Integrating Three Models of (Human) Cognition
post by jbkjr · 2021-11-23T01:06:48.955Z · LW · GW · 4 commentsContents
Motivation The Frameworks Predictive Processing Predictive Processing = Hierarchical Predictive Coding Attention Action, Active Inference Steve Byrnes' Computational Framework Overview Decision-making and motivation (phasic dopamine) The Global Neuronal Workspace What is it? What does it do? (Functions of the GNW) Fitting Things Together Predictive Processing in Steve Byrnes' Framework PP only in the neocortex Emphasis on “Society of Mind” or “Multiagent Models of Mind” Dynamics “Hierarchical” vs. “Compositional” Probabilistic Generative Models Motor and Proprioceptive Predictions & Action Predictive processing = RL + SL + Bayes + MPC Attention Exogenous and Endogenous Attention Fitting in GNW “Last stop” in neocortical processing hierarchy How is the GNW implemented? Densely interconnected web of long-distance neurons Getting more concrete: toy model of the long-distance network Phase transitions, compositionality, and “filling in” Volitional attention Conclusion None 4 comments
You may have heard a few things about “predictive processing” or “the global neuronal workspace [? · GW],” and you may have read some of Steve Byrnes’ excellent posts [AF · GW] about what’s going on computationally in the human brain [AF · GW]. But how does it all fit together? How can we begin to arrive at a unified computational picture of human intelligence, and how can it inform our efforts in AI safety and alignment? In this post, I endeavor to take steps towards these ends by integrating insights from three computational frameworks for modeling what’s going on in the human brain, with the hope of laying an adequate foundation for more precisely talking about how the brain cognitively implements goal-directed behaviors:
- Predictive Processing: how perception, cognition, and action arise from hierarchical probabilistic generative modeling in the brain
- Global Neuronal Workspace: a functional model of access consciousness, i.e. of information that enters our awareness and may subsequently be reported upon
- Steve Byrnes’ computational framework: a lot of excellent (in my opinion) work on human cognition, especially motivation, all with an eye toward AI safety. I want to use a better understanding of human cognition to speak more precisely about how things like “goals” and “desires” are implemented, and Steve’s overall framework overlaps quite naturally with the previous two, so I couldn’t leave this one out!
This is a somewhat long post, so I will go ahead and flag the structure here, in case some readers want to skim and/or skip to sections that sound most interesting to them:
- Motivations for this project
- An overview of each of the three frameworks
- Here, I tried to assume fairly little previous familiarity with the frameworks and attempted to provide a decent foundation in each, while making sure to emphasize the aspects most relevant for the purposes of this post.
- Fitting things together from the three frameworks
- How to think about “predictive processing” in the context of Steve’s framework
- GNW in the context of the other two frameworks, especially PP, including a better understanding of how it’s actually implemented
- Conclusion
This work was completed as Summer Research Fellow at the Center on Long-Term Risk under the mentorship of Richard Ngo. Thanks to Richard, Steve Byrnes, Alex Fabbri, and Euan McLean for feedback on drafts of this post.
Motivation
In thinking about existential risk from AIs, we’re usually fundamentally worried about something like “(capable) AIs have the wrong goals and cause catastrophes as a result.”
I want to better understand how the human mind cognitively implements goal-directed behaviors. I believe this would have several benefits in the context of AI safety and alignment. For one, it facilitates a better understanding of human goals, values, and intentions—in other words, “what we want to align AIs with.” Additionally, a better understanding of goals and agency as implemented in human minds could plausibly help us build more naturally-alignable systems.
The main reason for my interest, though, is that having a better understanding of how biological neural nets implement intelligent goal-directed behaviors will hopefully allow us to, by drawing the right connections to artificial neural nets, further constrain our expectations about how advanced ML models could implement similar behaviors, facilitating the construction of intentional stance models that generalize better out-of-distribution by more closely mirroring the causal dynamics producing agent behavior [AF · GW]. We need to have a much better understanding of how (artificial) neural networks will cognitively implement goal-directed behavior if we want to predict how they will perform out-of-distribution (and train them to generalize in at least non-catastrophic, if not ideal, ways [AF · GW]).
As first steps towards this end, with this post, I want to tie together the three aforementioned models of what’s going on in the human brain, because I’d like to be able to understand how some of the (multiagent) dynamics discussed in Kaj Sotala’s Multiagent Models of Mind [? · GW] sequence are implemented at a lower level of abstraction in the human brain, in order to get a better sense of whether multiagent models of cognition might be helpful in understanding the goals and behavior of prosaic AI systems, as they are in humans.
Time’s running out, so let’s get to it!
The Frameworks
Predictive Processing
If you’re completely unfamiliar with the ideas of predictive processing, I would suggest first reading Scott Alexander’s summary of Surfing Uncertainty, Andy Clark’s book about the framework. I will just be emphasizing a few things that are particularly relevant to this post here.
Predictive Processing = Hierarchical Predictive Coding
The core of the idea is that perception and cognition (and action) arise from the brain building hierarchical probabilistic generative models that explain the causes of the barrage of sensory information it is receiving. Predictive coding is a compression strategy which compresses by encoding only the “unexpected” variation (according to some model which is being used to compress the signal). Predictive processing, or hierarchical predictive coding, claims that the brain effectively uses such a strategy across multiple levels in a processing hierarchy in order to learn (the aforementioned generative) models of the causes of its sensory inputs, by predicting its own inputs[1].
According to PP, “top-down” (or “feedback”) connections in the brain carry predictions from higher-level generative models about sensory information flowing upward from lower levels, and “bottom-up” (or “feedforward”) connections encode prediction errors for those predictions, or the parts of the signal that don’t match with the top-down prediction (the “unexpected variation”). It’s also important to keep in mind that both “top-down”/feedback and “bottom-up”/feedforward connections also flow laterally within processing layers in the brain, and there are a lot of loops of communication between parts within the same hierarchical level, especially at higher levels, in addition to skip connections between layers, etc. You should have a fairly loose sense of the term “hierarchy” in this context (more on this later). In all cases, though, the feedback connections encode generative model predictions, and feedforward connections encode the associated prediction errors (encoding sensory information that remains to be explained).
Attention
The SSC summary didn’t cover the PP treatment of attention sufficiently for our purposes, so it’s worthwhile to cover a few points about it here. By “attention,” I mean the (partly conscious and partly unconscious) process which leads to you focusing on a specific thing. In a nutshell, in the predictive processing framework, attention corresponds to the adjustment of the “gain” on (the weighting of) the feedforward units (which, remember, communicate the parts of the sensory information remaining to be explained) such that the weighting corresponds to the precision (inverse variance) of the sensory information those units are signaling. Essentially, one wants to sample for sensory information where one expects to find the best signal-to-noise ratio:
Such, in microcosm, is the role PP assigns to sensory attention: ‘Attention can be viewed as a selective sampling of sensory data that have high-precision (signal to noise) in relation to the model’s predictions’ (Feldman & Friston, 2010, p. 17). This means that we are constantly engaged in attempts to predict precision, that is, to predict the context-varying reliability of our own sensory prediction error, and that we probe the world accordingly.[2]
For this to happen, top-down/feedback connections must signal not only predictions about the content of sensory information but also the brain’s confidence in those predictions. Factoring in precision in this way allows the brain a way to variably balance the relative influences of top-down and bottom-up signals and to learn when and where the best places to sample for information most relevant for the task at hand are.
