Posts
Comments
Thank you for the clarifying response, which might aid in a successful rephrasing of the Question I've asked above. This line is particularly helpful:
These risks become worse as patents become easier to obtain (relaxed definitions of novelty, usefulness, and obviousness).
Perhaps I will move this back to draft mode and reconsider.
Upvoted on the basis of clarity, useful / mentoring tone, and the value of the suggestions. Thank you for coming back to this.
In a first-pass read, there is not much I would add, save for mentioning that I’d expect (1)-(4) to change from what they are now were they to actually be implemented in some capacity, given the complexities (jurisdictional resources, public desire, participation, etc…).
I have the Myth of The Rational Voter on my shelf unread!
If I have any sufficiently useful or interesting ideas or comments regarding your remarks, I will add them here.
Agree. This post captures the fact that, time and again, historical and once perceived as insurmountable benchmarks in AI have been surpassed. Those not fully cognizant of the situation have been iteratively surprised. People, for reasons I cannot fully work out, will continue to engage in motivated reasoning against current and near-term-future-expected AI capabilities and or economical value, with some part of the evidence-downplaying consisting of shifting AGI-definitional or capability-threshold-to-impress goalposts (see moving goalposts). On a related note, your post also makes me imagine the apologue of the boiling frog of late w.r.t. scaling curves.
Although this is an old question, I want to provide an answer, since this is a topic that I am interested in and believe matters for GCR and X-Risk reduction, though it seems quite plausible that this field will radically transform under different level of AI capabilities.
First, if the author of this post has updated their believes about the field of decline and collapse or has formulated a resource list of their own, I would appreciate these being remarked, so I may engage with them.
Of note, I have not fully read some of these books and other resources, but I have minimally skimmed all of them. There are resources I am not including, since these I feel are not worth their time in opportunity costs.
The following are not put in priority order, but I have provided simple ratings of one to three ✯ indicating how much I believe the books are valuable to thinking about collapse. Ratings come after titles so as not to prime the reader.
Books:
- How Worlds Collapse ✯✯✯
- The Collapse Of Complex Societies ✯✯✯
- Secular Cycles ✯✯
- Modernity And Cultural Decline ✯
- Historical Dynamics ✯✯✯
- Social and Cultural Dynamics ✯
- Understanding Collapse ✯✯
- The Evolution of Civilizations ✯
- After 1177 B.C.: The Survival of Civilizations ✯
- Prophets Of Doom ✯✯ [1]
- The Idea Of Decline In Western History ✯
- The Decline and Fall of the Roman Empire ✯✯
Web-Links:
- The Seshat Dataset (here and here) [2]
- Google Scholar citations for Historical Dynamics
- Google Scholar citations for The Collapse Of Complex Societies
- The Seshat Database on GitHub
- Peter Turchin's Website
Some further considerations
Anna's previous comment used the term "proto-model" and alluded to the greater dearth of formalization in this field. It is worth adding here that "this field" (which, at times, I have referred to as "cliodynamics", "studies in complex societies", "historical dynamics", "studies in collapse", "civilizational dynamics"), is a collection of different academic disciplines, each of which has different levels of quantitative rigor.
Many who have entertained theorizing about human societies and their rise and fall (even the notions of "rise" and "fall" are somewhat dubious) have seldom incorporated quantitative measures or models, though I have still found their work valuable.
The authors in the anthology How Worlds Collapse seem not to interact and or collaborate much with those who study global catastrophic risk (e.g., those who would cite books such as X-Risk or Global Catastrophic Risks), which seems to be a loss for both fields, since those studying GCR and or X-Risks have adopted, more readily (or seemingly so), models and mathematics, with a good canonical paper for the latter entry being Classifying Global Catastrophic Risks (2018), and those in the field of collapse typically are more ready to consider patterns across historical complex societies and psychological dynamics relevant to recovery of complex societies under forces of calamity.
Anyway, best of wishes in your studies of human societies and their dynamics, including their decline.
This covers Toynbee, Spengler, Gobineau, and other historical figures in the field of "collapse" or "complex societies", including Peter Turchin. ↩︎
From their sites: Seshat: Global History Databank was founded in 2011 to bring together the most current and comprehensive body of knowledge about human history in one place. The huge potential of this knowledge for testing theories about political and economic development has been largely untapped. Our unique Databank systematically collects what is currently known about the social and political organization of human societies and how civilizations have evolved over time. This massive collection of historical information allows us and others to rigorously test different hypotheses about the rise and fall of large-scale societies across the globe and human history. ↩︎
I expect to post additional comments on this thread, but for now, w.r.t.
Sometimes the preferences people report or even try to demonstrate are better modeled as a political strategy and response to coercion, than as an honest report of intrinsic preferences.
has the author of this post read Private Truths, Public Lies: The Social Consequences of Preference Falsification (Kuran, 1997)? I've read but have not yet written a review of the book, so I cannot comment too critically on its value in this present conversation, but I believe the author should minimally check it out or skim its table of contents. To pull a better overview (from GoodReads) than I can provide off hand:
Preference falsification, according to the economist Timur Kuran, is the act of misrepresenting one's wants under perceived social pressures. It happens frequently in everyday life, such as when we tell the host of a dinner party that we are enjoying the food when we actually find it bland. In Private Truths, Public Lies Kuran argues convincingly that the phenomenon not only is ubiquitous but has huge social and political consequences. Drawing on diverse intellectual traditions, including those rooted in economics, psychology, sociology, and political science, Kuran provides a unified theory of how preference falsification shapes collective decisions, orients structural change, sustains social stability, distorts human knowledge, and conceals political possibilities.
A common effect of preference falsification is the preservation of widely disliked structures. Another is the conferment of an aura of stability on structures vulnerable to sudden collapse. When the support of a policy, tradition, or regime is largely contrived, a minor event may activate a bandwagon that generates massive yet unanticipated change.
In distorting public opinion, preference falsification also corrupts public discourse and, hence, human knowledge. So structures held in place by preference falsification may, if the condition lasts long enough, achieve increasingly genuine acceptance. The book demonstrates how human knowledge and social structures co-evolve in complex and imperfectly predictable ways, without any guarantee of social efficiency.
Private Truths, Public Lies uses its theoretical argument to illuminate an array of puzzling social phenomena. They include the unexpected fall of communism, the paucity, until recently, of open opposition to affirmative action in the United States, and the durability of the beliefs that have sustained India's caste system.
Thank you for the typo-linting.
To provide a better response to your first question than the one I’ve provided below, I would need to ask him to explain more than he has already.
