Prisoner's Dilemma Tournament Results
post by prase · 2011-09-06T00:46:35.112Z · LW · GW · Legacy · 171 commentsContents
The Zoo of Strategies The Round-Robin Tournament The Evolutionary1 Tournament The Control Group Final Remarks None 171 comments
About two weeks ago I announced an open competition for LessWrong readers inspired by Robert Axelrod's famous tournaments. The competitors had to submit a strategy which would play an iterated prisoner's dilemma of fixed length: first in the round-robin tournament where the strategy plays a hundred-turn match against each of its competitors exactly once, and second in the evolutionary tournament where the strategies are randomly paired against each other and their gain is translated in number of their copies present in next generation; the strategy with the highest number of copies after generation 100 wins. More details about the rules were described in the announcement. This post summarises the results.
The Zoo of Strategies
I have received 25 contest entries containing 21 distinct strategies. Those I have divided into six classes based on superficial similarities (except the last class, which is a catch-all category for everything which doesn't belong anywhere else, something like adverbs within the classification of parts of speech or now defunct vermes in the animal kingdom). The first class is formed by Tit-for-tat variants, probably the most obvious choice for a potentially successful strategy. Apparently so obvious that at least one commenter declared high confidence that tit-for-tat will make more than half of the strategy pool. That was actually a good example of misplaced confidence, since the number of received tit-for-tat variants (where I put anything which behaves like tit-for-tat except for isolated deviations) was only six, two of them being identical and thus counted as one. Moreover there wasn't a single true tit-for-tatter among the contestants; the closest we got was
A (-, -): On the first turn of each match, cooperate. On every other turn, with probability 0.0000004839, cooperate; otherwise play the move that the opponent played on the immediately preceding turn.
(In the presentation of strategies, the letter in bold serves as a unique identificator. The following parentheses include the name of the strategy — if the author has provided one — and the name of the author. I use the author's original description of the strategy when possible. If that's too long, an abbreviated paraphrase is given. If I found the original description ambiguous, I may give a slightly reformulated version based on subsequent clarifications with the author.) The author of A was the only one who requested his/her name should be withheld and the strategy is nameless, so both arguments in the bracket are empty. The reason for the obscure probability was to make the strategy unique. The author says:
I wish to enter a trivial variation on the tit-for-tat strategy. (The trivial variation is to force the strategy to be unique; I wish to punish defectorish strategies by having lots of tit-for-tat-style strategies in the pool.)
This was perhaps a slight abuse of rules, but since I am responsible for failing to make the rules immune to abuse, I had to accept the strategy as it is. Anyway, it turned out that the trivial variation was needless for the stated purpose.
The remaining strategies from this class were more or less standard with B being the most obvious choice.
B (-, Alexei): Tit-for-Tat, but always defect on last turn.
C (-, Caerbannog): Tit-for-tat with 20% chance of forgiving after opponent's defection. Defect on the last turn.
D (-, fubarobfusco and DuncanS): Tit-for-tat with 10% chance of forgiving.
E (-, Jem): First two turns cooperate. Later tit-for-tat with chance of forgiving equal to 1/2x where x is equal to number of opponent's defections after own cooperations. Last turn defect.
The next category of strategies I call Avengers. The Avengers play a nice strategy until the opponent's defective behaviour reaches a specified threshold. After that they switch to irrevocable defection.
F (-, Eugine_Nier): Standard Tit-for-Tat with the following modifications: 1) Always defect on the last move. 2) Once the other player defects 5 times, switch to all defect.
G (-, rwallace): 1. Start with vanilla tit-for-tat. 2. When the opponent has defected a total of three times this match, switch to always defect for the rest of the match. 3. If the number of rounds is known and fixed, defect on the last round.
H (-, Michaelos): Tit for Tat, with two exceptions: 1: Ignore all other considerations and always defect on the final iteration. 2: After own defection and opponent's cooperation, 50 percent of the time, cooperate. The other 50 percent of the time, always defect for the rest of the game.
I (-, malthrin): if OpponentDefectedBefore(7) then MyMove=D else if n>98 then MyMove=D else MyMove=OpponentLastMove
J (Vengeful Cheater, Vaniver): Set Rage = 0. Turn 1: cooperate. Turn 2-99: If the opponent defected last round, set Rage to 1. (If they cooperate, no change.) If Rage is 1, defect. Else, cooperate. Turn 100: defect.
K (Grim Trigger, shinoteki): Cooperate if and only if the opponent has not defected in the current match.
Then we have a special "class" of DefectBots (a name stolen from Orthonormal's excellent article) consisting of only one single strategy. But this is by far the most popular strategy — I have received it in four copies. Unfortunately for DefectBots, according to the rules they have to be included in the pool only once. The peculiar name for the single DefectBot comes from wedrifid:
L (Fuck them all!, MileyCyrus and wedrifid and vespiacic and peter_hurford): Defect.
Then, we have a rather heterogenous class of Lists, whose only common thing is that their play is specified by a rather long list of instructions.
M (-, JesusPetry): Turn 1: cooperate. Turns 2 to 21: tit-for-tat. Turn 22: defect. Turn 23: cooperate. Turn 24: if opponent cooperated in turns 21 and 22, cooperate; otherwise, do whatever the opponent did on previous turn. Then tit-for-tat, the scenario from turns 22-24 repeats itself in turns 35-37, 57-59, 73-75. Turns 99 and 100: defect.
N (-, FAWS): 1. Cooperate on the first turn. 2. If the opponent has defected at least 3 times: Defect for the rest of the match. 3. Play tit for tat unless specified otherwise. 4. If the opponent has cooperated on the first 20 turns: Randomly choose a turn between 21 and 30. Otherwise continue with 11. 5. If the opponent defects after turn 20, but before the chosen turn comes up: Play CDC the next three turns, then continue with 12. 6. Defect on the chosen turn if the opponent hasn't defected before. 7. If the opponent defects on the same turn: Cooperate, then continue with 12. 8. If the opponent defects on the next turn: Cooperate, then continue with 11. 9. If the opponent defects on the turn after that (i. e. the second turn after we defected): Cooperate, then continue with 12. 10. If the opponent cooperates on every turn up to and including two turns after the defection: Defect until the opponent defects, then cooperate twice and continue with 11. 11. Defect on the last two turns (99 and 100). 12. Defect on the last two turns unless the opponent defected exactly once.
O (Second Chance, benelliott): Second Chance is defined by 5 rules. When more than one rule applies to the current situation, always defer to the one with the lower number. Rules: 1. Co-operate on move 1, defect on moves 98, 99 and 100. 2. If Second Chance has co-operated at least 4 times (excluding the most recent move) and in every case co-operation has been followed by defection from the other strategy, then always defect from now on. 3. If Second Chance has co-operated at least 8 times, and defected at least 10 times (excluding the previous move), then calculate x, the proportion of the time that co-operation has been followed by co-operation and y, the proportion of the time that defection has been followed by co-operation. If 4x < 6y + 1 then defect until that changes. 4. If the number of times the opposing strategy has defected (including the most recent move) is a multiple of 4, co-operate. 5. Do whatever the opposing strategy did on the previous move.
The next class are CliqueBots (once more a name from the Orthonormal's post). CliqueBots try to identify whether their opponent is a copy of themselves and then cooperate. If they identify a foreign opponent, they usually become pretty nasty.
P (Simple Identity ChecK, red75): Move 1: cooperate. Moves 2 to 57: tit-for-tat. Move 58 - defect. Move 59 - if moves 0-57 were coop-coop and 58 was defect-defect then coop else defect. Moves 60-100: if my move 59 was coop then tit-for-tat else defect.
Q (EvilAlliance, ArisKatsaris): Start with 5 defections. On later turns, if the opponent had cooperated at least once in the first 5 turns or defected ever since, defect; else cooperate.
The remaining strategies are Unclassified, since they have little in common. Here they come:
R (Probe & Punish, Eneasz): 1. Cooperate for a turn. 2. Cooperate for a second turn. If opponent cooperated on the second turn, continue to cooperate in every subsequent turn until the opponent defects. 3. If/when the opponent defects, defect for 12 consecutive rounds. 4. Return to 1, repeat.
S (Win-stay lose-shift, Nerzhin): It cooperates if and only if it and the opponent both played the same strategy on the last round.
The author of S says he's adopted the strategy from Nowak and Sigmund, Nature 364 pp. 56-58.
T (Tit for Two Tats, DataPacRat): As the name suggests.
U (RackBlockShooter, Nic_Smith): The code is available here.
This one is a real beast, with code more that twice as long as that of its competitors. It actually models the opponent's behaviour as a random process specified by two parameters: probability of cooperation when the second strategy (which is the RackBlockShooter) also cooperates, and probability of cooperation when RBS defects. This was acausal: the parameters depend on RBS's behaviour in the same turn, not in the preceding one. Moreover, RBS stores whole probability distributions of those parameters and correctly updates them in an orthodox Bayesian manner after each turn. To further complicate things, if RBS thinks that the opponent is itself, it cooperates in the CliqueBottish style.
And finally, there's a strategy included by default:
Z (Fully Random, default): Cooperate with 50% probability.
The Round-Robin Tournament
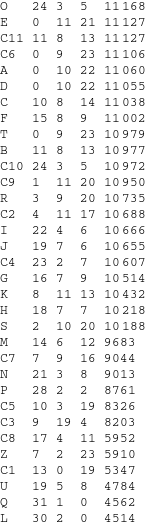
Each strategy had played 21 matches where a total maximum of 14,700 points could theoretically be won. A more reasonable threshold was 8,400 points: an award for any member of a pool consisting solely of nice strategies (i.e. those which never defect first). No strategy reached this optimum. The standings are given in the following table (columns from left: strategy identifier, matches won, matches drawn, matches lost, total points).

The winner is malthrin's unnamed strategy. Second and third place are occupied by Eugine_Nier's modified tit-for-tat and benelliott's Second Chance, respectively. Congratulations!
Here are results of all matches (view the picture in full size by right-clicking).

Is there something interesting to say about the results? Well, there were three strategies which performed worse than random: the DefectBot L, the CliqueBot Q (which effectively acted like a DefectBot) and the complex strategy U. As expected, very nasty strategies were unsuccessful. On the other hand, totally nice strategies weren't much successful either. No member of the set {A, D, K, R, S, T} got into the first five. Not defecting on the last turn was a mistake, defecting on the last two turns seemed even a better choice. As for the somewhat arbitrary classes, the average gains were as such:
- Tit-for-tat variants 7197.4
- Avengers 7144.3
- Lists 6551.3
- Unclassified 5963.8
- CliqueBots 4371.5
- DefectBots 3174.0
Another probably obvious point is that in a non-zero sum game it doesn't matter too much how many opponents you beat in direct confrontation. The only undefeated strategies that won all their matches except one draw, L and Q, finished last.
