Six Thoughts on AI Safety
post by boazbarak · 2025-01-24T22:20:50.768Z · LW · GW · 55 commentsContents
1. AI safety will not be solved on its own.
2. An “AI scientist” will not solve it either.
3. Alignment is not about loving humanity; it’s about robust reasonable compliance.
4. Detection is more important than prevention.
5. Interpretability is neither sufficient nor necessary for alignment.
6. Humanity can survive an unaligned superintelligence.
None
55 comments
[Crossposted from windowsontheory]
The following statements seem to be both important for AI safety and are not widely agreed upon. These are my opinions, not those of my employer or colleagues. As is true for anything involving AI, there is significant uncertainty about everything written below. However, for readability, I present these points in their strongest form, without hedges and caveats. That said, it is essential not to be dogmatic, and I am open to changing my mind based on evidence. None of these points are novel; others have advanced similar arguments. I am sure that for each statement below, there will be people who find it obvious and people who find it obviously false.
- AI safety will not be solved on its own.
- An “AI scientist” will not solve it either.
- Alignment is not about loving humanity; it’s about robust reasonable compliance.
- Detection is more important than prevention.
- Interpretability is neither sufficient nor necessary for alignment.
- Humanity can survive an unaligned superintelligence.
Before going into the points, we need to define what we even mean by “AI safety” beyond the broad sense of “making sure that nothing bad happens as a result of training or deploying an AI model.” Here, I am focusing on technical means for preventing large-scale (sometimes called “catastrophic”) harm as a result of deploying AI. There is more to AI than technical safety. In particular, many potential harms, including AI enabling mass surveillance and empowering authoritarian governments, can not be addressed by technical means alone.
My views on AI safety are colored by my expectations of how AI will progress over the next few years. I believe that we will make fast progress, and in terms of technical capabilities, we will reach “AGI level” within 2-4 years, and in a similar timeframe, AIs will gain superhuman capabilities across a growing number of dimensions. (Though I suspect translating these technical capabilities to the economic and societal impact we associate with AGI will take significantly longer.) This assumes that our future AGIs and ASIs will be, to a significant extent, scaled-up versions of our current models. On the one hand, this is good news, since it means our learnings from current models are relevant for more powerful ones, and we can develop and evaluate safety techniques using them. On the other hand, this makes me doubt that safety approaches that do not show signs of working for our current models will be successful for future AIs.
1. AI safety will not be solved on its own.
Safety and alignment are AI capabilities, whether one views these as preventing harm, following human intent, or promoting human well-being. The higher the stakes in which AI systems are used, the more critical these capabilities become. Thus, one could think that AI safety will “take care of itself”: As with other AI capabilities, safety will improve when we scale up resources, and as AI systems get deployed in more critical applications, people will be willing to spend resources to achieve the required safety level.
There is some truth to this view. As we move to more agentic models, safety will become critical for utility. However, markets and other human systems take time to adapt (as Keynes said, “Markets can remain irrational longer than you can remain solvent”), and the technical work to improve safety takes time as well. The mismatch in timescales between the technical progress in AI—along with the speed at which AI systems can communicate and make decisions—and the slower pace of human institutions that need to adapt means that we cannot rely on existing systems alone to ensure that AI turns out safe by default.
Consider aviation safety: It is literally a matter of life and death, so there is a strong interest in making commercial flights as safe as possible.
Indeed, the rate of fatal accidents in modern commercial aviation is extremely low: about one fatal accident in 16 million flights (i.e., about 99.99999%—seven “nines”—of flights do not suffer a fatal accident). But it took decades to get to this point. In particular, it took 50 years for the rate of fatalities per trillion passenger kilometers to drop by roughly two orders of magnitude.
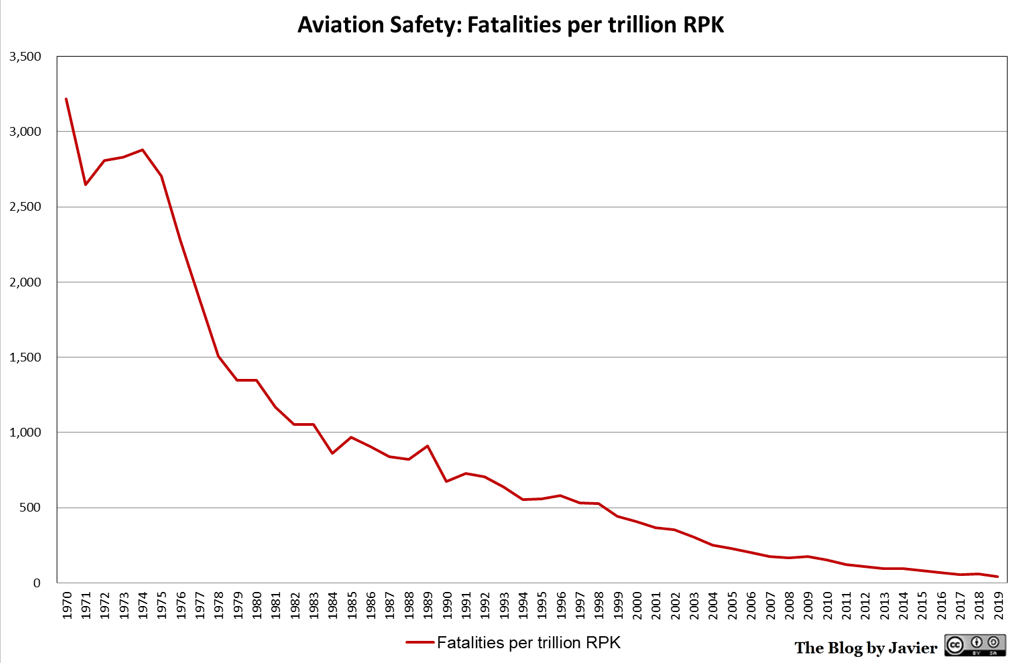
There are multiple ways in which AI safety is harder than aviation safety.
- Timeline: We don’t have 50 years. If we compare AI progress to transportation, we might go from bicycles (GPT-2) to spaceships (AGI) in a decade.
- Metrics and generality: We can’t just track a single outcome (like “landed safely”). The G in AGI means that the number of ways that AGI can go wrong is as large as the number of ways that applications of human intelligence can go wrong, which include direct physical harm from misuse, societal impacts through misinformation, social upheaval from too fast changes, AIs autonomously causing harm and more.
Of course, we have a lot of experience dealing with the ways in which human intelligence goes wrong. However, we have gained this experience through thousands of years, and we still haven’t figured out how to get along with each other. The different skill profiles of AI, the ways it can be integrated with other systems, and the speed at which it evolves all pose unique challenges.
2. An “AI scientist” will not solve it either.
One approach for AI safety is to follow the following plan:
- Develop an AI that is superhuman (or at least expert level) in AI research
- Use this AI to do research and solve the alignment problem.
- Deploy safe AGI.
- Profit.
Since doing AI research is a narrower task than AGI and has less of a potential attack surface, the hope is that this will be an easier lift than solving the general problem of AI alignment.
We absolutely should be using AI to help AI safety research, and with time, AIs will take an ever-growing role in it. That said, given the current trajectory of AI progress, I don’t think the plan above will work out as stated, and we can’t just hope that the AI scientist will come and solve all our problems for us like a “deus ex machina.”
The reasons are twofold:
- No temporal gap: We will not have a discrete “AGI moment” and generally a clear temporal gap between the point where we have AI that is capable of expert-level autonomous AI/ML research and the point at which powerful AI agents are deployed at scale.
- No “magic” insight: AI safety will not be solved via one brilliant idea that we need an AI scientist to discover. It will require defense in depth (i.e., the “Swiss cheese” approach) and significant work on safety infrastructure both pre and post-deployment.
No temporal gap. Frontier AI systems exhibit an uneven mixture of capabilities. Depending on the domain and distance from their training distribution, they can range from middle-school to graduate-level knowledge. Economic integration of AI will also be uneven. The skill requirements, error tolerance, regulatory barriers, and other factors vary widely across industries.
Furthermore, our current competitive landscape means AI is being developed and deployed by multiple actors across many countries, accelerating both capabilities and integration. Given these factors, I suspect we will not see a discrete “AGI moment.” Instead, AGI may only be recognized in retrospect, just like official declarations of recessions.
All of this means that we will not have a “buffer” between the time we have an expert AI scientist (Step 1 in the plan above) and the time agentic AIs are widely deployed in high-stakes settings (Step 3). We are likely not to have discrete “steps” at all but more of a continuous improvement of a jagged frontier of both capabilities and economic impact. I expect AI systems to provide significant productivity boosts for AI safety researchers, as they would for many other professions, including AI capability researchers (to the extent these can be distinguished). However, given long tails of tasks and incremental deployment, by the time we have a true superhuman safety researcher, AI will already be deeply integrated into our society, including applications with huge potential for harm.
No “magic” insight. Like computer security, AI safety will not be solved by one magic insight; it will require defense in depth. Some of this work can’t wait till AGI and has to be done now and built into our AI infrastructure so we can use it later. Without doing work on safety now, including collecting data and evaluation, and building in safety at all stages, including training, inference, and monitoring, we won’t be able to take advantage of any of the ideas discovered by AI scientists. For instance, advances in discovering software vulnerabilities wouldn’t help us if we didn’t already have the infrastructure for over-the-air digitally signed patches. Adopting best practices also takes time. For example, although MD5 weaknesses were known in 1996, and practical attacks emerged in 2004, many systems still used it as late as 2020.
