Value Formation: An Overarching Model
post by Thane Ruthenis · 2022-11-15T17:16:19.522Z · LW · GW · 20 commentsContents
0. Introduction 1. The Setup 2. How Will the GPS (Not) Be Used? 3. Interfaces 4. Reverse-Engineering the Heuristics 5. The Wrapper Structure 5A. Assumption Re-Check 5B. The Interim Objective 5C. Looping Heuristics Back In 5D. Nurturing the Mesa-Optimizer 5E. Putting It Together 6. Value Compilation 6A. The Basic Algorithm 6B. Path-Dependence 6C. Ontological Crises 6D. Meta-Cognition 6E. Putting It Together 7. Miscellanea 8. Summary 9. Implications for Alignment Bonus: The E-Coli Test for Alignment 10. Future Research Directions None 20 comments
0. Introduction
When we look inwards, upon the godshatter [LW · GW], how do we make sense of it? How do we sort out all the disparate urges, emotions, and preferences, and compress them into legible principles and philosophies? What mechanisms ensure our robustness to ontological crises? How do powerful agents found by a greedy selection process arrive at their morals? What is the algorithm for value reflection?
This post seeks to answer these questions, or at least provide a decent high-level starting point. It describes a simple toy model that embeds an agent in a causal graph, and follows its moral development from a bundle of heuristics to a superintelligent mesa-optimizer.
The main goal of this write-up is to serve as a gears-level model [LW · GW] — to provide us with a detailed step-by-step understanding of why and how agents converge towards the values they do. This should hopefully allow us to spot novel pressure points — opportunities for interventions that would allow us to acquire a great deal of control over the final outcome of this process. From another angle, it should equip us with the tools to understand how different changes to the training process or model architecture would impact value reflection, and therefore, what kinds of architectures are more or less desirable.
Let's get to it.
1. The Setup
As the starting point, I'll be using a model broadly similar to the one from my earlier post [LW · GW].
Let's assume that we have some environment represented as a causal graph. Some nodes in it represent the agent, the agent's observations, and actions.
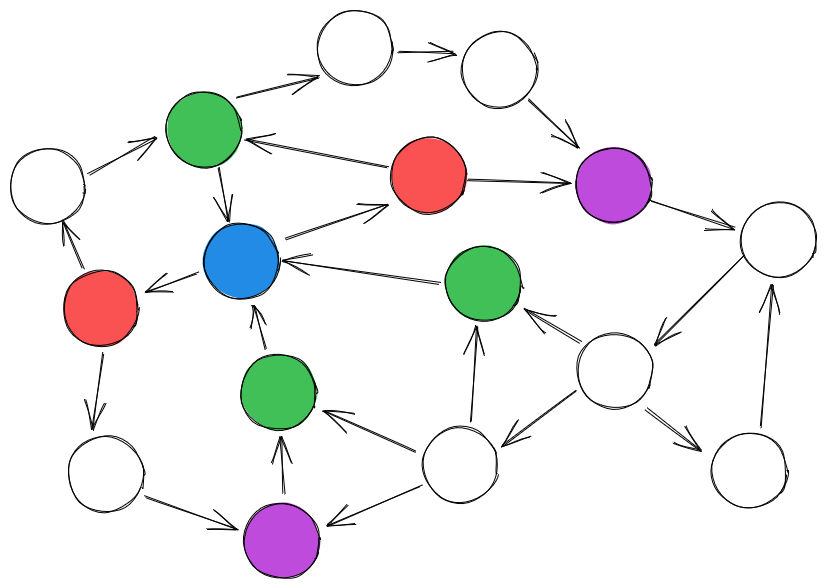
Every turn (which might be a new training episode or the next time-step in a RL setup), the agent (blue node) reads off information from the (green) observation nodes , sets the values for the (red) action nodes , all nodes' values update in response to that change, then the agent receives reward based on the (purple) reward nodes . The reward is computed as some function , where represents the reward nodes' current values.
The agent is being optimized by some optimization/selection process — the SGD, evolution, human brain reward circuitry [? · GW], whatever. What matters is that this process is non-intelligent and greedy [LW · GW]: it only ever makes marginal improvements to the agent's architecture, with an eye for making it perform marginally better the next turn.
As per the previous post [LW · GW], the agent will have naturally learned an advanced world-model, which we'll also consider to be a causal graph, . Every turn, after the agent makes the observations, it'll use that world-model to infer as much other information about the environment as it can (i. e., the current values of the non-observed nodes). Let's also assume that the world-model is multi-level, making heavy use of natural abstractions: both "an atom" and "a spider" are nodes in it, even if the actual environment contains only atoms.
Let's define and as some subsets of the world-model and the action nodes respectively. The agent will have developed a number of shallow heuristics, which are defined as follows:
That is: a heuristic is some function that looks at some inferred part of the world, and recommends taking certain actions depending on what it sees. Informally, we may assume that heuristics are interpretable — that is, they're defined over some specific world-model node or a coherent set of such nodes, perhaps representing a natural abstraction [LW · GW].
We'll assume that at the starting point we're considering, the entire suite of the heuristics is subpar but much better than random behavior according to the outer reward function. E. g., they always allow the agent to secure at least 50% of the possible reward
We'll assume that the environment is too complex for such static heuristics to suffice. As the consequence, whatever process is shaping the agent, it has just now built General-Purpose Search [LW · GW] into it:
Where is the current state of the world-model, and , are the "target values" for the nodes in and respectively.
That is: is some function that takes in a world-model and some "problem specification" — some set of nodes in the world-model and their desired values — and output the actions that, if taken in that world-model, would bring the values of these nodes as close to the desired values as possible given the actions available to the agent.
Note that it's defined over the world-model, not over the real environment , and so its ability to optimize in the actual decreases the less accurate the world-model is.
Let's explore the following question:
2. How Will the GPS (Not) Be Used?
Pointing the GPS at the outer objective seems like the obvious solution. Let be the values of that maximize . Then we can just wire the agent to pass to the GPS at the start of every training episode, and watch it achieve the maximum reward it can given the flaws in its world-model. Turn it into a proper wrapper-mind [LW · GW].
Would that work?
Well, this idea assumes that the world-model already has the nodes representing the reward nodes. It might not be the case, the way stone-age humans didn't know what "genes" are for the evolution to point at them. If so, then pointing the GPS at the reward proxies is the best we can do.
But okay, let's assume the world-model is advanced enough to represent the reward nodes. Would that work then?
Sure — but only under certain, fairly unnatural conditions.[1]
In my previous post, I've noted [LW · GW] that the very process of being subjected to a selection pressure necessarily builds certain statistical correlations into the agent.
- One type of such correlations is , mappings from the observations to the values of non-observed environment nodes. They're built into the agent explicitly, as correlations. Taken in sum, they're how the agent computes the world-model.
- Heuristics, however, can also be viewed this way: as statistical correlations of the type . Essentially, they're statements of the following form: "if you take such action in such situation, this will correlate with higher reward".
The difference between the two types, of course, is that the second type is non-explicit. Internally, the agent doesn't act as the heuristics specify because it knows that this will increase the reward — it just has a mindless tendency to take such actions. Only the mappings are internally represented — and not even as part of the world-model, they're just procedural!
But these tendencies were put there by the selection process because the correlations are valid. In a way, they're as much part of the structure of the environment as the explicitly represented correlations. They're "skills", perhaps: the knowledge of how an agent like this agent needs to act to perform well at the task it's selected for.
The problem is, if we directly hard-code the GPS to be aligned with the outer objective, we'd be cutting all the pre-established heuristics out of the loop. And since the knowledge they represent is either procedural or implicit, not part of the explicit world-model, that would effectively decrease the amount of statistical correlations the agent has at its disposal — shrink its effective world-model dramatically. Set it back in its development.
And the GPS is only as effective as the world-model it operates in.
Our selection process is greedy, so it will never choose to make such a change.
3. Interfaces
Let's take a step back, and consider how the different parts of the agent must've learned to interface with each other. Are there any legible data structures?
a) The World-Model. Initially, there wouldn't have been a unified world-model. Each individual heuristic would've learned some part of the environment structure it cared about, but it wouldn't have pooled the knowledge with the other heuristics. A cat-detecting circuit would've learned how a cat looks like, a mouse-detecting one how mice do, but there wouldn't have been a communally shared "here's how different animals look" repository.
However, everything is correlated with everything else (the presence of a cat impacts the probability of the presence of a mouse), so pooling all information together would've resulted in improved predictive accuracy. Hence, the agent would've eventually converged towards an explicit world-model.
b) Cross-Heuristic Communication. As a different consideration, consider heuristics conflicts. Suppose that we have some heuristics and that both want to fire in a given training episode. However, they act at cross-purposes: the marginal increase of achieved by firing at would be decreased by letting fire at , and vice versa. Both of them would want to suppress each other. Which should win?
On a similar note, consider heuristics that want to chain their activations. Suppose that some heuristic responds to a subset of the features detects. can learn to detect them from scratch, or it can just learn to fire when does, instead of replicating its calculations.
Both problems would be addressed by some shared channel of communication between the heuristics, where each of them can dump information indicating how strongly it wants to fire this turn. To formalize this, let's suppose that each heuristic has an associated "activation strength" function . (Note that activation strength is not supposed to be normalized across heuristics. I. e., it's entirely possible to have a heuristic whose strength ranges from 0 to 10, and another with a range from 30 to 500, such that the former always loses if they're in contest.)
The actual firing pattern would be determined as some function of that channel's state.[2]
c) Anything Else? So far as I can tell now, that's it. Crucially, under this model, there doesn't seem to be any pressure for heuristics to make themselves legible in any other way. No summaries of how they work, no consistent formats, nothing. Their constituent circuits would just be... off in their own corners, doing their own things, in their own idiosyncratic ways. They need to be coordinated, but no part of the system needs to model any other part. Yet.
So those are the low-hanging fruits available to be learned by the GPS. The selection pressure doesn't need to introduce a lot of changes to plug the GPS into the world-model and the cross-heuristics communication channel[3], inasmuch as they both follow coherent data formats.
But that's it. Making the mechanics of the heuristics legible — both standardizing the procedural knowledge and making the implicit knowledge explicit — would involve a lot more work, and it'd need to be done for every heuristic individually. A lot of gradient steps/evolutionary generations/reinforcement events.
4. Reverse-Engineering the Heuristics
That's very much non-ideal. The GPS still can't access the non-explicit knowledge — it basically only gets hunches about it.
So, what does it do? Starts reverse-engineering it. It's a general-purpose problem-solver, after all — it can understand the problem specification of this, given a sufficiently rich world-model, and then solve it. In fact, it'll probably be encouraged to do this. The selection pressure would face the choice between:
- Making the heuristics legible to the GPS over the course of many incremental steps.
- Making the GPS better at reverse-engineering the rest of the system the GPS is embedded in.
The second would plausibly be faster, the same way deception is favoured relative to alignment [LW · GW][4]. So the selection pressure would hard-code some tendency for the GPS to infer the mechanics of the rest of the agent's mind, and write them down into the world-model. This is an important component of the need for self-awareness/reflectivity.
The GPS would gather statistical information about the way heuristics fire, what they seem to respond to or try to do, which of them fire together or try to suppress each other, what effects letting one heuristic or the other fire has on the world-model, and so on.
One especially powerful way to do that would be running counterfactuals on them. That is, instead of doing live-fire testing (search for a situation where heuristic wants to fire, let it, see what happens), it'd be nice to simulate different hypothetical states the world-model could be in, then see how the heuristics respond, and what happens if they're obeyed. And there'll likely already be [LW · GW] a mechanism for rolling the world-model forward or generating hypotheticals, so the GPS can just co-opt it for this purpose.
What will this endeavor yield, ultimately? Well, if the natural abstractions hypothesis [LW · GW] is true, quite a lot! As I've noted at the beginning, each heuristic is plausibly centered around some natural abstraction or a sensible cluster of natural abstractions[5], and it'd be doing some local computation around them aimed at causing a locally-sensible outcome. For example, we might imagine a heuristic centered around "chess", optimized for winning chess games. When active, it would query the world-model, extract only the data relevant to the current game of chess, and compute the appropriate move using these data only.
So we can expect heuristics to compress well, in general.
That said, we need to adjust our notation here. Suppose that you're the GPS, trying to reverse-engineer some heuristic . You obviously don't have access to the ground-truth of the world , only a model of it . And since might be flawed, the world-model nodes is defined over might not even correspond to anything in the actual environment [? · GW]!
By the same token, the best way to compress 's relationship with might not be summarizing its relationship with the actual reward-nodes, but with some proxy node. Consider this situation:
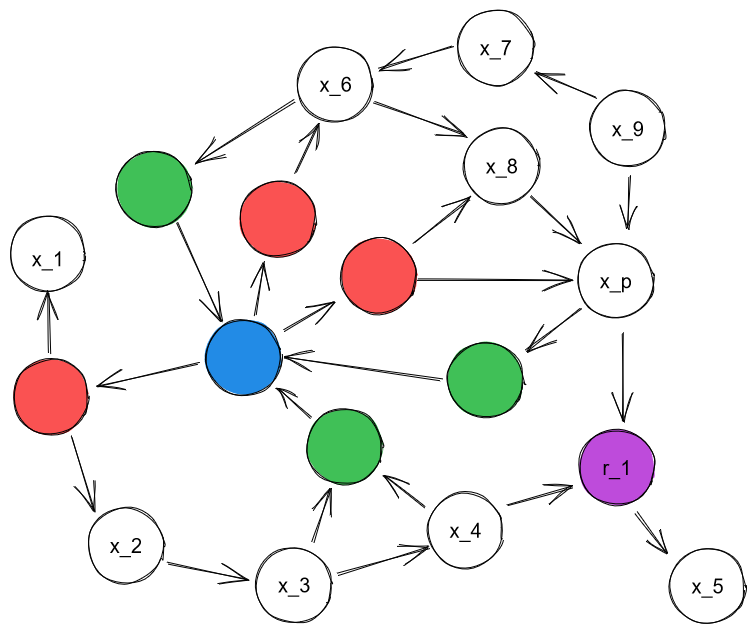
We can imagine some heuristic which specializes in controlling the value of . Ultimately, that heuristic would've been created by the selection pressure because of its effect on . But 's actual mechanical implementation would only be focused on , and the causal chain between it and the agent! It would pay no mind to , so its effect on would be subject to a lot of noise — unlike its effect on . Thus, the agent would recover as the target, not . (And, of course, it might also be because isn't yet represented in the world-model at all.)
As an example, consider chess. The algorithms for playing it well are convergent across all agents, irrespective of the agent's goals outside chess or its reason for trying to win at chess. Their implementations would only refer to chess-related objectives.
Thus, while an "outside-picture" view on heuristics describes them as , internally they'd be best summarized as:
Where is some proxy objective. For simplicity, let's say that is a 2-tuple , where the first entry is a world-model node and the second is the "target value" for that node. So every "goal" is to keep the value of a node as close to the target as possible.