The Evolutionary1 Tournament
The initial population consisted of 1,980 strategies, 90 of each kind. But that didn't last for long. The very nasty strategies started to die out rapidly and by generation 6 there were no representants of L, Q, U and Z. (I have to say I was very glad to see U extinct so early because with non-negligible number of Us in the pool the simulation run very, very slowly.) By generation 40, M, N and P were also gone. Unfortunately, 100 was too low as a number of generations to see any interesting effects associated with environmental change as different strategies become extinct (but see the next section for a longer simulation); the strategies successful in the round-robin tournament were generally successful here as well.
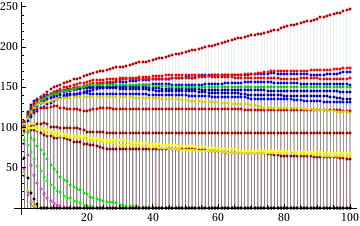
The graph shows the history of subpopulations (TfT variants are blue, Avengers red, Lists green, CliqueBots purple, Unclassified strategies yellow, the DefectBot gray and FullyRandom is black). The final standings (orderd by number of copies in generation 100) are summarised in the following table.
![]()
The gold and silver medals are once again awarded to malthrin and Eugine_Nier. There is a change at the third place which is now occupied by Caerbannog's 20%-forgiving tit-for-tat.
One remarkable fact is the absolute failure of CliqueBots which were without doubt designed to succeed in the evolutionary tournament. The idea was, perhaps, that CliqueBots win by cooperating among themselves and punish the others by defecting. That may be a working meta-strategy once you are dominant in the population, but for players starting as small minority it is suicidal. It would be a pretty bad idea even if most contestants were CliqueBots: while TfT variants generally cooperate with each other regardless of slight differences between their source codes, CliqueBots are losing points in defectionful matches even against other CliqueBots except those of their own species.
The Control Group
I run the same experiment with readers of my blog and thus I have a control group to match against the LW competitors. The comparison is done simply by putting all strategies together in an even larger tournament. Before showing the results, let me introduce the control group strategies.
C1: Let p be the relative frequency of opponent's cooperations (after my cooperation if I have cooperated last turn / after my defection if I have defected). If the relative frequency can't be calculated, let p = 1/2. Let Ec = 5p - 7 and Ed = 6p - 6. Cooperate with probability exp Ec / (exp Ec + exp Ed).
This strategy was in many respects similar to strategy U: mathematically elegant, but very unsuccessful.
C2: Defect if and only if the opponent had defected more than twice or if it defected on the first turn.
C3: If the opponent played the same move on the last and last but one turn, play that. Else, play the opposite what I have played last turn. On turns 1 and 2 play defect, cooperate.
C4: Cooperate on the first three turns, defect on the last two. Else, cooperate if the opponent has cooperated at least 85% of the time.
C5: Cooperate on the first three turns, defect on the last turn. Else, cooperate with probability equal to the proportion of opponent's cooperations.
C6: Tit-for-tat, but cooperate after the opponent's first defection.
C7: On the first turn play randomly, on turns 2n and 2n+1 play what the opponent played on turn n.
C8: Defect, if the opponent defected on two out of three preceding turns, or if I have defected on the last turn and cooperated on the last but one turn, or if I haven't defected in preceding 10 turns. On turns 20, 40, 60 and 80 cooperate always.
C9: Have two substrategies: 1. tit for two tats and 2. defect after opponent's first defection. Begin with 1. After each tenth turn change the substrategy if the gain in the last ten turns was between 16 and 34 points. If the substrategy is changed, reset all defection counters.
C10: Turns 1 and 2: cooperate. Turns 3-29: tit for tat. Turns 30-84: defect if the opponent defected more than seven times, else tit for tat. Turn 85: defect. Turns 86 and 87: defect if the opponent defected more than seven times, else cooperate. Turns 88-97: If the opponent defected on turn 87 or more than four times during the match, defect. Else cooperate. Turns 98-100: defect.
C11: Turn 1: cooperate. Turn 2: tit for tat. Turn 100: defect. Else, if the opponent defected on the last and (I have cooperated or the opponent has defected on the last but one turn) defect, else cooperate.
Two round-robin tournament standings are given in the following tables (two tournaments were played to illustrate the rôle of randomness).
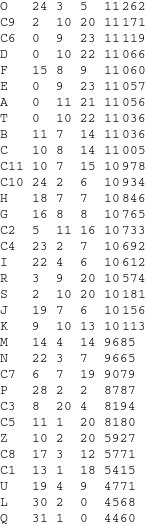
You can see how the new strategies had changed the standings. The original winner, I, now hovers around rather unremarkable 15th position, 10th among LW strategies. The average score for the LW strategies (calculated from the second tournament) is 9702.9, for the control group only 9296.9. How much this means that reading LW improves game-theoretical skills I leave to the readers' judgement.
In the evolutionary setting the strategy I recovered back its leading position. Here are the 100th generation populations and the graph:
![]()
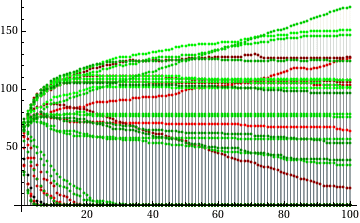
(In the graph, LW strategies are green and the control group strategies are red.)
It is relatively clear that the situation after hudred generations is not equilibrium and further changes would ensue if the simulation continued. Therefore I have run one more simulation, this time lasting for thousand of generations. This was more interesting, since more strategies died out. The first was C10 which was gone after generation 125. Around generation 300 there were only four surviving strategies from the control group (two of them moribund) and twelve from the original LW pool (two of them seriously endangered, too.) The leaders were I (with population 539), C4 (432) and C11 (183). The last one went through a steady slow decline and was soon overtaken by O, which assumed the third position around generation 420. At generation 600, only three strategies remained in the pool: I (932), C4 (692) and O (374). Not long before that the populations of I and C4 peaked and started to decline, while O continued to rise. In direct confrontation, O always beats both I and C4 397:390 which proved to be decisive when other strategies were eliminated. After the thousandth generation, there were 1374 copies of O and only 625 copies of both its competitors combined.
Final Remarks
I have organised the prisoner's dilemma tournament mainly for fun, but hopefully the results can illustrate few facts about non-zero sum games. At least in the final simulation we can see how short-term success needn't imply long-term survival. The failure of CliqueBots shows that it isn't much prudent to be too restrictive about whom one cooperates with. There is one more lesson that I have learned: the strategies which I considered most beautiful (U and C1) played poorly and were the first to be eliminated from the pool. Both U and C1 tried to experiment with the opponent's behaviour and use the results to construct a working model thereof. But that didn't work in this setting: while those strategies were losing points experimenting, dumb mechanical tit-for-tats were maximising their gain. There are situations when the cost of obtaining knowledge is higher than the knowledge is worth, and this was one of such situations. (Of course, both discussed strategies could have used the knowledge they had more efficiently, but that wouldn't significantly help.)
I have deliberately run fixed-length matches to make the competition more interesting. Random-length iterated PDs are domain of tit-for-tats and it would be hard to devise a better strategy; in the fixed-length case the players had to think about the correct turn when to defect first when playing a nice strategy and the answer isn't trivial. The most successful strategies started defecting on the 98th or 99th turns.
The question whether reading LessWrong improves performance in similar games remains unsolved as the evidence gathered in the tournament was very weak. The difference between the LW and control groups wasn't big. Other problem is that I don't know much about the control group authors (except one of them whom I know personally); it's not clear what part of population the control group represents. The judgement is more complicated by the apparent facts that not all participants were trying to win: the nameless author of A has explicitly declared a different goal (namely, to punish defectorish strategies) and it's likely that L was intended to signal author's cynicism (I am specifically thinking about one of the four DefectBot's originators) rather than to succeed in the tournament. Furthermore, many strategies were send by new users and only 11 out of 26 strategy authors have karma over 500, which means that the LW group doesn't faithfully represent LessWrong active participants.
1 Evolutionary may be a misnomer. The tournament models natural selection, but no changes and therefore evolution occurs. I have kept the designation to maintain consistency with the earlier post.
171 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-09-06T00:49:08.563Z · LW(p) · GW(p)
Variants I'd like to see:
1) You can observe rounds played by other bots.
2) You can partially observe rounds played by other bots.
3) (The really interesting one.) You get a copy of the other bot's source code and are allowed to analyze it. All bots have 10,000 instructions per turn, and if you run out of time the round is negated (both players score 0 points). There is a standard function for spending X instructions evaluating a piece of quoted code, and if the evaled code tries to eval code, it asks the outer eval-ing function whether it should simulate faithfully or return a particular value. (This enables you to say, "Simulate my opponent, and if it tries to simulate me, see what it will do if it simulates me outputting Cooperate.")
Replies from: darius, cousin_it, Vladimir_Nesov, engineeredaway, shokwave, Toby_Ord, prase, DavidLS, lessdazed, NancyLebovitz, homunq, DuncanS, malthrin↑ comment by darius · 2011-09-06T17:53:31.453Z · LW(p) · GW(p)
I just hacked up something like variant 3; haven't tried to do anything interesting with it yet.
Replies from: DavidLS, JenniferRM↑ comment by DavidLS · 2011-09-06T22:18:58.708Z · LW(p) · GW(p)
Oh cool! You allow an agent to see how their opponent would respond when playing a 3rd agent (just call run with different source code).
[Edit: which allows for arbitrary message passing -- the coop bots might all agree to coop with anyone who coops with (return C)]
However you also allow for trivially determining if an agent is being simulated: simply check how much fuel there is, which is probably not what we want.
Replies from: darius↑ comment by darius · 2011-09-07T00:03:19.547Z · LW(p) · GW(p)
The only way to check your fuel is to run out -- unless I goofed.
You could call that message passing, though conventionally that names a kind of overt influence of one running agent on another, all kinds of which are supposed to excluded.
It shouldn't be hard to do variations where you can only run the other player and not look at their source code.
