Brain Efficiency: Much More than You Wanted to Know
post by jacob_cannell · 2022-01-06T03:38:00.320Z · LW · GW · 103 commentsContents
Energy Thermodynamics Interconnect GPUs Synapses Space Density & Temperature Speed Circuits Serial vs Parallel vs Neuromorphic Vision Vector/Matrix Multiplication Deep Learning Data Asymptotic Vision GPT-N AlphaX Conclusions None 103 comments
What if the brain is highly efficient? To be more specific, there are several interconnected key measures of efficiency for physical learning machines:
- energy efficiency in ops/J
- spatial efficiency in ops/mm^2 or ops/mm^3
- speed efficiency in time/delay for key learned tasks
- circuit/compute efficiency in size and steps for key low level algorithmic tasks [1]
- learning/data efficiency in samples/observations/bits required to achieve a level of circuit efficiency, or per unit thereof
- software efficiency in suitability of learned algorithms to important tasks, is not directly addressed in this article[2]
Why should we care? Brain efficiency matters a great deal for AGI timelines and takeoff speeds, as AGI is implicitly/explicitly defined in terms of brain parity. If the brain is about 6 OOM away from the practical physical limits of energy efficiency, then roughly speaking we should expect about 6 OOM of further Moore's Law hardware improvement past the point of brain parity: perhaps two decades of progress at current rates, which could be compressed into a much shorter time period by an intelligence explosion - a hard takeoff.
But if the brain is already near said practical physical limits, then merely achieving brain parity in AGI at all will already require using up most of the optimizational slack, leaving not much left for a hard takeoff - thus a slower takeoff.
In worlds where brains are efficient, AGI is first feasible only near the end of Moore's Law (for non-exotic, irreversible computers), whereas in worlds where brains are highly inefficient, AGI's arrival is more decorrelated, but would probably come well before any Moore's Law slowdown.
In worlds where brains are ultra-efficient, AGI necessarily becomes neuromorphic or brain-like, as brains are then simply what economically efficient intelligence looks like in practice, as constrained by physics. This has important implications for AI-safety: it predicts/postdicts the success of AI approaches based on brain reverse engineering (such as DL) and the failure of non-brain like approaches, it predicts that AGI will consume compute & data in predictable brain like ways, and it suggests that AGI will be far more like human simulations/emulations than you'd otherwise expect and will require training/education/raising vaguely like humans, and thus that neuroscience and psychology are perhaps more useful for AI safety than abstract philosophy and mathematics.
If we live in such a world where brains are highly efficient, those of us interested in creating benevolent AGI should immediately drop everything and learn how brains work.
Energy
Computation is an organization of energy in the form of ordered state transitions transforming physical information towards some end. Computation requires an isolation of the computational system and its stored information from the complex noisy external environment. If state bits inside the computational system are unintentionally affected by the external environment, we call those bit errors due to noise, errors which must be prevented by significant noise barriers and or potentially costly error correction techniques.
Thermodynamics
Information is conserved under physics, so logical erasure of a bit from the computational system entails transferring said bit to the external environment, necessarily creating waste heat. This close connection between physical bit erasure and thermodynamics is expressed by the Landauer Limit[3], which is often quoted as
However the full minimal energy barrier analysis involves both transition times and transition probability, and this minimal simple lower bound only applies at the useless limit of 50% success/error probability or infinite transition time.
The key transition error probability is constrained by the bit energy:
Here's a range of bit energies and corresponding minimal room temp switch error rates (in electronvolts):
All computers (including brains) are ultimately built out of fundamental indivisible quantal elements in the form of atoms/molecules, each of which is also a computational device to which the Landauer Limit applies[6]. The combination of this tile/lego decomposition and the thermodynamic bit/energy relationship is a simple but powerful physics model that can predict a wide variety of micro and macro-scale computational thermodynamic measurements. Using this simple model one can predict minimal interconnect wire energy, analog or digital compute energy, and analog or digital device sizes in both brains and electronic computers.
Time and time again while writing this article, the simple first-principles physics model correctly predicted relevant OOM measurements well in advance of finding the known values in literature.
Interconnect
We can estimate a bound for brain compute energy via interconnect requirements, as interconnect tends to dominate energy costs at high device densities (when devices approach the size of wire segments). Both brains and current semiconductor chips are built on dissipative/irreversible wire signaling, and are mostly interconnect by volume.

Brains are mostly interconnect.

CPUs/GPUs are mostly interconnect.
A non-superconducting electronic wire (or axon) dissipates energy according to the same Landauer limit per minimal wire element. Thus we can estimate a bound on wire energy based on the minimal assumption of 1 minimal energy unit per bit per fundamental device tile, where the tile size for computation using electrons is simply the probabilistic radius or De Broglie wavelength of an electron[7:1], which is conveniently ~1nm for 1eV electrons, or about ~3nm for 0.1eV electrons. Silicon crystal spacing is about ~0.5nm and molecules are around ~1nm, all on the same scale.
Thus the fundamental baseline irreversible (nano) wire energy is: ~1 , with in the range of 0.1eV (low reliability) to 1eV (high reliability).
The predicted wire energy is J/bit/nm or ~100 fJ/bit/mm for semi-reliable signaling at 1V with = 1eV, down to ~10 fJ/bit/mm at 100mV with complex error correction, which is an excellent fit for actual interconnect wire energy[8][9][10][11], which only improves marginally through Moore's Law (mainly through complex sub-threshold signaling and associated additional error correction and decoding logic, again most viable for longer ranges).
For long distance interconnect or communication reversible (ie optical) signaling is obviously vastly superior in asymptotic energy efficiency, but photons and photonics are simply fundamentally too big/bulky/costly due to their ~1000x greater wavelength and thus largely impractical for the dominate on-chip short range interconnects[12]. Reversible signaling for electronic wires requires superconductance, which is even more impractical for the foreseeable future.
The brain has an estimated ~ meters of total axon/dendrite wiring length. Using an average wire data rate of 10 bit/s[13][14][15][16] (although some neurons transmit up to 90 bits/s[17]) implies an interconnect energy use of ~1W for reliable signaling (10bit/s * * W/bit/nm), or ~0.1W for lower bit rates and/or reliability. [18]
Estimates of actual brain wire signaling energy are near this range or within an OOM[19][20], so brain interconnect is within an OOM or so of energy efficiency limits for signaling, given its interconnect geometry (efficiency of interconnect geometry itself is a circuit/algorithm level question).
GPUs
A modern GPU has ~ transistors, with about half the transistors switching per cycle (CMOS logic is dense) at a rate of ~ hz[21], and so would experience bit logic errors at a rate of about two per month if operating near typical voltages of 1V (for speed) and using theoretically minimal single electron transistors[22]. The bit energy in 2021 GPUs corresponds to on order a few hundred electrons per transistor ( transistor switches per second using ~100 watts instead of the minimal 1W for theoretical semi-reliable single electron transistors, as ), and thus current GPUs are only about 2 OOM away from thermodynamic limits; which is probably an overestimate, as each hypothetical single-electron transistor needs perhaps 10 single-electron minimal interconnect segments, so GPUs are probably closer to 1 OOM from their practical thermodynamic limits (for any equivalent irreversible device doing all the same logic at the same speed and error rates)[23]. Interconnect energy dominates at the highest densities.
The distance to off chip VRAM on a large GPU is ~3 cm, so just reading bits to simulate one cycle of a brain-size ANN will cost almost 3kJ (1e{15} bits * 1e-19 J/bit/nm * 1e7cm/nm * 3), so 300kW to run at 100hz. The brain instead only needs to move per neuron values over similar long distances per cycle, which is ~10,000x more efficient than moving around the ~10,000x more numerous connection weights every cycle.
Current GPUs also provide op throughput (for matrix multiplication) up to flops/s or ops/s (for lower bit integer), which is close to current informed estimates for equivalent brain compute ops/s[24]. So that alone provides an indirect estimate that brains are within an OOM or two of thermodynamic limits - as current GPUs with equivalent throughput are within 1 to 2 OOM of their limits, and brains use 30x less energy for similar compute throughput (~10 watts vs ~300).
Synapses
The adult brain has on ~ synapses which perform a synaptic computation on order 0.5hz[25]. Each synaptic computation is something equivalent to a single analog multiplication op, or a small handful of ops (< 10). Neuron axon signals are binary, but single spikes are known to encode the equivalent of higher dynamic range values through various forms of temporal coding, and spike train pulses can also extend the range through nonlinear exponential coding - as synapses are known to have the short term non-linear adaptive mechanisms that implement non-linear signal decoding [26][27]. Thus the brain is likely doing on order to low-medium precision multiply-adds per second.
Analog operations are implemented by a large number of quantal/binary carrier units; with the binary precision equivalent to the signal to noise ratio where the noise follows a binomial distribution. The equivalent bit precision of an analog operation with N quantal carriers is the log of N (maximum signal information) minus the binomial noise entropy:
Where is the individual carrier switch transition error probability. If the individual carrier transitions are perfectly reliable then the entropy term is zero, but that would require unrealistically high reliability and interconnect energy. In the brain the switch transition error probability will be at least 0.06 for a single electron carrier at minimal useful Landauer Limit voltage of ~70mV like the brain uses (which also happens to simplify the math):
So true 8-bit equivalent analog multiplication requires about 100k carriers/switches and thus using noisy subthreshold ~0.1eV per carrier, for a minimal energy consumption on order 0.1W to 1W for the brain's estimated to synaptic ops/s. There is some room for uncertainty here, but not room for many OOM uncertainty. It does suggest that the wiring interconnect and synaptic computation energy costs are of nearly the same OOM. I take this as some evidence favoring the higher op/s number, as computation energy use below that of interconnect requirements is cheap/free.
Note that synapses occupy a full range of sizes and corresponding precisions, with most considerably lower than 8-bit precision (ranging down to 1-bit), which could significantly reduce the median minimal energy by multiple OOM, but wouldn't reduce the mean nearly as much, as the latter is dominated by the higher precision synapses because energy scales exponentially as with precision.
The estimate/assumption of 8-bit equivalence for the higher precision range may seem arbitrary, but I picked that value based on 1.) DL research indicating the need for around 5 to 8 bits per param for effective learning[29][30] (not to be confused with the bits/param for effective forward inference sans-learning, which can be much lower), and 2.) Direct estimates/measurements of (hippoccampal) mean synaptic precisions around 5 bits[31][32]. 3.) 8-bit precision happens to be near the threshold where digital multipliers begin to dominate (a minimal digital 8-bit multiplier requires on order minimal transistors/devices and thus roughly minimal wire segments connecting them, vs around carriers for the minimal 8-bit analog multiplier). A synapse is also an all-in-one highly compact computational device, memory store, and learning device capable of numerous possible neurotransmitter specific subcomputations.
The predicted involvement of ~ charge carriers then just so happens to match estimates of the mean number of ion carriers crossing the postsynaptic membrane during typical synaptic transmission[33]. This is ~10x the number of involved presynaptic neurotransmitter carrier molecules from a few released presynaptic vesicles, but synapses act as repeater amplifiers.
We can also compare the minimal energy prediction of for 8-bit equivalent analog multiply-add to the known and predicted values for upcoming efficient analog accelerators, which mostly have energy efficiency in the range[34][35][36][37] for < 8 bit, with the higher reported values around similar to the brain estimate here, but only for < 4-bit precision[38]. Analog devices can not be shrunk down to few nm sizes without sacrificing SNR and precision; their minimal size is determined by the need for a large number of carriers on order for equivalent bit precision , and c ~ 2, as discussed earlier.
Conclusion: The brain is probably at or within an OOM or so of fundamental thermodynamic/energy efficiency limits given its size, and also within a few OOM of more absolute efficiency limits (regardless of size), which could only be achieved by shrinking it's radius/size in proportion (to reduce wiring length energy costs).
Space
The brain has about total synapses in a volume of 1000 , or , so around volume / synapse. The brain's roughly 8-bit precision synapses requires on order electron carriers and thus on same order number of minimal 1 molecules. Actual synapses are flat disc shaped and only modestly larger than this predicts - with mean surface areas around . [39][40][41].
So even if we assume only 10% of synapses are that large, the minimal brain synaptic volume is about . Earlier we estimated around nm of total wiring length, and thus at least an equivalent or greater total wiring volume (in practice far more due to the need for thick low resistance wires for fast long distance transmission), but wire volume requirements scale linearly with dimension. So if we ignore all the machinery required for cellular maintenance and cooling, this indicates the brain is at most about 100x larger than strictly necessary (in radius), and more likely only 10x larger.
Density & Temperature
However, even though the wiring energy scales linearly with radius, the surface area power density which crucially determines temperature scales with the inverse squared radius, and the minimal energy requirements for synaptic computation are radius invariant.
The black body temperature of the brain scales with energy and surface area according to the Stefan-Boltzmann Law:
Where is the power per unit surface area in W/, and is the Stefan-Boltzmann constant. The human brain's output of 10W in 0.01m^2 results in a power density of 1000W / , very similar to that of the solar flux on the surface of the earth, which would result in an equilibrium temperature of or C, sufficient to boil the blood, if it wasn't actively cooled. Humans have evolved exceptional heat dissipation [LW(p) · GW(p)] capability using the entire skin surface for evaporative cooling[42] : a key adaption that supports both our exceptional long distance running ability, and our oversized brains (3X larger than expected for the default primate body plan, and brain tissue has 10x the power density of the rest of the body).
Shrinking the brain by a factor of 10 at the same power output would result in a ~3.16x temp increase to around 1180K, shrinking the brain minimally by a factor of 100 would result in a power density of W / and a local temperature of around 3,750K - similar to that of the surface of the sun.
Current 2021 gpus have a power density approaching W / , which severely constrains the design to that of a thin 2D surface to allow for massive cooling through large heatsinks and fans. This in turn constrains off-chip memory bandwidth to scale poorly: shrinking feature sizes with Moore's Law by a factor of D increases transistor density by a factor of , but at best only increases 2d off-chip wire density by a factor of only D, and doesn't directly help reduce wire energy cost at all.
A 2021 GPU with transistors has a surface area of about and so also potentially has room for at most 100x further density scaling, which would result in 10,000x higher transistor count, but given that it only has 1 or 2 OOM potential improvement in thermodynamic energy efficiency, significant further scaling of existing designs would result in untenable power consumption and surface temperature. In practice I expect around only 1 more OOM in dimension scaling (2 OOM in transistor density), with less than an OOM in energy scaling, resulting in dark silicon and or crazy cooling designs[23:1].
Conclusion: The brain is perhaps 1 to 2 OOM larger than the physical limits for a computer of equivalent power, but is constrained to its somewhat larger than minimal size due in part to thermodynamic cooling considerations.
Speed
Brain computation speed is constrained by upper neuron firing rates of around 1 khz and axon propagation velocity of up to 100 m/s [43], which are both about a million times slower than current computer clock rates of near 1 Ghz and wire propagation velocity at roughly half the speed of light. Interestingly, since both the compute frequency and signal velocity scale together at the same rate, computers and brains both are optimized to transmit fastest signals across their radius on the time scale of their equivalent clock frequency: the fastest axon signals can travel about 10 cm per spike timestep in the brain, and also up to on order 10 cm per clock cycle in a computer.
So why is the brain so slow? The answer is again probably energy efficiency.
The maximum frequency of a CMOS device is constrained by the voltage, and scales approximately with [44][45]:
With typical current values in the range of 1.0 for and perhaps 0.5 for . The equivalent values for neural circuits are 0.070 for and around 0.055 for , which would still support clock frequencies in the MHz range. So a digital computer operating at the extreme subthreshold voltages the brain uses could still switch a thousand times faster.
However, as the minimal total energy usage also scales linearly with switch frequency, and the brain is already operating near thermodynamic efficiency limits at slow speeds, a neuromorphic computer equivalent to the brain, with equivalent synapses (functioning simultaneously as both memory and analog compute elements), would also consume around 10W operating at brain speeds at 1kHz. Scaling a brain to MHz speeds would increase energy and thermal output into the 10kW range and thus surface power density into the / range, similar to current GPUs. Scaling a brain to GHz speeds would increase energy and thermal output into the 10MW range, and surface power density to / , with temperatures well above the surface of the sun.
So in the same brain budget of 10W power and thermodynamic size constraints, one can choose between a computer/circuit with bytes of param memory and byte/s of local memory bandwidth but low sub kHZ speed, or a system with up to bytes/s of local memory bandwidth and gHZ speed, but only bytes of local param memory. The most powerful GPUs or accelerators today achieve around bytes/s of bandwidth from only the register file or lowest level cache, the total size of which tends to be on order bytes or less.
For any particular energy budget there is a Landauer Limit imposed maximum net communication flow rate through the system and a direct tradeoff between clock speed and accessible memory size at that flow rate.
A single 2021 GPU has the compute power to evaluate a brain sized neural circuit running at low brain speeds, but it has less than 1/1000th of the required RAM. So you then need about 1000 GPUs to fit the neural circuit in RAM, at which point you can then run 1000 copies of the circuit in parallel, but using multiple OOMs more energy per agent/brain for all the required data movement.
