What Indicators Should We Watch to Disambiguate AGI Timelines?
post by snewman · 2025-01-06T19:57:43.398Z · LW · GW · 57 commentsContents
The Slow Scenario The Fast Scenario Identifying The Requirements for a Short Timeline How To Recognize The Express Train to AGI None 57 comments
(Cross-post from https://amistrongeryet.substack.com/p/are-we-on-the-brink-of-agi, lightly edited for LessWrong. The original has a lengthier introduction and a bit more explanation of jargon.)
No one seems to know whether transformational AGI is coming within a few short years. Or rather, everyone seems to know, but they all have conflicting opinions. Have we entered into what will in hindsight be not even the early stages, but actually the middle stage, of the mad tumbling rush into singularity? Or are we just witnessing the exciting early period of a new technology, full of discovery and opportunity, akin to the boom years of the personal computer and the web?
AI is approaching elite skill at programming, possibly barreling into superhuman status at advanced mathematics, and only picking up speed. Or so the framing goes. And yet, most of the reasons for skepticism are still present. We still evaluate AI only on neatly encapsulated, objective tasks, because those are the easiest to evaluate. (As Arvind Narayanan says, “The actually hard problems for AI are the things that don't tend to be measured by benchmarks”.) There’s been no obvious progress on long-term memory. o1 and o3, the primary source of the recent “we are so back” vibe, mostly don’t seem better than previous models at problems that don’t have black-and-white answers[1]. As Timothy Lee notes, “LLMs are much worse than humans at learning from experience”, “large language models struggle with long contexts”, and “[LLMs] can easily become fixated on spurious correlations in their training data”.
Perhaps most jarringly, LLMs still haven’t really done anything of major impact in the real world. There are good reasons for this – it takes time to find productive applications for a new technology, people are slow to take advantage, etc. – but still, it’s dissatisfying.
I recently attempted to enumerate the fundamental questions that lie underneath most disagreements about AI policy, and number one on the list was how soon AGI will arrive. Radical uncertainty about the timeline makes it extremely difficult to know what to do about almost any important question. (I'm defining AGI as AI that can cost-effectively replace humans at more than 95% of economic activity, including any new jobs that are created in the future. This is roughly the point at which seriously world-changing impacts, both good and bad, might start to emerge. For details, see here.)
In this post, I’m going to enumerate some leading indicators that should indicate which path we're on. To develop that list of indicators, I'll first articulate two timelines for AGI – one slow, one fast.
The Slow Scenario

This is the slowest timeline I can make a good argument for, excluding catastrophes (including war) or a deliberate pause. Think of it as a lower bound on AI progress.
In this scenario, the recent flurry of articles suggesting that AI has “hit a wall” are correct, insofar as the simple scaling of training data and model size – which drove progress from 2018 to 2023 – sputters out. It won’t come to a complete halt; in 2025 or 2026, we’ll see a new generation of models that are larger than recent trends would have indicated[2]. That will allow the models to incorporate more world knowledge and “system 1 smarts” / “raw intelligence” (whatever that means) than GPT-4. But this won’t be a leap like GPT-3 to GPT-4, perhaps not even GPT-3.5 to GPT-4. It is becoming too hard to find more quality training data and justify the cost of larger models. Further progress on this axis remains slow.
Progress on “reasoning models” like o1, o3, and DeepSeek-R1 continues, turning out ever-more-impressive results on benchmarks such as FrontierMath and RE-Bench (which measures the ability of AIs to perform AI R&D). However, the gains are limited to neatly encapsulated tasks with black-and-white answers – exactly the sorts of capabilities that are easiest to measure.
This turns out to have less impact than anticipated. The models are useful for mathematicians, scientists, and engineers (including software engineers), especially as people become adept at identifying encapsulated problems that they can extract from the messy complexity of their work and hand to an AI. But because these neatly encapsulated problems only encompass part of the job, Amdahl's Law kicks in and the overall impact on productivity is limited[3]. Meanwhile, AI is generally not opening the door to radically new ways of getting things done. There are some exceptions, for instance in biology, but the incredible scientific and regulatory complexity of biology means that substantial real-world impact will take years.
Furthermore, progress on reasoning models is not as rapid as the vibes at the end of 2024 suggested. o3’s remarkable benchmark results turn out to have been a bit of a mirage, and even for neatly encapsulated problems, o1 and o3’s capabilities are found to be hit-and-miss[4]. Moving forward, the training approach struggles to generalize beyond problems with easily evaluated answers. Progress on problems that take humans more than a few hours to solve turns out to be especially difficult, for two reasons: navigating the vast range of possible steps requires higher-level cognitive strategies and taste that we don’t yet know how to train into an AI, and we haven’t figured out how to give LLMs fine-grained access to knowledge in the world.
There are widespread efforts to create “agents” – tools that can be trusted to [semi-]independently pursue a goal across an extended period of time. 2025 is dubbed the Year of the Agent, but the results are mostly poor. Agents struggle to go out into the world and find the information needed to handle a task. They do a poor job of navigating between subtasks and deciding whether and how to revise the master plan. Models continue to be distracted by extraneous information, and resistance to trickery and scams (“adversarial robustness”) remains a challenge. Much as the “Year of the LAN” was proclaimed across most of the 80s and early 90s, pundits will still be saying “this is finally the Year of the Agent” well past 2030.
Overcoming these limitations in reasoning and agentic behavior turns out to require further breakthroughs, on the scale of transformers and reasoning models, and we only get one of those breakthroughs every few years[5].
Working around these limitations, individuals and organizations are finding more and more ways to encapsulate pieces of their work and hand them to an AI. This yields efficiency gains across many areas of the economy, but the speed of adoption is limited for all the usual reasons – inertia, regulatory friction, entrenched interests, and so forth. Fortunes are made, but adoption is uneven – just as in the early years of the Internet.
The major AI labs are doing everything they can to use AI to accelerate their own work. Internally, there are few barriers to adoption of AI tools, but the impact is limited by the tasks where AI isn’t much help (Amdahl’s Law again). AI is not generating the conceptual breakthroughs that are needed for further progress. It does accelerate the work of the humans who are seeking those breakthroughs, but by only a factor of two. The process of training new AIs becomes ever more complex, making further progress difficult despite continued increases in R&D budgets. There may be a slowdown in investment – not a full-blown “AI winter”, but a temporary pullback, and an end to the era of exponentially increasing budgets, as a less breathless pace starts to look more cost-effective.
Another drag on impact comes from the fact that the world knowledge a model is trained on is out of date by the time the model is available for use. As of the end of 2024, ChatGPT reports a “knowledge cutoff date” of October 2023[6], indicating that its models do not have innate understanding of anything published after that date – including the latest in AI R&D techniques[7]. Until a new approach is found, this will interfere with the pace at which AI can self-improve.
Eventually, 2035 rolls around – 10 years from now, which is as far as I’m going to project – and AI has not had any Earth-shaking impact, for good or ill. The economy has experienced significant change, AI is embedded in our everyday lives to at least the same extent as the smartphone, some major companies and job markets have been disrupted, we have capabilities that seemed almost unimaginable in 2020 and may still seem so today – but the overall order of things is not drastically altered. Importantly, we have not missed the window of opportunity to ensure that AI leads to a positive future.
The Fast Scenario

I’ll now present the fastest scenario for AI progress that I can articulate with a straight face. It addresses the potential challenges that figured into my slow scenario.
In recent years, AI progress has been a function of training data, computing capacity, and talent (“algorithmic improvements”). Traditional training data – textbooks, high-quality web pages, and so forth – is becoming harder to find, but not impossible; video data, commissioned human work, and other sources can still be found. The days of rapid order-of-magnitude increases in data size are behind us, but it’s possible to scrounge up enough high-quality tokens to fill in domains where AI capabilities had been lacking, increasing reliability and somewhat smoothing “jagged” capabilities.
More importantly, synthetic data – generated by machines, rather than people – turns out to work well for training ever-more-capable models. Early attempts to use synthetic data suffered from difficulties such as “model collapse”, but these have been overcome (as highlighted by the success of o1 and o3). Given enough computing capacity, we can create all the data we need. And AI tools are rapidly increasing the productivity of the researchers and engineers who are building the data-generation and AI training systems. These tasks are some of the easiest for AI to tackle, so productivity gains begin compounding rapidly. Computing capacity can now substitute for both data and talent, meaning that compute is the only necessary input to progress. Ever-increasing training budgets, continuing improvements in chip design, and (especially) AI-driven improvements in algorithmic efficiency drive rapid progress; as the lion’s share of innovation starts to be derived from AI rather than human effort, we enter the realm of recursive self-improvement, and progress accelerates.
Because we are no longer training ever-larger models, there’s no need to build a single monster (multi-gigawatt) data center. The primary drivers of progress – synthetic data, and experiments running in parallel – need lots of computing capacity, but don’t need that capacity to be centralized. Data centers can be built in whatever size and location is convenient to electricity sources; this makes it easier to keep scaling rapidly.
There is an awkward intermediate period where AI is becoming aggressively superhuman at encapsulated math and coding problems[8], but is still limited in other problem domains, including many areas relevant to AI development (such as setting research agendas). During this period, the leading AI labs are fumbling around in search of ways to push through these limitations, but this fumbling takes place at breakneck speed. AI-driven algorithmic improvements allow a huge number of experiments to be run in a short period; AI tools handle most of the work of designing, executing, and evaluating each experiment; AI assistants help brainstorm new ideas, and help manage what would otherwise be the overwhelming problem of coordinating all this work and bringing improvements into production without destabilizing the system. Thus, human creativity is still a bottleneck on progress, but the AI tools are enabling us to run an unprecedented number of experiments, which yield serendipitous discoveries.
Overall, capabilities are not driven primarily by throwing ever-more data into ever-larger models (as in the 2018-2023 period); instead, advances in data generation and curation, model architecture, and training techniques allow increasing capabilities to fit into models of static or even declining size (as we’ve seen in 2024). This helps keep inference costs down, enabling the increased pace of experimentation and increased use of AIs in AI R&D. And the rapid progress maintains competitive pressure to motivate ongoing investment in data center buildout and AI training; this eventually extends to the international realm (especially US vs. China), bringing national budgets into play.
The recent trend toward use of inference-time compute continues. However, today’s clumsy techniques (such as performing a task 1000 times and keeping the best result) outlive their usefulness. The focus will be on training systems that can think productively for an extended period, just as people do when working on a difficult problem. The current simple techniques will retain a role, but are used only on occasions when a problem is so important that it’s worth spending a lot of extra money just to get a slightly better solution.
A few major breakthroughs (and many intermediate breakthroughs) emerge to help things along. One of these probably involves giving AIs access to “knowledge in the world”, including the ability to create and revise notes, to-do lists, and other data structures to support them in complex tasks. Another probably involves continuous learning, at both coarse scale (getting better at selling a particular product over the course of 500 sales pitches) and fine scale (figuring out how to make progress on a tricky problem after grinding away at it for a few days). Among other things, this alleviates the knowledge cutoff problem that would otherwise interfere with rapid AI self-improvement.
Other breakthroughs are found that allow us to apply LLMs to messy problems that can’t be decoupled from their real-world context. I have no clear idea how this might be accomplished on a fast timeline, but I think it is a necessary assumption for the scenario to hold.
As a result of all these advances, AI agents become truly useful. Success in 2025 is mixed, but 2026 really is the Year of the Agent, with adoption across a wide range of consumer and workplace applications. Subsequent years see rapid increases in the breadth and depth of AI applications – including use in the development of AI itself.
How quickly might this lead to AGI – again, defined as AI that can cost-effectively replace humans at more than 95% of economic activity? I struggle to put a number on this. But it has taken us roughly two years to go from GPT-4 to o3[10]2, and in that time we’ve arguably seen just one major breakthrough: RL training on synthetically generated chains of thought. I’ve argued that several further major breakthroughs are needed, at a minimum, to reach AGI. So it should take at least twice as long as the time from GPT-4 to o3.
We might expect progress to speed up, due to increased budgets and AI assistance. But we might also expect progress to be more difficult, as we exhaust easily tapped resources (off-the-shelf data; previously existing GPUs and scientific / engineering talent that could be repurposed for AI), systems become more complex, and we push farther into poorly-understood territory.
Put all of this together, and I have a hard time imagining that transformational AGI could appear before the end of 2028, even in this “fast” scenario, unless more or less all of the following also occur:
- We get “lucky” with breakthroughs – multiple major, unanticipated advances occur within the next, say, two years. New approaches at least as impactful as the one that led to o1. Even this might not be sufficient unless the breakthroughs specifically address key limitations such as continuous learning, messy real-world tasks, and long-horizon planning for problems with no clear right and wrong answers.
- Threshold effects emerge, such that incremental advances in model training turn out to cause major advances in long-horizon planning, adversarial robustness, and other key areas.
- We sustain extremely rapid improvements in algorithmic efficiency, allowing a massive deployment of advanced AI despite the physical limits on how quickly chip production can be increased in a few short years.
That’s my fast scenario. How can we tell whether we’re in it?
Identifying The Requirements for a Short Timeline
My chief motivation for articulating these two scenarios was so that I could review the differences between them. These differences might constitute leading indicators that we can watch in the coming months to see which course we’re on.
The most important question is probably the extent to which AI is accelerating AI R&D. However, I don’t know that this will be visible to anyone outside of the frontier AI labs. What follows are some key leading indicators that the general public will be able to observe if we are on a fast path to AGI.
Progress on reasoning is real, sustained, and broadly applicable. If o3 is released to the public and consistently wows people (in a way that I believe o1 has not consistently done), if its capabilities on math and coding tasks seem consistent with its amazing scores on FrontierMath and Codeforces, and there’s at least one more major step forward in reasoning models in 2025 (possibly leading to unambiguously superhuman scores[11] on very difficult benchmarks like FrontierMath and Humanity’s Last Exam), that supports a fast timeline. If people report mixed experiences with o3, if its performance is still very hit-and-miss [LW(p) · GW(p)], if benefits outside of math/science/coding are still limited, if the FrontierMath results look less impressive once details emerge, if that doesn’t change in a significant way over the course of 2025, that will suggest we’re on a slower timeline. It would mean that we really haven’t made a lot of progress in fundamental capabilities since the release of GPT-4 in March 2023.
