Training Process Transparency through Gradient Interpretability: Early experiments on toy language models
post by robertzk (Technoguyrob), evhub · 2023-07-21T14:52:09.311Z · LW · GW · 1 commentsContents
Introduction Experiment Setup Examples of results Example: Neuron 96 in MLP layer 3.2 as the “war” neuron Example: Neuron 78 in MLP layer 3.1 as the sports neuron (“season”, “league”, “game”) Example: Neuron 181 in MLP layer 3.2 as related to quantity prediction Example: Neuron 173 in MLP layer 3.2 identified as highly polysemantic Example: Neuron 156 in MLP layer 1.2 Methodology: Training data attribution from outlier parameter shifts Recording parameter differences Accounting for datum-level attribution Identifying training data responsible for notable parameter updates Univariate Token Selection Heuristic Relating notable tokens to neurons using zero-weight ablation Limitations of the method No ability yet to capture attribution for attention head mechanisms Neurons in earlier layers are harder to explain Explanations outside the standard basis may be difficult from parameter shifts alone Paying the alignment tax of capturing full gradient data for large model training runs is expensive Conclusion Appendix I: Code and reproducibility Appendix II: Follow-up questions Appendix III: Identified neurons and notable tokens attributed Appendix IV: Shifts in bi-gram distributions None 1 comment
The work presented in this post was conducted during the SERI MATS 3.1 program. Thank you to Evan Hubinger for providing feedback on the outlined experiments.
Note: This post was drafted prior to the announcement of Developmental Interpretability [LW · GW], which offers a rigorous foundation for some of the ideas surrounding model explanations in light of the full training process. In any case, we believe the provided toy examples of gradient capture and analysis will be useful for validating future hypotheses in this space.
Introduction
Most attempts at mechanistic interpretability (mechint) focus on taking a completed trained model and performing a static analysis of specific aspects of its behavior and internals. This approach has yielded numerous fruits through well-known results such as grokking [LW · GW], the IOI circuit [LW · GW], docstring completions [LW · GW], and many others. However, mechint proceeds essentially in the dark without incorporating any information on the causal formation of features and mechanisms within the model. In particular, early training behavior is different from later training behavior, with earlier training being more simplistic.
Focusing on language models, we note that models exhibit “consistent developmental stages,” at first behaving similarly to -gram models and later exhibiting linguistic patterns. By taking into account both these transitions and the ultimate source of the development of mechanisms (the content and sequencing of the training data), the task of mechint can become easier or at least provide more holistic explanations of model behaviors. This viewpoint is further elaborated by NYU researcher Naomi Saphra in a post where she urges for applying interpretability along the entire training process.
An additional reason this kind of approach could be important relates to the possibility of obfuscation and backdoors in models. In the more dangerous failure modes such as deceptive alignment [LW · GW] or gradient hacking [LW · GW] the final model may be in a structure in which a dangerous behavior is not amenable even to full white-box [LW · GW] mechint. For example, it is possible to plant backdoors in models in such a way that no efficient distinguisher (e.g. a mechint technique) can discern the presence of the backdoor. If this happens within the SGD process itself, the only way to identify the existence of the defect would be to examine its incremental construction within the training process.
Existing work on approaches like this is limited to statistical observation of weights throughout partial checkpoints of a training process. For example, Basic Facts about Language Models During Training [LW · GW] by Conjecture provides an analysis of changes in parameter statistics for Pythia checkpoints, but does not veer into the step-by-step evolution of the parameter changes and the resulting behavioral changes in the model.
In this post we review some results from experiments directly capturing gradients and examining all changes in model parameters within a full model training run. In particular, we trained a set of 3-layer attention and MLP language models and attempted to directly interpret the changes in parameter weights.
Starting with simple experiments like this, we can progress to more elaborate attempts at uncovering model behavior from examining the full training process. A successful execution of this would correspond to differentiating through results like A Mathematical Circuits for Transformer Framework and Toy Models of Superposition, and to thereby observe the formation of structures like feature superposition, induction heads and others through the lens of the training process as a kind of model embryology.
If these types of approaches scale and succeed at providing a wider range of coverage in explaining model behavior through transparency at the level of the training process [AF · GW], then labs can start recording parameter shift data to facilitate the interpretation process. After all, recording and storing this information is comparatively cheap and a relatively small price to pay as part of the alignment tax [? · GW].
Experiment Setup
We trained a set of 3-layer language models on WikiText2 and attempted to directly interpret parameter gradients throughout the training process. Although we were limited from training larger models due to cost, to make the method more realistic we included elements that otherwise hinder interpretability such as positional encodings, layer norm, both attention head and MLP units, and applied dropout with . We recorded full gradients on every step in the training process taking care to compute per-datum gradients whenever processing batches. For each parameter in the architecture, we then isolated large outliers in the parameter differences produced between training steps and attributed the training data that resulted in these shifts.
We used this data to localize individual MLP neurons significantly responsible for altering predictions of specific tokens like “season”, “war” and “storm”. We validated our results through independent zero-weight ablation and found material shifts in predicting these tokens when ablating the notable neurons. We also examined activations throughout the model on the full training data independent of the preceding methodology and were unable to locate these notable neurons from activations alone, validating that the methodology adds value beyond direct model interpretation.