From what he has remarked, the first several meetings were very stressful (for most people, this would, of course, be the case!) but soon he adjusted and developed a routine for his meetings.
While the routine could go off course based on the responsiveness of the individual(s) present (one staffer kept nodding Yes, had no questions, and then 20 minutes later remarked that they “take into account” what had been said; another staffer remarked that the US simply needed to innovate AI as much as possible, and that safety that stifled this was not to be prioritized; these are statements paraphrased from my friend), I get the sense that in most instances he has been able to provide adequate context on his organization and the broader situation with AI first (not sure which of these two comes first and for how long they are discussed).
Concerning provision of a description of the AI context, I am not sure how dynamic they are; I think he mentioned querying the staffers on their familiarity, and the impression he had was that most staffers listened well and thought critically about his remarks.
After the aforementioned descriptions, my friend begins discussing measures that can be taken in support of AI Safety.
He mentioned that he tries to steer framings away from those invoking thoughts of arms races or weaponization and instead focuses on uncontrollability “race to the bottom” scenarios, since the former categorization(s) given by others to the staffers has, in his experience, in some instances downplayed concerns for catastrophe and increased focus on further expanding AI capabilities to “outcompete China”.
My friend’s strategy framings seem appropriate and he is a good orator, but I have not the nuanced suggestion that I wanted for my conversation with him, as I’ve not thought enough about which AI risk framings and safety proposals to have ready for staffers and as I believe talking to staffers qualifies as an instance of the proverb “an ounce of practice outweighs a pound of precept”.
Constraining and/or lowering (via bans, information concealment, raised expenses, etc…) capabilities gains via regulation of certain AI research and production components (weights, chips, electricity, code, etc…) is a strategy pursued in part or fully by different AI Safety organizations.
One friend (who works in this space) and I were very recently reflecting on AI progress, along with strategies to contend with AI related catastrophes. While we disagree on the success probabilities of different AI Safety plans and their facets, including those pertaining to policy and governance, we broadly support similar measures. He does, however, believe “shut down” strategies ought to be prioritized much more than I do.
This friend has, in the last year, met with between 10-50 (providing this range for preservation of anonymity) congressional staffers; the stories of these meetings he has could make for both an entertaining and informative short book, and I was grateful for the experiences and the details of how he prepares for conversations and framing AI that he imparted on me.
The density of familiarity with AI risk across the staffers was concentrated on weaponization; most staffers (save for 3) did not have much if any sense of AI catastrophe. This point is interesting, but I found how my friend perceived his role in AI Safety with these meetings more intriguing.
To prelude, both him and I believe that, generally speaking, individual humans and governments (including the US government) require some (the more spontaneous, the more impactful) catastrophe to engender productive responses. Examples of this include near-death experiences (for people) and the 11 September 2001 bombings for the US government.
With this remark made: my friend perceives his role to be one primarily of priming the staffers i.e. “the US government” to respond more effectively to catastrophe (e.g. 100s of thousands to millions but not billions dead) than they otherwise would have been able.
Any immediate actions taken by the staffers towards AI Safety, especially with respect to a full cessation of certain lines of research, access to computational resources, or information availability, my friend finds excellent, but due to the improbability of these occurring, he believes the brunt of his impact comes to fruition if there is an AI catastrophe that humans can recover from.
This updated how I perceive the “slow down” focused crowd in AI Safety from being one focused on literally having many aspects of AI progress stalled partially or fully to one of governmental and institutional response enhancement in fire-alarm moments.
Kudos to the authors for this nice snapshot of the field; also, I find the Editorial useful.
Beyond particular thoughts (which I might get to later) for the entries (with me still understanding that quantity is being optimized for, over quality), one general thought I had was: How can this be made into more of "living document"?.
This helps
If we missed you or got something wrong, please comment, we will edit.
but seems less effective a workflow than it could be. I was thinking more of a GitHub README where individuals can PR in modifications to their entries or add in their missing entries to the compendium. I imagine most in this space have GitHub accounts, and with the git tracking, there could be "progress" (in quotes, since more people working doesn't necessarily translate to more useful outcomes) visualization tools.
The spreadsheet works well internally but does not seem as visible as would a public repository. Forgive me if there is already a repository and I missed it. There are likely other "solutions" I am missing, but regardless, thank you for the work you've contributed to this space.
The below captures some of my thoughts on the "Jobs hits first" scenario.
There is probably something with the sort of break down I have in mind (though, whatever this may be, I have not encountered it, yet) w.r.t. Jobs hits first but here goes: the landscape of AI induced unemployment seems highly heterogeneous, at least in expectation over the next 5 years. For some jobs, it seems likely that there will be instances of (1) partial automation, which could mean either not all workers are no longer needed (even if their new tasks no longer fully resemble their previous tasks), i.e. repurposing of existing workers, or most workers remain employed but do more labor with help from AI and of (2) prevalent usage of AI across the occupational landscape but without much unemployment, with human work (same roles pre-automation) still being sought after, even if there are higher relative costs associated with the human employment (basically, the situation: human work + AI work > AI work, after considering all costs). Updating based on this more nuanced (but not critically evaluated) situation w.r.t. Jobs hits first, I would not expect the demand for a halt to job automation to be any less but perhaps a protracted struggle over what jobs get automated might be less coordinated if there are swaths of the working population still holding out career-hope, on the basis that they have not had their career fully stripped away, having possibly instead been repurposed or compensated less conditional on the automation.
The phrasing
...a protracted struggle...
nevertheless seems a fitting description for the near-term future of employment as it pertains to the incorporation of AI into work.
I decided to run the same question through the latest models to gauge their improvements.
Not exactly sure if there is much advantage at all in you having done this, but I feel inclined to say Thank You for persisting in persuading your cousin to at least consider concerns regarding AI, even if he perceptually filters those concerns to mostly regard job automation over others, such as a global catastrophe.
In my own life, over the last several years, I have found it difficult to persuade those close to me to really consider concerns from AI.
I thought that capabilities advancing observably before them might stoke them to think more about their own future and how possibly to behave and or live differently conditional on different AI capabilities, but this has been of little avail.
Expanding capabilities seem to best dissolve skepticism but conversations seem to have not had as large an effect as I would have expected. I've not thought or acted as much as I want to on how to coordinate more of humanity around decision-making regarding AI (or the consequences of AI), partially since I do not have a concrete notion where to steer humanity or justification for where to steer (even I knew it was highly likely I was actually contributing to the steering through my actions).
