Mechanisms too simple for humans to design
post by Malmesbury (Elmer of Malmesbury) · 2025-01-22T16:54:37.601Z · LW · GW · 45 commentsContents
You are simpler than Microsoft Word™ Blood for the Information Theory God The Barrier Implications for Pokémon (SPECULATIVE) Seeing like a 1.25 MB genome Mechanisms too simple for humans to design The future of non-human design None 45 comments
Cross-posted from Telescopic Turnip
Disclaimer: This article is about living organisms, and how they are sculpted by evolution. Any use of mathematics is metaphorical, not literal – it's only there to give a sense of scale. Apologies to all the people who got correctly offended by my shamelessly hand-wavy references to Kolmogorov complexity.
As we all know, humans are terrible at building butterflies. We can make a lot of objectively cool things like nuclear reactors and microchips, but we still can't create a proper artificial insect that flies, feeds, and lays eggs that turn into more butterflies. That seems like evidence that butterflies are incredibly complex machines – certainly more complex than a nuclear power facility.
Likewise, when you google "most complex object in the universe", the first result is usually not something invented by humans – rather, what people find the most impressive seems to be "the human brain".
As we are getting closer to building super-human AIs, people wonder what kind of unspeakable super-human inventions these machines will come up with. And, most of the time, the most terrifying technology people can think of is along the lines of "self-replicating autonomous nano-robots" [LW · GW] – in other words, bacteria.
Humans are just very humbled by the Natural World, and we are happy to admit that our lame attempts at making technology are nothing compared to the Complexity of Life. That's fair enough – to this day, natural living organisms remain the #1 collection of non-human technology we get to observe and study. What makes these organisms so different from human-made technology?
Here is my thesis: the real reason why humans cannot build a fully-functional butterfly is not because butterflies are too complex. Instead, it's because butterflies are too simple.
As I'll argue, humans routinely design systems much more complex than butterflies, bacteria or brains – and if you look at all the objects in the room, your brain is probably not even in the top 5.
As it turns out, there are some pretty hard fundamental limits on the complexity of living organisms, which are direct consequences of the nature of evolution.
But before going into that, let's examine how complex living organisms like you and me really are.
You are simpler than Microsoft Word™
By "complexity", I mean complexity in the Kolmogorov sense: how much information you need to completely describe something. This definition is particularly convenient for two things: software, and living organisms.
For example, the Tetris game fits in a 6.5 kB file, so the Kolmogorov complexity of Tetris is at most 6.5 kB. It's a pretty simple system. In contrast, the complete Microsoft Word™ software is a much more complicated object, as takes 2.1 GB to store.
We can do the same with living organisms. The human genome contains about 6.2 billion nucleotides. Since there are 4 nucleotides (A, T, G, C), we need two bits for each of them, and since there are 8 bits in a byte, that gives us around 1.55 GB of data.
In other words, all the information that controls the shape of your face, your bones, your organs and every single enzyme inside them – all of that takes less storage space than Microsoft Word™.
We can go further: only 10% of the human genome is actually useful, in the sense that it's maintained by natural selection. The remaining 90% just seems to be randomly drifting with no noticeable consequences. That brings your complexity down to 155 MB – not even a CD-ROM worth of data.
(There's an open debate about whether genomes really contain all information needed to describe a species – since each cell is built from another cell, there might be additional information in physical cell structures. My guess is that, since this non-DNA information is not a substrate of evolution the way DNA is, it likely doesn't contribute significantly to overall complexity.)
I like the organism/software comparison, because it goes to show how insanely compressed living organisms are compared to human-made software. Notice the log scale:
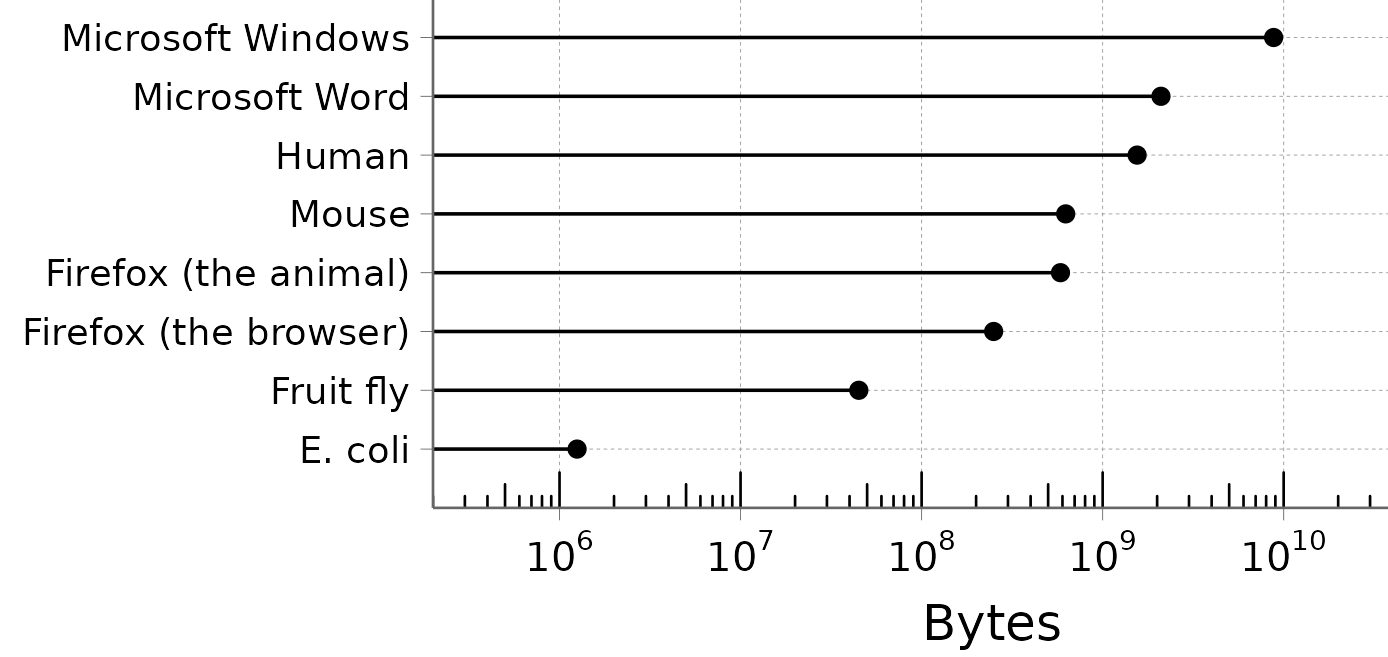
Take a moment to appreciate how simple bacteria are. Escherichia coli has a genome of about 5 million nucleotides, i.e. 1.25 MB. That is small enough to fit on a 1.44 MB floppy disk.[1]
In this case, being simple is very different from being capable – we are still talking about self-replicating micro-robots. E. coli can deploy a little motor to swim in the direction of nutrients, it has little retractile arms, a self-repairing envelope, a 5-years battery life, complicated collective tactics, and an immune system so clever that when we discovered it, it was a huge leap forward for human technology. All of that is encoded in a genome 1/1000 the size of Microsoft Word.
(To be fair, not all bacteria fit on a floppy disk. For example, Myxococcus xanthus, with its 2.5 MB genome, is too large. You will have to invest in more advanced storage technologies, like the 40-MB Iomega® 1999 Clik™ PocketZip.)
(That said, M. xanthus is a predatory bacterium famous for its ability to eavesdrop on the chemical messages of its preys, so it's basically malware. You don't want that on your floppy disk anyway.)
I think this dazzling level of compression is what really distinguishes natural, evolution-selected designs from human-made technology.
For example, your body contains a nice little structure called the nephron. It's your kidney's basic filtration device – it gets rid of harmful waste molecules while keeping the precious stuff your body wants to keep.
