Posts
Comments
Well, yeah, it bothers me that the "bayesian" part of rationalism doesn't seem very bayesian―otherwise we'd be having a lot of discussions about where priors come from, how to best accomplish the necessary mental arithmetic, how to go about counting evidence and dealing with ambiguous counts (if my friends Alice and Bob both tell me X, it could be two pieces of evidence for X or just one depending on what generated the claims; how should I count evidence by default, and are there things I should be doing to find the underlying evidence?)
So―vulnerable in the current culture, but rationalists should strive to be the opposite of the "gishy" dark-epistemic people I have on my mind. Having many reasons to think X isn't necessarily a sin, but dark-epistemic people gather many reasons and have many sins, which are a good guide of what not to do.
TBH, a central object of interest to me is people using Dark Epistemics. People with a bad case of DE typically have "gishiness" as a central characteristic, and use all kinds of fallacies of which motte-and-bailey (hidden or not) is just one. I describe them together just because I haven't seen LW articles on them before. If I were specifically naming major DE syndromes, I might propose the "backstop of conspiracy" (a sense that whatever the evidence at hand doesn't explain is probably still explained by some kind of conspiracy) and projection (a tendency to loudly complain that one's political enemies have whatever negative characteristics you yourself, or your political heroes, are currently exhibiting). Such things seem very effective at protecting the person's beliefs from challenge. I think there's also a social element ("my friends all believe the same thing") but this is kept well-hidden. EDIT: other telltale signs include refusing to acknowledge that one got anything wrong or made any mistake, no matter how small; refusing to acknowledge that the 'opponent' is right about anything, no matter how minor; an allergy to detail (refusing to look at the details of any subtopic); and shifting the playfield repeatedly (changing the topic when one appears to be losing the argument).
The Hidden-Motte-And-Bailey fallacy: belief in a Bailey inspires someone to invent a Motte and write an article about it. The opinion piece describes the Motte exclusively with no mention of the Bailey. Others read it and nod along happily because it supports their cherished Bailey, and finally they share it with others in an effort to help promote the Bailey.
Example: Christian philosopher describes new argument for the existence of a higher-order-infinity God which bears no resemblance to any Abrahamic God, and which no one before the 20th century had ever conceived of.
Maybe the Motte is strong, maybe it isn't, but it feels very strong when combined with the Gish Fallacy: the feeling of safety some people (apparently) get by collecting large numbers of claims and arguments, whether or not they routinely toss them out as Gish Gallops at anyone who disagrees. The Gish Fallacy seems to be the opposite of the mathematician's mindset, for mathematicians know that a single flaw can destroy proofs of any length. While the mathematician is satisfied by a single a short and succinct proof or disproof, the Gish mindset wishes to read a thousand different descriptions of three dozen arguments, with another thousand pithy rejections of their counterarguments, so they're thoroughly prepared to dismiss the evil arguments of the enemies of truth―or, if the enemy made a good point, there are still 999 articles supporting their view, and more where that came from!
Example: my dad
I know this comment was 17 years ago, but nearly half of modern US politics in 2024 is strongly influenced by the idea "don't trust experts". I have listened to a lot of cranks (ex), and the popular ones are quite good at what they do, rhetorically, so most experts have little chance against them in a debate. Plus, if the topic is something important, the public was already primed to believe one side or the other by whatever media they happen to consume, and if the debate winner would otherwise seem close (to a layman) then such preconceptions will dominate perceptions about who won.
One thing these winning cranks take advantage is that the audience (like the cranks themselves!) tend to believe they are "knowledgeable enough to understand all the technical arguments" when they're not. Also, most experts have much worse teaching skills than these cranks (who are popular for a reason) so the expert tends to provide worse explanations, while also overlooking key counterarguments they could make against the crank's case.
So: in today's environment, I see a large fraction of the population as giving too little credence to authority in cases where they only partially evaluate the arguments. Related SSC. Like proofs, arguments can be completely wrong due to a single flaw. A partial evaluation will not necessarily uncover the flaw, but pop cranks are often good at pointing out things that appear as flaws to the uneducated (perhaps because they have a shorter inferential distance to the audience than the experts do, but also because they have more practice in public debate). And needless to say, people who are undecided don't know that they're listening to a crank, and would be offended if you claimed that the one who they thought won the debate was a crank.
I actually think Yudkowsky's biggest problem may be that he is not talking about his models. In his most prominent posts about AGI doom, such as this and the List of Lethalities, he needs to provide a complete model that clearly and convincingly leads to doom (hopefully without the extreme rhetoric) in order to justify the extreme rhetoric. Why does attempted, but imperfect, alignment lead universally to doom in all likely AGI designs*, when we lack familiarity with the relevant mind design space, or with how long it will take to escalate a given design from AGI to ASI?
* I know his claim isn't quite this expansive, but his rhetorical style encourages an expansive interpretation.
I'm baffled he gives so little effort to explaining his model. In List of Lethalities he spends a few paragraphs of preamble to cover some essential elements of concern (-3, -2, -1), then offers a few potentially-reasonable-but-minimally-supported assertions, before spending much of the rest of the article prattling off the various ways AGI can kill everyone. Personally I felt like he just skipped over a lot of the important topics, and so didn't bother to read it to the end.
I think there is probably some time after the first AGI or quasi-AGI arrives, but before the most genocide-prone AGI arrives, in which alignment work can still be done. Eliezer's rhetorical approach confusingly chooses to burn bridges with this world, as he and MIRI (and probably, by association, rationalists) will be regarded as a laughing stock when that world arrives. Various techbros including AI researchers will be saying "well, AGI came and we're all still alive, yet there's EY still reciting his doomer nonsense". EY will uselessly protest "I didn't say AGI would necessarily kill everyone right away" while the techbros retweet old EY quotes that kinda sound like that's what he's saying.
Edit: for whoever disagreed & downvoted: what for? You know there are e/accs on Twitter telling everyone that the idea of x-risk is based on Yudkowsky being "king of his tribe", and surely you know that this is not how LessWrong is supposed to work. The risk isn't supposed to be based on EY's say-so; a complete and convincing model is needed. If, on the other hand, you disagreed that his communication is incomplete and unconvincing, it should not offend you that not everyone agrees. Like, holy shit: you think humanity will cause apocalypse because it's not listening to EY, but how dare somebody suggest that EY needs better communication. I wrote this comment because I think it's very important; what are you here for?
P.S. if I'm wrong about the timeline―if it takes >15 years―my guess for how I'm wrong is (1) a major downturn in AGI/AI research investment and (2) executive misallocation of resources. I've been thinking that the brightest minds of the AI world are working on AGI, but maybe they're just paid a lot because there are too few minds to go around. And when I think of my favorite MS developer tools, they have greatly improved over the years, but there are also fixable things that haven't been fixed in 20 years, and good ideas they've never tried, and MS has created a surprising number of badly designed libraries (not to mention products) over the years. And I know people close to Google have a variety of their own pet peeves about Google.
Are AGI companies like this? Do they burn mountains cash to pay otherwise average engineers who happen to have AI skills? Do they tend to ignore promising research directions because the results are uncertain, or because results won't materialize in the next year, or because they don't need a supercomputer or aren't based mainly on transformers? Are they bad at creating tools that would've made the company more efficient? Certainly I expect some companies to be like that.
As for (1), I'm no great fan of copyright law, but today's companies are probably built on a foundation of rampant piracy, and litigation might kill investment. Or, investors may be scared away by a persistent lack of discoveries to increase reliability / curtail hallucinations.
Doesn't the problem have no solution without a spare block?
Worth noting that LLMs don't see a nicely formatted numeric list, they see a linear sequence of tokens, e.g. I can replace all my newlines with something else and Copilot still gets it:

brief testing doesn't show worse completions than when there are newlines. (and in the version with newlines this particular completion is oddly incomplete.)

Anyone know how LLMs tend to behave on text that is ambiguous―or unambiguous but "hard to parse"? I wonder if they "see" a superposition of meanings "mixed together" and produce a response that "sounds good for the mixture".
I'm having trouble discerning a difference between our opinions, as I expect a "kind-of AGI" to come out of LLM tech, given enough investment. Re: code assistants, I'm generally disappointed with Github Copilot. It's not unusual that I'm like "wow, good job", but bad completions are commonplace, especially when I ask a question in the sidebar (which should use a bigger LLM). Its (very hallucinatory) response typically demonstrates that it doesn't understand our (relatively small) codebase very well, to the point where I only occasionally bother asking. (I keep wondering "did no one at GitHub think to generate an outline of the app that could fit in the context window?")
A title like "some people can notice more imperfections than you (and they get irked)" would be more accurate and less clickbaity, though when written like that it it sounds kind of obvious.
