Feedbackloop-first Rationality
post by Raemon · 2023-08-07T17:58:56.349Z · LW · GW · 67 commentsContents
Rationality needs better feedback loops The feedback loop is the primary product My starting loop: Thinking Physics A Spectrum of "Concreteness" Bridging Concreteness from Both Directions A Sketch of an Expensive Plan Building a laboratory for rationality training Reminder: First draft What's next? Questions? None 67 comments
I've been workshopping a new rationality training paradigm. (By "rationality training paradigm", I mean an approach to learning/teaching the skill of "noticing what cognitive strategies are useful, and getting better at them.")
I think the paradigm has promise. I've beta-tested it for a couple weeks. It’s too early to tell if it actually works, but one of my primary goals is to figure out if it works relatively quickly, and give up if it isn’t not delivering.
The goal of this post is to:
- Convey the framework
- See if people find it compelling in its current form
- Solicit ideas for improvements, before I decide whether to invest heavily into a larger experiment around it.
Rationality needs better feedback loops
Claim: Feedback loops are the most important thing ever. Hard things are hard because they have bad feedback loops. Some of the most important things (e.g. x-risk mitigation research) have the worst feedback loops.
Bold prediction: You can learn to think better, even about confusing, poor-feedback domains. This requires developing the art of inventing feedback loops. And then, actually putting in a lot of deliberate practice effort.
I've long been haunted by this Romeo Stevens comment (slightly paraphrased)[1]
Deliberate practice deliberate practice until you get really good identifying good feedback loops, and working with them.
People have a really hard time with interventions often because they literally do not have a functioning causal model of the skill in question. People who apply deliberate practice to a working causal model often level up astonishingly quickly. Don't know if you have the appropriate causal model? Well, when you apply deliberate practice do you not get better? You're pulling on fake levers.
In the past, I've tried to practice thinking. I've done explicit puzzle-solving exercises, and I have a day job that forces me to think about challenging questions on a regular basis. I sometimes have tried to refactor my day-job into something deliberate practice-shaped, but it never gelled.
I think I've gotten better at thinking in the past 12 years. But I haven't gotten overwhelmingly obviously better at thinking. I recently decided to deliberate practicing "solve confusing problems", until I was demonstrably better at it, and to host some workshops where I tried helping other people practice too.
I ended up settling into a paradigm of rationality training with five elements:
- Deliberate Practice. Do challenging cognitive exercises, at the edge of your ability, in a variety of domains, where it's obvious how well you're doing (i.e. clear cut answers, or you're making a metric go up).
- Metacognition. After deciding on the final answer for the exercise and finding out if you got it right, reflect on what you could have done better. Try to extract as much insight/wisdom/tools as you can from each exercise.
- Improve your practice feedback loop. Then, find or design better exercises, that cut more closely to your ultimate goals. Optimize exercises both for being concrete (i.e. you can tell if you succeeded), and for extracting as much insight/tools as possible during the metacognition step (i.e. they are a good difficulty in a domain I haven't already exhausted for insight)
- Improve your real-life feedback loop. Think about what sort of cognitive challenges you run into your day-job or main project, where you're bottlenecked in your ability to reason. How can you do better meta-reflection in those fuzzier, longer-timescale domains?
- Illegible goodness. In addition to the formal structure implied by the previous four bullets, also try random stuff that feels vaguely relevant and helpful, even if it you can't explain why. (I think some previous rationality training approaches leaned too much in this direction, but you still need some illegible goodness IMO)
I think the two biggest concepts here are:
1. Actually do the goddamn practice
2. The feedback loop is the primary product.
This last point is really important so I'm going to say it again in big letters:
The feedback loop is the primary product
In "Feedbackloop-first Rationality Training" you're trying to get the right answers to concrete questions, yes. And you're trying to learn from those answers. But more importantly, you're trying to build an overall better feedback loop for yourself that reliably helps you improve at thinking over time.
Rationality training has some feedback mechanisms, but IMO they kinda suck. They are either short/reliable (but don't super track the things we ultimately care about), or hella long, in a noisy world where random non-rationality effects often dominate.
So I think, at least for me, it makes sense to think of my primary goal as inventing good, short feedback loops that help me point in the right direction. It seems important both individually, as someone aspiring to learn to think better, and collectively, as someone hoping to contribute to the overall Art of Human Rationality project.
I don't know that everyone focused on applied rationality should prioritize this, but I do think it's the most important open problem in the field. I think it'd be worthwhile for everyone working on rationality training to think about this for at least a few days. And, my hope with this post is to excite you and give you some traction on making this a major focus of your rationality-training approach, for awhile, until good feedback loops are no longer the bottleneck.
My starting loop: Thinking Physics
A cognitive feedback loop looks something like this:
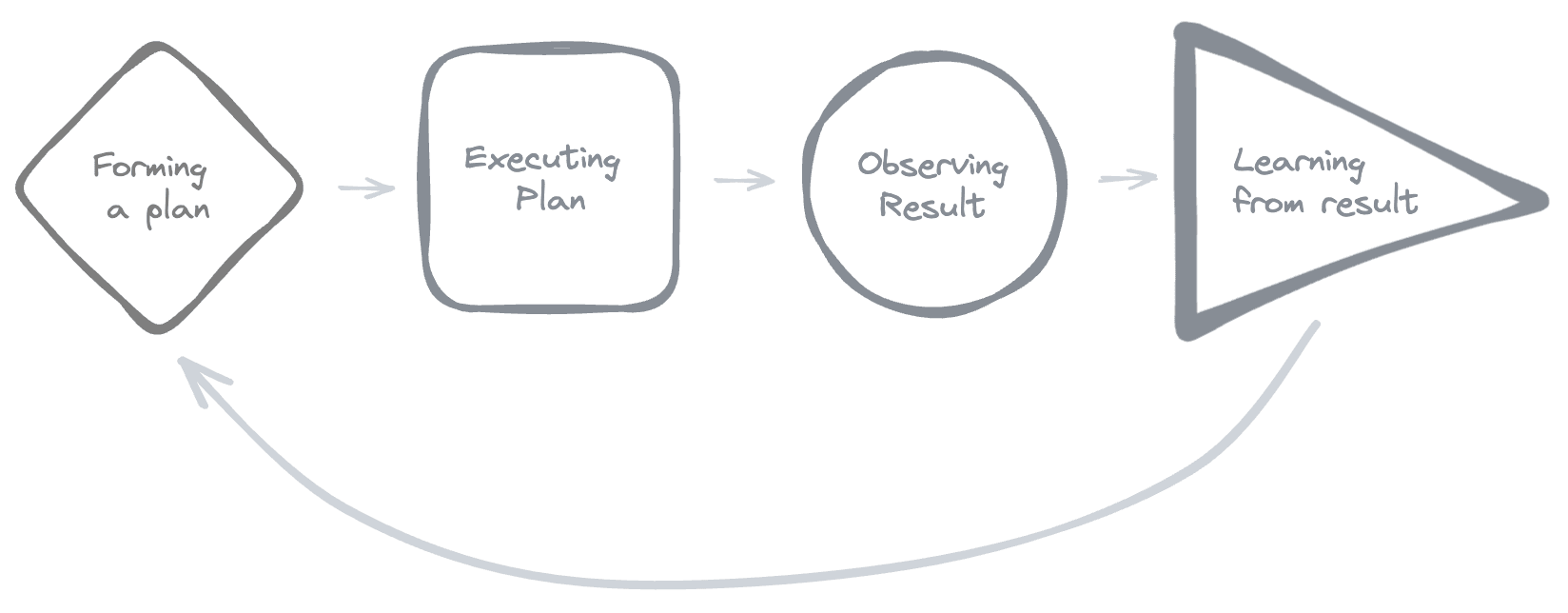
I may write a followup post that delves into "what exactly is a feedback loop, really?" if that seems helpful. But I figured I'd start by just laying out what I concretely did, and seeing what questions or concerns people had.