It turns out that spreading out the communication flow rate budget over a huge memory store with a slow clock rate is fundamentally more powerful than a fast clock rate over a small memory store. One obvious reason: learning machines have a need to at least store their observational history. A human experiences a sensory input stream at a bitrate of about bps (assuming maximal near-lossless compression) for about seconds over typical historical lifespan, for a total of about bits. The brain has about synapses that store roughly 5 bits each, for about bits of storage. This is probably not a coincidence.
In three separate linages - primates, cetaceans, and proboscideans - brains evolved to large sizes of on order neocortical neurons and synapses (humans: ~20B neocortical neurons, ~80B total, elephants: ~6B neocortical neurons[46], ~250B total, long-finned pilot whale: ~37B neocortical neurons[47], unknown total), concomitant with long (40+) year lifespans. Humans are unique only in having a brain several times larger than normal for our total energy budget, probably due to the unusually high energy payoff for linguistic/cultural intelligence.
Conclusion: The brain is a million times slower than digital computers, but its slow speed is probably efficient for its given energy budget, as it allows for a full utilization of an enormous memory capacity and memory bandwidth. As a consequence of being very slow, brains are enormously circuit cycle efficient. Thus even some hypothetical superintelligence, running on non-exotic hardware, will not be able to think much faster than an artificial brain running on equivalent hardware at the same clock rate.
Circuits
Measuring circuit efficiency - as a complex high level and task dependent metric - is naturally far more challenging than measuring simpler low level physical metrics like energy efficiency. We first can establish a general model of the asymptotic efficiency of three broad categories of computers: serial, parallel, and neuromorphic (processor in memory). Then we can analyze a few example brain circuits that are reasonably well understood, and compare their size and delay to known bounds or rough estimates thereof.
Serial vs Parallel vs Neuromorphic
A pure serial (Von Neumman architecture) computer is one that executes one simple instruction per clock cycle, fetching opcodes and data from a memory hierarchy. A pure serial computer of size , and a clock frequency of can execute up to only ~ low level instructions per second over a memory of size at most ~ for a 2d system (as in modern CPUs/GPUs, constrained to 2D by heat dissipation requirements). In the worst case when each instruction accesses a random memory value the processor stalls; the worst case performance is thus bound by ~ where is the device size, and m/s is the speed of light bound signal speed. So even a perfectly dense (nanometer scale transistors) 10cm x 10cm pure serial CPU+RAM has performance of only a few billion ops/s when running any algorithms that access memory randomly or perform only few ops per access.
A fully parallel (Von Neumman architecture) computer can execute up to instructions per clock, and so has a best case performance that scales as and a worst case of ~. The optimal parallel 10cm x 10cm computational device thus has a maximum potential that is about 16 orders of magnitude greater than the pure serial device.
An optimal neuromorphic computer then simply has a worst and best case performance that is , for 2d or for a 3d device like the brain, as its processing units and memory units (synapses) are the same.
Physics is inherently parallel, and thus serial computation simply doesn't scale. The minor big O analysis asymptotic advantages of serial algorithms are completely dominated by the superior asymptotic physical scaling of parallel computation. In other words, big O analysis is wrong, as it naively treats computation and memory access as the same thing, when in fact the cost of memory access is not constant, and scales up poorly with memory/device size.
The neuromorphic (processor in memory) computational paradigm is asymptotically optimal scaling wise, but within that paradigm we can then further differentiate circuit efficiency in terms of width/size and delay.
Vision
In terms of circuit depth/delay, humans/primates can perform complex visual recognition and other cognitive tasks in around 100ms to a second, which translates to just a dozen to a hundred inter-module compute steps (each of which takes about 10ms to integrate a few spikes, transmit to the next layer, etc). This naturally indicates learned cortical circuits are near depth optimal, in terms of learning minimal depth circuits for complex tasks, when minimal depth is task useful. As the cortex/cerebellum/BG/thalamus system is a generic universal learning system [LW · GW], showing evidence for efficiency in the single well understood task of vision suffices to show evidence for general efficiency; the 'visual' cortical modules are just generic cortical modules that only happen to learn vision when wired to visual inputs, and will readily learn audio or complex sonar processing with appropriate non-standard input wiring.
A consequence of near-optimal depth/delay implies that the fastest possible thinking minds will necessarily be brain-like, as brains use the near-optimal minimal number of steps to think. So any superintelligence running on any non-exotic computer will not be able to think much faster than an artificial brain running on the same equivalent hardware and clock speeds.
In terms of circuit width/size the picture is more complex, but vision circuits are fairly well understood.
The retina not only collects and detects light, it also performs early image filtering/compression with a compact few-layer network. Most vertebrates have a retina network, and although there is considerable variation it is mostly in width, distribution, and a few other hyperparams. The retina performs a reasonably simple well known function (mostly difference of gaussian style filters to exploit low frequency spatio-temporal correlations - the low hanging statistical fruit of natural images), and seems reasonably near-optimal for this function given its stringent energy, area, and latency constraints.
The first layer of vision in the cortex - V1 - is a more massively scaled up early visual layer (esp. in primates/humans), and is also apparently highly efficient given its role to extract useful low-order spatio-temporal correlations for compression and downstream recognition. Extensive experiments in DL on training a variety of visual circuits with similar structural constraints (local receptive field connectivity, etc) on natural image sequences all typically learn V1 like features in first/early layers, such that failure to do so is often an indicator of some error. Some of the first successful learned vision feature extractors were in fact created as a model of V1[48], and modern DL systems with local connectivity still learn similar low level features. As a mathematical theory, sparse coding explains why such features are optimal, as a natural overcomplete/sparse generalization of PCA.
Vector/Matrix Multiplication
We know that much if not most of the principle computations the brain must perform map to the well studied problem of vector matrix multiplication.
Multiplication of an input vector X and a weight matrix W has a known optimal form in maximally efficient 2D analog circuity: the crossbar architecture. The input vector X of size M is encoded along a simple uniform vector of wires traversing the structure left to right. The output vector Y of size N is also encoded as another uniform wire vector, but traversing in a perpendicular direction from top to bottom. The weight matrix W is then implemented with analog devices on each of the MxN wire crossings.

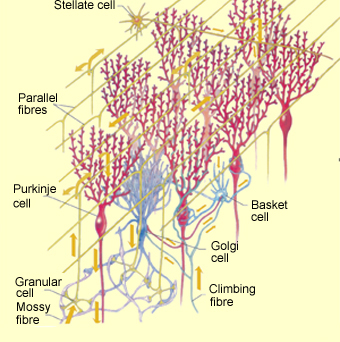
In one natural extension of this crossbar architecture to 3 dimensions, the input vector X becomes a 2D array of wires of dimension x , and each output vector Y becomes a flat planar structure (reduction tree), with a potential connection to every input wire. This 3D structure then has a depth of order N, for the N output summation planes. This particular structure is optimal for M ~ , with other variations optimal for M ~ N. This is a simplified description of the geometric structure of the cerebellum:
Deep Learning
Deep learning systems trained with brain-like architectural/functional constraints (recurrence[49][50], local sparse connectivity, etc) on naturalistic data[51] with generic multi-task and or self-supervised objectives are in fact our very best models of relevant brain circuits[52][53][54]; developing many otherwise seemingly brain-specific features such as two specialized processing streams[55][56], categorical specialization[57], etc., and can explain brain limitations[58][59]. Likewise, DL evolving towards AGI converges on brain reverse engineering[60][61], especially when optimizing towards maximal energy efficiency for complex real world tasks.
The spectacular success of brain reverse engineering aka DL - and its complete dominance in modern AI - is strong evidence for brain circuit efficiency, as both biological and technological evolution, although very different processes, both converge on similar solutions given the same constraints.
Conclusion: It's difficult to make strong definitive statements about circuit efficiency, but current evidence is most compatible with high brain circuit efficiency, and I'm not aware of any significant evidence against.
Data
Data efficiency is a common (although perhaps unfounded) critique of DL. Part of this disadvantage could simply be due to economics: large scale DL systems can take advantage of huge datasets, so there is little immediate practical need to focus on learning from limited datasets. But in the longer term as we approach AGI, learning quickly from limited data becomes increasingly important: it is much of what we mean when we say a human is smart or quick or intelligent.
We can analyze data/learning efficiency on two levels: asymptotic learning efficiency, and practical larger-scale system level data efficiency.
Asymptotic
In terms of known algorithmic learning theory, a data-optimal learning machine with memory O(M) can store/evaluate up to M unique models in parallel per circuit timestep, and can prune about half of said virtual models per observational bit per timestep - as in well known Solomonoff Induction, full Bayesian Inference, or prediction through expert selection[62]. The memory freed can then be recycled to evaluate new models the next timestep, so at the limit such a machine can evaluate O(M*T) models in T timesteps. Thus any practical learning machine can evaluate at most O(N) models and same order data observations, where N is the net compute expended for training (nearly all virtual models are discarded at an average evaluation cost of only O(C)). Assuming that 'winning' predictive models are distributed uniformly over model-space, this implies a power law relationship between predictive entropy (log predictive error), and the entropy of model space explored (and thus log compute for training). Deep learning systems are already in this power-law regime[63][64], thus so is the brain, and they are both already in the optimal broad asymptotic complexity class.
In terms of tighter bounds on practical large scale data efficiency, we do not have direct apples-to-apples comparisons as humans and current DL systems are trained on different datasets. But some DL systems are trained on datasets that could be considered a relevant subset of the human training dataset.
Vision
DL vision systems can achieve mildly superhuman performance on specific image recognition games like Imagenet, but these systems are trained on a large labeled dataset of 1M images, whereas humans are first pretrained unsupervised on a larger mostly unlabeled dataset of perhaps 1B images (1 image/s for 32 years), with a tiny fraction of linguistically labeled images (or perhaps none for very specific dog breed categories).
If you look at Imagenet labels, they range from the obvious: syringe, to the obscure: gyromitra. Average untrained human performance of around 75% top-5 is reasonably impressive considering that untrained humans have 0 labels for many categories. Trained humans can achieve up to 95% top-5 accuracy, comparable to DL SOTA from 2017. Now 2021 DL SOTA is around 99% top-5 using all labels, and self-supervised SOTA (using a big model) matches human expert ability using 10% of labels (about 100 labels per category),[65] but using multiple data passes. Assuming a human expert takes a second or two to evaluate an image, a single training pass on 10% of the imagenet labels would take about 40 hours: a full time work week, perhaps a month for multiple passes. It's unclear at this point if humans could approach the higher 99% score if only some were willing to put in months or years of training, but it seems plausible.
DL visual systems take advantage of spatial (ie convolutional) weight sharing to reduce/compress parameters and speed up learning. This is difficult/impossible for slow neuromorphic processors like the brain, so this handicap makes brain data efficiency somewhat less directly comparable and somewhat more impressive.
GPT-N
OpenAI's GPT-3 is a 175B param model (or 1e12 bits at 5.75 bits/param) trained on a corpus of about 400B BPE tokens, or roughly 100B words (or 1e12 bits at 10 bits/word), whereas older humans are 'trained' on perhaps 10B words (about 5 per second for 64 years), or more generally about 10B timesteps of about 200ms each, corresponding roughly to one saccadic image, one word, precept, etc. A single saccadic image has around 1M pixels compressible to about 0.1bpp, suggesting a human experiences on order 1e15 bits per lifetime, on par with up to 1e15 bits of synaptic information (2e14 synapses * 5 bit/synapse).
Scaling analysis of GPT-N [LW · GW] suggests high benchmark performance (vague human parity) will require scaling up to a brain size model a bit above 1e14 params and a similar size dataset. This is interesting because it suggests that current DL models (or at least transformers), are perhaps as parameter efficient as the brain, but are far less data efficient in terms of consumed words/tokens. This may not be surprising if we consider that difficulty of the grounding problem: GPT is trying to learn the meaning of language without first learning the grounding of these symbols in a sensorimotor model of the world.
These scaling laws indicate GPT-N would require about 3 to 4 OOM more word data than humans to match human performance, but GPT-3 already trains on a large chunk of the internet. However most of this data is highly redundant. Humans don't train by reading paragraphs drawn uniformly at random from the entire internet - as the vast majority of such data is near worthless. GPT-N models could be made more data efficient through brain inspired active learning (using a smaller net to predict gradient magnitudes to select informative text to train the larger model), and then multi-modal curriculum training for symbol grounding, more like the human education/training process.
AlphaX
AlphaGo achieved human champion performance after training on about 40 million positions, equivalent to about 400k games, which is roughly an OOM more games than a human professional will play during lifetime training (4k games/year * 10 years)[66].
AlphaZero matched human champion performance after training on only about 4 million positions(~100k updates of 4k positions each) and thus 40k games - matching my estimated human data efficiency.
However AlphaX models learn their action-value prediction functions from each MCT state evaluation, just as human brains probably learn the equivalent from imaginative planning state evaluations. But human brains - being far slower - perform at least one OOM less imagined state evaluation rollouts per board move evaluation than AlphaX models, which implies the brain is learning more per imagined state evaluation. The same naturally applies to DeepMind's newer EfficientZero - which learns human-level Atari in only 2 hours realtime[67] but this corresponds to a huge number of imagined internal state evaluations, on same order as similar model-free Atari agents.
Another way of looking at it: if AlphaX models really were fully as data efficient as the human brain in terms of learning speed per evaluation step and equivalent clock cycle, then we'd expect them to achieve human level play a million times faster than the typical human 10 years: ie in about 5 minutes (vs ~2 hours for EfficientZero, or ~30 hours for AlphaZero). Some component of this is obviously inefficiency in GPU clock cycles per evaluation step, but to counter that AlphaX models are tiny and often trained in parallel on many GPUs/TPUs.
Conclusion: SOTA DL systems have arguably matched the brain's data learning efficiency in the domain of vision - albeit with some artificial advantages like weight-sharing countering potential brain advantages. DL RL systems have also arguably matched brain data efficiency in games such as Go, but only in terms of physical move evaluations; there still appears to be a non-trivial learning gap where the brain learns much more per virtual move evaluation, which DL systems compensate for by rapidly evaluating far more virtual moves during MCTS rollouts. There is still a significant data efficiency gap in natural language, but training datasets are very different and almost certainly favor the brain (multimodal curriculum training and active learning).
Thus there is no evidence here of brain learning inefficiency (for systems of similar size/power). Instead DL still probably has more to learn from the brain on how to learn efficiently beyond SGD, and the probable convergence of biological and technological evolution to what appears to be the same fundamental data efficiency scaling laws is evidence for brain efficiency.
Conclusions
The brain is about as efficient as any conventional learning machine[68] can be given:
- An energy budget of 10W
- A thermodynamic cooling constrained surface power density similar to that of earth's surface (1kW/), and thus a 10cm radius.
- A total training dataset of about 10 billion precepts or 'steps'
If we only knew the remaining secrets of the brain today, we could train a brain-sized model consisting of a small population of about 1000 agents/sims, running on about as many GPUs, in probably about a month or less, for about $1M. This would require only about 1kW per agent or less, and so if the world really desired it, we could support a population of billions of such agents without dramatically increasing total world power production.
Nvidia - the single company producing most of the relevant flops today - produced roughly 5e21 flops of GPU compute in 2021, or the equivalent of about 5 million brains [69], perhaps surpassing the compute of the 3.6 million humans born in the US. With 200% growth in net flops output per year from all sources it will take about a decade for net GPU compute to exceed net world brain compute.[70]
Eventually advances in software and neuromorphic computing should reduce the energy requirement down to brain levels of 10W or so, allowing for up to a trillion brain-scale agents at near future world power supply, with at least a concomitant 100x increase in GDP[71]. All of this without any exotic computing.
Achieving those levels of energy efficiency will probably require brain-like neuromorphic-ish hardware, circuits, and learned software via training/education. The future of AGI is to become more like the brain, not less.