Do you mean the "send us a message" popup at bottom-right?
Yikes! Apparently I said "strong disagree" when I meant "strong downvote". Fixed. Sorry. Disagree votes generally don't bother me either, they just make me curious what the disagreer disagrees about.
Shoot, I forgot that high-karma users have a "small-strength" of 2, so I can't tell if it was strong-downvoted or not. I mistakenly assumed it was a newish user. Edit: P.S. I might feel better if karma was hidden on my own new comments, whether or not they are hidden on others, though it would then be harder to guess at the vote distribution, making the information even more useless than usual if it survives the hiding-period. Still seems like a net win for the emotional benefits.
I wrote a long comment and someone took the "strong downvote, no disagreement, no reply" tack again. Poppy-cutters[1] seem way more common at LessWrong than I could've predicted, and I'd like to see statistics to see how common they are, and to see whether my experience here is normal or not.
- ^
Meaning users who just seem to want to make others feel bad about their opinion, especially unconstructively. Interesting statistics might include the distributions of users who strong-downvote a positive score into a negative one (as compared to their other voting behaviors), who downvote more than they disagree, who downvote more than they upvote, who strong-downvote more than they downvote, and/or strong-downvote more often than they reply. Also: is there an 80/20 rule like "20% of the people do 80% of the downvotes"? Is the distribution different for "power users" than "casual users"?
Given that I think LLMs don't generalize, I was surprised how compelling Aschenbrenner's case sounded when I read it (well, the first half of it. I'm short on time...). He seemed to have taken all the same evidence I knew about it, and arranged it into a very different framing. But I also felt like he underweighted criticism from the likes of Gary Marcus. To me, the illusion of LLMs being "smart" has been broken for a year or so.
To the extent LLMs appear to build world models, I think what you're seeing is a bunch of disorganized neurons and connections that, when probed with a systematic method, can be mapped onto things that we know a world model ought to contain. A couple of important questions are
- the way that such a world model was formed and
- how easily we can easily figure out how to form those models better/differently[1].
I think LLMs get "world models" (which don't in fact cover the whole world) in a way that is quite unlike the way intelligent humans form their own world models―and more like how unintelligent or confused humans do the same.
The way I see it, LLMs learn in much the same way a struggling D student learns (if I understand correctly how such a student learns), and the reason LLMs sometimes perform like an A student is because they have extra advantages that regular D students do not: unlimited attention span and ultrafast, ultra-precise processing backed by an extremely large set of training data. So why do D students perform badly, even with "lots" of studying? I think it's either because they are not trying to build mental models, or because they don't really follow what their teachers are saying. Either way, this leads them to fall back on secondary "pattern-matching" learning mode which doesn't depend on a world model.
If, when learning in this mode, you see enough patterns, you will learn an implicit world model. The implicit model is a proper world model in terms of predictive power, but
- It requires much more training data to predict as well as a human system-2 can, which explains why D students perform worse than A students on the same amount of training data―and this is one of the reasons why LLMs need so much more training data than humans do in order to perform at an A level (other reasons: less compute per token, fewer total synapses, no ability to "mentally" generate training data, inability to autonomously choose what to train on). The way you should learn is to first develop an explicit worldmodel via system-2 thinking, then use system-2 to mentally generate training data which (along with external data) feeds into system-1. LLMs cannot do this.
- Such a model tends to be harder to explain in words than an explicit world model, because the predictions are coming from system-1 without much involvement from system-2, and so much of the model is not consciously visible to the student, nor is it properly connected to its linguistic form, so the D student relies more on "feeling around" the system-1 model via queries (e.g. to figure out whether "citation" is a noun, you can do things like ask your system-1 whether "the citation" is a valid phrase―human language skills tend to always develop as pure system-1 initially, so a good linguistics course teaches you explicitly to perform these queries to extract information, whereas if you have a mostly-system-2 understanding of a language, you can use that to decide whether a phrase is correct with system-2, without an intuition about whether it's correct. My system-1 for Spanish is badly underdeveloped, so I lean on my superior system-2/analytical understanding of grammar).
When an LLM cites a correct definition of something as if it were a textbook, then immediately afterward fails to apply that definition to the question you ask, I think that indicates the LLM doesn't really have a world model with respect to that question, but I would go further and say that even if it has a good world model, it cannot express its world-model in words, it can only express the textbook definitions it has seen and then apply its implicit world-model, which may or may not match what it said verbally.
So if you just keep training it on more unique data, eventually it "gets it", but I think it "gets it" the way a D student does, implicitly not explicitly. With enough experience, the D student can be competent, but never as good as similarly-experienced A students.
A corollary of the above is that I think the amount of compute required for AGI is wildly overestimated, if not by Aschenbrenner himself then by less nuanced versions of his style of thinking (e.g. Sam Altman). And much of the danger of AGI follows from this. On a meta level, my own opinions on AGI are mostly not formed via "training data", since I have not read/seen that many articles and videos about AGI alignment (compared to any actual alignment researcher). No coincidence, then, that I was always an A to A- student, and the one time I got a C- in a technical course was when I couldn't figure out WTF the professor was talking about. I still learned, that's why I got a C-, but I learned in a way that seemed unnatural to me, but which incorporated some of the "brute force" that an LLM would use. I'm all about mental models and evidence; LLMs are about neither.
Aschenbrenner did help firm up my sense that current LLM tech leads to "quasi-AGI": a competent humanlike digital assistant, probably one that can do some AI research autonomously. It appears that the AI industry (or maybe just OpenAI) is on an evolutionary approach of "let's just tweak LLMs and our processes around them". This may lead (via human ingenuity or chance discovery) to system-2s with explicit worldmodels, but without some breakthough, it just leads to relatively safe quasi-AGIs, the sort that probably won't generate groundbreaking new cancer-fighting ideas but might do a good job testing ideas for curing cancer that are "obvious" or human-generated or both.
Although LLMs badly suck at reasoning, my AGI timelines are still kinda short―roughly 1 to 15 years for "real" AGI, with quasi-AGI in 2 to 6 years―mainly because so much funding is going into this, and because only one researcher needs to figure out the secret, and because so much research is being shared publicly, and because there should be many ways to do AGI, and because quasi-AGI (if invented first) might help create real AGI. Even the AGI safety people[2] might be the ones to invent AGI, for how else will they do effective safety research? FWIW my prediction is that quasi-AGI is consists of a transformer architecture with quite a large number of (conventional software) tricks and tweaks bolted on to it, while real AGI consists of transformer architecture plus a smaller number of tricks and tweaks, plus a second breakthrough of the same magnitude as transformer architecture itself (or a pair of ideas that work so well together that combining them counts as a breakthrough).
EDIT: if anyone thinks I'm on to something here, let me know your thoughts as to whether I should redact the post lest changing minds in this regard is itself hazardous. My thinking for now, though, is that presenting ideas to a safety-conscious audience might well be better than safetyists nodding along to a mental model that I think is, if not incorrect, then poorly framed.
I have a feature request for LessWrong. It's the same as my feature request for every site: you should be able to search within a user (i.e. visit a user page and begin a search from there). This should be easy to do technically; you just have to add the author's name as one of the words in the search index. And in terms of UI, I think you could just link to https://www.lesswrong.com/search?query=@author:username.
Preferably do it in such a way that a normal post cannot do the same, e.g. if "foo authored this post" is placed in the index as @author:foo, if a normal post contains the text @author:foo then perhaps the index only ends up with @author (or author) and foo, while the full string is not in the index (or, if it is in the index, can only be found by searching with quotes a la Google: "@author:foo"
P.S. we really should be able to search by date range, too. I'm looking for something posted by Yudkowsky at some point before 2010... and surely this is not an unusual thing to want to search for.
Wow, is this the newest feature-request thread? Well, it's the newest I easily find given that LessWrong search has very poor granularity when it comes to choosing a time frame within which to search...
My feature request for LessWrong is the same as my feature request for every site: you should be able to search within a user. This is easy to do technically; you just have to add the author's name as one of the words in the search index.
Preferably do it in such a way that a normal post cannot do the same, e.g. you might put "foo authored this post" in the index as @author:foo but if a normal post contains the text "@author:foo" then perhaps the index only ends up with @author (or author) and foo, while the full string is not in the index (or, if it is in the index, can only be found by searching with quotes a la Google: "@author:foo"
I have definitely taken actions within the bounds of what seems reasonable that have aimed at getting the EA community to shut down or disappear (and will probably continue to do so).
Wow, what a striking thing for you to say without further explanation.
Personally, I'm a fan of EA. Also am an EA―signed the GWWC/10% pledge and all that. So, I wonder what you mean.