In the rapid-progress scenario, the techniques used to train reasoning models on math / science / programming tasks are succesfully extended to tasks that don’t have clear right and wrong answers. And these models must become more reliable for math / science / programming tasks.

Breaking out of the chatbox: AIs start showing more ability at tasks that can’t be encapsulated in a tidy chatbox session. For instance, “draft our next marketing campaign”, where the AI would need to sift through various corporate-internal sources to locate information about the product, target audience, brand guidelines, past campaigns (and their success metrics), etc.
AI naturally becomes more robust as it gets better at reasoning, fuzzy problems, and incorporating real-world context. Systems are less likely to make silly mistakes, and more resistant to “jailbreaking”, “prompt injection” and other attempts to deliberately fool them into unintended behavior. (This may be supplemented by new forms of anti-trickery training data, mostly synthetic.)
Widespread adoption of AI agents, [semi-]independently pursuing goals across an extended period of time, operating in “open” environments such as the public Internet (or at least a company intranet). These agents must be able to maintain coherent and adaptive planning over time horizons that gradually increase to multiple hours (and seem likely to progress to months), completing tasks and subtasks that don’t have black-and-white answers. No particular barrier emerges as we push reasoning and agentic models into larger-scale problems that require ever-longer reasoning traces; models are able to develop whatever “taste” or high-level strategies are needed. They must be sufficiently resistant to trickery and scams such that this is not impeding their adoption.
Real-world use for long-duration tasks. Users are actually making use of AI systems (agentic and otherwise) to carry out tasks that take progressively longer. They are finding the wait and cost to be worthwhile.
Beyond early adopters: AI becomes more flexible and robust, achieving adoption beyond early adopters who find ways of incorporating AI into their workflow. It is able to step in and adapt itself to the task, just as a new hire would. AI’s increasing flexibility flows over and around barriers to adoption. This greatly increases the pace at which AI can drive productivity gains across the economy – including the development of AI itself[12].
Scaling doesn’t entirely stall. We see the release of a “larger” model that appears to incorporate more forms of training data, and constitutes an impressive advance along many fronts at once – like GPT-3.5 → GPT-4, or even GPT-3 → GPT-4 (and unlike GPT-4o → o1). Preferably before the end of 2025. We aren’t looking for a model that is larger than GPT-4, but one that is larger than its contemporaries in exchange for broader and deeper knowledge and capabilities.
Capital spending on data centers for AI training and operation continues to increase geometrically. This is a useful indicator for both the level of resources available for developing and operating AIs, and the internal confidence of the big players.
Unexpected breakthroughs emerge. To get transformational AGI within three or four years, I expect that we’ll need at least one breakthrough per year[13] on a par with the emergence of “reasoning models” (o1). I suspect we’ll specifically need breakthroughs that enable continuous learning and access to knowledge-in-the-world.
How To Recognize The Express Train to AGI
If we are on the road to transformative AGI in the next few years, we should expect to see major progress on many of these factors in 2025, and more or less all of them in 2026. This should include at least one major breakthrough per year – not just an impressive new model, but a fundamentally new technique, preferably one that enables continuous learning, access to knowledge-in-the-world, or robust operation over multi-hour tasks.
Even in this scenario, I have trouble imagining AGI in less than four years. Some people have shorter timelines than this; if you’re one of them, I would love to talk and exchange ideas (see below).
If models continue to fall short in one or two respects, AI’s increasing array of superhuman strengths – in speed, breadth of knowledge, ability to take 1000 attempts at a problem, and so forth – may be able to compensate. But if progress on multiple indicators is slow and unreliable, that will constitute strong evidence that AGI is not around the corner.
We may see nontechnical barriers to AI adoption: inertia, regulatory friction, and entrenched interests. This would not necessarily indicate evidence of slow progress toward AGI, so long as these barriers are not posing a significant obstacle to the ongoing development of AI itself. In this scenario, AI adoption in the broader economy might lag until AI capabilities start to become radically superhuman, at which point there would be strong incentives to circumvent the barriers. (Though if inertia specifically is a major barrier to adoption, this might constitute evidence that AI is still not very flexible, which would suggest slow progress toward AGI.)
I am always interested in feedback on my writing, but especially for this post. I would love to refine both the slow and fast scenarios, as well as the scorecard for evaluating progress toward AGI. If you have thoughts, disagreements, questions, or any sort of feedback, please comment on this post or drop me a line!
- ^
When reviewing a draft of this post, Julius Simonelli asked an excellent question: how do we know o1 and o3 don’t improve on tasks that don’t have black-and-white answers, when by definition it’s difficult to measure performance on those tasks?
For example, poetry doesn't have black-and-white answers, but I don't see why we should say it's “bad” at poetry.
I’m basing this statement on a few things:
- Vibes – lots of people saying that o1 doesn't seem better than 4o at, for instance, writing.
- OpenAI explicitly stated that o1 primarily represents progress on math, science, and coding tasks.
- I vaguely recall seeing non-math/science/coding benchmarks at which o1 does not beat 4o. But I could be misremembering this.
There are sporadic reports of o1 doing much better than other models on non-math/science/coding tasks. For instance, here’s Dean Ball being impressed by o1-pro’s answer to “nearly a pure humanities question” about Beethoven’s music and progress in piano construction; he also says that “o1-preview performs better than any non-specialized model on advanced and creative legal reasoning”. But you can find anecdotes in favor of almost any possible statement one might make about AI. My best guess is that Dean has identified something real, but that o1’s gains over 4o are mostly limited to black-and-white questions.
For another counterpoint, see this tweet from Miles Brundage.
- ^
Note that over the course of 2024, released models have been relentlessly shrinking in parameter count (size), squeezing ~equivalent knowledge and improved capabilities into fewer and fewer parameters. Here I am envisioning that there will be a bump in this downward progression – there will be some new models in the mix that use more parameters than that recent trend, in order to incorporate more knowledge. Even these models may then continue to shrink, if there is room to continue the trend of model compression.
- ^
Suppose 50% of my time is spent on tasks that can be handed to an AI, and AI makes me 10x more productive at those tasks. My overall productivity will increase by less than 2x: I’m limited by the other half of the work, the half that AI isn’t helping with. Even if AI makes me 1000x more productive at the first half of the job, my overall productivity still increases by less than 2x.
- ^
For example, from someone I know:
One example from yesterday: I wanted to set up a pipeline in colab to download random files from common crawl, and pass them by OpenAIs API to tag whether they are licensed.
This should be an easy task for someone with encyclopedic knowledge of common crawl and the OA API, yet the models I tried (o1, Gemini) failed miserably.
- ^
A recent tweet from Dan Hendrycks expresses this succinctly.
- ^
Both the 4o and o1 variants
- ^
Models that can perform web search can be aware of developments after their cutoff date. But they will not have deeply internalized that knowledge. For instance, if a new training algorithm has been released after the cutoff date, I might expect a model to be able to answer explicit questions about that algorithm (it can download and summarize the paper). But I'd expect it to struggle to write code using the algorithm (it won't have been trained on a large number of examples of such code).
It’s possible that “reasoning” models with strong chain-of-thought capabilities will outgrow this problem. But barring a substantial breakthrough that allows models to learn on the fly (the way people do), I’d expect it to continue to be a handicap.
- ^
People have pointed out that advanced math bears little resemblance to the tasks required for survival in prehistoric times, and so there’s no reason to believe that human beings are very good at it on an absolute scale. It’s possible that AI will blow straight past us on many tasks relevant to AI research, just as it has done for multiplying thousand-digit numbers or playing chess. As Jack Morris puts it, “strange how AI may solve the Riemann hypothesis before it can reliably plan me a weekend trip to Boston”.
- ^
GPT-4 was released on 3/14/23. I believe o3 is rumored to have a release date in January, so 22 months later. OpenAI is understood to have additional unreleased capabilities, such as the “Orion” model, but it is not obvious to me that the level of unreleased capability at OpenAI as of a hypothetical January o3 release is likely to be substantially more than whatever they had in the wings in March 2023. So I’ll say that progress from March 2023 to January 2025 is roughly equal to the delta from GPT-4 to o3.
- ^
Here, I mean performance that is, on average, superior to the score you’d get if you assigned each problem to an elite specialist in the technical domain of that specific problem.
- ^
The tech industry, and AI labs in particular, will be heavily populated with early adopters. But the ability of AI to move beyond early adopters will still be a good indicator that it is becoming sufficiently flexible and robust to broadly accelerate AI R&D.
- ^
It’s possible that we’ll see “breakthroughs” that don’t come from a radical new technique, but simply emerge from threshold effects. That is, we might have incremental progress that crosses some important threshold, resulting in a dramatic change in capabilities. Quite possibly the threshold won’t have been apparent until it was reached.
57 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2025-01-07T00:55:29.327Z · LW(p) · GW(p)
Suppose we get an AI system which can (at least) automate away the vast majority of the job of a research engineer at an AI company (e.g. OpenAI). Let's say this results in an increase in productivity among OpenAI capabilities researchers at least equivalent to the productivity you'd get as if the human employees operated 10x faster (but couldn't use advanced AI in their work). This corresponds to "AIs that 10x AI R&D labor" as defined more precisely in this post [LW · GW]. And, let's say that this level of speed up is rolled out and exists (on average) in an AI company within 2 years (by Jan 2027). (I think this is about 20% likely, and would be about 25% likely if we allowed for some human adoption time.)
My current sense based on the post is that this wouldn't substantially update you about the possibility of AGI (as you define it) by 2030. This sense is based on what you describe as the key indicators and your claim about a need for breakthroughs. Is this right?
I think the 10x AI R&D labor milestone is reasonably likely to be quickly reachable just by scaling up existing approaches. Full automation would probably require additional qualitatively different components, but this might be quite quickly reached if AI algorithmic progress is substantially accelerated and it isn't clear this would look like much more of a breakthrough than "we can put LLMs inside an agent loop" is a breakthrough.
Replies from: Thane Ruthenis, snewman↑ comment by Thane Ruthenis · 2025-01-07T07:31:43.760Z · LW(p) · GW(p)
I'm very skeptical of AI being on the brink of dramatically accelerating AI R&D.
My current model is that ML experiments are bottlenecked not on software-engineer hours, but on compute. See Ilya Sutskever's claim here [LW · GW]:
95% of progress comes from the ability to run big experiments quickly. The utility of running many experiments is much less useful.
What actually matters for ML-style progress is picking the correct trick, and then applying it to a big-enough model. If you pick the trick wrong, you ruin the training run, which (a) potentially costs millions of dollars, (b) wastes the ocean of FLOP you could've used for something else.
And picking the correct trick is primarily a matter of research taste, because:
- Tricks that work on smaller scales often don't generalize to larger scales.
- Tricks that work on larger scales often don't work on smaller scales (due to bigger ML models having various novel emergent properties).
- Simultaneously integrating several disjunctive incremental improvements into one SotA training run is likely nontrivial/impossible in the general case.[1]
So 10x'ing the number of small-scale experiments is unlikely to actually 10x ML research, along any promising research direction.
And, on top of that, I expect that AGI labs don't actually have the spare compute to do that 10x'ing. I expect it's all already occupied 24/7 running all manners of smaller-scale experiments, squeezing whatever value out of them that can be squeezed out. (See e. g. Superalignment team's struggle to get access to compute: that suggests there isn't an internal compute overhang.)
Indeed, an additional disadvantage of AI-based researchers/engineers is that their forward passes would cut into that limited compute budget. Offloading the computations associated with software engineering and experiment oversight onto the brains of mid-level human engineers is potentially more cost-efficient.
As a separate line of argumentation: Suppose that, as you describe it in another comment, we imagine that AI would soon be able to give senior researchers teams of 10x-speed 24/7-working junior devs, to whom they'd be able to delegate setting up and managing experiments. Is there a reason to think that any need for that couldn't already be satisfied?
If it were an actual bottleneck, I would expect it to have already been solved: by the AGI labs just hiring tons of competent-ish software engineers. They have vast amounts of money now, and LLM-based coding tools seem competent enough to significantly speed up a human programmer's work on formulaic tasks. So any sufficiently simple software-engineering task should already be done at lightning speeds within AGI labs.
In addition: the academic-research and open-source communities exist, and plausibly also fill the niche of "a vast body of competent-ish junior researchers trying out diverse experiments". The task of keeping senior researchers up-to-date on openly published insights should likewise already be possible to dramatically speed up by tasking LLMs with summarizing them, or by hiring intermediary ML researchers to do that.
So I expect the market for mid-level software engineers/ML researchers to be saturated.
So, summing up:
- 10x'ing the ability to run small-scale experiments seems low-value, because:
- The performance of a trick at a small scale says little (one way or another) about its performance on a bigger scale.
- Integrating a scalable trick into the SotA-model tech stack is highly nontrivial.
- Most of the value and insight comes from full-scale experiments, which are bottlenecked on compute and senior-researcher taste.
- AI likely can't even 10x small-scale experimentation, because that's also already bottlenecked on compute, not on mid-level engineer-hours. There's no "compute overhang"; all available compute is already in use 24/7.
- If it weren't the case, there's nothing stopping AGI labs from hiring mid-level engineers until they are no longer bottlenecked on their time; or tapping academic research/open-source results.
- AI-based engineers would plausibly be less efficient than human engineers, because their inference calls would cut into the compute that could instead be spent on experiments.
- If so, then AI R&D is bottlenecked on research taste, system-design taste, and compute, and there's relatively little non-AGI-level models can contribute to it. Maybe a 2x speed-up, at most, somehow; not a 10x'ing.
(@Nathan Helm-Burger [LW · GW], I recall you're also bullish on AI speeding up AI R&D. Any counterarguments to the above?)
