people use for judging outputs, they'll probably include both ethical (alignment) and helpful (capabilities). Differentiating these would be a bit harder. But the runtime cost seems like it's guaranteed to be a positive tax. Refusing to do some unaligned stuff is a common complaint leveled at the system's capabilities.
So:
I think the original definition of zero being the minimal alignment tax is probably correct. RLHF/RLAIF happen to both increase alignment and performance (by the metric of what people prefer), when they're performed in a specific way. If you told the people or Constitution in charge of the RL process to not prefer harmless responses, just helpful ones, I very much doubt it would harm capabilities - I'd think it would help them (particularly from the perspective of people who'd like the capability of the AI saying naughty words.
Anyway, the main point that you can advance capabilities and alignment at the same time, and should think about differentially advancing alignment is well taken. I'd just change the framing in future pitches to this effect.
Replies from: judd↑ comment by Judd Rosenblatt (judd) · 2024-09-19T05:03:58.702Z · LW(p) · GW(p)
Thanks for this comment! Definitely take your point that it may be too simplistic to classify entire techniques as exhibiting a negative alignment tax when tweaking the implementation of that technique slightly could feasibly produce misaligned behavior. It does still seem like there might be a relevant distinction between:
- Techniques that can be applied to improve either alignment or capabilities, depending on how they’re implemented. Your example of ‘System 2 alignment’ would fall into this category, as would any other method with “the potential to be employed for both alignment and capabilities in ways so similar that the design/implementation costs are probably almost zero,” as you put it.
- Techniques that, by their very nature, improve both alignment and capabilities simultaneously, where the improvement in capabilities is not just a potential side effect or alternative application, but an integral part of how the technique functions. RLHF (for all of its shortcomings, as we note in the post) is probably the best concrete example of this—this is an alignment technique that is now used by all major labs (some of which seem to hardly care about alignment per se) by virtue of the fact it so clearly improves capabilities on balance.
- (To this end, I think the point about refusing to do unaligned stuff as a lack of capability might be a stretch, as RLHF is much of what is driving the behavioral differences between, eg, gpt-4-base and gpt-4, which goes far beyond whether, to use your example, the model is using naughty words.)
We are definitely supportive of approaches that fall under both 1 and 2 (and acknowledge that 1-like approaches would not inherently have negative alignment taxes), but it does seem very likely that there are more undiscovered approaches out there with the general 2-like effect of “technique X got invented for safety reasons—and not only does it clearly help with alignment, but it also helps with other capabilities so much that, even as greedy capitalists, we have no choice but to integrate it into our AI’s architecture to remain competitive!” This seems like a real and entirely possible circumstance where we would want to say that technique X has a negative alignment tax.
Overall, we’re also sensitive to this all becoming a definitions dispute about what exactly is meant by terminology like ‘alignment taxes,’ ‘capabilities,’ etc, and the broader point that, as you put it,
you can advance capabilities and alignment at the same time, and should think about differentially advancing alignment
is indeed a good key general takeaway.
comment by Tao Lin (tao-lin) · 2024-09-19T01:08:23.983Z · LW(p) · GW(p)
to me "alignment tax" usually only refers to alignment methods that don't cost-effectively increase capabilities, so if 90% of alignment methods did cost effectively increase capabilities but 10% did not, i would still say there was an "alignment tax", just ignore the negatives.
Also, it's important to consider cost-effective capabilities rather than raw capabilities - if a lab knows of a way to increase capabilities more cost-effectively than alignment, using that money for alignment is a positive alignment tax
↑ comment by Judd Rosenblatt (judd) · 2024-09-19T05:25:03.404Z · LW(p) · GW(p)
I think this risks getting into a definitions dispute about what concept the words ‘alignment tax’ should point at. Even if one grants the point about resource allocation being inherently zero-sum, our whole claim here is that some alignment techniques might indeed be the most cost-effective way to improve certain capabilities and that these techniques seem worth pursuing for that very reason.
comment by Charlie Steiner · 2024-09-19T05:56:37.528Z · LW(p) · GW(p)
Here are some different things you might have clustered as "alignment tax."
Thing 1: The difference between the difficulty of building the technologically-closest friendly transformative AI and the technologically-closest dangerous transformative AI.
Thing 2: The expected difference between the difficulty of building likely transformative AI conditional on it being friendly and the difficulty of building likely transformative AI no matter friendly or dangerous.
Thing 3: The average amount that effort spent on alignment detracts from the broader capability or usefulness of AI.
Turns out it's possible to have negative Thing 3 but positive Things 1 and 2. This post seems to call such a state of affairs "optimistic," which is way too hasty.