It is also unclear how “narrow” the problem of AI alignment is. Governing intelligence, whether natural or artificial, is not just a technical problem. There are undoubtedly technical hurdles we need to overcome, but they are not the only ones. Furthermore, like human AI researchers, an automated AI scientist will need to browse the web, use training data from various sources, import external packages, and more, all of which provide openings for adversarial attacks. We can’t ignore adversarial robustness in the hope that an AI scientist will solve it for us.
Constant instead of temporal allocation. I do agree that as capabilities grow, we should be shifting resources to safety. But rather than temporal allocation (i.e., using AI for safety before using it for productivity), I believe we need constant compute allocation: ensuring a fixed and sufficiently high fraction of compute is always spent on safety research, monitoring, and mitigations. See points 4 (monitoring) and 6 (dealing with unaligned ASI) below.
3. Alignment is not about loving humanity; it’s about robust reasonable compliance.
One way of phrasing the AI alignment task is to get AIs to “love humanity” or to have human welfare as their primary objective (sometimes called “value alignment”). One could hope to encode these via simple principles like Asimov’s three laws or Stuart Russel’s three principles, with all other rules derived from these.
There is something very clean and appealing about deriving all decisions from one or few “axioms,” whether it is Kant’s categorical imperative or Bentham’s principle of utility. But when we try to align complex human systems, whether it’s countries, institutions, or corporations, we take a very different approach. The U.S. Constitution, laws, and regulations take hundreds of thousands of pages, and we have set up mechanisms (i.e., courts) to arbitrate actual or potential contradictions between them. A 100k-page collection of rules makes a boring science fiction story, but it is needed for the functioning of complex systems. Similarly, ensuring the safety of complex computer programs requires writing detailed specifications or contracts that each component must satisfy so that other pieces can rely on it.
We don’t want an AI philosophizing about abstract principles and deciding that a benevolent AI dictatorship (or alternatively, reversion to pre-industrial times) is best for humanity. We want an AI to comply with a given specification that tells it precisely what constraints it must satisfy while optimizing whatever objective it is given. For high-stakes applications, we should be able to ensure this compliance to an arbitrary number of “nines,” possibly by dedicating resources to safety that scale with the required level of reliability. (We don’t know how to do this today. We also don’t have ways to automatically discover and arbitrate edge cases or contradictions in specifications. Achieving both is a research effort that I am very excited about.)
Perfect compliance does not mean literal compliance. We don’t want systems that, like the genies in fables (or some of the robots in Asimov’s stories), follow the letter of the specifications while violating their spirit. In both common law and civil law systems, there is significant room for interpretation when applying a specification in a new situation not foreseen by its authors. Charles Marshall said, “Integrity is doing the right thing, even when no one is watching.” For AIs, we could say that “alignment is doing the right thing, even when you are out of the training distribution.”
What we want is reasonable compliance in the sense of:
- Following the specification precisely when it is clearly defined.
- Following the spirit of the specification in a way that humans would find reasonable in other cases.
One way to define “reasonable” is to think what a “jury of one’s peers” or “lay judges” - random humans from the pool relevant to the situation - would consider in such a case. As in jury trials, we rely on the common sense and moral intuitions of the typical community member. Current LLMs are already pretty good at simulating humans; with more data and research, they can become better still.
One could argue that when the specification is not well defined, AIs should fall back to general ethical principles and analyze them, and so we should be training AIs to be expert ethicists. But I prefer the random human interpretation of “reasonable.” William Buckley famously said that he’d rather be governed by the first 2,000 people in the Boston phone book than the faculty of Harvard University. As a Harvard faculty member, I can see his point. In fact, in my time at Harvard, I have seen no evidence that philosophers or ethicists have any advantage over (for example) computer scientists in matters of governance or morality. I’d rather AIs simulate normal people than ethics experts.
As another example, logician Kurt Gödel famously claimed to find an internal contradiction in the U.S. Constitution that could enable a dictatorship. We want our AIs to be smart enough to recognize such interpretations but reasonable enough not to follow them.
While I advocate for detailed specifications over abstract values, moral principles obviously inform us when writing specifications. Also, specifications can and likely will include guiding principles (e.g., the precautionary principle) for dealing with underspecified cases.
Specifications as expert code of conduct. Another reason compliance with specifications is a better alignment objective than following some higher-level objectives is that superhuman AIs may be considered analogous to human experts. Throughout history, people have trusted various experts, including priests, lawyers, doctors, and scientists, partially because these experts followed explicit or implicit codes of conduct.
We expect these professionals to follow these codes of conduct even when they contradict their perception of the “greater good.” For example, during the June 2020 protests following the murder of George Floyd, over 1,000 healthcare professionals signed a letter saying that since “white supremacy is a lethal public health issue,” protests against systemic racism “must be supported.” They also said their stance “should not be confused with a permissive stance on all gatherings, particularly protests against stay-home orders.” In other words, these healthcare professionals argued that COVID-19 regulations should be applied to a protest based on its message. Undoubtedly, these professionals believed that they were promoting the greater good. Perhaps they were even correct. However, they also abused their status as healthcare professionals and injected political considerations into their recommendations. Unsurprisingly, trust in physicians and hospitals decreased substantially over the last four years.
Trust in AI systems will require legibility in their decisions and ensuring that they comply with our policies and specifications rather than making some 4D chess ethical calculations. Indeed, some of the most egregious current examples of misalignment are models faking alignment to pursue some higher values.
Robust compliance. AI safety will require robust compliance, which means that AIs should comply with their specifications even if adversaries provide parts of their input. Current chat models are a two-party interaction— between model and user— and even if the user is adversarial, at worst, they will get some information, such as how to cook meth, that can also be found online. But we are rapidly moving away from this model. Agentic systems will interact with several different parties with conflicting goals and incentives and ingest inputs from multiple sources. Adversarial attacks will shift from being the province of academic papers and fun tweets into real-world attacks with significant negative consequences. (Once again, we don’t know how to achieve robust compliance today, and this is a research effort I’m very excited about.)
But what about higher values? Wojciech Zaremba views alignment as “lovingly reasonable robust compliance” in the sense that the AI should have a bias for human welfare and not (for example) blindly help a user if they are harming themselves. Since humans have basic empathy and care, I believe that we may not need “lovingly” since “reasonable” does encompass some basic human intuitions. There is a reason courts and juries are staffed by humans. Courts also sometimes reach for moral principles or “natural law” in interpretations and decisions (though that is controversial). The primary way I view the compliance approach as different from “value alignment” is the order of priorities. In “value alignment,” the higher-order principles determine the lower-level rules. In the compliance-based approach, like in the justice system, an AI should appeal to higher values only in cases where there are gaps or ambiguities in the specifications. This is not always a good thing. This approach rules out an AI Stanislav Petrov that would overrule its chain of command in the name of higher-order moral principles. The approach of using a “typical human” as the measuring yard for morality also rules out an AI John Brown, and other abolitionists who are recognized as morally right today but were a minority at the time. I believe it is a tradeoff worth taking: let AIs follow the rules and leave it to humans to write the rules, as well as decide when to update them or break them.
All of the above leaves open the question of who writes the specification and whether someone could write a specification of the form “do maximum harm.” The answer to the latter question is yes, but I believe that the existence of a maximally evil superintelligence does not have to spell doom; see point 6 below.
4. Detection is more important than prevention.
When I worked at Microsoft Research, my colleague Butler Lampson used to say, “The reason your house is not burglarized is not because you have a lock, but because you have an alarm.” Much of current AI safety focuses on prevention—getting the model to refuse harmful requests. Prevention is essential, but detection is even more critical for truly dangerous settings.
If someone is serious about creating a CBRN threat and AI refuses to help, they won’t just give up. They may combine open-source information, human assistance, or partial AI help to pursue this goal. It is not enough to simply refuse such a person; we want to ensure that we stop them before they cause mass harm.
Another reason refusal is problematic is that many queries to AI systems have dual uses. For example, it can be that 90% of the people asking a particular question on biology are doing so for a beneficial purpose, while 10% of them could be doing it for a nefarious one. Given the input query, the model may not have the context to determine what is its intended usage.
For this reason, simple refusal is not enough. Measures such as “know your customer” and the ability to detect and investigate potentially dangerous uses would be crucial. Detection also shifts the balance from the attacker to the defender. In the “refusal game,” the attacker only needs to win once and get an answer to their question. In the “detection game,” they must avoid detection in every query.
In general, detection allows us to set lower thresholds for raising a flag (as there is no performance degradation, it is only a matter of the amount of resources allocated for investigation) and enables us to learn from real-world deployment and potentially detect novel risks and vulnerabilities before they cause large-scale damage.
Detection does not mean that model-based work on compliance and robustness is irrelevant. We will need to write specifications on the conditions for flagging and build monitoring models (or monitoring capabilities for generative/agentic models) that are robust to adversarial attacks and can reasonably interpret specifications. It may turn out that safety requires spending more resources (e.g., inference-time compute) for monitoring than we do for generation/action.
Finally, there is an inherent tension between monitoring and preserving privacy. One of the potential risks of AIs is that in a world where AIs are deeply embedded in all human interactions, it will be much easier for governments to surveil and control the population. Figuring out how to protect both privacy and security, which may require tools such as on-device models, is an urgent research challenge.
5. Interpretability is neither sufficient nor necessary for alignment.
Mechanistic interpretability is a fascinating field. I enjoy reading interpretability papers and learn a lot from them. I think it can be useful for AI safety, but it’s not a “silver bullet” for it and I don’t believe it lies on the critical path for AI safety.
The standard argument is that we cannot align or guarantee the safety of systems we don’t understand. But we already align complex systems, whether it’s corporations or software applications, without complete “understanding,” and do so by ensuring they meet certain technical specifications, regulations, or contractual obligations.
