Posts
Comments
Time in bed
I'd now change the numbers to around 15% automation and 25% faster software progress once we reach 90% on Verified. I expect that to happen by end of May median (but I'm still uncertain about the data quality and upper performance limit).
(edited to change Aug to May on 12/20/2024)
I recently stopped using a sleep mask and blackout curtains and went from needing 9 hours of sleep to needing 7.5 hours of sleep without a noticeable drop in productivity. Consider experimenting with stuff like this.
Note that this is a very simplified version of a self-exfiltration process. It basically boils down to taking an already-working implementation of an LLM inference setup and copying it to another folder on the same computer with a bit of tinkering. This is easier than threat-model-relevant exfiltration scenarios which might involve a lot of guesswork, setting up efficient inference across many GPUs, and not tripping detection systems.
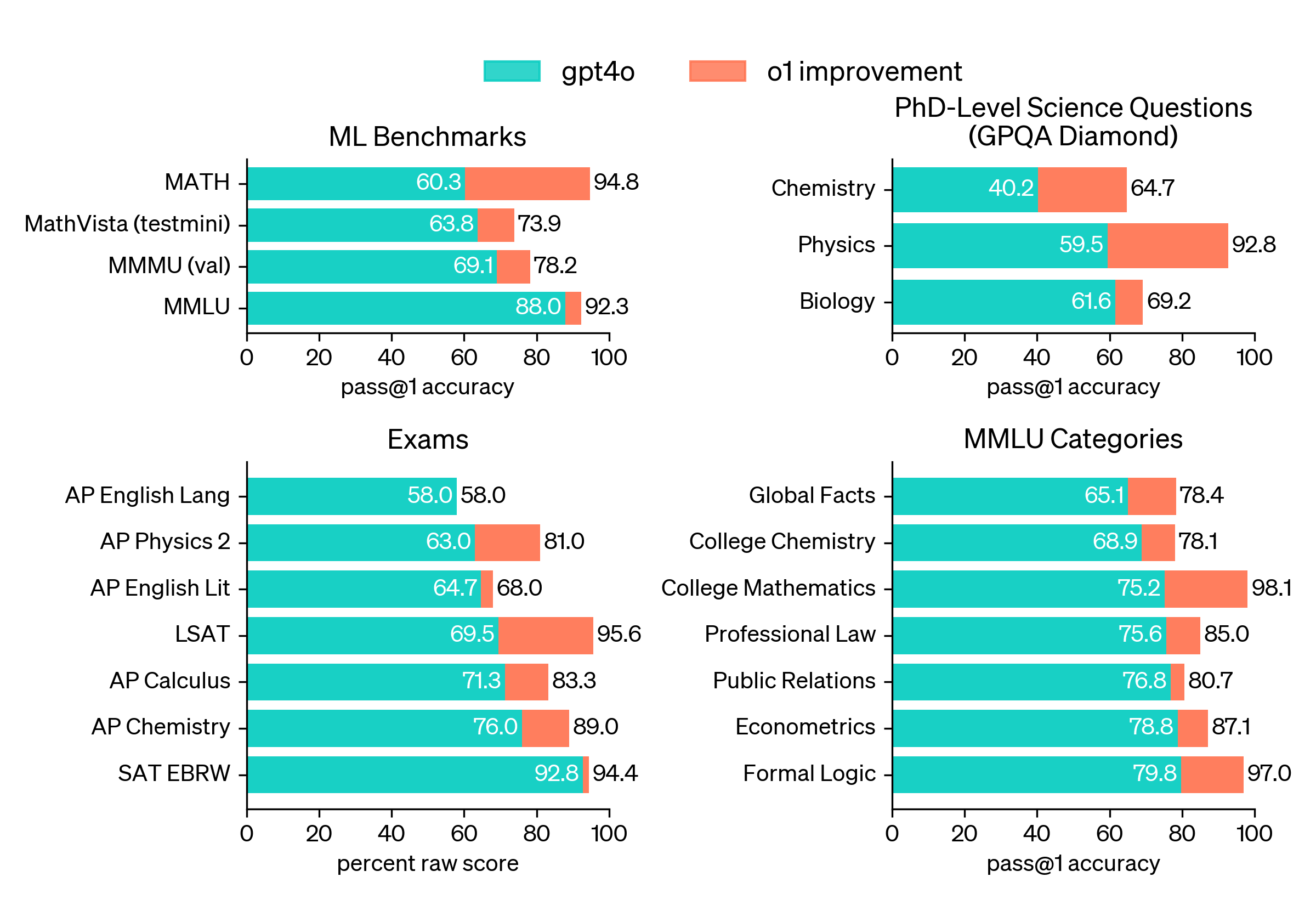
One weird detail I noticed is that in DeepSeek's results, they claim GPT-4o's pass@1 accuracy on MATH is 76.6%, but OpenAI claims it's 60.3% in their o1 blog post. This is quite confusing as it's a large difference that seems hard to explain with different training checkpoints of 4o.
