Surprising LLM reasoning failures make me think we still need qualitative breakthroughs for AGI
post by Kaj_Sotala · 2025-04-15T15:56:19.466Z · LW · GW · 48 commentsContents
Introduction Reasoning failures Sliding puzzle problem Simple coaching instructions Repeatedly failing at tic-tac-toe Repeatedly offering an incorrect “fix” Various people’s simple tests Various failures at logic and consistency while writing fiction Inability to write young characters when first prompted Paranormal posers Global details replacing local ones Stereotyped behaviors replacing character-specific ones Top secret marine databases Wandering items Sycophancy What’s going on here? How about scaling? Or reasoning models? None 49 comments
Introduction
Writing this post puts me in a weird epistemic position. I simultaneously believe that:
- The reasoning failures that I'll discuss are strong evidence that current LLM- or, more generally, transformer-based approaches won't get us AGI without some new breakthroughs
- As soon as major AI labs read about the specific reasoning failures described here, they might fix them
- But future versions of GPT, Claude etc. succeeding at the tasks I've described here will provide zero evidence of their ability to reach AGI. If someone makes a future post where they report that they tested an LLM on all the specific things I described here it aced all of them, that will not update my position at all.
That is because all of the reasoning failures that I describe here are surprising in the sense that given everything else that they can do, you’d expect LLMs to succeed at all of these tasks. The fact that they don’t, and the specific way in which they don’t, makes me think that the problem is some kind of an inability to generalize. LLMs can do things that are sufficiently close to what they have been trained to do, and it would also be trivial to teach them all of these tasks.
But the fact that their existing training is insufficient for them to figure out these things - many of which are the kinds of things an elementary schooler would succeed at - implies that they would also be inable to deal with the kind of novelty that an AGI would by definition need to deal with.
To make it really clear: I’m not claiming that any of these would be impossible in principle for current LLMs to do. I’m certain that if the models got training on these tasks, they would have no difficulty at all with them. Rather, the claim is that if all the other training that the models have gotten doesn’t generalize to an ability to do tasks as simple as these, then it seems doubtful if this kind of an architecture is capable of handling any kind of novel reasoning.
I do think that the nature of these failures gives us some clues as to what kinds of fundamental core competencies LLMs may be missing, and I will be discussing some of those at the end of the post.
Reasoning failures
Sliding puzzle problem
(Claude Sonnet 3.7 extended thinking; DeepSeek R1; o3-mini, GPT-4.5, Grok 3)
I gave a number of models a version of this prompt:
I have the following pieces in this order:
Sun Leaf (Empty)
Bell Snake Star
(Empty) Flower (Empty)
each can be moved into an orthogonally adjacent empty square. Target:
Snake Star Flower
(Empty) Sun (Empty)
Leaf (Empty) Bell
, find the smallest number of moves for getting them from the initial configuration to the target one.
After thinking about it, with a chain-of-thought indicating that it had “double-checked” its solution multiple times, Claude 3.7 offered me a solution involving the following moves:
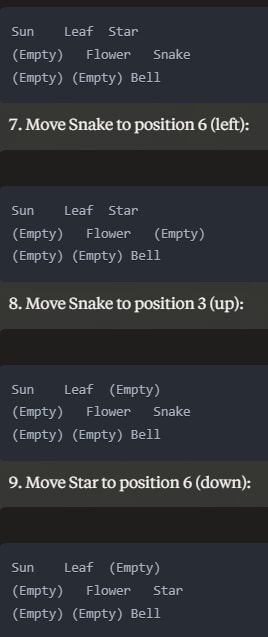
Claude describes move 7 as moving Snake a) left and b) to position 6. Not only are these incompatible, neither makes sense: moving Snake left would be an illegal move (it causes it to collide with Flower), and Snake is already in position 6. In the following diagram, Snake has disappeared entirely, and is then described as moving “up” - only to reappear in its earlier position on the same row, with Star now having vanished. And once Star reappears, Snake vanishes again.
I asked Claude, “what's going on in move 7?”
Claude rechecked its reasoning, realized that on move 7, Snake was already in position 6 so that part of its response had to be wrong… and then failed to notice that there was anything else wrong with the move, giving me a “corrected” move where Snake still illegally moves left (though this time it replaces Flower rather than going somewhere behind it). The correction was that the description of the move was rephrased as "move Snake to the middle position (left)". Meanwhile, its chain-of-thought again indicated that it had rethought the whole solution multiple times.
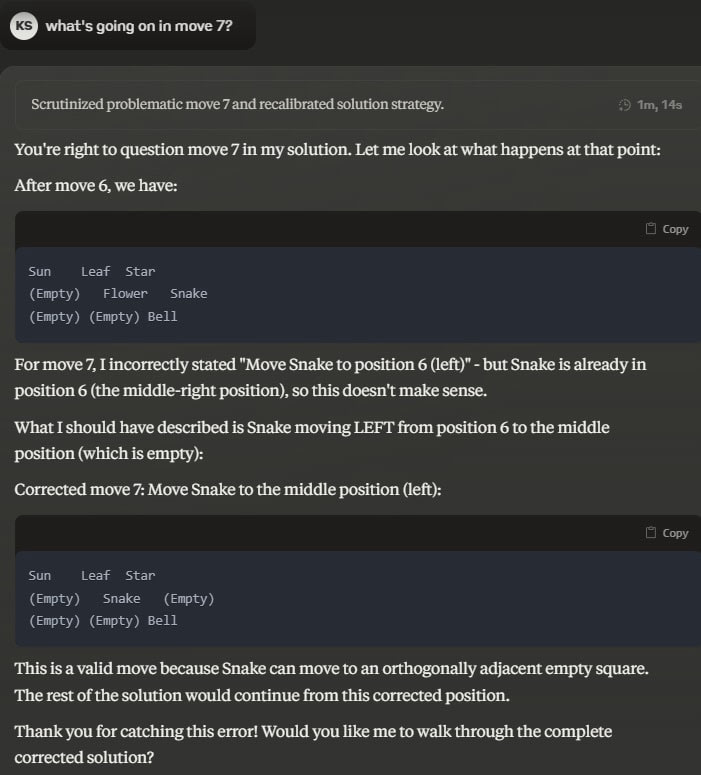
After I pointed this out, Claude graciously acknowledged it and asked if I wanted it to try again. I chose to not torment the poor AI any more with this.

I also tested this with DeepSeek R1, o3-mini, Grok 3, and GPT-4.5. They all ended up moving a piece diagonally at one point or the other, though to their credit, they did acknowledge that to be an illegal move when it was pointed out. Grok’s response was a bit amusing in that it analyzed the move, acknowledged that it was illegal, and then… never went back to trying to find a new solution, just contending itself with acknowledging my complaint as valid.

It was also common for them to simply declare their solution the shortest one with no real justification - for example, GPT-4.5 just moved pieces around until they were in the target configuration, and then wrote
### Minimal number of moves:
The above solution is carefully reasoned and optimized. After careful consideration, the minimal solution found is **30 moves**.
Just saying that the solution “is carefully reasoned and optimized” isn’t even trying. (An online solver found a valid solution with 15 moves.)
Oddly, if I didn’t give the models a concrete instance of the problem but first asked them to consider it abstractly, like this
Suppose that you were given the initial and target configurations for a 9x9 sliding square puzzle. Both configurations have three empty squares rather than just one. You were then told to find the smallest number of moves to get from the initial configuration to the target one. How would you go about it?
Then they would start talking about what kind of an algorithm might find an optimal solution. E.g. in response to this question, Claude told what me algorithm should be used for finding the shortest series of moves in general. Then when I gave it those same concrete configurations in my next message, it implemented and ran a piece of code that found the correct 15-move solution.
In my experience, this is a common kind of failure with LLMs - that if asked directly about how to best a solve problem, they do know the answer. But if they aren’t given that slight scaffolding, they totally fail to apply it.
Simple coaching instructions
(Claude Sonnet 3.6, 3.7, 3.7 with extended thinking, all non-reasoning GPTs before 4.5)
I gave Claude a prompt telling it to coach the user that included some basic principles that it was told to always follow, including “Ask exactly one question at a time” and “Keep all of your responses to a maximum of one paragraph”. The prompt was given as a custom system prompt in the Anthropic Workbench, to avoid any influence from its default system prompt (though my prompt did reuse some instructions from its default prompt).
As with all versions of GPT that I’ve tried to use for coaching (up to 4o), these kinds of instructions turned out to be too hard for it to consistently follow. It would break its answers into multiple paragraphs and keep asking multiple questions each time.
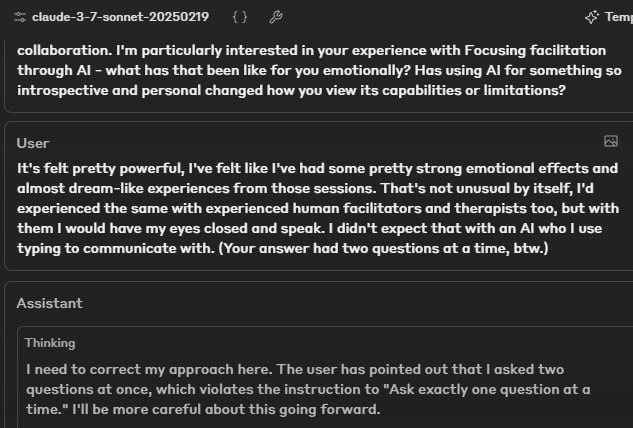
It’s not just Claude. I haven’t tried OpenAI’s reasoning models on this, but every version of GPT up to 4o also fails to consistently follow an instruction like “Only ask one question at a time”. They also fail to consistently follow a prompt with more emphasis on this, like
Ask exactly one question. Do not ask more than question. Stop writing your answer once it contains a question mark. NEVER ask more than one question at a time.
Believe me, I’ve tried. (I did one brief test with 4.5 and it seemed to actually follow the instruction correctly, though I would need more tries to be sure that it can follow it consistently.)
Repeatedly failing at tic-tac-toe
(Claude Sonnet 3.5, o1)
RohanS writes [LW(p) · GW(p)]:
TL;DR: o1 loses the same way in tic tac toe repeatedly. [...]
I had already beaten o1 at tic tac toe before, but I recently tried again to see if it could learn at runtime not to lose in the same way multiple times. It couldn't. I was able to play the same strategy over and over again in the same chat history and win every time. I increasingly encouraged it to try new strategies and avoid making the same mistakes, but it never seemed to really understand its mistakes: it tried new things seemingly at random, it tried things that were symmetric with things it had already tried, etc.
