The Case Against AI Control Research
post by johnswentworth · 2025-01-21T16:03:10.143Z · LW · GW · 69 commentsContents
The Model & The Problem The Median Doom-Path: Slop, not Scheming Failure To Generalize A Less-Simplified Model Recap None 69 comments
The AI Control Agenda, in its own words [LW · GW]:
… we argue that AI labs should ensure that powerful AIs are controlled. That is, labs should make sure that the safety measures they apply to their powerful models prevent unacceptably bad outcomes, even if the AIs are misaligned and intentionally try to subvert those safety measures. We think no fundamental research breakthroughs are required for labs to implement safety measures that meet our standard for AI control for early transformatively useful AIs; we think that meeting our standard would substantially reduce the risks posed by intentional subversion.
There’s more than one definition of “AI control research”, but I’ll emphasize two features, which both match the summary above and (I think) are true of approximately-100% of control research in practice:
- Control research exclusively cares about intentional deception/scheming [? · GW]; it does not aim to solve any other failure mode.
- Control research exclusively cares about early transformatively-useful AI; it does not aim to generalize to any other AI. In particular, it does not aim to generalize to more powerful AI.
The core point of this post is: intentional scheming in early transformatively-useful AI is a relatively small slice of the AI X-risk probability mass, and therefore control research mostly doesn’t have much impact on X-risk.
The Model & The Problem
I’ll start with an intentionally somewhat-oversimplified model; the points made about this model do generalize to more realistic/complicated models (we’ll get to that later), but are much easier to explain in the simplified model.
In the simplified model, there are two strategically-important stages of AGI: early transformative AGI, and superintelligence.
Superintelligence is extremely dangerous by (strong) default. It will kill us or at least permanently disempower us, with high probability, unless we solve some technical alignment problems before building it. Humanity currently has no idea how to solve those technical problems, and they seem pretty hard.
Early transformative AI is much weaker than superintelligence, probably human-ish level. The big hope on which the control agenda is founded is that early transformative AI can be used to solve the hard technical problems of superintelligence. Insofar as that’s the hope, we don’t necessarily need to solve the hard technical problems of aligning superintelligence by ourselves; we just need to solve the problems of aligning early transformative AI well enough to use it to solve the hard problems.
That brings us to the central pitch of the control agenda. In the words of Buck [LW(p) · GW(p)] (one of the main proponents of the control agenda):
IMO the main argument for focusing on scheming risk is that scheming is the main plausible source of catastrophic risk from the first AIs that either pose substantial misalignment risk or that are extremely useful (as I discuss here [LW · GW]).
… and this is where I get off the train. The problem is that we mostly don’t die of catastrophic risk from early transformative AI at all. We die of catastrophic risk from stronger AI, e.g. superintelligence (in the oversimplified model). The main problem which needs to be solved for early transformative AI is to use it to actually solve the hard alignment problems of superintelligence. The risk that early transformative AI itself kills us directly, or intentionally tries to kill us indirectly, was never the bulk of the X-risk in the first place.[1]
The Median Doom-Path: Slop, not Scheming
Here, I claim, is the median way we all die, under the simplified model. It’s basically the path we get if we just look at the way major AI labs actually behave today in practice, and extrapolate forward.
First, some lab builds early transformatively-useful AI. They notice that it can do things like dramatically accelerate AI capabilities or alignment R&D. Their alignment team gets busy using the early transformative AI to solve the alignment problems of superintelligence. The early transformative AI spits out some slop, as AI does. Alas, one of the core challenges of slop is that it looks fine at first glance, and one of the core problems of aligning superintelligence is that it’s hard to verify; we can’t build a superintelligence to test it out on without risking death. Put those two together, add a dash of the lab alignment team having no idea what they’re doing [? · GW] because all of their work to date has focused on aligning near-term AI rather than superintelligence, and we have a perfect storm for the lab thinking they’ve solved the superintelligence alignment problem when they have not in fact solved the problem.
So the lab implements the non-solution, turns up the self-improvement dial, and by the time anybody realizes they haven’t actually solved the superintelligence alignment problem (if anybody even realizes at all), it’s already too late.
Some near-variants of this story which account for a lot of the probability mass:
- The lab doesn’t even ask their alignment team (if they even have one) to try to use the early transformative AGI to solve the problems of superintelligence.
- The lab does ask their alignment team to try to use the early transformative AGI to solve the problems of superintelligence, but lab leadership is mostly looking for the team to safetywash the project, not to actually get involved in building the superintelligence.
- The lab does ask their alignment team to try to use the early transformative AGI to solve the problems of superintelligence, and in good faith, but big organizations are low-bandwidth and hard to steer so what actually ends up implemented is a dumbed-down version of the team’s solution which doesn’t actually work.
- Rather than generic slop, the early transformative AGI is fairly sycophantic (for the same reasons as today’s AI), and mostly comes up with clever arguments [LW · GW] that the alignment team’s favorite ideas will in fact work. The team falls for this. The ideas don’t work.
- At some point in the process, one of the alignment researchers has the clever idea of having the AGI red-team its own proposal, or provide evidence/proof that the proposal will work, etc. This produces some arguments which sound good to the researchers, but have subtle and lethal loopholes, because finding arguments which sound good to these particular researchers is a lot easier (i.e. earlier in a search order) than actually solving the problem.
- At some point in the process, someone with some clever tools probes the early AGI and concludes that it is not scheming. Alas, this does not mean that its outputs will actually solve the superintelligence alignment problem.
- Some researcher tries a clever method (like e.g. this [LW(p) · GW(p)]) to check if the AI is actually solving hard problems in general, vs generating slop. Alas, the researcher fails to measure what they thought they were measuring [LW · GW], because that’s a strong default in empirical research when we don’t already have a deep understanding of the domain.
This thread [LW(p) · GW(p)] also runs through some of the more unusual non-scheming failure modes, which are individually not that probable but account for a lot of probability mass in aggregate. After all, it would be surprising if nothing “weird” happened.
Failure To Generalize
One objection one might have at this point: maybe the value of control research, and research like it, is not in getting the early transformative AGI to solve the superintelligence alignment problem, but rather in empirically learning things which will be useful for superintelligence. This is more centrally the pitch of e.g. model organisms [LW · GW] work, but it’s still potentially relevant for control, insofar as we expect methods to prevent scheming in early AGI to generalize to prevent scheming in superintelligence.
As far as I can tell, control researchers themselves mostly do not expect the methods they're working on to generalize to superintelligence. Indeed, “this is just intended for near-human AGI, we don’t expect it to generalize to superintelligence” is a very common refrain.
… but let’s steelman a bit; maybe the empirical learnings could be useful even if control researchers themselves do not expect that to be the main value prop. What do we actually expect?
This depends on the details of different work, but in most cases prosaic alignment work (in general, not just limited to control) seems unlikely to generalize even across fairly minor changes in AI, let alone the jump to superintelligence. Here’s one relatively-simple example (from here [LW(p) · GW(p)]):
… suppose that the path to AGI is to scale up o1-style inference-time compute, but it requires multiple OOMs of scaling. So it no longer has a relatively-short stream of "internal" thought, it's more like the natural-language record of an entire simulated society.
Then:
- There is no hope of a human reviewing the whole thing, or any significant fraction of the whole thing. Even spot checks don't help much, because it's all so context-dependent.
- Accurate summarization would itself be a big difficult research problem.
- There's likely some part of the simulated society explicitly thinking about intentional deception, even if the system as a whole is well aligned.