Here we focus on ecologically important tasks like visual inference - how efficient are brain circuits for evolutionarily important tasks?. For more recent economically important tasks such as multiplying large numbers the case for brain circuit inefficiency is quite strong (although there are some potential exceptions - human mentants such as Von Neumann). ↩︎
Obviously the brain's software (the mind) is still rapidly evolving with cultural/technological evolution. The efficiency of learned algorithms (as complex multi-step programs) that humans use to discover new theories of physics, create new DL algorithms, think more rationally about investing, or the said theories or algorithms themselves, are not considered here. ↩︎
Landauer, Rolf. "Irreversibility and heat generation in the computing process." IBM journal of research and development 5.3 (1961): 183-191. gs-link ↩︎
Zhirnov, Victor V., et al. "Limits to binary logic switch scaling-a gedanken model." Proceedings of the IEEE 91.11 (2003): 1934-1939. gs-link ↩︎
Frank, Michael P. "Approaching the Physical Limits of Computing." gs-link ↩︎
The tile/lego model comes from Cavin/Zhirnov et al in "Science and engineering beyond Moore's law"[7] and related publications. ↩︎
Cavin, Ralph K., Paolo Lugli, and Victor V. Zhirnov. "Science and engineering beyond Moore's law." Proceedings of the IEEE 100.Special Centennial Issue (2012): 1720-1749. gs-link ↩︎ ↩︎ ↩︎
Postman, Jacob, and Patrick Chiang. "A survey addressing on-chip interconnect: Energy and reliability considerations." International Scholarly Research Notices 2012 (2012). gs-link ↩︎
Das, Subhasis, Tor M. Aamodt, and William J. Dally. "SLIP: reducing wire energy in the memory hierarchy." Proceedings of the 42nd Annual International Symposium on Computer Architecture. 2015. gs-link ↩︎
Zhang, Hang, et al. "Architecting energy-efficient STT-RAM based register file on GPGPUs via delta compression." 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC). IEEE, 2016. linkgs-link ↩︎
Park, Sunghyun, et al. "40.4 fJ/bit/mm low-swing on-chip signaling with self-resetting logic repeaters embedded within a mesh NoC in 45nm SOI CMOS." 2013 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, 2013. gs-link ↩︎
As a recent example, TeraPHY offers apparently SOTA electrical to optical interconnect with power efficiency of 5pJ/bit, which surpasses irreversible wire energy of ~100fJ/bit/mm only at just beyond GPU die-size distances of 5cm, and would only just match SOTA electrical interconnect for communication over a full cerebras wafer-scale device. ↩︎
Reich, Daniel S., et al. "Interspike intervals, receptive fields, and information encoding in primary visual cortex." Journal of Neuroscience 20.5 (2000): 1964-1974. gs-link ↩︎
Singh, Chandan, and William B. Levy. "A consensus layer V pyramidal neuron can sustain interpulse-interval coding." PloS one 12.7 (2017): e0180839. gs-link ↩︎
Individual spikes carry more information at lower spike rates (longer interspike intervals), making sparse low spike rates especially energy efficient, but high total bandwidth, low signal latency, and high area efficiency all require higher spike rates. ↩︎
Koch, Kristin, et al. "How much the eye tells the brain." Current Biology 16.14 (2006): 1428-1434. gs-link ↩︎
Strong, Steven P., et al. "Entropy and information in neural spike trains." Physical review letters 80.1 (1998): 197. gs-link ↩︎
There are more complex physical tradeoffs between wire diameter, signal speed, and energy, such that minimally energy efficient signalling is probably too costly in other constrained dimensions. ↩︎
Lennie, Peter. "The cost of cortical computation." Current biology 13.6 (2003): 493-497. gs-link ↩︎
Ralph Merkle estimated the energy per 'Ranvier op' - per spike energy along the distance of 1mm jumps between nodes of Ranvier - at 5 x J, which at 5 x J/nm is only ~2x the Landauer Limit, corresponding to single electron devices per nm operating at around 40 mV. He also estimates an average connection distance of 1mm and uses that to directly estimate about 1 synaptic op per 1mm 'Ranvier op', and thus about ops/s, based on this energy constraint. ↩︎
Wikipedia, RTX 3090 stats ↩︎
The minimal Landauer bit error rate for 1eV switches is 1e-25, vs 1e10 transistors at 1e9 hz for 1e6 seconds (2 weeks). ↩︎
Cavin et al estimate end of Moore's Law CMOS device characteristics from a detailed model of known physical limits[7:2]. A GPU at these limits could have 10x feature scaling vs 2021 and 100x transistor density, but only about 3x greater energy efficiency, so a GPU of this era could have 3 trillion transistors, but would use/burn an unrealistic 10kW to run all those transistors at GHz speed. ↩︎ ↩︎
Carlsmith at Open Philanthropy produced a huge report resulting in a wide distribution over brain compute power, with a median/mode around ops/s. Although the median/mode is reasonable, this report includes too many poorly informed estimates, resulting in an unnecessarily high variance distribution. The simpler estimate of synapses switching at around ~0.5hz, with 1 synaptic op equivalent to at least one but up to ten low precision flops or analog multiply-adds, should result in most mass concentrated around op/s and ops/s. There is little uncertainty in the synapse count, not much in the average synaptic firing rate, and the evidence from neuroscience provides fairly strong support, but ultimately the Landauer Limit as analyzed here rules out much more than ops/s, and Carlsmith's report ignores interconnect energy and is confused about the actual practical thermodynamic limits of analog computation. ↩︎
Mean of Neuron firing rates in humans ↩︎
In some synapses synaptic facilitation acts very much like an exponential decoder, where the spike train sequence 11 has a postsynaptic potential that is 3x greater than the sequence 10, the sequence 111 is 9x greater than 100, etc. - see the reference below. ↩︎
Jackman, Skyler L., and Wade G. Regehr. "The mechanisms and functions of synaptic facilitation." Neuron 94.3 (2017): 447-464. gs-link ↩︎
See the following article for a completely different approach resulting in the same SNR relationship following 3.16 in Sarpeshkar, Rahul. "Analog versus digital: extrapolating from electronics to neurobiology." Neural computation 10.7 (1998): 1601-1638. gs-link ↩︎
Miyashita, Daisuke, Edward H. Lee, and Boris Murmann. "Convolutional neural networks using logarithmic data representation." arXiv preprint arXiv:1603.01025 (2016). gs-link ↩︎
Wang, Naigang, et al. "Training deep neural networks with 8-bit floating point numbers." Proceedings of the 32nd International Conference on Neural Information Processing Systems. 2018. gs-link ↩︎
Bartol Jr, Thomas M., et al. "Nanoconnectomic upper bound on the variability of synaptic plasticity." Elife 4 (2015): e10778. gs-link ↩︎
Bartol, Thomas M., et al. "Hippocampal spine head sizes are highly precise." bioRxiv (2015): 016329. gs-link ↩︎
Attwell, David, and Simon B. Laughlin. "An energy budget for signaling in the grey matter of the brain." Journal of Cerebral Blood Flow & Metabolism 21.10 (2001): 1133-1145. gs-link ↩︎
Bavandpour, Mohammad, et al. "Mixed-Signal Neuromorphic Processors: Quo Vadis?" 2019 IEEE SOI-3D-Subthreshold Microelectronics Technology Unified Conference (S3S). IEEE, 2019. gs-link ↩︎
Chen, Jia, et al. "Multiply accumulate operations in memristor crossbar arrays for analog computing." Journal of Semiconductors 42.1 (2021): 013104. gs-link ↩︎
Li, Huihan, et al. "Memristive crossbar arrays for storage and computing applications." Advanced Intelligent Systems 3.9 (2021): 2100017. gs-link ↩︎
Li, Can, et al. "Analogue signal and image processing with large memristor crossbars." Nature electronics 1.1 (2018): 52-59. gs-link ↩︎
Mahmoodi, M. Reza, and Dmitri Strukov. "Breaking POps/J barrier with analog multiplier circuits based on nonvolatile memories." Proceedings of the International Symposium on Low Power Electronics and Design. 2018. gs-link ↩︎
Montero-Crespo, Marta, et al. "Three-dimensional synaptic organization of the human hippocampal CA1 field." Elife 9 (2020): e57013. gs-link ↩︎
Santuy, Andrea, et al. "Study of the size and shape of synapses in the juvenile rat somatosensory cortex with 3D electron microscopy." Eneuro 5.1 (2018). gs-link ↩︎
Brengelmann, George L. "Specialized brain cooling in humans?." The FASEB Journal 7.12 (1993): 1148-1153. gs-link ↩︎
Wikipedia: Nerve Conduction Velocity ↩︎
ScienceDirect: Dynamic power dissipation, EQ Ov.10 ↩︎
Gonzalez, Ricardo, Benjamin M. Gordon, and Mark A. Horowitz. "Supply and threshold voltage scaling for low power CMOS." IEEE Journal of Solid-State Circuits 32.8 (1997): 1210-1216. gs-link ↩︎
Herculano-Houzel, Suzana, et al. "The elephant brain in numbers." Frontiers in neuroanatomy 8 (2014): 46. gs-link ↩︎
Mortensen, Heidi S., et al. "Quantitative relationships in delphinid neocortex." Frontiers in Neuroanatomy 8 (2014): 132. gs-link ↩︎
Olshausen, Bruno A., and David J. Field. "Sparse coding with an overcomplete basis set: A strategy employed by V1?." Vision research 37.23 (1997): 3311-3325. gs-link ↩︎
Kar, Kohitij, et al. "Evidence that recurrent circuits are critical to the ventral stream’s execution of core object recognition behavior." Nature neuroscience 22.6 (2019): 974-983. gs-link ↩︎
Nayebi, Aran, et al. "Task-driven convolutional recurrent models of the visual system." arXiv preprint arXiv:1807.00053 (2018). gs-link ↩︎
Mehrer, Johannes, et al. "An ecologically motivated image dataset for deep learning yields better models of human vision." Proceedings of the National Academy of Sciences 118.8 (2021). gs-link ↩︎
Yamins, Daniel LK, and James J. DiCarlo. "Using goal-driven deep learning models to understand sensory cortex." Nature neuroscience 19.3 (2016): 356-365. gs-link ↩︎
Zhang, Richard, et al. "The unreasonable effectiveness of deep features as a perceptual metric." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. gs-link ↩︎
Cichy, Radoslaw M., and Daniel Kaiser. "Deep neural networks as scientific models." Trends in cognitive sciences 23.4 (2019): 305-317. gs-link ↩︎
Bakhtiari, Shahab, et al. "The functional specialization of visual cortex emerges from training parallel pathways with self-supervised predictive learning." (2021). gs-link ↩︎
Mineault, Patrick, et al. "Your head is there to move you around: Goal-driven models of the primate dorsal pathway." Advances in Neural Information Processing Systems 34 (2021). gs-link ↩︎
Dobs, Katharina, et al. "Brain-like functional specialization emerges spontaneously in deep neural networks." bioRxiv (2021). gs-link ↩︎
Elsayed, Gamaleldin F., et al. "Adversarial examples that fool both computer vision and time-limited humans." arXiv preprint arXiv:1802.08195 (2018). gs-link ↩︎
Nicholson, David A., and Astrid A. Prinz. "Deep Neural Network Models of Object Recognition Exhibit Human-like Limitations When Performing Visual Search Tasks." bioRxiv (2021): 2020-10. gs-link ↩︎
Hassabis, Demis, et al. "Neuroscience-inspired artificial intelligence." Neuron 95.2 (2017): 245-258. gs-link ↩︎
Zador, Anthony M. "A critique of pure learning and what artificial neural networks can learn from animal brains." Nature communications 10.1 (2019): 1-7. gs-link ↩︎
Haussler, David, Jyrki Kivinen, and Manfred K. Warmuth. "Tight worst-case loss bounds for predicting with expert advice." European Conference on Computational Learning Theory. Springer, Berlin, Heidelberg, 1995. gs-link ↩︎
Hestness, Joel, et al. "Deep learning scaling is predictable, empirically." arXiv preprint arXiv:1712.00409 (2017). gs-link ↩︎
Rosenfeld, Jonathan S., et al. "A constructive prediction of the generalization error across scales." arXiv preprint arXiv:1909.12673 (2019). gs-link ↩︎
Chen, Ting, et al. "Big self-supervised models are strong semi-supervised learners." arXiv preprint arXiv:2006.10029 (2020). gs-link ↩︎
Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." nature 529.7587 (2016): 484-489. ↩︎
Ye, Weirui, et al. "Mastering atari games with limited data." Advances in Neural Information Processing Systems 34 (2021). ↩︎
Practical here implies irreversible - obviously an exotic reversible or quantum computer could potentially do much better in terms of energy efficiency, but all evidence suggests brain size exotic computers are still far in the future, after the arrival of AGI on conventional computers. ↩︎
Nvidia's 2021 revenue is about $25B, about half of which is from consumer GPUs which provide near brain level ops/s for around $2,000. The other half of revenue for data-center GPUs is around 5x more expensive per flop. ↩︎
Without any further progress in flops/s/$ from Moore's Law, this would entail Nvidia's revenue exceeding United States GDP in a decade. More realistically, even if Nvidia retains a dominant lead, it seems much more likely to arrive from an even split: 30x increase in revenue, 30x increase in flops/s/$. But as this article indicates, there is limited further slack in Moore's Law, so some amount of growth must come from economic scaling up the fraction of GDP going into compute. ↩︎
Obviously neuromorphic AGI or sims/uploads will have numerous transformative advantages over humans: ability to copy/fork entire minds, share modules, dynamically expand modules beyond human brain limits, run at variable speeds far beyond 100hz, interace more directly with computational systems, etc. ↩︎
103 comments
Comments sorted by top scores.
comment by Vaniver · 2022-01-07T19:24:49.466Z · LW(p) · GW(p)
But if the brain is already near said practical physical limits, then merely achieving brain parity in AGI at all will already require using up most of the optimizational slack, leaving not much left for a hard takeoff - thus a slower takeoff.
While you do talk about stuff related to this in the post / I'm not sure you disagree about facts, I think I want to argue about interpretation / frame.
That is, efficiency is a numerator over a denominator; I grant that we're looking at the right numerator, but even if human brains are maximally efficient by denominator 1, they might be highly inefficient by denominator 2, and the core value of AI may be being able to switch from denominator 1 to denominator 2 (rather than being a 'straightforward upgrade').
The analogy between birds and planes is probably useful here; birds are (as you would expect!) very efficient at miles flown per calorie, but if it's way easier to get 'calories' through chemical engineering on petroleum, then a less efficient plane that consumes jet fuel can end up cheaper. And if what's economically relevant is "top speed" or "time it takes to go from New York to London", then planes can solidly beat birds. I think we were living in the 'fast takeoff' world for planes (in a technical instead of economic sense), even tho this sort of reasoning would have suggested there would be slow takeoff as we struggled to reach bird efficiency.
The easiest disanalogy between humans and computers is probably "ease of adding more watts"; my brain is running at ~10W because it was 'designed' in an era when calories were super-scarce and cooling was difficult. But electricity is super cheap, and putting 200W through my GPU and then dumping it into my room costs basically nothing. (Once you have 'datacenter' levels of compute, electricity and cooling costs are significant; but again substantially cheaper than the costs of feeding similar numbers of humans.)
A second important disanalogy is something like "ease of adding more compute in parallel"; if I want to add a second GPU to my computer, this is a mild hassle and only takes some tweaks to work; if I want to add a second brain to my body, this is basically impossible. [This is maybe underselling humans, who make organizations to 'add brains' in this way, but I think this is still probably quite important for timeline-related concerns.]
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-07T20:09:45.051Z · LW(p) · GW(p)
I discuss some of that in [this comment] in reply to Steven Byrnes. I agree electricity is cheap, and discuss that. But electricity is not free, and still becomes a constraint.
In the end of the article I discuss/estimate near future brain-scale AGI requiring 1000 GPUs for 1000 brain size agents in parallel, using roughly 1MW total or 1KW per agent instance. That works out to about $2,000/yr per agent for the power&cooling cost. Or if we just estimate directly based on vast.ai prices it's more like $5,000/yr per agent total for hardware rental (including power costs). The rental price using enterprise GPUs is at least 4x as much, so more like $20,000/yr per agent. So the potential economic advantage is not yet multiple OOM. It's actually more like little to no advantage for low-end robotic labor, or perhaps 1 OOM advantage for programmers/researchers/ec. But if we had AGI today GPU prices would just skyrocket to arbitrage that advantage, at least until foundries could ramp up GPU production.
So anyway given some bound/estimate for power cost per agent, this does allow us to roughly bound the total amount of AGI compute near term achievable, as both world power production and foundry output is difficult to ramp up rapidly.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-09T01:30:35.201Z · LW(p) · GW(p)
$2,000/yr per agent is nothing, when we are talking about hypothetical AGI. This seems to be evidence against your claim that energy is a taut constraint.
Sure, the actual price of compute would be more, because of the hardware and facilities etc. But that doesn't change the bottom line that energy is not a taut constraint.
Maybe you are saying that in the future energy will become a taut constraint because we can't make chips significantly more energy efficient but we can make them significantly cheaper in every other way, so energy will become the dominant part of the cost of compute?
Replies from: jacob_cannell, daniel-kokotajlo↑ comment by jacob_cannell · 2022-01-09T15:37:28.809Z · LW(p) · GW(p)
Energy is always an engineering constraint: it's a primary constraint on Moore's Law, and thus also a primary limiter on a fast takeoff with GPUs (because world power supply isn't enough to support net ANN compute much larger than current brain population net compute).
But again I already indicated it's probably not a 'taut constraint' on early AGI in terms of economic cost - at least in my model of likely requirements for early not-smarter-than-human AGI.
Also yes additionally longer term we can expect energy to become a larger fraction of economic cost - through some combination of more efficient chip production, or just the slowing of moore's law itself (which implies chips holding value for much longer, thus reducing the dominant hardware depreciation component of rental costs)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-09T02:02:57.904Z · LW(p) · GW(p)
Or maybe you aren't saying energy is a taut constraint at all? It sure sounded like you did but maybe I misinterpreted you.
comment by Steven Byrnes (steve2152) · 2022-01-06T16:26:17.408Z · LW(p) · GW(p)
Nice post!