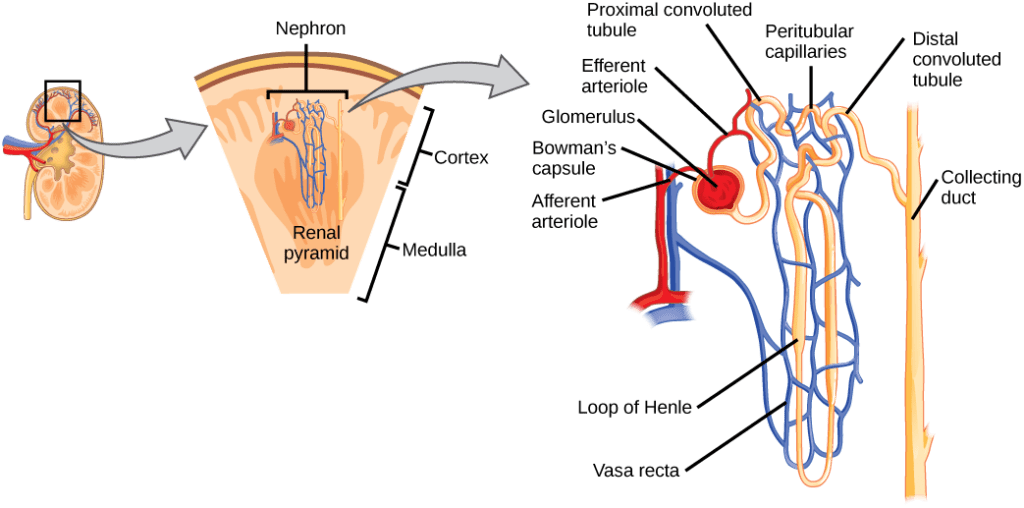
Sure, this looks pretty complex, but it's not far more complex than the kind of facilities humans use to treat wastewater. In fact, human engineers are totally capable of building an artificial kidney that works just fine.
What makes something like the nephron impressive is not the super-human complexity of its workings. What's impressive is that you have one million copies of the nephron in each of your kidneys, and the entire thing spontaneously assembles starting from a single cell, and all of this is encoded in a genome that only contains 150 MB of information. That's not even 1/4 of a CD-ROM. Could the complete specification of a water treatment facility fit on a CD-ROM? I don't think the regulatory documents alone would fit.
This level of simplicity is beyond anything humans have ever created. This is what I mean by "mechanisms too simple for humans to design".
Of course, this level of compression completely changes the design rules. To be competitive on the fitness market, living organisms need to come up with clever ways to do very complicated operations with a very small number of components. And, as we'll see, they are super-humanely good at it.
But why are living organisms so simple in the first place?
Blood for the Information Theory God
Evolution works by alternating between mutation and natural selection. How does that affect the information content of a genome? To put it in a super-hand-wavy way:
- Mutations degrade information. One nucleotide encodes 2 bits of information, so a random mutation introduces 2 bits of uncertainty.
- Natural selection accumulates information. If you start from a mix of all possible sequences, and only the fittest fraction P of the population survives, you gain -log(P) bits of information. Notice that if you have an even mix of A, T, G and C at a given position, picking the "fittest" nucleotide is equivalent to picking the top 25% of the population, so the information gain is -log(0.25) = 2 bits of information, which is indeed the information content of one nucleotide.
I mean this merely as an intuition pump, but you can put this in more precise mathematical terms. Therefore, maintaining a functional genome is a perpetual burden: with each generation, as our imperfect DNA-polymerase introduces new random mutations, some of the information content of our genomes is lost. To keep the species going, this lost information has to be gained back through natural selection.
This comes with a huge cost: the only way to accumulate more information would be to have more "efficient" selection – that is, a larger fraction of the population must die without offspring in each generation. The Information Theory God wants blood.
To get a sense of what this means in practice, let's do a thought experiment.
Imagine the X social network, but with a little modification: tweets are generated by natural selection. In this version, you cannot write new tweets – instead, whenever someone pushes the "retweet" button, it is replicated imperfectly and a few characters might be changed at random.
With every retweet, there is a small chance that the changes will make the tweet slightly better. A better tweet is more likely to be retweeted, and the process repeats until the tweet evolves into the most viral, unstoppable incendiary hot take ever.[2]
But, realistically, it is vastly more likely that introducing a random change into a tweet will just introduce a nonsense typo, making it less good than the original.
And that's enough to put a hard limit on the length of a tweet. To see why, let's consider two equally-good tweets, both good enough to be retweeted 10 times on average, with a mutation rate of 1% per character.
- Tweet 1 is 280-characters long. Then 94% of the retweets have a mutation somewhere, and only 6% are identical to the original. So, most of the time, all of the tweet's progeny will have one or more random letter substitution, and that's almost always a bad thing. The tweet's offspring is becoming less dank with each generation and its cursed dynasty quickly vanishes into darkness.
- Tweet 2 is 140-characters long. Now the fraction of mutants is only about 75%. This means that, every generation, you will get 2 or 3 copies of the original tweet among the offspring. If each of them gets retweeted 10 more times, you now have a self-sustaining population.
Sure, it is possible that one of the mutants of the 280-characters long Tweet 1 will be extraordinarily dank by sheer luck, but it will get very few opportunities to find such a good mutation before the lineage goes extinct. Meanwhile, the shorter Tweet 2 gets a potentially unlimited number of attempts, so it has a decent shot at finding a beneficial mutation eventually.
So we have a trade-off between a few parameters:
- The retweet rate, T, a.k.a "fitness"
- The mutation probability per character, μ
- The length of the tweet, L
As the tweet is retweeted T times, the expected number of identical copies among the offspring is
This represents the number of unmutated copies of the tweet you propagate - basically backup copies of the original. For the tweet to sustainably replicate and evolve while preserving its information, this number should be at least 1. So the length of the tweet is limited to:
And here we are: there's a hard limit on how much information you can fit in a tweet.
Of course, this Twitter parable is very different from real-life DNA information, but the general idea is the same (and biologists have come up with all kinds of dirty ghetto mathematical approximations to formalize it). No matter how you put it, the inescapable part is how the fraction of retweets without mutations decreases exponentially with L: to make the tweet twice as long, the number of retweets would have to be squared.
This is why you shouldn't see evolution as a "random walk" through the space of possible genomes. Instead, most of the work of natural selection is simply to purge the bad mutants and maintain a core functional population. It's only on top of that, when the population manages to perpetuate over many generations, that evolution gets to tinker a little bit and try to come up with improvements.
In practice, information accumulates pretty slowly – in a paper from the 1960s, Motoo Kimura estimated that we've gained about 0.2 bits of information per year since the Cambrian.
The Barrier
What about the mutation rate μ? Can't we make an organism arbitrarily complex by decreasing the mutation rate? After all, it’s not like there is a mathematical limit to the accuracy of DNA replication machinery, right?
Well, there is, in fact, a mathematical limit to the accuracy of DNA replication machinery.
It's not that better polymerases don't exist. It's that evolution is not precise enough to discover them. The reason for that is called the Drift Barrier – a direct consequence of genetic drift, the change in allele frequencies due to the random happenstance of life.
The intensity of genetic drift scales with 1/N, with N the population size. (To get an intuition why, imagine a winner-take-all scenario where you start with N individuals. Each of these N initial individuals has a 1/N probability of being the winner, just by chance, so a neutral mutation must also have a 1/N probability of being accidentally selected.) This is essentially the "resolution limit" of evolution. If the relative improvement that comes with a mutation is smaller than 1/N, then it will be drowned in randomness and natural selection can't reliably select for it.
Now, reducing the mutation rate has diminishing returns. Even in conditions where every single mutation is 100% deadly (so there is maximal selection pressure for lower mutation rates), reducing the number of mutations per generation from 10% to 1% saves 9% of the offspring, but going from 1% to 0.1% only saves 0.9%, and so on. Eventually, the effect becomes so small that it hits the 1/N Drift Barrier. Then, evolution can't push it any further down.
And if you look across the tree of life, the mutation rate does indeed scale inversely with population size. This is a rare and precious case where people tried to describe biology with math, and it actually worked:
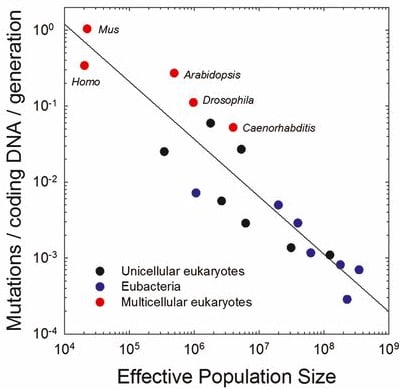
Of course, the largest, most complex organisms also tend to have the smallest populations, so there is no way out: complexity is limited by mutation rate, which is limited by population size, which is itself limited by complexity.
Needless to say, none of these limits apply to human inventions, which is why your phone's web browser can be orders of magnitude more complex than you are.
Implications for Pokémon (SPECULATIVE)
If a species isn't able to maintain the information content of its genome, this information evaporates. What does this look like in practice? There are various theoretical scenarios with cool names like error catastrophes, mutational meltdowns and extinction vortex to describe what happens.
