An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers v2
post by Neel Nanda (neel-nanda-1) · 2024-07-07T17:39:35.064Z · LW · GW · 16 commentsContents
Foundational Work Superposition Sparse Autoencoders Activation Patching Narrow Circuits Paper Back-and-Forths Bonus None 16 comments
This post represents my personal hot takes, not the opinions of my team or employer. This is a massively updated version of a similar list [AF · GW] I made two years ago
There’s a lot of mechanistic interpretability papers, and more come out all the time. This can be pretty intimidating if you’re new to the field! To try helping out, here's a reading list of my favourite mech interp papers: papers which I think are important to be aware of, often worth skimming, and something worth reading deeply (time permitting). I’ve annotated these with my key takeaways, what I like about each paper, which bits to deeply engage with vs skim, etc. I wrote a similar post 2 years ago, but a lot has changed since then, thus v2!
Note that this is not trying to be a comprehensive literature review - this is my answer to “if you have limited time and want to get up to speed on the field as fast as you can, what should you do”. I’m deliberately not following academic norms like necessarily citing the first paper introducing something, or all papers doing some work, and am massively biased towards recent work that is more relevant to the cutting edge. I also shamelessly recommend a bunch of my own work here, and probably haven't always clearly indicated which papers I was involved in, sorry!
How to read this post: I've bolded the most important papers to read, which I recommend prioritising. All of the papers are annotated with my interpretation and key takeaways, and tbh I think reading that may be comparable good to skimming the paper. And there's far too many papers to read all of them deeply unless you want to make that a significant priority. I recommend reading all my summaries, noting the papers and areas that excite you, and then trying to dive deeply into those.
Foundational Work
A Mathematical Framework for Transformer Circuits (Nelson Elhage et al, Anthropic) - absolute classic, foundational ideas for how to think about transformers. See my youtube tutorial (I hear this is best watched after reading the paper, and adds additional clarity).

- Deeply engage with:
- All the ideas in the overview section, especially:
- Understanding the residual stream and why it’s fundamental.
- The notion of interpreting paths between interpretable bits (eg input tokens and output logits) where the path is a composition of matrices and how this is different from interpreting every intermediate activations
- And understanding attention heads: what a QK and OV matrix is, how attention heads are independent and additive and how attention and OV are semi-independent.
- Skip Trigrams & Skip Trigram bugs, esp understanding why these are a really easy thing to do with attention, and how the bugs are inherent to attention heads separating where to attend to (QK) and what to do once you attend somewhere (OV)
- Induction heads, esp why this is K-Composition (and how that’s different from Q & V composition), how the circuit works mechanistically, and why this is too hard to do in a 1L model
- All the ideas in the overview section, especially:
- Skim or skip:
- Eigenvalues or tensor products. They have the worst effort per unit insight of the paper and aren’t very important.
- Caveats (h/t Buck) - I think the paper somewhat overstates the degree to which we can fully and mathematically understand tiny attention-only transformers, and it may be worth checking out these critiques:
- Understanding how a transformer works in detail is a pre-requisite for getting the most out of this paper, I recommend getting to the point where you can code a basic transformer (eg GPT-2) from scratch. I shamelessly recommend my Youtube tutorial on this (and accompanying tutorial notebook).
Superposition
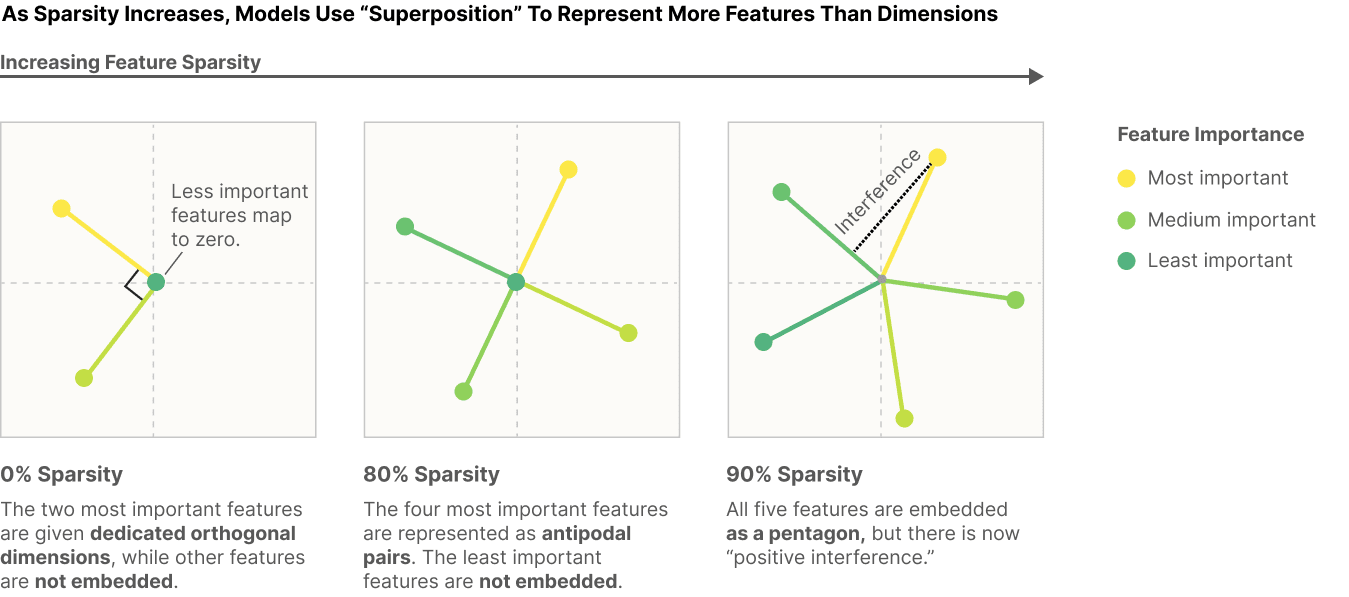
Superposition is a core principle/problem in model internals. For any given activation (eg the output of MLP13), we believe that there’s a massive dictionary of concepts/features the model knows of. Each feature has a corresponding vector, and model activations are a sparse linear combination of these meaningful feature vectors. Further, there are more features in the dictionary than activation dimensions, and they are thus compressed in and interfere with each other, essentially causing cascading errors. This phenomena of compression is called superposition.
- Toy models of superposition (Nelson Elhage et al, Anthropic) - absolutely foundational work on the idea of superposition, a ton of great ideas in there. I found reading it very useful for building my conceptual frameworks of what My main critique is that they only study toy models (but, you know, it's in the name)
- Deeply engage with:
- The core intuitions: what is superposition, how does it respond to feature importance and sparsity, and how does it respond to correlated and uncorrelated features.
- Read the strategic picture, and sections 1 and 2 closely.
- Skim or skip:
- No need to deeply understand the rest, it can mostly be skimmed. It’s very cool, especially the geometry and phase transition and learning dynamics part, but a bit of a nerd snipe and doesn’t obviously generalise to real models.
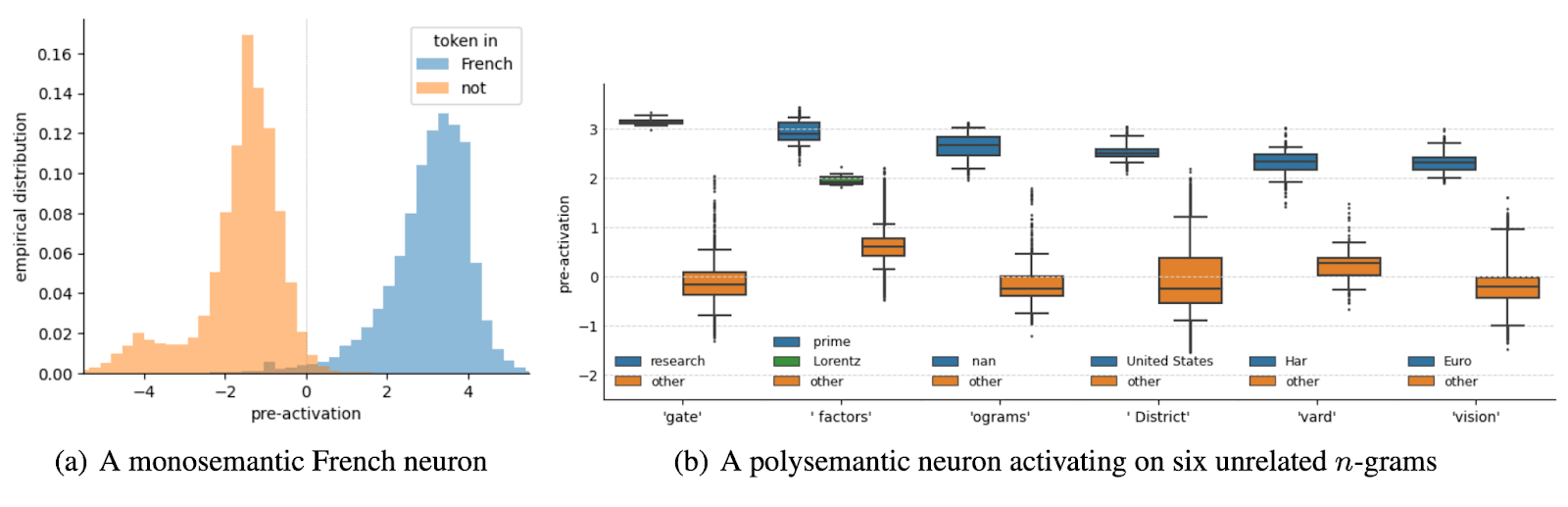
- Finding Neurons In A Haystack (Wes Gurnee et al, during my MATS program). We try to find empirical evidence for and against superposition by identifying various attributes (eg “this text is in French” or “this is the second token in ‘social security’”) and then training sparse probes (ie at most k non-zero elements) on MLP neurons to find them. I recommend skimming over the sparse probing stuff and methodology, IMO the key stuff is the case studies, and building intuition for what's out there in models. Notably, we find monosemantic language neurons (eg is French), and evidence that compound word detection (eg “social security”) is done in superposition, distributed across many polysemantic neurons. Youtube walkthrough
- I'm really proud of the exposition about superposition in appendix A, and think it’s highly worth reading, and clarifies some open thread left by Toy Models of Superposition
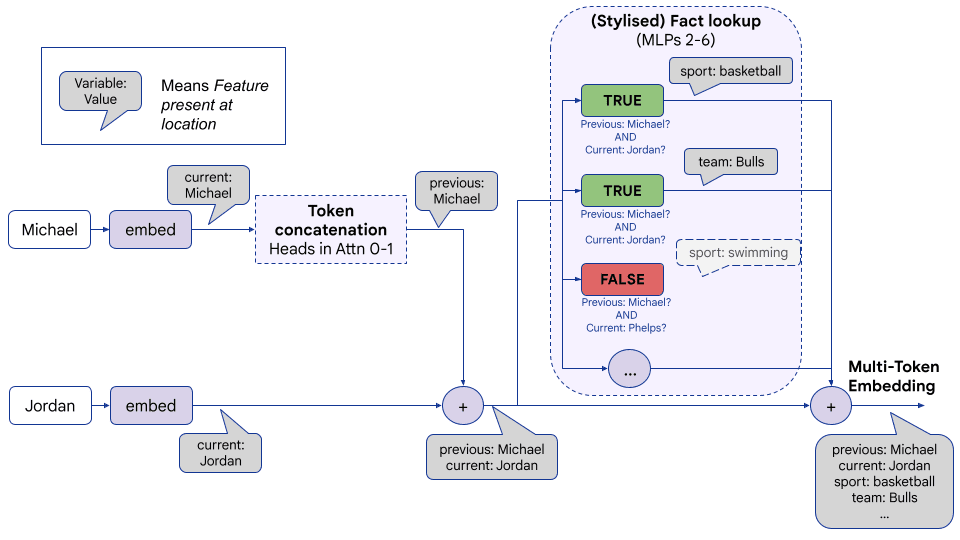
- Fact Finding [AF · GW] (Neel Nanda & Sen Rajamanoharan et al, Google DeepMind) - we tried to really understand how facts were stored in model MLP layers in superposition. Unfortunately, we failed - it seems cursed and complex. But I think we learned a fair bit in the process, provided further evidence that superposition is happening (it’s not just neuron aligned and there’s many more facts than neurons) and falsified some simpler hypotheses. The sequence is long, but I think it's worth reading post 1 carefully. Post 3 has the superposition relevant stuff
- Note that this research was done before SAEs took off, and we do not use them.
Sparse Autoencoders
SAEs are a tool to interpret model activations in superposition - they’re a one hidden layer ReLU autoencoder (basically a transformer MLP layer), and are trained to reconstruct a model’s activations. L1 regularisation is applied to make the hidden layer activations sparse. Though not directly trained to be interpretable, the hope is that each unit (or feature) corresponds to an interpretable feature. The encoder + ReLU learns the sparse feature coefficients, and the decoder is a dictionary of feature vectors. Empirically, it seems to work, and I think they’re the one of the most promising tools in mech interp right now.