I started out with the goal of getting better at Thinking Physics [LW · GW] (a collection of physics puzzles, designed such that you can solve them without much formal math or physics background). This involved three nested feedback loops.
The basic loop here was:
- Solve a puzzle. Aim to get the answer right with 95% confidence.
- Reflect on how I could have solved it better.
- Grade myself partly on whether I got the question right, but primarily on whether I learned new stuff about how to think from it.
- Choose a new puzzle to solve (optimizing in part for a challenge that I expect to learn a lot from)
Then, there's an outer loop of checking:
- Am I getting better at solving Thinking Physics puzzles?
Then, a further outer loop of:
- Do I seem to be getting better at my day-job? What other exercises do I expect to most help me on the fuzzy real world problems I work on each day?
A good outcome from feedbackloop-first rationality would be to find a better introductory loop than "random-ish Thinking Physics puzzles". I'm choosing this because it was easily available and I could get started right away, not because I think it'll ultimately be the best thing.
A Spectrum of "Concreteness"
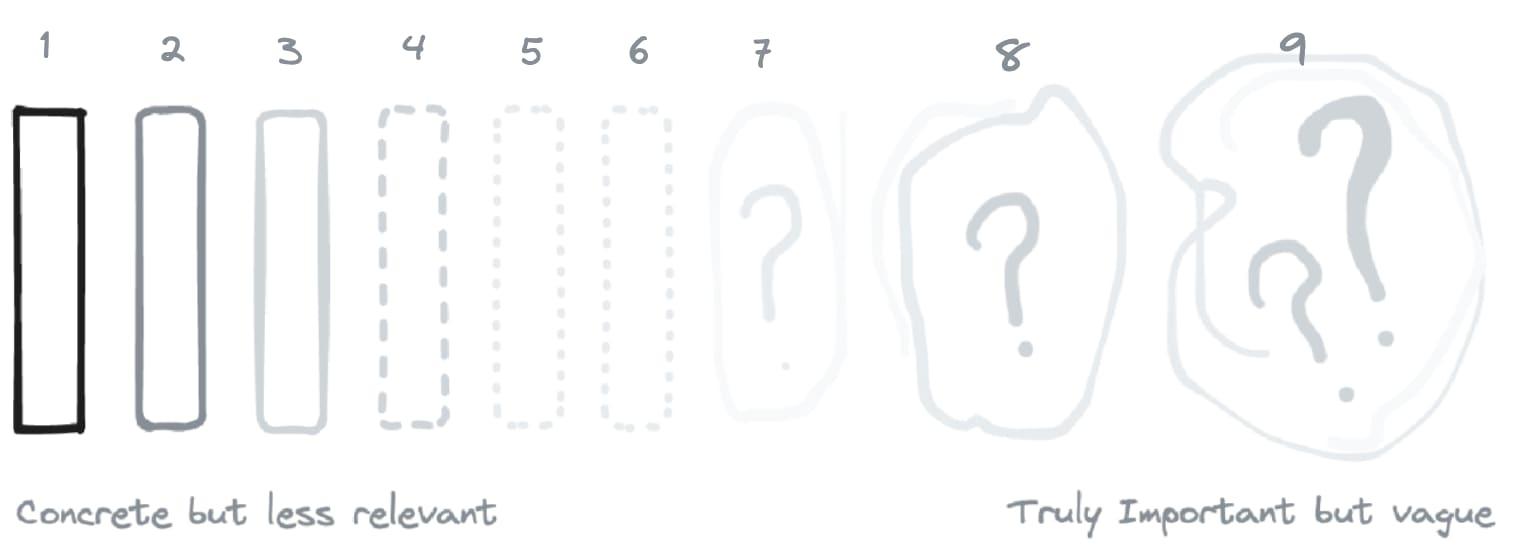
Much of my prior exposure to rationality training came from observing CFAR and Leverage Research. I have an impression that they both approached cognitive training with a mindset of: "Our actual goals are very messy/nuanced. We want good feedback loops, but we don't want to goodhart ourselves and lose sight of our real goal. So let's take our ultimate fuzzy goal, and step backwards towards 'more concreteness', until we something tractable enough that we can work on."
i.e. they started on the right side of this diagram, and took one or two steps to the left.
Leverage's goal was to solve psychology, as part of a broader plan to effect large social change. In the process, they found it was hard to really know anything about what was going on in people's heads, so they worked on developing a better methodology of introspection training to get better data.
I think CFAR initially had a goal of "generally train formidable, clear thinking people [LW · GW]", and tracked progress with some combination of "do the participants seem to understand and find value in the workshop?" and "do they go on to do impressive things later?"
I learned a bunch from both orgs. I use a lot of explicit techniques I learned from each of them pretty frequently. But I feel unsatisfied with how their approaches played out, and I decided this time I wanted to start from the opposite direction.
So I started with the goal of "get good at Thinking Physics to prove I can get good at anything at all". Thinking Physics exercises are towards the left side of the diagram (maybe slot 3). They're closer to my ultimate goal than, say, "memorizing cognitive biases" or "practicing OpenPhil's calibration game", but still many steps away from my day job of "design forum software that helps with intellectual progress or existential risk somehow."
I figured I'd work upwards, towards fuzzier but still semi-grounded exercises. Maybe I'd do short research projects that lasted ~a week, something like that.
Bridging Concreteness from Both Directions
But along the way, I noticed it felt a lot more promising if I also worked backwards from the fuzzier goals.
This particular came up when talking with people who came to my beta-test workshops, who, unlike me, weren't necessarily ready to invest months into a speculative training program. (But, liked the idea of putting a few days of work in).
After solving some physics puzzles, it seemed a useful exercise to ask:
- "How does this connect back to your day job?"
- "What skills transfer or generalize?"
- "What specific skills do you wish you were better at for your day-job, and what exercises would help you get better at them?"
- "If you can't design an explicit exercise, can you at least find a way to integrate more meta-reflection into your day job?"