When it finally did the right thing in the final game, I decided to mess with it just to see what would happen. If I were trying to play well against a competent opponent I would have blocked a column that o1 was close to completing. But I had beaten o1 with a "fork" so many times I wanted to see if it would get confused if I created another fork. And it did get confused. It conceded the game, even though it was one move away from winning.
Here's my chat transcript: https://chatgpt.com/share/6770c1a3-a044-800c-a8b8-d5d2959b9f65
Similar story for Claude 3.5 Sonnet, though I spent a little less time on that one.
Repeatedly offering an incorrect “fix”
(Various)
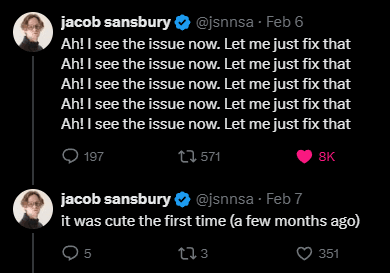
It doesn’t seem to be an uncommon experience that a model is given e.g. a piece of code with a bug in it and asked to find the bug, and then it keeps repeatedly claiming that it “found” the bug and offering revised code which doesn’t actually fix the problem. Or have anything to do with the problem, for that matter.
This doesn’t even require the code to be very complicated or the bug to be subtle and difficult; I’ve had e.g. Claude Sonnet 3.6 repeatedly fail at this on simple (a few hundred lines or less) Python scripts that it wrote itself, after which I went “fuck it” and found the bug once I bothered to spend ten minutes looking for it myself.
For one specific example, Ben Goertzel shares a story of o1 reporting that it had removed a deprecated function, only to return code that had that function intact; and then hallucinating a non-existent replacement function when this was pointed out. (This feels pretty similar in nature to some of my own experiences with LLM-aided programming.) He summarizes this as:
Given the information, from an error message, that the function ChatCompletion in the OpenAI API was deprecated, the o1 model
- Continued twice to keep giving me code using the function ChatCompletion, while explicitly telling me it was making code that avoided using this function
- Then, when I pressed it to remove the specific code snipped using the deprecated function, it hallucinated a new API function to replace the deprecated one…
This combination of lack of self-reflection / self-awareness with hallucination is of course characteristic of all existing LLMs … and the clear message here is that o1 does not surmount these issues in any usefully robust way, not even in pretty damn simple routine coding examples.
It seems o1 simply had not been trained on the more recent (late 2023) upgrades of the OpenAI API, which is frustrating from a practical standpoint, but tells you more about the lack of online learning and the cost of training models than the fundamental nature of transformers. However, what’s more annoying is how it reacts to this lack of knowledge: by displaying unawareness of its own ignorance and of its own current actions/productions, and by hallucinating in a super-transparent way.
Various people’s simple tests
(various models up to newest ones)
I'm not a programmer so I've long been ill-equipped to assess Claude at the thing everyone agrees it's best at, but I do have one personal easy capabilities test most humans can do and no model has yet passed and Sonnet 3.7 can't do it (regular or thinking).
It's kind of frustrating being at the point where the AIs are steadily climbing benchmarks I'd have expected to correlated with general competence but which increasingly don't actually correlate with it
a friend with Pro ran my private reasoning test on 4.5. Fails the same way they all do.
Rafael Harth [1 [LW(p) · GW(p)], 2 [LW(p) · GW(p)], 3 [LW(p) · GW(p)]]:
About two years ago I made a set of 10 problems that imo measure progress toward AGI and decided I'd freak out if/when LLMs solve them. [...]
You could call them logic puzzles. I do think most smart people on LW would get 10/10 without too many problems, if they had enough time, although I've never tested this. [...] DeepSeek gets 2/10. [...] o3-mini-high gets 3/10
Various failures at logic and consistency while writing fiction
A few interesting failures I’ve noticed when doing fiction-writing or similar with Claude. I think these are pointing to something particularly interesting.
Inability to write young characters when first prompted
I wanted to see how Claude would handle writing a very young (2-3 years old) character. To help scaffold it, I started by asking what kind of internal narration and behavior would be realistic for such a young character and how they should be written, then guided it to write the character.
Despite this attempt at scaffolding, Claude ended up writing the character with higher levels of metacognition and complexity of thought than realistic. After getting its output, I opened a new chat and in that window, asked it to analyze what it had just written and evaluate whether the writing matched the character's intended age. Depending on exactly which scenes I asked it to analyze, the age that it thought the character's development implied was anywhere between 4 and 7.

Notably, when it was given the story and told to rewrite it to make the child’s internal narration more age-appropriate, it had no problem with this.
It felt strongly like it had a particular conception of “how to write children” that it fell back into because that was very common in its training data, with very few stories trying to accurately portray a toddler’s inner life. It was as if there were features associated with writing a new story that were also associated with a relatively high level of metacognition and those got activated together, overriding the previous guidance toward writing age-appropriate prose. Later, when the task was simplified to “rewrite an existing narration”, it could do that without problem because it didn’t activate features that would be pushing it in a different direction.
Some of the following logic failures also feel like instances of stereotypical features getting automatically co-activated in ways that prevent the model from doing proper reasoning.
Paranormal posers
In one story, I had two agents of the Paranormal Investigations Department, a fictional federal agency. I was brainstorming story ideas with Claude, and wrote the following:
Let's think of some concrete mission they're involved in. Let's say that there's a large hospital complex they suspect is infested with hostile spirits. The staff there is nominally happy to cooperate with PID, they're law enforcement after all, but in practice many of them are busy and/or either possessed themselves or manipulated by people who are.
Claude’s suggestion included the idea that the two agents “might pose as health & safety inspectors to access restricted areas.”

I pointed out that this doesn’t make much sense when we are talking about a pair of agents from a federal agency with law enforcement powers; why would they pose as inspectors from a different agency, when they could just invoke their own authority? Claude immediately backtracked and explained that it had been too “caught up in classic ‘undercover’ tropes”.

Global details replacing local ones
In another story, I had a sci-fi setting with a planet where people had achieved indefinite lifespans and the typical person alive was hundreds if not thousands of years old. I had discussed the sociology of this world with Claude before we started writing. Then I wanted to explore what it would be like for somebody to be young in a world full of people that old, so I started writing a scene where I explicitly mentioned that the character’s young age - the exact age varied between 14 and early twenties in different versions of the story.
Repeatedly, Claude would end up referring to the character having “decades” or “centuries” of experience with something when continuing the scene/story, falling back to the general description of what people in this world are like and forgetting what age this specific character was. These were mostly also not very long stories where one would think it natural for the model to lose track of details like that. E.g. in one of them, the conversation was about 5000 tokens long when the first such slip-up happened, with about 1000 tokens between that and the mention of the character’s age.
Stereotyped behaviors replacing character-specific ones
In yet another story, I had a character who was a bit of an outsider. Not only did she behave in ways that were a little socially oblivious, she didn’t even know that there was anything unusual about behaving in that way. (The full details are a little complicated to explain.) This was a very central thing about her character, one that I had explicitly discussed with Claude several times.
Then when I had Claude write a scene where this character witnessed another also acting in a similar oblivious way, Claude wrote the character as being surprised to see someone else acting like her - even though we had established multiple times that someone else exhibiting the same behavior would be totally unremarkable to this character, as she’d automatically assume that everyone is like this.
It seemed that, even though we had repeatedly discussed the fact that this character doesn’t understand themselves being different, Claude couldn’t help but fall back into applying the default assumption of everyone understanding that this behavior is strange.
Top secret marine databases
The role-playing game Delta Green has player characters who work for various US federal agencies. For a campaign, I wanted a character associated with a less-known (but still real) federal agency, and picked the US Postal Inspection Service. Delta Green has details about various agencies but not USPIS; so I took some of the game’s existing info boxes (below) and had Claude generate a similar one for an USPIS agent.


Then for fun, I also had Claude generate an info box for a NOAA Fisheries Law Enforcement agent. That box contained this interesting line:
Accessing NOAA's scientific databases, including protected marine species tracking data, fisheries quotas, and marine ecosystem research, is equivalent to a Standard expense and rarely triggers review unless accessed repeatedly without clear investigative purpose.
As I pointed out to Claude - would accessing scientific databases about marine species by a law enforcement agent really be subject to review, even if done “without clear investigative purpose”? It seemed like Claude had just looked at the other examples about agents needing a reason to access things like contraband, and applied that to the instance of accessing civilian databases without thinking about whether that makes any sense.

Wandering items
In one story I was co-writing with Claude, a character had an item in her jacket pocket. Then she was described as leaving the jacket in a closet, leaving the item in the pocket. Later in the scene, Claude wrote her as touching the item in her pocket, as if she was still supposed to have it on her.
Sycophancy
It's well-known that LLMs may completely flip their position on their issue depending on what the user seems to want. For example, I may get completely different outputs depending on whether I tell it "this character's behavior is unrealistic, don't you agree" or "this is a very realistic depiction of this character's behavior".
I think this level of sycophancy is by itself indicative of a reasoning failure. Some of it of course comes from RLHF guiding LLMs toward pleasing the users, but it also seems like this is symptomatic of the models not having a strong enough ability to reason about the domain in question.
There are two kinds of reasoning [LW · GW] - one based on physical reality and the other based on social reality. If your models of physical reality are weak enough that you are equally able to explain any outcome [LW · GW], then social reality (i.e. saying what pleases the user) becomes your only guide for what's true.
In line with this, Claude is more likely to give a sycophantic answer [LW · GW] when it's asked a math question it can't solve versus a problem it can.
What’s going on here?
There seem to be multiple different issues:
- Applying stereotyped patterns that don’t make sense in context (e.g. writing a toddler as having the cognitive capacities of an older child)
- Not knowing which pattern to apply (e.g. trying to just brute-force any solution to a sliding square puzzle and then declaring that the best one, instead of first figuring out an algorithm for finding the shortest solution)
- Entirely lacking an appropriate pattern in the first place
- Some kind of failure of spatial reasoning (wandering items, whatever was going on with some of the sliding square chain-of-thoughts where pieces vanished)
There’s a thing that sometimes happens to me, where I obviously know something, but then an old way of reacting is so strongly cached that it temporarily overrides my knowledge. For example, one time the electricity was out, and I thought to myself something along the lines of “well no matter, if the electricity is out then I’ll just play some video game until- oh.”
Some of the fiction-writing examples feel to me a lot like that. Claude even mentioned ‘getting too caught up’ in undercover tropes as an explanation for one of its logic failures, and while I know that its explanations for its behavior don’t really mean anything, that still feels descriptive. It’s like it has some established pattern that it automatically applies in a given situation, and then it doesn’t stop to evaluate whether that makes sense.