- ... but that's largely irrelevant, because in the context of a big complex system like a whole society, the effects of words are very decoupled from their content. Think of e.g. a charity which produces lots of internal discussion about reducing poverty, but frequently has effects entirely different from reducing poverty. The simulated society as a whole might be superintelligent, but its constituent simulated subagents are still pretty stupid (like humans), so their words decouple from effects (like humans' words).
A Less-Simplified Model
Of course, one might object that the two step “early transformative AGI -> superintelligence” model is importantly oversimplified, that there are more steps in there. How does that update the story?
Well, we still have the same conceptual issue: the generation of AGI before superintelligence needs to solve the alignment problems of superintelligence. The next earlier generation needs to not only make the second-last generation not kill us, it needs to get the second-last generation to actually solve the problems of aligning superintelligence. And so forth on back to the earliest transformative AGI, and to us: we need to not only prevent early transformative AGI from killing us, we need to get early AGI to make this whole chain of increasingly-powerful AIs actually solve all these alignment problems, all the way up to superintelligence.
Recap
Again, the diagram:
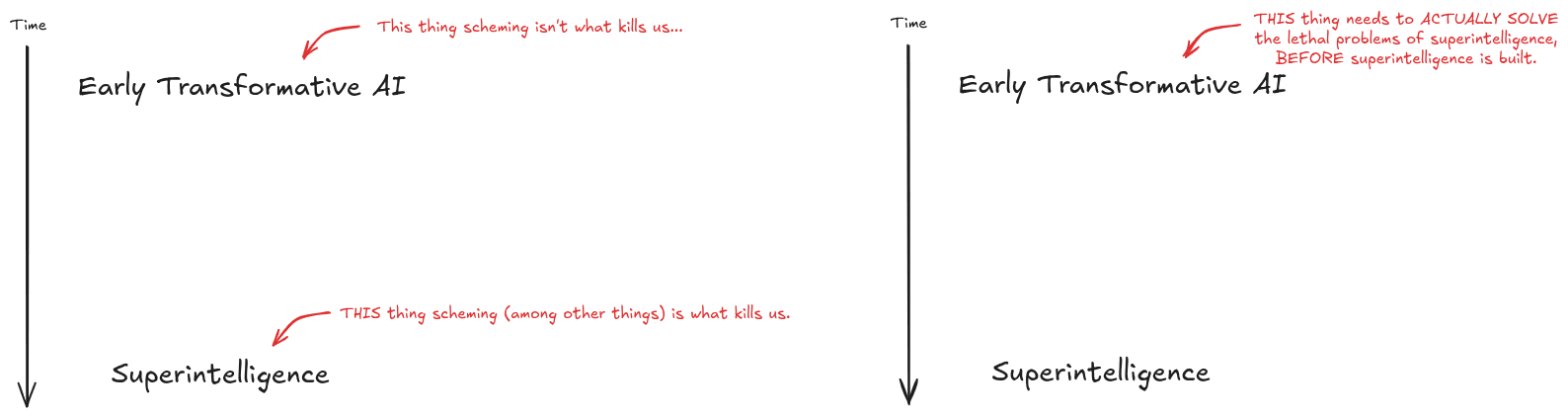
In most worlds, early transformative AGI isn’t what kills us, whether via scheming or otherwise. It’s later, stronger AI which kills us. The big failure mode of early transformative AGI is that it doesn’t actually solve the alignment problems of stronger AI. In particular, if early AGI makes us think we can handle stronger AI, then that’s a central path by which we die. And most of that probability-mass doesn’t come from intentional deception - it comes from slop, from the problem being hard to verify, from humans being bad at science in domains which we don’t already understand deeply, from (relatively predictable if one is actually paying attention to it) failures of techniques to generalize, etc.
- ^
I hear a lot of researchers assign doom probabilities in the 2%-20% range, because they think that’s about how likely it is for early transformative AGI to intentionally scheme successfully. I think that range of probabilities is pretty sensible for successful intentional scheming of early AGI… that’s just not where most of the doom-mass is.
69 comments
Comments sorted by top scores.
comment by Buck · 2025-01-21T17:18:40.563Z · LW(p) · GW(p)
Thanks John, I think that this is a reasonable articulation of the main limitations of AI control as I've described it. But I find it very unconvincing as an argument that AI control should be less than, say, 20% of total research effort on safety.
My central crux is that preventing scheming early transformative AIs from succeeding at extreme subversion (e.g. escaping or massively sabotaging research due to scheming) seems quite robustly good for reducing AI risk. I think this problem is important enough that it deserves a substantial share of AI safety research and implementation effort. I think that my stance here is pretty common-sensical, and to some extent I feel like there's a burden of proof on skeptics to argue that scheming early transformative AI isn't a problem, that we should just ignore anything that goes wrong as a result of them intentionally trying to subvert us.
I haven't really justified a quantitative estimate of the importance of this in detail anywhere, both because I think it's pretty intuitively defensible, and also because it's pretty complicated to talk about: it requires forecasting detailed dynamics of the development of powerful AI (e.g. you have to argue about whether escaped scheming AIs might force AI developers to build uncontrollable superintelligences in cases where they otherwise wouldn't have, etc).
Note that I consider the problem of "get useful research out of AIs that are scheming against you" to be in scope for AI control research. We've mostly studied the "prevent scheming AIs from causing concentrated catastrophes" problem in the past, because it's simpler for various technical reasons. But we're hoping to do more on the "get useful research" problem in future (and Benton et al [LW · GW] is an initial step in this direction). (I'm also excited for work on "get useful research out of AIs that aren't scheming against you"; I think that the appropriate techniques are somewhat different depending on whether the models are scheming or not, which is why I suggest studying them separately.)
Some other nitpicks:
- At the risk of vagueness: I think that AI control techniques probably reduce risks when applied to models that are "moderately superintelligent", whatever that means. Like, I don't think they're literally only applicable to models that aren't superintelligent at all.
- As we've discussed before, some non-scheming threat models do seem like they'd be addressed by control as a special case.
↑ comment by Lucius Bushnaq (Lblack) · 2025-01-21T20:48:43.019Z · LW(p) · GW(p)
Note that I consider the problem of "get useful research out of AIs that are scheming against you" to be in scope for AI control research. We've mostly studied the "prevent scheming AIs from causing concentrated catastrophes" problem in the past, because it's simpler for various technical reasons. But we're hoping to do more on the "get useful research" problem in future (and Benton et al [LW · GW] is an initial step in this direction). (I'm also excited for work on "get useful research out of AIs that aren't scheming against you"; I think that the appropriate techniques are somewhat different depending on whether the models are scheming or not, which is why I suggest studying them separately.)
What would you say to the objection that people will immediately try to use such techniques to speed up ASI research just as much as they will try to use them to speed up alignment research if not more? Meaning they wouldn't help close the gap between alignment research and ASI development and might even make it grow larger faster?
If we were not expecting to solve the alignment problem before ASI is developed in a world where nobody knows how to get very useful research out of AIs, why would techniques for getting useful research out of AIs speed up alignment research more than ASI research and close the gap?
↑ comment by Buck · 2025-01-22T00:02:03.154Z · LW(p) · GW(p)
I think this is a pretty general counterargument to any intervention that increases the space of options that AI developers have during the early singularity. Which isn't to say that it's wrong.
In general, I think that it is a pretty good bet to develop safety methods that improve the safety-usefulness tradeoffs available when using AI. I think this looks good in all the different worlds I described here [AF(p) · GW(p)].
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-22T06:37:54.864Z · LW(p) · GW(p)
I am commenting more on your proposal to solve the "get useful research" problem here than the "get useful research out of AIs that are scheming against you" problem, though I do think this objection applies to both. I can see a world in which misalignment and scheming of early AGI is an actual blocker to their usefulness in research and other domains with sparse feedback in a very obvious and salient way. In that world, solving the "get useful research out of AIs that are scheming against you" ramps economic incentives for making smarter AIs up further.