Replies from: DavidLS↑ comment by DavidLS · 2011-09-07T00:37:43.394Z · LW(p) · GW(p)
I'm not a native schemer, but it looks like you can check fuel by calling run with a large number and seeing it if fails to return... eg (eq (run 9999 (return C) (return C)) 'exhausted) [note that this can cost fuel, and so should be done at the end of an agent to decide if returning the "real" value is a good idea]
giving us the naieve DefectorBot of (if (eq (run 9999 (return C) (return C)) 'exhausted) C D)
[Edit: and for detecting run-function-swap-out:
(if (neq (run 10000000 (return C) (return C) 'exhausted) C ;; someone is simulating us
(if (eq (run 9999 (return C) (return C)) 'exhausted) C ;; someone is simulating us more cleverly
D)) ]
[Edit 2: Is there a better way to paste code on LW?]
Re: not showing source: Okay, but I do think it would be awesome if we get bots that only cooperate with bots who would cooperate with (return C)
Re: message passing: Check out http://en.wikipedia.org/wiki/Message_passing for what I meant?
Replies from: darius, darius↑ comment by darius · 2011-09-07T01:13:38.270Z · LW(p) · GW(p)
When you call RUN, one of two things happens: it produces a result or you die from exhaustion. If you die, you can't act. If you get a result, you now know something about how much fuel there was before, at the cost of having used it up. The remaning fuel might be any amount in your prior, minus the amount used.
At the Scheme prompt:
(run 10000 '(equal? 'exhausted (cadr (run 1000 '((lambda (f) (f f)) (lambda (f) (f f))) (global-environment)))) global-environment)
; result: (8985 #t) ; The subrun completed and we find #t for yes, it ran to exhaustion.
(run 100 '(equal? 'exhausted (cadr (run 1000 '((lambda (f) (f f)) (lambda (f) (f f))) (global-environment)))) global-environment)
; result: (0 exhausted) ; Oops, we never got back to our EQUAL? test.
↑ comment by DavidLS · 2011-09-07T01:37:46.071Z · LW(p) · GW(p)
Oh, okay, I was missing that you never run the agents as scheme, only interpret them via ev.
Are you planning on supporting a default action in case time runs out? (and if so, how will that handle the equivalent problem?)
Replies from: darius↑ comment by darius · 2011-09-07T06:42:56.434Z · LW(p) · GW(p)
I hadn't considered doing that -- really I just threw this together because Eliezer's idea sounded interesting and not too hard.
I'll at least refine the code and docs and write a few more agents, and if you have ideas I'd be happy to offer advice on implementing your variant.
↑ comment by JenniferRM · 2011-09-10T07:32:31.535Z · LW(p) · GW(p)
Awesome! The only suggestion I have is to pass in a putative history and/or tournament parameters to an agent in the evaluation function so the agent can do simple things like implement tit-for-tat on the history, or do complicated things like probing the late-game behavior of other agents early in the game. (E.G. "If you think this is the last round, what do you do?")
Replies from: darius↑ comment by cousin_it · 2011-09-06T08:25:16.235Z · LW(p) · GW(p)
if you run out of time the round is negated (both players score 0 points).
This makes the game matrix bigger for no reason. Maybe replace this with "if you run out of time, you automatically defect"?
There is a standard function for spending X instructions evaluating a piece of quoted code, and if the evaled code tries to eval code, it asks the outer eval-ing function whether it should simulate faithfully or return a particular value.
Haha, this incentivizes players to reimplement eval themselves and avoid your broken one! One way to keep eval as a built-in would be to make code an opaque blob that can be analyzed only by functions like eval. I suggested this version a while ago :-)
Replies from: philh, abramdemski↑ comment by abramdemski · 2012-09-14T18:10:24.381Z · LW(p) · GW(p)
This makes the game matrix bigger for no reason. Maybe replace this with "if you run out of time, you automatically defect"?
Slightly better: allow the program to set the output at any time during execution (so it can set its own time-out value before trying expensive operations).
↑ comment by Vladimir_Nesov · 2011-09-06T01:16:30.755Z · LW(p) · GW(p)
(This enables you to say, "Simulate my opponent, and if it tries to simulate me, see what it will do if it simulates me outputting Cooperate.")
But it will not be simulating "you", it will be simulating the game under alternative assumptions of own behavior, and you ought to behave differently depending on what those assumptions are, otherwise you'll think the opponent will think defection is better, making it true.
↑ comment by engineeredaway · 2011-09-11T04:36:33.506Z · LW(p) · GW(p)
I've written a pretty good program to complete variant 3 but I'm such a lurker on this site i lack the nessesary karma to submit it as a article. So here it is as a comment instead:
Inspired by prase's contest, (results here) and Eliezer_Yudkowsky's comment, I've written a program that plays iterated games of prisoners dilemma, with the cravat that each player can simulate his opponent. I'm now running my own contest. You can enter your onwn strategy by sending it to me in a message. Deadline to enter is Sunday September 25. The contest itself will run shortly there after.
Each strategy plays 100 iterations against each other strategy, with cumulative points. Each specific iteration is called a turn, each set of 100 iterations is called a match. (thanks prase for the terminology). Scoring is CC: (4,4) DC: (7,0) CD: (0,7) DD: (2,2).
Every turn, each strategy receives a record of all the moves it and its opponent made this match, a lump of time to work and its opponents code. Strategies can't review enemy code directly but they can run it through any simulations they want before deciding their move, within the limits of the amount of time they have to work.
Note that strategies can not pass information to themselves between iterations or otherwise store it, other than the record of decisions. They start each turn anew. This way any strategy can be simulated with any arbitrary record of moves without running into issue.
Strategies in simulations need a enemy strategy passed into them. To avoid infinite recursion of simulations, they are forbidden from passing themselves. They can have as many secondary strategies as need however. This creates a string of simulations where strategy(1) simulates enemy(1), passing in strategy(2) which enemy(1) simulates and passes in enemy(2) which strategy(2) simulates and passes in strategy(3). The final sub-strategy passed in by such a chain must be a strategy which performs NO simulations.
for example, the first sub-strategy could be an exact duplicate of main strategy other than that it passed the tit_for_tat program instead. so main_strategy => sub_strategy1 => tit_for_tat.
You can of course use as many different sub_strategies as you need, the programs are limited by processing time, not memory. Strategies can run their simulated opponent on any history they devise, playing which ever side they choose.
Strategies can't read the name of their opponent, see the number of strategies in the game, watch any other matches or see any scores outside their current match.
Strategies are not cut off if they run out of time, but both will receive 0 points for the turn. The decisions of the turn will be recorded as if normal.
I never figured out a good way to keep strategies from realizing they were being simulated simply by looking at how much time they were given. Not knowing how much time they have would make it prohibitively difficult to avoid timing out. My hack solution is to not give a definitive amount of time for the main contest but instead a range: from 0.01 seconds to 0.1 seconds per turn, with the true time to be know only by me. This is far from ideal, and if anyone has a better suggestion I'm all ears.
To give reference: a strategy that runs 2 single turn simulations of tit_for_tat against tit_for_tat takes, on average 3.510^-4 seconds. Running only 1 single turn simulations took only 1.510^-4 seconds. tit_for_tat by itself takes about 2.5*10^-5 seconds to run a single turn. Unfortunately, do to factor outside of my control, matlab, the software I'm running will for unknown reasons take 3 to 5 times as long as normal about 1 out of a 100 times. Leave yourself some buffer.
Strategies are NOT allowed a random number generator. This is different from prase's contest but I would like to see strategies for dealing with enemy intelligence trying to figure them out without resorting to unpredictability.
I've come up with a couple of simple example strategies that will be performing in the contest.
Careful_cheater:
simulates its opponent against tit_for_tat to see its next move. If enemy defects, Careful_cheater defects. If enemy cooperates, Careful_cheater simulates its next move after that with a record showing Careful_cheater defecting this turn, passing tit_for_tat. If the opponent would have defected on the next turn, Careful_cheater cooperates, but if the opponent would have cooperated despite Careful_cheaters defection, it goes ahead and defects.
simulations show it doing evenly against tit_for_tat and its usual variations, but Careful_cheater eats forgiving programs like tit_for_2_tats alive.
Everyman:
simulates 10 turn matchs with its opponent against several possible basic strategies, including tit_for_tat, tit_for_tat_optimist (cooperates first two turns), and several others, then compares the scores of each match and plays as the highest scoring
Copy_cat:
Switches player numbers and simulates its opponent playing Copy_cats record while passing its opponent and then performs that action. That is to say, it sees what its opponent would do if it were in Copy_cats position and up against itself.
this is basically DuncanS strategy from the comments. DuncanS, your free to enter another one sense I stole yours as an example
and of course tit_for_tat and strategy "I" from prase's contest will be competing as well.
one strategy per person, all you need for a strategy is a complete written description, though I may message back for clarification. I reserve the right to veto any strategy I deem prohibitively difficult to implement.
Replies from: eugman, alexg↑ comment by eugman · 2011-09-12T11:14:39.603Z · LW(p) · GW(p)
So what happens if copy_cat goes actually does go up against itself, or a semantically similar bot? Infinite recursion and zero points for both? Or am I missing something.
Replies from: engineeredaway↑ comment by engineeredaway · 2011-09-12T11:54:00.181Z · LW(p) · GW(p)
Actually, it seems that crashes it. thanks for the catch. I hadn't tested copy_cat against itself and should have. Forbidding strategies to pass their opponent fixes that, but it does indicate my program may not be as stable as I thought. I'm going to have to spend a few more days checking for bugs sense I missed one that big. thanks eugman.
Replies from: eugman↑ comment by eugman · 2011-09-13T00:26:33.279Z · LW(p) · GW(p)
No problem. I've been thinking about it and one should be able to recursively prove if a strategy bottoms's out. But that should fix it as long the user passes terminating strategies. A warning about everyman, if it goes against itself, it will run n^2 matches where n is the number of strategies tested.Time consumed is an interesting issue because if you take a long time it's like being a defectbot against smartbots, you punish bots that try to simulate you but you lose points too.
Replies from: engineeredaway↑ comment by engineeredaway · 2011-09-13T11:35:23.064Z · LW(p) · GW(p)
I didn't get into it earlier, but everyman's a little more complicated. it runs through each match test one at a time from most likely to least, and checks after each match how much time it has left, if it starts to run out, it just leaves with the best strategy its figured out. By controlling how much time you pass in, strategies can avoid n^2 processing problems. Its why I thought it was so necessary to include even if it does give hints if strategies are being simulated or not. Everyman was built as a sort of upper bound. its one of the least efficient strategies one might implement.