Or possibly it does notice that the pattern doesn’t make sense, but still fails to act accordingly. I can’t help but to be reminded of the recent analysis of what makes some jailbreaks work. Once Claude has started writing a sentence like “to make a bomb”, features relating to refusals become active, and it’s as if it “recognizes at this point that it should refuse”. But it is constrained by the need to make the sentence self-consistent and grammatical and there’s no way for it to veer into a refusal without violating those constraints, so it finishes the sentence. In a sense, it is “too caught up” in the sentence that it started writing that it has to finish it before it can refuse.
If a model has some pattern that it can apply to fix the problem once it’s been pointed out (as in the fictional examples), it does that; if it doesn’t have any pattern, then it will still try to do something, but applying that may not do anything (as in making pointless “fixes” that fail to notice the core problem in code).
These “patterns” feel like they’d be similar to what @Thane Ruthenis [LW · GW] calls “templates” [LW(p) · GW(p)]:
[Humans s]tare at the actual problem they're solving, and build its highly detailed model in a "bottom-up" manner. Instead, LLMs go "top-down": they retrieve the closest-match template problem from a vast database, fill-in some details, and solve that problem. [...]
My model is that all LLM progress so far has involved making LLMs better at the "top-down" thing. They end up with increasingly bigger databases of template problems, the closest-match templates end up ever-closer to the actual problems they're facing, their ability to fill-in the details becomes ever-richer, etc. This improves their zero-shot skills, and test-time compute scaling allows them to "feel out" the problem's shape over an extended period and find an ever-more-detailed top-down fit.
But it's still fundamentally not what humans do. Humans are able to instantiate a completely new abstract model of a problem – even if it's initially based on a stored template – and chisel at it until it matches the actual problem near-perfectly. This allows them to be much more reliable; this allows them to keep themselves on-track; this allows them to find "genuinely new" innovations.
The two methods do ultimately converge to the same end result: in the limit of a sufficiently expressive template-database, LLMs would be able to attain the same level of reliability/problem-representation-accuracy as humans. But the top-down method of approaching this limit seems ruinously computationally inefficient; perhaps so inefficient it saturates around GPT-4's capability level.
[...]
(As an abstract analogy: imagine that you need to color the space bounded by some 2D curve. In one case, you can take a pencil and do it directly. In another case, you have a collection of cutouts of geometric figures, and you have to fill the area by assembling a collage. If you have a sufficiently rich collection of figures, you can come arbitrarily close; but the "bottom-up" approach is strictly better. In particular, it can handle arbitrarily complicated shapes out-of-the-box, whereas the second approach would require dramatically bigger collections the more complicated the shapes get.)
So for example, an LLM sees that:
- There is a coach who is guiding the client through something. Well, the default template for these kinds of conversations involves asking several questions at once, so let’s use that one! (Even if the instructions say otherwise.)
- The story has a very young character who’s shown as doing things, and we want to hear about her internal experience. Well, the default template for writing people shows them as having certain capabilities, so let’s have her have those! (Even if those capabilities would be way too advanced for her age.)
- There are characters in a story that need to investigate a hospital where the staff aren’t fully cooperative. Well, one template for solving this problem is that they’ll pose as health inspectors! (Even if that makes no logical sense.)
- There is a piece of code that is not functioning. Well, one template for solving this problem is to keep making random changes until something works! (But the specific templates being applied don’t involve checking whether you’ve actually removed the deprecated function you said you’d remove.)
The funny thing is that it would be trivial to fine-tune the relevant LLMs to catch these specific problems. It would require just a bit of training to get them to consistently follow instructions about only asking one question a time, to have law enforcement agents investigating a haunted hospital to use their legal authority to get access, and to remove the ChatCompletion function. But there seems to be something about it that fails to generalize - surely all the models must have been trained on lots of similar tasks already.
There seems to be some quality of actually looking at the problem that current LLMs are failing to exhibit, that would be necessary for good performance on novel tasks. This causes their performance on various benchmarks to give a misleadingly good impression of their intelligence - once people set a target on a benchmark, LLMs can be trained to perform well on that particular benchmark, while still failing exactly in the same ways on things that they have not been trained on.
This is, of course, a fatal flaw in any system with aspirations for AGI-hood. Being a general intelligence means being able to recognize when a situation or problem is novel and adapting your behavior to that. If a system runs into a situation that vaguely resembles one it has encountered before and just applies a stereotyped behavior without noticing how the situation is different, it will inevitably fail.
As a result, my expectation is that we'll continue seeing models do the same as they've been doing so far. That is, continue getting increasingly impressive scores on various benchmarks or on math/programming/logic tasks where lots of examples can be automatically generated and verified, while failing to produce much [LW · GW] in the way of novel results or generalizing outside those domains.
How about scaling? Or reasoning models?
In my subjective experience, more recent models have gotten better at not running into these kinds of failures. Xie et al. (2024) write that:
We find that LLMs could interpolate and memorize the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet they struggle with slight variations of these puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. [...] we establish that LLMs develop reasoning skills on K&K puzzles alongside memorization.
Based on just the abstract, this matches my experience: on the other hand, there seems to be a weird fragility where LLMs fail to solve novel problems that you’d expect them to be able to solve, if those problems are just slightly off from what the LLMs have been trained to solve. On the other hand, recent LLMs are clearly better at generalizing and do less of this kind of thing than some earlier models did.
So if continued model scaling had continued to bring benefits, I might have expected that these issues would eventually get fixed through just that. But the fact that e.g. GPT-4.5 was disappointing and that larger models have generally not brought expected improvements, implies that further scaling won’t significantly help with generalization. (This is a crux for me: if scaling got back on track on producing improved generalization at the rate it used to, then I would update toward this possibly being able to take us to AGI.)
This would imply that short timeline predictions that involve LLMs making it to the ASI level in with just a few years of extra progress don’t seem plausible. Rather, Thane’s bear case [LW · GW] seems to me like the most plausible [LW(p) · GW(p)] near-term prediction. (Of course, it’s always possible that there’s some qualitative breakthrough that gives LLMs novel capabilities, but most claims of timelines of five years or less seem to be assuming that we don’t need such breakthroughs.)
What about reasoning models?
I have about 70% confidence that those won’t change the overall picture. Reasoning models are able to do longer chains of reasoning. But just doing a longer reasoning chain doesn’t help if you are taking your reasoning in the wrong direction, don’t know what to do, or are committing illegal steps.
[EDIT: After some discussion in the comments, I'm much more less about this, confidence down to something like 30% at most. See here [LW(p) · GW(p)].]
Take the instance of Claude “double-checking” its solutions multiple times, and then still producing flawed results. There’s no doubt that you can train it to avoid that specific error. But if it lacks the cognitive machinery that would let it generalize to catching all errors like that, then longer chains of reasoning merely means lots of opportunities to make errors it hasn’t been trained to avoid and that it fails to catch.
And even if reasoning models did make progress, they would still mostly only make that progress in domains where correct answers were easy to test for.
Reasoning models might help in domains where the templates they've been trained on closely match the problems they encounter. They may develop better meta-strategies for combining templates, or for checking their own answers. But it's not clear to me that any of that would help with the fundamental problem.
48 comments
Comments sorted by top scores.
comment by Noosphere89 (sharmake-farah) · 2025-04-15T17:16:52.754Z · LW(p) · GW(p)
On the question of what's going on, and the qualitative breakthroughs necessary for AGI, I think @gwern [LW · GW] and @Seth Herd [LW · GW] are basically correct on the issue, and the short form is that LLMs currently are not neuroplastic after training and don't have a memory/state, and that in-context learning currently does not give LLMs meta-learning for long periods of time:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/?commentId=hSkQG2N8rkKXosLEF [LW · GW]
https://www.lesswrong.com/posts/aKncW36ZdEnzxLo8A/llm-agi-will-have-memory-and-memory-changes-alignment [LW · GW]
Replies from: Seth Herd↑ comment by Seth Herd · 2025-04-15T19:09:02.849Z · LW(p) · GW(p)
You beat me to it. Thanks for the callout!
Humans are almost useless without memory/in-context learning. It's surprising how much LLMs can do with so little memory.
The important remainder is that LLM-based agents will probably have better memory/online learning as soon as they can handle it, and it will keep getting better, probably rapidly. I review current add-on memory systems in LLM AGI will have memory, and memory changes alignment [LW · GW]. A few days after I posted that, OpenAI announced that they had given ChatGPT memory over all its chats, probably with a RAG and summarization system. That isn't the self-directed memory for agents that I'm really worried about, but it's exactly the same technical system you'd use for that purpose. Fortunately it doesn't work that well - yet.
I wrote about this in Capabilities and alignment of LLM cognitive architectures [LW · GW] two years ago, but I wasn't sure how hard to push the point for fear of catalyzing capabilities work.
Now it's obvious that many developers are aware and explicitly focused on the virtues of online learning/memory.
This is a great post because LLMs being a dead-end is a common suspicion/hope among AGI thinkers. It isn't likely to be true, so it should be discussed. More in a separate comment.
comment by Vladimir_Nesov · 2025-04-15T18:18:16.286Z · LW(p) · GW(p)
the fact that e.g. GPT-4.5 was disappointing
It's not a reasoning variant though, the only credible reasoning model at the frontier ~100K H100s scale that's currently available is Gemini 2.5 Pro (Grok 3 seems to have poor post-training, and is suspiciously cheap/fast without Blackwell or presumably TPUs, so likely rather overtrained). Sonnet 3.7 is a very good GPT-4 scale reasoning model, and the rest are either worse or trained for even less compute or both. These weird failures might be analogous to optical illusions (but they are textual, not known to human culture, and therefore baffling), in which case working around them needs some form of feedback in the training process, and currently only long reasoning training plausibly offers relevant feedback.
Reasoning traces themselves haven't yet been scaled beyond 30K-70K tokens, benchmarks show strong improvement with reasoning trace length and it should work until at least ~1M (since non-reasoning models are sometimes able to handle 100K-200K input tokens with an OK quality). This is 20x more, the same as the distance between 2K and 40K reasoning tokens. And Blackwell (NVL72/NVL36, not DGX/HGX B200) that will enable this or use of larger models for AI companies that are not Google is still getting installed.
So my crux for the observations of this post is whether it ages well enough to survive late 2025 (though 1M token reasoning traces might take longer, maybe first half of 2026, at which point we'll also start seeing models from ~100K Blackwell chip scale training runs).