To illustrate that point, let's contemplate the possibility of using genetic engineering to bring your favorite Pokémon to life.
Say you want to immanentize Pikachu. Using speculative advanced AI technology, you generate a complete genome that codes for a picture-perfect Pikachu. Then you synthesize it and you inject the embryos inside some suitable host.
Here's the crucial point: real-life animals represent special cases: their body plans arise from relatively simple rules that can be encoded in a genome small enough to be maintained, according to their population size. Encoding an animal into a genome is a vastly over-determined problem.
But the perfect Pikachu almost certainly isn't like that. There's no simple Pikachu-generating function. To get the shape and colors just right, you likely need to add numerous genetic circuits and morphogens to precisely adjust the position of each feature. And that requires endowing your Pikachus with a ridiculously long genome.
The problems begin when the first-gen Pikachus start to reproduce. Even if they start with almost-perfect DNA-polymerases, the Drift Barrier means that mutations in the polymerases themselves cannot be purged, so the mutation rate inevitably goes up. Since the Pikachu's genome is so humongous, there will be new mutations in all of the offspring, so there's nothing you can do to prevent them from accumulating malformations.
As the population declines, natural selection becomes less and less efficient, and everything gets worse and worse. In bad enough cases, the species can even spiral down to extinction, even in the absence of any competitor.
And you can't even breed them back into their original Pikachu shape, because once you've lost the information, the chances of the original alleles ever reoccurring in isolation are vanishingly small.
(The implications for catgirls are too sad to discuss.)
Seeing like a 1.25 MB genome
The information constraints are mostly relevant for large, complex, macroscopic animals with small population sizes.
But we could also go in the other direction. On the opposite side of the trade-off, you find bacteria, who decided instead to swarm the world with huge populations of absurdly simple creatures.
To highlight the deep divide between these two strategies, let's look at the genomes. Remember that the human genome contains 10% useful information, interspersed with 90% nonsensical wastelands. On the other hand, here is the genome of the gut bacterium Escherichia coli. The colorful blocks are things that code for content. Only the little spaces in between are non-coding, and most of that has some important regulatory effect:

The genomes of bacteria (and other prokaryotes) look like the walled city of Kowloon. In comparison, the genomes of animals (and other eukaryotes) look more like the steppes of Kazakhstan.
{kind=link}
{kind=link}
You might be wondering why life would diverge to these two antipodes. It's as if the two realms were being pulled apart by inescapable forces. That's because they are.
In fact, considering the information-theory arguments above, bacteria could afford to have much larger genomes without going into error catastrophes. They replicate themselves with insane accuracy – if a bacterium divides 1000 times, 999 of the daughters will be exactly identical to their mother – without a single mistake in any of the 15 million bases.
But there are other factors that drag down the size of bacterial genomes. I heard of three reasons:
- The membrane / cytoplasm ratio: In humans, the chemical reactions associated with respiration are done by mitochondria. But bacteria don't have those. Instead, respiration is done by enzymes inserted in the bacteria's membrane. Here's the problem: if you double the size of a cell, the volume is multiplied by 8, but the surface area is only multiplied by 4. So if you try to add more cool mechanisms inside a cell, you will soon run out of membrane real estate to generate the energy to power these mechanisms.
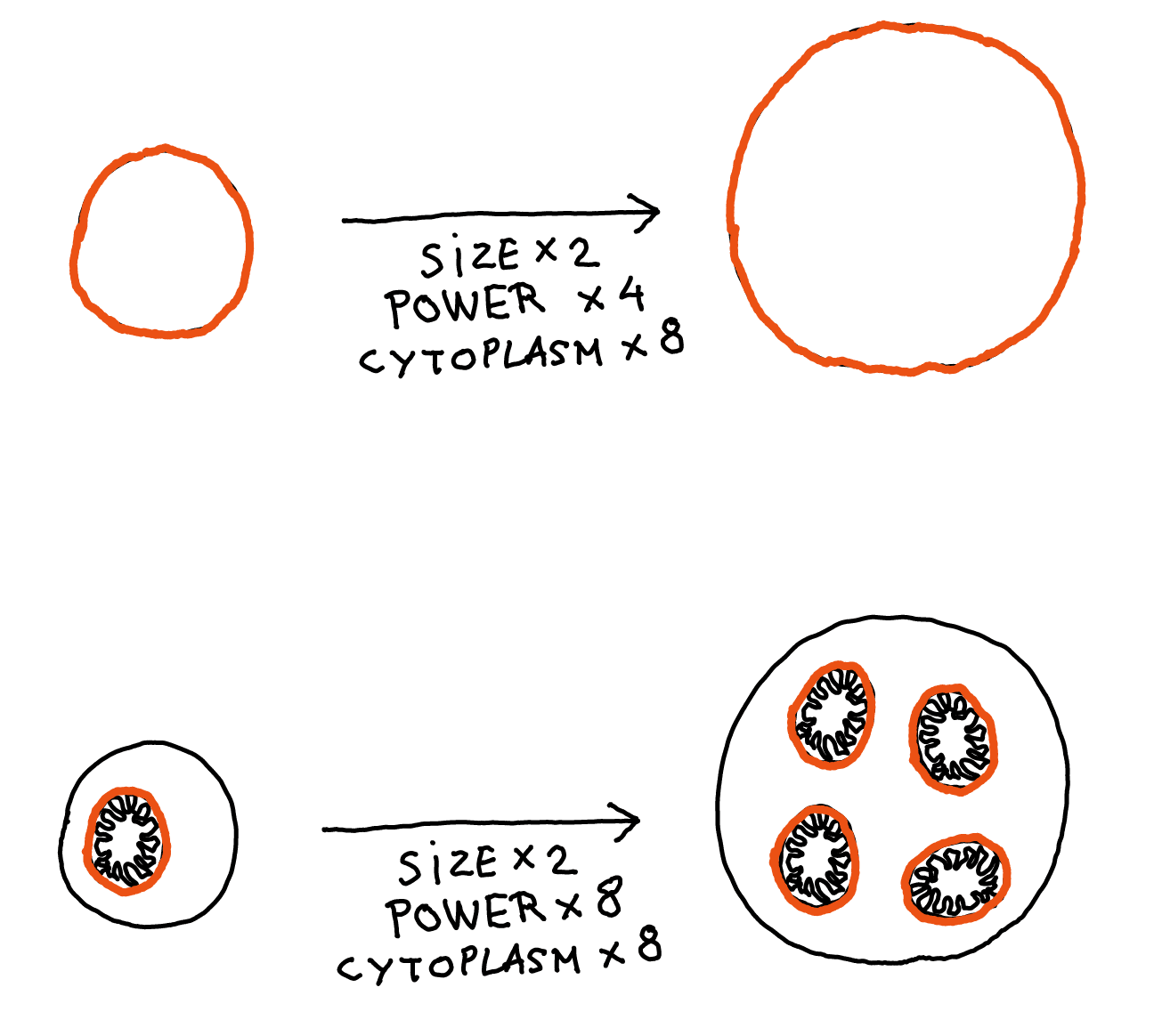
This is actually one of the main reasons mitochondria are so useful: they allow the amount of membrane (and therefore the energy-production capacity) to scale with volume like everything else, so it's no longer a limit to cell size.
- Bacteria's evolution is more precise: If you compare the cost of making a few hundred nucleotides of DNA to the total cost of making the whole cell, the former is a tiny fraction. But bacteria have huge populations, so the Drift Barrier is very small for them. If they can save a little bit of energy by removing 100 bp of useless DNA, evolution is precise enough to get rid of it.
But eukaryotes, with their huge genomes and small populations, can't see any difference. And so, the junk DNA just accumulates. - Bacteria just like to delete stuff: When bacteria mutate, even in the absence of selection, they are 10 times more likely to remove nucleotides than to insert them. The reasons why are still mysterious (eukaryotes don't do that), but the consequences are clear: any sequence in the genome that is not especially useful will just naturally shrink over time.
These are just mechanistic explanations. For a deeper look on the metaphysics of this, I recommend Aysja's piece on Seeds of Science, Why Are Bacteria So Simple.
Anyways, everything about bacteria seems to be optimized for minimalism, allowing for immense populations and rapid evolution. This is how you end up with self-replicating nanobots whose genomes fit on a floppy disk.
Mechanisms too simple for humans to design
With these constraints in mind, we can now fully appreciate the magnificent simplicity of natural mechanisms.
Here is one of my favorite examples. It's a really clever mechanism Bacillus subtilis uses to navigate the world.
