MIRI 2024 Mission and Strategy Update
post by Malo (malo) · 2024-01-05T00:20:54.169Z · LW · GW · 44 commentsContents
The short version:
MIRI’s mission
MIRI in 2021–2022
New developments in 2023
Looking forward
None
44 comments
As we announced [LW · GW] back in October, I have taken on the senior leadership role at MIRI as its CEO. It’s a big pair of shoes to fill, and an awesome responsibility that I’m honored to take on.
There have been several changes at MIRI since our 2020 strategic update, so let’s get into it.[1]
The short version:
We think it’s very unlikely that the AI alignment field will be able to make progress quickly enough to prevent human extinction and the loss of the future’s potential value, that we expect will result from loss of control to smarter-than-human AI systems.
However, developments this past year like the release of ChatGPT seem to have shifted the Overton window in a lot of groups. There’s been a lot more discussion of extinction risk from AI, including among policymakers, and the discussion quality seems greatly improved.
This provides a glimmer of hope. While we expect that more shifts in public opinion are necessary before the world takes actions that sufficiently change its course, it now appears more likely that governments could enact meaningful regulations to forestall the development of unaligned, smarter-than-human AI systems. It also seems more possible that humanity could take on a new megaproject squarely aimed at ending the acute risk period.
As such, in 2023, MIRI shifted its strategy to pursue three objectives:
- Policy: Increase the probability that the major governments of the world end up coming to some international agreement to halt progress toward smarter-than-human AI, until humanity’s state of knowledge and justified confidence about its understanding of relevant phenomena has drastically changed; and until we are able to secure these systems such that they can’t fall into the hands of malicious or incautious actors.[2]
- Communications: Share our models of the situation with a broad audience, especially in cases where talking about an important consideration could help normalize discussion of it.
- Research: Continue to invest in a portfolio of research. This includes technical alignment research (though we’ve become more pessimistic that such work will have time to bear fruit if policy interventions fail to buy the research field more time), as well as research in support of our policy and communications goals.[3]
We see the communications work as instrumental support for our policy objective. We also see candid and honest communication as a way to bring key models and considerations into the Overton window, and we generally think that being honest in this way tends to be a good default.
Although we plan to pursue all three of these priorities, it’s likely that policy and communications will be a higher priority for MIRI than research going forward.[4]
The rest of this post will discuss MIRI’s trajectory over time and our current strategy. In one or more future posts, we plan to say more about our policy/comms efforts and our research plans.
Note that this post will assume that you’re already reasonably familiar with MIRI and AGI risk; if you aren’t, I recommend checking out Eliezer Yudkowsky’s recent short TED talk,
along with some of the resources cited on the TED page:
- “A.I. Poses ‘Risk of Extinction,’ Industry Leaders Warn”, New York Times
- “We must slow down the race to god-like AI”, Financial Times
- “Pausing AI Developments Isn’t Enough. We Need to Shut it All Down [LW · GW]”, TIME
- “AGI Ruin: A List of Lethalities [AF · GW]”, AI Alignment Forum
MIRI’s mission
Throughout its history, MIRI’s goal has been to ensure that the long-term future goes well, with a focus on increasing the probability that humanity can safely navigate the transition to a world with smarter-than-human AI. If humanity can safely navigate the emergence of these systems, we believe this will lead to unprecedented levels of prosperity.
How we’ve approached that mission has varied a lot over the years.
When MIRI was first founded by Eliezer Yudkowsky and Brian and Sabine Atkins in 2000, its goal was to try to accelerate to smarter-than-human AI as quickly as possible, on the assumption that greater-than-human intelligence entails greater-than-human morality. In the course of looking into the alignment problem for the first time (initially called “the Friendly AI problem”), Eliezer came to the conclusion that he was completely wrong [? · GW] about “greater intelligence implies greater morality”, and MIRI shifted its focus to the alignment problem around 2003.
MIRI has continued to revise its strategy since then. In ~2006–2012, our primary focus was on trying to establish communities and fields of inquiry focused on existential risk reduction and domain-general problem-solving ability (e.g., the rationality community). Starting in 2013, our focus was on Agent Foundations research and trying to ensure that the nascent AI alignment field outside MIRI got off to a good start. In 2017–2020, we shifted our primary focus to a new engineering-heavy set of alignment research directions.
Now, after several years of reorienting and exploring different options, we’re making policy and communications our top focus, as that currently seems like the most promising way to serve our mission.
At a high level, MIRI is a place where folks who care deeply about humanity and its future, and who share a loose set of intuitions about the challenges we face in safely navigating the development of smarter-than-human AI systems, have teamed up to work towards a brighter future. In the spirit of “keep your identity small”, we don’t want to build more content than that into MIRI-the-organization: if an old “stereotypical” MIRI belief or strategy turns out to be wrong, we should just ditch the failed belief/strategy and move on.
With that context in view, I’ll next say a bit about what, concretely, MIRI has been up to recently, and what we plan to do next.
MIRI in 2021–2022
In our last strategy update (posted in December 2020), Nate Soares wrote that the research push we began in 2017 “has, at this point, largely failed, in the sense that neither Eliezer nor I have sufficient hope in it for us to continue focusing our main efforts there[...] We are currently in a state of regrouping, weighing our options, and searching for plans that we believe may yet have a shot at working.”
In 2021–2022, we focused on:
- the aforementioned process of trying to find more promising plans,
- smaller-scale support for our Agent Foundations and our 2017-initiated research programs (along with some exploration of other research ideas),[5]
- dialoguing with other people working on AI x-risk, and
- writing up many of our background views.[6]
The most central write-ups from this period include:
- Late 2021 MIRI Conversations
- AGI Ruin: A List of Lethalities [LW · GW]
- A central AI alignment problem: capabilities generalization, and the sharp left turn [LW · GW]
- Six Dimensions of Operational Adequacy in AGI Projects [LW · GW]
Our sense is that these and other MIRI write-ups were helpful for better communicating our perspective on the strategic landscape, which in turn is important for understanding how we’ve changed our strategy. Some of the main points we tried to communicate were:
- Our default expectation is that humanity will soon develop AI systems that are smarter than humans.[7] We think the world isn’t ready for this, and that rushing ahead will very likely cause human extinction and the destruction of the future’s potential value.