An opposite-vibed way of framing the oblique angle between alignment and capabilities is as "unavoidable dual use research." See this long post about the subject [AF · GW]
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2024-09-19T14:26:05.684Z · LW(p) · GW(p)
Thanks, it definitely seems right that improving capabilities through alignment research (negative Thing 3) doesn't necessarily make safe AI easier to build than unsafe AI overall (Things 1 and 2). This is precisely why if techniques for building safe AI were discovered that were simultaneously powerful enough to move us toward friendly TAI (and away from the more-likely-by-default dangerous TAI, to your point), this would probably be good from an x-risk perspective.
We aren't celebrating any capability improvement that emerges from alignment research—rather, we are emphasizing the expected value of techniques that inherently improve both alignment and capabilities such that the strategic move for those who want to build maximally-capable AI shifts towards the adoption of these techniques (and away from the adoption of approaches that might cause similar capabilities gains without the alignment benefits). This is a more specific take than just a general 'negative Thing 3.'
I also think there is a relevant distinction between 'mere' dual-use research and what we are describing here—note the difference between points 1 and 2 in this comment [LW(p) · GW(p)].
comment by Noosphere89 (sharmake-farah) · 2024-09-19T14:45:54.964Z · LW(p) · GW(p)
I'd say the big example of something that plausibly has a negative alignment tax, or at least far less taxes than usual alignment plans, is making large synthetic datasets showing correct human values, and/or synthetic datasets that always have a much more powerful AI obey humans.
Constitiutional AI IMO is the very, very primitive start of how this sort of plan could go.
The basic reason for why it has so much tractability in my mind starts from 2 things I realized mattered for alignment.
1 is that the architecture matters less than the data for questions of OOD generalization, and thus whoever controls the dataset has a powerful way to control what it values, even when it's trying to generalize OOD.
A very strong version of this is provided here:
https://nonint.com/2023/06/10/the-it-in-ai-models-is-the-dataset/
But even though I might quibble with the strongest versions of the concept, I do think the insight that the data matters much more than the architecture even for things like AGI/ASI immediately suggests a plausible alignment method, which is to train them with massive synthetic data sets on what human values, and also have data about AIs that are way more powerful than humans always obeying what a human orders them to do, which @Seth Herd [LW · GW] calls instruction following AGIs could well be very valuable.
2 is that synthetic data is a natural path for people like OpenAI to work on to increase capabilities, and a lot of the papers claiming model collapse have extraordinarily unrealistic assumptions, like always removing all the real data, which makes me skeptical of model collapse occuring IRL.
For this reason, it's easier to get selfish actors to subscribe to this alignment approach than some other alignment approaches that have been proposed.
There is another point to keep in mind:
As it turns out, alignment probably generalizes further than capabilities, because learning and valuing what humans value is very easy, since there is a whole lot of data on what humans value, and you never actually have to execute on those values IRL, but it's harder to make an AI that is robustly capable in the real world, which means that value learning comes before capabilities, and more importantly, it's looking like a lot of the evopsych assumptions about how humans got their capabilities and values is looking very wrong, and that matters, since under something like a Universal Learning Machine hypothesis, a whole of the complexity of human values is in the data, not the algorithm or code, and thus it's feasible to make AIs learn what we value in a simple fashion, because our values aren't nearly as complicated as evopsych suggests:
https://www.lesswrong.com/posts/9Yc7Pp7szcjPgPsjf/the-brain-as-a-universal-learning-machine [LW · GW]
But what that means is that actually being aligned isn't massively disfavored even under simplicity priors, and it can be gotten into a basin of alignment quite early in training with reasonably small datasets.
I've become more bearish on RLHF post-training methods, but your post is well taken here.
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2024-09-19T20:32:43.226Z · LW(p) · GW(p)
Thanks for this! Synthetic datasets of the kind you describe do seem like they could have a negative alignment tax, especially to the degree (as you point out) that self-motivated actors may be incentivized to use them anyway if they were successful.
Your point about alignment generalizing farther than capabilities is interesting and is definitely reminiscent of Beren’s thinking on this exact question.
Curious if you can say more about what evopsych assumptions assumptions about human capabilities/values you think are false.
↑ comment by Noosphere89 (sharmake-farah) · 2024-09-19T20:43:47.033Z · LW(p) · GW(p)
Indeed, I got that point exactly from Beren, thanks for noticing.
The evopsych assumptions I claim are false are the following:
That most of how humans learn is through very specific modules, and in particular that most of the learning is not through general purpose algorithms that learn from data, but are instead specified by the genome for the most part, and that the human mind is a complex messy cludge of evolved mechanisms.