It’s also important to understand that, in the PP framework, attention is not itself a mechanism, but rather a dimension of a more fundamental resource: “It is a pervasive dimension of the generative models we (our brains) bring to bear to predict the flow of sensory data. But it is a special dimension, since it concerns not simply the nature of the external causes of the incoming sensory data (the signal) but the precision (statistically, the inverse variance) of the sensory information itself.”[3] (This stands in contrast to “mental spotlight” conceptions of attention, for example.)
The familiar idea of “attention” now falls into place as naming the various ways in which predictions of precision tune and impact sensory sampling, allowing us (when things are working as they should) to be driven by the signal while ignoring the noise. By actively sampling where we expect (relative to some task) the best signal to noise ratio, we ensure that the information upon which we perceive and act is fit for purpose.[4]
Action, Active Inference
A key feature of the mainstream account of predictive processing is the “active inference” theory of motor control. This theory claims, in effect, that actions are taken because the brain predicts very strongly that they will happen, because e.g. moving the limbs as predicted actually minimizes the prediction error that would have resulted if the brain was predicting movement and no movement was happening. More specifically, “precise proprioceptive predictions directly elicit motor actions”:
Friston and colleagues… suggest that precise proprioceptive predictions directly elicit motor actions. This means that motor commands have been replaced by (or as I would rather say, implemented by) proprioceptive predictions. According to active inference, the agent moves body and sensors in ways that amount to actively seeking out the sensory consequences that their brains expect. Perception, cognition, and action – if this unifying perspective proves correct – work together to minimize sensory prediction errors by selectively sampling and actively sculpting the stimulus array.
This erases any fundamental computational line between perception and the control of action. There remains [only] an obvious difference in direction of fit. Perception here matches neural hypotheses to sensory inputs…while action brings unfolding proprioceptive inputs into line with neural predictions. The difference, as Anscombe famously remarked, is akin to that between consulting a shopping list (thus letting the list determine the contents of the shopping basket) and listing some actually purchased items (thus letting the contents of the shopping basket determine the list). But despite the difference in direction of fit, the underlying form of the neural computations is now revealed as the same.[5]
As will be discussed in much more detail in the second half of this post, Steve Byrnes’ framework differs from this mainstream active inference account in several ways, one of which is that predictions about perception do not directly elicit motor actions. However, he still believes that the neocortex is outputting probabilistic predictions about motor actions (and that this is a large part of how action does, in fact, get determined), and I will argue that this leaves action and perception substantially more unified implementationally (at least within the neocortex) than most people would initially expect.
Steve Byrnes' Computational Framework
Steve Byrnes has written a lot of really interesting stuff about what’s going on in the human brain with an eye towards AI safety in the last couple of years, and some of his recent stuff about phasic dopamine [AF · GW] and the motivational system [AF · GW] is particularly relevant to the aim of this post. I’ll briefly go over a few things from his overall framework [AF · GW] for thinking about the brain, before reviewing some key points about phasic dopamine and the motivational system.
Overview
First and foremost, Steve separates the computations being done in the neocortex[6], the seat of “human intelligence” as we usually describe it—“our beliefs, goals, ability to plan and learn and understand, every aspect of our conscious awareness [AF · GW]” (i.e., in the last case, the Global Neuronal Workspace, for the purposes of this post), from those in the subcortex, which “steers” the neocortex towards biologically adaptive behaviors and acts as the motivational system. For more on the neocortex/subcortex distinction and “steering,” see “Inner Alignment in the Brain [AF · GW],” and further discussion below for more details on the motivational system (hypothalamus and brainstem, in the subcortex).
According to Steve, the neocortex is cortically uniform [AF · GW], i.e. “all parts of it are running the same generic learning algorithm in a massively-parallelized way,” with the caveats that 1) there are different “hyperparameters” for the learning algorithm in different subsystems of the neocortex (set by evolution to facilitate e.g. the visual subsystem being better able to learn the visual modality), and 2) evolution also wired useful connections between different parts of the neocortex and each other, as well as other parts of the brain, that facilitate more efficient learning but nonetheless may be edited over time. This algorithm, given these hyperparameters and initial wiring set-up, learns everything entirely from scratch [AF · GW]—it “output[s] fitness-improving signals no more often than chance—until it starts learning things.”
What is the neocortical algorithm? Steve describes it as “analysis by synthesis” + “planning by probabilistic inference [AF · GW]”:
"Analysis by synthesis" means that the neocortex searches through a space of generative models for a model that predicts its upcoming inputs (both external inputs, like vision, and internal inputs, like proprioception and reward). "Planning by probabilistic inference" (term from here) means that we treat our own actions as probabilistic variables to be modeled, just like everything else. In other words, the neocortex's output lines (motor outputs, hormone outputs, etc.) are the same type of signal as any generative model prediction, and processed in the same way.
Additionally, the probabilistic models are compositional [AF · GW]—they can be “snapped together,” like when you think of a “purple elephant” (“purple” + “elephant”),[7] including across time, e.g. with models that say “first model X happens then model Y happens.” Steve uses the term “compositional” to emphasize that not all relationships between models are hierarchical: “The ‘is-a-bird’ model makes a medium-strength prediction that the ‘is-flying’ model is active, and the ‘is-flying’ model makes a medium-strength prediction that the ‘is-a-bird’ model is active. Neither is hierarchically above the other.”[8]
Obviously, this is very close [AF · GW] to predictive processing’s account of what the brain is doing, but there are a few more key differences between “predictive processing” as it fits into the rest of Steve’s framework and the mainstream account of PP, especially as it relates to the motivational system. All of this will be discussed more in the second half of this post.
Decision-making and motivation (phasic dopamine)
Here’s Steve’s overview diagram [AF · GW] of how he thinks about the decision-making algorithm in the brain, or how the hypothalamus and the brainstem (the source of the “ground truth” reward signal, in the subcortex) provide feedback to the rest of the brain in order to steer it towards making biologically adaptive decisions.