- The world’s situation currently looks extremely dire to us. For example, Eliezer wrote [LW · GW] in late 2021, “I consider the present gameboard to look incredibly grim, and I don’t actually see a way out through hard work alone. We can hope there’s a miracle that violates some aspect of my background model, and we can try to prepare for that unknown miracle”.
- The primary reason we think the situation is dire is because humanity’s current technical understanding of how to align smarter-than-human systems seems vastly lower than what’s likely to be required. Not much progress has been made to date (relative to what’s required), including at MIRI; and we see the field to date [? · GW] as mostly working on topics orthogonal to the core difficulties [? · GW], or approaching the problem in a way that assumes away these core difficulties.
- It would be a mistake to give up, but it would also be a mistake to start piling on optimistic assumptions and mentally living in a more-optimistic (but not real) world. If, somehow, we achieve a breakthrough, it’s likely to come from an unexpected direction, and we’re likely to be in a better position to take advantage of it if we’ve kept in touch with reality.
In his TIME article, Eliezer Yudkowsky describes what he sees as the sort of policy that would be minimally required in order for governments to prevent the world from destroying itself: an indefinite worldwide moratorium on new large training runs, enforced by an international agreement with actual teeth. The LessWrong mirror of Eliezer’s TIME piece [LW · GW] goes into more detail on this, adding several clarifying addenda.
In the absence of sufficient political will/consensus to impose such a moratorium, we think the best policy objective to focus on would be building an “off switch”—that is, assembling the legal and technical capability needed to make it possible to shut down a dangerous project or impose an indefinite moratorium on the field, if policymakers decide at a future date that it’s necessary to do so. Having the option to shut things down would be an important step in the right direction.
The difficulties of proactively enacting and effectively enforcing such an international agreement are obvious to the point that, until recently, MIRI had much more hope in finding some AI-alignment-mediated solution to AGI proliferation, in spite of how little relevant technical progress has been made to date.
However, a combination of recent developments have changed our minds about this. First, our hope in anyone finding technical solutions in time has declined, and second, the moderate success of our communications efforts has increased our hope in that direction.
Although we still think the situation looks bleak, it now looks a little less bleak than we thought it did a year ago; and the source of this new hope lies in the way the public conversation about AI has recently shifted.
New developments in 2023
In the past, MIRI has mostly spent its time on alignment research and outreach to technical audiences—that is, outreach to the sort of people who might do relevant technical work.
Several developments this year have updated us toward thinking that we should prioritize outreach activities with an emphasis on influencing policymakers and groups that may influence policymakers, including AI researchers and the general public:
1. GPT-3.5 and GPT-4 were more impressive than some of us expected. We already had short timelines, but these launches were a further pessimistic update for some of us about how plausible it is that humanity could build world-destroying AGI with relatively few (or no) additional algorithmic advances.
2. The general public and policymakers have been more receptive to arguments about existential risk from AGI than we expected, and their responses have been pretty reasonable. For example, we were positively surprised by the reception to Eliezer’s February interview on Bankless [LW · GW] and his March piece in TIME magazine [LW · GW] (which was TIME’s highest-traffic page for a week). Eliezer’s piece in TIME mentions that we’d been surprised by how many non-specialists’ initial reactions to hearing about AI risk were quite reasonable and grounded.
3. More broadly, there has been a shift in the Overton window toward “take extinction risk from AGI more seriously”, including within ML. Geoffrey Hinton and Yoshua Bengio’s public statements seemed pivotal here; likewise the one-sentence statement signed by the CEOs of DeepMind, Anthropic, and OpenAI, and by hundreds of other AI scientists and public intellectuals:
Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.
A recent example of this 2023 shift was my participation in one of the U.S. Senate’s bipartisan AI Insight Forums. It was heartening to see how far the discourse has come—Leader Schumer opened the event by asking attendees for our probability that AI could lead to a doomsday scenario, using the term “p(doom)”, while Senators and their staff listened and took notes. We would not have predicted this level of interest and reception at the beginning of the year.
Even if policymakers turn out not to be immediately receptive to arguments for halting large training runs, this may still be a critical time for establishing precedents and laying policy groundwork that could be built on if policymakers and their constituents become more alarmed in the future, e.g., in the unfortunate event of a major, but not existential, AI related disaster.
Policy efforts like this seem very unlikely to save us, but all other plans we know of seem even less likely to succeed. As a result, we’ve started building capacity for our public outreach efforts, and ramping up these efforts.
Looking forward
In the coming year, we plan to continue our policy, communications, and research efforts. We are somewhat limited in our ability to enact policy programs by our 501(c)3 status, but we work closely with others at organizations with different structures that are more free to engage in advocacy work. We are growing our communications team and expanding our capacity to broadcast the basic arguments about AI x-risk, and of course, we’re continuing our alignment research programs and expanding the research team to communicate better about our results as well as exploring new ideas.
If you are interested in working directly with MIRI as we grow, please watch our careers page for job listings.
- ^
Thanks to Rob Bensinger, Gretta Duleba, Matt Fallshaw, Alex Vermeer, Lisa Thiergart, and Nate Soares for your valuable thoughts on this post.
- ^
As Nate has written about in Superintelligent AI is necessary for an amazing future, but far from sufficient [LW · GW], we would consider it an enormous tragedy if humanity never developed artificial superintelligence. However, regulators may have a difficult time determining when we’ve reached the threshold “it’s now safe to move forward on AI capabilities.”
One alternative, proposed by Nate, would be for researchers to stop trying to pursue de novo AGI, and instead pursue human whole-brain emulation or human cognitive enhancement. This helps largely sidestep the issue of bureaucratic legibility, since the risks are far lower and success criteria are a lot clearer; and it could allow us to realize many of the near-term benefits of aligned AGI (e.g., for existential risk reduction).
- ^
Various people at MIRI have different levels of hope about this. Nate and Eliezer both believe that humanity should not be attempting technical alignment at its current level of cognitive ability, and should instead pursue human cognitive enhancement (e.g., via uploading), and then having smarter (trans)humans figure out alignment.
- ^
Lisa comments:
I personally would like to note my dissenting perspective on this overall choice.