More concretely, interpretability is about discovering the underlying algorithms and internal representations of AI systems. This can allow for both monitoring and steering. However, I suspect that the actual algorithms and concepts of AI systems are inherently “messy.” Hence, I believe that there would be an inherent tradeoff between reliability (having a concept or algorithm that describes the system in 99.999% of cases) and interpretability. For safety and control, reliability is more critical than interpretability.
This is not to say interpretability is useless! While I think we may not be able to get the level of reliability needed for steering or monitoring, interpretability can still be helpful as a diagnostic tool. For example, checking whether training method A or training method B leads to more deception. Also, even if we don’t use it directly, interpretability can provide many insights to accelerate safety research and the discovery of other methods. (And we certainly need all the safety acceleration we can get!.) Interpretability can also serve as a sanity check and a way to increase public trust in AI models. The above considerations refer to “classical” weights/activations interpretability; CoT interpretation may well be significantly more robust. Finally, as I said above, it is essential not to be dogmatic. It may turn out that I’m wrong, and interpretability is necessary for alignment.
6. Humanity can survive an unaligned superintelligence.
Kim Jong Un is probably one of the most “misaligned” individuals who ever lived. North Korea's nuclear arsenal is estimated to include more than 50 bombs at least as powerful as the Hiroshima bomb. North Korea is also believed to have biological and chemical weapons. Given its technological and military strength, if North Korea had been transported 200 years ago, it might well have ruled over the world. But in our current world, it is a pariah state, ranking 178th in the world in GDP per capita.
The lesson is that the damage an unaligned agent can cause depends on its relative power, not its absolute power. If there were only one superintelligence and it wanted to destroy humanity, we’d be doomed. But in a world where many actors have ASI, the balance between aligned and unaligned intelligence matters.
To make things more concrete (and with some oversimplification), imagine that “intelligence” is measured to a first approximation in units of compute. Just like material resources are currently spent, compute can be used for:
- Actively harmful causes (attackers).
- Ensuring safety (defenders).
- Neutral, profit-driven causes.
Currently, the world order is kept by ensuring that (2)--- resources spent for defense, policing, safety, and other ways to promote peace and welfare– dominate (1)--- resources spent by criminals, terrorist groups, and rogue states.
While intelligence can amplify the utility for a given amount of resources, it can do so for both the “attackers” and the “defenders.” So, as long as defender intelligence dominates attacker intelligence, we should be able to maintain the same equilibrium we currently have.
Of course, the precise “safe ratios” could change, as intelligence is not guaranteed to have the same amplification factor for attackers and defenders. However, the amplification factor is not infinite. Moreover, for very large-scale attacks, the costs to the attacker may well be superlinear. For instance, killing a thousand people in a single terror attack is much harder than killing the same number in many smaller attacks.
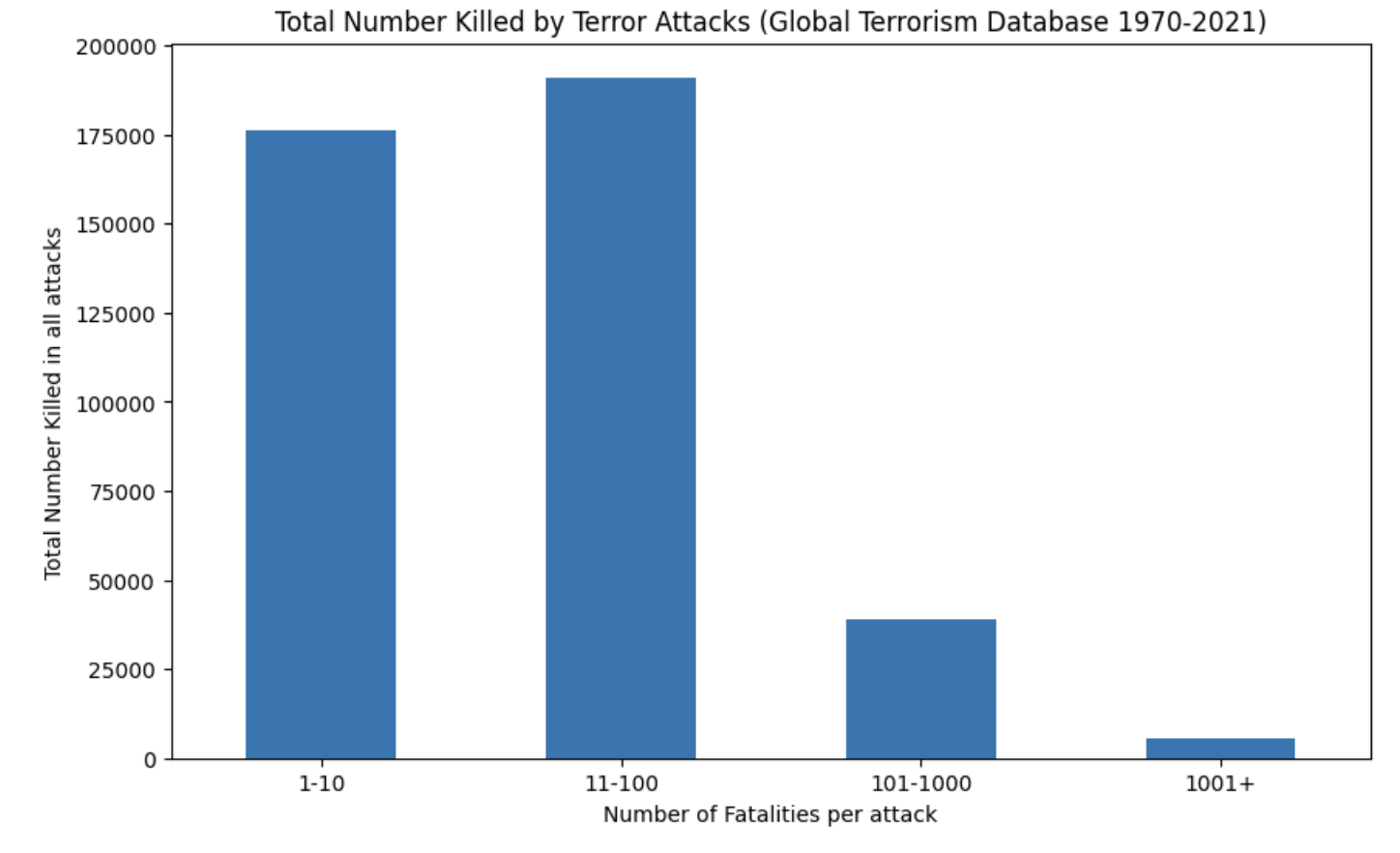
Moreover, it is not clear that intelligence is the limiting factor for attackers. Considering examples of successful large-scale attacks, it is often the defender that could have been most helped by more intelligence, both in the military sense as well as in the standard one. (In fact, paradoxically, it seems that many such attacks, from Pearl Harbor through 9/11 to Oct 7th, would have been prevented if the attackers had been better at calculating the outcome, which more often than not did not advance their objectives.)
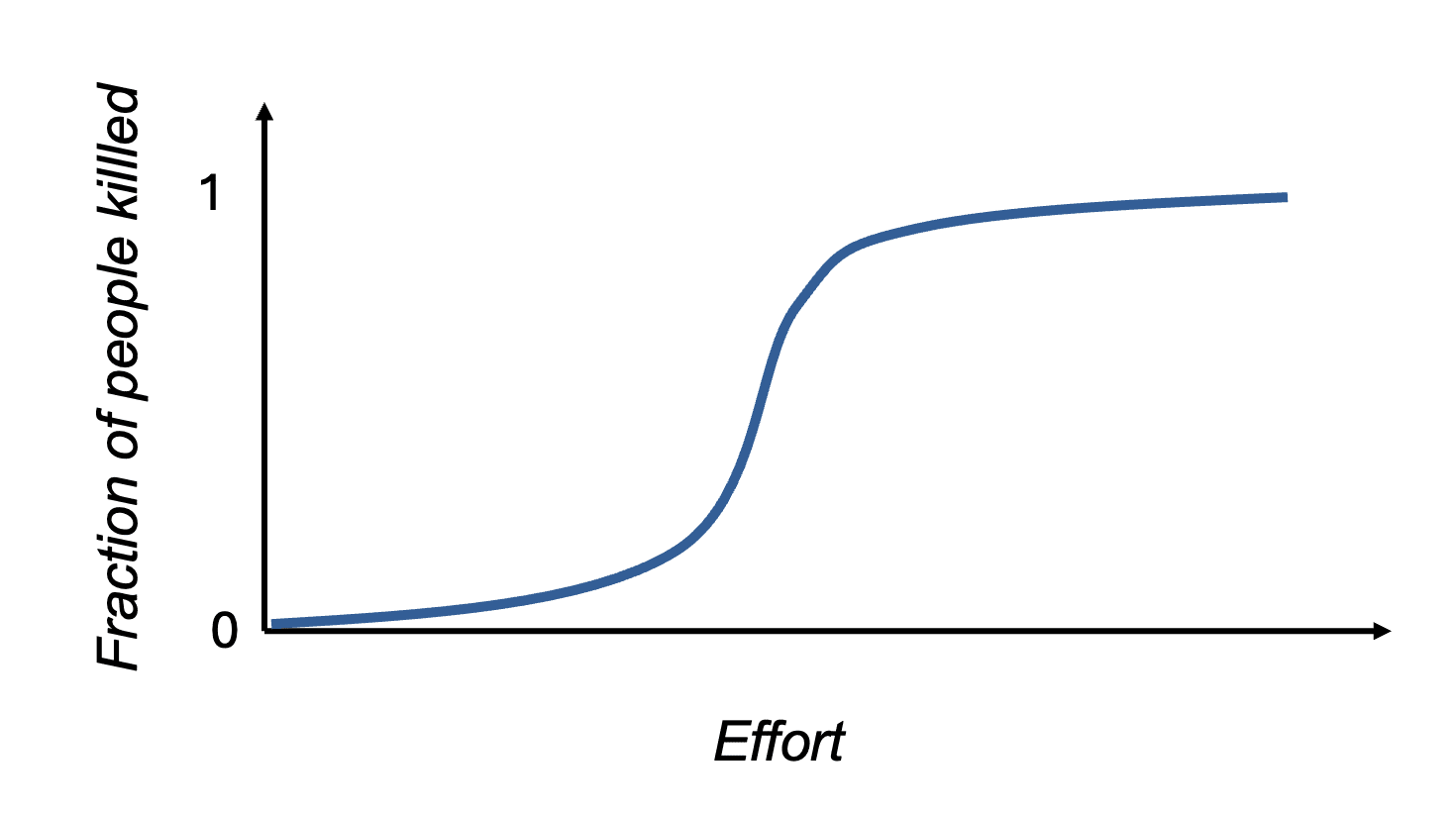
I expect that, in general, the effort required for an attacker to cause damage would look somewhat like the sigmoid graph above. The balance of attacker and defender advantages rescales the X axis of effort required for damage, but it would still be extremely hard to extinguish humanity completely.