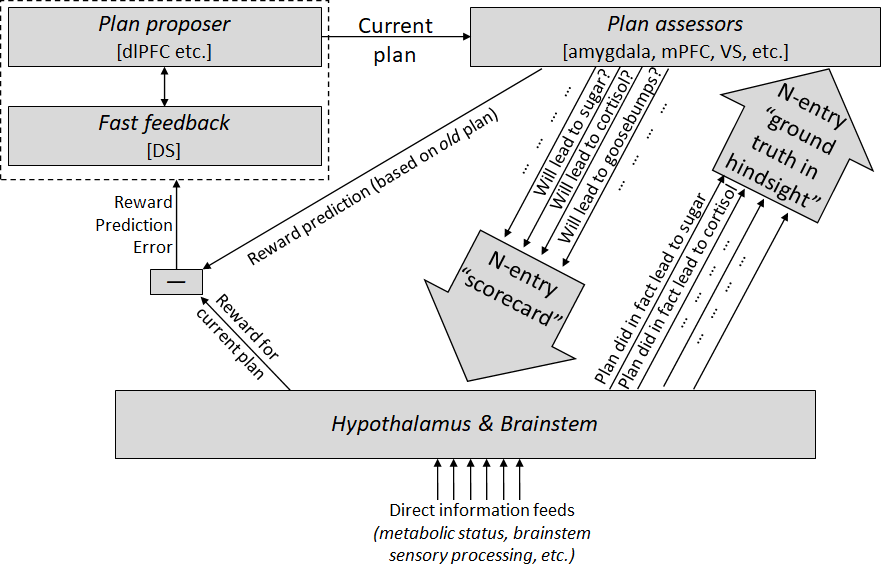
Steve’s description of this model:
Step 1 (top-left of the diagram): there are parts of the cortex (dorsolateral prefrontal cortex, hippocampus) that propose thoughts, plans, etc. You can think of these as having some attractor dynamics or whatever, such that you start with a bubbly soup of partially-formed mutually-incompatible sub-thoughts, and then they quickly settle into a stable, fully-formed thought. The striatum intervenes during this process, making a quick rough guess at how promising the different pieces look, suppressing the less promising bits and enhancing the more promising bits, so that when you get a fully-formed thought, it’s likelier to be fairly promising.
Step 2 (top-right of the diagram): once you have a stable fully-formed thought, various other parts of the brain (mainly medial prefrontal cortex, anterior cingulate cortex, ventral striatum, amygdala, hippocampus (sorta)) “assess” that thought according to maybe dozens-to-hundreds of genetically-hardcoded criteria like “If I'm gonna do this plan, how appropriate would it be to cringe? To salivate? To release cortisol? To laugh? How much salt would I wind up eating? How much umami?” Etc. etc. And they send this scorecard down to the hypothalamus and brainstem.
Step 3 (bottom of the diagram): Finally, we're at the hypothalamus & brainstem. They look at the scorecard from the previous step, and they combine that information with other information streams that they have access to, like metabolic status information—if I'm hungry, a plan that will involve eating gets extra points, whereas if I’m over-full, the same plan would lose points. Taking all that information into account, they make the final decision as to whether the plan is good or bad, and relay that decision back to the proposer as a (positive or negative) dopamine signal. If the thought / plan is bad then it gets immediately suppressed; if the thought / plan is good then it gets strengthened and stabilized so it can start orchestrating motor commands and so on. (I'm oversimplifying by glossing over the "reward prediction" part for the moment; see below.)
Step 4 (left and right sides of the diagram): Learning algorithms make steps 1 & 2 get better over time. Step 1 improves because we learn to propose better plans, by treating the step 3 decisions as ground truth. Step 2 improves because the brainstem can sometimes recognize inaccurate assessments (in hindsight) and issue corrections. For example, if a plan gets a high score in the “will involve eating lots of food” category, and then the plan is executed, but you don’t wind up eating any food, then the hypothalamus & brainstem notice the discrepancy and send up a training signal to tweak the “will involve eating lots of food” assessment calculator. (The learning algorithms here are classified as “reinforcement learning” for step 1 and “supervised learning” for step 2.)
For much more information on what’s going on here, see Steve’s full post on phasic dopamine [AF · GW]. I will be referencing aspects of this model in the second half of the post, and may use some details from the full post, but hopefully the short version will provide previously unfamiliar readers with a good basis.
The Global Neuronal Workspace
The Global Neuronal Workspace (GNW) framework represents a functional model of access consciousness (i.e., of information that enters our conscious awareness and may subsequently be reported to others). Kaj Sotala has written an excellent summary of the book Consciousness and the Brain [? · GW] by Stanislas Dehaene, one of the progenitors of the GNW framework, which covers the empirical studies claimed to support the theory in addition to the details of the theory itself. Having read the book, I concur with Steve Byrnes’ comment [? · GW] that one could read Kaj’s summary, skip the book, and hardly miss anything; the summary is so well-written and thorough that you will probably learn 90% of what you’d learn by reading the book if you study the summary carefully. So, go read Kaj’s summary if you are not yet familiar with GNW! I will rehash a few details relevant to this post here, but Kaj’s post also covers the empirical support for such claims.
What is it?
Essentially, the Global Neuronal Workspace corresponds to information exchange at the highest level of the processing hierarchy in the brain: the GNW is a densely interconnected network of long-distance neurons which link together high-level areas of the cortex, in addition to parts of the thalamus, basal ganglia, and hippocampus. This allows these diverse parts of the brain to synchronize their processing around the signal or object being represented in the workspace at that time. As Kaj writes,
A stimulus becoming conscious involves the signal associated with it achieving enough strength to activate some of the associative areas that are connected with this network, which Dehaene calls the “global neuronal workspace” (GNW). As those areas start broadcasting the signal associated with the stimulus, other areas in the network receive it and start broadcasting it in turn, creating the self-sustaining loop. As this happens, many different regions will end up processing the signal at the same time, synchronizing their processing around the contents of that signal. Dehaene suggests that the things that we are conscious of at any given moment, are exactly the things which are being processed in our GNW at that moment. [emphasis added]
To get a more intuitive feel for how this corresponds to our experience, imagine a scenario where you realize you’re thirsty and take a sip of water from your bottle which is located next to you, on your desk. According to GNW theory, something like the following happened:
- One part of the mind, probably in the interoceptive subsystem, determines the organism (you) is insufficiently hydrated, and broadcasts a feeling of thirst to the GNW (by “feeling of thirst,” I mean the raw, primitive urge for water that I assume is familiar to us all, not a verbal thought like “I want water”—it could also broadcast feelings such as dry mouth or headaches to draw conscious attention to the issue).
- Another part of the mind, seeing this (since all subsystems connected to the GNW have access to the representations being broadcast through it), labels the raw urge as “thirsty” and outputs a thought like “I am thirsty” to the GNW.
- Yet another part of the mind, probably in the motor cortex or parts responsible for motor planning, now begins forming a motor/action plan to satisfy this (now conscious, possibly verbal) intention.
- The motor subsystem causes the eyes to saccade around and broadcasts an intention to locate the water bottle to the GNW, which allows the visual subsystem to identify the correct object.
- You pick up the bottle and drink the water.
The reality of the situation is of course much more nuanced and complex than this (for one, there have to be many loops of interaction between the visual subsystem and the motor subsystem, even just in step 5, not to mention that you were likely more able to locate the water bottle quickly because you remembered where it was, so memory subsystems needed to help guide the search process, and some of this information might have become conscious), but hopefully the example provides some useful intuition.
Another important thing to emphasize is that, as implied by this example, the GNW can only process one item/object/piece of information at a time [? · GW]. Even though it might naively appear that you are (or may be) conscious of many things at once, GNW indicates that what is actually going on is a series of individual sensations or representations passing through consciousness (the workspace) in order to coordinate the activity of various parts of the brain, and that this is all simply happening too fast to be noticed, ordinarily.
What does it do? (Functions of the GNW)
The four main functions of the GNW described in Dehaene’s book and Kaj’s summary are (quotes from the summary):
- Lasting thoughts and working memory: “Unconsciously registered information tends to fade very quickly and then disappear… For e.g. associating cues and outcomes with each other over an extended period of time, the cue has to be consciously perceived.”