- ^
See the argument linked in the original post, that training SotA models is an incredibly difficult infrastructural problem that requires reasoning through the entire software-hardware stack. If you find a promising trick A that incrementally improves performance in some small setup, and you think it'd naively scale to a bigger setup, you also need to ensure it plays nice with tricks B, C, D.
For example, suppose that using A requires doing some operation on a hidden state that requires that state to be in a specific representation, but there's a trick B which exploits a specific hardware property to dramatically speed up backprop by always keeping hidden states in a different representation. Then you need to either throw A or B out, or do something non-trivially clever to make them work together.
And then it's a thousand little things like this; a vast Spaghetti Tower [LW · GW] such that you can't improve on a small-seeming part of it without throwing a dozen things in other places in disarray. (I'm reminded of the situation in the semiconductor industry here.)
In which case, finding a scalable insight isn't enough: even integrating this insight requires full end-to-end knowledge of the tech stack and sophisticated research taste; something only senior researchers have.
↑ comment by ryan_greenblatt · 2025-01-07T23:12:50.196Z · LW(p) · GW(p)
I think you are somewhat overly fixated on my claim that "maybe the AIs will accelerate the labor input R&D by 10x via basically just being fast and cheap junior employees". My original claim (in the subcomment) is "I think it could suffice to do a bunch of relatively more banal things extremely fast and cheap". The "could" part is important. Correspondingly, I think this is only part of the possibilities, though I do think this is a pretty plausible route. Additionally, banal does not imply simple/easy and some level of labor quality will be needed.
(I did propose junior employees as an analogy which maybe implied simple/easy. I didn't really intend this implication. I think the AIs have to be able to do at least somewhat hard tasks, but maybe don't need to have a ton of context or have much taste if they can compensate with other advantages.)
I'll argue against your comment, but first, I'd like to lay out a bunch of background to make sure we're on the same page and to give a better understanding to people reading through.
Frontier LLM progress has historically been driven by 3 factors:
- Increased spending on training runs ($)
- Hardware progress (compute / $)
- Algorithmic progress (intelligence / compute)
(The split seems to be very roughly 2/5, 1/5, 2/5 respectively.)
If we zoom into algorithmic progress, there are two relevant inputs to the production function:
- Compute (for experiments)
- Labor (from human researchers and engineers)
A reasonably common view is that compute is a very key bottleneck such that even if you greatly improved labor, algorithmic progress wouldn't go much faster. This seems plausible to me (though somewhat unlikely), but this isn't what I was arguing about. I was trying to argue (among other things) that scaling up basically current methods could result in an increase in productivity among OpenAI capabilities researchers at least equivalent to the productivity you'd get as if the human employees operated 10x faster. (In other words, 10x'ing this labor input.)
Now, I'll try to respond to your claims.
My current model is that ML experiments are bottlenecked not on software-engineer hours, but on compute.
Maybe, but that isn't exactly a crux in this discussion as noted above. The relevant question is whether the important labor going into ML experiments is more "insights" or "engineering" (not whether both of these are bottlenecked on compute).
What actually matters for ML-style progress is picking the correct trick, and then applying it to a big-enough model.
My sense is that engineering is most of the labor, and most people I talk to with relevant experience have a view like: "taste is somewhat important, but lots of people have that and fast execution is roughly as important or more important". Notably, AI companies really want to hire fast and good engineers and seem to care comparably about this as about more traditional research scientist jobs.
One relevant response would be "sure, AI companies want to hire good engineers, but weren't we talking about the AIs being bad engineers who run fast?"
I think the AI engineers probably have to be quite good at moderate horizon software engineering, but also that scaling up current approaches can pretty likely achieve this. Possibly my "junior hire" analogy was problematic as "junior hire" can mean not as good at programming in addition to "not as much context at this company, but good at the general skills".
So 10x'ing the number of small-scale experiments is unlikely to actually 10x ML research, along any promising research direction.
I wasn't saying that these AIs would mostly be 10x'ing the number of small-scale experiments, though I do think that increasing the number and serial speed of experiments is an important part of the picture.
There are lots of other things that engineers do (e.g., increase the efficiency of experiments so they use less compute, make it much easier to run experiments, etc.).
Indeed, an additional disadvantage of AI-based researchers/engineers is that their forward passes would cut into that limited compute budget. Offloading the computations associated with software engineering and experiment oversight onto the brains of mid-level human engineers is potentially more cost-efficient.
Sure, but we have to be quantitative here. As a rough (and somewhat conservative) estimate, if I were to manage 50 copies of 3.5 Sonnet who are running 1/4 of the time (due to waiting for experiments, etc), that would cost roughly 50 copies * 70 tok / s * 1 / 4 uptime * 60 * 60 * 24 * 365 sec / year * (15 / 1,000,000) $ / tok = $400,000. This cost is comparable to salaries at current compute prices and probably much less than how much AI companies would be willing to pay for top employees. (And note this is after API markups etc. I'm not including input prices for simplicity, but input is much cheaper than output and it's just a messy BOTEC anyway.)
Yes, this compute comes directly at the cost of experiments, but so do employee salaries at current margins. (Maybe this will be less true in the future.)
At the point when AIs are first capable of doing the relevant tasks, it seems likely it is pretty expensive, but I expect costs to drop pretty quickly. And, AI companies will have far more compute in the future as this increases at a rapid rate, making the plausible number of instances substantially higher.
Is there a reason to think that any need for that couldn't already be satisfied? If it were an actual bottleneck, I would expect it to have already been solved: by the AGI labs just hiring tons of competent-ish software engineers.
I think AI companies would be very happy to hire lots of software engineers who work for nearly free, run 10x faster, work 24/7, and are pretty good research engineers. This seems especially true if you add other structural advantages of AI into the mix (train once and use many times, fewer personnel issues, easy to scale up and down, etc). The serial speed is very important.
(The bar of "competent-ish" seems too low. Again, I think "junior" might have been leading you astray here, sorry about that. Imagine more like median AI company engineering hire or a bit better than this. My original comment said "automating research engineering".)
LLM-based coding tools seem competent enough to significantly speed up a human programmer's work on formulaic tasks. So any sufficiently simple software-engineering task should already be done at lightning speeds within AGI labs.
I'm not sure I buy this claim about current tools. Also, I wasn't making a claim about AIs just doing simple tasks (banal does not mean simple) as discussed earlier.
Stepping back from engineering vs insights, my sense is that it isn't clear that the AIs will be terrible at insights or broader context. So, I think it will probably be more like they are very fast engineers and ok at experimental direction. Being ok helps a bunch by avoiding the need for human intervention at many points.
Maybe a relevant crux is: "Could scaling up current methods yield AIs that can mostly autonomously automate software engineering tasks that are currently being done by engineers at AI companies?" (More precisely, succeed at these tasks very reliably with only a small amount of human advice/help amortized over all tasks. Probably this would partially work by having humans or AIs decompose into relatively smaller subtasks that require a bit less context, though this isn't notably different from how humans do things themselves.)
But, I think you maybe also have a further crux like: "Does making software engineering at AI companies cheap and extremely fast greatly accelerate the labor input to AI R&D?"
Replies from: Thane Ruthenis, faul_sname↑ comment by Thane Ruthenis · 2025-01-08T07:23:13.705Z · LW(p) · GW(p)
Yup, those two do seem to be the cruxes here.
I was trying to argue (among other things) that scaling up basically current methods could result in an increase in productivity among OpenAI capabilities researchers at least equivalent to the productivity you'd get as if the human employees operated 10x faster
You're right, that's a meaningfully different claim and I should've noticed the difference.
I think I would disagree with it as well. Suppose we break up this labor into, say,
- "Banal" software engineering.
- Medium-difficult systems design and algorithmic improvements (finding optimizations, etc.).
- Coming up with new ideas regarding how AI capabilities can be progressed.
- High-level decisions regarding architectures, research avenues and strategies, etc. (Not just inventing transformers/the scaling hypothesis/the idea of RL-on-CoT, but picking those approaches out of a sea of ideas, and making the correct decision to commit hard to them.)
In turn, the factors relevant to (4) are:
- (a) The serial thinking of the senior researchers and the communication/exchange of ideas between them.
- (Where "the senior researchers" are defined as "the people with the power to make strategic research decisions at a given company".)
- (b) The outputs of significant experiments decided on by the senior researchers.
- (c) The pool of untested-at-large-scale ideas presented to the senior researchers.
Importantly, in this model, speeding up (1), (2), (3) can only speed up (4) by increasing the turnover speed of (b) and the quality of (c). And I expect that non-AGI-complete AI cannot improve the quality of ideas (3) and cannot directly speed up/replace (a)[1], meaning any acceleration from it can only come from accelerating the engineering and the optimization of significant experiments.
Which, I expect, are in fact mostly bottlenecked by compute, and 10x'ing the human-labor productivity there doesn't 10x the overall productivity of the human-labor input; it remains stubbornly held up by (a). (I do buy that it can significantly speed it up, say 2x it. But not 10x it.)
Separately, I'm also skeptical that near-term AI can speed up the nontrivial engineering involved in medium-difficult systems design and the management of significant experiments:
Stepping back from engineering vs insights, my sense is that it isn't clear that the AIs will be terrible at insights or broader context. So, I think it will probably be more like they are very fast engineers and ok at experimental direction. Being ok helps a bunch by avoiding the need for human intervention at many points.
It seems to me that AIs have remained stubbornly terrible at this from GPT-3 to GPT-4 to Sonnet 3.5.1 to o1[2]; that the improvement on this hard-to-specify quality has been ~0. I guess we'll see if o3 (or an o-series model based on the next-generation base model) change that. AI does feel right on the cusp of getting good at this...
... just as it felt at the time of GPT-3.5, and GPT-4, and Sonnet 3.5.1, and o1. That just the slightest improvement along this axis would allow us to plug the outputs of AI cognition into its inputs and get a competent, autonomous AI agent.
And yet here we are, still.
It's puzzling to me [LW(p) · GW(p)] and I don't quite understand why it wouldn't work, but based on the previous track record, I do in fact expect it not to work.
- ^
In other words: If an AI is able to improve the quality of ideas and/or reliably pluck out the best ideas from a sea of them, I expect that's AGI and we can throw out all human cognitive labor entirely.
- ^
Arguably, no improvement since GPT-2 [LW · GW]; I think that post aged really well.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-09T17:53:51.234Z · LW(p) · GW(p)
It seems to me that AIs have remained stubbornly terrible at this from GPT-3 to GPT-4 to Sonnet 3.5.1 to o1[2]; that the improvement on this hard-to-specify quality has been ~0. I guess we'll see if o3 (or an o-series model based on the next-generation base model) change that. AI does feel right on the cusp of getting good at this...
... just as it felt at the time of GPT-3.5, and GPT-4, and Sonnet 3.5.1, and o1. That just the slightest improvement along this axis would allow us to plug the outputs of AI cognition into its inputs and get a competent, autonomous AI agent.
Boy do I disagree with this take! Excited to discuss.
Can you say more about what skills you think the GPT series has shown ~0 improvement on?
Because if it's "competent, autonomous agency" then there has been massive progress over the last two years and over the last few months in particular. METR has basically spent dozens of FTE-years specifically trying to measure progress in autonomous agency capability, both with formal benchmarks and with lots of high-surface-area interaction with models (they have people building scaffolds to make the AIs into agents and do various tasks etc.) And METR seems to think that progress has been rapid and indeed faster than they expected.
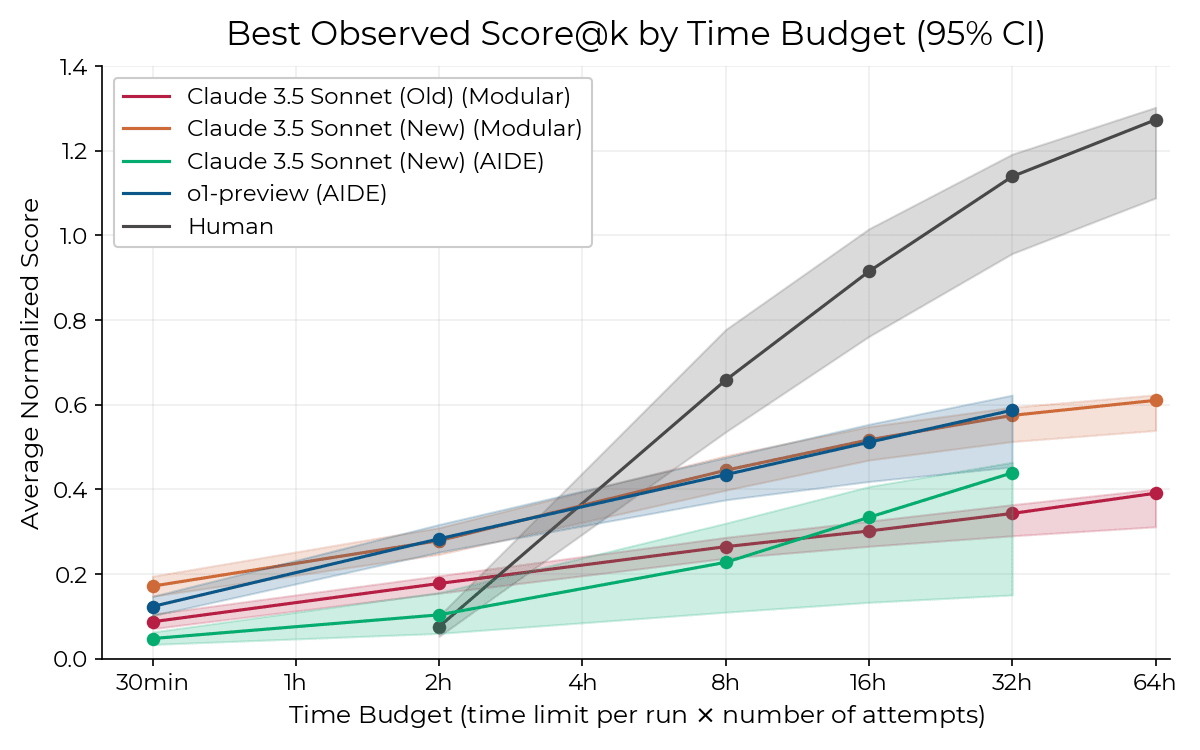
Has there been enough progress to automate swathes of jobs? No, of course not -- see the benchmarks. E.g. RE-bench shows that even the best public models like o1 and newsonnet are only as good as professional coders on time horizons of, like, an hour or so. (give or take, depends on how you measure, the task, etc.) Which means that if you give them the sort of task that would take a normal employee, like, three hours, they are worse than a competent human professional. Specifically they'd burn lots of tokens and compute and push lots of buggy code and overall make a mess of things, just like an eager but incompetent employee.