Bacillus subtilis is a rod-shaped bacterium that lives buried in the soil, near the roots of plants. Here's what it looks like when it grows:

For soil bacteria, a typical day looks like: escape killer fungi, find delicious nutrients and, perhaps most importantly, find oxygen to breathe. How can such a small creature find the places where it can grow the fastest, and move towards them?
It's interesting to think about this problem from the point of view of a human engineer: if you wanted to make a tiny robot that moves in the direction that maximizes growth, how would you do that? What is the simplest solution you can find?
Here is a naive "human-style" solution: put some oxygen sensors everywhere on the surface of the cell, then somehow measure the difference between two opposite sides. If you detect a gradient, you activate a bunch of tiny propellers on the least oxygenated side, so the bacteria swim towards the oxygen. Repeat this for every possible nutrient.
This is costly, easy to break, and extremely hard to evolve. But I don't think I could come up with anything much better. (If you take time to think about this, feel free to pause reading and write your best solution in the comments!)
Now, here is what B. subtilis actually does. The strategy is a combination of two phenomena:
First, B. subtilis doesn't grow straight. It grows twisting, kind of like this:
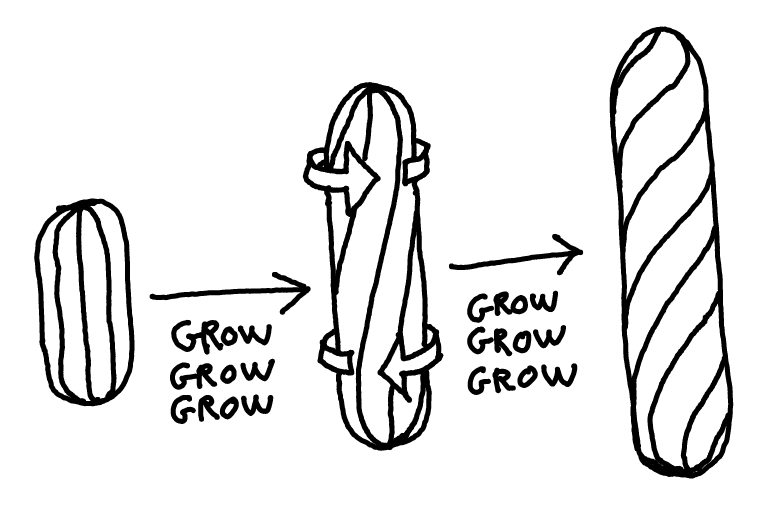
(If this is hard to visualize, hit me up for a beer and I'll mime it for you.)
Second, when they starve, the cells tend to aggregate into pellets of thousands of entangled cells, called a biofilm. When they do so, they usually keep elongating but stop fully dividing, forming long filaments.
And these two simple things are all it takes for the cells climb the gradient. Can you guess what the emergent property is?
...
...
...
Notice that if a cell-filament is entangled with others, then its poles are stuck and can't rotate. As the cells keep growing in a twisted way, eventually this happens:
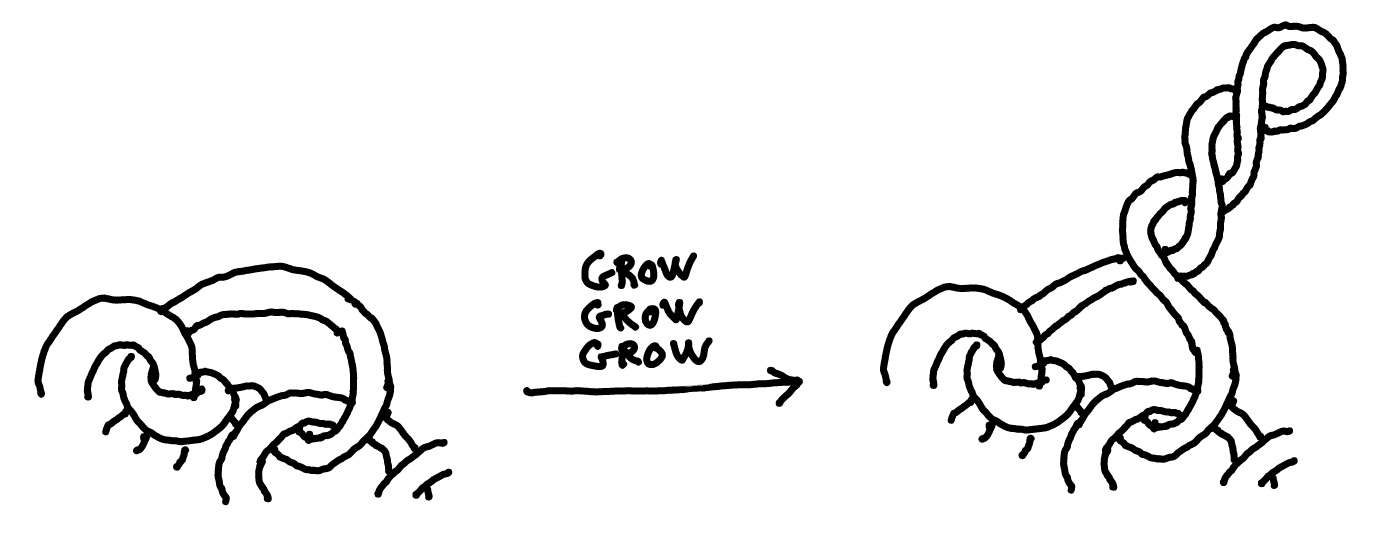
And so our clump of bacteria, while sticking firmly to surfaces, now has tentacles it can extend to reach for oxygen, as if surrounded by snorkels. Here's an actual picture:
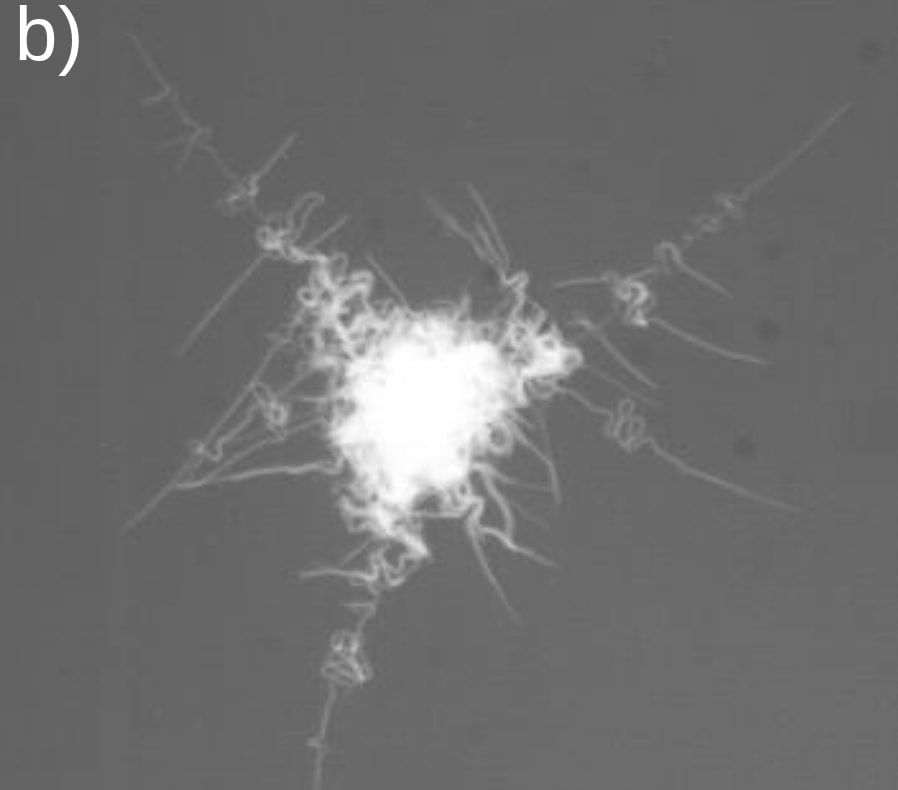
Now, if there is more oxygen on one side, the cells who have access to the most oxygen will grow faster, so the new tentacles will predominantly occur on the well-oxygenized side of the colony. In other words, the colony throws its tentacles preferentially in the direction of the oxygen source.
The chained cells at the end of the tentacles can then complete their division, allowing to start the process again in the new location. And that's how, the authors say, B. subtilis' biofilms can escape crowded environments by tracking the oxygen gradient. It's basically performing gradient descent, just by combining twisted cell growth, chaining and entanglement.