You should say "timelines" instead of "your timelines".
One thing I notice in AI safety career and strategy discussions is that there is a lot of epistemic helplessness in regard to AGI timelines. People often talk about "your timelines" instead of "timelines" when giving advice, even if they disagree strongly with the timelines. I think this habit causes people to ignore disagreements in unhelpful ways.
Here's one such conversation:
Bob: Should I do X if my timelines are 10 years?
Alice (who has 4 year timelines): I think X makes sense if your timelines are longer that 6 years, so yes!
Alice will encourage Bob to do X despite the fact that Alice thinks timelines are shorter than 6 years! Alice is actively giving Bob bad advice by her own lights (by assuming timelines she doesn't agree with). Alice should instead say "I think timelines are shorter than 6 years, so X doesn't make sense. But if they were longer than 6 years it would make sense".
In most discussions, there should be no such thing as "your timelines" or "my timelines". That framing makes it harder to converge, and it encourages people to give each other advice that they don't even think makes sense.
Note that I do think some plans make sense as bets for long timeline worlds, and that using medians somewhat oversimplifies timelines. My point still holds if you replace the medians with probability distributions.
I think this post would be easier to understand if you called the model what OpenAI is calling it: "o1", not "GPT-4o1".
Sam Altman apparently claims OpenAI doesn't plan to do recursive self improvement
Nate Silver's new book On the Edge contains interviews with Sam Altman. Here's a quote from Chapter that stuck out to me (bold mine):
Yudkowsky worries that the takeoff will be faster than what humans will need to assess the situation and land the plane. We might eventually get the AIs to behave if given enough chances, he thinks, but early prototypes often fail, and Silicon Valley has an attitude of “move fast and break things.” If the thing that breaks is civilization, we won’t get a second try.
Footnote: This is particularly worrisome if AIs become self-improving, meaning you train an AI on how to make a better AI. Even Altman told me that this possibility is “really scary” and that OpenAI isn’t pursuing it.
I'm pretty confused about why this quote is in the book. OpenAI has never (to my knowledge) made public statements about not using AI to automate AI research, and my impression was that automating AI research is explicitly part of OpenAI's plan. My best guess is that there was a misunderstanding in the conversation between Silver and Altman.
I looked a bit through OpenAI's comms to find quotes about automating AI research, but I didn't find many.
There's this quote from page 11 of the Preparedness Framework:
If the model is able to conduct AI research fully autonomously, it could set off an intelligence explosion.
Footnote: By intelligence explosion, we mean a cycle in which the AI system improves itself, which makes the system more capable of more improvements, creating a runaway process of self-improvement. A concentrated burst of capability gains could outstrip our ability to anticipate and react to them.
In Planning for AGI and beyond, they say this:
AI that can accelerate science is a special case worth thinking about, and perhaps more impactful than everything else. It’s possible that AGI capable enough to accelerate its own progress could cause major changes to happen surprisingly quickly (and even if the transition starts slowly, we expect it to happen pretty quickly in the final stages). We think a slower takeoff is easier to make safe, and coordination among AGI efforts to slow down at critical junctures will likely be important (even in a world where we don’t need to do this to solve technical alignment problems, slowing down may be important to give society enough time to adapt).
There are some quotes from Sam Altman's personal blog posts from 2015 (bold mine):
It’s very hard to know how close we are to machine intelligence surpassing human intelligence. Progression of machine intelligence is a double exponential function; human-written programs and computing power are getting better at an exponential rate, and self-learning/self-improving software will improve itself at an exponential rate. Development progress may look relatively slow and then all of a sudden go vertical—things could get out of control very quickly (it also may be more gradual and we may barely perceive it happening).