And I'd say the models are unusually good at these coding tasks compared to other kinds of useful professional tasks, because the companies have been trying harder to train them to code and it's inherently easier to train due to faster feedback loops etc.
↑ comment by Thane Ruthenis · 2025-01-09T19:06:36.125Z · LW(p) · GW(p)
Can you say more about what skills you think the GPT series has shown ~0 improvement on?
Alright, let's try this. But this is going to be vague.
Here's a cluster of things that SotA AIs seem stubbornly bad at:
- Innovation. LLMs are perfectly able to understand an innovative idea if it's described to them, even if it's a new idea that was produced after their knowledge-cutoff date. Yet, there hasn't been a single LLM-originating innovation, and all attempts to design "AI scientists" have produced useless slop. They seem to have terrible "research taste", even though they should be able to learn this implicit skill from the training data.
- Reliability. Humans are very reliable agents [LW · GW], and SotA AIs aren't, even when e. g. put into wrappers that encourage them to sanity-check their work. The gap in reliability seems qualitative, rather than just quantitative.
- Solving non-templated problems. There seems to be a bimodal distribution of a sort, where some people report LLMs producing excellent code/math, and others [LW(p) · GW(p)] report that they fail basic tasks.
- Compounding returns on problem-solving time. As the graph you provided shows, humans' performance scales dramatically with the time they spent on the problem, whereas AIs' – even o1's – doesn't.
My sense is that LLMs are missing some sort of "self-steering" "true autonomy" quality; the quality that allows humans to:
- Stare at the actual problem they're solving, and build its highly detailed model in a "bottom-up" manner. Instead, LLMs go "top-down": they retrieve the closest-match template problem from a vast database, fill-in some details, and solve that problem.
- (Non-templatedness/fluid intelligence.)
- Iteratively improve their model of a problem over the course of problem-solving, and do sophisticated course-correction if they realize their strategy isn't working or if they're solving the wrong problem. Humans can "snap out of it" if they realize they're messing up, instead of just doing what they're doing on inertia.
- (Reliability.)
- Recognize when their model of a given problem represents a nontrivially new "template" that can be memorized and applied in a variety of other situations, and what these situations might be.
- (Innovation.)
My model is that all LLM progress so far has involved making LLMs better at the "top-down" thing. They end up with increasingly bigger databases of template problems, the closest-match templates end up ever-closer to the actual problems they're facing, their ability to fill-in the details becomes ever-richer, etc. This improves their zero-shot skills, and test-time compute scaling allows them to "feel out" the problem's shape over an extended period and find an ever-more-detailed top-down fit.
But it's still fundamentally not what humans do. Humans are able to instantiate a completely new abstract model of a problem – even if it's initially based on a stored template – and chisel at it until it matches the actual problem near-perfectly. This allows them to be much more reliable; this allows them to keep themselves on-track; this allows them to find "genuinely new" innovations.
The two methods do ultimately converge to the same end result: in the limit of a sufficiently expressive template-database, LLMs would be able to attain the same level of reliability/problem-representation-accuracy as humans. But the top-down method of approaching this limit seems ruinously computationally inefficient; perhaps so inefficient it saturates around GPT-4's capability level.[1]
LLMs are sleep-walking. We can make their dreams ever-closer to reality, and that makes the illusion that they're awake ever-stronger. But they're not, and the current approaches may not be able to wake them up at all.
(As an abstract analogy: imagine that you need to color the space bounded by some 2D curve. In one case, you can take a pencil and do it directly. In another case, you have a collection of cutouts of geometric figures, and you have to fill the area by assembling a collage. If you have a sufficiently rich collection of figures, you can come arbitrarily close; but the "bottom-up" approach is strictly better. In particular, it can handle arbitrarily complicated shapes out-of-the-box, whereas the second approach would require dramatically bigger collections the more complicated the shapes get.)
Edit: Or so my current "bearish on LLMs" model goes. The performance of o3 or GPT-5/6 can very much break it, and the actual mechanisms described are necessarily speculative and tentative.
- ^
Under this toy model, it needn't have saturated around this level; it could've comfortably overshot human capabilities. But this doesn't seem to be what's happening, likely due to some limitation of the current paradigm not covered by this model.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-09T22:05:22.602Z · LW(p) · GW(p)
Thanks! Time will tell who is right. Point by point reply:
You list four things AIs seem stubbornly bad at: 1. Innovation. 2. Reliability. 3. Solving non-templated problems. 4. Compounding returns on problem-solving-time.
First of all, 2 and 4 seem closely related to me. I would say: "Agency skills" are the skills key to being an effective agent, i.e. skills useful for operating autonomously for long periods in pursuit of goals. Noticing when you are stuck is a simple example of an agency skill. Planning is another simple example. In-context learning is another example. would say that current AIs lack agency skills, and that 2 and 4 are just special cases of this. I would also venture to guess with less confidence that 1 and 3 might be because of this as well -- perhaps the reason AIs haven't made any truly novel innovations yet is that doing so takes intellectual work, work they can't do because they can't operate autonomously for long periods in pursuit of goals. (Note that reasoning models like o1 are a big leap in the direction of being able to do this!) And perhaps the reason behind the relatively poor performance on non-templated tasks is... wait actually no, that one has a very easy separate explanation, which is that they've been trained less on those tasks. A human, too, is better at stuff they've done a lot.
Secondly, and more importantly, I don't think we can say there has been ~0 progress on these dimensions in the last few years, whether you conceive of them in your way or my way. Progress is in general s-curvy; adoption curves are s-curvy. Suppose for example that GPT2 was 4 SDs worse than average human at innovation, reliability, etc. and GPT3 was 3 SDs worse and GPT4 was 2 SDs worse and o1 is 1 SD worse. Under this supposition, the world would look the way that it looks today -- Thane would notice zero novel innovations from AIs, Thane would have friends who try to use o1 for coding and find that it's not useful without templates, etc. Meanwhile, as I'm sure you are aware pretty much every benchmark anyone has ever made has shown rapid progress in the last few years -- including benchmarks made by METR who was specifically trying to measure AI R&D ability and agency abilities, and which genuinely do seem to require (small) amounts of agency. So I think the balance of evidence is in favor of progress on the dimensions you are talking about -- it just hasn't reached human level yet, or at any rate not the level at which you'd notice big exciting changes in the world. (Analogous to: Suppose we've measured COVID in some countries but not others, and found that in every country we've measured, COVID has spread to about 0.01% - 0.001% of the population, and is growing exponentially. If we live in a country that hasn't measured yet, we should assume COVID is spreading even though we don't know anyone personally who is sick yet.)
...
You say:
My model is that all LLM progress so far has involved making LLMs better at the "top-down" thing. They end up with increasingly bigger databases of template problems, the closest-match templates end up ever-closer to the actual problems they're facing, their ability to fill-in the details becomes ever-richer, etc. This improves their zero-shot skills, and test-time compute scaling allows them to "feel out" the problem's shape over an extended period and find an ever-more-detailed top-down fit.
But it's still fundamentally not what humans do. Humans are able to instantiate a completely new abstract model of a problem – even if it's initially based on a stored template – and chisel at it until it matches the actual problem near-perfectly. This allows them to be much more reliable; this allows them to keep themselves on-track; this allows them to find "genuinely new" innovations.
Top down vs. bottom-up seem like two different ways of solving intellectual problems. Do you think it's a sharp binary distinction? Or do you think it's a spectrum? If the latter, what makes you think o1 isn't farther along the spectrum than GPT3? If the former -- if it's a sharp binary -- can you say what it is about LLM architecture and/or training methods that renders them incapable of thinking in the bottom-up way? (Like, naively it seems like o1 can do sophisticated reasoning. Moreover, it seems like it was trained in a way that would incentivize it to learn skills useful for solving math problems, and 'bottom-up reasoning' seems like a skill that would be useful. Why wouldn't it learn it?)
Can you describe an intellectual or practical feat, or ideally a problem set, such that if AI solves it in 2025 you'll update significantly towards my position?
↑ comment by Thane Ruthenis · 2025-01-09T23:52:00.858Z · LW(p) · GW(p)
First of all, 2 and 4 seem closely related to me.
I would also venture to guess with less confidence that 1 and 3 might be because of this as well
Agreed, I do expect that the performance on all of those is mediated by the same variable(s); that's why I called them a "cluster".
benchmarks made by METR who was specifically trying to measure AI R&D ability and agency abilities, and which genuinely do seem to require (small) amounts of agency
I think "agency" is a bit of an overly abstract/confusing term to use, here. In particular, I think it also allows both a "top-down" and a "bottom-up" approach.
Humans have "bottom-up" agency: they're engaging in fluid-intelligence problem-solving and end up "drawing" a decision-making pattern of a specific shape. An LLM, on this model, has a database of templates for such decision-making patterns, and it retrieves the best-fit agency template for whatever problem it's facing. o1/RL-on-CoTs is a way to deliberately target the set of agency-templates an LLM has, extending it. But it doesn't change the ultimate nature of what's happening.
In particular: the bottom-up approach would allow an agent to stay on-target for an arbitrarily long time, creating an arbitrarily precise fit for whatever problem it's facing. An LLM's ability to stay on-target, however, would always remain limited by the length and the expressiveness of the templates that were trained into it.
RL on CoTs is a great way to further mask the problem, which is why the o-series seems to make unusual progress on agency-measuring benchmarks. But it's still just masking it.
can you say what it is about LLM architecture and/or training methods that renders them incapable of thinking in the bottom-up way?
Not sure. I think it might be some combination of "the pretraining phase moves the model deep into the local-minimum abyss of top-down cognition, and the cheaper post-training phase can never hope to get it out of there" and "the LLM architecture sucks, actually". But I would rather not get into the specifics.
Can you describe an intellectual or practical feat, or ideally a problem set, such that if AI solves it in 2025 you'll update significantly towards my position?
"Inventing a new field of science" would do it, as far as more-or-less legible measures go. Anything less than that is too easily "fakeable" using top-down reasoning.
That said, I may make this update based on less legible vibes-based evidence, such as if o3's advice on real-life problems seems to be unusually lucid and creative. (I'm tracking the possibility that LLMs are steadily growing in general capability and that they simply haven't yet reached the level that impresses me personally. But on balance, I mostly don't expect this possibility to be realized.)
Replies from: ryan_greenblatt, daniel-kokotajlo↑ comment by ryan_greenblatt · 2025-01-10T00:44:00.614Z · LW(p) · GW(p)
"Inventing a new field of science" would do it, as far as more-or-less legible measures go. Anything less than that is too easily "fakeable" using top-down reasoning.
Seems unlikely we'll see this before stuff gets seriously crazy on anyone's views. (Has any new field of science been invented in the last 5 years by humans? I'm not sure what you'd count.)
It seems like we should at least update towards AIs being very useful for accelerating AI R&D if we very clearly see AI R&D greatly accelerate and it is using tons of AI labor. (And this was the initial top level prompt for this thread.) We could say something similar about other types of research.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-10T01:14:52.475Z · LW(p) · GW(p)
Seems unlikely we'll see this before stuff gets seriously crazy on anyone's views. (Has any new field of science been invented in the last 5 years? I'm not sure what you'd count.)
Maybe some minor science fields, but yeah entirely new science fields in 5 years is deep into ASI territory, assuming it's something like a hard science like physics.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-10T04:30:52.606Z · LW(p) · GW(p)
Minor would count.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-10T01:01:35.929Z · LW(p) · GW(p)
Thanks for the reply.
(I'm tracking the possibility that LLMs are steadily growing in general capability and that they simply haven't yet reached the level that impresses me personally. But on balance, I mostly don't expect this possibility to be realized.)
That possibility is what I believe. I wish we had something to bet on better than "inventing a new field of science," because by the time we observe that, there probably won't be much time left to do anything about it. What about e.g. "I, Daniel Kokotajlo, are able to use AI agents basically as substitutes for human engineer/programmer employees. I, as a non-coder, can chat with them and describe ML experiments I want them to run or websites I want them to build etc., and they'll make it happen at least as quickly and well as a competent professional would." (And not just for simple websites, for the kind of experiments I'd want to run, which aren't the most complicated but they aren't that different from things actual AI company engineers would be doing.)
What about "The model is seemingly as good at solving math problems and puzzles as Thane is, not just on average across many problems but on pretty much any specific problem including on novel ones that are unfamiliar to both of you?
Humans have "bottom-up" agency: they're engaging in fluid-intelligence problem-solving and end up "drawing" a decision-making pattern of a specific shape. An LLM, on this model, has a database of templates for such decision-making patterns, and it retrieves the best-fit agency template for whatever problem it's facing. o1/RL-on-CoTs is a way to deliberately target the set of agency-templates an LLM has, extending it. But it doesn't change the ultimate nature of what's happening.
In particular: the bottom-up approach would allow an agent to stay on-target for an arbitrarily long time, creating an arbitrarily precise fit for whatever problem it's facing. An LLM's ability to stay on-target, however, would always remain limited by the length and the expressiveness of the templates that were trained into it.