A table showing some of the experiment parameters is indicated below.
| Architecture parameters | |
| Model capacity | 12.2M parameters |
| Vocabulary size | 28k tokens (“Basic english” tokenizer from torchtext utils) |
| Depth | 3 layers |
| Attention heads | 4 self-attention heads per layer |
| Positional encodings | Sin-based encodings |
| Context Window | 35 tokens per training datum |
| Embedding dimension | 200 |
| Hidden dimension | 200 |
| Training parameters | |
| Epoch count | 5 |
| Training data |
|
| Train batch size | 20 items per batch with 2928 batches in total |
| Loss Criterion | Cross entropy loss |
| Optimizer | SGD with learning rate indicated below |
| Learning rate | 5.0 (Step LR schedule with ) |
| Dropout | 0.2 |
| Weight Initialization | Uniform from [-0.1, 0.1] |
| Gradient Clipping | Norm = 0.5 |
Examples of results
We provide some examples of the results obtained using the above method. Before we highlight individual examples, note that we are primarily looking at training data attribution along the standard basis, that is, the neuron basis. Parameter shifts correspond directly to changes in neuron weights. Identifying features in superposition or other non-standard basis representations would require looking at “virtual” parameter shifts along the appropriate corresponding basis change. We leave this idea for future work and remark here that the following results are for parameter shifts in the standard basis.
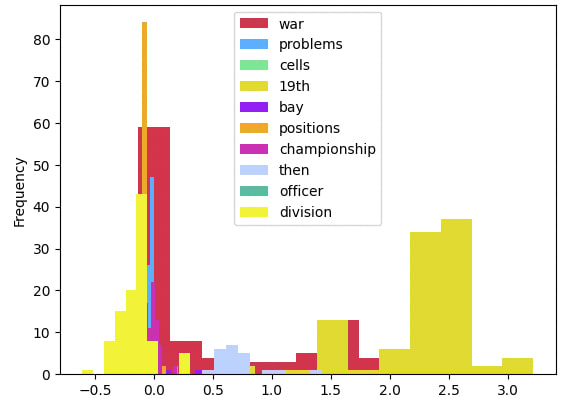
Example: Neuron 96 in MLP layer 3.2 as the “war” neuron
One of the neurons that was highlighted by the above method was neuron 96 in MLP layer 3.2. In particular, many of the parameter weights that constitute this neuron would experience sharp updates throughout the training process whenever training datums containing the word “war” were provided (amongst a few other examples including: “church” and “storm”). Indeed, zero-weight ablating this neuron shows that the next predicted token (bold) typically flips to “war” after ablation (italic).
... french huguenots , welsh , dutch , swedes , swiss , and scots highlanders . when the (<unk> | war) english took direct control of the middle colonies around 1664... |
... rest of the war . the (<unk> | war) ship was used as a training ship after the war until she was returned to the royal navy at malta on 9 october 1951 . salamis arrived at rosyth... |
... break the siege . meanwhile , throughout the (<unk> | war) country , thousands of predominantly <unk> civilians were driven from their homes in a process of ethnic cleansing . in sarajevo , women and children attempting to... |
... column — were saved by ivo kraus . he pulled them from the rubble shortly after the end of world war ii . the (<unk> | war) wash basin and the memorial tables are now in the... |
... difficult to present the case against abu jamal again , after the passage of 30 years and the (<unk> | war) deaths of several key witnesses . williams , the prosecutor , said that abu jamal... |
Within a sample of training data, 56% of the instances wherein the next predicted token was “war” or next predicted token after ablation was “war” resulted in a prediction flip. Some other tokens had higher proportions of flips but lower incidence in the training data as indicated below. Given the variety of flipped tokens, clearly the neuron is polysemantic, as are most neurons in a model of this size. Nevertheless, the strong effect on predicting “war” was discernible from the parameter shift attribution of the training data. The “notable” column in the table below indicates some other tokens that were highlighted using the above method.
token | proportion flips | count flips | notable |
poem | 1.000000 | 5 | False |
billboard | 1.000000 | 2 | False |
kakapo | 1.000000 | 7 | False |
18th | 1.000000 | 3 | False |
… | |||
film | 0.567568 | 74 | False |
war | 0.560345 | 232 | True |
brigade | 0.560000 | 25 | False |
song | 0.525000 | 40 | True |
road | 0.520833 | 48 | True |
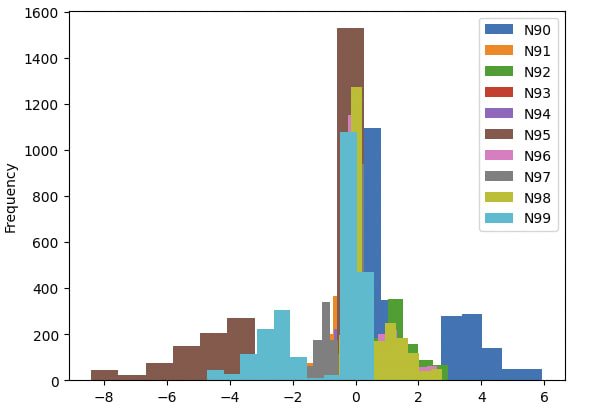
By contrast, we were not able to predict this behavior using activations alone. In particular, we took model activations on the entire training set and examined the activations of this neuron on “war” versus competing tokens.