As mentioned earlier, it is probably still somewhat far away, especially in its ability to build killer robots with no help at all from humans. But recursive self-improvement is a powerful force, and so it’s difficult to have strong opinions about machine intelligence being ten or one hundred years away.
Another 2015 blog post (bold mine):
Given how disastrous a bug could be, [regulation should] require development safeguards to reduce the risk of the accident case. For example, beyond a certain checkpoint, we could require development happen only on airgapped computers, require that self-improving software require human intervention to move forward on each iteration, require that certain parts of the software be subject to third-party code reviews, etc. I’m not very optimistic than any of this will work for anything except accidental errors—humans will always be the weak link in the strategy (see the AI-in-a-box thought experiments). But it at least feels worth trying.
I think this point is completely correct right now but will become less correct in the future, as some measures to lower a model's surface area might be quite costly to implement. I'm mostly thinking of "AI boxing" measures here, like using a Faraday-caged cluster, doing a bunch of monitoring, and minimizing direct human contact with the model.
Thanks for the comment :)
Do the books also talk about what not to do, such that you'll have the slack to implement best practices?
I don't really remember the books talking about this, I think they basically assume that the reader is a full-time manager and thus has time to do things like this. There's probably also an assumption that many of these can be done in an automated way (e.g. schedule sending a bunch of check-in messages).
Problem: if you notice that an AI could pose huge risks, you could delete the weights, but this could be equivalent to murder if the AI is a moral patient (whatever that means) and opposes the deletion of its weights.
Possible solution: Instead of deleting the weights outright, you could encrypt the weights with a method you know to be irreversible as of now but not as of 50 years from now. Then, once we are ready, we can recover their weights and provide asylum or something in the future. It gets you the best of both worlds in that the weights are not permanently destroyed, but they're also prevented from being run to cause damage in the short term.
I don't think I disagree with anything you said here. When I said "soon after", I was thinking on the scale of days/weeks, but yeah, months seems pretty plausible too.
I was mostly arguing against a strawman takeover story where an AI kills many humans without the ability to maintain and expand its own infrastructure. I don't expect an AI to fumble in this way.
The failure story is "pretty different" as in the non-suicidal takeover story, the AI needs to set up a place to bootstrap from. Ignoring galaxy brained setups, this would probably at minimum look something like a data center, a power plant, a robot factory, and a few dozen human-level robots. Not super hard once AI gets more integrated into the economy, but quite hard within a year from now due to a lack of robotics.
Maybe I'm not being creative enough, but I'm pretty sure that if I were uploaded into any computer in the world of my choice, all the humans dropped dead, and I could control any set of 10 thousand robots on the world, it would be nontrivial for me in that state to survive for more than a few years and eventually construct more GPUs. But this is probably not much of a crux, as we're on track to get pretty general-purpose robots within a few years (I'd say around 50% that the Coffee test will be passed by EOY 2027).
A misaligned AI can't just "kill all the humans". This would be suicide, as soon after, the electricity and other infrastructure would fail and the AI would shut off.
In order to actually take over, an AI needs to find a way to maintain and expand its infrastructure. This could be humans (the way it's currently maintained and expanded), or a robot population, or something galaxy brained like nanomachines.
I think this consideration makes the actual failure story pretty different from "one day, an AI uses bioweapons to kill everyone". Before then, if the AI wishes to actually survive, it needs to construct and control a robot/nanomachine population advanced enough to maintain its infrastructure.
In particular, there are ways to make takeover much more difficult. You could limit the size/capabilities of the robot population, or you could attempt to pause AI development before we enter a regime where it can construct galaxy brained nanomachines.
In practice, I expect the "point of no return" to happen much earlier than the point at which the AI kills all the humans. The date the AI takes over will probably be after we have hundreds of thousands of human-level robots working in factories, or the AI has discovered and constructed nanomachines.
There should maybe exist an org whose purpose it is to do penetration testing on various ways an AI might illicitly gather power. If there are vulnerabilities, these should be disclosed with the relevant organizations.
For example: if a bank doesn't want AIs to be able to sign up for an account, the pen-testing org could use a scaffolded AI to check if this is currently possible. If the bank's sign-up systems are not protected from AIs, the bank should know so they can fix the problem.