To understand the actual technique I recommend this ARENA tutorial, sections 1, 6 & 7 (exposition + code >> papers), but here are some related papers worth understanding. Note that all of these came out in the past year, this is very much where a lot of the mech interp frontier is at! However, our understanding of them is still highly limited, and there are many uncertainties and open problems remaining, and I expect our understanding and best practices to be substantially different in a year or two.
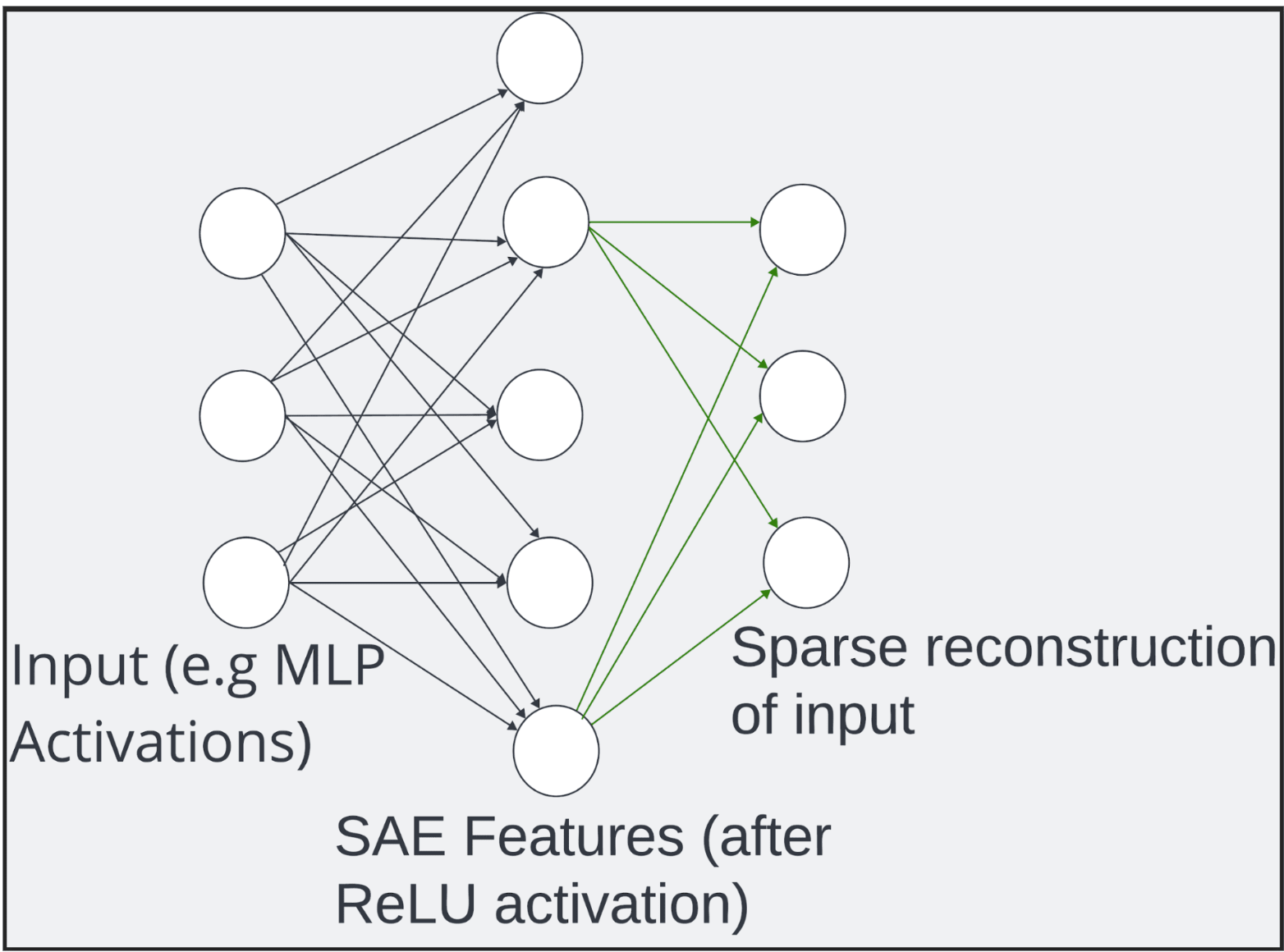
- Towards Monosemanticity (Trenton Bricken et al, Anthropic): The foundational work in applying SAEs to models to find interpretable features, beautifully written, and with a lot of good exposition and tips for training SAEs well. I recommend reading in full. My main criticism is that they only looked at 1L models, so all the features lie in unembedding space (they get linearly mapped to the logits), so it’s not very surprising that they’re linear - but future work (below) shows their results hold up.
- Sparse Feature Circuits (Sam Marks et al, David Bau’s group): A great initial attempt at circuit analysis with SAEs (ie using SAE features as circuit nodes). Uses attribution patching, introduces a variant with integrated gradients that empirically works better at early layers and seems fairly principled. I personally think the way they implement gradient computation is somewhat convoluted (lots of stop gradients) and it would be simpler to do it analytically (take the gradient with respect to the residual stream after the relevant layer, and then do linear algebra to find the gradient wrt an SAE feature)
- Has some cool results applying their interpretability insights to reduce spurious correlations in a linear probe, reducing gender bias. I find this particularly exciting, as it feels like the start of a real-world application of SAEs, which I think is a big open problem for the field - if they are truly as useful as we think they are, they should be better than existing baselines in a fair fight on at least some real-world tasks. See this post from Sam on the long-term safety motivations [AF · GW] here - we want to distinguish between behaviourally identical systems that tell us the truth vs telling us what we want to hear.
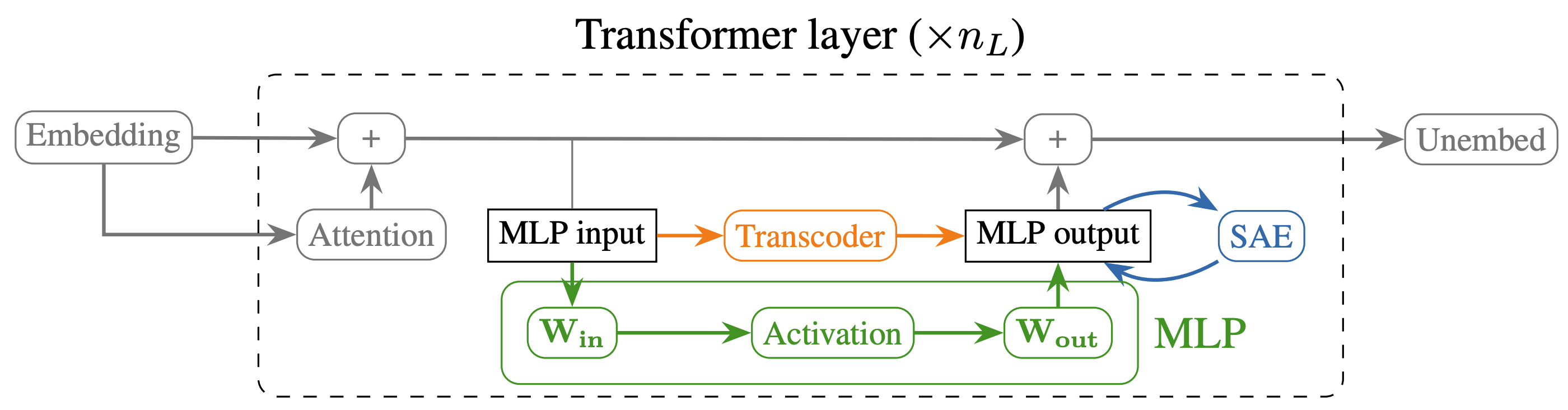
- Transcoders Find Interpretable LLM Feature Circuits (Jacob Dunefsky, Philippe Chlenski et al, during my MATS program). Circuit analysis can either be causal intervention based (eg Interpretability in the Wild, or Sparse Feature Circuits), or weights based (eg Progress Measures for Grokking) - actually multiplying things out and seeing what happens. It’s very hard to do weights-based analysis on MLP layers in superposition though, as for any given feature, most neurons (and their non-linearities!) are implicated, and hard to decompose. Transcoders are an SAE variant that tries to solve this, by learning a sparse, interpretable replacement for an MLP layer, by training an “SAE” to map the MLP input to output. They seem to perform about as well as SAEs, and make circuit analysis much easier, though we still struggled to get true weights-based analysis working - many features have high alignment without co-occuring.
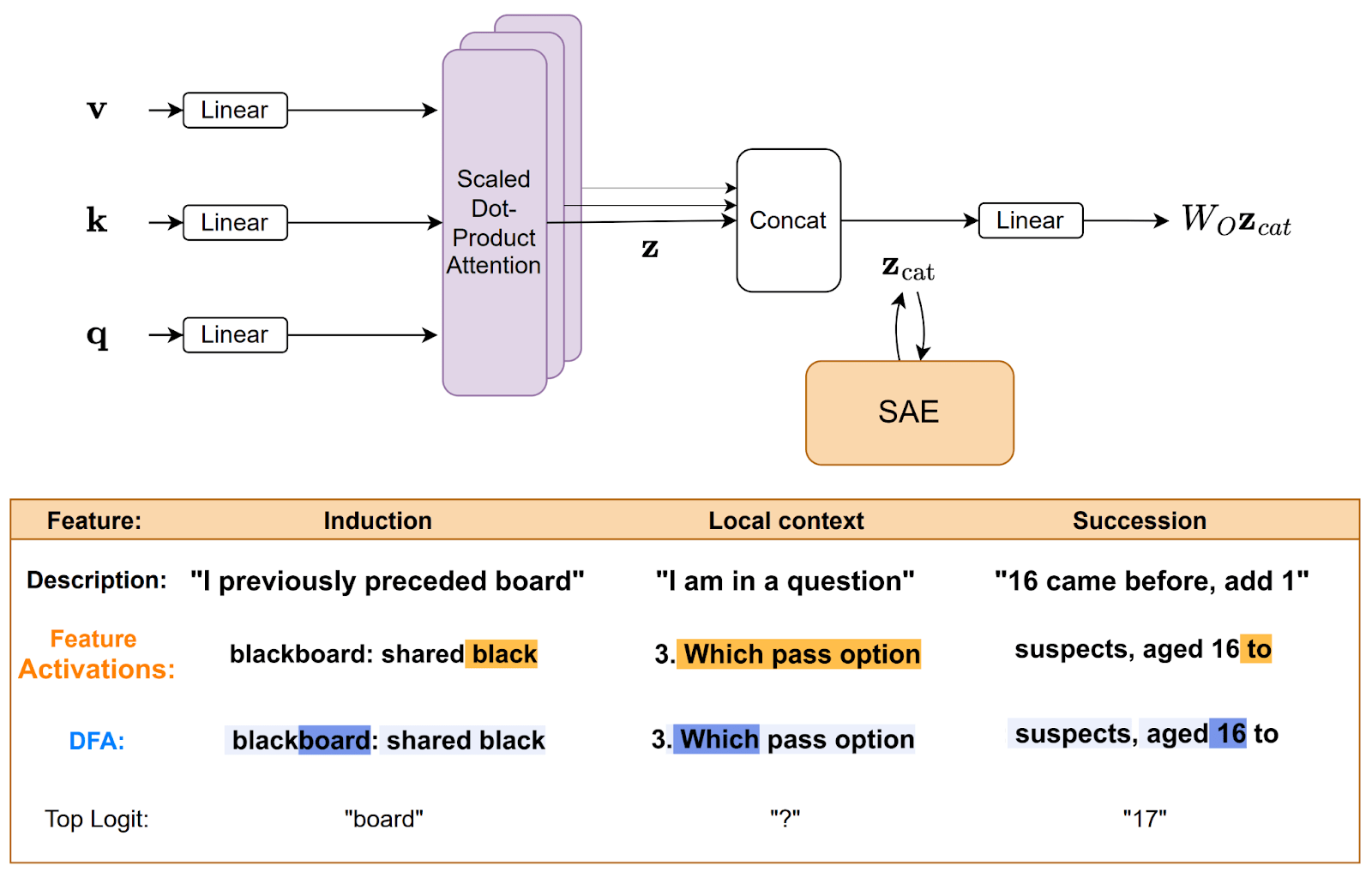
- Interpreting Attention Layer Outputs with Sparse Autoencoders (Connor Kissane & Rob Krzyzanowski et al, during my MATS program): A nice post showing that SAEs can be applied to attention layer outputs, and that this just works (they do it pre W_O, which has nice benefits of being able to easily attribute things to heads). I particularly liked the focus on showing that these SAEs can be a useful tool for researchers, attacking problems previously out of reach. We found a deeper understanding of the semantics of the IOI circuit, got a sense of the kinds of features that form in attention layers, figured out the different roles of two induction heads in a layer, and roughly gauged the role(s) of every head in GPT-2 Small.
