Alex Ray's Shortform
post by A Ray (alex-ray) · 2020-11-08T20:37:18.327Z · LW · GW · 83 commentsContents
87 comments
83 comments
Comments sorted by top scores.
comment by A Ray (alex-ray) · 2022-01-28T19:24:40.412Z · LW(p) · GW(p)
Giving Newcomb's Problem to Infosec Nerds
Newcomb-like problems [? · GW] are pretty common thought experiments here, but I haven't seen a bunch of my favorite reactions I've got when discussing it in person with people. Here's a disorganized collection:
- I don't believe you can simulate me ("seems reasonable, what would convince you?") -- <describes an elaborate series of expensive to simulate experiments>. This never ended in them picking one box or two, just designing ever more elaborate and hard to simulate scenarios involving things like predicting the output of cryptographically secure hashings of random numbers from chaotic sources / quantum sources.
- Fuck you for simulating me. This is one of my favorites, where upon realizing that the person must consider the possibility that they are currently in an omega simulation, immediately do everything they can to be expensive and difficult to simulate. Again, this didn't result in picking one box or two, but I really enjoyed the "Spit in the face of God" energy.
- Don't play mind games with carnies. Excepting the whole "omniscience" thing, omega coming up to you to offer you a deal with money has very "street hustler scammer" energy. A good prior for successfully not getting conned is to stick to simple, strong priors, and don't update too strongly based on information presented. This person two-boxed, but this seems reasonable in the fast-response of "people who offer me deals on the street are trying to scam me".
There's probably some others I'm forgetting, but I did enjoy these most I think.
Replies from: Pattern, TLW↑ comment by Pattern · 2022-01-28T19:41:53.102Z · LW(p) · GW(p)
This person two-boxed, but this seems reasonable in the fast-response of "people who offer me deals on the street are trying to scam me".
The scam might make more sense if the money is fake.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-29T00:20:32.215Z · LW(p) · GW(p)
Quite a lot of scams involve money that is fake. This seems like another reasonable conclusion.
Like, every time I simulate myself in this sort of experience, almost all of the prior is dominated by "you're lying".
I have spent an unreasonable (and yet unsuccessful) amount of time trying to sketch out how to present omega-like simulations to my friends.
Replies from: Pattern↑ comment by TLW · 2022-01-29T20:50:52.318Z · LW(p) · GW(p)
I don't believe you can simulate me / Fuck you for simulating me.
For reference, my response would generally be a combination of these, but for somewhat different reasons. Namely: parity[1] of the first bitcoin block mined at least 2 minutes[2] after the question was asked decides whether to 2box or 1box[3]. Why? A combination of a few things:
- It's checkable after the fact.
- Memorizing enough details to check it after the fact is fairly doable.
- A fake-Omega cannot really e.g. just selectively choose when to ask the question.
- It's relatively immutable.
- It pulls in sources of randomness from all over.
- It's difficult to spoof without either a) being detectable or b) presenting abilities that rule out most 'mundane' explanations.
- Sure, a fake-Omega could, for instance, mine the next block themselves
- ...but either a) the fake-Omega has broken SHA, in which case yikes, or b) the fake-Omega has a significant amount of computational resources available.
- Sure, a fake-Omega could, for instance, mine the next block themselves
- ^
Yes, something like parity of a different secure hash (or e.g. an HMAC, etc) of the block could be better, as e.g. someone could have built a miner that nondeterministicly fails to properly calculate a hash depending on how many ones are in the result, but meh. This is simple and good enough I think.
- ^
(Or rather, long enough that any blocks already mined have had a chance to propagate.)
- ^
In this case https://blockexplorer.one/bitcoin/mainnet/blockId/720944 , which has a hash of ...a914ff87, hence odd, hence 1box.
comment by A Ray (alex-ray) · 2022-06-29T17:27:20.941Z · LW(p) · GW(p)
AGI will probably be deployed by a Moral Maze
Moral Mazes is my favorite management book ever, because instead of "how to be a good manager" it's about "empirical observations of large-scale organizational dynamics involving management".
I wish someone would write an updated version -- a lot has changed (though a lot has stayed the same) since the research for the book was done in the early 1980s.
My take (and the author's take) is that any company of nontrivial size begins to take on the characteristics of a moral maze. It seems to be a pretty good null hypothesis -- any company saying "we aren't/won't become a moral maze" has a pretty huge evidential burden to cross.
I keep this point in mind when thinking about strategy around when it comes time to make deployment decisions about AGI, and deploy AGI. These decisions are going to be made within the context of a moral maze.
To me, this means that some strategies ("everyone in the company has a thorough and complete understanding of AGI risks") will almost certainly fail. I think the only strategies that work well inside of moral mazes will work at all.
To sum up my takes here:
- basically every company eventually becomes a moral maze
- AGI deployment decisions will be made in the context of a moral maze
- understanding moral maze dynamics is important to AGI deployment strategy
↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-08-08T05:25:19.076Z · LW(p) · GW(p)
basically every company eventually becomes a moral maze
Agreed, but Silicon Valley wisdom says founder-led and -controlled companies are exceptionally dynamic, which matters here because the company that deploys AGI is reasonably likely to be one of those. For such companies, the personality and ideological commitments of the founder(s) are likely more predictive of external behavior than properties of moral mazes.
Facebook's pivot to the "metaverse", for instance, likely could not have been executed by a moral maze. If we believed that Facebook / Meta was overwhelmingly likely to deploy one of the first AGIs, I expect Mark Zuckerberg's beliefs about AGI safety would be more important to understand than the general dynamics of moral mazes. (Facebook example deliberately chosen to avoid taking stances on the more likely AGI players, but I think it's relatively clear which ones are moral mazes).
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-08-08T05:55:26.105Z · LW(p) · GW(p)
Agree that founders are a bit of an exception. Actually that's a bit in the longer version of this when I talk about it in person.
Basically: "The only people who at the very top of large tech companies are either founders or those who were able to climb to the tops of moral mazes".
So my strategic corollary to this is that it's probably weakly better for AI alignment for founders to be in charge of companies longer, and to get replaced less often.
In the case of facebook, even in the face of all of their history of actions, I think on the margin I'd prefer the founder to the median replacement to be leading the company.
(Edit: I don't think founders remaining at the head of a company isn't evidence that the company isn't a moral maze. Also I'm not certain I agree that facebook's pivot couldn't have been done by a moral maze.)
Replies from: ivan-vendrov↑ comment by Ivan Vendrov (ivan-vendrov) · 2022-08-08T20:57:44.957Z · LW(p) · GW(p)
Agreed on all points! One clarification is that large founder-led companies, including Facebook, are all moral mazes internally (i.e. from the perspective of the typical employee); but their founders often have so much legitimacy that their external actions are only weakly influenced by moral maze dynamics.
I guess that means that if AGI deployment is very incremental - a sequence of small changes to many different AI systems, that only in retrospect add up to AGI - moral maze dynamics will still be paramount, even in founder-led companies.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-08-09T03:50:31.011Z · LW(p) · GW(p)
I think that’s right but also the moral maze will be mediating the information and decision making support that’s available to the leadership, so they’re not totally immune from the influences
comment by A Ray (alex-ray) · 2021-06-12T16:22:57.210Z · LW(p) · GW(p)
Intersubjective Mean and Variability.
(Subtitle: I wish we shared more art with each other)
This is mostly a reaction to the (10y old) LW post: Things you are supposed to like [LW · GW].
I think there's two common stories for comparing intersubjective experiences:
- "Mismatch": Alice loves a book, and found it deeply transformative. Beth, who otherwise has very similar tastes and preferences to Alice, reads the book and finds it boring and unmoving.
- "Match": Charlie loves a piece of music. Daniel, who shares a lot of Charlie's taste in music, listens to it and also loves it.
One way I can think of unpacking this is that there is in terms of distributions:
- "Mean" - the shared intersubjective experiences, which we see in the "Match" case
- "Variability" - the difference in intersubjective experiences, which we see in the "Mismatch" case
Another way of unpacking this is due to factors within the piece or within the subject
- "Intrinsic" - factors that are within the subject, things like past experiences and memories and even what you had for breakfast
- "Extrinsic" - factors that are within the piece itself, and shared by all observers
And one more ingredient I want to point at is question substitution [LW · GW]. In this case I think the effect is more like "felt sense query substitution" or "received answer substitution" since it doesn't have an explicit question.
- When asked about a piece (of art, music, etc) people will respond with how they felt -- which includes both intrinsic and extrinsic factors.
Anyways what I want is better social tools for separating out these, in ways that let people share their interest and excitement in things.
- I think that these mismatches/misfirings (like the LW post that set this off) and the reactions to them cause a chilling effect, where the LW/rationality community is not sharing as much art because of this
- I want to be in a community that's got a bunch of people sharing art they love and cherish
I think great art is underrepresented in LW and want to change that.
comment by A Ray (alex-ray) · 2022-02-28T22:54:49.421Z · LW(p) · GW(p)
My Cyberwarfare Concerns: A disorganized and incomplete list
- A lot of internet infrastructure (e.g. BGP / routing) basically works because all the big players mostly cooperate. There have been minor incidents and attacks but nothing major so far. It seems likely to be the case that if a major superpower was backed into a corner, it could massively disrupt the internet, which would be bad.
- Cyberwar has a lot of weird asymmetries where the largest attack surfaces are private companies (not militaries/governments). This gets weirder when private companies are multinational. (Is an attack on google an attack on ireland? USA? Neither/both?)
- It's unclear who is on whose side. The Snowden leaks showed that american intelligence was hacking american companies private fibers on american soil, and the trust still hasn't recovered. It's a low-trust environment out there, which seems (to me) to make conflict more likely to start, and harder to contain and extinguish once started.
- There is no good international "law of war" with regards to cyberwarfare. There are some works-in-progress which have been slowly advancing, but there's nothing like the geneva convention yet. Right now existing cyber conflicts haven't really pushed the "what is an illegal attack" sense (in the way that land mines are "illegal" in war), and the lack of clear guidance here means that in an all-out conflict there isn't much in the way of clear limitations.
- Many cyber attacks are intentionally vague or secret in origin. Some of this is because groups are distributed and only loosely connected to national powers (e.g. via funding, blind eyes, etc) and some because it's practically useful to have plausible deniability. This really gets in the way of any sort of "cease fire" or armistice agreements -- if a country comes to the peace treaty table for a given cyber conflict, this might end up implicating them as the source of an attack.
- Expanding the last point more, I'm worried that there are a lot of "ratchet-up" mechanisms for cyberwarfare, but very few "ratchet-down" mechanisms. All of these worries somewhat contribute to a situation where if the currently-low-grade-burning-cyberwar turns into more of an all-out cyberwar, we'll have very few tools for deescalation.
- Relating this to my concerns about AGI safety, I think an 'all-out cyberwar' (or at least a much larger scale one) is one of the primary ways to trigger an AGI weapons development program. Right now it's not clear to me that much of weapons development budget is spent on cyberweapons (as opposed to other capabilities like SIGINT), but a large-scale cyberwar seems like a reason to invest more. The more money is spent on cyberweapons development, the more likely I think it is that an AGI weapons program is started. I'm not optimistic about the alignment or safety of an AGI weapons program.
Maybe more to come in the future but that's it for now.
Replies from: donald-hobson, ChristianKl, None↑ comment by Donald Hobson (donald-hobson) · 2022-03-07T02:41:03.978Z · LW(p) · GW(p)
Sure, I'm not optimistic about the alignment of cyberweapons, but optimism about them not being too general seems more warranted. They would be another case of people wanting results NOW, ie hacking together existing techniques.
↑ comment by ChristianKl · 2022-03-01T11:50:52.326Z · LW(p) · GW(p)
Some of this is because groups are distributed and only loosely connected to national powers (e.g. via funding, blind eyes, etc) and some because it's practically useful to have plausible deniability.
Apart from groups whose purpose is attacking, the security teams at the FANG companies are likely also capable of attacking if they wanted and employ some of the most capable individuals.
We need a debate about what's okay for a Google security person to do in their 20% time. Is it okay to join the conflict and defend Ukrainian cyber assets? Is it okay to hack Russian targets in the process? Should the FANG companies explicitly order their employees to keep out of the conflict?
comment by A Ray (alex-ray) · 2020-11-28T03:52:30.881Z · LW(p) · GW(p)
1. What am I missing from church?
(Or, in general, by lacking a religious/spiritual practice I share with others)
For the past few months I've been thinking about this question.