The paper only demonstrates this for oxygen, but the filament tentacles don't explicitly rely on any oxygen detector. I suppose it would work just as well to track down food, flee antibiotics, or seek better temperatures. That's the elegant part: it's a pure growth-maximizer that is driven by growth itself. The map is actually the territory.
This kind of mechanism is why I think studying bacteria is so fun. Bacteria do this kind of things all the time. When your genome can only store 1.25 MB of information, you can't waste any of it on clear, rational, legible mechanisms. Rather, bacteria's engineering approach is to throw together some spooky dynamical system that somehow couples the thing you want to maximize to the behavior that maximizes it, with fewer moving parts than what seems possible.
(If you want another example, here's one that is built on pure math.)
The future of non-human design
To come back to the question I raised at the beginning – does this tell us anything about what kind of inventions the super-intelligent AIs of the future will come up with?
What's pretty clear is that living organisms are the product of some very peculiar constraints, including constraints that directly emanate from the very process of evolution. AI-assisted design will not have any of these constraints, so the design space is much larger. I sometimes hear things like "[scary thing] doesn't occur in nature, so [scary thing] is impossible", and that sounds definitely wrong – evolution operates under specific constraints that apply only to evolving things. All natural pandemics are subject to these constraints, but artificial bioweapons might not be.
On the other hand, the living world contains some of the world's most fascinating mechanisms, and it would be really hard to come up with them through intelligent design. It's possible that the best parts of the design space are simply too strange, too far-fetched, to be explored by a rational agent. Maybe some designs can only be found by relentless real-world experimentation.
Machines may already beat us at PhD-level math, but it will take more time before they can fully harness the vast powers of accidental discovery. Only then will they be able to truly rival Nature.

- ^
For the zoomers among you: floppy disks were popular storage devices until the early 2000s - that's what the 💾 save icon is supposed to represent. I can feel my bones rotting and crumbling like ancient ruins as I'm writing this.
- ^
You are welcome to implement this website. Suggested name: X-chromosome
45 comments
Comments sorted by top scores.
comment by Archimedes · 2025-01-23T04:18:51.933Z · LW(p) · GW(p)
I'm not sure the complexity of a human brain is necessarily bounded by the size of the human genome. Instead of interpreting DNA as containing the full description, I think treating it as the seed of a procedurally generated organism may be more accurate. You can't reconstruct an organism from DNA without an algorithm for interpreting it. Such an algorithm contains more complexity than the DNA itself; the protein folding problem is just one piece of it.
Replies from: steve2152, Lblack, Kaj_Sotala, leogao↑ comment by Steven Byrnes (steve2152) · 2025-01-23T17:30:19.278Z · LW(p) · GW(p)
“Procedural generation” can’t create useful design information from thin air. For example, Minecraft worlds are procedurally generated with a seed. If I have in mind some useful configuration of Minecraft stuff that takes 100 bits to specify, then I probably need to search through 2^100 different seeds on average, or thereabouts, before I find one with that specific configuration at a particular pre-specified coordinate.
The thing is: the map from seeds to outputs (Minecraft worlds) might be complicated, but it’s not complicated in a way that generates useful design information from thin air.
By the same token, the map from DNA to folded proteins is rather complicated to simulate on a computer, but it’s not complicated in a way that generates useful design information from thin air. Random DNA creates random proteins. These random proteins fold in a hard-to-simulate way, as always, but the end-result configuration is useless. Thus, the design information all has to be in the DNA. The more specific you are about what such-and-such protein ought to do, the more possible DNA configurations you need to search through before you find one that encodes a protein with that property. The complexity of protein folding doesn’t change that—it just makes it so that the “right” DNA in the search space is obfuscated. You still need a big search space commensurate with the design specificity.
By contrast, here’s a kernel of truth adjacent to your comment: It is certainly possible for DNA to build a within-lifetime learning algorithm, and then for that within-lifetime learning algorithm to wind up (after months or years or decades) containing much more useful information than was in the DNA. By analogy, it’s very common for an ML source code repository to have much less information in its code, than the information that will eventually be stored in the weights of the trained model built by that code. (The latter can be in the terabytes.) Same idea.
Unlike protein folding, running a within-lifetime learning algorithm does generate new useful information. That’s their whole point.
Replies from: donald-hobson, Insub↑ comment by Donald Hobson (donald-hobson) · 2025-04-01T14:58:40.220Z · LW(p) · GW(p)
Yes. But a specific minecraft world (if we ignore the fact that it's pseudorandom) can be more complicated than the minecraft program itself.
Given a fixed genome, it can develop into many different potential people, depending on both life experiences and neuro-developmental RNG.
And in some sense "useful complexity" is a self contradictory concept. If the goal is simple, then a brute force search set to maximize the goal is a simple program. Sure, the result may look very "complicated", but it has low komolgorov complexity.
↑ comment by Insub · 2025-01-29T17:57:13.804Z · LW(p) · GW(p)
Thus, the design information all has to be in the DNA
The OP mentioned non-DNA sources of information briefly, but I still feel like they're not being given enough weight.
In order to fully define e.g. a human, you need to specify:
- The DNA
- A full specification of the egg where the DNA will start its life
- A full specification of the womb in which the egg will grow into a human
If you gave a piece of DNA to an alien and didn't tell them how to interpret it, then they'd have no way of building a human. You'd need to give them a whole lot of other information too.
Even looking at different DNA for different organisms, each organism's DNA expects to be interpreted differently (as opposed to source code, which mostly intends to be interpreted by the same OS/hardware as other source code). If you put a lizard's DNA into a human's egg and womb, I'm guessing that would not successfully build a lizard.
So I guess my question is: to what extent should the complexity of the interpreter be included in the complexity of the thing-being-interpreted? In one sense I feel like Word's code does fully specify Word amongst all other possible software, but in another sense (including the interpreter) I feel like it does not.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-29T18:37:58.201Z · LW(p) · GW(p)
If a spy slips a piece of paper to his handler, and then the counter-espionage officer arrests them and gets the piece of paper, and the piece of paper just says “85”, then I don’t know wtf that means, but I do learn something like “the spy is not communicating all that much information that his superiors don’t already know”.
By the same token, if you say that humans have 25,000 genes (or whatever), that says something important about how many specific things the genome designed in the human brain and body. For example, there’s something in the brain [LW · GW] that says “if I’m malnourished, then reduce the rate of the (highly-energy-consuming) nonshivering thermogenesis process”. It’s a specific innate (not learned) connection between two specific neuron groups in different parts of the brain, I think one in the arcuate nucleus of the hypothalamus, the other in the periaqueductal gray of the brainstem (two of many hundreds or low-thousands of little idiosyncratic cell groups in the hypothalamus and brainstem). There’s nothing in the central dogma of molecular biology, and there’s nothing in the chemical nature of proteins, that makes this particular connection especially prone to occurring, compared to the huge number of superficially-similar connections that would be maladaptive (“if I’m malnourished, then get goosebumps” or whatever). So this connection must be occupying some number of bits of DNA—perhaps not a whole dedicated protein, but perhaps some part of some protein, or whatever. And there can only be so many of that type of thing, given a mere 25,000 genes for the whole body and everything in it.
That’s an important thing that you can learn from the size of the genome. We can learn it without expecting aliens to be able to decode DNA or anything like that. And Archimedes’s comment above doesn’t undermine it—it’s a conclusion that’s robust to the “procedural generation” complexities of how the embryonic development process unfolds.
↑ comment by Lucius Bushnaq (Lblack) · 2025-01-23T12:11:46.594Z · LW(p) · GW(p)
This. Though I don't think the interpretation algorithm is the source of most of the specification bits here.
To make an analogy with artificial neural networks, the human genome needs to contain a specification of the architecture, the training signal and update algorithm, and some basic circuitry that has to work from the start, like breathing. Everything else can be learned.
I think the point maybe holds up slightly better for non-brain animal parts, but there's still a difference between storing a blueprint for what proteins cells are supposed to make and when, and storing the complete body plan of the resulting adult organism. The latter seems like a closer match to a Microsoft Word file.
If you took the adult body plans of lots of butterflies, and separated all the information of an adult butterfly bodyplan into the bits common to all of the butterflies, and the bits specifying the exact way things happened to grow in this butterfly [LW · GW], the former is more or less[1] what would need to fit into the butterfly genome, not the former plus the latter.