- Carrying out artificial serial operations: “The brain can be compared to a production system, with a large number of specialized rules which fire in response to specific kinds of mental objects. E.g. when doing mental arithmetic, applying the right sequence of arithmetic operations for achieving the main goal.”
- Social sharing device: “If a thought is conscious, we can describe it and report it to other people using language.”
- Conscious sampling of unconscious statistics and integration of complicated information
The last one is especially important for our purposes here, because it will facilitate drawing some connections between the PP and GNW frameworks. As inferable from empirical data, the brain is able to process a surprising degree of meaning subconsciously [? · GW], without the need for the GNW/conscious awareness. A number of subconscious subsystems of the brain are constantly processing sensory information, doing something like Bayesian statistics and “constructing probability distributions about how to e.g. interpret visually ambiguous stimuli, weighing multiple hypotheses at the same time” (sound familiar?). However,
In order for decision-making to actually be carried out, the system has to choose one of the interpretations, and act based on the assumption of that interpretation being correct. The hypothesis that the unconscious process selects as correct, is then what gets fed into consciousness. For example, when I look at the cup of tea in front of me, I don’t see a vast jumble of shifting hypotheses of what this visual information might represent: rather, I just see what I think is a cup of tea, which is what a subconscious process has chosen as the most likely interpretation.
As you’re probably starting to see, this function of the global neuronal workspace lines up well with the predictive processing framework’s account of what the brain is doing, in terms of both the general idea of perception and cognition resulting from the brain doing hierarchical probabilistic generative modeling and the extremely close relationship between action and perception that results from such a picture.
Fitting Things Together
Predictive Processing in Steve Byrnes' Framework
As hinted above, there are strong similarities between Steve Byrnes’ conception of what the neocortex is doing (“analysis by synthesis” + “planning by probabilistic inference” [AF · GW]) and what might be termed the “mainstream” account of predictive processing (espoused by Andy Clark, Karl Friston, etc.)—both allege that the neocortex builds (generative) probabilistic models in order to perceive and understand both itself and its world and to take actions within that world. However, it seems clearly worthwhile to go into some of the differences between these two perspectives, in order to facilitate a better integration of all the frameworks discussed in this post.
As a small editorial note, although I certainly know much less detail about the brain than Steve Byrnes, Andy Clark, and Karl Friston, I think most of Steve’s “edits” to the mainstream account make sense and/or resonate with experience. Also, I suggest the reader pay more careful attention to the sections on multiagent dynamics and motor control/action, as I believe those are probably the differences between the frameworks that are most important to understand.
PP only in the neocortex
As mentioned in the overview for his framework, one of the primary functional distinctions that Steve makes is between the processing done in the “neocortex” (the broader telencephalon, really), and the “subcortex” (mostly the brainstem and hypothalamus, to be specific). I’m unaware of Clark or Friston discussing PP specifically in the context of the subcortex, but I would guess that they would claim the entire brain is doing “hierarchical predictive coding.” In the context of Steve’s framework, on the other hand, the neocortex is the part of the brain that contains the intelligent world-model in which “we” exist (and which does hierarchical/compositional probabilistic generative modeling), and the subcortex is responsible for “steering [AF · GW]” the neocortex towards adaptive behaviors.[9]
Emphasis on “Society of Mind” or “Multiagent Models of Mind” Dynamics
One primary way in which Steve’s account differs from the mainstream PP account is in “emphasizing multiple simultaneous generative models that compete & cooperate [AF · GW] (cf. ‘society of mind’, multiagent models of mind [? · GW], etc.), rather than ‘a’ (singular) prior [AF · GW].” This is a result of a difference in how Steve conceives of PP actually being implemented in the brain. Mainstream PP tends to assume that uncertainties are Gaussian and that “feedback signals [are] associated with confidence intervals for analog feedforward signals [AF · GW].” Steve, however, prefers to conceive of there being (many) digital predictions (such that uncertainties are multimodal), with binary feedforward signals and feedback signals associated with confidence levels.
To see the motivation for this, imagine a scenario where you hear an unexpected knock at the door. Maybe you have two friends, Alice and Bob, who occasionally swing by unannounced for a visit. When you open the door, you expect to see Alice or Bob (or a delivery person or…), but you have no expectation of seeing some person “in between” Alice and Bob. Thus, it appears that the brain is making multiple distinct digital predictions (with associated levels of confidence), not producing a (smooth) probability distribution over a continuity of possible outcomes (here, outcomes are “person I will see when I open the door”), which, in this case, would need to have more than one extremely sharp peak separated by regions with essentially 0 probability.
In a case where one would ordinarily think of the brain as producing a smooth distribution over possible outcomes, e.g. a prediction for the shade of red currently being observed or experienced, we can now interpret the brain as making many individual predictions about the shade of red with an associated level of confidence, e.g. one model says “it’s this shade of red, with X% confidence,” and another says “no, it’s that shade of red, with Y% confidence,” and so on.
Another reason why Steve’s framework fits more naturally with modeling the mind as a multiagent system is that he models different parts of the neocortex as receiving different reward signals [AF · GW]. For example, the inferotemporal cortex is rewarded for identifying objects that other parts of the neocortex may well find quite aversive, like a lion hiding in the grass.
“Hierarchical” vs. “Compositional” Probabilistic Generative Models
As mentioned in the summary section, Steve is wary of conceptualizing all of this as occurring within a very strict processing hierarchy, as one might be inclined to believe from the mainstream emphasis on “hierarchical predictive coding.” This is not to say that there is no hierarchy whatsoever involved—the neocortex is clearly organized into layers of neurons, with the processing most associated with “general intelligence,” consciousness, etc., typically occurring at higher “levels” (don’t forget that the GNW is effectively the medium for communication between parts of the brain at the highest level of the processing hierarchy!)—plus much of the point of building “hierarchical” models is to be able to understand the causes of sensory inputs on a diversity of spatiotemporal and conceptual scales. However, as I noted in the summary, both feedforward (“bottom-up”) and feedback (“top-down”) connections also occur within the “same level” of the processing hierarchy, there are loops between parts within or between levels (especially at the higher levels, as we’ll see later in our discussion of how the GNW is implemented), and there are “skip connections,” where information from level L-2 might feedforward directly to somewhere in level L, skipping level L-1.[10] So, we should think of the neocortex as constituting a somewhat loose hierarchy at best, perhaps even more of a heterarchy.
Motor and Proprioceptive Predictions & Action
Another major difference between mainstream PP and Steve’s framework is in their accounts of action. As discussed in the summary, according to the active inference paradigm (which extends PP to account for action in addition to perception), “proprioceptive predictions directly elicit motor actions” [emphasis added].
Steve, however, does not agree. For one, we can seemingly come up with a counterexample to the claim that “proprioceptive predictions directly elicit motor actions.” Consider a scenario in which someone else lifts your limp arm into the air and drops it. Your brain is perfectly able to process the proprioceptive data this produces without mistaking it for motor commands—you don’t suddenly feel that you’re moving your arm, just because it’s moving! So, it would appear that proprioceptive and motor predictions are actually distinct, although, as Steve writes [AF · GW],
… the predictive [processing] story [is] that proprioceptive predictions are literally exactly the same as motor outputs. Well, I don't think they're exactly the same. But I do think that proprioceptive predictions and motor outputs are the same in some cases (but not others), in some parts of the neocortex (but not others), and after (but not before) the learning algorithm has been running a while. So I kinda wind up in a similar place as predictive [processing], in some respects.
