Why Not Subagents?
post by johnswentworth, David Lorell · 2023-06-22T22:16:55.249Z · LW · GW · 52 commentsContents
Context The Pizza Example No Utility Function A Contract One More Trick: Randomization Claim Stronger Subclaim Argument First Step: Strong Incompleteness Third Step: Equilibrium Conditions Second Step: No Strong Incompleteness High-Level Potential Problems With This Argument (And Potential Solutions) Value vs Utility Inconsistent Myopia Updating Different Beliefs Implications For… AI Alignment: So much for that idea… Economists: If there’s no representative agent, then why ain’t you rich yet? Conclusions None 52 comments
Alternative title for economists: Complete Markets Have Complete Preferences
The justification for modeling real-world systems as “agents” - i.e. choosing actions to maximize some utility function - usually rests on various coherence theorems [LW · GW]. They say things like “either the system’s behavior maximizes some utility function, or it is throwing away resources” or “either the system’s behavior maximizes some utility function, or it can be exploited” or things like that. [...]
Now imagine an agent which prefers anchovy over mushroom pizza when it has anchovy, but mushroom over anchovy when it has mushroom; it’s simply never willing to trade in either direction. There’s nothing inherently “wrong” with this; the agent is not necessarily executing a dominated strategy, cannot necessarily be exploited, or any of the other bad things we associate with inconsistent preferences. But the preferences can’t be described by a utility function over pizza toppings.
… that’s what I (John) wrote four years ago, as the opening of Why Subagents? [LW · GW]. Nate convinced me [LW · GW] that it’s wrong: incomplete preferences do imply a dominated strategy. A system with incomplete preferences, which can’t be described by a utility function, can contract/precommit/self-modify to a more-complete set of preferences which perform strictly better even according to the original preferences.
This post will document that argument.
Epistemic Status: This post is intended to present the core idea in an intuitive and simple way. It is not intended to present a fully rigorous or maximally general argument; our hope is that someone else will come along and more properly rigorize and generalize things. In particular, we’re unsure of the best setting to use for the problem setup; we’ll emphasize some degrees of freedom in the High-Level Potential Problems (And Potential Solutions) [LW · GW] section.
Context
The question which originally motivated my interest was: what’s the utility function of the world’s financial markets? Just based on a loose qualitative understanding of coherence arguments, one might think that the inexploitability (i.e. efficiency) of markets implies that they maximize a utility function. In which case, figuring out what that utility function is seems pretty central to understanding world markets.
In Why Subagents? [LW · GW], I argued that a market of utility-maximizing traders is inexploitable, but not itself a utility maximizer. The relevant loophole is that the market has incomplete implied preferences (due to path dependence). Then, I argued that any inexploitable system with incomplete preferences could be viewed as a market/committee of utility-maximizing subagents, making utility-maximizing subagents a natural alternative to outright utility maximizers for modeling agentic systems.
More recently, Nate counterargued [LW · GW] that a market of utility maximizers will become a utility maximizer. (My interpretation of) his argument is that the subagents will contract with each other in a way which completes the market’s implied preferences. The model I was previously using got it wrong because it didn’t account for contracts, just direct trade of goods.
More generally, Nate’s counterargument implies that agents with incomplete preferences will tend to precommit/self-modify in ways which complete their preferences.
… but that discussion was over a year ago. Neither of us developed it further, because it just didn’t seem like a core priority. Then the AI Alignment Awards contest came along, and an excellent entry by Elliot Thornley [LW · GW] proposed that incomplete preferences could be used as a loophole to make the shutdown problem tractable. Suddenly I was a lot more interested in fleshing out Nate’s argument.
To that end, this post will argue that systems with incomplete preferences will tend to contract/precommit in ways which complete their preferences.
The Pizza Example
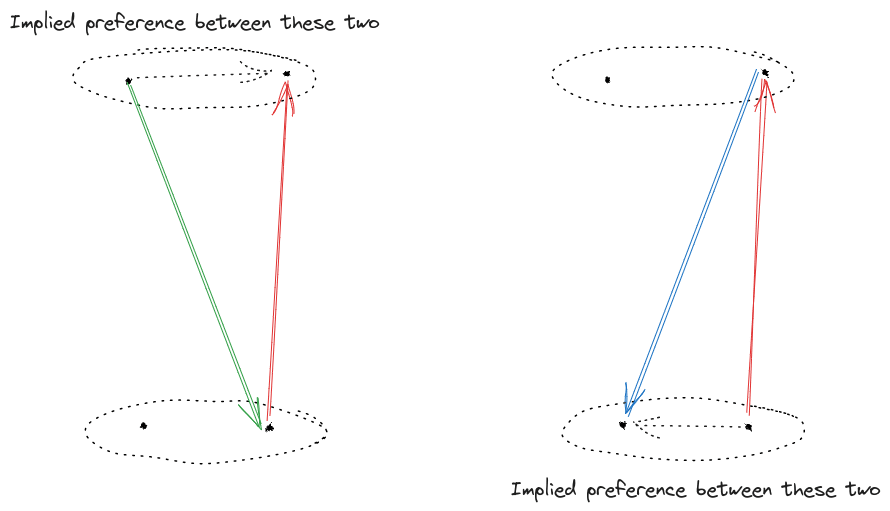
As a concrete example of a system of two subagents with incomplete preference, suppose that John and David have different preferences for pizza toppings, and need to choose one together. We both agree that cheese (C) is the least-preferred default option, and sausage (S) is the best. But in between, John prefers pepperoni > mushroom > anchovy (because John lacks taste), while David prefers anchovy > pepperoni > mushroom (because David is a heathen). Specifically, our utilities are:
| David's Utility | John's Utility | |
| Cheese | 0 | 0 |
| Mushroom | 1 | 2 |
| Pepperoni | 2 | 3 |
| Anchovy | 3 | 1 |
| Sausage | 4 | 4 |
Or, visually,
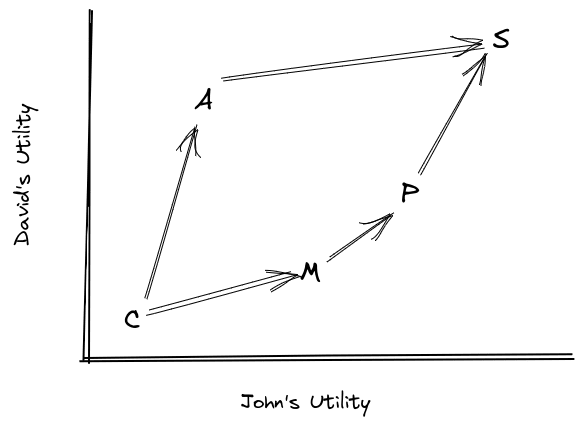
Mechanically, for this weird toy model, we’ll imagine that John and David will be offered some number of opportunities (let’s say 3) to trade their current pizza for another, randomly chosen, pizza. If the offered topping is preferred by both of them, then they take the trade. Otherwise, one of them vetos, so they don’t take the trade. Why these particular mechanics? Well, with those mechanics, the preferences can be interpreted in a pretty straightforward way which plays well with other coherence-style arguments - in particular, it’s easy to argue against circular preferences.
(Note that we're not saying trades have the form e.g. "(mushroom -> pepperoni)?" as we would probably usually imagine trades; they instead have the form "(whatever you have now -> pepperoni)". The section Value vs Utility [LW · GW] talks about moving our core claim/argument to a more standard notion of trade.)
No Utility Function
One reasonable-seeming way to handle incomplete preferences using a utility function is to just say that two options with “no preference” between them have the same utility - i.e. “no preference” = “indifference”. What goes wrong with that?
Well, in the pizza example, there’s no preference between mushroom and anchovy, so they would have to have the same utility. And there’s no preference between anchovy and pepperoni, so they would have to have the same utility. But that means mushroom and pepperoni have the same utility, which conflicts with the preference for pepperoni over mushroom. So, we can’t represent these preferences via a utility function.
Generalizing: whenever we have state B preferred over state A, and some third state C which has no preference relative to either A or B, we cannot represent the preferences using a utility function. Later, we’ll call that condition “strong incompleteness”, and show that non-strongly incomplete preferences can be represented using a utility function.
Next, let’s see what kind of tricks we can use when preferences are strongly incomplete.
A Contract
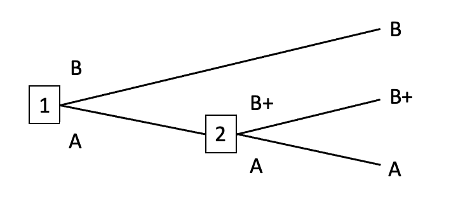
Now for the core idea. With these preferences, John and David will turn down trades from mushroom to anchovy (because John vetos it), and turn down trades from anchovy to pepperoni (because David vetos it), even though both prefer pepperoni over mushroom. In principle, both might do better in expectation if John could give up some anchovy for pepperoni, and David could give up some mushroom for anchovy, so that the net shift is from mushroom to pepperoni (a shift which they both prefer).
Before any trade offers come along, John and David sign a contract. John agrees to not veto mushroom -> anchovy trades. In exchange, David agrees to not veto anchovy -> pepperoni trades. Now the two together have completed their preferences: sausage > pepperoni > anchovy > mushroom > cheese.
… but that won’t always work; it depends on the numbers. For instance, what if there were a lot more opportunities to trade anchovy -> pepperoni than mushroom -> anchovy? Then an agreement to not veto anchovy -> pepperoni would be pretty bad for David, and wouldn’t be fully balanced out by the extra mushroom -> anchovy trades. We need some way to make the anchovy -> pepperoni trade happen less often (in expectation), to balance things out. If the two trades happen the same amount (in expectation), then there is no expected change in anchovy, just a shift of probability mass from mushroom to pepperoni. Then David and John both do better.
So how do we make the two trades happen the same amount (in expectation)?
One More Trick: Randomization
Solution: randomize the contract. As soon as the contract is signed, some random numbers will be generated. With some probability, John will agree to never veto mushroom -> anchovy trades. With some other probability, David will agree to never veto anchovy -> pepperoni trades. Then, we choose the two probabilities so that the net expected anchovy states is unchanged by the contract: increasing John’s probability continuously increases expected anchovy, increasing David’s probability continuously decreases expected anchovy, so with the right choice of the two probabilities we can achieve zero expected change in anchovy. Then, the net effect of the contract is to shift some expected mushroom into expected pepperoni; it’s basically a pure win.
That’s the general trick: randomize the preference-completion in such a way that expected anchovy stays the same, while expected mushroom is turned into expected pepperoni.
Claim
Suppose a system has incomplete preferences over a set of states. (For simplicity, we’ll assume the set of states is finite.) Mechanically, this means that there is a “current state” at any given time, and over time the system is offered opportunities to “trade”, i.e. transition to another state; the system accepts a trade A -> B if-and-only-if it prefers B over A.
Claim: the system’s preferences can be made complete (via a potentially-randomized procedure) in such a way that the new distribution of states can be viewed as the old distribution with some probability mass shifted from less-preferred to more-preferred states.
Stronger Subclaim
For the argument, we’ll want to split out the case where a strict improvement can be achieved by completing the preferences.
Suppose there exists three states A, B, C such that:
- The system prefers B over A
- The system has no preference between either A and C or B and C
We’ll call this case “strongly incomplete preferences”. The pizza example involves strongly incomplete preferences: take A to be mushroom, B to be pepperoni, and C to be anchovy.
Claims:
- Strongly incomplete preferences can be randomly completed in such a way that the new distribution of states can be viewed as the old distribution with some strictly positive probability mass shifted from less-preferred to more-preferred states.
- Non-strongly incomplete preferences (either complete or “weakly incomplete”) encode a utility maximizer.
In other words: strongly incomplete preferences imply that a strict improvement can be achieved by (possibly randomly) completing the preferences, while non-strongly incomplete preferences imply that the system is a utility maximizer.