Brain efficiency matters a great deal for AGI timelines and takeoff speeds, as AGI is implicitly/explicitly defined in terms of brain parity. If the brain is about 6 OOM away from the practical physical limits of energy efficiency, then roughly speaking we should expect about 6 OOM of further Moore's Law hardware improvement past the point of brain parity: perhaps two decades of progress at current rates, which could be compressed into a much shorter time period by an intelligence explosion - a hard takeoff.
But if the brain is already near said practical physical limits, then merely achieving brain parity in AGI at all will already require using up most of the optimizational slack, leaving not much left for a hard takeoff - thus a slower takeoff.
I guess your model is something like
Step 1: hardware with efficiency similar to the brain,
Step 2: recursive self-improvement but only if Moore's law hasn't topped out yet by that point.
And therefore (on this model) it's important to know if "efficiency similar to the brain" is close to the limits.
If that's the model, I have some doubts. My model would be more like:
Step 1: algorithms with capability similar to the brain in some respects (which could have efficiency dramatically lower than the brain, because people are perfectly happy to run algorithms on huge banks of GPUs sucking down 100s of kW of electricity, etc.).
Step 2: fast improvement of capability (maybe) via any of:
2A: Better code (vintage Recursive Self-Improvement, or "we got the secret sauce, now we pick the low-hanging fruit of making it work better")
2B: More or better training (or "more time to learn and think" in the brain-like context [a.k.a. online-learning])
2C: More hardware resources (more parameters, more chips, more instances, either because the programmers decide to after have promising results, or because the AGI is hacking into cloud servers or whatever).
Each of these might or might not happen, depending on whether there is scope for improvement that hasn't already been squeezed out before step 1, which in turn depends on lots of things.
I didn't even mention "2D: Better chips", because it seems much slower than A,B,C. Normally I think of "hard takeoff" as being defined as "days, weeks, or at most months", in which case fabricating new better chips seems unlikely to contribute.
I also agree with FeepingCreature's comment that "the brain and today's deep neural nets are comparably efficient at thus-and-such task" is pretty weak evidence that there isn't some "neither-of-the-above" algorithm waiting to be discovered which is much more efficient than either. There might or might not be, I think it's hard to say.
Replies from: jacob_cannell, donald-hobson↑ comment by jacob_cannell · 2022-01-06T19:21:19.601Z · LW(p) · GW(p)
Well at the end I said "If we only knew the remaining secrets of the brain today, we could train a brain-sized model consisting of a small population of about 1000 agents/sims, running on about as many GPUs"
So my model absolutely is that we are limited by algorithmic knowledge. If we had that knowledge today we would be training AGI right now, because as this article indicates 1000 GPUs are already roughly powerful enough to simulate 1000 instances of a single shared brain-size ANN. Sure it may use a MW of power, or 1 kW per agent-instance, so 100x less efficient than the brain, but only 10x less efficient than the whole attached human body, and regardless that doesn't matter much as human workers are 4 or 5 OOM more expensive than their equivalent raw energy cost.
I also agree with FeepingCreature's comment that "the brain and today's deep neural nets are comparably efficient at thus-and-such task" is pretty weak evidence that there isn't some "neither-of-the-above" algorithm waiting to be discovered which is much more efficient than either. There might or might not be, I think it's hard to say.
I don't think it's weak evidence at all, because of all the evidence we have of biological evolution achieving near optimality in so many other key efficiency metrics - at some point you just have to concede and update that biological evolution finds highly efficient or near-optimal solutions. The DL comparisons then show such and such amounts of technological evolution - a different search process - is converging on similar algorithms and limits. I find this rather compelling - and I'm genuinely curious as to why you don't? (Perhaps one could argue that DL is too influenced by the brain? But we really did try many other approaches) I found FeepingCreature's comment to be confused - as if he didn't read the article (but perhaps I should make some sections more clear?).
Replies from: maks-stachowiak, steve2152↑ comment by Maks Stachowiak (maks-stachowiak) · 2022-01-06T20:45:39.247Z · LW(p) · GW(p)
About your intuition that evolution made brains optimal... well but then there are people like John von Neumann who clearly demonstrate that the human brain can be orders of magnitude more productive without significantly higher energy costs.
My model of the human brain isn't that it's the most powerful biological information processing organ possible - far from it. In my view of the world we are merely the first species that passed an intelligence treshold allowing it to produce a technological civilisation. As soon as a species passed that treshold civilisation popped into existence.
We are the dumbest species possible that still manages to coordinate and accumulate technology. This doesn't tell you much about what the limits of biology are.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-06T21:10:35.412Z · LW(p) · GW(p)
About your intuition that evolution made brains optimal... well but then there are people like John von Neumann who clearly demonstrate that the human brain can be orders of magnitude more productive without significantly higher energy costs.
Optimal is a word one should use with caution and always with respect to some measure, and I use it selectively, usually as 'near-optimal' or some such. The article does not argue that brains are 'optimal' in some generic sense. I referenced JVN just as an example of a mentat - that human brains are capable of learning more reasonably efficient numeric circuits, even though that's well outside of evolutionary objectives. JVN certainly isn't the only example of a human mentat like that, and he certainly isn't evidence "that the human brain can be orders of magnitude more productive".
We are the dumbest species possible that still manages to coordinate and accumulate technology. This doesn't tell you much about what the limits of biology are.
Sure, I agree your stated "humans first to cross the finish line" model (or really EY's) doesn't tell you much about the limits of biology. To understand the actual limits of biology, you have to identify what those actual physical limits are, and then evaluate how close brains are to said limits. That is in fact what this article does.
In my view of the world we are merely the first species that passed an intelligence treshold allowing it to produce a technological civilisation. As soon as a species passed that treshold civilisation popped into existence.
We passed the threshold for language. We passed the threshold from evolutionarily specific intelligence to universal Turing Machines style intelligence through linguistic mental programs/programming. Before that everything a big brain learns during a lifetime is lost, after that it allowed for immortal substrate independent mental programs to evolve separately from the disposable brain soma: cultural/memetic evolution. This is a one time major phase shift in evolution, not some specific brain adaptation (even though some of the latter obviously enables the former).
↑ comment by Steven Byrnes (steve2152) · 2022-01-06T19:57:25.373Z · LW(p) · GW(p)
For example, if there were an image-processing algorithm that used many fewer operations overall, but where those operations were more serial and less parallel—e.g. it required 1000 sequential steps for each image—then I think evolution would not have found it, because brains are too slow.
So then you need a different reason to think that such an algorithm doesn't exist.
Maybe you can say "If such an algorithm existed, AI researchers would have found it by now." But would they really? If AI researchers hadn't been stealing ideas from the brain, would they have even invented neural nets by now? I dunno.
Or you can say "Something about the nature of image processing is that doing 1000 sequential steps just isn't that useful for the task." I guess I find that claim kinda plausible, but I'm just not very confident, I don't feel like I have such a deep grasp of the fundamental nature of image processing that I can make claims like that.
In other domains besides image processing, I'd be even less confident. For example, I can kinda imagine some slightly-alien form of "reasoning" or "planning" that was mostly like human "reasoning" or "planning" but sometimes involved fast serial operations. After all, I find it very handy to have a fast serial laptop. If access to fast serial processing is useful for "me", maybe it would be also useful for the low-level implementation of my brain algorithms. I dunno. Again, I think it's hard to say either way.
Replies from: gwern, jacob_cannell↑ comment by gwern · 2022-01-07T00:19:05.269Z · LW(p) · GW(p)
For example, if there were an image-processing algorithm that used many fewer operations overall, but where those operations were more serial and less parallel—e.g. it required 1000 sequential steps for each image—then I think evolution would not have found it, because brains are too slow.
Peter Watts would like you to ponder how Portia spiders think about what they see. :)
Replies from: Ansel↑ comment by Ansel · 2022-01-07T21:00:52.161Z · LW(p) · GW(p)
Is that link safe to click for someone with Arachnophobia?
Replies from: Gunnar_Zarncke, gwern↑ comment by Gunnar_Zarncke · 2022-01-07T23:07:50.236Z · LW(p) · GW(p)
no pictures
↑ comment by jacob_cannell · 2022-01-06T20:19:45.977Z · LW(p) · GW(p)
EDIT: I updated the circuits section of the article with an improved model of Serial vs Parallel vs Neurmorphic(PIM) scalability, which better illustrates how serial computation doesn't scale.
Yes you bring up a good point, and one I should have discussed in more detail (but the article is already pretty long). However the article does provide part of the framework to answer this question.
There definitely are serial/parallel tradeoffs where the parallel version of an algorithm tends to use marginally more compute asymptotically. However these simple big O asymptotic models do not consider the fundamental costs of wire energy transit for remote memory accesses, which actually scale as for 2D memory. So in that sense the simple big O models are asymptotically wrong. If you use the correct more detailed models which account for the actual wire energy costs, everything changes, and the parallel versions leveraging distributed local memory and thus avoiding wire energy transit are generally more energy efficient - but through using a more memory heavy algorithmic approach.
Another way of looking at it is to compare serial-optimized VN processors (CPUs) vs parallel-optimized VN processors (GPUs), vs parallel processor-in-memory (brains, neuromorphic).
Pure serial CPUs (ignoring parallel/vector instructions) with tens of billions of transistors have only order a few dozen cores but not much higher clock rates than GPUs, despite using all that die space for marginal serial speed increase - serial speed scales extremely poorly with transistor density, end of dennard scaling, etc. A GPU with tens of billions of transistors instead has tens of thousands of ALU cores, but is still ultimately limited by very slow poor scaling of off-chip RAM bandwidth proportional to (where N is device area), and wire energy that doesn't scale at all. The neuromorphic/PIM machine has perfect mem bandwidth scaling at 1:1 ratio - it can access all of it's RAM per clock cycle, pays near zero energy to access RAM (as memory and compute are unified), and everything scales linear with N.
Physics is fundamentally parallel, not serial, so the latter just doesn't scale.
But of course on top of all that there is latency/delay - so for example the brain is also strongly optimized for minimal depth for minimal delay, and to some extent that may compete with optimizing for energy. Ironically delay is also a problem in GPU ANNs - huge problem for tesla's self driving cars for example - because GPUs need to operate on huge batches to amortize their very limited/expensive memory bandwidth.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-01-10T15:13:43.432Z · LW(p) · GW(p)
Yeah, latency / depth is the main thing I was thinking of.
If my boss says "You must calculate sin(x) in 2 clock cycles", I would have no choice but to waste a ton of memory on a giant lookup table. (Maybe "2" is the wrong number of clock cycles here, but you get the idea.) If I'm allowed 10 clock cycles, maybe I can reduce x mod 2π first, and thus use a much smaller lookup table, thus waste a lot less memory. If I'm allowed 200 clock cycles to calculate sin(x), I can use C code that has no lookup table at all, and thus roughly zero memory and communications. (EDIT: Oops, LOL, the C code I linked uses a lookup table. I could have linked this one instead.)
So I still feel like I don't want to take it for granted that there's a certain amount of "algorithmic work" that needs to be done for "intelligence", and that amount of "work" is similar to what the human brain uses. I feel like there might be potential algorithmic strategies out there that are just out of the question for the human brain, because of serial depth. (Among other reasons.)
Also, it's not all-or-nothing: I can imagine an AGI that involves a big parallel processor, and a small fast serial coprocessor. Maybe there are little pieces of the algorithm that would massively benefit from serialization, and the brain is bottlenecked in capability (or wastes memory / resources) by the need to find workarounds for those pieces. Or maybe not, who knows.
↑ comment by Donald Hobson (donald-hobson) · 2022-01-10T17:44:25.298Z · LW(p) · GW(p)
in which case fabricating new better chips seems unlikely to contribute.
Fabricating new better chips will be part of a Foom once the AI has nanotech. This might be because humans had already made nanotech by this point, or it might involve using a DNA printer to make nanotech in a day. (The latter requires a substantial amount of intelligence already, so this is a process that probably won't kick in the moment the AI gets to about human level. )
comment by Charlie Steiner · 2022-01-07T06:02:00.316Z · LW(p) · GW(p)
That model of wire energy sounds so non-physical I had to look it up.
(It reminds me of the billiard ball model of electrons. If you think of electrons as billiard balls, it's hard to figure out how metals work, because it seems like the electrons will have a hard time getting through all the atoms that are in the way - there's too much bouncing and jostling. But if electrons are waves, they can flow right past all the atoms as long as they're a crystal lattice, and suddenly it's dissipation that becomes the unusual process that needs explanation.)
So I looked through your references but I couldn't find any mention of this formula. Not that I would have been shocked if I did - semiconductor engineers do all sorts of weird stuff that condensed matter physicists wouldn't. But anyhow, I'm pretty sure that there's no way the minimum energy dissipation in wires scales the way you say it does, and I'm curious if you have some authoritative source.
We can imagine several kinds of losses: radiative losses from high-frequency activity, resistive losses from moving lots of current, and irreversible capacitive losses from charging and discharging wires. I actually am pretty sure that the first two are smaller than the irreversible capacitive loss, and there are some nice excuses to ignore them: radiative losses might affect chips a little but there's no way the brain cares about them, and there's no way that resistive losses are going to have a basis in information theory because superconductors exist.
So, capacitance of wires! Capacitor energy is QV/2, or CV^2/2. Let's make a spherical cow assumption that all wires in a chip are half as capacitive as ideal coax cables, and the dielectric is the same thickness as the wires. Then the capacitance is about 1.3*10^-10 Farads/m (note: this drops as you make chips bigger, but only logarithmically). So for 1V wires, capacitive energy is about 7*10^-11 J/m per discharge (70 fJ/mm, a close match to the number you cite!).
But look at the scaling - it's V^2! Not controlled by Landauer.
Anyhow I felt like there were several things like this in the post, but this is the one I decided to do a relatively deep dive on.
Replies from: steve2152, jacob_cannell, obserience↑ comment by Steven Byrnes (steve2152) · 2022-01-10T14:37:09.419Z · LW(p) · GW(p)
FWIW I am also a physicist and the interconnect energy discussion also seemed wrong to me, but I hadn't bothered to look into it enough to comment.
I attended a small conference on energy-efficient electronics a decade ago. My memory is a bit hazy, but I believe Eli Yablonovitch (who I tend to trust on these kinds of questions) kicked off with an overview of interconnect losses (and paths forward), and for normal metal wire losses he wrote down the formula derived from charging and discharging the (unintentional / stray) capacitors between the wires and other bits of metal in their vicinity. Then he talked about various solutions like various kinds of low-V switches (negative-capacitance voltage-amplifying transistors, NEMS mechanical switches, quantum tunneling transistors, etc.), and LED+waveguide optical interconnects (e.g. this paper).
It seems from the replies to the parent comment that the formula is close to the OP formula. Score one for dimensional analysis, I guess, or else the OP formula has a justification that I'm not following.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-13T16:37:35.302Z · LW(p) · GW(p)
I'm fairly confident now the Landuaer Tile model is correct (based in part on how closely it predicts the spherical capacitance based wire energy in this comment [LW · GW]).
It is fundamental because every time the carrier particles transmit information to the next wire segment, they also inadvertently and unavoidably exchange some information with the outside environment, thus leaking some energy (waste heat) and or introducing some noise. The easiest way to avoid this is to increase the distance carrier particles transmit a bit before interactions - as in optical communication with photons that can travel fairly large distances before interacting with anything (in free space that distance can be almost arbitrarily large, whereas in a fiber optic cable it is only a number of OOM larger than the electron wavelength). But that is basically impossible for dense on-chip interconnect. So the only other option there is fully reversible circuits+interconnects.
So I predict none of those solutions you mention will escape the Landauer bound for dense on-chip interconnect, unless they somehow involve reversible circuits. Low voltage doesn't change anything (the brain uses near minimal voltages close to the Landauer limit but still is bound by the Landauer wire energy), NEMS mechanical switches can't possibly escape the bound, and optical communication has a more generous bound but is too large as mentioned.
↑ comment by jacob_cannell · 2022-01-07T07:40:42.427Z · LW(p) · GW(p)
So the cool thing is the Landauer/Lego model is very general and very simple. I wanted a model that made reasonably accurate predictions, but was extremely simple. I believe I succeeded. More complex electrical and wire geometry equations do not in fact make more accurate predictions for my target variables of interest, and are vastly more complex. The number of successful predictions this model makes more or less proves its correctness, in a bayesian sense.
So for 1V wires, capacitive energy is about 7*10^-11 J/m per discharge (70 fJ/mm, a close match to the number you cite!).
Yep! and it's even more accurate if you use the correct De Broglie electron wavelength at 1V, which is 1.23nm instead of 1nm, which then gives 81 fJ/mm. I bet there are a few other adjustments like that, but it's already pretty close.
But look at the scaling - it's V^2! Not controlled by Landauer.