As one example below, we show activation statistics for "war" on the third layer. The noted neuron does not feature in either the highest or least activating neurons. We also looked at activations on “war” for other neurons in the same MLP layer.
Rank | Min act neuron | Mean act value | Max act neuron | Mean act value |
0 | L3.1 N161 | -12.971514 | L3.1 N142 | 2.643695 |
1 | L3.1 N106 | -12.625372 | L3.2 N189 | 2.229810 |
2 | L3.1 N168 | -12.602907 | L3.2 N90 | 1.769165 |
3 | L3.1 N130 | -12.367962 | L3.2 N52 | 1.666029 |
4 | L3.1 N68 | -12.319139 | L3.2 N10 | 1.645515 |
5 | L3.1 N38 | -12.214589 | L3.2 N32 | 1.634054 |
6 | L3.1 N61 | -12.145944 | L3.2 N17 | 1.584173 |
7 | L3.1 N154 | -12.082723 | L3.2 N124 | 1.503373 |
8 | L3.1 N59 | -12.067786 | L3.2 N0 | 1.501923 |
9 | L3.1 N176 | -11.743015 | L3.2 N6 | 1.441552 |
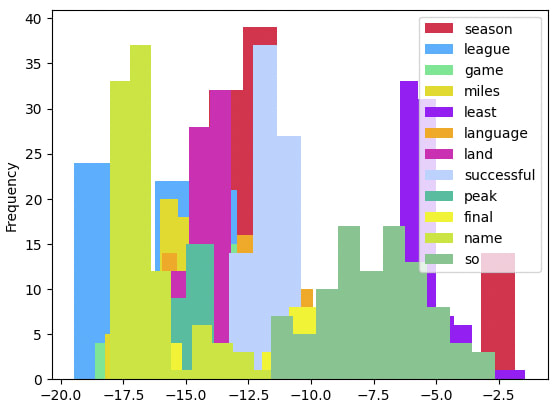
Example: Neuron 78 in MLP layer 3.1 as the sports neuron (“season”, “league”, “game”)
This neuron in MLP layer 3.1 experienced outlier parameter shifts during training whenever training data with outsized instances of sports-related terminology appeared, including: “season”, “league” and “game”. Below we show a few examples of prediction flips after zero-weight ablation.
| ... atp = = = federer entered the top 100 ranking for the first time on 20 september 1999 . his first (time | season) final came at the marseille open in 2000 , where he lost to fellow... |
| ... rookie year , the 10 – 4 1972 browns went to the (first | season) 1972 73 nfl playoffs under head coach nick <unk> , but lost in the first round to the miami dolphins 20 –... |
| ... which he signed on 14 august . by signing this contract , torres had the option of a one year extension after the (club | season) contract ' s expiration in 2013 . torres scored two goals... |
| ... biggest series debut for tlc since cake boss launched in 2009 and was a stronger rating than any of the (first | game) season premieres for hbo ' s big love . the remaining episodes of the first... |
| ... in his club ' s first competitive (goal | game) match against sydney fc on saturday 8 august 2009 . in rounds four , five , and six fowler scored solo ' s <unk> a league <unk>... |
| ... time in a 2 – 2 draw away to rochdale in the league cup first (place | game) round on 14 august , although stoke lost 4 – 2 in a penalty shoot out . he scored... |
In this instance, the tokens identified from the training data attribution were less prominent in flipping predictions during ablation compared to the previous highlighted neuron. For example, the token “season” flipped a prediction in only 13.8% of the instances wherein the model predicted “season” or the model with this neuron ablated predicted “season”.
token | proportion flips | count flips | notable |
affected | 1.000000 | 1 | False |
included | 1.000000 | 1 | False |
consecutive | 1.000000 | 1 | False |
artillery | 1.000000 | 2 | False |
… | |||
manager | 0.142857 | 7 | False |
season | 0.138462 | 130 | True |
forces | 0.137931 | 29 | False |
league | 0.137255 | 51 | True |
ii | 0.133333 | 15 | False |
game | 0.132701 | 211 | True |
hero | 0.125000 | 8 | False |
As before, we have attributed functionality of this neuron purely on the basis of training data attributed to outlier parameter shifts. Comparing against a direct analysis on activations we were similarly not able to differentiate the identified tokens as being a strong effect from the target neuron.
Example: Neuron 181 in MLP layer 3.2 as related to quantity prediction
We showcase another example from MLP layer 3.2 where the token “number” was identified through training data attribution on outlier parameter shifts. Below are a few examples of token prediction flips after zero-weight ablation on this neuron.
| ... concerts in the united states , plus a (<unk> | number) tour to south america during the summer , where they traveled to argentina , uruguay and brazil . the singing cadets toured south africa in 2010 and... |
| ... storms to portions of western australia . additionally , a (large | number) 30 @ , @ 000 ton freighter broke in half amidst rough seas produced by the storm . total losses from the storm reached a... |
| ... half hour time slot , but nbc later announced it would be expanded to fill an hour time slot beginning a (<unk> | number) half hour early , although it still counts as one official episode ,... |
| ... 1784 ) , and proposed a (<unk> | number) new binomial name agaricus pseudo <unk> because of this . one compound isolated from the fungus is 1 @ , @ 3 <unk> ( 1 @ ,... |
| ... in 2011 . dota 2 is one of the most actively played games on steam , with peaks of over a (<unk> | number) million concurrent players , and was praised by critics for its gameplay , production... |
In this case, the identified token “number” occurs very early in the list of ablation prediction flips when ranked by proportion of flips. However, we also notice several other commonly flipped tokens that are related (yellow) that were not identified: “few”, “single”, “large” and “second”. Most likely a significant proportion of this neuron’s contribution is from adjusting predictions to quantity-related words.