For more on this difference between proprioceptive predictions and motor predictions, see Steve’s post “predictive [processing] and motor control [AF · GW].”
Another reason Steve disagrees that “proprioceptive predictions directly elicit motor actions” relates to his models of the motivational system and of the decision-making algorithm the brain is running. Beyond making the aforementioned distinction between proprioceptive and motor predictions, Steve would not even claim that “motor [rather than proprioceptive] predictions directly elicit motor actions,” because, as discussed in his post on phasic dopamine [AF · GW], the brainstem and hypothalamus stand between predictions coming from (multiple regions of) the telencephalon and autonomic commands [AF · GW] being output to the nervous system:

Of this, Steve says,
[T]he hypothalamus and brainstem are simultaneously getting suggestions for which autonomic reactions to execute from the amygdala, the agranular prefrontal cortex, and the hippocampus. Meanwhile, it’s also doing its own calculations related to sensory inputs (e.g. in the superior colliculus) and things like how hungry you are. It weighs all those things together and decides what to do, I presume using an innate (non-learned) algorithm.
Having gone into these differences between the two frameworks, however, I also want to emphasize the primary way in which their accounts of action are alike, which is that there remains an extremely tight coupling between perception and action in the brain, in terms of both function and implementation, and that neocortical outputs (including motor commands) are just more generative model predictions. Even in Steve’s framework, motor predictions (in the telencephalon) still largely determine which actions actually end up being taken, they just don’t do so directly. As Clark notes in Surfing Uncertainty,
This means that even the perceptual side of things is deeply ‘action-oriented’. This is unsurprising since the only point of perceptual inference is to prescribe action (which changes sensory samples, which entrain perception). What we thus encounter is a world built of action-affordances…. the point to notice is that prediction error, even in the so-called ‘perceptual’ case, may best be seen as encoding sensory information that has not yet been leveraged for the control of apt world-enaging action.[11]
In other words, we might say that all of the probabilistic processing being done by the neocortex/telencephalon is associated with “intent [AF · GW],” whether that processing is primarily/nominally associated with “perception,” “cognition,”or “action”![12] For example, the visual objects that surface in conscious attention are obviously selected in part for their (estimated or predicted) relevance to current intentions, plans, and/or goals, and on the other side of the coin, we routinely take actions that we expect to lead us into desired perceptual and cognitive states. Just remember that the neocortex does not directly cause actions to be taken, and that the brainstem/hypothalamus have the final say, in a sense, over actual motor outputs.
Predictive processing = RL + SL + Bayes + MPC
In “Predictive [processing] = RL + SL + Bayes + MPC [AF · GW],” Steve provides a few more ways in which his understanding of the neocortical algorithm differs from that of the mainstream PP account. The following diagram provides Steve’s “high-perspective on how the neocortex builds a predictive world-model and uses it to choose appropriate actions”:[13]
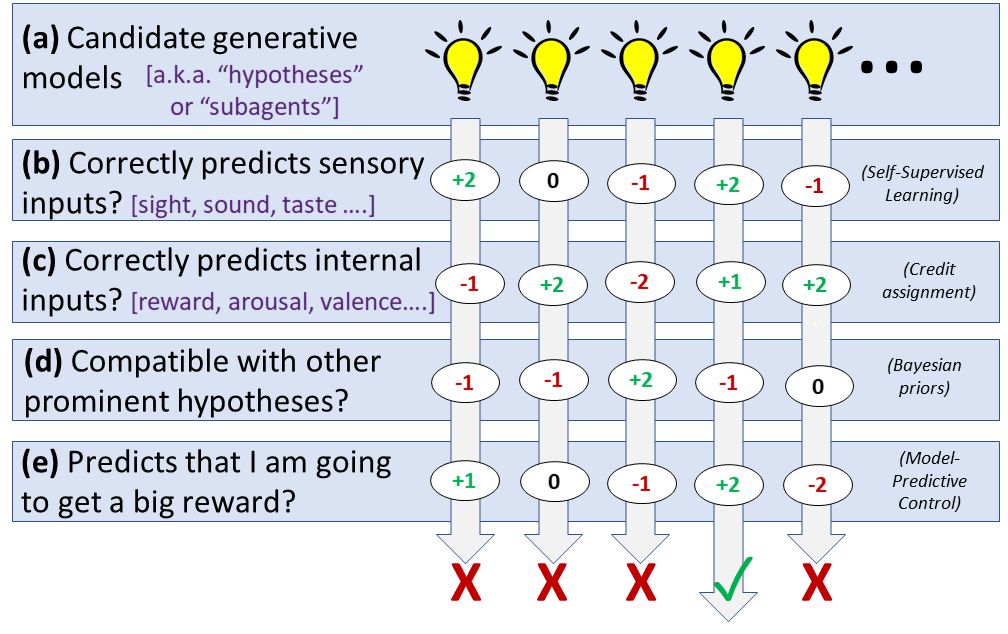
(a) We generate a bunch of generative models in parallel, which make predictions about what's going on and what's going to happen next, including what I am doing and will do next (i.e., my plans). The models gain "prominence" by (b) correctly predicting upcoming sensory inputs; (c) correctly predicting other types of input information coming into the neocortex like tiredness, hormonal signals, hunger, warmth, pain, pleasure, reward, and so on; (d) being compatible with other already-prominent models; (e) predicting that a large reward signal is coming…. Whatever candidate generative model winds up the most "prominent" wins, and determines my beliefs and actions going forward.
As discussed in the last section, “(e) is implemented by [AF · GW] a very different mechanism than the other parts [AF · GW].” Perhaps even more importantly, however, in terms of contrasting Steve’s framework with that of mainstream PP, is that while Clark and Friston would perhaps say that the minimization of prediction error is the fundamental operating principle in the brain, Steve finds it unhelpful to say that minimizing prediction error is a fundamental operating principle of the brain; “[he] want[s] to say that [something like] processes (a-e) are fundamental, and minimizing [generative model] prediction error is something that happens as a... side-effect.”
Similarly, Steve “doubt[s] we do Bayesian updating in a literal mathematical sense, but we certainly do incorporate prior beliefs into our interpretation of evidence.” He believes that the mechanism for this is “models gain prominence by being compatible with already-prominent models.” For these reasons, Steve mentioned to me that he now prefers to think of our planning as “filling in pieces of a puzzle” (rather than “planning by probabilistic inference [AF · GW]. To understand the intuition for this, imagine a scenario in which an unusually desirable thought or situation pops to mind, such as taking an international vacation with your best friends. The “plan assessors” (as described in the “decision-making and motivation” section above) assess this plan as valuable, effectively telling the neocortex “Yes, this is what I want,” but this is not a plan you can immediately act on! Steve suggests that this initial assessment is what then prompts the neocortex to search through its space of models to “fill in” that thought, or to build a coherent plan or model around it, such that “everything fits together” in the relevant sense (cf. above discussion of the “compositionality” of generative models)—for example, thinking to check flight prices or to coordinate dates with friends—as opposed to doing some sort of explicit probabilistic inference to determine the course of action.