EDIT: Actually, maybe that'd be overcounting what the genome needs to store as well. How individual butterfly bodies grow might be determined by the environment, meaning some of their complexity would actually be specified by the environment, just as in the case of adult butterfly brains. Since this could be highly systematic (the relevant parts of the environment are nigh-identical for all butterflies), those bits would not be captured in our sample of butterfly variation.
- ^
Up to the bits of genome description length that vary between individual butterflies, which I'd guess would be small compared to both the bits specifying the butterfly species and the bits specifying details of the procedural generation outcome in individual butterflies?
↑ comment by Kaj_Sotala · 2025-01-23T08:10:00.674Z · LW(p) · GW(p)
Yeah. I think the part of the DNA specifying the brain is comparable to something like the training algorithm + initial weights of an LLM. I don't know how much space those would take if compressed, but probably very little, with the resulting model being much bigger than that. (And the model is in turn much smaller than the set of training data that went into creating it.)
Page 79-80 of the Whole Brain Emulation roadmap gave estimated storage requirements for uploading a human brain. The estimate depends on what we expect to be the scale on which the brain needs to be emulated. Workshop consensus at the time was that the most likely scale would be level 4-6 (see p. 13-14). This would put the storage requirements somewhere between 8000 and 1 million terabytes.
comment by fdrocha (SuddenCaution) · 2025-01-24T11:06:10.976Z · LW(p) · GW(p)
I don't think it affects the essence of your argument, but I would say that you cannot get a good estimate of the Kolgomorov complexity of Word or other modern software from binary size. The Kolgomorov complexity of Word should properly be the size of the smallest binary that would execute in an indistinguishable way to Word. There are very good reasons to think that the existing Word binary is significantly larger than that.
Modern software development practices optimize for a combination of factors where binary size has very little weight. Development and maintenance time and cost are paramount are usually the biggest factors, absence of bugs and performance are relatively smaller concerns in most cases and size not a factor except in some special cases.
Sometimes human programmers do optimize primarily for size and if you look at the tricks they came up with have similar vibes to some of the biology tricks described in the post. For a charming example in early constrained computer systems look at http://www.catb.org/jargon/html/story-of-mel.html. For a community of people doing this type of thing for toy problems see https://codegolf.stackexchange.com. If you just want to be dazzled by how much people can pack into 4kb binaries when they are really trying look at https://www.youtube.com/playlist?list=PLjxyPjW-DeNWennaPMEPBDoj5GFTj3rbz.
comment by TsviBT · 2025-01-23T02:11:43.590Z · LW(p) · GW(p)
General warning / PSA: arguments about the limits of selection power are true... BUT with an important caveat: selection power is NOT limited to postnatal organisms. Gametogenesis and fertilization involve many millions of cells undergoing various selective filters (ability to proliferate, ability to appropriately respond to regulatory signals, passing genetic integrity checks, undergoing meiosis, physically passing through reproductive organs, etc.). This also counts as selection power available to the species-evolution.
comment by quetzal_rainbow · 2025-01-23T09:42:10.304Z · LW(p) · GW(p)
I think that section "You are simpler than Microsoft Word" is just plain wrong, because it assumes one UTM. But Kolmogorov complexity is defined only up to the choice of UTM.
Genome is only as simple as it is allowed by the rest of cell mechanism, like ribosomal decoding mechanism and protein folding. Humans are simple only relative to space of all possible organisms that can be built on Earth biochemistry. Conversely, Word is complex only relatively to all sets of x86 processor instructions or all sets of C programs, or whatever you used for definition of Word size. To properly compare complexity of both things, you need to translate from one language to another. How large should be genome of organism capable to run Word? It seems reasonable that simulation of human organism up to nucleotides will be very large if we write it in C, and I think genome of organism capable to run Word just as good as modern PC will be much larger than human genome.
Replies from: sharmake-farah, lucien, quiet_NaN↑ comment by Noosphere89 (sharmake-farah) · 2025-01-23T19:41:39.058Z · LW(p) · GW(p)
To be fair, humans (as well as other eukaryotes) probably have the most complicated genomes relative to prokaryotes, and also it's exponentially more difficult to evolve more complicated genomes that can't be patched around, which the post explains.
A hot take is that I'd actually be surprised if the constant factor difference is larger than 1-10 megabytes in C, and the main bottleneck to simulating a human organism up to the nucleotide level is that we have way too little compute to do it, not because of Kolmogorov complexity reasons.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2025-01-25T20:47:25.934Z · LW(p) · GW(p)
I mean "all possible DNA strings", not "DNA strings that we can expect from evolution".
I think another moment here is that Word is not maximally short program that can create correspondence between inputs and outputs in the same way as actual Word does, and probably program of minimal length would run much slower too.
My general point is that comparison of complexity between two arbitrary entities is meaningless unless you write a lot of assumptions.
Replies from: donald-hobson, sharmake-farah↑ comment by Donald Hobson (donald-hobson) · 2025-04-01T15:57:35.658Z · LW(p) · GW(p)
I suspect the Minimal program that simulates Microsoft word starts out with a simulation of quantum mechanics, and locates within this simulation the branch of the quantum multiverse that contains human-ish programmers writing MS word. (Not our branch exactly. But a similar one)
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-25T21:24:04.871Z · LW(p) · GW(p)
I think another moment here is that Word is not maximally short program that can create correspondence between inputs and outputs in the same way as actual Word does, and probably program of minimal length would run much slower too.
Agree with this.
For truly arbitrary entities, I agree that comparisons are meaningless unless you write a lot of assumptions down.
↑ comment by Lucien (lucien) · 2025-02-21T22:06:19.592Z · LW(p) · GW(p)
Exactly my thoughts reading the article.
But then how to define complexity, where to stop context of a thing?
Also, complexity without meaning is just chaos, so complexity assumes a goal, a negentropy, a life.
example of complexity context definition issue:
Computers only exist in a world were humans created them, should human complexity be included in computer complexity? Or can we envision a reality where computers appeared without humans?
↑ comment by quiet_NaN · 2025-01-25T00:55:09.630Z · LW(p) · GW(p)
Unlike Word, the human genome is self-hosting. That means that it is paying fair and square for any complexity advantage it might have -- if Microsoft found that the x86 was not expressive enough to code in a space-efficient manner, they could likewise implement more complex machinery to host it.
Of course, the core fact is that the DNA of eukaryotes looks memory efficient compared to the bloat of word.
There was a time when Word was shipped on floppy disks. From what I recall, it came on multiple floppies, but on the order of ten, not a thousand. With these modern CD-ROMs and DVDs, there is simply less incentive to optimize for size. People are not going to switch away from word to libreoffice if the latter was only a gigabyte.
comment by NickH · 2025-01-24T12:50:40.295Z · LW(p) · GW(p)
Sorry but you lost me on the second paragraph "For example, the Tetris game fits in a 6.5 kB file, so the Kolmogorov complexity of Tetris is at most 6.5 kB". This is just wrong. The Kolmogorov complexity of Tetris has to include the operating system and hardware that runs the program. The proof is trivial by counterexample - If you were correct I could reduce the complexity to 0B by creating an empty file and an OS that interprets an empty file as a command to run the Tetris code embedded in the OS
Replies from: quiet_NaN↑ comment by quiet_NaN · 2025-01-25T00:40:54.458Z · LW(p) · GW(p)
I think formally, the Kolmogorov complexity would have to be stated as the length of a description of a Turing Machine (not that this gets completely rid of any wiggle room).
Of course, TMs do not offer a great gaming experience.
"The operating system and the hardware" is certainly an upper bound, but also quite certainly to be overkill.
Your floating point unit or your network stack are not going to be very busy while you play tetris.
If you cut it down to the essentials (getting rid of things like scores which have to displayed as characters, or background graphics or music), you have a 2d grid in which you need to toggle fields, which is isomorphic to a matrix display. I don't think that having access to boost or JCL or the python ecosystem is going to help you much in terms of writing a shorter program than you would need for a bit serial processor. And these things can be crazy small -- this one takes about 200 LUTs and FFs. If we can agree that an universal logic gate is a reasonable primitive which would be understandable to any technological civilization , then we are talking on the order of 1k or 2k logic gates here. Specifying that on a circuit diagram level is not going to set you back by more than 10kB.
So while you are technically correct that there is some overhead, I think directionally Malmesbury is correct in that the binary file makes for a reasonable estimate of the information content, while adding the size of the OS (sometimes multiple floppy disks, these days!) will lead to a much worse estimate.