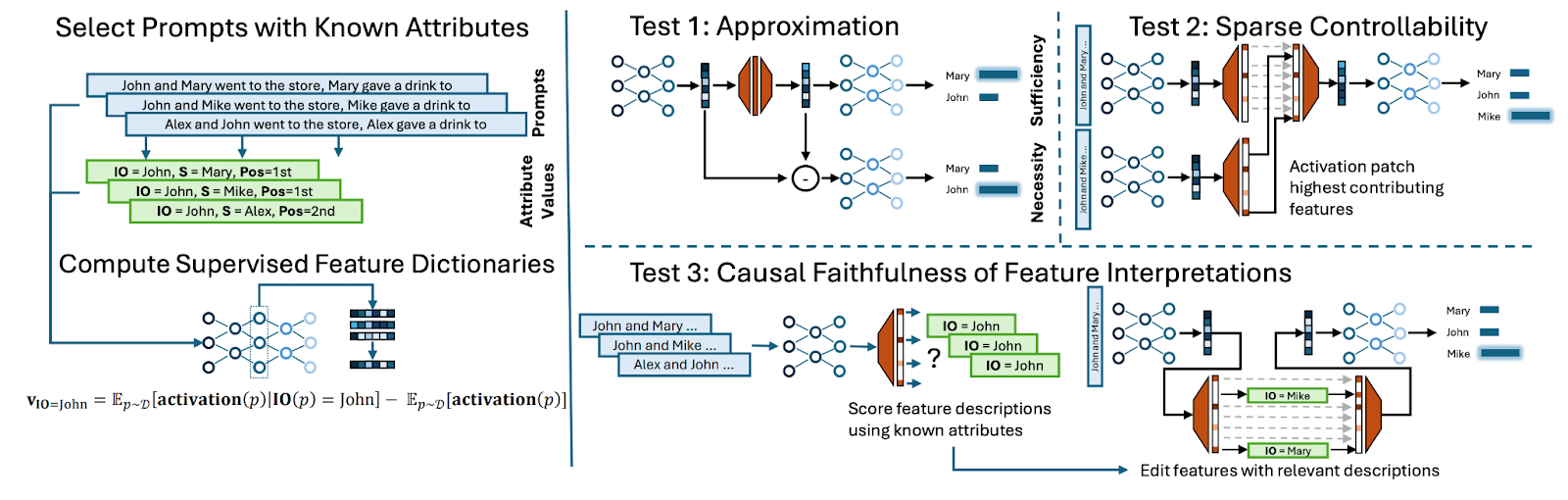
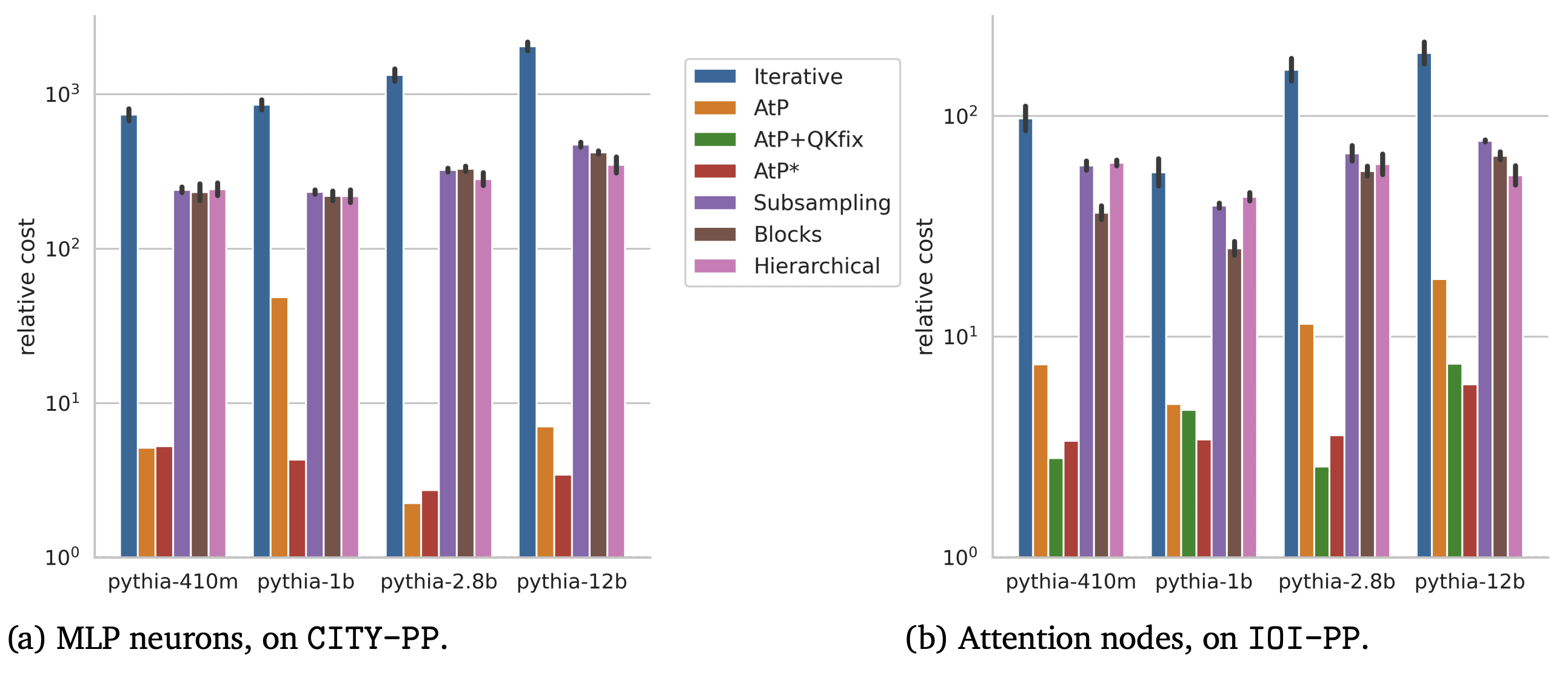
- Towards principled evaluations of sparse autoencoders for interpretability and control (Alex Makelov & Georg Lange et al, during my MATS program). One of my favourite attempts to design better metrics for SAE quality, one of the major open problems in the field. We took the well-studied Indirect Object Identification circuit, trained SAEs on every head and layer, and evaluated two metrics: sparse control, whether the output could change from input A to input B by changing a sparse set of input A SAE features, and interpretability, whether we could use SAE features as probes to find the expected features. Because we roughly know what features to expect, we can also train dictionary vectors for them in a supervised way, measure the quality of these, and use this to get a baseline for our benchmark
- One of the hard parts of this analysis is that, though we think we know what important features to expect in the IOI circuit (the value and position of the names), we can’t be sure we aren’t missing something (eg the gender of the names). We discuss this at length, and how we try to deal with it.
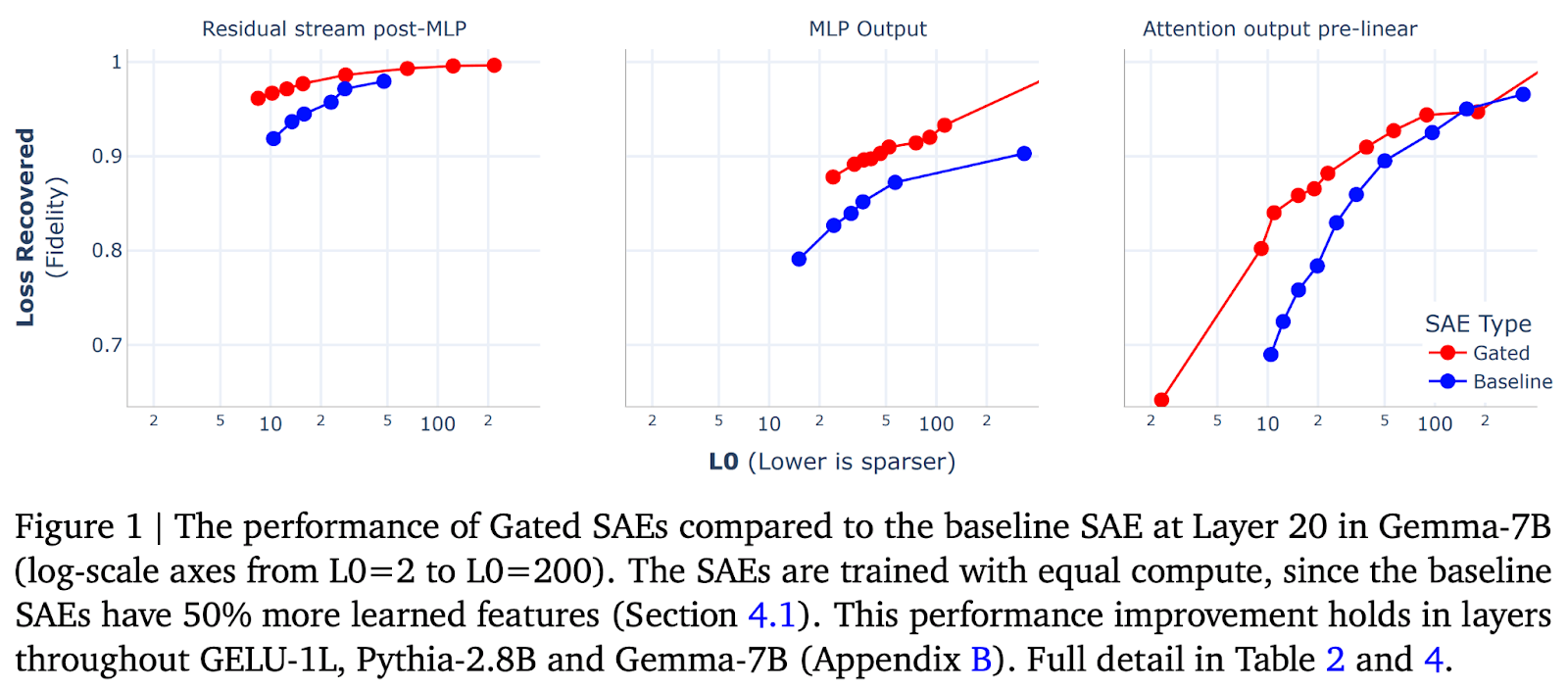
- Gated SAEs (Sen Rajamanoharan et al, from my team at DeepMind): Introduced Gated SAEs, a new architecture for SAEs that gets similar reconstruction at half as many firing features while being either comparably or more interpretable. We also scaled SAEs to Gemma-7B. I (very biasedly) think this is worth reading as a good exemplar of how to rigorously evaluate whether an SAE change was an improvement, and because I recommend using Gated SAEs where possible.
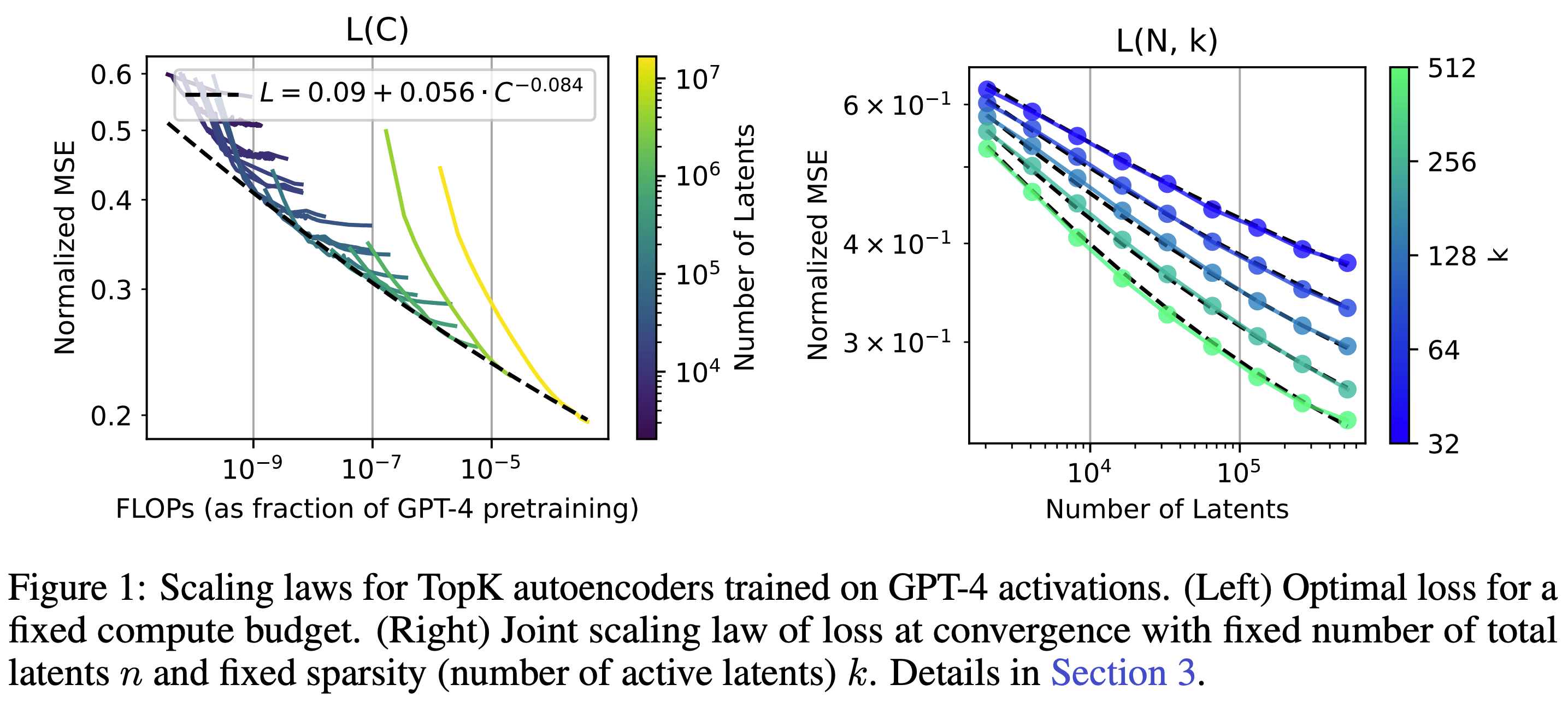
- Scaling and evaluating sparse autoencoders (Leo Gao et al, from the OpenAI superalignment team RIP 😢). Shows that top-k SAEs (ie replace the ReLU with “keep the top k pre-activations, set the rest to zero) are an effective technique, scale SAEs to GPT-4 (the largest model SAEs have been trained on!), do some rigorous exploration of SAE scaling laws, and propose several creative ideas for measuring SAE quality. I’m particularly excited about the ideas for how to measure SAE quality, since this is a big open problem in the field, and would be keen to see the metrics proposed fleshed out and applied in more detail. The work provided a feature viewer, but did little qualitative case studies itself - anecdotally the GPT-4 SAE features don’t seem that interpretable, but I haven’t explored this properly.