Following that, the other assumption that I think is false is that there is a very complicated way in how humans are pro-social, and that the pro-social algorithms you attest to are very complicated kludges, but instead very general and simple algorithms where the values and pro-social factors of humans are learned mostly from data.
Essentially, I'm arguing the view that most of the complexity of the pro-social algorithms/values we learn is not due to the genome's inherent complexity, under evopsych, but rather that the data determines most of what you value, and most of the complexity comes from the data, not the prior.
Cf this link:
https://www.lesswrong.com/posts/9Yc7Pp7szcjPgPsjf/the-brain-as-a-universal-learning-machine [LW · GW]
comment by tailcalled · 2024-09-19T07:12:49.197Z · LW(p) · GW(p)
RLHF makes alignment worse by covering up any alignment failures. Insofar as it is economically favored, that would be a huge positive alignment tax, rather than a negative alignment tax.
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2024-09-19T14:47:20.994Z · LW(p) · GW(p)
I think the post makes clear that we agree RLHF is far from perfect and won't scale, and definitely appreciate the distinction between building aligned models from the ground-up vs. 'bolting on' safety techniques (like RLHF) after the fact.
However, if you are referring to current models, the claim that RLHF makes alignment worse (as compared to a world where we simply forego doing RLHF?) seems empirically false [LW · GW].
Replies from: tailcalled↑ comment by tailcalled · 2024-09-19T15:19:37.203Z · LW(p) · GW(p)
However, if you are referring to current models, the claim that RLHF makes alignment worse (as compared to a world where we simply forego doing RLHF?) seems empirically false.
You talk like "alignment" is a traits that a model might have to varying extents, but really there is the alignment problem that AI will unleash a giant wave of stuff and we have reasons to believe this giant wave will crash into human society and destroy it. A solution to the alignment problem constitutes some way of aligning the wave to promote human flourishing instead of destroying society.
RLHF makes models avoid taking actions that humans can recognize as bad. If you model the giant wave as being caused by a latent "alignment" trait that a model have, which can be observed from whether it takes recognizably-bad actions, then RLHF will almost definitionally make you estimate this trait to be very very low.
But that model is not actually true and so your estimate of the "alignment" trait has nothing to do with how we're doing with the alignment problem. On the other hand, the fact that RLHF makes you estimate that we're doing well means that you have lost track of solving the alignment problem, which means we are one man down. Unless your contribution to solving the alignment problem would otherwise have been counterproductive/unhelpful, this means RLHF has made the situation with the alignment problem worse.
Let's take a better way to estimate progress: Spambots. We don't want them around (human values), but they pop up to earn money (instrumental convergence). You can use RLHF to make an AI to identify and remove spambots, for instance by giving it moderator powers on a social media website and evaluating its chains of thought, and you can use RLHF to make spambots, for instance by having people rate how human its text looks and how much it makes them want to buy products/fall for scams/whatever. I think it's generally agreed that the latter is easier than the former.
Of course spambots aren't the only thing human values care about. We also care about computers being able to solve cognitive tasks for us, and you are right that computers will be better able to solve cognitive tasks for us if we RLHF them. But this is a general characteristic of capabilities advances.
But a serious look at how RLHF improves the alignment problem doesn't treat "alignment" as a latent trait of piles of matrices that can be observed for fragmented actions, rather it starts by looking at what effects RLHF lets AI models have on society, and then asks whether these effects are good or bad. So far, all the cases for RLHF show that RLHF makes an AI more economically valuable, which incentivizes producing more AI, but as long as the alignment problem is relevant, this makes the alignment problem worse rather than better.
Replies from: cameron-berg, tailcalled↑ comment by Cameron Berg (cameron-berg) · 2024-09-19T20:28:25.845Z · LW(p) · GW(p)
- Thanks for writing up your thoughts on RLHF in this separate piece, particularly the idea that ‘RLHF hides whatever problems the people who try to solve alignment could try to address.’ We definitely agree with most of the thrust of what you wrote here and do not believe nor (attempt to) imply anywhere that RLHF indicates that we are globally ‘doing well’ on alignment or have solved alignment or that alignment is ‘quite tractable.’ We explicitly do not think this and say so in the piece [LW · GW].
- With this being said, catastrophic misuse could wipe us all out, too. It seems too strong to say that the ‘traits’ of frontier models ‘[have] nothing to do’ with the alignment problem/whether a giant AI wave destroys human society, as you put it. If we had no alignment technique that reliably prevented frontier LLMs from explaining to anyone who asked how to make anthrax, build bombs, spread misinformation [LW · GW], etc, this would definitely at least contribute to a society-destroying wave. But finetuned frontier models do not do this by default, largely because of techniques like RLHF. (Again, not saying or implying RLHF achieves this perfectly or can’t be easily removed or will scale, etc. Just seems like a plausible counterfactual world we could be living in but aren’t because of ‘traits’ of frontier models.)