I'm confused why this is so popular.

Sure, it appears to be espousing something important to me ("actually caring about stuff, and for the right reasons"). But specifically it appears to be about how non-serious people can become serious. Have you met non-serious people who long to be serious? People like that seem very rare to me. I've spent my life surrounded by people who work 9 to 5 and will not talk shop at 6; you do some work, then you stop working and enjoy life.
some of the most serious people I know do their serious thing gratis and make their loot somewhere else.
Yeah, that's me. So it seems like the audience for the piece can't be the audience that the piece appears to be for. Unserious people are unserious because they don't care to be. Also:
For me, I felt like publishing in scientific journals required me to be dishonest.
...what?
it's wrong to assume that because a bunch of Nazis appeared, they were mostly there all along but hidden
I'd say it's wrong as an "assumption" but very good as a prior. (The prior also suggests new white supremacists were generated, as Duncan noted.) Unfortunately, good priors (as with bad priors) often don't have ready-made scientific studies to justify them, but like, it's pretty clear that gay and mildly autistic people were there all along, and I have no reason to think the same is not true of white supremacists, so the prior holds. I also agree that it has proven easy for some people to "take existing sentiments among millions of people and hone them", but you call them "elites", so I'd point out that some of those people spend much of their time hating on "elites" and "elitism"...
I think this post potentially does a very good job getting at the core of why things like Cryonics and Longtermism did not rapidly become mainstream
Could you elaborate?
I'd say (1) living in such a place just makes you much less likely to come out, even if you never move, (2) suspecting you can trust someone with a secret is not a good enough reason to tell the secret, and (3) even if you totally trust someone with your secret, you might not trust that he/she will keep the secret.
And I'd say Scott Alexander meets conservatives regularly―but they're so highbrow that he wasn't thinking of them as "conservatives" when he wrote that. He's an extra step removed from the typical Bush or MAGA supporter, so doesn't meet those. Or does he? Social Dark Matter theory suggests that he totally does.
that the person had behaved in actually bad and devious ways
"Devious" I get, but where did the word "bad" come from? (Do you appreciate the special power of the sex drive? I don't think it generalizes to other areas of life.)
Your general point is true, but it's not necessarily true that a correct model can (1) predict the timing of AGI or (2) that the predictable precursors to disaster occur before the practical c-risk (catastrophic-risk) point of no return. While I'm not as pessimistic as Eliezer, my mental model has these two limitations. My model does predict that, prior to disaster, a fairly safe, non-ASI AGI or pseudo-AGI (e.g. GPT6, a chatbot that can do a lot of office jobs and menial jobs pretty well) is likely to be invented before the really deadly one (if any[1]). But if I predicted right, it probably won't make people take my c-risk concerns more seriously?
- ^
technically I think AGI inevitably ends up deadly, but it could be deadly "in a good way"
Evolutionary Dynamics
The pressure to replace humans with AIs can be framed as a general trend from evolutionary dynamics. Selection pressures incentivize AIs to act selfishly and evade safety measures.
Seems like the wrong frame? Evolution is based on mutation, which AIs won't have. However, in the human world there is a similar and much faster dynamic based on the large natural variability between human agents (due to both genetic and environmental factors) which tends to cause people with certain characteristics to rise to the top (e.g. high intelligence, grit, power-seeking tendencies, narcissism, sociopathy). AIs and AGIs will have the additional characteristics of rapid training and being easy to copy, though I expect they'll have less variety than humans.
Given the exponential increase in microprocessor speeds, AIs could process information at a pace that far exceeds human neurons. Due to the scalability of computational resources, AI could collaborate with an unlimited number of other AIs and form an unprecedented collective intelligence.
Worth noting that this was the case since long ago. Old AIs haven't so much been slow as undersized.
Not sure what I would add to "Suggestions" other than "don't build AGI" :D
Speaking of AGI, I'm often puzzled about the extent to which authors here say "AI" when they are talking about AGI. It seems to me that some observers think we're crazy for worrying humanity GPT5 is going to kill all humans, when in fact our main concern is not AI but AGI.
given intense economic pressure for better capabilities, we shall see a steady and continuous improvement, so the danger actually is in discontinuities that make it harder for humanity to react to changes, and therefore we should accelerate to reduce compute overhang
I don't feel like this is actually a counterargument? You could agree with both arguments, concluding that we shouldn't work for OpenAI but a outfit better-aligned to your values is okay.
I expect there are people who are aware that there was drama but don't know much about it and should be presented with details from safety-conscious people who closely examined what happened.
I think there may be merit in pointing EAs toward OpenAI safety-related work, because those positions will presumably be filled by someone and I would prefer it be filled by someone (i) very competent (ii) who is familiar with (and cares about) a wide range of AGI risks, and EA groups often discuss such risks. However, anyone applying at OpenAI should be aware of the previous drama before applying. The current job listings don't communicate the gravity or nuance of the issue before job-seekers push the blue button leading to OpenAI's job listing:

I guess the card should be guarded, so that instead of just having a normal blue button, the user should expand some sort of 'additional details' subcard first. The user then sees some bullet points about the OpenAI drama and (preferably) expert concerns about working for OpenAI, each bullet point including a link to more details, followed by a secondary-styled button for the job application (typically, that would be a button with a white background and blue border). And of course you can do the same for any other job where the employer's interests don't seem well-aligned with humanity or otherwise don't have a good reputation.
Edit: actually, for cases this important, I'd to replace 'View Job Details' with a "View Details" button that goes to a full page on 80000 Hours in order to highlight the relevant details more strongly, again with the real job link at the bottom.
Hi Jasper! Don't worry, I definitely am not looking for rapid responses. I'm always busy anyway. And I wouldn't say there are in general 'easy or strong answers in how to persuade others'. I expect not to be able to persuade the majority of people on any given subject. But I always hope (and to some extent, expect) people in the ACX/LW/EA cluster to be persuadable based on evidence (more persuadable than my best friend whom I brought to the last meetup, who is more of an average person).
By the way, after writing my message I found out that I had a limited picture of Putin's demands for a peace deal―because I got that info from two mainstream media articles. When the excellent Anders Puck Neilson got around to talking about Putin's speech, he noticed other very large demands such as "denazification" (apparently meaning the Zelensky administration must be replaced with a more Kremlin-friendly government) and demilitarization (🤦♂️).
Yeah, Oliver Stone and Steven Seagal somehow went pro-Putin, just as Dennis Rodman befriended Kim Jong Un. There's always some people who love authoritarians, totalitarians, "strong leaders" or whatever. I don't understand it, but at least the Kremlin's allies are few enough that they decided to be friends with North Korea and Iran, and to rely on a western spokesman who is a convicted underage sex offender. So they seem a bit desperate―on the other hand, China has acted like a friend to North Korea since forever.
I'm not suggesting all the mainstream media got it wrong―only that enough sources repeated the Kremlin's story enough times to leave me, as someone who wasn't following the first war closely, the impression that the fight was mainly a civil war involving Kremlin-supplied weapons. (Thinking In hindsight, I'm like "wait a minute, how could a ragtag group of rebels already know how to use tanks, heavy artillery systems and Buk missile launchers in the same year the war started?") So my complaint is about what seems like the most typical way that the war was described.
A video reminded me tonight that after the war in Ukraine started, Russia pulled lots of its troops from all other borders, including the borders with NATO, in order to send them to Ukraine, and after Finland joined NATO, Russia pulled troops (again?) from its border with Finland―indicating that Putin has no actual fear of a NATO invasion.
Followup: this morning I saw a really nice Vlad Vexler video that ties Russian propaganda to the decline of western democracy. The video gives a pretty standard description of modern Russian propaganda, but I always have to somewhat disagree with that. Vlad's variant of the standard description says that Russian propaganda wants you to be depoliticized (not participate in politics) and to have "a theory of Truth which says 'who knows what if anything is true'".
This is true, but what's missing from this description is a third piece, which is that the Kremlin also wants people to believe particular things. Most of all, they want people to believe that Putin is a good leader who needs to stay in power, so while there may be all kinds of contradictory messages going around to explain what's happening in Russia and Ukraine, there is a strong consistency in trying to avoid linking bad facts to Putin, and to maximize the impression that Russia is doing fine. I think this only works to the extent Russians (and westerners) don't think about it, so one of my counterpropaganda ideas was to get Russians thinking about Putin and about how their system works―better yet, to instruct Russians of things to watch out for, things to pay attention to that Putin wants people to ignore.
Also, of course, the video is about how our democracies are dysfunctional, and I have my own ideas about how to address that problem (I have little ability to execute, but I have to work with what I've got and at least my ideas are neglected, which is very frustrating but also a good sign in the ITN framework.)