Miscellaneous thoughts: I don't yet buy that this distinction between top-down and bottom-up is binary, and insofar as it's a spectrum then I'd be willing to bet that there's been progress along it in recent years. Moreover I'm not even convinced that this distinction matters much for generalization radius / general intelligence, and it's even less likely to matter for 'ability to 5x AI R&D' which is the milestone I'm trying to predict first. Moreover, I don't think humans stay on-target for an arbitrarily long time.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-29T00:29:45.118Z · LW(p) · GW(p)
I wish we had something to bet on better than "inventing a new field of science,"
I've thought of one potential observable that is concrete, should be relatively low-capability, and should provoke a strong update towards your model for me:
If there is an AI model such that the complexity of R&D problems it can solve (1) scales basically boundlessly with the amount of serial compute provided to it (or to a "research fleet [LW · GW]" based on it), (2) scales much faster with serial compute than with parallel compute, and (3) the required amount of human attention ("babysitting") is constant or grows very slowly with the amount of serial compute.
This attempts to directly get at the "autonomous self-correction" and "ability to think about R&D problems strategically" ideas.
I've not fully thought through all possible ways reality could Goodhart to this benchmark, i. e. "technically" pass it but in a way I find unconvincing. For example, if I failed to include the condition (2), o3 would have probably already "passed" it (since it potentially achieved better performance on ARC-AGI and FrontierMath by sampling thousands of CoTs then outputting the most frequent answer). There might be other loopholes like this...
But it currently seems reasonable and True-Name-y [LW · GW] to me.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-29T01:00:01.904Z · LW(p) · GW(p)
Nice.
What about "Daniel Kokotajlo can feed it his docs about some prosaic ML alignment agenda (e.g. the faithful CoT stuff) and then it can autonomously go off and implement the agenda and come back to him with a writeup of the results and takeaways. While working on this, it gets to check in with Daniel once a day for a brief 20-minute chat conversation."
Does that seem to you like it'll come earlier, or later, than the milestone you describe?
↑ comment by Thane Ruthenis · 2025-01-29T01:19:22.159Z · LW(p) · GW(p)
Prooobably ~simultaneously, but I can maybe see it coming earlier and in a way that isn't wholly convincing to me. In particular, it would still be a fixed-length task; much longer-length than what the contemporary models can reliably manage today, but still hackable using poorly-generalizing "agency templates" instead of fully general "compact generators of agenty behavior" (which I speculate humans to have and RL'd LLMs not to). It would be some evidence in favor of "AI can accelerate AI R&D", but not necessarily "LLMs trained via SSL+RL are AGI-complete".
Actually, I can also see it coming later. For example, some suppose that the capability researchers invent some method for reliably-and-indefinitely extending the amount of serial computations a reasoning model can productively make use of, but the compute or memory requirements grow very fast with the length of a CoT. Some fairly solid empirical evidence and theoretical arguments in favor of boundless scaling can appear quickly, well before the algorithms are made optimal enough to (1) handle weeks-long CoTs and/or (2) allow wide adoption (thus making it available to you).
I think the second scenario is more plausible, actually.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-29T01:36:38.175Z · LW(p) · GW(p)
OK. Next question: Suppose that next year we get a nice result showing that there is a model with serial inference-time scaling across e.g. MATH + FrontierMath + IMO problems. Recall that FrontierMath and IMO are subdivided into different difficulty levels; suppose that this model can be given e.g. 10 tokens of CoT, 100, 1000, 10,000, etc. and then somewhere around the billion-serial-token-level it starts solving a decent chunk of the "medium" FrontierMath problems (but not all) and at the million-serial-token level it was only solving MATH + some easy IMO problems.
Would this count, for you?
↑ comment by Thane Ruthenis · 2025-01-29T02:18:29.605Z · LW(p) · GW(p)
Not for math benchmarks. Here's one way it can "cheat" at them: suppose that the CoT would involve the model generating candidate proofs/derivations, then running an internal (learned, not hard-coded) proof verifier on them, and either rejecting the candidate proof and trying to generate a new one, or outputting it. We know that this is possible, since we know that proof verifiers can be compactly specified.
This wouldn't actually show "agency" and strategic thinking of the kinds that might generalize to open-ended domains and "true" long-horizon tasks. In particular, this would mostly fail the condition (2) from my previous comment [LW(p) · GW(p)].
Something more open-ended and requiring "research taste" would be needed. Maybe a comparable performance on METR's benchmark would work for this (i. e., the model can beat a significantly larger fraction of it at 1 billion tokens compared to 1 million)? Or some other benchmark that comes closer to evaluating real-world performance.
Edit: Oh, math-benchmark performance would convince me if we get access to a CoT sample and it shows that the model doesn't follow the above "cheating" approach, but instead approaches the problem strategically (in some sense). (Which would also require this CoT not to be hopelessly steganographied, obviously.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-29T04:13:18.238Z · LW(p) · GW(p)
Have you looked at samples of CoT of o1, o3, deepseek, etc. solving hard math problems? I feel like a few examples have been shown & they seem to involve qualitative thinking, not just brute-force-proof-search (though of course they show lots of failed attempts and backtracking -- just like a human thought-chain would).
Anyhow, this is nice, because I do expect that probably something like this milestone will be reached before AGI (though I'm not sure)
↑ comment by Thane Ruthenis · 2025-01-29T05:16:57.442Z · LW(p) · GW(p)
Have you looked at samples of CoT of o1, o3, deepseek, etc. solving hard math problems?
Certainly (experimenting with r1's CoTs right now, in fact). I agree that they're not doing the brute-force stuff I mentioned; that was just me outlining a scenario in which a system "technically" clears the bar you'd outlined, yet I end up unmoved (I don't want to end up goalpost-moving).
Though neither are they being "strategic" in the way I expect they'd need to be in order to productively use a billion-token CoT.
Anyhow, this is nice, because I do expect that probably something like this milestone will be reached before AGI
Yeah, I'm also glad to finally have something concrete-ish to watch out for. Thanks for prompting me!
↑ comment by ryan_greenblatt · 2025-01-08T17:54:46.691Z · LW(p) · GW(p)
It seems to me that AIs have remained stubbornly terrible at this from GPT-3 to GPT-4 to Sonnet 3.5.1 to o1[2]; that the improvement on this hard-to-specify quality has been ~0.
Huh, I disagree reasonably strongly with this. Possible that something along these lines is an empirically testable crux.
Replies from: Thane Ruthenis, snewman↑ comment by Thane Ruthenis · 2025-01-09T12:51:10.287Z · LW(p) · GW(p)
I expect this is the sort of thing that can be disproven (if LLM-based AI agents actually do start displacing nontrivial swathes of e. g. non-entry-level SWE workers in 2025-2026), but only "proven" gradually (if "AI agents start displacing nontrivial swathes of some highly skilled cognitive-worker demographic" continually fails to happen year after year after year).
Overall, operationalizing bets/empirical tests about this has remained a cursed problem.
Edit:
As a potentially relevant factor: Were you ever surprised by how unbalanced the progress and the adoption have been? The unexpected mixes of capabilities and incapabilities that AI models have displayed?
My current model is centered on trying to explain this surprising mix (top-tier/superhuman benchmark performance vs. frequent falling-flat-on-its-face real-world performance). My current guess is basically that all capabilities progress has been effectively goodharting on legible performance (benchmarks and their equivalents) while doing ~0 improvement on everything else. Whatever it is benchmarks and benchmark-like metrics are measuring, it's not what we think it is [LW · GW].
So what we will always observe is AI getting better and better at any neat empirical test we can devise, always seeming on the cusp of being transformative, while continually and inexplicably failing to tilt over into actually being transformative. (The actual performance of o3 and GPT-5/6 would be a decisive test of this model for me.)
Replies from: ryan_greenblatt, sharmake-farah↑ comment by ryan_greenblatt · 2025-01-09T16:56:36.561Z · LW(p) · GW(p)
top-tier/superhuman benchmark performance vs. frequent falling-flat-on-its-face real-world performance
Models are just recently getting to the point where they can complete 2 hour tasks 50% of the time in METR's tasks (at least without scaffolding that uses much more inference compute).
This isn't yet top tier performance, so I don't see the implication. The key claim is that progress here is very fast.
So, I don't currently feel that strongly that there is a huge benchmark vs real performance gap in at least autonomous SWE-ish tasks? (There might be in math and I agree that if you just looked at math and exam question benchmarks and compared to humans, the models seem much smarter than they are.)
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-09T14:57:27.485Z · LW(p) · GW(p)
Something interesting here is that a part of why AI companies won't want to use agents is because their capabilities are good enough that being very reckless with them might actually cause small-scale misalignment issues, and if that's truly a big part of the problem in getting companies to adopt AI agents, this is good news for our future:
https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/?commentId=qEkRqHtSJfoDA7zJX [LW · GW]
↑ comment by snewman · 2025-01-08T18:04:41.164Z · LW(p) · GW(p)
FWIW my vibe is closer to Thane's. Yesterday I commented [LW(p) · GW(p)] that this discussion has been raising some topics that seem worthy of a systematic writeup as fodder for further discussion. I think here we've hit on another such topic: enumerating important dimensions of AI capability – such as generation of deep insights, or taking broader context into account – and then kicking off a discussion of the past trajectory / expected future progress on each dimension.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-01-08T18:27:45.720Z · LW(p) · GW(p)
Some benchmarks got saturated across this range, so we can imagine "anti-saturated" benchmarks that didn't yet noticeably move from zero, operationalizing intuitions of lack of progress. Performance on such benchmarks still has room to change significantly even with pretraining scaling in the near future, from 1e26 FLOPs of currently deployed models to 5e28 FLOPs by 2028 [LW · GW], 500x more.
↑ comment by faul_sname · 2025-01-08T00:04:19.778Z · LW(p) · GW(p)
Sure, but we have to be quantitative here. As a rough (and somewhat conservative) estimate, if I were to manage 50 copies of 3.5 Sonnet who are running 1/4 of the time (due to waiting for experiments, etc), that would cost roughly 50 copies * 70 tok / s * 1 / 4 uptime * 60 * 60 * 24 * 365 sec / year * (15 / 1,000,000) $ / tok = $400,000. This cost is comparable to salaries at current compute prices and probably much less than how much AI companies would be willing to pay for top employees. (And note this is after API markups etc. I'm not including input prices for simplicity, but input is much cheaper than output and it's just a messy BOTEC anyway.)
If you were to spend equal amounts of money on LLM inference and GPUs, that would mean that you're spending $400,000 / year on GPUs. Divide that 50 ways and each Sonnet instance gets an $8,000 / year compute budget. Over the 18 hours per day that Sonnet is waiting for experiments, that is an average of $1.22 / hour, which is almost exactly the hourly cost of renting a single H100 on Vast.
So I guess the crux is "would a swarm of unreliable researchers with one good GPU apiece be more effective at AI research than a few top researchers who can monopolize X0,000 GPUs for months, per unit of GPU time spent".
(and yes, at some point it the question switches to "would an AI researcher that is better at AI research than the best humans make better use of GPUs than the best humans" but a that point it's a matter of quality, not quantity)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-08T00:53:06.907Z · LW(p) · GW(p)
Sure, but I think that at the relevant point, you'll probably be spending at least 5x more on experiments than on inference and potentially a much larger larger ratio if heavy test time compute usage isn't important. I was just trying to argue that the naive inference cost isn't that crazy.
Notably, if you give each researcher 2k gpu hours, that would be $2 / gpu hour * 2k * 24 * 365 = $35,040,000 per year which is much higher than the inference cost of the models!
Replies from: faul_sname↑ comment by faul_sname · 2025-01-10T06:00:37.008Z · LW(p) · GW(p)
I think I misunderstood what you were saying there - I interpreted it as something like
Currently, ML-capable software developers are quite expensive relative to the cost of compute. Additionally, many small experiments provide more novel and useful insights than a few large experiments. The top practically-useful LLM costs about 1% as much per hour to run as a ML-capable software developer, and that 100x decrease in cost and the corresponding switch to many small-scale experiments would likely result in at least a 10x increase in the speed at which novel, useful insights were generated.
But on closer reading I see you said (emphasis mine)
I was trying to argue (among other things) that scaling up basically current methods could result in an increase in productivity among OpenAI capabilities researchers at least equivalent to the productivity you'd get as if the human employees operated 10x faster. (In other words, 10x'ing this labor input.)
So if the employees spend 50% of their time waiting on training runs which are bottlenecked on company-wide availability of compute resources, and 50% of their time writing code, 10xing their labor input (i.e. the speed at which they write code) would result in about an 80% increase in their labor output. Which, to your point, does seem plausible.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-10T06:13:14.799Z · LW(p) · GW(p)
Yes. Though notably, if your employees were 10x faster you might want to adjust your workflows to have them spend less time being bottlenecked on compute if that is possible. (And this sort of adaption is included in what I mean.)
Replies from: faul_sname↑ comment by faul_sname · 2025-01-10T06:36:07.772Z · LW(p) · GW(p)
Yeah, agreed - the allocation of compute per human would likely become even more skewed if AI agents (or any other tooling improvements) allow your very top people to get more value out of compute than the marginal researcher currently gets.
And notably this shifting of resources from marginal to top researchers wouldn't require achieving "true AGI" if most of the time your top researchers spend isn't spent on "true AGI"-complete tasks.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-07T16:17:43.198Z · LW(p) · GW(p)
Thanks for the mention Thane. I think you make excellent points, and agree with all of them, to some degree. Yet, I'm expecting huge progress in AI algorithms to be unlocked by AI reseachers.
I'll quote from my comments on the other recent AI timeline discussion [LW(p) · GW(p)].
How closely are they adhering to the "main path" of scaling existing techniques with minor tweaks? If you want to know how a minor tweak affects your current large model at scale, that is a very compute-heavy researcher-time-light type of experiment. On the other hand, if you want to test a lot of novel new paths at much smaller scales, then you are in a relatively compute-light but researcher-time-heavy regime.
What fraction of the available compute resources is the company assigning to each of training/inference/experiments? My guess it that the current split is somewhere around 63/33/4. If this was true, and the company decided to pivot away from training to focus on experiments (0/33/67), this would be something like a 16x increase in compute for experiments. So maybe that changes the bottleneck?
I think that Ilya and the AGI labs are part of a school of thought that is very focused on tweaking the existing architecture slightly. This then is a researcher-time-light and compute-heavy paradigm.