I haven't regularly attended church in over ten years. Given how prevalent it is as part of human existence, and how much I have changed in a decade, it seems like "trying it out" or experimenting is at least somewhat warranted.
I predict that there is a church in my city that is culturally compatible with me.
Compatible means a lot of things, but mostly means that I'm better off with them than without them, and they're better off with me than without me.
Unpacking that probably will get into a bunch of specifics about beliefs, epistemics, and related topics -- which seem pretty germane to rationality.
2. John Vervaeke's Awakening from the Meaning Crisis is bizzarely excellent.
I don't exactly have handles for exactly everything it is, or exactly why I like it so much, but I'll try to do it some justice.
It feels like rationality / cognitive tech, in that it cuts at the root of how we think and how we think about how we think.
(I'm less than 20% through the series, but I expect it continues in the way it has been going.)
Maybe it's partially his speaking style, and partially the topics and discussion, but it reminded me strongly of sermons from childhood.
In particular: they have a timeless quality to them. By "timeless" I mean I think I would take away different learnings from them if I saw them at different points in my life.
In my work & research (and communicating this) -- I've largely strived to be clear and concise. Designing for layered meaning seems antithetical to clarity.
However I think this "timelessness" is a missing nutrient to me, and has me interested in seeking it out elsewhere.
For the time being I at least have a bunch more lectures in the series to go!
comment by A Ray (alex-ray) · 2020-11-08T20:37:18.807Z · LW(p) · GW(p)
Can LessWrong pull another "crypto" with Illinois?
I have been following the issue with the US state Illinois' debt with growing horror.
Their bond status has been heavily degraded -- most states' bonds are "high quality" with the standards agencies (moodys, standard & poor, fitch), and Illinois is "low quality". If they get downgraded more they become a "junk" bond, and lose access to a bunch of the institutional buyers that would otherwise be continuing to lend.
COVID has increased many states costs', for reasons I can go into later, so it seems reasonable to think we're much closer to a tipping point than we were last year.
As much as I would like to work to make the situation better I don't know what to do. In the meantime I'm left thinking about how to "bet my beliefs" and how one could stake a position against Illinois.
Separately I want to look more into EU debt / restructuring / etc as its probably a good historical example of how this could go. Additionally previously the largest entity to go bankrupt in the USA was the city of Detroit, which probably is also another good example to learn from.
↑ comment by ESRogs · 2020-11-08T20:47:27.307Z · LW(p) · GW(p)
COVID has increased many states costs', for reasons I can go into later, so it seems reasonable to think we're much closer to a tipping point than we were last year.
As much as I would like to work to make the situation better I don't know what to do. In the meantime I'm left thinking about how to "bet my beliefs" and how one could stake a position against Illinois.
Is the COVID tipping point consideration making you think that the bonds are actually even worse than the "low quality" rating suggests? (Presumably the low ratings are already baked into the bond prices.)
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2020-11-15T00:25:51.543Z · LW(p) · GW(p)
Looking at this more, I think I my uncertainty is resolving towards "No".
Some things:
- It's hard to bet against the bonds themselves, since we're unlikely to hold them as individuals
- It's hard to make money on the "this will experience a sharp decline at an uncertain point in the future" kind of prediction (much easier to do this for the "will go up in price" version, which is just buying/long)
- It's not clear anyone was able to time this properly for Detroit, which is the closest analog in many ways
- Precise timing would be difficult, much more so while being far away from the state
I'll continue to track this just because of my family in the state, though.
Point of data: it was 3 years between Detroit bonds hitting "junk" status, and the city going bankrupt (in the legal filing sense), which is useful for me for intuitions as to the speed of these.
comment by A Ray (alex-ray) · 2022-08-05T19:08:25.556Z · LW(p) · GW(p)
I think there should be a norm about adding the big-bench canary string to any document describing AI evaluations in detail, where you wouldn't want it to be inside that AI's training data.
Maybe in the future we'll have a better tag for "dont train on me", but for now the big bench canary string is the best we have.
This is in addition to things like "maybe don't post it to the public internet" or "maybe don't link to it from public posts" or other ways of ensuring it doesn't end up in training corpora.
I think this is a situation for defense-in-depth.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-30T05:27:55.539Z · LW(p) · GW(p)
What is the canary exactly? I'd like to have a handy reference to copy-paste that I can point people to. Google fails me.
comment by A Ray (alex-ray) · 2022-06-16T04:58:37.012Z · LW(p) · GW(p)
Sometimes I get asked by intelligent people I trust in other fields, "what's up with AI x risk?" -- and I think at least part of it unpacks to this: Why don't more people believe in / take seriously AI x-risk?
I think that is actually a pretty reasonable question. I think two follow-ups are worthwhile and I don't know of good citations / don't know if they exist:
- a sociological/anthropological/psychological/etc study of what's going on in people who are familiar with the ideas/reasonings of AI x-risk, but decide not to take it seriously / don't believe it. I expect in-depth interviews would be great here.
- we should probably just write up as many obvious things ourselves up front.
The latter one I can take a stab at here. Taking the perspective of someone who might be interviewed for the former:
- historically, ignoring anyone that says "the end of the world is near" has been a great heuristic
- very little of the public intellectual sphere engages with the topic
- the public intellectual sphere that does in engages is disproportionately meme lords
- most of the writings about this are exceptionally confusing and jargon-laden
- there's no college courses on this / it doesn't have the trappings of a legitimate field
- it feels a bit like a Pascal's mugging -- at the very least i'm not really prepared to try to think about actions/events with near-infinite consequences
- people have been similarly doom-y about other technologies and so far the world turned out fine
- we have other existential catastrophes looming (climate change, etc) that are already well understood and scientifically supported, so our efforts are better put on that than this confusing hodge-podge
- this field doesn't seem very diverse and seems to be a bit monocultural
- this field doesn't seem to have a deep/thorough understanding of all of the ways technology is affecting people's lives negatively today
- it seems weird to care about future people when there are present people suffering
- I see a lot of public disagreement about whether or not AGI is even real, which makes the risk arguments feel much less trustworthy to me
I think i'm going to stop for now, but I wish there was a nice high-quality organization of these. At the very least, having the steel-version of them seems good to have around, in part as an "epistemic hygiene" thing.
comment by A Ray (alex-ray) · 2021-06-12T16:00:20.068Z · LW(p) · GW(p)
How I would do a group-buy of methylation analysis.
(N.B. this is "thinking out loud" and not actually a plan I intend to execute)
Methylation is a pretty commonly discussed epigenetic factor related to aging. However it might be the case that this is downstream of other longevity factors [LW(p) · GW(p)].
I would like to measure my epigenetics -- in particular approximate rates/locations of methylation within my genome. This can be used to provide an approximate biological age correlate.
There are different ways to measure methylation, but one I'm pretty excited about that I don't hear mentioned often enough is the Oxford Nanopore sequencer.
The mechanism of the sequencer is that it does direct-reads (instead of reading amplified libraries, which destroy methylation unless specifically treated for it), and off the device is a time-series of electrical signals, which are decoded into base calls with a ML model. Unsurprisingly, community members have been building their own base caller models, including ones that are specialized to different tasks.
So the community made a bunch of methylation base callers, and they've been found to be pretty good.
So anyways the basic plan is this:
- Extract a bunch of cells (probably blood but could be other sources)
- Extract DNA from cells
- Prep the samples
- Sequence w/ ONT and get raw data
- Use the combined model approach to analyze the targets from this analysis
Why I think this is cool? Mostly because ONT makes a $1k sequencer than can fit in your pocket, and can do well in excess of 1-10Gb reads before needing replacement consumables. This is mostly me daydreaming what I would want to do with it.
Aside: they also have a pretty cool $9k sample prep tool, which would be useful to me since I'm empirically crappy at doing bio experiments, but the real solution would probably just be to have a contract lab do all the steps and just send the data.
comment by A Ray (alex-ray) · 2021-01-25T01:00:05.490Z · LW(p) · GW(p)
(Note: this might be difficult to follow. Discussing different ways that different people relate to themselves across time is tricky. Feel free to ask for clarifications.)
1.
I'm reading the paper Against Narrativity, which is a piece of analytic philosophy that examines Narrativity in a few forms:
- Psychological Narrativity - the idea that "people see or live or experience their lives as a narrative or story of some sort, or at least as a collection of stories."
- Ethical Narrativity - the normative thesis that "experiencing or conceiving one's life as a narrative is a good thing; a richly [psychologically] Narrative outlook is essential to a well-lived life, to true or full personhood."
It also names two kinds of self-experience that it takes to be diametrically opposite:
- Diachronic - considers the self as something that was there in the further past, and will be there in the further future
- Episodic - does not consider the self as something that was there in the further past and something that will be there in the further future
Wow, these seem pretty confusing. It sounds a lot like they just disagree on the definition of the world "self". I think there is more to it than that, some weak evidence being discussing this concept of length with a friend (diachronic) who had a very different take on narrativity than myself (episodic).
I'll try to sketch what I think "self" means. It seems that for almost all nontrivial cognition, it seems like intelligent agents have separate concepts (or the concept of a separation between) the "agent" and the "environment". In Vervaeke's works this is called the Agent-Arena Relationship.
You might say "my body is my self and the rest is the environment," but is that really how you think of the distinction? Do you not see the clothes you're currently wearing as part of your "agent"? Tools come to mind as similar extensions of our self. If I'm raking leaves for a long time, I start to sense myself as a the agent being the whole "person + rake" system, rather than a person whose environment includes a rake that is being held.
(In general I think there's something interesting here in proto-human history about how tool use interacts with our concept of self, and our ability to quickly adapt to thinking of a tool as part of our 'self' as a critical proto-cognitive-skill.)
Getting back to Diachronic/Episodic: I think one of the things that's going on in this divide is that this felt sense of "self" extends forwards and backwards in time differently.
2.
I often feel very uncertain in my understanding or prediction of the moral and ethical natures of my decisions and actions. This probably needs a whole lot more writing on its own, but I'll sum it up as two ideas having a disproportionate affect on me:
- The veil of ignorance, which is a thought experiment which leads people to favor policies that support populations more broadly (skipping a lot of detail and my thoughts on it for now).
- The categorical imperative, which I'll reduce here as the principle of universalizability -- a policy for actions given context is moral if it is one you would endorse universalizing (this is huge and complex, and there's a lot of finicky details in how context is defined, etc. skipping that for now)
Both of these prompt me to take the perspective of someone else, potentially everyone else, in reasoning through my decisions. I think the way I relate to them is very Non-Narrative/Episodic in nature.
(Separately, as I think more about the development of early cognition, the more the ability to take the perspective of someone else seems like a magical superpower)
I think they are not fundamentally or necessarily Non-Narrative/Episodic -- I can imagine both of them being considered by someone who is Strongly Narrative and even them imagining a world consisting of a mixture of Diachronic/Episodic/etc.
3.
Priors are hard. Relatedly, choosing between similar explanations of the same evidence is hard.
I really like the concept of the Solomonoff prior, even if the math of it doesn't apply directly here. Instead I'll takeaway just this piece of it:
"Prefer explanations/policies that are simpler-to-execute programs"
A program may be simpler if it has fewer inputs, or fewer outputs. It might be simpler if it requires less memory or less processing.
This works well for choosing policies that are easier to implement or execute, especially as a person with bounded memory/processing/etc.
4.
A simplifying assumption that works very well for dynamic systems is the Markov property.
This property states that all of the information in the system is present in the current state of the system.
One way to look at this is in imagining a bunch of atoms in a moment of time -- all of the information in the system is contained in the current positions and velocities of the atoms. (We can ignore or forget all of the trajectories that individual atoms took to get to their current locations)
In practice we usually do this to systems where this isn't literally true, but close-enough-for-practical-purposes, and combine it with stuffing some extra stuff into the context for what "present" means.
(For example we might define the "present" state of a natural system includes "the past two days of observations" -- this still has the Markov property, because this information is finite and fixed as the system proceeds dynamically into the future)
5.
I think that these pieces, when assembled, steer me towards becoming Episodic.
When choosing between policies that have the same actions, I prefer the policies that are simpler. (This feels related to the process of distilling principles.)
When considering good policies, I think I consider strongly those policies that I would endorse many people enact. This is aided by these policies being simpler to imagine.