The second paragraph puts into words something I've noticed but not really mentally formalized before. Some anecdotal evidence from my own life in support of the claims made in this paragraph: I've met individuals whose tested IQ exceeds those of other, lower but not much lower, IQ individuals I know who are more educated / trained in epistemological thinking and tangential disciplines. For none of the individual-pairs I have in mind would I declare that one person "ran circles around" the other, however, the difference (advantage going to the lower but better "trained" IQ individual) in conversational dynamics were notable enough for me to remember well. The catch here is the accuracy of the IQ claims made by some of these individuals, as some did not personally reveal their scores to me.
So far I've not had this issue (i.e, ...that one thing will come back to bite me a few days later...) with my obligations but have had it with some private projects. Infrequently referencing my obligations in to-do list format allows them to stress me adequately, as they occur first on my mind and aren't detracted from by the gravity of the other tasks I have, which would be easily visible and "present" if on a nearby to-do list.
Having a complex task system containing both job-related obligations and private work tasks somewhat deprioritizes the job-related obligations for me [1], relative to how I believe most people might prioritize their job-related obligations, and the near absence of my multiple to-do lists has allowed me, of late, to "calibrate my stress" (the levels of stress I mention here are not severe).
Do you find that you're able to mentally keep track of things better than before...
I am better mentally able to keep track of job-related obligations (which, for the time being and as far as I've surmised, are more important than my private projects / tasks) but less able to remember private project tasks. The magnitude of a task that comes to mind naturally is felt more strongly than if I had proceeded through the same task from a list. I've been tackling tasks that cause me higher levels of stress sooner.
Why? I expect that I have more trouble than is average separating "job" versus "non-job" work, meaning that how much I value one over the other oscillates. ↩︎
W.r.t. maintaining a to-do list, I've noticed that, for me, at this time in my life (the last year or so), seldomly referencing a to-do has aided me in more quickly getting my work finished (both at my job and with my projects). As a result of seldomly referencing (looking at / thinking about) the to-do list, my behavior surrounding task completion has changed: I now pause, think of a task, and then decide to do the task, knowing that while I am doing this task I am getting closer to my end, whereas previously I could not be doing any task with often thinking about the other tasks remaining on the to-do list. Of late, there is just me and the task at hand, with very rare planning sessions, usually on the order of every 2-4 weeks where I reference a to-do list.
Historically, I've maintained long to-do lists, sorted by urgency and importance. Oftentimes I would go back and forth between tasks, i.e. task-switching, within the same day. To counter this, I would maintain another to-do list (keeping the longer one away), where this one I'd keep before me during my tasks, with a single written task, which I would cross out once completed. Despite these methods (the "backlog" and the one-task-at-a-time list), I found that, at times, the existence of these to-do lists resulted in my mind frequently reciting their items, and this recitation was enough to pull me away from the task at hand.
I've not attempted to quantitatively measure my productivity, so I do not have metrics to coincide with the aforementioned change in productivity.
it very much depends on where the user came from
Can you provide any further detail here, i.e. be more specific on origin-stratified-retention rates? (I would appreciate this, even if this might require some additional effort searching)
Similar situation in my life...there are times when I am attempting to fall asleep and I realize suddenly that I am clenching my teeth and that there is considerable tension in my face. Beginning from my closed eyes down to my mouth I relax my facial muscles and I find it becomes easy for me to fall asleep.
In waking life too there are instances where I recognize my facial and bodily tension but I notice these situations less often than when I am trying to sleep. Being conscious of tension in my body and then addressing that tension when it occurs has on occasion made me calmer.
I am uncertain regarding the utility of more expensive interventions and or intensive investigations for alleviating tension, and have not really looked into it (but want to, somewhat).
Maybe the "I love this" refers to an appreciation for the existence of a post like this one on LW, not the content (i.e., the child's unusual and partially unsettling behavior) of this post; I do think a "reference to the post existing in the LW ecosystem" is a less probable scenario than "reference to the content of the post". Anyway, I find the content somewhat unsettling, but appreciate that I saw a post like this one today on LW.
Minor point: I think it would be useful to have, at the top of the census, a box for people to click "I see this census, but don't want to fill it out". Such an option could help with understand what % of active users saw but didn't fill out the census, which is information that, while I can't immediately see how it is valuable, might be found to be valuable in the future.
I experience something similar. On some work days, I might rotating somewhat distractedly between tasks. In this state of task-rotation, I find that I am not very focused or motivated. However, when I formally decide that I am going to Do This Thing, And Only This Thing (where the "thing" is usually my most pressing obligation), I usually gain a moderate productivity boost and the quality of my work typically rises as well. There is a cost to making this decision, though, and that cost consists of creating the psychological state necessary to "focus up and decide", which consists partially of taking a moment to ignore the nagging "false urgencies", i.e. my other obligations.
Somewhat relevant forecasting question for those who are interested (soon-to-open):
This question resolves positive if the International Maritime Organization (IMO) puts forth regulation that increases the limit of sulphur content in the fuel oil used on board ships to the pre-2020 limit of 3.5%, or greater, i.e. at least 3.5%. Otherwise this question resolves negative. Metaculus admins in conjunction with the community will be consulted should any disputes concerning this question's resolution arise over its lifetime.
The voluntary consent of the human subject is absolutely essential.
This means that the person involved should have legal capacity to give consent; should be so situated as to be able to exercise free power of choice, without the intervention of any element of force, fraud, deceit, duress, over-reaching, or other ulterior form of constraint or coercion; and should have sufficient knowledge and comprehension of the elements of the subject matter involved, as to enable him to make an understanding and enlightened decision. This latter element requires that, before the acceptance of an affirmative decision by the experimental subject, there should be made known to him the nature, duration, and purpose of the experiment; the method and means by which it is to be conducted; all inconveniences and hazards reasonably to be expected; and the effects upon his health or person, which may possibly come from his participation in the experiment.
The duty and responsibility for ascertaining the quality of the consent rests upon each individual who initiates, directs or engages in the experiment. It is a personal duty and responsibility which may not be delegated to another with impunity
Important to remember and stand by the Nuremberg Code in these contexts.
Thank you for this comment (sorry this Thank You was delayed; I came back here to add what I've added below, but realize that I hadn't replied to you).
I came across this today: https://www.newsminimalist.com/
The Homepage:
This is another interesting use case of LLMs, this time for meaningful content sorting and tracking, and is helpful in a way different from how you utilized GPT-4 for my initial question. With some additional modification / development, perhaps LLMs can produce a site with all the features I indicated above, or at least something closer to them than https://www.newsminimalist.com/, which I view as a stepping stone. Anyway, I thought you might find the link / concept interesting!