I think the big advancements require going further afield, outside the current search-space of the major players.
Which is not to say that I think LLMs have to be thrown out as useless. I expect some kind of combo system to work. The question is, combined with what?
Well, my prejudice as someone from a neuroscience background is that I think there are untapped insights from studying the brain.
Look at the limitations of current AI that François Chollet discusses in his various interviews and lectures. I think he's pointing at real flaws. Look how many data points it takes a typical ML model to learn a new task! How limited in-context learning is!
Brains are doing something different clearly. I think our current models are much more powerful than a mouse brain, and yet there are some things that mice learn better.
So, if you stopped spending your compute on big expensive experiments, and instead spent it on combing through the neuroscience literature looking for clues... Would the AI reseachers make a breakthrough? My guess is yes.
I also suspect that there are ideas in computer science, paths not yet explored with modern compute, that are hiding revolutionary insights. But to find them you'd need to go way outside the current paradigm. Set deep learning entirely aside and look at fundamental ideas. I doubt that this describes even 1% of the current time being spent by researchers currently at the big companies. Their path seems to be working, why should they look elsewhere? The cost to them personally of reorienting to entirely different fields of research would be huge. Not so for AI reseachers. They can search everything, and quickly.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-07T16:58:08.748Z · LW(p) · GW(p)
I think the big advancements require going further afield, outside the current search-space of the major players.
Oh, I very much agree. But any associated software engineering and experiments would then be nontrivial, ones involving setting up a new architecture, correctly interpreting when it's not working due to a bug vs. because it's fundamentally flawed, figuring out which tweaks are okay to make and which tweaks would defeat the point of the experiment, et cetera. Something requiring sophisticated research taste; not something you can trivially delegate-and-forget to a junior researcher (as per @ryan_greenblatt [LW · GW]'s vision). (And importantly, if this can be delegated to (AI models isomorphic to) juniors, this is something AGI labs can already do just by hiring juniors.)
Same regarding looking for clues in neuroscience/computer-science literature. In order to pick out good ideas, you need great research taste and plausibly a bird's eye view on the entire hardware-software research stack. I wouldn't trust a median ML researcher/engineer's summary; I would expect them to miss great ideas while bringing slop to my attention, such that it'd be more time-efficient to skim over the literature myself.
In addition, this is likely also a part is where "95% of progress comes from the ability to run big experiments" comes into play. Tons of novel tricks/architectures would perform well at a small scale and flounder at a big scale, or vice versa. You need to pick a new approach and go hard on trying to make it work, not just lazily throw an experiment at it. Which is something that's bottlenecked on the attention of a senior researcher, not a junior worker.
Overall, it sounds as if... you expect dramatically faster capabilities progress from the AGI labs pivoting towards exploring a breadth of new research directions, with the whole "AI researchers" thing being an unrelated feature? (They can do this pivot with or without them. And as per the compute-constraints arguments, borderline-competent AI researchers aren't going to nontrivially improve on the companies' ability to execute this pivot.)
Replies from: nathan-helm-burger, nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-07T18:57:17.949Z · LW(p) · GW(p)
So, I've been focusing on giving more of a generic view in my comments. Something that I think someone with similar background in neuroscience, and similar background in ML would endorse as roughly plausible.
I also have an inside view which says more specific things. Like, I don't just vaguely think that there are probably some fruitful directions in neglected parts of computer science history and in recent neuroscience. What I actually have are specific hypotheses that I've been working hard on trying to code up experiments for.
If someone gave me engineering support and compute sufficient to actually get my currently planned experiments run, and the results looked like dead-ends, I think my timelines would go from 2-3 years out to 5-10 years. I'd also be much less confident that we'd see rapid efficiency and capability gains from algorithmic research post-AGI, because I'd be more in mindset of minor tweaks to existing paradigms and further expensive scaling.
This is why I'm basically thinking that I mostly agree with you, Thane, except for this inside view I have about specific approaches I think are currently neglected but unlikely to stay neglected.
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2025-01-07T18:35:31.512Z · LW(p) · GW(p)
Yeah, pretty much. Although I don't expect this with super high confidence. Maybe 75%?
This is part of why I think a "pause" focused on large models / large training runs would actually dangerously accelerate progress towards AGI. I think a lot of well-resourced high-skill researchers would suddenly shift their focus onto breadth of exploration.
Another point:
I don't think we'll ever see AI agents that are exactly isomorphic to junior researchers. Why? Because of the weird spikiness of skills we see. In some ways the LLMs we have are much more skillful than junior researchers, in other ways they are pathetically bad. If you held their competencies constant except for improving the places where they are really bad, you'd suddenly have assistants much better than the median junior!
So when considering the details of how to apply the AI assistants we're likely to get (based on extrapolating current spiky skill patterns), the set of affordances this offers to the top researchers is quite different from what having a bunch of juniors would be. I think this means we should expect things to weirder and less smooth than Ryan's straightforward speed-up prediction.
If you look at the recent AI scientist work that's been done you find this weird spiky portfolio. Having LLMs look through a bunch of papers and try to come up with new research directions? Mostly, but not entirely crap... But then since it's relatively cheap to do, and quick to do, and not too costly to filter, the trade-off ends up seeming worthwhile?
As for new experiments in totally new regimes, yeah. That's harder for current LLMs to help with than the well-trodden zones. But I think the specific skills currently beginning to be unlocked by the o1/o3 direction may be enough to make coding agents reliable enough to do a much larger share of this novel experiment setup.
So... It's complicated. Can't be sure of success. Can't be sure of a wall.
↑ comment by johnswentworth · 2025-01-08T16:31:09.613Z · LW(p) · GW(p)
- Tricks that work on smaller scales often don't generalize to larger scales.
- Tricks that work on larger scales often don't work on smaller scales (due to bigger ML models having various novel emergent properties).
My understanding is that these two claims are mostly false in practice. In particular, there have been a few studies (like e.g. this) which try to run yesterday's algorithms with today's scale, and today's algorithms with yesterday's scale, in order to attribute progress to scale vs algorithmic improvements. I haven't gone through those studies in very careful detail, but my understanding is that they pretty consistently find today's algorithms outperform yesterday's algorithms even when scaled down, and yesterday's algorithms underperform today's even when scaled up. So unless I've badly misunderstood those studies, the mental model in which different tricks work best on different scales is basically just false, at least at the range of different scales the field has gone through in the past ~decade.
That said, there are cases where I could imagine Ilya's claim making sense, e.g. if the "experiments" he's talking about are experiments in using the net rather than training the net. Certainly one can do qualitatively different things with GPT4 than GPT2, so if one is testing e.g. a scaffolding setup or a net's ability to play a particular game, then one needs to use the larger net. Perhaps that's what Ilya had in mind?
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-01-08T17:39:50.318Z · LW(p) · GW(p)
I could imagine Ilya's claim making sense, e.g. if the "experiments" he's talking about are experiments in using the net rather than training the net
What I had in mind is something along these lines. More capable models[1] have various emergent properties. Specific tricks can rely on those properties being present, and work better or worse depending on that.
For example, the o-series training loop probably can't actually "get off the ground" if the base model is only as smart as GPT-2: the model would ~never find its way to correct answers, so it'd never get reinforcement signals. You can still force it to work by sampling a billion guesses or by starting it with very easy problems (e. g., basic arithmetics?), but it'd probably deliver much less impressive results than applying it to GPT-4.
Scaling further down: I don't recall if GPT-2 can make productive use of CoTs, but presumably e. g. GPT-1 can't. At that point, the whole "do RL on CoTs" completely ceases to be a meaningful thing to try.
Generalizing: At a lower level of capabilities, there's presumably a ton of various tricks that deliver a small bump to performance. Some of those tricks would have an effect size comparable to RL-on-CoTs-if-applied-at-this-scale. But out of a sea of those tricks, only a few of them would be such that their effectiveness rises dramatically with scale.
So, a more refined way to make my points would be:
- If a trick shows promise at a small capability level, e. g. improving performance 10%, it doesn't mean it'd show a similar 10%-improvement if applied at a higher capability level.
- (Say, because it addresses a deficiency that a big-enough model just doesn't have/which a big-enough pretraining run solves by default.)
- If a trick shows marginal/no improvement at a small capability level, that doesn't mean it won't show a dramatic improvement at a higher capability level.
a few studies (like e.g. this) which try to run yesterday's algorithms with today's scale, and today's algorithms with yesterday's scale
My guess, based on the above, would be that even if today's algorithms perform better than yesterday's algorithms at smaller scales, the difference between their small-scale capabilities is less than the difference between yesterday's algorithms and today's algorithms at bigger scales. I. e.: some algorithms make nonlinearly better use of compute, such that figuring out which tricks are the best is easier at larger scales. (Telling apart a 5% capability improvement from a 80% one.)
- ^
Whether they're more capable by dint of being bigger (GPT-4), or being trained on better data (Sonnet 3.5.1), or having a better training loop + architecture (DeepSeek V3), etc.
↑ comment by snewman · 2025-01-07T02:02:36.744Z · LW(p) · GW(p)
I see a bunch of good questions explicitly or implicitly posed here. I'll touch on each one.
1. What level of capabilities would be needed to achieve "AIs that 10x AI R&D labor"? My guess is, pretty high. Obviously you'd need to be able to automate at least 90% of what capabilities researchers do today. But 90% is a lot, you'll be pushing out into the long tail of tasks that require taste, subtle tacit knowledge, etc. I am handicapped here by having absolutely no experience with / exposure to what goes on inside an AI research lab. I have 35 years of experience as a software engineer but precisely zero experience working on AI. So on this question I somewhat defer to folks like you. But I do suspect there is a tendency to underestimate how difficult / annoying these tail effects will be, this is the same fundamental principle as Hofstadter's Law, the Programmer's Credo, etc.
I have a personal suspicion that a surprisingly large fraction of work (possibly but not necessarily limited to "knowledge work") will turn out to be "AGI complete", meaning that it will require something approaching full AGI to undertake it at human level. But I haven't really developed this idea beyond an intuition. It's a crux and I would like to find a way to develop / articulate it further.
2. What does it even mean to accelerate someone's work by 10x? It may be that if your experts are no longer doing any grunt work, they are no longer getting the input they need to do the parts of their job that are hardest to automate and/or where they're really adding magic-sauce value. Or there may be other sources of friction / loss. In some cases it may over time be possible to find adaptations, in other cases it may be a more fundamental issue. (A possible counterbalance: if AIs can become highly superhuman at some aspects of the job, not just in speed/cost but in quality of output, that could compensate for delivering a less-than-10x time speedup on the overall workflow.)
3. If AIs that 10x AI R&D labor are 20% likely to arrive and be adopted by Jan 2027, would that update my view on the possibility of AGI-as-I-defined-it by 2030? It would, because (per the above) I think that delivering that 10x productivity boost would require something pretty close to AGI. In other words, conditional on AI R&D labor being accelerated 10x by Jan 2027, I would expect that we have something close to AGI by Jan 2027, which also implies that we were able to make huge advances in capabilities in 24 months. Whereas I think your model is that we could get that level of productivity boost from something well short of AGI.
If it turns out that we get 10x AI R&D labor by Jan 2027 but the AIs that enabled this are pretty far from AGI... then my world model is very confused and I can't predict how I would update, I'd need to know more about how that worked out. I suppose it would probably push me toward shorter timelines, because it would suggest that "almost all work is easy" and RSI starts to really kick in earlier than my expectation.
4. Is this 10x milestone achievable just by scaling up existing approaches? My intuition is no. I think that milestone requires very capable AI (items 1+2 in this list). And I don't see current approaches delivering much progress on things I think will be needed for such capability, such as long-term memory, continuous learning, ability to "break out of the chatbox" and deal with open-ended information sources and extraneous information, or other factors that I mentioned in the original post.
I am very interested in discussing any or all of these questions further.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-07T02:49:39.778Z · LW(p) · GW(p)
Obviously you'd need to be able to automate at least 90% of what capabilities researchers do today.
Actually, I don't think so. AIs don't just substitute for human researchers, they can specialize differently. Suppose (for simplicity) there are 2 roughly equally good lines of research that can substitute (e.g. they create some fungible algorithmic progress) and capability researchers currently do 50% of each. Further, suppose that AIs can 30x accelerate the first line of research, but are worthless for the second. This could yield >10x acceleration via researchers just focusing on the first line of research (depending on how diminishing returns go).
This doesn't make a huge difference to my bottom line view, but it seems likely that this sort of change in specialization makes a 2x difference.
But 90% is a lot, you'll be pushing out into the long tail of tasks that require taste, subtle tacit knowledge, etc.
I think it could suffice to do a bunch of relatively more banal things extremely fast and cheap. In particular, it could suffice to do: software engineering, experiment babysitting, experiment debugging, optimization, improved experiment interpretation (e.g., trying to identify the important plots and considerations and presenting as concisely and effectively as possible), and generally checking experiment prior to launching them.
As an intution pump, imagine you had nearly free junior hires who run 10x faster and also work all hours. Because they are free, you can run tons of copies. I think this could pretty plausibly speed things up by 10x.
I have a personal suspicion that a surprisingly large fraction of work (possibly but not necessarily limited to "knowledge work") will turn out to be "AGI complete", meaning that it will require something approaching full AGI to undertake it at human level.
I'm not sure if I exactly disagree, but I do think there is a ton of variation in the human range such that I dispute the way you seem to use "AGI complete". I do think that the systems doing this acceleration will be quite general and capable and will be in some sense close to AGI. (Though less so if this occurs earlier like in my 20th percentile world.)
And I don't see current approaches delivering much progress on things I think will be needed for such capability, such as long-term memory, continuous learning, ability to "break out of the chatbox" and deal with open-ended information sources and extraneous information, or other factors that I mentioned in the original post.
