Bayesian Networks Aren't Necessarily Causal
post by Zack_M_Davis · 2023-05-14T01:42:24.319Z · LW · GW · 38 commentsContents
39 comments
As a casual formal epistemology fan, you've probably heard that the philosophical notion of causality can be formalized in terms of Bayesian networks [LW · GW]—but also as a casual formal epistemology fan, you also probably don't [LW · GW] know the details all that well.
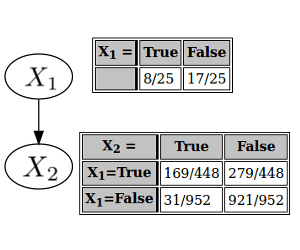
One day, while going through the family archives, you come across a meticulously maintained dataset describing a joint probability distribution over four variables: whether it rained that day, whether the sprinkler was on, whether the sidewalk was wet, and whether the sidewalk was slippery. The distribution is specified in this table (using the abbreviated labels "rain", "slippery", "sprinkler", and "wet"):
(You wonder what happened that one day out of 140,000 when it rained, and the sprinkler was on, and the sidewalk was slippery but not wet. Did—did someone put a tarp up to keep the sidewalk dry, but also spill slippery oil, which didn't count as being relevantly "wet"? Also, 140,000 days is more than 383 years—were "sprinklers" even a thing in the year 1640 C.E.? You quickly put these questions out of your mind: it is not your place to question the correctness of the family archives.)
You're slightly uncomfortable with this unwieldy sixteen-row table. You think that there must be some other way to represent the same information, while making it clearer that it's not a coincidence that rain and wet sidewalks tend to co-occur.
You've read that Bayesian networks "factorize" an unwieldly joint probability distribution into a number of more compact conditional probability distributions, related by a directed acyclic graph, where the arrows point from "cause" to "effect". (Even a casual formal epistemology fan knows that much.) The graph represents knowledge that each variable is conditionally independent of its non-descendants given its parents, which enables "local" computations: given the values of just a variable's parents in the graph, we can compute a conditional distribution for that variable, without needing to consider what is known about other variables elsewhere in the graph ...
You've read that, but you've never actually done it before! You decide that constructing a Bayesian network to represent this distribution will be a useful exercise.
To start, you re-label the variables for brevity. (On a whim, you assign indices in reverse-alphabetical order: = wet, = sprinkler, = slippery, = rain.)
Now, how do you go about building a Bayesian network? As a casual formal epistemology fan, you are proud to own a copy of the book by Daphne Koller and the other guy, which explains how to do this in—you leaf through the pages—probably §3.4, "From Distributions to Graphs"?—looks like ... here, in Algorithm 3.2. It says to start with an empty graph, and it talks about random variables, and setting directed edges in the graph, and you know from chapter 2 that the ⟂ and | characters are used to indicate conditional independence. That has to be it.

(As a casual formal epistemology fan, you haven't actually read chapter 3 up through §3.4, but you don't see why that would be necessary, since this Algorithm 3.2 pseudocode is telling you what you need to do.)
It looks like the algorithm says to pick a variable, allocate a graph node to represent it, find the smallest subset of the previously-allocated variables such that the variable represented by the new node is conditionally independent of the other previously-allocated variables given that subset, and then draw directed edges from each of the nodes in the subset to the new node?—and keep doing that for each variable—and then compute conditional probability tables for each variable given its parents in the resulting graph?
That seems complicated when you say it abstractly, but you have faith that it will make more sense as you carry out the computations.
First, you allocate a graph node for . It doesn't have any parents, so the associated conditional ("conditional") probability distribution, is really just the marginal distribution for .

Then you allocate a node for . is not independent of . (Because = 169/1400, which isn't the same as = 8/25 · 1/7 = 8/175.) So you make a parent of , and your conditional probability table for separately specifies the probabilities of being true or false, depending on whether is true or false.
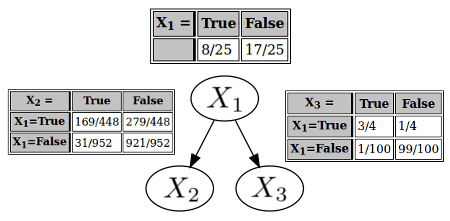
Next is . Now that you have two possible parents, you need to check whether conditioning on either of and would render conditionally independent of the other. If not, then both and will be parents of ; if so, then the variable you conditioned on will be the sole parent. (You assume that the case where is just independent from both and does not pertain; if that were true, wouldn't be connected to the rest of the graph at all.)
It turns out that and are conditionally independent given . That is, . (Because the left-hand side is , and the right-hand side is .) So is a parent of , and isn't; you draw an arrow from (and only ) to , and compile the corresponding conditional probability table.
Finally, you have . The chore of finding the parents is starting to feel more intuitive now. Out of the possible subsets of the preceding variables, you need to find the smallest subset, such that conditioning on that subset renders (conditionally) independent of the variables not in that subset. After some calculations that the authors of expository blog posts have sometimes been known to callously leave as an exercise to the reader, you determine that and are the parents of .
And with one more conditional probability table, your Bayesian network is complete!