In the case of weakly incomplete preferences (i.e. incomplete but not strongly incomplete), we also claim that the preferences can be randomly completed in such a way that the system is indifferent between its original preferences and the (expected) randomly-completed preferences, via a similar trick to the rest of the argument. But that’s not particularly practically relevant, so we won’t talk about it further.
Argument
First Step: Strong Incompleteness
In the case of strong incompleteness, we can directly re-use our argument from the pizza example. We have three states A, B, C such that B is preferred over A, and there is no preference between either A and C or B and C. Then, we randomly add a preference for C over A with probability , and we randomly add a preference for B over C with probability .
Frequency of state C increases continuously with , decreases continuously with , and is equal to its original value when both probabilities are 0. So:
- Check whether frequency of state C is higher or lower than original when both probabilities are set to 1.
- If higher, then set = 1. With = 0 the frequency of state C must then be lower than original (since frequency of C is decreasing in ), with = 1 it’s higher than original by assumption, so by the intermediate value theorem there must be some value such that the frequency of C stays the same. Pick that value.
- If lower, swap with and “higher” with “lower” in the previous bullet.
The resulting randomized transformation of the preferences keeps the frequencies of each state the same, except it shifts some probability mass from a less-preferred state (A) to a more-preferred state (B).
(Potential issue with the argument: shifting probability mass from A to B may also shift around probability mass among states downstream of those two states. However, it should generally only shift things in net “good” ways, once we account for the terminal vs instrumental value issue discussed under Value vs Utility [LW · GW]. In other words, if we’re using the instrumental value functions, then shifting probability mass from an option valued less by all subagents to one valued more by all subagents should be an expected improvement for all subagents, after accounting for downstream shifts.)
Third Step: Equilibrium Conditions
The second step will argue that non-strongly incomplete preferences encode a utility maximizer. But it’s useful to see how that result will be used before spelling it out, so we’ll do the third step first. To that end, assume that non-strongly incomplete preferences encode a utility maximizer.
Then we have:
- If the preferences are strongly incomplete, then there exists some contract/precommitment which “strictly improves” expected outcome states (under the original preferences)
- If the preferences are not strongly incomplete, then the system is a utility maximizer.
The last step is to invoke stable equilibrium: strongly incomplete preferences are “unstable” in the sense that the system is incentivized to update from them to more complete preferences, via contract or precommitment. The only preferences which are stable under contracts/precommitments are non-strongly-incomplete preferences, which encode utility maximizers.
Now, we haven't established which distribution of preferences the system will end up sampling from when randomly completing its preferences, in more complex cases where preferences are strongly incomplete in many places at once. But so long as it ends up at some non-dominated choice, it must end up with non-strongly-incomplete preferences with probability 1 (otherwise it could modify the contract for a strict improvement in cases where it ends up with non-strongly-incomplete preferences). And, so long as the space of possibilities is compact and arbitrary contracts are allowed, all we have left is a bargaining problem. The only way the system would end up with dominated preference-distribution is if there's some kind of bargaining breakdown.
Point is: non-dominated strategy implies utility maximization.
Second Step: No Strong Incompleteness
Assume the preferences have no strong incompleteness. We’re going to construct a utility function for them. The strategy will be:
- Construct “indifference sets” - i.e. sets of states between which the utility function will be indifferent
- Show that there is a complete ordering between the “indifference sets”, so we can order them and assign each a utility based on the ordering
Indifference set construction: put each state in its own set. Then, pick two sets such that there is no preference between any states in either set, and merge the two. Iterate to convergence. At this point, the states are partitioned into sets such that:
- there are no preferences between any two states in the same set, and
- there is at least one preference between at least one pair of states in any two different sets.
Those will turn out to be our indifference sets.
In order to order the indifference sets, we need to show that:
- for any pair of states in two different sets, there is a preference between them
- the ordering is consistent - i.e. if one state in set S is preferred to one state in set T, then any state in S is preferred to any state in T.
(Also we need acyclicity, but that follows trivially from acyclicity of the preferences once we have these two properties.)
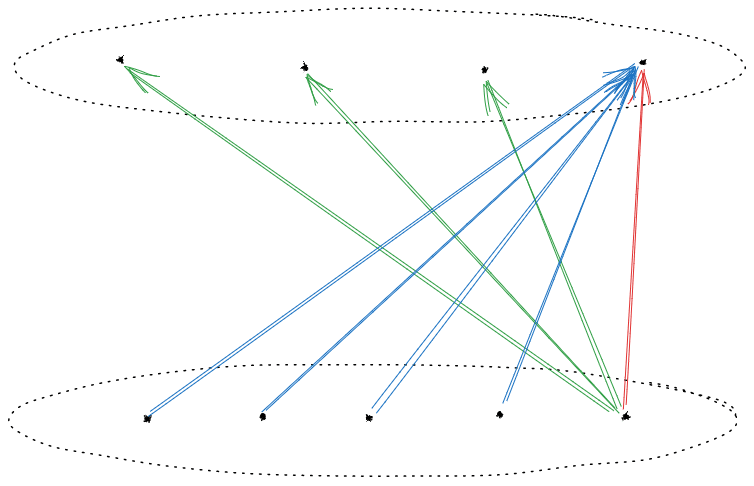
To show those, first recall that there is at least one preference between at least one pair of states in any two different sets. Visually:
In order to have no strong incompleteness, all these preferences must also be present (though we don’t yet know their direction):
Those preferences must be present because, otherwise, we could establish strong incompleteness like this:
We can also establish the direction of each of the preferences by noting that, by assumption, there is no preference between any two states in the same set:
So:
Finally, notice that we’ve now established some more preferences between states in the two sets, so we can repeat the argument with another edge to show that even more preferences are present:
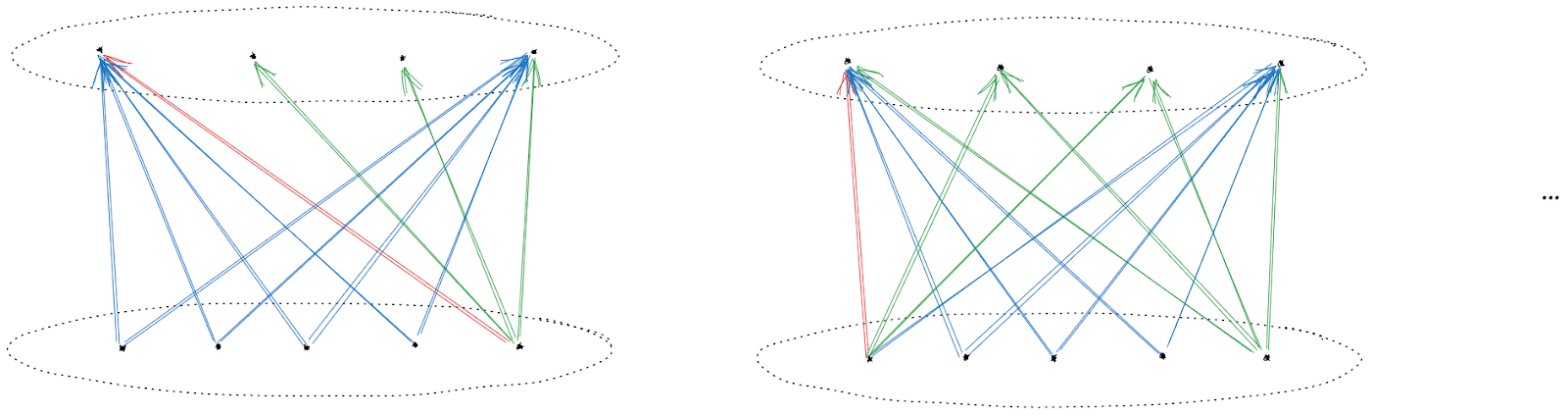
… and once we’ve iterated the argument to convergence, we’ll have the key result: if one state in one set is preferred to another state in another set, then any state in the first set is preferred to any state in the second.
And now we can assign a utility function: order the sets, enumerate them in order, then the number of each set is the utility assigned to each state in that set. A state with a higher utility is always preferred over a state with a lower utility, and there is indifference/no preference between two states with the same utility.
(Note that this is a little different from standard definitions - for mathematical convenience, people typically define utility maximizers to take trades in both directions when indifferent, whereas here our utility maximizer might take trades in both directions between an indifferent pair, or take trades in neither direction between an indifferent pair. For practical purposes, the distinction does not matter; just assume that the agent maintains some small “bid/ask spread”, so a nonzero incentive is needed to induce trade, and the two models become equivalent.)
High-Level Potential Problems With This Argument (And Potential Solutions)
Value vs Utility
Suppose that, in the pizza example, instead of offers to trade a new pizza for whatever pizza David and John currently have, there are offers to trade a specific type of pizza for another specific type - e.g. a mushroom <-> anchovy trade, rather than a mushroom <-> (whatever we have) trade.
In that setup, we might sometimes want to trade “down” to a less-preferred option, in hopes of trading it for a more-preferred option in the future. For instance, if there are lots of vegetarians around offering to trade their sausage pizza for mushroom, then David and John would have high instrumental value for mushroom pizza (because we can probably trade it for sausage), even though neither of us terminally values mushroom. Instrumental and terminal value diverge.
Then, the right way to make the argument would be to calculate the (instrumental) value functions of each subagent (in the dynamic programming sense of the phrase), and use that in place of the (terminal) utilities of each subagent. The argument should then mostly carry over, but there will be one major change: the value function is potentially time-dependent. It’s not “mushroom pizza” which has a value assigned to it, but rather “mushroom pizza at time t”. That, in turn, gets into issues of updating and myopia.
Inconsistent Myopia
A myopic agent in this context would be one which just always trades to more (terminally) preferred options, and never to less (terminally) preferred options, without e.g. strategically trading for a less-preferred mushroom pizza in hopes of later trading the mushroom for more-preferred sausage.
As currently written, our setup implicitly assumed that kind of myopia, which means the subagents are implicitly not thinking about the future when making their choices. … which makes it really weird that the subagents would make contracts/precommitments/self-modications entirely for the sake of future performance. They’re implicitly inconsistently myopic: myopic during trading, but nonmyopic beforehand when choosing to contract/precommit/self-modify.
That said, that kind of inconsistent myopia does make sense for plenty of realistic situations. For instance, maybe the preferences will be myopic during trading, but a designer optimizes those preferences beforehand. Or instead of a designer, maybe evolution/SGD optimizes the preferences.
Alternatively, if the argument is modified to use instrumental values rather than terminal utilities (as the previous section suggested), then the inconsistent myopia issue would be resolved; subagents would simply be non-myopic.
Updating
Once we use instrumental values rather than terminal utilities on states, it’s possible that those values will change over time. They could change purely due to time - for instance, if David and John are hoping to trade a mushroom pizza for sausage, then as the time left to trade winds down, we’ll become increasingly desperate to get rid of that mushroom pizza; its instrumental value falls.
Instrumental value could also change due to information. For instance, if David and John learn that there aren’t as many vegetarians as we expected looking to trade away sausage for mushroom, then that also updates our instrumental value for mushroom pizza.
In order for the argument to work in such situations, the contract/precommitment/self-modification will probably also need to allow for updating over time - e.g. commit to a policy rather than a fixed set of preferences.
Different Beliefs
The argument implicitly assumes that David and John have the same beliefs about what distribution of trade offers we’ll see. If we have different beliefs, then there might not be completion-probabilities which we both find attractive.
On the other hand, if our beliefs differ, then that opens up a whole different set of possible contract-types - e.g. bets and insurance. So there may be some way to use bets/insurance to make the argument work again.
Implications For…
AI Alignment: So much for that idea…
Either we can’t leverage incomplete preferences for safety properties (e.g. shutdownability), or we need to somehow circumvent the above argument.