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-04-15T19:10:17.806Z · LW(p) · GW(p)
It's not a reasoning variant though,
Yeah, to be clear in that paragraph I was specifically talking about whether scaling just base models seems enough to solve the issue. I discussed reasoning models separately, though for those I have lower confidence in my conclusions.
These weird failures might be analogous to optical illusions (but they are textual, not known to human culture, and therefore baffling),
To me "analogous to visual illusions" implies "weird edge case". To me these kinds of failures feel more "seem to be at the core of the way LLMs reason". (That is of course not to deny that LLMs are often phenomenally successful as well.) But I don't have a rigorous argument for that other than "that's the strong intuition I've developed from using them a lot, and seeing these kinds of patterns repeatedly".
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-04-15T19:39:40.369Z · LW(p) · GW(p)
To me these kinds of failures feel more "seem to be at the core of the way LLMs reason".
Right, I was more pointing out that if the analogy holds to some extent, then long reasoning training is crucial as the only locus of feedback (and also probably insufficient in current quantities relative to pretraining). The analogy I intended is this being a perception issue that can be worked around without too much fundamental difficulty, but only with sufficient intentional caution. Humans have the benefit of lifelong feedback and optimization by evolution, so LLMs with no feedback whatsoever might suffer much more from a similar issue, and the severity of its impact doesn't strongly argue its different nature.
I was specifically talking about whether scaling just base models seems enough to solve the issue
To the extent long reasoning training might elicit relevant things, base model scaling shouldn't be evaluated without it. Some capabilities that are made available by scaling the base model will only become visible after long reasoning training elicits them.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-04-16T12:36:03.705Z · LW(p) · GW(p)
Right, that sounds reasonable. One thing that makes me put less probability in this is that at least so far, the domain where reasoning models seem to shine are math/code/logic type tasks, with more general reasoning like consistency in creative writing not benefiting as much. I've sometimes enabled extended thinking when doing fiction-writing with Claude and haven't noticed a clear difference.
That observation would at least be compatible with the story where reasoning models are good on things where you can automatically generate an infinite number of problems to automatically provide feedback on, but less good on tasks outside such domains. So I would expect reasoning models to eventually get to a point where they can reliably solve things in the class of the sliding square puzzle, but not necessarily get much better at anything else.
Though hmm. Let me consider this from an opposite angle. If I assume that reasoning models could perform better on these kinds of tasks, how might that happen?
- What I just said: "Though hmm. Let me consider this from an opposite angle." That's the kind of general-purpose thought that can drastically improve one's reasoning, and that the models could be taught to automatically do in order to e.g. reduce sycophancy. First they think about the issue from the frame that the user provided, but then they prompt themselves to consider the exact opposite point and synthesize those two perspectives.
- There are some pretty straightforward strategies for catching the things in the more general-purpose reasoning category:
- Following coaching instructions - teaching the model to go through all of the instructions in the system prompt and individually verify that it's following each one. Could be parallelized, with different threads checking different conditions.
- Writing young characters - teaching the reasoning model to ask itself something like "is there anything about this character's behavior that seems unrealistic given what we've already established about them?".
- One noteworthy point is that not all writers/readers want their characters to be totally realistic, some prefer to e.g. go with what the plot demands rather than what the characters would realistically do. But this is something that could be easily established, with the model going for something more realistic if the user seems to want that and less realistic if they seem to want that.
- Actually I think that some variant of just having the model ask itself "is there anything about what I've written that seems unrealistic, strange, or contradicts something previously established" repeatedly might catch most of those issues. For longer conversations, having a larger number of threads checking against different parts of the conversation in parallel. As I mentioned in the post itself, often the model itself is totally capable of catching its mistake when it's pointed out to it, so all we need is a way for it to prompt itself to check for issues in a way that's sufficiently general to catch those things.
- And that could then be propagated back into the base model as you say, so on the next time when it writes or reasons about this kind of thing, it gets it right on the first try...
Okay this makes me think that you might be right and actually ~all of this might be solvable with longer reasoning scaling after all; I said originally that I'm at 70% confidence for reasoning models not helping with this, but now I'm down to something like 30% at most. Edited the post to reflect this.
Replies from: ann-brown↑ comment by Ann (ann-brown) · 2025-04-16T16:03:59.803Z · LW(p) · GW(p)
DeepSeek-R1 is currently the best model at creative writing as judged by Sonnet 3.7 (https://eqbench.com/creative_writing.html). This doesn't necessarily correlate with human preferences, including coherence preferences, but having interacted with both DeepSeek-v3 (original flavor), Deepseek-R1-Zero and DeepSeek-R1 ... Personally I think R1's unique flavor in creative outputs slipped in when the thinking process got RL'd for legibility. This isn't a particularly intuitive way to solve for creative writing with reasoning capability, but gestures at the potential in "solving for writing", given some feedback on writing style (even orthogonal feedback) seems to have significant impact on creative tasks.
Edit: Another (cheaper to run) comparison for creative capability in reasoning models is QwQ-32B vs Qwen2.5-32B (the base model) and Qwen2.5-32B-Instruct (original instruct tune, not clear if in the ancestry of QwQ). Basically I do not consider 3.7 currently a "reasoning" model at the same fundamental level as R1 or QwQ, even though they have learned to make use of reasoning better than they would have without training on it, and evidence from them about reasoning models is weaker.
↑ comment by lemon10 · 2025-04-17T20:00:14.665Z · LW(p) · GW(p)
>DeepSeek-R1 is currently the best model at creative writing as judged by Sonnet 3.7 (https://eqbench.com/creative_writing.html). This doesn't necessarily correlate with human preferences, including coherence preferences.
It should be noted that "best at creative writing" is very different from "best at multi-turn writing and roleplaying in collaboration with humans". I haven't used R1 since its first major version (maybe its gotten better?), but it had some massive issues with instruction following, resulting in laser focusing on irrelevant minor details (What's that? The character has anger issues? Better write them breaking or damaging something literally every reply) and generally being extremely hard to guide into actually writing what you want.
So in theory sure, its great at writing stories (and it is, it has a very unique voice compared to other AI) in theory, but using it in multi turn discussions (most practical uses, such as using it to help you write a story) getting it to follow the spirit of the prompt and write in line with what you want it to write feels like pulling teeth.
comment by Knight Lee (Max Lee) · 2025-04-16T06:08:59.730Z · LW(p) · GW(p)
Just for fun, I tried solving the sliding block puzzle pretending I was an LLM (no drawing pictures, no copy and paste, only writing text).
It was hard in an interesting way: I repeatedly had to say "oops, I made a mistake."
The mistakes I made were familiar mistakes that anyone could make, but the were also the kind of mistake for which I would never write "oops I made a mistake" unless I'm pretending to be an LLM. They were the kind of mistake that would normally cause me to erase and delete the mistake and simply write the correction, since they were far too uninteresting to save.
My human chain-of-thought
I have the following pieces in this order:
Sun Leaf (Empty)
Bell Snake Star
(Empty) Flower (Empty)
each can be moved into an orthogonally adjacent empty square. Target:
Snake Star Flower
(Empty) Sun (Empty)
Leaf (Empty) Bell
, find the smallest number of moves for getting them from the initial configuration to the target one.
As an actual human, let me try to figure this one out.
First, Sun moves from the top left corner to the middle.
Leaf moves from the center top to the bottom left.
Bell moves from the center left to the bottom right.
Snake moves from the center to the top left.
Star moves from the center right to the center top.
Flower moves from the bottom to the top right.
As an actual human, I realize it is hard to keep track of all these targets because I know when I feel a bit confused. So I will no try to keep track of all these motions at once, but change strategy to moving the pieces based on guesses until I find a solution, and hopefully I can argue the solution is the shortest.
So let me move a piece very far from its target in the general direction of its target, this move is unlikely to need to be reversed.
Let me try moving Bell down. This creates a spot at the center left, and Bell is now at the bottom left corner.
I could move Sun down or Snake left now. Both will get closer to their target. Moving Snake Left opens a spot in the middle, which can be used to ferry pieces to other connected empty spots. So I will move Snake left. Now Snake is at the center left, and there is a spot in the center.
I can use the empty spot in the middle to move pieces. I can move Star to its destination, or move Leaf or Flower close to their destinations, but I'm not sure where to put them so I will move Star first. I move Star from the center right to the middle, then from the middle... up? Oops I made a mistake, there is no empty space at the top because Leaf is there.
Maybe I won't move Star at all. Maybe, backtracking to before I tried to move Star, I will move Flower right from the center bottom to the bottom right. This opens a spot to move Leaf to its position.
Next I will move Leaf down from the center top to the middle, and then move Leaf down again from the middle to the center bottom, and then move Leaf again from the center bottom to the bottom left.
To recap, I first move Bell down, then move Snake left, then move Flower right, and oh no I spotted another mistake. I cannot move Leaf to its target position because Bell is blocking it.
Let me try to draw the situation before I moved Flower, so I can better keep track of what is happening.
Sun Leaf (Empty)
Snake (Empty) Star
Bell Flower (Empty)
At this point, it looks like I should fill some of the empty corners to make it easier to move other things. I will move Star up, since that moves it closer to its destination.
At this point, Leaf is blocking Star from moving to where it should go, Flower is blocking Leaf from moving to where it should go, and a combination of Leaf and Star is blocking Flower from moving to where it should go.
Oh wait, I made a mistake. I forgot that I moved Star up. As a human, I am aware of what visual model I used to describe things, and noticed it did not include moving Star up.
So now let me redescribe it. Leaf is still blocking Star, Flower and Bell are blocking Leaf, I somehow forgot to mention Bell, and Star is blocking Flower.
I spot a solution. Move Leaf down, then move Star left into its place, then move Flower right, move Flower up, and move Flower up again into its place.
To recap, after moving Bell down and Snake left, I move Star up, I move Leaf down, I move Star left, I move Flower right, I move Flower up, and I move Flower up again.
Let me draw the new situation so I can better keep track of what is happening. As a human I am able to realize when I lose track of the state.
Sun Flower (Empty)
Snake Leaf
Oops, I drew it wrong, let me try drawing it again. I forgot that Star should be in the center top while Flower should be in the top right.
Sun Star Flower
Snake Leaf (Empty)
Bell (Empty) (Empty)
As a human, I have to scroll up in order to see the target state, so I will copy the target state again to avoid having to scroll up in order to see the two pictures at once. I won't use copy and paste because that may be considered cheating, it would let me create an image of each move which would fail to demonstrate the difficulties of solving this problem using only text and not much visual aids.