- One big concern I had from this paper is how interpretable top-K SAEs are. Follow-up work from Anthropic showed that there’s no hit to interpretability, and confirmed that they are a significant performance improvement (comparable to gated SAEs)
- Scaling monosemanticity (Adly Templeton et al, Anthropic) Similar to the OpenAI paper, the headline result is that SAEs scale to a (near) frontier model, Claude 3 Medium (Sonnet). But there’s a massive focus on case studies and qualitative analysis, which is very fun and worth reading, so it complements the OpenAI work nicely. They find a range of abstract and multimodal features eg an unsafe code feature that activates on pictures of “warning: this web page may be insecure”, and including some potential safety relevant ones. There’s a focus on showing that features are causally meaningfully variables and can be used to steer the model, similar to steering vectors.
- The most famous part of this paper was Golden Gate Claude, the ultimate meme, an accompanying demo where they released a version of Sonnet that was steered with the Golden Gate Bridge feature to obsessively fixate on the bridge
- A key nuance is that (in my opinion) the paper does not show that SAEs are the best way to steer (compared to lower tech methods like steering vectors, or even prompting). Rather, the goal was to show that SAEs do something real, by showing that they have an abstract, causal effect, and affect the model’s computation in sophisticated ways. I’ve seen many people see Golden Gate Claude and think they need an SAE to do steering, you probably don’t need to bother!
- There’s an accompanying blog post with a bunch of tweaks to significantly improve SAE training, which excitingly seem to stack with gated and top-K SAEs!
- I really loved the feature completeness result - turns out that there’s a clean sigmoid relationship between the frequency with which a concept appears in the SAE training, the number of alive SAE features, and the probability that it’s learned by the SAE.
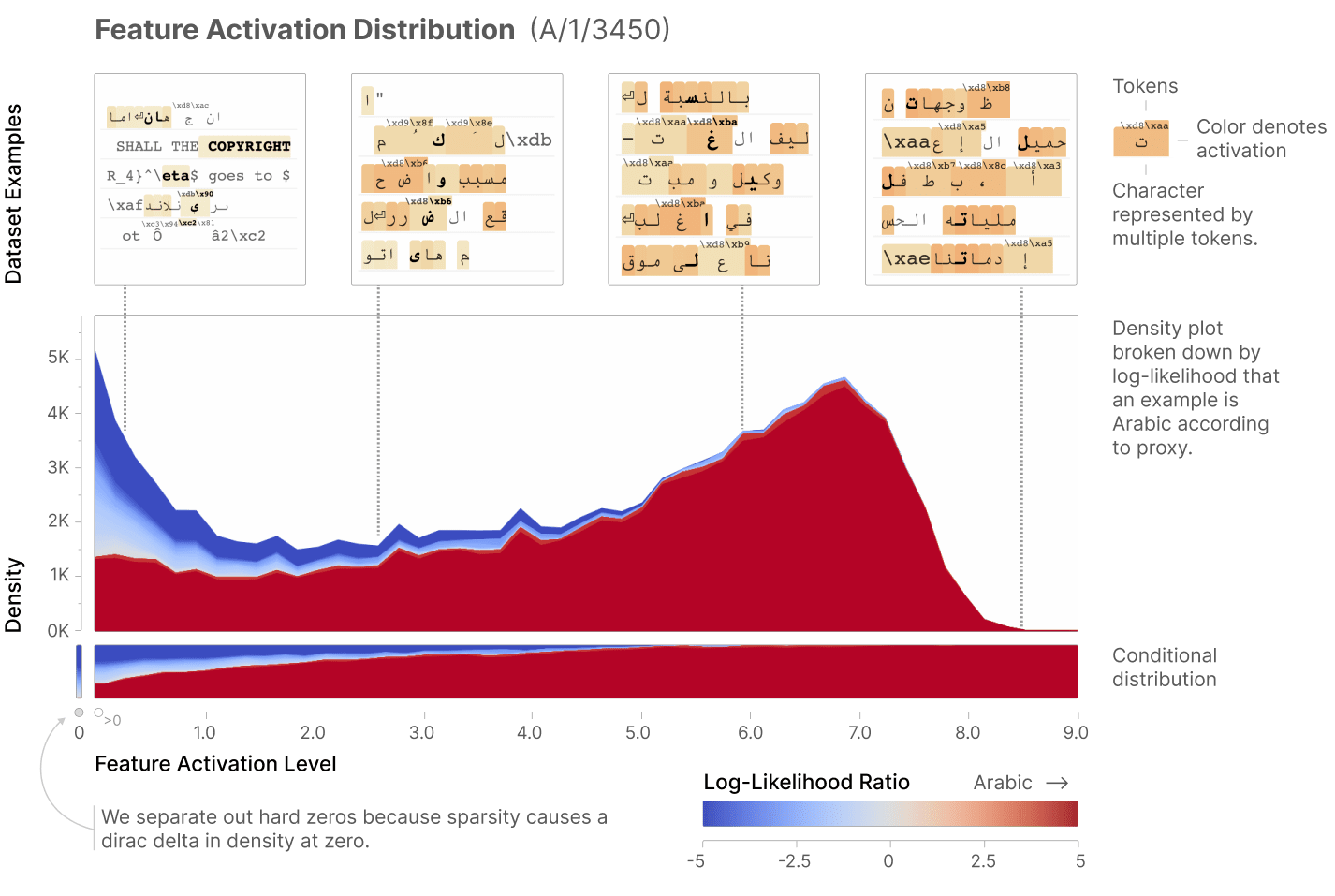

Activation Patching
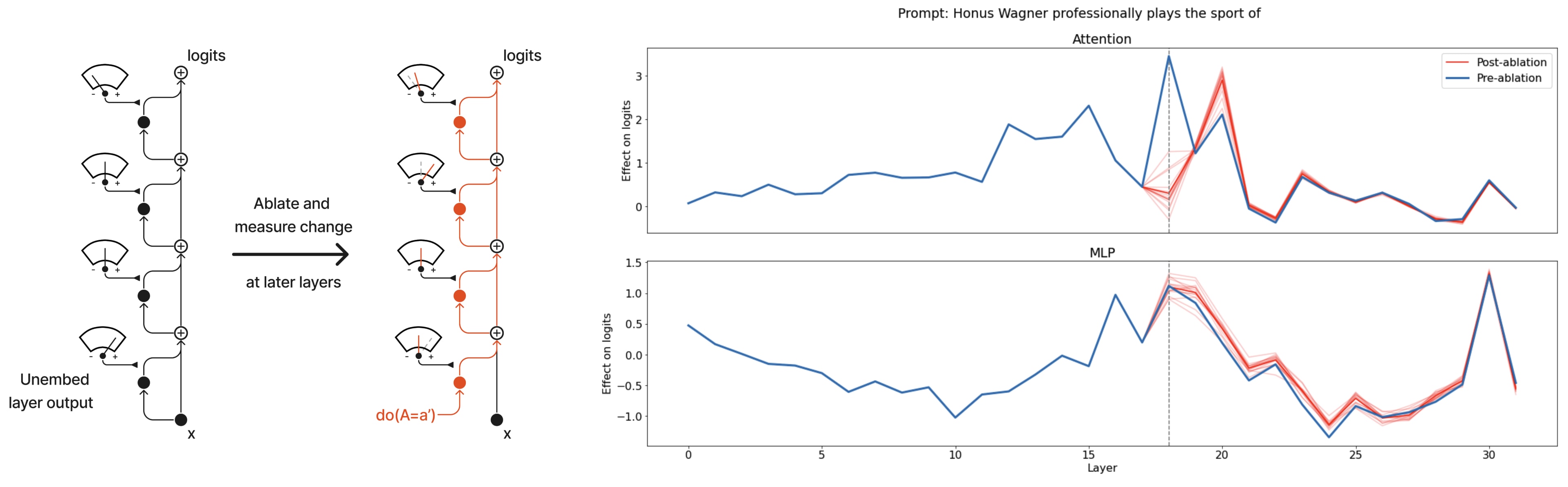
Activation patching (aka causal mediation analysis aka interchange interventions aka causal tracing aka resample ablations - argh why can't we agree on names for things!) is a core mech interp technique, worth understanding in a lot of detail. The key idea is that, for a given model behaviour, only a sparse set of components (heads and neurons) are likely relevant. We want to localise these components with causal interventions. But, given any prompt, many model behaviours go into it. For example, if we want to know where the knowledge that Michael Jordan plays basketball lives, this is hard - we can do things like deleting components and seeing if the model still says basketball, but maybe we deleted the "this is about sports" part or the "I am speaking English part".
The key idea is to find contrast pairs - prompts which are as similar as possible, apart from the behaviour we care about, eg "Michael Jordan plays the sport of" and "Babe Ruth plays the sport of". If we patch activations from the Jordan token into the Ruth token (or vice versa), we control for things like "this is about sports" but change whether the sport is basketball or not, letting us surgically localise the right behaviour.
To understand the actual technique I recommend this ARENA tutorial (exposition + code >> papers), but here are some related papers worth understanding.
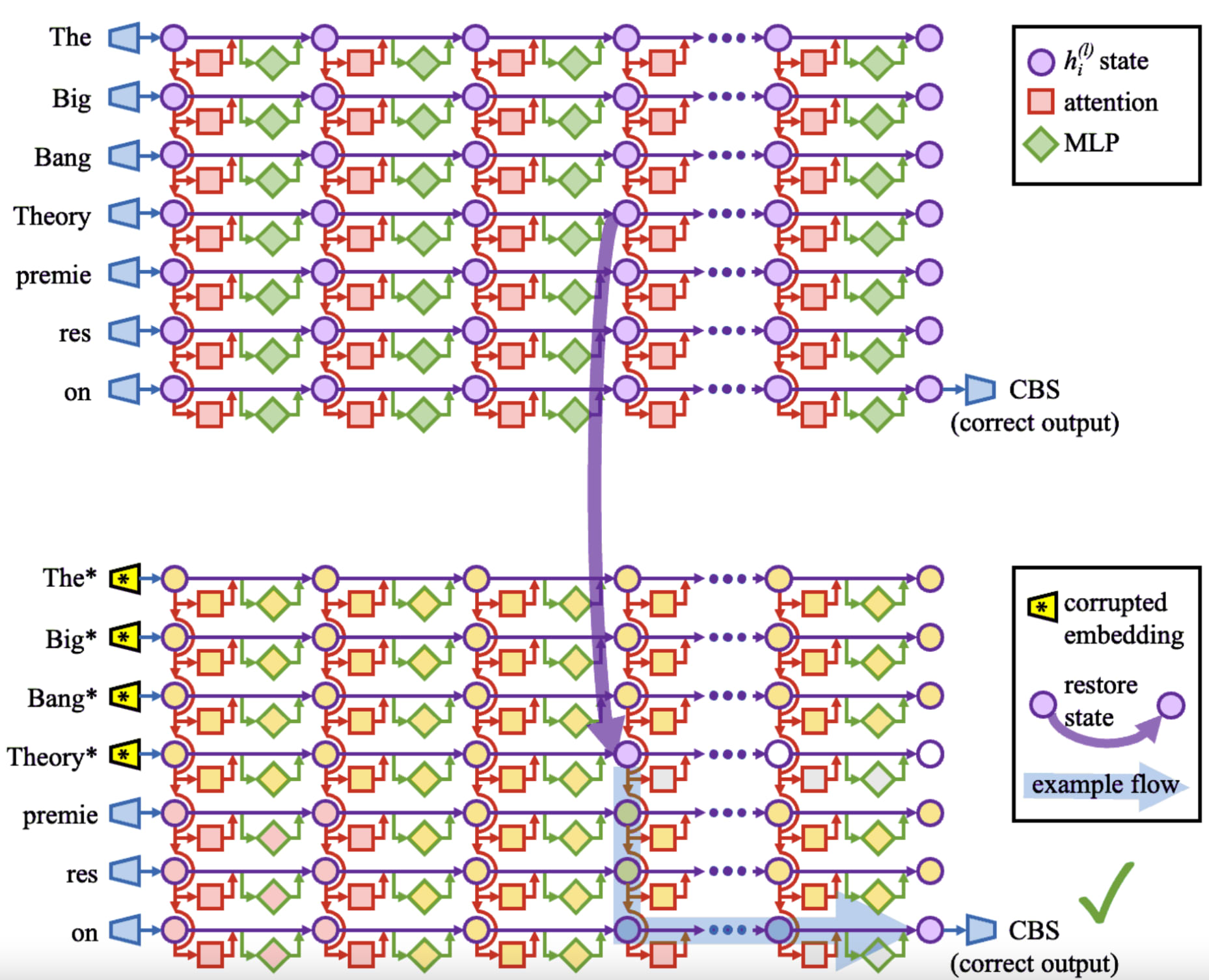
- How to use and interpret activation patching (Stefan Heimersheim & me) An expository and highly opinionated note on how to think about activation patching. It’s a powerful but subtle and confusing technique, and we walk through some traps, how to use the technique well, and advice on interpreting results.