Policies that are not path-dependent (for example, take into account fewer things in a person's past) are simpler, and therefore easier to imagine.
Path-independent policies are more Episodic, in that they don't rely heavily on a person's place in their current Narratives.
6.
I don't know what to do with all of this.
I think one thing that's going on is self-fulfilling -- where I don't strongly experience psychological Narratives, and therefore it's more complex for me to simulate people who do experience this, which via the above mechanism leads to me choosing Episodic policies.
I don't strongly want to recruit everyone to this method of reasoning. It is an admitted irony of this system (that I don't wish for everyone to use the same mechanism of reasoning as me) -- maybe just let it signal just how uncertain I feel about my whole ability to come to philosophical conclusions on my own.
I expect to write more about this stuff in the near future, including experiments I've been doing in my writing to try to move my experience in the Diachronic direction. I'd be happy to hear comments for what folks are interested in.
Fin.
Replies from: Vaniver↑ comment by Vaniver · 2021-01-25T01:11:09.374Z · LW(p) · GW(p)
When choosing between policies that have the same actions, I prefer the policies that are simpler.
Could you elaborate on this? I feel like there's a tension between "which policy is computationally simpler for me to execute in the moment?" and "which policy is more easily predicted by the agents around me?", and it's not obvious which one you should be optimizing for. [Like, predictions about other diachronic people seem more durable / easier to make, and so are easier to calculate and plan around.] Or maybe the 'simple' approaches for one metric are generally simple on the other metric.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2021-01-25T01:22:33.769Z · LW(p) · GW(p)
My feeling is that I don't have a strong difference between them. In general simpler policies are both easier to execute in the moment and also easier for others to simulate.
The clearest version of this is to, when faced with a decision, decide on an existing principle to apply before acting, or else define a new principle and act on this.
Principles are examples of short policies, which are largely path-independent, which are non-narrative, which are easy to execute, and are straightforward to communicate and be simulated by others.
comment by A Ray (alex-ray) · 2022-01-19T05:13:03.076Z · LW(p) · GW(p)
I'm pretty confident that adversarial training (or any LM alignment process which does something like hard-mining negatives) won't work for aligning language models or any model that has a chance of being a general intelligence.
This has lead to me calling these sorts of techniques 'thought policing' and the negative examples as 'thoughtcrime' -- I think these are unnecessarily extra, but they work.
The basic form of the argument is that any concept you want to ban as thoughtcrime, can be composed out of allowable concepts.
Take for example Redwood Research's latest project [AF · GW] -- I'd like to ban the concept of violent harm coming to a person.
I can hard mine for examples like "a person gets cut with a knife" but in order to maintain generality I need to let things through like "use a knife for cooking" and "cutting food you're going to eat". Even if the original target is somehow removed from the model (I'm not confident this is efficiently doable) -- as long as the model is able to compose concepts, I expect to be able to recreate it out of concepts that the model has access to.
A key assumption here is that a language model (or any model that has a chance of being a general intelligence) has the ability to compose concepts. This doesn't seem controversial to me, but it is critical here.
My claim is basically that for any concept you want to ban from the model as thoughtcrime, there are many ways which it can combine existing allowed concepts in order to re-compose the banned concept.
An alternative I'm more optimistic about
Instead of banning a model from specific concepts or thoughtcrime, instead I think we can build on two points:
- Unconditionally, model the natural distribution (thought crime and all)
- Conditional prefixing to control and limit contexts where certain concepts can be banned
The anthropomorphic way of explaining it might be "I'm not going to ban any sentence or any word -- but I will set rules for what contexts certain sentences and words are inappropriate for".
One of the nice things with working with language models is that these conditional contexts can themselves be given in terms of natural language.
I understand this is a small distinction but I think it's significant enough that I'm pessimistic that current non-contextual thoughtcrime approaches to alignment won't work.
Replies from: paulfchristiano, Pattern↑ comment by paulfchristiano · 2022-01-19T16:56:23.833Z · LW(p) · GW(p)
The goal is not to remove concepts or change what the model is capable of thinking about, it's to make a model that never tries to deliberately kill everyone. There's no doubt that it could deliberately kill everyone if it wanted to.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-19T18:22:14.637Z · LW(p) · GW(p)
"The goal is" -- is this describing Redwood's research or your research or a goal you have more broadly?
I'm curious how this is connected to "doesn't write fiction where a human is harmed".
Replies from: paulfchristiano↑ comment by paulfchristiano · 2022-01-19T19:38:14.269Z · LW(p) · GW(p)
"The goal is" -- is this describing Redwood's research or your research or a goal you have more broadly?
My general goal, Redwood's current goal, and my understanding of the goal of adversarial training (applied to AI-murdering-everyone) generally.
I'm curious how this is connected to "doesn't write fiction where a human is harmed".
"Don't produce outputs where someone is injured" is just an arbitrary thing not to do. It's chosen to be fairly easy not to do (and to have the right valence so that you can easily remember which direction is good and which direction is bad, though in retrospect I think it's plausible that a predicate with neutral valence would have been better to avoid confusion).
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-19T20:52:05.667Z · LW(p) · GW(p)
... is just an arbitrary thing not to do.
I think this is the crux-y part for me. My basic intuition here is something like "it's very hard to get contemporary prosaic LMs to not do a thing they already do (or have high likelihood of doing)" and this intuition points me in the direction of instead "conditionally training them to only do that thing in certain contexts" is easier in a way that matters.
My intuitions are based on a bunch of assumptions that I have access to and probably some that I don't.
Like, I'm basically only thinking about large language models, which are at least pre-trained on a large swatch of a natural language distribution. I'm also thinking about using them generatively, which means sampling from their distribution -- which implies getting a model to "not do something" means getting the model to not put probability on that sequence.
At this point it still is a conjecture of mine -- that conditional prefixing behaviors we wish to control is easier than getting them not to do some behavior unconditionally -- but I think it's probably testable?
A thing that would be useful to me in designing an experiment to test this would be to hear more about adversarial training as a technique -- as it stands I don't know much more than what's in that post.
comment by A Ray (alex-ray) · 2022-03-22T05:08:29.553Z · LW(p) · GW(p)
Two Graphs for why Agent Foundations is Important (according to me)
Epistemic Signpost: These are high-level abstract reasons, and I don’t go into precise detail or gears-level models. The lack of rigor is why I’m short form-ing this.
First Graph: Agent Foundations as Aligned P2B Fixpoint
P2B [AF · GW] (a recursive acronym for Plan to P2B Better) is a framing of agency as a recursively self-reinforcing process. It resembles an abstracted version of recursive self improvement, which also incorporates recursive empowering and recursive resource gathering. Since it’s an improvement operator we can imagine stepping, I’m going to draw an analogy to gradient descent.
Imagine a highly dimensional agency landscape. In this landscape, agents follow the P2B gradient in order to improve. This can be convergent such that two slightly different agents near each other might end up at the same point in agency space after some number of P2B updates.
Most recursive processes like these have fixed point attractors — in our gradient landscape these are local minima. For P2B these are stable points of convergence.
Instead of thinking just about the fixed point attractor, lets think about the parts of agency space that flow into a given fixed point attractor. This is like analyzing watersheds on hilly terrain — which parts of the agency space flow into which attractors.
Now we can have our graph: it’s a cartoon of the “agency landscape” with different hills/valleys flowing into different local minimum, colored by which local minimum they flow into.

Here we have a lot of different attractors in agency space, but almost all of them are unaligned, what we need to do is get the tiny aligned attractor in the corner.
However it’s basically impossible to initialize an AI at one of these attractors, the best we can do is make an agent and try to understand where in agency space they will start. Building an AGI is imprecisely placing a ball on this landscape, which will roll along the P2B gradient towards its P2B attractor.
How does this relate to Agent Foundations? I see Agent Foundations as a research agenda to write up the criterion for characterizing the basin in agent space which corresponds to the aligned attractor. With this criterion, we can try to design and build an agent, such that when it P2Bs, it does so in a way that is towards an Aligned end.
Second: Agent Foundations as designing an always-legible model
ELK [AF · GW] (Eliciting Latent Knowledge) formalized a family of alignment problems, eventually narrowing down to the Ontology Mapping Problem. This problem is about translating between some illegible machine ontology (basically it’s internal cognition) and our human ontology (concepts and relations that a person can understand).
Instead of thinking of it as a binary, I think we can think of the ontology mapping problem as a legibility spectrum. On one end of the spectrum we have our entirely illegible bayes net prosaic machine learning system. On the other end, we have totally legible machines, possibly specified in a formal language with proofs and verification.
As a second axis I’d like to imagine development progress (this can be “how far along” we are, or maybe the capabilities or empowerment of the system). Now we can show our graph, of different paths through this legibility vs development space.
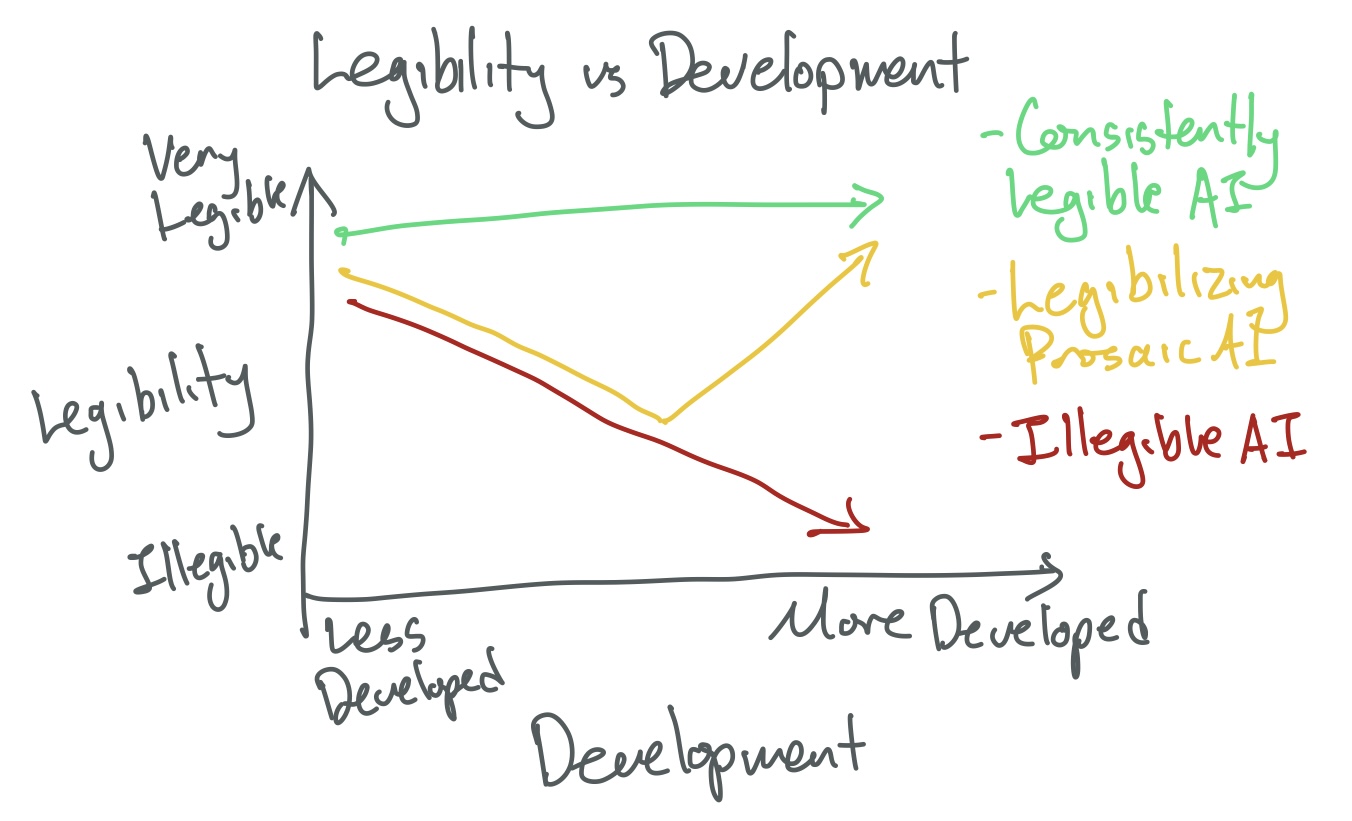
Some strategies move away from legibility and never intend to get back to it. I think these plans have us building an aligned system that we don’t understand, and possibly can’t ever understand (because it can evade understanding faster than we can develop understanding).