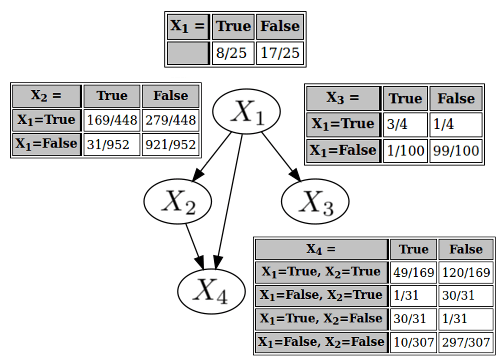
Eager to interpret the meaning of this structure regarding the philosophy of causality, you translate the variable labels back to English:
...
This can't be right. The arrow from "wet" to "slippery" seems fine. But all the others are clearly absurd. Wet sidewalks cause rain? Sprinklers cause rain? Wet sidewalks cause the sprinkler to be on?
You despair. You thought you had understood the algorithm. You can't find any errors in your calculations—but surely there must be some? What did you do wrong?
After some thought, it becomes clear that it wasn't just a calculation error: the procedure you were trying to carry out couldn't have given you the result you expected, because it never draws arrows from later-considered to earlier-considered variables. You considered "wet" first. You considered "rain" last, and then did independence tests to decide whether or not to draw arrows from "wet" (or "sprinkler" or "slippery") to "rain". An arrow from "rain" to "wet" was never a possibility. The output of the algorithm is sensitive to the ordering of the variables.
(In retrospect, that probably explains the "given an ordering" part of Algorithm 3.2's title, "Procedure to build a minimal I-map given an ordering." You hadn't read up through the part of chapter 3 that presumably explains what an "I-map" is, and had disregarded the title as probably unimportant.)
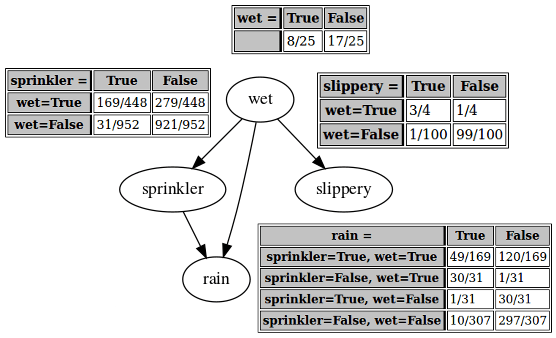
You try carrying out the algorithm with the ordering "rain", "sprinkler", "wet", "slippery" (or , , , using your labels from before), and get this network:
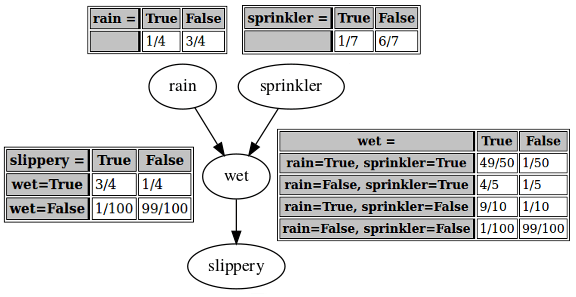
—for which giving the arrows a causal interpretation seems much more reasonable.
You notice that you are very confused. The "crazy" network you originally derived, and this "true" network derived from a more intuitively causal variable ordering, are different: they don't have the same structure, and (except for the wet → slippery link) they don't have the same conditional probability tables. You would assume that they can't "both be right". If the network output by the algorithm depends on what variable ordering you use, how are you supposed to know which ordering is correct? In this example, you know from reasons outside the math, that "wet" shouldn't cause "rain", but you couldn't count on that were you to apply these methods to problems further removed from intuition.
Playing with both networks, you discover that despite their different appearances, they both seem to give the same results when you use them to calculate marginal or conditional probabilities. For example, in the "true" network, is 1/4 (read directly from the "conditional" probability table, as "rain" has no parents in the graph). In the "crazy" network, the probability of rain can be computed as
... which also equals 1/4.
That actually makes sense. You were wrong to suppose that the two networks couldn't "both be right". They are both right; they both represent the same joint distribution. The result of the algorithm for constructing a Bayesian network—or a "minimal I-map", whatever that is—depends on the given variable ordering, but since the algorithm is valid, each of the different possible results is also valid.
But if the "crazy" network and the "true" network are both right, what happened to the promise of understanding causality using Bayesian networks?! (You may only be a casual formal epistemology fan, but you remember reading a variety of secondary sources unanimously agreeing that this was a thing; you're definitely not misremembering or making it up.) If both networks give the same answers to marginal and conditional probability queries, that amounts to them making the same predictions about the world. So if beliefs are supposed to correspond to predictions, in what sense could the "true" network be better? What does your conviction that rain causes wetness even mean, if someone who believed the opposite could make all the same predictions?
You remember the secondary sources talking about interventions on causal graphs: severing a node from its parents and forcing it to take a particular value. And the "crazy" network and the "true" network do differ with respect to that operation: in the "true" network, setting "wet" to be false—you again imagine putting a tarp up over the sidewalk—wouldn't change the probability of "rain". But in the "crazy" network, forcing "wet" to be false would change the probability of rain—to , which is (greatly reduced from the 1/4 you calculated a moment ago). Notably, this intervention—, if you're remembering correctly what some of the secondary sources said about a do operator—isn't the same thing as the conditional probability .