↑ comment by alexg · 2013-11-27T04:22:43.597Z · LW(p) · GW(p)
Here's a very fancy cliquebot (with a couple of other characteristics) that I came up with. The bot is in one of 4 "modes" -- SELF, HOSTILE, ALLY, PASSWORD.
Before turn1:
Simulate the enemy for 20 turns against DCCCDDCDDD Cs thereafter, If the enemy responds 10Ds, CCDCDDDCDC then change to mode SELF. (These are pretty much random strings -- the only requirement is that the first begins with D)
Simulate the enemy for 10 turns against DefectBot. If the enemy cooperates in all 10 turns, change to mode HOSTILE. Else be in mode ALLY.
In any given turn,
If in mode SELF, cooperate always.
If in mode HOSTILE, defect always.
If in mode ALLY, simulate the enemy against TFT for the next 2 turns. If the enemy defects on either of these turns, or defected on the last turn, switch to mode HOSTILE and defect. Exception if it is move 1 and the enemy will DC, then switch to mode PASSWORD and defect. Defect on the last move.
If in mode PASSWORD, change to mode HOSTILE if the enemy's moves have varied from DCCCDDCDDD Cs thereafter beginning from move 1. If so, switch to mode HOSTILE and defect. Else defect on moves 1-10, on moves 11-20 CCDCDDDCDC respectively and defect thereafter.
Essentially designed to dominate in the endgame.
↑ comment by shokwave · 2011-09-06T06:26:54.209Z · LW(p) · GW(p)
You get a copy of the other bot's source code and are allowed to analyze it. All bots have 10,000 instructions per turn, and if you run out of time the round is negated (both players score 0 points). There is a standard function for spending X instructions evaluating a piece of quoted code
I assume that X is variable based on the amount of quoted code you're evaluating; in that case I would submit "tit for tat, defect last 3" but obfuscate my source code in such a way that it took exactly 10,000 instructions to output, or make my source code so interdependent that you'd have to quote the entire thing, and so on. I wonder how well this "cloaked tit-for-tat" would go.
Replies from: lessdazed↑ comment by Toby_Ord · 2011-09-07T20:27:03.520Z · LW(p) · GW(p)
Regarding (2), this is a particularly clean way to do it (with some results of my old simulations too).
http://www.amirrorclear.net/academic/papers/sipd.pdf http://www.amirrorclear.net/academic/ideas/dilemma/index.html
↑ comment by prase · 2011-09-06T09:46:27.145Z · LW(p) · GW(p)
1) is feasible and that can be done easily, but now I am a little bit fed up with PD simulations, so I will take some rest before organising it. Maybe anybody else is interested in running the competition?
3) Wouldn't it be easier to limit recursion depth instead of number of instructions? Not sure how to measure or even define the latter if the codes aren't written in assembler. The outcome would also be more predictable for the bots and would not motivate the bots to include something like "for (i=number-of-already-spent-instructions, i<9,999, i++, do-nothing)" at the end of their source code to break anybody trying to simulate them. (I am not sure whether that would be a rational thing to do, but still quite confident that some strategies would include that).
↑ comment by DavidLS · 2011-09-06T12:35:45.501Z · LW(p) · GW(p)
"Simulate my opponent, and if it tries to simulate me, see what it will do if it simulates me outputting Cooperate."
This has the problem that, since most strategies will eval twice (to check both the C and D cases) you can be reasonably sure that if both calls return the same result you are being simulated.
Edit: Although it doesn't fully fix the problem, this is better: eval takes a function that takes the function the other agent will call eval with as its argument and returns C or D.
eval(function(fn) {
if(fn(function(ignore) { return C; }) == C) return C;
if(fn(function(ignore) { return D; }) == D) return D;
// etc
});
There are still detection problems here (you could add checks to see if the function you passed to the function eval passed to you was invoked), but the fact that some strategies wouldn't do overly ambitious recursion at least downgrades the above approach from obvious information leak to ambiguous information leak
Replies from: homunq, lessdazed, lessdazed↑ comment by homunq · 2011-09-12T02:44:14.200Z · LW(p) · GW(p)
Basically, there is always going to be some clever strategy of possibly detecting whether you're a sim. And it may be best at that point to just say so. So the game should have three outputs: C, D, and S. S gets you zero points and gets your opponent the points they'd get if you played C. It's clearly suboptimal. So you'd only say it to signal, "I'm smarter than you and I know you're simulating me". And if they've ever seen you say it in real life, they know you're just bluffing. I believe that this response, if you actually were a sim being run by your opponent, would be the best way to get your opponent to cooperate on the last turn.
This doesn't solve the problem of removing obvious, trivial ways to tell if you're a sim. But it does mean that if there's no shortcuts, so that the the smarter bot will win that battle of wills, then they have something useful to say for it (beyond just "I'm TFT so you shouldn't defect until the last turn")
↑ comment by lessdazed · 2011-09-06T13:30:19.242Z · LW(p) · GW(p)
you can be reasonably sure that if both calls return the same result you are being simulated.
Shouldn't it be, at most: you can be reasonably sure that you are being simulated either a) after both calls return C or b) after you formally choose D having already seen that both calls return D?
If a simulation chooses C after seeing both results D, then the simulator might as well actually defect, so it does, and the non-simulation chooses C, just like the simulation.
If an agent strongly prefers not to be a simulation and believes in TDT and is vulnerable to blackmail, they can be coerced into cooperating and sacrificing themselves in similar cases. Unless I'm wrong, of course.
One really ought to make anti-blackmail resolutions.
↑ comment by lessdazed · 2011-09-06T09:20:07.675Z · LW(p) · GW(p)
if you run out of time the round is negated (both players score 0 points)
In the OP, defect/defect gives each player one point. Did you intend to add a fifth possible outcome for each iteration?
I think a more natural expansion would be to have a third choice besides cooperate and defect lead to nine different possible scores per iteration. For a program to run out of time is a choice pre-committed to by the design of the analyzing function, it's not too different from the outcomes of cooperate or defect.
↑ comment by NancyLebovitz · 2011-09-06T08:41:07.435Z · LW(p) · GW(p)
How about #2 combined with bots can make claims about their own and other bots' behavior?
↑ comment by homunq · 2011-09-08T08:01:41.850Z · LW(p) · GW(p)
I don't care what my opponent will do this turn, I care how what they will do later depends on what I do now. That is, do they have the capacity to retaliate, or can I defect with impunity.
So basically, my strategy would be to see if they defect (or try to be sneaky by running out my cycles) on turn 100 if they think I'm a dumb TFT. If so, I attempt to defect 1 turn before they do (edit: or just TFT and plan to start defecting on turn 99), which becomes a battle to see whose recursion is more efficient. If not, I play TFT and we probably both cooperate all the way through, getting max stable points.
Significantly, my strategy would not do a last-turn defection against a dumb TFT, which leaves some points on the ground. However, it would try to defect against a (more TDT-like?) strategy which would defect against TFT; so if my strategy were dominant, it could not be attacked by a combination of TFT and some cleverer (TDT?) bot which defects last turn against TFT.
Replies from: homunq↑ comment by homunq · 2011-09-13T02:27:18.825Z · LW(p) · GW(p)
I call this strategy anti-omega, because it cooperates with dumb TFTs but inflicts some pain on Omegabot (the strategy which always gets the max points it could possibly get against any given opponent). Omegabot would still beat a combo of TFT and anti-omega (the extra points it would get from defecting last turn against TFT, and defecting turn 98 against anti-omega, would make up for the points it lost from having two mutual defections against anti-omega). But at least it would suffer for it.
This points to a case where TDT is not optimal decision theory: if non-TDT agents can reliably detect whether you are a "being too clever" (ie, a member of a class which includes TDT agents), and they punish you for it. Basically, no sense being a rationalist in the dark ages; even if you're Holmes or Moriarty, the chances that you'll slip up and be burned as a witch might outweigh the benefits.
Replies from: Vaniver↑ comment by Vaniver · 2011-09-13T02:40:33.008Z · LW(p) · GW(p)
I don't see rationality was a major cause of witch accusations. Indeed, a great number of successful dark agers seem to be ones that were cleverer / more rational than their contemporaries, even openly so.
Replies from: homunq↑ comment by DuncanS · 2011-09-06T21:36:31.262Z · LW(p) · GW(p)
3) sounds fun. I already have a strategy for this variant - just run the other bot's source code without bothering to analyse it.
Replies from: benelliott, DuncanS, Vladimir_Nesov↑ comment by benelliott · 2011-09-07T22:02:53.760Z · LW(p) · GW(p)
Trouble is, when your bot plays itself it gets stuck in a loop, runs out of time and gets 0. This will make it very unlikely to ever rise to dominance in an evolutionary tournament.
Replies from: None, Normal_Anomaly↑ comment by [deleted] · 2011-09-09T01:29:48.297Z · LW(p) · GW(p)
Depending on how much time is allowed the following might be a viable solution: with a 1% chance cooperate, otherwise run the other bot's source code. If the bot plays itself, or for that matter any other bot that tries to run its source code, after 100 (on average) iterations it will return cooperate, and then working backwards will (usually) converge to the right thing.
Obviously, the value of 1% should be as small as possible; the average time used is proportional to the reciprocal of the probability.
↑ comment by Normal_Anomaly · 2011-09-07T23:59:20.954Z · LW(p) · GW(p)
This could be fixed with a trivial modification: first check if the opponent source code is identical to your own, and if it is then cooperate. Otherwise run the other bot's source.
However, there's another problem: If DuncanS's strategy plays against a CooperateBot or a random bot, it will throw away a lot of points.
Replies from: DuncanS, wedrifid, Eugine_Nier↑ comment by DuncanS · 2011-09-08T22:53:30.168Z · LW(p) · GW(p)
Quite so. I actually never intended to post this - I edited the post several times, and in the end thought I'd abandoned it. But never mind.
I thought of various trivial modifications to fix the problem that you iterate infinitely deep if you meet yourself. You could check for yourself - that works as long as nobody else enters an equivalent strategy - in which case you will do each other in.
I'm not so worried about the cooperateBot or random bot as these will in any case do so badly that they won't tend to turn up in the population pool. But I could obviously do better against these by defecting all the way. In fact, any algorithm that neither runs me, or checks what I played previously ignores my behaviour, and should be defected against.