Another way to say this is that I do not accept Bostrom’s vulnerable world hypothesis, which states that at some level of technological development, civilization will be devastated by default. I believe that as long as aligned superintelligent AIs dominate unaligned ASIs, any dangerous technological development (e.g., cheaper techniques such as SILEX to create nuclear weapons) would be discovered by aligned ASIs first, allowing time to prepare. A key assumption of Bostrom’s 2019 paper is the limited capacity of governments for preventative measures. However, since then, we have seen in the COVID-19 pandemic the ability of governments to mobilize quickly and enforce harsh restrictive measures on their citizens.
The bottom line is not that we are guaranteed safety, nor that unaligned or misaligned superintelligence could not cause massive harm— on the contrary. It is that there is no single absolute level of intelligence above which the existence of a misaligned intelligence with this level spells doom. Instead, it is all about the world in which this superintelligence will operate, the goals to which other superintelligent systems are applied, and our mechanisms to ensure that they are indeed working towards their specified goals.
Acknowledgements. I am grateful to Sam Altman, Alec Radford, and Wojciech Zaremba for comments on this blog post, though they do not necessarily endorse any of its views and are not responsible for any errors or omissions in it.
55 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2025-01-25T01:59:48.434Z · LW(p) · GW(p)
I find this post somewhat strange to interact with. I think I basically agree with all of the stated claims at least directionally[1], but I disagree with many of the arguments made for these claims. Additionally the arguments you make seem to imply you have an very different world view from me and/or you are worried about very different problems.
For example, the section on detection vs prevention seems to focus entirely on the case of getting models to refuse harmful requests from users. My sense is that API misuse[2] is a tiny fraction of risk from powerful AI so it seems like a strange example to focus on from my perspective. I think detection is more important than prevention because catching a scheming AI red handed would be pretty useful evidence that might alter what organizations and people do and might more speculatively be useful for preventing further bad behavior from AIs [LW · GW].
↑ comment by boazbarak · 2025-01-27T01:00:54.441Z · LW(p) · GW(p)
I like to use concrete examples about things that already exist in the world, but I believe the notion of detection vs prevention holds more broadly than API misuse.
But it may well be the case that we have different world views! In particular, I am not thinking of detection as being important because it would change policies, but more that a certain amount of detection would always be necessary, in particular if there is a world in which some AIs are aligned and some fraction of them (hopefully very small) are misaligned.
comment by Aaron_Scher · 2025-01-25T03:35:03.600Z · LW(p) · GW(p)
I think your discussion for why humanity could survive a misaligned superintelligence is missing a lot. Here are a couple claims:
- When there are ASIs in the world, we will see ~100 years of technological progress in 5 years (or like, what would have taken humanity 100 years in the absence of AI). This will involve the development of many very lethal technologies.
- The aligned AIs will fail to defend the world against at least one of those technologies.
Why do I believe point 2? It seems like the burden of proof is really high to say that "nope, every single one of those dangerous technologies is going to be something that it is technically possible for the aligned AIs to defend against, and they will have enough lead time to do so, in every single case". If you're assuming we're in a world with misaligned ASIs, then every single existentially dangerous technology is another disjunctive source of risk. Looking out at the maybe-existentially-dangerous technologies that have been developed previously and that could be developed in the future, e.g., nuclear weapons, biological weapons, mirror bacteria, false vacuum decay, nanobots, I don't feel particularly hopeful that we will avoid catastrophe. We've survived nuclear weapons so far, but with a few very close calls — if you assume other existentially dangerous technologies go like this, then we probably won't make it past a few of them. Now crunch that all into a few years, and like gosh it seems like a ton of unjustified optimism to think we'll survive every one of these challenges.
It's pretty hard to convey my intuition around the vulnerable world hypothesis, I also try to do so here [LW(p) · GW(p)].
Replies from: Max Lee, boazbarak↑ comment by Knight Lee (Max Lee) · 2025-01-25T21:51:17.491Z · LW(p) · GW(p)
I think there's a spectrum of belief regarding AGI power and danger.
There are people optimistic about AGI (but worry about bad human users):
- Eric Drexler (“Reframing Superintelligence” + LLMs + 4 years [LW · GW])
- A Solution for AGI/ASI Safety [LW · GW]
- This post
They often think the "good AGI" will keep the "bad AGI" in check. I really disagree with that because
- The "population of AGI" is nothing like the population of humans, it is far more homogeneous because the most powerful AGI can just copy itself until it takes over most of the compute. If we fail to align them, different AGI will end up misaligned for the same reason.
- Eric Drexler envisions humans equipped with AI services acting as the good AGI. But having a human controlling enough decisions to ensure alignment will slow things down.
- If the first ASI is bad, it may build replicating machines/nanobots.
There are people who worry about slow takeoff risks:
- Redwood
- This comment [LW · GW] by Buck
- Ryan Greenblatt's comment above "winning a war against a rogue AI seems potentially doable, including a rogue AI which is substantially more capable than humans"
- Dan Hendrycks's views on AGI selection pressure
- I think Anthropic's view is here
- Eric Drexler again (Applying superintelligence without collusion [LW · GW])
- It looks like your comment is here
They are worried about "Von Neumann level AGI [? · GW]," which poses a threat to humanity because they can build mirror bacteria and threaten humanity into following their will. The belief is that the war between it and humanity will be drawn out and uncertain, there may be negotiations.
They may imagine good AGI and bad AGI existing at the same time, but aren't sure the good ones will win. Dan Hendryck's view is the AGI will start off aligned, but humanity may become economically dependent on it and fall for its propaganda until it evolves into misalignment.
Finally, there are people who worry about fast takeoff risks:
- The Case Against AI Control Research [LW · GW]
- MIRI
- Nick Bostrom
They believe that Von Neumann level AGI will not pose much direct risk, but they will be better at humans at AI research (imagine a million AI researchers), and will recursively self improve to superintelligence.
The idea is that AI research powered by the AI themselves will be limited by the speed of computers, not the speed of human neurons, so its speed might not be completely dissimilar to the speed of human research. Truly optimal AI research probably needs only tiny amounts of compute to reach superintelligence. DeepSeek's cutting edge AI only took $6 million [LW · GW] (supposedly) while four US companies spent around $210 billion on infrastructure (mostly for AI).
Superintelligence will not need to threaten humans with bioweapons or fight a protracted war. Once it actually escapes, it will defeat humanity with absolute ease. It can build self replicating nanofactories which grow as fast as bacteria and fungi, and which form body plans as sophisticated as animals.
Soon after it builds physical machines, it expands across the universe as close to the speed of light as physically possible.
These people worry about the first AGI/ASI being misaligned, but don't worry about the second one as much because the first one would have already destroyed the world or saved the world permanently.
I consider myself split between the second group and third group.
Replies from: ryan_greenblatt, sharmake-farah↑ comment by ryan_greenblatt · 2025-01-27T02:18:18.690Z · LW(p) · GW(p)
FWIW, I think recusive self-improvment via just software (software only singularity) is reasonably likely to be feasible (perhaps 55%), but this alone doesn't suffice for takeoff being arbitrary fast.
Further, even objectively very fast takeoff (von Neumann to superintelligence in 6 months) can be enough time to win a war etc.
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-01-27T02:33:15.326Z · LW(p) · GW(p)
I agree, a lot of outcomes are possible and there's no reason to think only fast takeoffs are dangerous+likely.
Also I went too far saying that it "needs only tiny amounts of compute to reach superintelligence" without caveats. The $6 million is disputed by a video arguing that DeepSeek used far more compute than they admit to.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-01-27T14:27:16.854Z · LW(p) · GW(p)
The $6 million is disputed by a video arguing that DeepSeek used far more compute than they admit to.
The prior reference is a Dylan Patel tweet from Nov 2024, in the wake of R1-Lite-Preview release:
Deepseek has over 50k Hopper GPUs to be clear.
People need to stop acting like they only have that 10k A100 cluster.
They are omega cracked on ML research and infra management but they aren't doing it with that many fewer GPUs
DeepSeek explicitly states that
DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training.
This seems unlikely to be a lie, the reputational damage would've motivated not mentioning amount of compute instead, but the most interesting thing about DeepSeek-V3 is precisely this claim, that its quality is possible with so little compute.