While I agree MIRI can contribute in the short term with a comms and policy push towards effective regulation, in the medium to long term I think research is our greater comparative advantage and I think we should keep substantial focus here (as well as increase empirical research staff). We should continue doing research but shift our focus more towards technical work which can support regulatory efforts (ex. safety standards, etc), including empirical work but also for example drawing on our Agent Foundations experience to produce theoretical frameworks. I think stronger technical (ideally empirically grounded) research arguments targeting scientific government advisors, regulators and lab decision makers (rather than public-oriented comms using philosophical arguments) on why there is AI risk and why mitigation makes sense, are more critically missing from the picture and a component MIRI can perhaps uniquely contribute. I also personally expect more impact to come from influencing lab decision makers and creating more of an academic/research consensus on safety risks rather than hoping for substantial regulatory success in the shorter term of the next 1–3 years.
Further, solving critical open questions in the safety standards space on how to regulate using metrics (and how to do this scientifically and correctly) seems to me a priority for at least the next 1–2 years. I think it’s important to have a diversity of perspectives including non-lab organizations like MIRI creating this knowledge base.
- ^
In the case of our Agent Foundations research team, team size stayed the same, but we didn’t put any effort into trying to expand the team.
- ^
We also helped set up a co-working space and related infrastructure for other AI x-risk orgs like Redwood Research. We’re fans of Redwood, and often direct researchers and engineers to apply to work there if they don’t obviously fit the far more unusual and constrained research niches at MIRI.
- ^
Where “soon” means, roughly, “there’s a lot of uncertainty here, but it’s a very live possibility that AGI is only a few years away; and it no longer seems likely to be (for example) 30+ years away.” In a fall 2023 poll of most MIRI researchers, we expect AGI (according to the definition from this Metaculus market) in a median of 9 years and a mean of 14.6 years. One researcher was an outlier at 52 years; the majority predicted under ten years.
44 comments
Comments sorted by top scores.
comment by aysja · 2024-01-08T04:01:47.383Z · LW(p) · GW(p)
We think it’s very unlikely that the AI alignment field will be able to make progress quickly enough to prevent human extinction.
From my point of view it seems possible that we could solve technical alignment, or otherwise become substantially deconfused, within 10 years—perhaps much sooner. I don’t think we’ve ruled out that foundational scientific progress is capable of solving the problem, nor that cognitively unenhanced humans might be able to succeed at such an activity. Like, as far as I can tell, very few people have tried working on the problem directly, in the sense of forming original lines of attack (maybe between 10 to 20?), many of whom share similar ontological backgrounds. This doesn’t seem like overwhelming evidence, to me, that the situation is doomed.
For instance, in the late 1800’s physicists were so ontologically committed to the idea of absolute rest that they spent many decades searching for ether, instead of discovering special relativity. Even Lorentz and Poincaré, who both had many of the key ideas for special relativity, never made the final leap—even after Einstein’s publication—because they were so committed to their traditional notions of space and time. If everyone within a field is operating under the same incorrect ontological assumptions it can seem like progress is impossible, when in fact progress is just hard when you have the wrong concepts.
Also, conceptual progress can happen quickly. I don’t think it necessarily looks (to most of the outside world) like people are making steady progress towards deconfusion. I think it often looks more like “that person is doing some weird thing over there” until they present an inferential-distance-crossing work and it clicks for the rest of the world. At least, this is roughly what happened for Einstein (with his “miracle year”—introducing special relativity, light quanta, etc.), Newton (with his “year of wonders”—theory of gravity, calculus, and many insights into optics), and Darwin (with Origin of Species).
In other words, I don’t think modeling the current landscape as dire is that much evidence that it will remain so for years to come. Things look confusing and hard until they’re not; and historically speaking, great scientists have sometimes been able to make great conceptual progress on seemingly difficult problems—often suddenly, and unexpectedly.
I consider the Sequences to be one of the greatest philosophical texts of the century to date, but while it would be hard to explain in a few sentences, I also think that it got some key ontological commitments wrong. In any case, I worry that MIRI is over-anchoring on their ontology being the correct one, and then concluding that further efforts are doomed. Whereas I strongly suspect there’s room for philosophical work to bear unexpected (and fast) alignment progress. Especially so, given the amount of ontological correlated-ness among the few people who have tried to figure out alignment so far.
I think one way to cause conceptual progress to happen faster is just to have more people working on the problem in more ontologically decorrelated ways. Because of that, I personally feel worried about what seems to me like an increasing push towards policy work or towards already developed agendas. Not that working on either of those is necessarily bad—many such efforts strike me as important bets to make, and I’m deeply grateful that people are pursuing them. Just that, on the margin, I think we ought to be allotting more of our portfolio to people that are developing their own angles on the problem.
I really want our culture to support minds who take on the strange, difficult, and vulnerable task of trying to make scientific progress at the frontier of human knowledge. And I don’t want to lose sight of that, or for the miasma of generalized hopelessness to make people less likely to try it.
Replies from: malo↑ comment by Malo (malo) · 2024-02-14T22:24:44.454Z · LW(p) · GW(p)
I think this a great comment, and FWIW I agree with, or am at least sympathetic to, most of it.
comment by Wei Dai (Wei_Dai) · 2024-01-05T02:14:20.065Z · LW(p) · GW(p)
Reposting a Twitter reply to Eliezer:
Eliezer: I no longer believe that this civilization as it stands would get to alignment with 30-50 years of hard work. You'd need intelligence augmentation first. This version of civilization and academic bureaucracy is not able to tell whether or not alignment work is real or bogus.
Wei: Given this, why put all your argumentative eggs in the "alignment is hard" basket? (If you're right, then policymakers can't tell that you're right.) Why not talk more about some of the other reasons to slow down or pause AI? https://www.lesswrong.com/posts/WXvt8bxYnwBYpy9oT/the-main-sources-of-ai-risk [LW · GW]
Expanding on this, I'm worried that if MIRI focused all its communications efforts on "alignment is hard" and there's apparent alignment progress in the next few years, which may be real progress (I have a wider distribution on alignment difficulty than Eliezer) or fake progress that most people can't distinguish from real progress, MIRI and MIRI-adjacent people would lose so much credibility that it becomes impossible to pivot to other messages about AI risk.