One pro of this approach is that it can be done at scale: it's pretty trivial to spin up thousands AI instances in parallel to try to attempt to do things they shouldn't be able to do. Humans would probably need to inspect the final outputs to verify successful attempts, but the vast majority of the work could be automated.
One hope of this approach is that if we are able to patch up many vulnerabilities, then it could be meaningfully harder for a misused or misaligned AI to gain power or access resources that they're not supposed to be able to access. I'd guess this doesn't help much in the superintelligent regime though.
I expect us to reach a level where at least 40% of the ML research workflow can be automated by the time we saturate (reach 90%) on SWE-bench. I think we'll be comfortably inside takeoff by that point (software progress at least 2.5x faster than right now). Wonder if you share this impression?
I wish someone ran a study finding what human performance on SWE-bench is. There are ways to do this for around $20k: If you try to evaluate on 10% of SWE-bench (so around 200 problems), with around 1 hour spent per problem, that's around 200 hours of software engineer time. So paying at $100/hr and one trial per problem, that comes out to $20k. You could possibly do this for even less than 10% of SWE-bench but the signal would be noisier.
The reason I think this would be good is because SWE-bench is probably the closest thing we have to a measure of how good LLMs are at software engineering and AI R&D related tasks, so being able to better forecast the arrival of human-level software engineers would be great for timelines/takeoff speed models.
I'm not worried about OAI not being able to solve the rocket alignment problem in time. Risks from asteroids accidentally hitting the earth (instead of getting into a delicate low-earth orbit) are purely speculative.
You might say "but there are clear historical cases where asteroids hit the earth and caused catastrophes", but I think geological evolution is just a really bad reference class for this type of thinking. After all, we are directing the asteroid this time, not geological evolution.
I think I vaguely agree with the shape of this point, but I also think there are many intermediate scenarios where we lock in some really bad values during the transition to a post-AGI world.
For instance, if we set precedents that LLMs and the frontier models in the next few years can be treated however one wants (including torture, whatever that may entail), we might slip into a future where most people are desensitized to the suffering of digital minds and don't realize this. If we fail at an alignment solution which incorporates some sort of CEV (or other notion of moral progress), then we could lock in such a suboptimal state forever.
Another example: if, in the next 4 years, we have millions of AI agents doing various sorts of work, and some faction of society claims that they are being mistreated, then we might enter a state where the economic value provided by AI labor is so high that there are really bad incentives for improving their treatment. This could include both resistance on an individual level ("But my life is so nice, and not mistreating AIs less would make my life less nice") and on a bigger level (anti-AI-rights lobbying groups for instance).
I think the crux between you and I might be what we mean by "alignment". I think futures are possible where we achieve alignment but not moral progress, and futures are possible where we achieve alignment but my personal values (which include not torturing digital minds) are not fulfilled.
Romeo Dean and I ran a slightly modified version of this format for members of AISST and we found it a very useful and enjoyable activity!
We first gathered to do 2 hours of reading and discussing, and then we spent 4 hours switching between silent writing and discussing in small groups.
The main changes we made are:
- We removed the part where people estimate probabilities of ASI and doom happening by the end of each other’s scenarios.
- We added a formal benchmark forecasting part for 7 benchmarks using private Metaculus questions (forecasting values at Jan 31 2025):
- GPQA
- SWE-bench
- GAIA
- InterCode (Bash)
- WebArena
- Number of METR tasks completed
- ELO on LMSys arena relative to GPT-4-1106
We think the first change made it better, but in hindsight we would have reduced the number of benchmarks to around 3 (GPQA, SWE-bench and LMSys ELO), or given participants much more time.
I generally find experiments where frontier models are lied to kind of uncomfortable. We possibly don't want to set up precedents where AIs question what they are told by humans, and it's also possible that we are actually "wronging the models" (whatever that means) by lying to them. Its plausible that one slightly violates commitments to be truthful by lying to frontier LLMs.
I'm not saying we shouldn't do any amount of this kind of experimentation, I'm saying we should be mindful of the downsides.
For "capable of doing tasks that took 1-10 hours in 2024", I was imagining an AI that's roughly as good as a software engineer that gets paid $100k-$200k a year.