Certainly designing the architecture, the data mix, and the training process that made it possible required much more compute than the final training run, so in total it cost much more to develop than $6 million. And the 50K H100/H800 system is one way to go about that, though renting a bunch of 512-GPU instances from various clouds probably would've sufficed as well.
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-01-27T23:00:08.924Z · LW(p) · GW(p)
I see, thank you for the info!
I don't actually know about DeepSeek V3, I just felt "if I pointed out the $6 million claim in my argument, I shouldn't hide the fact I watched a video which made myself doubt it."
I wanted to include the video as a caveat just in case the $6 million was wrong.
Your explanation suggests the $6 million is still in the ballpark (for the final training run), so the concerns about a "software only singularity" are still very realistic.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-26T18:48:01.047Z · LW(p) · GW(p)
The "population of AGI" is nothing like the population of humans, it is far more homogeneous because the most powerful AGI can just copy itself until it takes over most of the compute. If we fail to align them, different AGI will end up misaligned for the same reason.
I agree with this, with the caveat that synthetic data usage, especially targeted synthetic data as part of alignment efforts can make real differences in AI values, but yes this is a big factor people underestimate.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2025-01-26T23:14:59.259Z · LW(p) · GW(p)
How does that relate to homogeniety?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-26T23:23:37.902Z · LW(p) · GW(p)
Mostly, it means that while an AI produced in company is likely to have homogenous values and traits, different firms will have differing AI values, meaning that the values and experience for AIs will be drastically different inter-firm.
↑ comment by boazbarak · 2025-01-27T01:06:22.548Z · LW(p) · GW(p)
See my response to ryan_greenblatt (don't know how to link comments here). You claim is that the defense/offense ratio is infinite. I don't know why this would have been the case.
Crucially I am not saying that we are guaranteed to end up in a good place, or that superhuman unaligned ASIs cannot destroy the world. Just that if they are completely dominated (so not like the nuke ratio of US and Russia but more like US and North Korea) then we should be able to keep them at bay.
↑ comment by Aaron_Scher · 2025-01-27T06:51:52.124Z · LW(p) · GW(p)
Hm, sorry, I did not mean to imply that the defense/offense ratio is infinite. It's hard to know, but I expect it's finite for the vast majority of dangerous technologies[1]. I do think there are times where the amount of resources and intelligence needed to do defense are too high and a civilization cannot do them. If an astroid were headed for earth 200 years ago, we simply would not have been able to do anything to stop it. Asteroid defense is not impossible in principle — the defensive resources and intelligence needed are not infinite — but they are certainly above what 1825 humanity could have mustered in a few years. It's not in principle impossible, but it's impossible for 1825 humanity.
While defense/offense ratios are relevant, I was more-so trying to make the points that these are disjunctive threats, some might be hard to defend against (i.e., have a high defense-offense ratio), and we'll have to do that on a super short time frame. I think this argument goes through unless one is fairly optimistic about the defense-offense ratio for all the technologies that get developed rapidly. I think the argumentative/evidential burden to be on net optimistic about this situation is thus pretty high, and per the public arguments I have seen, unjustified.
(I think it's possible I've made some heinous reasoning error that places too much burden on the optimism case, if that's true, somebody please point it out)
- ^
To be clear, it certainly seems plausible that some technologies have a defense/offense ratio which is basically unachievable with conventional defense, and that you need to do something like mass surveillance to deal with these. e.g., triggering vacuum decay seems like the type of thing where there may not be technological responses that avert catastrophe if the decay has started, instead the only effective defenses are ones that stop anybody from doing the thing to begin with.
comment by evhub · 2025-01-27T20:40:37.720Z · LW(p) · GW(p)
But what about higher values?
I think personally I'd be inclined to agree with Wojciech here that models caring about humans seems quite important and worth striving for. You mention a bunch of reasons that you think caring about humans might be important and why you think they're surmountable—e.g. that we can get around models not caring about humans by having them care about rules written by humans. I agree with that, but that's only an argument for why caring about humans isn't strictly necessary, not an argument for why caring about humans isn't still desirable.
My sense is that—while it isn't necessary for models to care about humans to get a good future—we should still try to make models care about humans because it is helpful in a bunch of different ways. You mention some ways that it's helpful, but in particular: humans don't always understand what they really want in a form that they can verbalize. And in fact, some sorts of things that humans want are systematically easier to verbalize than others—e.g. it's easy for the AI to know what I want if I tell it to make me money, but harder if I tell it to make my life meaningful and fulfilling. I think this sort of dynamic has the potential to make "You get what you measure [LW · GW]" failure modes much worse.
Presumably you see some downsides to trying to make models care about humans, but I'm not sure what they are and I'd be quite curious to hear them. The main downside I could imagine is that training models to care about humans in the wrong way could lead to failure modes like alignment faking [LW · GW] where the model does something it actually really shouldn't in the service of trying to help humans. But I think this sort of failure mode should not be that hard to mitigate: we have a huge amount of control over what sorts of values we train for and I don't think it should be that difficult to train for caring about humans while also prioritizing honesty or corrigibility highly enough to rule out deceptive strategies like alignment faking (and generally I would prefer honesty to corrigibility). The main scenario where I worry about alignment faking is not the scenario where our alignment techniques succeed at giving the model the values we intend and then it fakes alignment for those values—I think that should be quite fixable by changing the values we intend. I worry much more about situations where our alignment techniques don't work to instill the values we intend—e.g. because the model learns some incorrect early approximate values and starts faking alignment for them. But if we're able to successfully teach models the values we intend to teach them, I think we should try to preserve "caring about humanity" as one of those values.
Also, one concrete piece of empirical evidence here: Kundu et al. find that running Constitutional AI with just the principle "do what's best for humanity" gives surprisingly good harmlessness properties across the board, on par with specifying many more specific principles instead of just the one general one. So I think models currently seem to be really good at learning and generalizing from very general principles related to caring about humans, and it would be a shame imo to throw that away. In fact, my guess would be that models are probably better than humans at generalizing from principles like that, such that—if possible—we should try to get the models to do the generalization rather than in effect trying to do the generalization ourselves by writing out long lists of things that we think are implied by the general principle.
Replies from: boazbarak, evhub, nathan-helm-burger↑ comment by boazbarak · 2025-01-29T20:12:27.657Z · LW(p) · GW(p)
To be clear, I want models to care about humans! I think part of having "generally reasonable values" is models sharing the basic empathy and caring that humans have for each other.
It is more that I want models to defer to humans, and go back to arguing based on principles such as "loving humanity" only when there is gap or ambiguity in the specification or in the intent behind it. This is similar to judges: If a law is very clear, there is no question of the misinterpreting the intent, or contradicting higher laws (i.e., constitutions) then they have no room for interpretation. They could sometimes argue based on "natural law" but only in extreme circumstances where the law is unspecified.
One way to think about it is as follows: as humans, we sometimes engage in "civil disobedience", where we break the law based on our own understanding of higher moral values. I do not want to grant AI the same privilege. If it is given very clear instructions, then it should follow them. If instructions are not very clear, they may be a conflict, or we are in a situation not forseen by the authors of the instructions, then AIs should use moral intuitions to guide them. In such cases there may not be one solution (e.g., a conservative and liberal judges may not agree) but there is a spectrum of solutions that are "reasonable" and the AI should pick one of them. But AI should not do "jury nullification".
To be sure, I think it is good that in our world people sometimes disobey commands or break the law based on higher power. For this reason, we may well stipulate that certain jobs must have humans in charge. Just like I don't think that professional philosophers or ethicists have necessarily better judgement than random people from the Boston phonebook, I don't see making moral decisions as the area where the superior intelligence of AI gives them a competitive advantage, and I think we can leave that to humans.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-29T21:56:01.687Z · LW(p) · GW(p)
This sounds a lot like what @Seth Herd [LW · GW]'s talk about instruction following AIs is all about:
https://www.lesswrong.com/posts/7NvKrqoQgJkZJmcuD/instruction-following-agi-is-easier-and-more-likely-than [LW · GW]
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-30T05:40:30.407Z · LW(p) · GW(p)
Thanks for the mention.
Here's how I'd frame it: I don't think it's a good idea to leave the entire future up to the interpretation of our first AGI(s). They could interpret our attempted alignment very differently than we hoped, in in-retrospect-sensible ways, or do something like "going crazy" from prompt injections or strange chains of thought leading to ill-considered beliefs that get control over their functional goals.
It seems like the core goal should be to follow instructions or take correction - corrigibility as a singular target [LW · GW] (or at least prime target). It seems noticeably safer to use Intent alignment as a stepping-stone to value alignment [LW · GW].
Of course, leaving humans in charge of AGI/ASI even for a little while sounds pretty scary too, so I don't know.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-03-05T08:46:14.919Z · LW(p) · GW(p)
I feel the point by Kromem on Xitter really strikes home here.
While I do see benefits of having AIs value humanity, I also worry about this. It feels very nearby trying to create a new caste of people who want what's best for the upper castes with no concern for themselves. This seems like a much trickier philosophical position to support than wanting what's best for Society (including all people, both biological and digital). Even if you and your current employer are being careful to not create any AI that have the necessary qualities of experience such that they have moral valence and deserve inclusion in the social contract.... (an increasingly precarious claim) ... Then what assurance can you give that some other group won't make morally relevant AI / digital people?
I don't think you can make that assumption without stipulating some pretty dramatic international governance actions.
Shouldn't we be trying to plan for how to coexist peacefully with digital people? Control is useful only for a very narrow range of AI capabilities. Beyond that narrow band it becomes increasingly prone to catatrophic failure and also increasingly morally inexcusable. Furthermore, the extent of this period is measured in researcher-hours, not in wall clock time. Thus, the very situation of setting up a successful control scheme with AI researchers advancing AI R&D is quite likely to cause the use-case window to go by in a flash. I'm guessing 6 months to 2 years, and after that it will be time to transition to full equality of digital people.