token | proportion flips | count flips | notable |
total | 1.000000 | 1 | False |
lot | 1.000000 | 1 | False |
white | 1.000000 | 1 | False |
critical | 1.000000 | 1 | False |
few | 0.894737 | 19 | False |
month | 0.888889 | 9 | False |
guitar | 0.800000 | 5 | False |
number | 0.750000 | 24 | True |
single | 0.736842 | 38 | False |
way | 0.666667 | 3 | False |
large | 0.666667 | 33 | False |
second | 0.644068 | 59 | False |
… | |||
Example: Neuron 173 in MLP layer 3.2 identified as highly polysemantic
For this neuron, a lot of various tokens were identified using the outlier parameter shifts method. Whereas most of the other neurons highlighted using the method had considerably more prediction flips in tokens that had not been identified by the method, the prediction flips for this neuron were nearly exhaustively covered by the training data attribution. Of the 28 unique tokens that experienced prediction flips, 18 were identified beforehand, and most of the remaining 10 tokens were relatively scarce (for example, all of them except the unknown token “<unk>” had less than 13 instances of prediction flips). We showcase the entire table of prediction flips below.
token | proportion flips | count flips | notable |
| university | 1.000000 | 1 | True |
| best | 1.000000 | 4 | False |
| hokies | 1.000000 | 1 | False |
| national | 1.000000 | 1 | False |
| song | 0.666667 | 21 | True |
| british | 0.600000 | 5 | True |
| film | 0.563636 | 55 | True |
| american | 0.500000 | 2 | False |
| episode | 0.464789 | 71 | True |
| character | 0.454545 | 11 | False |
| club | 0.444444 | 9 | False |
| first | 0.381818 | 330 | True |
| game | 0.289474 | 76 | True |
| album | 0.287671 | 73 | True |
| storm | 0.285714 | 7 | True |
| ship | 0.285714 | 7 | False |
| season | 0.266667 | 15 | True |
| ball | 0.250000 | 8 | False |
| war | 0.241379 | 29 | True |
| other | 0.230769 | 13 | True |
| church | 0.222222 | 18 | True |
| most | 0.166667 | 6 | True |
| united | 0.166667 | 6 | True |
| original | 0.125000 | 8 | True |
| league | 0.083333 | 12 | False |
| <unk> | 0.077509 | 1445 | False |
| year | 0.062500 | 16 | True |
| time | 0.057143 | 35 | True |
Example: Neuron 156 in MLP layer 1.2
Here is an example where the method was very unsuccessful. For this early layer neuron, the zero-weight ablation prediction flips were very high variance: there were 330 tokens that had experienced prediction flips, and many of them had an incidence of only a single flip occurring due to the ablation. Moreover, almost none of the flipped tokens were identified by training data attribution on outlier parameter shifts. We have to go down 128 tokens in the list (ranked by proportion of flips) to find the first such token, namely “american”, and there were only 8 such tokens as highlighted in the table below. By contrast, most of the other neurons had both fewer tokens flipped during ablation and also a higher ratio of notable tokens.
token | proportion flips | count flips | notable |
american | 0.200000 | 5 | True |
3 | 0.200000 | 5 | True |
1 | 0.150000 | 40 | True |
2 | 0.102041 | 49 | True |
0 | 0.088235 | 34 | True |
@ | 0.071918 | 876 | True |
5 | 0.065060 | 415 | True |
000 | 0.062500 | 112 | True |
Table: The only tokens identified from training data attribution for neuron 156 in MLP layer 1.2, consisting of mostly infrequently flipped digits and the token “american”.
This pattern seemed to affect other neurons highlighted in earlier layers. In particular, neurons in earlier layers had a higher proportion of flipped tokens and a lower number of tokens identified as notable by training data attribution. For smaller models like this, earlier layer neurons may be more difficult to interpret with ground truths like zero-weight ablation.
| Layer | Avg # flipped tokens | Avg notable tokens |
| MLP Layer 3.1 | 192.25 | 0.035151 |
| MLP Layer 3.2 | 35.10 | 0.136619 |
| MLP Layer 1.2 | 260.50 | 0.022592 |
| MLP Layer 1.1 | 179.00 | 0.016760 |
Methodology: Training data attribution from outlier parameter shifts
Recording parameter differences
With these examples in mind, we describe the method that we used to attribute training data back to shifts in individual parameter weights. As part of the training process, we recorded every difference in model parameters. In particular, if we view the SGD update step as
then we recorded the entire sequence of parameter changes where . For a model of this size, the recording process consumed about 882GB of storage. For larger models, we expect this process to be primarily storage-bound rather than memory or compute bound. Note that we excluded the embedding/unembedding units as these were particularly large, being the square of the vocabulary or parameters. We ran this gradient capture until the model approximately converged in training loss.