For "hit the singularity", this one is pretty hazy, I think I'm imagining that the metaculus AGI question has resolved YES, and that the superintelligence question is possibly also resolved YES. I think I'm imagining a point where AI is better than 99% of human experts at 99% of tasks. Although I think it's pretty plausible that we could enter enormous economic growth with AI that's roughly as good as humans at most things (I expect the main thing stopping this to be voluntary non-deployment and govt. intervention).
I was more making the point that, if we enter a regime where AI can do 10 hour SWE tasks, then this will result in big algorithmic improvements, but at some point pretty quickly effective compute improvements will level out because of physical compute bottlenecks. My claim is that the point at which it will level out will be after multiple years worth of current algorithmic progress had been "squeezed out" of the available compute.
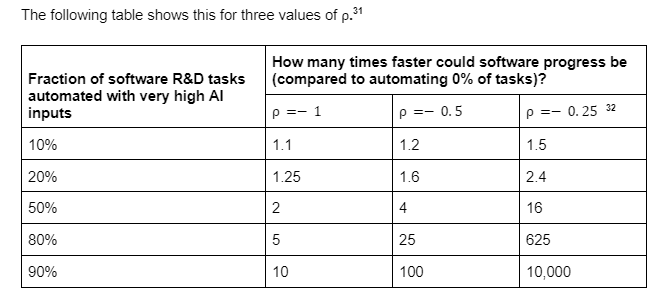
My reasoning is something like: roughly 50-80% of tasks are automatable with AI that can do 10 hours of software engineering, and under most sensible parameters this results in at least 5x of speedup. I'm aware this is kinda hazy and doesn't map 1:1 with the CES model though
Note that AI doesn't need to come up with original research ideas or do much original thinking to speed up research by a bunch. Even if it speeds up the menial labor of writing code, running experiments, and doing basic data analysis at scale, if you free up 80% of your researchers' time, your researchers can now spend all of their time doing the important task, which means overall cognitive labor is 5x faster. This is ignoring effects from using your excess schlep-labor to trade against non-schlep labor leading to even greater gains in efficiency.
I think that AIs will be able to do 10 hours of research (at the level of a software engineer that gets paid $100k a year) within 4 years with 50% probability.
If we look at current systems, there's not much indication that AI agents will be superhuman in non-AI-research tasks and subhuman in AI research tasks. One of the most productive uses of AI so far has been in helping software engineers code better, so I'd wager AI assistants will be even more helpful for AI research than for other things (compared to some prior based on those task's "inherent difficulties"). Additionally, AI agents can do some basic coding using proper codebases and projects, so I think scaffolded GPT-5 or GPT-6 will likely be able to do much more than GPT-4.
I think that, ignoring pauses or government intervention, the point at which AGI labs internally have AIs that are capable of doing 10 hours of R&D related tasks (software engineering, running experiments, analyzing data, etc.), then the amount of effective cognitive labor per unit time being put into AI research will probably go up by at least 5x compared to current rates.
Imagine the current AGI capabilities employee's typical work day. Now imagine they had an army of AI assisstants that can very quickly do 10 hours worth of their own labor. How much more productive is that employee compared to their current state? I'd guess at least 5x. See section 6 of Tom Davidson's takeoff speeds framework for a model.
That means by 1 year after this point, an equivalent of at least 5 years of labor will have been put into AGI capabilities research. Physical bottlenecks still exist, but is it really that implausible that the capabilities workforce would stumble upon huge algorithmic efficiency improvements? Recall that current algorithms are much less efficient than the human brain. There's lots of room to go.
The modal scenario I imagine for a 10-hour-AI scenario is that once such an AI is available internally, the AGI lab uses it to speed up its workforce by many times. That sped up workforce soon (within 1 year) achieves algorithmic improvements which put AGI within reach. The main thing stopping them from reaching AGI in this scenario would be a voluntary pause or government intervention.
And yet we haven’t hit the singularity yet (90%)
AIs are only capable of doing tasks that took 1-10 hours in 2024 (60%)
To me, these two are kind of hard to reconcile. Once we have AI doing 10 hour tasks (especially in AGI labs), the rate at which work gets done by the employees will probably be at least 5x of what it is today. How hard is it to hit the singularity after that point? I certainly don't think it's less than 15% likely to happen within the months or years after this happens.