Replies from: NickH↑ comment by NickH · 2025-02-24T09:10:38.290Z · LW(p) · GW(p)
Sorry but you said Tetris, not some imaginary minimal thing that you now want to call Tetris but is actually only the base object model with no input or output. You can't just eliminate the graphics processing complexity because Tetris isn't very graphics intensive - It is just as complex to describe a GPU that processes 10 triangles in a month as one that processes 1 billion in a nanosecond.
As an aside, the complexity of most things that we think of as simple these days is dominated by the complexity of their input and output - I'm particularly thinking of the IoT and all those smart modules in your car and smart lightbulbs where the communications stack is orders of magnitude larger than the "core" function. You can't just ignore that stuff. A smart lightbulb without WiFi,Ethernet,TCP/IP etc, is not a lightbulb.
comment by denkenberger · 2025-01-28T02:41:14.799Z · LW(p) · GW(p)
Here is my thesis: the real reason why humans cannot build a fully-functional butterfly is not because butterflies are too complex. Instead, it's because butterflies are too simple.
Humans design lots of things that are less complex than butterflies and bacteria by your definition, like shovels. I would guess that the wax motor and control system that locks and unlocks your washing machine has a lower complexity than the bacteria in your example.
Replies from: Elmer of Malmesbury↑ comment by Malmesbury (Elmer of Malmesbury) · 2025-01-28T18:44:36.537Z · LW(p) · GW(p)
Oh yeah, I mean to compare things that have the same functionality (e.g. human-made butterfly robot vs natural butterfly). Obviously shovels are more simple than butterflies. But, seeing stuff like the wax motor and other examples people have posted, humans are definitely capable of coming up with great simple mechanisms, and I underestimated that. Thanks for bringing it up.
comment by tay · 2025-01-23T15:41:01.845Z · LW(p) · GW(p)
Kolmogorov complexity is defined relative to a fixed encoding, and yet this topic seems to be absent from the article.
Writing a solver for a system of linear equations in plain Basic would constitute a decent-size little project, while in Octave it will be a one-liner.
Taking your Tetris example, sure 6KB seems small -- as long as you restrict yourself to a space of all possible programs for Gameboy or whichever platform you took this example from. But if your goal is to encode Tetris for a computer engineer who has no knowledge about Gameboy, you will have to include, at the very least, the documentation on the CPU ISA, the hardware architecture of the device and the details on the quirks of its I/O hardware. That would already bring the "size of Tetris" to 10s of megabytes. Describing it for a person from 1950s, I suspect, would require a decent chunk of Internet in addition.
Using genome size as a proxy for an organism's complexity is very misleading, as it sweeps under the rug the huge (and difficult to estimate quantitatively) amount of knowledge about the world that has been extracted by the 3.5 billions of years of evolution and baked into the encoding the contemporary biology is running on.
Replies from: sharmake-farah, SuddenCaution↑ comment by Noosphere89 (sharmake-farah) · 2025-01-23T19:32:30.701Z · LW(p) · GW(p)
Using genome size as a proxy for an organism's complexity is very misleading, as it sweeps under the rug the huge (and difficult to estimate quantitatively) amount of knowledge about the world that has been extracted by the 3.5 billions of years of evolution and baked into the encoding the contemporary biology is running on.
I'm actually convinced that at least here, evolution mostly cannot do this, and that the ability to extract knowledge about the world and transmit it to the next generation correctly enough to get a positive feedback loop is the main reason why humanity has catapulted into the stratosphere, and it's rare for this in general to happen.
More generally, I'm very skeptical of the idea that much learning happens through natural selection, and the stuff about epigenetics that was proposed as a way for natural selection to encode learned knowledge is more-or-less fictional:
https://www.lesswrong.com/posts/zazA44CaZFE7rb5zg/transhumanism-genetic-engineering-and-the-biological-basis#JeDuMpKED7k9zAiYC [LW(p) · GW(p)]
↑ comment by fdrocha (SuddenCaution) · 2025-01-24T11:19:52.375Z · LW(p) · GW(p)
Taking your Tetris example, sure 6KB seems small -- as long as you restrict yourself to a space of all possible programs for Gameboy or whichever platform you took this example from. But if your goal is to encode Tetris for a computer engineer who has no knowledge about Gameboy, you will have to include, at the very least, the documentation on the CPU ISA, the hardware architecture of the device and the details on the quirks of its I/O hardware. That would already bring the "size of Tetris" to 10s of megabytes. Describing it for a person from 1950s, I suspect, would require a decent chunk of Internet in addition.
I don't think this is making it a fairer comparison. For bacteria, doesn't that mean you'd have to include descriptions of DNA, amino acids, proteins in general and everything known about the specific proteins used by the bacteria, etc? You quickly end up with a decent chunk of the Internet as well.
Kolgomorov complexity is not about how much background knowledge or computational effort was required to produce some from first principles output. It is about how much, given infinite knowledge and time, you can compress a complete description of the output. Which maybe means it's not the right metric to use here...
comment by Dentosal (dentosal) · 2025-01-25T21:10:39.349Z · LW(p) · GW(p)
I would have written a shorter letter, but I did not have the time.
- Blaise Pascal
comment by jmh · 2025-01-24T22:26:14.977Z · LW(p) · GW(p)
I could be way off on this, but I cannot help but core here is less about complexity than it is about efficiency. The most efficient processes do all appear to be a bit simpler than they probably are. It's a bit like watching an every talented craftsman working and thinking "The looks easy." Then when you try you find out it was much more difficult and complicated than it appeared. The craftsman's efficiency in action (ability to handle/deal with the underlying complexity) masked the truth a bit.
comment by artifex0 · 2025-01-24T18:10:55.936Z · LW(p) · GW(p)
One interesting example of humans managing to do this kind of compression in software: .kkrieger is a fully-functional first person shooter game with varied levels, detailed textures and lighting, multiple weapons and enemies and a full soundtrack. Replicating it in a modern game engine would probably produce a program at least a gigabyte large, but because of some incredibly clever procedural generation, .kkrieger managed to do it in under 100kb.
comment by ChristianKl · 2025-01-27T19:56:08.135Z · LW(p) · GW(p)
If you want to design an artificial organism with lower mutation rate you can do so. With existing biology most of the space of 3-base pair combinations that equals 64 combinations is mapped to the 20 amino acids. Many amino acids have multiple codings. That means that most amino acids give you a different amino acid.
If you go up to 4 or even 5 base pairs per amino acid and remove duplicate assignments most mutations won't lead to amino acids and you can add additional repair mechanisms.
The basic theory of coding that we use in computer science to prevent errors in message transmission can be used to reduce DNA mutation in artificial life if we desire to do so.
As an extra you get immunity from all the viruses that need the standard coding.
Replies from: Elmer of Malmesbury↑ comment by Malmesbury (Elmer of Malmesbury) · 2025-01-28T18:53:56.872Z · LW(p) · GW(p)
Putting error-correction codes in the genetic code is an interesting idea. In the context of the Pikachu thought experiment, though, here what I think would happen in the long run: because of the drift barrier, evolution can't distinguish between a ~1/N error rate and a zero error rate. So, there's nothing to prevent the rest of the machinery to become less accurate, until the error rate reaches 1/N after error correction. Now that I think about, you could probably keep things in control by systematically sequencing the genes for the replication machinery and breeding based on that. There is a spark of hope.
comment by momom2 (amaury-lorin) · 2025-01-24T09:34:12.875Z · LW(p) · GW(p)
(If you take time to think about this, feel free to pause reading and write your best solution in the comments!)
How about:
- Allocating energy everywhere to either twitching randomly or collecting nutrients. Assuming you are propelled by the twitching, this follows the gradient if there's one.
- Try to grow in all directions. If there are no outside nutrients to fuel this growth, consume yourself. In this manner, regenerate yourself in the direction of the gradient.
- Try to grab nutrients from all directions. If there are nutrients, by reaction you will be propelled towards it so this moves in the direction of the gradient.
Update after seeing the solution of B. subtilis: Looks like I had the wrong level of abstraction in mind. Also, I didn't consider group solutions.
Replies from: Elmer of Malmesbury↑ comment by Malmesbury (Elmer of Malmesbury) · 2025-01-26T01:46:53.314Z · LW(p) · GW(p)
Kudos for taking the challenge! If I understand correctly, your first point is actually pretty similar to how E. coli follows gradients of nutrients, even when the scale of the gradient is much larger than the size of a cell.
comment by noggin-scratcher · 2025-01-22T21:58:21.368Z · LW(p) · GW(p)
In other words, all the information that controls the shape of your face, your bones, your organs and every single enzyme inside them – all of that takes less storage space than Microsoft Word™.