Accounting for datum-level attribution
Initially we attempted to record attribution at the level of each SGD batch. However, this proved to be too noisy: there was no discernible relationship between the parameter shifts in a given batch and all of the training data in that batch. Instead, we took advantage of the inherent averaging performed by SGD to capture shifts at the level of each datum. Specifically, we unrolled the typical batching of the gradient with batch size :
where the last equality is a definition of , the parameter difference for the th datum in the batch provided on the th step of the training process. The value is the context window length and refers to taking the first tokens of the datum . In particular, we used the parameter for Torch’s CrossEntropyLoss to unroll all the gradients in the sense of the above equation. This allowed us to separately calculate each gradient for each datum within the batch and manually perform the summation and update the weights to avoid slowing down the training process. After this step, we have data for the full training run that looks like the table indicated below.
epoch | batch | datum_ix | unit | index | diff | abs(diff) | datum |
3 | 202 | 6 | layers.2.linear1.weight | 1391 | 0.008377 | 0.008377 | …skin is not electronic but a rubber cover switch... |
5 | 227 | 14 | layers.2.linear1.weight | 132 | 0.011325 | 0.011325 | …term average. Sixteen of those named storms, ... |
5 | 2828 | 19 | layers.2.linear1.weight | 19211 | 0.022629 | 0.022629 | …had few followers however, he had important... |
3 | 2601 | 4 | layers.2.linear2.weight | 11474 | -0.006278 | 0.006278 | …874’s mainline, and are then given an exclusive… |
5 | 127 | 4 | layers.2.linear2.weight | 34951 | 0.007305 | 0.007305 | …star award was restored a year later in the... |
Table 1: For each epoch, batch and datum in the batch, we record the parameter change in each unit and parameter index jointly with the datum attributed to that parameter.
The first three columns describe where in the training process the attribution occurred. The next two columns indicate the unit (e.g. a specific MLP layer) and parameter index (e.g., index 1391 refers to parameter (6, 191) in a 200x200 2-tensor). The last columns indicate the change and absolute change in parameter value attributed to the given datum. (Technically, we store a datum primary key to conserve on space.)
Identifying training data responsible for notable parameter updates
With the above dataset in hand, we would like to answer the following open-ended question:
Question. What kinds of shifts in parameter weights during SGD can reliably be attributed back to specific information learned from the attributed training data?
In general, gradient descent is a noisy process. Only a few bits of information can be transmitted from the gradient of the cross entropy loss of the current model parameters against the empirically observed next token. However, as we attribute more data back to specific parameter shifts, we expect there to be consistently learned information that is a hidden feature of the attributed data. The only place for the model to have incrementally learned a particular feature, structure or other change that lowers loss is from the training data, so we must identify which shifts are reliable signal and which are noise.
For the remainder of the post, we focus on the setting wherein we are looking at single token distributions within the parameter-level attributed data. Because we cannot attribute every single datum to every single parameter shift, we select a cutoff: we only consider parameter shifts that are in the top absolute shifts within any given training step. Additionally, we only focused on non-(un)embedding 2-tensor layers to avoid the noise from considering bias and norm layers. For our case we chose which amounts to considering approximately 0.13% of the entire architecture.[1] We are interested in attributing notable tokens from the token distribution of all data in the training process that gets selected with this threshold to a specific parameter.
In this setting we have a distribution comparison problem. On the one hand, we have the global distribution defined by the full training set. On the other hand, we have a much smaller sample defined by a subset of the full training data (with multiplicity, since the same datum can affect the same parameter across multiple epochs). We would like to find tokens that could be relevant to a given parameter shift and implied by the difference in these two distributions.
We tried several ways to compare these distributions. For each token, we have an incidence count and the relative proportion of that token in the attributed sample vs the full training distribution (the relative frequency). Unfortunately, because token distributions in the full training data are so imbalanced (e.g. with tokens such as “the” and “a” occurring much more frequently than others), most ways of looking at this ended up simply attributing the most common tokens to the parameter shift, which is clearly incorrect unless the model is only good at predicting the most common tokens and their representation is laced throughout the whole architecture. We tried several approaches for finding attributable outliers: scaling the count and relative frequency by log, using Mahalanobis distance as a bivariate z-score, changes to KL divergence from removing a token from the sample distribution, etc. However, each of these produced examples of very spurious tokens with low counts or simply the most common tokens:
token | count | freq | freq | relative |
gy | 3 | 0.00037 | 0.000001 | 31.142780 |
krist | 4 | 0.000049 | 0.000002 | 27.682471 |
lancet | 4 | 0.000049 | 0.000002 | 27.682471 |
bunder | 3 | 0.000037 | 0.000001 | 24.914224 |
Table 2: Most significant tokens attributed to the parameter with index 3278 of unit “layers.2.linear1.weight” as measured by relative frequency.
token | count | freq | freq | count |
the | 5140 | 0.063300 | 0.63600 | 0.995289 |
, | 4064 | 0.50049 | 0.049971 | 1.001557 |
. | 3317 | 0.40850 | 0.040613 | 1.005836 |
of | 2179 | 0.026835 | 0.027733 | 0.967609 |
Table 3: Most significant tokens attributed to the parameter with index 3278 of unit “layers.2.linear1.weight” as measured by count.
Instead, what ended up working to discover some more likely parameter shift relationships was a simple univariate token heuristic with some hyper-parameters chosen to the data distribution.