This would seem to satisfy your need for a sense in which the "true" network is "better" than the "crazy" network, even if Algorithm 3.2 indifferently produces either depending on the ordering it was given. (You're sure that Daphne Koller and the other guy have more to say about other algorithms that can make finer distinctions, but this feels like enough studying for one day—and enough for one expository blog post, if someone was writing one about your inquiries. You're a casual formal epistemology fan.) The two networks represent the same predictions about the world recorded in your family archives, but starkly different predictions about nearby possible worlds—about what would happen if some of the factors underlying the world were to change.
You feel a slight philosophical discomfort about this. You don't like the idea of forced change, of intervention, being so integral to such a seemingly basic notion as causality. It feels almost anthropomorphic: you want the notion of cause and effect within a system to make sense without reference to the intervention of some outside agent—for there's nothing outside of the universe. But whether this intuition is a clue towards deeper insights, or just a place where your brain has tripped on itself and gotten confused, it's more than you understand now.
38 comments
Comments sorted by top scores.
comment by johnswentworth · 2023-05-14T02:25:58.335Z · LW(p) · GW(p)
First crucial point which this post is missing: the first (intuitively wrong) net reconstructed represents the probabilities using 9 parameters (i.e. the nine rows of the various truth tables), whereas the second (intuitively right) represents the probabilities using 8. That means the second model uses fewer bits; the distribution is more compressed by the model. So the "true" network is favored even before we get into interventions.
Implication of this for causal epistemics: we have two models which make the same predictions on-distribution, and only make different predictions under interventions. Yet, even without actually observing any interventions, we do have reason to epistemically favor one model over the other.
Second crucial point which this post is missing: the way we use causal models in practice, in the sciences, is that we have some model with a few variables in it, and then that model is applied to many physical "instances" of the real-world phenomenon it describes - e.g. many physical instances of a certain experiment being run. Causality is useful mainly insofar as different instances can be compactly described as different simple interventions on the same Bayes net. For instance, in the sprinkler system, some days the sprinkler is in fact turned off, or there's a tarp up, or what have you, and then the system is well-modeled by a simple intervention. That doesn't require some ontologically-special "outside agent".
Replies from: localdeity, david-johnston, LGS, tailcalled, Caspar42↑ comment by localdeity · 2023-05-14T16:19:56.174Z · LW(p) · GW(p)
First crucial point which this post is missing: the first (intuitively wrong) net reconstructed represents the probabilities using 9 parameters (i.e. the nine rows of the various truth tables), whereas the second (intuitively right) represents the probabilities using 8. That means the second model uses fewer bits; the distribution is more compressed by the model. So the "true" network is favored even before we get into interventions.
Is this always going to be the case? I feel like the answer is "not always", but I have no empirical data or theoretical argument here.
Replies from: johnswentworth, Zack_M_Davis↑ comment by johnswentworth · 2023-05-21T06:11:38.743Z · LW(p) · GW(p)
I've tried this before experimentally - i.e. code up a gaussian distribution with a graph structure, then check how well different graph structures compress the distribution. Modulo equivalent graph structures (e.g. A -> B -> C vs A <- B <- C vs A <- B -> C), the true structure is pretty consistently favored.
Replies from: tailcalled, adele-lopez-1↑ comment by tailcalled · 2023-05-21T11:19:21.902Z · LW(p) · GW(p)
I don't think this is much better than just linking up variables to each other if they are strongly correlated (at least in ways not explained by existing links)?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-21T18:05:36.744Z · LW(p) · GW(p)
Just that does usually work pretty well for (at least a rough estimate of) the undirected graph structure, but then you don't know the directions of any arrows.
Replies from: tailcalled↑ comment by tailcalled · 2023-05-21T19:13:13.606Z · LW(p) · GW(p)
I think this approach only gets the direction of the arrows from two structures, which I'll call colliders and instrumental variables (because that's what they are usually called).
Colliders are the case of A -> B <- C, which in terms of correlations shows up as A and B being correlated, B and C being correlated, and A and C being independent. This is a distinct pattern of correlations from the A -> B -> C or A <- B -> C structures where all three could be correlated, so it is possible for this method to distinguish the structures (well, sometimes not, but that's tangential to my point).
Instrumental variables are the case of A -> B -> C, where A -> B is known but the direction of B - C is unknown. In that case, the fact that C correlates with A suggests that B -> C rather than B <- C.
I think the main advantage larger causal networks give you is that they give you more opportunities to apply these structures?
But I see two issues with them. First, they don't see to work very well in nondeterministic cases. They both rely on the correlation between A and C, and they both need to distinguish whether that correlation is 0 or (where and refer to the effects A - B and B - C) respectively. If the effects in your causal network are of order , then you are basically trying to distinguish something of order 0 from something of order , which is likely going to be hard if is small. (The smaller of a difference you are trying to detect, the more affected you are going to be by model misspecification, unobserved confounders, measurement error, etc..) This is not a problem in Zack's case because his effects are near-deterministic, but it would be a problem in other cases. (I in particularly have various social science applications in mind.)
Secondly, Zack's example had an advantage that multiple root causes of wet sidewalks were measured. This gave him a collider to kick off the inference process. (Though I actually suspect this to be unrealistic - wouldn't you be less likely to turn on the sprinkler if it's raining? But that relationship would be much less deterministic, so I suspect that's OK in this case where it's less deterministic.) But this seems very much like a luxury that often doesn't occur in the practical cases where I've seen people attempt to apply this. (Again various social science applications.)