Economists: If there’s no representative agent, then why ain’t you rich yet?
In economic jargon, completion of the preferences means there exists a representative agent - i.e. the system’s preferences can be summarized by a single utility maximizer. These days most economists assert that there is no representative agent in most real-world markets, so: if there’s no representative agent, then why aren’t you rich yet? And if there is, then what’s its utility function?
Insofar as we view the original incomplete preferences in this model as stemming from multiple subagents with veto power (as in the pizza example), there’s an expected positive sum gain from the contract which completes the preferences. Which means that some third party could, in principle, get paid a share of those gains in exchange for arranging the contract. In practice, most of the work would probably be in designing the contracts in such a way that the benefits are obvious to laypeople, and marketing them. Classic financial engineering business.
So this is the very best sort of economic theorem, where either a useful model holds in the real world, or there’s money to be made.
Conclusions
Main claim, stated two ways:
- A group of utility-maximizing subagents have an incentive to form contracts under which they converge to a single utility maximizer
- A system with incomplete preferences has an incentive to precommit/self-modify in such a way that the preferences are completed
In general, they do this using randomization over preference-completions. The only expected change each contract/precommitment/self-modification induces is a shift of probability mass from some states to same-or-more-preferred states for all of the subagents; thus each contract is positive-sum.
There is lots more work to be done here, as outlined in the potential problems section. The argument should probably be reframed in terms of value functions (over time) rather than static utility functions in order to more clearly handle instrumentally, though not terminally, valuable actions. The commitments that the subagents make may be better cast as policies rather than fixed preferences. Also, the subagents may have different beliefs about the future, which the argument in this post did not handle.
If the argument holds then this is bad news for alignment hopes that leverage robust incomplete preferences / non E[Utility] maximizers, and also raises some questions about the empirical consensus that modern real-world markets are not expected utility maximizers.
52 comments
Comments sorted by top scores.
comment by Logan Zoellner (logan-zoellner) · 2023-06-24T18:10:13.634Z · LW(p) · GW(p)
Can we crank this in reverse: given a utility function, design a market that whose representative agent has this utility function?
It seems like trivially, we could just have the market where a singleton agent has the desired utility function. But I wonder if there's some procedure where we can "peel off" sub-agents within a market and end up at a market composed of the simplest possible sub-agents for some metric of complexity.
Either there is some irreducible complexity there, or maybe there is a Universality theorem proving that we can express any utility function using a market of agents who all have some extremely simple finite state, similar to how we can show any form of computation can be expressed using Turing Machines.
comment by EJT (ElliottThornley) · 2023-06-28T21:20:57.048Z · LW(p) · GW(p)
Great post! Lots of cool ideas. Much to think about.
systems with incomplete preferences will tend to contract/precommit in ways which complete their preferences.
Point is: non-dominated strategy implies utility maximization.
But I still think both these claims are wrong.
And that’s because you only consider one rule for decision-making with incomplete preferences: a myopic veto rule, according to which the agent turns down a trade if the offered option is ranked lower than its current option according to one or more of the agent’s utility functions.
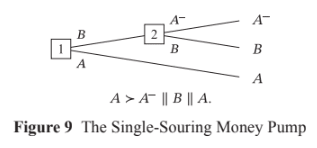
The myopic veto rule does indeed lead agents to pursue dominated strategies in single-sweetening money-pumps like the one that you set out in the post. I made this point in my coherence theorems post [LW · GW]:
John Wentworth’s ‘Why subagents? [LW · GW]’ suggests another policy for agents with incomplete preferences: trade only when offered an option that you strictly prefer to your current option. That policy makes agents immune to the single-souring money-pump. The downside of Wentworth’s proposal is that an agent following his policy will pursue a dominated strategy in single-sweetening money-pumps, in which the agent first has the opportunity to trade in A for B and then (conditional on making that trade) has the opportunity to trade in B for A+. Wentworth’s policy will leave the agent with A when they could have had A+.
But the myopic veto rule isn’t the only possible rule for decision-making with incomplete preferences. Here’s another. I can’t think of a better label right now, so call it ‘Caprice’ since it’s analogous to Brian Weatherson’s rule of the same name for decision-making with multiple probability functions:
- Don’t make a sequence of trades (with result X) if there’s another available sequence (with result Y) such that Y is ranked at least as high as X on each of your utility functions and ranked higher than X on at least one of your utility functions. Choose arbitrarily/stochastically among the sequences of trades that remain.
The Caprice Rule implies the policy that I suggested in my coherence theorems post:
- If I previously turned down some option Y, I will not settle on any option that I strictly disprefer to Y.
And that makes the agent immune to single-souring money-pumps [LW · GW] (in which the agent first has the opportunity to trade in A for B and then (conditional on making that trade) has the opportunity to trade in B for A-).
The Caprice Rule also implies the following policy:
- If in future I will be able to settle on some option Y, I will not instead settle on any option that I strictly disprefer to Y.
And that makes the agent immune to single-sweetening money-pumps like the one that you discuss. If the agent recognises that – conditional on trading in mushroom (analogue in my post: A) for anchovy (B) – they will be able to trade in anchovy (B) for pepperoni (A+), then they will make at least the first trade, and thereby avoid pursuing a dominated strategy. As a result, an agent abiding by the Caprice Rule can’t shift probability mass from mushroom (A) to pepperoni (A+) by probabilistically precommitting to take certain trades in a way that makes their preferences complete. The Caprice Rule already does the shift.
And an agent abiding by the Caprice Rule can’t be represented as maximising utility, because its preferences are incomplete. In cases where the available trades aren’t arranged in some way that constitutes a money-pump, the agent can prefer (/reliably choose) A+ over A, and yet lack any preference between (/stochastically choose between) A+ and B, and lack any preference between (/stochastically choose between) A and B. Those patterns of preference/behaviour are allowed by the Caprice Rule.
For a Caprice-Rule-abiding agent to avoid pursuing dominated strategies in single-sweetening money-pumps, that agent must be non-myopic: specifically, it must recognise that trading in A for B and then B for A+ is an available sequence of trades. And you might think that this is where my proposal falls down: actual agents will sometimes be myopic, so actual agents can’t always use the Caprice Rule to avoid pursuing dominated strategies, so actual agents are incentivised to avoid pursuing dominated strategies by instead probabilistically precommitting to take certain trades in ways that make their preferences complete (as you suggest).
But there’s a problem with this response. Suppose an agent is myopic. It finds itself with a choice between A and B, and it chooses A. As a matter of fact, if it had chosen B, it would have later been offered A+. Then the agent leaves with A when it could have had A+. But since the agent is myopic, it won’t be aware of this fact, and so note two things. First, it’s unclear whether the agent’s behaviour deserves the name ‘dominated strategy’. The agent pursues a dominated strategy only in the same sense that I pursue a dominated strategy when I fail to buy a lottery ticket that (unbeknownst to me) would have won. Second and more importantly, the agent’s failure to get A+ won’t lead the agent to change its preferences, since it’s myopic and so unaware that A+ was available.
And so we seem to have a dilemma for money-pumps for completeness. In money-pumps where the agent is non-myopic about the available sequences of trades, the agent can avoid pursuit of dominated strategies by acting in accordance with the Caprice Rule. In money-pumps where the agent is myopic, failing to get A+ exerts no pressure on the agent to change its preferences, since the agent is not aware that it could have had A+.
You recognise this in the post and so set things up as follows: a non-myopic optimiser decides the preferences of a myopic agent. But this means your argument doesn’t vindicate coherence arguments as traditionally conceived. Per my understanding, the conclusion of coherence arguments was supposed to be: you can’t rely on advanced agents not to act like expected-utility-maximisers, because even if these agents start off not acting like EUMs, they’ll recognise that acting like an EUM is the only way to avoid pursuing dominated strategies. I think that’s false, for the reasons that I give in my coherence theorems post and in the paragraph above. But in any case, your argument doesn’t give us that conclusion. Instead, it gives us something like: a non-myopic optimiser of a myopic agent can shift probability mass from less-preferred to more-preferred outcomes by probabilistically precommitting the agent to take certain trades in a way that makes its preferences complete. That’s a cool result in its own right, and maybe your post isn’t trying to vindicate coherence arguments as traditionally conceived, but it seems worth saying that it doesn’t.
For instance, maybe the preferences will be myopic during trading, but a designer optimizes those preferences beforehand. Or instead of a designer, maybe evolution/SGD optimizes the preferences.
You’re right that a non-myopic designer might set things up so that their myopic agent’s preferences are complete. And maybe SGD makes this hard to avoid. But if I’m right about the shutdown problem, we as non-myopic designers should try to set things up so that our agent’s preferences are incomplete. That’s our best shot at getting a corrigible agent. Training by SGD might present an obstacle to this (I’m still trying to figure this out), but coherence arguments don’t.
That’s how I think the argument in your post can be circumvented, and why I still think we can use incomplete preferences for shutdownability/corrigibility:
Either we can’t leverage incomplete preferences for safety properties (e.g. shutdownability), or we need to somehow circumvent the above argument.
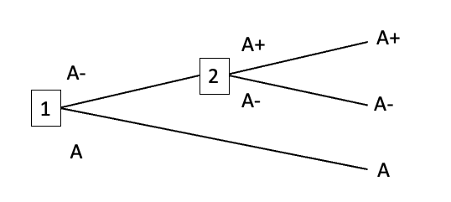
That’s the main point I want to make. Here’s a more minor point: I think that even in the case where you have a non-myopic optimiser deciding the preferences of a myopic agent, non-domination by itself doesn’t imply utility maximisation. You also need the assumption that the non-myopic optimiser takes some kinds of money-pumps to be more likely than others. Here’s an example to illustrate why I think that. Suppose that our non-myopic optimiser predicts that each of the following money-pumps are equally likely to occur, with probability 0.5. Call the first ‘the A+ money-pump’ and the second ‘the B+ money-pump’:
A+ money-pump
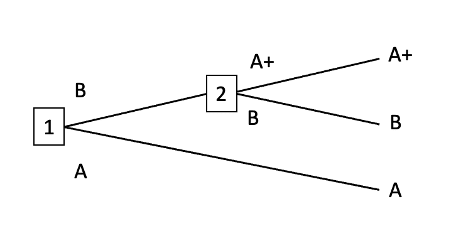
B+ money-pump
The non-myopic optimiser knows that the agent will be myopic in deployment. Currently, the agent’s preferences are incomplete: it lacks a preference between A and B. Either it abides by the veto rule and sticks with whatever it already has, or it chooses stochastically between A and B. That difference won’t matter here: we can just say that the agent chooses A with probability p and chooses B with probability 1-p. The non-myopic optimiser is considering precommitting the agent to choose either A or B with probability 1, with the consequence that the agent’s preferences would then be complete. Does precommitting dominate not precommitting?
No. The agent pursues a dominated strategy if and only if the A+ money-pump occurs and the agent chooses A or the B+ money-pump occurs and the agent chooses B. As it stands, those probabilities are 0.5, p, 0.5, and 1-p respectively, so that the agent’s probability of pursuing a dominated strategy is 0.5p+0.5(1-p)=0.5. And the non-myopic optimiser can’t change this probability by precommitting the agent to choose A or B. Doing so changes only the value of p, and 0.5p+0.5(1-p)=0.5 no matter what the value of p.