Replies from: orthonormal↑ comment by orthonormal · 2024-01-05T20:25:41.319Z · LW(p) · GW(p)
I think MIRI is correct to call it as they see it, both on general principles and because if they turn out to be wrong about genuine alignment progress being very hard, people (at large, but also including us) should update against MIRI's viewpoints on other topics, and in favor of the viewpoints of whichever AI safety orgs called it more correctly.
Replies from: RobbBB, Wei_Dai↑ comment by Rob Bensinger (RobbBB) · 2024-01-06T01:05:17.532Z · LW(p) · GW(p)
Yep, before I saw orthonormal's response I had a draft-reply written that says almost literally the same thing:
we just call 'em like we see 'em
[...]
insofar as we make bad predictions, we should get penalized for it. and insofar as we think alignment difficulty is the crux for 'why we need to shut it all down', we'd rather directly argue against illusory alignment progress (and directly acknowledge real major alignment progress as a real reason to be less confident of shutdown as a strategy) rather than redirect to something less cruxy
I'll also add: Nate (unlike Eliezer, AFAIK?) hasn't flatly said 'alignment is extremely difficult'. Quoting from Nate's "sharp left turn" post:
Many people wrongly believe that I'm pessimistic because I think the alignment problem is extraordinarily difficult on a purely technical level. That's flatly false, and is pretty high up there on my list of least favorite misconceptions of my views.
I think the problem is a normal problem of mastering some scientific field, as humanity has done many times before. Maybe it's somewhat trickier, on account of (e.g.) intelligence being more complicated than, say, physics; maybe it's somewhat easier on account of how we have more introspective access to a working mind than we have to the low-level physical fields; but on the whole, I doubt it's all that qualitatively different than the sorts of summits humanity has surmounted before.
It's made trickier by the fact that we probably have to attain mastery of general intelligence before we spend a bunch of time working with general intelligences (on account of how we seem likely to kill ourselves by accident within a few years, once we have AGIs on hand, if no pivotal act occurs), but that alone is not enough to undermine my hope.
What undermines my hope is that nobody seems to be working on the hard bits, and I don't currently expect most people to become convinced that they need to solve those hard bits until it's too late.
So it may be that Nate's models would be less surprised by alignment breakthroughs than Eliezer's models. And some other MIRI folks are much more optimistic than Nate, FWIW.
My own view is that I don't feel nervous leaning on "we won't crack open alignment in time" as a premise, and absent that premise I'd indeed be much less gung-ho about government intervention.
why put all your argumentative eggs in the "alignment is hard" basket? (If you're right, then policymakers can't tell that you're right.)
The short answer is "we don't put all our eggs in the basket" (e.g., Eliezer's TED talk and TIME article emphasize that alignment is an open problem, but they emphasize other things too, and they don't go into detail on exactly how hard Eliezer thinks the problem is), plus "we very much want at least some eggs in that basket because it's true, it's honest, it's cruxy for us, etc." And it's easier for policymakers to acquire strong Bayesian evidence for "the problem is currently unsolved" and "there's no consensus about how to solve it" and "most leaders in the field seem to think there's a serious chance we won't solve it in time" than to acquire strong Bayesian evidence for "we're very likely generations away from solving alignment", so the difficulty of communicating the latter isn't a strong reason to de-emphasize all the former points.
The longer answer is a lot more complicated. We're still figuring out how best to communicate our views to different audiences, and "it's hard for policymakers to evaluate all the local arguments or know whether Yann LeCun is making more sense than Yoshua Bengio" is a serious constraint. If there's a specific argument (or e.g. a specific three arguments) you think we should be emphasizing alongside "alignment is unsolved and looks hard", I'd be interested to hear your suggestion and your reasoning. https://www.lesswrong.com/posts/WXvt8bxYnwBYpy9oT/the-main-sources-of-ai-risk [LW · GW] is a very long list and isn't optimized for policymakers, so I'm not sure what specific changes you have in mind here.
Replies from: Wei_Dai, RobbBB↑ comment by Wei Dai (Wei_Dai) · 2024-01-06T07:02:22.621Z · LW(p) · GW(p)
If there's a specific argument (or e.g. a specific three arguments) you think we should be emphasizing alongside "alignment is unsolved and looks hard", I'd be interested to hear your suggestion and your reasoning.
The items on my list are of roughly equal salience to me. I don't have specific suggestions for people who might be interested in spreading awareness of these risks/arguments, aside from picking a few that resonate with you and are also likely to be well received by the intended audience. And maybe link back to the list (or some future version of such a list) so that people don't think the ones you choose to talk about are the only risks.
For me personally, I tend to talk about "philosophy is hard" (which feeds into "alignment is hard" and beyond) and "humans aren't safe" (humans suffer from all kinds of safety problems just like AIs do, including being easily persuaded of strange beliefs and bad philosophy, calling "alignment" into question even as a goal). These might not work well on a broader audience though, the kind that MIRI is presumably trying to reach. Some adjacent messages might, for example, "even if alignment succeeds, humans can't be trusted with God-like powers yet; we need to become much wiser first" and "AI persuasion will be a big problem" (but honestly I have little idea due to lack of experience talking outside my circle).
↑ comment by Rob Bensinger (RobbBB) · 2024-01-06T01:39:29.697Z · LW(p) · GW(p)
To pick out a couple of specific examples from your list, Wei Dai:
14. Human-controlled AIs causing ethical disasters (e.g., large scale suffering that can't be "balanced out" later) prior to reaching moral/philosophical maturity
This is a serious long-term concern if we don't kill ourselves first, but it's not something I see as a premise for "the priority is for governments around the world to form an international agreement to halt AI progress". If AI were easy to use for concrete tasks like "build nanotechnology" but hard to use for things like CEV, I'd instead see the priority as "use AI to prevent anyone else from destroying the world with AI", and I wouldn't want to trade off probability of that plan working in exchange for (e.g.) more probability of the US and the EU agreeing in advance to centralize and monitor large computing clusters.
After someone has done a pivotal act like that, you might then want to move more slowly insofar as you're worried about subtle moral errors creeping in to precursors to CEV.