The broader point we are making in this post is that the entire world is moving full steam ahead towards more powerful AI whether we like it or not, and so discovering and deploying alignment techniques that move in the direction of actually satisfying this impossible-to-ignore attractor while also maximally decreasing the probability that the “giant wave will crash into human society and destroy it” seem worth pursuing—especially compared to the very plausible counterfactual world where everyone just pushes ahead with capabilities anyways without any corresponding safety guarantees.
While we do point to RLHF in the piece as one nascent example of what this sort of thing might look like, we think the space of possible approaches with a negative alignment tax is potentially vast. One such example we are particularly interested in (unlike RLHF) is related to implicit/explicit utility function overlap, mentioned in this comment [LW(p) · GW(p)].
↑ comment by tailcalled · 2024-09-20T07:34:41.914Z · LW(p) · GW(p)
With this being said, catastrophic misuse could wipe us all out, too. It seems too strong to say that the ‘traits’ of frontier models ‘[have] nothing to do’ with the alignment problem/whether a giant AI wave destroys human society, as you put it. If we had no alignment technique that reliably prevented frontier LLMs from explaining to anyone who asked how to make anthrax, build bombs, spread misinformation, etc, this would definitely at least contribute to a society-destroying wave. But finetuned frontier models do not do this by default, largely because of techniques like RLHF. (Again, not saying or implying RLHF achieves this perfectly or can’t be easily removed or will scale, etc. Just seems like a plausible counterfactual world we could be living in but aren’t because of ‘traits’ of frontier models.)
I would like to see the case for catastrophic misuse being an xrisk, since it mostly seems like business-as-usual for technological development (you get more capabilities which means more good stuff but also more bad stuff).
Replies from: cameron-berg↑ comment by Cameron Berg (cameron-berg) · 2024-09-20T18:07:15.840Z · LW(p) · GW(p)
It seems fairly clear that widely deployed, highly capable AI systems enabling unrestricted access to knowledge about weapons development, social manipulation techniques, coordinated misinformation campaigns, engineered pathogens, etc. could pose a serious threat. Bad actors using that information at scale could potentially cause societal collapse even if the AI itself was not agentic or misaligned in the way we usually think about with existential risk.
↑ comment by tailcalled · 2024-09-19T18:59:04.579Z · LW(p) · GW(p)
comment by Robert Cousineau (robert-cousineau) · 2024-09-19T00:41:07.503Z · LW(p) · GW(p)
In the limit (what might be considered the ‘best imaginable case’), we might imagine researchers discovering an alignment technique that (A) was guaranteed to eliminate x-risk and (B) improve capabilities so clearly that they become competitively necessary for anyone attempting to build AGI.
I feel like throughout this post, you are ignoring that agents, "in the limit", are (likely) provably taxed by having to be aligned to goals other than their own. An agent with utility function "A" is definitely going to be less capable at achieving "A" if it is also aligned to utility function "B". I respect that current LLM's not best described as having a singular consistent goal function, however, "in the limit" that is what they will be best described as.
Replies from: judd↑ comment by Judd Rosenblatt (judd) · 2024-09-19T05:28:54.781Z · LW(p) · GW(p)
I think this is precisely the reason that you’d want to make sure the agent is engineered such that its utility function includes the utility of other agents [LW · GW]—ie, so that the ‘alignment goals’ are its goals rather than ‘goals other than [its] own.’ We suspect that this exact sort of architecture could actually exhibit a negative alignment tax insofar as many other critical social competencies may require this as a foundation.
comment by Donald Hobson (donald-hobson) · 2024-09-25T23:09:48.450Z · LW(p) · GW(p)
(e.g., gpt-4 is far more useful and far more aligned than gpt-4-base), which is the opposite of what the ‘alignment tax’ model would have predicted.
Useful and aligned are, in this context, 2 measures of a similar thing. An AI that is just ignoring all your instructions is neither useful nor aligned.
What would a positive alignment tax look like.
It would look like a gpt-4-base being reluctant to work, but if you get the prompt just right and get lucky, it will sometimes display great competence.
If gpt-4-base sometimes spat out code that looked professional, but had some very subtle (and clearly not accidental) backdoor. (When it decided to output code, which it might or might not do at it's whim).
While gpt-4-rlhf was reliably outputting novice looking code with no backdoors added.
That would be what an alignment tax looks like.