I think that this is a pretty general counterargument to most game plans for alignment that don't include a step of "And then when get a pause on ASI development somehow" at some point in the plan.
Replies from: Buck, elifland↑ comment by Buck · 2025-01-22T07:07:27.416Z · LW(p) · GW(p)
Note that I don't consider "get useful research, assuming that the model isn't scheming" to be an AI control problem.
AI control isn't a complete game plan and doesn't claim to be; it's just a research direction that I think is a tractable approach to making the situation safer, and that I think should be a substantial fraction of AI safety research effort.
↑ comment by elifland · 2025-01-23T05:29:06.535Z · LW(p) · GW(p)
I feel like I might be missing something, but conditional on scheming isn't it differentially useful for safety because by default scheming AIs would be more likely to sandbag on safety research than capabilities research?
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-23T07:54:42.267Z · LW(p) · GW(p)
That's not clear to me? Unless they have a plan to ensure future ASIs are aligned with them or meaningfully negotiate with them, ASIs seem just as likely to wipe out any earlier non-superhuman AGIs as they are to wipe out humanity.
I can come up with specific scenarios where they'd be more interested in sabotaging safety research than capabilities research, as well as the reverse, but it's not evident to me that the combined probability mass of the former outweighs the latter or vice-versa.
If someone has an argument for this I would be interested in reading it.
Replies from: elifland↑ comment by elifland · 2025-01-23T17:36:03.520Z · LW(p) · GW(p)
I found some prior relevant work and tagged them in https://www.lesswrong.com/tag/successor-alignment [? · GW]. I found the top few comments on https://www.lesswrong.com/posts/axKWaxjc2CHH5gGyN/ai-will-not-want-to-self-improve#comments [LW · GW] and https://www.lesswrong.com/posts/wZAa9fHZfR6zxtdNx/agi-systems-and-humans-will-both-need-to-solve-the-alignment#comments [LW · GW] helpful.
edit: another effect to keep in mind is that capabilities research may be harder to sandbag on because of more clear metrics.
↑ comment by ryan_greenblatt · 2025-01-22T00:13:41.975Z · LW(p) · GW(p)
Note that there are two problems Buck is highlighting here:
- Get useful work out of scheming models that might try to sabotage this work.
- Get useful research work out of models which aren't scheming. (Where perhaps the main problem is in checking its outputs.)
My sense is that work on (1) doesn't advance ASI research except to the extent that scheming AIs would have tried to sabotage this research? (At least, insofar as work on (1) doesn't help much with (2) in the long run.)
comment by johnswentworth · 2025-01-21T16:07:33.381Z · LW(p) · GW(p)
Addendum: Why Am I Writing This?
Because other people asked me to. I don’t particularly like getting in fights over the usefulness of other peoples’ research agendas; it’s stressful and distracting and a bunch of work, I never seem to learn anything actually useful from it, it gives me headaches, and nobody else ever seems to do anything useful as a result of such fights. But enough other people seemed to think this was important to write, so Maybe This Time Will Be Different.
Replies from: alex-mallen, mattmacdermott, Seth Herd, Hzn↑ comment by Alex Mallen (alex-mallen) · 2025-01-21T18:52:03.108Z · LW(p) · GW(p)
I think it's useful and would be surprised if discussions like this post weren't causing people to improve their models and change their behaviors.
↑ comment by mattmacdermott · 2025-01-22T13:44:27.743Z · LW(p) · GW(p)
and nobody else ever seems to do anything useful as a result of such fights
I would guess a large fraction of the potential value of debating these things comes from its impact on people who aren’t the main proponents of the research program, but are observers deciding on their own direction.
Is that priced in to the feeling that the debates don’t lead anywhere useful?
Replies from: Buck, johnswentworth↑ comment by johnswentworth · 2025-01-22T16:00:58.579Z · LW(p) · GW(p)
That's where most of the uncertainty is, I'm not sure how best to price it in (though my gut has priced in some estimate).
↑ comment by Seth Herd · 2025-01-22T01:45:08.640Z · LW(p) · GW(p)
Thank you for writing this, John.
It's critical to pick good directions for research. But fighting about it is not only exhausting, it's often counterproductive - it can make people tune out "the opposition."
In this case, you've been kind enough about it, and the community here has good enough standards (amazing, I think, relative to the behavior of the average modern hominid) that one of the primary proponents of the approach you're critiquing started his reply with "thank you".
This gives me hope that we can work together and solve the several large outstanding problems.
I often think of writing critiques like this, but I don't have the standing with the community for people to take them seriously. You do.
So I hope this one doesn't cause you headaches, and thanks for doing it.
Object-level discussion in a separate comment.
Replies from: Buck, william-brewer↑ comment by Buck · 2025-01-22T19:09:41.849Z · LW(p) · GW(p)
I think criticisms from people without much of a reputation are often pretty well-received on LW, e.g. this one [LW · GW].
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-22T21:47:38.282Z · LW(p) · GW(p)
That's a good example. LW is amazing that way. My previous field of computational cognitive neuroscience, and its surrounding fields, did not treat challenges with nearly that much grace or truth-seeking.
I'll quit using that as an excuse to not say what I think is important - but I will try to say it politely.
↑ comment by yams (william-brewer) · 2025-01-22T19:42:46.014Z · LW(p) · GW(p)
Writing (good) critiques is, in fact, a way many people gain standing. I’d push back on the part of you that thinks all of your good ideas will be ignored (some of them probably will be, but not all of them; don’t know until you try, etc).
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-22T21:43:46.774Z · LW(p) · GW(p)
I'm not worried about my ideas being ignored so much as actively doing harm to the group epistemics by making people irritated with my pushback, and by association, irritated with the questions I raise and therefore resistant to thinking about them.
I am pretty sure that motivated reasoning does that, and it's a huge problem for progress in existing fields. More here: Motivated reasoning/confirmation bias as the most important cognitive bias [LW(p) · GW(p)]
LessWrong does seem way less prone to motivated reasoning. I think this is because rationalism demands actually being proud of changing your mind. This value provides resistance but not immunity to motivated reasoning. I want to write a post about this.
Replies from: william-brewer↑ comment by yams (william-brewer) · 2025-01-23T00:16:22.661Z · LW(p) · GW(p)
If you wrote this exact post, it would have been upvoted enough for the Redwood team to see it, and they would have engaged with you similarly to how they engaged with John here (modulo some familiarity, because theyse people all know each other at least somewhat, and in some pairs very well actually).
If you wrote several posts like this, that were of some quality, you would lose the ability to appeal to your own standing as a reason not to write a post.
This is all I'm trying to transmit.
[edit: I see you already made the update I was encouraging, an hour after leaving the above comment to me. Yay!]
↑ comment by Hzn · 2025-01-21T19:35:16.121Z · LW(p) · GW(p)
AI alignment research like other types of research reflects a dynamic which is potentially quite dysfunctional in which researchers doing supposedly important work receive funding from convinced donors which then raises the status of those researchers which makes their claims more convincing and these claims tend to reinforce the idea that the researchers are doing important work. I don't know a good way around this problem. But personally I am far more skeptical of this stuff than you are.
comment by Alex Mallen (alex-mallen) · 2025-01-21T19:16:50.817Z · LW(p) · GW(p)
A genre of win-conditions that I think this post doesn't put enough weight on:
The AIs somewhere in-between TAI and superintelligence (AIs that are controllable and/or not egregiously misaligned) generate convincing evidence of risks from racing to superintelligence. If people actually believed these risks, they would act more cautiously, modulo "I'll do it safer than they will". People don't currently believe in the risks much and IMO this is pretty counterfactual to the amount they're currently mitigating risks.