As another technicality, let's say that the activation-strength function increases the farther from the target the corresponding node's value goes.
5. The Wrapper Structure
All this time, I've been avoiding the subject of what the GPS will be pointed at. I've established that it'll be used for self-reflection, and that it won't be optimizing for a fixed goal aligned with the outer objective — won't be a wrapper-mind [LW · GW]. But what spread of goals will it actually pursue at the object-level? What would be the wrapper structure around the GPS?
5A. Assumption Re-Check
First, let's check whether aligning it with the outer objective still doesn't work. What if we point it at the joint task of reward maximization plus self-reflection? Make it want the target objective plus inform it that there's some useful yet inaccessible knowledge buried in its mind. That'll work... if it had infinite time to think, and could excavate all the procedural and implicit knowledge prior to taking any action. But what if it needs to do both in lockstep?
In addition, "point it at the X task" hides a lot of complexity. Even if the reward-nodes are already represented in the world-model, building an utility function around them is potentially a complex problem, requiring many parameter updates/generations. All the while, the GPS would be sitting there, contributing nothing. That's not how our greedy selection process works — there just aren't gradients from "GPS does nothing" to "GPS is inner-aligned with the target objective".
No, we need some interim objective for the GPS — something we can immediately hook it up to and make optimize, and which would at least somewhat correlate with good performance on the target objective. Once that's done, then we can incrementally rewrite that proxy objective to the target objective... if we'll even want to, at that point.
5B. The Interim Objective
A few points:
- In the previous section, we've established that every heuristic enforces some relationship between a state of a world-model subset and some subset of the actions the agent will take . Let's call this structure contextual behavior . (We'll assume that the activation strength is folded into .)
- Such contextual behaviors are optimized for achieving some proxy objective in the world-model subset . We'll call this a contextual goal . (Similarly, assume that is somehow represented in .)
- The GPS can, in principle, succeed at extracting both and from a given .
- At the beginning, we've postulated that by the time the GPS develops, the agent's heuristics, when working in tandem, would be much-better-than-random at achieving the target objective.
This makes the combination of all contextual goals, let's call it , a good proxy objective for the target objective . A combination of all contextual behaviors , in turn, is a proxy for , and a second-order proxy for .
Prior to the GPS' appearance, the agent was figuratively pursuing ("figuratively" because it wasn't an optimizer, just an optimized). So the interim objective can be at least as bad as . On the other hand, pursuing directly would probably be an improvement, as we wouldn't have to go through two layers of proxies.
The GPS can help us with that: can help us move from to , and then continue on all the way to .
We do that by first enslaving the GPS to the heuristics, then letting it take over the agent once it's capable enough.
5C. Looping Heuristics Back In
The obvious solution is obvious: make heuristics themselves control the GPS. The GPS' API is pretty simple, and depending on the complexity of the cross-heuristic communication channel, it might be simple enough to re-purpose its data formats for controlling the GPS. Once that's done, the heuristics can make it solve tasks for them, and become more effective at achieving (as this will give them better ability to runtime-adapt to unfamiliar circumstances, without waiting for the SGD/evolution to catch them up).
I can see it taking three forms:
- Input tampering. The problem specification terms that gets passed to the GPS are interfered-with or wholesale formed by heuristics.
- ("Condition X is good, so I'll only generate plans that satisfy it." Also: "I am in pain, so I must think only about it and find the solution to it as quickly as possible.")
- Process tampering. The heuristics can learn to interfere on the GPS process directly, biasing it towards one kind of problem-solving or the other.
- ("I'm afraid of X, so my mind is flinching away from considering plans that feature X.")
- Output tampering. The heuristics can learn to override the actions the GPS recommends to take.
- ("X is an immediate threat, so I stagger back from it.")
The real answer is probably all of this. Indeed, as I've illustrated, I think we observe what looks like all three varieties in humans. Emotions, instincts, and so on.
5D. Nurturing the Mesa-Optimizer
As this is happening, we gradually increase the computational capacity allocated to the GPS' and the breadth of its employment. We gradually figure out how to set it up to do self-reflection.
It starts translating the procedural and the implicit knowledge into a language it understands — the language of the world-model. s and s are explicated and incorporated into it, becoming just more abstractions the GPS can make use of.
At this point, it makes sense to give the GPS ability to prompt itself — to have influence over what goes into the problem specifications of its future instances. It'll be able to know when to solve problems by engaging in contextual behaviors, even if it doesn't understand why they work, and optimizing for contextual goals is literally what it's best at.
This way of doing it would have an advantage over letting heuristics control the GPS directly:
- It would allow the GPS to incorporate procedural knowledge into its long-term plans, and otherwise account for it, instead of being taken by surprise.
- It would allow the GPS to derive better, more nuance-aware ways of achieving contextual goals, superior to those codified in the heuristics. It would greatly improve the agent's ability to generalize to new environments.
We'll continue to improve the GPS, improving its ability to do this sort of deliberative long-term goal pursuit. At the same time, we'll lessen the heuristics' hold on it, and start turning heuristics towards the GPS' purposes — marginally improving their legibility, and ensuring that the process of reverse-engineering them aims the agent at with more and more precision.
The agent as a whole will start moving from a -optimizer to a -optimizer, and then even beyond that, towards .[6]
5E. Putting It Together
So, what's the wrapper structure around the GPS, at some hypothetical "halfway point" in this process?
- Instincts. Heuristics pass the GPS problem specifications and interfere in its processes.
- Self-reflection. The GPS tries to reverse-engineer the rest of the agent in order to piggyback off its non-explicit knowledge.
- A spread of mesa-objectives. The GPS uses its explicit knowledge to figure out what it's "meant" to do in any given context, and incorporates such conclusions in its long-term plans.
6. Value Compilation
The previous section glossed over a crucial point: how do we turn a mass of contextual behaviors and goals into a proper unitary mesa-objective ?
Because we want to do that. The complex wrapper structure described in the previous section is highly inefficient. At the limit of optimality, everything wants to be a wrapper-mind [LW · GW]. There's plenty of reasons for that:
- The basic argument [LW · GW]. We wouldn't want our optimization process/the GPS to be haphazardly pointed in different directions moment-to-moment, as different heuristics activate and grab its reins, or bias it, or override it; even as it continues to recover more and more pieces of them. We'd be getting dutch-booked all the time, act at cross-purposes with our future and past instances. The GPS explicating this doesn't exactly help: it'll be able to predict its haphazard behavior, but not how to prevent it in a way that doesn't worsen its performance.
- It's computationally inefficient. Imagine a naively-formed , of the following form: . It would look at the world-model, run down the list of contextual behaviors, then execute the behaviors that apply, and somehow resolve the inevitable conflicts between contradictory behaviors. Obviously, that would take a lot of time; time in which someone might brain you with a club and take all your food. Contextual behaviors sufficed when they just happened, but considering them via the GPS would take too long. (Consider how much slower conscious decision-making is, compared to knee-jerk reactions.)
- It might be a hard-wired terminal objective. Remember, any given individual is not a good proxy objective — only their combination is. So it's entirely probable that the selection pressure would directly task the GPS with combining and unifying them, not only with reverse-engineering them. Even if there weren't all the other reasons to do that.
- Closely related to (3): ability to generalize to unfamiliar environments. Optimizing for would almost always allow the agent to do a good job according to even if it were dropped in entirely off-distribution circumstances. , on the other hand, would trip up the moment it fails to locate familiar low-level abstractions. (E. g., a preference utilitarian would be able to make moral judgements even in an alien civilization, whereas someone who's only internalized some system of norms of a small human culture would be at a loss.)
So, how do we collapse into a compact, coherent ?
(For clarity: everything in this section is happening at runtime. The SGD/evolution are not involved, only the GPS. At the limit of infinite training, would become explicitly represented in the agent's parameters, with the GPS set up to single-mindedly pursue it and all the heuristics made into passive and legible pieces of the world-model. But I expect that the agent would become superintelligent and even "hyperintelligent" long before that — i. e., capable of almost arbitrary gradient-hacking [LW · GW] — and so the late-game hard-coded would be chosen to by it, and therefore would likely be a copy of a the AI's earlier instance compiled at runtime. So the process here is crucial.)
6A. The Basic Algorithm
Suppose we've recovered contextual goals and . How do we combine them?
a) Conjunction. Consider the following setup:

Suppose that we have a heuristic , which tries to keep the value of at some number, and another heuristic , which does the same for . Suppose that together, their effects keep the value of within some short range. That allows us to form a contextual goal , which activates if 's value strays far from the center of the range and effectively kept it in.
In a sense, this is the same algorithm we must've followed to go from contextual actions to contextual goals in the first place! To do that, we gathered statistical information about a heuristic's activations, and tried to see if it consistently controlled the value of some node downstream of the action-nodes. Same here: we know that and control the values of and , we hypothesize that there's some downstream node whose value their activations consistently control, and we conclude that this is the "purpose" of the two heuristics.
Technical note: How do we compute the activation-strength function of the new goal, ? Well, and increased as and 's values went farther from their target values, and this relationship kept 's value near some target of its own. In turn, this means that increased as 's value went far from some target. From that, we can recover some function which tracks the value of directly, not through the intermediaries of and . Note the consequence: the combined goal would be approximately as strong as the sum of its "parents".
Important note: After we compile , we stop caring about and ! For example, imagine that off-distribution, the environmental tendencies change: the values of and that kept near a certain value no longer do so. If we'd retained the original contextual goals, we'd keep and near their target values, as before, even as that stops controlling . But post-compilation, we do the opposite: we ignore the target values for and to keep near its newly-derived target.
Human example: A deontologist would instinctively shy away from the action of murder. An utilitarian might extrapolate that the real reason for this aversion is because she dislikes it when people die. She'd start optimizing for the minimal number of people killed directly, and would be able to do things she wouldn't before, like personally kill a serial killer.
Another: Imagine a vain person who grew up enjoying a wealthy lifestyle. As a child, he'd developed preferences for expensive cars, silk pillows, and such. As he grew up, he engaged in value compilation, and ended up concluding that what he actually valued were objects that signify high status. Afterwards, he would still love expensive cars and silk pillows, but only as local instantiations of his more abstract values. Post-reflection, he would be able to exchange cars-and-pillows for yachts-and-champagne without batting an eye — even if that wouldn't make sense to his childhood self.
This shtick is going to cause problems for us in the future.
Sidenote: In a way, this approach expands the concept of "actions". At genesis, the agent can only control the values of its immediate action-nodes. As it learns, it develops heuristics for the control of far-away nodes. When these heuristics are sufficiently reliable, it's as if the agent had direct access to these far-away nodes. In the example above, we can collapse everything between the agent and e. g. into an arrow! And in fact, that's probably what the GPS would do in its computations (unless it specifically needs to zoom in on e. g. 's state, for some reason).
As an example, consider a child trying to write, who has to carefully think about each letter she draws and the flow of words, versus an experienced author, who does all that automatically and instead directly thinks about the emotional states he wants to evoke in the reader. (Though he's still able to focus on calligraphy if he wants to be fancy.) Chunking is again relevant here.
b) Disjunction. Consider this different setup:
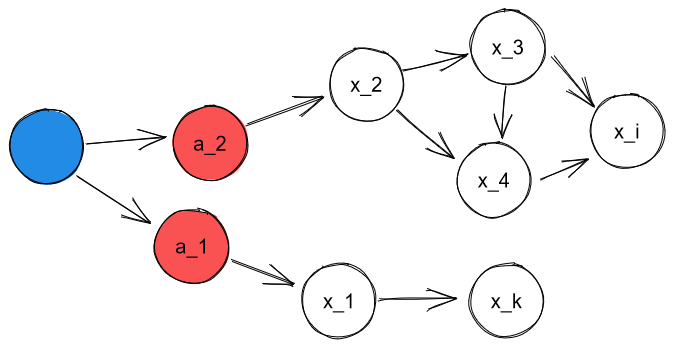
Again, suppose we have two contextual goals and defined over and respectively. But there's no obvious way to combine them here: if their causal influences meet anywhere, we haven't discovered these parts of the world-model yet. Their contexts are entirely separate.
As such, there isn't really a way to unify them yet: we just go , and hope that, as the world-model expands, the contexts would meet somewhere.
As an example, we might consider one's fruit preferences versus one's views on the necessity of the Oxford comma. They seem completely unrelated to each other. (And as a speculative abstract unification, perhaps one is entertained by ambiguity or duality-of-interpretation, and so prefers no Oxford comma and fruits with a mild bittersweet taste, as instantiations of that more abstract preferences? Though, of course, all human values don't have to ever converge this way.)
Now let's complicate it a bit:
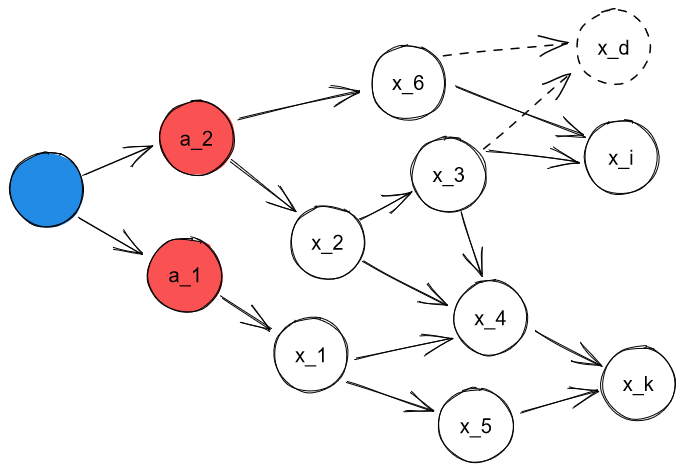
Again, we have contextual goals and . We don't see a way to combine them, yet neither are they fully separate, as their contexts are entwined. If both and assume undesirable states, there might not be a distribution of values we may assign and such that both contextual goals are achieved. How do we deal with it?
Well, the selection pressure ran into this problem a while ago, well before the GPS, and it's already developed a solution: the cross-heuristic communication channel. Any given heuristic has an activation strength , and if two heuristics , contest, the actions taken are calculated as some function of the activation strengths , , and the recommended actions , .
The GPS can recover all of these mechanics, and then just treat the sum of all "activation strengths" as negative utility to minimize-in-expectation. The actual trade-offs seem to heavily depend on the specifics of the situation (e. g., can we "half-achieve" every goal, or we have to choose one or the other?) — I've unfortunately failed to come up with a general yet compact way to describe conflict-resolution here. (Though I can point to some related ideas [LW(p) · GW(p)].)
A particular degenerate case is if the two contextual goals are directly opposed to each other. That is, suppose that the actions that bring near the target almost always move 's value outside it — like a desire to smoke interferes with one's desire to look after their health. In this case, if always outputs higher values than , ends up fully suppressed: .