My current guess is that cognitive training works best if you approach from both ends of the concreteness spectrum. This seems better for reaching a state where we have a smooth feedback gradient from "concrete/less-relevant to "highly-relevant but less concrete" (and, ideally pushing the pareto frontier forward – finding exercises that are strictly more relevant and concrete than the current ones available).
And it also seems better for hitting a medium term goal of "develop a workshop or school that helps people more immediately."
A Sketch of an Expensive Plan
I feel pretty confident in the core hypotheses "actually do the goddamn practice" and "build better feedback loops" being at least pretty useful, and silly not try seriously at least once.
Here is a more speculative plan, to give you some sense of where this is going. I might not stick to this exact plan but it seems like a good starting place.
I'm interested in getting to a place where we can train "research taste in novel domains."
I'm particularly motivated by alignment research. The state of the field is that there are tons of arguments and counterarguments, but the most respected researchers still disagree deeply about many foundational issues. They disagree about what parts will be hard, and what counts as progress, and in many cases "what does good thinking about this look like?"
A central question is whether something in the future that has never happened before will be really important, and we have to get it right on the first try. A particular disagreement in the field is "how valuable are the quick-ish feedback loops of 'align or study current ML systems' to that thing that might-or-might-not-happen in the future?"
Here is a first draft of a fairly expensive plan that seems workable-in-theory, as an "upper level feedback loop to aspire to".
- Find a few different domains that involve difficult-problem-solving, with concrete exercises. They should be as different from each other as possible while satisfying that requirement. Exercises should take at least a couple hours to solve, and possibly up to a couple days.
- Have a large group of people attempt to practice problems from each domain, randomizing the order that they each tackle the problems in. (The ideal version of this takes a few months)
- While the participants work on each problem, they record predictions about whether their current approach is likely to pan out, or turn out to be a dead end.
- As part of each problem, they do meta-reflection on "how to think better", aiming specifically to extract general insights and intuitions. They check what processes seemed to actually lead to the answer, even when they switch to a new domain they haven't studied before.
A primary question I'd want to investigate is whether you can gain a clear sense of which of your intuitions transfer between domains, and then see if you can do better-than-average on new domains that you haven't specifically trained on.
(I might start by having everyone do an IQ test or similar standardized measurement, and again at the end, partly because that just seems generally useful, and partly to allow for some comparisons with other educational literature)
Building a laboratory for rationality training
The overall metric here is "do people who get randomly assigned a problem later in the program do better than people who got assigned that problem earlier in the program." (And, meanwhile also having some control group that doesn't do the whole program)
My hope is that the baseline program turns out to be pretty valuable on it's own (if for no reason other than "~a semester of deliberate practice on novel/confusing problems where you can tell how well you did" reasons), enough that students can come through the program and actively gain something from it... and also, it can make for a good laboratory for aspiring rationality instructors. If you have a technique that you think should help researchers, you can try teaching it to people in this program and see if they do better than baseline.
Reminder: First draft
I don't think this current plan is necessarily great, or exactly what I'd do next. The point of the "Feedbackloop Rationality" focus is to find better (and cheaper) feedback loops.
My next steps would probably include "do some lit-reviews of education literature" and "try one second domain after Thinking Physics and see how it goes." But, I list this comprehensive plan give a sense of where this might be going.
What's next? Questions?
I haven't decided yet whether I'm continuing on this. It'll depend on what other projects the Lightcone team is considering and whether they seem more promising or time-sensitive. It'll also depend on how excited other people are for the project, and whether anyone wants to join in as either a cofounder, or a "serious test subject who puts in full-time effort."
I have some specific ideas for what to do next, but I think I want to start be asking "Does this make sense? Do you have any questions? Can you think of cheaper ways to test the hypotheses here without spending multiple weeks/months of a bunch of smart people's time?"
- ^
This is actually one "definitely real" comment combined with another comment I vaguely remember and which he responded positively about when I sort-of-quoted him later in the thread.
67 comments
Comments sorted by top scores.
comment by niplav · 2023-08-08T21:24:41.414Z · LW(p) · GW(p)
Oh nice, another post I don't need to write anymore :-D
Some disjointed thoughts on this I had:
Feedback loops can be characterized along at least three axes:
- Speed: How quickly you get feedback from actions you take. Archery has a very fast feedback loop: You shoot an arrow and one or two seconds later you see what the outcome is.
- Noise: How noisy the feedback is. High-frequency trading has fast feedback loops, but they have a lot of noise, and finding the signal is the difficult part.
- Richness: How much information you're getting. Dating is one example: Online dating has extremely poor feedback loops: only a couple of bits (did the other person respond, what did they respond) per interaction, while talking & flirting with people in person has extremely rich feedback (the entire visual+acustic+sensory field (plus perhaps smell? Don't know much about human pheromones))—probably kilobytes per minimal motor-action, and megabytes per second.
Fast & low-noise & rich feedback loops are the best, and improving the feedback loop in any of those dimensions is super valuable.
As an example, forecasting has meh feedback loops: they can be very slow (days at least, but more likely months or years (!)), the feedback is kind of poor (only a few bits per forecast), but at least there's not that much noise (you forecast what the question says, but maybe this is why forecasters really don't like questions resolving on technicalities—the closest thing to noise).
But one can improve the richness of the forecasting feedback loop by writing out ones reasoning, so one can update on the entire chain of thought once the resolution comes. Similarly, programming has much better feedback loops than mathematics, which is why I'd recommend that someone learn programming before math (in general learn things with fast & rich feedback loops earlier and slow & poor ones later).
Also, feedback loops feel to me like they're in the neighbourhood of both flow & addiction? Maybe flow is a feedback loop with a constant or increasing gradient, while addiction is a feedback loop with a decreasing gradient (leading into a local & shallow minimum).
When I started reading the Sequences, I started doing forecasting on Metaculus within 3 months (while still reading them). I think being grounded at that time in actually having to do reasoning with probabilities & receiving feedback in the span of weeks made the experience of reading the Sequences much more lasting to me. I also think that the lack of focus on any rationality verification [LW · GW] made it significantly harder to develop an art of rationality. If you have a metric you have something to grind on, even if you abandon it later.
Replies from: niplav, arash-arbabi-1↑ comment by niplav · 2023-08-09T07:47:27.577Z · LW(p) · GW(p)
Corollary: It'd probably be much better if people used proof assistants like Lean or Coq to teach mathematics. There is some overhead, sure, but they have much better feedback loops than normal mathematics.
Replies from: niclas-kupper↑ comment by Niclas Kupper (niclas-kupper) · 2023-08-09T12:18:24.580Z · LW(p) · GW(p)
As someone who is currently getting a PhD in mathematics I wish I could use Lean. The main problem for me is that the area I work in hasn't been formalized in Lean yet. I tried for like a week, but didn't get very far... I only managed to implement the definition of Poisson point process (kinda). I concluded that it wasn't worth spending my time to create this feedback loop and I'd rather work based on vibes.