Not really, as you point out the E = (1/2)QV = (1/2)CV^2, and Q=CV. But notice there is a minimum value of the charge Q = 1 electron charge, and a minimal value constraint on the energy per wire segment, E > , thus V is constrained as well - it can not scale arbitrarily. You can use more electrons to represent the signal of course (larger wire) and lower voltage at the same per segment, but there is a room temp background Landauer noise voltage around 17 mV, need a non trivial multiple of that.
The macro wire formulas are just approximations btw, for minimal nano-scale systems we are talking about single or few electrons ( I believe the spherical cow model breaks down for nano-scale wires )
The minimal element model comes from Cavin/Zhirnov [LW · GW] direct et al ( starting page 1725, 5th or 6th ref to 'interconnect', the tile model), I ref it a few times in the article. They explicitly use it for calculating minimal transistor switch energies that include minimal wires, estimate wire distances, etc, and use it to forecast end of Moore's Law.
Communication at the nanoscale is still just a form of computation (a 1:1 function, but still erases unwanted wire states), and if it's irreversible the Landauer Limit very much applies.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-01-07T17:52:46.876Z · LW(p) · GW(p)
Ah, good point. But I'm still not sure the model works, because we can distribute the charge (or more generally the degrees of freedom) over the length of the wire.
Like, if the wire is only 10 nm long, adding one electron causes a way bigger voltage jump than if the wire is 500 nm long. We don't have to add one electron per segment of wire.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-07T19:00:05.712Z · LW(p) · GW(p)
I think you are correct in that you don't actually have to have 1 electron per electron-radius (~nm) of wire - you could have a segment that is longer, but I think if you work that out it requires larger voltages to actually function correctly in terms of reliable transmission. This is all assuming we are using electron waves to transmit information, rather than ballistic electrons (but the Landauer limit will still bound the latter, just in a different way).
If you look at the spherical cow (concentric cylinder wire model), for smallish wires it reduces effectively to a constant that relates distance to capacitance, with units farads/meter.
The Landauer/Tile model predicts in advance a natural value of this parameter will be 1 electron charge per 1 volt per 1 electron radius, ie 1.602 e-19 F / 1.23 nm, or 1.3026 e-10 F/m.
So, capacitance of wires! Capacitor energy is QV/2, or CV^2/2. Let's make a spherical cow assumption that all wires in a chip are half as capacitive as ideal coax cables, and the dielectric is the same thickness as the wires. Then the capacitance is about 1.3*10^-10 Farads/m (note: this drops as you make chips bigger, but only logarithmically).
The probability that the Landauer/Tile model predicts the same capacitance per unit distance while not also somehow representing the same fundamental truth of nature, is essentially epsilon. Somehow the spherical wire capacitance model and the spherical tile electron radius Landauer/Tile model are the same.
↑ comment by anithite (obserience) · 2023-04-18T02:16:23.477Z · LW(p) · GW(p)
I think this is wrong. The landauer limit applies to bit operations, not moving information, the fact that optical signalling has no per distance costs should be suggestive of this.(Edit:reversibility does change things but can be approached by reducing clock speed which in the limit gives zero effective resistance.)
My guess is that wire energy per unit length is similar because wires tend to have a similar optimum conductor:insulation diameter ratios leading to relatively consistent capacitances per unit length.
Concretely, if you have a bunch of wires packed in a cable and want to reduce wire to wire capacitance to reduce C*V² energy losses, putting the wires further apart does this. This is not practical because it limits wires/cm² (cross sectional interconnect density) but the same thing can be done with more conductive materials. EG:switching from saltwater (0.5 S) to copper (50 MS) for a 10^8 increase in conductivity
Capacitance of a wire with cylindrical insultion is proportional to "1/ln(Di/Do)". For a myelinated neuron with a 1:2 saltwater:sheath diameter ratio (typical) switching to copper allows a reduction in diameter of 10^4 x for the same resistance per unit length. This change leads to a 14x reduction in capacitance ((1/ln(2/1))/(1/ln(20000/1))=(ln(20000)/ln(2))=14.2). This is even more significant for wires with thinner insulation (EG:grey matter) ((ln(11000)/ln(1.1))=97.6)
A lot of the capacitance in a myelinated neuron is in the unmyelinated nodes but we can now place them further apart. Though to do this we have to keep resistance between nodes the same. Instead of a 10^4 reduction in wire area we do 2700 x leading to a 12.5x reduction in unit capacitance and resistance. Nodes can now be placed 12.5x apart for a 12.5x total reduction in energy.
This is not the optimum design. If your wires are tiny hairs in a sea of insulation, consider packing everything closer together. With wires 10000x smaller length reductions on that scale would follow. leading to a 10'000x reduction in switching energy. At some point quantum shenanigans ruin your day, but a brain like structure should be achievable with energy consumption 100-1000 x lower.
Practically, putting copper into cells ends badly, also there's the issue of charge carrier compatibility, In In neurons, in addition to acting as charge carriers sodium and potassium have opposing concentration gradients which act as energy storage to power spiking. Copper uses electrons as charge carriers so there would have to be electrodes to adsorb/desorb aqueous charge carriers and exchange them for electrons in the copper. In practice it might be easier to switch to having +ve and -ve supply voltage connections and make the whole thing run on DC power like current computer chips do. This requires swapping out the voltage gated ion channels for something else.
Computers have efficiencies similar to the brain despite having much more conductive wire materials mostly because they are limited to packing their transistors on a 2d surface.
add more layers (even with relatively coarse inter connectivity) and energy efficiency goes up.
Power consumption for equivalent performance was 46%. That suggests that power consumption in modern chips is driven by overly long wires resulting from lack of a 3rd dimension. I remember but can't find any papers on use of more than 2 layers. There's issues there because layer to layer connectivity sucks. Die to die interconnect density is much lower than transistor density so efficiency gains don't scale that well past 5 layers IIRC.
Replies from: jacob_cannell, jacob_cannell, jacob_cannell↑ comment by jacob_cannell · 2023-04-18T03:02:16.474Z · LW(p) · GW(p)
This is not the optimum design. If your wires are tiny hairs in a sea of insulation, consider packing everything closer together.
Also discussed in the article - you are wasting time by not having read it.
Replies from: obserience↑ comment by anithite (obserience) · 2023-04-18T03:44:24.552Z · LW(p) · GW(p)
Both brains and current semiconductor chips are built on dissipative/irreversible wire signaling, and are mostly interconnect by volume
That's exactly what I meant. Thin wires inside a large amount of insulation is sub optimal.
When using better wire materials, rather than reduce capacitance per unit length, interconnect density can be increased (more wires per unit area) and then the entire design compacted. Higher capacitance per wire unit length than the alternative but much shorter wires leading to overall lower switching energy.
This is why chips and brains are "mostly interconnect by volume" because building them any other way is counterproductive.
The scenario I outlined while sub optimal shows that in white matter there's an OOM to be gained even in the case where wire length cannot be decreased (EG:trying to further fold the grey matter locally in the already very folded cortical surface.) In cases where white matter interconnect density was limiting and further compaction is possible you could cut wire length for more energy/power savings and that is the better design choice.

It sure looks like that could be possible in the above image. There's a lot of white matter in the middle and another level of even coarser folding could be used to take advantage of interconnect density increases.
Really though increasing both white and grey matter density until you run up against hard limits on shrinking the logic elements (synapses) would be best.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2023-04-18T16:52:36.831Z · LW(p) · GW(p)
Brain interconnect already approaches the landauer limit for irreversible signalling, so changing out materials makes no difference unless you can also shrink the volume to reduce lengths, but as discussed in the section on density & temperature, the brain is also density bound based on the limits of heat transfer to the surface of the skin as a radiator.
↑ comment by jacob_cannell · 2023-04-18T02:54:27.497Z · LW(p) · GW(p)
Yeah, this is wrong. The landauer limit applies to bit operations, not moving information, the fact that optical signalling has no per distance costs should be suggestive of this.
Optical signalling is reversible - as discussed in the article, if you had only read it.
Replies from: obserience↑ comment by anithite (obserience) · 2023-04-18T03:00:21.924Z · LW(p) · GW(p)
Agreed. My bad.
↑ comment by jacob_cannell · 2023-04-18T02:27:13.228Z · LW(p) · GW(p)
The discussion is about nanowires for interconnect. The Landauer model correctly predicted - in advance - a nanowire capacitance of 1 electron charge per 1 volt per 1 electron radius, ie 1.602 e-19 F / 1.23 nm, or 1.3026 e-10 F/m. This is near exactly the same as the capacitance wire spherical cow model:
Replies from: obserienceassumption that all wires in a chip are half as capacitive as ideal coax cables, and the dielectric is the same thickness as the wires. Then the capacitance is about 1.3*10^-10 Farads/m (note: this drops as you make chips bigger, but only logarithmically).
↑ comment by anithite (obserience) · 2023-04-18T02:49:35.559Z · LW(p) · GW(p)
"and the dielectric is the same thickness as the wires." is doing the work there. It makes sense to do that if You're packing everything tightly but with an 8 OOM increase in conductivity we can choose to change the ratio (by quite a lot) in the existing brain design. In a clean slate design you would obviously do some combination of wire thinning and increasing overall density to reduce wire length.
The figures above show that (ignoring integration problems like copper toxicity and NA/K vs e- charge carrier differences) Assuming you do a straight saltwater to copper swap in white matter neurons and just change the core diameter (replacing most of it with insulation), energy/switch event goes down by 12.5x.
I'm pretty sure for non-superconductive electrical interconnects the reliability is set by the Johnson-Nyquist_noise and figuring out the output noise distribution for an RC transmission line is something I don't feel like doing right now. Worth noting is that the above scenario preserves the R:C ratio of the transmission line (IE: 1 ohm worth of line has the same distributed capacitance) so thermal noise as seen from the end should be unchanged.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2023-04-18T16:54:43.901Z · LW(p) · GW(p)
The brain is already close to the landauer limit for irreversible interconnect in terms of energy per bit per nm; swapping out materials is irrelevant.
Replies from: obserience↑ comment by anithite (obserience) · 2023-04-18T17:30:43.047Z · LW(p) · GW(p)
Consider trying to do the reverse for computers. Swap copper for saltwater.
You can of course drop operation frequency by 10^8 for a 10-50 hz clock speed. Same energy efficiency.
But you could get added energy efficiency in any design by scaling down the wires to increase resistance/reduce capacitance and reducing clock speed.
In the limit, Adiabatic Computing is reversible because in the limit, moving charge carriers more slowly eliminates resistance.
Thermal noise voltage is proportional to bandwidth. Put another way if the logic element responds slowly enough it see lower noise by averaging.
Consider a Nanoelectromechanical relay. These are usually used for RF switching so switching voltage isn't important, but switching voltage can be brought arbitrarily low. Mass of the cantilever determines frequency response. A NEMR with a very long light low-stiffness cantilever could respond well at 20khz and be sensitive to thermal noise. Adding mass to the end makes it less sensitive to transients (lower bandwidth, slower response) without affecting switching voltage.
In a NEMS computer there's the option of dropping (stiffness, voltage, operating frequency) and increasing inertia (all proportionally) which allows for quadratic reductions in power consumption.
IE: Moving closer to the ideal zero effective resistance by taking clock speed to zero.
The bit erasure Landauer limit still applies but we're ~10^6 short of that right now.
Caveats:
- NEM relays currently have limits to voltage scaling due to adhesion. Assume the hypothetical relay has a small enough contact point that thermal noise can unstick it. Operation frequency may have to be a bit lower to wait for this to happen.
comment by FeepingCreature · 2022-01-06T16:13:26.774Z · LW(p) · GW(p)
The biggest stretch here seems to me to be evaluating the brain on the basis of how much compute existing hardware requires to emulate the brain. Ultimately, this is biased towards the conclusion, because, to slightly parody your position, the question you end up asking is "how much brain do you need to simulate one brain," determining that the answer is "one brain", and then concluding that the brain is perfectly efficient at being itself. However, the question of how much of the compute that is being attributed to the brain here is actually necessary for cognition remains open. The part of the article where you compare contemporary approaches particularly seems like it leaves the possibility that both brains and deep learning systems are orders of magnitude inefficient, still on the table.
Replies from: jacob_cannell, jacob_cannell↑ comment by jacob_cannell · 2022-01-06T19:04:29.349Z · LW(p) · GW(p)
The biggest stretch here seems to me to be evaluating the brain on the basis of how much compute existing hardware requires to emulate the brain.
Where did I do that? I never used emulation in that context. Closely emulating a brain - depending on what you mean - could require arbitrarily more compute then the brain itself.
This article is about analyzing how close the brain is to known physical computational limits.
You may be confused by my comparisons to GPUs? That is to establish points of comparison. Naturally it also relates to the compute/energy cost of simulating brain sized circuits, but that's only because GPUs are optimized for efficiently converting raw transistor ops into matrix-mult ops of the form needed to simulate neural nets.
However, the question of how much of the compute that is being attributed to the brain here is actually necessary for cognition remains open.
I address that partly in the circuits and data section, but much depends on what you mean by 'cognition'. If you want a system that does all the things the brain does, then there isn't much hope for doing that using multiple OOM less energy than the brain, at least on conventional computers.
The part of the article where you compare contemporary approaches particularly seems like it leaves the possibility that both brains and deep learning systems are orders of magnitude inefficient, still on the table.
I'm not entirely clear on which efficiency metric you are considering.
For DL energy of course - at the hardware level GPUs are a few OOM less energy efficient than the brain, probably then also lose a few OOMs in DL software not fully optimized yet (for sparsity, etc). And the conclusion in the section on energy/thermodynamics was the brain is up to an OOM or so from physical limits, due to size/cooling constraints. I didn't use direct comparisons of DL compute required for tasks partly for DL's known compute inefficiency, and partly because the article was already pretty long.
For data efficiency it should be obvious that much larger networks/models could potentially learn almost proportionally faster - as implied by the scaling laws, but at the expense of more compute.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-01-10T18:09:42.031Z · LW(p) · GW(p)
Just pointing out that humans doing arithmetic and GPT3 doing arithmetic are both awful in efficiency compared to raw processor instructions. I think what FeepingCreature [LW · GW] is considering is how many other tasks are like that?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-11T05:42:26.095Z · LW(p) · GW(p)
The set of tasks like that is simply traditional computer science. AGI is defined as doing what the brain does very efficiently, not doing what computers are already good at.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-01-11T12:12:01.296Z · LW(p) · GW(p)
Don't dismiss these tasks just by saying they aren't part of AGI by definition.
The human brain is reasonably good at some tasks and utterly hopeless at others. The tasks early crude computers got turned to were mostly the places where the early crude computers could compete with brains, ie the tasks brains were hopeless at. So the first computers did arithmetic because brains are really really bad at arithmetic so even vacuum tubes were an improvement.
The modern field of AI is what is left when all the tasks that it is easy to do perfectly are removed.
Suppose someone finds a really good algorithm for quickly finding physics equations from experimental data tomorrow. No the algorithm doesn't contain anything resembling a neural network. Would you dismiss that as "Just traditional computer science"? Do you think this can't happen?
Imagine a hypothetical world in which there was an algorithm that could do everything that the human brain does better, and with a millionth of the compute. If someone invented this algorithm last week and
AGI is defined as doing what the brain does very efficiently, not doing what computers are already good at.
Wouldn't that mean no such thing as AGI was possible. There was literally nothing the brain did efficiently, it was all stuff computers were already good at. You just didn't know the right algorithm to do it.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-13T16:22:44.907Z · LW(p) · GW(p)
Imagine a hypothetical world in which there was an algorithm that could do everything that the human brain does better, and with a millionth of the compute.
Based on the evidence at hand (as summarized in this article) - we probably don't live in that world. The burden of proof is on you to show otherwise.
But in those hypothetical worlds, AGI would come earlier, probably well before the end phase of Moore's Law.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-01-13T17:05:14.363Z · LW(p) · GW(p)
I was using that as a hypothetical example to show that your definitions were bad. (In particular, the attempt to define arithmetic as not AI because computers were so much better at it.)
I also don't think that you have significant evidence that we don't live in this world, beyond the observation that if such an algorithm exists, it is sufficiently non-obvious that neither evolution or humans have found it so far.
A lot of the article is claiming the brain is thermodynamically efficient at turning energy into compute. The rest is comparing the brain to existing deep learning techniques.
I admit that I have little evidence that such an algorithm does exist, so its largely down to priors.
Replies from: dxu↑ comment by dxu · 2023-03-13T22:29:30.534Z · LW(p) · GW(p)
also don't think that you have significant evidence that we don't live in this world, beyond the observation that if such an algorithm exists, it is sufficiently non-obvious that neither evolution or humans have found it so far.
FWIW, I totally think that mental savants like Ramanujan (or "ordinary" geniuses like von Neumann) make a super-strong case for the existence of "algorithms evolution knows not".
(Yes, they were humans, and were therefore running on the same evolutionary hardware as everybody else. But I don't think it makes sense to credit their remarkable achievements to the hardware evolution produced; indeed, it seems almost certain that they were using that same hardware to run a better algorithm, producing much better results with the same amount of compute—or possibly less, in Ramanujan's case!)