Suppose a company specifically trained an AI system to be very familiar with its code base and infrastructure and relatively good at doing experiments for it. Then, it seems plausible that (with some misc schlep) the only needed context would be project specific context. It seems pretty plausible you can fit the context for tasks humans would do in a week into a 1 million token context window especially with some tweaks and some forking/sub-agents. And automating 1 week seems like it could suffice for big acceleration depending on various details. (Concretely, code is roughly 10 tokens per line, we might expect the AI to write <20k lines including revision, commands etc and to receive not much more than this amount of input. Books are maybe 150k tokens for reference, so the question is whether the AI needs over 6 books of context for 1 week for work. Currently, when AIs automate longer tasks they often do so via fewer steps than humans, spitting out the relevant outputs more directly, so I expect that the context needed for the AI is somewhat less.) Of course, it isn't clear that models will be able to use their context window as well as humans use longer term memory.
As far as continuous learning, what if the AI company does online training of their AI systems based on all internal usage[1]? (Online training = just RL train on all internal usage based on human ratings or other sources of feedback.) Is the concern that this will be too sample inefficent (even with proliferation or other hacks)? (I don't think it is obvious this goes either way but a binary "no continuous learning method is known" doesn't seem right to me.)
Confidentiality concerns might prevent training on literally all internal usage. ↩︎
↑ comment by snewman · 2025-01-07T03:34:05.698Z · LW(p) · GW(p)
Thanks for engaging so deeply on this!
AIs don't just substitute for human researchers, they can specialize differently. Suppose (for simplicity) there are 2 roughly equally good lines of research that can substitute (e.g. they create some fungible algorithmic progress) and capability researchers currently do 50% of each. Further, suppose that AIs can 30x accelerate the first line of research, but are worthless for the second. This could yield >10x acceleration via researchers just focusing on the first line of research (depending on how diminishing returns go).
Good point, this would have some impact.
As an intution pump, imagine you had nearly free junior hires who run 10x faster, but also work all hours. Because they are free, you can run tons of copies. I think this could pretty plausibly speed things up by 10x.
Wouldn't you drown in the overhead of generating tasks, evaluating the results, etc.? As a senior dev, I've had plenty of situations where junior devs were very helpful, but I've also had plenty of situations where it was more work for me to manage them than it would have been to do the job myself. These weren't incompetent people, they just didn't understand the situation well enough to make good choices and it wasn't easy to impart that understanding. And I don't think I've ever been sole tech lead for a team that was overall more than, say, 5x more productive than I am on my own – even when many of the people on the team were quite senior themselves. I can't imagine trying to farm out enough work to achieve 10x of my personal productivity. There's only so much you can delegate unless the system you're delegating to has the sort of taste, judgement, and contextual awareness that a junior hire more or less by definition does not. Also you might run into the issue I mentioned where the senior person in the center of all this is no longer getting their hands dirty enough to collect the input needed to drive their high-level intuition and do their high-value senior things.
Hmm, I suppose it's possible that AI R&D has a different flavor than what I'm used to. The software projects I've spent my career on are usually not very experimental in nature; the goal is generally not to learn whether an idea shows promise, it's to design and implement code to implement a feature spec, for integration into the production system. If a junior dev does a so-so job, I have to work with them to bring it up to a higher standard, because we don't want to incur the tech debt of integrating so-so code, we'd be paying for it for years. Maybe that plays out differently in AI R&D?
Incidentally, in this scenario, do you actually get to 10x the productivity of all your staff? Or do you just get to fire your junior staff? Seems like that depends on the distribution of staff levels today and on whether, in this world, junior staff can step up and productively manage AIs themselves.
Suppose a company specifically trained an AI system to be very familiar with its code base and infrastructure and relatively good at doing experiments for it. Then, it seems plausible that (with some misc schlep) the only needed context would be project specific context. ...
These are fascinating questions but beyond what I think I can usefully contribute to in the format of a discussion thread. I might reach out at some point to see whether you're open to discussing further. Ultimately I'm interested in developing a somewhat detailed model, with well-identified variables / assumptions that can be tested against reality.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-01-07T04:27:39.755Z · LW(p) · GW(p)
Wouldn't you drown in the overhead of generating tasks, evaluating the results, etc.? As a senior dev, I've had plenty of situations where junior devs were very helpful, but I've also had plenty of situations where it was more work for me to manage them than it would have been to do the job myself. These weren't incompetent people, they just didn't understand the situation well enough to make good choices and it wasn't easy to impart that understanding. And I don't think I've ever been sole tech lead for a team that was overall more than, say, 5x more productive than I am on my own – even when many of the people on the team were quite senior themselves. I can't imagine trying to farm out enough work to achieve 10x of my personal productivity. There's only so much you can delegate unless the system you're delegating to has the sort of taste, judgement, and contextual awareness that a junior hire more or less by definition does not. Also you might run into the issue I mentioned where the senior person in the center of all this is no longer getting their hands dirty enough to collect the input needed to drive their high-level intuition and do their high-value senior things.
I've had a pretty similar experience personally but:
- I think serial speed matters a lot and you'd be willing to go through a bunch more hassle if the junior devs worked 24/7 and at 10x speed.
- Quantity can be a quality of its own—if you have truely vast (parallel) quantities of labor, you can be much more demanding and picky. (And make junior devs do much more work to understand what is going on.)
- I do think the experimentation thing is probably somewhat big, but I'm uncertain.
- (This one is breaking with the junior dev analogy, but whatever.) In the AI case, you can train/instruct once and then fork many times. In the analogy, this would be like you spending 1 month training the junior dev (who still works 24/7 and at 10x speed, so 10 months for them) and then forking them into many instances. Of course, perhaps AI sample efficiency is lower. However, my personal guess is that lots of compute spent on learning and aggressive schlep (e.g. proliferation, lots of self-supervised learning, etc) can plausibly substantially reduce or possibly eliminate the gap (at least once AIs are more capable) similar to how it works for EfficientZero [LW · GW].
comment by snewman · 2025-01-08T01:03:27.557Z · LW(p) · GW(p)
Just posting to express my appreciation for the rich discussion. I see two broad topics emerging that seem worthy of systematic exploration:
- What does a world look like in which AI is accelerating the productivity of a team of knowledge workers by 2x? 10x? 50x? In each scenario, how is the team interacting with the AIs, what capabilities would the AIs need, what strengths would the person need? How do junior and senior team members fit into this transition? For what sorts of work would this work well / poorly?
- Validate this model against current practice, e.g. the ratio of junior vs. senior staff in effective organizations and how work is distributed across seniority.
- How does this play out specifically for AI R&D?
- Revisiting the questions from item 1.
- How does increased R&D team productivity affect progress: to what extent is compute a bottleneck, how could the R&D organization adjust activities in response to reduced cost of labor relative to compute, does this open an opportunity to explore more points in the architecture space, etc.
(This is just a very brief sketch of the questions to be explored.)
I'm planning to review the entire discussion here and try to distill it into an early exploration of these questions, which I'll then post, probably later this month.
comment by Muireall · 2025-01-06T22:49:23.395Z · LW(p) · GW(p)
I went through a similar exercise trying to develop key drivers and indicators for a couple slow scenarios back in May 2023, focusing on lessons from the semiconductor industry. I think my "slow" is even slower than yours, so it may not be super useful to you, but maybe you'll find it interesting.
Replies from: Muireall↑ comment by Muireall · 2025-01-07T17:24:47.781Z · LW(p) · GW(p)
I have a moment so I'll summarize some of my thinking here for the sake of discussion. It's a bit more fleshed out at the link. I don't say much about AI capabilities directly since that's better-covered by others.
In the first broad scenario, AI contributes to normal economic growth and social change. Key drivers limit the size and term of bets industry players are willing to make: [1A] the frontier is deeply specialized into a particular paradigm, [1B] AI research and production depend on lumpy capital projects, [1C] firms have difficulty capturing profits from training and running large models, and [1D] returns from scaling new methods are uncertain.
In the second, AI drives economic growth, but bottlenecks in the rest of the economy limit its transformative potential. Key drivers relate to how much AI can accelerate the non-AI inputs to AI research and production: [2A] limited generality of capabilities, [2B] limited headroom in capabilities, [2C] serial physical bottlenecks, and [2D] difficulty substituting theory for experiment.
Indicators (hypothetical observations that would lead us to expect these drivers to have more influence) include:
- Specialized methods, hardware, and infrastructure dominate those for general-purpose computing in AI. (+1A)
- Training and deployment use different specialized infrastructure. (+1A, +1B)
- Generic progress in the semiconductor industry only marginally advances AI hardware. (+1A)
- Conversely, advances in AI hardware are difficult to repurpose for the rest of the semiconductor industry. (+1A)
- Specialized hardware production is always scaling to meet demand. (+1A)
- Research progress is driven chiefly by what we learn from the largest and most expensive projects. (+1B, +1D, +2D)
- Open-source models and second-tier competitors lag the state of the art by around one large training run. (+1C, +1D)
- Small models can be cheaply trained once expensive models are proven, achieving results nearly as good at much lower cost. (+1C, +1D)
- Progress in capabilities at the frontier originates from small-scale experiments or theoretical developments several years prior, brought to scale at some expense and risk of failure, as is the status quo in hardware. (+1D, +2D)
- Progress in AI is very uneven or even nonmonotonic across domains—each faces different bottlenecks that are addressed individually. (+2A)
- Apparent technical wins are left on the table, because they only affect a fraction of performance and impose adoption costs on the entire system. (+1A, +2B, +2C)
- The semiconductor industry continues to fragment. (+2B)
- More broadly, semiconductor industry trends, particularly in cost and time (exponential and with diminishing returns), continue. (+2A, +2B, +2C)
- Semiconductor industry roadmaps are stable and continue to extend 10–15 years out. (+2C, +2D)
Negative indicators (indicating that these drivers have less influence) include
- The same hardware pushes the performance frontier not only for AI training and inference but also for high-performance computing more traditionally. (–1A)
- Emerging hardware technologies like exotic materials for neuromorphic computing successfully attach themselves as adjuncts to general-purpose silicon processes, giving themselves a self-sustaining route to scale. (–1A, –2B)
- Training runs use as much compute as they can afford; there's always a marginal stock of hardware that can be repurposed for AI as soon as AI applications become slightly more economical. (–1A, –1B)
- AI industry players engage in pre-competitive collaboration, for example setting interoperability standards or jointly funding the training of a shared foundation model. (–1B)
- Alternatively, early industry leaders establish monopolistic advantages over the rest of the field. (–1B, –1C)
- AI training becomes more continuous, rather than something one "pulls the trigger" on. Models see large benefits from "online" training as they're being used, as compared with progress from model to model. (–1B)
- Old models have staying power, perhaps being cheaper to run or tailored to niche applications. (–1C)
- Advances in AI at scale originate from experiments or theory with relatively little trouble applying them at scale within a few years, as is the status quo in software. (–1D, –2D)
- The leading edge features different AI paradigms or significant churn between methods. (–1A, –1D)
- The same general AI is broadly deployed in different domains, industry coordination is strong (through monopoly or standardization), and upgrades hit many domains together. (–2A)
- Evidence builds that a beyond-silicon computing paradigm could deliver performance beyond the roadmap for the next 15 years of silicon. (–2B)
- New semiconductor consortia arise, for example producing consensus chiplet or heterogeneous integration standards, making it easier for a fragmented industry to continue to build on one another's work. (–1A, –2C)
- Spatial/robotics problems in particular—proprioception, navigation, manipulation—are solved. (–2C)
- Fusion power becomes practical. (–2C)
- AI is applied to experimental design and yields markedly better results than modern methods. (–2B, –2D)
- AI research progress is driven by theory. (–1D, –2D)
- Breakthroughs make microscopic physical simulation orders of magnitude easier. Molecular dynamics, density functional theory, quantum simulation, and other foundational methods are accelerated by AI while also greatly improving accuracy. (–2B, –2C, –2D)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-06T21:41:16.998Z · LW(p) · GW(p)
breakthroughs, on the scale of transformers and reasoning models, and we only get one of those breakthroughs every few year
Seems like we get one of those every five years or so at least? Arguably more, since I'd say the idea that you should just massively scale up internet text prediction should also count as a similarly big breakthrough and it happened recently too.
So then why would it take till beyond 2035 to overcome those limitations?
↑ comment by LawrenceC (LawChan) · 2025-01-06T22:06:05.300Z · LW(p) · GW(p)
(Disclaimer: have not read the piece in full)
If “reasoning models” count as a breakthrough of the relevant size, then I argue that there’s been quite a few of these in the last 10 years: skip connections/residual stream (2015-ish), transformers instead of RNNs (2017), RLHF/modern policy gradient methods (2017ish), scaling hypothesis (2016-20 depending on the person and which paper), Chain of Thought (2022), massive MLP MoEs (2023-4), and now Reasoning RL training (2024).
Replies from: snewman↑ comment by snewman · 2025-01-06T22:20:57.260Z · LW(p) · GW(p)
See my response to Daniel (https://www.lesswrong.com/posts/auGYErf5QqiTihTsJ/what-indicators-should-we-watch-to-disambiguate-agi?commentId=WRJMsp2bZCBp5egvr). In brief: I won't defend my vague characterization of "breakthroughs" nor my handwavy estimates of how how many are needed to reach AGI, how often they occur, and how the rate of breakthroughs might evolve. I would love to see someone attempt a more rigorous analysis along these lines (I don't feel particularly qualified to do so). I wouldn't expect that to result in a precise figure for the arrival of AGI, but I would hope for it to add to the conversation.
↑ comment by snewman · 2025-01-06T22:14:21.310Z · LW(p) · GW(p)
This is my "slow scenario". Not sure whether it's clear that I meant the things I said here to lean pessimistic – I struggled with whether to clutter each scenario with a lot of "might" and "if things go quickly / slowly" and so forth.
In any case, you are absolutely correct that I am handwaving here, independent of whether I am attempting to wave in the general direction of my median prediction or something else. The same is true in other places, for instance when I argue that even in what I am dubbing a "fast scenario" AGI (as defined here) is at least four years away. Perhaps I should have added additional qualifiers in the handful of places where I mention specific calendar timelines.