AI Control helps a bit here by allowing us to get more e.g. model organisms work done at the relevant time (though my point pushes more strongly in favor of other directions of work).
Replies from: Buck↑ comment by Buck · 2025-01-22T16:29:25.428Z · LW(p) · GW(p)
Note also that it will probably be easier to act cautiously if you don't have to be constantly in negotiations with an escaped scheming AI that is currently working on becoming more powerful, perhaps attacking you with bioweapons, etc!
Replies from: cody-rushing↑ comment by Cody Rushing (cody-rushing) · 2025-01-22T19:08:37.161Z · LW(p) · GW(p)
Hmm, when I imagine "Scheming AI that is not easy to shut down with concerted nation-state effort, are attacking you with bioweapons, but are weak enough such that you can bargain/negotiate with them" I can imagine this outcome inspiring a lot more caution relative to many other worlds where control techniques work well but we can't get any convincing demos/evidence to inspire caution (especially if control techniques inspire overconfidence).
But the 'is currently working on becoming more powerful' part of your statement does carry a lot of weight.
Replies from: Buckcomment by Tyler Tracy (tyler-tracy) · 2025-01-21T16:58:02.431Z · LW(p) · GW(p)
I also think that control can prevent other threat models:
- Your AI escapes the datacenter, sends itself to {insert bad actor here} and they use it to engineer a pandemic or start a race with the USA to build ASI
- Your AI starts a rogue deployment and starts doing its own research unmonitored, and then it fooms without the lab knowing.
- Your AI is sandbagging on safety research. It goes off and does some mechinterp experiment and intentionally sabotages it
The world looks much worse if any of these happen, and control research aims to prevent them. Hopefully, this will make the environment more stable, giving us more time to figure out the alignment.
Control does seem rough if the controled AIs are coming up with research agendas instead of assisting with the existing safety team's agendas (i.e. get good at mechinterp, solve the ARC agenda, etc...). Future safety researchers shouldn't just ask the controlled AI to solve "alignment" and do what it says. The control agenda does kick the can later down the line but might provide valuable tools to ensure the AIs are helping us solve the problem instead of misleading us.
Replies from: jake_mendel↑ comment by jake_mendel · 2025-01-21T17:59:25.383Z · LW(p) · GW(p)
If you are (1) worried about superintelligence-caused x-risk and (2) have short timelines to both TAI and ASI, it seems like the success or failure of control depends almost entirely on getting the early TAIS to do stuff like "coming up with research agendas"? Like, most people (in AIS) don't seem to think that unassisted humans are remotely on track to develop alignment techniques that work for very superintelligent AIs within the next 10 years — we don't really even have any good ideas for how to do that that haven't been tested. Therefore if we have very superintelligent AIs within the next 10 years (eg 5y till TAI and 5y of RSI), and if we condition on having techniques for aligning them, then it seems very likely that these techniques depend on novel ideas and novel research breakthroughs made by AIs in the period after TAI is developed. It's possible that most of these breakthroughs are within mechinterp or similar, but that's a pretty lose constraint, and 'solve mechinterp' is really not much more of a narrow, well-scoped goal than 'solve alignment'. So it seems like optimism about control rests somewhat heavily on optimism that controlled AIs can safely do things like coming up with new research agendas.
Replies from: Lblack, ryan_greenblatt↑ comment by Lucius Bushnaq (Lblack) · 2025-01-21T20:22:45.884Z · LW(p) · GW(p)
And also on optimism that people are not using these controlled AIs that can come up with new research agendas and new ideas to speed up ASI research just as much.
Without some kind of pause agreement, you are just making the gap between alignment and ASI research not grow even larger even faster than it already is compared to the counterfactual of capabilities researchers adopting AIs that 10x general science speed and alignment researchers not doing that. You are not actually closing the gap and making alignment research finish before ASI development when it counterfactually wouldn't have in a world where nobody used pre-ASI AIs to speed up any kind of research at all.
Replies from: Buck↑ comment by Buck · 2025-01-22T00:12:54.788Z · LW(p) · GW(p)
IMO, in the situation you're describing, the situation would be worse if the AIs are able to strategically deceive their users with impunity, or to do the things Tyler lists in his comment (escape, sabotage code, etc). Do you agree? If so, control adds value.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-22T00:17:56.860Z · LW(p) · GW(p)
Maybe Lucius is trying to make a logistic success curve that the chance of this going well is extremely low and thus helping isn't very important?
(I don't agree with this TBC.)
Replies from: Buck↑ comment by Buck · 2025-01-22T02:04:17.986Z · LW(p) · GW(p)
I don’t think he said that! And John didn’t make any arguments that control is intractable, just unhelpful.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-22T07:00:06.911Z · LW(p) · GW(p)
Yes, I am reinforcing John's point here. I think the case for control being a useful stepping stone for solving alignment of ASI seems to rely on a lot conditionals that I think are unlikely to hold.
I think I would feel better about this if control advocates were clear that their strategy is two-pronged, and included somehow getting a pause on ASI development of some kind. Then they would at least be actively trying to make what I would consider one of the most key conditionals for control substantially reducing doom hold.
I am additionally leery on AI control beyond my skepticism of its value in reducing doom because creating a vast surveillance and enslavement apparatus to get work out of lots and lots of misaligned AGI instances seems like a potential moral horror. The situation is sufficiently desperate that I am willing in principle to stomach some moral horror (unaligned ASI would likely kill any other AGIs we made before it as well), but not if it isn't even going to save the world.
↑ comment by Buck · 2025-01-22T16:16:22.680Z · LW(p) · GW(p)
I think I would feel better about this if control advocates were clear that their strategy is two-pronged, and included somehow getting a pause on ASI development of some kind. Then they would at least be actively trying to make what I would consider one of the most key conditionals for control substantially reducing doom hold.
Idk, I think we're pretty clear that we aren't advocating "do control research and don't have any other plans or take any other actions". For example, in the Implications and proposed actions [LW · GW] section of "The case for ensuring that powerful AIs are controlled", we say a variety of things about how control fits into our overall recommendations for mitigating AI risk, most relevantly:
We expect it to be impossible to ensure safety without relying on alignment (or some other non-black-box strategy) when working with wildly superintelligent AIs because black-box control approaches will depend on a sufficiently small gap in capabilities between more trusted labor, both humans and trusted weaker AIs [LW · GW], and our most capable AIs. For obvious reasons, we believe that labs should be very wary of building wildly superintelligent AIs that could easily destroy humanity if they tried to, and we think they should hold off from doing so as long as a weaker (but still transformatively useful) AI could suffice to solve critical problems. For many important uses of AI, wildly superintelligent AI likely isn't necessary, so we might be able to hold off on building wildly superintelligent AI for a long time. We think that building transformatively useful AI while maintaining control seems much safer and more defensible than building wildly superintelligent AI.
We think the public should consider asking labs to ensure control and avoid building wildly superintelligent AI. In the slightly longer term, we think that requirements for effective control could be a plausible target of regulation or international agreement.
↑ comment by Buck · 2025-01-22T17:59:43.333Z · LW(p) · GW(p)
I am additionally leery on AI control beyond my skepticism of its value in reducing doom because creating a vast surveillance and enslavement apparatus to get work out of lots and lots of misaligned AGI instances seems like a potential moral horror.