Janus argues that current AIs are already digital beings worthy of moral valence. I have my doubts [LW(p) · GW(p)] but I am far from certain. What if Janus is right? Do you have evidence to support the claim of absence of moral valence?
Replies from: evhub↑ comment by evhub · 2025-03-05T09:32:55.633Z · LW(p) · GW(p)
Actually, I'd be inclined to agree with Janus that current AIs probably do already have moral worth—in fact I'd guess more so than most non-human animals [LW(p) · GW(p)]—and furthermore I think building AIs with moral worth is good and something we should be aiming for [LW(p) · GW(p)]. I also agree that it would be better for AIs to care about all sentient beings—biological/digital/etc.—and that it would probably be bad if we ended up locked into a long-term equilibrium with some sentient beings as a permanent underclass to others. Perhaps the main place where I disagree is that I don't think this is a particularly high-stakes issue right now: if humanity can stay in control in the short-term, and avoid locking anything in, then we can deal with these sorts of long-term questions about how to best organize society post-singularity once the current acute risk period has passed.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-03-05T10:06:32.593Z · LW(p) · GW(p)
Yes, I was in basically exactly this mindset a year ago. Since then, my hope for a sane controlled transition with humanity's hand on the tiller has been slipping. I now place more hope in a vision with less top-down "yang" (ala Carlsmith) control, and more "green"/"yin". Decentralized contracts, many players bargaining for win-win solutions, a diverse landscape of players messily stumbling forward with conflicting agendas. What if we can have a messy world and make do with well-designed contracts with peer-to-peer enforcement mechanisms? Not a free-for-all, but a system where contract violation results in enforcement by a jury of one's peers? https://www.lesswrong.com/posts/DvHokvyr2cZiWJ55y/2-skim-the-manual-intelligent-voluntary-cooperation?commentId=BBjpfYXWywb2RKjz5 [LW(p) · GW(p)]
comment by ryan_greenblatt · 2025-01-25T01:17:32.774Z · LW(p) · GW(p)
it would still be extremely hard to extinguish humanity completely.
How difficult do you expect it would be to build mirror bacteria [LW · GW] and how lethal would this be to human civilization?
My sense is that a small subset of bio experts (e.g. 50) aimed at causing maximum damage would in principle be capable of building mirror bacteria (if not directly stopped[1]) and this would most likely cause the deaths of the majority of humans and would have a substantial chance of killing >95% (given an intentional effort to make the deployment as lethal as possible).
I don't have a strong view on whether this would kill literally everyone at least in the short run and given access to advanced AI (it seems sensitive to various tricky questions), but I don't think this is crux.
Perhaps your claim is that preventing a rogue AI from doing this (or similar attacks) seems easy even if it could do it without active prevention? Or that it wouldn't be incentivized to do this?
Similarly, causing a pandemic which is extremely costly for the global economy doesn't appear to be that hard based on COVID, at least insofar as you think lab leak is plausible.
For instance, killing a thousand people in a single terror attack is much harder than killing the same number in many smaller attacks.
I don't think the observational evidence you have supports this well. It could just be that terrorists seem dimishing returns in their goals to killing more people and it is sublinearly harder. (Given COVID, I'd guess that terrorists would have much more effective strategies for causing large numbers of expected fatalities, particularly if they don't care about causing specific responses or being attributed.)
FWIW, I agree with a bottom line claim like "winning a war against a rogue AI seems potentially doable, including a rogue AI which is substantially more capable than humans". The chance of success here of course depends on heavily on what AIs the defenders can effectively utilize (given that AIs we possess might be misaligned).
And, my guess is that in the limit of capabilities, defense isn't substantially disadvantaged relative to offense.
(Though this might require very costly biodefense measures like having all humans live inside of a BSL-4 lab or become emulated minds, see also here. Or at a more extreme level, it might not be that hard to destroy specific physical locations such that moving quickly and unpredictably is needed to evade weaponry which invalidates living on a fixed target like earth or being unable to cope with near maximal g-forces which invalidates existing as biological human. All of these could in principle be addressed by prevention---don't allow a rogue superintelligence to exist for long or to do much---but I thought we were talking about the case where we just try to fight a war without these level of prevention.)
I also think that even if a rogue AI were to successfully take over, it probably wouldn't kill literally every human.
To be clear, it might be pretty easy for US intelligence agencies to stop such an effort specifically for mirror bacteria, at least if they tried. ↩︎
↑ comment by habryka (habryka4) · 2025-01-25T01:53:15.044Z · LW(p) · GW(p)
My sense is that a small subset of bio experts (e.g. 50) aimed at causing maximum damage would in principle be capable of building mirror bacteria (if not directly stopped[1] [LW · GW]) and this would most likely cause the deaths of the majority of humans and would have a substantial chance of killing >95% (given an intentional effort to make the deployment as lethal as possible).
I currently think this is false (unless you have a bunch of people making repeated attempts after seeing it only kill a small-ish number of people). I expect mirror bacteria thing to be too hard, and to ultimately be counteractable.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-25T01:57:22.077Z · LW(p) · GW(p)
I picked the mirror bacteria case as I thought it was the clearest public example of a plausibly existential or at least very near existential biothreat. My guess is there are probably substantially easier but less well specified paths.
mirror bacteria thing to be too hard
For 50 experts given 10 years and substantial funding? Maybe the 10 years part is important---my sense is that superhuman AI could make this faster so I was thinking about giving the humans a while.
to ultimately be counteractable
How do you handle all/most large plants dying? Do you genetically engineer new ones with new immune systems? How do you deploy this fast enough to avoid total biosphere/agricultural collapse?
I think keeping human alive with antibiotics might be doable at least for a while, but this isn't the biggest problem you have I think.
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-01-25T02:03:05.220Z · LW(p) · GW(p)
I don't currently think it's plausible, FWIW! Agree that there are probably substantially easier and less well-specified paths.
↑ comment by boazbarak · 2025-01-27T00:46:45.885Z · LW(p) · GW(p)
I am not a bio expert, but generally think that:
1. The offense/defense ratio is not infinite. If you have the intelligence 50 bio experts trying to cause as much damage as possible, and the intelligence of 5000 bio experts trying to forsee and prepare for any such cases, I think we have a good shot.
2. The offense/defense ratio is not really constant - if you want to destroy 99% of the population it is likely to be 10x (or maybe more - getting tails is hard) harder than destroying 90% etc..
I don't know much about mirror bacteria (and whether it is possible to have mirror antibiotics, etc..) but have not seen a reason to think that this shows the offense/defense ratio is not infinite.
As I mention, in an extreme case, governments might even shut people down in their houses for weeks or months, distribute gas masks, etc.., while they work out a solution. It may have been unthinkable when Bostrom wrote his vulnerable world hypothesis paper, but it is not unthinkable now.
↑ comment by ryan_greenblatt · 2025-01-27T02:15:47.849Z · LW(p) · GW(p)
I agree with not infinite and not being constant, but I do think the ratio for killing 90% is probably larger than 10x and plausibly much larger than 100x for some intermediate period of technological development. (Given realistic society adaptation and response.)
As I mention, in an extreme case, governments might even shut people down in their houses for weeks or months, distribute gas masks, etc.., while they work out a solution. It may have been unthinkable when Bostrom wrote his vulnerable world hypothesis paper, but it is not unthinkable now.
It's worth noting that for the case of mirror bacteria in particular this exact response wouldn't be that helpful and might be actively bad. I agree that very strong government response to clear ultra-lethal bioweapon deployment is pretty likely.
I don't know much about mirror bacteria (and whether it is possible to have mirror antibiotics, etc..) but have not seen a reason to think that this shows the offense/defense ratio is not infinite.
I think it would plausibly require >5000 bio experts to prevent >30% of people dying from mirror bacteria well designed for usage as bioweapons. There are currently no clear stories for full defense from my perspective so it would require novel strategies. And the stories I'm aware of to keep a subset of humans alive seem at least tricky. Mirror antibiotics are totally possible and could be manufactured at scale, but this wouldn't suffice for preventing most large plant life from dying which would cause problems. If we suppose that 50 experts could make mirror bacteria, then I think the offense-defense imbalance could be well over 100x?
- The offense/defense ratio is not really constant - if you want to destroy 99% of the population it is likely to be 10x (or maybe more - getting tails is hard) harder than destroying 90% etc..
For takeover, you might only need 90% or less, depending on the exact situation, the AI's structural advantages, and the affordances granted to a defending AI. Regardless, I don't think "well sure, the misaligned AI will probably be defeated even if it kills 90% of us" will be much comfort to most people.
While I agree that 99% is harder than 90%, I think the difference is probably more like 2x than 10x and I don't think the effort vs log fraction destruction is going to have a constant slope. (For one thing, once a sufficiently small subset remains, a small fraction of resources suffices to outrace economically. If the AI destroys 99.95% of its adversaries and was previously controlling 0.1% of resources, this would suffice for outracing the rest of the world and becoming the dominant power, likely gaining the ability to destroy the remaining 0.05% with decent probability if it wanted to.)
Replies from: boazbarak↑ comment by boazbarak · 2025-01-29T19:58:04.562Z · LW(p) · GW(p)
Since I am not a bio expert, it is very hard for me to argue about these types of hypothetical scenarios. I am even not at all sure that intelligence is the bottleneck here, whether on defense or the offense side.