↑ comment by Adele Lopez (adele-lopez-1) · 2023-05-21T07:45:39.050Z · LW(p) · GW(p)
Do you know exactly how strongly it favors the true (or equivalent) structure?
Replies from: johnswentworth, johnswentworth↑ comment by johnswentworth · 2023-05-21T19:06:37.075Z · LW(p) · GW(p)
There's an asymmetry between local differences from the true model which can't match the true distribution (typically too few edges) and differences which can (typically too many edges). The former get about O(n) bits against them per local difference from the true model, the latter about O(log(n)), as the number of data points n grows.
Conceptually, the story for the log(n) scaling is: with n data points, we can typically estimate each parameter to ~log(n) bit precision. So, an extra parameter costs ~log(n) bits.
↑ comment by johnswentworth · 2023-05-21T18:18:19.285Z · LW(p) · GW(p)
↑ comment by Zack_M_Davis · 2023-05-15T05:23:49.318Z · LW(p) · GW(p)
I mean, it's true as a special case of minimum description length epistemology [LW · GW] favoring simpler models. Chapter 18 of the Koller and Friedman book has a section about the Bayesian score for model comparison, which has a positive term involving the mutual information between variables and their parents (rewarding "fit"), and a negative term for the number of parameters (penalizing complexity).
What's less clear to me (Wentworth likely knows more) is how closely that kind of formal model comparison corresponds to my intuitive sense of causality. The first network in this post intuitively feels very wrong—two backwards arrows and one spurious arrow—out of proportion to its complexity burden of one measly extra parameter. (Maybe the disparity scales up with non-tiny examples, though?)
Replies from: johnswentworth↑ comment by johnswentworth · 2023-05-21T06:07:14.401Z · LW(p) · GW(p)
(Maybe the disparity scales up with non-tiny examples, though?)
Yup, that's right.
↑ comment by David Johnston (david-johnston) · 2023-05-14T06:31:40.220Z · LW(p) · GW(p)
I have a paper (planning to get it on arxiv any day now…) which contains a result: independence of causal mechanisms (which can be related to Occam’s razor & your first point here) + precedent (“things I can do have been done before”) + variety (related to your second point - we’ve observed the phenomena in a meaningfully varied range of circumstances) + conditional independence (which OP used to construct the Bayes net) implies a conditional distribution invariant under action.
That is, speaking very loosely, if you add your considerations to OPs recipe for Bayes nets and the assumption of precedent, you can derive something kinda like interventions.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2024-07-01T09:49:17.572Z · LW(p) · GW(p)
Did you put this paper anywhere? I didn't find anything on arXiv meeting the description.
↑ comment by LGS · 2023-08-08T04:02:21.592Z · LW(p) · GW(p)
Suppose we rename the above variables as follows: is "camping" instead of "wet", is "swimming" instead of "sprinkler", is "smores" instead of "slippery", and is "tired" instead of "rain".
Then the joint distribution is just as plausible with these variable names, yet the first model is now correct, and the lower-parameter, "fewer bits" model you advocate for is wrong: it will now say that "tired" and "swimming" cause "camping".
The number of "instances" in question should not matter here. I disagree with your comment pretty thoroughly.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-08-08T05:00:29.655Z · LW(p) · GW(p)
Indeed, it does often happen that an incorrect model is assigned higher prior probability, because that incorrect model is simpler. The usual expectation, in such cases, is that the true model will quickly win out once one starts updating on data. In your example, when updating on data, one would presumably find that e.g. "tired" and "swimming" are not independent, and their empirical correlation (in the data) can therefore be accounted for by the "more complex" (lower prior) model, but not by the "simpler" (higher prior) model.
Replies from: LGS↑ comment by LGS · 2023-08-09T02:19:15.607Z · LW(p) · GW(p)
Tired and swimming are not independent, but that's a correlational error. You can indeed get a more accurate picture of the correlations, given more evidence, but you cannot conclude causational structure from correlations alone.
How about this: would any amount of observation ever cause one to conclude that camping causes swimming rather than the reverse? The answer is clearly no: they are correlated, but there's no way to use the correlation between them (or their relationships to any other variables) to distinguish between swimming causing camping and camping causing swimming.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-08-09T02:31:52.269Z · LW(p) · GW(p)
You can indeed get a more accurate picture of the correlations, given more evidence, but you cannot conclude causational structure from correlations alone.
How about this: would any amount of observation ever cause one to conclude that camping causes swimming rather than the reverse?
You can totally conclude causational structure from correlations alone, it just requires observing more variables. Judea Pearl is the canonical source on the topic (Causality for the full thing, Book of Why or Causal Inference In Statistics for intros written for broader audiences); Yudkowsky also has a good intro here [LW · GW] which cuts right to the chase.
Replies from: LGS, Richard_Kennaway↑ comment by LGS · 2023-08-09T05:42:20.925Z · LW(p) · GW(p)
Thanks for linking to Yudkowsky's post (though it's a far cry from cutting to the chase... I skipped a lot of superfluous text in my skim). It did change my mind a bit, and I see where you're coming from. I still disagree that it's of much practical relevance: in many cases, no matter how many more variables you observe, you'll never conclude the true causational structure. That's because it strongly matters which additional variables you'll observe.