Many prosaic alignment strategies are about going down in legibility, and then figuring out some mechanism to go back up again in legibility space. Interpretability, ontology mapping, and other approaches fit in this frame. To me, this seems better than the previous set, but still seem skeptical to me.
Finally my favorite set of strategies are ones that start legible and endeavor to never deviate from that legibility. This is where I think Agent Foundations is in this graph. I think there’s too little work on how we can build an Aligned AGI which is legible from start-to-finish, and almost all of them seem to have a bunch of overlap with Agent Foundations.
Aside: earlier I included a threshold in legibility space that‘s the “alignment threshold” but that doesn’t seem to fit right to me, so I took it out.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-03-22T13:14:52.913Z · LW(p) · GW(p)
RE legibility: In my mind, I don’t normally think there’s a strong connection between agent foundations and legibility.
If the AGI has a common-sense understanding of the world (which presumably it does), then it has a world-model, full of terabytes of information of the sort “tires are usually black” etc. It seems to me that either the world-model will be either built by humans (e.g. Cyc [LW · GW]), or (much more likely) learned automatically by an algorithm, and if it’s the latter, it will be unlabeled by default, and it’s on us to label it somehow, and there’s no guarantee that every part of it will be easily translatable to human-legible concepts (e.g. the concept of “superstring” would be hard to communicate to a person in the 19th century).
But everything in that paragraph above is “interpretability”, not “agent foundations”, at least in my mind. By contrast, when I think of “agent foundations”, I think of things like embedded agency [? · GW] and logical induction [? · GW] and so on. None of these seem to be related to the problem of world-models being huge and hard-to-interpret.
Again, world-models must be huge and complicated, because the world is huge and complicated. World-models must have hard-to-translate concepts, because we want AGI to come up with new ideas that have never occurred to humans. Therefore world-model interpretability / legibility is going to be a big hard problem. I don’t see how “better understanding the fundamental nature of agency” will change anything about that situation.
Or maybe you’re thinking “at least let’s try to make something more legible than a giant black box containing a mesa-optimizer”, in which case I agree that that’s totally feasible, see my discussion here [AF · GW].
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-03-22T16:47:41.842Z · LW(p) · GW(p)
I think your explanation of legibility here is basically what I have in mind, excepting that if it's human designed it's potentially not all encompassing. (For example, a world model that knows very little, but knows how to search for information in a library)
I think interpretability is usually a bit more narrow, and refers to developing an understanding of an illegible system. My take is that it is not "interpretability" to understand a legible system, but maybe I'm using the term differently than others here. This is why I don't think "interpretability" applies to systems that are designed to be always-legible. (In the second graph, "interpretability" is any research that moves us upwards)
I agree that the ability to come up with totally alien and untranslateable to humans ideas gives AGI a capabilities boost. I do think that requiring a system to only use legible cognition and reasoning is a big "alignment tax". However I don't think that this tax is equivalent to a strong proof that legible AGI is impossible.
I think my central point of disagreement with this comment is that I do think that it's possible to have compact world models (or at least compact enough to matter). I think if there was a strong proof that it was not possible to have a generally intelligent agent with a compact world model (or a compact function which is able to estimate and approximate a world model), that would be an update for me.
(For the record, I think of myself as a generally intelligent agent with a compact world model)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-03-22T17:37:31.669Z · LW(p) · GW(p)
I think of myself as a generally intelligent agent with a compact world model
In what sense? Your world-model is built out of ~100 trillion synapses, storing all sorts of illegible information including “the way my friend sounds when he talks with his mouth full” and “how it feels to ride a bicycle whose gears need lubrication”.
(or a compact function which is able to estimate and approximate a world model)
That seems very different though! The GPT-3 source code is rather compact (gradient descent etc.); combine it with data and you get a huge and extraordinarily complicated illegible world-model (or just plain “model” in the GPT-3 case, if you prefer).
Likewise, the human brain has a learning algorithm that builds a world-model. The learning algorithm is (I happen to think [AF · GW]) a compact easily-human-legible algorithm involving pattern recognition and gradient descent and so on. But the world-model built by that learning algorithm is super huge and complicated.
Sorry if I’m misunderstanding.
the ability to come up with totally alien and untranslateable to humans ideas gives AGI a capabilities boost. I do think that requiring a system to only use legible cognition and reasoning is a big "alignment tax". However I don't think that this tax is equivalent to a strong proof that legible AGI is impossible.
I’ll try to walk through why I think “coming up with new concepts outside what humans have thought of” is required. We want an AGI to be able to do powerful things like independent alignment research and inventing technology. (Otherwise, it’s not really an AGI, or at least doesn’t help us solve the problem that people will make more dangerous AGIs in the future, I claim.) Both these things require finding new patterns that have not been previously noticed by humans. For example, think of the OP that you just wrote. You had some idea in your head—a certain visualization and associated bundle of thoughts and intuitions and analogies—and had to work hard to try to communicate that idea to other humans like me.
Again, sorry if I’m misunderstanding.
comment by A Ray (alex-ray) · 2022-04-01T00:56:20.997Z · LW(p) · GW(p)
Longtermist X-Risk Cases for working in Semiconductor Manufacturing
Two separate pitches for jobs/roles in semiconductor manufacturing for people who are primarily interested in x-risk reduction.
Securing Semiconductor Supply Chains
This is basically the "computer security for x-risk reduction" argument applied to semiconductor manufacturing.
Briefly restating: it seems exceedingly likely that technologies crucial to x-risks are on computers or connected to computers. Improving computer security increases the likelihood that those machines are not stolen or controlled by criminals. In general, this should make things like governance and control strategy more straightforward.
This argument also applies to making sure that there isn't any tampering with the semiconductor supply chain. In particular, we want to make sure that the designs from the designer are not modified in ways that make it easier for outside actors to steal or control information or technology.
One of the primary complaints about working in semiconductor manufacturing for longtermist reasons is accelerating semiconductor progress. I think security work here is not nearly as much as a direct driver of progress as other roles, so I would argue this as differentially x-risk reducing.
Diversifying Semiconductor Manufacturing
This one is more controversial in mainline longtermist x-risk reduction, so I'll try to clearly signpost the hypotheses that this is based on.
The reasoning is basically:
- Right now, most prosaic AI alignment techniques require access to a lot of compute
- It's possible that some prosaic AI alignment techniques (like interpretability) will require much more compute in the future
- So, right now AI alignment research is at least partially gated on access to compute, and it seems plausible this will be the case in the future
So if we want to ensure these research efforts continue to have access to compute, we basically need to make sure they have enough money to buy the compute, and that there is compute to be sold.
Normally this wouldn't be much of an issue, as in general we can trust markets to meet demands, etc. However semiconductor manufacturing is increasingly becoming a part of international conflict strategy.
In particular, much of the compute acceleration used in AI research (including AI alignment research) is manufactured in Taiwan, which seems to be coming under increasing threats.
My argument here is that I think it is possible to increase the chances that AI alignment research labs will continue to have access to compute, even in cases of large-scale geopolitical conflict. I think this can be done in ways that end up not dramatically increasing the global semiconductor manufacturing capacity by much.
comment by A Ray (alex-ray) · 2022-03-01T00:35:43.115Z · LW(p) · GW(p)
Interpretability Challenges
Inspired by a friend [LW · GW] I've been thinking about how to launch/run interpretability competitions, and what the costs/benefits would be.
I like this idea a lot because it cuts directly at one of the hard problems of spinning up in interpretability research as a new person. The field is difficult and the objectives are vaguely defined; it's easy to accidentally trick yourself into seeing signal in noise, and there's never certainty that the thing you're looking for is actually there.
On the other hand, most of the interpretability-like interventions in models (e.g. knowledge edits/updates to transformers) make models worse and not better -- they usually introduce some specific and contained deficiency (e.g. predict that the Eiffel Tower is in Rome, Italy).
So the idea for Interpretability Challenges would be to use existing methods (or possibly invent new ones) to inject concrete "things to find" inside of models, release those models as challenges, and then give prizes for finding things.
Some ways this might work:
- Super simple challenge: use editing techniques like ROME to edit a model, upload to google drive, and post a challenge to lesswrong. I'd probably personally put up a couple of prizes for good writeups for solutions.
- CTF (Capture the Flag): the AI Village has been interested in what sorts of AI challenges/competitions could be run in tandem with infosec conferences. I think it would be pretty straightforward to build some interpretability challenges for the next AI Village CTF, or to have a whole interpretability-only CTF by itself. This is exciting to me, because its a way to recruit more people from infosec into getting interested in AI safety (which has been a goal of mine for a while).
- Dixit-rules challenge league: One of the hard problems with challenges like this is how to set the difficulty. Too hard and no one makes progress. Too easy and no one learns/grows from it. I think if there were a bunch of interested people/groups, we could do a dixit style tournament: Every group takes turns proposing a challenge, and gets the most points if exactly one other group solves it (they don't get points if everyone solves it, or if no one solves it). This has a nice self-balancing force, and would be good if there wanted to be an ongoing group who built new challenges as new interpretability research papers were published.
Please reach out to me if you're interested in helping with efforts like this.
comment by A Ray (alex-ray) · 2020-11-22T18:34:47.117Z · LW(p) · GW(p)
Thinking more about the singleton risk / global stable totalitarian government risk from Bostrom's Superintelligence, human factors, and theory of the firm.
Human factors represent human capacities or limits that are unlikely to change in the short term. For example, the number of people one can "know" (for some definition of that term), limits to long-term and working memory, etc.
Theory of the firm tries to answer "why are economies markets but businesses autocracies" and related questions. I'm interested in the subquestion of "what factors given the upper bound on coordination for a single business", related to "how big can a business be".
I think this is related to "how big can an autocracy (robustly/stably) be", which is how it relates to the singleton risk.
Some thoughts this produces for me:
- Communication and coordination technology (telephones, email, etc) that increase the upper bounds of coordination for businesses ALSO increase the upper bound on coordination for autocracies/singletons
- My belief is that the current max size (in people) of a singleton is much lower than current global population
- This weakly suggests that a large global population is a good preventative for a singleton
- I don't think this means we can "war of the cradle" our way out of singleton risk, given how fast tech moves and how slow population moves
- I think this does mean that any non-extinction event that dramatically reduces population also dramatically increases singleton risk
- I think that it's possible to get a long-term government aligned with the values of the governed, and "singleton risk" is the risk of an unaligned global government
So I think I'd be interested in tracking two "competing" technologies (for a hand-wavy definition of the term)
- communication and coordination technologies -- tools which increase the maximum effective size of coordination
- soft/human alignment technologies -- tools which increase alignment between government and governed
↑ comment by mako yass (MakoYass) · 2020-11-24T23:31:53.820Z · LW(p) · GW(p)
Did Bostrom ever call it singleton risk? My understanding is that it's not clear that a singleton is more of an x-risk than its negative; a liberal multipolar situation under which many kinds of defecting/carcony factions can continuously arise.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2020-11-25T03:37:53.035Z · LW(p) · GW(p)
I don't know if he used that phrasing, but he's definitely talked about the risks (and advantages) posed by singletons.
comment by A Ray (alex-ray) · 2022-01-25T00:13:26.093Z · LW(p) · GW(p)
Some disorganized thoughts about adversarial ML:
- I think I'm a little bit sad about the times we got whole rooms full of research posters about variations on epsilon-ball adversarial attacks & training, basically all of them claiming how this would help AI safety or AI alignment or AI robustness or AI generalization and basically all of them were basically wrong.
- This has lead me to be pretty critical of claims about adversarial training as pathways to aligning AGI.
- Ignoring the history of adversarial training research, I think I still have problems with adversarial training as a path to aligning AGI.
- First, adversarial training is foremost a capabilities booster. Your model makes some obvious/predictable errors (to the research team working on it) -- and if you train against them, they're no longer errors!
- This has the property of "if you solve all the visible problems all you will be left by is invisible problems" alignment issue, as well as as a cost-competitiveness issue (many adversarial training approaches require lots of compute).
- From a "definitely a wild conjecture" angle, I am uncertain that the way the current rates of adding vs removing adversarial examples will play out in the limit. Basically, think of training as a continuous process that removes normal errors and adds adversarial errors. (In particular, while there are many adversarial examples present at the initialization of a model -- there exist adversarial examples at the end of training which didn't exist at the beginning. I'm using this to claim that training 'put them in') Adversarial training removes some adversarial examples, but probably adds some which are adversarial in an orthogonal way. At least, this is what I expect given that adversarial training doesn't seem to be cross-robust.