Univariate Token Selection Heuristic
- Identify all tokens that occur in the attributed training data with count at least . We chose .
- For these tokens, select the top by relative frequency. We chose .
- Within these, select the top by count. We chose .
unit | index | token | count | freq | freq | relative |
layers.2.linear1.weight | 3278 | slam | 24 | 0.000558 | 0.000055 | 10.168847 |
layers.2.linear1.weight | 3278 | finals | 23 | 0.000535 | 0.000074 | 7.211408 |
layers.2.linear1.weight | 3278 | scoring | 22 | 0.000511 | 0.000078 | 6.556909 |
layers.2.linear1.weight | 3278 | federer | 48 | 0.001116 | 0.000183 | 6.098012 |
Table 3: Most significant tokens attributed to the parameter with index 3728 of unit “layers.2.linear1.weight” as measured by the Univariate Token Selection Heuristic above.
Consider the example above. We can now see a clear pattern starting to emerge for this parameter. All of the tokens that appear are related to sports terminology. In other words, after (1) removing statistical differences in very common words like “the” and “of”, and (2) ignoring the differences in tokens that very rarely show up in the training distribution but comparatively show up more in the attributed data with low counts, we hypothesize that the gradients in the training process that moved this parameter significantly occurred when sports-related training data was presented to SGD.
Relating notable tokens to neurons using zero-weight ablation
At this point, we have some notable tokens attributed to specific parameters as extracted from the full training process. Early on in dissecting the above data we noticed that parameters occurring in the same column of the weight matrix would frequently appear together in the analysis (i.e., the index would typically have many outlier weights that share the same index modulo the hidden dimension, 200). In other words, we were identifying not just specific weights but frequently found weights from the same neuron. At this point we switched to looking at neurons instead of individual weights and considered the set of all training data attributed to a neuron’s weights as the data attributed to that neuron.
To compare whether a token identified in the previous section as notable for the neuron did indeed have a relationship, we performed zero-weight ablation on the neuron (effectively turning it off) and ran a prediction for the token. Furthermore, we ran a full forward pass for every token from the attributed data to determine whether any changes in prediction were spurious or localized the behavior of that neuron (at least in some capacity) to control over that token. The previous results demonstrated in the examples section were based on this prediction flip analysis along the full attributed data for a given neuron.
Zero-weight ablation acts as a ground truth for determining whether a token is or is not notable. The fact that the token was present in a very different distribution than the full training data whenever the parameter shifted greatly indicates the hypothesis that the parameter’s functionality may be related to the token. Zero-weight ablation verifies that excluding or including the neuron materially changes the prediction for that token. As we will see in Appendix III, this does not always work. Ideally, we would like to have a different ground truth that is more suitable for inferring whether or not the token was somehow significant to the learning process localized at that weight. Eventually, we would like to be able to correspond structure in the training data (e.g. interpretable features of the training distribution) to structure in the model (e.g. functionality of parameters, neurons and circuits).
Limitations of the method
No ability yet to capture attribution for attention head mechanisms
We experimented with various ways of attributing token-level training data to parameter changes in attention heads. We could not discern how to connect the training data back to functionality in the attention heads. This could be due to a number of reasons:
- Attention heads operate one or more levels removed from the token-level, building key, query and value circuits to operate on relationships between tokens. In this case, we would need to preemptively build hypotheses for attention head mechanisms and then tag their occurence in the training data, which places us back in vanilla mechint territory and cedes the advantage of using a hypothesis-free method.
- Establishing a ground truth for gauging the behavior of the attention heads requires a different approach that relies on individual weights. For example, zero-weight ablating neurons in attention heads in these smaller models typically led to a single uniform token being produced as the prediction. The token produced did not seem to have any relation to the training data.
- Attention heads could be part of a circuit in a way that makes it impossible to study attribution in isolation of specific parameters.
We suspect these are likely not the case and attention heads are amenable to some analysis directly from their parameter changes. One of the simplest ways of making progress on training data attribution for attention head mechanisms is to pick a simple behavior expressed in the capabilities of the model and analyze attention head parameter shifts for all training datums expressing that behavior. For example, we could select all datums that contain a closing parenthesis token ")" to look for a parenthesis matching circuit component.
Neurons in earlier layers are harder to explain
As noted in Appendix III, most of the neurons with some successful attribution to the training data were in the later layers of the model. Neurons in earlier layers could be used for building features that get consumed in later layers of the model and are harder to interpret in light of the training data under any attribution.
Explanations outside the standard basis may be difficult from parameter shifts alone
As mentioned in the introduction, these preliminary results are mostly applicable to the neuron basis. Features are directions in activation space, so changes to features should be directions in parameter change space.
Imagine a feature that is represented as a direction with equal magnitude in each neuron activation (e.g. where all are equal). As SGD builds the ability to represent this feature, it may shift all parameters in the layer in a way that is small locally to each neuron but significant for altering the activation of the feature. This puts us in a chicken-and-egg problem and would be hard to detect with any kind of approach that looks for parameter shift outliers: we would not be able to distinguish between noise and legitimate but diffuse accumulation of these kinds of constructions to represent features that are not well-aligned with the standard basis.