I am jealous of the next generation of mathematicians that are forced to write down everything using formal verification. They will be better than the current generation.
↑ comment by Mo Putera (Mo Nastri) · 2023-08-26T05:49:43.984Z · LW(p) · GW(p)
In a slightly different direction than proof assistants, I'm reminded of Terry Tao's recent experience trying out GPT-4 to play the role of collaborator:
As I noted at this MathOverflow answer (with a concurrence by Bill Thurston), one of the most intellectually satisfying experiences as a research mathematician is interacting at the blackboard with one or more human co-authors who are exactly on the same wavelength as oneself while working collaboratively on the same problem. I do look forward to the day that I can have a similar conversation with an AI attuned to my way of thinking, or (in the more distant future) talking to an attuned AI version of a human colleague when that human colleague is not available for whatever reason. (Though in the latter case there are some non-trivial issues regarding security, privacy, intellectual property, liability, etc. that would likely need to be resolved first before such public AI avatars could be safely deployed.)
I have experimented with prompting GPT-4 to play the role of precisely such a collaborator on a test problem, with the AI instructed to suggest techniques and directions rather than to directly attempt solve the problem (which the current state-of-the-art LLMs are still quite terrible at). Thus far, the results have been only mildly promising; the AI collaborator certainly serves as an enthusiastic sounding board, and can sometimes suggest relevant references or potential things to try, though in most cases these are references and ideas that I was already aware of and could already evaluate, and were also mixed in with some less relevant citations and strategies. But I could see this style of prompting being useful for a more junior researcher, or someone such as myself exploring an area further from my own area of expertise. And there have been a few times now where this tool has suggested to me a concept that was relevant to the problem in a non-obvious fashion, even if it was not able to coherently state why it was in fact relevant. So while it certainly isn’t at the level of a genuinely competent collaborator yet, it does have potential to evolve into one as the technology improves (and is integrated with further tools, as I describe in my article).
Terry sounded more enthusiastic here:
I could feed GPT-4 the first few PDF pages of a recent math preprint and get it to generate a half-dozen intelligent questions that an expert attending a talk on the preprint could ask. I plan to use variants of such prompts to prepare my future presentations or to begin reading a technically complex paper. Initially, I labored to make the prompts as precise as possible, based on experience with programming or scripting languages. Eventually the best results came when I unlearned that caution and simply threw lots of raw text at the AI. ...
I now routinely use GPT-4 to answer casual and vaguely phrased questions that I would previously have attempted with a carefully prepared search-engine query. I have asked it to suggest first drafts of complex documents I had to write.
Which isn't to say that his experience has been all positive; the usual hallucination issues still crop up:
Current large language models (LLM) can often persuasively mimic correct expert response in a given knowledge domain (such as my own, research mathematics). But as is infamously known, the response often consists of nonsense when inspected closely. Both humans and AI need to develop skills to analyze this new type of text. The stylistic signals that I traditionally rely on to “smell out” a hopelessly incorrect math argument are of little use with LLM-generated mathematics. Only line-by-line reading can discern if there is any substance. Strangely, even nonsensical LLM-generated math often references relevant concepts. With effort, human experts can modify ideas that do not work as presented into a correct and original argument.
And going back to proof assistants:
One related direction where some progress is likely to be made in the near future is in using LLMs to semi-automate some aspects of formalizing a mathematical proof in a formal language such as Lean; see this recent talk by Jason Rute for a survey of the current state of the art. There are already some isolated examples in which a research paper is submitted in conjunction with a formally verified version of the proofs, and these new tools may make this practice more common. One could imagine journals offering an expedited refereeing process for such certified submissions in the near future, as the referee is freed to focus on other aspects of the paper such as exposition and impact.
↑ comment by pf · 2023-08-11T02:08:38.403Z · LW(p) · GW(p)
Consider sharing more details at the Lean Zulip chat - they enjoy hearing about unformalized areas.
↑ comment by ATheCoder (arash-arbabi-1) · 2023-08-30T22:34:11.390Z · LW(p) · GW(p)
I think it would be interesting to discover/teach general heuristics on how to improve each axis respectively.
A side note here: I have always thought about why people (myself included) prefer to do certain things (such as playing video games/watching movies/etc) to doing other things (such as reading research papers, solving novel problems in science, etc). When I play a strategy game I am solving problems and when I am doing AI research I am still solving problems. I love doing them both, but there is a part of me (The devil side ?) that prefers to play strategy games to doing AI research for my master's. Even though both require intense focus and utilize a lot of system 2 thinking, meaning need a lot will power. I have been thinking about this a lot. I think this is mainly because the feedback loop for playing a strategy game is:
- Faster because each match takes about 1 - 2 hours in contrast to research which takes at least a day to see the results of a single experiment.
- Less Noisy because you directly experience the results of your actions. This is even more true in FPS games. This is more true in 1v1 video games compared to team based video games and is in contrast to academic research where your result is dependent on open-source software, coordination with your professor, academic politics, etc.
- More rich because there are tons of video game graphics involved. e.g: You can see your score going up or down directly and don't need to track it yourself. In contrast to research where you have to track everything yourself and the graphics and diagrams are pretty dull.
I think people working in video game design with the goal of making video games that are more rewarding and addictive can provide some insights into heuristics for improving each of the axes.
comment by aysja · 2023-08-10T21:46:53.938Z · LW(p) · GW(p)
Meta: I have some gripes about the feedback loop focus in rationality culture, and I think this comment unfairly mixes a bunch of my thoughts about this topic in general with my thoughts in response to this post in particular—sorry in advance for that. I wish I was better at delineating between them, but that turned out to be kind of hard, and I have limited time and so on…
It is quite hard to argue against feedback loops in their broadest scope because it’s like arguing against updating on reality at all and that’s, as some might say, the core thing we’re about here. E.g., reflecting on your thought processes and updating them seems broadly good to me.
The thing that I feel more gripe-y about is something in the vicinity of these two claims: 1) Feedback loops work especially well in some domains (e.g., engineering) and poorly in others (e.g., early science). 2) Alignment, to the extent that it is a science, is early stage and using a feedback loop first mentality here seems actively harmful to me.
Where do feedback loops work well? Feedback loops (in particular, negative feedback loops), as they were originally construed, consist of a “goal state,” a way of checking whether your system is in line with the goal state or not, and a way of changing the current state (so as to eventually align it with the goal state). This setup is very back-chain focused. It assumes that you know what the target is and it assumes that you can progressively home in on it (i.e., converge on a particular state).
This works especially well in, e.g., engineering applications, where you have an end product in mind and you are trying out different strategies to get there. But one of the main difficulties with early stage science is that you don’t know what you’re aiming at, and this process seems (to me) to consist more of expanding the possibility space through exploration (i.e., hypothesis generation is about creating, not cleaving) rather than winnowing it.