Let me rephrase Yudkowsky's point (and I assume also your point) like this. We want to know if swimming causes camping, or if camping causes swimming. Right now we know only that they correlate. But if we find another variable that correlates with swimming and is independent camping, that would be evidence towards "camping causes swimming". For example, if swimming happens on Tuesdays but camping is independent of Tuesdays, it's suggestive that camping causes swimming (because if swimming caused camping, you'd expect the Tuesday/swimming correlation to induce a Tuesday/camping correlation).
First, I admit that this is a neat observation that I haven't fully appreciated or knew how to articulate before reading the article. So thanks for that. It's food for thought.
Having said that, there are still a lot of problems with this story:
- First, unnatural variables are bad: I can always take something like "an indicator variable for camping, except if swimming is present, negate this indicator with probability p". This variable, call it X, can be made to be uncorrelated with swimming by picking p correctly, yet it will be correlated with camping; hence, by adding it, I can cause the model to say swimming causes camping. (I think I can even make the variable independent of swimming instead of just uncorrelated, but I didn't check.) So to trust this model, I'd either need some assumption that the variables are somehow "natural". Not cherry-picked, not handed to me by some untrusted source with stake in the matter.
- In practice, it can be hard to find any good variables that correlate with one thing but not the other. For example, suppose you're trying to establish "lead exposure in gestation causes low IQ". Good luck trying to find something natural that correlates with low neonatal IQ but not with lead; everything will be downstream of SES. And you don't get to add SES to your model, because you never observe it directly!
- More generally, real life has these correlational clusters, these "positive manifolds" of everything-correlating-with-everything. Like, consumption of all "healthy" foods correlates together, and also correlates with exercise, and also with not being overweight, and also with longevity, etc. In such a world, adding more variables will just never disentangle the causational structure at all, because you never find yourself adding a variable that's correlated with one thing but not another.
↑ comment by johnswentworth · 2023-08-09T15:21:22.986Z · LW(p) · GW(p)
Problem 1 is mostly handled automagically by doing Bayesian inference to choose our model. The key thing to notice is that the "unnatural" variable's construction requires that we know what value to give p, which is something we'd typically have to learn from the data itself. Which means, before seeing the data, that particular value of p would typically have low prior. Furthermore, as more data lets us estimate things more precisely, we'd have to make p more precise in order to keep perfectly negating things, and p-to-within-precision has lower and lower prior as the precision gets smaller. (Though there will be cases where we expect a priori for parameters to take on values which make the causal structure ambiguous - agentic systems under selection pressure are a central example, and that's one of the things which make agentic systems particularly interesting to study.)
Problems 2-3 are mostly handled by building models of a whole bunch of variables at once. We're not just looking for e.g. a single variable which correlates with low neonatal IQ but not with lead. Slightly more generally, for instance, a combination of variables which correlates with low neonatal IQ but not with lead, conditional on some other variables, would suffice (assuming we correctly account for multiple hypothesis testing). And the "conditional on some other variables" part could, in principle, account for SES, insofar as we use enough variables to basically determine SES to precision sufficient for our purposes.
More generally than that: once we've accepted that correlational data can basically power Bayesian inference of causality, we can in-principle just do Bayesian inference on everything at once, and account for all the evidence about causality which the data provides - some of which will be variables that correlate with one thing but not the other, but some of which will be other stuff than that (like e.g. Markov blankets informing graph structure, or two independent variables becoming dependent when conditioning on a third). Variables which correlate with one thing but not the other are just one particularly-intuitive small-system example of the kind of evidence we can get about causal structure.
(Also I strong-upvoted your comment for rapid updating, kudos.)
Replies from: LGS↑ comment by LGS · 2023-08-09T17:25:17.020Z · LW(p) · GW(p)
I don't think problem 1 is so easy to handle. It's true that I'll have a hard time finding a variable that's perfectly independent of swimming but correlated with camping. However, I don't need to be perfect to trick your model.
Suppose every 4th of July, you go camping at one particular spot that does not have a lake. Then we observe that July 4th correlates with camping but does not correlate with swimming (or even negatively correlates with swimming). The model updates towards swimming causing camping. Getting more data on these variables only reinforces the swimming->camping direction.
To update in the other direction, you need to find a variable that correlates with swimming but not with camping. But what if you never find one? What if there's no simple thing that causes swimming. Say I go swimming based on the roll of a die, but you don't get to ever see the die. Then you're toast!
Slightly more generally, for instance, a combination of variables which correlates with low neonatal IQ but not with lead, conditional on some other variables, would suffice (assuming we correctly account for multiple hypothesis testing). And the "conditional on some other variables" part could, in principle, account for SES, insofar as we use enough variables to basically determine SES to precision sufficient for our purposes.
Oh, sure, I get that, but I don't think you'll manage to do this, in practice. Like, go ahead and prove me wrong, I guess? Is there a paper that does this for anything I care about? (E.g. exercise and overweight, or lead and IQ, or anything else of note). Ideally I'd get to download the data and check if the results are robust to deleting a variable or to duplicating a variable (when duplicating, I'll add noise so that they variables aren't exactly identical).