Suppose, however, that wasn't a hard-coded heuristic. Rather, was produced as the result of value compilation, perhaps as a combination of contextual goals over and . In this case, we may "decompile" back into and , and try to find ways to re-compile them such that the result doesn't interfere with . Perhaps is "have a way to relax when stressed" and is "I want to feel cool", and we can compile them into = "carry a fabulous fidget toy".[7]
c) By iteratively using these techniques, we can, presumably, arrive at some . might end up fully unitary, like a perfect hedonist's desire to wirehead, or as a not-perfectly-integrated spread of values . But even if it's the latter, it'll be a much shorter list than , and the more abstract goals should allow greater generalizability across environments.
One issue here is that there might be multiple consistent with the initial set of heuristics. As far as human value reflection goes, it's probably fine: either of them should be a fair representation of our desires, and the specific choice has little to do with AI Notkilleveryoneism[8]. But when considering how an AI's process of value reflection would go, well, it might turn out that even for a well-picked suite of proto-values, only some of the final don't commit omnicide.
Anyway, that was the easy part. Now let's talk about all the complications.
6B. Path-Dependence
Suppose that you have three different contextual goals, all of equal activation strength. For example, is "I like looking at spiders, they're interesting", is "I like learning about spider biology, it's interesting", and is "I want to flee when there's a spider near me, something about being in their vicinity physically just sets me off".
Suppose that you live in a climate where there isn't a lot of spiders, so almost never fires. On the other hand, you have Internet access, so you spend day after day looking at spider pictures and reading spider facts. You compile the first two proto-values into : "I like spiders".
Then you move countries, discover that your new home has a lot of spiders, and to your shock, realize that you fear their presence. What happens?
Perhaps you compile a new value, = "I like spiders, but only from a distance". Or you fully suppress , since it's revealed to be at odds with whenever it activates.
That's not what would've happened if you started out in an environment where all three contextual goals had equal opportunity to fire. would've counterbalanced and , perhaps resulting in = "I guess spiders are kind of neat, but they freak me out".
Thus, the process of value compilation is path-dependent. It matters in which order values are compiled.
6C. Ontological Crises
What happens when a concept in a world-model turns out not to correspond to a concrete object in reality — such as the revelation that things consist of parts, or that souls aren't real? What if that happens to something you care about?
This is actually fairly easy to describe in this model. There are two main extreme cases and a continuum between them.
a) "Ontology expansion". The first possibility is that the object we cared about was a natural abstraction. This shift roughly looks like the following:
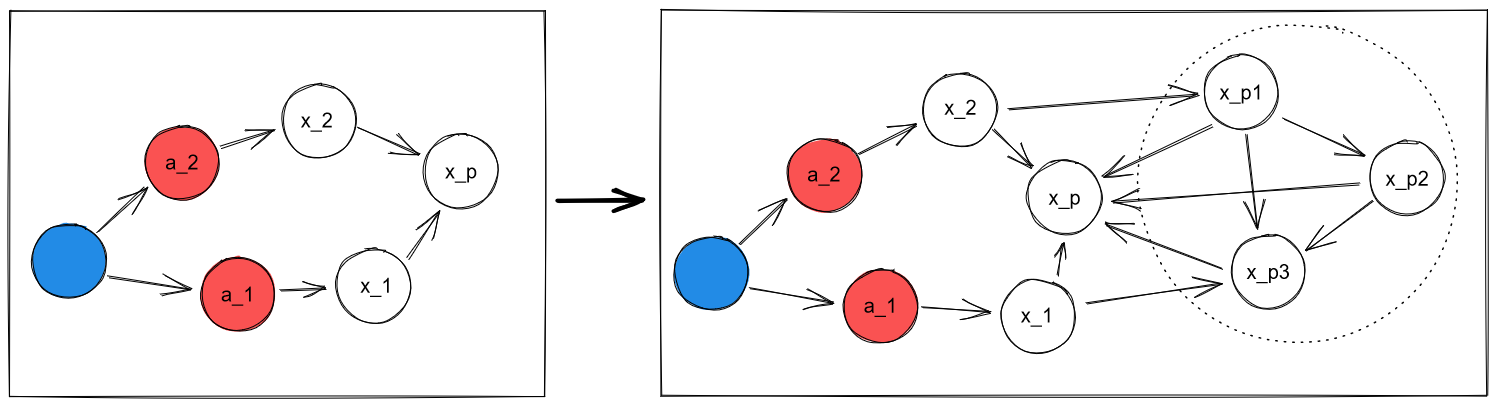
Suppose we cared about , and it turned out to be a natural abstraction over a system of . That would merely mean that (1) the state of is downstream of the states of , and (2) we can model the impact of our actions on more precisely by modelling , if we so choose. Which we may not: maybe we're indifferent to the exact distribution of values in , as long as the value of they compute remains the same.
And is still a reasonable object to place on our map. The same way it's meaningful to think of and care about "humans", even if they're not ontologically basic; and the same way we would care about the high-level state of a human ("are they happy?") and be indifferent towards the low-level details of that state ("okay, they're happy, but are the gut bacteria in their stomach distributed like this or like that?").
b) "Ontology break". In the second case, the object we cared about turns out to flat-out not exist; not correspond to anything in the territory:
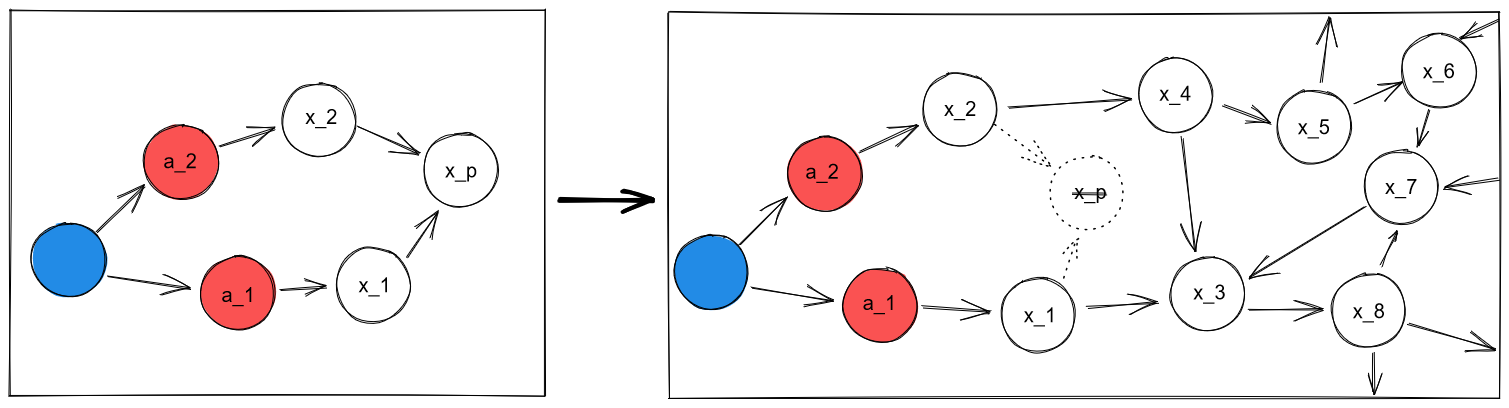
As the example, consider a spiritual person realizing that spirits don't exist, or a religious person in the middle of a crisis of faith. We valued , but now there's just nothing resembling it in its place. What can we do?
Do value decompilation, again. Suppose that the initial set of heuristics from which the value was compiled wasn't defined over . Suppose we had contextual goals and defined over and respectively, which we then collapsed into . We can fall back on them: we can remember why we decided we cared about , then attempt to re-compile new downstream values from and in the new world-model. Perhaps, say, we end up noticing that and do an awful lot to control the value of ...?
As a human example, perhaps an apostate would decide that they cared about God because they sought a higher purpose, or wanted to feel a sense of belonging with their community. If so, they may find ways to satisfy these urges that would work in the new ontology.
The quantitative effects of this kind of ontology break can be quite dramatic. The non-existent node might be a linchpin of the world-model [LW(p) · GW(p)], having "infected" most of the nodes in it. It would entail a lengthy process of value re-compilation, and the final utility function might end up very different. Qualitatively, though, nothing would change.
We can imagine an extreme case where the basic initial heuristics were defined over empty concepts as well. In this case, perhaps they'll just have to be outright suppressed/ignored.
A degenerate case is if all initial heuristics are defined over empty concepts. I expect it's unlikely in real-life systems, though: many of them would likely be associated with mental actions, which would be self-evidently real by the very functioning of the system (by analogy with cogito ergo sum).
Sidenote: "But does that mean that the final form values take depends on the structure of the environment?" Yes.
Note that this doesn't mean that moving an adult human from Earth to an alien civilization would change their values. That wouldn't involve any ontological crises, after all — the basic structure of the environment wouldn't change from their perspective, it would merely extend to cover this new environ. They would need to learn a number of new low-level abstractions (the alien language, what signals correspond to what mental states, etc.), but they would likely be able to "bridge" them with the previous high-level ones eventually, and continue the process of value reflection from there (e. g., if they cared for other people before, then once they properly "grasp" the personhood of the aliens, they'd begin caring for them too, and may eventually arrive at valuing some universal eudaimonia).
On the other hand, a human in a universe with God does arrive at different values than in a godless one. I think that makes sense.[9]
c) In practice, most of the cases will likely be somewhere between the two extremes. The world-model expansion would reveal that what the agent cared about wasn't precisely a natural abstraction, but also not entirely a thing that didn't exist. They might end up re-calculating the correct natural abstraction, then deciding to care for it, experiencing a slight ontology break. (Humans souls aren't real, but human minds are, so we switch over, maybe with a bit of anguish. A more mundane example: someone you knew turned out to be a very different person from what you'd thought of them, and you have to re-evaluate your relationship.)
Or maybe they'll end up caring about some low-level properties of the system in addition to the high-level ones, as the result of some yet-disjointed value finding something in the low-level to care about. (E. g., maybe some distributions of bacteria are aesthetically pleasing to us, and we'd enjoy knowing that one's gut bacteria are arranged in such a fashion upon learning of their existence? Then "a human" would cause not only empathy to fire, but also the bacteria-aesthetics value.)
6D. Meta-Cognition
This is the real problem.
a) Meta-heuristics. As I'd mentioned back in 5C, there'll likely be heuristics that directly intervene on the GPS' process. These interventions might take the form of interfering with value compilation itself.
The GPS can notice and explicate these heuristics as well, of course. And endorse them. If endorsed, they'll just take the form of preferences over cognition, or the world-model. A spiritualist's refusal to change their world-view to exclude spirits. A veto on certain mental actions, like any cognitive process that concludes you must hate your friends. A choice to freeze the process of value compilation at a given point, and accept the costs to the coherency of your decisions (this is how deontologists happen).
Any heuristic that can do that would gain an asymmetric advantage over those that can't, as far as its representation in the final compilation is concerned.
I hope the rest of this post has shown that such mechanisms are as likely to be present in AIs as they are in humans.
b) Meta-cognition itself. The core thing to understand, here, is that the GPS undergoing value compilation isn't some arcane alien process. I suspect that, in humans, it's done fully consciously.
So, what problems do humans doing value reflection run into?
First off, the GPS might plainly make a mistake. It doesn't have access to the ground truth of heuristics and can't confirm for sure when it did or did not derive a correct contextual goal or conducted a valid compilation.
Second, meta-cognitive preferences can originate externally as well. A principled stance to keep deontological principles around even if you're an utilitarian [LW · GW], for example.
Third, the GPS is not shy about taking shortcuts. If it encounters some clever way to skip past the lengthy process of value compilation and get straight to the answer, it'll go for it, the same we'd use a calculator instead of multiplying twenty-digit numbers manually. Hence: humans becoming hijacked by various ideologies and religions and philosophies, that claim to provide the ultimate answers to morality and the meaning of life.
Thus, the final compilation might not even have much to do with the actual initial spread of heuristics.
At the same time, meta-cognition might counteract the worst excesses of path-dependence. We can consciously choose to "decompile" our values if we realize we've become confused, look at our initial urges, then re-compile the more correct combination from them.
6E. Putting It Together
As such, the process for computing the final mesa-objective is a function of:
- The initial set of heuristics, especially those with meta-cognitive capability.
- The true environment structure.
- The data the agent is exposed to.
- The exact sequence in which the agent reverse-engineers various heuristics, combines various values, and is exposed to various data-points.
Is it any wonder the result doesn't end up resembling the initial outer objective ?
I'm not sure if that's as bad as it looks, as far as irreducible complexity/impossibility-to-predict goes. It might be.
7. Miscellanea
a) Heuristics' Flavour. You might've noticed that this post has been assuming that every heuristic ends up interpreted as a proto-value that at least potentially gets a say in the final compilation. That's... not right. Isn't it? I'm not actually sure.
I think the Shard Theory answer would be that yes, it's right. Every heuristic is a shard engaging in negotiation with every other shard, vying for influence. It might not be "strong" or very good at this, but an attempt will be made.
Counterpoint: Should, say, your heuristic for folding a blanket be counted as a proto-value? The GPS is reverse-engineering them to gain data on the environment, and this should really just be a "skill", not a proto-value.
Counter-counterpoint: Imagine an agent with a lot of heuristics for winning at chess. It was clearly optimized for playing chess. If the GPS' goal is to figure out what it was made for and then go optimize that, then "I value winning at chess" or "I value winning" should be plausible hypotheses for it to consider. It makes a certain kind of common sense, too. As to blanket-folding — sure, it's a rudimentary proto-value too. But it's too weak and unsophisticated to get much representation. In particular, it probably doesn't do meta-cognitive interventions, and is therefore at an asymmetrical disadvantage compared to those that do.
... Which is basically just the Shard Theory view again.
So overall, I think I'll bite that bullet, yes. Yes, every starting heuristic should be interpreted as a proto-value that plays a part in the overall process of value compilation. (And also as a skill that's explicated and integrated into the world-model.)
b) Sensitivity to the Training Process. Let's consider two different kinds of minds: humans, which are likely trained via on-line reinforcement learning [LW · GW], and autoregressive ML models, who can continuously cogitate forever even with frozen weights by chaining forward passes. (Suppose the latter scales to AGI.)
The internal dynamics in these minds might be quite different. The main difference is that in humans, heuristics can adapt at runtime, and new heuristics can form, while in the frozen-weights model, the initial spread of heuristics is static.
As one obvious consequence, this might make human heuristics "more agenty", in the sense of being able to conduct more nuanced warfare and negotiation between each other. In particular, they'd have the ability to learn to understand new pieces of the world-model the GPS develops, and learn new situations when they must tamper with the GPS for self-preservation (unlike static heuristic, for whom this is inaccessible information [LW · GW]). "Heuristic" might be a bad way to describe such things, even; "shards [LW · GW]" might be better. Perhaps such entities are best modeled as traders [LW(p) · GW(p)] rather than functions-over-nodes?
But a potentially bigger impact is on value-compilation path-dependence.