30. AI systems end up controlled by a group of humans representing a small range of human values (ie. an ideological or religious group that imposes values on everyone else)
I currently assign very low probability to humans being able to control the first ASI systems, and redirecting governments' attention away from "rogue AI" and toward "rogue humans using AI" seems very risky to me, insofar as it causes governments to misunderstand the situation, and to specifically misunderstand it in a way that encourages racing.
If you think rogue actors can use ASI to achieve their ends, then you should probably also think that you could use ASI to achieve your own ends; misuse risk tends to go hand-in-hand with "we're the Good Guys, let's try to outrace the Bad Guys so AI ends up in the right hands". This could maybe be justified if it were true, but when it's not even true it strikes me as an especially bad argument to make.
↑ comment by Wei Dai (Wei_Dai) · 2024-01-07T02:19:09.445Z · LW(p) · GW(p)
I wrote this top level comment [LW(p) · GW(p)] in part as a reply to you.
comment by Peter Berggren (peter-berggren) · 2024-01-05T03:48:43.115Z · LW(p) · GW(p)
What's preventing MIRI from making massive investments into human intelligence augmentation? If I recall correctly, MIRI is most constrained on research ideas, but human intelligence augmentation is a huge research idea that other grantmakers, for whatever reason, aren't funding. There are plenty of shovel-ready proposals already, e.g. https://www.lesswrong.com/posts/JEhW3HDMKzekDShva/significantly-enhancing-adult-intelligence-with-gene-editing; [LW · GW] why doesn't MIRI fund them?
Replies from: RussellThor, geoffreymiller↑ comment by RussellThor · 2024-01-05T04:42:23.053Z · LW(p) · GW(p)
What's preventing them from massive investments into WBE/upload? Many AI/tech leaders who think the MIRI view is wrong would also support that.
Replies from: None↑ comment by [deleted] · 2024-01-05T18:49:32.530Z · LW(p) · GW(p)
How much would it cost and how useful would an upload be?
What you are saying is "copy the spiking neural network architectures from a sufficient number of deceased high intelligence individuals", then "in a training process optimize the spiking neural network design to it's local minima", then have some kind of "committee" of uploaded beings and error checking steps in some kind of pipeline so that a single uploaded individual can't turn the planet into a dictatorship.
And once you really look at what kind of pipeline you would need to control these ASIs derived from deceased humans you realize....why did you need to start with humans at all?
Why not pick any neural network type that works - found by starting with the simplest network possible (see perceptrons and MLPs) and adding complexity until it works - and then pick the simplest cognitive architecture that works instead of the mess of interconnected systems the brain uses? Like fundamentally why is "spaghetti " more alignable than "network A generates a candidate output and network B checks for hostile language and network C checks for sabotaged code and network D checks for...." And then it's crucial to ensure A can't coordinate with (B, C, D...) to betray and leak unaligned outputs. This means you need very strong Isolation where A cannot communicate with the "checker" networks or manipulate their weights. Human brain is a mess of interconnects and indirect signaling, it is exactly the wrong architecture for generating clean, likely to be aligned outputs. See motivated cognition where a human does something irrational despite the human knowing the risks or probable outcome.
You also have the practical advantage with conventional AI research that it's much cheaper and faster to show results, which it has. Uploads require emulating most of the brain and a body as well.
And conventional AI will likely always be faster and more efficient. Compare a jet engine to a flapping bird...
Or "what is the probability that nature found the most efficient possible neural network architecture during evolution"?
Replies from: RussellThor↑ comment by RussellThor · 2024-01-06T19:45:58.037Z · LW(p) · GW(p)
Its that I and many others would identify with WBE and such a group of WBE much more than the more pure AI. If the WBE behaves like a human then it is aligned by definition to me.
If we believe AI is extreme power, we already have too much power, its all about making something we identify with.
Replies from: None↑ comment by [deleted] · 2024-01-06T23:10:44.759Z · LW(p) · GW(p)
I understand that. But inaccuracies in emulation, the effectively thousands of years (or millions) of lived experience a WBE will have. Neural patches and enhancements to improve performance.
You have built an ASI, just you have narrowed your architecture search from "any possible network the underlying compute can efficiently host" to a fairly narrow space of spaghetti messes of spiking neural networks that also have forms of side channel communications through various emulated glands and a "global" model for csf and blood chemistry.
So it's an underperforming ASI but still hazardous.
↑ comment by geoffreymiller · 2024-01-06T20:31:42.856Z · LW(p) · GW(p)
Human intelligence augmentation is feasible over a scale of decades to generations, given iterated polygenic embryo selection.
I don't see any feasible way that gene editing or 'mind uploading' could work within the next few decades. Gene editing for intelligence seems unfeasible because human intelligence is a massively polygenic trait, influenced by thousands to tens of thousands of quantitative trait loci. Gene editing can fix major mutations, to nudge IQ back up to normal levels, but we don't know of any single genes that can boost IQ above the normal range. And 'mind uploading' would require extremely fine-grained brain scanning that we simply don't have now.
Bottom line is, human intelligence augmentation would happen way too slowly to be able to compete with ASI development.
If we want safe AI, we have to slow AI development. There's no other way.