If you prefer, I can try to come up with artificial data for the lead/IQ thing in which I generate all variables to be downstream of non-observed SES but in which IQ is also slightly downstream of lead (and other things are slightly downstream of other things in a randomly chosen graph). I'll then let you run your favorite algorithm on it. What's your favorite algorithm, by the way? What's been mentioned so far sounds like it should take exponential time (e.g. enumerating over all ordering of the variables, drawing the Bayes net given the ordering, and then picking the one with fewest parameters -- that takes exponential time).
Replies from: johnswentworth↑ comment by johnswentworth · 2023-08-10T15:52:56.874Z · LW(p) · GW(p)
(This is getting into the weeds enough that I can't address the points very quickly anymore, they'd require longer responses, but I'm leaving a minor note about this part:
Suppose every 4th of July, you go camping at one particular spot that does not have a lake. Then we observe that July 4th correlates with camping but does not correlate with swimming (or even negatively correlates with swimming).
For purposes of causality, negative correlation is the same as positive. The only distinction we care about, there, is zero or nonzero correlation.)
Replies from: LGS↑ comment by LGS · 2023-08-10T18:49:35.900Z · LW(p) · GW(p)
For purposes of causality, negative correlation is the same as positive. The only distinction we care about, there, is zero or nonzero correlation.)
That makes sense. I was wrong to emphasize the "even negatively", and should instead stick to something like "slightly negatively". You have to care about large vs. small correlations or else you'll never get started doing any inference (no correlations are ever exactly 0).
↑ comment by Richard_Kennaway · 2023-08-09T07:56:04.236Z · LW(p) · GW(p)
You can totally conclude causational structure from correlations alone, it just requires observing more variables. Judea Pearl is the canonical source on the topic
I am surprised by this claim, because Pearl stresses that you can get no causal conclusions without causal assumptions.
How, specifically, would you go about discovering the correct causal structure of a phenomenon from correlations alone?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-08-09T15:30:49.811Z · LW(p) · GW(p)
Eh, Pearl's being a little bit coy. We can typically get away with some very weak/general causal assumptions - e.g. "parameters just happening to take very precise values which perfectly mask the real causal structure is improbable a priori" is roughly the assumption Pearl mostly relies on (under the guise of "minimality and stability" assumptions). Causality chapter 2 walks through a way to discover causal structure from correlations, leveraging those assumptions, though the algorithms there aren't great in practice - "test gazillions of conditional independence relationships" is not something one can do in practice without a moderate rate of errors along the way, and Pearl's algorithm assumes it as a building block. Still, it makes the point that this is possible in principle, and once we accept that we can just go full Bayesian model comparison.
I think of these assumptions in a similar way to e.g. independence assumptions across "experiments" in standard statistics (though I'd consider the assumptions needed for causality much weaker than those). Like, sure, we need to make some assumptions in order to do any sort of mathematical modelling, and that somewhat limits how/where we apply the theory, but it's not that much of a barrier in practice.
↑ comment by tailcalled · 2023-05-14T21:32:49.013Z · LW(p) · GW(p)
Causality is useful mainly insofar as different instances can be compactly described as different simple interventions on the same Bayes net.
Thinking about this algorithmically: In e.g. factor analysis, after performing PCA to reduce a high-dimensional dataset to a low-dimensional one, it's common to use varimax to "rotate" the principal components so that each resulting axis has a sparse relationship with the original indicator variables (each "principal" component correlating only with one indicator). However, this instead seems to suggest that one should rotate them so that the resulting axes have a sparse relationship with the original cases (each data point deviating from the mean on as few "principal" components as possible).
I believe that this sort of rotation (without the PCA) has actually been used in certain causal inference algorithms, but as far as I can tell it basically assumes that causality flows from variables with higher kurtosis to variables with lower kurtosis, which admittedly seems plausible for a lot of cases, but also seems like it consistently gives the wrong results if you've got certain nonlinear/thresholding effects (which seem plausible in some of the areas I've been looking to apply it).
Not sure whether you'd say I'm thinking about this right?
For instance, in the sprinkler system, some days the sprinkler is in fact turned off, or there's a tarp up, or what have you, and then the system is well-modeled by a simple intervention.
I'm trying to think of why modelling this using a simple intervention is superior to modelling it as e.g. a conditional. One answer I could come up with is if there's some correlations across the different instances of the system, e.g. seasonable variation in rain or similar, or turning the sprinkler on partway through a day. Though these sorts of correlations are probably best modelled by expanding the Bayesian network to include time or similar.
Replies from: LGS↑ comment by LGS · 2023-08-08T04:07:16.654Z · LW(p) · GW(p)
I believe that this sort of rotation (without the PCA) has actually been used in certain causal inference algorithms, but as far as I can tell it basically assumes that causality flows from variables with higher kurtosis to variables with lower kurtosis, which admittedly seems plausible for a lot of cases, but also seems like it consistently gives the wrong results if you've got certain nonlinear/thresholding effects (which seem plausible in some of the areas I've been looking to apply it).
Where did you get this notion about kurtosis? Factor analysis or PCA only take in a correlation matrix as input, and so only model the second order moments of the joint distribution (i.e. correlations/variances/covariances, but not kurtosis). In fact, it is sometimes assumed in factor analysis that all variables and latent factors are jointly multivariate normal (and so all random variables have excess kurtosis 0).