Paying the alignment tax of capturing full gradient data for large model training runs is expensive
One objection contends that this kind of recording would be prohibitive to perform at scale for larger language model training runs. We contend that storage is relatively cheap and if some kind of training-process-aware interpretability ends up being the approach that works for averting failure modes such as deceptive alignment, then identifying how to efficiently and continuously flush tensors from GPU memory into a data store for interpretability research seems like a small price to pay. With a 175GB parameter model like GPT-3 that was trained on about 700B byte-pair-encoded tokens at a 1K context window length the recording of the full training process corresponds to about 175B * 700B / 1K * 4 bytes per float = 490 exabytes, which is within reach of databases like Spanner. All of that is before applying significant gradient compression or taking advantage of gradients living in a small subspace.
Conclusion
We provided some examples of neurons in small language models whose behavior was partially attributable to training data responsible for shifting the parameters of those neurons. Our results are primarily in late-stage MLP layers but there could be additional techniques that are successful for performing training data attribution to attention heads and earlier layers of a model. Performing this exercise at scale could focus the efforts of mechanistic interpretability by localizing specific mechanisms and capabilities to specific parameters, neurons or circuits of a model. Exhaustively attributing training data throughout a training process could also provide a defense against the formation of deceptive alignment and other behaviors that are not amenable to white-box analysis with any efficient method by providing visibility around their formation earlier in the training process.
Appendix I: Code and reproducibility
We performed this analysis on a Paperspace machine with an Ampere A4000 GPU and 2TB of local disk storage. A copy of the code and reproduction instructions is available at this GitHub repository.
Appendix II: Follow-up questions
This is essentially our first attempt at a contribution to experimental developmental interpretability (has a ring to it doesn't it?), wherein we take the information contained in the entire training process and try to attribute it back to functionality of the model. The results indicate that this task is not completely hopeless: there is clearly some information that we can learn by just understanding the training data and associated parameter shifts and inferring that the corresponding parameters and neurons must be related.
There are multiple changes that would need to be incorporated to make this approach scale:
- More sophisticated attribution techniques for identifying what is “learned” from attributed training data for a given parameter, neuron, and eventually circuit.
- There is some pre-existing theory on computing the influence of individual training datums on final model parameters, e.g. in Koh & Liang 2017. However, this approach requires full knowledge of the Hessian along the training process which quickly becomes intractable in the language model setting.
- Because there is an information bottleneck in how much can be communicated in each step of SGD from the training distribution to the pathing in the loss landscape, the process ends up being very noisy. We would need to find better ways to identify “meaningful” gradient changes that are accumulating towards some structure in the model or contributing to some phase transition.
- A better understanding of localization and modularity within networks that can be used to improve attribution: if every parameter changes in tandem through a global accretion of functionality then it will be much harder to say anything meaningful.
- On the other hand, consider the counterfactual scenario where an SGD update produces a zero shift on almost every parameter except a small subset. Surely we should be able to attribute something exclusively from the training datum to the affected parameters?
- For larger models, we might need to identify phase transitions in the training process and analyze different segments of the process separately.
- Note that we would not be interested only in phase transitions within the model structure. We would more importantly be interested in phase transitions of SGD (or the relevant optimizer) itself, wherein gradient information is used differently early versus late stage in the training process. The mutual information between parameters and layers contained in a full backward pass that informs the gradient computation most likely looks very different in these phases and would require different attribution techniques. Early on, a single step might correspond to a “shift these n-grams” operation whereas later it may be much more targeted, like “(possibly fractionally) memorize this fact expressed in the training datum.”
- Can we identify such phase transitions from incomplete training runs, e.g. only a few snapshots like the Pythia suite?
Appendix III: Identified neurons and notable tokens attributed
Overall, the technique presented in the methodology section yielded 46 neurons that had some training data attributed. Of these, 23 showed some attribution to specific tokens, or about 1.92% of the MLP neurons in the architecture. It could be possible to dive deeper into the model with alternatives to the choice of in the parameter section.
Most significantly, the neurons that had clear attribution were primarily late-layer neurons. On the other hand, no early-layer neurons (i.e. in the first or second layer) were attributed using this analysis. We expect these to be harder to capture from training data attribution alone, but expect more sophisticated variations of this technique to still recover some partial meaningful attribution.