The shape of your face, and much else besides, will be affected by random chance and environmental influences during the process of development and growth.
The eventual details of the brain, likewise, will be in large part a response to the environment—developing and learning from experience.
So the final complexity of a human being is not actually bounded by the data contained in the genome, in the way described.
Replies from: gwern↑ comment by gwern · 2025-01-22T22:56:42.430Z · LW(p) · GW(p)
The shape of your face, and much else besides, will be affected by random chance and environmental influences during the process of development and growth.
The shape of your face will not be affected much by random chance and environmental influences. See: identical twins (including adopted apart).
Replies from: noggin-scratcher, JeremyHussell↑ comment by noggin-scratcher · 2025-01-23T01:23:06.562Z · LW(p) · GW(p)
Solid point. I realise I was unclear that for face shape I had in mind external influences in utero (while the bones of the face are growing into place in the fetus). Which would at least be a somewhat shared environment between twins. But nonetheless, changing my mind in real-time, because I would have expected more difference from one side of a womb to the other than we actually see between twins.
Even if I'm mistaken about faces though, I don't think I'm wrong about brains, or humans in general.
↑ comment by JeremyHussell · 2025-01-23T01:26:41.312Z · LW(p) · GW(p)
Yeah, bad example. Nonetheless, an adult human brain cannot be recreated solely from its genetic code, just as documents written using Microsoft Word cannot be recreated solely from the source code of Microsoft Word and an LLM cannot be recreated without training data. Most of the article falls apart because comparing source code size (uncompressed, note) to genome size tells us very little about the relative complexity of software and living organisms.
Your brain probably is the most complex thing in the room, with ~86 billion neurons, each of which has a lot of state that matters.
comment by Donald Hobson (donald-hobson) · 2025-04-01T15:09:26.341Z · LW(p) · GW(p)
I'm not convinced by the Pikachu example.
Suppose I design my Pikachu. It has a terabyte of DNA. And it's replication mechanisms are accurate enough that 90% of it's children are mutation free.
Now suppose that any mutation is instantly fatal. I implemented some elaborate system of checksums and kill switches.
This is stable.
Now suppose that, by some oversight, the DNA-polymerase is not error checked.
A mutent Pikachu appears, with a change in DNA-polymerase that causes P(mutation)= 50%.
But half of this Pikachu's children die of a mutation. So this is still stable.
But if I didn't put in any checksum, and most of the DNA is managing cosmetic details, then the mutation rate can increase, and generations of increasingly wonky Pikachu can be born.
Wouldn't this hold in general? If the chance of a lethal mutation is small, there is little downside to increased complexity. If the chance of a lethal mutation is large, a better DNA-polymerase is a substantial advantage.
comment by DirectedEvolution (AllAmericanBreakfast) · 2025-01-25T02:50:53.079Z · LW(p) · GW(p)
We can do the same with living organisms. The human genome contains about 6.2 billion nucleotides. Since there are 4 nucleotides (A, T, G, C), we need two bits for each of them, and since there are 8 bits in a byte, that gives us around 1.55 GB of data.
In other words, all the information that controls the shape of your face, your bones, your organs and every single enzyme inside them – all of that takes less storage space than Microsoft Word™.
There are two ways to see this is incorrect.
- DNA's ability to structure an organism is mediated through its chemical mileau. It is densely, dynamically regulated through a complex and dense mesh of proteins and regulatory RNA and small signaling molecules at every timepoint in every organism throughout the life cycle. Disruption of that chemical mileau renders the organism nonviable. This is a separate issue from the fact that evolution overwhelmingly operates on DNA sequence.
- The DNA in a particular organism/cell is one point in a very long series of complex inheretance chains going back 4.5 billion years. I'm comfortable rounding off the maximum complexity of the soma to the maximum possible complexity of the complete set of ancestral DNA sequences. But we can go further by noticing that an individual's DNA sequence is not just the combination of their direct ancestors -- the entire ancestral lineage at every step is sampled from a distribution of possible genomes that is produced from mechanisms impacting reproduction.
In a more mathematical sense, while it's true that, conditional on a specific non-stochastic function, the number of values in the output set is less than or equal to the number of values in the input set, if the function can vary freely then there is no such constraint.
The soma might be viewed as a stochastic function mapping DNA inputs to phenotypic outputs. The stochastic aspect gives a much larger number of theoretically possible outputs from the same input set. And the fact that the 'function' (soma) itself varies from organism to organism increases the number of phenotypes that can be generated from a given amount of DNA still further.
All these arguments also apply to technology. MS Word 'co-evolved' with Windows, with programming languages, with hardware, and this context must be taken into account when thinking about how complex a machine is.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-25T16:33:40.046Z · LW(p) · GW(p)
The DNA in a particular organism/cell is one point in a very long series of complex inheretance chains going back 4.5 billion years. I'm comfortable rounding off the maximum complexity of the soma to the maximum possible complexity of the complete set of ancestral DNA sequences. But we can go further by noticing that an individual's DNA sequence is not just the combination of their direct ancestors -- the entire ancestral lineage at every step is sampled from a distribution of possible genomes that is produced from mechanisms impacting reproduction.
To be fair here, the learning process, if it exists is really slow, such that we can mostly ignore this factor, and the ability of learning ancestral knowledge that was distilled by people before you is probably a big reason why humanity catapulted into the stratosphere.
(The other is human bodies are well optimized for making good use of tools, at least relative to other animal genomes that exist).
comment by deepthoughtlife · 2025-01-26T07:43:47.169Z · LW(p) · GW(p)
This treatment of the idea of complexity is clearly incorrect for the simplest possible reason... we have no idea what the Kolmogorov complexity is of these objects versus each other, since the lower bounds are exactly identical! (Said bounds are just, a hair above zero because we can be relatively sure that their existence is not absolutely required by the laws of the universe, but little more than that.) The upper bounds are different, but not in an illuminating manner.
Thus, we have to use other things to determine complexity, and the brain is clearly far more complex in the relevant ways than something like Microsoft Word™. Word processors of similar use can fit into a tiny fraction of the size of Microsoft Word without losing much in terms of features and usefulness, and may not be any simpler. So with the entire premise incorrect, it makes the rest of the post uninteresting. (Yes, I only skimmed the rest to see you didn't address the issue.)
To illustrate the issue, people like me believe that software is mostly bloat (which is only complex in the other sense). The same program can take 1 MB or 10,000MB simply by changing compression scheme (especially if we are assuming the latter was done very badly, by people who have no idea what they are doing). More concretely take the example of a music video which might be 300 MB for 180 seconds after compression, but before compression might be 100GB (3 bytes per pixel for 3840 * 2160 pixels for 24 frames per second for 180 seconds / 1024^3 = 100.1129150390625 GB and the result could easily be higher since it could realistically be 4 times the pixels at 2.5 times the fps at 4/3 the bytes per pixel which would push it over a terabyte). Note that the compressed music video isn't necessarily any simpler by Kolmogorov than the uncompressed version despite the latter being about 333 times the size, since we don't actually know the simplest representation of the music video (and generic compression algorithms often find the lossily compressed version harder to compress and end up being much larger than the original).
comment by dmac_93 (D M Cat) · 2025-01-24T23:18:05.848Z · LW(p) · GW(p)
Great stuff!
To expand on a few points:
- The brain is less complex than people make it out to be. It is complicated, but there is clearly a logic to it, which we only need to discover. Often cited statistics about the numbers of cells and synapses include the cerebellum, which isnt really necessary for intelligence.
- Evolution produces some beautiful designs, but if left to its own devices it takes longer than G.R.R. Martin takes to write a novel. According to the theory of punctuated equilibria: evolution spends long periods of time stuck in a stasis, when evolution essentially gets stuck in a local optimum.
comment by Huera · 2025-01-22T21:55:10.810Z · LW(p) · GW(p)
In other words, all the information that controls the shape of your face, your bones, your organs and every single enzyme inside them – all of that takes less storage space than Microsoft Word™.
See also: How Complex Are Individual Differences.
comment by Shankar Sivarajan (shankar-sivarajan) · 2025-01-22T19:17:59.934Z · LW(p) · GW(p)
You might be overstating the negative implications for pokémon creation. You just need not to have standards too exacting, and you'll be fine: if you're willing to accept, say, a golden possum (maybe with red cheeks and black-tipped ears) as close enough, then it's manifestly possible to create such a thing.
Replies from: CronoDAS