I'm, as are most, familiar with Google Trends. What I'm interested is something more analytical than Google Trends. Maybe Google Trends would be closer to what I am imagining if it displayed and detailed how individual trends in aggregate constitute some portion of a larger historical event(s) playing out. For example, that Tucker Carlson is trending now might be a component of multiple other, larger phenomena unfolding. Also, beyond Google Trend's measure of normalized search interest, I would be interested in seeing the actual numbers across social networks / platforms by token or related tokens. Again, my phrasing here may be poor, but I feel that Google Trends misses some level of cohesiveness with the trends it measures (maybe stated as "some inadequacy on part of Google Trends to integrate multiple trend histories into the larger picture"). Thank you for your comment.
I asked it to give me a broad overview of measure theory. Then, I asked for it to provide me with a list of measure theory terms and their meanings. Then, I asked it to provide me some problems to solve. I haven't entered an solutions yet, but upon doing so I would ask for it to evaluate my work.
Further on this last sentence, I have given it things I've written, including arguments, and have asked for it to play Devil's Advocate or to help me improve my writing. I do not think I've been thorough in the examples I've given it, but its responses have been somewhat useful.
I imagine that many others have used GPT systems to help them evaluate and improve their writing, but, in my experience, I haven't seen many people to use these systems to tutor them or keep track of their progress in learning something like measure theory.
I have (what may be) a simple question - please forgive my ignorance: Roughly speaking, how complex is this capability, i.e. writing Quines? Perhaps stated differently, how surprising is this feat? Thank you for posting about / bringing attention to this.
Strong agreement here. I find it unlikely that most of these details will still be concealed after 3 months or so, as it seems unlikely, combined, that no one will be able to infer some of these details or that there will be no leak.
Regarding the original thread, I do agree that OpenAI's move to conceal the details of the model is a Good Thing, as this step is risk-reducing and creates / furthers a norm for safety in AI development that might be adopted elsewhere. Nonetheless, the information being concealed seems likely to become known soon, in my mind, for the general reasons I outlined in the previous paragraph.
Does anyone here have any granular takes what GPT-4's multimodality might mean for the public's adoption of LLMs and perception of AI development? Additionally, does anyone have any forecasts (1) for when this year (if at all) OpenAI will permit image output and (2) for when a GPT model will have video input & output capabilities?
...GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs)...
These masks are also exceedingly uncommon in my Northeastern US town + the surrounding area; I think I've seen fewer than 5 people wearing one since late 2020. None of them were unusually coloured, either. In my experience, most establishments where masks can be purchased don't carry these pouch-masks. It would be surprising and funny to see a whole group of people will yellow duckbill masks. Also, thank you for teaching me a new word (anatine "of or belonging to the surface-feeding ducks of Anas and closely related genera"). I wish your daughter a hasty recovery.
For those who may not have seen and would like to make a prediction (on Metaculus; current uniform median community prediction is 15%)
Will WHO declare H5N1 a Public Health Emergency of International Concern before 2024?
So why should you dress nice, even given this challenge? Because dressing nice makes your vibes better and people treat you better and are more willing to accommodate your requests.
This is a compelling argument to me, as someone who also had a fuzzy belief that "dressing nicely was a type of bullshit signaling game" (though perhaps with less conviction than you had).
It was around the time (several years ago) that I saw someone dressed like me (pants tucked into the socks and shirt tucked into the pants) that I had the realization that I would probably benefit from dressing better.
This realization was compelling enough to stoke me into initial action, which took the form of testing out new clothing that had passed the rough vibe check of my family and friends, who dress well and seem to care a decent amount about how they dress, but was not strong enough to keep me trying out new clothing.
I found that all the clothing I was trying on was too physically uncomfortable for me. There was also a minor psychological component as a well that I can only describe as a feeling of mismatch between my self-perception and the expected perception people would have of the clothed object before me in the mirror.
As a result of these "failed" experiments, I opted to wear flannels and make sure that the color of my socks matched the color of my pants; to me, this intervention was enough to get me above a vague status threshold and did not require much effort. With very few exceptions, I have not deviated from this dress code.
I cannot recall if I observed a difference in how I was treated after following change, which occurred several years ago.
Thank you writing this post Gordon. After reading and bookmarking it, I think I am marginally more likely to again attempt to dress better in the near-term future.
For the person who strong downvoted this, it would be helpful to me if you also shared which facets of the idea you found inadequate; the 5 or so people I've talked to online have generally supported this idea and found it interesting. I would appreciate some transparency on exactly why you believe the idea is a waste of time or resources, since I want to avoid wasting either of those. Thanks you.
Great piece.
Note: small thank you for the link https://www.etymonline.com/word/patience; I've never seen this site but I will probably have a lot of fun with it.
Thank you for your input on this. The idea is to show people something like the following image [see below] and give a few words of background on it before asking for their thoughts. I agree that this part wouldn't be too helpful for getting people's takes on the future, but my thinking is that it might be nice to see some people's reactions to such an image. Any more thoughts on the entire action sequence?

I understand its performance is likely high variance and that it misses the details.
My use with it is in structuring my own summaries. I can follow the video and fill in the missing pieces and correct the initial summary as I go along. I haven't viewed it as a replacement for a human summarization.
Thank you for bringing my attention to this.
It seems quite useful, hence my strong upvote.
I will use it to get an outline of two ML Safety videos before summarizing them in more detail myself. I will put these summaries in a shortform, and will likely comment on this tool's performance after watching the videos.
Is there a name for the discipline or practice of symbolically representing the claims and content in language (this may be part of Mathematical Logic, but I am not familiar enough with it to know)?
Practice: The people of this region (Z) typically prefer hiking in the mountains of the rainforest to walking in the busy streets (Y), given their love of the mountaintop scenery (X).
XYZ Output: Given their mountaintop scenery love (X), rainforest mountain hiking is preferred over walking in the busy streets (Y) by this region's people (Z).
Thoughts, Notes: 10/14/0012022 (2)
Contents:
- Track Record, Binary, Metaculus, 10/14/0012022
- Quote: Universal Considerations [Forecasting]
- Question: on measuring importance of forecasting questions
Please tell me how my writing and epistemics are inadequate.
1.