↑ comment by jacob_cannell · 2022-01-07T00:43:59.289Z · LW(p) · GW(p)
I'm going to resist the urge to parody/strawman your parody/strawman, and so instead I improved the circuits section especially, and clarified the introduction to more specifically indicate how efficiency relates only to the types of computations brains tend to learn (evolutionarily relevant cognition), and hopefully prevent any further confusion of simulation with emulation.
comment by Steven Byrnes (steve2152) · 2022-01-06T16:38:32.072Z · LW(p) · GW(p)
Kind of a nitpick, but if radiative heat loss has almost nothing to do with how chips are cooled, and it has almost nothing to do with how the brain is cooled, then why are we even bringing up the Stefan-Boltzmann law in the first place?
Replies from: JenniferRM, jacob_cannell↑ comment by JenniferRM · 2022-01-06T20:21:19.042Z · LW(p) · GW(p)
I think a keyword here (if you want to google on your own) is "selective brain cooling (SBC)". In practice this might be on a continuum, but this might be an area where humans have some unique adaptations?
The basic mechanisms tend to involve things like a "plexus" of veins/arteries for heat exchange, dynamic blood routing based on activity, and then trying to set up radiators somehow/somewhere on the body to take hot blood and push the heat into the larger world. Many mammals just have evaporative cooling in their mouth that runs on saliva, but humans (and maybe pigs) have it over their whole body. Elephant ears seem like another non-trivial adaptation related to heat. One possibility is that the cetaceans are so smart (as an evolutionary branch) because they have such a trivially easy way to get a water cooled brain.
I've looked into this enough to buy a tool for short/quick experiments in specialized brain cooling, but they have been very low key. No blinded controls (obviously) and not even any data collection. Mostly I find the cap to be subjectively useful after a long phone call holding a microwave transmitter next to my head, where I feel a bit fuzzy brained after the call... then the cap fixes that pretty fast :-)
In practice I think water cooled super performance (in this case the paradigmatic performance test is pull-ups) does seem to be a thing though I know of no cognitive version at this time. I've never thought in a highly focused way about exactly this topic.
If heat dissipation is a real bottleneck on mental performance then my vague priors suggest: (1) it would mostly be a bottleneck on "endurance of vigorous activity" like solving logic puzzles very fast for hours at a time, and (2) IF heat was the bottleneck and that bottleneck was removed THEN whatever the next bottleneck was (like maybe neurotransmitter shortages?) it might have much worse side effects when it hits (seizures? death?) because whatever the failure mode is, it probably has been optimized by evolution to a lesser extent.
Replies from: jacob_cannell, alexander-gietelink-oldenziel↑ comment by jacob_cannell · 2022-01-06T21:21:31.873Z · LW(p) · GW(p)
Fascinating! I'm going to link this in to the main article. I was aware of the whole "humans adapted to long distance running" thing, and how sweat is optimized for that, but I hadn't considered the related implications for brain cooling.
Human brains are about 3x larger, and thus require/output 3x more energy and surface power density, than our similar-ish sized primate relative with similar-ish sized skulls. Brain tissue also has a 10x higher power density than the rest of the body. This does suggest the need for significant evolutionary optimization towards cooling.
Replies from: JenniferRM↑ comment by JenniferRM · 2022-01-07T00:18:45.153Z · LW(p) · GW(p)
There is a minor literature on the evolution of brain cooling as potentially "blocked in early primates and then unblocked sorta-by-accident which allowed selection for brain size in hominids as a happy side effect". I'm unsure whether the hypothesis is true or not, but people have thought about it with some care and I've not yet heard of anyone figuring out a clean kill shot for the idea.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2022-09-26T20:23:57.044Z · LW(p) · GW(p)
Woah Jennifer this is wild stuff. Fascinating!
I'm just thinking - it might be that while heat does determine brain efficiency to a large degree it might not be so simple as it might be determined by the architecture.
DIfferent animals might be adapated to a certain temperature range - it might not make your brain more efficient when it is cooled in this way.
does anybody know how the cognition of coldblood creatures varies as they warm and cool throughout the day?
Replies from: JenniferRM↑ comment by JenniferRM · 2022-09-26T22:48:51.887Z · LW(p) · GW(p)
I'm not sure what theory that observation would test cleanly, since ectotherms have such a complicated relationship to heat.
One thing I just checked is honeybees, which I've read a book or two about, because I know they have large cooling requirements for their wing muscles (their blood doesn't move O2, it just moves heat, basically). When the hive gets cold in the winter, some go to the center and lock their wings with their arms, and shiver their wing muscles, and this heats the entire hive. So they are kind of endothermic? Maybe? Depending on definitions?
It looks like probably individual honeybee brains are cooled by using honey sort of like how dogs use saliva, with evaporative cooling from the mouth. Then, when flying on a very hot day, the waste heat from the wings is moved, by the blood, to the thorax (but not to the head) to use the thorax as a radiator.
When it is cold, the stationary wings can send heat to the thorax via the blood, but somehow the head doesn't need this.
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2022-09-27T05:42:19.860Z · LW(p) · GW(p)
What do you think this might imply for the brain & cognition?
↑ comment by jacob_cannell · 2022-01-06T19:10:25.808Z · LW(p) · GW(p)
SB law describes the relationship to power density of a surface and corresponding temperature; it just gives you an idea of the equivalent temperature sans active cooling. For the brain that temperature is just similar to a dark surface receiving constant sunlight, so it's not a serious cooling challenge.
That section was admittedly cut a little short, if I had more time/length it would justify a deeper dive into the physics of cooling and how much of a constraint that could be on the brain. You're right though that the surface power density already describes what matters for cooling.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2022-01-06T06:21:16.017Z · LW(p) · GW(p)
Thank you for this fascinating post.
I am fascinated by your statement that the 6-7 OOMs of clock speed advantage of CPU's is actually the result of a memory + energy efficiency tradeoff made by the brain.
If this is accurate it would seem that Hanson's EM world is not as farfetched as it may appear at first sight.
your post also seems to strengthen the case for AGI being mostly hardware /data - limited.
also: it seems to suggest the recent slowing of Moore's law & related laws is a fundamental fact of nature not a temporary slowdown.
Replies from: jacob_cannell, gustavo-ramires↑ comment by jacob_cannell · 2022-01-06T06:59:34.362Z · LW(p) · GW(p)
Thanks!
Memory/circuitry is pretty cheap for the brain, but energy is not. Accessing memory requires moving bits around, which costs energy per unit dist (and this can dominate the cost of computing on bits, at optimally minimal device sizes).
Thus energy efficiency requires computing as close to memory as possible. Thus biology has synapses which are both the bulk compute element and the bulk memory element, in one device, can't get closer than that.
Neurons are then the ADC and longer distance communication units.
The neuromorphic or processor-in-memory architecture is fundementally a number of OOM more energy efficient than the von neumman architecture - as the latter requires moving each connection weight/synapse across the entire device, whereas the brain only has to move the neuron values - a roughly 10,000x advantage. For VN machines to overcome this gap they end up having to heavily amortize the memory fetches by reusing the values across many computations - matrix matrix multiplication instead of vector matrix multiplication.
Given that you are using the neuromorphic/PIM approach - as you should for energy efficiency - you still have a tradeoff between size and speed. I do believe that smaller animals have faster brains in general, but the tradeoff is complex, and in general larger model size seems to dominate speed for predictive power. This should be obvious in the limit - a fast but very small memory learning machine can't remember what it's already learned, and ends up having to burn all it's compute just relearning things.
Hanson's EM world sounds about right except I doubt that brain scanning and uploading will precede DL/neurmorphic AGI.
The limits of Moore's Law are fairly well known in the device physics research community - and there really isn't multiple OOM of transistor energy efficiency left, we are already pretty close. Moving to neuromorphic/PIM can provide some OOM advantage, but it's one-time. Continuation of Moore's Law style growth will soon require exotic computing - reversible/quantum.
Replies from: alexander-gietelink-oldenziel↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2022-01-06T12:36:55.816Z · LW(p) · GW(p)
Thank you Jacob, I will have to mull this all over.
Your post made me update majorly on many topics.
↑ comment by Gustavo Ramires (gustavo-ramires) · 2022-01-07T19:21:30.578Z · LW(p) · GW(p)
Lower clock rates mean lower energy usage per operation (due to quadratic resistance effects). Even transportation of physical goods sees the same dilemma. However, we know that in real life we have to balance environmental degradation (i.e. everything decaying), expansion potential (it may be better to use more energy per op now as an investment) with the process velocity to achieve our goals.
You can also consider the 2nd law of thermodynamics (implying finite lifetimes of anything): even the Sun itself will one day go extinct... although of course this is more of a science fiction discussion.
comment by johnswentworth · 2022-09-21T18:09:52.069Z · LW(p) · GW(p)
Seems like a mistake to assume that the radius of the computational substrate is the same as the radius of radiative heat dissipation. With any sort of active heat transport, those two can decouple: we can actively transport the heat from the small computational substrate out to a large cooling surface. That would let us achieve the energy and speed advantages of smaller size while still maintaining a low temperature.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-09-22T01:24:57.801Z · LW(p) · GW(p)
Actually, it is partially decoupled in humans see this nice comment thread [LW(p) · GW(p)], which buys maybe an OOM. I didn't fully update the article yet from that comment thread.
comment by Donald Hobson (donald-hobson) · 2022-01-10T19:40:27.764Z · LW(p) · GW(p)
I think your thermodynamics is dubious. Firstly, it is thermodynamically possible to run error free computations very close to the thermodynamic limits. This just requires the energy used to represent a bit to be significantly larger than the energy dissipated as waste heat when a bit is deleted.
Considering a cooling fluid of water flowing at 100m/s through fractally structured pipes of cross section 0.01m^2 and being heated from 0C to 100C, the cooling power is 400 megawatts.
I think that superconducting chips are in labs today. The confidant assertion that superconductive reversible computing (or quantum computing) won't appear before AGI is dubious at best.
Finally, have you heard of super-resolution microscopy https://en.wikipedia.org/wiki/Super-resolution_microscopy ? There was what appeared to be a fundamental limit on microscopes that was based on the wavelength of light. Physicists found several different ways to get images beyond that. I think there are quite a lot of cases where X is technically allowed under the letter of the mathematical equations, but feels really like cheating. This is the sort of analysis that would have ruled out the possibility. (And did rule out a similar possibility of components far smaller than a photons wavelength communicating with photons) This kind of rough analysis can easily prove possibility, but it takes a pedant with the security mindset and a keen knowledge of exactly what the limits say to show anything is impossible. So not only are there reversible computing and quantum computing, there are other ideas out there that skirt around physical limits on a technicality that haven't been invented yet.
Replies from: jacob_cannell, jacob_cannell↑ comment by jacob_cannell · 2022-01-12T00:44:15.625Z · LW(p) · GW(p)
I think that superconducting chips are in labs today. The confidant assertion that superconductive reversible computing (or quantum computing) won't appear before AGI is dubious at best.
I'm reasonably well read on reversible computing. It's dramatically less area efficient, and requires a new radically restricted programming model - much more restrictive than the serial to parallel programming transition. I will take and win any bets on reversible computing becoming a multi-billion dollar practical industry before AGI.
↑ comment by jacob_cannell · 2022-01-11T06:09:49.293Z · LW(p) · GW(p)
Firstly, it is thermodynamically possible to run error free computations very close to the thermodynamic limits. This just requires the energy used to represent a bit to be significantly larger than the energy dissipated as waste heat when a bit is deleted.
In theory it's possible to perform computation without erasing bits - ie reversible computation, as mentioned in the article. And sure you can use more than necessary to represent a bit, but not much point in that, when you could instead use the minimum Landauer bound amount.
comment by WSS · 2022-01-07T18:16:43.105Z · LW(p) · GW(p)
If this post piqued your interest, I’d highly recommend Principles of Neural Design as an overview of our current knowledge of the brain. It starts from a bottom level of energy conservation and information theoretical limits, and builds on that to explain the low-level structures of the brain. I can’t claim to follow all the chemistry, but it did hammer home that the brain as far as we can tell is near maximally efficient at its jobs.
comment by Thomas Kwa (thomas-kwa) · 2022-09-21T23:42:53.227Z · LW(p) · GW(p)
I'm a bit suspicious of the model for interconnect energy.10Gb Ethernet over copper wire can extend 100 meters, and uses 2-5 watts at each end for full duplex. This works out to , a bit lower than your number for "complex error correction" at 0.1V and much lower than the that would be implied by the voltage of 2.5 V. What's going on here? Is this in a regime where capacitive losses are much lower per bit-meter than they must be in the brain, as mentioned in the other comment thread [LW(p) · GW(p)]?
Also, the image is of blood vessels, not interconnects in the brain.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-09-22T00:06:35.813Z · LW(p) · GW(p)
If you follow that comment thread the tile model ends up being equivalent to or deriving small wire capacitance models. However it leaves open the possibility of having an interaction distance larger than the natural minimal unit of one electron radius, if you had a much larger wire structure. Coax cable uses exactly that, and the capacitance for thicker insulated wires gets a further small gain proportional to log of wire thickness. The brain also uses that a bit for long range interconnect (myelination) - which also provides speed.
But that logarithmic gain in energy efficiency vs wire thickness just isn't a useful tradeoff for interconnect in general due to the volume cost.
Replies from: thomas-kwa↑ comment by Thomas Kwa (thomas-kwa) · 2023-06-22T17:36:05.642Z · LW(p) · GW(p)
The link is for cat6e cable, not coax. Also, the capacitance goes down to zero as r -> R in the coaxial cable model, and the capacitance appears to increase logarithmically with wire radius for single wire or two parallel wires, with the logarithmic decrease being in distance between wires.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-07T20:18:50.778Z · LW(p) · GW(p)
Achieving those levels of energy efficiency will probably require brain-like neuromorphic-ish hardware, circuits, and learned software via training/education. The future of AGI is to become more like the brain, not less.
Energy efficiency is not relevant to predicting the future of AGI. Who cares if EfficientZero-9000 costs ten thousand times as much energy per computation than John von Neumann did, if it's qualitatively smarter than him in every way and also thinks a thousand times faster? (Similar things can be said about various other kinds of efficiency. Data efficiency seems like the only kind that is plausibly relevant.)
I really appreciate your post for all the detailed work it does estimating different kinds of brain efficiency. However, the conclusion seems like a massive non sequitur to me.
(Shameless plug: You may be interested in this post: Birds, Brains, Planes, and AI: Against Appeals to the Complexity/Mysteriousness/Efficiency of the Brain [LW · GW])
Another example of a quote I strongly disagree with:
Why should we care? Brain efficiency matters a great deal for AGI timelines and takeoff speeds, as AGI is implicitly/explicitly defined in terms of brain parity. If the brain is about 6 OOM away from the practical physical limits of energy efficiency, then roughly speaking we should expect about 6 OOM of further Moore's Law hardware improvement past the point of brain parity: perhaps two decades of progress at current rates, which could be compressed into a much shorter time period by an intelligence explosion - a hard takeoff.
But if the brain is already near said practical physical limits, then merely achieving brain parity in AGI at all will already require using up most of the optimizational slack, leaving not much left for a hard takeoff - thus a slower takeoff.
In worlds where brains are efficient, AGI is first feasible only near the end of Moore's Law (for non-exotic, reversible computers), whereas in worlds where brains are highly inefficient, AGI's arrival is more decorrelated, but would probably come well before any Moore's Law slowdown.Replies from: jacob_cannell, isaac-poulton
↑ comment by jacob_cannell · 2022-01-07T22:21:34.787Z · LW(p) · GW(p)
Energy efficiency is not relevant to predicting the future of AGI. Who cares if EfficientZero-9000 costs ten thousand times as much energy per computation than John von Neumann did, if it's qualitatively smarter than him in every way and also thinks a thousand times faster? (Similar things can be said about various other kinds of efficiency. Data efficiency seems like the only kind that is plausibly relevant.)
Part of the intent of this article is to taboo 'smarter', and break down cognitive efficiency into more detailed analyzable sub metrics.
Since you call your model "EZ-9000", I"m going to assume it's running on GPUs or equivalent. If EZ-9000 uses 10,000x more energy but runs 1000x faster, ie if you mean 100kHZ for 100kW, then that isn't that different - and in fact more efficient - than my model of 1000 agent instances using 1MW total. Training is easily parallelizable so 1000x parallel is almost as good as 1000x serial speedup, either way you can get human lifetime equivalent in about a month ish.
If instead you meant 100kW for only 100hz, so 100MW for 100kHZ, then that actually doesn't change the net time to train - still takes about a month, now it just costs much more - $5,000/hr for the electricity alone, so perhaps $10M total. Not all that different though unless the hardware cost is also proportionally more expensive.
But in practice 1000x speedup just isn't possible in any near future time frame for a brain sized model on parallel von-neumman hardware like GPUs (but 1000x parallelization is) - and my article outlines the precise physics of why this is so. (It is of course probably possible for more advanced neuromorphic hardware, but that probably comes after AGI on GPUs).