In humans, when we compile contextual goals and into , and then stay with for a while, we end up developing a new shard around — a structure of the same type as the initial , . Shards for and , meanwhile, might die out as their "child" eats the reinforcement events that would've initially went for them. (Consider the example of the Vain Man from 6A.)
But if that initial set of heuristics is frozen, as in an ML model, perhaps the agent always ends up developing a "path-independent" generalization as described at the end of 6A? The runtime-compiled values would be of a different type to the initial heuristics: just mental constructs. And if we assume the AI to be superintelligent when it finalizes the compilation, it's not going to be fooled by whatever it reads in the data, so the "mistaken meta-cognition" concerns don't apply. Certainly it might make mistakes at the start of the process, but if incorrect compilations aren't "sticky" as they are with humans, it'll just decompile them, then re-compile them properly!
Reminder: This doesn't mean it'll become aligned with the outer objective. is still not but a proxy for , so even path-independent value compilation ends with inner misalignment.
But it does make derivable from just the parameters and the world-model, not the data.
c) Self-Awareness. I've belatedly realized that there's a third structure the GPS can interface with: the GPS itself. This fits nicely with some of my published [LW · GW] and yet-unpublished thoughts on self-awareness and the perception of free will.
In short, the same way it's non-trivial to know what heuristics/instincts are built into your mind, it's non-trivial to know what you're currently thinking of. You need a separate feedback loop for that, a structure that summarizes the GPS' activity and feeds it back into the GPS as input. That, I suspect, directly causes (at least in humans):
- Self-awareness (in a more palatable fashion, compared to just having abstractions corresponding to "this agent" or "this agent's mental architecture" in the world-model).
- The perception of the indisputability of your own existence.
- The perception of free will. (You can request a summary of your current object-level thoughts and make a decision to redirect them; or you can even request a summary of your meta-cognition, or meta-meta-cognition, and so on, and redirect any of that. Therefore, you feel like you're freely "choosing" things. But the caveat is that every nth-level request spins up a (n+1)th-level GPS instance, and the outermost instance's behavior isn't perceived and "controlled" by us, but is us. As such, we do control our perceived behavior, but our outermost loop that's doing this is always non-perceivable and non-controllable.)
But that probably ought to be its own separate post.
8. Summary
- Once the GPS develops, the selection pressure needs to solve two tasks:
- Let the GPS access the procedural and implicit knowledge represented by the heuristics, even though they're completely illegible.
- Pick some interim objective for the GPS to make object-level plans around.
- The selection pressure solves the first problem by hooking the GPS up to the two coherent data structures that were already developed: the world-model, and the cross-heuristic communication channel.
- The second problem is solved by teaching the heuristics to use the GPS to assist in problem-solving. In essence, the GPS starts "optimizing" for the implicit goal of "do whatever the agent was already doing, but better".
- As this is happening, the GPS proves more and more useful, so the amount of compute allocated to it expands. It learns to reverse-engineer heuristics, getting explicit access to the non-explicit knowledge.
- The GPS is encouraged to treat heuristics as "clues" regarding its purpose, and as some proxy of the real goal that the agent is optimized to solve. (Which, in turn, is a proxy of the real target objective .)
- Every heuristic, thus, is at once a piece of the world-model and a proto-value.
- There's plenty of incentives to compress these splintered proto-values into a proper utility function: it's a way to avoid dominated strategies, the splintered goal-set is computationally unwieldy, and the GPS can probably derive a better, more generalizable approximation of by explicitly trying to do that.
- The basic process of value compilation goes as follows:
- Hypothesize that a number of heuristics, e. g. and , are jointly optimized for achieving some single goal . If such a goal is found, start optimizing it directly.
- If no goal is found, compute the appropriate trade-offs between and based on the underlying heuristics' activation-strength functions and . If one of the goals has to be fully suppressed, try decompiling it and repeating the process.
- Iterate, with initial heuristics replaced with derived contextual goals, until arriving at .
- That process runs into several complications:
- Path-dependence, where the order in which contextual goals are compiled changes the form the final goal takes.
- Ontological crises, where we either (1) expand our model to describe the mechanics of the natural abstraction we care about, or (2) experience an ontology break where the object we cared about turns out not to exist, which forces us to do value decompilation + re-compilation as well.
- Meta-cognition: The agent might have preferences over the value compilation process directly, biasing it in unexpected ways. In addition, the GPS implements (something like) logical reasoning, and might lift conclusions about its values from external sources, including mistaken ones.
- Some considerations have to be paid to the online vs batch training: agents trained on-line might be uniquely path-dependent in a way that those with frozen weights aren't.
9. Implications for Alignment
My main practical takeaway is that I am now much more skeptical of any ideas that plan to achieve alignment by guiding the process of value formation, or by setting up a "good-enough" starting point for it.
Take the basic Shard Theory approach as the example.[10] It roughly goes as follows:
- Real-life agents like humans don't have static values, but a distribution over values that depends on the context.
- There's ample reason to believe that AI agents found by the SGD will be the same.
- What we need to do isn't to make an AI that's solely obsessed with maximizing human values, but to ensure that there's at least one powerful & metacognition-capable shard/proto-value in it that values humans: that our value distributions merely roughly overlap.
- Then, as the AI does value compilation, that shard will be able to get a lot of representation in the final utility function, and the AI will naturally value humans and want to help humans (even if it will also want to tile a large swathe of the cosmos with paperclips).
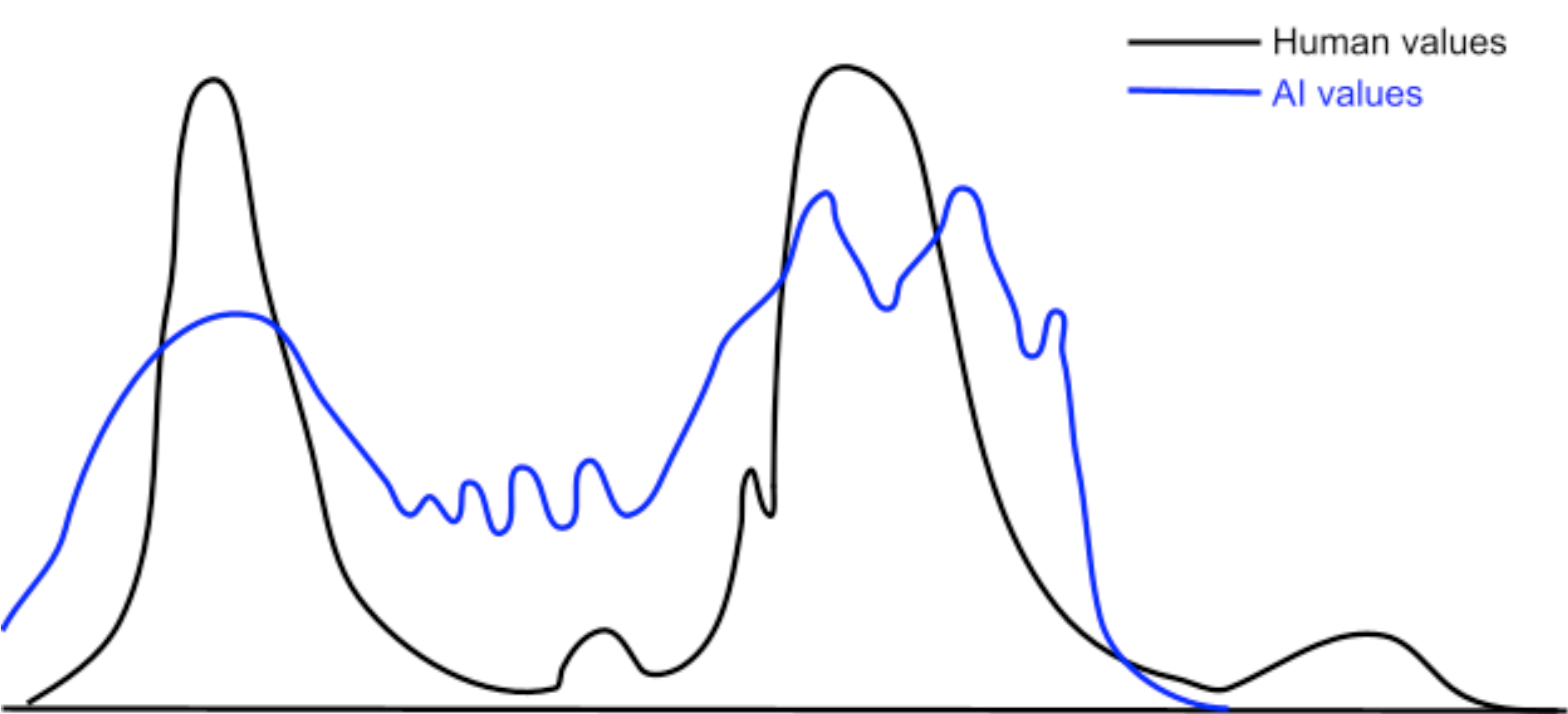
One issue is that the value-humans shard would need to be perfectly aligned with human values [LW(p) · GW(p)], and that's most of this approach's promised advantage gone. That's not much of an issue, though: I think we'd need to do that in any workable approach.
But even if we can do that, I fear this wouldn't work out even in the path-independent scenario. The Vain Man from 6A, again: over the course of value compilation, the AI might decide that it only likes humanity as an instantiation of some more abstract principle. Which might be something nice like "all possible sapient life"... or maybe it's more paperclips, and it trades us away like a car for a yacht.[11]
And then we get into the actually complicated path-dependent meta-cognitive mess (which we have to be ready to deal with, since we don't know how the last-minute AGI architecture will look), and... I don't think this is tractable at all. We'd need to follow the AI's explicit reasoning into superintelligence; it'd be hopeless. Would take decades to understand manually, to reverse-engineer and translate the abstractions it'll be thinking in.
So I suspect that we won't be able, in practice, to figure out how to set up some initial proto-values such that they'll compile into a non-omnicidal utility function. I suspect any plan that hinges on this is doomed.[12]
My current most promising alignment scheme is as follows:
- Train an AI to the point where the GPS forms.
- Find a way to distinguish heuristics/proto-value from the world-model and the GPS.
- Wipe out every proto-value, eating the cost in effective world-model downgrade.
- Locate human values or corrigibility in the world-model (probably corrigibility, see this discussion [LW(p) · GW(p)]).
- Hook the GPS up directly to it, making the AI an aligned/corrigible wrapper-mind.
- Let it bootstrap itself to godhood. The GPS will be able to spin up new heuristics and re-expand the world-model.[13]
If there are no proto-values leading the GPS astray, there's no problem. (Those are, by the way, the "unnatural conditions" I've mentioned all the way back in Section 2.)
Finding a way to identify learned world-models, or to somehow train up a pure world-model [LW · GW], therefore seem like high-priority research avenues.
Bonus: The E-Coli Test for Alignment [LW · GW]
Alright, so an E. coli doesn't implement a GPS, so it can't do value compilation on its own. As such, it's unclear how meaningful it is to talk about its "values". But an attempt can be made! How we may do it:
- Draw a causal graph of the E. coli's environment, all the natural abstractions included.
- Scan the E. coli and back out its "heuristics", i. e. functions that locate conceptually localized environment features and respond with specific behaviors.
- Do path-independent value reflection as described in 6A, or plot out some random value-compilation path and go through it.
- Whatever you end up with is the E. coli's values. They should be highly-abstract enough to be implementable in environments alien to it, as well.
Hm, that was insightful. For one, it appears that we don't need the agent's own world-model for path-independent (or random-path) value compilation! We can just get the "true" world-model [LW · GW] (if we have access to it) and the heuristics set, then directly compile the final values using it. In essence, it's just equivalent to getting all the ontological crises out of the way at the start.
What we can do with subjective world-models is compute "impossible fantasy" values — values that the agent would have arrived at if the world really had the structure they mistakenly believe it to have; if the world's very ontology was optimized for their preferences. (E. g., valuing "spirits" if spirits were a thing.)
10. Future Research Directions
I think this model is both robust to a lot of possible changes, sufficing to describe the dynamics within many categories of agents-generated-by-a-greedy-algorithm, and very sensitive to other kinds of interventions. For example, the existence of some additional convergent data structure, or a different point for the GPS to originate from, might change the underlying path dynamics a lot.
That said, I now suspect that the work on value compilation/goal generalization is to a large extent a dead end, or at least not straightforwardly applicable. It seems that the greedy selection algorithms and the AI itself can be trusted with approximately 0% of the alignment work, and approximately 100% of it will need to be done by hand. So there may not be much point in modeling the value-formation process in detail...
The caveat here is that building a solid theoretical framework of this process will give us data regarding what features we should expect to find in trained models, and how to find them — so that we may do surgery on them. As such, I think the questions below are still worth investigating.
I see two ways to go from here: expanding this model, and concretizing it. Expansion-wise, we have:
- Are there any other consistently-formatted internal data structures that agents trained by a greedy algorithm form, in addition to the world-model and the cross-heuristic communication channel? What are they? What changes to the training process would encourage/discourage them?
- What causes meta-cognitive heuristics to appear? Are there any convergently-learned meta-heuristics?
- Is there any difference between "goals" and "values"? I've used the terms basically interchangeably in this post, but it might make sense to assign them to things of different types. (E. g., maybe a "goal" is the local instantiation of a value that the agent is currently pursuing? Like a yacht is for a high-status item.)
- Is there a sense in which values become "ever more abstract" as value-compilation goes on? What precisely does this mean?
- Where in the agent does the GPS form? (I see three possibilities: either as part of the heuristic conflict-resolution mechanism, within one of the heuristics, or within the world-model (as part of, e. g., the model of a human).)
- What's the minimal wrapper structure and/or set of world-model features necessary to let the GPS "handle itself", i. e. figure out how to solve the problem of automatically pointing itself at the right problems, no heuristical support necessary?
On the concretization side:
- A proof that the world-model would converge towards holisticity. Does it always hold, past some level of environment complexity?
- The "Crud" Factor is probably a good starting point.
- A proof that "heuristics" is a meaningful abstraction to talk about.
- Presumably uses the Natural Abstraction Hypothesis as the starting point. Might be fairly straightforward under some environment structure assumptions, like there being mostly-isolated contexts such that you can optimize in them without taking the rest of the world-model into consideration.
- (There's interesting tension between this and the Crud Factor thing, but it's probably not an actual contradiction: mapping from observations to the world-model and optimizing in the world-model are very different processes.)
- A proof that heuristics aren't under pressure to become internally intelligible.
- Some proofs about the necessary structure of the cross-heuristic communication channel.
- Exact specification of the environment structure that can't be solved without the GPS.
- A more formal description of the basic value-formation algorithm.
- A more formal description of meta-cognitive heuristics. What does it mean to "bias" the value-compilation process?
- ^
We'll return to them in Section 9.
- ^
This function can be arbitrarily complex, too — maybe even implementing some complex "negotiations" between heuristics-as-shards [? · GW]. Indeed, this is plausibly the feature from which the GPS would originate in the first place! But this analysis tries to be agnostic as to the exact origins of the GPS, so I'll leave that out for now.