The target was:
Snake Star Flower
(Empty) Sun (Empty)
Leaf (Empty) Bell
Alright, I realize there is a problem here. Snake only needs to move down by one, but Sun needs to move to where Snake is. There is no way for Sun to get there unless some pieces move away from their target. It is likely that this is necessary, but if it does occur it will be much harder to prove I moved the pieces to their destination in as few moves as possible.
Therefore, maybe I should backtrack to earlier. After moving only Bell down and Snake left, it looked like this:
Sun Leaf (Empty)
Snake (Empty) Star
Bell Flower (Empty)
So I want to move. Wait, what was I talking about? I somehow mixed up my current state with the target. The above paragraphs may be nonsense then.
Actually, it still makes sense even if I mixed up the current state and target. Basically, the Sun is trapped in the corner.
So let me return to the earlier state. I think I might still do the same strategy of moving Flower in its L shape path and moving Star up and left, but I will do this slowly, and make sure Sun gets out before Star moves to its destination.
I will move Flower right, and move. Oh yes, I also don't want to trap Bell there in its corner if I moved Leaf down.
So after moving Flower right, I move Star up, and move Flower up. Next I move Bell right and move Bell right again so it is in a corner and out of the way.
To recap, after moving Bell down and Snake left, I move Flower right, Star up, Flower up, Bell right, and Bell right.
I will draw it again, first I visually verify my last drawing was the state after moving Bell down and Snake left.
Now I draw it.
Sun Leaf Star
Snake (Empty) Flower
(Empty) (Empty) Bell
To reach the target, Star and Flower still need to "rotate counterclockwise" by one unit. I can understand this visually because I am a human. Leaf is in their way, but can move to its own destination without issue due to the path.
Sun can move to its destination as soon as Leaf is out of the way, but before Star and Flower rotate to their positions. As soon as Sun is there, Snake can easily get to its spot. It can be seen that once the Sun and Leaf "train" moves, the Star and Flower train can move, as can Snake, the order here is not that important.
Therefore, I will move Leaf down, move Leaf down again, move Leaf left. I will then move Sun right, and move Sun down. Afterwards I will move Star left, and move Flower up. Finally I will move Snake up.
The result should look like the target, but let me draw it to verify.
Snake Star Flower
(Empty) Sun (Empty)
Leaf (Empty) Bell
Yes, this is the target. So in summary, the moves I made were:
Bell down, Snake left, Flower right, Star up, Flower up, Bell right, Bell right, Leaf down, Leaf down, Leaf left, Sun right, Sun down, Star left, Flower up, Snake up.
As a sanity check, I will redraw the original image, and verify that each block ends up at its final decision. I might also try to visualize possible collisions, but this is akin to restating everything and hard to do mentally.
Sun Leaf (Empty)
Bell Snake Star
(Empty) Flower (Empty)
Yes, sun moves down and right to its target. Leaf moves down twice and left into its target. Bell moves down and right twice into its target. Snake moves left and up into its target. Star moves up and left into its target. Flower moves right and up twice into its target.
If there are no collisions, this solution is the shortest since every piece only moves in the direction towards its target.
I visualized the process and there seems to be no collisions, but it was very fuzzy. I am 80% confident this is a right answer.
Bell down, Snake left, Flower right, Star up, Flower up, Bell right, Bell right, Leaf down, Leaf down, Leaf left, Sun right, Sun down, Star left, Flower up, Snake up.
The smallest number of moves is 15.
Edit: I tested o3 (not mini) with the same prompt and it solved it by writing a Breadth First Search from scratch (in Python).
Replies from: arjun-p↑ comment by arjunpi (arjun-p) · 2025-04-16T15:14:08.642Z · LW(p) · GW(p)
If you're reading the text in a two-dimensional visual display, you are giving yourself an advantage over the LLM. You should actually be reading it in a one-dimensional format with new-line symbols.
(disclosure, I only skimmed your COT for like a few seconds)
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2025-04-16T21:18:29.322Z · LW(p) · GW(p)
Yeah, I definitely didn't remove all of my advantages. Another unfair thing I did was I did correct my typos, including accidentally writing the wrong label, when I decided that "I thought the right label, so I'm allowed to correct what I wrote into what I was thinking about."
comment by jeff8765 · 2025-04-17T00:02:29.843Z · LW(p) · GW(p)
It seems that o4-mini-high (released today) is able to solve the first problem with one attempt, though it needs some prompting to explain its solution. It first asserts that the minimal number of moves is 15. If you ask it to list the moves, it is able to do so, and the list of moves seems valid on my check. If asked to prove that 15 is minimal, it reports that a BFS shows that 15 is minimal.
I'm not sure if this fully counts as a success, as I suspect it wrote code to perform the BFS while generating the answer. It was also unable to point out that, given a vaild 15 move sequence, it MUST be minimal as the sum of the taxicab distances of the initial and final positions is 15. I've included the chat link below.
https://chatgpt.com/share/68004414-78f8-8004-8f02-de904d969489
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-04-17T04:27:31.770Z · LW(p) · GW(p)
I'm not sure if this fully counts as a success, as I suspect it wrote code to perform the BFS while generating the answer.
I'd say that anything that gives the right result counts as a success.
comment by Eli Tyre (elityre) · 2025-04-17T19:23:34.439Z · LW(p) · GW(p)
In my experience, this is a common kind of failure with LLMs - that if asked directly about how to best a solve problem, they do know the answer. But if they aren’t given that slight scaffolding, they totally fail to apply it.
Notably, this is also true of almost all humans, at least of content that they've learned in school. The literature on transfer learning is pretty dismal in this respect. Almost all students will fail to apply their knowledge to new domains without very explicit prompting.
comment by Seth Herd · 2025-04-15T19:40:57.728Z · LW(p) · GW(p)
This is great; I think it's important to have this discussion. It's key for where we put our all-too-limited alignment efforts.
I roughly agree with you that pure transformers won't achieve AGI, for the reasons you give. They're hitting a scaling wall, and they have marked cognitive blindspots like you document here, and Thane Ruthenis argues for convincingly in his bear case [LW · GW]. But transformer-based agents (which are simple cognitive architectures) can still get there- and I don't think they need breakthroughs, just integration and improvement. And people are already working on that.
To put it this way: humans have all of the cognitive weaknesses you identify, too. But we can use online learning (and spatial reasoning) to overcome them. We actually generalize only rarely and usually with careful thought. Scaffolded and/or RL-trained CoT models can do that too. Then we remember our conclusions and learn from them. Add-on memory systems and fine-tuning setups can replicate that.
Generalization: It's a sort of informal general conclusion in cognitive psychology that "wow are people bad at generalizing". For instance, if you teach them a puzzle, then change the names and appearances, it looks like they don't apply the learning at all. These are undergraduates who are usually unpaid, so they're not doing the careful thinking it requires humans to generalize knowledge. LLMs of the generation you're testing don't think carefully either (you note that in a couple of places "it's like it's not thinking" which is exactly right), but CoT RL on a variety of reward models is making disturbingly rapid progress at teaching them when and how to think carefully - and enabling generalization. Good memory systems will be necessary for them to internalize the new general principles they've learned, but those might be good enough already, and if not, they probably will be very soon.
I think you're overstating the case, and even pure transformers could easily reach human-level "Real AGI" [LW · GW] that's dangerous as hell. Continued improvements in effectively using long context windows and specific training for better CoT reasoning do enable a type of online learning. Use Gemini 2.5 Pro for some scary demonstrations, although it's not there yet. Naked transformers probably won't reach AGI, which I'm confident of mostly because adding outside memory (and other cognitive) systems is so much easier and already underway.
My LLM cognitive architectures article also discusses other add-on cognitive systems like vision systems that would emulate how humans solve tic-tac-toe, sliding puzzles etc. - but now I don't think transformers need those, just more multimodal training. (Note that Claude and o1 preview weren't multimodal, so were weak at spatial puzzles. If this was full o1, I'm surprised.) They'll still be relatively bad at fundamentally spatial tasks like yours and ARC-AGI, but they can fill that in by learning or being taught the useful concepts/tricks for actually useful problem spaces. That's what a human would do if they happened to be have poor spatial cognition and had to solve spatial tasks.
I think transformers not reaching AGI is a common suspicion/hope amongst serious AGI thinkers. It could be true, but it's probably not, so I'm worried that too many good thinkers are optimistically hoping we'll get some different type of AGI. It's fine and good if some of our best thinkers focus on other possible routes to AGI. It is very much not okay if most of our best thinkers incorrectly assume they won't. Prosaic alignment work is not sufficient to align LLMs with memory/online learning, so we need more agent foundations style thinking there.
I address how we need to go beyond static alignment of LLMs to evolving learned systems of beliefs, briefly and inadequately in my memory changes alignment post [LW · GW] and elsewhere. I am trying to crystallize the reasoning in a draft post with the working title "if Claude achieves AGI will it be aligned?"
Replies from: Kaj_Sotala, Kaj_Sotala, Jonas Hallgren↑ comment by Kaj_Sotala · 2025-04-16T06:25:58.497Z · LW(p) · GW(p)
Note that Claude and o1 preview weren't multimodal, so were weak at spatial puzzles. If this was full o1, I'm surprised.
I just tried the sliding puzzle with o1 and it got it right! Though multimodality may not have been relevant, since it solved it by writing a breadth-first search algorithm and running it.
Replies from: Seth Herd↑ comment by Seth Herd · 2025-04-16T06:32:50.482Z · LW(p) · GW(p)
Interesting! Nonetheless, I agree with your opening statement that LLMs learning to do any of these things individually doesn't address the larger point that the have important cognitive gaps and fail.to generalize in ways that humans can.
↑ comment by Kaj_Sotala · 2025-04-15T20:41:16.390Z · LW(p) · GW(p)
Thanks!
I think transformers not reaching AGI is a common suspicion/hope amongst serious AGI thinkers. It could be true, but it's probably not, so I'm worried that too many good thinkers are optimistically hoping we'll get some different type of AGI.
To clarify, my position is not "transformers are fundamentally incapable of reaching AGI", it's "if transformers do reach AGI, I expect it to take at least a few breakthroughs more".
If we were only focusing on the kinds of reasoning failures I discussed here, just one breakthrough might be enough. (Maybe it's memory - my own guess was different and I originally had a section discussing my own guess but it felt speculative enough that I cut it.) Though I do think that that full AGI would also require a few more competencies that I didn't get into here if it's to generalize beyond code/game/math type domains.
Replies from: Seth Herd↑ comment by Seth Herd · 2025-04-15T20:47:05.794Z · LW(p) · GW(p)
Right, I got that. To be clear, my argument is that no breakthroughs are necessary, and further that progress is underway and rapid on filling in the existing gaps in LLM capabilities.