Hi all, I wanted to follow up on some of the things I said about the Ukraine war at the last meetup, partly because I said some things that were inaccurate, but also because I didn't complete my thoughts on the matter.
(uh, should I have put this on the previous meetup's page?)
First, at one point I said that Russia was suffering about 3x as many losses as Russia and argued that this meant the war was sustainable for Ukraine, as Russia has about 3½ times the population of Ukraine and is unlikely to be able to mobilize as many soldiers as Ukraine can (as a percentage). I thought there were credible sources saying this, but it turns out the source I was thinking of gave only a ~2.36x ratio, and more importantly, I realized about two seconds later that I myself didn't actually believe that number. In fact, I believed that Ukrainian losses were 50%-90% of Russian losses, so 1.1x to 2x[1] (and if there is some difference in the kill/wound ratio between the two sides, I have no information on that). So, I'm sorry. I remember feeling annoyed and I guess I just wanted to win the argument at that point.
However, I did believe, and continue to believe, the overall idea that Ukraine can hold on as long as it receives enough western aid. The reason for this is that I believe Ukrainian losses are currently "propped up" by the Russian advantage in materiel, and this problem should resolve itself in time.[2] During this war Ukraine has always been at a disadvantage in terms of equipment, because although older western equipment is generally superior to Soviet equipment, Ukraine always had limited supplies of them, and usually they've been at an even larger disadvantage in terms of artillery shells. With rare exceptions, Russia has typically fired several times more artillery shells than Ukraine (I would guess 6x more by mass, varying from ~1x to ~15x in different times and places). The thing about Russia's materiel advantage is that it relies heavily on deep stocks of weapons left over from the Soviet Union. Those stocks will not last forever. You can see Covert Cabal's OSINT videos about this for detail; for instance, this recent video estimated that Russia has "2, maybe 2½ years left" in its Soviet tank supply (edit: Euromaiden Press estimates tanks will last until "2027-2029" but artillery will run low sooner―unless, I would add, Russia develops more barrel production capacity). Regarding artillery shells, they've already switched to North Korea as a major supplier, and rumor has it that the quality of those shells is lower. If I remember right (and my memory is clearly fallible, admittedly) Russia makes new tanks at about 20% of the rate it is losing them in Ukraine, with the rest being Soviet refurbishments. So my thinking is that Ukraine just needs to hold out until Soviet stocks run low, after which one of two things will happen: (1) Putin finally gives up on the war, or (2) Russia keeps fighting with much less materiel, which will be much easier for Ukraine to manage (edit: if western support doesn't drop).
The second inaccuracy was that I said that the rules to join NATO include a requirement not to have contested territory. After the meetup I looked up the formal rules, and they did not include this requirement. Instead it's more of a de-facto expectation of NATO members. Wikipedia puts it this way:
In practice, diplomats and officials have stated that having no territorial disputes is a prerequisite to joining NATO, as a member with such a dispute would be automatically considered under attack by the occupying entity. However, West Germany joined NATO in 1955 despite having territorial disputes with East Germany and other states until the early 1970s.
Still, as far as I know, Ukraine made no actual progress on joining NATO prior to the invasion.
The third inaccuracy was I said that Zaporizhzhia city has a population of over a million people. Not sure how I got this wrong; its pre-war population is estimated at 732,000.
The other thing I didn't get to say about this topic during the meetup was to talk about how life is like an iterated prisoner's dilemma. The Ukraine war isn't just about Ukraine, it's about Taiwan. Whereas Russia has a 3.5:1 population advantage over Ukraine, the PRC has a 54:1 population advantage over Taiwan even if ideas about China inflating its population numbers are true.
I strongly suspect that Xi Jinping (unlike his predecessor) really would like to invade Taiwan (or at least launch a naval military blockade aimed at taking over Taiwan). While a naval invasion would be much more difficult than simply driving over the Ukrainian border, I can't imagine China could actually lose a war against a country more than 50 times smaller than itself, unless the U.S. military directly engages in fighting on Taiwan's behalf.
This creates a problem for the U.S., which does not want Taiwan to fall under the CCP's control, because Taiwan is a democracy, and because Taiwan is full of TSMC chip factories that the U.S. and its allies depend on. However, the U.S. also very much doesn't want a war with China, because it would be extremely costly for U.S. military forces, it would heavily disrupt the U.S. and global economy, it would empower India's authoritarian BJP party, it would heighten the trade war with China (e.g. China has a global monopoly on rare earths), it would heighten China's propaganda war against the U.S. (an area of obvious advantage for China), China may attack the U.S. mainland directly, and last but not least, there's a risk of nuclear escalation. (Did I miss anything? Probably!)
But Taiwan by itself would lose the war, so the U.S. needs to deter Xi from invading in the first place. So one thing Biden did was to say directly that U.S. forces would defend Taiwan (breaking from the previous U.S. policy of strategic ambiguity). But talk is cheap, so it's no surprise that Metaculus says there's only a 65% chance that the U.S. will actually respond to the invasion with military force, including even covert force. What else can the U.S. do to signal a willingness to defend Taiwan? The obvious answer: defend Ukraine. Conversely, to the extent the U.S. doesn't defend Ukraine, that implies it wouldn't defend Taiwan either. Ukraine, after all, is globally recognized as a sovereign country while Taiwan is not. If a country universally recognized as sovereign (except by Russia) can't get a strong defense against a nuclear-armed neighbor, why should Xi expect a strong U.S. defense of Taiwan?
So far the U.S. response in Ukraine has been underwhelming. To the 2014 invasion they initially responded only with a sprinkling of sanctions, and while they gave a much stronger response in 2022, they've sent no troops to defend Ukraine, they did not impose a no-fly zone (though eventually they sent Patriot batteries, which are pretty similar), and they've spent only 3% of the military budget as detailed below (plus, I don't know, some dozens of $billions in other forms of aid). I think I heard officials "explain" this at one point by saying that the rest of the budget would be needed in case of an invasion of Taiwan, but I think that actually if you want to show you're serious about defending Taiwan, the clearest way to do that is to defend Ukraine directly, troops and all. Biden doesn't do that because he's very afraid of nuclear escalation. But this implies that if Xi Jinping wants to keep the Biden Administration on the sidelines, he just needs to build more nuclear weapons and make a veiled nuclear threat when his invasion starts. I'm not sure if it's a coincidence that reports of an expanded Chinese nuclear arsenal appeared in late 2022.
A couple of other things I'd like to say...
First, the price the U.S. is paying to destroy Russian military capacity (Soviet stockpiles) is probably much lower than it would spend if it were in a direct shooting war with Russia. According to this article from March, U.S. direct military aid has been $46.3 billion (over two years), which was less than 3% of the U.S. military budget that exceeds $800 billion annually (the new aid bill passed in May would've increased this percentage modestly, and I think the amount of nonmilitary aid is greater than this.) The numbers so far compare favorably to Iraq + Afghanistan war spending ("at least" $757.8 billion for Iraq, and about $2 trillion for Afghanistan, more or less). But Iraq and Afghanistan had small enemy forces compared to Russia.
Second, people keep making this bizarre mistake of treating Putin as a truthful person, and the mainstream media seems to keep making this mistake sometimes even today. Putin insisted in 2014 he didn't know who those little green men were who invaded Crimea. Then he said that Russia wasn't militarily involved in the Donbass region of Ukraine, when in fact many Russian soldiers were directly fighting in Ukraine (e.g. here and here)―yet I remember the media telling me the whole time that it was "Russian-backed separatists". I didn't know any better until the 2022 invasion was well underway. And of course, Putin said he had no intention of invading Ukraine in 2022 (and notice that since his official policy was "we won't invade", he never said "we will invade unless Ukraine promises not to join NATO".)
State propaganda told the Russian people in 2014 that Ukraine was full of "nazis" which is why, even after a Jew was elected president in 2019, Putin started the invasion with a speech about "denazification". This is utterly cynical: neonazis certainly existed as they do in every country, and Ukraine agreed to command a far-right group in the armed forces during the 2014-15 war, but only 2% of Ukrainians voted for the far-right Svoboda party in the 2019 election, the head commander of the Russian Wagner group had nazi tattoos, I could point you to a video where a Russian with nazi tattoos gets a reward in a Russian military ceremony, and Russia has the Rusich group. Also, is it fascist to propose on Russian State TV to kill 10% of all Ukrainians? Seems fascist-adjacent, anyway. So "Nazi" functions as a magic word in the modern retelling of how Russia rescued Europe from Nazism in the Great Patriotic War, and is now forced once again to fight the modern decadent Nazis of Ukraine, the U.S. and Europe.