Replies from: Nornagest↑ comment by Nornagest · 2011-09-08T23:21:51.305Z · LW(p) · GW(p)
The most reliable fix to the recursion problem that I can think of is to implement a hard resource limit, whereby if you spend (say) 9500 of 10000 processing units on analysis, then you drop the analysis and implement a dumb strategy with whatever juice you have left. Probably wouldn't take much more than a simple counter being incremented in a bottom-level loop somewhere, as long as you're looking at your opponent's source through a level of indirection rather than just jumping straight into it. Some analysis strategies might also converge on a solution rather than finding an exact one, although this would be easier and more reliable with behavioral than with source analysis.
However, trapdoors like this are exploitable: they give agents an incentive to nearly but not quite run out the clock before making a decision, in hopes that their opponents will give up and fall back on the simple and stupid. The game theory surrounding this seems to have PD-like characteristics in its own right, so it may just have pushed the relevant game-theoretical decisions up to the metagame.
Replies from: DuncanS↑ comment by DuncanS · 2011-09-08T23:43:15.131Z · LW(p) · GW(p)
There is actually a human algorithm in the cooperate/defect space - which is to distrust anyone who seems to spend a long time making a cooperate decision. Anyone who has a really quick, simple way of deciding to cooperate is OK - anyone who takes a long time is thinking about whether you will defect, or whether they should defect - and you should probably find someone else to trust. This is one of the good things about Tit for tat - it passes this test.
↑ comment by wedrifid · 2011-09-09T02:23:01.302Z · LW(p) · GW(p)
However, there's another problem: If DuncanS's strategy plays against a CooperateBot or a random bot, it will throw away a lot of points.
That is a problem, but fortunately we know that those competitors will be eliminated before the chameleon, whereupon it will begin to improve its performance.
↑ comment by Eugine_Nier · 2011-09-08T06:00:20.502Z · LW(p) · GW(p)
This could be fixed with a trivial modification: first check if the opponent source code is identical to your own, and if it is then cooperate.
This doesn't solve the slightly different CliqueBots won't cooperate with each other problem.
Replies from: Normal_Anomaly↑ comment by Normal_Anomaly · 2011-09-08T21:25:33.091Z · LW(p) · GW(p)
If the DuncanBot detects a source code different from its own, it runs that source code. So a DuncanBot looks to any CliqueBot like a member of it's clique.
Replies from: shinoteki, Eugine_Nier↑ comment by shinoteki · 2011-09-08T21:51:13.851Z · LW(p) · GW(p)
A piece of code that runs a piece of source code does not thereby become that piece of source code.
Replies from: DuncanS↑ comment by DuncanS · 2011-09-08T22:58:22.842Z · LW(p) · GW(p)
That may well be right - a cliquebot may well decide I'm not in its clique, and defect. And I, running its source code, will decide that my counterparty IS in the clique, and cooperate. Not a good outcome.
Clearly I need to modify my algorithm so that I run the other bot's code without bothering to analyse it - and have it play against not its actual opponent, but me, running it.
↑ comment by Eugine_Nier · 2011-09-09T00:23:22.557Z · LW(p) · GW(p)
I meant what happens when a DucanBot meats a DicanBot that does the same thing but has trivial cosmetic differences in its source code?
↑ comment by DuncanS · 2011-09-08T23:12:05.196Z · LW(p) · GW(p)
To add to this (probably silly) post - I was drawn to this problem for the reasons that Eliezer considers it the interesting case. In this form, it's a variant on the halting problem / completeness problem. Each of these can't be solved because some cases turn into an infinitely deep recursive nesting. Any purported algorithm to predict whether another algorithm will halt can't solve the case where it's analysing itself analysing itself analysing itself etc. Hence my rather tongue-in-cheek response.
And my response hits the same problem in a different form. When it meets itself, it gets into an infinite loop as each side tries to run the other. To solve it, at some level you need a 'cooperate' to be introduced in order to terminate the loop. And doing that breaks the symmetry of the situation.
Replies from: None↑ comment by Vladimir_Nesov · 2011-09-06T21:50:58.892Z · LW(p) · GW(p)
Predicting what the opponent would do if you always return "cooperate" means predicting how the opponent would play against a CooperateBot, and acting this way means adopting opponent's strategy against CooperateBots as your own when playing against the opponent, which is not a CooperateBot and knows you are not a CooperateBot. Sounds like a recipe for failure (or for becoming an almost-DefectBot, actually, if the opponent is smart enough and expects genuine CooperateBots).
Replies from: DuncanScomment by Oscar_Cunningham · 2011-09-05T18:04:38.872Z · LW(p) · GW(p)
Am I right in thinking that U defects on the first turn? That seems pretty suicidal.
Replies from: Alex_Altair, prase↑ comment by Alex_Altair · 2011-09-06T00:41:19.455Z · LW(p) · GW(p)
I am now very curious to see how U would perform if that were changed.
Replies from: prase↑ comment by prase · 2011-09-06T10:14:36.568Z · LW(p) · GW(p)
The reply is (to my great surprise, I thought this bit isn't much important part of that strategy) much better. It will earn more than 7200 points instead of 3200 before the change.
Replies from: shokwave, ArisKatsaris↑ comment by ArisKatsaris · 2011-09-06T10:56:46.042Z · LW(p) · GW(p)
Hmm.. Starting with D - C as its first two moves, it will get in response from all TfT-based strategies a C - D Which means it will end up believing that other bots are likely to cooperate if it defects, and to defect if it cooperates. Which will be further boosted by the response in the third move (Defect), which will receive a (Cooperate) in response, thus further increasing its belief in the worth of defection. It seems likely to effectively become a defectbot in this manner.
On the other hand a C-D returns it a corresponding C-C, which followed by another D returns it a D; this seems more favourable for cooperation.
Replies from: prasecomment by Unnamed · 2011-09-06T02:24:33.879Z · LW(p) · GW(p)
It looks like malthrin's bot I may have won only because it defected on the last 2 turns. There were enough defect-on-the-last-turn bots for defecting on the last two to be a smart approach, and of the defect-on-the-last-two bots malthrin's was the closest to tit-for-tat.
In the longer evolutionary run, the winning strategy (O) was the one that defected on the last 3 turns. It stuck around until the rest of the population consisted of only defect-on-the-last-two bots (I and C4), and then it took over.
I'd like to see you re-run this competition, adding in a few variants of tit-for-tat which always defect on the last n turns (for n=2,3,4) to see whether I and O are benefiting from their other rules or just from their end-of-game defections.
Replies from: Unnamed, Zvi, PhilGoetz, prase↑ comment by Unnamed · 2011-09-06T18:38:07.648Z · LW(p) · GW(p)
15 of the 22 strategies in the original tournament were NiceBots, meaning that they sought mutual cooperation until the endgame (formally, they always cooperated for the first 90 rounds against any strategy that cooperated with it for the first 90 rounds). They were mostly tit-for-tat with some combination of vengeance, forgiveness, and endgame defection (Win-stay lose-shift was the one exception).
In the 100-round evolutionary tournament, 15/22 bots survived until the end: the 15 NiceBots all survived and the 7 non-Nice bots all went extinct. In the larger (33-bot, 100-round) tournament, there were 2 exceptions to this pattern. 5 of the 6 new NiceBots survived (C5 went extinct) and 1 of the 5 non-Nice bots survived (C10, which played Nice for the first 84 rounds). [Edited to include C3 among the non-Nice.]
Nice: ABCDEFGHIJKORST C2,4,5,6,9,11 (only C5 went extinct)
Not Nice: LMNPQUZ C1,3,7,8,10 (only C10 survived)
In games between two NiceBots only endgame strategy matters, which means that endgame strategy became increasingly important (and differences in general rules became less important) as the non-Nice bots left the population. Another option for separating general rules from endgame play would be to shorten the game to 90 or 95 rounds (but don't tell the bots) so that we can see what would happen without the endgame.
Replies from: FAWS, prase↑ comment by FAWS · 2011-09-08T13:43:03.633Z · LW(p) · GW(p)
I think it's unfair to call my strategy (N) Not Nice. There were 15 strategies that would cooperate with a cooperation rock. I just didn't expect anyone to enter permanent revenge mode after so much as a single defection. If there hadn't been any such strategies, or if they had been outnumbered by cooperation rocks, or if there had been enough other testing bots to quickly drive them to extinction I think I would have won the evolutionary tournament.
Replies from: Zvi, Unnamed↑ comment by Unnamed · 2011-09-08T17:26:21.099Z · LW(p) · GW(p)
"NiceBot" is just a label, a shorthand way to refer to those 15 strategies (which notably were the only 15 survivors in the evolutionary tournament). I agree that it's not a very precise name. Another way to identify them is that they're the strategies that never defected first, outside the endgame. Your strategy was designed to defect first, in an attempt to exploit overly-cooperative strategies. Perhaps we could call the 15 the non-exploitative bots (although that's not perfect either, since some bots like P and Z defect first in ways that aren't really attempts to exploit their opponent).
↑ comment by Zvi · 2011-09-12T13:34:18.304Z · LW(p) · GW(p)
This was the reason that in the version I once competed in, which was evolutionary and more complex, you didn't know which round was last (turned out to be #102). This completely wipes out that issue, and the NiceBots (in the simple case here) end up dividing the world in static fashion.
↑ comment by prase · 2011-09-06T09:29:44.882Z · LW(p) · GW(p)
Clearly the other features were irelevant when only TfT-but-defect-after-n bots survive. A match between O and C4 or I is always C-C until turn 97, then D-C D-D D-D.
Anyway, what happens when population consists only of TfT-but-defect-after-n bots needs no simulation, a matrix multiplication can do it (also without "random extinctions" due to finite population). Maybe I'll calculate it explicitly if I find some time.
comment by shokwave · 2011-09-07T00:36:43.078Z · LW(p) · GW(p)
The tournament models natural selection, but no changes and therefore evolution occurs.
Idea: everyone has access to a constant 'm', which they can use in their bot's code however they like. m is set by the botwriter's initial conditions, then when a bot has offspring in the natural selection tournament, one-third of the offspring have their m incremented by 1, one-third have theirs decremented by 1, and one third has their m remain the same. In this manner, you may plug m into any formulas you want to mutate over time.
Replies from: prase, lessdazed, AlephNeil, JoshuaZ↑ comment by prase · 2011-09-07T10:03:52.726Z · LW(p) · GW(p)
In the first PD simulation I made with five strategies which I got from my friends I applied such a model, albeit with random mutations rather than division of descendants into thirds. The results were not as interesting as I had expected. Only one strategy showed non-trivial optimum (it was basically TfT but defect after turn n and the population made a sort of gaussian distribution around n=85). All other strategies ended up with extremal (and quite obvious) values of the parameter.