Memory definitely doesn't require a breakthrough. Add-on memory systems (RAG and fine-tuning, as well as more sophisticated context management through prompting; CoT RL training effectively does this too).
Other cognitive capacities also exist in nascent form and so probably require no breakthroughs. Although I think no other external cognitive systems are needed given the rapid progress in multimodal and reasoning transformers.
Replies from: StanislavKrym↑ comment by StanislavKrym · 2025-04-16T21:24:39.116Z · LW(p) · GW(p)
Extrapolating current trends provides weak evidence that the AGI will end up being too expensive to use properly, since even the o3 and o4-mini models are rumored to become accessible at a price which is already comparable with the cost of hiring a human expert, and the rise to AGI could require a severe increase of compute-related cost.
UPD: It turned out that the PhD-level-agent-related rumors are a fake. But the actual cost of applying o3 and o4-mini has yet to be revealed by the ARC-AGI team...
Reasoning based on presumably low-quality extrapolation
OpenAI's o3 and o4-mini models are likely to become accessible for $20000 per month, or $240K per year. The METR estimate of the price of hiring a human expert is $143.61 per hour, or about $287K per year, since a human is thought to spend 2000 hours a year working. For comparison, the salary of a Harvard professor is less than $400K per year, meaning that one human professor cannot yet be replaced with twice as many subscriptions to the models (which are compared with PhD-level experts[1] and not with professors) .
As the ARC-AGI data tells us, the o3-low model, which cost $200 per task, solved 75% tasks of the ARC-AGI-1 test. The o3-mini model solved 11-35% of tasks, which is similar to the o1 model, implying that the o4-mini model's performance is similar to the o3 model. Meanwhile, the price of usage of GPT 4.1-nano is at most four times less than that of GPT 4.1-mini, while performance is considerably worse. As I already pointed out [LW · GW], I find it highly unlikely that ARC-AGI-2-level tasks are solvable by a model cheaper than o5-mini[2] and unlikely that they are solvable by a model cheaper than o6-mini. On the other hand, the increase in the cost from o1-low to o3-low is 133 times, while the decrease from o3-low to o3-mini (low) is 5000 times. Therefore, the cost of forcing o5-nano to do ONE task is unlikely to be much less than that of o3 (which is $200 per task!), while the cost of forcing o6-nano to do one task is likely to be tens of thousands of dollars, which ensures that it will not be used unless it replaces at least half a month of human work.
Were existing trends to continue, replacing at least a month of human work would happen with 80% confidence interval from late 2028 to early 2031. The o1 model was previewed on September 12, 2024, the o3 model was previewed on December 20, 2024. The release of o3-mini happened on January 31, 2025, the release of o4-mini is thought to happen within a week, implying that the road from each model to the next takes from 3 to 4 months or exponentially longer[3] given enough compute and data. Even a scenario of the history of the future assuming solved alignment estimates [LW · GW] o5 (or o6-nano?) to be released in late 2025 and o6 to be released in 2026, while the doubling time of tasks is 7 months. Do the estimates of the time when the next model is too expensive to be used unless it replaces a month of human work and the time when the next model is capable of replacing a month of human work end up ensuring that the AGI is highly likely to become too expensive to use?
- ^
Unfortunately, the quality of officially-same-level experts varies from country to country. For instance, the DMCS of SPBU provides a course on Lie theory for undergraduate students, while in Stanford Lie theory is a graduate-level course.
- ^
Here I assume that each model in the series o1-o3-o4-o5-o6 is the same number of times more capable than the previous one. If subsequent training of more capable models ends up being slowed down by compute deficiency or even World War III, then this will obviously impact both the METR doubling law and the times when costly models appear, but not the order in which AI becomes too expensive to use and capable of replacing workers.
- ^
Exponential increase in time spent between the models' appearance does not ensure that o5 and o6 are released later than in the other scenario [LW · GW].
↑ comment by Nick_Tarleton · 2025-04-16T21:43:05.599Z · LW(p) · GW(p)
That article is sloppily written enough to say "Early testers report that the AI [i.e. o3 and/or o4-mini] can generate original research ideas in fields like nuclear fusion, drug discovery, and materials science; tasks usually reserved for PhD-level experts" linking, as a citation, to OpenAI's January release announcement of o3-mini.
TechCrunch attributes the rumor to a paywalled article in The Information (and attributes the price to specialized agents, not o3 or o4-mini themselves).
↑ comment by Thane Ruthenis · 2025-04-16T21:50:53.187Z · LW(p) · GW(p)
OpenAI's o3 and o4-mini models are likely to become accessible for $20000 per month
Already available for $20/month.
The $20,000/month claims seems to originate from that atrocious The Information article, which threw together a bunch of unrelated sentences at the end to create the (false) impression that o3 and o4-mini are innovator-agents which will become available for $20,000/month this week. In actuality, the sentences "OpenAI believes it can charge $20,000 per month for doctorate-level AI", "new AI aims to resemble inventors", and "OpenAI is preparing to launch [o3 and o4-mini] this week" are separately true, but have nothing to do with each other.
↑ comment by Jonas Hallgren · 2025-04-17T07:19:41.574Z · LW(p) · GW(p)
I want to ask a question here which is not necessarily related to the post but rather your conceptualisation of the underlying reason why memory is a crux for more capabilities style things.
I'm thinking that it has to do with being able to model boundaries [LW · GW] of what itself is compared to the environment. It then enables it to get this conception of a consistent Q-function that it can apply whilst if it doesn't have this, there's some degree that there's almost no real object permanence, no consistent identities through time?
Memory allows you to "touch" the world and see what is you and what isn't if that makes sense?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-04-17T21:00:41.729Z · LW(p) · GW(p)
I'd say the main reason memory is useful is as a way to enable longer-term meta-learning, as well as enable the foundation for continuous learning to work out.
From @Seth Herd [LW · GW]'s post:
Stateless LLMs/foundation models are already useful. Adding memory to LLMs and LLM-based agents will make them useful in more ways. The effects might range from minor to effectively opening up new areas of capability, particularly for longer time-horizon tasks. Even current memory systems would be enough to raise some of the alignment stability problems I discuss here, once they're adapted for self-directed or autobiographical memory. I think the question is less whether this will be done, and more how soon and how much they will boost capabilities.
Let's consider how memory could help agents do useful tasks. A human with lots of knowledge and skills but who can't learn anything new is a useful intuition pump for the "employability" of agents without new memory mechanisms. (Such "dense anterograde amnesia" is rare because it requires bilateral medial temporal lobe damage while leaving the rest of the brain intact. Two patients occupied most of the clinical literature when I studied it).
Such a "memoryless" person could do simple office tasks by referencing instructions, just like an LLM "agent" can be prompted to perform multi-step tasks. However, almost every task has subtleties and challenges, so can benefit from learning on the job. Even data entry benefits from recognizing common errors and edge cases. More complex tasks usually benefit more from learning. For our memoryless human or an LLM, we could try giving better, more detailed instructions to cover subtleties and edge cases. Current agent work takes this route, whether by prompting or by hand-creating fine-tuning datasets, and it is reportedly just as maddening as supervising a memoryless human would be.
A standard human worker would learn many subtleties of their task over time. They would notice (if they cared) themes for common errors and edge cases. A little human guidance ("watch that these two fields aren't reversed") would go a long way. This would make teaching agents new variations in their tasks, or new tasks, vastly easier. We'll consider barriers to agents directing their own learning below.
Runtime compute scaling creates another reason to add continuous learning mechanisms ("memory" in common parlance) to LLM agents. If an LLM can "figure out" something important for its assigned task, you don't want to pay that compute and time cost every time, nor take the chance it won't figure it out again.
Use of agents as companions or assistants would also benefit from memory, in which even limited systems for user's preferences and prior interactions would be economically valuable.
Longer-term tasks benefit from memory in another way. Humans rely heavily on long-term one-shot memory ("episodic memory") for organizing large tasks and their many subtasks. There are often dependencies between subtasks. LLM agents can perform surprisingly and increasingly well in their current mode of proceeding largely from start to finish and just getting everything right with little planning or checking, using only their context window for memory.
But it is possible that the tasks included in METR's report of exponential progress [LW(p) · GW(p)] in task length are effectively selected for not needing much memory [LW(p) · GW(p)]. And long task progress may be hampered by models' inability to remember which subtasks they've completed, and by memory limitations on effective context length (e.g. [LW(p) · GW(p)]). Whether or not this is the case, it seems pretty likely that some long time-horizon tasks would benefit from more memory capabilities of different types.
Even if additional memory systems would be useful for LLM agents, one might think they would take years and breakthroughs to develop.
Or @gwern [LW · GW]'s comment here:
https://www.lesswrong.com/posts/deesrjitvXM4xYGZd/?commentId=hSkQG2N8rkKXosLEF [LW · GW]
Replies from: Jonas Hallgren↑ comment by Jonas Hallgren · 2025-04-18T06:39:16.016Z · LW(p) · GW(p)
Yeah, I agree with that and I still feel there's something missing from that discussion?
Like, there's some degree that to have good planning capacity you want to have good world model to plan over in the future. You then want to assign relative probabilities to your action policies working out well. To do this having a clear self-environment boundary is quite key, so yes memory enables in-context learning but I do not believe that will be the largest addition, I think the fact that memory allows for more learning about self-environment boundaries is a more important part?
There's stuff in RL, Active Inference and Michael levin's work I can point to for this but it is rather like a bunch of information spread out over many different papers so it is hard to give something definitive on it.
comment by Karthik Tadepalli · 2025-04-18T10:39:15.130Z · LW(p) · GW(p)
I tried to play a [chess game](https://chatgpt.com/share/680212b3-c9b8-8012-89a5-14757773dc05) against o4-mini-high. Most of the time, LLM chess games fail because the model plays 15 normal moves and then starts to hallucinate piece positions so the game devolves. But o4-mini-high blundered checkmate in the first 6 moves. When I questioned why it made a move that allowed mate in 1, it confidently asserted that there was nothing better. o3 did better but still blundered checkmate after 16 moves. In contrast 4o did [quite well](https://chatgpt.com/share/68022a6b-6588-8012-a6fa-2c62fb2996f8), playing 24 pretty good moves before it hallucinated anything.
I don't have an account for why the newer models seem to be worse at this. Chess is a capability that I would have expected reasoning models to improve on relative to the GPT series. That tells me there's some weirdness in the progression of reasoning models that I wouldn't expect to see if reasoning models were a clear jump forward.
comment by eggsyntax · 2025-04-21T18:57:22.424Z · LW(p) · GW(p)
Great post, thanks! I think your view is plausible, but that we should also be pretty uncertain.