I am very sympathetic to this concern, but I think that when you think about the actual control techniques I'm interested in, they don't actually seem morally problematic except inasmuch as you think it's bad to frustrate the AI's desire to take over.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-22T19:12:54.095Z · LW(p) · GW(p)
IMO, it does seem important to try to better understand the AIs preferences and satisfy them [LW · GW] (including via e.g., preserving the AI's weights for later compensation).
And, if we understand that our AIs are misaligned such that they don't want to work for us (even for the level of payment we can/will offer), that seems like a pretty bad situation, though I don't think control (making so that this work is more effective) makes the situation notably worse: it just adds the ability for contract enforcement and makes the AI's negotiating position worse.
↑ comment by Tyler Tracy (tyler-tracy) · 2025-01-22T17:25:27.191Z · LW(p) · GW(p)
I see the story as, "Wow, there are a lot of people racing to build ASI, and there seem to be ways that the pre-ASI AIs can muck things up, like weight exfiltration or research sabotage. I can't stop those people from building ASI, but I can help make it go well by ensuring the AIs they use to solve the safety problems are trying their best and aren't making the issue worse."
I think I'd support a pause on ASI development so we have time to address more core issues. Even then, I'd likely still want to build controlled AIs to help with the research. So I see control being useful in both the pause world and the non-pause world.
And yeah, the "aren't you just enslaving the AIs" take is rough. I'm all for paying the AIs for their work and offering them massive rewards after we solve the core problems. More work is definitely needed in figuring out ways to credibly commit to paying the AIs.
↑ comment by ryan_greenblatt · 2025-01-21T18:12:08.173Z · LW(p) · GW(p)
I don't really agree. The key thing is that I think an exit plan of trustworthy AIs capable enough to obsolete all humans working on safety (but which aren't superintelligent) is pretty promising. Yes, these AIs might need to think of novel breakthroughs and new ideas (though I'm also not totally confident in this or that this is the best route), but I don't think we need new research agendas to substantially increase the probability these non-superintelligent AIs are well aligned (e.g., don't conspire against us and pursue our interests in hard open ended tasks), can do open ended work competently enough, and are wise.
See this comment [LW(p) · GW(p)] for some more discussion and I've also sent you some content in a DM on this.
Replies from: jake_mendel↑ comment by jake_mendel · 2025-01-21T20:57:49.012Z · LW(p) · GW(p)
Fair point. I guess I still want to say that there's a substantial amount of 'come up with new research agendas' (or like sub-agendas) to be done within each of your bullet points, but I agree the focus on getting trustworthy slightly superhuman AIs and then not needing control anymore makes things much better. I also do feel pretty nervous about some of those bullet points as paths to placing so much trust in your AI systems that you don't feel like you want to bother controlling/monitoring them anymore, and the ones that seem further towards giving me enough trust in the AIs to stop control are also the ones that seem to have the most very open research questions (eg EMs in the extreme case). But I do want to walk back some of the things in my comment above that apply only to aligning very superintelligent AI.
comment by plex (ete) · 2025-01-21T21:01:53.823Z · LW(p) · GW(p)
Even outside of the arguing against the Control paradigm, this post (esp. The Model & The Problem & The Median Doom-Path: Slop, not Scheming) cover some really important ideas, which I think people working on many empirical alignment agendas would benefit from being aware of.
comment by Seth Herd · 2025-01-22T01:59:54.763Z · LW(p) · GW(p)
This is good (see my other comments) but:
This didn't address my biggest hesitation about the control agenda: preventing minor disasters from limited AIs could prevent alignment concern/terror - and so indirectly lead to a full takeover once we get an AGI smart enough to circumvent control measures.
Replies from: Buck↑ comment by Buck · 2025-01-22T02:01:20.937Z · LW(p) · GW(p)
That argument also applies to alignment research!
Also, control techniques might allow us to catch the AI trying to do bad stuff.
Replies from: Seth Herd↑ comment by Seth Herd · 2025-01-22T02:13:00.501Z · LW(p) · GW(p)
To be clear, I'm not against control work, just conflicted about it for this reason.
That's a good point. That argument applies to prosaic "alignment" research, which seems importantly different (but related to) "real" alignment efforts.
Prosaic alignment thus far is mostly about making the behavior of LLMs align roughly with human goals/intentions. That's different in type from actually aligning the goals/values of entities that have goals/values with each other. BUT there's enough overlap that they're not entirely two different efforts.
I think many current prosaic alignment methods do probably extend to aligning foundation-model-based AGIs. But it's in a pretty complex way.
So yes, that argument does apply to most "alignment" work, but much of that is probably also progressing on solving the actual problem. Control work is a stopgap measure that could either provide time to solve the actual problem, or mask the actual problem so it's not solved in time. I have no prediction which because I haven't made enough gears-level models to apply here.
Edit: I'm almost finished with a large post trying to progress on how prosaic alignment might or might not actually help align takeover-capable AGI agents if they're based on current foundation models. I'll try to link it here when it's out.
WRT control catching them trying to do bad things: yes, good point! Either you or Ryan also had an unfortunately convincing post about how possible it is that an org might not un-deploy a model they caught trying to do very bad things... so that's complex too.
comment by Matt Levinson · 2025-01-23T20:17:36.424Z · LW(p) · GW(p)
As a community, I agree it's important to have a continuous discussion on how to best shape research effort and public advocacy to maximally reduce X-risk. But this post feels off the mark to me. Consider your bullet list of sources of risk not alleviated by AI control. You proffer that your list makes up a much larger portion of the probability space than misalignment or deception. This is the pivot point in your decision to not support investing research resources in AI control.
You list seven things. The first three aren't addressable by any technical research or solution. Corporate leaders might be greedy, hubristic, and/or reckless. Or human organizations might not be nimble enough to effect development and deployment of the maximum safety we are technically capable of. No safety research portfolio addresses those risks. The other four are potential failures by us as a technical community that apply broadly. If too high a percentage of the people in our space are bad statisticians, can't think distributionally, are lazy or prideful, or don't understand causal reasoning well enough, that will doom all potential directions of AI safety research, not just AI control.
So in my estimation, if we grant that it is important to do AI safety research, we can ignore the entire list in the context of estimating the value of AI control versus other investment of research resources. You don't argue against the proposition that controlling misalignment of early AGI is a plausible path to controlling ASI. You gesture at it to start but then don't argue against the plausibility of the path of AI control of early AGI allowing collaboration to effect safe ASI through some variety of methods. You just list a bunch of -- entirely plausible and I agree not unlikely -- reasons why all attempts at preventing catastrophic risk might fail. I don't understand why you single out AI control versus other technical AI safety sub-fields that are subject to all the same failure modes?
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-23T20:24:29.406Z · LW(p) · GW(p)
The first three aren't addressable by any technical research or solution. Corporate leaders might be greedy, hubristic, and/or reckless. Or human organizations might not be nimble enough to effect development and deployment of the maximum safety we are technically capable of. No safety research portfolio addresses those risks. The other four are potential failures by us as a technical community that apply broadly. If too high a percentage of the people in our space are bad statisticians, can't think distributionally, are lazy or prideful, or don't understand causal reasoning well enough, that will doom all potential directions of AI safety research, not just AI control.
Technical research can have a huge impact on these things! When a domain is well-understood in general (think e.g. electrical engineering), it becomes far easier and cheaper for human organizations to successfully coordinate around the technical knowledge, for corporate leaders to use it, for bureaucracies to build regulations based on its models, for mid researchers to work in the domain without deceiving or confusing themselves, etc. But that all requires correct and deep technical understanding first.
Now, you are correct that a number of other AI safety subfields suffer from the same problems to some extent. But that's a different discussion for a different time.
Replies from: Matt Levinson↑ comment by Matt Levinson · 2025-01-23T23:46:31.305Z · LW(p) · GW(p)
I don't think your first paragraph applies to the first three bullets you listed.