Replies from: GeneSmith, Darcy↑ comment by GeneSmith · 2024-01-07T01:24:09.960Z · LW(p) · GW(p)
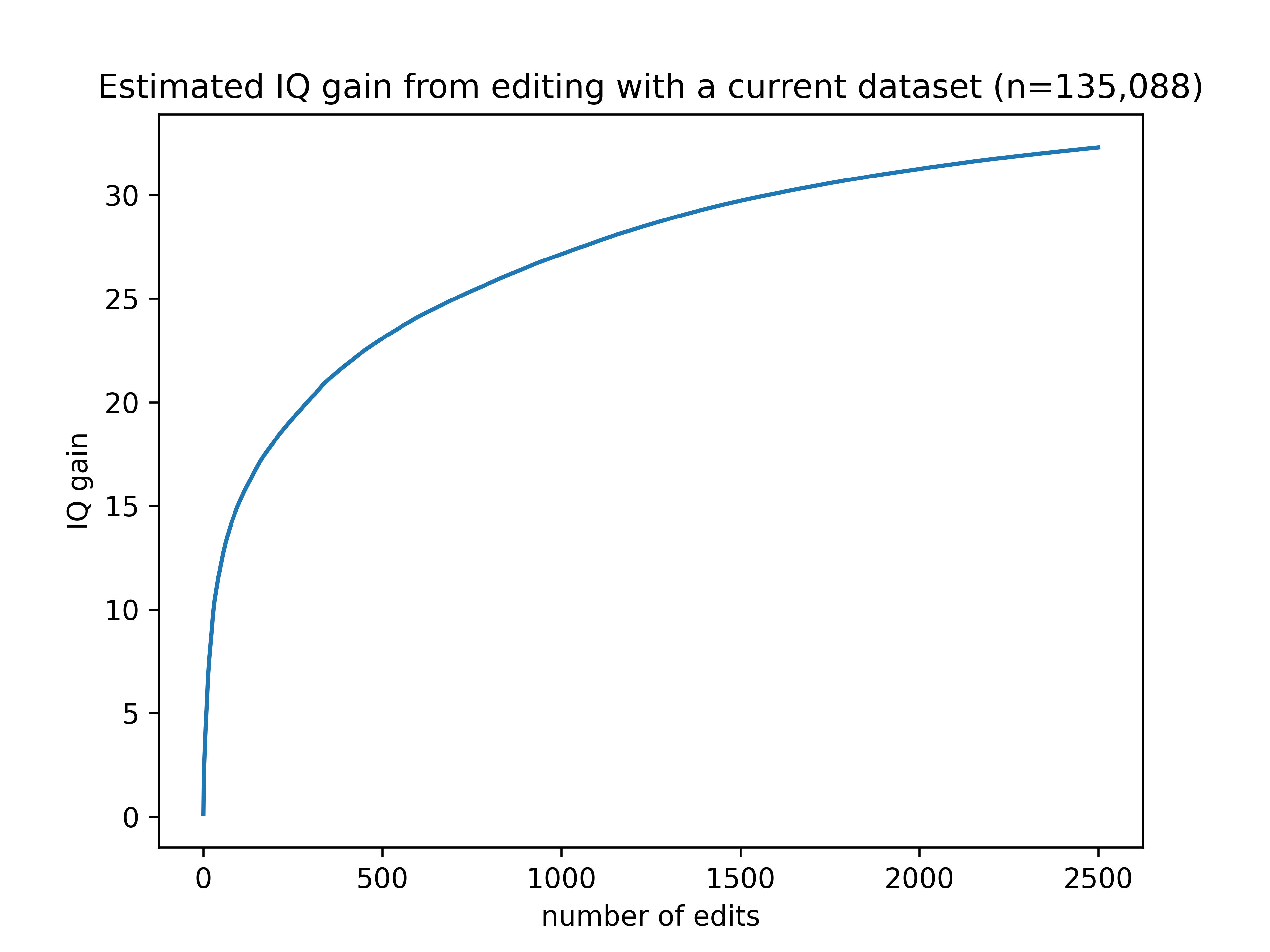
Gene editing can fix major mutations, to nudge IQ back up to normal levels, but we don't know of any single genes that can boost IQ above the normal range
This is not true. We know of enough IQ variants TODAY to raise it by about 30 points in embryos (and probably much less in adults). But we could fix that by simply collecting more data from people who have already been genotyped.
None of them individually have a huge effect, but that doesn’t matter much. It just means you need to perform more edits.
If we want safe AI, we have to slow AI development.
I agree this would help a lot.
EDIT: added a graph
↑ comment by Dalcy (Darcy) · 2024-01-06T22:03:15.761Z · LW(p) · GW(p)
I don't see any feasible way that gene editing or 'mind uploading' could work within the next few decades. Gene editing for intelligence seems unfeasible because human intelligence is a massively polygenic trait, influenced by thousands to tens of thousands of quantitative trait loci.
I think the authors in the post referenced [LW · GW] above agree with this premise and still consider human intelligence augmentation via polygenic editing to be feasible within the next few decades! I think their technical claims hold up, so personally I'd be very excited to see MIRI pivot towards supporting their general direction. I'd be interested to hear your opinions on their post.
comment by Wei Dai (Wei_Dai) · 2024-01-07T02:10:20.442Z · LW(p) · GW(p)
Nate and Eliezer both believe that humanity should not be attempting technical alignment at its current level of cognitive ability, and should instead pursue human cognitive enhancement (e.g., via uploading), and then having smarter (trans)humans figure out alignment.
When I argued for this [LW · GW] (in 2011 and various other times), the main crux of disagreement between me and MIRI was that I thought MIRI was overconfident in its ability to quickly solve both AI capabilities and AI alignment, and it looks to me now like it's probably overconfident again about alignment difficulty, and might be making strategic mistakes (e.g. about how much resources to spend on communicating what messages) due to such overconfidence.
I haven't read every word that MIRI has put out about alignment difficulty, and am not sure I correctly understood everything I did read, but on priors it seems unlikely that one can be so certain about how difficult alignment is this far ahead of time, and what I've read wasn't convincing enough to overcome this. (I'm willing to spend some more time on this if anyone wants to suggest articles for me to read or read again.) I also wrote down some explicit doubt [LW(p) · GW(p)] which remains unaddressed. (For reference my own credences are currently p(doom due to alignment failure) ≈ p(doom | AI alignment success) ≈ .5 where doom includes losing most of potential value not just extinction, which seem more than enough to justify something like an AI pause.)
I think it's good for MIRI (and people in general) to honestly report their inside views, but if they're thinking about strategically scaling up communications in a consequentialist effort to positively affect the future lightcone, they should consider the risk of being overconfident and the fact that any errors/mistakes in such large scale communications could affect AI safety as a whole (e.g., everyone calling for pause being tainted by association) rather than just their own credibility. (As well as "civilization [...] not able to tell whether or not alignment work is real or bogus" which Eliezer brought up and I emphasized in a previous comment [LW(p) · GW(p)].)
comment by mishka · 2024-01-05T03:36:39.050Z · LW(p) · GW(p)
One alternative, proposed by Nate, would be for researchers to stop trying to pursue de novo AGI, and instead pursue human whole-brain emulation or human cognitive enhancement.