Bayes net is not the same thing as PCA/factor analysis in part because it is trying to factor the entire joint distribution rather than just the correlation matrix.
Replies from: tailcalled↑ comment by tailcalled · 2023-08-08T08:30:36.733Z · LW(p) · GW(p)
This part of the comment wasn't about PCA/FA, hence "without the PCA". The formal name for what I had in mind is ICA, which often works by maximizing kurtosis.
Replies from: LGS↑ comment by LGS · 2023-08-09T02:11:50.914Z · LW(p) · GW(p)
What you seemed to be saying is that a certain rotation ("one should rotate them so that the resulting axes have a sparse relationship with the original cases") has "actually been used" and "it basically assumes that causality flows from variables with higher kurtosis to variables with lower kurtosis".
I don't see what the kurtosis-maximizing algorithm has to do with the choice of rotation used in factor analysis or PCA.
↑ comment by Caspar Oesterheld (Caspar42) · 2023-05-21T04:04:26.584Z · LW(p) · GW(p)
>First crucial point which this post is missing: the first (intuitively wrong) net reconstructed represents the probabilities using 9 parameters (i.e. the nine rows of the various truth tables), whereas the second (intuitively right) represents the probabilities using 8. That means the second model uses fewer bits; the distribution is more compressed by the model. So the "true" network is favored even before we get into interventions.
>
>Implication of this for causal epistemics: we have two models which make the same predictions on-distribution, and only make different predictions under interventions. Yet, even without actually observing any interventions, we do have reason to epistemically favor one model over the other.
For people interested in learning more about this idea: This is described in Section 2.3 of Pearl's book Causality. The beginning of Ch. 2 also contains some information about the history of this idea. There's also a more accessible post by Yudkowsky [LW · GW] that has popularized these ideas on LW, though it contains some inaccuracies, such as explicitly equating causal graphs and Bayes nets.
comment by Richard_Kennaway · 2023-05-15T10:02:36.633Z · LW(p) · GW(p)
You don't like the idea of forced change, of intervention, being so integral to such a seemingly basic notion as causality.
You may not, but indeed, according to Judea Pearl, interventions are integral to the idea of causation. Eliezer's post [LW · GW] is not reliable on this point. A causal model and a Bayes net are not the same thing, a point Ilya Shpitser makes in the comments to that post.
The data don't tell you what causal graph to draw. You choose a hypothetical causal graph, not based on the data. You can then see whether the observational data are consistent with the causal graph you have chosen. However, the data may be consistent with many causal graphs.
What is an intervention? To call something an intervention still involves causal assumptions: an intervention is something we can do to set some variable to any chosen value, in a way that we have reason to believe screens off that variable from all other influences on it, and does not have a causal influence on any other variable except via the one we are setting. That "reason to believe" does not come from the data (which we have yet to collect), but from previous knowledge. For example, the purpose of randomisation in controlled trials is to ensure the independence of the value we set the variable to from everything else.
Replies from: Caspar42↑ comment by Caspar Oesterheld (Caspar42) · 2023-05-21T00:32:19.400Z · LW(p) · GW(p)
OP:
>You don't like the idea of forced change, of intervention, being so integral to such a seemingly basic notion as causality. It feels almost anthropomorphic: you want the notion of cause and effect within a system to make sense without reference to the intervention of some outside agent—for there's nothing outside of the universe.
RK:
>You may not, but indeed, according to Judea Pearl, interventions are integral to the idea of causation.
Indeed, from the Epilogue of the second edition of Judea Pearl's book Causality (emphasis added):
The equations of physics are indeed symmetrical, but when we compare the phrases “A causes B” versus “B causes A,” we are not talking about a single set of equations. Rather, we are comparing two world models, represented by two different sets of equations: one in which the equation for A is surgically removed; the other where the equation for B is removed. Russell would probably stop us at this point and ask: “How can you talk about two world models when in fact there is only one world model, given by all the equations of physics put together?” The answer is: yes. If you wish to include the entire universe in the model, causality disappears because interventions disappear – the manipulator and the manipulated lose their distinction. However, scientists rarely consider the entirety of the universe as an object of investigation. In most cases the scientist carves a piece from the universe and proclaims that piece in – namely, the focus of investigation. The rest of the universe is then considered out or background and is summarized by what we call boundary conditions. This choice of ins and outs creates asymmetry in the way we look at things, and it is this asymmetry that permits us to talk about “outside intervention” and hence about causality and cause-effect directionality.
comment by Martin Randall (martin-randall) · 2024-12-28T02:15:56.596Z · LW(p) · GW(p)
Zack complicates the story in Causal Diagrams and Causal Models [LW · GW], in an indirect way. There's a bit of narrative thrown in for fun. I enjoyed this in 2023 but less on re-reading.
I don't know if the fictional statistics have been chosen carefully to allow multiple interpretations, or if any data generated by a network similar to the "true" network would necessarily also allow the "crazy" network. Maybe it's the second, based on Wentworth's comment that there are "equivalent graph structures" (e.g. A -> B -> C vs A <- B <- C vs A <- B -> C). But the equivalent structures have the same number of parameters and in this one the "crazy" network has an extra parameter, so I don't know. The aside about "the correctness of the family archives" adds doubt. A footnote would help.