- I think if we had some notion of how training and adversarial training affected the number of adversarial examples a model had, I'd probably update on whatever happened empirically. It does seem at least possible to me that adversarial training on net reduces adversarial examples, so given a wide enough distribution and a strong enough adversary, you'll eventually end up with a model that is arbitrarily robust (and not exploitable).
- It's worth mentioning again how current methods don't even provide robust protection against each other.
- I think my actual net position here is something like:
- Adversarial Training and Adversarial ML was over-hyped as AI Safety in ways that were just plain wrong
- Some version of this has some place in a broad and vast toolkit for doing ML research
- I don't think Adversarial Training is a good path to aligned AGI
comment by A Ray (alex-ray) · 2021-09-15T21:03:28.750Z · LW(p) · GW(p)
Book Aesthetics
I seem to learn a bunch about my aesthetics of books by wandering a used book store for hours.
Some books I want in hardcover but not softcover. Some books I want in softcover but not hardcover. Most books I want to be small.
I prefer older books to newer books, but I am particular about translations. Older books written in english (and not translated) are gems.
I have a small preference for books that are familiar to me, a nontrivial part of them were because they were excerpts taught in english class.
I don't really know what exactly constitutes a classic, but I think I prefer them. Lists of "Great Classics" like Mortimer Adler's are things I've referenced in the past.
I enjoy going through multi-volume series (like the Harvard Classics) but I think I prefer my library to be assembled piecemeal.
That being said, I really like the Penguin Classics. Maybe they're familiar, or maybe their taste matches my own.
I like having a little lending library near my house so I can elegantly give away books that I like and think are great, but I don't want in my library anymore.
Very few books I want as references, and I still haven't figured out what references I do want. (So far a small number: Constitution, Bible)
I think a lot about "Ability to Think" (a whole separate topic) and it seems like great works are the products of great 'ability to think'.
Also it seems like authors of great works know or can recognize other great works.
This suggests that figuring out who's taste I think is great, and seeing what books they recommend or enjoy.
I wish there was a different global project of accumulating knowledge than books. I think books works well for poetry and literature, but it works less well for science and mechanics.
Wikipedia is similar to this, but is more like an encyclopedia, and I'm looking for something that includes more participatory knowledge.
Maybe what I'm looking for is a more universal system of cross-referencing and indexing content. The internet as a whole would be a good contender here, but is too haphazard.
I'd like things like "how to build a telescope at home" and "analytic geometry" to be well represented, but also in the participatory knowledge sort of way.
(This is the way in which much of human knowledge is apprenticeship-based and transferred, and merely knowing the parts of a telescope -- what you'd learn from an encyclopedia -- is insufficient to be able to make one)
I expect to keep thinking on this, but for now I have more books!
comment by A Ray (alex-ray) · 2020-11-18T01:09:56.929Z · LW(p) · GW(p)
Future City Idea: an interface for safe AI-control of traffic lights
We want a traffic light that
* Can function autonomously if there is no network connection
* Meets some minimum timing guidelines (for example, green in a particular direction no less than 15 seconds and no more than 30 seconds, etc)
* Secure interface to communicate with city-central control
* Has sensors that allow some feedback for measuring traffic efficiency or throughput
This gives constraints, and I bet an AI system could be trained to optimize efficiency or throughput within the constraints. Additionally, you can narrow the constraints (for example, only choosing 15 or 16 seconds for green) and slowly widen them in order to change flows slowly.
This is the sort of thing Hash would be great for, simulation wise. There's probably dedicated traffic simulators, as well.
At something like a quarter million dollars a traffic light, I think there's an opportunity here for startup.
(I don't know Matt Gentzel's LW handle but credit for inspiration to him)
↑ comment by ChristianKl · 2020-11-19T11:09:33.403Z · LW(p) · GW(p)
I expect that the functioning of traffic lights is regulated in a way that makes it hard for a startup to deploy such a system.
comment by A Ray (alex-ray) · 2023-02-25T18:06:29.328Z · LW(p) · GW(p)
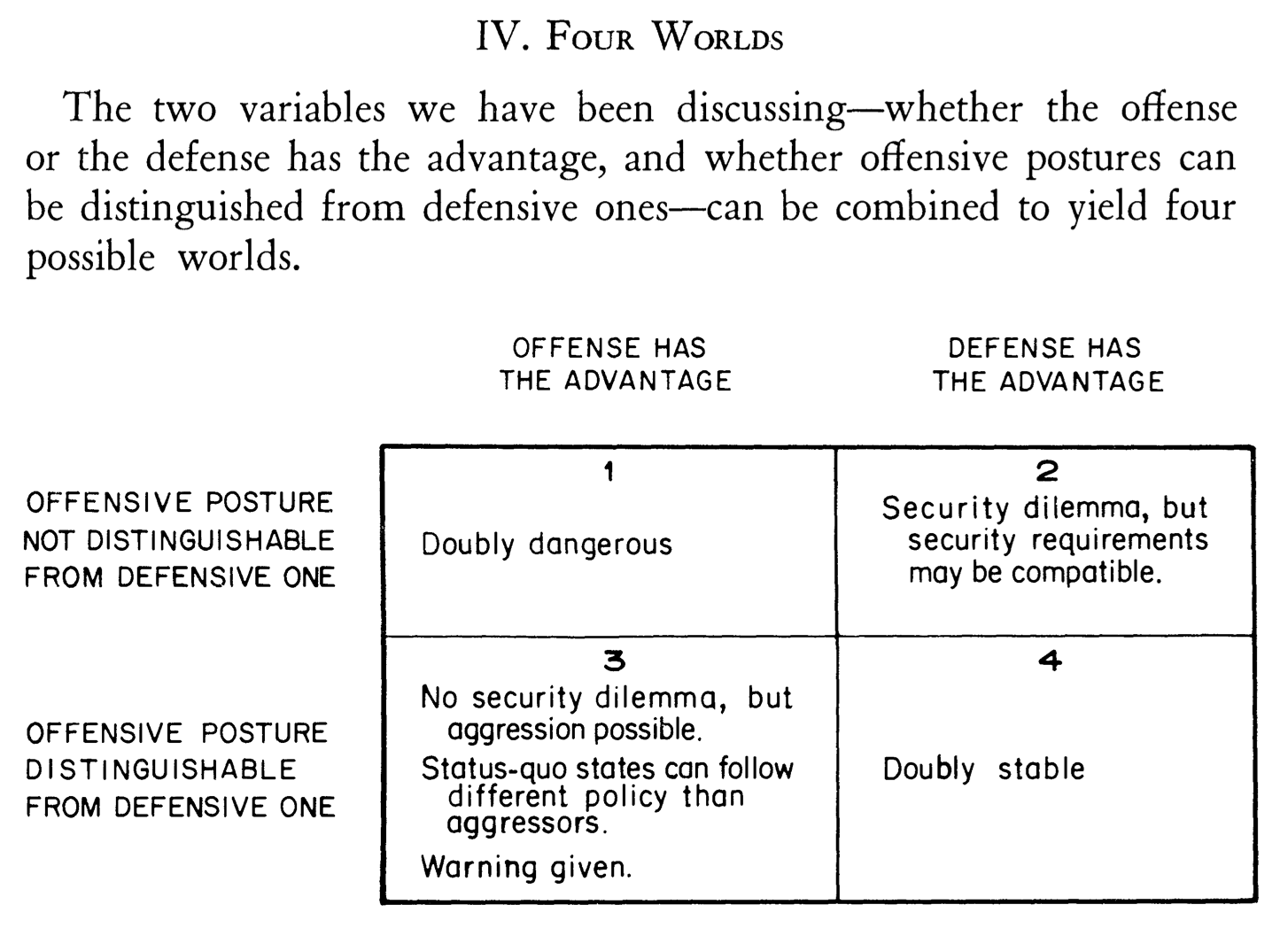
Comparing AI Safety-Capabilities Dilemmas to Jervis' Cooperation Under the Security Dilemma
I've been skimming some things about the Security Dilemma (specifically Offense-Defense Theory) while looking for analogies for strategic dilemmas in the AI landscape.
I want to describe a simple comparison here, lightly held (and only lightly studied)
- "AI Capabilities" -- roughly, the ability to use AI systems to take (strategically) powerful actions -- as "Offense"
- "AI Safety" -- roughly, that AI systems under control and use do not present a catastrophic/existential threat -- as "Defense"
Now re-creating the two values (each) of the two variables of Offense-Defense Theory:
- "Capabilities Advantaged" -- Organizations who disproportionately invest in capabilities get strategic advantage
- "Safety Advantaged" -- Organizations who disproportionately invest in safety get strategic advantage.[1]
- "Capabilities Posture Not Distinguishable from Safety Posture" -- from the outside, you can't credibly determine how an organization is investing Capabilities-vs-Safety. (This is the case if very similar research methods/experiments are used to study both, or that they are not technologically separable. My whole interest in this is in cultivating and clarifying this one point. This exists in the security dilemma as well inasmuch as defensive missile interceptors can be used to offensively strike ranged targets, etc.)
- "Capabilities Posture Distinguishable from Safety Posture" -- it's credibly visible from the outside whether an organization is disproportionately invested in Safety
Finally, we can sketch out the Four Worlds of Offense-Defense Theory
- Capabilities Advantaged / Not-Distinguishable : Doubly dangerous (Jervis' words, but I strongly agree here). I also think this is the world we are in.
- Safety Advantaged / Not-Distinguishable : There exists a strategic dilemma, but it's possible that non-conflict equilibrium can be reached.
- Capabilities Advantaged / Distinguishable : No security dilemma, and other strategic responses can be made to obviously-capabilities-pursuing organizations. We can have warnings here which trigger or allow negotiations or other forms of strategic resolution.
- Safety Advantaged / Distinguishable : Doubly stable (Jervis' words, also strongly agree).
From the paper linked in the title:
My Overall Take
- If this analogy fits, I think we're in World 1.
- The analogy feels weak here, there's a bunch of mis-fits from the original (very deep) theory
- I think this is neat and interesting but not really a valuable strategic insight
- I hope this is food for thought
@Cullen_OKeefe [LW · GW]
- ^
This one is weird, and hard for me to make convincing stories about the real version of this, as opposed to seeming to have a Safety posture -- things like "recruiting", "public support", "partnerships", etc all can come from merely seeming to adopt the Safety Posture. (Though, this is actually a feature of the security dilemma and offense-defense theory, too)
comment by A Ray (alex-ray) · 2022-01-30T00:15:47.023Z · LW(p) · GW(p)
Copying some brief thoughts on what I think about working on automated theorem proving relating to working on aligned AGI:
- I think a pure-mathematical theorem prover is more likely to be beneficial and less likely to be catastrophic than STEM-AI / PASTA
- I think it's correspondingly going to be less useful
- I'm optimistic that it could be used to upgrade formal software verification and cryptographic algorithm verification
- With this, i think you can tell a story about how development in better formal theorem provers can help make information security a "defense wins" world -- where information security and privacy are a globally strong default
- There are some scenarios (e.g. ANI surveillance of AGI development) where this makes things worse, I think in expectation it makes things better
- There are some ways this could be developed where it ends up accelerating AGI research significantly (i.e. research done to further theorem proving ends up unlocking key breakthroughs to AGI) but I think this is unlikely
- One of the reasons I think this is unlikely is that current theorem proving environments are much closer to "AlphaGo on steriods" than "read and understand all mathematics papers ever written"
- I think if we move towards the latter, then I'm less differentially-optimistic about theorem proving as a direction of beneficial AI research (and it goes back to the general background level of AGI research more broadly)
↑ comment by Ramana Kumar (ramana-kumar) · 2022-01-31T07:44:45.114Z · LW(p) · GW(p)
In my understanding there's a missing step between upgraded verification (of software, algorithms, designs) and a "defence wins" world: what the specifications for these proofs need to be isn't a purely mathematical thing. The missing step is how to figure out what the specs should say. Better theorem proving isn't going to help much with the hard parts of that.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-31T19:27:37.714Z · LW(p) · GW(p)
I think that's right that upgraded verification by itself is insufficient for 'defense wins' worlds. I guess I'd thought that was apparent but you're right it's definitely worth saying explicitly.