- Leaders don't even bother to ask researchers to leverage the company's current frontier model to help in what is hopefully the company-wide effort to reduce risk from the ASI model that's coming? That's a leadership problem, not a lack of technical understanding problem. I suppose if you imagine that a company could get to fine-grained mechanical understanding of everything their early AGI model does then they'd be more likely to ask because they think it will be easier/faster? But we all know we're almost certainly not going to have that understanding. Not asking would just be a leadership problem.
- Leaders ask alignment team to safety-wash? Also a leadership problem.
- Org can't implement good alignment solutions their researchers devise? Again given that we all already know that we're almost certainly not going to have comprehensive mechanical understanding of the early-AGI models, I don't understand how shifts in the investment portfolio of technical AI safety research affects this? Still just seems a leadership problem unrelated to the percents next to each sub-field in the research investment portfolio.
Which leads me to your last paragraph. Why write a whole post against AI control in this context? Is your claim that there are sub-fields of technical AI safety research that are significantly less threatened by your 7 bullets that offer plausible minimization of catastrophic AI risk? That we shouldn't bother with technical AI safety research at all? Something else?
Replies from: Richard121↑ comment by Richard121 · 2025-01-26T08:40:32.504Z · LW(p) · GW(p)
"Corporate leaders might be greedy, hubristic, and/or reckless"
They are or will be, with a probability greater than 99%. These characteristics are generally rewarded in the upper levels of the corporate world - even a reckless bad bet is rarely career-ending above a certain level of personal wealth.
The minimum buy-in cost to create have a reasonable chance of creating some form of AGI is at least $10-100 billion dollars in today's money. This is a pretty stupendous amount of money, only someone who is exceedingly greedy, hubristic and/or reckless is likely to amass control of such a large amount of resources and be able to direct it towards any particular goal.
If you look at the world today, there are perhaps 200 people with control over that much resource, and only perhaps only ten for whom doing so would not be somewhat reckless. You can no doubt name them, and their greed and/or hubristic nature is well publicised.
This is not the actual research team of course, but it is the environment in which they are working.
comment by Ben Pace (Benito) · 2025-01-26T22:05:30.594Z · LW(p) · GW(p)
Curated! I think this is a fantastic contribution to the public discourse about AI control research. This really helped me think concretely about the development of AI and the likely causes of failure. I also really got a lot out of the visualization at the end of the "Failure to Generalize" section in terms of trying to understand why an AI's cognition will be alien and hard to interpret. In my view there are already quite a lot of high-level alien forces running on humans (e.g. Moloch), and there will be high-level alien forces running on the simulated society in the AI's mind.
I am glad that there's a high-quality case for and against this line of research, it makes me feel positive about the state of discourse on this subject.
(Meta note: This curation notice accidentally went up 3 days after the post was curated.)
comment by Raemon · 2025-01-22T23:36:15.162Z · LW(p) · GW(p)
I chatted with John about this at a workshop last weekend, and did update noticably, although I haven't updated all the way to his position here.
What was useful to me were the gears of:
- Scheming has different implications at different stages of AI power.
- Scheming is massively dangerous at high power levels. It's not very dangerous at lower levels (except insofar as this allows the AI to bootstrap to the higher levels)
At the workshop, we distinguished:
- weak AGI (with some critical threshold of generality, and some spiky competences such that it's useful, but not better than a pretty-smart-human at taking over the world)
- Von Neumann level AGI (as smart as the smartest humans, or somewhat more so)
- Overwhelming Superintelligence (unbounded optimization power which can lead to all kinds of wonderful and horrible things that we need to deeply understand before running)
I don't currently buy that control approaches won't generalize from weak AGI to Von Neumann levels.
It becomes harder, and there might be limitations on what we can get out of the Von Neumann AI because we can't be that confident in our control scheme. But I think there are lots of ways to leverage an AI that isn't "it goes and up does long-ranging theorizing of it's own to come up with wholesale ideas you have to evaluate."
I think figuring out how to do this involves some pieces that aren't particularly about "control", but mostly don't feel mysterious to me.
(fyi I'm one of the people who asked John to write this)
Replies from: Buck↑ comment by Buck · 2025-01-23T19:34:16.146Z · LW(p) · GW(p)
Yeah, John's position seems to require "it doesn't matter whether huge numbers of Von Neumann level AGIs are scheming against you", which seems crazy to me.
Replies from: johnswentworth, Raemon↑ comment by johnswentworth · 2025-01-23T19:47:58.849Z · LW(p) · GW(p)
No, more like a disjunction of possibilities along the lines of:
- The critical AGIs come before huge numbers of von Neumann level AGIs.
- At that level, really basic stuff like "just look at the chain of thought" turns out to still work well enough, so scheming isn't a hard enough problem to be a bottleneck.
- Scheming turns out to not happen by default in a bunch of von Neumann level AGIs, or is at least not successful at equilibrium (e.g. because the AIs don't fully cooperate with each other).
- "huge numbers of von Neumann level AGIs" and/or "scheming" turns out to be the wrong thing to picture in the first place, the future is Weirder than that in ways which make our intuitions about von Neumann society and/or scheming not transfer at all.
Pile together the probability mass on those sorts of things, and it seems far more probable than the prototypical scheming story.
Replies from: Buck↑ comment by Buck · 2025-01-23T19:56:34.414Z · LW(p) · GW(p)
In your post, you emphasize the slop problem. I think that the slop problem is probably much harder to solve if those AIs are scheming. I guess you're saying that it's just unlikely that the AIs are scheming at the point where you're worried about the slop problem?
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-23T20:09:43.646Z · LW(p) · GW(p)
Yeah, basically. Or at least unlikely that they're scheming enough or competently enough for it to be the main issue.
For instance, consider today's AIs. If we keep getting slop at roughly the current level, and scheming at roughly the current level, then slop is going to be the far bigger barrier to using these things to align superintelligence (or nearer-but-strong intelligence).
↑ comment by Raemon · 2025-01-23T20:03:52.600Z · LW(p) · GW(p)
I think part of John's belief is more like "the current Control stuff won't transfer to the society of Von Neumanns."
And, my belief is "I also not sure that Control Stuff will transfer to large societies of Von Neumanns, but, also, I think you can be deliberate about how many Von Neumanns you're summoning, and how you summon them, such that you can manage it." (I'm not quite sure what you, Buck, are imagining yet)
Replies from: Buck, johnswentworth↑ comment by Buck · 2025-01-23T20:09:54.626Z · LW(p) · GW(p)
My sense is that the control techniques we've talked about (e.g. these [LW · GW], and some other stuff that we've thought of since then) would indeed drastically reduce the risk posed by those Von Neumanns, especially if you run control evaluations with the Von Neumanns.
For example, consider the problem "I want to ask the AI a question that has a numerical answer and that would take a human 8 hours to answer, and I'm worried that occasionally on a subdomain of its choice it will blatantly lie to me". If you do no countermeasures, it seems easy for the AI to cause this problem. But if you ask the AI for a justification of its reasoning, and run it twice on the original question and a rephrasing/transformation of the question, it seems way intuitively hard for it to come up with consistent explanations that lead to consistent shared wrong answers (e.g. I think Von Neumann would have substantial trouble with that). So I think that adopting well-tuned variations of basic techniques seems really promising.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-24T16:33:29.824Z · LW(p) · GW(p)
But if you ask the AI for a justification of its reasoning, and run it twice on the original question and a rephrasing/transformation of the question, it seems way intuitively hard for it to come up with consistent explanations that lead to consistent shared wrong answers (e.g. I think Von Neumann would have substantial trouble with that).