That’s why I think you also need the assumption that the non-myopic optimiser believes that the myopic agent is more likely to encounter some kinds of money-pumps than others in deployment. The non-myopic optimiser has to think, e.g., that the A+ money-pump is more likely than the B+ money-pump. Then making the agent’s preferences complete can decrease the probability that the agent pursues a dominated strategy. But note a few things:
(1) If the probabilities of the A+ money-pump and the B+ money-pump are each non-zero, then precommitting the agent to choose one of A and B doesn’t just shift probability mass from a less-preferred outcome to a more-preferred outcome. It also shifts probability mass between A and B, and between A+ and B+. For example, precommitting to always choose A sends the probability of B and of A+ down to zero. And it’s not so clear that the new probability distribution is superior to the old one. This new probability distribution does give a smaller probability of the agent pursuing a dominated strategy, but minimising the probability of pursuing a dominated strategy isn’t always best. Consider an example with complete preferences:
First A- money-pump
Second A- money-pump
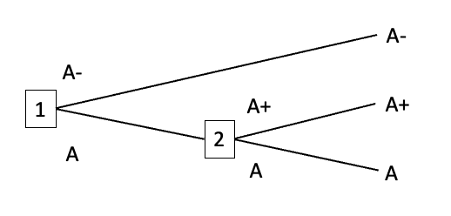
Suppose the probability of the First A- money-pump is 0.6 and the probability of the Second A- money-pump is 0.4. Then precommitting to always choose A- minimises the probability of pursuing a dominated strategy. But if the difference in value between A- and A is much greater than the difference in value between A and A+, then it would be better to precommit to choosing A.
(2) As the point above suggests, given your set-up of a non-myopic optimiser deciding the preferences of a myopic agent, and the assumption that some kinds of decision-trees are more likely than others, it can also be that the non-myopic optimiser can decrease the probability that an agent with complete preferences pursues a dominated strategy by precommitting the agent to take certain trades. You make something like this point in the ‘Value vs Utility’ section: if there are lots of vegetarians around, you might want to trade down to mushroom pizza. And you can see it by considering the First A- money-pump above: if that’s especially likely, the non-myopic optimiser might want to precommit the agent to trade in A for A-. This makes me think that the lesson of the post is more about the instrumental value of commitments in your non-myopic-then-myopic setting than it is about incomplete preferences.
(3) Return to the A+ money-pump and the B+ money-pump from above, and suppose that their probabilities are 0.6 and 0.4 respectively. Then the non-myopic optimiser can decrease the probability of the myopic agent pursuing a dominated strategy by precommitting the agent to always choose B, but doing so will only send that probability down to 0.4. If the non-myopic optimiser wants the probability of a dominated strategy lower than that, it has to make the agent non-myopic. And in cases where an agent with incomplete preferences is non-myopic, it can avoid pursuing dominated strategies by acting in accordance with the Caprice Rule.
Replies from: johnswentworth, SharkoRubio, johnswentworth↑ comment by johnswentworth · 2023-07-08T17:34:45.573Z · LW(p) · GW(p)
Wait... doesn't the caprice rule just directly modify its preferences toward completion over time? Like, every time a decision comes up where it lacks a preference, a new preference (and any implied by it) will be added to its preferences.
Intuitively: of course the caprice rule would be indifferent to completing its preferences up-front via contract/commitment, because it expects to complete its preferences over time anyway; it's just lazy about the process (in the "lazy data structure" sense).
Replies from: ElliottThornley, SharkoRubio↑ comment by EJT (ElliottThornley) · 2023-08-07T20:08:35.166Z · LW(p) · GW(p)
Yeah 'indifference to completing preferences' remains an issue and I'm still trying to figure out if there's a way to overcome it. I don't think 'expects to complete its preferences over time' plays a role, though. I think the indifference to completing preferences is just a consequence of the fact that turning preferential gaps into strict preferences won't lead the agent to behave in ways that it disprefers from its current perspective. I go into a bit more detail on this in my contest entry:
I noted above that goal-content integrity is a convergent instrumental subgoal of rational agents: agents will often prefer to maintain their current preferences rather than have them changed, because their current preferences would be worse-satisfied if they came to have different preferences.
Consider, for example, an agent with a preference for trajectory x over trajectory y. It is offered the opportunity to reverse its preference so that it comes to prefer y over x. This agent will prefer not to have its preferences changed in this way. If its preferences are changed, it will choose y over x if offered a choice between the two, and that would mean its current preference for x over y would not be satisfied. That’s why agents tend to prefer to keep their current preferences rather than have them changed.
But things seem different when we consider preferential gaps. Suppose that our agent has a preferential gap between trajectories x and y: it lacks any preference between the two trajectories, and this lack of preference is insensitive to some sweetening or souring, such that the agent also lacks a preference between x and some sweetening or souring of y, or it lacks a preference between y and some sweetening or souring of x. Then, it seems, the agent won’t necessarily prefer to maintain its preferential gap between x and y rather than come to have some preference. If it comes to develop a preference for (say) x over y, it will choose x when offered a choice between x and y, but that action isn’t dispreferred to any other available action from its current perspective.
So, it seems, considerations of goal-content integrity give us no reason to think that agents with preferential gaps will choose to preserve their preferential gaps. And since preferential gaps are key to keeping the agent shutdownable, this is bad news. Considerations of goal-content integrity give us no reason to think that agents with preferential gaps will keep themselves shutdownable.
This seems like a serious limitation, and I’m not yet sure if there’s any way to overcome it. Two strategies that I plan to explore:
- Tim L. Williamson argues that agents with preferential gaps will often prefer to maintain them, because turning them into preferences will lead the agent to make choices between other options such that these choices look bad from the agent’s current perspective. I wasn’t convinced by the quick version of this argument, but I haven’t yet had the time to read the longer argument.
- Perhaps, as above, we can train the agent to have ‘maintaining its current pattern of preferences’ as one of its terminal goals. As above, the fact that the agent’s current pattern of preferences are incomplete will help to mitigate concerns about the agent behaving deceptively to avoid having new preferences trained in. If we train against the agent modifying its own preferences in a diverse-enough array of environments, perhaps that will inscribe into the agent a general preference for maintaining its current pattern of preferences. I wouldn’t want to rely on this though.
On directly modifying preferences towards completion over time, that's right but the agent's preferences will only become complete once it's had the opportunity to choose a sufficiently wide array of options. Depending on the details, that might never happen or only happen after a very long time. I'm still trying to figure out the details.
↑ comment by Jesse Richardson (SharkoRubio) · 2023-07-12T15:23:26.402Z · LW(p) · GW(p)
Can you explain more how this might work?
↑ comment by Jesse Richardson (SharkoRubio) · 2023-07-12T15:56:53.109Z · LW(p) · GW(p)
You recognise this in the post and so set things up as follows: a non-myopic optimiser decides the preferences of a myopic agent. But this means your argument doesn’t vindicate coherence arguments as traditionally conceived. Per my understanding, the conclusion of coherence arguments was supposed to be: you can’t rely on advanced agents not to act like expected-utility-maximisers, because even if these agents start off not acting like EUMs, they’ll recognise that acting like an EUM is the only way to avoid pursuing dominated strategies. I think that’s false, for the reasons that I give in my coherence theorems post and in the paragraph above. But in any case, your argument doesn’t give us that conclusion. Instead, it gives us something like: a non-myopic optimiser of a myopic agent can shift probability mass from less-preferred to more-preferred outcomes by probabilistically precommitting the agent to take certain trades in a way that makes its preferences complete. That’s a cool result in its own right, and maybe your post isn’t trying to vindicate coherence arguments as traditionally conceived, but it seems worth saying that it doesn’t.
I might be totally wrong about this, but if you have a myopic agent with preferences A>B, B>C and C>A, it's not totally clear to me why they would change those preferences to act like an EUM. Sure, if you keep offering them a trade where they can pay small amounts to move in these directions, they'll go round and round the cycle and only lose money, but do they care? At each timestep, their preferences are being satisfied. To me, the reason you can expect a suitably advanced agent to not behave like this is that they've been subjected to a selection pressure / non-myopic optimiser that is penalising their losses.
If the non-myopic optimiser wants the probability of a dominated strategy lower than that, it has to make the agent non-myopic. And in cases where an agent with incomplete preferences is non-myopic, it can avoid pursuing dominated strategies by acting in accordance with the Caprice Rule.
This seems right to me. It feels weird to talk about an agent that has been sufficiently optimized for not pursuing dominated strategies but not for non-myopia. Doesn't non-myopia dominate myopia in many reasonable setups?
↑ comment by johnswentworth · 2023-06-29T01:47:56.417Z · LW(p) · GW(p)
For a Caprice-Rule-abiding agent to avoid pursuing dominated strategies in single-sweetening money-pumps, that agent must be non-myopic: specifically, it must recognise that trading in A for B and then B for A+ is an available sequence of trades. And you might think that this is where my proposal falls down: actual agents will sometimes be myopic, so actual agents can’t always use the Caprice Rule to avoid pursuing dominated strategies, so actual agents are incentivised to avoid pursuing dominated strategies by instead probabilistically precommitting to take certain trades in ways that make their preferences complete (as you suggest).
That's almost the counterargument that I'd give, but importantly not quite. The problem with the Caprice Rule is not that the agent needs to be non-myopic, but that the agent needs to know in advance which trades will be available. The agent can be non-myopic - i.e. have a model of future trades and optimize for future state - but still not know which trades it will actually have an opportunity to make. E.g. in the pizza example, when David and I are offered to trade mushroom for anchovy, we don't yet know whether we'll have an opportunity to trade anchovy for pepperoni later on.
More general point: I think relying on decision trees as our main model of the agents' "environment" does not match the real world well, especially when using relatively small/simple trees. It seems to me that things like the Caprice rule are mostly exploiting ways in which decision trees are a poor model of realistic environments.
The assumption that we know in advance which trades will be available is one aspect of the problem, which could in-principle be handled by adding random choice nodes to the trees.
Another place where I suspect this is relevant (though I haven't pinned it down yet): the argument in the post has a corner case when the probability of being offered some trade is zero. In that case, the agent will be indifferent between the completion and its original preferences, because the completion will just add a preference which will never actually be traded upon. I suspect that most of your examples are doing a similar thing - it's telling that, in all your counterexamples, the agent is indifferent between original preferences and the completion; it doesn't actively prefer the incomplete preferences. (Unless I'm missing something, in which case please correct me!) That makes me think that the small decision trees implicitly contain a lot of assumptions that various trades have zero probability of happening, which is load-bearing for your counterexamples. In a larger world, with a lot more opportunities to trade between various things, I'd expect that sort of issue to be much less relevant.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-06-29T21:05:15.762Z · LW(p) · GW(p)
The problem with the Caprice Rule is not that the agent needs to be non-myopic, but that the agent needs to know in advance which trades will be available. The agent can be non-myopic - i.e. have a model of future trades and optimize for future state - but still not know which trades it will actually have an opportunity to make.
It's easy to extend the Caprice Rule to this kind of case. Suppose we have an agent that’s uncertain whether – conditional on trading mushroom (A) for anchovy (B) – it will later have the chance to trade in anchovy (B) for pepperoni (A+). Suppose in its model the probabilities are 50-50.
Then our agent with a model of future trades can consider what it would choose conditional on finding itself in node 2: it can decide with what probability p it would choose A+, with the remaining probability 1-p going to B. Then, since choosing B at node 1 has a 0.5 probability of taking the agent to node 2 and a 0.5 probability of taking the agent to node 3, the agent can regard the choice of B at node 1 as the lottery 0.5p(A+)+(1-0.5p)(B) (since, conditional on choosing B at node 1, the agent will end up with A+ with probability 0.5p and end up with B otherwise).
So for an agent with a model of future trades, the choice at node 1 is a choice between A and 0.5p(A+)+(1-0.5p)(B). What we’ve specified about the agent’s preferences over the outcomes A, B, and A+ doesn’t pin down what its preferences will be between A and 0.5p(A+)+(1-0.5p)(B) but either way the Caprice-Rule-abiding agent will not pursue a dominated strategy. If it strictly prefers one of A and 0.5p(A+)+(1-0.5p)(B) to the other, it will reliably choose its preferred option. If it has no preference, neither choice will constitute a dominated strategy.