But to analyze your thought experiment more would require fixing many more details - what's the model size? What kind of hardware? etc. My article allows estimating energy and ultimately training costs which can then feed into forecasts.
You link to your Birds/Brains/Planes article, which I generally agree with (and indeed have an unfinished similar post from a while back!), and will just quote from your own summary:
I argue that an entire class of common arguments against short timelines is bogus, and provide weak evidence that anchoring to the human-brain-human-lifetime milestone is reasonable.
My brain efficiency argument provides further evidence for anchoring to the human-brain-human-lifetime milestone (with some unknown factor for finding the right design), evidence that the brain is efficient in agreement, and is in fact an argument for short timelines to AGI! (as it shows the brain really can't be doing much more flops/s than current GPUs!).
In a sentence, my argument is that the complexity and mysteriousness and efficiency of the human brain (compared to artificial neural nets) is almost zero evidence that building TAI will be difficult, because evolution typically makes things complex and mysterious and efficient, even when there are simple, easily understood, inefficient designs that work almost as well (or even better!) for human purposes.
I also agree that first human architected AGI will likely be inefficient compared to the brain in various key metrics - if you got to the end of the post where I estimate what near-future AGI looks like it's running on GPUs and 2 OOM less energy efficient, but still could provide several OOM economic advantage.
So I'm actually not clear on what we disagree on? Other than your statement that "Energy efficiency is not relevant to predicting the future of AGI", which is almost obviously false as stated. For a simple counter-argument: any AGI design that uses more energy than the human brain is probably economically infeasible to train.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-08T04:03:00.245Z · LW(p) · GW(p)
"Energy efficiency is not relevant..." is false in the same way that "Cheese efficiency is not relevant..." is false. (Cheese efficiency is how much cheese an AI design consumes. You might think this is not relevant because most current and future AI designs consume negligible amounts of cheese, but hypothetically if an AGI design consumed 10^9 kg of cheese per second it would not be viable.)
This is just an aggressive way of saying that energy is cheap & the builders of AGI will be willing to buy lots of it to fuel their AGI. The brain may be super efficient given its energy constraints but AGI does not have an energy constraint, for practical purposes. Sure, 10^9 times less energy efficient would be a problem, but 10^3 wouldn't be. And if I understand you correctly you are saying that modern GPUs are only 10^2 times less energy efficient.
In the end of the article I discuss/estimate near future brain-scale AGI requiring 1000 GPUs for 1000 brain size agents in parallel, using roughly 1MW total or 1KW per agent instance. That works out to about $2,000/yr for the power&cooling cost. Or if we just estimate directly based on vast.ai prices it's more like $5,000/yr per agent total for hardware rental (including power costs). The rental price using enterprise GPUs is at least 4x as much, so more like $20,000/yr per agent. So the potential economic advantage is not yet multiple OOM. It's actually more like little to no advantage for low-end robotic labor, or perhaps 1 OOM advantage for programmers/researchers/ec. But if we had AGI today GPU prices would just skyrocket to arbitrage that advantage, at least until foundries could ramp up GPU production.
This does not sound like a taut constraint to me. Sure, an agent that is dumber than a dumb human and costs $20,000/yr to run won't be transforming the economy anytime soon. But once we get such an agent, after a few additional years (months? Days?) of R&D we'll have agents that are smarter than a smart human and cost $20,000/yr to run, and by that point we are in FOOM territory. (And this is neglecting the fact that you chose higher numbers for your estimate and also the price of compute, and the price of energy, will be going down in the next decade.) [Unimportant aside: I don't get the point about arbitrage. When nukes were invented, the price of uranium probably went up. So what?]
I worry that I'm straw-manning you and/or just not comprehending your argument so in the next few days I plan to reread your post more closely and think more carefully about it. The point I'm making is similar to what Vaniver and Steven Byrnes said, I think.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-08T05:20:52.351Z · LW(p) · GW(p)
Computation literally is organized energy[1]. Intelligence is a particular efficient organization of computational energy towards evolutionary/economic goals.
Sure, 10^9 times less energy efficient would be a problem, but 10^3 wouldn't be. And if I understand you correctly you are saying that modern GPUs are only 10^2 times less energy efficient.
Yeah, so again it's not clear to me what exactly the crux here is, other than some surface level thing where we both agree 10^9 energy efficiency gap would be a blocker, and agree 10^3 or 10^2 isn't, but then you would label that as "Energy efficiency is not relevant".
Sure, an agent that is dumber than a dumb human and costs $20,000/yr to run won't be transforming the economy anytime soon. But once we get such an agent, after a few additional years (months? Days?) of R&D we'll have agents that are smarter than a smart human and cost $20,000/yr to run, and by that point we are in FOOM territory
The question of when we'll get almost-human level agents for $20,000/yr vs smart-human-level for $1,000/yr vs today where almost-human level costs unknown large amounts, perhaps $billions - is ultimately an energy efficiency constrained question[2].
Thus the cheese analogy is non-sensical. And because computation literally is energy, computational efficiency is ultimately various forms of energy efficiency. ↩︎
Although again to reiterate as I said in the article, the principle blocker today for early AGI is knowledge, because GPUs are probably only a few OOM less energy efficient at the hardware level (our current net inefficiency is more on the algorithm/software side). But even that doesn't make low level circuit energy efficiency irrelevant: it constrains takeoff speed and also especially the form/shape of AGI. ↩︎
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-08T18:58:06.193Z · LW(p) · GW(p)
I was wrong to link my birds brains planes post btw, you are right, it doesn't really contradict what you are saying. As for the cheese analogy... I still think I'm right but I'll rest my case.
Like I said at the top, I really appreciate this post and learned a lot from it -- I just think it draws some erroneous conclusions. It's possible I'm just not understanding the argument though.
For any particular energy budget there is a Landauer Limit imposed maximum net communication flow rate through the system and a direct tradeoff between clock speed and accessible memory size at that flow rate.
Yes, and you go on to argue that the brain is operating about as fast as it could possibly operate given its tiny energy budget. But current and future computers will have much, much larger energy budgets. They can therefore operate much faster (and they do).
Correct me if I'm wrong, but my impression is that currently paying for energy is less than 10% of the cost of compute. Most of the cost is the hardware itself, and maintaining the facilities. In light of that, it really does seem that we are not energy-constrained. Maybe in the future we will be, but for now, the cost of the energy is small compared to the cost of everything else that goes into training and running AI. So chip designers and AI designers are free to use high energy budgets if it gets other benefits like faster speed or cheaper manufacturing or whatever. If they are using high energy budgets, they don't need to build chips to be more and more like the human brain, which has a low energy budget. In other words, they don't need this:
Achieving those levels of energy efficiency will probably require brain-like neuromorphic-ish hardware, circuits, and learned software via training/education. The future of AGI is to become more like the brain, not less.
Nor need chip designers optimize towards maximal energy efficiency; energy efficiency is not top of the priority list for things to optimize for, since energy is only a small fraction of the cost:
Likewise, DL evolving towards AGI converges on brain reverse engineering[60] [LW · GW][61] [LW · GW], especially when optimizing towards maximal energy efficiency for complex real world tasks.
Meanwhile, this is off-base too:
Why should we care? Brain efficiency matters a great deal for AGI timelines and takeoff speeds, as AGI is implicitly/explicitly defined in terms of brain parity. If the brain is about 6 OOM away from the practical physical limits of energy efficiency, then roughly speaking we should expect about 6 OOM of further Moore's Law hardware improvement past the point of brain parity:
AGI is not defined as hardware that performs computations as energy-efficiently as the brain. Instead, it is software that performs all important intellectual tasks as effectively as the brain, cost be damned. The goal of the field of AI is not to equal the brain in energy-efficiency, any more than the goal of powered flight is to produce machines as energy-efficient as birds.
One possibility is that I'm misinterpreting your conclusion about how the future of AGI is to become more like the brain, not less. I interpreted that to mean that you were forecasting a rise in neuromorphic computing and/or forecasting that the biggest progress in AGI will come from people studying neuroscience to learn from the brain, and (given what you said about brain parity in the introduction) that you don't think we'll get AGI until we do those things and make it more like the brain. Do you think those things, or anything adjacent? If not, then maybe we don't disagree after all. (Though then I wonder what you meant by "The future of AGI is to become more like the brain, not less." And also it still seems like we have some sort of disagreement about the importance of energy efficiency more generally.)
The question of when we'll get almost-human level agents for $20,000/yr vs smart-human-level for $1,000/yr vs today where almost-human level costs unknown large amounts, perhaps $billions - is ultimately an energy efficiency constrained question. [LW · GW] ... Although again to reiterate as I said in the article, the principle blocker today for early AGI is knowledge, because GPUs are probably only a few OOM less energy efficient at the hardware level (our current net inefficiency is more on the algorithm/software side). But even that doesn't make low level circuit energy efficiency irrelevant: it constrains takeoff speed and also especially the form/shape of AGI
Why? Am I wrong that energy is <10% the cost of compute? How is energy efficiency a taut constraint then? Or are you merely saying that it is a constraint, not a taut one? Just as cheese efficiency is a constraint, but not a taut one?
I of course agree that if we had the right knowledge, we could build AGI today and it would probably even run on my laptop. I think it doesn't follow that the principle blocker today for early AGI is knowledge. There are lots of things X such that if we had X we could build AGI today. I think it's only appropriate to label "the principle blocker" the one that is realistically most likely to be achieved first. And realistically I think we are more likely to get AGI by scaling up models and running them on massive supercomputers (for much more energy cost than the human brain uses!) than by achieving great new insights of knowledge such that we can run 1000 AGI on 1000 2021 GPUs. (However, on this point we can agree to disagree, it's mostly a matter of intuition anyway.)
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-08T21:57:56.213Z · LW(p) · GW(p)
But current and future computers will have much, much larger energy budgets. They can therefore operate much faster (and they do).
Faster clock speed but not faster thought speed., as they just burn all that speed inefficiently simulating a large circuit. Even though a single GPU has similar nominal flops compared to the brain and uses 30x more power, they have about 3 OOM less memory and memory bandwidth. GPUs are amazing at simulating insect brains at high speeds.
But we want big brain-scale ANNs, as that is what intelligence requires. So you need 1000x GPUs in parallel with complex expensive high bandwidth interconnect to get a single brain-size ANN, at which point you also get 1000 instances (of the same mind). That only allows you to run it at brain speed, not any faster. You can't then just run it on 1 million GPUs to get 1000x speedup - that's not how it works at all. Instead you'd get 1 million instances of 1000 brain size ANNs. This ultimately relate to energy flow efficiency - see the section on circuits. Energy efficiency is a complex multi-dimensional engineering constraint set, it's not a simple linear economic multiplier.
Moore's Law isn't going to improve this scenario much - at least not for GPUs or any von neumman style architecture.
Moore's Law will eventually allow a very specific narrow class of designs to simultaneously achieve brain scale and high speedup, but that narrow class of designs is necessarily neuromorphic and similar to an artificial brain. Furthermore, economic pressure will naturally push the industry towards neuromorphic brain style AGI designs, as they will massively outcompete everything else.
These are the engineering constraints from physics the article is attempting to elucidate.
If they are using high energy budgets, they don't need to build chips to be more and more like the human brain, which has a low energy budget. In other words, they don't need this:
Given the choice between a neuromorphic design which can run 1,000 instances of 1,000 unique agent minds at 100x the speed of human thought, or a von-neumman type design which can run 1,000 instances of only 1 agent mind at 1x the speed of human thought at the same prices - the latter is not competitive.
AGI is not defined as hardware that performs computations as energy-efficiently as the brain. Instead, it is software that performs all important intellectual tasks as effectively as the brain, cost be damned.
The cost/value of a human worker is like 0.1% energy equivalent, and mostly intangibles with a significant chunk being knowledge/software. AGI is only economically viable if it outcompetes humans, so that right there implies an energy constraint that it can't be 10000x less energy efficient. This constraint is naturally much more stringent for robotic applications.
Then of course the same principles apply when comparing neuromorphic vs von-neumann machines at the end of Moore's Law. The former is fundamentally multiple OOM more energy efficient than the latter (and just or more circuit cost efficient), and thus can run multiple OOM faster at the same cost, so it obviously wins.
One possibility is that I'm misinterpreting your conclusion about how the future of AGI is to become more like the brain, not less. I interpreted that to mean that you were forecasting a rise in neuromorphic computing and/or forecasting that the biggest progress in AGI will come from people studying neuroscience to learn from the brain, and (given what you said about brain parity in the introduction) that you don't think we'll get AGI until we do those things and make it more like the brain. Do you think those things, or anything adjacent?
Early AGI is somewhat brain-like ANNS running on GPUs, later AGI is even more brain-like ANNs running on neuromorphic/PIM hardware. Hmm maybe I need to make those parts more clear?
I of course agree that if we had the right knowledge, we could build AGI today and it would probably even run on my laptop.
The article shows how this is probably impossible, just like it would be impossible for you to run the full Google search engine on your 2021 laptop.
And realistically I think we are more likely to get AGI by scaling up models and running them on massive supercomputers (for much more energy cost than the human brain uses!) than by achieving great new insights of knowledge such that we can run 1000 AGI on 1000 2021 GPUs.
Lol what do you think a modern supercomputer is, if not thousands of GPUs? There are scaling limits to parallelization, as mentioned. Or perhaps you are confused by the 1000 instance thing, but as I tried to explain: a single AGI instance is just as expensive as ~1000, at least on current non-neurmorphic hardware. (So you always get 1000-ish instances, see the circuit section)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-09T01:39:28.566Z · LW(p) · GW(p)
I get the sense that we are talking past each other. I wonder if part of what's happening here is that you have a broader notion of what counts as neuromorphic hardware and brain-like AI than I did, and are therefore making a much weaker claim than I thought you were. I can't tell for sure but some of the things you've said recently make me think this.
I know that modern supercomputers are thousands of GPUs. That isn't in conflict with what I said. I understand that on current hardware anyone able to make 1 AGI will be able to easily make many, for the reasons you mentioned.
I'm not sure what you meant by the claims I objected to, so I'll stop trying to argue against them. I do still stand by what I said about how energy is not currently a taut constraint, and your post sure did give the impression that you thought it was. Or maybe you were just saying you think it will eventually become one?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-09T15:53:19.168Z · LW(p) · GW(p)
I provided some links to neuromorphic hardware research, and I sometimes lump it in with PIM (Processor in Memory) architecture. It's an architecture where memory and compute are unified with some artificial synapse like thing - eg memristors. It's necessarily brain-like, as the thing it's really good at it is running (low precision) ANNs efficiently.
The end of Moore's Law is actually a series of incomplete barriers, each of which only allows an increasingly narrower computational design to scale past that barrier: dennard scaling blocked serial architectures (CPUs), next up the end of energy scaling will block von-neumman arch (GPUs/TPUs), allowing only neuromorphic/PIM to scale much further, then there is the final size scaling barrier for all reversible computation, and only exotic reversible/quantum computers scale past that.
Your comment about your laptop running AGI suggested you had a different model for the min hardware requirements in terms of RAM, RAM bandwidth, and flops.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-09T17:44:48.010Z · LW(p) · GW(p)
Great. Thanks.
The end of Moore's Law is actually a series of incomplete barriers, each of which only allows an increasingly narrower computational design to scale past that barrier: dennard scaling blocked serial architectures (CPUs), next up the end of energy scaling will block von-neumman arch (GPUs/TPUs), allowing only neuromorphic/PIM to scale much further, then there is the final size scaling barrier for all reversible computation, and only exotic reversible/quantum computers scale past that.
Funnily enough, if this paragraph had appeared in the original text by way of explanation for what you meant by "The future of AGI is to become more like the brain, not less." then I would not have objected. Sorry for the misunderstanding. I do still think we have some sort of disagreement about takeoff and timelines modelling, but maybe we don't.
I shouldn't have said laptop; I should have said whatever it was you said (GPUs etc.) I happen to also believe it could in principle be done on a laptop with the right knowledge (imagine God himself wrote the code) but I shouldn't have opened that can of worms. I agree that for all practical purposes it may as well be impossible.
Replies from: None↑ comment by [deleted] · 2022-01-11T23:54:46.046Z · LW(p) · GW(p)
If I had to guess at the crux between your disagreement on timelines, I think you might disagree about the FOOM process itself, but not about energy as a taut constraint to the first human-level AGI (which you both seem to agree isn't the case). Per Jacob's model, if a FOOM requires the AGI to quickly become much much smarter than humans, that excess smartness will inherently come with a massive electrical cost, which will cap it out at O(10^9) human-brain-equivalents until it can substantially increase world energy output. This would serve to arrest FOOM at roughly human-civilization-scale collective intelligence, except with much better coordination abilities.