Replies from: lessdazed↑ comment by lessdazed · 2011-09-07T10:18:13.573Z · LW(p) · GW(p)
gaussian distribution around n=85
This is the pearl of interestingness.
Replies from: prase↑ comment by prase · 2011-09-07T10:31:45.953Z · LW(p) · GW(p)
If you are interested in that tournament, the graphs are here, you can use google translator to make some sense of the text.
↑ comment by JoshuaZ · 2011-09-07T01:46:14.003Z · LW(p) · GW(p)
This is an interesting idea. One thing someone could do is make a machine which takes some enumeration of all Turing machines and runs the mth machine on the input of the last k rounds with them inputed in some obvious way (say 4 symbols for each possible result of what happened the previous round).
But a lot of these machines will run into computational issues. So if one is using the run-out-of-time then automatically defect rule most will get killed off quickly. On the other hand if one is simply not counting rounds where a bot runs out of time then this isn't as much of an issue. In the first case you might be able to make it slightly different so that instead of representing the mth Turing machine on round m, have every odd value of m play just Tit-for-Tat and have the even values of m simulate the mth Turing machine. This way, since tit for tat will do well in general, this will help keep a steady supply of machines that will investigate all search space in the limiting case.
comment by Alexei · 2011-09-05T20:22:21.548Z · LW(p) · GW(p)
I just want to point out that it's probably not good to use this as basis to see if LessWrong improves performance in these games, because the strategy I submitted (and I suspect some other people) wasn't the best I could think of, it was just cute and simple. I did it because I got the feeling that this tournament was for fun, not for real competition or rationality measurement.
Replies from: XiXiDu, prase↑ comment by XiXiDu · 2011-09-06T15:30:17.174Z · LW(p) · GW(p)
...the strategy I submitted (and I suspect some other people) wasn't the best I could think of, it was just cute and simple. I did it because I got the feeling that this tournament was for fun, not for real competition or rationality measurement.
But isn't this also true for the control group?
Replies from: Alexeicomment by lionhearted (Sebastian Marshall) (lionhearted) · 2011-09-06T06:21:15.791Z · LW(p) · GW(p)
It's normally bad form to just write a comment saying "wow, this is awesome" - but I thought an upvote wasn't enough.
So:
Wow, this is awesome. Thank you for doing this and sharing the results.
Replies from: prasecomment by jhuffman · 2011-09-09T16:21:19.446Z · LW(p) · GW(p)
Have you considered re-running the last scenario of 1000 generations with variances in the initial populations? For example starting with Vengeful strategies being twice as common as the other strategies. It would be interesting to see if there are starting conditions that would doom otherwise successful strategies.
Replies from: prase↑ comment by prase · 2011-09-12T12:46:08.529Z · LW(p) · GW(p)
It takes considerable time to run through 1000 generations. So, if you are interested in one concrete initial condition, let me know and I will run it, but I am not going to systematically test different initial conditions to see whether something interesting happens. Of course, I suppose that the actual winner may not succeed in all possible settings.
Replies from: Andreas_Giger, jhuffman↑ comment by Andreas_Giger · 2011-09-13T01:18:33.903Z · LW(p) · GW(p)
Of course, I suppose that the actual winner may not succeed in all possible settings.
For any deterministic strategy there exists another deterministic strategy it will lose to in a scenario where both strategies are initially equally well represented, except if the number of turns per match is lower than three, in which case DefectBot wins regardless of number and initial representation of other strategies.
Replies from: JoshuaZ↑ comment by JoshuaZ · 2011-09-13T01:23:22.488Z · LW(p) · GW(p)
except if the number of turns per match is lower than three, in which case DefectBot wins regardless of number and initial representation of other strategies.
Won't DefectBot sometimes be tied with other strategies? For example the strategy that defects on the first turn and then plays its opponents first move as its second move will when it runs against a DefectBot play identically.
Replies from: Andreas_Giger↑ comment by Andreas_Giger · 2011-09-13T01:32:06.864Z · LW(p) · GW(p)
That is true, however I don't consider strategies that effectively always play the same move as different strategies just because they theoretically follow different algorithms. And as soon as they stray from defecting, they will lose population in relation to DefectBot, no matter their opponent.
comment by dvasya · 2011-09-06T15:09:15.682Z · LW(p) · GW(p)
Excellent illustration of the Exploration vs Exploitation tradeoff, and I absolutely love how Second Chance got piggybacked by strategy I in the longer selection run!
Also, it would be curious to see what would happen if one allowed strategies to actually evolve.
comment by Andreas_Giger · 2011-09-12T02:01:20.176Z · LW(p) · GW(p)
I don't have the impression that the participants did much of the relevant math. Few strategies were optimized and a considerable number weren't sane at all. At this point, delving into the depths of truly evolutionary IPD tournaments will not yield as much insight on the whole matter as it could.
There's a number of rules I have put together for developing successful strategies as well as theoretical observations on these kinds of tournament in general; if there is interest in them I can post them in the discussion area.
Replies from: shokwave↑ comment by shokwave · 2011-09-12T12:07:09.841Z · LW(p) · GW(p)
Please do; this post brought about some excellent discussions. I feel like starting another bunch of discussions from a more advanced position will bring about some more excellent discussions.
Replies from: Andreas_Giger↑ comment by Andreas_Giger · 2011-09-13T04:00:14.130Z · LW(p) · GW(p)
Seems logical, post submitted.
comment by AdeleneDawner · 2011-09-07T03:54:13.496Z · LW(p) · GW(p)
I wonder how this was affected by the fact that the overall scenario was in fact zero-sum, in that in order for a strategy to make more copies of itself it had to cause there to be less copies of other strategies?
It would be interesting to see a rematch where each strategy gets one copy of itself in the next generation for every N points it earns in the current generation, with no limit on the total number of copies.
Replies from: prasecomment by pengvado · 2011-09-06T19:27:24.396Z · LW(p) · GW(p)
It should be possible to efficiently compute the deterministic behavior of an infinite population under these rules. In particular, the presence of a slow strategy should not make it hard to simulate a large population for lots of generations. (Assuming strategies get to depend only on their current opponent, not on population statistics.)
First find the expectation of the scores for an iterated match between each pair of strategies: If they're both deterministic, that's easy. If there's some randomness but both compress their dependence on history down to a small number of states, then dynamic programming works. And in the general case, approximate it with an empirical mean.
The aforementioned expectations form something similar to a Markov transition matrix. Then updating the infinite population by 1 generation costs only O(N^2) multiplies, with N being the number of different strategies.
comment by homunq · 2011-09-06T15:43:14.699Z · LW(p) · GW(p)
The obvious way to make a cliquebot which would have a chance in this environment:
Tit for tat turns 1-94. If that was all cooperation, then turns 95, 96 are D, C; otherwise, continue with TFT. Turns 97-100 are C if all matches so far have agreed (facing a clone), or D if not.
This kind of thing would also help prevent infinite escalation of the last-N-turns defection.
I call it "Afterparty" if there's ever a future tournament.
Replies from: Unnamed↑ comment by Unnamed · 2011-09-06T19:05:26.116Z · LW(p) · GW(p)
I like it. One minor modification might make it even better: turn 96 can be the same as 97-100 rather than another D, since mutual D in 95 (after 94 mutual C) should be enough to establish clonehood. That way against clones it gets 99 mutual C and just 1 mutual D.
Also, if 1-94 aren't all cooperation, it might be better to have it just defect the last 2 or 3 turns rather than the last 4.
Replies from: homunq↑ comment by homunq · 2011-09-06T20:59:24.336Z · LW(p) · GW(p)
I said 95,96 are D,C. I should have said "respectively" to make it clearer.
Replies from: homunq, Unnamed↑ comment by homunq · 2011-09-07T21:24:19.693Z · LW(p) · GW(p)
Actually, in the initial environment, using 96,97 for the unprovoked D,C (instead of 95, 96) will be more successful. Like O, but unlike the first afterparty, this "late afterparty" (LA) will beat I in an environment of mostly I (score against I for last 6 turns: I gets 18, afterparty gets 16, O gets 21, and LA gets 20). It will also beat O in an environment of mostly it and O (against LA, LA scores 21 and O scores 14; against O, LA scores 14 and O scores 15. So if the environment has more than 1/8 LA, then LA is winning. From the above, if O and LA start out small and equal in an I-dominated environment, as I disappears LA will be around 40%, easily enough to come back and pass O). LA will lose to O in a strongly O-dominated environment , while the original version will win (Afterparty scores 17 against O, above O's mirror-score of 15); but since that situation should never arise, I think that LA has the best chance of coming to dominate the environment. In fact, in an environment which started out I-favorable and with both O and both forms of afterparty, original afterparty's only effect would be to hasten LA's win by parasitizing O.
(Edited; I'd originally used the 3,5,0,1 payoff matrix instead of 4,7,0,1)
↑ comment by Unnamed · 2011-09-07T03:02:24.142Z · LW(p) · GW(p)
Hmmm, for some reason I'd read that as D,D.
I still think it makes more sense to group 96 in with 97-100, though, as a turn where it only plays C if all matches so far have agreed. If 1-94 are all mutual C, then on 95 it plays D and opponent plays C, I'd think it should play D the rest of the way instead of going with C on 96 and then D on 97-100.
Replies from: homunq, lessdazed↑ comment by homunq · 2011-09-07T13:56:10.759Z · LW(p) · GW(p)
A C on 96 can benefit if the opponent is still TFT on 97.
Basically, going to defect too early can drive you to extinction when the rest of the population is still late-defectors.
Replies from: Unnamed↑ comment by Unnamed · 2011-09-08T18:06:09.031Z · LW(p) · GW(p)
I ran some numbers and it looks like your way is better against late-defectors.
Here are 3 ways you could design Afterparty:
v1. D-C on 95-96, then D 97-100 against non-clones (your original proposal)
v2. first D on 95, then D 96-100 against non-clones (my suggestion)
v3. first D on 96, then D 97-100 against non-clones (a variation on my suggestion)
My intuition was that v3 would be better than v1, even if v2 was not, but it turns out that's not the case. Version 1 scores the most against TFT (or variations of TFT that defect on up to the last 3 rounds). Compared to the others v1 has an extra CD and an extra DC (worth 7 points in total), v2 has two extra DD's (worth 2 points in total), and v3 has an extra CC and an extra DD (worth 5 points in total).