And this point generalises to arbitrarily complex/realistic decision trees, with more choice-nodes, more chance-nodes, and more options. Agents with a model of future trades can use their model to predict what they’d do conditional on reaching each possible choice-node, and then use those predictions to determine the nature of the options available to them at earlier choice-nodes. The agent’s model might be defective in various ways (e.g. by getting some probabilities wrong, or by failing to predict that some sequences of trades will be available) but that won’t spur the agent to change its preferences, because the dilemma from my previous comment recurs: if the agent is aware that some lottery is available, it won’t choose any dispreferred lottery; if the agent is unaware that some lottery is available and chooses a dispreferred lottery, the agent’s lack of awareness means it won’t be spurred by this fact to change its preferences. To get over this dilemma, you still need the ‘non-myopic optimiser deciding the preferences of a myopic agent’ setting, and my previous points apply: results from that setting don’t vindicate coherence arguments, and we humans as non-myopic optimisers could decide to create artificial agents with incomplete preferences.
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-06-19T03:46:13.689Z · LW(p) · GW(p)
If it has no preference, neither choice will constitute a dominated strategy.
I think this statement doesn't make sense. If it has no preference between choices at node 1, then it has some chance of choosing outcome A. But if it does so, then that strategy is dominated by the strategy that always chooses the top branch, and chooses A+ if it can. This is because 50% of the time, it will get a final outcome of A when the dominating strategy gets A+, and otherwise the two strategies give incomparable outcomes.
I'm assuming dominated means a strategy that gives a final outcome that is incomparable or > in the partial order of preferences, for all possible settings of random variables. (And strictly > for at least one setting of random variables). Maybe my definition is wrong? But it seems like this is the definition I want.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2024-06-19T15:12:52.752Z · LW(p) · GW(p)
We say that a strategy is dominated iff it leads to a lottery that is dispreferred to the lottery led to by some other available strategy. So if the lottery 0.5p(A+)+(1-0.5p)(B) isn’t preferred to the lottery A, then the strategy of choosing A isn’t dominated by the strategy of choosing 0.5p(A+)+(1-0.5p)(B). And if 0.5p(A+)+(1-0.5p)(B) is preferred to A, then the Caprice-rule-abiding agent will choose 0.5p(A+)+(1-0.5p)(B).
You might think that agents must prefer lottery 0.5p(A+)+(1-0.5p)(B) to lottery A, for any A, A+, and B and for any p>0. That thought is compatible with my point above. But also, I don't think the thought is true:
- Think about your own preferences.
- Let A be some career as an accountant, A+ be that career as an accountant with an extra $1 salary, and B be some career as a musician. Let p be small. Then you might reasonably lack a preference between 0.5p(A+)+(1-0.5p)(B) and A. That's not instrumentally irrational.
- Think about incomplete preferences on the model of imprecise exchange rates.
- Here's a simple example of the IER model. You care about two things: love and money. Each career gets a real-valued love score and a real-valued money score. Your exchange rate for love and money is imprecise, running from 0.4 to 0.6. On one proto-exchange-rate, love gets a weight of 0.4 and money gets a weight of 0.6, on another proto-exchange rate, love gets a weight of 0.6 and money gets a weight of 0.4. You weakly prefer one career to another iff it gets at least as high an overall score on both proto-exchange-rates. If one career gets a highger score on one proto-exchange-rate and the other gets a higher score on the other proto-exchange-rate, you have a preferential gap between the two careers. Let A’s <love, money> score be <0, 10>, A+’s score be <0, 11>, and B’s score be <10, 0>. A+ is preferred to A, because 0.4(0)+0.6(11) is greater than 0.4(0)+0.6(10), and 0.6(0)+0.4(11) is greater than 0.6(0)+0.4(10), but the agent lacks a preference between A+ and B, because 0.4(0)+0.6(11) is greater than 0.4(10)+0.6(0), but 0.6(0)+0.4(11) is less than 0.6(10)+0.4(0). And the agent lacks a preference between A and B for the same sort of reason.
- To keep things simple, let p=0.2, so your choice is between 0.1(A+)+0.9(B) and A. The expected <love, money> score of the former is <9, 0.11>. The expected <love, money> score of the latter is <0, 10>. You lack a preference between them, because 0.6(9)+0.4(0.11) is greater than 0.6(0)+0.4(10), and 0.4(0)+0.6(10) is greater than 0.4(9)+0.6(0.11).
- The general principle that you appeal to (If X is weakly preferred to or pref-gapped with Y in every state of nature, and X is strictly preferred to Y in some state of nature, then the agent must prefer X to Y) implies that rational preferences can be cyclic. B must be preferred to p(B-)+(1-p)(A+), which must be preferred to A, which must be preferred to p(A-)+(1-p)B+, which must be preferred to B.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-06-20T00:37:04.635Z · LW(p) · GW(p)
It seems we define dominance differently. I believe I'm defining it a similar way as "uniformly better" here. [Edit: previously I put a screenshot from that paper in this comment, but translating from there adds a lot of potential for miscommunication, so I'm replacing it with my own explanation in the next paragraph, which is more tailored to this context.].
A strategy outputs a decision, given a decision tree with random nodes. With a strategy plus a record of the outcome of all random nodes we can work out the final outcome reached by that strategy (assuming the strategy is deterministic for now). Let's write this like Outcome(strategy, environment_random_seed). Now I think that we should consider a strategy s to dominate another strategy s* if for all possible environment_random_seeds, Outcome(s, seed) ≥ Outcome(s*,seed), and for some random seed, Outcome(s, seed*) > Outcome(s*, seed*). (We can extend this to stochastic strategies, but I want to avoid that unless you think it's necessary, because it will reduce clarity).
In other words, a strategy is better if it always turns out to do "equally" well or better than the other strategy, no matter the state of nature. By this definition, a strategy that chooses A at the first node will be dominated.
Relating this to your response:
We say that a strategy is dominated iff it leads to a lottery that is dispreferred to the lottery led to by some other available strategy. So if the lottery 0.5p(A+)+(1-0.5p)(B) isn’t preferred to the lottery A, then the strategy of choosing A isn’t dominated by the strategy of choosing 0.5p(A+)+(1-0.5p)(B). And if 0.5p(A+)+(1-0.5p)(B) is preferred to A, then the Caprice-rule-abiding agent will choose 0.5p(A+)+(1-0.5p)(B).
I don't like that you've created a new lottery at the chance node, cutting off the rest of the decision tree from there. The new lottery wasn't in the initial preferences. The decision about whether to go to that chance node should be derived from the final outcomes, not from some newly created terminal preference about that chance node. Your dominance definition depends on this newly created terminal preference, which isn't a definition that is relevant to what I'm interested in.
I'll try to back up and summarize my motivation, because I expect any disagreement is coming from there. My understanding of the point of the decision tree is that it represents the possible paths to get to a final outcome. We have some preference partial order over final outcomes. We have some way of ranking strategies (dominance). What we want out of this is to derive results about the decisions the agent must make in the intermediate stage, before getting to a final outcome.
If it has arbitrary preferences about non-final states, then it's behavior is entirely unconstrained and we cannot derive any results about its decisions in the intermediate state.
So we should only use a definition of dominance that depends on final outcomes, then any strategy that doesn't always choose B at decision node 1 will be dominated by a strategy that does, according to the original preference partial order.
(I'll respond to the other parts of your response in another comment, because it seems important to keep the central crux debate in one thread without cluttering it with side-tracks).
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2024-06-25T14:49:13.899Z · LW(p) · GW(p)
Things are confusing because there are lots of different dominance relations that people talk about. There's a dominance relation on strategies, and there are (multiple) dominance relations on lotteries.
Here are the definitions I'm working with.
A strategy is a plan about which options to pick at each choice-node in a decision-tree.
Strategies yield lotteries (rather than final outcomes) when the plan involves passing through a chance-node. For example, consider the decision-tree below:
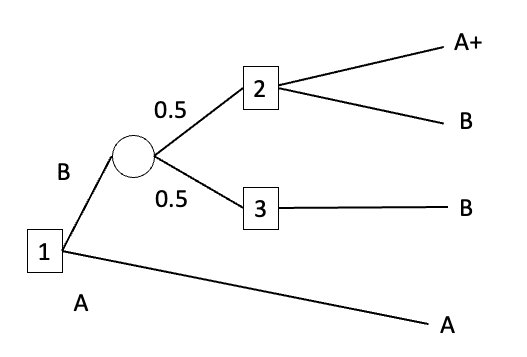
A strategy specifies what option the agent would pick at choice-node 1, what option the agent would pick at choice-node 2, and what option the agent would pick at choice-node 3.
Suppose that the agent's strategy is {Pick B at choice-node 1, Pick A+ at choice-node 2, Pick B at choice-node 3}. This strategy doesn't yield a final outcome, because the agent doesn't get to decide what happens at the chance-node. Instead, the strategy yields the lottery 0.5(A+)+0.5(B). This just says that: if the agent executes the strategy, then there's a 0.5 probability that they end up with final outcome A+ and a 0.5 probability that they end up with final outcome B.
The dominance relation on strategies has to refer to the lotteries yielded by strategies, rather than the final outcomes yielded by strategies, because strategies don't yield final outcomes when the agent passes through a chance-node.[1] So we define the dominance relation on strategies as follows:
Strategy Dominance (relation)
A strategy S is dominated by a strategy S' iff S yields a lottery X that is strictly dispreferred to the lottery X' yielded by S'.
Now for the dominance relations on lotteries.[2] One is:
Statewise Dominance (relation)
Lottery X statewise-dominates lottery Y iff, in each state [environment_random_seed], X yields a final outcome weakly preferred to the final outcome yielded by Y, and in some state [environment_random_seed], X yields a final outcome strictly preferred to the final outcome yielded by Y.
Another is:
Statewise Pseudodominance (relation)
Lottery X statewise-pseudodominates lottery Y iff, in each state [environment_random_seed], X yields a final outcome weakly preferred to or pref-gapped to the final outcome yielded by Y, and in some state [environment_random_seed], X yields a final outcome strictly preferred to the final outcome yielded by Y.
The lottery A (that yields final outcome A for sure) is statewise-pseudodominated by the lottery 0.5(A+)+0.5(B), but it isn't statewise-dominated by 0.5(A+)+0.5(B). That's because the agent has a preferential gap between the final outcomes A and B.
Advanced agents with incomplete preferences over final outcomes will plausibly satisfy the Statewise Dominance Principle:
Statewise Dominance Principle
If lottery X statewise-dominates lottery Y, then the agent strictly prefers X to Y.
And that's because agents that violate the Statewise Dominance Principle are 'shooting themselves in the foot' in the relevant sense. If the agent executes a strategy that yields a statewise-dominated lottery, then there's another available strategy that - in each state - gives a final outcome that is at least as good in every respect that the agent cares about, and - in some state - gives a final outcome that is better in some respect that the agent cares about.
But advanced agents with incomplete preferences over final outcomes plausibly won't satisfy the Statewise Pseudodominance Principle:
Statewise Pseudodominance Principle
If lottery X statewise-pseudodominates lottery Y, then the agent strictly prefers X to Y.
And that's for the reasons that I gave in my comment above. Condensing:
- A statewise-pseudodominated lottery can be such that, in some state, that lottery is better than all other available lotteries in some respect that the agent cares about.
- The statewise pseudodominance relation is cyclic, so the Statewise Pseudodominance Principle would lead to cyclic preferences.
- ^
You say:
The decision about whether to go to that chance node should be derived from the final outcomes, not from some newly created terminal preference about that chance node.
But:
- The decision can also depend on the probabilities of those final outcomes.
- The decision is constrained by preferences over final outcomes and probabilities of those final outcomes. I'm supposing that the agent's preferences over lotteries depends only on these lotteries' possible final outcomes and their probabilities. I'm not supposing that the agent has newly created terminal preferences/arbitrary preferences about non-final states.