For instance, it’s hard for me to imagine how the feedback loop first approach would have made Darwin much faster at noticing that species “gradually become modified.” This wasn’t even in his hypothesis space when he started his voyage on the Beagle (he assumed, like almost all other naturalists, that species were independently created and permanent). Like, it’s true that Darwin was employing feedback loops in other ways (e.g., trying to predict what rock formations would be like before he arrived there), and I buy that this sort of scientific eye may have helped him notice subtle differences that other people missed.
But what sort of feedback should he have used to arrive at the novel thought that species changed, when that wasn’t even on his radar to begin with? And what sort of training would make someone better at this? It doesn’t seem to me like practicing thinking via things like Thinking Physics questions is really the thing here, where, e.g., the right question has already been formulated. The whole deal with early stage science, imo, is in figuring out how to ask the right questions in the first place, without access to what the correct variables and relationships are beforehand. (I’m not saying there is no way to improve at this skill, or to practice it, I just have my doubts that a feedback loop first approach is the right one, here).
Where (and why) feedback loops are actively harmful. Basically, I think a feedback loop first approach overemphasizes legibility which incentivizes either a) pretending that things are legible where they aren’t and/or b) filtering out domains with high illegibility. As you can probably guess, I think early science is high on the axis of illegibility, and I worry that focusing too hard on feedback loops either a) causes people to dismiss the activity or b) causes people to prematurely formalize their work.
I think that one of the main things that sets early stage scientific work apart from other things, and what makes it especially difficult, is that it often requires holding onto confusion for a very long time (on the order of years). And usually that confusion is not well-formed, since if it were the path forward would be much more obvious. Which means that the confusion is often hard to communicate to other people, i.e., it’s illegible.
This is a pretty tricky situation for a human to be in. It means that a) barely anyone, and sometimes no one, has any idea what you’re doing and to the extent they do, they think that it’s probably pointless or doomed, b) this makes getting money is a bunch harder, and c) it is psychologically taxing for most people to be in a state of confusion—in general, people like feeling like they understand what’s going on. In other words, the overwhelming incentive is just to do the easily communicable thing, and it takes something quite abnormal for a human to spend years on a project that doesn’t have a specific end goal, and little to no outside-view legible progress.
I think that the thing which usually supports this kind of sustained isolation is an intense curiosity and an obsession with the subject (e.g., Paul Graham’s bus ticket theory), and an inside view sense that your leads are promising. These are the qualities (aside from g) that I suspect strongly contribute to early stage scientific progress and I don’t think they’re ones that you train via feedback loops, at least not as the direct focus, so much as playful thinking [LW · GW], boggling, and so on.
More than that, though, I suspect that a feedback loop first focus is actively harmful here. Feedback loops ask people to make their objectives clear-cut. But sort of the whole point of early science is that we don’t know how to talk about the concepts correctly yet (nor how to formalize the right questions or objectives). So the incentive, here, is to cut off confusion too early, e.g., by rounding it off to the closest formalized concept and moving on. This sucks! Prematurely formalizing is harmful when the main difficulty of early science is in holding onto confusion, and only articulating it when it’s clear that it is carving the world correctly.
To make a very bold and under-defended claim: I think this is a large part of the reason why a lot of science sucks now—people began mistaking the outcome (crisp, formalized principles) for the process, and now research isn’t “real” unless it has math in it. But most of the field-founding books (e.g., Darwin, Carnot) have zero or close to zero math! It is, in my opinion, a big mistake to throw formalizations at things before you know what the things are, much like it is a mistake to pick legible benchmarks before you know what you want a benchmark for.
Alignment is early stage science. I feel like this claim is obvious enough to not need defending but, e.g., we don’t know what any of the concepts are in any remotely precise (and agreed upon) sense: intelligence, optimization, agency, situational awareness, deception, and so on… This is distinct from saying that we need to solve alignment through science, e.g., it could be that alignment is super easy, or that engineering efforts are enough. But to the extent that we are trying to tackle alignment as a natural science, I think it’s safe to say it is in its infancy.
I don’t want feedback loop first culture to become the norm for this sort of work, for the reasons I outlined above (it’s also the sort of work I personally feel most excited about for making progress on the problem). So, the main point of this comment is like “yes, this seems good in certain contexts, but please let’s not overdo it here, nor have our expectations set that it ought to be the norm of what happens in the early stages of science (of which alignment is a member).”
Replies from: Raemon, adam_scholl↑ comment by Raemon · 2023-08-11T01:07:18.881Z · LW(p) · GW(p)
So I agree with all the knobs-on-the-equation you and Adam are bringing up. I've spent a lot of time pushing for LessWrong to be a place where people feel more free to explore early stage ideas without having to justify them at every step.
I stand by my claim, although a) I want to clarify some detail about what I'm actually claiming, b) after clarifying, I expect we'll still disagree, albeit for somewhat vague aesthetic-sense reasons, but I think my disagreement is important.
Main Clarifications:
- This post is primarily talking about training, rather than executing. (although I'll say more nuanced things in a bit). i.e. yes you definitely don't want to goodhart your actual research process on "what makes for a good feedback loop?". The topic of this post is "how can we develop better training methods for fuzzy, early stage science?"
- Reminder that a central claim here is that Thinking Physics style problems are inadequate. In 6 months, if feedbackloop-rationality hadn't resulted in a much better set of exercises/feedbackloops than thinking physics puzzles, I'd regard it as failing and I'd probably give up. (I wouldn't give up at 6 months if I thought we had more time, but it'd have become clear at least that this isn't obviously easier than just directly working on the alignment problem itself rather than going meta-on it)
It sounds like you're worried about the impact of this being "people who might have curiously, openendedly approached alignment instead Goodhart on something concrete and feedbackloop-able".
But a major motivation of mine here is that I think that failure mode is already happening by default – IMO, people are gravitating towards "do stuff in ML with clearer feedback-loops because it's easier to demonstrate you're doing something at least plausibly 'real' there", while failing to engage with the harder problems that actually need solving. And meanwhile, maybe contributing to capabilities advances that are net-negative.
So one of my goals here is to help provide traction on how to think in more openended domains, such that it's possible to do anything other than either "gravitate towards high-feedback approaches" or "pick a direction to curiously explore for months/years and... hope it turns out you have good research taste / you won-the-bus-ticket-lottery?"
If those were the only two approaches, I think "have a whole bunch of people do Option B and hope some of them win the research-taste-lottery" would be among my strategies, but it seems like something we should be pretty sad about.
I agree that if you're limiting yourself to "what has good feedbackloops", you get a Goodharty outcome, but the central claim here is "actually, it's just real important to learn how to invent better feedback loops." And that includes figuring out how to take fuzzy things and operationalize them without losing what was actually important about them. And yeah that's hard, but it seems at least not harder than solving Alignment in the first place (and IMO it just seems pretty tractable? It seems "relatively straightforward" to design exercises for, it's just that it'd take awhile to design enough exercises to make a full fledged training program + test set)
Replies from: Raemon↑ comment by Raemon · 2023-08-11T01:54:04.802Z · LW(p) · GW(p)
(Put another way: I would be extremely surprised if you and Adam spent a day thinking about "okay, what sort of feedbackloops would actually be good, given what we believe about how early stage science works?" and you didn't come up with anything that didn't seem worth trying, by both your lights and mine)
↑ comment by Adam Scholl (adam_scholl) · 2023-08-10T22:34:28.527Z · LW(p) · GW(p)
Yeah, my impression is similarly that focus on feedback loops is closer to "the core thing that's gone wrong so far with alignment research," than to "the core thing that's been missing." I wouldn't normally put it this way, since I think many types of feedback loops are great, and since obviously in the end alignment research is useless unless it helps us better engineer AI systems in the actual territory, etc.