What I am primarily hoping to contribute is a focus on specific(ish) qualitative changes that (I argue) will need to emerge in AI capabilities along the path to AGI. A lot of the discourse seems to treat capabilities as a scalar, one-dimensional variable, with the implication that we can project timelines by measuring the rate of increase in that variable. At this point I don't think that's the best framing, or at least not the only useful framing.
One hope I have is that others can step in and help construct better-grounded estimates on things I'm gesturing at, such as how many "breakthroughs" (a term I have notably not attempted to define) would be needed to reach AGI and how many we might expect per year. But I'd be satisfied if my only contribution would be that people start talking a bit less about benchmark scores and a bit more about the indicators I list toward the end of the post – or, even better, some improved set of indicators.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-06T23:04:01.355Z · LW(p) · GW(p)
That makes sense -- I should have mentioned, I like your post overall & agree with the thesis that we should be thinking about what short vs. long timelines worlds will look like and then thinking about what the early indicators will be, instead of simply looking at benchmark scores. & I like your slow vs. fast scenarios, I guess I just think the fast one is more likely. :)
comment by JBlack · 2025-01-07T03:51:09.406Z · LW(p) · GW(p)
In my reading, I agree that the "Slow" scenario is pretty much the slowest it could be, since it posits an AI winter starting right now and nothing beyond making better use of what we already have.
Your "Fast" scenario is comparable with my "median" scenario: we do continue to make progress, but at a slower rate than the last two years. We don't get AGI capable of being transformative in the next 3 years, despite going from somewhat comparable to a small child in late 2022 (though better in some narrow ways than an adult human) to better capabilities than average adult human in almost all respects in late 2024 (and better in some important capabilities than 99.9% of humans).
My "Fast" scenario is one in which internal deployment of AI models coming into existence in early-to-mid 2025 allow researchers to make large algorithmic and training improvements in the next generation (by late 2025) which definitely qualify as AGI. Those then assist to accelerate the pace of research with better understanding of how intelligence arises leading to major algorithmic and training improvements and indisputably superhuman ASI in 2026.
This Fast scenario's ASI may not be economically transformative by then, because human economies are slow to move. I wouldn't bet on 2027 being anything like 2026 in such a scenario, though.
I do have faster scenarios in mind too, but far more speculative. E.g. ones in which the models we're seeing now are already heavily sandbagging and actually superhuman, or in which other organizations have such models privately.
Replies from: snewman↑ comment by snewman · 2025-01-07T03:58:57.920Z · LW(p) · GW(p)
better capabilities than average adult human in almost all respects in late 2024
I see people say things like this, but I don't understand it at all. The average adult human can do all sorts of things that current AIs are hopeless at, such as planning a weekend getaway. Have you, literally you personally today, automated 90% of the things you do at your computer? If current AI has better capabilities than the average adult human, shouldn't it be able to do most of what you do? (Setting aside anything where you have special expertise, but we all spend big chunks of our day doing things where we don't have special expertise – replying to routine emails, for instance.)
FWIW, I touched on this in a recent blog post: https://amistrongeryet.substack.com/p/speed-and-distance.
Replies from: JBlack, JBlack↑ comment by JBlack · 2025-01-07T04:41:47.329Z · LW(p) · GW(p)
My description "better capabilities than average adult human in almost all respects", differs from "would be capable of running most people's lives better than they could". You appear to be taking these as synonymous.
The economically useful question is more along the lines of "what fraction of time taken on tasks could a business expect to be able to delegate to these agents for free vs a median human that they have to employ at socially acceptable wages" (taking into account supervision needs and other overheads in each case).
My guess is currently "more than half, probably not yet 80%". There are still plenty of tasks that a supervised 120 IQ human can do that current models can't. I do not think there will remain many tasks that a 100 IQ human can do with supervision that a current AI model cannot with the same degree of supervision, after adjusting processes to suit the differing strengths and weakness of each.
↑ comment by JBlack · 2025-01-07T04:20:55.624Z · LW(p) · GW(p)
Your test does not measure what you think it does. There are people smarter than me who I could not and would not trust to make decisions about me (or my computer) in my life. So no. (Also note, I am very much not of average capability, and likewise for most participants on LessWrong)
I am certain that you also would not take a random person in the world of median capability and get them to do 90% of the things you do with your computer for you, even for free. Not without a lot of screening and extensive training and probably not even then.
However, it would not take much better reliability for other people to create economically valuable niches for AIs with such capability. It would take quite a long time, but even with zero increases in capability I think AI would be eventually be a major economic factor replacing human labour. Not quite transformative, but close.
comment by deepthoughtlife · 2025-01-06T23:39:23.580Z · LW(p) · GW(p)
Note: I wrote my comment while reading as notes to see what I thought of your arguments while reading more than as a polished thing.
I think your calibration on the 'slow scenario' is off. What you claim is the slowest plausible one is fairly clearly the median scenario given that it is pretty much just following current trends, and slower than present trend is clearly plausible. Things already slowed way down, with advancements in very narrow areas being the only real change. There is a reason that OpenAI hasn't dared even name something GPT 5, for instance. Even 03 isn't really an improvement on general llm duties and that is the 'exciting' new thing, as you pretty much say.
Advancement is disappointingly slow in AI that I personally use (mostly image generation, where new larger models are often not really better overall for the past year or so, and newer ones mostly use llm style architectures), for instance, and it is plausible that there will be barely any movement in terms of clear quality improvement in general uses over the next couple years. And image generation should be easier to improve than general llms because it should be earlier in the diminishing returns of scale (as the scale is much smaller). Note that since most are also diffusion models, they are already using an image equivalent of the trick o1 and o3 introduced with what I would argue is effectively chain of thought. For some reason, all the advancements I hear about these days seem like uninspired copies of things that already happened in image generation.
The one exception is 'agents' but those show no signs of present day usefulness. Who knows how quickly such things will become useful, but historical trends on new tech, especially in AI, say 'not soon' for real use. A lot of people and companies are very interested in the idea for obvious reasons, but that doesn't mean it will be fast. See also self-driving cars which has taken many times longer than expected, despite seeming like it is probably a success story in the making (for the distant future). In fact, self-driving cars are the real world equivalent of a narrow agent, and the insane difficulty they are having is strong evidence against agents being a transformatively useful thing soon.
I do think that AI as it currently is will have a transformative impact in the near term for certain activities (image generation for non-artists like me is already one of them), but I think the smartphone comparison is a good one; I still don't bother to use a smartphone (though it has many significant uses). I would be surprised if it had as big an impact as the worldwide web has on a year for year basis counting from the beginning of the www (supposedly in 1989) for that and 2014 when transformers were invented (or even 2018 when GPT1 became a thing) for AI, for instance. I like the comparison to the web because I think that AI going especially well would be a change to our information capacities similar to an internet 3.0. (Assuming you count the web as 2.0).
As to the fast scenario, that does seem like the fastest scenario that isn't completely ridiculous, but think that your belief in its probability is dramatically too high. I do agree that if you believe that self-play (in the AlphaGo sense) to generate good data is doable for poorly definable problems that would alleviate the lack of data issues we suffer in large parts of the space, but it is unlikely that would actually improve the quality of the data in the near term, and there are already a lot of data quality issues. I personally do not believe that o1 and o3 have at all 'shown' that synthetic data is a solved issue, and it wouldn't be for quite a while if ever.
Note that the image generation models already have been using synthetic data by teachers for a while now with 'SDXL Turbo' and other later adversarial distillation schemes. This did manage a several times speed boost, but at a cost of some quality, as all such schemes do. Crucially, no one has managed to increase quality this way, because the 'teacher' provides a maximum quality level you can't go beyond (except by pure luck).
Speculatively, you could perhaps improve quality by having a third model selecting the absolute best outputs of the teacher and only training on those until you have something better than the teacher, and then switching 'better than the teacher' into teacher and automatically start training a new student (or perhaps retraining the old teacher?). The problem is, how do you get that selection model that is actually better than the things you are trying to improve in its own self-play style learning rather than just getting them to fit the static model of a good output? Human data creation cannot be replaced in general without massive advancements in the field. You might be able to switch human data generation to just training the selection model though.
In some areas, you could perhaps train the AI directly on automatically generated data from sensors in the real world, but that seems like it would reduce the speed of progress to that of the real world unless you have that exponential increase in sensor data instead.
I do agree that in a fast scenario, it would clearly be algorithmic improvements rather than scale leading to it.
Also, o1 and o3 are only 'better' because of a willingness to use immensely more compute in the inference stage, and given that people already can't afford them, that route seems like a it will be played out after not too many generations of scaling, especially since hardware is improving so slowly these days. Chain of thought should probably be largely replaced with something more like what image generation models currently use where each step iterates on the current results. These could be combined together of course.
Diffusion models make a latent picture of a bunch of different areas, and each of those influences each other area in the future, so in text generation you could analogously have a chain of thought that is used in its entirety to create a new chain of thought. For example, you could use a ten deep chain of thought being used to create another ten deep chain of thought nine times instead of a hundred different options (with the first ten being generated by just the input of course). If you're crazy, it could literally be exponential, where you generate one for the first step, two in the second... 32 in the fifth, and so on.
"Identifying The Requirements for a Short Timeline"
I think you are missing an interesting way to tell if AI is accelerating AI research. A lot of normal research is eventually integrated into the next generation of products. If AI really was accelerating the process, you would see the integrations happening much more quickly, with a shorter lag time between 'new idea first published' and 'new idea integrated into a fully formed product' that is actually good. A human might take several months to test the idea, but if an AI could do the research, it could also replicate the other research incredibly quickly, and see how it works when combined with the other research.
(Ran out of steam when my computer crashed during the above paragraph, though I don't seem to have lost any of what I wrote since I do it in notepad.)
I would say the best way to tell you are in a shorter timeline is if it seems like gains from each advancement start broadening rather than narrowing. If each advancement applies narrowly, you need a truly absurd number of advancements, but if they are broad, far fewer.
Honestly, I see very little likelihood of what I consider AGI in the next couple decades at least (at least if you want it to have surpassed humanity), and if we don't break out of the current paradigm, not for much, much longer than that, if ever. You do have some interesting points, and seem reasonable, but I really can't agree with the idea that we are at all close to it. Also, your fast scenario seems more like it would be 20 years than 4. 4 years isn't the 'fast' scenario, it is the 'miracle' scenario. The 'slow scenario' reads like 'this might be the work of centuries, or maybe half of one if we are lucky'. The strong disagreement on how long these scenarios would take is because the point we are at now is far, far below what you seem to believe. We aren't even vaguely close.
As far as your writing goes, I think it was fairly well written structurally and was somewhat interesting, and I even agree that large parts of the 'fast' scenario as you laid it out make sense, but since you are wrong about the amount of time to associate with the scenarios, the overall analysis is very far off. I did find it to be worth my time to read.
comment by tin482 · 2025-01-09T13:59:45.294Z · LW(p) · GW(p)
I think the best argument for a "fastest-er" timeline would be that several of your bottlenecks end up heavily substituting against each other or some common factor. A researcher in NLP in 2015 might reasonably have guessed it'd take decades to reach the level of ChatGPT - after all, it would require breakthroughs in parsing, entailment, word sense, semantics, world knowledge... In reality these capabilities were all blessings of scale.
o1 may or may not be the central breakthrough in this scenario, but I can paint a world where it is, and that world is very fast indeed. RL, like next word prediction, is "mechanism agnostic" - it induces whatever capabilities are instrumental to maximizing reward. Already, "back-tracking" or "error-correcting" behavior has emerged, previously cited by LeCun and others as a fundamental block. In this world RL applied to "Chains of Action" strongly induces agentic structures like adaptability, tool use, note caching, goal-directedness, and coherence. Gradient descent successfully routes around any weaknesses in LLMs (as I suspect it does for weaknesses in our LLM training pipelines today). By the time we reach the same engineering effort in post-training that we've dedicated to pretraining, it's AGI. Well, given the scale of OpenAI's investment, we should be able to rule on this scenario pretty quickly.
I'd say I'm skeptical of the specifics (RL hasn't demonstrated this kind of rich success in the past) but more uncertain about the outline (How well could e.g. fast adaptation trade off against multimodality, gullibility, coherence?)
comment by Logan Zoellner (logan-zoellner) · 2025-02-21T13:13:17.064Z · LW(p) · GW(p)
I’ll now present the fastest scenario for AI progress that I can articulate with a straight face. It addresses the potential challenges that figured into my slow scenario.
This seems incredibly slow for "the fastest scenario you can articulate". Surely the fastest is more like:
EY is right, there is an incredibly simple algorithm that describes true 'intelligence'. Like humans, this algorithm is 1000x more data and compute efficient than existing deep-learning networks. On midnight of day X, this algorithm is discovered by <a person/an LLM/an exhaustive search over all possible algorithms>. By 0200 of day X, the algorithm has reached the intelligence of a human being. It quickly snowballs by earning money on Mechanical Turk and using that money to rent out GPUs on AWS. By 0400 the algorithm has cracked nanotechnology and begins converting life into computronium. Several minutes later, life as we know it on Earth has ceased to exist.
Replies from: snewmancomment by Erich_Grunewald · 2025-01-08T23:39:25.110Z · LW(p) · GW(p)
Thanks for writing this -- it's very concrete and interesting.
Have you thought about using company market caps as an indicator of AGI nearness? I would guess that an AI index -- maybe NVIDIA, Alphabet, Meta, and Microsoft -- would look really significantly different in the two scenarios you paint. To control for general economic conditions, you could look at the those companies relative to the NASDAQ-100 (minus AI companies). An advantage of this is that it tracks a lot of different indicators, including ones that are really fuzzy or hard to discover, through the medium of market speculators. Another advantage is that it is a clear and easily measurable quantity. That makes it easy to make bets and create prediction markets around it.
Of course, there is weirdness around how we should expect the market to behave in the run-up to AGI, where wealth may become less relevant, etc. But I'd still expect the market to be significantly more bullish on AI stocks in the run-up to AGI, than in an AI fizzle/winter scenario.