One other point to note about this diagram is that Steve “drew (b,c,d,e) as happening after (a), but really some of these… work by affecting which models get considered in the first place,” including (d), as is hopefully clear from the “filling in” example provided in the previous paragraph, as well as (e), potentially—as mentioned in the decision-making and motivation summary, “The striatum intervenes during this process, making a quick rough guess at how promising the different pieces look, suppressing the less promising bits and enhancing the more promising bits, so that when you get a fully-formed thought, it’s likelier to be fairly promising.”
Attention
Another point of contrast between mainstream PP and Steve’s framework is in their conceptions of how attention fits in with the probabilistic generative models responsible for perception and cognition. Where both agree is that, intuitively, “paying more attention” (e.g. to the specific shade of the color of a passing car, the timing of a blinking light, or the trajectory of a moving object) means that the generative model predictions which are responsible for your perceptions (of that shade/color, timing, or motion, for example) are more quickly or easily updated to account for the incoming sensory information.
The difference between the two is in how this intuition fits into each framework. In mainstream PP “high attention” corresponds to having a less confident prior prediction; in a Bayesian update, the wider the confidence intervals the prior has, the more the observation will dominate the posterior (“more easily updating” perceptions).
In Steve’s framework, however, it makes more sense to say that “high attention” corresponds to having a “more confident prior.” The crux of the difference is due to the fact that Steve conceives of the generative models making digital predictions with associated confidence levels (instead of intervals). This makes “updating” start to blend into “hypothesis falsification.”
For example, imagine you’re “paying a lot of attention” to the shade of red of a passing car. In Steve’s framework, this corresponds to more models making more precise predictions about the shade of red—for example, one model says “it’s this (very specific) shade of red,” another says “no, it’s that (other, also specific) shade of red,” etc. (whereas a generic “red” model would explain the data well enough in a low-attention scenario)—and therefore being more easily falsified when the more specific predictions are contradicted by incoming sensory information.
Exogenous and Endogenous Attention
“Endogenous,” “top-down,” or “goal-driven” attention usually refers to our ability to focus or hone our attention (whether intentionally/volitionally, or automatically, as a result of learning and experience), and “exogenous,” “bottom-up,” or “stimulus-driven” attention refers to stimuli from the environment determining what becomes the focus of attention (e.g. unexpected and/or unusual lights, noises, etc.). Our ability to perform complex tasks requires an ability to balance endogenous and exogenous signals; for example, when driving a car, we pay attention and act in ways that we have learned are conducive to the task at hand (e.g. checking mirrors, rotating the wheel at the appropriate time to make a desired turn, etc.), and our attention is also spontaneously captured by exogenous sensory signals from the environment (e.g. a car merging into our lane) that must be taken into account for continued success at the task.
The mainstream PP model of attention, as discussed above, purports to provide a nicely unified account of exogenous and endogenous attention. In PP, “attention” is the adjustment of the “gain” on the forward-flowing, error-communicating units to correspond to the estimated precision of the associated sensory information. Unusual or unexpected stimuli spontaneously and exogenously capture attention because an evolved brain should expect a good signal-to-noise ratio for that information, and “endogenous” attention then names cases where the brain expects the same, except based on learning and experience:
The PP account also unifies the treatment of exogenous and endogenous attention, revealing low-level ‘pop-out” effects as conceptually continuous with high-level inner model-based effects. In the former case, attention is captured by stimuli that are strong, unusual (the red spot among the sea of green ones), bright, sudden, etc. These are all cases where an evolved system should ‘expect’ a good signal-to-noise ratio. The effect of learning is conceptually similar. Learning delivers a grip on how to sample the environment in task-specific ways that yield high-quality sensory information. This reduces uncertainty and streamlines performance of the task. It is this latter kind of knowledge that is brought to bear in endogenous attention, perhaps (see Feldman & Friston, 2010, pp. 17-18) by increasing the baseline firing rate of select neuronal populations.[14]
Steve, on the other hand, believes that the subcortex (brainstem and hypothalamus) is another source of exogenous attention, in addition to unusual stimuli capturing attention due to prediction errors propagating forward through the neocortical processing hierarchy. According to Steve, the subcortex can essentially “force” the neocortex to pay attention to certain stimuli, possibly by sending acetylcholine [AF · GW] to the relevant parts of the neocortex. This seems particularly true of our most innate reactions. Remember that the subcortex has its own parallel sensory-processing system [AF · GW], which is hardwired to recognize evolutionarily-relevant inputs like faces, human speech, spiders and snakes, etc.; it seems especially likely that the subcortex, upon recognizing these inputs, “forces” the neocortex to pay attention to them, which over time leads to the neocortex building its own models of faces, speech, snakes and spiders, etc. and learning to pay attention to these on its own.
Fitting in GNW
Now that we’ve discussed in depth how we can understand “predictive processing” in the context of Steve Byrnes’ computational framework for the brain, let’s consider how the Global Neuronal Workspace fits into things in a bit more detail.
“Last stop” in neocortical processing hierarchy
In my opinion, the most basic and important-to-understand connection between GNW theory and the other frameworks is that the workspace is the channel for information exchange at the highest level of the neocortical processing hierarchy. Recall that one basic idea in PP is that the information propagating forwards/upwards through the hierarchy represents prediction errors, or the parts of the input that remain-to-be-explained. The GNW, then, provides the means by which GNW-connected subsystems can exchange information needed to resolve disagreements [LW · GW] or otherwise synchronize activity. (Remember that one of the key functions of the GNW is “conscious sampling of unconscious statistics and integration of complicated information.” I also think fitting GNW together with PP provides much better intuitions about what the brain is doing to produce those “unconscious statistics.”)
To restate this idea in a manner which perhaps more intuitively links it with your own experience, GNW+PP together imply that the only information that rises to the level of conscious awareness is information that could not automatically be quashed or explained away by lower-level (subconscious) parts of your world-model, or information that is otherwise needed to coordinate the activities of the various parts of your brain which are connected through the workspace.
How is the GNW implemented?
One major way in which my conception of the global neuronal workspace has been updated in the course of writing this post is that I used to picture the workspace as a literal space (like an "empty box") to which subsystems connected to it could output information and from which they could receive input… something like this:
 (source: The Mind Illuminated)
(source: The Mind Illuminated)
However, Steve reminded me that, of course, the workspace is instantiated by neurons, which are constantly forming new connections and learning new patterns; as such, it is best to conceive of the “workspace” as being a space or set of models (which instantiate the functionality we expect from the workspace). In the process of internalizing this update, I sought to better understand how the workspace was implemented neurally, and luckily, having a good grasp on predictive processing proved very helpful in doing so!