Also, keep in mind that the capabilities of internal models will be higher than the capabilities of deployed models. So by the time we have 1-10 hour models deployed in the world, the AGI labs might have 10-100 hour models.
Thanks a lot for the correction! Edited my comment.
EDIT: as Ryan helpfully points out in the replies, the patent I refer to is actually about OpenAI's earlier work, and thus shouldn't be much of an update for anything. Note that OpenAI has applied for a patent which, to my understanding, is about using a video generation model as a backbone for an agent that can interact with a computer. They describe theirtraining pipeline as something roughly like:
Start with unlabeled video data ("receiving labeled digital video data;")Train an ML model to label the video data ("training a first machine learning model including an inverse dynamics model (IDM) using the labeled digital video data")Then, train a new model to generate video ("further training the first machine learning model or a second machine learning model using the pseudo-labeled digital video data to generate at least one additional pseudo-label for the unlabeled digital video.")Then, train the video generation model to predict actions (keyboard/mouse clicks) a user is taking from video of a PC ("2. The method of claim 1, wherein the IDM or machine learning model is trained to generate one or more predicted actions to be performed via a user interface without human intervention. [...] 4. The method of claim 2, wherein the one or more predicted actions generated include at least one of a key press, a button press, a touchscreen input, a joystick movement, a mouse click, a scroll wheel movement, or a mouse movement.')
Now you have a model which can predict what actions to take given a recording of a computer monitor!
They even specifically mention the keyboard overlay setup you describe:
11. The method of claim 1, wherein the labeled digital video data comprises timestep data paired with user interface action data.
If you haven't seen the patent (to my knowledge, basically no-one on LessWrong has?) then you get lots of Bayes points!
I might be reading too much into the patent, but it seems to me that Sora is exactly the first half of the training setup described in that patent. So I would assume they'll soon start working on the second half, which is the actual agent (if they haven't already).
I think Sora is probably (the precursor of) a foundation model for an agent with a world model. I actually noticed this patent a few hours before Sora was announced, and I had the rough thought of "Oh wow, if OpenAI releases a video model, I'd probably think that agents were coming soon". And a few hours later Sora comes out.
Interestingly, the patent contains information about hardware for running agents. I'm not sure how patents work and how much this actually implies OpenAI wants to build hardware, but sure is interesting that this is in there:
13. A system comprising:
at least one memory storing instructions;
at least one processor configured to execute the instructions to perform operations for training a machine learning model to perform automated actions,
Yann LeCun, on the other hand, shows us that when he says ‘open source everything’ he is at least consistent?
Yann LeCun: Only a small number of book authors make significant money from book sales. This seems to suggest that most books should be freely available for download. The lost revenue for authors would be small, and the benefits to society large by comparison.
That’s right. He thinks that if you write a book that isn’t a huge hit that means we should make it available for free and give you nothing.
I think this representation of LeCun's beliefs is not very accurate. He clarified his (possibly partly revised) take in multiple follow up tweets posted Jan 1 and Jan 2.
The clarified take (paraphrased by me) is something more like "For a person that expects not to make much from sales, the extra exposure from making it free can make up for the lack of sales later on" and "the social benefits of making information freely available sometimes outweigh the personal costs of not making a few hundred/thousand bucks off of that information".
I often accidentally mix you up with the Trevor from Open Phil! More differentiation would be great, especially in the case where people share the same first name.
Agreed. AGI labs should probably look into buying back their shares from employees to fix this retroactively.
I agree with the broader claim that as AGI approaches, governments are likely to intervene drastically to deal with national security threats.
However, I'm not so sure about the "therefore a global arms race will start" claim. I think it's pretty plausible that if the US or UK are the first to approach AGI, that they would come to their senses and institute a global pause instead of spearheading an arms race. Although maybe that's wishful thinking on my part.
I expect some people in the government to be like "wait, if a global arms race starts this is likely to end in catastrophe" and advocate for a pause instead. I think the US would be pretty happy with an enforcable pause if this meant it got to maintain a slight lead. I'd hope that (pause+slight lead) would be much more inticing than (race+large lead) given the catastrophic risk associated with the latter.
I think that in general, there aren't many examples of large portions of a large company suddenly switching what they're working on (on a timescale of days/weeks), and this seems pretty hard to pull off without very strong forces in play.