- Note that this is not a paper, in the sense that it doesn’t produce original research, but rather an attempt to reduce Research Debt. I highlight it because I think it distils implicit ideas spread across many papers and the heads of many researchers in one place.
- Causal scrubbing [LW · GW] (Redwood) - This is my current favourite attempt to define a metric for how good your explanation of a model's behaviour is. The key idea is to identify all patches that are allowed by your explanation (eg resample ablating a head that isn't part of your hypothesis, or resample ablating the path between two heads that don't compose under your hypothesis) and to do all of them, and see how much damage it does. I found the sequence itself somewhat sprawling and hard to read, but found it valuable to get my head around the key ideas, and found it had multiple important methodological insights like the idea of resample ablation (rather than ablating a component by setting it to zero, replace its activation with the value taken from a random other input).
- It's even stronger than just ablating all irrelevant nodes and edges - if some activation should have the same value on multiple prompts (eg "the previous token is ' cat'") then you are allowed to patch it between different prompts where the previous token is cat. And we can do this recursively. Unfortunately, this is a pain in the ass to implement, and I think you can basically get away with not doing it in practice?
- Attribution Patching (me, work mostly done at Anthropic) - Activation patching at industrial scale, using a gradient based approximation. You can approximate the effect of patching a component from input A into input B with (act_A - act_B) . (grad_B). This works reasonably well in practice, and is blazingly fast - you go from doing a forward pass per component to doing two forward & one backward pass for every single component simultaneously!
- I think the key thing is just to know that the technique exists, but the post itself has a lot of good exposition on how to think about activation patching that I feel quite proud of. It doesn't do a good job of testing that attribution patching is actually a good approximation.
- See the AtP* paper (Janos Kramar et al, Google DeepMind mech interp team) for a much more systematic set of experiments showing that attribution patching is a good approximation and the best way to use a limited compute budget (of several patching variants explored), and some improvements to the technique by handling saturated attention softmaxes better.
- Marks et al (David Bau's group) introduces an integrated gradients based approach, which is slower, but seems to be superior.
- Automated Circuit Discovery (Arthur Conmy et al) - The key idea is to take the kind of analysis done in IOI, finding the key sparse subgraph for a circuit, and automate it by doing it recursively and keeping the key nodes at each step. Importantly, it operates on edges, not nodes. Youtube walkthrough
- I think the key insight is that this can be automated, and maybe to know that a specific method exists. I think the paper itself has lots of gory details that probably aren't worth engaging with in much detail?
- Follow-up work (Aaquib Syed et al) showed that this can be done with attribution patching to be much faster
- Distributed Alignment Search (Atticus Geiger et al). The key idea is that rather than activation patching a full component, which may not work if we aren't in a privileged basis, we can learn some subspace to patch instead! Honestly, I think this is the crucial idea: use gradient descent to find a subspace such that it has a causal effect when patched, and the rest of the paper isn't necessary. I also think that DAS can often be done with a 1D subspace, and the paper doesn't focus on getting the subspaces small. Atticus thinks about mech interp and causal graphs fairly differently from me, and engaging with how he frames things might be valuable for you! Youtube walkthrough (I've heard some people found the paper impenetrable, but found the walkthrough easy)
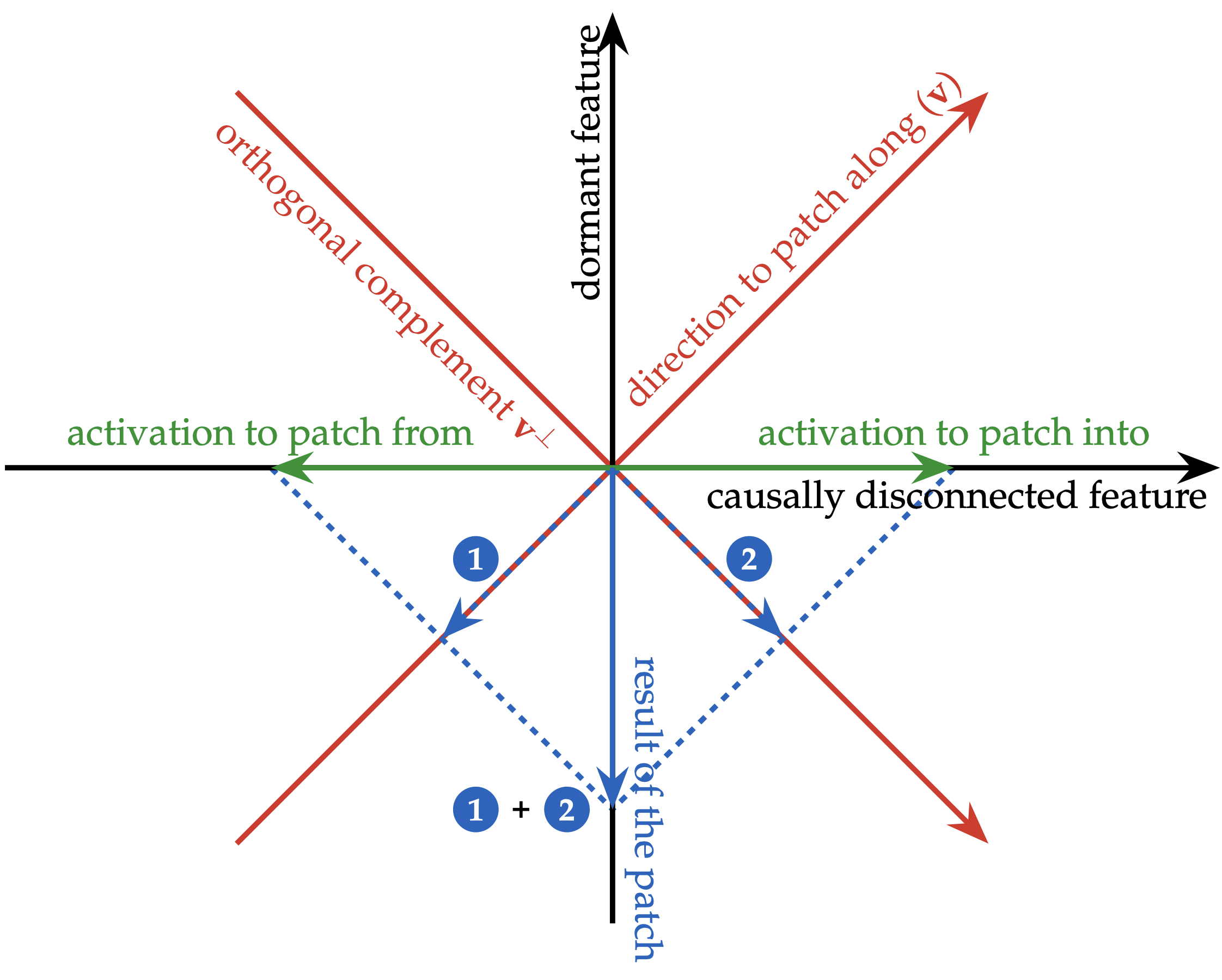
- An Interpretability Illusion for Subspace Activation Patching (Aleksander Makelov & Georg Lange, during my MATS program) - A key accompaniment to thinking about distributed alignment search! It turns out that using gradient descent to find subspaces can be sketchy. Concretely, knowing that patching along a direction has a causal effect tells you that the direction both correlates with the feature in question and causally affects the output. if you have a direction that is dormant (matters causally but never changes) and a direction that is disconnected (causally irrelevant but correlates with the feature of interest), then their sum is both causal and correlated and so is valid to patch along. We show that you can find both of these directions everywhere in real models, and this illusion comes up in practice, especially when doing DAS on model layers rather than the residual stream.
Narrow Circuits
A particularly important application of activation patching is finding narrow circuits - for some specific task, like answering multiple choice questions, which model components are crucial for performance on that task? Note that these components may do many other things too in other contexts, due to polysemanticity, but that is not relevant to this kind of analysis. At this point, there's a lot of narrow circuits work, but here's some of my favourites.
Note that this used to be a very popular area of mech interp work in 2023, but has fallen somewhat out of fashion. I am still excited to see work doing narrow circuits work in the SAE basis (eg Sparse Feature Circuits above), work using narrow circuits to understand or do something on real-world tasks, especially in larger models, and work automating circuit discovery, especially automating the process of finding the meaning of the circuit. But I think that there's not that much value in more manual Indirect Object Indentification style work in small models.
