Is there an easy way to turn a LW sequence into an epub?
post by ChristianKl · 2020-07-18T18:20:03.795Z · LW · GW · No commentsThis is a question post.
Contents
Answers 19 habryka 8 mr-hire 6 NunoSempere 2 Richard Horvath None No comments
I'm interested in reading Kaj's sequence on my Kindle. What's the best way to get a sequence like this into a form that I can load on my Kindle?
Answers
There is a Github repository that I fixed up a few months ago that allows you to do this, though it's definitely not a great UI experience:
https://github.com/LessWrong2/LessWrong-Portable
I've had it on my to-do list for a while to add a "download as PDF" and "download as Epub" button to sequence-pages, but I haven't gotten around to it, and it's not super high on the priority list, though if enough people want that, it's likely to happen faster.
↑ comment by migueltorrescosta · 2020-07-19T00:01:04.902Z · LW(p) · GW(p)
I'd really like this feature as well
Replies from: Yoav Ravid↑ comment by Yoav Ravid · 2020-08-05T12:01:30.783Z · LW(p) · GW(p)
Same
↑ comment by Mark Xu (mark-xu) · 2020-12-24T21:35:28.892Z · LW(p) · GW(p)
A button that changes a sequence into one really long post might also be sufficient when paired with other tools, e.g. instapaper.
I just checked the WebToEpub parser on the sequence page and the default parser does a fairly decent job of this. Simply copy the first link from the sequence and put it in the "URL of first chapter" link.
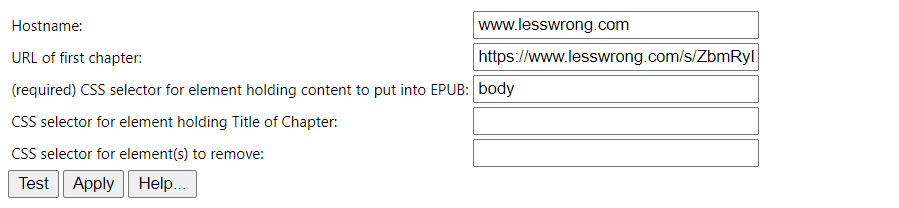
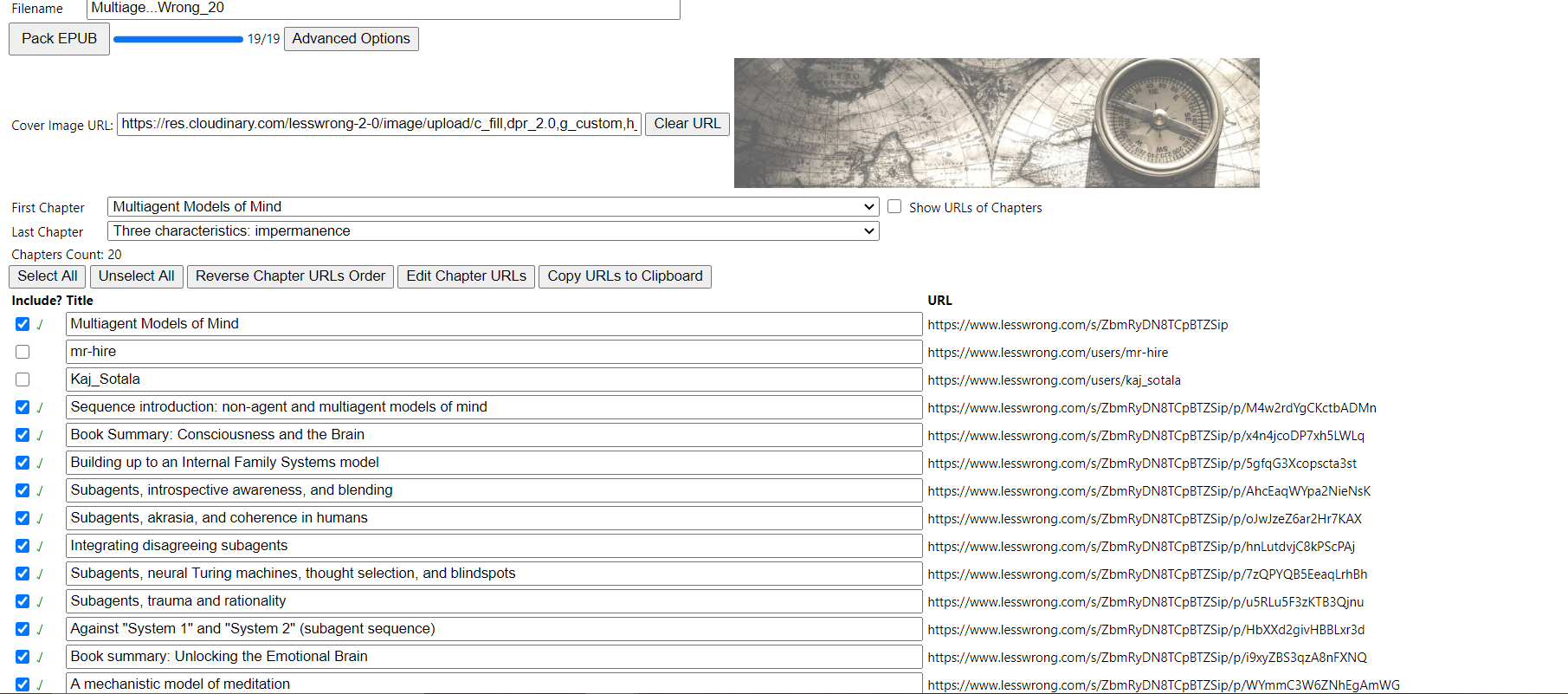
then, on the second page, uncheck the 3 irrelevant links and click pack epub. It's not perfect but it correctly creates a table of contents, does a decent job of formatting, and pulls in only the articles not the comments.
↑ comment by kubanetics (jakub-nowak) · 2022-03-16T13:36:36.198Z · LW(p) · GW(p)
I came here for this tip specifically to read Kaj's sequence as well! Used this plugin for now but I hope it becomes a feature.
↑ comment by Yoav Ravid · 2020-08-06T16:28:06.168Z · LW(p) · GW(p)
Could be cool to add download links to some sequences. for example Zvi's Immoral Mazes sequence is one i'm more likely to read on an e-reader, and i think it's pretty much book-length.
Use the LW GraphQL API (https://www.lesswrong.com/posts/LJiGhpq8w4Badr5KJ/graphql-tutorial-for-lesswrong-and-effective-altruism-forum [LW · GW]) to query for the html of the posts, and then use something like pandoc to translate said html into latex, and then to epub.
Link to the graphQL API [? · GW]
The command needed to get a particular post:
{
post(input: {
selector:{
_id: "ZyWyAJbedvEgRT2uF"
}
}) {
result {
htmlBody
}
}
}
There is now:
https://www.lesswrong.com/posts/C3tDuQEikma4gQ56j/enjoy-lesswrong-in-ebook-format [LW · GW]
(https://github.com/bartbussmann/lesswrong_ebook_library)
Contains not just the code to scrape sequences, but all sequences and monthly "best of LessWrong" compilations up until February 2023 in both pdf and epub format, which you can individually download from the github link.
No comments
Comments sorted by top scores.