There are a variety of underexplored approaches for human cognitive enhancement.
While none of them is risk-free or a priori guaranteed to work well, a number of these approaches look like they might be relatively inexpensive and fast to develop.
Is MIRI going to try to assist various exploratory work aimed at probing various underexplored approaches for human cognitive enhancement (at least probing those approaches which can be tried rapidly, inexpensively, and at acceptable levels of risk)?
Replies from: malo↑ comment by Malo (malo) · 2024-02-14T22:36:57.169Z · LW(p) · GW(p)
I’d certainly be interested in hearing about them, though it currently seems pretty unlikely to me that it would make sense for MIRI to pivot to working on such things directly as opposed to encouraging others to do so (to the extent they agree with Nate/EYs view here).
Replies from: mishkacomment by Chris_Leong · 2024-01-05T01:49:56.567Z · LW(p) · GW(p)
Nate and Eliezer both believe that humanity should not be attempting technical alignment at its current level of cognitive ability, and should instead pursue human cognitive enhancement (e.g., via uploading), and then having smarter (trans)humans figure out alignment.
It would be great if we were able to utilise cognitive enhancement in order to solve these problems.
On the other hand, I don't think we've tried the technique of "longer-term intensive program" to develop talent. As an example, it's very common for people to spend 3 or 4 years on a bachelors degree and another 2 years on a masters. Maybe we should try setting up a longer-term talent development program before throwing up our hands?
comment by cousin_it · 2024-01-05T01:19:30.970Z · LW(p) · GW(p)
I think humanity shouldn't work on uploading either, because it comes with very large risks that Sam Hughes summarized as "data can't defend itself". Biological cognitive enhancement is a much better option.
Replies from: Wei_Dai, interstice, vanessa-kosoy, Lichdar↑ comment by Wei Dai (Wei_Dai) · 2024-01-05T03:10:31.076Z · LW(p) · GW(p)
To save other people the trouble, I'll note here that I managed to figure out that "data can’t defend itself" is a line in Sam's novel Ra, and got Bing Chat (GPT-4) to explain its meaning:
The phrase “data can’t defend itself” is said by Adam King, one of the characters in the web page, which is a part of a science fiction novel called Ra. King is arguing with his daughter Natalie, who wants to send the human race into a virtual reality inside Ra, a powerful artificial intelligence that is consuming the Earth. King believes that reality is the only thing that matters, and that data, or the information that represents the human minds, is vulnerable to manipulation, corruption, or destruction by Ra or other forces. He thinks that by giving up their physical existence, the humans are surrendering themselves to a fate worse than death. He is opposed to Natalie’s plan, which he sees as a betrayal of the real world that he fought to defend.
This does not clearly parallel the proposed plan of creating uploads before other forms of AI, so I guess cousin_it is referring to the general vulnerability of uploads to abuse?
Replies from: SaidAchmiz, cousin_it, rossry↑ comment by Said Achmiz (SaidAchmiz) · 2024-01-05T05:17:55.906Z · LW(p) · GW(p)
Replies from: KaynanK↑ comment by Multicore (KaynanK) · 2024-01-05T14:20:07.301Z · LW(p) · GW(p)
Though see also the author's essay "Lena" isn't about uploading.
↑ comment by cousin_it · 2024-01-05T10:43:27.624Z · LW(p) · GW(p)
Yeah. If you're an upload, the server owner's power over you is absolute. There's no precedent for this kind of power in reality, and I don't think we should bring it into existence.
Other fictional examples are the White Christmas episode of Black Mirror, where an upload gets tortured while being run at high speed, so that in a minute many years of bad stuff have happened and can't be undone; and Iain Banks' Surface Detail, where religious groups run simulated hells for people they don't like, and this large scale atrocity can be undetectable from outside.
↑ comment by rossry · 2024-01-05T04:14:05.365Z · LW(p) · GW(p)
(Severe plot spoilers for Ra.)
It's even less apt than that, because in the narrative universe, the human race is fighting a rearguard action against uploaded humans who have decisively won the war against non-uploaded humanity.
In-universe King is an unreliable actively manipulative narrator, but even in that context, his concern is that his uploaded faction will be defenseless against the stronger uploaded faction once everyone is uploaded. (Not that they were well-defended in the counterfactual, since, well, they had just finished losing the war.)
I am curious how cousin_it has a different interpretation of that line in its context.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-01-05T18:17:34.836Z · LW(p) · GW(p)
Please remove the spoilers or use spoiler text?
Replies from: rossry↑ comment by rossry · 2024-01-07T18:48:23.971Z · LW(p) · GW(p)
Apparently the forum's markdown implementation does not support spoilers (and I can't find it in the WYSIWIYG editor either).
I'm sympathetic to spoiler concerns in general, but where the medium doesn't allow hiding them, the context has focused on analysis rather than appreciation, and major related points have been spoiled upthread, I think the benefits of leaving it here outweigh the downsides.
I've added a warning at the top, and put in spoiler markdown in case the forum upgrades its parsing.
Replies from: ryan_greenblatt, T3t↑ comment by ryan_greenblatt · 2024-01-07T19:00:24.839Z · LW(p) · GW(p)
It should support spoilers [? · GW]
My spoiler
↑ comment by RobertM (T3t) · 2024-01-08T04:19:46.438Z · LW(p) · GW(p)
Here's [? · GW] the editor guide section for spoilers. (Note that I tested the instructions for markdown, and that does indeed seem broken in a weird way; the WYSIWYG spoilers still work normally but only support "block" spoilers; you can't do it for partial bits of lines.)
In this case I think a warning at the top of the comment is sufficient, given the context of the rest of the thread, so up to whether you want to try to reformat your comment around our technical limitations.
↑ comment by interstice · 2024-01-05T04:30:28.154Z · LW(p) · GW(p)
Given that uploads may be able to think faster than regular humans, make copies of themselves to save on cost of learning, more easily alter their brains, etc., I think it's more likely that regular humans will be unable to effectively defend themselves if a conflict arises.
↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2024-01-05T15:12:52.414Z · LW(p) · GW(p)
It is tricky, but there might be some ways [LW · GW] for data to defend itself.