My Metaculus Track Record, Binary, [06/21/0012021 - 10/14/0012022]
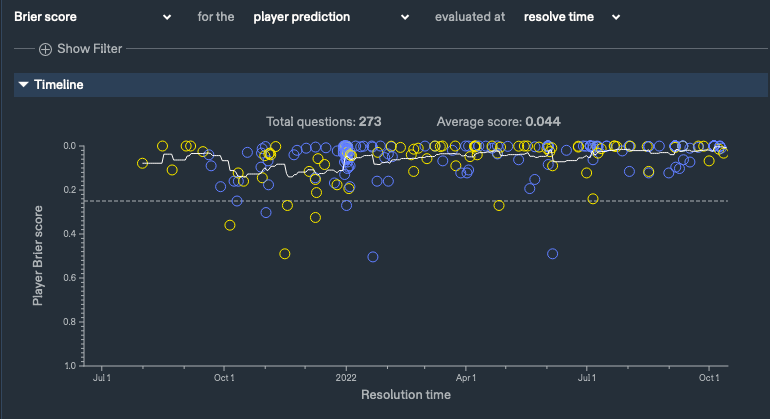
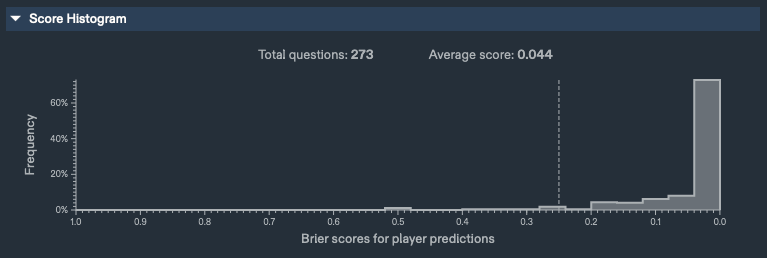
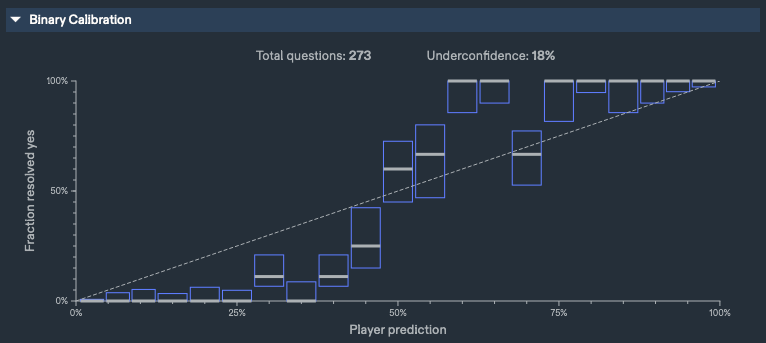
2.
The Universal Considerations for forecasting in Chapter 2 of Francis X. Diebold's book Forecasting in Economics, Business, Finance and Beyond:
(Forecast Object) What is the object that we want to forecast? Is it a time series, such as sales of a firm recorded over time, or an event, such as devaluation of a currency, or something else? Appropriate forecasting strategies depend on the nature of the object being forecast.
(Information Set) On what information will the forecast be based? In a time series environment, for example, are we forecasting one series, several, or thousands? And what is the quantity and quality of the data? Appropriate forecasting strategies depend on the information set, broadly interpreted to not only quantitative data but also expert opinion, judgment, and accumulated wisdom.
(Model Uncertainty and Improvement) Does our forecasting model match the true GDP? Of course not. One must never, ever, be so foolish as to be lulled into such a naive belief. All models are false: they are intentional abstractions of a much more complex reality. A model might be useful for certain purposes and poor for others. Models that once worked well may stop working well. One must continually diagnose and assess both empirical performance and consistency with theory. The key is to work continuously toward model improvement.
(Forecast Horizon) What is the forecast horizon of interest, and what determines it? Are we interested, for example, in forecasting one month ahead, one year ahead, or ten years ahead (called h-step-ahead fore- casts, in this case for h = 1, h = 12 and h = 120 months)? Appropriate forecasting strategies likely vary with the horizon.
(Structural Change) Are the approximations to reality that we use for forecasting (i.e., our models) stable over time? Generally not. Things can change for a variety of reasons, gradually or abruptly, with obviously important implications for forecasting. Hence we need methods of detecting and adapting to structural change.
(Forecast Statement) How will our forecasts be stated? If, for exam- ple, the object to be forecast is a time series, are we interested in a single “best guess” forecast, a “reasonable range” of possible future values that reflects the underlying uncertainty associated with the forecasting prob- lem, or a full probability distribution of possible future values? What are the associated costs and benefits?
(Forecast Presentation) How best to present forecasts? Except in the simplest cases, like a single h-step-ahead point forecast, graphical methods are valuable, not only for forecast presentation but also for forecast construction and evaluation.
(Decision Environment and Loss Function) What is the decision environment in which the forecast will be used? In particular, what decision will the forecast guide? How do we quantify what we mean by a “good” forecast, and in particular, the cost or loss associated with forecast errors of various signs and sizes?
(Model Complexity and the Parsimony Principle) What sorts of models, in terms of complexity, tend to do best for forecasting in business, finance, economics, and government? The phenomena that we model and forecast are often tremendously complex, but it does not necessarily follow that our forecasting models should be complex. Bigger forecasting models are not necessarily better, and indeed, all else equal, smaller models are generally preferable (the “parsimony principle”).
(Unobserved Components) In the leading time case of time series, have we successfully modeled trend? Seasonality? Cycles? Some series have all such components, and some not. They are driven by very different factors, and each should be given serious attention.
3.
Question: How should I measure the long-term civilizational importance of the subject of a forecasting question?
I've used the Metaculus API to collect my predictions on open, closed, and resolved questions.


I would like to organize these predictions; one way I want to do this is by the "civilizational importance" of the forecasting question's content.
Right now, I've thought to given subjective ratings of importance on logarithmic scale, but want a more formal system of measurement.
Another idea for each question is to give every category a score of 0 (no relevance), 1 (relevance), or 2 (relevant and important). For example, if all of my categories "Biology, Astronomy, Space_Industry, and Sports", then the question - Will SpaceX send people to Mars by 2030? - would have this dictionary {"Biology":0, "Space_Industry":2, "Astronomy":1, "Sports":0}. I'm unsure whether this system is helpful.
Does anyone have any thoughts for this?
Thank you for taking a look Martin Vlach.
For the latter comment, there is a typo. I meant:
Coverage of this topic is sparse relative to coverage of CC's direct effects.
The idea is that the corpus of work on how climate change is harmful to civilization includes few detailed analyses of the mechanisms through which climate change leads to civilizational collapse but does includes many works on the direct effects of climate change.
For the former comment, I am not sure what you mean w.r.t "engender".
Definition of engender
2 : to cause to exist or to develop : produce
"policies that have engendered controversy"
Thoughts, Notes: 10/14/0012022 (1)
Contents:
- Summary, comment: Climate change and the threat to civilization (10/06/2022)
- Compression of (1)
- Thoughts: writing and condensing information
- Quote: my friend Evan on concision
To the reader: Please point out inadequacies in my writing.