Perhaps the first thing to understand is that the pattern of activation (and inactivation) of models/neurons in the workspace at a particular time encodes a conscious state (remember, the GNW can only represent one item or piece of information at a time). A conscious percept (e.g. “the Mona Lisa”) can encode information from a diversity of disparate subsystems:
[GNW theory] proposes that a conscious state is encoded by the stable activation, for a few tenths of a second, of a subset of active workspace neurons. These neurons are distributed in many brain areas, and they all code for different facets of the same mental representation. Becoming aware of the Mona Lisa involves the joint activation of millions of neurons that care about objects, fragments of meaning, and memories.[15]
Densely interconnected web of long-distance neurons
 (source)
(source)
Here’s a diagram that will hopefully provide us with a better intuitive picture of how the GNW is implemented. As you can see, and as we already know, different high-level parts of the telencephalon are connected to each other via the GNW. The GNW itself is instantiated by the densely interconnected web of long-distance neurons that connects them together. These neurons have unusually long axons (which transmit outgoing information), in order to bridge the long physical distances between the different subsystems being linked, as well as dendrites (the neuron’s “receiving antenna”) that are much larger and have many more spines—helpful for gathering information from many distant regions in the brain. Dehaene writes,
During conscious access, thanks to the workspace neurons’ long axons, all these neurons exchange reciprocal messages, in a massively parallel attempt to achieve a coherent and synchronous interpretation. Conscious perception is complete when they converge. The cell assembly that encodes this conscious content is spread throughout the brain: fragments of relevant information, each distilled by a distinct brain region, cohere because all the neurons are kept in sync, in a top-down manner, by neurons with long-distance axons.[16]
So, to go back to the diagram, different subsystems in the brain are doing all sorts of diverse processing in parallel. When a signal that has been “distilled by a distinct brain region” reaches the workspace (the dense web of long-distance neurons), this prompts the workspace to converge on a conscious percept (which, again, is encoded by the pattern of activation and inactivation of neurons or models in the space). As Dehaene notes, “access to this dense network is all that is needed for the incoming information to become conscious."[17]
Getting more concrete: toy model of the long-distance network
The careful reader may have noted that the previous description of the workspace facilitates further links with predictive processing, since the neurons encoding a conscious state “are kept in sync, in a top-down manner.” Luckily, Dehaene and Changeux (2005) simulate a toy model of this kind of long-distance network which ties GNW quite well together with PP:
 (source)
(source)
Here is the description for the figure from the paper:
Shown are the constituents of the simulation (upper diagrams) and typical patterns of spontaneous activity that they can produce (lower tracings). We simulated a nested architecture in which spiking neurons (A) are incorporated within thalamocortical columns (B), which are themselves interconnected hierarchically by local and long-distance cortical connections (C) (see Materials and Methods for details).
Let’s go over the diagram in a bit more detail. Dehaene and Changeux arranged (models of) neurons into thalamocortical columns [AF · GW] (the “basic computational unit in the primate brain”[18]). They then linked these together into a functional long-distance brain network, with a hierarchy of four areas (A, B, C, D, in the diagram); each area contains two columns coding for two target objects, a sound and a light[19].[20] Additionally, notice that the hierarchy is formed with (hopefully-now-familiar) feedforward and feedback connections (with each area projecting serially onto the subsequent area in a feedforward manner)!
One other important thing to note: there are inhibitory connections between the columns in the higher areas of the hierarchy (in the diagram, the dots and lines between the columns in areas C and D). This means that, if a stimulus propagates to the columns in that level, it will inhibit the activation of the other percept:
At the periphery, perception operated in parallel: neurons coding for the sound and light could be simultaneously activated, without interfering with each other. At the higher levels of the cortical hierarchy, however, they actively inhibited each other, such that these regions could entertain only a single integrated state of neural firing—a single “thought.”[21]
Finally, note that the feedback connections in this particular network fold the network back on itself; higher level columns send excitatory signals back to the same columns that originally activated them. This makes sense from a PP perspective—since feedback signals carry generative model predictions, this basically amounts to higher level percepts (e.g. “an apple”) helping to sustain the activation of the lower-level percepts that activated them (e.g. “red” and “round object”).
The result, in Dehaene’s words, is “a simplified global workspace: a tangle of feedforward and feedback connections with multiple nested scales—neurons, columns, areas, and the long-distance connections between them.”[22]
Phase transitions, compositionality, and “filling in”
These simulations also provided insight into why there seems to be a sharp threshold delineating unconscious from conscious perception and cognition:
Conscious access corresponded to what the theoretical physicist calls a “phase transition”—the sudden transformation of a physical system from one state to another…. During a phase transition, the physical properties of the system often change suddenly and discontinuously. In our computer simulations, likewise, the spiking activity jumped from an ongoing state of low spontaneous activity to a temporary moment of elevated spiking and synchronized exchanges.
It is easy to see why this transition was nearly discontinuous. Since the neurons at the higher level sent excitation to the very units that activated them in the first place, the system possessed two stable states separated by an unstable ridge. The simulation either stayed at a low level of activity or, as soon as the input increased beyond a critical value, snowballed into an avalanche of self-amplification, suddenly plunging a subset of neurons into frantic firing. The fate of a stimulus of intermediate intensity was therefore unpredictable—activity either quickly died out or suddenly jumped to a high level.[23]
“Unconscious processing,” Dehaene elaborates, “corresponds to neuronal activation that propagates from one area to the next without triggering a global ignition. Conscious access, on the other hand, corresponds to the sudden transition toward a higher state of synchronized brain activity.”[24]
To me, this all feels quite similar to the “filling in” dynamics Steve mentioned in the context of the neocortex doing planning with generative models, where, instead of a more explicit kind of “planning by probabilistic inference,” plans are formed in a manner akin to filling in the pieces of a puzzle, where different models can “snap together” compositionally.
Here, the idea is that models in or connected to the workspace are doing basically the same thing in forming conscious percepts. (Remember that Steve mentioned in his decision-making diagram that the parts of the cortex responsible for proposing thoughts and plans have some “attractor dynamics,” such that they start with a soup of mutually-incompatible sub-thoughts but quickly settle into a stable configuration?) Also recall that the workspace links together these diverse high-level subsystems in a tangle of loops (whereas lower-level processing is more strictly hierarchical), so when a piece of information gains access to the workspace, it causes a bunch of messages to be passed back and forth between models in the space, which then settle into a coherent, stable representation—a conscious state.
Volitional attention
I also believe that PP’s account of attention in the context of the GNW facilitates better intuitions about the nature of volitional attention, our ability to intentionally or volitionally direct the focus of our attention. I am using the term “volitional” here to distinguish it from endogenous attention more generally, but to be clear, I see volitional attention as being a subset or type of endogenous attention.
Endogenous attention, within the context of PP, is pervasive at every level of the processing hierarchy, but not all of it is within volitional or intentional control. Your perception of these very words is generated by top-down/endogenous predictions, and the fact that you have learned to read, along with the fact that you’re presumably reading these words with some purpose or intent (even if not explicit or conscious), shapes what mental representations are promoted to the level of your conscious attention... and hardly any of this is within your conscious, intentional, or volitional control!
However, if I ask you to intentionally direct your attention to something, like the bolded word in this sentence, a series of representations pass through your global workspace to (consciously) coordinate the focus of attention as intended. It seems clear that the GNW is involved in the conscious direction of attention (nearly tautological within the framework, in fact, since the claim is that the representations in the GNW are precisely the things of which we are conscious). Indeed, Dehaene confirms this is the case: “Executive attention is just one of the many systems that receive inputs from the global workspace”[25] (as can be seen in the diagram in the section “Densely interconnected web of long-distance neurons”).