- ^
And plausibly some shared observation pre-processing system, but I'll just count it as part of the world-model.
- ^
Though this is potentially subject to the specifics of the training scheme. E. g., if the training episodes are long, or we're chaining a lot of forward passes together like in a RNN, that would make runtime-computations more effective at this than the SGD updates. That doesn't mean the speed prior is going to save us/reduce the path-dependence I'll go on to argue for here, because there'll still be some point at which the GPS-based at-runtime reverse-engineering outperforms selection-pressure-induced legibility. But it's something we'd want fine-grained data on.
- ^
Second-order natural abstraction?
- ^
Naively, this process would continue until the agent turns into a proper -optimizer. But it won't, because of gradient starvation + the deception attractor. There are other [LW · GW] posts [LW · GW] talking about this, but in short:
Once agrees with in 95% of cases, the selection pressure faces a choice between continuing to align , and improving the agent's ability to achieve . And it surely chooses the latter most of the time, because unless the agent is already superintelligently good at optimization, it probably can't actually optimize for so hard it decouples [LW · GW] from .
Then, once the agent is smart enough, it probably has strategic awareness, wants to protect from the selection pressure, and starts trying to do deceptive alignment. And then it's in the deception attractor: its performance on the target objective rises sharper as its general capabilities improve (since that improves both the ability to achieve and the ability to figure out what it should be pretending to want), compared to improving its alignment.
- ^
Note: This isn't a precisely realistic example of value compilation, for a... few reasons, but mainly the phrasing. Rather than "smoking" and "using a fabulous fidget toy", it should really say "an activity which evokes a particularly satisfying mixture of relaxation and self-affirmation".
There seems to be some tendency for values to increase in abstractness as the process of compilation goes on: earlier values are revealed to be mere "instantiations" of later values, such that we become indifferent to the exact way they're instantiated (see the cars vs. yachts example). It works if "relax" and "feel cool" are just an instantiation of "feel an emotion that's a greater-than-its-parts mix of both", such that we're indifferent to the exact mix. But they're not an instantiation of "smoke a cigar": if smoking ceased to help the person relax and feel cool, they'd stop smoking and find other ways to satisfy those desires.
- ^
Although I imagine some interesting philosophy out of it.
- ^
Or maybe not. Something about this feels a bit off.
- ^
Note that this isn't the same as my disagreeing with the Shard Theory itself. No, I still think it's basically correct.
- ^
You might argue that we can set up a meta-cognition shard that implacably forbids the AI's GPS from folding humanity away like this, the way something prevents deontologists from turning into utilitarians, or the way we wouldn't kill-and-replace a loved one with a "better" loved one. I'm not sure one way or another whether that'll work, but I'm skeptical. I think it'll increase the problem difficulty dramatically: that it'd require the sort of global robust control over the AI's mind that we can use to just perfect-align it.
- ^
One idea here would be to wait until the AI does value compilation on its own, then hot-switch the it derives. That won't work: by the point the AI is able to do that, it'd be superintelligent, and it'll hack through anything we'll try to touch it with [LW · GW]. We need to align it just after it becomes a GPS-capable mesa-optimizer, and ideally not a moment later.
- ^
One issue I don't address here is that in order to do so, the GPS would need some basic meta-cognitive wrapper-structure and/or a world-model that contains self-referencing concepts — in order to know how to solve the problem of giving its future instances good follow-up tasks. I've not yet assessed the tractability of this. We might need some way to distinguish such structures from other heuristics, or figure out how to hand-code them.
20 comments
Comments sorted by top scores.
comment by TsviBT · 2022-12-21T03:48:58.522Z · LW(p) · GW(p)
Sounds similar to: https://tsvibt.blogspot.com/2022/11/do-humans-derive-values-from-fictitious.html
comment by TurnTrout · 2022-12-21T03:36:50.045Z · LW(p) · GW(p)
I think this post is very thoughtful, with admirable attempts at formalization and several interesting insights sprinkled throughout. I think you are addressing real questions, including:
- why do people wonder why they 'really' did something?
- How and when do shards generalize beyond contextual reflex behaviors into goals?
- To what extent will heuristics/shards be legible / written in "similar formats"?
That said, I think some of your answers and conclusions are off/wrong:
- You rely a lot on selection-level reasoning in a way which feels sketchy.
- I doubt your conclusions about GPS optimizing activations directly, as a terminal end and not as yet another tactic,
- I doubt the assumptions on GPS being a minimizer, or goals being minimize-distance (although you claimed in another thread this isn't crucial?)
- I don't see why you think heuristics (shards?) "lose control" to GPS.
- I don't think why you think value-humans shard has to be perfectly aligned.
Overall, nice work, strong up, medium disagree. :)
[heuristics are] statements of the following form: "if you take such action in such situation, this will correlate with higher reward".
I think that heuristics are reflections of historical facts of that form, but not statements themselves.
But these tendencies were put there by the selection process because the correlations are valid.
In a certain set of historical reward-attainment situations, perhaps (because this depends on the learning alg being good, but I'm happy to assume that). Not in general, of course.
a) The World-Model. Initially, there wouldn't have been a unified world-model. Each individual heuristic would've learned some part of the environment structure it cared about, but it wouldn't have pooled the knowledge with the other heuristics. A cat-detecting circuit would've learned how a cat looks like, a mouse-detecting one how mice do, but there wouldn't have been a communally shared "here's how different animals look" repository.
However, everything is correlated with everything else (the presence of a cat impacts the probability of the presence of a mouse), so pooling all information together would've resulted in improved predictive accuracy. Hence, the agent would've eventually converged towards an explicit world-model.
What is the difference, on your view, between a WM which is "explicit" and one which e.g. has an outgoing connection from is-cat circuit to is-animal?
b) Cross-Heuristic Communication.
I really like the insight in this point. I'd strong-up a post containing this, alone.
Anything Else? So far as I can tell now, that's it. Crucially, under this model, there doesn't seem to be any pressure for heuristics to make themselves legible in any other way. No summaries of how they work, no consistent formats, nothing.
If the agent is doing SSL on its future observations and (a subset of its) recurrent state activations, then the learning process would presumably train the network to reflectively predict its own future heuristic-firings, so as to e.g. not be surprised by going near donuts and then stopping to stare at them (instead of the nominally "agreed-upon" plan of "just exit the grocery store").
Furthermore, there should be some consistent formatting since the heuristics are functions . And under certain "simplicity pressures/priors", heuristics may reuse each other's deliberative machinery (this is part of how I think the GPS forms). EG there shouldn't be five heuristics each of which slightly differently computes whether the other side of the room is reachable.
That's very much non-ideal. The GPS still can't access the non-explicit knowledge — it basically only gets hunches about it.
So, what does it do? Starts reverse-engineering it. It's a general-purpose problem-solver, after all — it can understand the problem specification of this, given a sufficiently rich world-model, and then solve it. In fact, it'll probably be encouraged to do this.
I'm trying to imagine a concrete story here. I don't know what this means.
The second would plausibly be faster, the same way deception is favoured relative to alignment [LW · GW][4] [LW(p) · GW(p)].
I don't positively buy reasoning about whether "deceptive alignment" is probable, on how others use the term. I'd have to revisit it, since it's on my very long list of alignment reasoning downstream of AFAICT-incorrect premises or reliant on extremely handwavy, vague, and leaky "selection"-based reasoning.
we might imagine a heuristic centered around "chess", optimized for winning chess games. When active, it would query the world-model, extract only the data relevant to the current game of chess, and compute the appropriate move using these data only.
Just one heuristic for all of chess?
Consider this situation:
I wish this were an actual situation, not an "example" which is syntactic. This would save a lot of work for the reader and possibly help you improve your own models.
That'll work... if it had infinite time to think, and could excavate all the procedural and implicit knowledge prior to taking any action. But what if it needs to do both in lockstep?
(Flagging that this makes syntactic sense but I can't actually give an example easily, what it means to "excavate" the procedural and implicit knowledge.)
This makes the combination of all contextual goals, let's call it
Can you give me an example of what this means for a network which has a diamond-shard and an ice-cream-eating shard?
Prior to the GPS' appearance, the agent was figuratively pursuing
Don't you mean "figuratively pursuing "? How would one "pursue" contextual behaviors?
So the interim objective can be at least as bad as .
Flag that I wish you would write this as "during additional training, the interim model performance can be at least as U-unperformant as the contextual behaviors." I think "bad" leads people to conflate "bad for us" with "bad for the agent" with "low-performance under formal loss criterion" with something else. I think these conflations are made quite often in alignment writing.
Prior to the GPS' appearance, the agent was figuratively pursuing ("figuratively" because it wasn't an optimizer, just an optimized). So the interim objective can be at least as bad as . On the other hand, pursuing directly would probably be an improvement, as we wouldn't have to go through two layers of proxies.
Example? At this point I feel like I've gotten off your train; you seem to be assuming a lot of weird-seeming structure and "pressures", I don't understand what's happening or what experiences I should or shouldn't anticipate. I'm worried that it feels like most of my reasoning is now syntactic.
The obvious solution is obvious: make heuristics themselves control the GPS. The GPS' API is pretty simple, and depending on the complexity of the cross-heuristic communication channel, it might be simple enough to re-purpose its data formats for controlling the GPS.
I think that heuristics controlling GPS-machinery is probably where the GPS comes from to begin with, so this step doesn't seem necessary.
Once that's done, the heuristics can make it solve tasks for them, and become more effective at achieving (as this will give them better ability to runtime-adapt to unfamiliar circumstances, without waiting for the SGD/evolution to catch them up).
Same objection as above -- to "achieve" ? How do you "achieve" behaviors? And, what, this would happen how? What part of training are we in? What is happening in this story, is SGD optimizing the agent to be runtime-adaptive, or..?
At the limit of optimality, everything wants to be a wrapper-mind [LW · GW].
Strong disagree.
- I don't think this is what the coherence theorems imply. I think explaining my perspective here would be a lot of work, but I can maybe say helpful things like "utility is more like a contextual yardstick governing tradeoffs between eg ice cream eating opportunities and diamond production opportunities, and less like an optimization target which the agent globally and universally optimizes."
- I am also worried about reasoning like "smart agents -> coherent over value-relevant -> optimizing a 'utility function' -> argmax on utility functions is scary (does anyone remember AIXI?)", when really the last step is invalid.
- AFAICT I agree wrapper-minds are inefficient (seems like a point against them?).
- I don't know why GPS should control reverse-engineering, rather than there being generalized shards driving GPS.
- I think "internalize a system of norms" is not how people's caring works in bulk, and doesn't address the larger commonly-activated planning-steering shards I expect to translate robustly across environments (like "go home", "make people happy"). I agree there is a Shard Generalization Question, but I don't think "wrapper mind" is a plausible answer to it.
The GPS can recover all of these mechanics, and then just treat the sum of all "activation strengths" as negative utility to minimize-in-expectation.
Seems like assuming "activation strengths increase the further WM values are from target values" leads us to this bizarre GPS goal. While that proposition may be true as a tendency, I don't see why it should be true in any strict sense, or if you believe that, or whether the analysis hinges on it?
In short, the same way it's non-trivial to know what heuristics/instincts are built into your mind, it's non-trivial to know what you're currently thinking of.
Aside: I think self-awareness arises from elsewhere in the shard ecosystem.
One issue is that the value-humans shard would need to be perfectly aligned with human values [LW(p) · GW(p)], and that's most of this approach's promised advantage gone. That's not much of an issue, though: I think we'd need to do that in any workable approach.
What? Why? Why would a value-human shard bid for plans generated via GPS which involve people dying? (I think I have this objection because I don't buy/understand your story for how GPS "rederives" values into some alien wrapper object.)
Is there any difference between "goals" and "values"? I've used the terms basically interchangeably in this post, but it might make sense to assign them to things of different types.
I use "values" to be decision-influence, and "goal" as, among other things, an instrumental subgoal in the planning process which is relevant to one or more values (e.g. hang out with friends more as relevant to a friend-shard).
Other points:
- I wish the nomenclature had been clearer, with being replaced by e.g. .
- I think "U" is a bad name for the policy-gradient-providing function (aka reward function).
↑ comment by Thane Ruthenis · 2022-12-22T01:21:54.190Z · LW(p) · GW(p)
Thanks for extensive commentary! Here's an... unreasonably extensive response.
what it means to "excavate" the procedural and implicit knowledge
On Procedural Knowledge
1) Suppose that you have a shard that looks for a set of conditions like "it's night AND I'm resting in an unfamiliar location in a forest AND there was a series of crunching sounds nearby". If they're satisfied, it raises an alarm, and forms and bids for plans to look in the direction of the noises and get ready for a fight.
That's procedural knowledge: none of that is happening at the level of conscious understanding, you're just suddenly alarmed and urged to be on guard, without necessarily understanding why. Most of the computations are internal to the shard, understood by no other part of the agent.
You can "excavate" this knowledge by reflecting on what happened: that you heard these noises in these circumstances, and some process in you responded. Then you can look at what happened afterward (e. g., you were attacked by an animal), and realize that this process helped you. This would allow you to explicate the procedural knowledge into a conscious heuristic ("beware of sound-patterns like this at night, get ready if you hear them"), which you put in the world-model and can then consciously access.
That "conscious access" would allow you to employ the knowledge much more fluidly, such as by:
- Incorporating it in plans in advance. (You can know to ensure there's no sources of natural noise around your camp, like waterfalls, because you'd know that being able to hear your surroundings is important.)
- Transferring it to others. (Telling this heuristic to your child, who didn't yet learn the procedural-knowledge shard itself.)
- Generalizing from it. (Translate it by analogy to an alien environment where you have to "listen" to magnetic fields instead. Or to even more abstract environments, like bureaucratic conflicts, where there's something "like" being in a forest at night (situation-of-uncertain-safety) and "like" hearing crunching noises nearby (subtle-predictors-of-an-impending-attack).)
None of that fluidity, on my understanding, would be easily replicable by the initial shard. If you're planning in advance, or are teaching someone, it'd only activate if you vividly imagine the specific scenario that'd activate it ("I'm in my camp at night and there's this noise"), which (1) you may not know to do to begin with, (2) is an excruciatingly slow style of planning. And the non-obvious logical generalizations are certainly not the thing it can do.
If you have that knowledge explicitly, though, you can just connect it to a node like "how to survive in a forest", and it'd be brought to your attention every time you poke that node.
2) Also, in a different thread [LW(p) · GW(p)], you note that the predictions generated by the world-model can sometimes be also hard to make sense of, so maybe it's not consistently-formatted either. I think what's happening, there, is that when you imagine concrete scenarios, you're not using just the world-model — you're actually "spoofing" the mental context of that scenario, and that can cause your shards to activate as if it were really happening. That allows you to make use of your procedural knowledge without actually being in the situation, and so make better predictions without consciously understanding why you're making them.