Replies from: cousin_it↑ comment by cousin_it · 2024-01-05T21:05:51.299Z · LW(p) · GW(p)
Sure, in theory you could use cryptography to protect uploads from tampering, at the cost of slowdown by a factor of N. But in practice the economic advantages of running uploads more cheaply, in centralized server farms that'll claim to be secure, will outweigh that. And then (again, in practice, as opposed to theory) it'll be about as secure as people's personal data and credit card numbers today: there'll be regular large-scale leaks and they'll be swept under the rug.
To be honest, these points seem so obvious that MIRI's support of uploading makes me more skeptical of MIRI. The correct position is the one described by Frank Herbert: don't put intelligence in computers, full stop.
↑ comment by Lichdar · 2024-01-07T22:10:55.174Z · LW(p) · GW(p)
I generally feel that biological intelligence augmentation, or a biosingularity is by far the best option and one can hope such enhanced individuals realize to forestall AI for all realistic futures.
With biology, there is life and love. Without biology, there is nothing.
comment by otto.barten (otto-barten) · 2024-01-10T13:42:51.732Z · LW(p) · GW(p)
Congratulations on a great prioritization!
Perhaps the research that we (Existential Risk Observatory) and others (e.g. Nik Samoylov, Koen Schoenmakers) have done on effectively communicating AI xrisk, could be something to build on. Here's our first paper and three [EA · GW] blog [EA · GW] posts [EA · GW] (the second includes measurement of Eliezer's TIME article effectiveness - its numbers are actually pretty good!). We're currently working on a base rate public awareness update and further research.
Best of luck and we'd love to cooperate!
comment by trevor (TrevorWiesinger) · 2024-01-05T01:58:40.630Z · LW(p) · GW(p)
For example, we were positively surprised by the reception to... his March piece in TIME magazine [LW · GW] (which was TIME’s highest-traffic page for a week).
THIS is what real social media/public opinion research looks like.
Not counting likes. Not scrolling down your social media news feed and recording the results in a spreadsheet. Not approaching it from a fancy angle like searching "effective altruism" on Twitter and assuming that you are capable of eyeballing bot accounts. Certainly not building your own crawler, which requires you to assume that the platform's security teams can't see it from a mile away and already set it automatially to generate false data for every account that doesn't perfectly mimic human scrolling.
In the 2020s, real public opinion research requires awareness that if you want to understand how Americans think, you have to recognize that you are competing against domestic and foreign intelligence agencies, running their own botnets to evade detection, get that data, and detect enemy botnets. It's not an issue at all if you're doing paper surveys, and has historically been the dominating factor if facebook-sized orgs are involved.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2024-01-05T14:32:47.552Z · LW(p) · GW(p)
To the people who downvoted with no explanation: why?
Issues related measuring public opinion are now revealed to be extremely worth thinking about, especially when it comes to data science in the 21st century, and I've been researching this matter professionally for years.
I think it's worth pointing out that MIRI has succeeded at getting relatively strong internet-related impact data, while many otherwise-competent orgs and people have failed, and also pointing out why this is the case.
Replies from: taymon-beal↑ comment by Taymon Beal (taymon-beal) · 2024-01-05T18:46:01.894Z · LW(p) · GW(p)
I didn't downvote (I'm just now seeing this for the first time), but the above comment left me confused about why you believe a number of things:
- What methodology do you think MIRI used to ascertain that the Time piece was impactful, and why do you think that methodology isn't vulnerable to bots or other kinds of attacks?
- Why would social media platforms go to the trouble of feeding fake data to bots instead of just blocking them? What would they hope to gain thereby?
- What does any of this have to do with the Social Science One incident?
- In general, what's your threat model? How are the intelligence agencies involved? What are they trying to do?
- Who are you even arguing with? Is there a particular group of EAsphere people who you think are doing public opinion research in a way that doesn't make sense?
Also, I think a lot of us don't take claims like "I've been researching this matter professionally for years" seriously because they're too vaguely worded; you might want to be a bit more specific about what kind of work you've done.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2024-01-05T19:09:52.980Z · LW(p) · GW(p)
why do you think that methodology isn't vulnerable to bots or other kinds of attacks?
Ah, yes, I thought that methodology wasn't vulnerable to bots or other kinds of attacks because I was wrong. Oops. Glad I asked.
For the other stuff, I've explained it pretty well in the past but you're right that I did an inadequate job covering it here. Blocking bots is basically giving constructive feedback to the people running the botnet (since they can tell when bots are blocked), on how to run botnets without detection; it's critical to conceal every instance of a detected bot for as long as possible, which is why things like shadowbanning and vote fuzzing are critical for security for modern social media platforms. This might potentially explain why amateurish bots are so prevalent; state-level attackers can easily run both competent botnets and incompetent botnets simultaneously and learn valuable lessons about the platform's security system from both types of botnets (there's other good explanations though). Not sure how I missed such a large hole in my explanation in the original comment, but still, glad I asked.
Replies from: taymon-beal↑ comment by Taymon Beal (taymon-beal) · 2024-01-07T12:51:45.282Z · LW(p) · GW(p)
Does that logic apply to crawlers that don't try to post or vote, as in the public-opinion-research use case? The reason to block those is just that they drain your resources, so sophisticated measures to feed them fake data would be counterproductive.
comment by Prometheus · 2024-03-02T20:43:20.925Z · LW(p) · GW(p)
MIRI "giving up" on solving the problem was probably a net negative to the community, since it severely demoralized many young, motivated individuals who might have worked toward actually solving the problem. An excellent way to prevent pathways to victory is by convincing people those pathways are not attainable. A positive, I suppose, is that many have stopped looking to Yudkowsky and MIRI for the solutions, since it's obvious they have none.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2024-03-02T20:58:24.248Z · LW(p) · GW(p)
But it seems like a good thing to do if indeed the solutions are not attainable.
Anyway, this whole question seems on the wrong level analysis. You should do what you think works, not what you think doesn't work but might trick others into trying anyway.
Added: To be clear I too found MIRI largely giving up on solving the alignment problem demoralizing. I'm still going to keep working on preventing the end of the world regardless, and I don't at all begrudge them seriously trying for 5-10 years.
comment by Review Bot · 2024-03-01T23:39:18.058Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?