1.
Article: Climate change and the threat to civilization (10/06/2022)
Context: My work for Rumtin Sempasspour (gcrpolicy.com) includes summarizing articles relevant to GCRs and GCR policy.
Summary: An assessment of the conditions under which civilizational collapse may occur due to climate change would greatly improve the ability of the public and policymakers to address the threats from climate change, according to academic researchers Steela et al. in a PNAS opinion piece. While literature on climate change (e.g., reports from the Intergovernmental Panel on Climate Change) typically covers the deleterious effects that climate change is having or will have on human activities, there has been much less focus on exactly how climate change might factor into different scenarios for civilization collapse. Given the deficits in this research topic, Steela et al. outline three civilizational collapse scenarios that could stem from climate change - local collapse, broken world, and global collapse - and then discuss three groups of mechanisms - direct impacts, socio-climate feedbacks, and exogenous shock vulnerability - for how these scenarios might be realised. (6 October 2022)
Policy comment: Just as governments and policymakers have directed funding and taken action to mitigate the harmful, direct effects of climate change, it seems natural that they should take the next step and address making the aspects of civilization most vulnerable to climate change more robust. The recommendation in this paper for policymakers and researchers alike to promote more rigorous scientific investigation of the mechanisms and factors of civilizational collapse involving climate change seems keen. While this paper does not perform a detailed examination of the scenarios and mechanisms of civilizational collapse that it proposes, it is a call-to-action for more work to understand how climate change affects civilization stability and the role of climate change in civilization collapse.
2.
A condensed version of the summary and policy comment in (1)
Summary: Humanity must understand how climate change (CC) could engender civilizational collapse. Coverage of this topic is sparse relative coverage of CC's direct effects. Steela et al.'s PNAS opinion piece is a call to action for more research on this topic; they contribute an outline of 3 collapse scenarios - local collapse, broken world, and global collapse - and 3 collapse mechanisms - direct impacts, socio-climate feedbacks, and exogenous shock vulnerability (6 October 2022).
Policy comment: Policymakers and researchers need to promote research on the effects of climate change on civilizational stability so that critical societal institutions and infrastructure are protected from collapse. Such research efforts would include further investigations of the many scenarios and mechanisms through which civilization may collapse due to climate change; Steela et al. lay some groundwork in this regard, but fail to provide a detailed examination.
3.
One issue I have is being concise with my writing. This was recently pointed out to me by my friend Evan, when I asked him to read (1), and I want to write some thoughts of mine that were evoked by the conversation.
My first thought: What do I want myself and others to get from my writing?
I want to learn, and writing helps with this. I want to generate novel and useful ideas and to share them with people. I want to show people what I've done or am doing. I want a record of my thinking on certain topics
I want my writing to help others learn efficiently and I want to tell people entertaining stories, ones that engender curiosity.
My next thought: How is my writing inadequate?
I aim for transparency, informativeness, clarity, and efficiency in my writing, but feel that my writing is much less transparent, informative, clear, and efficient than it could be.
- W.r.t. transparency, my model is Reasoning Transparency. My writing sometimes includes answers to these questions[1] (this comment).
- W.r.t. informativeness, I assume someone has already thought about or attempted what I am working on, so I try not to repeat (Don't repeat yourself) and to synthesize works when synthesizing has not yet occurred or has occurred but inadequately.
- W.r.t. clarity, I try to edit my work multiple times and make it clear what I want to be understood. I read my writing aloud to determine if hearing it is pleasurable.
- W.r.t. efficiency, my sense of where to allocate attention across my writing is fuzzy. I use editing and footnotes to consolidate, but still have trouble.
I don't have good ways to measure or assess these things in my writing, and I haven't decided which hypothetical audiences to gear my writing towards; I believe this decision affects how much effort I expend optimizing at least transparency and efficiency.
I will address my writing again at some point, but think it best I read the advice of others first.
4.
My friend Evan on concision:
Yelling at people on the internet is a general waste of time, but it does teach concision. No matter how sound your argument, if you say something in eight paragraphs and then your opponent comes in and summarizes it perfectly in twenty words, you look like an idiot. Don't look like an idiot in front of people! Be concise.
- ^
- Why does this writing exist?
- Who is this writing for?
- What does this content claim?
- How good is this content?
- Can you trust the author?
- What are the author's priors?
- What beliefs ought to updated?
- What has the author contributed here?
Sometimes failing at things makes it harder to try in future even if you expect things to go well, and sometimes people are so afraid that they give up on trying, but you can break out of this by making small, careful bets with your energy.
reminds me of this article
Researchers and educators have long wrestled with the question of how best to teach their
clients be they humans, non-human animals or machines. Here, we examine the role of a
single variable, the difficulty of training, on the rate of learning. In many situations we find that
there is a sweet spot in which training is neither too easy nor too hard, and where learning
progresses most quickly....the optimal error rate for training is around 15.87% or, conversely, that the optimal training accuracy is about 85%
One might benefit from modulating their learning so that their failure rate falls in the above range (assuming the findings are accurate).
Thoughts and Notes: October 10th 0012022 (1)
Summary: Introduction (I introduce this shortform series), Year 0 for Human History (I discuss when years for humanity should begin to be counted)
Introduction
This shortform post marks the beginning of me trying to share on LessWrong some of the thoughts and notes I generate each day.
I suspect that every "thoughts and notes" shortform I write will contain a brief summary of its content at the start, and there will very likely be days where I post multiple shortforms of this nature, hence the (X) after the date.
As for the year in the date on these posts, I want to use something other than the Gregorian calendar's current year. Moreover, I want to better capture the time of origin for a key moment in human history, such as the origin of agriculture, writing, or permanent settlement. The rest of this shortform consists of some notes on this topic.
A Starting Year for Our Calendars
In 2019, after I watched the Kurzgesagt - In a Nutshell video A New History for Humanity – The Human Era (2016), I opted to change the year in the date in my journal entries from 2019 to 12019. This Kurzgesagt video describes the idea that different choices for "year 0" for the "human era" result in different perceptions of human history.
Regarding this claim, I generally agree. If "year 0" for humanity began when the first anatomically modern humans appeared, then the year would be ~202022, and if "year 0" began when the first nuclear weapon was deployed, the "human era" would be only 77 years old. These scenarios seem to strongly allocate my attention in different areas, with the former placing my attention on the thickness and mysteries of what we today call "prehistory" and the latter focusing my attention on the rapid progress and dangers that are characteristic of modernity.