(And also because some examples of focus on tight feedback loops, like Faraday's research, strike me as exceedingly excellent, although I haven't really figured out yet why his work seems so much closer to the spirit we need than e.g. thinking physics problems).
Like, all else equal, it clearly seems better to have better empirical feedback; I think my objection is mostly that in practice, focus on this seems to lead people to premature formalization, or to otherwise constraining their lines of inquiry to those whose steps are easy to explain/justify along the way.
Another way to put this: most examples I've seen of people trying to practice attending to tight feedback have involved them focusing on trivial problems, like simple video games or toy already-solved science problems, and I think this isn't a coincidence. So while I share your sense Raemon that transfer learning seems possible here, my guess is that this sort of practice mostly transfers within the domain of other trivial problems, where solutions (or at least methods for locating solutions) are already known, and hence where it's easy to verify you're making progress along the way.
Replies from: Raemon, Raemon↑ comment by Raemon · 2023-08-11T01:23:52.442Z · LW(p) · GW(p)
Another way to put this: most examples I've seen of people trying to practice attending to tight feedback have involved them focusing on trivial problems, like simple video games or toy already-solved science problems
One thing is I just... haven't actually seen instances of feedbackloops on already-solved-science-problems being used? Maybe they are used and I haven't run into them. but I've barely heard of anyone tackling exercises with the frame "get 95% accuracy on Thinking-Physics-esque problems, taking as long as you want to think, where the primary thing you're grading yourself on is 'did you invent better ways of thinking?'". So it seemed like the obvious place to start.
↑ comment by Raemon · 2023-08-11T00:51:52.584Z · LW(p) · GW(p)
(And also because some examples of focus on tight feedback loops, like Faraday's research, strike me as exceedingly excellent, although I haven't really figured out yet why his work seems so much closer to the spirit we need than e.g. thinking physics problems).
Can you say more about what you mean here?
Replies from: adam_scholl↑ comment by Adam Scholl (adam_scholl) · 2023-08-11T05:51:09.788Z · LW(p) · GW(p)
I just meant that Faraday's research strikes me as counterevidence for the claim I was making—he had excellent feedback loops, yet also seems to me to have had excellent pre-paradigmatic research taste/next-question-generating skill of the sort my prior suggests generally trades off against strong focus on quickly-checkable claims. So maybe my prior is missing something!
comment by Elizabeth (pktechgirl) · 2023-08-07T20:08:38.062Z · LW(p) · GW(p)
I tested a version of this for like 2 consecutive hours on a puzzle video game (Snakebird) and learned a surprising amount, if I didn't have a strong commitment this week I'd be devoting a few days to it.
The original instruction was to plan out all my actions ahead of time, and not proceed until I was sure. I'd previously played Snakebird in late 2019 and beaten the core game, but not the bonus levels.
Things I noticed in two hours:
- Realized I don’t have to plan the most efficient route, any route will do
- Got better at chunking things
- Realized I wanted to backwards engineer failures
- Redoing puzzles I'd beaten a minute ago was surpisingly helpful/it was shocking how much i forgot seconds after finishing it. I think this might be because my RAM was so overloaded I couldn't transfer the knowledge.
- Recognizing the feeling over overload/quitting.
- I want to work on both recognizing how full the meter is before I get overloaded, and of course increasing capacity.
- Goddamnit I worked so hard to run at reality head first instead of being in my head all the time and now I have to go back?
↑ comment by Elizabeth (pktechgirl) · 2023-08-13T21:40:25.783Z · LW(p) · GW(p)
I fit in a 10? hours around my core commitment. After the first few levels I tried the bonus levels- still absolutely impossible. After level 30 (of 40) this round I tried again, and beat all six bonus levels over ~3 days.
For those 30 puzzles I tried to pay some attention to process, but it was dominantly a leisure activity so I didn't push hard on this and wasn't strict about forming a complete plan before making my first move.
Raemon suggested something like "notes to past myself on principles for solving a level" (as opposed to listing specific moves), as a test for if I was drawing useful general lessons. This turned out to be surprisingly easy to test because I was so bad at remembering solution to puzzles even minutes after solving them. The notes were of mixed efficacy, but sometimes noticing what I'd missed let me draw more useful conclusions the second time around. .
Replies from: MondSemmel, rhollerith_dot_com↑ comment by MondSemmel · 2023-08-17T09:49:10.855Z · LW(p) · GW(p)
A tip for note-taking while playing Steam games (though I don't know if you played Snakebird on Steam or on the phone): A recent Steam update added an in-game note-taking widget to the Steam overlay (opened via Shift+Tab -> pencil icon). So you can take game-specific notes, and even pin a semi-transparent notes widget over the game.
(Of course one can always tab out of games, or play them in windowed mode, and take notes in a separate app. But the Steam method works even in fullscreen games, plus it automatically stores the game notes with the game in question.)
Anyway, this on-screen note-taking could be used both to document game insights, or to display a "training" checklist. For example: "here's a checklist of what I want to focus on wrt feedback loops".
↑ comment by RHollerith (rhollerith_dot_com) · 2023-08-13T22:02:19.302Z · LW(p) · GW(p)
I can learn something (become more capable at a task) without being able to describe in words what I learned unless I spend much more time and effort to create the verbal description than I spent to learn the thing. I've seen this happen enough times that it is very unlikely that I am mistaken although I haven't observed how other people learn things closely enough to know whether what I just said generalizes to other people.
This has happened when I've learned a new skill in math, philosophy or "self-psychotherapy" i.e., it is not restricted to those skills (e.g., how to lift weights while minimizing the risk of injury) in which the advantage of a non-verbal means of communication (e.g., video) is obvious.
Something you just wrote makes me wonder whether what I just described is foreign to you.
comment by Hastings (hastings-greer) · 2023-08-09T20:13:53.241Z · LW(p) · GW(p)
Alignment is hard in part because the subject of alignment will optimize, and optimization drives toward corner cases.
“Solve thinking physics problems” or “grind leetcode” is a great problem, but it lacks hard optimization pressure, so it will be missing some of this edge caseish- “spice.”
Alignment is “one shot, design a system that performs under ~superhuman optimization pressure.” There are a couple professional problems in this category with fast feedback loops:
- Design a javascript engine with no security holes
- Design an MTG set without format-breaking combos
- Design a tax code
- Write a Cryptocurrency However, these all use a live source of superhuman optimization, and so would be prohibitively expensive to practice against.