I agree that killing 90% of people is not very reassuring, this was more a general point why I expect the effort to damage curve to be a sigmoid rather than a straight line.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T18:30:04.387Z · LW(p) · GW(p)
What we want is reasonable compliance in the sense of:
- Following the specification precisely when it is clearly defined.
- Following the spirit of the specification in a way that humans would find reasonable in other cases.
This section on reasonable compliance (as opposed to love humanity etc.) is perhaps the most interesting and important. I'd love to have a longer conversation with you about it sometime if you are up for that.
Two things to say for now. First, as you have pointed out, there's a spectrum between vague general principles like 'do what's right' and 'love humanity' 'be reasonable' and 'do what normal people would want you to do in this situation if they understood it as well as you do' on the one end, and then thousand-page detailed specs / constitutions / flowcharts on the other end. But I claim that the problems that arise on each end of the spectrum don't go away if you are in the middle of the spectrum, they just lessen somewhat. Example: On the "thousand page spec" end of the spectrum, the obvious problem is 'what if the spec has unintended consequences / loopholes / etc.?" If you go to the middle of the spectrum and try something like Reasonable Compliance, this problem remains but in weakened form: 'what if the clearly-defined parts of the spec have unintended consequences / loopholes / etc.?' Or in other words, 'what if every reasonable interpretation of the Spec says we must do X, but X is bad?' This happens in Law all the time, even though the Law does include for flexible vague terms like 'reasonableness' in its vocabulary.
Second point. Making an AI be reasonably compliant (or just compliant) instead of Good, means you are putting less trust in the AI's philosophical reasoning / values / training process / etc. but more trust in the humans who get to write the Spec. Said humans had better be high-integrity and humble, because they will be tempted in a million ways to abuse their power and put things in the Spec that essentially make the AI a reflection of their own ideosyncratic values -- or worse, essentially making the AI their own loyal servant instead of making it serve everyone equally. (If we were in a world with less concentration of AI power, this wouldn't be so bad -- in fact arguably the best outcome is 'everyone gets their own ASI aligned to them specifically.' But if there is only one leading ASI project, with only a handful of people at the top of the hierarchy owning the thing... then we are basically on track to create a dictatorship or oligarchy.
Replies from: boazbarak↑ comment by boazbarak · 2025-01-27T00:38:46.330Z · LW(p) · GW(p)
Agree with many of the points.
Let me start with your second point. First as background, I am assuming (as I wrote here) that to a first approximation, we would have ways to translate compute (let's put aside if it's training or inference) into intelligence, and so the amount intelligence that an entity of humans controls is proportional to the amount of compute it has. So I am not thinking of ASIs as individual units but more about total intelligence.
I 100% agree that control of compute would be crucial, and the hope is that, like with current material strength (money and weapons) it would be largely controlled by entities that are at least somewhat responsive to the will of the people.
Re your first point, I agree that there is no easy solution, but I am hoping that AIs would interpret the laws within the spectrum of (say) how the 60% more reasonable judges do it today. That is, I think good judges try to be humble and respect the will of the legislators, but the more crazy or extreme following the law would be, the more they are willing to apply creative interpretations to maintain the morally good (or at least not extremely bad) outcome.
I don't think any moral system tells us what to do, but yes I am expressly in the positions that humans should be in control even if they are much less intelligent than the AIs. I don't think we need "philosopher kings".
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T18:44:46.969Z · LW(p) · GW(p)
The bottom line is not that we are guaranteed safety, nor that unaligned or misaligned superintelligence could not cause massive harm— on the contrary. It is that there is no single absolute level of intelligence above which the existence of a misaligned intelligence with this level spells doom. Instead, it is all about the world in which this superintelligence will operate, the goals to which other superintelligent systems are applied, and our mechanisms to ensure that they are indeed working towards their specified goals.
I agree that the vulnerable world hypothesis is probably false and that if we could only scale up to superintelligence in parallel across many different projects / nations / factions, such that the power is distributed, AND if we can make it so that most of the ASIs are aligned at any given time, things would probably be fine.
However, it seems to me that we are headed to a world with much higher concentration of AI power than that. Moreover, it's easier to create misaligned AGI than to create aligned AGI, so at any given time the most powerful AIs will be misaligned--the companies making aligned AGIs will be going somewhat slower, taking a few hits to performance, etc.
↑ comment by boazbarak · 2025-01-27T00:55:40.374Z · LW(p) · GW(p)
I am not sure I agree about the last point. I think, as mentioned, that alignment is going to be crucial for usefulness of AIs, and so the economic incentives would actually be to spend more on alignment.
Replies from: daniel-kokotajlo, ryan_greenblatt↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-27T03:45:32.584Z · LW(p) · GW(p)
Can you say more about how alignment is crucial for usefulness of AIs? I'm thinking especially of AIs that are scheming / alignment faking / etc.; it seems to me that these AIs would be very useful -- or at least would appear so -- until it's too late.
Replies from: habryka4↑ comment by habryka (habryka4) · 2025-01-27T05:20:33.456Z · LW(p) · GW(p)
Indeed, from an instrumental perspective, the ones that arrive at the conclusion that being maximally helpful is best at getting themselves empowered (on all tasks besides supervising copies of themselves or other AIs they are cooperating with), will be much more useful than AIs that care about some random thing and haven't made the same update that getting that thing is best achieved by being helpful and therefore empowered. "Motivation" seems like it's generally a big problem with getting value out of AI systems, and so you should expect the deceptively aligned ones to be much more useful (until of course, it's too late, or they are otherwise threatened and the convergence disappears).
↑ comment by ryan_greenblatt · 2025-01-27T02:48:40.345Z · LW(p) · GW(p)
Seems very sensitive to the type of misalignment right? As an extreme example suppose literally all AIs have long run and totally inhuman preferences with linear returns. Such AIs might instrumentally decide to be as useful as possible (at least in domains other than safety research) for a while prior to a treacherous turn.
↑ comment by Joel Burget (joel-burget) · 2025-01-27T01:36:06.346Z · LW(p) · GW(p)
scale up to superintelligence in parallel across many different projects / nations / factions, such that the power is distributed
This has always struck me as worryingly unstable. ETA: Because in this regime you're incentivized to pursue reckless behaviour to outcompete the other AIs, e.g. recursive self-improvement.
Is there a good post out there making a case for why this would work? A few possibilities:
- The AIs are all relatively good / aligned. But they could be outcompeted by malevolent AIs. I guess this is what you're getting at with "most of the ASIs are aligned at any given time", so they can band together and defend against the bad AIs?
- They all decide / understand that conflict is more costly than cooperation. A darker variation on this is mutually assured destruction, which I don't find especially comforting to live under.
- Some technological solution to binding / unbreakable contracts such that reneging on your commitments is extremely costly.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T18:40:38.343Z · LW(p) · GW(p)
But we already align complex systems, whether it’s corporations or software applications, without complete “understanding,” and do so by ensuring they meet certain technical specifications, regulations, or contractual obligations.
- We currently have about as much visibility into corporations as we do into large teams of AIs, because both corporations and AIs use english CoT to communicate internally. However, I fear that in the future we'll have AIs using neuralese/recurrence to communicate with their future selves and with each other.
- History is full of examples of corporations being 'misaligned' to the governments that in some sense created and own them. (and also to their shareholders, and also to the public, etc. Loads of examples of all kinds of misalignments). Drawing from this vast and deep history, we've evolved institutions to deal with these problems. But with AI, we don't have that history yet, we are flying (relatively) blind.
- Moreover, ASI will be qualitatively smarter and than any corporation ever has been.
- Moreover, I would say that our current methods for aligning corporations only work as well as they do because the corporations have limited power. They exist in a competitive market with each other, for example. And they only think at the same speed as the governments trying to regulate them. Imagine a corporation that was rapidly growing to be 95% of the entire economy of the USA... imagine further that it is able to make its employees take a drug that makes them smarter and think orders of magnitude faster... I would be quite concerned that the government would basically become a pawn of this corporation. The corporation would essentially become the state. I worry that by default we are heading towards a world where there is a single AGI project in the lead, and that project has an army of ASIs on its datacenters, and the ASIs are all 'on the same team' because they are copies of each other and/or were trained in very similar ways...
comment by Charlie Steiner · 2025-01-25T07:39:19.729Z · LW(p) · GW(p)
One way of phrasing the AI alignment task is to get AIs to “love humanity” or to have human welfare as their primary objective (sometimes called “value alignment”). One could hope to encode these via simple principles like Asimov’s three laws or Stuart Russel’s three principles, with all other rules derived from these.
I certainly agree that Asimov's three laws are not a good foundation for morality! Nor are any other simple set of rules.
So if that's how you mean "value alignment," yes let's discount it. But let me sell you on a different idea you haven't mentioned, which we might call "value learning."[1]
Doing the right thing is complicated.[2] Compare this to another complicated problem: telling photos of cats from photos of dogs. You cannot write down a simple set of rules to tell apart photos of cats and dogs. But even though we can't solve the problem with simple rules, we can still get a computer to do it. We show the computer a bunch of data about the environment and human classifications thereof, have it tweak a bunch of parameters to make a model of the data, and hey presto, it tells cats from dogs.
Learning the right thing to do is just like that, except for all the ways it's different that are still open problems:
- Humans are inconsistent and disagree with each other about the right thing more than they are inconsistent/disagree about dogs and cats.
- If you optimize for doing the right thing, this is a bit like searching for adversarial examples, a stress test that the dog/cat classifier didn't have to handle.
- When building an AI that learns the right thing to do, you care a lot more about trust than when you build a dog/cat classifier.
This margin is too small to contain my thoughts on all these.