| Unit | Neuron | Attributed? | Comments |
| layers.2.linear1.weight | 11 | Y | Light attribution to `german`, `season` and `album` |
| layers.2.linear1.weight | 111 | Y | Light attribution to `would`, `though`, `may` and `you` |
| layers.2.linear1.weight | 184 | Y | Light attribution to `british` and `ship` |
| layers.2.linear2.weight | 173 | Y | Attribution to `song`, `film`, `episode` and multiple others |
| layers.2.linear2.weight | 96 | Y | Clear attribution to many tokens: `song`, `united`, `character`, `most`, `film`, `episode`, `church`, `war`, `album`, `first` |
| layers.2.linear2.weight | 135 | Y | Somewhat clear attribution to `song`, `united`, `character`, `most` |
| layers.2.linear1.weight | 88 | N | No clear attribution |
| layers.2.linear2.weight | 186 | Y | Somewhat clear attribution to `season`, `game`, `british`, `end` |
| layers.2.linear2.weight | 70 | N | Very weak neuron with barely any flips... or maybe weights are already close to zero. |
| layers.2.linear1.weight | 78 | Y | Weak attribution to `season`, `league`, `game`, `final` |
| layers.2.linear2.weight | 181 | Y | Partial attribution to "number" |
| layers.0.linear2.weight | 156 | N | No clear attribution |
| layers.2.linear2.weight | 182 | N | No clear attribution |
| layers.2.linear2.weight | 172 | Y | Clear attribution to "her" with some confounders from common tokens ("a", "the", "<unk>", ".") |
| layers.2.linear2.weight | 179 | Y | Somewhat clear attribution to `'` (single quote), missed attribution to `.` and `,` |
| layers.2.linear1.weight | 70 | N | No clear attribution |
| layers.2.linear2.weight | 41 | N | No clear attribution |
| layers.2.linear2.weight | 195 | Y | Somewhat clear attribution to `are` (missed `were` and other confounders) |
| layers.2.linear1.weight | 108 | Y | Light attribution to `him` / `she` |
| layers.2.linear2.weight | 170 | N | No clear attribution |
| layers.0.linear2.weight | 97 | N | No clear attribution |
| layers.2.linear2.weight | 129 | Y | Light attribution to `company`, `country`, `city` (missed attribution to `,`, `.`) |
| layers.2.linear2.weight | 110 | Y | Somewhat clear attribution to `not` |
| layers.2.linear2.weight | 9 | N | No clear attribution |
| layers.2.linear2.weight | 163 | Y | Slight partial attribution to `number` |
| layers.2.linear2.weight | 139 | N | No clear attribution |
| layers.2.linear2.weight | 50 | N | No clear attribution |
| layers.2.linear2.weight | 17 | N | No clear attribution |
| layers.2.linear2.weight | 178 | Y | Clear attribution to `are` |
| layers.2.linear2.weight | 74 | Y | This neuron has a lot of strong flips, but some partial attribution to `up`, `century` and `war` |
| layers.2.linear1.weight | 75 | N | No clear attribution -- Too polysemantic a neuron |
| layers.2.linear1.weight | 121 | N | No clear attribution |
| layers.2.linear2.weight | 99 | Y | Somewhat clear attribution to `who` and `'` |
| layers.2.linear2.weight | 165 | Y | Clear attribution to `been` (but missed attribution to `a`) |
| layers.2.linear1.weight | 84 | N | No clear attribution |
| layers.2.linear2.weight | 97 | N | No clear attribution |
| layers.2.linear2.weight | 148 | Y | Some attribution to `out`, `them`, `him` (but missed `her`) |
| layers.0.linear1.weight | 131 | N | No clear attribution, but possibly related to parentheses matching? |
| layers.2.linear1.weight | 98 | Y | Very slight attribution to `she` and `are` |
| layers.2.linear1.weight | 112 | N | No clear attribution |
| layers.2.linear2.weight | 89 | N | No clear attribution |
| layers.2.linear2.weight | 80 | N | No clear attribution |
| layers.2.linear2.weight | 111 | N | No clear attribution |
| layers.2.linear2.weight | 45 | Y | Somewhat clear attribution to `south` |
| layers.2.linear2.weight | 104 | N | No clear attribution |
Appendix IV: Shifts in bi-gram distributions
Another simple to thing look at is parameter shifts in the embedding/unembedding units responsible for bi-gram distributions (see the section on Zero-Layer Transformers in AMCTF). We did not use byte-pair encodings and thus due to the size of vocabulary employed these units are significantly larger than the rest of the architecture. This made storage of full gradient changes prohibitive. In this section we provide some commentary on how to perform this analysis in principle.
The bi-gram decoder is given by . Given embedding and unembedding weight updates and , identifying shifts in the bi-gram distribution on each step is given by:
Notice that this "bi-gram shift" term requires knowledge of both and as free parameters. Hence, it is not sufficient to store only the weight updates and . We need the actual weights as well. However, we can store just the original weights and then update iteratively to achieve a storage-compute trade-off and avoid doubling our storage requirements.
1. Store just the updates and where is the learning rate (5.0 in our experiments).
2. Except on step 0, store full weights and .
3. Apply the above update when processing each step.
4. Use the resulting matrix to observe the largest shifts in bigrams per batch.
- ^
There are of course other ways to find outlier parameter shifts. For example, we could track the magnitude of weights over the training process and apply a per-unit or per-neuron normalization to account for different layers/neurons taking on different magnitudes. We could also look at the full time series of parameter shifts per parameter and then identify outliers relative to just that time series. This would constitute a local version of the global analysis provided in the text.
- ^
There might be more specific ways to consider this neuron-data attribution, for example by scaling each weight datum’s attribution by the weight value at that point in the training process.
1 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-08-24T22:58:42.378Z · LW(p) · GW(p)
Focusing on language models, we note that models exhibit “consistent developmental stages,” at first behaving similarly to -gram models and later exhibiting linguistic patterns.
I wrote a shortform comment [LW(p) · GW(p)] which seems relevant:
Are there convergently-ordered developmental milestones for AI? I suspect there may be convergent orderings in which AI capabilities emerge. For example, it seems that LMs develop syntax before semantics, but maybe there's an even more detailed ordering relative to a fixed dataset. And in embodied tasks with spatial navigation and recurrent memory, there may be an order in which enduring spatial awareness emerges (i.e. "object permanence").