- ^
There are stochastic versions of each of these relations, which ignore how states line up across lotteries and instead talk about probabilities of outcomes. I think everything I say below is also true for the stochastic versions.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-07-11T09:47:52.239Z · LW(p) · GW(p)
[Edit: I think I misinterpreted EJT in a way that invalidates some of this comment, see downthread comment clarifying this].
That is really helpful, thanks. I had been making a mistake, in that I thought that there was an argument from just "the agent thinks it's possible the agent will run into a money pump" that concluded "the agent should complete that preference in advance". But I was thinking sloppily and accidentally sometimes equivocating between pref-gaps and indifference. So I don't think this argument works by itself, but I think it might be made to work with an additional assumption.
One intuition that I find convincing is that if I found myself at outcome A in the single sweetening money pump, I would regret having not made it to A+. This intuition seems to hold even if I imagine A and B to be of incomparable value.
In order to avoid this regret, I would try to become the sort of agent that never found itself in that position. I can see that if I always follow the Caprice rule, then it's a little weird to regret not getting A+, because that isn't a counterfactually available option (counterfacting on decision 1). But this feels like I'm being cheated. I think the reason that if feels like I'm being cheated is that I feel like getting to A+ should be a counterfactually available option.
One way to make it a counterfactually available option in the thought experiment is to introduce another choice before choice 1 in the decision tree. The new choice (0), is the choice about whether to maintain the same decision algorithm (call this incomplete), or complete the preferential gap between A and B (call this complete).
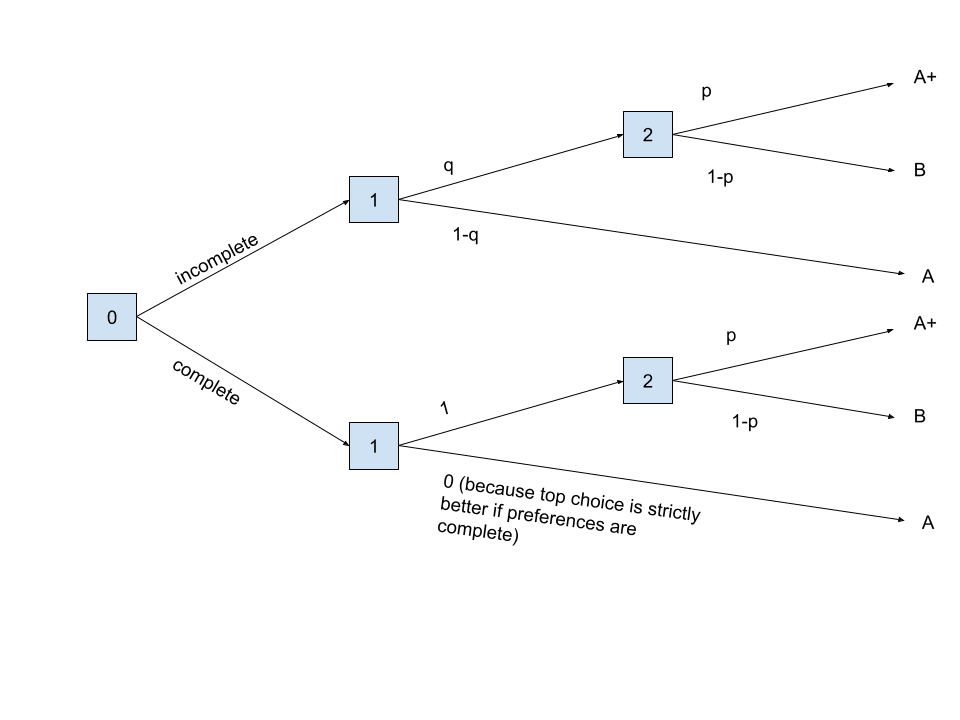
I think the choice complete statewise dominates incomplete. This is because the choice incomplete results in a lottery {B: , A+: , A:} for .[1] However, the choice complete results in the lottery {B: , A+: , A:0}.
Do you disagree with this? I think this allows us to create a money pump, by charging the agent $ for the option to complete its own preferences.
The statewise pseudodominance relation is cyclic, so the Statewise Pseudodominance Principle would lead to cyclic preferences.
This still seems wrong to me, because I see lotteries as being an object whose purpose is to summarize random variables and outcomes. So it's weird to compare lotteries that depend on the same random variables (they are correlated), as if they are independent. This seems like a sidetrack though, and it's plausible to me that I'm just confused about your definitions here.
- ^
Letting be the probability that the agent chooses 2A+ and the probability the agent chooses 2B (following your comment above). And is defined similarly, for choice 1.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-07-18T07:20:54.577Z · LW(p) · GW(p)
I made a mistake again. As described above, complete only pseudodominates incomplete.
But this is easily patched with the trick described in the OP. So we need the choice complete to make two changes to the downstream decisions. First, change decision 1 to always choose up (as before), second, change the distribution of Decision 2 to {, }, because this keeps the probability of B constant. Fixed diagram:
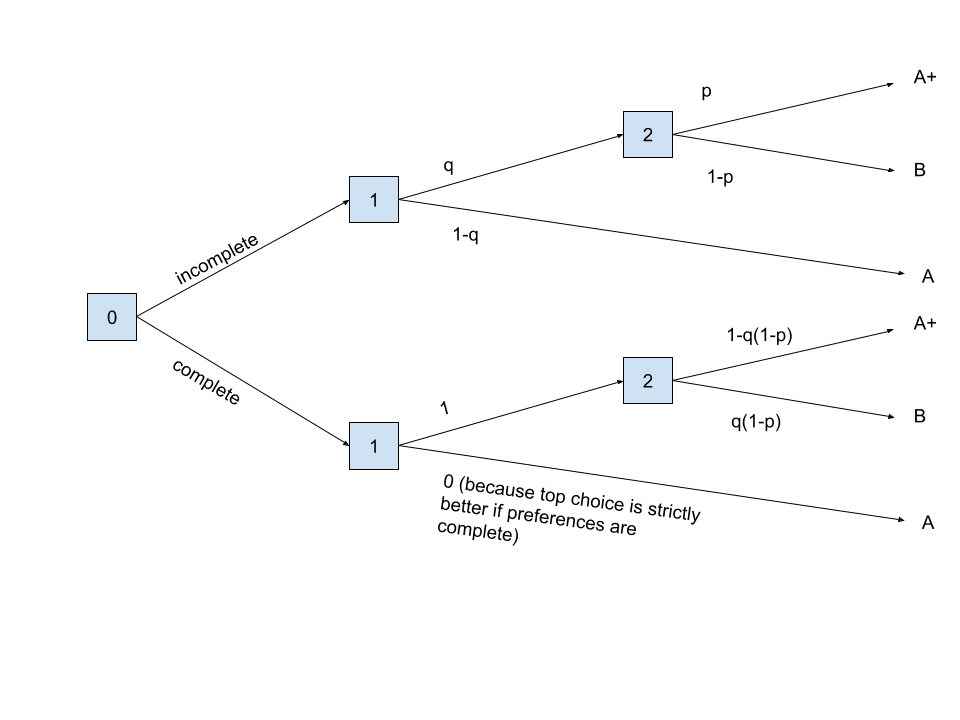
Now the lottery for complete is {B: , A+: , A:}, and the lottery for incomplete is {B: , A+: , A:}. So overall, there is a pure shift of probability from A to A+.
[Edit 23/7: hilariously, I still had the probabilities wrong, so fixed them, again].
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-10-02T12:16:14.600Z · LW(p) · GW(p)
I think the above money pump works, if the agent sometimes chooses the A path, but I was incorrect in thinking that the caprice rule sometimes chooses the A path.
I misinterpreted one of EJT's comments as saying it might choose the A path. The last couple of days I've been reading through some of the sources he linked to in the original "there are no coherence theorems" post and one of them (Gustafsson) made me realize I was interpreting him incorrectly, by simplifying the decision tree in a way that doesn't make sense. I only realized this yesterday.
Now I think that the caprice rule is essentially equivalent to updatelessness. If I understand correctly, it would be equivalent to 1. choosing the best policy by ranking them in the partial order of outcomes (randomizing over multiple maxima), then 2. implementing that policy without further consideration. And this makes it immune to money pumps and renders any self-modification pointless. It also makes it behaviorally indistinguishable from an agent with complete preferences, as far as I can tell.
The same updatelessness trick seems to apply to all money pump arguments. It's what scott uses in this post [LW · GW] to avoid the independence money pump.
So currently I'm thinking updatelessness removes most of the justification for the VNM axioms (including transitivity!). But I'm confused because updateless policies still must satisfy local properties like "doesn't waste resources unless it helps achieve the goal", which is intuitively what the money pump arguments represent. So there must be some way to recover properties like this. Maybe via John's approach here [LW · GW].
But I'm only maybe 80% sure of my new understanding, I'm still trying to work through it all.
↑ comment by dxu · 2024-11-01T23:27:36.361Z · LW(p) · GW(p)
It looks to me like the "updatelessness trick" you describe (essentially, behaving as though certain non-local branches of the decision tree are still counterfactually relevant even though they are not — although note that I currently don't see an obvious way to use that to avoid the usual money pump against intransitivity) recovers most of the behavior we'd see under VNM anyway; and so I don't think I understand your confusion re: VNM axioms.
E.g. can you give me a case in which (a) we have an agent that exhibits preferences against whose naive implementation there exists some kind of money pump (not necessarily a repeatable one), (b) the agent can implement the updatelessness trick in order to avoid the money pump without modifying their preferences, and yet (c) the agent is not then representable as having modified their preferences in the relevant way?
Replies from: jeremy-gillen↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-11-05T19:42:58.156Z · LW(p) · GW(p)
Good point.
What I meant by updatelessness removes most of the justification is the reason given here at the very beginning of "Against Resolute Choice". In order to make a money pump that leads the agent in a circle, the agent has to continue accepting trades around a full preference loop. But if it has decided on the entire plan beforehand, it will just do any plan that involves <1 trip around the preference loop. (Although it's unclear how it would settle on such a plan, maybe just stopping its search after a given time). It won't (I think?) choose any plan that does multiple loops, because they are strictly worse.
After choosing this plan though, I think it is representable as VNM rational, as you say. And I'm not sure what to do with this. It does seem important.
However, I think Scott's argument here [LW · GW] satisfies (a) (b) and (c). I think the independence axiom might be special in this respect, because the money pump for independence is exploiting an update on new information.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2024-11-19T13:46:08.881Z · LW(p) · GW(p)
I don't think agents that avoid the money pump for cyclicity are representable as satisfying VNM, at least holding fixed the objects of preference (as we should). Resolute choosers with cyclic preferences will reliably choose B over A- at node 3, but they'll reliably choose A- over B if choosing between these options ex nihilo. That's not VNM representable, because it requires that the utility of A- be greater than the utility of B and. that the utility of B be greater than the utility of A-
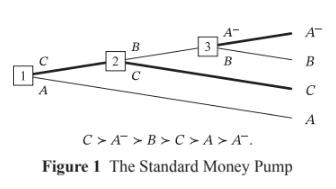
↑ comment by Jeremy Gillen (jeremy-gillen) · 2025-02-03T18:24:25.856Z · LW(p) · GW(p)
Perhaps I'm misusing the word "representable"? But what I meant was that any single sequence of actions generate by the agent could also have been generated by an outcome-utility maximizer (that has the same world model). This seems like the relevant definition, right?
↑ comment by EJT (ElliottThornley) · 2024-11-19T13:37:43.226Z · LW(p) · GW(p)
It also makes it behaviorally indistinguishable from an agent with complete preferences, as far as I can tell.
That's not right. As I say in another comment:
And an agent abiding by the Caprice Rule can’t be represented as maximising utility, because its preferences are incomplete. In cases where the available trades aren’t arranged in some way that constitutes a money-pump, the agent can prefer (/reliably choose) A+ over A, and yet lack any preference between (/stochastically choose between) A+ and B, and lack any preference between (/stochastically choose between) A and B. Those patterns of preference/behaviour are allowed by the Caprice Rule.