And by the way, I don't understand why this needs to be explained, but it's important to realize that refusing to join a defensive alliance does not assure safety against a huge neighbor with a history of invading its neighbors to annex territory (i.e. Chechnya 1994, Chechnya 1999, Georgia 2008, Ukraine 2014... and the USSR's history is also relevant given Putin's attitude). If NATO refused Ukraine's requests to join, that would not protect Ukraine either. NATO is a defensive alliance! Protecting against invasions is its raison d'etre! Surely all the countries that have ever joined (or tried to join) NATO thought it was in their best interest to do so, which would be a weird thing for everyone to think if it wasn't true.
So where does this idea come from that countries not joining NATO would keep them safe? I suspect it comes from Russia. Russia spends a lot on disinformation and misinformation, after all. They're always field-testing and boosting messages that fit their interests. Obviously their disinformation budget is a secret, but if Russia spends 1% as much on its information war as it does on its actual war, that would buy a lot of social media personalities!
Russia lies constantly. Many of the lies are not very convincing ― their greatest hits include "the Ukrainians are bombing themselves", "after we surrounded the city, Ukrainian soldiers planted explosives in their own drama theater to kill their own civilians", "Bucha was a provocation", and "we didn't invade Ukraine". But here is one that almost fooled me.
With that in mind, today I learned the "news" about Putin's "fresh demands" in Ukraine.
To me it's neither news nor fresh. It has the same headline items as their demands from last December[3] that I was telling you guys about. Putin is still asking Ukraine to:
- give up the rest of the Kherson oblast including all the territory Ukraine retook in November 2022, including Kherson city (pre-war population ~280,000)
- give up the rest of the Zaporizhzhia oblast including Zaporizhzhia city, which Russian troops have never before been able to approach (p.w.p. 732,000) ― which would also give Russians a major strategic victory in the form of a second large bridgehead on the west bank of the Dnipro river, and control over the defensive lines Ukraine has been building in northern Zaporizhzhia
- give up what little of Luhansk Ukrainians were able to retake
- give up the rest of the Donetsk oblast, including the small cities of Sloviansk, Kramatorsk and Pokrovsk, countless towns and villiages, plus all the defensive lines Ukraine has been building in that region
- never join NATO
As if expecting not to be laughed out of town, he also demands that the West drop all sanctions.
So as I was saying, the media. How does the media report on this? Sometimes, exactly as Putin wants:
"withdraws from occupied regions" is a very Russian way of saying it, since Russia consistently describes any land it takes as "liberated" from the Ukrainian "nazi regime" occupying the fake country of Ukraine.
(on the other hand AP had a nice documentary from their journalist who was on-scene in Mariupol.)
Half of these headlines don't mention the huge land grab, so they help communicate Putin's message that "Russia just wants peace, unlike the Kyiv Regime and NATO warmongers..."
While I didn't highlight The Hill there, I think they screwed it up by saying "ceding land" rather than "ceding additional land without a fight".
More broadly the media tends to ignore Putin's history of bald-face lies. Saying "Trump says the trial is a witch hunt, Biden denies it" cannot hurt Trump. In the same way, reporting like "Putin says X, Ukraine denies it" can't hurt Putin, but it can help him by planing X in people's heads.
Final thought: although Sarcasmitron has a clear liberal bias, I don't know of anyone offering a better documentary of the history of the Ukraine conflict, so here you go: Part 1, Part 2, Part 3, Part 4.
- ^
I don't have a source for "50%-90%", it's basically a gut feeling based on following the war closely. However, after the meetup I encountered a new video that reaches roughly the same conclusion with Ukrainian data that I hadn't seen before (to be more specific, based on that video I think Meduza's conclusion can be summarized by saying that the ratio is roughly 0.95x to 1.9x, not counting DPR and LPR losses on the Russian side.
- ^
Though at the current moment Ukraine is in a difficult spot since they waited too long to mobilize, won't have new soldiers for months, and won't be able to use F-16s for months
- ^
I couldn't locate original source where I saw these demands in December, but based on this ISW report the demands in December likely came from Russian Foreign Ministry Spokesperson Maria Zakharova.
9 respondents were concerned about an overreliance or overemphasis on certain kinds of theoretical arguments underpinning AI risk
I agree with this, but that "the horsepower of AI is instead coming from oodles of training data" is not a fact that seems relevant to me, except in the sense that this is driving up AI-related chip manufacturing (which, however, wasn't mentioned). The reason I argue it's not otherwise relevant is that the horsepower of ASI will not, primarily, come from oodles of training data. To the contrary, it will come from being able to reason, learn and remember better than humans do, and since (IIUC) LLMs function poorly if they are trained only on a dataset sized for human digestion, this implies AGI and ASI need less training data than LLMs, probably much less, for a given performance level (which is not to say more data isn't useful to them, it's just not what makes them AGI). So in my view, making AGI (and by extension AGI alignment) is mainly a matter of algorithms that have not yet been invented and therefore cannot be empirically tested, and less a matter of training data. Making ASI, in turn, is mainly a matter of compute (which already seems too abundant).
(disclaimer: I'm not an AI expert. Also it's an interesting question whether OpenAI will find a trick that somehow turns LLMs into AGI with little additional innovation, but supposing that's true, does the AGI alignment community have enough money and compute to do empirical research in the same direction, given the disintegration of OpenAI's Superalignment Team?)
I agree the first AGIs probably won't be epistemically sound agents maximizing an objective function: even rationalists have shown little interest in computational epistemology, and the dangers of maximizers seem well-known so I vaguely doubt leading AGI companies are pursuing that approach. Epistemically-poor agents without an objective function are often quite dangerous even with modest intelligence, though (e.g. many coup attempts have succeeded on the first try). Capabilities people seem likely to try human-inspired algorithms, which argues for alignment research along the same lines, but I'm not sure if this will work:
- A random alignment researcher would likely invent something different than a random (better-funded) capabilities researcher, so they'd end up aligning the "wrong" architecture (edit: though I expect some transferability of whatever was learned about alignment to comparable architectures)
- Like GoF research, developing any AGI has a risk that the key insight behind it, or even the source code, escapes into the wild before alignment is solved
- Solving alignment doesn't force others to use the solution.
So while the criticism seems sound, what should alignment researchers do instead?
Other brief comments:
- Too insular: yes, ticking off "AI safety" and e/acc researchers does us no favors ― but to what extent can it be avoided?
- Bad messaging―sure, can we call it AGI alignment please? And I think a thing we should do even for our own benefit is to promote detailed and realistic stories (ideally after review by superforecasters and alignment researchers) of how an AGI world could play out. Well-written stories are good messaging, and Moloch knows human fiction needs more realism. (I tried to write such a story, had no time to finish it, so published a draft before noticing the forum's special rules, and it was not approved for publication) P.S. It doesn't sound like Evan and Krueger contradict each other. P.P.S. a quip for consideration: psychopathy is not the presence of evil, but the absence of empathy. Do you trust AI corporations to build empathy? P.P.P.S. what about mimetic countermessaging? I don't know where the "AI safety is a immense juggernaut turning everyone into crazy doomers" meme comes from (Marc Andreesson?) but it seems very popular.
- "Their existence is arguably making AGI come sooner, and fueling a race that may lead to more reckless corner-cutting": yes, but (1) was it our fault specifically and (2) do we have a time machine?
- "general mistrust of governments in rationalist circles, not enough faith in our ability to solve coordination problems, and a general dislike of “consensus views”" Oh hell yes. EAs have a bit different disposition, though?
Another thing: not only is my idea unpopular, it's obvious from vote counts that some people are actively opposed to it. I haven't seen any computational epistemology (or evidence repository) project that is popular on LessWrong, either. Have you seen any?
If in fact this sort of thing tends not to interest LessWrongers, I find that deeply disturbing, especially in light of the stereotypes I've seen of "rationalists" on Twitter and EA forum. How right are the stereotypes? I'm starting to wonder.
I can't recall another time when someone shared their personal feelings and experiences and someone else declared it "propaganda and alarmism". I haven't seen "zero-risker" types do the same, but I would be curious to hear the tale and, if they share it, I don't think anyone one will call it "propaganda and killeveryoneism".
My post is weirdly aggressive? I think you are weirdly aggressive against Scott.
Since few people have read the book (including, I would wager, Cade Metz), the impact of associating Scott with Bell Curve doesn't depend directly on what's in the book, it depends on broad public perceptions of the book.