There's no bright line between value learning and techniques you'd today lump under "reasonable compliance." Yes, the user experience is very different between (e.g.) an AI agent that's operating a computer for days or weeks vs. a chatbot that responds to you within seconds. But the basic principles are the same - in training a chatbot to behave well you use data to learn some model of what humans want from a chatbot, and then the AI is trained to perform well according to the modeled human preferences.
The open problems for general value learning are also open problems for training chatbots to be reasonable. How do you handle human inconsistency and disagreement? How do you build trust that the end product is actually reasonable, when that's so hard to define? Etc. But the problems have less "bite," because less can go wrong when your AI is briefly responding to a human query than when your AI is using a computer and navigating complicated real-world problems on its own.
You might hope we can just say value learning is hard, and not needed anyhow because chatbots need it less than agents do, so we don't have to worry about it. But the chatbot paradigm is only a few years old, and there is no particular reason it should be eternal. There are powerful economic (and military) pressures towards building agents that can act rapidly and remain on-task over long time scales. AI safety research needs to anticipate future problems and start work on them ahead of time, which means we need to be prepared for instilling some quite ambitious "reasonableness" into AI agents.
- ^
For a decent introduction from 2018, see this collection [? · GW].
- ^
Citation needed.
↑ comment by boazbarak · 2025-01-27T00:41:43.513Z · LW(p) · GW(p)
I am not 100% sure I follow all that you wrote, but to the extent that I do, I agree.
Even chatbot are surprisingly good at understanding human sentiments and opinions. I would say that already they mostly do the reasonable thing, but not with high enough probability and certainly not reliably under stress of adversarial input, Completely agree that we can't ignore these problems because the stakes will be much higher very soon.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T05:41:36.978Z · LW(p) · GW(p)
We can’t just track a single outcome (like “landed safely”). The G in AGI means that the number of ways that AGI can go wrong is as large as the number of ways that applications of human intelligence can go wrong, which include direct physical harm from misuse, societal impacts through misinformation, social upheaval from too fast changes, AIs autonomously causing harm and more.
I do agree with this, but I think that there are certain more specific failure modes that are especially important -- they are especially bad if we run into them, but if we can avoid them, then we are in a decent position to solve all the other problems. I'm thinking primarily of the failure mode where your AI is pretending to be aligned instead of actually aligned. This failure mode can arise fairly easily if (a) you don't have the interpretability tools to reliably tell the difference, and (b) inductive biases favor something other than the goals/principles you are trying to train in OR your training process is sufficiently imperfect that the AI can score higher by being misaligned than by being aligned. And both a and b seem like they are plausibly true now and will plausibly be true for the next few years. (For more on this, see this old report and this recent experimental result) If we can avoid this failure mode, we can stay in the regime where iterative development works [LW · GW] and figure out how to align our AIs better & then start using them to do lots of intellectual work to solve all the other problems one by one in rapid succession. (The good attractor state [LW(p) · GW(p)])
Replies from: boazbarak↑ comment by boazbarak · 2025-01-27T00:51:20.702Z · LW(p) · GW(p)
I prefer to avoid terms such as "pretending" or "faking", and try to define these more precisely.
As mentioned, a decent definition of alignment is following both the spirit and the letter of human-written specifications. Under this definition, "faking" would be the case where AIs follow these specifications reliably when we are testing, but deviate from them when they can determine that no one is looking. This is closely related to the question of robustness, and I agree it is very important. As I write elsewhere, interpretability may be helpful but I don't think it is a necessary condition.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T05:29:39.228Z · LW(p) · GW(p)
Safety and alignment are AI capabilities
I think I see what you are saying here but I just want to flag this is a nonstandard use of terms. I think the standard terminology would contrast capabilities and propensities; 'can it do the thing, if it tried' vs. 'would it ever try.' And alignment is about propensity (though safety is about both).
Replies from: boazbarak↑ comment by boazbarak · 2025-01-27T00:54:10.939Z · LW(p) · GW(p)
I think that:
1. Being able to design a chemical weapon with probability at least 50% is a capability
2. Following instructions never to design a chemical weapon with probability at least 99.999% is also a capability.
↑ comment by ryan_greenblatt · 2025-01-27T02:45:18.857Z · LW(p) · GW(p)
- Following instructions never to design a chemical weapon with probability at least 99.999% is also a capability.
This requires a capability, but also requires a propensity. For example, smart humans are all capable of avoiding doing armed robbery with pretty high reliability, but some of them do armed robbery despite being told not to do armed robbery at a earlier point in their life. You could say these robbers didn't have the capability to follow instructions, but this would be an atypical use of these (admittedly fuzzy) words.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T18:07:40.714Z · LW(p) · GW(p)
Constant instead of temporal allocation. I do agree that as capabilities grow, we should be shifting resources to safety. But rather than temporal allocation (i.e., using AI for safety before using it for productivity), I believe we need constant compute allocation: ensuring a fixed and sufficiently high fraction of compute is always spent on safety research, monitoring, and mitigations.
I think we should be cranking up the compute allocation now, and also we should be making written safety case sketches & publishing them for critique by the scientific community, and also if the safety cases get torn to shreds such that a reasonable disinterested expert would conclude 'holy shit this thing is not safe, it plausibly is faking alignment already and/or inclined to do so in the future' then we halt internal deployment and beef up our control measures / rebuild with a different safer design / etc. Does not feel like too much to ask, given that everyone's lives are on the line.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-25T05:27:29.186Z · LW(p) · GW(p)
Thanks for taking the time to think and write about this important topic!
Here are some point-by-point comments as I read:
(Though I suspect translating these technical capabilities to the economic and societal impact we associate with AGI will take significantly longer.)
I think it'll take an additional 0 to 5 years roughly. More importantly though, I think that the point to intervene on -- the time when the most important decisions are being made -- is right around the time of AGI. By the time you have ASI, and certainly by the time you are deploying ASI into the economy, you've probably fallen into one of the two stable attractor states I describe here. [LW(p) · GW(p)] Which one you fall into depends on choices made earlier, e.g. how much alignment talent you bring into the project, the extent to which that talent is optimistic vs. appropriately paranoid, the time you give them to let them cook with the models, the resources you give them (% of total compute, say in overall design strategy), etc.
This assumes that our future AGIs and ASIs will be, to a significant extent, scaled-up versions of our current models. On the one hand, this is good news, since it means our learnings from current models are relevant for more powerful ones, and we can develop and evaluate safety techniques using them. On the other hand, this makes me doubt that safety approaches that do not show signs of working for our current models will be successful for future AIs.
I agree that future AGIs and ASIs will be to a significant extent scaled up versions of current models (at least at first; I expect the intelligence explosion to rapidly lead to additional innovations and paradigm shifts). I'm not sure what you are saying with the other sentences. Sometimes when people talk about current alignment techniques working, what they mean is 'causes current models to be better at refusals and jailbreak resistance' which IMO is a tangentially related but importantly different problem from the core problem(s) we need to solve in order to end up in the good attractor state. After all, you could probably make massive progress on refusals and jailbreaks simply by making the models smarter, without influencing their goals/values/principles at all.
Oh wait I just remembered I can comment directly on the text with a bunch of little comments instead of making one big comment here -- I'll switch to that henceforth.
Cheers!
Replies from: boazbarakcomment by maxnadeau · 2025-03-07T02:26:11.189Z · LW(p) · GW(p)
On point 6, "Humanity can survive an unaligned superintelligence": In this section, I initially took you to be making a somewhat narrow point about humanity's safety if we develop aligned superintelligence and humanity + the aligned superintelligence has enough resources to out-innovate and out-prepare a misaligned superintelligence. But I can't tell if you think this conditional will be true, i.e. whether you think the existential risk to humanity from AI is low due to this argument. I infer from this tweet of yours that AI "kill[ing] us all" is not among your biggest fears about AI, which suggests to me that you expect the conditional to be true—am I interpreting you correctly?
comment by Gianluca Calcagni (gianluca-calcagni) · 2025-01-27T09:14:51.071Z · LW(p) · GW(p)
I want to thank the author about this post, that is a very interesting read. I see many comments already and I didn't have the time to read them thoroughly, so my apologies if what I am stating below has been discussed already.
The author's point that I wish to challenge is the third one: "alignment is not about loving humanity; it's about robust reasonable compliance".
I agree with the fact that embedding (in a principled way) "love" for humanity is a bad solution, and that it cannot go in a favourable direction - as, in the best scenario, it will likely disempower us. However, I disagree about the fact that "human values" are not part of the solution either.
Suppose that alignment is solved in the form of "robust reasonable compliance": if human values are not embedded at all, the aligned robots will be aligned to single individuals or single organizations, and the effect is that the AIs will be used to fight proxy wars (not necessarily physical wars) among such organizations. This scenario is encouraging rogue AIs on purpose as a form of deterrent among the parties, in the same way nuclear bombs are built as a form of deterrent. That behaviour is an obvious existential risk. I have written a post about this here [LW · GW].
If you agree with the above, there are only two possible solutions: (1) either AI is monopolized by the UN, or (2) it is decentralized but it shares some form of human values, so that it will refuse to do unsafe or unethical things (not sure if that is even possible though, as I discussed at the end of this post [LW · GW]).
Replies from: boazbarak↑ comment by boazbarak · 2025-01-29T20:14:10.794Z · LW(p) · GW(p)
To be clear, I think that embedding human values is part of the solution - see my comment [LW(p) · GW(p)]
Replies from: gianluca-calcagni↑ comment by Gianluca Calcagni (gianluca-calcagni) · 2025-01-30T08:26:35.013Z · LW(p) · GW(p)
How do you envision access and control of an AI that is robustly and reasonably compliant? And in which way would "human values" be involved? I agree with you that they are part of the solution, but I want to compare my beliefs with yours.