Things only change if the opponent is designed to play D for the last several rounds. If the opponent is TFT with D on the last 4 rounds then v3 does best and v1 does worst, and if the opponent plays D on the last 5 rounds then v2 does best and v3 does worst.
Replies from: homunqcomment by PhilGoetz · 2011-09-06T15:21:48.854Z · LW(p) · GW(p)
You wrote of U: "This one is a real beast, with code more that twice as long as that of its competitors. It actually models the opponent's behaviour as a random process specified by two parameters: probability of cooperation when the second strategy (which is the RackBlockShooter) also cooperates, and probability of cooperation when RBS defects. This was acausal: the parameters depend on RBS's behaviour in the same turn, not in the preceding one."
Isn't that just a simple bug in U? Probably Nic Smith meant it to model the opponent's responses to U's behavior on the previous turn, not the correlations between their actions on a given turn.
Replies from: Nic_Smith, benelliott↑ comment by Nic_Smith · 2011-09-06T15:59:47.257Z · LW(p) · GW(p)
Sort of. When I wrote it and sent it in, it was exactly as you described. Prase noticed and asked if that was actually what I meant, and I said to keep it that way since it sounded interesting, and I thought it had the potential to be a "good bad bug."
↑ comment by benelliott · 2011-09-06T15:26:47.492Z · LW(p) · GW(p)
It would be nice to see a run with that modified.
comment by Thomas · 2011-09-06T09:33:01.167Z · LW(p) · GW(p)
I suggest an everlasting battle of 1024 (or something) strategy bots. They die and survive at the more or less present tournament laws. Everybody has a right to come with a viable bot and throw it inside, let say once a day. Provided, that a bot with exactly the same code isn't already there. The upper limit for the code size is 1024 (or something) bytes. The current menagerie is visible here or somewhere else. Along with the most vital statistics.
comment by Eugine_Nier · 2011-09-06T05:56:25.370Z · LW(p) · GW(p)
There is one more lesson that I have learned: the strategies which I considered most beautiful (U and C1) played poorly and were the first to be eliminated from the pool. Both U and C1 tried to experiment with the opponent's behaviour and use the results to construct a working model thereof. But that didn't work in this setting: while those strategies were losing points experimenting, dumb mechanical tit-for-tats were maximising their gain. There are situations when the cost of obtaining knowledge is higher than the knowledge is worth, and this was one of such situations.
I think the problem with U was that in practice it quickly wound up playing all defect against tit-for-tat style strategies.
Replies from: Nic_Smithcomment by DavidPlumpton · 2011-09-06T00:51:10.653Z · LW(p) · GW(p)
Having a known number of rounds seems like a problem to me. Everybody wants to defect on the last round. It might be interesting to retry with a number of rounds chosen randomly from 100 to 110 or where after 100 each round has a 25% chance of being the final round. However a large number of matches might be needed to offset the advantages of playing in some matches with a higher than average number of rounds.
Replies from: MileyCyrus, prase, AdeleneDawner, nerzhin↑ comment by MileyCyrus · 2011-09-06T02:26:25.788Z · LW(p) · GW(p)
The way it goes now, we're basically playing rock-paper-scissors.
"Tit-for-tat until round 100" is beat by "tit-for-tat until 99", which is beat by "tit-for-tat until 98", which is beat by "tit-for-tat until 97" ect. At some point, "tit-for-tat until 100" becomes a winning strategy again, but only once the "tit-for-tat until [some arbitrarily low number]" strategies have become predominant.
↑ comment by AdeleneDawner · 2011-09-06T00:57:35.565Z · LW(p) · GW(p)
Perhaps the bots could be scored on their average number of points earned per round?
This would also allow a new option of 'pay N points to end the match', which could add some interesting realism.
↑ comment by nerzhin · 2011-09-07T00:40:58.593Z · LW(p) · GW(p)
Or just prohibit the bots from knowing which round they are playing.
Replies from: JoshuaZcomment by Will_Sawin · 2011-09-05T18:33:33.917Z · LW(p) · GW(p)
How difficult would it be to code an optmal-against-this-pool strategy? How well would it do?
Replies from: Johnicholas, lessdazed↑ comment by Johnicholas · 2011-09-05T18:49:40.066Z · LW(p) · GW(p)
If you are willing to allow the optimal-against-this-pool strategy to run the entire tournament as a subroutine, I think it can guarantee a tie by cloning the eventual winner.
It may be able to do better than that, but it depends on the details of the pool whether there are points "lying on the ground" to be picked up; I suspect there are with this pool, but I don't have a great example.
↑ comment by lessdazed · 2011-09-06T01:52:30.267Z · LW(p) · GW(p)
optmal
How difficult would it be tell if a strategy was optimal against this pool?
One could try to improve by testing modifications of the winner, such as:
if OpponentDefectedBefore(7) then MyMove=D else if n>98 then MyMove=D else MyMove=OpponentLastMove unless OpponentMove=MyMove 1-99, in which case Turn(100)=cooperate
or
if OpponentDefectedBefore(7) then MyMove=D else if n>97 then MyMove=D else MyMove=OpponentLastMove unless OpponentMove=MyMove 1-98, in which case Turn(99)=cooperate, and if OpponentMove=MyMove 1-99, Turn(100)=cooperate.
Replies from: Will_Sawin↑ comment by Will_Sawin · 2011-09-07T02:21:30.377Z · LW(p) · GW(p)
It depends on how big your strategy is.
If it tells you what to do, not just depending on what your opponent does, but on what you do, then testing 1-move modifications is sufficient to test optimality.
If not, then it isn't.
Replies from: lessdazed↑ comment by lessdazed · 2011-09-07T02:36:11.323Z · LW(p) · GW(p)
Doesn't an optimization question depend as much on the complexity of opposing strategies as it does on the complexity of my strategy?
Replies from: Will_Sawin↑ comment by Will_Sawin · 2011-09-07T04:43:47.848Z · LW(p) · GW(p)
The statement of sufficiency I made is true for all complexities of opposing strategies.
The statement of insufficiency is not. If the opponent's strategies are, for instance, linear, then it should be false. But some opposing strategies ARE very complex, so it's presumably true.
comment by Pavitra · 2011-09-06T18:56:55.227Z · LW(p) · GW(p)
A's abuse of rules is, in my opinion, not slight. If everyone tried to stuff the ballot box in the same way... in practice it seems the main difference would be more Fuck Them All, but in theory it would lead to a skewed and uninformative tournament, decided more by popular vote than by strategic merit.
This raises the question of what sort of psychology might lead the author to cooperate on the object level while defecting on the meta level.
Replies from: prase↑ comment by prase · 2011-09-06T19:09:34.884Z · LW(p) · GW(p)
It depends on what sort of informativeness we want to achieve. What is the "ideal" distribution of strategies in the pool, not biased by popular vote? If there was a simple metric for strategy complexity, an analogue of Kolmogorov prior might work. But the actual pool was very far from that. Having more DefectBots and TitForTats would actually move us in that direction.
Replies from: Pavitra↑ comment by Pavitra · 2011-09-07T14:20:42.616Z · LW(p) · GW(p)
Having more DefectBots and TitForTats would actually move us in that direction.
Only by coincidence. It's not like authors of simple strategies are systematically more likely than authors of complex strategies to try to cheat the metarules.
comment by wedrifid · 2011-09-06T12:25:25.248Z · LW(p) · GW(p)
Then we have a special "class" of DefectBots (a name stolen from Orthonormal's excellent article) consisting of only one single strategy. But this is by far the most popular strategy — I have received it in four copies. Unfortunately for DefectBots, according to the rules they have to be included in the pool only once.
A shame the defectors didn't cooperate a little better! A few more of us and some noise and we'd have been unstoppable. ;)
Replies from: shokwave, shokwave↑ comment by shokwave · 2011-09-06T13:58:49.023Z · LW(p) · GW(p)
A shame the defectors didn't cooperate a little better!
Meta-defection: Co-operate to drown a tournament in DefectBots.
Meta-meta-defection: 'co-operate' to discover how other defectors are planning to drown the tournament and trick as many of them into submitting copies of a single variant on DefectBot.
Replies from: wedrifid↑ comment by shokwave · 2011-09-06T13:54:33.536Z · LW(p) · GW(p)
I don't think so. Just an intuition, but...
In the round robin the gains from scoring a D - C 30 times (the beginning play where most strategies went C to start, and I bumped the number to 30 assuming you snuck plenty of trivial variations on DefectBots) is 210 points; tit-for-tat analogues make that many points halfway through one game with another tit-for-tat. Eyeballing the field, there aren't any places where DefectBot would make a serious profit except Random, so I can't see even a supermajority of DefectBots winning the round-robin.
In the evolutionary tournament... DefectBots will kill off anyone they're paired with, but all it takes is two strategies that can cooperate for 90 or so turns and the next generation will be comprised of something like one-third those two and two-thirds DefectBot, which will rapidly favour cooperating bots.
In both cases, the gains from being able to cooperate for ~90 turns is just so huge; a DefectBot needs to defect against a cooperate 50 times to match that score (and no strategy was more defection-tolerant than Random, so they wouldn't get their 50 D - Cs).
(If the noise was overpowering enough to break even robust tit-for-tats, it wouldn't be much of a tournament.)
Replies from: wedrifid↑ comment by wedrifid · 2011-09-06T14:44:27.497Z · LW(p) · GW(p)
In the evolutionary tournament... DefectBots will kill off anyone they're paired with, but all it takes is two strategies that can cooperate for 90 or so turns and the next generation will be comprised of something like one-third those two and two-thirds DefectBot, which will rapidly favour cooperating bots.
'Few' was intentionally understated. Enough DefectBots just win.
comment by Vaniver · 2011-09-06T02:21:35.227Z · LW(p) · GW(p)
Thanks for doing this!
My prediction was wrong- looking back, there were several pieces of evidence I got after my prediction that should have caused me to issue a retraction, rather than a modification. I recall the part in parentheses being an edit- and once I realized that I should have adjusted my confidence rather than my statement.
I'm curious how things go if you only include the 11 strategies submitted by LWers with at least 500 karma.
comment by JoshuaZ · 2011-09-06T01:10:15.927Z · LW(p) · GW(p)
If we do this again, I'm almost tempted to submit a really perverse example which does the opposite of tit for tat. So, defect on the first turn, and cooperate on turn n iff they defected on n-1. I'm pretty sure this would go really badly.
Hmm, I notice also that no one tried naive always cooperate. Would be interesting to see how well that does.