Or consider another example. The agent trades A for B, then B for A, then declines to trade A for B+. That's compatible with the Caprice rule, but not with complete preferences.
Or consider the pattern of behaviour that (I elsewhere argue [LW · GW]) can make agents with incomplete preferences shutdownable. Agents abiding by the Caprice rule can refuse to pay costs to shift probability mass between A and B, and refuse to pay costs to shift probability mass between A and B+. Agents with complete preferences can't do that.
The same updatelessness trick seems to apply to all money pump arguments.
[I'm going to use the phrase 'resolute choice' rather than 'updatelessness.' That seems like a more informative and less misleading description of the relevant phenomenon: making a plan and sticking to it. You can stick to a plan even if you update your beliefs. Also, in the posts on UDT, 'updatelessness' seems to refer to something importantly distinct from just making a plan and sticking to it.]
That's right, but the drawbacks of resolute choice depend on the money pump to which you apply it. As Gustafsson notes, if an agent uses resolute choice to avoid the money pump for cyclic preferences, that agent has to choose against their strict preferences at some point. For example, they have to choose B at node 3 in the money pump below, even though - were they facing that choice ex nihilo - they'd prefer to choose A-.
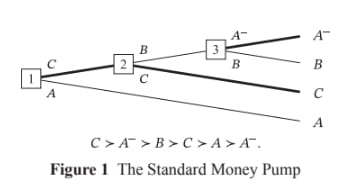
There's no such drawback for agents with incomplete preferences using resolute choice. As I note in this post [LW · GW], agents with incomplete preferences using resolute choice need never choose against their strict preferences. The agent's past plan only has to serve as a tiebreaker: forcing a particular choice between options between which they'd otherwise lack a preference. For example, they have to choose B at node 2 in the money pump below. Were they facing that choice ex nihilo, they'd lack a preference between B and A-.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2025-02-03T18:17:20.371Z · LW(p) · GW(p)
That's not right
Are you saying that my description (following) is incorrect?
[incomplete preferences w/ caprice] would be equivalent to 1. choosing the best policy by ranking them in the partial order of outcomes (randomizing over multiple maxima), then 2. implementing that policy without further consideration.
Or are you saying that it is correct, but you disagree that this implies that it is "behaviorally indistinguishable from an agent with complete preferences"? If this is the case, then I think we might disagree on the definition of "behaviorally indistinguishable"? I'm using it like: If you observe a single sequence of actions from this agent (and knowing the agent's world model), can you construct a utility function over outcomes that could have produced that sequence.
Or consider another example. The agent trades A for B, then B for A, then declines to trade A for B+. That's compatible with the Caprice rule, but not with complete preferences.
This is compatible with a resolute outcome-utility maximizer (for whom A is a maxima). There's no rule that says an agent must take the shortest route to the same outcome (right?).
As Gustafsson notes, if an agent uses resolute choice to avoid the money pump for cyclic preferences, that agent has to choose against their strict preferences at some point.
...
There's no such drawback for agents with incomplete preferences using resolute choice.
Sure, but why is that a drawback? It can't be money pumped, right? Agents following resolute choice often choose against their local strict preferences in other decision problems. (E.g. Newcomb's). And this is considered an argument in favour of resolute choice.
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-06-20T01:29:19.502Z · LW(p) · GW(p)
(sidetrack comment, this is not the main argument thread)
Think about your own preferences.
- Let A be some career as an accountant, A+ be that career as an accountant with an extra $1 salary, and B be some career as a musician. Let p be small. Then you might reasonably lack a preference between 0.5p(A+)+(1-0.5p)(B) and A. That's not instrumentally irrational.
I find this example unconvincing, because any agent that has finite precision in their preference representation will have preferences that are a tiny bit incomplete in this manner. As such, a version of myself that could more precisely represent the value-to-me of different options would be uniformly better than myself, by my own preferences. But the cost is small here. The amount of money I'm leaving on the table is usually small, relative to the price of representing and computing more fine-grained preferences.
I think it's really important to recognize the places where toy models can only approximately reflect reality, and this is one of them. But it doesn't reduce the force of the dominance argument. The fact that humans (or any bounded agent) can't have exactly complete preferences doesn't mean that it's impossible for them to be better by their own lights.
Think about incomplete preferences on the model of imprecise exchange rates.
I appreciate you writing out this more concrete example, but that's not where the disagreement lies. I understand partially ordered preferences. I didn't read the paper though. I think it's great to study or build agents with partially ordered preferences, if it helps get other useful properties. It just seems to me that they will inherently leave money on the table. In some situations this is well worth it, so that's fine.
- The general principle that you appeal to (If X is weakly preferred to or pref-gapped with Y in every state of nature, and X is strictly preferred to Y in some state of nature, then the agent must prefer X to Y) implies that rational preferences can be cyclic. B must be preferred to p(B-)+(1-p)(A+), which must be preferred to A, which must be preferred to p(A-)+(1-p)B+, which must be preferred to B.
No, hopefully the definition in my other comment makes this clear. I believe you're switching the state of nature for each comparison, in order to construct this cycle.
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2024-06-25T15:33:29.379Z · LW(p) · GW(p)
There could be agents that only have incomplete preferences because they haven't bothered to figure out the correct completion. But there could also be agents with incomplete preferences for which there is no correct completion. The question is whether these agents are pressured by money-pump arguments to settle on some completion.
I understand partially ordered preferences.
Yes, apologies. I wrote that explanation in the spirit of 'You probably understand this, but just in case...'. I find it useful to give a fair bit of background context, partly to jog my own memory, partly as a just-in-case, partly in case I want to link comments to people in future.
I believe you're switching the state of nature for each comparison, in order to construct this cycle.
I don't think this is true. You can line up states of nature in any way you like.
comment by David Lorell · 2023-06-22T22:31:47.228Z · LW(p) · GW(p)
Some nits we know about but didn't include in the problems section:
- P[mushroom->anchovy] = 0. The current argument does not handle the case where subagents believe that there is a probability of 0 on one of the possible states. It wouldn't be possible to complete the preferences exactly as written, then.
- Indifference. If anchovy were placed directly above mushroom in the preference graph above (so that John is truly indifferent between them), then that might require some special handling. But also it might just work if the "Value vs Utility" issue is worked out. If the subagents are not myopic / handle instrumental values, then whether anchovy is less, identically, or more desirable than mushroom doesn't really matter so much on its own as opposed to what opportunities are possible afterward from the anchovy state relative to the mushroom state.
Also, I think I buy the following part but I really wish it were more constructive.
Now, we haven't established which distribution of preferences the system will end up sampling from. But so long as it ends up at some non-dominated choice, it must end up with non-strongly-incomplete preferences with probability 1 (otherwise it could modify the contract for a strict improvement in cases where it ends up with non-strongly-incomplete preferences). And, so long as the space of possibilities is compact and arbitrary contracts are allowed, all we have left is a bargaining problem. The only way the system would end up with dominated preference-distribution is if there's some kind of bargaining breakdown.
comment by xuan · 2023-06-25T03:14:14.628Z · LW(p) · GW(p)
Interesting argument! I think it goes through -- but only under certain ecological / environmental assumptions:
- That decisions / trades between goods are reversible.
- That there are multiple opportunities to make such trades / decisions in the environment.
But this isn't always the case! Consider:
- Both John and David prefer living over dying.
- Hence, John would not trade (John Alive, David Dead) for (John Dead, David Alive), and vice versa for David.
This is already a case of weakly incomplete preferences which, while technically reducible to a complete order over "indifference sets", doesn't seem well described by a utility function! In particular, it seems really important to represent the fact that neither person would trade their life for the other's life, even though both (John Alive, David Dead) and (John Dead, David Alive) lie in the same "indifference / incommensurability set".
(I think it's better to call it an "incommensurability set" -- just because two elements in a lattice share a least upper bound, it doesn't mean they are themselves comparable).
Now let's try and make the preferences strongly incomplete:
- John prefers living freely over imprisonment, and imprisonment to dying.
- Even if David was dead, he would prefer that John be alive over John being imprisoned.
Apart from the fact that you can't reverse death (at least with current technology), this is similar to the pizza scenario: The system as a whole prefers:
- (John Free, David Alive) > (John Free, David Dead) > (John Imprisoned, David Dead) > Both Dead
- (John Free, David Alive) > (John Imprisoned, David Alive) > (John Dead, David Alive) > Both Dead
- No preferences between options of the form (X, David Dead) and (John Dead, Y).
If John and David could contract to go from (John Imprisoned, David Dead) to (John Dead, David Alive) and then to (John Alive, David Dead) when those trades are offered, that would result in an improvement in achieving preferred outcomes on average. But of course, they can't because death is irreversible!
↑ comment by Dweomite · 2023-06-25T11:39:26.014Z · LW(p) · GW(p)
Rather than talking about reversibility, can this situation be described just by saying that the probability of certain opportunities is zero? For example, if John and David somehow know in advance that no one will ever offer them pepperoni in exchange for anchovies, then the maximum amount of probability mass that can be shifted from mushrooms to pepperoni by completing their preferences happens to be zero. This doesn't need to be a physical law of anchovies; it could just be a characteristic of their trade partners.
But in this hypothetical, their preferences are effectively no longer strongly incomplete--or at least, their trade policy is no longer strongly incomplete. Since we've assumed away the edge between pepperoni and anchovies, we can (vacuously) claim that John and David will collectively accept 100% of the (non-existent) trades from anchovies to pepperoni, and it becomes possible to describe their trade policy as being a utility maximizer. (Specifically, we can say anchovies = mushrooms because they won't trade between them, and say pepperoni > mushrooms because they will trade mushrooms for pepperoni. The original problem was that this implies that pepperoni > anchovies, which is false in their preferences, but it is now (vacuously) true in their trade policy if such opportunities have probability zero.)
Replies from: xuan↑ comment by xuan · 2023-06-25T13:00:05.201Z · LW(p) · GW(p)
It seems to me that it's not right to assume the probability of opportunities to trade are zero?
Suppose both John and David are alive on a desert island right now (but slowly dying), and there's a chance that a rescue boat will arrive that will save only one of them, leaving the other to die. What would they contract to? Assuming no altruistic preferences, presumably neither would agree to only the other person being rescued.
It seems more likely here that bargaining will break down, and one of them will kill off the other, resulting in an arbitrary resolution of who ends up on the rescue boat, not a "rational" resolution.
Replies from: Dweomite↑ comment by Dweomite · 2023-06-25T16:23:54.428Z · LW(p) · GW(p)
Doesn't irreversibility imply that there is zero probability of a trade opportunity to reverse the thing? I'm not proposing a new trait that your original scenario didn't have; I'm proposing that I identified which aspect of your scenario was load-bearing.
I don't think I understand how your new hypothetical is meant to be related to anything discussed so far. As described, the group doesn't have strongly incomplete preferences, just 2 mutually-exclusive objectives.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-06-25T17:38:48.852Z · LW(p) · GW(p)
Zero probability of trade is indeed the feature which would make the argument in the OP potentially not go through, when irreversibility is present. (Though we would still get a weakened form of the argument from the OP, in which we complete the preferences by adding a preference for a trade which has zero probability, and the original system is indifferent between that completion and its original preferences.)
↑ comment by quetzal_rainbow · 2023-06-25T11:16:16.937Z · LW(p) · GW(p)
Well, it can be overcame by future contracts, no? We replace "Jonh dead" with "John dies tomorrow" and perform trades today.