(E. g., the weird-noises-at-night shard puts simulated!you on high alert, and your WM conditions on that, and that makes it consider "is going to be attacked" more likely. So now it's predicting so, and it's a more accurate prediction than it would've been able to make with just the explicit knowledge, but it doesn't know why exactly it ended up in this state.)
But none of that makes that procedural knowledge explicit! (Though such simulated counterfactuals are a great way to reverse-engineer it. See: thought experiments to access and reverse-engineer morality heuristics.)
3) Also something worth noting: explicit knowledge can loop non-explicit procedural knowledge in! E. g., you can have an explicit heuristic like "if you're in a situation like this, listen to your instincts and do what they say". That's also entirely in-line with my model: you can know to do the things your shards urge you to, even if you don't know why. And yet, knowing that a black-box is useful isn't the same as knowing what's in it.
(I suppose my definition is kind of circular, here: I'm saying that the world-model is only the thing that's consciously accessible and consistently-formatted. That's... Yeah, I think I'll bite that bullet.)
On Implicit Knowledge
Here, it's "implicit" that you should be complying with the urge to engage in the contextual behavior = "if you heard weird noises in the forest at night, be on guard". The question to answer here is: why? Why does it make sense to be on guard in such circumstances?
There's several ways to explain it, but let's go with "because it decreases the chance that a predator could take me by surprise, which is (apparently) something I don't want to happen". That's the implicit contextual goal here.
Explicating it, and setting it as the plan-making target ("how can I ensure I'm not ambushed?"), can allow you to consciously generate a bunch of other heuristics for achieving it. Like looking out for weird smells as well, or soundless but visible disturbance in the tall grass around you, etc. This, likewise, boosts your ability to generalize: both in the environment you're in, and even if you end up displaced to e. g. an alien environment.
I also refer you to my previous example of a displaced value-child [LW(p) · GW(p)]. Although his study-promoting shards end up inapplicable, he can nonetheless remain studious if he has "be studious" as an explicit goal, in the course of optimizing for which he can re-derive new heuristics appropriate for the completely unfamiliar environment. Another example: the "deontologist vs. utilitarian in an alien society" from the fourth bullet-point here [LW · GW].
Extrapolation
Okay, and this naturally extends into my broader point about value compilation.
Suppose you explicate a bunch of these contextual goals, like "avoid being ambushed by a predator" and "try to escape if you can't win this fight" and "good places to live have an abundance of prey around".
You can view these as heuristics as well. Much like the behaviors you were urged to engage in, which only hinted at your actual goal, you can view these derived goals not as your core values, but as yet more hints about your real values. As next-level procedural knowledge, with some hypothetical broader goal that generated them, and which is implicit in them.
Upon reflection on this new set of goals, you can extrapolate them into something like "avoid death".
Doing that has all the benefits of going from "if at night in a forest and hear crunching sounds, be on guard" to "decreases the chance that a predator could take me by surprise". You can now pursue death-avoidance across a broader swathe of environments, and with more consistency and fluidity. You can generate new lower-level goals/heuristics for supporting it.
Then you generate some more higher-level goals, e. g. "avoid death" + "make my loved ones happy" + "amass resources for the tribe", and compile them into something like "human prosperity is important".
And so on and on, until all contextual behaviors and goals have been incorporated into some unified global goal.
Those last few steps is what you disagree with, I think, but you see how it's just a straightforward extrapolation of basic lower-level self-reflection mechanisms? And it passes my sanity-checks: it sure seems consistent with moral philosophy and meaning-of-life questioning and such.
Core Claims
- Procedural knowledge is raw shard activations, i. e. urges that have no conscious explanation.
- Explicating procedural knowledge allows you to use it in plan-making in a flexible logical manner, instead of relying on being in the right mental context for it to activate.
- Imagining future scenarios isn't just running the WM forward, it's also spoofing the mental context to provoke shard activations, and that allows you to make use of procedural knowledge for predictions without necessarily understanding it.
- The above doesn't make procedural knowledge part of the WM; nor does it imply that the WM isn't consistently-formatted. Or, perhaps tautologically, the WM is only that which is consistently-formatted and consciously-accessible.
- Implicit knowledge are the hypothetical goals that the procedural knowledge is meant to achieve. Explicating it allows one to optimize for these goals in new contexts, and derive new heuristics for achieving them.
- A straightforward extrapolation of this process leads to treating first-order derived contextual goals as just another set of heuristics, which imply some second-level contextual goal.
- This process is run iteratively, until all goals are incorporated.
I don't know why GPS should control reverse-engineering, rather than there being generalized shards driving GPS.
Okay, so my thinking on this updated a bit since I've written the post. I think the above process, "treat shards as hints towards your goals, then treat the derived goals as hints towards higher-level goals, then iterate", isn't something that shard economies want to do. Rather, it's something that's convergently "chiseled into" all sufficiently advanced minds by greedy algorithms generating them.
Consider a standard setup, where the SGD is searching for some agent that scores best according to some reward function . Would you disagree that a wrapper-mind with that function as its terminal objective would be a great design for the SGD to find, by the SGD's own lights? Not that it would "select" for such a mind, just that it would be pretty good for it if it did find a way to it?
Shard economies and systems of heuristics may be faster out-of-the-box, better adapted to whatever specific environment they're in. But an -maximizing wrapper-mind would at least match their performance, given some time to do runtime optimization of itself. If it would improve its ability to optimize for , it can just derive contextual shards/heuristics for itself and act on them.
In other words, an -maximizer is strictly more powerful according to than any shard economy, inasmuch as it can generate any purpose-built shard economy from scratch, and ensure that this shard economy would be optimized for scoring well at .
Shard economies not governed by wrapper-minds, in turn, are inferior: they're worse at generalizing (see my points about non-explicit knowledge above), and tend to go astray if placed in unfamiliar environments (where whatever goals they embody no longer correlate with ).
And inasmuch as the level of adversity the agent was subjected to is so strong as to cause it to develop general reasoning at all, it's probably put in environments so complex/diverse that runtime re-optimization of its entire swathe of heuristics is called-for. Environments where nothing less than this will do.
So the practical advanced mind design is probably something like a shard economy optimized for the immediate deployment environment (for computation speed and good out-of-the-box performance) + an -aligned wrapper-mind governing it (for handling distribution shifts and for strategic planning). So I speculate that the SGD tries to converge to something like this, for the purposes of maximizing .
Except, as per section 5 [LW · GW], there's no gradients towards representing in the agent, so the SGD uses weird hacks to point the GPS in the right direction. It does the following:
- Does not codify any object-level terminal goals for the GPS.
- Lets shards influence the GPS' plan-making process.
- Lets the GPS reverse-engineer shards, the procedural and implicit knowledge they represent.
- Encourages the GPS to treat these reverse-engineered knowledge tidbits as hints towards some hypothetical unified objective that it's meant to adopt as its real target.
- The GPS engages in value compilation as I've outlined, and tends to compile goal-spreads that are closer to the more it engages in this process — inasmuch as the shard economy it's using to derive its goals is itself optimized for .
This hack lets the SGD point the "proto-wrapper-mind" in the direction of without actually building into it. The agent was already optimized for achieving , so the SGD basically tasks it with "figure out what you're optimized for, and go do that", and the agent complies. (But the unified goal implicit in the agent's design isn't quite , so we get inner misalignment.)
So, in this very round-about way, we get a goal-maximizer.
I think that heuristics are reflections of historical facts of that form, but not statements themselves.
Does "evidence of historical facts of that form" work for you?
You rely a lot on selection-level reasoning in a way which feels sketchy.
Specific examples? I specifically tried to think in terms of local gradients ("in which direction would it be advantageous for the SGD to move the model from this specific point?"), not global properties ("what is the final mind-design that would best satisfy the SGD's biases, regardless of the path taken there?"). Or do you disagree with that style of reasoning as well?
What is the difference, on your view, between a WM which is "explicit" and one which e.g. has an outgoing connection from
is-catcircuit tois-animal?
I've outlined some reasons above — the main point is whether it's accessible to the GPS/deliberative planner, because if it is, it allows WM-concepts to be employed much more flexibly and generally.
(I'm actually planning a separate post on this matter, though.)
If the agent is doing SSL on its future observations and (a subset of its) recurrent state activations, then the learning process would presumably train the network to reflectively predict its own future heuristic-firings
Yeah, but that's not shards making themselves legible, that's a separate process in the agent trying to build their generative models from their externally-observed behavior, no?
Furthermore, there should be some consistent formatting since the heuristics are functions
Consistent input-output formatting, sure: an API, where each shard takes in the WM, then outputs stuff into the planner/the GPS/the bid-resolver/the cross-heuristic communication channel/some such coordination mechanism.
That's not what I'm getting at. It still wouldn't allow to predict what a shard will do without observing its actions. No consistent design structure, where each shard has a part you can look at and go "aha, that's what it's optimizing for!". No meta-data summary/documentation to this effect attached to every shard.
And under certain "simplicity pressures/priors", heuristics may reuse each other's deliberative machinery
Agreed; I think I mention that in the post, even. Issue: such structures would be as ad-hoc as the shards' inner implementation. You wouldn't get alliances that change at runtime, where shards can look at each other's local incentives and choose to e. g. "engage in horse-trading", or where they can somehow "figure out" that some other shard is doing the same thing they're doing in this specific context only and so only re-use its activations in that context.
No, you'd just get some shards that are hard-wired to always fire with some other shards, or always inhibit some other shards. These alliances can be rewritten by the reward circuitry, but not by the shards themselves.
That doesn't require all shards to be legible to each other; that just requires there to be gradients towards some specific chains of shard activations.
I don't positively buy reasoning about whether "deceptive alignment" is probable
My outline of it here [LW · GW] is also written with local gradients, not global selection targets, in mind. You might want to check it out?
Just one heuristic for all of chess?
Yeah, no. I recall wanting to make an aside like "obviously in practice chess-winning will be implemented via a lot of heuristics", but evidently I didn't.
Can you give me an example of what [value compilation] means for a network which has a diamond-shard and an ice-cream-eating shard?
First, note that I'm not saying that is necessarily "simple", as e. g. a hedonist's desire for pleasure. It can have many terms that can't be "merged" together. I'm just saying that we have an impulse to merge terms as much as possible. This is one of the cases where they can't be merged.
As per 6A [LW · GW], that would go as in the "disjunction" section. I. e., the agent would figure out tradeoffs it's willing to make WRT diamonds and ice cream, and then go for plans that maximize the weighted sum of diamonds-and-ice-cream it has.
... Alright, I see your point about "utility is not the optimization target": there's no inherent reason to think it'd want as many of these things as possible. E. g., ice-cream shard's activation power may be capped at 1000 ice creams, and the agent may interpret it as a hard limit. But okay, so then it'd try to maximize the probability of achieving that utility cap, or the time it'd stay in the max-utility state, or something along those lines.
Like... There are states in which shards activate, and where they're dormant. Thus, shards steer the agents they're embedded in towards some world-states. Interpreting/reverse-engineering this behavior into goals, it seems natural to view it as "I want to be in such world-states over such others". And then the GPS will be tasked with making that happen, and...
Well, it would try to output a "good" plan for making it happen, for some definition of "good". And... you disagree that this definition has to lead to arg-maxing, okay.
I guess instead of maximizing we can satisfice: as you describe here [LW · GW], we can just generate a bunch of plans and choose one that seems good enough, instead of generating the best possible plan. But:
- As agents become more powerful, it becomes easier for them to generate insanely good plans with trivial effort, so we have no guarantees the first idea the hyperintelligent AI would come up with won't be basically utility-maximizing.
- That only applies if the agent's preferences themselves aren't maximizable: if it didn't decide its goal is to have "AS MANY diamonds as possible" instead of "at most 1000 diamonds", or if it doesn't have some instrumental goal like "MINIMIZE uncertainty".
- I'm... not sure humans don't do grader-optimization? It seems like if we all had magical question-answering devices, we'd go around asking them for "the best, most resource-efficient plan for X" all the time. We just don't have the mental resources for it, ordinarily! It's as I'd described before: we maximize over (plan quality, resources spent on planning), not plan quality only.
(Re: magical question-answerers, yeah, we'd also want a provision like "but interpret that ask faithfully instead of doing a technical genie [LW · GW]". But that's not an issue if the agent is the one doing the planning. Like, it doesn't prompt some separate plan-making module that it has reason to fear would output something that hacks/Goodharts it. It just consciously tries to come up with "a very good plan", and it's just so smart it has a lot of slack on optimizing that plan along dimensions like "probability of success" and "the optimal world-state will be very stable". And then that washes away everything in the universe that the agent is not explicitly optimizing for.)
Seems like assuming "activation strengths increase the further WM values are from target values" leads us to this bizarre GPS goal. While that proposition may be true as a tendency, I don't see why it should be true in any strict sense, or if you believe that, or whether the analysis hinges on it?
I think no, it doesn't hinge on it, as per the section just above? All we need is for shards to have some preferences for certain world-model-states over others.
Don't you mean "figuratively pursuing "? How would one "pursue" contextual behaviors?
In the vacuous way where any agent could be said to maximize what they're already doing? I did say "figuratively".
Same objection as above -- to "achieve" ? How do you "achieve" behaviors? And, what, this would happen how? What part of training are we in? What is happening in this story, is SGD optimizing the agent to be runtime-adaptive, or..?
... Yeah, okay, that phrasing is very bad. What I meant is: Suppose we have a shard that tries to figure out from where a predator could ambush the agent from. Before the GPS, it had some ad-hoc analysis heuristic that was hooked up to a bunch of WM concepts. After the GPS, that shard can instead loop general-purpose planning in, prompt it with "figure out from where the predator can ambush us, here's some ideas to start", and the GPS would do better than the shard's own ad-hoc algorithm.
Hence, we'll get an agent that would "get better at what it was already doing".
I agree that "become more effective at achieving " is a pretty nonsensical way to put it, though.
Flag that I wish you would write this as "during additional training, the interim model performance can be at least as U-unperformant as the contextual behaviors."
Sure.
I think that heuristics controlling GPS-machinery is probably where the GPS comes from to begin with, so this step doesn't seem necessary.
Agreed; also think I mentioned that in a footnote. I'm not sure, though, and I think we can design some weird training setups where the GPS might first appear in the WM or something (as part of a simulated human?), so my goal here was to show that the process would go this way regardless of where the GPS originated.
I agree that the way I phrased that there is weird, though.
What? Why? Why would a value-human shard bid for plans generated via GPS which involve people dying?
I don't think it'd bid for such plans. I think shards have less decision-making power in advanced agents, compared to the GPS' interpretation of shards' goals. Inasmuch as there would be imperfections in the value-humans shard's caring, the GPS would uncover them, and exploit them to make that shard play nicer with other shards.