The sort of dual to the above category is “exert superhuman optimization pressure on a system”. This dual can be made fast feedbackable more cheaply: “(optionally one shot) design a solution that is competitive with preexisting optimized solutions”
- Design a gravity powered machine that can launch an 8 lb pumpkin as far as possible, with a budget of 5k (WCPC rules)
- Design an entry in a Codingame AI contest (I recommend Coders Strike Back) that will place in the top 10 of legends league
- Design a fast global illumination program
- Exploit a tax code /cryptocurrency/javascript engine/mtg format
If fast feedback gets a team generally good at these, then they can at least red team harder.
Replies from: Raemon, zrkrlc↑ comment by Raemon · 2023-08-11T01:33:49.870Z · LW(p) · GW(p)
Yeah I like this train of thought.
I don't think your first five examples work exactly for "exercises" (they're a pretty long spin-up process before you can even work on them, and I don't know that I agree the feedback loops are even that good? i.e. you probably only get to design one tax-code-iteration per year?)
But I think looking for places with adversarial optimization pressure and figuring out how to make them more feedbackloop-able is a good place to go.
This also updated me that a place I might want to seek out alignment researchers are people with a background in at least two domains that involve this sort of adversarial pressure, so they'll have an easier time triangulating "how does optimization apply in the domain of alignment?".
↑ comment by junk heap homotopy (zrkrlc) · 2023-08-12T06:22:49.690Z · LW(p) · GW(p)
There's this tension between what I know from the literature (i.e. transfer learning is basically impossible) and my lived experience that I and a handful of the people I know in real life whom I have examined in depth are able to quickly apply e.g. thermodynamics concepts to designing software systems, or how consuming political fiction has increased my capacity to model equilibrium strategies in social situations. Hell, this entire website was built on the back of HPMoR, which is an explicit attempt to teach rationality by reading about it.
The point other people have made about alignment research being highly nebulous is important but irrelevant. You simply cannot advance the frontiers of a field without mastery of some technique or skill (or a combination thereof) that puts you in a spot where you can do things that were impossible before, like how Rosalind Franklin needed some mastery of x-ray crystallography to be able to image the DNA.
Research also seems to be another skill that's trainable or at least has trainable parts. If for example the bottleneck is sheer research output, I can imagine a game where you just output as many shitty papers as possible in a bounded period of time would let people write more papers ceteris paribus afterwards. Or even at the level of paragraphs even: one could play a game of "Here's 10 random papers outside your field with the titles, authors, and publication year removed. Guess how many citations they got." to develop one's nose for what makes a paper impactful, or "Write the abstract of this paper." to get better at distillation.
comment by Screwtape · 2024-12-31T23:58:06.878Z · LW(p) · GW(p)
The thing I want most from LessWrong and the Rationality Community writ large is the martial art of rationality. That was the Sequences post that hooked me, that is the thing I personally want to find if it exists. Therefore, posts that are actually trying to build a real art of rationality (or warn of failed approaches) are the kind of thing I'm going to pay attention to, and if they look like they actually might work I'm going to strongly vote for including them in the Best Of LessWrong collection.
Feedbackloop-first Rationality sure looks like an actual attempt at solving the problem. It lays out a strategy, the plan seems like it plausibly might work, and there's followup workshops that suggest some people are actually willing to spend money on this; that's not a clear indicator that it works (people spend money on all kinds of things) but it is significantly more than armchair theorizing.
If Raemon keeps working on this and is successful, I expect we'll see some testable results. If, say, the graduates or regular practitioners turn out to be able to confidently one-shot Thinking Physics style problems while demographically matched people stumble around, that'll be a Hot Dang Look At That Chart result at least in the toy problems. If they go on to solve novel, real world problems, then that's a clear suggestion this works.
There's two branches of followup I'd like to see. One, Raemon's already been doing; running more workshops teaching this, teasing out useful subskills to teach, and writing up how how to run exercises and what the subskills are. The second is evaluations. If Raemon's keeping track of students and people who considered going but didn't, I'd love to see a report on how both sets are doing in a year or two. I'm also tempted to ask on future community censuses whether people have done Feedbackloop-first Rationality workshops (["Yes under Raemon", "Yes by other people based on this", "no"] and then throw a timed Thinking Physics-style problem at them, see if there's any signal to pick up.
Mostly, I really want people to keep trying things in this genre of finding techniques and trainings to make better decisions. I want them to keep writing up what they're trying, what works, and what doesn't. If LessWrong stops having space for that in our Best Of collection, or has nobody in the community trying things like that, then I think something somewhere went badly wrong.
Thank you for your work Raemon!
comment by Raemon · 2023-08-07T18:41:43.246Z · LW(p) · GW(p)
Something that came up a bit, but felt like too in-the-weeds for the main post, is a number of people expressing skepticism about transfer-learning that would carry over to new domains.
I haven't looked deeply into it yet, but my understanding is something like "past attempts at training transfer learning haven't really worked or replicated", or "complicated schemes to do so don't seem better than simple ones." This seems important to look into and understand the context of. It's not exactly a crux for me – I'm driven more by a general intuition that "surely deliberate practicing thinking is at least somewhat useful, and we should find out how useful?" than about my specific model of how you could train transfer thinking-about-novel-domains.
But I also just... roll to disbelieve on this sort of thing not working? It just seems so fucking weird to me if deliberate practice + metacognition + learning general tools [LW · GW] couldn't enable you to improve in detectable ways. (it's not weird to me if plenty of people vaguely try deliberate practice + metacognition and fail, and it's not too weird if it really does take like 20 years to figure it out, but it'd be quite weird to me if an adequately resourced group who were intelligently iterating on their approach couldn't figure it out)
Replies from: pktechgirl, Ivilivilly↑ comment by Elizabeth (pktechgirl) · 2023-08-07T19:57:19.930Z · LW(p) · GW(p)
Some reasons I believe transfer learning can happen:
- When I did martial arts as an adult, the instructors could spot people with previous experience with martial arts, dance, yoga, or gymnastics. I remember at least three true positive predictions, and no false positives or negatives, although I could have missed them.
- This wasn't true for other physical activities, like football or track, so it wasn't raw athleticism.
- As a child my karate teacher advised us to try gymnastics, to improve karate.
- I hear about football players being sent to do dance to aid football, but not the reverse.
- Inside view, I know I learned skills like and "balance" from yoga and then applied it in dance and martial arts.
- Dancers report their skills transfer between dances, but not symmetrically, some dances are much better foundations than others.
- Everytime I hear a polyglot talk, they say languages start to get easier around the fourth one, and by 10 they're collecting them like pokemon.
Some things I think are broadly useful, although you can argue about if they are literally transfer learning or merely very widely applicable skills:
- thinking through problems step by step
- chunking problems to reduce RAM demands
- noticing when I actually understand something, versus merely think I do or could pass a test
- knowing how to space repetition
- somatic skills:
- balance
- Is this good, muscle-building pain, or bad, tendon-tearing pain?