↑ comment by xuan · 2023-06-25T03:14:30.026Z · LW(p) · GW(p)
While I've focused on death here, I think this is actually much more general -- there are a lot of irreversible decisions that people make (and that artificial agents might make) between potentially incommensurable choices. Here's a nice example from Elizabeth Anderson's "Value in Ethics & Economics" (Ch. 3, P57 re: the question of how one should live one's life, to which I think irreversibility applies

Similar incommensurability applies, I think, to what kind of society we collectively we want to live in, given that path dependency makes many choices irreversible.
comment by Thomas Kwa (thomas-kwa) · 2023-06-23T09:23:45.607Z · LW(p) · GW(p)
I commented [LW(p) · GW(p)] on the original post last year regarding the economics angle:
Ryan Kidd and I did an economics literature review a few weeks ago for representative agent stuff, and couldn't find any results general enough to be meaningful. We did find one paper that proved a market's utility function couldn't be of a certain restricted form, but nothing about proving the lack of a coherent utility function in general. A bounty also hasn't found any such papers.
Based on this lit review and the Wikipedia page and ChatGPT [1], I'm 90% sure that "representative agent" in economics means the idea that the market's aggregate preferences are similar to the typical individuals' preferences, and the general question of whether a market has any complete preference ordering does not fall within the scope of the term.
[1] GPT4 says "The representative agent is assumed to behave in a way that represents the average or typical behavior of the group in the aggregate. In macroeconomics, for instance, a representative agent might be used to describe the behavior of all households in an economy.
This modeling approach is used to reduce the complexity of economic models, making them more tractable, but it has also received criticism."
comment by cfoster0 · 2023-06-24T18:56:24.560Z · LW(p) · GW(p)
As I understand this, the rough sketch of this approach is basically to realize that incomplete preferences are compatible with a family of utility functions rather than a single one (since they don't specify how to trade-off between incomparable outcomes), and that you can use randomization to select within this family (implemented via contracts), thereby narrowing in on completed preferences / a utility function. Is that description on track?
If so, is it a problem that the subagents/committee/market may have preferences that are a function of this dealmaking process, like preferences about avoiding the coordination/transaction costs involved, or preferences about how to do randomization? Like, couldn't you end up with a situation where "completing the preferences" is dispreferred, such that the individual subagents do not choose to aggregate into a single utility maximizer?
comment by Nicolas Macé (NicolasMace) · 2023-06-26T07:49:47.360Z · LW(p) · GW(p)
I think the idea of contracts is interesting. I’m probably less optimistic (or pessimistic?) than the authors that the sub-agents can always contract to complete their preferences. For one thing, contracts might be expensive to make. Second, even free contracts might not be incentivized, for the usual reasons rational agents cannot always avoid inefficiencies in trading (cf the Myerson-Satterthwaite theorem).
On might object that Myerson–Satterthwaite doesn't allow for smart contracts that can conditionally disclose private information. But then I'd argue that these types of smart contracts are probably expensive to make, and thus not always incentivized.
comment by Max H (Maxc) · 2023-06-23T01:43:39.444Z · LW(p) · GW(p)
How do agents with preferential gaps [LW · GW] fit into this? I think preferential gaps are a kind of weak incompleteness, and thus handled by your second step?
Context: I'm pretty interested in the claims in this post, and their implications. A while ago, I went back and forth with EJT a bit on his coherence theorems [LW · GW] post. The thread ended here [LW(p) · GW(p)] with a claim by EJT:
And agents with many preferential gaps may behave quite differently to expected utility maximizers.
I didn't have a counterpoint at the time, but I am pretty skeptical that this claim is true, intuitively.
An agent with even infinitely many preferential gaps seems very close in mind-space to an agent with complete preferences: all it is missing is a relatively simple-to-describe function which "breaks the tie" on things it is already very close to indifferent about. And different choices of tiebreaker function seem unlikely to lead to importantly different behavior: for any choice of tiebreaker function, you are back to an EU maximizer.
The only remaining hope is to avoid having the agent ever pick or be imbued with a tiebreaker function at all. That requires at least two things:
- The agent's creators must not initialize it with such a tiebreaker function (seems unlikely to happen by default, but maybe if the creators are alignment researchers who know what they are doing, it's possible)
- The agent itself must be stable enough that it never chooses to self-modify or drift into completeness on its own. And I think your claim, if I'm understanding it correctly, is that such stability is unlikely, because completing the preferences can lead to a strict improvement in outcomes under the preferences of the original agent.
Am I understanding your claims correctly, and do you agree with my reasoning that EJT's claim is thus unlikely to be true?
comment by Kaj_Sotala · 2023-06-26T07:54:23.725Z · LW(p) · GW(p)
Just based on a loose qualitative understanding of coherence arguments, one might think that the inexploitability (i.e. efficiency) of markets implies that they maximize a utility function.
This is probably a dumb beginner question indicative of not understanding the definition of key terms, but to reveal my ignorance anyway - isn't any company that consistently makes a profit successfully exploiting the market? And if it is, why do we say that markets are inexploitable, if they're built on the existence of countless actors exploiting them?
Replies from: johnswentworth↑ comment by johnswentworth · 2023-06-26T15:57:17.801Z · LW(p) · GW(p)
Two answers here.
First, the standard economics answer: economic profit accounting profit. Economic profit is how much better a company does than their opportunity cost; accounting profit is revenue minus expenses. A trading firm packed with top-notch physicists, mathematicians, and programmers can make enormous accounting profit and yet still make zero economic profit, because the opportunity costs for such people are quite high. "Efficient markets" means zero economic profits, not zero accounting profits.
Second answer: as Zvi is fond of pointing out, the efficient market hypothesis is false (even after accounting for the distinction between economic and accounting profit). For instance, Renaissance - a real trading firm packed with top-notch physicists, mathematicians, and programmers - in fact makes far more money than the opportunity cost of its employees and capital. That said, market efficiency is still a very good approximation for a lot of purposes, and I'd be very curious to know whether selection pressures have already induced the trades which would make markets approximately aggregate into a utility maximizer.
comment by Wei Dai (Wei_Dai) · 2023-06-23T00:06:43.011Z · LW(p) · GW(p)
Then the AI Alignment Awards contest came along, and an excellent entry by Elliot Thornley [LW · GW] proposed that incomplete preferences could be used as a loophole to make the shutdown problem tractable.
Where is this contest entry? All my usual search methods are failing me...
Replies from: xuan, johnswentworth↑ comment by xuan · 2023-06-25T02:24:27.214Z · LW(p) · GW(p)
Not sure if this is the same as the awards contest entry, but EJT also made this earlier post ("There are no coherence theorems" [AF · GW]) arguing that certain Dutch Book / money pump arguments against incompleteness fail!
↑ comment by johnswentworth · 2023-06-23T00:15:15.688Z · LW(p) · GW(p)
I don't think it's been posted publicly yet. Elliot said I was welcome to cite it publicly, but didn't explicitly say whether I should link it. @EJT [LW · GW] ?
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-06-26T02:00:28.404Z · LW(p) · GW(p)
Hi Wei, happy to send it your way! I plan to post it publicly once I've had a chance to go back over it and improve the structure/writing/exposition.
John and David, great post! I'm going to write a reply this week.
Replies from: SharkoRubio↑ comment by Jesse Richardson (SharkoRubio) · 2023-07-06T09:29:45.010Z · LW(p) · GW(p)
Hi EJT, I'm starting research on incomplete preferences / subagents and would love to see this entry too if possible!
Replies from: ElliottThornley↑ comment by EJT (ElliottThornley) · 2023-07-07T18:25:13.685Z · LW(p) · GW(p)
Yep, sent!
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-01-03T22:45:58.251Z · LW(p) · GW(p)
With some probability, John will agree to never veto mushroom -> anchovy trades. With some other probability, David will agree to never veto anchovy -> pepperoni trades.
So, what this might look like in practice (to check my understanding):
Entrepreneur approaches deadlocked bay area nimbys who are all vetoing each other's stuff. Entrepreneur proposes a deal where each party i is supposed to agree to refrain from vetoing [initiative] with probability Xi, for various initiatives. The probabilities are cleverly chosen such that they all think it's a good deal... supposing they all have similar credences, this should be possible, according to this theorem?
comment by Morpheus · 2024-12-10T18:02:29.168Z · LW(p) · GW(p)
This argument against subagents is important and made me genuinely less confused. I love the concrete pizza example and the visual of both agent's utility in this post. Those lead me to actually remember the technical argument when it came up in conversation.
comment by Jesse Richardson (SharkoRubio) · 2023-07-07T12:49:41.101Z · LW(p) · GW(p)
Epistemic Status: Really unsure about a lot of this.
It's not clear to me that the randomization method here is sufficient for the condition of not missing out on sure gains with probability 1.
Scenario: B is preferred to A, but preference gap between A & C and B & C, as in the post.
Suppose both your subagents agree that the only trades that will ever be offered are A->C and C->B. These trades occur with a Poisson distribution, with = 1 for the first trade and = 3 for the second. Any trade that is offered must be immediately declined or accepted. If I understand your logic correctly, this would mean randomizing the preferences such that
= 1/3,
= 1
In the world where one of each trade is offered, the agent always accepts A->C but will only accept C->B 1/3 of the time, thus the whole move from A->B only happens with probability 1/3. So the agent misses out on sure gains with probability 2/3.
In other words, I think you've sufficiently shown that this kind of contract can taken a strongly-incomplete agent and make them not-strongly-incomplete with probability >0 but this is not the same as making them not-strongly-incomplete with probability 1, which seems to me to be necessary for expected utility maximization.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-07-07T15:42:06.232Z · LW(p) · GW(p)
Yeah, the argument is not intended to be "here's the optimal contract/modification to complete the preferences". The argument is roughly:
- If preferences are strongly incomplete, then there exists at least one contract/modification which is a pareto-improvement.
- Therefore, non-dominated strategies must not be strongly incomplete.
So, the argument in the post allows the possibility that the preferences will be completed in some other way which does even better.
comment by Jesse Richardson (SharkoRubio) · 2023-07-06T15:21:18.221Z · LW(p) · GW(p)
Really enjoyed this post, my question is how does this intersect with issues stemming from other VNM axioms e.g. Independence as referenced by Scott Garrabrant?
https://www.lesswrong.com/s/4hmf7rdfuXDJkxhfg/p/Xht9swezkGZLAxBrd [? · GW]
It seems to me that you don't get expected utility maximizers solely from not-strong-Incompleteness, as there are other conditions that are necessary to support that conclusion.
Replies from: johnswentworth↑ comment by johnswentworth · 2023-07-06T15:42:39.763Z · LW(p) · GW(p)
I haven't dug into independence violations much, and don't know what their analogues would be in the context of non-VNM coherence arguments, so I don't know.
Replies from: SharkoRubio↑ comment by Jesse Richardson (SharkoRubio) · 2023-07-06T16:24:09.830Z · LW(p) · GW(p)
Something I have a vague inkling about based on what you and Scott have written is that the same method by which we can rescue the Completeness axiom i.e. via contracts/commitments may also doom the Independence axiom. As in, you can have one of them (under certain premises) but not both?
This may follow rather trivially from the post I linked above so it may just come back to whether that post is 'correct', but it might also be a question of trying to marry/reconcile these two frameworks by some means. I'm hoping to do some research on this area in the next few weeks, let me know if you think it's a dead end I guess!
Replies from: johnswentworth↑ comment by johnswentworth · 2023-07-06T16:43:38.969Z · LW(p) · GW(p)
Huh, sounds cool. Definitely worth investigating.
comment by LVSN · 2023-06-25T07:57:50.071Z · LW(p) · GW(p)
I don't agree that focusing on extrinsic value is less myopic than focusing on intrinsic value. This world is full of false promises, self-delusion, rationalization of reckless commitment, complexity of value, bad incentives/cybernetics, and the fallaciousness of planning. My impression is that the conscientious sort of people who think so much about utility have overconfidence in the world's structural friendliness and are way more screwed than the so-called "myopic" value-focused individuals.