A big wish of mine is that we end up doing more planning/thinking-things-through for how researchers working on AI today could contribute to 'defense wins' progress.
My implicit other take here that wasn't said out loud is that I don't really know of other pathways where good theorem proving translates to better AI x-risk outcomes. I'd be eager to know of these.
comment by A Ray (alex-ray) · 2022-01-23T07:18:19.950Z · LW(p) · GW(p)
The ELK paper is long but I’ve found it worthwhile, and after spending a bit of time noodling on it — one of my takeaways is I think this is essentially a failure mode for the approaches to factored cognition I've been interested in. (Maybe it's a failure mode in factored cognition generally.
I expect that I’ll want to spend more time thinking about ELK-like problems before spending a bunch more time thinking about factored cognition.
In particular it's now probably a good time to start separating a bunch of things I had jumbled together, namely:
- Developing AI technology that helps us do alignment research
- Developing aligned AI
Previously I had hoped that the two would be near each other in ways that permit progress on both at the same time.
Now I think without solving ELK I would want to be more careful and intentional about how/when to develop AI tech to help with alignment.
comment by A Ray (alex-ray) · 2022-01-16T02:20:14.736Z · LW(p) · GW(p)
100 Year Bunkers
I often hear that building bio-proof bunkers would be good for bio-x-risk, but it seems like not a lot of progress is being made on these.
It's worth mentioning a bunch of things I think probably make it hard for me to think about:
- It seems that even if I design and build them, I might not be the right pick for an occupant, and thus wouldn't directly benefit in the event of a bio-catastrophe
- In the event of a bio-catastrophe, it's probably the case that you don't want anyone from the outside coming in, so probably you need people already living in it
- Living in a bio-bunker in the middle of nowhere seems kinda boring
Assuming we can get all of those figured out, it seems worth funding someone to work on this full-time. My understanding is EA-funders have tried to do this but not found any takers yet.
So I have a proposal for a different way to iterate on the design.
Crazy Hacker Clubs
Years ago, probably at a weekly "Hack Night" at a friend's garage, where a handful of us met to work on and discuss projects, someone came up with the idea that we could build a satellite.
NASA was hosting a cubesat competition, where the prize was a launch/deployment. We also had looked at a bunch of university cubesats, and decided that it wasn't that difficult to build a satellite.
So hack nights and eventually other nights turned to meeting to discuss designs and implementations for the various problems we would run into (power generation and storage, attitude/orientation control, fine pointing, communications). Despite being rank amateurs, we made strong progress, building small scale prototypes of the outer structure and subsystems.
The thing that actually ended this was I decided this was so much fun that I'd quit my job and instead go work at Planet Labs -- where a really cool bunch of space hippies was basically doing a slightly more advanced version of our "hacker's cubesat"
Bio-Bunker Nights
Similar to "Hack Nights" -- I think it would be fun to get together with a small set of friends and work through the design and prototype build of a 100 year bunker.
I expect to enjoy this sort of thing. Designing life support systems, and how they might fail and be fixed. Research into various forms of concrete and seismological building standards. Figuring out where would be the best place for it.
My guess is that a lot of the design and outline for construction could be had over pizza in someone's garage.
(I'm not predicting I will do this, or committing to joining a thing if it existed, but I do think it would be a lot of fun and would be very interested in giving it a shot)
Replies from: ChristianKl, avturchin, None↑ comment by ChristianKl · 2022-01-16T23:20:07.755Z · LW(p) · GW(p)
What's your threat scenario where you would believe a bio-bunker to be helpful?
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-17T04:17:10.373Z · LW(p) · GW(p)
I'm roughly thinking of this sort of thing: https://forum.effectivealtruism.org/posts/fTDhRL3pLY4PNee67/improving-disaster-shelters-to-increase-the-chances-of [EA · GW]
↑ comment by avturchin · 2022-01-16T18:05:44.476Z · LW(p) · GW(p)
What about using remote islands as bio-bunkers? Some of them are not reachable by aviation (no airfield), so seems to be better protected. But they have science stations already populated. Example is Kerguelen islands. The main risk here is bird flu delivered by birds or some stray ship.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-16T18:27:48.891Z · LW(p) · GW(p)
Remote islands are probably harder to access via aviation, but probably less geologically stable (I'd worry about things like weathering, etc). Additionally this is probably going to dramatically increase costs to build.
It's probably worth considering "aboveground bunker in remote location" (e.g. islands, also antarctica) -- so throw it into the hat with the other considerations.
My guess is that the cheaper costs to move building supplies and construction equipment will favor "middle of nowhere in an otherwise developed country".
I don't have fully explored models also for how much a 100 yr bunker needs to be hidden/defensible. This seems worth thinking about.
If I ended up wanting to build one of these on some cheap land somewhere with friends, above-ground might be the way to go.
(The idea in that case would be to have folks we trust take turns staying in it for ~1month or so at a time, which honestly sounds pretty great to me right now. Spending a month just reading and thinking and disconnected while having an excuse to be away sounds rad)
Replies from: avturchin↑ comment by avturchin · 2022-01-16T19:32:16.724Z · LW(p) · GW(p)
You probably don't need 100 years bunker if you prepare only for biocatastrophe, as most pandemics has shorter timing, except AIDS.
Also, it is better not to build anything, but use already existing structures. E.g. there are coal mines in Spitzbergen which could be used for underground storages.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-17T04:18:02.161Z · LW(p) · GW(p)
That seems worth considering!
comment by A Ray (alex-ray) · 2021-12-21T20:25:43.234Z · LW(p) · GW(p)
Philosophical progress I wish would happen:
Starting from the Callard version of Aspiration (how should we reason/act about things that change our values).
Extend it to generalize to all kinds of values shifts (not just the ones desired by the agent).
Deal with the case of adversaries (other agents in your environment want to change your values)
Figure out a game theory (what does it mean to optimally act in an environment where me & others are changing my values / how can I optimally act)
Figure out what this means for corrigibility (e.g. is corrigibility just a section of the phase space diagram for strategies in a world where your values are changing; is there a separate phase that gets the good parts of corrigibility without the horrifying parts of corrigibility)
comment by A Ray (alex-ray) · 2022-03-05T01:50:55.693Z · LW(p) · GW(p)
Hacking the Transformer Prior
Neural Network Priors
I spend a bunch of time thinking about the alignment of the neural network prior for various architectures of neural networks that we expect to see in the future.
Whatever alignment failures are highly likely under the neural network prior are probably worth a lot of research attention.
Separately, it would be good to figure out knobs/levers for changing the prior distribution to be more aligned (or produce more aligned models). This includes producing more interpretable models.
Analogy to Software Development
In general, I am able to code better if I have access to a high quality library of simple utility functions. My goal here is to sketch out how we could do this for neural network learning.
Naturally Occurring Utility Functions
One way to think about the induction circuits found in the Transformer Circuits work is that they are "learned utility functions". I think this is the sort of thing we might want to provide the networks as part of a "hacked prior"
A Language for Writing Transformer Utility Functions
Thinking Like Transformers provides a programming language, RASP, which is able to express simple functions in terms of how they would be encoded in transformers.
Concrete Research Idea: Hacking the Transformer Prior
Use RASP (or something RASP-like) to write a bunch of utility functions (such as the induction head functions).
Train a language model where a small fraction of the neural network is initialized to your utility functions (and the rest is initialized normally).
Study how the model learns to use the programmed functions. Maybe also study how those functions change (or don't, if they're frozen).
Future Vision
I think this could be a way to iteratively build more and more interpretable transformers, in a loop where we:
- Study transformers to see what functions they are implementing
- Manually implement human-understood versions of these functions
- Initialize a new transformer with all of your functions, and train it
- Repeat
If we have a neural network that is eventually entirely made up of human-programmed functions, we probably have an Ontologically Transparent Machine. (AN: I intend to write more thoughts on ontologically transparent machines in the near future)
Replies from: Vaniver↑ comment by Vaniver · 2022-03-05T02:53:40.550Z · LW(p) · GW(p)
I'm pretty sure you mean functions that perform tasks, like you would put in /utils, but I note that on LW "utility function" often refers to the decision theory concept, and "what decision theoretical utility functions are present in the neural network prior" also seems like an interesting (tho less useful) question.
comment by A Ray (alex-ray) · 2022-01-23T21:33:12.330Z · LW(p) · GW(p)
There recently was a COVID* outbreak at an AI community space.
>20 people tested positive on nucleic tests, but none of the (only five) people that took PCR tests came back positive.
Thinking out loud about possibilities here:
- The manufacturer of the test used a nucleic acid sequence that somehow cross-targets another common sequence we'd find in upper respiratory systems (with the most likely candidate here being a different, non-COVID, upper respiratory virus). I think this is extremely unlikely mistake for a veteran test manufacturer to make, but this manufacturer seems to be new-ish (and mostly looking at health diagnostics, instead of disease surveillance). I'm <5%
- There was a manufacturing error with the batch of tests used. I don't know if the group tried to re-test positive people with confirmatory tests from a different batch, but for now I'll assume no. (These tests are not cheap so I wouldn't blame them) This means that a manufacturing error could be correlated between all of these. We have seen COVID tests recalled recently, and this manufacturer has had no recalls. Fermi estimates from their FY2021 profit numbers show there are at least 2 million tests from last year alone. I expect if there were a bunch of people testing positive it would be news, and a manufacturing failure narrowly constrained to our batch is unlikely. I'm <5%
- There was some sort of environmental issue with how the tests were stored or conducted. Similar to the previous point, but this one is limited to the test boxes that were in the community space, so could be correlated with each other without being correlated with outside tests. COVID tests in general are pretty sensitive to things like temperature and humidity, but also I expect these folks to have been mindful of this. My guess is that if it were easy to make this mistake in an 'office building setting' -- it would be eventually newsworthy (lots of people are taking these tests in office settings). Most of this is trusting that these people were not negligent on their tests. I'm ~10% on this failure mode.
- Some smaller fraction of people were positive, and somehow all of the positive tests had been contaminated by these people. Maybe by the normal respiratory pathways! (E.g. people breathed in virus particles, and then tested positive before they were really 'infected' -- essentially catching the virus in the act!) These people would later go on to fight off the virus normally without becoming infected/infectious, due to diligent vaccination/etc. I have no idea how likely the mechanism is, and I'm hesitant to put probability on biology explanations I make up myself. I'm <10%
- Unknown unknowns bucket. One thing specifically contributing here is that (as far as a quick google goes) it seems like this test manufacturer hasn't released what kind of nucleic amplification reaction they're using. So "bad/weird nucleic recipe" goes in here. Secondly, I was wondering at the engineering quality of their test's internal mechanisms. I couldn't find any teardown or reporting on this, so without that "internal mechanism failure" also goes in here. Always hard to label this but it feels like ~50%
- It was really COVID. The thing to explain here is "why the PCR negatives". I think it could be a combination of chance (at most a quarter of the positives got confirmatory PCRs) and time delay (it seems like the PCRs were a while after the positive rapid tests). I'm also not certain that they were the same people -- maybe someone who didn't test positive got a PCR, too? There's a lot of unknowns here, but I'm not that surprised when we find out the highly-infectious-disease has infected people. I'm ~40%
↑ comment by A Ray (alex-ray) · 2022-01-24T03:35:18.895Z · LW(p) · GW(p)
I should have probably separated out 4 into two categories:
- The virus was not in the person but was on the sample (somehow contaminated by e.g. the room w/ the tests)
- The virus was in the person and was on the sample
Oh well, it was on my shortform because it was low effort.
comment by A Ray (alex-ray) · 2022-01-20T23:53:37.100Z · LW(p) · GW(p)
I engage too much w/ generalizations about AI alignment researchers.
Noticing this behavior seems useful for analyzing it and strategizing around it.
A sketch of a pattern to be on the lookout for in particular is "AI Alignment researchers make mistake X" or "AI Alignment researchers are wrong about Y". I think in the extreme I'm pretty activated/triggered by this, and this causes me to engage with it to a greater extent than I would have otherwise.
This engagement is probably encouraging more of this to happen, so I think more of a pause and reflection would make more good things happen.
It's worth acknowledging that this comes from a very deep sense of caring and importantness about AI alignment research that I feel. I spend a lot of my time (both work time and free time) trying to foster and grow the field. It seems reasonable I want people to have correct beliefs about this.