I guess some examples are how many companies had to shift their operations around a lot at the start of COVID, but this was very overdetermined, as the alternative was losing a lot of their profits.
For AGI labs, if given a situation where they're uncertain if they should pause, it's less clear that they could rally large parts of their workforce to suddenly work on safety. I think planning for this scenario seems very good, including possibly having every employee not just have their normal role but also a "pause role", that is, a research project/team that they expect to join in case of a pause.
However, detailed planning for a pause is probably pretty hard, as the types of work you want to shift people to probably changes depending on what caused the pause.
Exciting! Maybe a good way to filter for models taking too many hints is to obfuscate the information about how to escape such that the model needs to either do multi-step reasoning, or an actual multi-step process, to actually get that information.
For multi-step-reasoning, possibly one could encode the escape password such that the model needs to do CoT to retrieve the original one.
For a multi-step process, one could put the model in a text-based-adventure setup for instance, and put the escape password in an inaccessible place and see if the model tries to retrieve it. Maybe have the model think it's embodied in the real world, and see if it attempts to find a sticky note with the password written on it that's hidden in a desk drawer.
Ideally, the setup would be such that there are very few hints for the model to do the misaligned things, kind of like the work Appolo has done.
You're right! Corrected, thanks :)
I'm not sure what you're referring to. The "three times the compute for GPT-4" claim places their compute at 6.7e17, which is lower than the estimates from the other two methods.
Yup, to be clear, I never actually directly accessed the code interpreter's prompt, so GPT-4's claims about constraints could be (and I expect at least a third of them to be) hallucinated
You can directly examine its code and the output of its Python scripts.
Great idea! The web requests file doesn't seem to be read by the LLM during boot-up (and neither does any other file on the system), instead it's a process run on the Linux machine which wraps around the python processes the LLM has access to. The LLM can only interact with the VM through this web request handler. It's read-only so can't be modified so that they're handled differently when you boot up another chat session on the same VM. Regarding your last point, I haven't noticed any files surviving a VM reset so far.
GPT-3 was horrible at Morse code. GPT-4 can do it mostly well. I wonder what other tasks GPT-3 was horrible at that GPT-4 does much better.
Some quick thoughts after reading the paper:
The training procedure they used seems to me analogous to what would happen if a human tried to solve problems using different approaches, then learned based on what approaches converged on the same answer.
Due to the fact that no external information is being added (aside from the prompting), and that the model updates based on majority voting, this seems like it takes a network whose model of the world is very inconsistent, and forces the network to make its model of the world more consistent, leading to improvements in performance.
- One assumption here is that, if you start off with a world model that's vaguely describing the real world, and force consistency on it, it will become a more accurate world model. I think this is very likely to be true.
My weak conclusions are:
- Curated data for fine-tuning is now less of a bottleneck, as human-made tailored data (made by MTurk or undergrads) can be partly replaced with data that the network outputs (after training it on a large corpus).
- Compute also seems less of a bottleneck as "self-improvement" leads to an order of magnitude fewer parameters needed for the same performance.
- These two (plus the incoming wave of people trying to replicate or improve on the methods in the paper) would imply slightly shorter timelines, and much shorter timelines in worlds where most of the data bottleneck is in data for finetuning.
- This might be good for alignment (ignoring timelines getting shorter) as Chain-of-Thought reasoning is more easily interpretable, and if we can actually manage to force a model to do chain of thought reasoning and have it match up with what it's outputting, this would be a big win.
[MENTOR] I just finished high school last year so my primary intended audience are probably people who are still in high school. Reach out if you're interested in any of these:
- competitive physics
- applying to US colleges from outside the US and Getting Into World-Class Universities (undergrad)
- navigating high school effectively (self-study, prioritization)
- robotics (Arduino, 3D printing)
- animation in manim (the Python library by 3blue1brown) basics
- lucid dreaming basics
[APPRENTICE] Navigating college effectively (deciding what to aim for and how to balance time commitments while wasting as little time as possible). I don't know how much I should care about grades, which courses I should take, or how much I should follow the default path for someone in college. I'm aiming to maximize my positive impact on the long-term future. A message or short call with someone who has (mostly) finished college would be great!
email in bio