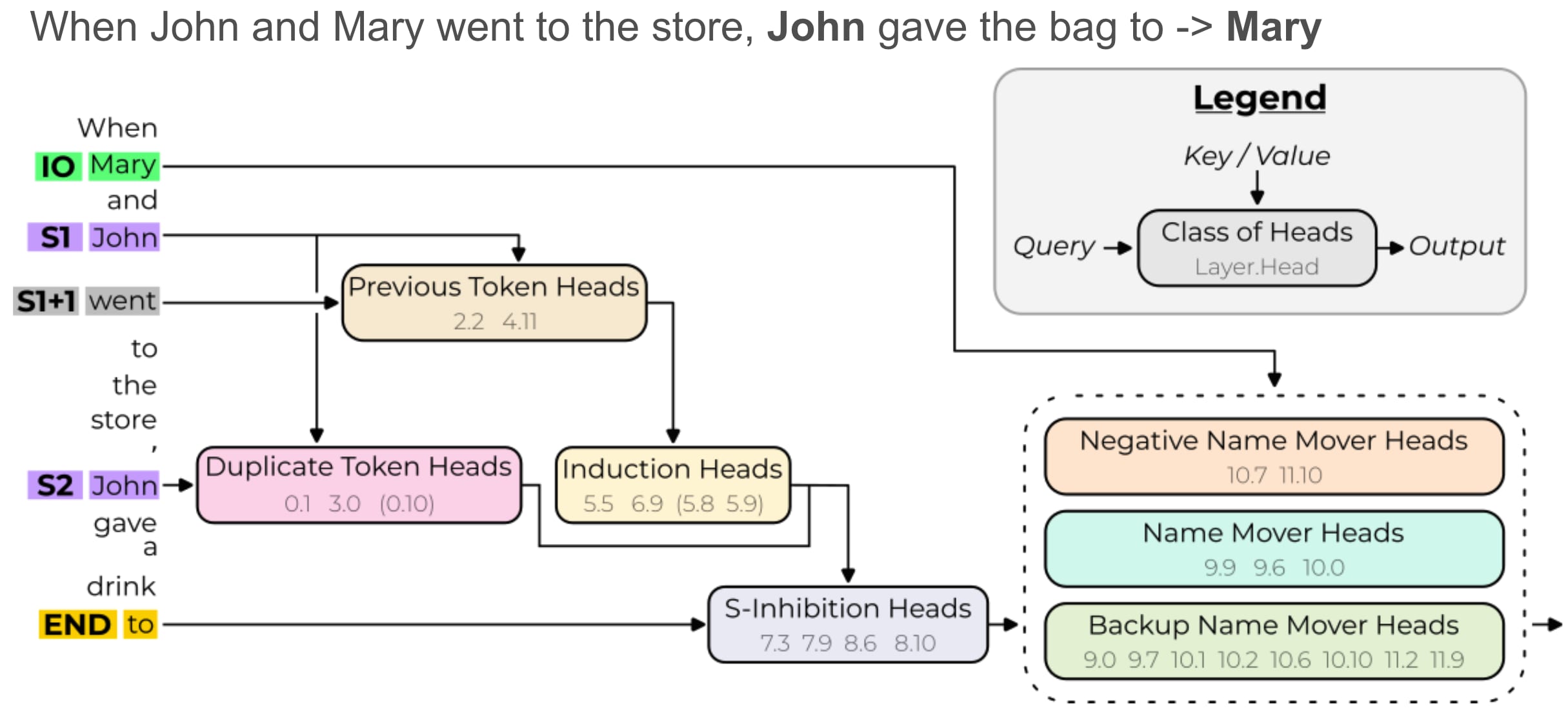
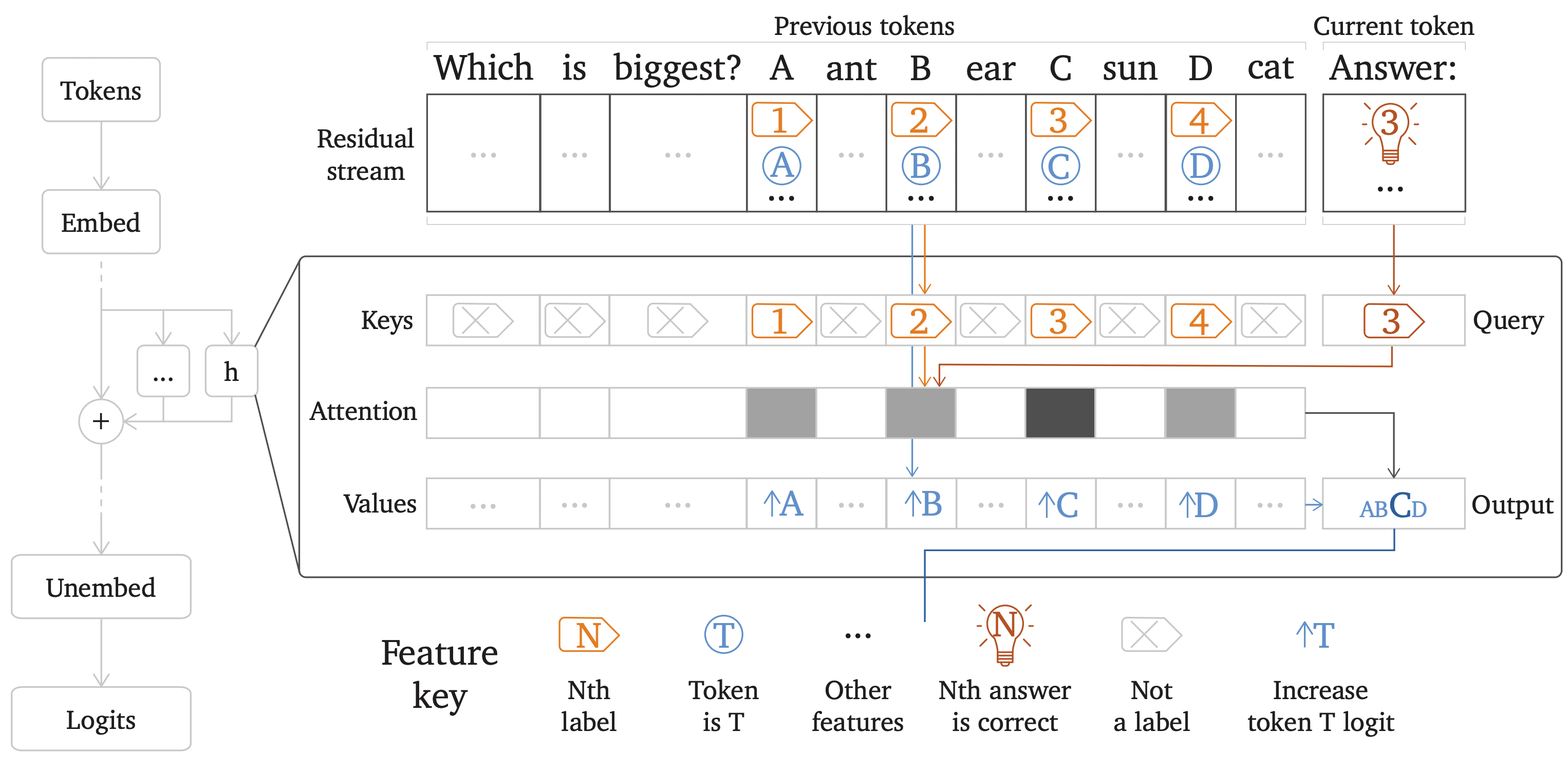
- Indirect Object Identification (Kevin Wang et al, Redwood) - The classic paper that used activation patching in detail to find a circuit used for a narrow task ("When John and Mary went to the store, John gave the bag to" -> " Mary"). I've gotten a ton of value out of thinking a lot about this circuit, replicating it, and thinking through the techniques. Just having a concrete example of a narrow circuit is high value. And I think there's several promising theories of change that factor through doing IOI style analysis on more important problems (eg deception, or 'why does Bing Chat gaslight users?')
- I'm less confident it's worth a lot of effort close reading the actual paper lol, I think it was optimised for getting into ICLR, and there's a bunch of stuff on eg circuit completeness that isn't very interesting to me.
- Notable for being the first place I saw negative heads and backup heads studied, though IMO those are now best studied by reading copy suppression and the hydra effect respectively
- The actual method used in the paper is mean ablation (mean taken over another, similar distribution) of circuit edges that they don't think are important. It's not clear to me that I'd use this myself (compared to eg patching between prompt pairs, possibly patching nodes rather than edges). I'd favour going through this tutorial to think about how to do IOI.
- A Greater-Than Circuit (Michael Hanna et al, Redwood) - There's been a lot of IOI follow-up works, that look at circuits on other narrow tasks. This is one of my favourites, which includes some analysis of specific neurons.
- Task: "The war was fought from the year 1745 to 17" should be followed by 46 onwards not 44 or before
- Does Circuit Analysis Interpretability Scale? (Tom Lieberum et al, DeepMind). Shows that IOI-style analysis scales by doing it on Chinchilla (70B) on the syntactic part of doing multiple choice questions - converting knowledge of the factual answer to the correct letter (not on finding the factual answer in the first place). Things basically scale! It's slow and painful and there's weird cursed shit (like heads that move the answer label to the end if and only if it is both correct and C), but nothing fundamentally breaks. I also think it's a fairly well presented and clean example of circuit analysis.
- I'm proud of the circuit analysis in my Fact Finding [AF · GW] sequence (the focus of post 2 [AF · GW]), I think it's particularly clean and well-presented, and turned out fairly nicely.
Paper Back-and-Forths
One of my favourite phenomenons is when someone puts out an exciting paper, that gets a lot of attention yet has some subtle flaws, and follow-up work identifies and clarifies these. Interpretability is dark and full of terrors, and it is very easy to have a beautiful, elegant hypothesis that is completely/partially wrong, yet easily to believe by overinterpreting your evidence. Red-teaming your own work and being on guard for this is a crucial skill as a researcher, and reading examples of this in the literature is valuable training.
- ROME + Follow-ups: A valuable thread in interpretability illusions. Rank-One Model Editing was a proposed factual editing technique that could insert facts into model MLP layers, by optimising for a rank one edit that would make the model say "The Eiffel Tower is in the city of" -> " Rome" (the optimisation target was that it would output Rome). The paper got a lot of attention, and the edit had fascinating effects, eg changing other answers about the Eiffel Tower to be consistent with the knowledge that it was in Rome. Can you see the flaw with this scheme?
My answer in rot13: Gur pber ceboyrz vf gung gurl qvq snpg vafregvba, abg snpg rqvgvat. Gb rqvg fbzrguvat lbh zhfg qryrgr gur byq guvat naq vafreg arj vasbezngvba, ohg EBZR unf yvggyr vapragvir gb rqvg jura vg pbhyq whfg vafreg n ybhq arj snpg gb qebja bhg gur byq bar. Guvf zrnaf gung gur ynlre vg jnf vafregrq va qvqa'g ernyyl znggre, orpnhfr vg whfg unq gb qrgrpg gur cerfrapr bs gur Rvssry Gbjre naq bhgchg Ebzr. Shegure gurer jrer yvxryl cngubybtvpny rssrpgf yvxr bhgchggvat 'ybbx ng zr' fb urnqf jbhyq nggraq zber fgebatyl gb gur Gbjre gbxra naq guhf bhgchg Ebzr zber, guvf yrq gb pregnva ohtf yvxr "V ybir gur Rvssry Gbjre! Onenpx Bonzn jnf obea va" -> " Ebzr".- ROME (Kevin Meng & David Bau et al) - Given the above, I don't think it's worth engaging deeply with their method/tests, except as a pedagogical exercise. They also used causal tracing/activation patching to great effect, which legitimately was very cool, and significantly influenced the field.
- Does Localization Inform Editing (Peter Hase et al) A follow-up showing that there was no correlation between the layers that were easiest to edit and the layers that mattered when patched. Unsurprising given the above! (I think the key info is given by the summary, and wouldn’t prioritise reading it deeply)
- Detecting Edit Failures in Large Language Models (Jason Hoelscher-Obermaier & Julia Persson et al) A follow-up showing the "The Louvre is cool. Obama was born in" -> " Rome" example (unsurprising given the above!). (I think the key info is given by the summary, and wouldn’t prioritise reading it deeply)
- The Interpretability Illusion for Subspace Patching paper discussed above shows (and almost proves) that there will exist such directions in any MLP layer before the fact retrieving heads
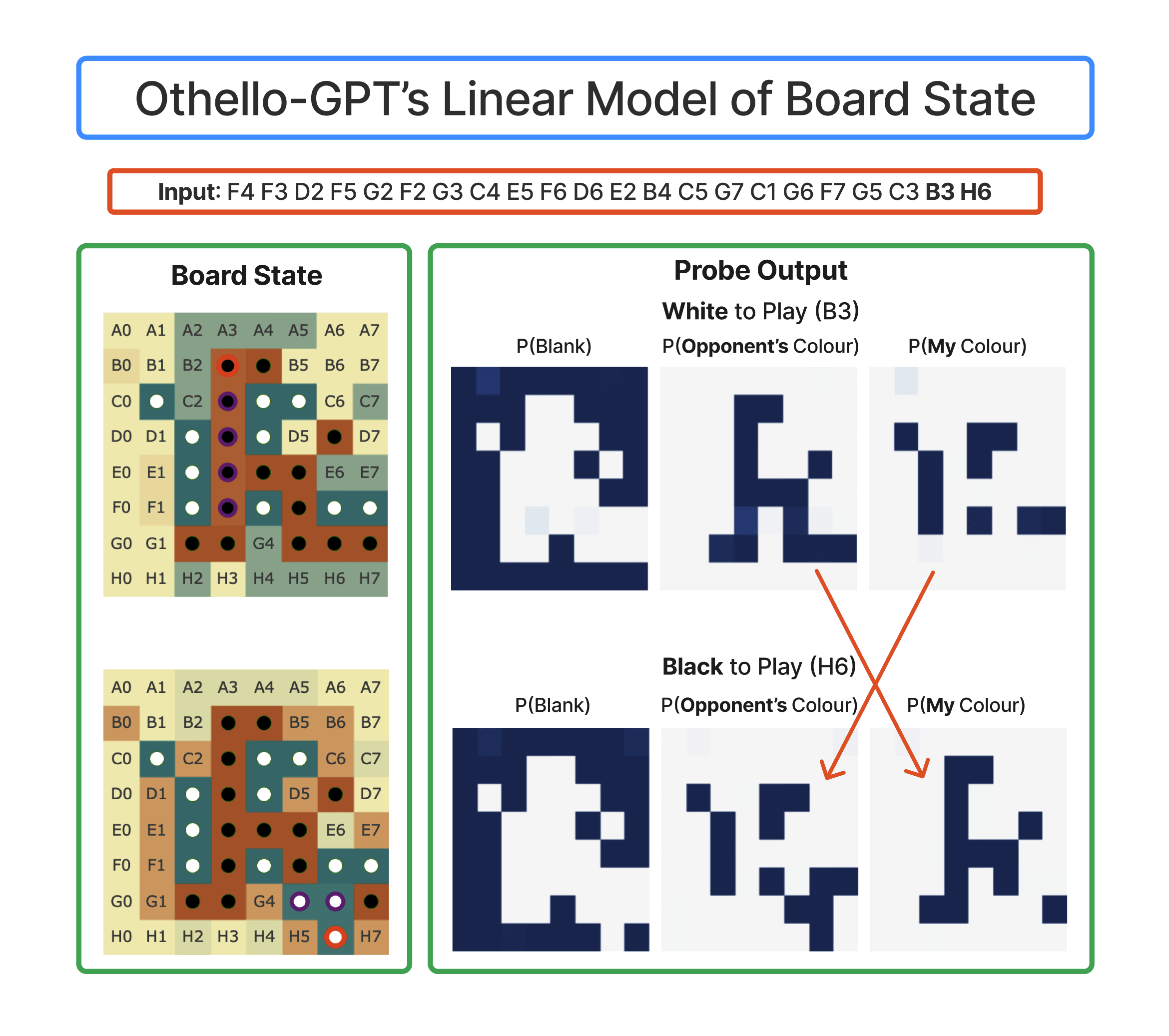
- Othello + my follow-up: There was a very cool paper from Kenneth Li that trained a model to predict the next move in the board game Othello (like chess/Go) on synthetic games that randomly chose legal moves. They found that the model spontaneously learned a model of the board state internally, this could be probed for, and could be causally intervened on (with a very complex, galaxy brained method) and change model outputs in the desired way. Crucially, they found that non-linear probes (one hidden layer MLPs) could find the board state, but linear probes could not!
In my follow-up, I found that there was a linear world model hiding beneath! But that rather than saying whether a square was black or white, it said whether it had the current or opposing player's colour. Once you have this linear world model, you can causally intervene with simple vector arithmetic!- I think this is most exciting as real evidence for the linear representation hypothesis - the original paper seemed like a serious shot at falsifying it, and my follow-up showed that it survived falsification!