Having said that, according to Shaun (here's that link again), the Bell Curve relies heavily of the work of Richard Lynn, who was funded by, and later became the head of, the Pioneer Fund, which the Southern Poverty Law Center classifies as a hate group. In contrast, as far as I know, the conclusions of the sources cited by Scott do not hinge upon Richard Lynn. And given this, it would surprise me if the conclusions of The Bell Curve actually did match the mainstream consensus.
One of Scott's sources says 25-50% for "heritability" of the IQ gap. I'm pretty confident the Bell Curve doesn't say this, and I give P>50% that The Bell Curve suggests/states/implies that the IQ gap is over 50% "heritable" (most likely near 100%). Shaun also indicated that the Bell Curve equated heritability with explanatory power (e.g. that if heritability is X%, Murray's interpretation would be that genetics explains or causes X% of the IQ gap). Shaun persuasively refuted this. I did not come away with a good understanding of how to think about heritability, but I expect experts would understand the subtlety of this topic better than Charles Murray.
And as Shaun says:
It's not simply that Herrnstein & Murray are breaking the supposed taboo of discussing IQ differences that sparked the backlash. It's that they explicitly linked those differences to a set of policy proposals. This is why The Bell Curve is controversial, because of its political ideas.
For example, that welfare programs should be stopped, which I think Scott has never advocated and which he would, in spirit, oppose. It also seems relevant that Charles Murray seems to use bad logic in his policy reasoning, as (1) this might be another reason the book was so controversial and (2) we're on LessWrong where that sort of thing usually matters.
Having said that, my prior argument that you've been unreasonable does not depend on any of this. A personal analogy: I used to write articles about climate science (ex1, ex2, ex3). This doesn't mean I'm "aligned" with Greta Thunberg and Al Gore or whatever specific person in the climate space you have in mind. I would instantly dislike someone who makes or insists upon claiming my views correspond to those particular people or certain others, as it would be inappropriate as well as untrue. Different people in the climate space do in fact take different positions on various questions other than the single most contested one (and they have different reputations, and I expect that human beings in the field of genetics work the same way). Even if you just say I have a "James Hansen poster on my bedroom wall" I'm going to be suspicious―sure, I respect the guy and I agree with him in some respects, but I'm not familiar with all his positions and what do you know about it anyway? And if you also argue against me by posting a Twitter thread by someone who appears to hate my guts... well... that is at least weirdly aggressive.
I also think that insisting on conflating two different things, after someone has pointed out to you that they are different, is a very anti-rationalist, un-LessWrong thing to do.
Edit: also weirdly aggressive is strong downvoting good faith replies. I don't have the faintest idea why you're acting like this, but it's scary as hell and I hope to Moloch that other people notice too. A downvote is not a counterargument! It's precisely as meaningful as a punch in the face! It doesn't make you right or me wrong, it merely illustrates how humanity is doomed.
I like that HowTruthful uses the idea of (independent) hierarchical subarguments, since I had the same idea. Have you been able to persuade very many to pay for it?
My first thought about it was that the true/false scale should have two dimensions, knowledge & probability:
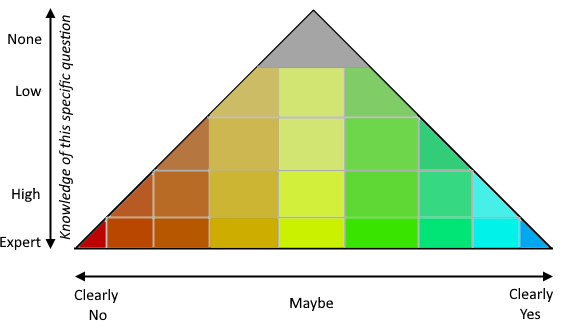
One of the many things I wanted to do on my site was to gather user opinions, and this does that. ✔ I think of opinions as valuable evidence, just not always valuable evidence about the question under discussion (though to the extent people with "high knowledge" really have high knowledge rather than pretending to, it actually is evidence). Incidentally I think it would be interesting to show it as a pyramid but let people choose points outside the pyramid, so users can express their complete certainty about matters they have little knowledge of...
Here are some additional thoughts about how I might enhance HowTruthful if it were my project:
(1) I take it that the statements form a tree? I propose that statements should form a DAG (directed acyclic graph ― a cyclic graph could possibly be useful, but would open a big can of worms). The answer to one question can be relevant to many others.
(2) Especially on political matters, a question/statement can be contested in various ways:
- "ambiguous/depends/conflated/confused": especially if the answer depends on the meaning of the question; this contestation can be divided into just registering a complaint, on the one hand, and proposing a rewording or that it be split into clearer subquestions, on the other hand. Note that if a question is split, the original question can reasonably keep its own page so that when someone finds the question again, they are asked which clarified question they are interested in. If a question is reworded, potentially the same thing can be done, with the original question kept with the possibility of splitting off other meanings in the future.
- "mu": reject the premise of the question (e.g. "has he stopped beating his wife?"), with optional explanation. Also "biased" (the question proposes its own answer), "inflammatory" (unnecessarily politicized language choice), "dog whistle" (special case of politicized language choice). Again one can imagine a UI to propose rewordings.
- sensitive (violence/nudity): especially if pic/vid support is added, some content can be simultaneously informative/useful and censored by default
- spam (irrelevant and inappropriate => deleted), or copyright claim (deleted by law)
(3) The relationship between parent and child statements can be contested, or vary in strength:
- "irrelevant/tangential": the statement has no bearing on its parent. This is like a third category apart from pro/evidence in favor and con/evidence against.
- "miscategorized": this claims that "pro" information should be considered "con" and vice versa. Theoretically, Bayes' rule is useful for deciding which is which.
This could be refined into a second pyramid representing the relationship between the parent and child statements. The Y axis of the pyramid is how relevant the child statement is to the parent, i.e. how correlated the answers to the two questions ought to be. The X axis is pro/con (how the answer to the question affects the answer to the parent question.) Note that this relationship itself could reasonably be a separate subject of debate, displayable on its own page.
(4) Multiple substatements can be combined, possibly with help from an LLM. e.g. user pastes three sources that all make similar points, then the user can select the three statements and click "combine" to LLM-generate a new statement that summarizes whatever the three statements have in common, so that now the three statements are children of the newly generated statement.
(5) I'd like to see automatic calculation of the "truthiness" of parent statements. This offers a lot of value in the form of recursion: if a child statement is disproven, that affects its parent statement, which affects the parent's parent, etc., so that users can get an idea of the likelihood of the parent statement based on how the debate around the great-grandchild statements turned out. Related to that, the answers to two subquestions can be highly correlated with each other, which can decrease the strength of the two points together. For example, suppose I cite two sources that say basically the same thing, but it turns out they're both based on the same study. Then the two sources and the study itself are nearly 100% correlated and can be treated altogether as a single piece of evidence. What UI should be used in relation to this? I have no idea.
(6) Highlighting one-sentence bullet points seems attractive, but I also think Fine Print will be necessary in real-life cases. Users could indicate the beginning of fine print by typing one or two newlines; also the top statement should probably be cut off (expandable) if it is more than four lines or so.
(7) I propose distinguishing evidentiary statements, which are usually but not always leaf nodes in the graph. Whenever you want to link to a source, its associated statement must be a relevant summary, which means that it summarizes information from that source relevant to the current question. Potentially, people can just paste links to make an LLM generate a proposed summary. Example: if the parent statement proposes "Crime rose in Canada in 2022", and in a blank child statement box the user pastes a link to "The root cause': Canada outlines national action plan to fight auto theft", an LLM generates a summary by quoting the article: "According to 2022 industry estimates [...], rates of auto theft had spiked in several provinces compared to the year before. [Fine print] In Quebec, thefts rose by 50 per cent. In Ontario, they were up 34.5 per cent."
(8) Other valuable features would include images, charts, related questions, broader/parent topics, reputation systems, alternative epistemic algorithms...
(9) Some questions need numerical (bounded or unbounded) or qualitative answers; I haven't thought much about those. Edit: wait, I just remembered my idea of "paradigms", i.e. if there are appropriate answers besides "yes/true" and "false/no", these can be expressed as a statement called a "paradigm", and each substatement or piece of available evidence can (and should) be evaluated separately against each paradigm. Example: "What explains the result of the Michelson–Morley experiment of 1881?" Answer: "The theory of Special Relativity". Example: "What is the shape of the Earth?" => "Earth is a sphere", "Earth is an irregularly shaped ellipsoid that is nearly a sphere", "Earth is a flat disc with the North Pole in the center and Antarctica along the edges". In this case users might first place substatements under the paradigm that they match best, but then somehow a process is needed to consider each piece of evidence in the context of each subparadigm. It could also be the case that a substatement doesn't fit any of the current paradigms well. I was thinking that denials are not paradigms, e.g. "What is the main cause of modern global warming?" can be answered with "Volcanoes are..." or "Natural internal variability and increasing solar activity are..." but "Humans are not the cause" doesn't work as an answer ("Nonhumans are..." sounds like it works, but allows that maybe elephants did it). "It is unknown" seems like a special case where, if available evidence is a poor fit to all paradigms, maybe the algorithm can detect that and bring it to users' attention automatically?