The Kurzgesagt video explores the idea of setting "year 0" to 12000 years ago (the 10th millennium BC), which is apparently around the time the first large scale human construction project seems to have taken place. Having 12000 years ago be "year 0" means that, when the current year is being considered, more attention would likely be allocated to the emergence of widespread agriculture, writing, and intensive construction of settlements and cities than is currently allocated.
Some notes for the preceding paragraph:
Agriculture seems to have started roughly 12k years ago (see History of agriculture).
Agriculture began independently in different parts of the globe, and included a diverse range of taxa. At least eleven separate regions of the Old and New World were involved as independent centers of origin. The development of agriculture about 12,000 years ago changed the way humans lived. They switched from nomadic hunter-gatherer lifestyles to permanent settlements and farming.[1]
Wild grains were collected and eaten from at least 105,000 years ago.[2] However, domestication did not occur until much later. The earliest evidence of small-scale cultivation of edible grasses is from around 21,000 BC with the Ohalo II people on the shores of the Sea of Galilee.
Following the emergence of agriculture, construction and architectural practices became more complex, leading to larger projects and settlements (see History of construction and Neolithic architecture)
The Neolithic, also known as the New Stone Age, was a time period roughly from 9000 BC to 5000 BC named because it was the last period of the age before woodworking began.
Neolithic architecture refers to structures encompassing housing and shelter from approximately 10,000 to 2,000 BC, the Neolithic period.
Architectural advances are an important part of the Neolithic period (10,000-2000 BC), during which some of the major innovations of human history occurred. The domestication of plants and animals, for example, led to both new economics and a new relationship between people and the world, an increase in community size and permanence, a massive development of material culture, and new social and ritual solutions to enable people to live together in these communities.
The oldest known surviving manmade building is Göbekli Tepe, which was make between 12k to 10k years ago (this is the structure alluded to in the Kurzgesagt video I mentioned earlier).
Located in southern Turkey. The tell includes two phases of use, believed to be of a social or ritual nature by site discoverer and excavator Klaus Schmidt, dating back to the 10th–8th millennium BC. The structure is 300 m in diameter and 15 m high.
Writing systems are believed to have emerged independently of each other, with the oldest instance of writing being in Mesopotamia potentially as early as 3.4k BCE.
However, the discovery of the scripts of ancient Mesoamerica, far away from Middle Eastern sources, proved that writing had been invented more than once. Scholars now recognize that writing may have independently developed in at least four ancient civilizations: Mesopotamia (between 3400 and 3100 BCE), Egypt (around 3250 BCE),[4][5][2] China (1200 BCE),[6] and lowland areas of Southern Mexico and Guatemala (by 500 BCE).[7]
Given that these historical developments I have outlined above seem very valuable to consider in context of modern civilizational progress, I've decided to take "year 0" to be 12000 years ago. The official name for this calendar system is actually the Holocene calendar, which was developed by Cesare Emiliani in 1993. The current year in the Holocene calendar is 12022 HE. Below are two comments on the benefits and accuracy, respectively, of the Holocene calendar's Wikipedia page:
Human Era proponents claim that it makes for easier geological, archaeological, dendrochronological, anthropological and historical dating, as well as that it bases its epoch on an event more universally relevant than the birth of Jesus. All key dates in human history can then be listed using a simple increasing date scale with smaller dates always occurring before larger dates. Another gain is that the Holocene Era starts before the other calendar eras, so it could be useful for the comparison and conversion of dates from different calendars.
When Emiliani discussed the calendar in a follow-up article in 1994, he mentioned that there was no agreement on the date of the start of the Holocene epoch, with estimates at the time ranging between 12,700 and 10,970 years BP.[5] Since then, scientists have improved their understanding of the Holocene on the evidence of ice cores and can now more accurately date its beginning. A consensus view was formally adopted by the IUGS in 2013, placing its start at 11,700 years before 2000 (9701 BC), about 300 years more recent than the epoch of the Holocene calendar.[6]
So, why is the year on this shortform 0012022 and not just 12022? There are two reasons for this. The first is that I would like for myself to think more deeply and frequently about my own future and about humanity's long-term future.
An organization developed around the idea of thinking about and safeguarding humanity's future is the Long Now Foundation (LNF), which most LWers have likely heard of. This is its description:
The Long Now Foundation
is a nonprofit established in 01996 to foster long-term thinking.
Our work encourages imagination at the timescale of civilization — the next and last 10,000 years —
a timespan we call the long now.
The LNF's foundation year consists of 1996 with a 0 appended to the front, indicating that the timeframe under consideration - 10k years - is slowly being reached, one year at a time.
I aim to do a similar thing but believe that the timescale of 10k years is too short, so I instead opt for 1 million years, given that 1 million years is roughly the base rate for hominin species survival duration. It is also very interesting to imagine what humanity will be doing (should they persist) 1 million years following the start of the agricultural revolution. So, 12022 0012022.
From An upper bound for the background rate of human extinction (Snyder-Beattie et al., 2019)
Snyder-Beattie, Andrew E., Toby Ord, and Michael B. Bonsall. "An upper bound for the background rate of human extinction." Scientific reports 9, no. 1 (2019): 1-9.
Hominin survival times. Next, we evaluate whether the upper bound is consistent with the broader hominin fossil record. There is strong evidence that Homo erectus lasted over 1.7 Myr and Homo habilis lasted 700 kyr [21], indicating that our own species’ track record of survival exceeding 200 kyr is not unique within our genus. Fossil record data indicate that the median hominin temporal range is about 620 kyr, and after accounting for sample bias in the fossil record this estimate rises to 970 kyr [22] . Although it is notable that the hominin lineage seems to have a higher extinction rate than those typical of mammals, these values are still consistent with our upper bound. It is perhaps also notable that some hominin species were likely driven to extinction by our own lineage [34], suggesting an early form of anthropogenic extinction risk.
I will close this shortform post here, but definitely want to parse out my thoughts concerning humanity's future more in subsequent posts, and enjoyed writing this first post.
Has anyone here considered working on the following?:
https://www.super-linear.org/prize?recordId=recT1AQw4H7prmDE8
$500 prize pool for creating an accurate, comprehensive, and amusing visual map of the AGI Safety ecosystem, similar to XKCD’s map of online communities or Scott Alexander’s map of the rationalist community.
Payout will be $400 to the map which plex thinks is highest quality, $75 to second place, $25 to third. The competition will end one month after the first acceptable map is submitted, as judged by plex.
Resources, advice, conditions:
- This is a partial list of items which might make sense to include.
- You are advised to iterate, initially posting a low-effort sketch and getting feedback from others in your network, then plex.