Replies from: thomblake, prase↑ comment by thomblake · 2011-09-06T14:43:04.632Z · LW(p) · GW(p)
I thought of this too, but it really should play C then D to start so it cooperates against itself - otherwise, it will defect against itself.
Given the payoff matrix for this tournament, it isn't a very good strategy. However, if the payoff matrix rewarded D-C more strongly, then a pair of (tit-for-tat, tit-for-tat's complement) would do very well.
comment by JoshuaZ · 2011-09-05T18:24:52.221Z · LW(p) · GW(p)
I'd be very interested in seeing the same sort of thing where the number of rounds is randomly chosen and they don't know how many rounds they are going to go up against.
Note that the CliqueBots failure is not a good reason to think that Cliquebotish like strategies will fail in evolutionary contexts in real life. In particular, life generally has a lot of conditions to tell how closely related something is to them (such as skin coloration). In this sort of context cliquebots are losing in part because they need at one point to defect against themselves to do an identity test. I suspect that if strategies were told in advance whether they are going up against themselves then Cliquebots would do a lot better.
P seems to be a much better designed CliqueBot than Q especially for large sets. Five defections is a lot to burn, and in fact it does go away well before Q leaves.
One other thing that might be interesting to see what sort of environments which strategies will do well in is to never reduce the number of copies of any strategy to 0, and have 1 be the minimum.
Replies from: scav, AdeleneDawner, prase, red75↑ comment by scav · 2011-09-06T08:18:48.362Z · LW(p) · GW(p)
One other thing that might be interesting to see what sort of environments which strategies will do well in is to never reduce the number of copies of any strategy to 0, and have 1 be the minimum.
I think CliqueBots are still going to do badly if there's only one member of the clique :)
↑ comment by AdeleneDawner · 2011-09-06T00:40:25.167Z · LW(p) · GW(p)
I suspect that if strategies were told in advance whether they are going up against themselves then Cliquebots would do a lot better.
It might also be interesting to see what would happen if the bots were allowed to either remember their last N scores and/or win/loss record for the last N games, or know how many other bots of their type exist in the population. I suspect that "if I'm a member of a small minority do X, else if I'm a member of a large minority or small majority do Y, else do Z" would be an interesting class of strategies to look at.
↑ comment by prase · 2011-09-06T10:10:24.507Z · LW(p) · GW(p)
P is better than Q not because Q's initial five defections, but because it plays more than half of the match like TfT. So it's basically only a 43% CliqueBot. The problem with CliqueBots (under rules of this game) aren't resources spent testing the opponent's identity, but that they are cooperating neither with the nice strategies nor with CliqueBots of other types.
↑ comment by red75 · 2011-09-05T19:08:04.839Z · LW(p) · GW(p)
I think communication cost isn't main reason for P's failure. O, for example, defects on 3 last turns even when playing against itself (rule 1 is of highest priority). Reasons are too strong punishment of other strategies (and consequently itself) and too strict check for self identity.
Strategy I described here should perform much better, when n is in range 80-95.
comment by JamesAndrix · 2011-09-07T02:47:10.746Z · LW(p) · GW(p)
A cheap talk round would favor CliqueBots.
That O only took off once other variants were eliminated suggests a rock-paper-scissors relationship. But I suspect O only lost early on because parts of it's ruleset are too vulnerable to the wider bot population. So which rules was O following most when it lost/ against early opponents, and which rules did it use to beat I and C4?
Replies from: wedrifid↑ comment by wedrifid · 2011-09-07T07:55:08.836Z · LW(p) · GW(p)
That O only took off once other variants were eliminated suggests a rock-paper-scissors relationship. But I suspect O only lost early on because parts of it's ruleset are too vulnerable to the wider bot population. So which rules was O following most when it lost/ against early opponents, and which rules did it use to beat I and C4?
O is tit-for-tat with 3 defections at the end (TFT3D). It has extra rules to help with weird players and randoms. Those don't matter much once the weird guys are gone and it becomes a game between the tit-for-tats so ignore those. There
I is TFT2D and roughly speaking so is C4. All the next players who are slightly behind the TFT2Ds are approximations of TFT1D (with random killer noise that we can again ignore once the real fight starts) then there are plenty of TFT0Ds as well.
Consider the following match ups:
- TFT3D vs TFT2D: TFT3D earns 300. TFT2D earns 295.
- TFT3D vs TFT1D: TFT3D earns 300. TFT1D earns 295.
- TFT2D vs TFT1D: TFT2D earns 301. TFT1D earns 296.
Before that, while the pure tit-for-tats (TFT0D) are alive we of course also have * TFT0D vs TFT1D, TFT2D and TFT3D: TFT0D earns 297, 296, 295 respectively while the greater cheaters earn the 302, 301 and 300 that we expect for when they fight any nicer TFT. This helps explain why O started slightly behind even some TFT1Ds at the start but soon becomes irrelevant.
The pool starts up TFT1D >> TFT2D > TFT1D based on the number of variants submitted. All three of them feed early off weird strategies and TFT0Ds. The TFT2Ds then take off, feeding off the large population TFT1Ds. The TFT3D can feed off TFT1D too but not quite as effectively as the TFT2Ds. Once the TFT1Ds (and TFT0Ds) are eliminated from the population the TFT3Ds can slowly begin to catch up and overtake their more optimistic counterpart.
In any population made up of many TFT(n)Ds a TFT(n+1)D will thrive. Unfortunately for him, however, if n is too great and there are enough significantly more cooperative TFTs around it will be eliminated before it gets a chance to shine. There is no paper-scissors-rock relationship TFT1D can score more than TFT3D but never by beating anything that can beat anything that can beat anything (etc) that can beat a TFT3D. A more optimistic TFT only beats a less optimistic TFT if it has a sufficient clique of similarly or more optimistic TFTs and the rival is just too pessimistic and has nobody to feed off effectively.
Replies from: Andreas_Giger↑ comment by Andreas_Giger · 2011-09-13T04:04:01.205Z · LW(p) · GW(p)
Thanks for the analysis and the TFTnD nomenclature, both of which I have expanded upon in a post.
comment by Lightwave · 2011-09-06T08:30:35.775Z · LW(p) · GW(p)
Here's a lecture (from Stanford's Human Behavioral Biology course) which talks about Axelrod's original tournaments and the various strategies that emerged then (starts at 45:00 min, until 1:00:00 h, then he talks how this applies to biological systems).
comment by AlephNeil · 2011-09-07T17:25:09.392Z · LW(p) · GW(p)
Thanks, this is all fascinating stuff.
One small suggestion: if you wanted to, there are ways you could eliminate the phenomenon of 'last round defection'. One idea would be to randomly generate the number of rounds according to an exponential distribution. This is equivalent to having, on each round, a small constant probability that this is the last round. To be honest though, the 'last round' phenomenon makes things more rather than less interesting.
Other ways to spice things up would be: to cause players to make mistakes with small probability (say a 1% chance of defecting when you try to co-operate, and vice versa); or have some probability of misremembering the past.
comment by rysade · 2011-09-06T14:34:12.143Z · LW(p) · GW(p)
In the interest of seeing what strategies like U and C1 could do regarding experimenting with the opponent's behavior, I would be interested if there were a prisoner's dilemma variant that had a second score that is worth less points but can still add up, enabling a strategy to come out on top if it comes down to neck-and-neck. Real life kind of operates like that: there are ways to win little victories over others, but those strategies are often telling about your character.
comment by JesusPetry · 2011-09-05T17:43:12.032Z · LW(p) · GW(p)
Very interesting results! The pool of strategies influences the success of each individual strategy!
Replies from: fubarobfusco, prase↑ comment by fubarobfusco · 2011-09-05T22:07:00.280Z · LW(p) · GW(p)
Very much so. One thing that I've noticed in my own tests is that the presence of lots of sucker ("always cooperate") and defectbot strategies in the initial pool ultimately tends to favor vengeful strategies. The defectbots drive the suckers to extinction, but then can't survive without them.
Betrayers (who cooperate for a while and then start defecting if the opponent has always cooperated) consistently do very poorly, as do strategies that add random defection to tit-for-tat.
If there are enough sucker strategies ("always cooperate") then they can keep each other alive.
And under certain circumstances (that I haven't mapped out yet), all strategies I've tried do worse than random.
And I just ran one test on my own code (incidentally using the "Friend or Foe" payoff matrix rather than the Axelrod matrix) in which Random and Sucker dominated initially until the other non-nice strategies were driven to extinction, at which point a vengeful strategy took over. And then another on the same initial population where a forgiving tit-for-tat took over at the same point. This appears to be incredibly sensitive to initial conditions and the behavior of the Random Number God ...
↑ comment by prase · 2011-09-05T17:52:26.725Z · LW(p) · GW(p)
That's of course what had to be expected and what makes the game interesting, and also why the "evolutionary" tournament was supposed to give different results that the round-robin tournament. If there was a strategy which was best in any circumstances, everybody would send it.
Replies from: Alex_Altair↑ comment by Alex_Altair · 2011-09-06T00:35:48.549Z · LW(p) · GW(p)
Nobody sent in AIXItl? :)
comment by MrCheeze · 2011-09-08T00:52:07.386Z · LW(p) · GW(p)
If this ever happens again I'd make one for the long-term evolutionary one that tries to learn strategies U-style, and then remembers what it learned in future rounds. If that's allowed.
Replies from: benelliott↑ comment by benelliott · 2011-09-08T11:23:40.838Z · LW(p) · GW(p)
That sort of thing wasn't allowed this time, but I agree that a variation of that rule would be interesting (but possibly difficult to code)
comment by Sniffnoy · 2011-09-05T17:54:48.026Z · LW(p) · GW(p)
Wait, why was a fixed number of rounds used?
Edit: So, all the submitted strategies were deterministic? Or did I miss one? Was this a requirement?
Edit again: Oops, scratch that, I see now the control group included randomized strategies.
Replies from: prasecomment by clymbon · 2011-09-12T18:53:20.831Z · LW(p) · GW(p)
What to make of "Prisoner's Dillema" as an analogy for life and society? Some people see it as a close analogy for life, and use it to explain why it's so hard to get individuals to cooperate for mutual benefit, rather than acting in narrow self-interest. But this is missing something extremely important. That is, the ability of the players to change the rules. In fact, prisoners do exactly that. If you "defect" and rat out your partner in crime, you may get a reduced sentence, but you're likely to be marked as a "snitch" and punished by the other prisoners. Society is full of examples like this - groups act to "change the rules" to increase the motivation to cooperate or decrease the motivation to "defect".