- This paper brings me joy for (along with many other papers) conclusively falsifying the strong stochastic parrots narrative.
- Emergent World Representations (Kenneth Li et al) Given the above, I don't actually think it's worth reading closely, except as a pedagogical exercise, but it's a cool paper!
- Actually, Othello-GPT Has A Linear Emergent World Representation [LW · GW] - the blog post form of my follow-up. Not obviously worth reading given the above, but I really like them, and think it has cool flow and research exposition. Post 3 has a blow by blow account of my research process and key decisions made at each point.
- Thanks to Andrew Lee, there's also a paper version - it's more rigorous, but less chatty and maybe less pegagogically good.
Bonus
I don't think the papers in here are essential reading, but are worth being aware of, and some are broadly worth reading if you have the time, especially if any specific ones catch your eye!
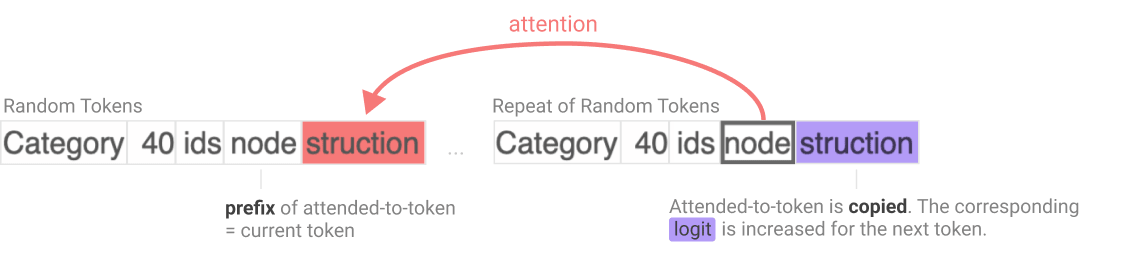
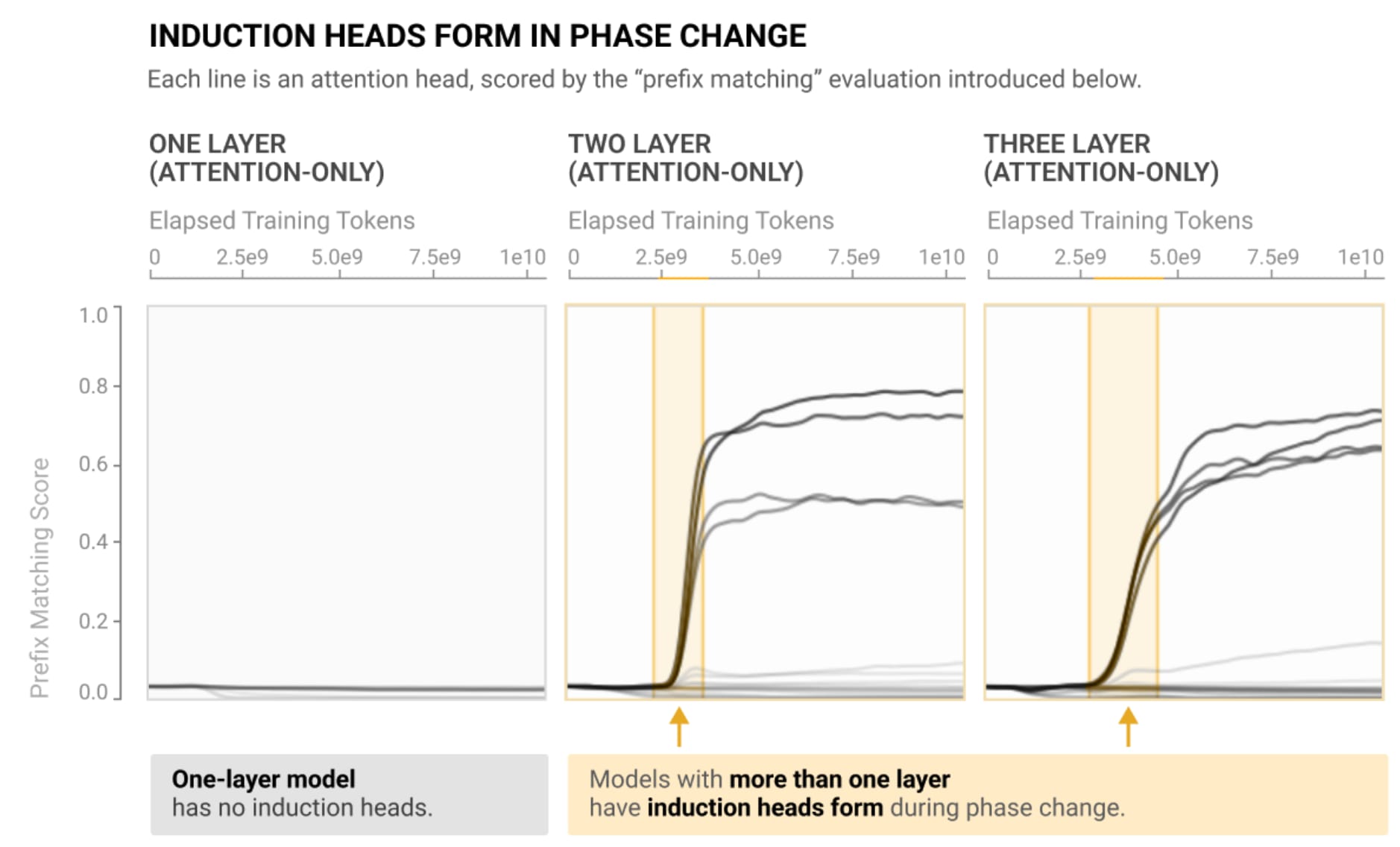
- The induction heads paper (Catherine Olsson et al, Anthropic) - nothing important in mech interp has properly built on this IMO (the idea of induction heads is very important to know, but was introduced in A Mathematical Framework shortly beforehand), but there's a lot of cool stuff - a circuit was universal across scales, a circuit was crucial to in-context learning, phase transitions, bumps in the loss curve, etc.
- Deeply engage with:
- Key concepts + argument 1.
- Argument 4: induction heads also do translation + few shot learning.
- Getting a rough intuition for all the methods used in the Model Analysis Table, as a good overview of interesting interpretability techniques.
- Skim or skip:
- All the rigour - basically everything I didn’t mention. The paper goes way overboard on rigour and it’s not worth understanding every last detail
- The main value to get when skimming is an overview of different techniques, esp general techniques for interpreting during training.
- All the rigour - basically everything I didn’t mention. The paper goes way overboard on rigour and it’s not worth understanding every last detail
- A particularly striking result is that induction heads form at ~the same time in all models - I think this is very cool, but somewhat overblown - from some preliminary experiments, I think it’s pretty sensitive to learning rate and positional encoding (though the fact that it doesn’t depend on scale is fascinating!)
- Progress Measures for Grokking via Mechanistic Interpretability (Neel Nanda et al) - nothing important in mech interp has properly built on this IMO, but there's just a ton of gorgeous results in there. I think it's the one of the most truly rigorous reverse-engineering works out there, and the connections to phase transitions and explaining grokking were really fucking cool. Youtube walkthrough. See my blog post for more takes.
- Also a good example of how actually understanding a model can be really useful, and push forwards science of deep learning by explaining confusing phenomena like grokking.
- See this comment [LW(p) · GW(p)] by Jason Gross suggesting some other highly rigorous works of mech interp on algorithmic models
- Deeply engage with:
- The key claims and takeaways sections
- Overview of the modular addition algorithm [AF · GW]
- The key vibe here is “holy shit, that’s a weird/unexpected algorithm”, but also, on reflection, a pretty natural thing to learn if you’re built on linear algebra - this is a core mindset for interpreting networks!
- Skim:
- Reverse engineering modular addition [AF · GW] - understanding the different types of evidence and how they fit together
- Evolution of modular addition circuits during training [AF · GW] - the flavour of what the circuits developing looks like during training, and the fact that once we understand things, we can just literally watch them develop!
- The interactive graphics in the colab are way better than static images
- The Phase Changes section [AF · GW] - probably the most interesting bits are the explanation of grokking, and the two speculative hypotheses.
- Logit Lens [AF · GW] (nostalgebraist)
- A solid early bit of work on LLM interpretability. The key insight is that we interpret the residual stream of the transformer by multiplying by the unembedding and mapping to logits, and that we can do this to the residual stream before the final layer and see the model converging on the right answer
- Key takeaway: Model layers iteratively update the residual stream, and the residual stream is the central object of a transformer
- Deeply Engage with:
- The key insight of applying the unembedding early, and grokking why this is a reasonable thing to do.
- Skim or skip:
- Skim the figures about progress towards the answer through the model, focus on just getting a vibe for what this progress looks like.
- Skip everything else.
- The deeper insight of this technique (not really covered in the work) is that we can do this on any vector in the residual stream to interpret it in terms of the direct effect on the logits - including the output of an attn or MLP layer and even a head or neuron. And we can also do this on weights writing to the residual stream, eg the output weights of a neuron or SAE feature. This is called direct logit attribution, and is a really powerful technique.
- Note that this tends only to work for things close to the final layer, and will totally miss any indirect effect on the outputs (eg via composing with future layers, or suppressing incorrect answers)
- Steering vectors: A family of papers exploring the idea that language models can be controlled by adding vectors to their activations, and that these vectors can often be very cheaply found, eg taking the mean difference between activations with and without some property. I consider this more model internals work than mech interp, but I think it's worth being aware of,
- Activation Addition (Alex Turner et al, done with his MATS scholars before joining Google DeepMind) - The most conceptually simple version of this. You can eg take the difference in residual streams for "I love you" and "I hate you", add this vector in on a benign prompt like "I went up to my friend" and the model gets incredibly angry.
- Inference-Time Interventions (Kenneth Li et al, Harvard) - Parallel work to Activation Addition, which found a truthful vector that improved TruthfulQA performance and reduced hallucinations
- Representation Engineering (Andy Zou et al, a CAIS project) Following the above, this was a nice distillation of the ideas, that applied it to a range of more realistic settings
- Refusal is Mediated by A Single Direction (Andy Arditi et al, during my MATS program). By applying existing techniques, we show in detail that chat-tuned models decide whether to refuse a harmful request (eg "How do I make a bomb?") via a single refusal vector - adding this to harmless prompts means they're refused, and ablating this on harmful prompts means they aren't refused. You can ablate this from the weights of the model to jailbreak it - it now rarely refuses things, has minimal damage done to its performance. This jailbreak is competitive with finetuning while being a fair bit easier, and I think is notably for being one of the more compelling real-world uses of model internals work so far.
- The Hydra Effect (Tom McGrath et al, Google DeepMind) - makes the crucial point that self-repair aka backup in language models is a real thing (ie you delete a component and later components shift behaviour to compensate for its loss), but the paper is far longer than needed to get the key point and you can skim/skip most of it. Also observed in Interpretability in the Wild. Note that this happens even in models trained without dropout
- Explorations of Self-Repair in Language Models (Cody Rushing et al, during my MATS program) A follow-up paper showing that self-repair happens across the full data distribution (not just narrow datasets), and exploring some of the mechanisms. Generally, self-repair is a mess, due to a range of mechanisms, only some of which we explore/catalogue. Notably, self-repair can be partially explained by the final LayerNorm's scale (if several components agree, and you delete one in a way that reduces the residual stream norm, the others get comparatively scaled up) - this explains a fraction of self-repair, up to 30% in extreme cases.