- You may create sub-prizes on Bountied Rationality for the best improvements to your map (if you borrow ideas from other group’s public bounties and win this prize you must cover the costs of their bounty payouts).
- You may use DALL-E 2 or other image generation AIs to generate visual elements.
- You may collaborate with others and split the prize, but agree internally on roles and financial division, and distribute it yourselves.
- You can use logos as fair-use, under editorial/educational provision.
- You can scale items based on approximate employee count (when findable), Alexa rank (when available), number of followers (when available) or wild guess (otherwise).
- You agree to release the map for public use.
I asked about FLI's map in this question and it received some traction. I might go ahead and try this, starting with FLI's map and expanding off of it.
Same question here as well.
I am sorry that I took such a long time replying to this. First, thank you for your comment, as it answers all of my questions in a fairly detailed manner.
The impact of a map of research that includes the labs, people, organizations, and research papers focused on AI Safety seems high, and FLI's 2017 map seems like a good start at least for what types of research is occurring in AI Safety. In this vein, it is worth noting that Superlinear is offering a small prize of $1150 for whoever can "Create a visual map of the AGI safety ecosystem", but I don't think this is enough to incentivize the creation of the resource that is currently missing from this community. I don't think there is a great answer to "What is the most comprehensive repository of resources on the work being done in AI Safety?". Maybe I will try to make a GitHub repository with orgs., people, and labs using FLI's map as an initial blueprint. Would you be interested in reviewing this?
I applied to this several days ago (5 days, I believe). Is / was there any formal confirmation that my application was received? I am mildly concerned, as the course begins soon. Thank you.
This entire post reminded me of this section from Human Compatible, especially the section I've put in bold:
“There are some limits to what AI can provide. The pies of land and raw materials are not infinite, so there cannot be unlimited population growth and not everyone will have a mansion in a private park. (This will eventually necessitate mining elsewhere in the solar system and constructing artificial habitats in space; but I promised not to talk about science fiction.) The pie of pride is also finite: only 1 percent of people can be in the top 1 percent on any given metric. If human happiness requires being in the top 1 percent, then 99 percent of humans are going to be unhappy, even when the bottom 1 percent has an objectively splendid lifestyle. It will be important, then, for our cultures to gradually down-weight pride and envy as central elements of perceived self-worth.”
In scenarios where transformative AI can perform nearly all research or reasoning tasks for humanity, my pride will be hurt to some degree. I also believe that I will not be in the 1% of humans still in work, perhaps overseeing the AI, and I find this prospect somewhat bleak, though I imagine that the severity of this sentiment would wane with time, especially if my life and the circumstances for humanity were otherwise great as a result of the AI.
The first point of your response calms me somewhat. Focusing more in the near-future on my body, health, friends, family, etc... the baselines would probably be good preparation for a future where AI forwards the state of human affairs to the point where humans are not needed for reasoning or research tasks.
My suggestions regarding the epistemics of the original post are fairly in line with the content in your first paragraph. I think allocating decision weight in proportion to the expected impacts different scenarios have on your life is the correct approach. Generating scenarios and forecasting their likelihood is difficult, and there is also a great deal of uncertainty with how you should change your behavior in light of these scenarios. I think that making peace with the outcomes of disastrous scenarios that you or humanity cannot avoid is a strong action-path for processing thinking about uncontrollable scenarios. As for scenarios that you can prepare for, such as the effects of climate change, shallow AI, embryo selection / gene-editing, and forms of gradual technological progress, among other things, perhaps determining what you value and want if you could only live / live comfortably for the next 5, 10, 15, 20, 30, etc... years might be a useful exercise, since each of these scenarios (e.g., only living 5 more years vs. only living 10 more years vs. only more 5 years in global business-as-usual) might lead you to make different actions. I am in a similar decision-boat as you, as I believe that in coming years the nature of the human operations in the world will change significantly and on many fronts. I am in my early 20s, I have been doing some remote work / research in the areas of forecasting and ML, want to make contributions to AI Safety, want to have children with my partner (in around 6 years), do not know where I would like to live, do not know what my investment behaviors should be, do not know what proportion of my time should be spent doing such things as reading, programming, exercising, etc... A useful heuristic for me has been to worry less. I think moving away from people and living closer to the wilderness have benefitted me as well; the location I am in currently seem robust to climate change and mass exoduses from cities (should they ever occur), has few natural disasters, has good air quality, is generally peaceful and quiet, and is agriculturally robust w/ sources of water. Perhaps finding some location or set of habits that are in line with "what I hoped to retire into / do in a few years or what I've always desired for myself" might make for a strong remainder-of-life / remainder-of-business-as-usual, whichever you attach more weight to.
This is great; thank you! I will send an email in the coming month. Also, I suppose a quick clarification, but what's the relation between: MQTransformer: Multi-Horizon Forecasts with Context Dependent and Feedback-Aware Attention and MQTransformer: Multi-Horizon Forecasts with Context Dependent Attention and Optimal Bregman Volatility
If there are any paper reading clubs out there that ask the presenter to replicate the results without looking at the author's code, I would love to join
This is something that I would be interested in as well. I've been attempting to reproduce MQTransformer: Multi-Horizon Forecasts with Context Dependent and Feedback-Aware Attention from scratch, but I am finding it difficult, partially due to my present lack of experience with reproducing DL papers. The code for MQTransformer is not available, at least to my knowledge. Also, there are several other papers which use LSTMs or Transformers architectures for forecasting that I hope to reproduce and/or employ for use on Metaculus API data in the coming few months. If reproducing ML papers from scratch and replicating their results (especially DL for forecasting) sounds interesting (perhaps I could publish these reproductions w/ additional tests in ReScience C) to anyone, please DM me, as I would be willing to collaborate.
I did not inquire anywhere about a way to measure human migration patterns under present-day circumstances.
I understand this is already known.
What the question concerns is a way to measure some aspects of humanity's reaction to a global catastrophe.
"If a line of bacteria or virus could be bred to reflect human migration and habitation patterns, then it might be possible to determine a rough estimate of humanity's robustness to the direct effects and subsequent environmental effects of a global catastrophe in terms of population resilience and migration patterns."
I am saying that if these known-migration patterns can be engineered into a culture of bacteria, then we might be able to test how these cultures react to catastrophes, and since the culture is a reflection of human population and migration, then we may be able to get some data on how humanity writ large would react to a global catastrophe, since there is a paucity of data on "how humans react to global catastrophes".
Do you have updated sentiments following this comment?
I would like to think about this more, but thank you for posting this and switching my mind from System I to System II