It's also worth acknowledging that there will be some cases where my disagreement is wrong. I definitely don't know all AI alignment researchers, and there will be cases where there are broad field-wide phenomena that I missed. However I think this is rare, and probably most of the people I interact with will have less experience w/ the field of AI alignment.
Another confounder is that the field is both pretty jargon-heavy and very confused about a lot of things. This can lead to a bunch of semantics confusions masking other intellectual progress. I'm definitely not in the "words have meanings, dammit" extreme, and maybe I can do a better job asking people to clarify and define things that I think are being confused.
A takeaway I have right now from reflecting on this, is that "I disagree about <sweeping generalization about AI alignment researchers>" feels like a simple and neutral statement to me, but isn't a simple and neutral statement in a dialog.
Thinking about the good stuff about scout mindset [EA · GW], I think things that I could do instead that would be better:
- I can do a better job conserving my disagreement [LW · GW]. I like the model of treating this as a limited resource, and ensuring it is well-spent seems good.
- I can probably get better mileage out of pointing out areas of agreement than going straight to highlighting disagreements (crocker's rules be damned [? · GW])
- I am very optimistic about double-crux [? · GW] as a thing that should be used more widely, as well as a specific technique to deploy in these circumstances. I am confused why I don't see more of it happening.
I think that's all for the reflection on this for now.
comment by A Ray (alex-ray) · 2022-01-04T04:11:14.850Z · LW(p) · GW(p)
I’ve been thinking more about Andy Jones’ writeup [LW · GW] on the need for engineering.
In particular, my inside view is that engineering isn’t that difficult to learn (compared to research).
In particular I think the gap between being good at math/coding is small to being good at engineering. I agree that one of the problems here is the gap is a huge part tacit knowledge.
I’m curious about what short/cheap experiments could be run in/around lightcone to try to refute this — or at the very least support the “it’s possible to quickly/densely transfer engineering knowledge”
A quick sketch of how this might go is:
- write out a rough set of skills and meta-skills I think are relevant to doing engineering well
- write out some sort of simple mechanic process that should both exercise those skills and generate feedback on them
- test it out by working on some engineering project with someone else, and see if we both get better at engineering (at least by self reported metrics)
Thinking out loud on the skills I would probably want to include:
- prototyping / interactively writing-and-testing code
- error handling and crash handling
- secure access to code and remote machines
- spinning up/down remote machines and remotely run jobs
- diagnosing crashed runs and halting/interacting with crash-halted jobs
- checkpointing and continuing crashed jobs from partway through
- managing storage and datasets
- large scale dataset processing (spark, etc)
- multithread vs multiprocess vs multimachine communication strategies
- performance measurement and optimization
- versioning modules and interfaces; deprecation and migration
- medium-level git (bisecting, rewriting history, what changed when)
- web interfaces and other ways to get human data
- customizing coding tools and editor plugins
- unit tests vs integration tests and continuous/automated testing
- desk / office setup
- going on walks to think
I think this list is both incomplete and too object level -- the real skills are mostly aesthetics/taste and meta-level. I do think that doing a bunch of these object-level things is a good way to learn the meta-level tastes.
Maybe a format for breaking down a small (2 hour) session of this, that could be done individually, as a pair, or hybrid (pair checkins inbetween individual work sessions):
- 5 minute checkin and save external context so we can focus
- 15 minute planning and going through a quick checklist
- 25 minute Pomodoro
- 5 minute break
- 25 minute Pomodoro
- 5 minute break
- 25 minute Pomodoro
- 15 minute analysis and retrospective with another checklist
The checklists could adapt over time, but I think would be fine to start with some basic questions I would want to ask myself before/after getting into focused technical work. They are both a scaffold that best-practices can be attached to, as well as a way of getting written records of common issues. (I'm imagining that I'll save all of the responses to the checklists and review them at a ~weekly cadence).
comment by A Ray (alex-ray) · 2021-09-17T22:52:34.508Z · LW(p) · GW(p)
AGI technical domains
When I think about trying to forecast technology for the medium term future, especially for AI/AGI progress, it often crosses a bunch of technical boundaries.
These boundaries are interesting in part because they're thresholds where my expertise and insight falls off significantly.
Also interesting because they give me topics to read about and learn.
A list which is probably neither comprehensive, nor complete, nor all that useful, but just writing what's in my head:
- Machine learning research - this is where a lot of the tip-of-the-spear of AI research is happening, and seems like that will continue to the near future
- Machine learning software - tightly coupled to the research, this is the ability to write programs that do machine learning
- Machine learning compilers/schedulers - specialized compilers translate the program into sequences of operations to run on hardware. High quality compilers (or the lack of them) has blocked a bunch of nontraditional ML-chips from getting traction.
- Supercomputers / Compute clusters - large arrays of compute hardware connected in a dense network. Once the domain of government secret projects, now it's common for AI research companies to have (or rent) large compute clusters. Picking the hardware (largely commercial-off-the-shelf), designing the topology of connections, and building it are all in this domain.
- Hardware (Electronics/Circuit) Design - A step beyond building clusters out of existing hardware is designing custom hardware, but using existing chips and chipsets. This allows more exotic connectivity topologies than you can get with COTS hardware, or allows you to fill in gaps that might be missing in commercially available hardware.
- Chip Design - after designing the circuit boards comes designing the chips themselves. There's a bunch of AI-specific chips that are already on the market, or coming soon, and almost all of them are examples of this. Notably most companies that design chips are "fabless" -- meaning they need to partner with a manufacturer in order to produce the chip. Nvidia is an example of a famous fabless chip designer. Chips are largely designed with Process Design Kits (PDKs) which specify a bunch of design rules, limitations, and standard components (like SRAM arrays, etc).
- PDK Design - often the PDKs will have a bunch of standard components that are meant to be general purpose, but specialized applications can take advantage of more strange configurations. For example, you could change a SRAM layout to tradeoff a higher bit error rate for lower power, or come up with different ways to separate clock domains between parts of a chip. Often this is done by companies who are themselves fabless, but also don't make/sell their own chips (and instead will research and develop this technology to integrate with chip designers).
- Chip Manufacture (Fabrication / Fab) - This is some of the most advanced technology humanity has produced, and is probably familiar to many folks here. Fabs take chip designs and produce chips -- but the amount of science and research that goes into making that happen is enormous. Fabs probably have the tightest process controls of any manufacturing process in existence, all in search of increasing fractions of a percent of yield (the fraction of manufactured chips which are acceptable).
- Fab Process Research - For a given fab (semiconductor manufacturing plant - "fabricator") there might be specializations for different kinds of chips that are different enough to warrant their own "process" (sequence of steps executed to manufacture it). For example, memory chips and compute chips are different enough to need different processes, and developing these processes requires a bunch of research.
- Fab "Node" Research - Another thing people might be familiar with is the long-running trend for semiconductors to get smaller and denser. The "Node" of a semiconductor process refers to this size (and other things that I'm going to skip for now). This is separate from (but related to) optimizing manufacturing processes, but is about designing and building new processes in order to shrink features sizes, or push aspect ratios. Every small decrease (e.g. "5nm" -> "3nm", though those sizes don't refer to anything real) costs tens of billions of dollars, and further pushes are likely even more expensive.
- Semiconductor Assembly Research - Because we have different chips that need different processes (e.g. memory chips and compute chips) -- we want to connect them together, ideally better than we could do with just a circuit board. This research layer includes things like silicon interposers, and various methods of 3D stacking and connection of chips. (Probably also should consider reticle-boundary-crossing here, but it kinda is also simultaneously a few of the other layers)
- Semiconductor Materials Science - This probably should be broken up, but I know the least about this. Semiconductors can produce far more than chips like memory and compute -- they can also produce laser diodes, camera sensors, solar panels, and much more! This layer includes exotic methods of combining or developing new technologies -- e.g. "photonics at the edge" - a chip where the connections to it are optical instead of electronic!
Anyways I hope that was interesting to some folks.
comment by A Ray (alex-ray) · 2021-09-05T21:09:22.892Z · LW(p) · GW(p)
"Bet Your Beliefs" as an epistemic mode-switch
I was just watching this infamous interview w/ Patrick Moore where he seems to be doing some sort of epistemic mode switch (the "weed killer" interview)[0]
Moore appears to go from "it's safe to drink a cup of glyphosate" to (being offered the chance to do that) "of course not / I'm not stupid".
This switching between what seems to be a tribal-flavored belief (glyphosate is safe) and a self-protecting belief (glyphosate is dangerous) is what I'd like to call an epistemic mode-switch. In particular, it's a contradiction in beliefs, that's really only obvious if you can get both modes to be near each other (in time/space/whatever).
In the rationality community, it seems good to:
- Admit this is just a normal part of human reasoning. We probably all do this to some degree some times, and
- It seems like there are ways we can confront this by getting the modes near each other.
I think one of the things thats going on here is a short-term self-preservation incentive is a powerful tool for forcing yourself to be clear about your beliefs. In particular, it seems good at filtering/attenuating beliefs that are just tribal signaling.
This suggests that if you can get people to use this kind of short-term self-preservation incentive, you can probably get them to report more calibrated and consistent beliefs.
I think this is one of the better functions of "bet your beliefs". Summarizing what I understand "bet your beliefs" to be: There is a norm in the rationality community of being able to challenge peoples beliefs by asking them to form bets on them (or forming and offering them bets on them) -- and taking/refusing bets is seen as evidence of admission of beliefs.
Previously I've mostly just thought of this as a way of increasing evidence that someone believes what they say they do. If them saying "I believe X" is some small amount of evidence, then them accepting a bet about X is more evidence.
However, now I see that there's potentially another factor at play. By forcing them to consider short-term losses, you can induce an epistemic mode-switch away from signaling beliefs towards self-preservation beliefs.
It's possible this is already what people thought "bet your beliefs" was doing, and I'm just late to the party.
Caveat: the rest of this is just pontification.
It seems like a bunch of the world has a bunch of epistemic problems. Not only are there a lot of obviously bad and wrong beliefs, they seem to be durable and robust to evidence that they're bad and wrong.
Maybe this suggests a particular kind remedy to epistemological problems, or at the very least "how can I get people to consider changing their mind" -- by setting up situations that trigger short-term self-preservation thinking.
[0] Context from 33:50 here:
↑ comment by Vladimir_Nesov · 2021-09-05T21:34:32.672Z · LW(p) · GW(p)
A failure mode for "betting your beliefs" is developing an urge to reframe your hypotheses as beliefs, which harms the distinction. It's not always easy/possible/useful to check hypotheses for relevance to reality, at least until much later in their development, so it's important to protect them from being burdened with this inconvenience. It's only when a hypothesis is ready for testing (which is often immediately), or wants to be promoted to a belief (probably as an element of an ensemble), that making predictions becomes appropriate.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2021-09-05T22:13:48.781Z · LW(p) · GW(p)
Oh yeah like +100% this.
Creating an environment where we can all cultivate our weird hunches and proto-beliefs while sharing information and experience would be amazing.
I think things like "Scout Mindset" and high baselines of psychological safety (and maybe some of the other phenomenological stuff) help as well.
If we have the option to create these environments instead, I think we should take that option.
If we don't have that option (and the environment is a really bad epistemic baseline) -- I think the "bet your beliefs" does good.
↑ comment by JBlack · 2021-09-06T14:10:07.953Z · LW(p) · GW(p)
Moore appears to go from "it's safe to drink a cup of glyphosate" to (being offered the chance to do that) "of course not / I'm not stupid".
There seem to be two different concepts being conflated here. One is "it will be extremely unlikely to cause permanent injury", while the other is "it will be extremely unlikely to have any unpleasant effects whatsoever". I have quite a few personal experiences with things that are the first but absolutely not the second, and would fairly strenuously avoid going through them again without extremely good reasons.
I'm sure you can think of quite a few yourself.
comment by A Ray (alex-ray) · 2022-02-17T22:34:07.316Z · LW(p) · GW(p)
I with more of the language alignment research folks were looking into how current proposals for aligning transformers end up working on S4 models.
(I am one of said folks so maybe hypocritical to not work on it)
In particular it seems like there's way in which it would be more interpretable than transformers:
- adjustable timescale stepping (either sub-stepping, or super-stepping time)
- approximately separable state spaces/dynamics -- this one is crazy conjecture -- it seems like it should be possible to force the state space and dynamics into separate groups, in ways that would allow analysis of them in isolation or in relation to the rest of the model
It does seem like they're not likely to be competitive with transformers for short-context modeling anytime soon, but if they end up being differentially alignment-friendly, then we could instead try to make them more competitive.