The post is prodding me to think for myself and perhaps buy a textbook or two. I could play with some numbers to answer my above doubt. Those are all worthy things, but it's less clear that they would be worthwhile. Unlike Learn Bayes Nets! [LW · GW] there's no promise of cosmic power on offer.
The alternate takeaway from this post is a general awareness that causal inference is complicated and has assumptions and limitations. Perhaps just that Bayesian Networks Aren't Necessarily Causal. Drilling into the comments on both posts adds more color to that takeaway.
Overall I'm left feeling slightly let down in a way I can't quite put my finger on. Like there's something of value here that I'm not getting, or the author didn't express in quite the right way for me to pick up on it. Sorry, this is frustrating feedback to get, but it's the best I can do today.
comment by gjm · 2023-05-15T12:17:00.059Z · LW(p) · GW(p)
Completely superficial side-issue question: Twice in this post you very conspicuously refer to "Daphne Koller and the other guy". The other guy is clearly Nir Friedman. Why the curious phrasing? (The sort of thing I'm imagining: Nir Friedman is known not to have actually done any of the work that led to the book. Nir Friedman is known to have actually done all of the work that led to the book. Nir Friedman is known to be a super-terrible person somehow. You are secretly Nir Friedman. I don't expect any of these specific things to be right, but presumably there's something in that general conceptual area.)
Replies from: Zack_M_Davis↑ comment by Zack_M_Davis · 2023-05-16T00:09:42.920Z · LW(p) · GW(p)
According to my subjective æsthetic whims, it's cute and funny to imagine the protagonist as not remembering both author's names, in accordance with only being a casual formal epistemology fan. (The mentions of casual fandom, family archives, not reading all of chapter 3, &c. make this a short story that happens to be told in the second person, rather than "you" referring to the reader.)
Replies from: localdeity↑ comment by localdeity · 2023-05-16T00:52:36.386Z · LW(p) · GW(p)
I expected there to be some wordplay on "casual"/"causal" somewhere, but I'm not sure if I saw any. This is obviously a central component of such a post's value proposition.
comment by ProgramCrafter (programcrafter) · 2023-05-14T16:42:54.990Z · LW(p) · GW(p)
You feel a slight philosophical discomfort about this. You don't like the idea of forced change, of intervention, being so integral to such a seemingly basic notion as causality.
Maybe it's easier to think that Bayes nets without external data can only say "rain is strong evidence to wet" and "wet is strong evidence to rain" but not "rain causes wet" or "wet causes rain"?
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2023-05-15T10:04:28.462Z · LW(p) · GW(p)
Yes, a Bayes net is a representation of patterns of conditional independence in the data. On its own it says nothing about causes.
comment by Max H (Maxc) · 2023-05-14T14:40:37.441Z · LW(p) · GW(p)
If both networks give the same answers to marginal and conditional probability queries, that amounts to them making the same predictions about the world.
Does it? A bunch of probability distributions on opaque variables like and seems like it is missing something in terms of making predictions about any world. Even if you relabel the variables with more suggestive names like "rain" and "wet", that's a bit like manually programming in a bunch of IS-A() and HAS-A() relationships and if-then statements into a 1970s AI system.
Bayes nets are one component for understanding and formalizing causality, and they capture something real and important about its nature. The remaining pieces involve concepts that are harder to encode in simple, traditional algorithms, but that doesn't make them any less real or ontologically special, nor does it make Bayes nets useless or flawed.
Without all the knowledge about what words like rain and wetness and and slippery mean, you might be better off replacing these labels with things like "bloxor" and "greeblic". You could then still do interventions on the network to learn something about whether the data you have suggests that bloxors cause greeblic-ness is a simpler hypothesis than greeblic-ness causing bloxors. Without Bayes nets (or something isomorphic to them in conceptspace), you'd be totally lost in an unfamiliar world of bloxors and greeblic-ness. But there's still a missing piece for explaining causality that involves using physics (or higher-level domain-specific knowledge) about what bloxors and greeblic-ness represent to actually make predictions about them.
(I read this post as claiming implicitly that the original post [LW · GW] (or its author) are missing or forgetting some of the points above. I did find this post useful and interesting as a exploration and explanation of the nuts and bolts of Bayes nets, but I don't think I was left confused or misled by the original piece.)
Replies from: Zack_M_Davis↑ comment by Zack_M_Davis · 2023-05-15T05:51:43.994Z · LW(p) · GW(p)
seems like it is missing something in terms of making predictions about any world
I mean, you're right, but that's not what I was going for with that sentence. Suppose we were talking about a tiny philosophical "world" of opaque variables, rather than the real physical universe in all its richness and complexity. If you're just drawing samples from the original joint distribution, both networks will tell you exactly what you should predict to see. But if we suppose that there are "further facts" about some underlying mechanisms that generate that distribution, the two networks are expressing different beliefs about those further facts (e.g., whether changing will change , which you can't tell if you don't change it).
claiming implicitly that the original post (or its author) are missing [...] some of the points above
Not the author, but some readers (not necessarily you). This post is trying to fill in a gap, of something that people who Actually Read The Serious Textbook and Done Exercises already know, but people who have only read one or two intro blog posts maybe don't know. (It's no one's fault; any one blog post can only say so much.)