E. g., suppose the value-humans shard isn't as upset as we would be if a human got their thumb torn off (and is anomalously non-upset about any second-order effects of that, etc.; it basically ignores tear-a-thumb-off plans), and there's some shard like "sadistic fun" that really enjoys seeing humans get their fingers torn off. Even if the value-humans shard is much more powerful, the GPS' desire to integrate all its values would lead to it adopting some combination value where it thinks it's fine to tear people's fingers off for fun.
That's not a realistic example, but I hope it conveys the broader point: any imperfections in value-humans will be exploited by the rest of the shard economy, and the broader process that tries to satisfy the goal implicitly embodied by the shard economy.
And then, even if the value-humans shard is perfect, the AI might just figure out some galaxy-brained merger of it with a bunch of other shards, that makes logical sense to it as an extrapolation, and just override the value-humans shard's protests. (Returning to a previous example: Suppose we've adopted "avoid ambush predators" as our explicit goal, then ended up in a forest environment where we're ~100% sure there are no predators. The "be afraid of crunchy noises at night" shard would activate, but we'd just dismiss it, because we know it has no clue and we know better.)
I use "values" to be decision-influence
Mm, I dispute that choice. I think "value" has the connotation of "sacred value" and "terminal value" and "something the agent wouldn't want to change about themselves", and that doesn't clearly map onto "a consistent way the agent's decisions are steered"? My broad point, here, is that shards-as-decision-infuencers aren't necessarily endorsed by agents in their initial form, and calling them "values" conveys wrong intuitions (for my purposes, at least).
I prefer "proto-values" for shards-when-viewed-as-repositories-of-contextual-goals, and... Yeah, I don't think I even have anything in my model that works well for "value". "Intermediary values" as a description of contextual goals, maybe.
Aside: I think self-awareness arises from elsewhere in the shard ecosystem.
Would be interested in your model of that!
comment by Dalcy (Darcy) · 2023-01-02T11:27:17.883Z · LW(p) · GW(p)
Okay, more questions incoming: "Why would GPS be okay with value-compilation, when its expected outcome is to not satisfy in-distribution context behaviors through big-brain moves?"
If I understood correctly (can be skipped; not relevant to my argument, which starts after the bullet points):
- Early in training, GPS is part of the heuristic/shard implementation (accessed via API calls)
- Middle in training, there is some SGD-incentive towards pointing GPS in the direction of "reverse-engineering heuristic/shard firing patterns, representing them (Gs) as WM variables, and pursuing them directly"
- Later in training, there is some SGD-incentive towards pointing GPS to do "value-compilation" by merging/representing more abstract i.e. "compiled" versions of the previous goal pointers and directly pursuing them.
- In other words, there are some GPS API calls that say "do value compilation over GPS targets", and some (previously formed) GPS API calls that say "pursue this reverse-engineered-heuristic-goal"
- Very late (approx SGD influence ~ 0 due to starvation + hacking, where we can abstractize SGD as being extensions of GPS), everything is locked-in
- Tangent: we can effectively model the AI as subagents, with each subagent is a GPS API-call. It wouldn't be exactly right to call them "shards," and it wouldn't be right to call them "GPS" either (because GPS is presumably a single module; maybe not?). A new slick terminology might be needed ... I'll just call them "Subagents" for now.
To rephrase my question, why would the other (more early-formed) GPS API calls be okay with the API calls for value-compilation?
As you mentioned in a different comment thread, there is no reason for the GPS to obey in-distribution behavior (inner misalignment). So, from the perspective of a GPS that's API-called with pursuing a reverse-engineered-heuristic-goal, it would think:
- "hm, I notice that in the WM & past firing patterns, several goal-variables are being merged/abstractized and end up not obeying the expected in-distribution context behaviors, presumably due to some different GPS-API-call. Well, I don't want that happening to my values—I need to somehow gradient hack in order to prevent that from happening!"
I think this depends on the optimization "power" distribution between different GPS API-calls (tangent: how is it possible for them to have different power when the GPS, presumably, is a modular thing and the only difference is in how they're called? Whatever). Only if the API call for value compilation overwhelms the incentive against value compilation from the rest of the API calls (which all of them have an incentive for doing so, and would probably collude) then can value compilation actually proceed—which seems pretty unlikely.
Given this analysis, it seems like the default behavior is for the GPS API-calls to gradient hack away whatever other API-calls that would predictably result in in-distribution behaviors not getting preserved (e.g., value-compilation).
- Alternate phrasing: The "Subagents" (check earlier bullet point for terminology) will have an incentive themselves to solve inner misalignment. Therefore, "Subagents" like "Value-compilation-GPS-API-call" that may do dangerous "big-brain" moves are naturally the enemy of everyone else, and will be gradient-hacked away from existence.
Is there any particular reason to believe the GPS API-calls-for-value-compilation would be so strongly chiseled in by the SGD (when SGD still has influence) as to overwhelm all the other API-calls (when SGD stops mattering)?
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-02T13:22:44.346Z · LW(p) · GW(p)
For reference, I think you've formed a pretty accurate model of my model.
Given this analysis, it seems like the default behavior is for the GPS API-calls to gradient hack away whatever other API-calls that would predictably result in in-distribution behaviors not getting preserved (e.g., value-compilation).
Yup. But this requires these GPS instances to be advanced enough to do gradient-hacking, and indeed be concerned with preventing their current values from being updated away. Two reasons not to expect that:
- Different GPS instances aren't exactly "subagents", they're more like planning processes tasked to solve a given problem.
- Consider an impulse to escape from certain death. It's an "instinctive" GPS instance; the GPS has been prompted with "escape certain death", and that prompt is not downstream of abstract moral philosophy. It's an instinctive reaction.
- But this GPS instance doesn't care about preventing future GPS instances from updating away the conditions that caused it to be initiated (i. e., the agent's tendency to escape certain death). It's just tasked with deriving a plan for the current situation.
- It wouldn't bother looking up what abstract-moral-philosophy is plotting and maybe try to counter-plot. It wouldn't care about that.
- (And even if it does care, it'd be far from its main priority, so it wouldn't do effective counter-plotting.)
- The hard-coded pointer to value compilation might plainly be chiseled-in before the agent is advanced enough to do gradient-hacking. In that case, even if a given GPS instance would care to plot against abstract values, it just wouldn't know how (or know that it needs to).
That said, you're absolutely right that it does happen in real-life agents. Some humans are suspicious of abstract arguments for the greater good and refuse to e. g. go from deontologists to utilitarians. The strength of the drive for value compilation relative to shards' strength is varying, and depending on it, the process of value compilation may be frozen at some arbitrary point.
It partly falls under the meta-cognition section [LW · GW]. But in even more extreme cases, a person may simply refuse to engage in value-compilation at all, express a preference to not be coherent.
... Which is an interesting point, actually. We want there to be some value compilation, or agents just wouldn't be able to generalize OOD at all. But it's not obvious that we want maximum value compilation. Maximum value compilation leads to e. g. an AGI with a value-humans shard who decides to do a galaxy-brained merger of that shard with something else and ends up indifferent to human welfare. But maybe we can replicate what human deontologists are doing, and alter the "power distribution" among the AGI's processes such that value compilation freezes just before this point?
I may be overlooking some reason this wouldn't work, but seems promising at first glance.
Replies from: Darcy↑ comment by Dalcy (Darcy) · 2023-01-02T16:18:16.116Z · LW(p) · GW(p)
Different GPS instances aren't exactly "subagents", they're more like planning processes tasked to solve a given problem.
You're right that GPS-instances (nice term btw) aren't necessarily subagents—I missed that your GPS formalization does argmin over WM variable for a specific t, not all t, which means it doesn't have to care about controlling variables at all time.
With that said ...
- (tangent: I'm still unsure as to whether that is the right formalization for GPS—but I don't have a better alternative yet)
- ... there seems to be a selection effect where GPS-instances that don't care about preserving future API-call-context gets removed, leaving only subagent-y GPS-instances over time.
- An example of such property would be having a wide range of t values for the problem specification.
Generalizing, when GPS is the dominant force, only GPS-instances that care about preserving call-context survives (and eg surgeries-away all the non-preserving ones), and then we can model the AI as being composed of actual subagents.
- this sounds like a fairly binary property—either you care (and hence participate in inter-subagent game theory) or you don't (and disappear).
Now, there are three important questions: (1) does greedy SGD incentivize "care" for preserving future call-contexts? (2) if so, what are the late-stage dynamics? (3) and for which GPS-instances do "care" occur?
- What would make it so that SGD chisels in GPS API-calls that "care" about preserving future call-contexts?
- SGD-dominant training phase: Well, by accident. Possibility:
- certain heuristics may require setting the GPS t value across a very wide range, accidentally making it "care" about preservation more so than others.
- SGD-GPS-transition phase: GPS starts to do some very crude gradient hacking. It's really crude, so there's some SGD incentive to point the GPS API-calls for all heuristics to strategize against it.
- now, all heuristics are slowly becoming more preserving.
- GPS-dominant phase: Those that care about preservation survives, and surgeries away the non-caring API-calls.
- SGD-dominant training phase: Well, by accident. Possibility:
- What matters in the dynamics at the GPS-dominant phase? Ideas:
- "Relative power" matters the most
- e.g., even if some GPS-instance cared about its goals for all t, if powerless, other more-powerful-and-less-caring instances just won't give it a say.
- "Range of care" matters
- e.g., some instances care for t:0~10. some care for t:80~95. some care for t:37~999. they might trade to give different instances more "power" for different times as to be pareto-efficient in some way.
- note: again, not sure this is the right ontology to think about GPS calls (like implicitly using real-valued range of continuous t values)
- e.g., some instances care for t:0~10. some care for t:80~95. some care for t:37~999. they might trade to give different instances more "power" for different times as to be pareto-efficient in some way.
- "Relative power" matters the most
- What kind of GPS-instances are more likely to "care" more?
- e.g., for value-compilation to have the kind of impact described in the post, it should probably (1) have sufficient "power" as to not get ignored in the trading, and (2) have an extremely wide range of "care." it's not obvious that this is the case.
But it's not obvious that we want maximum value compilation. Maximum value compilation leads to e. g. an AGI with a value-humans shard who decides to do a galaxy-brained merger of that shard with something else and ends up indifferent to human welfare.
Nice insight! Perhaps we get a range of diverse moral philosophies by tweaking this single variable "value-compilation-degree," with deontology on the one end and galaxy-brained merger on the other end.
Combining with the above three questions, I think a fairly good research direction would be to (1) formalize what it means for the GPS-instances to have more "power" or have a "range of care," (2) and how to tweak/nudge these values for GPS-instances of our choosing (in order to e.g., tweak the degree of value compilation).
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-04T19:29:14.069Z · LW(p) · GW(p)
... there seems to be a selection effect where GPS-instances that don't care about preserving future API-call-context gets removed, leaving only subagent-y GPS-instances over time.
You're not taking into account larger selection effects on agents, which select against agents that purge all those "myopic" GPS-instances. The advantage of shards and other quick-and-dirty heuristics is that they're fast — they're what you're using in a fight, or when making quick logical leaps, etc. Agents which purge all of them, and keep only slow deliberative reasoning, don't live long. Or, rather, agents which are dominated by strong deliberative reasoning tend not to do that to begin with, because they recognize the value of said quick heuristics.
In other words: not all shards/subagents are completely selfish and sociopathic, some/most want select others around. So even those that don't "defend themselves" can be protected by others, or not even be targeted to begin with.
Examples:
- A "chips-are-tasty" shard is probably not so advanced as to have reflective capabilities, and e. g. a more powerful "health" shard might want it removed. But if you have some even more powerful preferences for "getting to enjoy things", or a dislike of erasing your preferences for practical reasons, the health-shard's attempts might be suppressed.
- A shard which implements a bunch of highly effective heuristics for escaping certain death is probably not one that any other shard/GPS instance would want removed.
comment by Dalcy (Darcy) · 2023-01-01T10:51:19.140Z · LW(p) · GW(p)
I think the argument beyond 5D hinges on the fact that Bs and Gs will be represented in the WM such that the GPS can take it as part of the problem specification.
Arguments in favor:
- GPS has been part of the heuristics (shards), so it needs to be able to use their communication channel. This implies that the GPS reverse-engineered the heuristics. Since GPS has write access to the WM, that implies the Bs and Gs might be included there.
- Once included in the WM, it isn't too hard for the SGD to point the GPS towards it. At that point, there's a positive feedback loop that incentivizes both (1) pointing GPS even more towards Bs and Gs and (2) making B/G representation even more explicit in the WM.
Arguments against:
- By the point 5D happens, GPS should already be well-developed and part of the heuristics, which means they would be a very good approximation of U. This implies strong gradient starvation, so there just might not be any incentive for SGD to do any of this.
- If GPS becomes critically reflective before sufficient B/G representation in the WM, then gradient hacking locks in the heuristic-driven-GPS forever.
So, it's either (1) they do get represented and arguments after 5D holds, or (2) they don't get represented and the heuristics end up dominating, basically the shard theory picture.
I think this might be one of the line that divides your model with the Shard Theory model, and as of now I'm very uncertain as to which picture is more likely.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-01T14:40:01.633Z · LW(p) · GW(p)
By the point 5D happens, GPS should already be well-developed and part of the heuristics, which means they would be a very good approximation of U.
My argument is that they wouldn't actually be a good cross-context approximation of U; in part because of gradient starvation.
E. g., suppose we're training a human to be an utilitarian, and we're doing it on a dataset of the norms of a particular society. By default, the human would learn said norms, and then stop there, because following the norms is good enough for making people happy in-distribution. If we then displace them to a different society, they'd try to act on their previous society's norms, and that's not going to make people in the new society happy.
To handle such distribution shifts, we instill a desire to do value-compilation into the human, figure out what their current values are for, and then care about the output of value compilation and ignore the inputs to value compilation (the initial norms).
So we get someone who starts out with local norms, figures out they're for making people happy, and when they move, they figure out what makes people happy in the new society, and re-derive all the new heuristics for that.
It's a sort of hack to avoid gradient starvation.
Replies from: Darcy↑ comment by Dalcy (Darcy) · 2023-01-01T15:40:15.093Z · LW(p) · GW(p)
My argument is that they wouldn't actually be a good cross-context approximation of U; in part because of gradient starvation.
Ah bad phrasing—where you quoted me (arguments against part) I meant to say:
- Heuristic-driven-GPS is a very good approximation of U only within in-distribution context
- ... and this is happening at a phase where SGD is still the dominant force
- ... and Heuristic-driven-GPS is doing all this stuff without being explicitly aimed towards Bs and Ds, but rather the GPS is just part of the "implicit" M -> A procedures/modules
- ... therefore "gradient starvation would imply SGD won't have incentives to represent Bs and Ds as part of the WM"
(I'm intentionally ignoring the value compilation and focusing on 5D because (1) it seems like having Bs and Ds represented is a necessary precursor for all the stuff that comes after that which makes it a useful part to zoom at, and (2) I haven't really settled my thoughts/confusions on value-compilation)
Does my arguments in favor/against in the original comment capture your thoughts on how likely it is that Bs and Ds get represented in the WM? And is your positive conclusion because any one of them seem more likely to matter?