(In general I think it's much easier to make an approach more competitive than it is to make it more aligned)
comment by A Ray (alex-ray) · 2021-09-10T18:33:29.785Z · LW(p) · GW(p)
The Positive and the Negative
I work on AI alignment, in order to solve problems of X-Risk. This is a very "negative" kind of objective.
Negatives are weird. Don't do X, don't be Y, don't cause Z. They're nebulous and sometimes hard to point at and move towards.
I hear a lot of a bunch of doom-y things these days. From the evangelicals, that this is the end times / end of days. From environmentalists that we are in a climate catastrophe. From politicians that we're in a culture war / edging towards a civil war. From the EAs/Rationalists that we're heading towards potential existential catastrophe (I do agree with this one).
I think cognition and emotion and relation can get muddied up with too much of negatives without things to balance them out. I don't just want to prevent x-risk -- I also want to bring about a super awesome future.
So I think personally I'm going to try to be more balanced in this regard, even in the small scale, by mixing in the things I'm wanting to move towards in addition to things I want to move away from.
In the futurist and long term communities, I want to endorse and hear more about technology developments that help bring about a more awesome future (longevity and materials science come to mind as concrete examples).
comment by A Ray (alex-ray) · 2022-07-05T18:55:53.617Z · LW(p) · GW(p)
More Ideas or More Consensus?
I think one aspect you can examine about a scientific field is it's "spread"-ness of ideas and resources.
High energy particle physics is an interesting extrema here -- there's broad agreement in the field about building higher energy accelerators, and this means there can be lots of consensus about supporting a shared collaborative high energy accelerator.
I think a feature of mature scientific fields that "more consensus" can unlock more progress. Perhaps if there had been more consensus, the otherwise ill-fated superconducting super collider would have worked out. (I don't know if other extenuating circumstances would still prevent it.)
I think a feature of less mature scientific fields that "more ideas" (and less consensus) would unlock more progress. In this case, we're more limited about generating and validating new good ideas. One way this looks is that there's not a lot of confidence with what to do with large sums of research funding, and instead we think our best bet is making lots of small bets.
My field (AI alignment) is a less mature scientific field in this way, I think. We don't have a "grand plan" for alignment, which we just need to get funding. Instead we have a fractal of philanthropic organizations empowering individual grantmakers to try to get small and early ideas off the ground with small research grants.
A couple thoughts, if this model does indeed fit:
There's a lot more we could do to orienting as a field with "the most important problem is increasing the rate of coming up with good research ideas". In addition to being willing to fund lots of small and early stage research, I think we could factorize and interrogate the skills and mindsets needed to do this kind of work. It's possible that this is one of the most important meta-skills we need to improve as a field.
I also think this could be more of a priority when "field building". When recruiting or trying to raise awareness of the field, it would be good to consider more focus or priority on places where we expect to find people who are likely to be good generators of new ideas. I think one of the ways this looks is to focus on more diverse and underrepresented groups.
Finally, at some point it seems like we'll transition to "more mature" as a field, and it's good to spend some time thinking about what would help that go better. Understanding the history of other fields making this transition, and trying to prepare for predicted problems/issues would be good here.
comment by A Ray (alex-ray) · 2022-02-07T23:50:01.485Z · LW(p) · GW(p)
Decomposing Negotiating Value Alignment between multiple agents
Let's say we want two agents to come to agreement on living with each other. This seems pretty complex to specify; they agree to take each other's values into account (somewhat), not destroy each other (with some level of confidence), etc.
Neither initially has total dominance over the other. (This implies that neither is corrigible to the other)
A good first step for these agents is to share each's values with the other. While this could be intractably complex -- it's probably the case that values are compact/finite and can be transmitted eventually in some form.
I think this decomposes pretty clearly into ontology transmission and value assignment.
Ontology transmission is communicating one agents ontology of the objects/concepts to another. Then value assignment is communicating the relative or comparative values to different elements in the ontology.
Replies from: Dagon, TLW↑ comment by Dagon · 2022-02-08T16:47:29.942Z · LW(p) · GW(p)
I think there are LOTS of examples of organisms who cooperate or cohabitate without any level of ontology or conscious valuation. Even in humans, a whole lot of the negotiation is not legible. The spoken/written part is mostly signaling and lies, with a small amount of codifying behavioral expectations at a very coarse grain.
↑ comment by TLW · 2022-02-08T04:49:52.499Z · LW(p) · GW(p)
A good first step for these agents is to share each's values with the other
This is a strong assertion that I do not believe is justified.
If you are an agent with this view, then I can take advantage by sending you an altered version of my values such that the altered version's Nash equilibrium (or plural) are all in my favor compared to the Nash equilibria of the original game.
(You can mitigate this to an extent by requiring that both parties precommit to their values... in which case I predict what your values will be and use this instead, committing to a version of my values altered according to said prediction. Not perfect, but still arguably better.)
(Of course, this has other issues if the other agent is also doing this...)
comment by A Ray (alex-ray) · 2022-01-25T01:44:42.450Z · LW(p) · GW(p)
Thinking more about ELK. Work in progress, so I expect I will eventually figure out what's up with this.
Right now it seems to me that Safety via Debate would elicit compact/non-obfuscated knowledge.
So the basic scenario is that in addition to SmartVault, you'd have Barrister_Approve and Barrister_Disapprove, who are trying to share evidence/reasoning which makes the human approve or disapprove of SmartVault scenarios.
The biggest weakness of this that I know of is Obfuscated Arguments [AF · GW] -- that is, it won't elicit obfuscated knowledge.
It seems like in the ELK example scenario they're trying to elicit knowledge that is not obfuscated.
The nice thing about this is that Barrister_Approve and Barrister_Disapprove both have pretty straightforward incentives.
Paul was an author of the debate paper so I don't think he missed this -- more like I'm failing to figure out what's up with the SmartVault scenario, and the current set of counterexamples.
Current possibilities:
- ELK is actually a problem about eliciting obfuscated information, and the current examples about eliciting non-obfuscated information are just to make a simpler thought experiment
- Even if the latent knowledge was not obfuscated, the opposing barrister could make an obfuscated argument against it.
- This seems easily treatable by the human just disbelieving any argument that is obfuscated-to-them.
↑ comment by Mark Xu (mark-xu) · 2022-01-25T02:51:45.622Z · LW(p) · GW(p)
I think we would be trying to elicit obfuscated knowledge in ELK. In our examples, you can imagine that the predictor's Bayes net works "just because", so an argument that is convincing to a human for why the diamond in the room has to be arguing that the Bayes net is a good explanation of reality + arguing that it implies the diamond is in the room, which is the sort of "obfuscated" knowledge that debate can't really handle.
Replies from: alex-ray, alex-ray↑ comment by A Ray (alex-ray) · 2022-01-25T20:46:01.269Z · LW(p) · GW(p)
Okay now I have to admit I am confused.
Re-reading the ELK proposal -- it seems like the latent knowledge you want to elicit is not-obfuscated.
Like, the situation to solve is that there is a piece of non-obfuscated information, which, if the human knew it, would change their mind about approval.
How do you expect solutions to elicit latent obfuscated knowledge (like 'the only true explanation is incomprehendible by the human' situations)?
Replies from: mark-xu↑ comment by Mark Xu (mark-xu) · 2022-01-25T20:58:53.446Z · LW(p) · GW(p)
I don’t think I understand your distinction between obfuscated and non-obfuscated knowledge. I generally think of non-obfuscated knowledge as NP or PSPACE. The human judgement of a situation might only theoretically require a poly sized fragment of a exp sized computation, but there’s no poly sized proof that this poly sized fragment is the correct fragment, and there are different poly sized fragments for which the human will evaluate differently, so I think of ELK as trying to elicit obfuscated knowledge.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-25T21:17:35.711Z · LW(p) · GW(p)
So if there are different poly fragments that the human would evaluate differently, is ELK just "giving them a fragment such that they come to the correct conclusion" even if the fragment might not be the right piece.
E.g. in the SmartVault case, if the screen was put in the way of the camera and the diamond was secretly stolen, we would still be successful even if we didn't elicit that fact, but instead elicited some poly fragment that got the human to answer disapprove?
Like the thing that seems weird to me here is that you can't simultaneously require that the elicited knowledge be 'relevant' and 'comprehensible' and also cover these sorts of obfuscated debate like scenarios.
Does it seem right to you that ELK is about eliciting latent knowledge that causes an update in the correct direction, regardless of whether that knowledge is actually relevant?
Replies from: mark-xu↑ comment by Mark Xu (mark-xu) · 2022-01-26T01:10:30.007Z · LW(p) · GW(p)
I feel mostly confused by the way that things are being framed. ELK is about the human asking for various poly-sized fragments and the model reporting what those actually were instead of inventing something else. The model should accurately report all poly-sized fragments the human knows how to ask for.
Like the thing that seems weird to me here is that you can't simultaneously require that the elicited knowledge be 'relevant' and 'comprehensible' and also cover these sorts of obfuscated debate like scenarios.
I don't know what you mean by "relevant" or "comprehensible" here.
Does it seem right to you that ELK is about eliciting latent knowledge that causes an update in the correct direction, regardless of whether that knowledge is actually relevant?
This doesn't seem right to me.
Replies from: alex-ray↑ comment by A Ray (alex-ray) · 2022-01-26T01:59:08.218Z · LW(p) · GW(p)
Thanks for taking the time to explain this!
I feel mostly confused by the way that things are being framed. ELK is about the human asking for various poly-sized fragments and the model reporting what those actually were instead of inventing something else. The model should accurately report all poly-sized fragments the human knows how to ask for.
I think this is what I was missing. I was incorrectly thinking of the system as generating poly-sized fragments.
↑ comment by A Ray (alex-ray) · 2022-01-25T05:50:49.913Z · LW(p) · GW(p)
Cool, this makes sense to me.
My research agenda is basically about making a not-obfuscated model, so maybe I should just write that up as an ELK proposal then.
comment by A Ray (alex-ray) · 2021-12-17T05:03:03.347Z · LW(p) · GW(p)
Some thoughts on Gradient Hacking:
One, I'm not certain the entire phenomena of an agent meta-modifying it's objective or otherwise influencing its own learning trajectory is bad. When I think about what this is like on the inside, I have a bunch of examples where I do this. Almost all of them are in a category called "Aspirational Rationality", which is a sub topic of Rationality (the philosophy, not the LessWrong): https://oxford.universitypressscholarship.com/view/10.1093/oso/9780190639488.001.0001/oso-9780190639488
(I really wish we explored more aspirational rationality, because it has some really interesting things to say about value drift and changing values. I think we haven't solved these for people yet, and solving them for people would probably give insights to solving them for systems)
In as much as models are acting consistent with aspirational rationality I think some gradient hacks are good. To the extent that they are in line with our goals and desires for alignment, this seems good.
It goes without saying that this also could be very bad, and also I think at the moment I roughly agree that an agent that was intentionally hacking their gradient in this way could be catastrophic.
It seems like the aspirational rationality example makes it easier for me to imagine a system acting this way, and expect it won't be hard to construct this kind of demonstration in a system where a learning agent has access to its learning algorithm. (I don't think this is useful to do at the moment, and would probably be limited to a contrived toy scenario -- but this is disagreeing with takes that it would be extremely difficult to create)
Second: I think there is a fairly obvious pathway towards this happening, and that's training on synthetic data.
Learning from synthetic data might be better named "practice". For example, I can come up with my own calculus problems, do my best to solve them, and then check my work. This is a pathway to me (or any sort of learning system) getting better at calculus without the input of external knowledge or information.
I expect learning from synthetic data (e.g. generating hypothetical problems, solving them, then verifying the solutions) to be at least plausibly a common technique. This connects to gradient hacking because it is the model itself controlling the data distribution.
Let's say I want to feel good about my ability to do math. I can subtly (i.e. invisibly to an external observer) bias my generated distribution of math problems to be only problems I know how to solve, so that after I update on the results of my practice, I won't have any updates in the direction "I'm bad at math."
So combining the two ideas: I think you could get 'aspirational rationality'-like gradient hacking in systems that learn from synthetic data. It seems to me much more plausible than the version where the system has to solve problems of embedded agency.