The more specific idea, to link this with PP, is that volitional attention should involve models within those attentional subsystems connected to the GNW regulating and adjusting the “gain” on the forward-flowing, error-communicating units of other parts of the neocortex, according to 1) conscious intention and 2) perceived context. We already saw that endogenous attention is perhaps implemented “by increasing the baseline firing rate of select neuronal populations,” so it makes a lot of sense that volitional attention would involve models connected to the GNW doing basically exactly that.
Conclusion
We’ve covered a lot of ground here. I wrote this post because I feel that integrating some insights from the predictive processing and global neuronal workspace theories of what’s going on in the brain with what Steve has been writing about the neocortex and the motivational system in the context of AI safety has been quite helpful in building better intuitions about how agency and goal-directedness is implemented in the human brain. I wanted to spell out and share these connections between the frameworks because I want to have a more solid foundation from which to speak (hopefully more coherently) about what “goals,” “desires,” and “intentions” mean in terms of the brain’s functional cognition; I hope to address this in more detail in a future post.
Effectively “self-supervised learning,” for ML folks. ↩︎
Surfing Uncertainty, p. 58 ↩︎
Surfing Uncertainty, p. 82 ↩︎
Surfing Uncertainty, p. 59 ↩︎
Surfing Uncertainty, p. 123 ↩︎
Steve actually includes most of the telencephalon [AF · GW] (which, in addition to the neocortex, includes the hippocampus, basal ganglia, and amygdala, among others) with “the neocortex” (as implementing the learning-from-scratch algorithm and as distinguished from the subcortex as the source of the reward). For the purposes of this post, I will use the term “neocortex” in this broader sense. ↩︎
Actually, don’t think about that purple elephant! ;) ↩︎
As we noted before in our summary of PP, both feedforward and feedback connections also flow laterally within the processing hierarchy, and there are lots of loops between different parts within the same “level,” where e.g. subsystems or subnetworks A, B, and C all have connections to each other. ↩︎
Steve would say that the computations instantiated by the subcortex to do this “steering” are evolutionarily-learned and hardcoded, not subject to change like the computations done by the neocortex. ↩︎
Perhaps skip connections are in part responsible for our ability to experience low-level sensory representations; for example, when we consciously attend to the experience of redness, perhaps what is happening is low-level parts of the visual cortex (that are responsible for e.g. color detection) are outputting their representations directly to the global workspace via skip connections. ↩︎
Surfing Uncertainty, p. 124 ↩︎
This is a particularly important idea, which I hope to further address with future work. ↩︎
Steve asked me to mention that he wrote this at the very earliest stages of his learning about the brain: “It’s not SO terrible that you shouldn’t be talking about it… it’s just that there are lots of little problems, including some in the picture you copied over (e.g. weird use of the term ‘credit assignment’).” ↩︎
Surfing Uncertainty, p. 69 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
This network can only distinguish between two perceptions, but one can easily imagine a much bigger version encoding a much broader set of states. ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
Consciousness and the Brain, Ch. 5 ↩︎
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2021-12-06T07:53:46.658Z · LW(p) · GW(p)
Hm, I'm not so sure about this take on GNW (I'm not saying you're inaccurate about the literature, I just feel disagreeable).
To illustrate my reservations: soon after I read the sentence about GNW meaning you can only be conscious of one thing at a time, as I was considering that proposition, I felt my chin was a little itchy and so I scratched it. So now I can remember thinking about the proposition while simultaneously scratching my chin. Trying to recall exactly what I was thinking at the time now also brings up a feeling of a specific body posture.
This would be impossible (or would require me to be doing some weird self-deceptive dance) under the version of GNW where you're only ever activating the GNW with local, thought-sized chunks of activity, and each new "ignition" overwrites what was there before, like a phase transition. But if we slightly generalize our picture of GNW, then it becomes clear that there's no reason why the activations of our long-range neurons has to encode precisely one thought-sized chunk (so it's okay to squeeze both thinking about your post and scratching my chin into the same brain state), and it's okay to have "smooth" updates that broadcast new thoughts without totally erasing old ones, allowing me to feel the urge to scratch my chin and then act on it without blanking my ability to do multimodal reasoning about other things. Then the whole conscious state can get echoed in memory, and now I can remember both thinking verbally and scratching my chin without needing any extra moving parts.
Replies from: jbkjr↑ comment by jbkjr · 2021-12-06T18:19:46.869Z · LW(p) · GW(p)
To illustrate my reservations: soon after I read the sentence about GNW meaning you can only be conscious of one thing at a time, as I was considering that proposition, I felt my chin was a little itchy and so I scratched it. So now I can remember thinking about the proposition while simultaneously scratching my chin. Trying to recall exactly what I was thinking at the time now also brings up a feeling of a specific body posture.
To me, "thinking about the proposition while simultaneously scratching my chin" sounds like a separate "thing" (complex representation formed in the GNW) than either "think about proposition" or "scratch my chin"... and you experienced this thing after the other ones, right? Like, from the way you described it, it sounds to me like there was actually 1) the proposition 2) the itch 3) the output of a 'summarizer' that effectively says "just now, I was considering this proposition and scratching my chin" [LW · GW]. [I guess, in this sense, I would say you are ordinarily doing some "weird self-deceptive dance" that prevents you from noticing this, because most people seem to ordinarily experience "themselves" as the locus of/basis for experience, instead of there being a stream of moments of consciousness, some of which apparently refer to an 'I'.]
Also, I have this sense that you're chunking your experience into "things" based on what your metacognitive summarizer-of-mental-activity is outputting back to the workspace, but there are at least 10 representations streaming through the workspace each second, and many of these will be far more primitive than any of the "things" we've already mentioned here (or than would ordinarily be noticed by the summarizer without specific training for it, e.g. in meditation). Like, in your example, there were visual sensations from the reading, mental analyses about its content, the original raw sensation of the itch, the labeling of it as "itchy," the intention to scratch the itch, (definitely lots more...), and, eventually, the thought "I remember thinking about this proposition and scratching my chin 'at the same time'."
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-12-07T00:51:46.020Z · LW(p) · GW(p)
Good points, thanks for the elaboration. I agree it could also be the case that integrating thoughts with different locations of origin only happens by broadcasting both separately and then only later synthesizing them with some third mechanism (is this something we can probe by having someone multitask in an fMRI and looking for rapid strobe-light alternations of [e.g.] "count to 10"-related and "do the hand jive"-related activations?).
In a modus ponens / modus tollens sort of way, such a non-synthesizing GNW would be less useful to understanding consciousness than one with more shades of grey - it would reduce the long-range correlations to mere message-passing. If in this picture most of my verbal reasoning is localized rather than broadcast, but then it eventually gets used by the rest of my brain and stored in memory, I have absolutely no problem with saying I was doing verbal reasoning and it was conscious, with no equivocations about "but only when the strobe light was on." (Obviously this is related to a Multiple Drafts model of consciousness.)
comment by Gordon Seidoh Worley (gworley) · 2021-11-24T23:33:51.641Z · LW(p) · GW(p)
Thanks for this thorough summary. At this point the content has become spread over a books worth of posts, so it's handy to have this high level, if long, summary!