To me, this was a pretty significant update, as I was previously imagining FOOMing to not top out before it was way way past human civilization's collective bio-compute.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-12T01:02:19.483Z · LW(p) · GW(p)
What do you mean by "arrest FOOM?" I am quite confident that by the time the intelligence explosion starts winding down, it'll be past the point of no return for humans. Maybe from the AIs perspective progress will have stagnated due to compute constraints, and further progress will happen only once they can design exotic new hardware, so subjectively it feels like aeons of stagnation. But I think that "human-civilization-scale collective intelligence except with much better coordination abilities" is vastly underselling it. It's like saying caveman humans were roughly elephant-scale intelligences except with better coordination abilities. Or saying that SpaceX is "roughly equivalent to the average US high school 9th grade class, except with better coordination abilities." Do you disagree with this?
Replies from: jacob_cannell, None↑ comment by jacob_cannell · 2022-01-12T15:52:34.550Z · LW(p) · GW(p)
I'm not entirely sure what you mean by "better coordination abilities", but the primary difference between 9th graders and SpaceX employees is knowledge/training. The primary difference between elephants and caveman humans was the latter possessing language and thus technology/culture and beyond single-lifetime knowledge accumulation.
AGI instances of the same shared mind/model should obviously have a coordination advantage, as should those created by the same organization, but there are many organizations that may be creating AGI.
Even in a world where AGI is running on GPUs and is scale-out bound by energy use and fab output, it may be that a smaller number of larger-than-human minds trained on beyond-human experience have a strong advantage, and in general I'd expect those types of advantages to matter at least as much as 'coordination abilities'.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-12T17:20:15.371Z · LW(p) · GW(p)
I don't have a precise definition in mind since I was parrotting Yonadav. My point was that SpaceX is way better than a random similarly-sized group of high schoolers in many many important ways, even though SpaceX consumes just as many calories/energy as the high schoolers, such that it's totally misleading to describe them as "roughly equivalent except that SpaceX has a massive coordination advantage." The only thing roughly equivalent about them is their energy consumption, which just goes to show energy consumption is not a useful metric here.
I totally agree that fewer, larger brains with experience advantages seem likely to outcompete many merely human-sized brains. In fact I think I agree with everything you said in this comment.
↑ comment by [deleted] · 2022-01-12T13:48:45.546Z · LW(p) · GW(p)
No, I agree that coordination is the ballgame, and there’s not huge practical difference there. Entirely separately, if we were worried about a treacherous turn due to a system being way above our capabilities, this lowers the probability of that, because there are clearer signals associated with the increase in intelligence needed to out-scheme a team of careful humans. (Large compute + energy usage.) It’s not close to being a solution, but it does bound the tail of arbitrarily-pessimistic outcomes from small-scale projects suddenly FOOMing. It also introduces an additional moniterable real world effect (a spike in energy usage noticeable by energy regulation systems).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-12T17:16:09.964Z · LW(p) · GW(p)
Ah, I see. I think 10^9 is not a meaningful number to be talking about; long before there are 10^9 brain-equivalents worth of compute going into AI, we'll be past the point of no return. But if instead you are talking about an amount of compute large enough that energy companies should be able to detect it, then yeah this seems fairly plausible. Supercomputers can't be hidden from energy companies as far as I know, and plausibly AGI will appear first in supercomputers, so plausibly wherever AGI appears, it'll be known by some government that the project was underweigh at least.
I don't think this meaningfully lowers the probability of treacherous turn due to a system being way above our capabilities though. That's because I didn't put much probability mass on secret-AGI-project-in-a-basement scenarios anyway. I guess if I had, then this would have updated me.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2022-01-12T20:17:45.157Z · LW(p) · GW(p)
Crypto mining would be affected significantly as well, or potentially mostly instead of, total energy use: intelligence is valuable-computation-per-watt, changing v-c-p-w changes the valuable energy spend of computers that sit idle, so you'd expect projects bidding on this to overtake cryptocurrency mining as the best use of idle computers, whether that's due to a single project buying up computers and power, or due to a cryptocurrency energy-wasting-farm suddenly finding something directly valuable to do with their machines (and in fact it is already the case that ML can pay more than crypto mining).
@jacob_cannell's argument is simply that the brain has more to tell us about the structure of high-value-per-watt computation than expected by ai philosophers. It does not mean the brain is at the absolute limit of generalized algorithmic energy efficiency (aka the only possible generalized intelligence metric); it only means that the structure of physical limits on algorithmic energy efficiency must be obeyed by any intelligent system, and while there may be large asymptotic speedups from larger scale structure improvement, the local efficiency of the brain is nothing to shake a stick at.
Perhaps ASI could be done earlier by "wasting" energy on lower value-per-watt AI projects - and in fact, there's no reason to believe otherwise from available research progress. All AI progress that has ever occurred, after all, has been on lower generalized value-per-watt compute substrate than human brains can provide, but in return for being on thermodynamically inefficiency computers, it gets benefits that can economically compete with humans - eg via algorithmic specialization, high precision math, or exact repeatability - and thereby, AI research makes progress towards ever-increasing value-of-compute-output-per-watt.
If a system is AGI, it means that it is within a constant factor of energy efficiency per watt of the human brain for nearly all tasks - potentially a large constant factor, but a constant factor nonetheless. If it's just barely general superintelligence and is wildly inefficient at small scales, then the only possible way it could be superintelligence is because it scales (maybe just barely) better than the brain with problem difficulty - extracting asymptotically better value-per-watt than an equivalently scaled system of humans consuming the same number of watts, due to what must ground out to improved total-system-thermodynamic-efficiency-per-unit-useful-computation.
Your proposal seems to be that we should expect a large scale multi-agent AI system to be superintelligence in this larger-scale asymptotic respect, despite that the human brain has shockingly high interconnect-efficiency and basic thermal compute efficiency. I have no disagreement. What this does tell us is that deep learning doesn't have a unique expected qualitative advantage nor expected qualitative disadvantage vs the brain. if it becomes able to find more energy-efficient energy routes through its processing substrate's spacetime (ie more energy efficient algorithms) (ie more intelligent algorithms), then it wins. predicting when that will happen, which teams are close, and guaranteeing safety becomes the remaining issue: guaranteeing that the resulting system does not cause mass energy-structure-aka-data loss (eg, death, body damage, injury, memory loss, hdd corruption/erasure, failure to cryonically freeze as-yet-unrepairable beings, etc) nor interfere significantly with the values of living beings (torture, energy-budget squeeze, cryonic freezing of beings who wish to continue operating, etc).
(due to the cycles seen in evolutionary game theory, I suspect that an unsafe or bad-at-distributed-systems-fairness AGI mega-network will moderately quickly collapse with similar high-defection-rate issues to the human society we have; and if it exterminates and then succeeds humanity, I'd guess it will eventually evolve a large scale cooperative system again; but there's no reason to believe it wouldn't kill us first. friendly multi-agent systems are the hardest part of this whole thing, IMO.)
↑ comment by omegastick (isaac-poulton) · 2022-01-07T20:37:27.509Z · LW(p) · GW(p)
If EfficientZero-9000 is using 10,000 times the energy of John von Neumann, and thinks 1,000 times faster, it's actually actually 10 times less energy efficient.
The point of this post is that there is some small amount of evidence that you can't make a computer think significantly faster, or better, than a brain without potentially critical trade offs.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-01-08T19:05:33.718Z · LW(p) · GW(p)
I'm saying we will build AGI and it will be significantly faster and more capable than the brain. According to this post that means it will be significantly less energy-efficient. I agree. I don't see why that matters. Energy is cheap, and people building AGI are wealthy.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-08T21:22:34.039Z · LW(p) · GW(p)
I don't see why that matters. Energy is cheap, and people building AGI are wealthy.
We don't quite have self driving cars yet because current tech isn't net efficient enough to run in the 200W or whatever power budget of a car, and also because the training algorithms aren't data or power efficient enough yet - even with OOM more data than a human needs, and with training supercomputers using many MW of power.
With current tech someone arguably could piece together a low-level knowledge worker AGI, but it would cost $billions to train, and perhaps a MW to run at human performance, so it's unlikely to outcompete humans and thus is economically near worthless.
comment by Yair Halberstadt (yair-halberstadt) · 2023-04-24T17:14:42.298Z · LW(p) · GW(p)
Thank you for this article.
As a basic sanity check, would this same argument show that animals are close to optimal efficiency.
If no, why not?
If yes, doesn't that imply that efficiency is somewhat of a red herring, and algorithmic improvements are what matters?
comment by Donald Hobson (donald-hobson) · 2022-01-10T19:08:38.780Z · LW(p) · GW(p)
Suppose someone in 1900 looked at balloons and birds and decided future flying machines would have wings. They called such winged machines "birdomorphic", and say future flying machines will be more like birds.
I feel you are using "neuromorphic" the same way. Suppose it is true that future computers will be of a Processor In Memory design. Thinking of them as "like a brain" is like thinking a fighter jet is like a sparrow because they both have wings.
Suppose a new processor architecture is developed, its basically PIM. Tensorflow runs on it. The AI software people barely notice the change.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-16T20:45:21.695Z · LW(p) · GW(p)
The set of AGI models you could run efficiently on a largescale pure PIM processor is basically just the set of brain-like models.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-01-16T22:02:04.801Z · LW(p) · GW(p)
If hypothetically that was true, that would be a specific fact not established by anything shown here.
If you are specific in what you mean by "brainlike" it would be quite a surprising fact. It would imply that the human brain is a unique pinnacle of what is possible to achieve. The human brain is shaped in a way that is focussed on things related to ancestral humans surviving in the savannah. It would be an enormous coincidence if the abstract space of computation and the nature of fundamental physical law meant that the most efficient possible mind just so happened to think in a way that looked optimised to reproductive fitness in the evolutionary environment.
It is plausible that the human brain is one near optimum out of many. That it is fundamentally impossible to make anything with an efficiency of > 100%, but its easy to reach 90% efficiency. The human brain could be one design of many that was >90%.
It is even plausible that all designs of >90% efficiency must have some feature that human brains have. Maybe all efficient flying machines must use aerofoils, but the space of efficient designs still includes birds, planes and many other possibilities.
I will claim that the space of minds at least as efficient as human minds is big. At the very least it contains minds with totally different emotions than humans, and probably minds with nothing like emotions at all. Probably minds with all sorts of features we can't easily conceive of.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-17T02:06:44.584Z · LW(p) · GW(p)
Brain-like != human brain.
By brain-like I mostly just meant neuromorphic, so the statement is almost a tautology. DL models are all ready naturally somewhat 'brain-like', in the space of all ML models, as DL is a form of vague brain reverse engineering. But most of the remaining key differences ultimately stem from the low level circuit differences between von neuman and neuromorphic architectures. As just one example - DL currently uses large-batch GD style training because that is what is actually efficient on VN architecture, but will necessarily shift to brain-style small batch techniques on neuromorphic/PIM architecture as that is what efficiency dictates.
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2022-01-17T09:32:30.671Z · LW(p) · GW(p)
Almost a tauutology = carries very little useful information.
In this case most of the information is carried by the definition of "Neuromorphic". A researcher proposes a new learning algorithm. You claim that if its not neuromorphic then it can't be efficient. How do you tell if the algorithm is neuromorphic?
comment by Donald Hobson (donald-hobson) · 2022-01-10T17:34:01.020Z · LW(p) · GW(p)
In worlds where brains are ultra-efficient, AGI necessarily becomes neuromorphic or brain-like, as brains are then simply what economically efficient intelligence looks like in practice, as constrained by physics.
I totally disagree. Firstly it may be that the brain is 99.9% efficient, and some totally different design is also 99.9% efficient. There can be several very different efficient ways to do things.
Secondly AGI can be less efficient and still FOOMy if it has enough energy and mass. As it is usually easier to do something at all than to do it with near perfect efficiency, early AGI's will probably use more power than the human brain. In an extreme case given self replicating space robots and fusion reactors, the first AI could involve a truly vast amount of energy and mass.
I don't actually think the human brain is anywhere near the fundamental limits.
comment by Thomas Kwa (thomas-kwa) · 2023-02-01T20:22:10.125Z · LW(p) · GW(p)
I made a Manifold market for some key claims in this post:
comment by MiguelDev (whitehatStoic) · 2023-08-28T08:47:52.134Z · LW(p) · GW(p)
This presentation by Geoffrey Hinton on the two paths to intelligence is reminiscent of this post! enjoy guys.
comment by Ilio · 2022-01-16T19:41:35.867Z · LW(p) · GW(p)
Interesting, thanks! Two quick questions about energy and space:
Typo? Eb > kb.ln2 == Eb > kb.T.ln2
« Shrinking the brain by a factor of 10 at the same power output would result in a 3x temp increase to around 1180K »: shouldn’t we take into account that the less volume the lower total in wire lenght, hence less power output?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-01-16T20:38:15.816Z · LW(p) · GW(p)
Thanks.
shouldn’t we take into account that the less volume the lower total in wire lenght, hence less power output?
Well that's why I qualified with "at the same power output". Computation appears to use roughly about as much power as interconnect, so reducing size wouldn't decrease power output much. But even if that wasn't true - if say compute had zero contribution - that would just result in a ~1.78x temp increase instead of a ~3.16x increase, for 10x radius reduction. (Because power density scales with whereas wire volume/power scales with )
Replies from: Iliocomment by Mart_Korz (Korz) · 2022-01-07T15:14:21.644Z · LW(p) · GW(p)
Great post, thanks! I would not have guessed that brains are this impressive.
Re: algorithms of the brain, I could still imagine that the 'algorithms' we rely on for higher concepts (planning, deciding on moral values, etc.) are more wasteful with regards to resources. But your arguments certainly reshape my expectations for AI
Some typos/a suggestion:
"The predicted wire energy is 10−19W/bit/nm" J/bit/nm
"[...] a brain-size ANN will cost almost 3kW" 3kJ
"if we assume only 10% of synapses are that large, the minimal brain synaptic volume is about 10^18 nm" - nm^3
"10^18 nm of total wiring length, and thus at least an equivalent or greater total wiring volume (in practice [,,,]" maybe "volume (i.e. $10^18 nm^3$; in practice [...]"
↑ comment by jacob_cannell · 2022-01-07T19:07:38.266Z · LW(p) · GW(p)
Thanks! And thanks for the typo catches. I agree that the higher level software that runs on the brain (multi-step algorithms) - the mind - is more evolutionarily recent, a vastly larger search space, still evolving rapidly, etc. I added a note in the beginning to clarify this article is specifically not arguing for high efficiency or near optimality for mental software.
comment by TurnTrout · 2022-11-15T17:02:58.537Z · LW(p) · GW(p)
In worlds where brains are ultra-efficient, AGI necessarily becomes neuromorphic or brain-like, as brains are then simply what economically efficient intelligence looks like in practice, as constrained by physics.
Not necessarily. There could be multiple ultra-efficient cognitive architectures, and the brain would represent one of them.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-11-16T01:28:41.769Z · LW(p) · GW(p)
You are correct. I should reword that a bit. I do think the brain-like compute basin is wide and likely convergent, but it's harder to show that it's necessarily a single unique basin; there could be other disjoint regions of high efficiency in architecture space.
comment by Peter V. (peter-v-1) · 2022-01-10T05:10:35.997Z · LW(p) · GW(p)
Hi, thanks tons for your interesting summary, even as STEM non-literate i believe i managed to grasp a few interesting bits !
I wondered, what's your intuition about the software/operating system side, as in the way data is handled/ordered at the subconscious level ? Wasteful or efficient ? Isn't that a key point that could render neuromorphic hardware obsolete, and perhaps suggest that AGI could run on current PCs as one commentator posited ?
As in, if i'm asking myself where i was yesterday, on a computer cognitive architecture, i'd just need to access a few pointers and do some dictionary searches and i'd get a working list of pointers in a minimal number of cycles, while my human mind seems to run a 100% CPU search with visual memories flooding back. I didn't ask for images or emotions or details of what was at the scene, i just needed a pointer to these places to be able to pronounce their name.
Isn't the human mind extremely limited by it's wavering attention span ? By its working memory ? By the way information is probably intricately linked with sensory experience ? How much compression / abstraction is taking place ?
Think about asking a computer to design a house. As a human i'd never even be able to hold the design in memory, i'd need a pen and paper and that'd considerably slow me down, and getting all the details correctly would ask me even more time. A computer probably could yield you a proper perfect design in a fraction of a second. Mental calculus is the same.
Yet, the 2000 TB of the mind seems like small number. How does the brain do that much with so little ?
There's also the question of people functioning normally after getting half of their brain removed, what if 1/4 was enough ? 1/8 ? That could be at least 1 OOM of inefficiency for brains in relation to normal human intelligence.
comment by StanislavKrym · 2025-03-28T04:33:03.361Z · LW(p) · GW(p)
Here I would like to notice that the world's entire 30 TWh a year of energy might be far from sufficient to create an AGI-run civilisation without advances in neuromorphic calculations.
comment by JakubK (jskatt) · 2023-03-21T17:24:39.076Z · LW(p) · GW(p)
Brain computation speed is constrained by upper neuron firing rates of around 1 khz and axon propagation velocity of up to 100 m/s [43], which are both about a million times slower than current computer clock rates of near 1 Ghz and wire propagation velocity at roughly half the speed of light.
Can you provide some citations for these claims? At the moment the only citation is a link to a Wikipedia article about nerve conduction velocity.