Another thing I thought a little bit about was negative/universal statements, e.g. "no country has ever achieved X without doing Y first" (e.g. as evidence that we should do Y to help achieve X). Statements like this are not provable, only disproveable, but it seems like the more people who visit and agree with a statement, without it being disproven, the more likely it is that the statement is true... this may impact epistemic algorithms somehow. I note that when a negative statement is disproven, a replacement can often be offered that is still true, e.g. "only one country has ever achieved X without doing Y first".
(10) LLMs can do various other tasks, like help detect suspicious statements (spam, inflammatory language, etc.), propose child statements, etc. Also there could be a button for sending statements to (AI and conventional) search engines...
Ah, this is nice. I was avoiding looking at my notifications for the last 3 months for fear of a reply by Christian Kl, but actually it turned out to be you two :D
I cannot work on this project right now because busy I'm earning money to be able to afford to fund it (as I don't see how to make money on it). I have a family of 4+, so this is far from trivial. I've been earning for a couple of years, and I will need a couple more years more. I will leave my thoughts on HowTruthful on one of your posts on it.
Yesterday Sam Altman stated (perhaps in response to the Vox article that mentions your decision) that "the team was already in the process of fixing the standard exit paperwork over the past month or so. if any former employee who signed one of those old agreements is worried about it, they can contact me and we'll fix that too."
I notice he did not include you in the list of people who can contact him to "fix that", but it seems worth a try, and you can report what happens either way.
This is practice sentence to you how my brain. I wonder how noticeable differences are to to other people.
That first sentence looks very bad to me; the second is grammatically correct but feels like it's missing an article. If that's not harder for you to understand than for other people, I still think there's a good chance that it could be harder for other dyslexic people to understand (compared to correct text), because I would not expect that the glitches in two different brains with dyslexia are the same in every detail (that said, I don't really understand what dyslexia means, though my dad and brother say they have dyslexia.)
the same word ... foruthwly and fortunly and forrtunaly
You appear to be identifying the word by its beginning and end only, as if it were visually memorized. Were you trained in phonics/phonetics as a child? (I'm confused why anyone ever thought that whole-word memorization was good, but it is popular in some places.) This particular word does have a stranger-than-usual relationship between spelling and pronunciation, though.
> I can do that too. Thankfully. Unless I don’t recognize the sounds.
My buffer seems shorter on unfamiliar sounds. Maybe one second.
> reading out loud got a little obstructive. I started subvocalizing, and that was definitely less fun.
I always read with an "auditory" voice in my head, and I often move my tongue and voicebox to match the voice (especially if I give color to that voice, e.g. if I make it sound like Donald Trump). I can't can't speed-read but if I read fast enough, the "audio" tends to skip and garble some words, but I still mostly detect the meanings of the sentences. My ability to read fast was acquired slowly through much practice, though. I presume that the "subvocalization" I do is an output from my brain rather than necessary for communication within it. However, some people have noticed that sometimes, after I say something, or when I'm processing what someone has told me, I visibly subvocalize the same phrase again. It's unclear whether this is just a weird habit, or whether it helps me process the meaning of the phrase. (the thing where I repeat my own words to myself seems redundant, as I can detect flaws in my own speech the first time without repetition.)
Doublecrux sounds like a better thing than debate, but why such an event should be live? (apart from "it saves money/time not to postprocess")
Yeah, the lyrics didn't sit well with me either so I counterlyricized it.
You guys were using an AI that generated the music fully formed (as PCM), right?
It ticks me off that this is how it works. It's "good", but you see the problems:
Poor audio quality[edit: the YouTube version is poor quality, but the "Suno" versions are not. Why??]- You can't edit the music afterward or re-record the voices
- You had to generate 3,000-4,000 tracks to get 15 good ones
Is there some way to convince AI people to make the following?
- An AI (or two) whose input is a spectral decomposition of PCM music (I'm guessing exponentially-spaced wavelets will be better than FFT) whose job is to separate the music into instrumental tracks + voice track(s) that sum up to the original waveform (and to detect which tracks are voice tracks). Train it using (i) tracker and MIDI archives, which are inherently pre-separated into different instruments, (ii) AI-generated tracker music with noisy instrument timing (the instruments should be high-quality and varied but the music itself probably doesn't have to be good for this to work, so a quick & dirty AI could be used to make training data) and (iii) whatever real-world decompositions can be found.
- An AI that takes these instrumental tracks and decomposes each one into (i) a "music sheet" (a series of notes with stylistic information) and (ii) a set of instrument samples, where each sample is a C-note (middle C ± one or two octaves, drums exempt), with the goal of minimizing the set of instrument samples needed to represent an instrument while representing the input faithfully (if a large number of samples are needed, it's probably a voice track or difficult instrument such as guitar, but some voice tracks are repetitive and can still be deduplicated this way, and in any case the decomposition into notes is important). [alternate version of this AI: use a fixed set of instrument samples, so the AIs job is not to decompose but to select samples, making it more like speech-to-text rather than a decomposition tool. This approach can't handle voice tracks, though]
- Use the MIDI and tracker libraries, together with the output of the first two AIs inferencing on a music library, to train a third AI whose job is to generate tracker music plus a voice track (I haven't thought through how to do the part where lyrics drive the generation process). Train it on the world's top 30,000 songs or whatever.
And voila, the generated music is now editable "in post" and has better sound quality. I also conjecture that if high-quality training data can be found, this AI can either (i) generate better music, on average, than whatever was used for "I Have Been a Good Bing" or (ii) require less compute, because the task it does is simpler. Not only that, while the third AI was the goal, the first pair of AIs are highly useful in their own right and would be much appreciated by artists.
Even if the stars should die in heaven
Our sins can never be undone
No single death will be forgiven
When fades at last the last lit sun.Then in the cold and silent black
As light and matter end
We’ll have ourselves a last look back.And toast an absent friend.
[verse 2]
I heard that song which left me bitter
For all the sins that had been done
But I had thought the wrong way 'bout it
[cuz] I won't be there to see that sun
I noticed then I could let go
Before my own life ends
It could have been much worse you know
Relaxing with my friends
Hard work I leave with them
Someday they'll get it done
A million years too young
For now we'll have some fun
(Edit: Here's a rendition of this that I spliced together from two AI generations of it)
I guess you could try it and see if you reach wrong conclusions, but that only works isn't so wired up with shortcuts that you cannot (or are much less likely to) discover your mistakes.
I've been puzzling over why EY's efforts to show the dangers of AGI (most notably this) have been unconvincing enough so that other experts (e.g. Paul Christiano) and, in my experience, typical rationalists have not adopted p(doom) > 90% like EY, or even > 50%. I was unconvinced because he simply didn't present a chain of reasoning that shows what he's trying to show. Rational thinking is a lot like math: a single mistake in a chain of reasoning can invalidate the whole conclusion. Failure to generate a complete chain of reasoning is a sign that the thinking isn't rational. And failure to communicate a complete chain of reasoning, as in this case, should fail to convince people (except if the audience can mentally reconstruct the missing information).
I read all six "tomes" of Rationality: A-Z and I don't recall EY ever writing about the importance of having a solid and complete chain (or graph) of reasoning―but here is a post about the value of shortcuts (if you can pardon the strawman; I'm using the word "shortcut" as a shortcut). There's no denying that shortcuts can have value, but only if it leads to winning, which for most of us including EY includes having true beliefs, which in turn requires an ability to generate solid and complete chains of reasoning. If you used shortcuts to generate it, that's great insofar as it generates correct results, but mightn't shortcuts make your reasoning less reliable than it first appears? When it comes to AI safety, EY's most important cause, I've seen a shortcut-laden approach (in his communication, if not his reasoning) and wasn't convinced, so I'd like to see him take it slower and give us a more rigorous and clear case for AI doom ― one that either clearly justifies a very high near-term catastrophic risk assessment, or admits that it doesn't.
I think EY must have a mental system that is far above average, but from afar it seems not good enough.