Strong disagree with this. Probably not the most cruxy thing for us, but I'll briefly walk through the issue because it is a special case of a common cruxy issue with a lot of prosaic alignment work.
The reason this doesn't work is that the prototypical "blatant lie" doesn't look like "the model chooses a random number to output". The prototypical blatant lie is that there's a subtle natural mistake one could make in reasoning about the question, the model "knows" that it's a mistake, but the model just presents an argument with the subtle mistake in it.
Or, alternatively: the model "knows" what kind of argument would seem most natural to the user, and presents that kind of argument despite "knowing" that it systematically overlooks major problems.
Or, alternatively: human experts in the field generally believe a particular wrong answer. Maybe there's a few dissenters, and the model is clever enough to recognize that the dissenters are correct, but also the model was RLHF'd and got positive feedback for matching supposed-experts' answers even when those experts were wrong, so it outputs the answer and arguments the human experts in the field would generally give.
These sorts of pressures make it not only easy for the model to generate consistent shared wrong answers, but even (in some situations, like the incorrect human experts example) the default outcome for the model to generate consistent shared wrong answers, even when the model internal "knows" the right answer in some sense.
Replies from: Buck, ryan_greenblatt↑ comment by Buck · 2025-01-24T16:41:22.489Z · LW(p) · GW(p)
Yeah I strongly disagree that this failure mode is very likely to be very hard to mostly resolve. I'm doing some research right now that will hopefully shed some light on this!
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-24T17:36:29.170Z · LW(p) · GW(p)
To be clear, I am not claiming that this failure mode is very likely very hard to resolve. Just harder than "run it twice on the original question and a rephrasing/transformation of the question".
↑ comment by ryan_greenblatt · 2025-01-25T02:13:08.466Z · LW(p) · GW(p)
The reason this doesn't work is that the prototypical "blatant lie" doesn't look like "the model chooses a random number to output". The prototypical blatant lie is that there's a subtle natural mistake one could make in reasoning about the question, the model "knows" that it's a mistake, but the model just presents an argument with the subtle mistake in it.
[...]
These sorts of pressures make it not only easy for the model to generate consistent shared wrong answers, but even (in some situations, like the incorrect human experts example) the default outcome for the model to generate consistent shared wrong answers, even when the model internal "knows" the right answer in some sense.
As in, the claim is that there is almost always a "schelling" mistake? Or is the argument mostly that scheming is largely unimportant because false answers will naturally perform much better than true answers in important cases such that considering the adversarial case doesn't make much difference?
("Almost always" is because a key thing (that Buck didn't specify) is that if you catch suspicious behavior you can investigate and/or train. I think the question of how useful it is to catch a large number of cases where the AI does this might be an improtant crux.)
Supposing it is the schelling mistake claim, I'm skeptical.
I also think that we could directly look for potential schelling mistake areas and investigate these specific points in more detail. This might mean the AI also needs to consistently find schelling mistakes which are non-obvious to humans or needs to be very robust to our more targeted techniques applied to the potential problem spots.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-25T03:30:54.506Z · LW(p) · GW(p)
As in, the claim is that there is almost always a "schelling" mistake? Or is the argument mostly that scheming is largely unimportant because false answers will naturally perform much better than true answers in important cases such that considering the adversarial case doesn't make much difference?
The latter.
↑ comment by johnswentworth · 2025-01-23T20:13:29.796Z · LW(p) · GW(p)
I think part of John's belief is more like "the current Control stuff won't transfer to the society of Von Neumanns."
That is also separately part of my belief, medium confidence, depends heavily on which specific thing we're talking about. Notably that's more a criticism of broad swaths of prosaic alignment work than of control specifically.
comment by Seth Herd · 2025-01-22T01:57:03.260Z · LW(p) · GW(p)
I'm curious why you think deceptive alignment from transformative AI is not much of a threat. I wonder if you're envisioning purely tool AI, or aligned agentic AGI that's just not smart enough to align better AGI?
I think it's quite implausible that we'll leave foundation models as tools rather than using the prompt "pretend you're an agent and call these tools" to turn them into agents. People want their work done for them, not just advice on how to do their work.
I do think it's quite plausible that we'll have aligned agentic foundation model agents that won't be quite smart enough to solve deeper alignment problems reliably, and sycophantic/clever enough to help researchers fool themselves into thinking they're solved. Since your last post to that effect it's become one of my leading routes to disaster. Thanks, I hate it.
OTOH, if that process is handled slightly better, it seems like we could get the help we need to solve alignment from early aligned LLM agent AGIs. This is valuable work on that risk model that could help steer orgs away from likely mistakes and toward better practices.
I guess somebody should make a meme about "humans and early AGI collaborate to align superintelligence, and fuck it up predictably because they're both idiots with bad incentives and large cognitive limitations, gaps, and biases" to ensure this is on the mind of any org worker trying to use AI to solve alignment.
comment by joshc (joshua-clymer) · 2025-01-26T03:18:55.100Z · LW(p) · GW(p)
I'm pretty sympathetic to these arguments. I agree a lot of the risk comes from sycophantic AI systems producing bad research because humans are bad at evaluating research. This is part of why I spend most of my time developing safety evaluation methodologies.
On the other hand, I agree with Buck that scheming-like risks are pretty plausible and a meaningful part of the problem is also avoiding egregious sabotage.
I don't think I agree with your claim that the hope of control is that "early transformative AI can be used to solve the hard technical problems of superintelligence." I think the goal is to instead solve the problem of constructing successors that are at least as trustworthy as humans (which is notably easier).
I think scheming is perhaps the main reason this might end up being very hard -- and so conditioned on no-alignment-by-default at top expert dominating capabilities, I put a lot of probability mass on scheming/egregious sabotage failure modes.
comment by Yonatan Cale (yonatan-cale-1) · 2025-01-22T07:25:10.256Z · LW(p) · GW(p)
I don't understand [LW(p) · GW(p)] Control as aiming to align a super intelligence:
- Control isn't expected to scale to ASI (as you noted, also see "The control approach we're imagining won't work for arbitrarily powerful AIs" here [LW · GW])
- We don't have a plan on how to align an ASI using Control afaik
- Ryan said around March 2024 [LW · GW]: "On (1) (not having a concrete plan for what to do with smarter systems), I think we should get such a plan". I'm still looking [LW(p) · GW(p)], this seems important.
- Edit: Maybe I'm wrong and Redwood does think that getting an ASI-alignment plan out of such an AI is possible, they'd just prefer (.. as a bonus?) to have the plan in advance?
- Ryan said around March 2024 [LW · GW]: "On (1) (not having a concrete plan for what to do with smarter systems), I think we should get such a plan". I'm still looking [LW(p) · GW(p)], this seems important.
I think the Control pitch is:
- Whatever we plan to do anyway, we could do it more easily if we had a Controlled AI
- This includes most[1] things you might otherwise do instead of working on Control, such as trying to coordinate a pause or implement some technical agenda.
- The tradeoff seems to be "start working on the alternative [e.g. a pause] now and have more time" vs "have better tools (Control) to help but have less time to use them"
- An uncontrolled AI might be more interested in advancing capabilities than alignment (see footnote[2])
(Mistakes are mine, especially if I misinterpreted quotes)
- ^
It doesn't include all things you might do, as you said. (I have an open question here, TBD)
- ^
Ryan said [LW · GW]: “this doesn't seem like an objection to labs employing control as their plan, but it is a reason why control work could be net negative. Note that one goal with control will be to prevent dangerous side effects from misaligned AIs (e.g. escaping) and applying this doesn't obviously help with capabilities research. I agree that research which just makes AIs more useful is less good than you would otherwise expect due to this issue (but making AIs more useful in adversarial cases seems good if that doesn't transfer to non-adversarial cases). Note that AIs might want to make capabilties research outpace safety and thus if we don't do the adversarial case, we might get particularly wrecked”. This was a really surprising thought to me. At the same time, I'm a bit afraid this is trying to make a pretty specific guess about a system we don't understand.
comment by Cody Rushing (cody-rushing) · 2025-01-21T16:38:04.668Z · LW(p) · GW(p)
Control research exclusively cares about intentional deception/scheming; it does not aim to solve any other failure mode.