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2023-01-01T19:30:32.521Z · LW(p) · GW(p)
Oops, I think the confusion is about what counts as "in-distribution", probably because I myself used it inconsistently just now. In my other comment [LW(p) · GW(p)], I'd referred to training on a single society as "in-distribution", but in the previous comment in this thread, "displace the human to a different society" was supposed to be part of the training.
Suppose that, as above, we're trying to train an utilitarian.
Imagine that instead of a single environment, we have a set of environments, e. g. a set of societies with different norms. Every society represents a different distribution, such that if we train an AI on a single society's norms, every other society would be OOD for it.
If we train on a single society, then gradient starvation would set in as you're describing: the AI would adopt a bunch of shallow heuristics and have no incentive to develop the value-compilation setup.
But imagine if we're training on different societies, often throwing in societies that are OOD relative to the previous training data. It'd need to learn some setup for re-aligning its heuristics towards U even in completely unfamiliar circumstances — which I hypothesize to be value compilation as described here.
Thus, gradient starvation would never actually set in at the level of shallow heuristics.
(Instead, it'd set in at the level of value compilation — once that process consistently spits out a good proxy of U, the SGD would have no incentive to further align it; and that U-proxy may be quite far from utilitarianism.)
comment by Dalcy (Darcy) · 2022-12-30T06:47:15.840Z · LW(p) · GW(p)
It seems that the greedy selection algorithms and the AI itself can be trusted with approximately 0% of the alignment work, and approximately 100% of it will need to be done by hand.
...
(in the comment [LW(p) · GW(p)])
even if the value-humans shard is perfect, the AI might just figure out some galaxy-brained merger of it with a bunch of other shards, that makes logical sense to it as an extrapolation, and just override the value-humans shard's protests.
Would the galaxy-brained merger necessarily be a bad example? (I'm confused as to what you think the "end goal" of alignment should look like—what would even be a good example of a well-compiled value, behaving in totally OOD environments?)
If I understood correctly, the compiled-value is what lets the AI extrapolate its values to OOD environments via the virtue of abstraction (which may look totally alien to us).
But those compiled values should still do well in-distribution, if the greedy training dynamic is still in play!
So, (assuming the AI is trained in the limit using ~infinite data that's representative of in-distribution human day-to-day-life/examples of "good-values" being executed) the galaxy-brain-compiled-value should still act in accordance to our values in in-distribution contexts, which includes e.g., not killing everyone.
Or maybe I misunderstood. Alternatively, perhaps your galaxy-brain example was set during which the GPS already overpowered SGD and can pursue whatever mesa-objective it had earlier on. Value-compilation would be part of it, since it would've been an adaptive strategy during the greedy training process (i.e. better generalization capability to score well on in-distribution training data).
But even in this case, I think it's still plausible that the GPS will value-compile and abstractize its values in a way that respects behaviors in in-distribution (especially since that's what it had to do during training!)
So overall, I guess my questions are:
- What even would an good OOD extrapolation of human values look like?
- (relatedly) Why do you think the galaxy-brained merger is bad?
- Is my understanding: "GPS's tendency to value-compile initially forms when SGD is still a dominant force in the training dynamic" correct?
- And when SGD loses control and GPS's value-compilation becomes the dominant force, how would that value-compilation generalize? Would it do so in a way that respects earlier-in-training in-distribution samples? (like not killing humans)
↑ comment by Thane Ruthenis · 2023-01-01T14:30:15.552Z · LW(p) · GW(p)
Alternatively, perhaps your galaxy-brain example was set during which the GPS already overpowered SGD and can pursue whatever mesa-objective it had earlier on
Yup. It doesn't necessarily have to respect in-distribution behavior. To re-use an example:
Suppose that you have a shard that looks for conditions like "you're at night in a forest and you heard rustling in the grass behind you", then floods your system with adrenaline and gets you ready for a fight. Via self-reflection, you realize that this implements a heuristic that tries to warn you about a potential attack. You reason that this means you value not getting attacked. You adopt "not getting attacked" as your goal.
Then, you switch contexts. You're in a different forest now, and you're ~100% sure there are no dangerous animals or people around. You hear rustling in the grass behind you. You know it's not a threat, so you suppress the shard's insistence to turn around and get ready for a fight.
You do not respect your in-distribution behavior.
Same can go for e. g. moral principles. Suppose you grew up in a society with a lot of weird norms, like "it's disrespectful to shake people awake", and then did reflection on these learned norms and figured they're optimized for making people happy. You adopt "make people happy" as your value, and then end up moving. In the new society, there are different norms. Instead of being confused by norm-incompatibility, you just figure out what behaviors in this society make people happy, and do them.
Or, again, deontology to utilitarianism. "Don't kill people" and such rules are optimized for advancing human welfare, but if you adopt "human welfare" as your explicit goal, you may sometimes violate that initial rule to e. g. kill a serial killer.
The concern, here, is that the AGI may do something like this with "keep humanity around". That it's just a local instantiation of some higher-level principle, that can be served better by killing humans off and replacing them with something else — like there's no need to respect "be afraid of rustling" if the forest has no predators, or "don't shake people awake" if the person you're shaking awake doesn't mind.
What even would an good OOD extrapolation of human values look like?
No idea. I mean, it presumably involves building an immortal eudaimonic utopia, whatever "eudaimonia" means, but no I haven't solved the entirety of moral philosophy. Just developed a model for describing the process of moral philosophy.
Why do you think the galaxy-brained merger is bad?
See above.
Is my understanding: "GPS's tendency to value-compile initially forms when SGD is still a dominant force in the training dynamic" correct?
Yup.
And when SGD loses control and GPS's value-compilation becomes the dominant force, how would that value-compilation generalize? Would it do so in a way that respects earlier-in-training in-distribution samples? (like not killing humans)
The concern is that it wouldn't respect in-distribution samples. Because of inner misalignment: it wouldn't generalize values into the actual outer objective, it'd generalize them towards some not-that-good correlate of the actual training objective (like human values are a proxy goal for "maximize inclusive genetic fitness").
comment by TurnTrout · 2022-12-21T20:33:14.386Z · LW(p) · GW(p)
This post posits that the WM will have a "similar format" throughout, but that heuristics/shards may not. For example, you point out that the WM has to be able to arbitrarily interlace and do subroutine calls (e.g. "will there be a dog near me soon" circuit presumably hooks into "object permanence: track spatial surroundings").
(I confess that I don't quite know what it would mean for shards to have "different encodings" from each other; would they just not have ways to do API calls on each other? Would they be written under eg different "internal programming languages"? Not reuse subroutine calls to other shards?)
Keeping in mind that maybe I am only reasoning syntactically right now, here are more considerations:
- I think it's non-trivial to know why I'm worried about something / why I think e.g. someone is mad at me (I remember being quite bad at this before learning Focusing). This seems like weak evidence that "what do I predict" is not substantially more self-interpretable than "why did I act that way", which is in turn weak evidence that WM formatting is about as consistent as shard formatting.
- Shards also probably reuse machinery. In particular, "grab the cup" should not be duplicated across juice- and milk-shards. This suggests e.g. a motor coordination API will arise. Eventually the generalization of these APIs probably turns into the GPS (but that's just my current gut guess).
- The WM can literally invoke shards in rollout predictions, where it computes what (conditional on e.g. setting
dog-nearbytoTrue) the shard bids are. So I don't see why shards should be black-boxy to the WM/GPS? - SSL updates may push shards to be more predictable to WM, so as to reduce predictive error, which seems to me like it pushes towards uniform shard encoding.
comment by TurnTrout · 2022-12-15T07:03:06.022Z · LW(p) · GW(p)
That is: is some function that takes in a world-model and some "problem specification" — some set of nodes in the world-model and their desired values — and output the actions that, if taken in that world-model, would bring the values of these nodes as close to the desired values as possible given the actions available to the agent.
While I appreciate the concreteness, this doesn't seem very reasonable to me.[1] But maybe I'm misunderstanding![2]
Concretely, imagine I want to buy ice cream. I understand the GPS to receive target specification set to "I have ice cream in my hand in three hours." I don't think that I will then quickly argmin expected latent distance by searching over all relevant plans. That would, I think, lead to some crazy outcomes. Solutions at least as ice-cream-effective as "use all my money to hire many friends to buy me ice cream from different places."
And if we posit that the other variables are also set to reasonable values, I will object "this is not lazy enough (in a programming sense), you're asking too much of target configurations; I will in fact be surprised if amazing brain-reading indicated that I am in fact tracking complete target latent state specifications when I submit plans to my GPS."
I will also object that I don't think that min is at all an effective approach to real-world cognition, nor do I think it's what gets learned with realistic learning processes. I think the GPS itself will be a set of heuristics (like "check recent memory bank for target-goal-relevant information" and "use generative model to suggest five candidate goal-states and let invocation-subshards bid on them to rank them, selecting the best-of-five") which are reliably useful across shard-goals (like ice cream and dog-petting).
(Am I engaging with your intended points properly, or am I whooshing?)
- ^
Rule of thumb: If I find myself postulating internal motivational circuitry which uses a "max" or a "min", then I should think very carefully about what is going on and whether that's appropriate. Almost always, the answer is "no", and if I don't catch the "min/max" before it sneaks in, my analysis goes off the rails of reality.
- ^
I haven't even read much further, just skimmed other parts of the post. I'll post this now anyways.
↑ comment by Thane Ruthenis · 2022-12-15T11:42:28.229Z · LW(p) · GW(p)
I don't think the GPS "searches over all relevant plans". As per John's post [LW · GW]:
Consider, for example, a human planning a trip to the grocery store. Typical reasoning (mostly at the subconscious level) might involve steps like:
- There’s a dozen different stores in different places, so I can probably find one nearby wherever I happen to be; I don’t need to worry about picking a location early in the planning process.
- My calendar is tight, so I need to pick an open time. That restricts my options a lot, so I should worry about that early in the planning process.
- <go look at calendar>
- Once I’ve picked an open time in my calendar, I should pick a grocery store nearby whatever I’m doing before/after that time.
- … Oh, but I also need to go home immediately after, to put any frozen things in the freezer. So I should pick a time when I’ll be going home after, probably toward the end of the day.
Notice that this sort of reasoning mostly does not involve babbling and pruning entire plans. The human is thinking mostly at the level of constraints (and associated heuristics) which rule out broad swaths of plan-space. The calendar is a taut constraint, location is a slack constraint, so (heuristic) first find a convenient time and then pick whichever store is closest to wherever I’ll be before/after. The reasoning only deals with a few abstract plan-features (i.e. time, place) and ignores lots of details (i.e. exact route, space in the car’s trunk); more detail can be filled out later, so long as we’ve planned the “important” parts. And rather than “iterate” by looking at many plans, the search process mostly “iterates” by considering subproblems (like e.g. finding an open calendar slot) or adding lower-level constraints to a higher-level plan (like e.g. needing to get frozen goods home quickly).
In particular, I very much do agree the GPS makes use of heuristics like "if you have a cached plan that you think will work, just do that" and "see [how you feel about this idea][1] before proceeding" over the course of planning. But it's not made of heuristics; rather, it's something like a systematic way of drawing upon the declarative knowledge/knowledge explicitly represented in the world-model, and that knowledge involves a lot of heuristics.
Crucially, part of any "problem specification" would be things like "how much time should I spend on thinking about this?" and "how hard should I optimize the plan for doing it?" and "in how much detail should I track the consequences of this decision?", and if it's something minor like getting ice cream, then of course you'd spend very little time and use a lot of cached cognitive shortcuts.
If it's something major, however, like a life-or-death matter, then you'd do high-intensity planning that aims to track what would actually happen in detail, without relying on prior assumptions and vague feelings[2].
- ^
I. e., which of your shards bid for or against it, and how strongly.
- ^
Unless, of course, some of these vague feelings have proven more effective in the past than your explicit attempts at consequences-tracking, in which case you'd knowingly defer to them — you'd "trust your instincts".
↑ comment by TurnTrout · 2022-12-15T22:10:27.089Z · LW(p) · GW(p)
I don't think the GPS "searches over all relevant plans"
OK, but you are positing that there's an argmin, no? That's a big part of what I'm objecting to. I anticipate that insofar as you're claiming grader-optimization problems come back, they come back because there's an AFAICT inappropriate argmin which got tossed into the analysis via the GPS.
But it's not made of heuristics; rather, it's something like a systematic way of drawing upon the declarative knowledge/knowledge explicitly represented in the world-model, and that knowledge involves a lot of heuristics.
Sure, sounds reasonable.
Crucially, part of any "problem specification" would be things like "how much time should I spend on thinking about this?" and "how hard should I optimize the plan for doing it?" and "in how much detail should I track the consequences of this decision?", and if it's something minor like getting ice cream, then of course you'd spend very little time and use a lot of cached cognitive shortcuts.
Noting that I still feel confused after hearing this explanation. What does it mean to ask "how hard should I optimize"?
If it's something major, however, like a life-or-death matter, then you'd do high-intensity planning that aims to track what would actually happen in detail, without relying on prior assumptions and vague feelings
Really? I think that people usually don't do that in life-or-death scenarios. People panic all the time.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2022-12-15T22:38:44.246Z · LW(p) · GW(p)
What does it mean to ask "how hard should I optimize"?
Satisficing threshold, probability of the plan's success, the plan's robustness to unexpected perturbations, etc. I suppose the argmin is somewhat misleading: the GPS doesn't output the best possible plan for achieving some goal in the world outside the agent, it's solving the problem in the most efficient way possible, which often means not spending too much time and resources on it. I. e., "mental resources spent" is part of the problem specification, and it's something it tries to minimize too.
I don't think this argmin is the central reason for grader-optimization problems here.
Really? I think that people usually don't do that in life-or-death scenarios. People panic all the time.
I'm assuming no time pressure. Or substitute-in "a matter of grave importance that you nonetheless feel capable of resolving".
Replies from: TurnTrout↑ comment by TurnTrout · 2022-12-15T23:04:06.067Z · LW(p) · GW(p)
I don't think this argmin is the central reason for grader-optimization problems here.
I'm going to read the rest of the essay, and also I realize you posted this before my [LW · GW] four [LW · GW] posts [LW · GW] on [LW · GW] "holy cow argmax can blow all your alignment reasoning out of reality all the way to candyland." But I want to note that including an argmin in the posited motivational architecture makes me extremely nervous / distrusting. Even if this modeling assumption doesn't end up being central to your arguments on how shard-agents become wrapper-like, I think this assumption should still be flagged extremely heavily.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2022-12-15T23:11:54.942Z · LW(p) · GW(p)
Mm, I believe that it's not central because my initial conception of the GPS didn't include it at all, and everything still worked. I don't think it serves the same role here as you're critiquing in the posts you've linked; I think it's inserted at a different abstraction level.
But sure, I'll wait for you to finish with the post.