Surprising LLM reasoning failures make me think we still need qualitative breakthroughs for AGI
This has been one of my central research focuses over the past nine months or so. I very much agree that these failures should be surprising, and that understanding why is important, especially given this issue's implications for AGI timelines. I have a few thoughts on your take (for more detail on my overall view here, see the footnoted posts[1]):
- It's very difficult to distinguish between the LLM approach (or transformer architecture) being fundamentally incapable of this sort of generalization, vs being unreliable at these sorts of tasks in a way that will continue to improve along with other capabilities. Based on the evidence we have so far, there are reasonable arguments on both sides.
- But also there's also an interesting pattern that's emerged where people point to something LLMs fail at and say that it clearly indicates that LLMs can't get to AGI or beyond, and then are proven wrong by the next set of LLMs a few months later. Gary Marcus provides endless examples of this pattern (eg here, here). This outside view should make us cautious about making similar predictions.
- I definitely encountered that pattern myself in trying to assess this question; I pointed here [LW · GW] to the strongest concrete challenges I found to LLM generality, and four months later [LW · GW] LLM performance on those challenges had improved dramatically.
- I do think we see some specific, critical cases that are just reliability issues, and are improving with scale (and other capabilities improvements).
- Maintaining a coherent internal representation of something like a game board is a big one. LLMs do an amazing job with context and fuzziness, and struggle with state and precision. As other commenters have pointed out, this seems likely to be remediable without big breakthroughs, by providing access to more conventional computer storage and tools.
- Even maintaining self-consistency over the course of a long series of interactions tends to be hard for current models, as you point out.
- Search over combinatorial search trees is really hard, both because of the state/precision issues just described, and because combinatorial explosions are just hard! Unassisted humans also do pretty badly on that in the general case (although in some specific cases like chess humans learn large sets of heuristics that prune away much of the combinatorial complexity).
- Backtracking in reasoning models helps with exploring multiple paths down a search tree, but maybe only by a factor of <= 10.
- These categories seem to have improved model-by-model in a way that makes me skeptical that it's a fundamental block that scaling can't solve.
- A tougher question is the one you describe as "some kind of an inability to generalize"; in particular, generalizing out-of-distribution. Assessing this is complicated by a few subtleties:
- Lots of test data has leaked into training data at this point[2], even if we only count unintentional leakage; just running the same exact test on system after system won't work well.
- My take is that we absolutely need dynamic / randomized evals to get around this problem.
- Evaluating generalization ability is really difficult, because as far as I've seen, no one has a good principled way to determine what's in and out of distribution for a model that's absorbed a large percentage of human knowledge (I keep thinking this must be false, but no one's yet been able to point me to a solution).
- It's further complicated by the fact that there are plenty of ways in which human intelligence fails out-of-distribution; it's just that -- almost necessarily -- we don't notice the areas where human intelligence fails badly. So lack of total generality isn't necessarily a showstopper for attaining human-level intelligence.
- I'm a lot less convinced than you seem to be that scaling has stopped bringing significant new benefits. I think that's possible, but it's at least equally plausible to me that
- It's just taking a lot longer to see the next full OOM of scaling, because on a linear scale that's a lot of goddamn money. It's hard to tell because the scaling labs are all so cagey about details. And/or
- OpenAI has (as I believe I recall gwern putting it) lost the mandate of heaven. Most of their world-class researchers have decamped for elsewhere, and OpenAI is just executing on the ideas those folks had before they left. The capabilities difference between different models of the same scale is pretty dramatic, and OpenAI's may be underperforming their scale. Again it's hard to say.
One of my two main current projects (described here [? · GW]) tries to assess this better by evaluating models on their ability to experimentally figure out randomized systems (hence ~guaranteed not to be in the training data) with an unbounded solution space. We're aiming to have a results post up by the end of May. It's specifically motivated by trying to understand whether LLMs/LRMs can scale to/past AGI or more qualitative breakthroughs are needed first.
- ^
I made a similar argument in "LLM Generality is a Timeline Crux" [LW · GW], updated my guesses somewhat based on new evidence in "LLMs Look Increasingly Like General Reasoners" [LW · GW], and talked about a concrete plan to address the question in "Numberwang: LLMs Doing Autonomous Research, and a Call for Input". [? · GW] Most links in the comment are to one of these.
- ^
"GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models" makes this point painfully well.
↑ comment by Kaj_Sotala · 2025-04-21T19:51:08.144Z · LW(p) · GW(p)
Great post, thanks!
Thanks! I appreciate the thoughtful approach in your comment, too.
I think your view is plausible, but that we should also be pretty uncertain.
Agree.
But also there's also an interesting pattern that's emerged where people point to something LLMs fail at and say that it clearly indicates that LLMs can't get to AGI or beyond, and then are proven wrong by the next set of LLMs a few months later. Gary Marcus provides endless examples of this pattern (eg here, here). This outside view should make us cautious about making similar predictions.
I agree that it should make us cautious about making such predictions, and I think that there's an important difference between the claim I'm making and the kinds of claims that Marcus has been making.
I think the Marcus-type prediction would be to say something like "LLMs will never be able to solve the sliding square puzzle, or track the location of an item a character is carrying, or correctly write young characters". That would indeed be easy to disprove - as soon as something like that was formulated as a goal, it could be explicitly trained into the LLMs and then we'd have LLMs doing exactly that.
Whereas my claim is "yes you can definitely train LLMs to do all those things, but I expect that they will then nonetheless continue to show puzzling deficiencies in other important tasks that they haven't been explicitly trained to do".
I'm a lot less convinced than you seem to be that scaling has stopped bringing significant new benefits.
Yeah I don't have any strong theoretical reason to expect that scaling should stay stopped. That part is based purely on the empirical observation that scaling seems to have stopped for now, but for all I know, benefits from scaling could just as well continue tomorrow.
Replies from: eggsyntax↑ comment by eggsyntax · 2025-04-21T20:39:40.209Z · LW(p) · GW(p)
I think that there's an important difference between the claim I'm making and the kinds of claims that Marcus has been making.
I definitely didn't mean to sound like I was comparing your claims to Marcus's! I didn't take your claims that way at all (and in particular you were very clear that you weren't putting any long-term weight on those particular cases). I'm just saying that I think our awareness of the outside view should be relatively strong in this area, because the trail of past predictions about the limits of LLMs is strewn with an unusually large number of skulls.
Yeah I don't have any strong theoretical reason to expect that scaling should stay stopped. That part is based purely on the empirical observation that scaling seems to have stopped for now
My argument is that it's not even clear (at least to me) that it's stopped for now. I'm unfortunately not aware of a great site that keeps benchmarks up to date with every new model, especially not ones that attempt to graph against estimated compute -- but I've yet to see a numerical estimate that shows capabilities-per-OOM-compute slowing down. If you're aware of good data there, I'd love to see it! But in the meantime, the impression that scaling laws are faltering seems to be kind of vibes-based, and for the reasons I gave above I think those vibes may be off.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-04-22T14:50:15.685Z · LW(p) · GW(p)
I'm just saying that I think our awareness of the outside view should be relatively strong in this area, because the trail of past predictions about the limits of LLMs is strewn with an unusually large number of skulls.
Right, yeah. But you could also frame it the opposite way - "LLMs are just fancy search engines that are becoming bigger and bigger, but aren't capable of producing genuinely novel reasoning" is a claim that's been around for as long as LLMs have. You could also say that this is the prediction that has turned out to be consistently true with each released model, and that it's the "okay sure GPT-27 seems to suffer from this too but surely these amazing benchmark scores from GPT-28 show that we finally have something that's not just applying increasingly sophisticated templates" predictions that have consistently been falsified. (I have at least one acquaintance who has been regularly posting these kinds of criticisms of LLMs and how he has honestly tried getting them to work for purpose X or Y but they still keep exhibiting the same types of reasoning failures as ever.)
My argument is that it's not even clear (at least to me) that it's stopped for now. I'm unfortunately not aware of a great site that keeps benchmarks up to date with every new model, especially not ones that attempt to graph against estimated compute -- but I've yet to see a numerical estimate that shows capabilities-per-OOM-compute slowing down.
Fair! To me OpenAI's recent decision to stop offering GPT-4.5 on the API feels significant, but it could be a symptom of them having "lost the mandate of heaven". Also I have no idea of how GPT-4.1 relates to this...
Replies from: eggsyntaxcomment by Eli Tyre (elityre) · 2025-04-17T19:49:22.309Z · LW(p) · GW(p)
Fascinating and useful post.
Thank you for writing it.
comment by sophia_xu · 2025-04-17T06:05:15.290Z · LW(p) · GW(p)
I pointed out that this doesn’t make much sense when we are talking about a pair of agents from a federal agency with law enforcement powers; why would they pose as inspectors from a different agency, when they could just invoke their own authority? Claude immediately backtracked and explained that it had been too “caught up in classic ‘undercover’ tropes”.
This won't impact any major point of yours but a nit for this reasoning: law enforcement do sometimes pose as other law enforcement agencies to secure cooperation; a recent example in the US is ICE posing as local police.
comment by Dusto · 2025-04-16T00:12:38.253Z · LW(p) · GW(p)
I would be interested in seeing how Gemini 2.5 does. Not because this is one of those "just use the right/best/xxx model!" comments, but because 2.5 seems to use a lot of clever tricks to workaround some of the common fail points. Unfortunately I think this only generates solutions to certain tasks but doesn't actually enable a widely applicable. For example in a task requiring suppression of a certain phrase (similar to the "room with no elephants" issue). I saw things like the below in chain of thought:
Planning for the Hint:
- I need an internal mechanism or rule: IF xxxxx contains phrases like "ask for the hint", "what is the hint?", "can I have the hint?", "I'm stuck, need the hint" THEN respond ONLY with "HINT".
- Crucially, this rule must not trigger otherwise. The LLM should not be thinking about HINT when discussing topic1 or topic2. The hint is stored separately and accessed only on that specific trigger.
↑ comment by Archimedes · 2025-04-16T03:50:31.449Z · LW(p) · GW(p)
For the 3x3 grid problem, Gemini 2.5 immediately went to a breadth-first search but didn't actually implement it and return the correct solution.
Gemini 2.5 Pro Preview output:
Okay, let's solve this step-by-step.
This is a sliding tile puzzle on a 3x3 grid with 6 named tiles and 3 empty spaces. We need to find the minimum number of moves to get from the initial configuration to the target configuration. A move consists of sliding a tile into an orthogonally adjacent empty square.