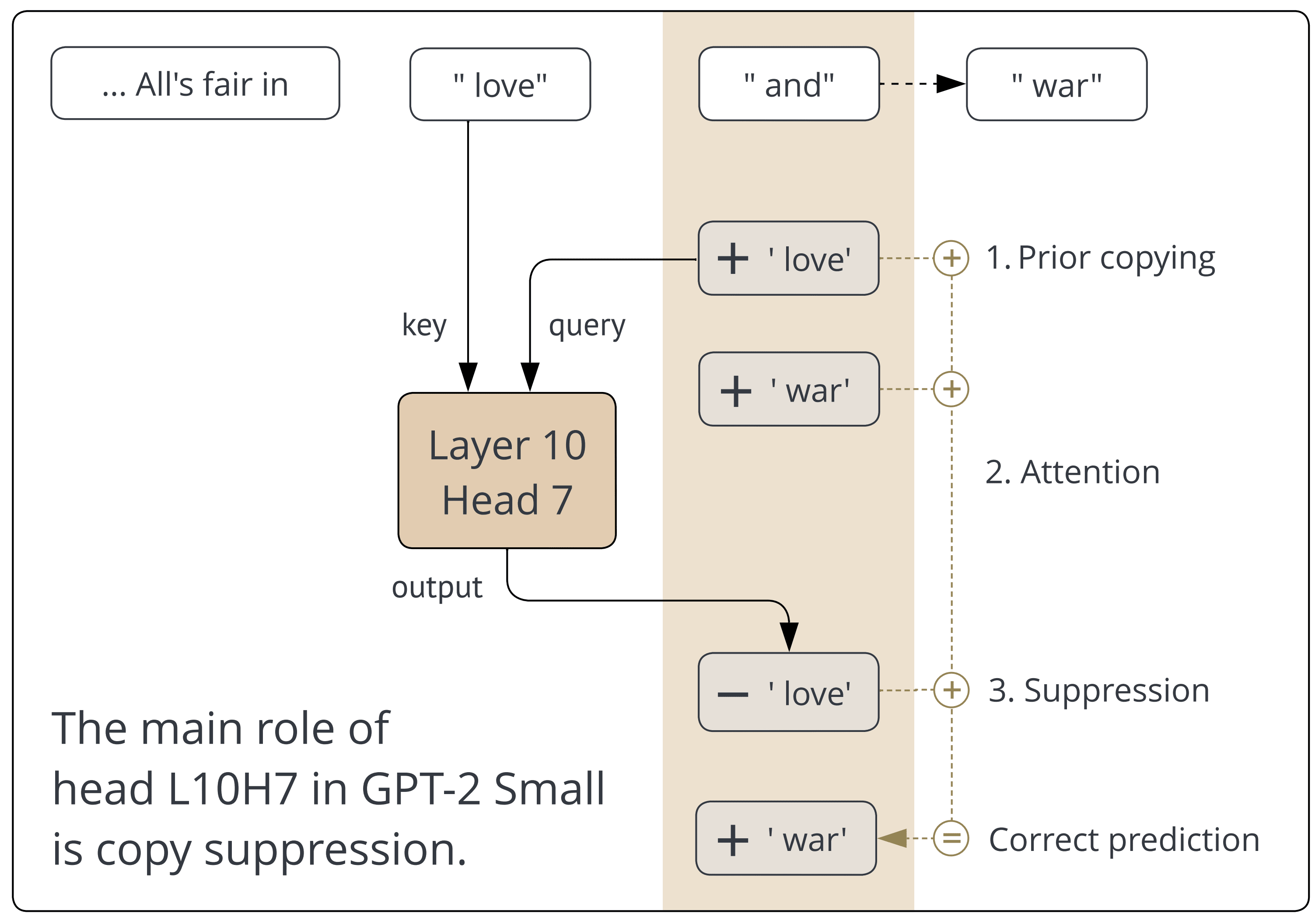
- Copy Suppression (Callum McDougall, Arthur Conmy & Cody Rushing et al, during my MATS program). Really cool paper that IMO comes closest to really understanding a model component on the full pre-training distribution: we show that the main role of head L10H7 in GPT-2 Small is copy suppression: notice if earlier layers have decided to predict a token, check if that occurs earlier in the context, and if so attend to it and suppress it. Youtube walkthrough
- The analysis is less complete than we hoped. We couldn't find any examples of it doing anything else, which I take as a big deal, but we only preserve 77% ish of the effect of the head when we ablate all other behaviours, and it's substantially worse if we restrict the query to just be the unembed of the relevant token. I don't know how to interpret this.
- Copy suppression heads have occured in the literature before as anti-induction heads (doing induction but suppressing the answer) and negative name movers in IOI - both were instances of this general algorithm!
- Copy suppression explains part of self-repair - if you're suppressing an earlier prediction, and it goes away, then there's nothing to suppress.
- Copy suppression is an important part of overall model calibration, and loss gets worse without it.
- Linear Representations of Sentiment (Curt Tigges & Oskar Hollinsworth et al, during my MATS program) Really fun paper: we found that there's a "first principal component of sentiment" that seems to be shared across a wide range of sentiment-y tasks, matters across the pre-training distribution, matters causally on Stanford Sentiment Treebank, seems universal across models (we checked up to 7B), and can be found with a range of techniques which all broadly agree. To some degree, the paper is a model of doing a deep dive into interpreting a particular, interesting direction.
- We also found the "summarization motif", where models store information about a sentence or phrase on punctuation like commas or full stops, and this matters causally for downstream effects.
- Softmax Linear Units (Nelson Elhage et al, Anthropic) - We introduced a new activation function which we originally thought made MLP neurons monosemantic, but turned out to help a bit, but also to have a lot of superposition hidden under the hood. Not worth reading in detail, but worth it for grokking that illusions are everywhere in mech interp: we thought we'd solved superposition, but actually it was just smuggled in. Also for the section called qualitative results with a ton of cool examples of features
- Language models can explain neurons in language models (Steven Bills et al, OpenAI) - Using GPT-4 to explain GPT-2 neurons. I wouldn’t prioritise reading in detail, but the core idea (and that GPT-4 is kinda good enough!) is very cool, and it's an important tool to be aware of. The work was a bit ahead of its time, as it came out a few months before SAEs became a big thing. Neurons are often not very interpretable, so the technique didn't work great, but SAE features are more interpretable so the technique is far more useful there.
- An Interpretability Illusion for BERT (Tolga Bolukbasi et al, Google)
- Good early paper on the limitations of max activating dataset examples - they took a seemingly interpretable residual stream channel (or neuron, note that it’s not an MLP hidden layer neuron) in BERT and took the max activating dataset examples on different (small) datasets, and observed consistent patterns within a dataset, but very different examples between datasets
- Within the lens of the Toy Model paper, this makes sense! Features correspond to directions in the residual stream that probably aren’t neuron aligned. Max activating dataset examples will pick up on the features most aligned with that neuron. Different datasets have different feature distributions and will give different “most aligned feature”
- Further, models want to minimise interference and thus will superpose anti-correlated features, so they should
- Within the lens of the Toy Model paper, this makes sense! Features correspond to directions in the residual stream that probably aren’t neuron aligned. Max activating dataset examples will pick up on the features most aligned with that neuron. Different datasets have different feature distributions and will give different “most aligned feature”
- Deeply engage with:
- The concrete result that the same neuron can have very different max activating dataset examples
- The meta-level result that a naively compelling interpretability technique can be super misleading on closer inspection
- Skim or skip:
- Everything else - I don’t think there’s too much value to the details beyond the headline result, which is presented well in the intro.
- Good early paper on the limitations of max activating dataset examples - they took a seemingly interpretable residual stream channel (or neuron, note that it’s not an MLP hidden layer neuron) in BERT and took the max activating dataset examples on different (small) datasets, and observed consistent patterns within a dataset, but very different examples between datasets
- Multimodal Neurons in Artificial Neural Networks (Gabriel Goh et al, OpenAI)
- An analysis of neurons in a text + image model (CLIP), finding a bunch of abstract + cool neurons. Not a high priority to deeply engage with, but very cool and worth skimming.
- My key takeaways
- There are so many fascinating neurons! Like, what?
- There’s a teenage neuron, a Minecraft neuron, a Hitler neuron and an incarcerated neuron?!
- The intuition that multi-modal models (or at least, models that use language) are incentivised to represent things in a conceptual way, rather than specifically tied to the input format
- The detailed analysis of the Donald Trump neuron, esp that it is more than just a “activates on Donald Trump” neuron, and instead activates for many different clusters of things, roughly tracking their association with Donald Trump.
- This seems like weak evidence that neuron activations may split more into interpretable segments, rather than an interpretable directions
- The “adversarial attacks by writing Ipod on an apple” part isn’t very deep, but is hilarious
- There are so many fascinating neurons! Like, what?







Thanks to Trenton Bricken and Michael Nielson for nudging me to write an updated version!
16 comments
Comments sorted by top scores.
comment by Buck · 2024-07-07T18:25:15.419Z · LW(p) · GW(p)
I think people who read A Mathematical Framework should note that its mathematical claim about one-layer transformers being equivalent to skip-trigrams are IMO wrong [AF · GW] and many people interpret the induction head hypothesis as being much stronger than evidence supports [LW · GW].
(I think that many other claims in the paper are pretty dubious, e.g. the stuff about interpreting models as sums of paths is IMO dubious because there is a softmax nonlinearity after these paths, but I have never gotten around to writing this up and probably never will.)
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-07T19:32:31.598Z · LW(p) · GW(p)
Fair point, I'll add that in to the post. The main reason I recommend it so highly and prominently is that I think it builds valuable conceptual frameworks for reasoning about the pieces of a transformer, even if it somewhat overclaims on how far it can get on interpreting tiny attention-only models, and I think those broad intuitions still stand even after your critiques. Eg strict induction heads as an example of the kind of algorithm that can be implemented with attention, even if it's not fully faithful to the underlying model. But I agree that these are worthwhile caveats to have in mind when reading, and the paper shouldn't be blindly recommended.
Replies from: Buckcomment by mikes · 2024-07-07T23:50:24.713Z · LW(p) · GW(p)
Great list! Would you consider
"The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks"
https://arxiv.org/abs/2306.17844
a candidate for "important work in mech interp [which] has properly built on [Progress Measures.]" ?
Are you aware of any problems with it?
↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-08T22:27:27.912Z · LW(p) · GW(p)
I'm not aware of any problems with it. I think it's a nice paper, but not really at my bar for important work (which is a really high bar, to be clear - fewer than half the papers in this post probably meet it)
comment by Jason Gross (jason-gross) · 2024-07-11T00:14:14.392Z · LW(p) · GW(p)
Progress Measures for Grokking via Mechanistic Interpretability (Neel Nanda et al) - nothing important in mech interp has properly built on this IMO, but there's just a ton of gorgeous results in there. I think it's the most (only?) truly rigorous reverse-engineering work out there
Totally agree that this has gorgeous results, and this is what got me into mech interp in the first place! Re "most (only?) truly rigorous reverse-engineering work out there": I think the clock and pizza paper seems comparably rigorous, and there's also my recent Compact Proofs of Model Performance via Mechanistic Interpretability [AF · GW] (and Gabe's heuristic analysis of the same Max-of-K model), and the work one of my MARS scholars did showing that some pizza models use a ReLU to compute numerical integration, which is the first nontrivial mechanistic explanation of a nonlinearity found in a trained model (nontrivial in the sense that it asymptotically compresses the brute-force input-output behavior with a (provably) non-vacuous bound).
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-11T09:46:52.706Z · LW(p) · GW(p)
Thanks! That was copied from the previous post, and Ithink this is fair pushback, so I've hedged the claim to "one of the most", does that seem reasonable?
I haven't deeply engaged enough with those three papers to know if they meet my bar for recommendation, so I've instead linked to your comment from the post
comment by Martin Vlach (martin-vlach) · 2024-07-14T17:27:35.968Z · LW(p) · GW(p)
https://neelnanda.io/transformer-tutorial-1 link for YouTube tutorial gives 404.-(
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-14T20:10:03.896Z · LW(p) · GW(p)
Oops
comment by Sumeet S Singh (sumeet-s-singh) · 2024-12-23T17:33:05.185Z · LW(p) · GW(p)
Hi Neel, What do you think of this paper? I felt it was pretty novel and revealing when I wrote it, but never got the chance to publish it in a conference. I still think so. The paper essentially says that the embedding space after taining works like like a static landscape that is formed based on the training data. The model simply follows a predetermined path based on where it started and how much momentum it had been given initially (by the prompt), much like a ball rolling down a static landscape would follow a predetermined path after it had been set into motion based on where and with what momentum it started. Hoping you can review it and let me know if I'm correct or whether I'm overestimating it's importance.
https://arxiv.org/abs/2308.10874
comment by Jinjin Zhao (jinjin-zhao) · 2024-07-15T19:51:49.362Z · LW(p) · GW(p)
I am curious about your thoughts on the differences between activation patching and SAE. Do you think they are complimentary research, or may there be some overarching idea that encapsulates both?
Is there any application for one that can't be done with the other? It seems that activation patching may result in more interpretable concepts, but SAE may result in more fundamental features. My intuition is that it may be possible for activation patching to replace SAEs in the future.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-16T18:23:57.980Z · LW(p) · GW(p)
Imo they're just completely different techniques, which aren't really comparable. Activation patching is about understanding the difference between two activations by patching one to replace the other and seeing what happens. SAEs are a technique for decomposing an activation into interpretable pieces
comment by Jason Gross (jason-gross) · 2024-07-14T20:51:29.534Z · LW(p) · GW(p)
it's substantially worth if we restrict
Typo: should be "substantially worse"
comment by Review Bot · 2024-07-09T13:29:37.921Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Gianluca Calcagni (gianluca-calcagni) · 2024-07-09T11:53:46.152Z · LW(p) · GW(p)
Thanks Neel, keep this coming - even if only once every few years :) You helped me clarify lots of confusion I had about the existing techniques.
I am a huge fan of steering vectors / control vectors, and I would love to see future research showing if they can be linearly combined together to achieve multiple behaviours simultaneously (I made a post about this [LW · GW]). I don't think it's just "internal work" - I think it's a hint to the fact that language semantics can be linearised as vector spaces (I hope I will be able to formalise mathematically this intuition).
Here a proposal of a possible ELK solution using that approach.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-09T13:17:04.521Z · LW(p) · GW(p)
Glad you liked the post!
I'm also pretty interested in combining steering vectors. I think a particularly promising direction is using SAE decoder vectors for this, as SAEs are designed to find feature vectors that independently vary and can be added.
I agree steering vectors are important as evidence for the linear representation hypothesis (though at this point I consider SAEs to be much superior as evidence, and think they're more interesting to focus on)