On the other hand, I've learned a lot about rationality from EY that I didn't already know, and perhaps many of the ideas he came up with are a product of this exact process of identifying necessary cognitive work and casting off the rest. Notable if true! But in my field I, too, have had various unique ideas that no one else ever presented, and I came about it from a different angle: I'm always looking for the (subjectively) "best" solutions to problems. Early in my career, getting the work done was never enough, I wanted my code to be elegant and beautiful and fast and generalized too. Seems like I'd never accept the first version, I'd always find flaws and change it immediately after, maybe more than once. My approach (which I guess earns the boring label 'perfectionism') wasn't fast, but I think it built up a lot of good intuitions that many other developers just don't have. Likewise in life in general, I developed nuanced thinking and rationalist-like intuitions without ever hearing about rationalism. So I am fairly satisfied with plain-old perfectionism―reaching conclusions faster would've been great, but I'm uncertain whether I could've or would've found a process of doing that such that my conclusions would've been as correct. (I also recommend always thinking a lot, but maybe that goes without saying around here)
I'm reminded of a great video about two ways of thinking about math problems: a slick way that finds a generalized solution, and a more meandering, exploratory way way that looks at many specific cases and examples. The slick solutions tend to get way more attention, but slower processes are way more common when no one is looking, and famous early mathematicians haven't shied away from long and even tedious work. I feel like EY's saying "make it slick and fast!" and to be fair, I probably should've worked harder at developing Slick Thinking, but my slow non-slick methods also worked pretty well.
Speaking for myself: I don't prefer to be alone or tend to hide information about myself. Quite the opposite; I like to have company but rare is the company that likes to have me, and I like sharing, though it's rare that someone cares to hear it. It's true that I "try to be independent" and "form my own opinions", but I think that part of your paragraph is easy to overlook because it doesn't sound like what the word "avoidant" ought to mean. (And my philosophy is that people with good epistemics tend to reach similar conclusions, so our independence doesn't necessarily imply a tendency to end up alone in our own school of thought, let alone prefer it that way.)
Now if I were in Scott's position? I find social media enemies terrifying and would want to hide as much as possible from them. And Scott's desire for his name not to be broadcast? He's explained it as related to his profession, and I don't see why I should disbelieve that. Yet Scott also schedules regular meetups where strangers can come, which doesn't sound "avoidant". More broadly, labeling famous-ish people who talk frequently online as "avoidant" doesn't sound right.
Also, "schizoid" as in schizophrenia? By reputation, rationalists are more likely to be autistic, which tends not to co-occur with schizophrenia, and the ACX survey is correlated with this reputation. (Could say more but I think this suffices.)
Scott tried hard to avoid getting into the race/IQ controversy. Like, in the private email LGS shared, Scott states "I will appreciate if you NEVER TELL ANYONE I SAID THIS". Isn't this the opposite of "it's self-evidently good for the truth to be known"? And yes there's a SSC/ACX community too (not "rationalist" necessarily), but Metz wasn't talking about the community there.
My opinion as a rationalist is that I'd like the whole race/IQ issue to f**k off so we don't have to talk or think about it, but certain people like to misrepresent Scott and make unreasonable claims, which ticks me off, so I counterargue, just as I pushed a video by Shaun once when I thought somebody on ACX sounded a bit racist to me on the race/IQ topic.
Scott and myself are consequentialists. As such, it's not self-evidently good for the truth to be known. I think some taboos should be broached, but not "self-evidently" and often not by us. But if people start making BS arguments against people I like? I will call BS on that, even if doing so involves some discussion of the taboo topic. But I didn't wake up this morning having any interest in doing that.
Huh? Who defines racism as cognitive bias? I've never seen that before, so expecting Scott in particular to define it as such seems like special pleading.
What would your definition be, and why would it be better?
Scott endorses this definition:
Definition By Motives: An irrational feeling of hatred toward some race that causes someone to want to hurt or discriminate against them.
Setting aside that it says "irrational feeling" instead of "cognitive bias", how does this "tr[y] to define racism out of existence"?
I think about it differently. When Scott does not support an idea, but discusses or allows discussion of it, it's not "making space for ideas" as much as "making space for reasonable people who have ideas, even when they are wrong". And I think making space for people to be wrong sometimes is good, important and necessary. According to his official (but confusing IMO) rules, saying untrue things is a strike against you, but insufficient for a ban.
Also, strong upvote because I can't imagine why this question should score negatively.
Scott had every opportunity to say "actually, I disagree with Murray about..." but he didn't, because he agrees with Murray
[citation needed] for those last four words. In the paragraph before the one frankybegs quoted, Scott said:
Some people wrote me to complain that I handled this in a cowardly way - I showed that the specific thing the journalist quoted wasn’t a reference to The Bell Curve, but I never answered the broader question of what I thought of the book. They demanded I come out and give my opinion openly. Well, the most direct answer is that I've never read it.
Having never read The Bell Curve, it would be uncharacteristic of him to say "I disagree with Murray about [things in The Bell Curve]", don't you think?
Strong disagree based on the "evidence" you posted for this elsewhere in this thread. It consists one-half of some dude on Twitter asserting that "Scott is a racist eugenics supporter" and retweeting other people's inflammatory rewordings of Scott, and one-half of private email from Scott saying things like
HBD is probably partially correct or at least very non-provably not-correct
It seems gratuitous for you to argue the point with such biased commentary. And what Scott actually says sounds like his judgement of ... I'm not quite sure what, since HBD is left without a definition, but it sounds a lot like the evidence he mentioned years later from
- a paper by scientists Mark Snyderman and Stanley Rothman, who, I notice, wrote this book with "an analysis of the reporting on intelligence testing by the press and television in the US for the period 1969–1983, as well as an opinion poll of 207 journalists and 86 science editors about IQ testing", and
- "Survey of expert opinion on intelligence: Intelligence research, experts' background, controversial issues, and the media"
(yes, I found the links I couldn't find earlier thanks to a quote by frankybegs from this post which―I was mistaken!―does mention Murray and The Bell Curve because he is responding to Cade Metz and other critics).
This sounds like his usual "learn to love scientific consensus" stance, but it appears you refuse to acknowledge a difference between Scott privately deferring to expert opinion, on one hand, and having "Charles Murray posters on his bedroom wall".
Almost the sum total of my knowledge of Murray's book comes from Shaun's rebuttal of it, which sounded quite reasonable to me. But Shaun argues that specific people are biased and incorrect, such as Richard Lynn and (duh) Charles Murray. Not only does Scott never cite these people, what he said about The Bell Curve was "I never read it". And why should he? Murray isn't even a geneticist!
So it seems the secret evidence matches the public evidence, does not show that "Scott thinks very highly of Murray", doesn't show that he ever did, doesn't show that he is "aligned" with Murray etc. How can Scott be a Murray fanboy without even reading Murray?
You saw this before:
I can't find any expert surveys giving the expected result that they all agree this is dumb and definitely 100% environment and we can move on (I'd be very relieved if anybody could find those, or if they could explain why the ones I found were fake studies or fake experts or a biased sample, or explain how I'm misreading them or that they otherwise shouldn't be trusted. If you have thoughts on this, please send me an email). I've vacillated back and forth on how to think about this question so many times, and right now my personal probability estimate is "I am still freaking out about this, go away go away go away". And I understand I have at least two potentially irresolveable biases on this question: one, I'm a white person in a country with a long history of promoting white supremacy; and two, if I lean in favor then everyone will hate me, and use it as a bludgeon against anyone I have ever associated with, and I will die alone in a ditch and maybe deserve it.
You may just assume Scott is lying (or as you put it, "giving a maximally positive spin on his own beliefs"), but again I think you are conflating. To suppose experts in a field have expertise in that field isn't merely different from "aligning oneself" with a divisive conservative political scientist whose book one has never read ― it's really obviously different how are you not getting this??
he definitely thinks this
He definitely thinks what, exactly?
Anyway, the situation is like: X is writing a summary about author Y who has written 100 books, but pretty much ignores all those books in favor of digging up some dirt on what Y thinks about a political topic Z that Y almost never discusses (and then instead of actually mentioning any of that dirt, X says Y "aligned himself" with a famously controversial author on Z.)
It's really weird to go HOW DARE YOU when someone says something you know is true about you, and I was always unnerved by this reaction from Scott's defenders
It's not true though. Perhaps what he believes is similar to what Murray believes, but he did not "align himself" with Murray on race/IQ. Like, if an author in Alabama reads the scientific literature and quietly comes to a conclusion that humans cause global warming, it's wrong for the Alabama News to describe this as "author has a popular blog, and he has aligned himself with Al Gore and Greta Thunberg!" (which would tend to encourage Alabama folks to get out their pitchforks 😉) (Edit: to be clear, I've read SSC/ACX for years and the one and only time I saw Scott discuss race+IQ, he linked to two scientific papers, didn't mention Murray/Bell Curve, and I don't think it was the main focus of the post―which makes it hard to find it again.)