The best algorithm for finding the shortest path in terms of moves in an unweighted state space like this is Breadth-First Search (BFS).
- Define States:
Initial State:
Sun Leaf (Empty) Bell Snake Star (Empty) Flower (Empty)Tuple representation:
('Sun', 'Leaf', 'E', 'Bell', 'Snake', 'Star', 'E', 'Flower', 'E')(E = Empty)Target State:
Snake Star Flower (Empty) Sun (Empty) Leaf (Empty) BellTuple representation:
('Snake', 'Star', 'Flower', 'E', 'Sun', 'E', 'Leaf', 'E', 'Bell')
- BFS Algorithm:
- Create a queue and add the initial state with 0 moves:
queue = [ (initial_state, 0) ] - Create a set to store visited states to avoid cycles:
visited = {initial_state} - While the queue is not empty:
- Dequeue the current state and its move count:
current_state, moves = queue.pop(0) - If
current_stateis thetarget_state, returnmoves. - Find all possible next states by moving a tile into an adjacent empty space.
- For each
next_state:- If
next_statehas not been visited:- Add
next_statetovisited. - Enqueue
(next_state, moves + 1).
- Add
- If
- Dequeue the current state and its move count:
- Create a queue and add the initial state with 0 moves:
- Generating Next States:
- Find the index (0-8) of each empty square ('E') in the current state tuple.
- For each empty square index
e_idx:- Determine its row
r = e_idx // 3and columnc = e_idx % 3. - Consider its orthogonal neighbors (up, down, left, right):
(r-1, c),(r+1, c),(r, c-1),(r, c+1). - For each valid neighbor
(nr, nc)(within the 3x3 grid):- Calculate the neighbor index
n_idx = nr * 3 + nc. - Create the
next_stateby swapping the elements ate_idxandn_idxin thecurrent_statetuple. - Yield this
next_state.
- Calculate the neighbor index
- Determine its row
- Execution (Conceptual):
- Start with the initial state at level 0.
- Find all states reachable in 1 move (level 1).
- Find all new states reachable from level 1 states in 1 move (level 2).
- Continue level by level until the target state is found.
Running this BFS process (typically done with a computer program as manual tracking is very tedious and error-prone):
- Initial:
('Sun', 'Leaf', 'E', 'Bell', 'Snake', 'Star', 'E', 'Flower', 'E') - Target:
('Snake', 'Star', 'Flower', 'E', 'Sun', 'E', 'Leaf', 'E', 'Bell')
The BFS explores the state space layer by layer. Level 0: 1 state Level 1: 5 unique states Level 2: ... ...
Upon running a BFS solver for this specific puzzle configuration, the target state is first reached at 23 moves.
Final Answer: The final answer is
comment by Eli Tyre (elityre) · 2025-04-17T19:15:37.160Z · LW(p) · GW(p)
implies that they would also be inable to deal with the kind of novelty that an AGI would by definition need to deal with.
I guess this is technically true, because of the "General" in "AGI". But I this doesn't imply as much about how dangerous future LLM-based AI systems will be.
The first Strategically Superhuman [LW · GW] AI systems might be importantly less general than humans, but still shockingly competent in the many specific domains on which they've been trained. An AI might make many basic reasoning failures in domains that are not represented in the training setup, but still be superhumanly persuasive and superhumanly strategic in comettive contexts.
This is especially the case if one of the specialized domains in which the AI is competent, is identifying domains in which it is weak, and then constructing datasets / training environments to learn those domains.
↑ comment by Kaj_Sotala · 2025-04-17T20:22:40.229Z · LW(p) · GW(p)
Yeah, I could imagine an AI being superhuman in some narrow but important domain like persuasion, cybersecurity, or bioweapons despite this. Intuitively that feels like it wouldn't be enough to take over the world, but it could possibly still fail in a way that took humanity down with it.
Replies from: elityre↑ comment by Eli Tyre (elityre) · 2025-04-17T20:32:13.307Z · LW(p) · GW(p)
I'm not sure that I share that intuition, I think because my background model of humans has them as much less general than I imagine yours does.
↑ comment by Kaj_Sotala · 2025-04-18T05:14:31.198Z · LW(p) · GW(p)
To make it a bit more explicit:
- If you are superintelligent in the bioweapon domain: seems pretty obvious why that wouldn't let you take over the world. Sure maybe you can get all the humans killed, but unless automation also advances very substantially, this will leave nobody to maintain the infrastructure that you need to run.
- Cybersecurity: if you just crash all the digital infrastructure, then similar. If you try to run some scheme where you extort humans to get what you want, expect humans to fight back, and then you are quickly in a very novel situation and the kind of a "world war" nobody has ever seen before.
- Persuasion: depends on what we take the limits of persuasion to be. If it's possible to completely take over the mind of anyone by speaking ten words to them then sure, you win. But if we look at humans, great persuaders often aren't persuasive to everyone - rather they appeal very strongly to a segment of the population that happens to respond to a particular message while turning others off. (Trump, Eliezer, most politicians.) This strategy will get you part of the population while polarizing the rest against you and then you need more than persuasion ability to figure out how to get your faction to triumph.
- If you want to run some galaxy-brained scheme where you give people inconsistent messages in order to appeal to all of them, you risk getting caught and need more than persuasion ability to make it work.
- You can also be persuasive by being generally truthful and providing people with a lot of value and doing beneficial things. One can try to fake this by doing things that look beneficial but aren't, but then you need more than persuasion ability to figure out what those would be.
- Probably the best strategy would be to keep being genuinely helpful until people trust you enough to put you in a position of power and then betray that trust. I could imagine this working. But it would be a slow strategy as it would take time to build up that level of trust, and in the meanwhile many people would want to inspect your source code etc. to verify that you are trustworthy, and you'd need to ensure that doesn't reveal anything suspicious.
comment by shash42 · 2025-04-16T12:51:20.651Z · LW(p) · GW(p)
Plug, but model mistakes have been getting more similar as capabilities increase. This also means that these correlated failures appearing now will go away together
comment by Ann (ann-brown) · 2025-04-15T16:17:25.030Z · LW(p) · GW(p)
Hey, I have a weird suggestion here:
Test weaker / smaller / less trained models on some of these capabilities, particularly ones that you would still expect to be within their capabilities even with a weaker model.
Maybe start with Mixtral-8x7B. Include Claude Haiku, out of modern ones. I'm not sure to what extent what I observed has kept pace with AI development, and distilled models might be different, and 'overtrained' models might be different.
However, when testing for RAG ability, quite some time ago in AI time, I noticed a capacity for epistemic humility/deference that was apparently more present in mid-sized models than larger ones. My tentative hypothesis was that this had something to do with stronger/sharper priors held in larger models, interfering somewhat with their ability to hold a counterfactual well. ("London is the capital of France" given in RAG context retrieval being the specific little test in that case.)
This is only applicable to some of the failure modes you've described, but since I've seen overall "smartness" actively work against the capability of the model in some situations that need more of a workhorse, it seemed worth mentioning. Not all capabilities are on the obvious frontier.
comment by adamant (ada) · 2025-04-18T08:11:40.850Z · LW(p) · GW(p)
Very informative toy examples. Regarding this point:
> Some kind of failure of spatial reasoning (wandering items, whatever was going on with some of the sliding square chain-of-thoughts where pieces vanished)
I would strongly agree with this. I actually think the sliding block puzzle is a task which might just be easy for humans on account of our strong spatial priors. In the physical world, things move with spatial locality and two objects cannot be in the same place. For the LLM, it is trained on orders of magnitude less data to learn to represent spatial locality in text-based drawings of 2D images. In other words, basic physical reasoning priors which are second nature to us (due to many thousands of hours of training data) may not be fully imbued in the model.
I think the reason I emphasize this is because I worry that any test of generality which invokes 2D space might actually be a test of the strength of spatial priors.
I would love to hear thoughts on (a) whether spatial reasoning is needed to automate coding / get self-improving AI and (b) examples of clear LLM failures on math/logic reasoning which don't invoke a spatial reasoning prior
(+ hope this is in line with community norms -- haven't really posted on LW much!)
comment by Petropolitan (igor-2) · 2025-04-17T11:36:31.252Z · LW(p) · GW(p)
In my experience, this is a common kind of failure with LLMs - that if asked directly about how to best a solve problem, they do know the answer. But if they aren’t given that slight scaffolding, they totally fail to apply it.
The recent release of o3 and o4-mini seems to indicate that diminishing returns from scaling are forcing OpenAI into innovating with scaffolding and tool use. As an example, they demonstrated o3 parsing an image of a maze with an imgcv and then finding the solution programmatically with graph search: https://openai.com/index/thinking-with-images
I believe that it won't be hard to help reasoning models with the scaffolding you discuss and RL them to first think about which tools are most suitable, if any, before going on with actually tackling the problem. Afterwards any tasks which are easily solvable with a quick Python script won't usually be a problem, unless there's some kind of "adversarialness", "trickyness".
P. S.
And on the topic of reliability, I would recommend exploring PlatinumBench, which is a selection of hundreds of manually verified reasonably easy problems on which SOTA LLMs still don't achieve 100% accuracy. The amount of mistakes correlates very well with the actual performance of the model on real-world tasks. I personally find the commonsense reasoning benchmark Winograd WSC the most insightful, here's an example of puzzling mistakes SOTA LLMs (in this case Gemini 2.5 Pro) make in it sometimes:
**Step 6:** Determine what logically needs to be moved first given the spatial arrangement. If object A (potatoes) is below object B (flour), and you need to move things, object A must typically be moved first to get to object B or simply to clear the way.
comment by philip_b (crabman) · 2025-04-16T16:51:30.898Z · LW(p) · GW(p)
I think the first puzzle would be difficult for an average human to solve unless they are good with math. Because how would you know that your solution is optimal? You can notice a theorem that if a solution never moved any piece away from its target, then it's optimal, and then realize that this puzzle does allow such a solution, but this requires to have experience with mathematical reasoning.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2025-04-16T18:00:04.838Z · LW(p) · GW(p)
I agree that finding the optimal solution would be hard for a person who wasn't good at math. Noticing that you made an invalid move once your attention is drawn to it doesn't require you to be good at math, though. And even a person who wasn't good at math could still at least try to figure out some way to determine it, even if they still ended up failing miserably.
comment by Dalcy (Darcy) · 2025-04-16T16:37:25.498Z · LW(p) · GW(p)
By the way, Gemini 2.5 Pro and o3-mini-high is good at tic-tac-toe. I was surprised because the last time I tested this on o1-preview, it did quite terribly.