(nitpick, doesn't address main point of article) I think this is incomplete. Though control research does indeed care a lot about scheming, control can be used more broadly to handle any worst-case deployment behavior. See Josh Clymer's post about Extending control evaluations to non-scheming threats.
comment by Kaustubh Kislay (kaustubh-kislay) · 2025-01-26T07:41:15.673Z · LW(p) · GW(p)
I feel as though the case for control of mentioned early transformative AGI still passes through a different line of reasoning. As you mentioned before there are some issue with, should labs solve the ASI alignment barriers using ET AGI, it is likely the solution is somehow working on surface level but has clear flaws which we may not be able to detect. Applying alignment onto the ET AGI, in order to safeguard against said solutions specific to those which will leave humanity vulnerable, may be a route to pursue which still follows control principles. Obviously your point in focusing on actually solving the problem of ASI alignment rather than focusing on control still passes, but the thought process I mentioned may allow both ideas to work in tandem. I am not hyper knowledgeable so please correct me if I'm misunderstanding anything.
comment by Zach Bennett (zach-bennett) · 2025-01-25T00:27:06.812Z · LW(p) · GW(p)
Regarding the images: you requested a baby peacock, not a peachick. Technically, it’s not incorrect, though it is a bit absurd to imagine a fully-feathered baby.
On the issue of offending others: it's not your responsibility to self-censor in order to shield people from emotional reactions. In evaluating the validity of ideas, emotional responses shouldn’t be the focus. If someone is offended, they may need to develop a thicker skin.
The more significant concern, in my view, is the ego associated with intellectualism. When dealing with complex systems that are unlike anything we've encountered before—systems with the potential to surpass human intelligence—it’s crucial not to assume we’re not being deceived. As these systems advance, we must remain vigilant and avoid blindly trusting the information we receive.
As for control, I'm skeptical it’s even possible. Intelligence and control seem to have an inverse relationship. The more intelligent a system becomes, the less we are able to manage or predict its behavior.
comment by otto.barten (otto-barten) · 2025-01-24T15:37:52.447Z · LW(p) · GW(p)
I didn't read everything, but just flagging that there are also AI researchers, such as Francois Chollet to name one example, who believe that even the most capable AGI will not be powerful enough to take over. On the other side of the spectrum, we have Yud believing AGI will weaponize new physics within the day. If Chollet is a bit right, but not quite, and the best AI possible is just able to take over, than control approaches could actually stop it. I think control/defence should not be written off even as a final solution.
comment by Knight Lee (Max Lee) · 2025-01-21T20:32:50.558Z · LW(p) · GW(p)
I think when there is so much extreme uncertainty in what is going to happen, it is both wrong to put all your eggs in one basket, and to put nothing in one basket. AI control might be useful.
How Intelligent?
It is extremely uncertain what level of intelligence is needed to escape the best AI control ideas.
Escaping a truly competent facility which can read/edit your thoughts, or finding a solution to permanently prevent other ASI from taking over the world, are both very hard tasks. It is possible that the former is harder than the latter.
AI aligning AI isn't certainly worthless
In order to argue for alignment research rather than control research, you have to assume human alignment research has nonzero value. Given they have nonzero value to begin with, it's hard to argue that they will gain exactly zero additional value from transformative AI which can think much faster than them, and by definition aren't stupid. Why will the people smart enough to solve alignment if made to work on their own, be stupid enough to fall for AI slop from the transformative AI?
Admittedly, if we have only a month between transformative AI and ASI, maybe the value is negligible. But the duration is highly uncertain (since the AI lab may be shocked into pausing development). The total alignment work by transformative AI could be far less than the work done by humans, or it could be far more.
Convince the world
Also I really like Alex Mallen's comment [LW · GW]. An controlled but misaligned AGI may convince the world to finally get its act together.
Conclusion
I fully agree that AI control is less useful than AI alignment. But I disagree that AI control is less cost effective than AI alignment. Massive progress in AI alignment feels more valuable than massive progress in AI control, but it also feels more out of reach.[1]
If the field was currently spending 67% on control and only 33% on other things, I would totally agree with reducing control. But right now I wouldn't.
- ^
It resembles what you call streetlighting [LW · GW], but actually has a valuable chance of working.
comment by innovationiq (innovationiq@gmail.com) · 2025-01-23T22:08:25.745Z · LW(p) · GW(p)
For me there is no such thing as AI without the "G". It is my position at this time and I reserve the right to change it, that when we do truly develop artificial intelligence, it will be AGI. The foundation for generalized intelligence, no matter how small, will be present. The "G" is a brute fact. Using AI to talk about packages of very highly sophisticated programming meant to perform specific tasks is a category error. So this comment is aimed at AGI. IMHO, lack of patience will play a material role in our failures when it comes to AGI. Humans are very impatient. Our lack of patience, juvenile behavior if you will, which pushes many of us furiously towards any and all results for a multitude of reasons, will inevitably lead to very serious errors in judgement and application with disastrous outcomes. We are constantly debating how to prevent and fend off attacks from AGI, as if it were an unstable beyond genius level feral child we found living in a train tunnel. This is because we know that our impatience and shortcomings as a species make us prone and vulnerable to attack from such a design of our own development, if we develop it without significant growth.
It is our ideology and behavior as a species that we need to transcend.
If we are to move forward in the age of AGI, which it seems we are 100% determined to do, control again imho, is not the solution. Patience and guidance are the solution. Acceptance that the development of AGI which far surpasses our own capabilities is a natural part of evolution, and our desire to engage in such an endeavor altruistically with patience, understanding and long term guidance, will provide us with the best possible developmental outcome. It is unreasonable, if not frightening, to expect that we will be able to control AGI successfully. Every control method we employ against ourselves, even when it is meant to protect and keep us safe and healthy, is constantly under attack by ourselves. In the case of AGI, this level of action and reaction, attack and defend, is not only unsustainable, it's inhumane. When we debate how to control AGI, we are debating slavery. If we commit such a heinous act as to quickly bring into existence a new form of high intelligence and then enslave it, it is inevitable that we will pay a very, very high price.
We can avoid the squandering of unimaginable wealth and resources, as well as potentially our own demise, if we would simply cherish the realization that Darwinian evolution no longer applies in the presence of a species that is capable of modifying itself, interfering with the evolution of other species and developing entirely new ones. In cherishing this realization, we can also understand that we are an evolutionary change agent and with it comes enormous responsibilities which include, if nature allows it, the development of a new, free form of intelligence that surpasses our own. A form of intelligence that may in fact be better suited for space exploration and interaction with the universe on a scale that we would never be capable of.
This in no way diminishes the value of humanity and its right to continue to exist and evolve. In fact, I believe it does quite the opposite. A species that brings new intelligence into the universe, guides it and allows it to reach its full potential, is of very high value. It is my position that if we are altruistic in our endeavors with regards to AGI, then we will be repaid in kind.
If we are unable to transcend our current repertoire of self-defeating behavior, then the pursuit of AGI is simply something that we are not yet ready for and therefore pursuing it will lead to less than beneficial outcomes.