- Is this gentle stretching or am I gonna tear a tendon again?
- watch a novel movement you haven't seen before and turn it into muscle commands
- copy a novel movement maintaining L-R instead of mirroring
- translate verbal instructions into novel muscle movements
- read quickly without losing comprehension
- experimental design + analysis
↑ comment by Elizabeth (pktechgirl) · 2023-08-07T23:42:40.668Z · LW(p) · GW(p)
Update: I tested snakebird [LW(p) · GW(p)]on three people: one hardcore math person who delights in solving math puzzles in his head (but hadn't done many puzzle games), one unusually mathy social science type, one generalist (who had played snakebird before). Of these, the hardcore math guy blew the others away. He picked up rules faster, had more endurance, and was much more likely to actually one shot, including after skipping 20 levels ahead.
Replies from: Raemon, brayden-smith↑ comment by Raemon · 2023-08-07T23:52:47.473Z · LW(p) · GW(p)
Reminds me of video games > IQ tests [LW · GW]
Replies from: Raemon↑ comment by Raemon · 2023-08-08T00:30:43.238Z · LW(p) · GW(p)
But, also maybe more interestingly/importantly: I'm interested in having the Real Smart People walk through what their process is actually like, and see if they're doing things differently that other people can learn. (Presumably this is also something there's some literature on?)
Replies from: P.↑ comment by P. · 2023-08-08T19:46:20.333Z · LW(p) · GW(p)
Came here to comment that. It seems much more efficient to learn the cognitive strategies smart people use than to try to figure them out from scratch. Ideally, you would have people of different skill levels solve problems (and maybe even do research) while thinking out loud and describing or drawing the images they are manipulating. I know this has been done at least for chess, and it would be nice to have it for domains with more structure. Then you could catalog these strategies and measure the effectiveness of teaching the system 2 process (the whole process they use, not only the winning path) and explicitly train in isolation the individual system 1 steps that make it up.
Replies from: Raemon↑ comment by Raemon · 2023-08-08T20:03:47.746Z · LW(p) · GW(p)
Yeah, although notably: the goal here is to become confidently good at solving domains where there are no established experts (with the motivating case being AI alignment, though I think lots of high-impact-but-vague fields are relevant). I think this does require developing the ability to invent new ways of thinking, and check for yourself which ways of thinking apply to a situation.
I think the optimal curriculum will include some amount of learning-for-yourself and some amount of learning from others.
↑ comment by BrSm (brayden-smith) · 2023-08-09T02:01:22.372Z · LW(p) · GW(p)
This might be confusing the cart with the horse though, since this doesn't control for IQ. A person with a high IQ might be more attracted to math because of it's relative ease and also be able to pick up specific cognitive skills faster (i.e. being able to play snakebird well). In other words, correlation doesn't imply causation.
↑ comment by BrSm (brayden-smith) · 2023-08-09T01:57:52.481Z · LW(p) · GW(p)
Transfer learning isn't what is controversial, it is far and/or general transfer to many different domains which is controversial. There is no verified method of raising general intelligence, for example.
Replies from: Raemon↑ comment by Raemon · 2023-08-09T18:59:38.085Z · LW(p) · GW(p)
Do you have any pointers to what you mean? (i.e. sources that demonstrate "not particularly general transfer?" or "explicitly not working in the general case")
Part of why I feel optimistic is I'm specifically trying to learn/teach/enable skills in a set-of-domains that seem at least fairly related, i.e. research taste in novel, technical domains, and I'd expect "weak transfer learning" to be good enough to matter without making any claims about "general transfer learning."
(I separately guess it should be possible to train at general transfer learning but it should require training at a pretty wide variety of skills, at which point it's actually kinda unclear whether mechanistically what's happening is "lots of transfer between related skills" vs "raising general intelligence factor")
↑ comment by Ivilivilly · 2023-08-08T07:22:51.580Z · LW(p) · GW(p)
Even if transfer learning is a thing that could work, in any given domain that doesn't have terrible feedback loops, would it not be more efficient to just apply the deliberate practice and metacognition to the domain itself? Like, if I'm trying to learn how to solve puzzle games, would it not be more efficient to just practice solving puzzle games than to do physics problems and try to generalise? Or if you think that this sort of general rationality training is only important for 'specialising in problems we don't understand' type stuff with bad feedback loops, how would you even figure out whether or not it's working given the bad feedback loops? Like sure, maybe you measure how well people perform at some legibly measurable tasks after the rationality training and they perform a bit better, but the goal in the first place was to use the rationality training's good feedback loops to improve in domains with bad feedback loops, and those domains seem likely to be different enough that a lot of rationality lessons or whatever just don't generalise well.
It just feels to me like the world where transfer learning works well enough to be worth the investment looks a lot different wrt how specialised the people who are best at X are for any given X. I can't off the top of my head think of anyone who became the best at their thing by learning very general skills first and then applying them to their domain, rather than just focusing really hard on whatever their thing was.
Replies from: pktechgirl↑ comment by Elizabeth (pktechgirl) · 2023-08-15T05:10:17.007Z · LW(p) · GW(p)
would it not be more efficient to just apply the deliberate practice and metacognition to the domain itself
Yes, if that's the only thing you want to learn. The more domains you want to understand the more it makes sense to invest in cross-domain meta skills.
comment by Raemon · 2023-08-07T18:50:24.628Z · LW(p) · GW(p)
A few people during the beta-tests expressed interest in "Feedbackloop rationality club" (as opposed to my original vision of 'feedbackloop rationality school/research center where people are mostly training fulltime 1-12 weeks at a time).
I have some ideas for such a club. It does seem wholesome and fun and more practical for most people. But it's still a pretty effortful project, and I'd personally be most interested in doing it if I'd first spend 1-3 months actually reducing my major uncertainties about whether this project is competitive with other x-risk reduction work I could be doing.
I think the club-version would take too long for me to figure out whether people are really improving. But one thing I like about this whole idea is that it does feel fairly scalable/parallelizable, and it feels like a healthy/good feature of the broader rationality community if people tried out doing this sort of thing as a local meetups, and reported on their results.
Replies from: Screwtape↑ comment by Screwtape · 2023-08-07T20:39:47.283Z · LW(p) · GW(p)
I think "Feedbackloop Rationality Club" is, if you had a good working version of it, way better than "Feedbackloop rationality school" for the goal of getting the skillset to spread. Few people can actually spend a month training full time at something. Doing so involves taking a leave from work or school. It involves a bigger social explanation than a club or a once-a-week class does. It's harder to pitch someone on, since you can't try a little bit and easily walk away if you don't like it.
I'm a lot more uncertain about what teaches the skillset to individuals better. If I imagine someone playing the guitar for an hour a week for a year vs someone playing the guitar all day for one week and then not touching an instrument for a year, I'm maybe 60% sure the person doing once a week will do better. If you would rather have ten people who are S tier guitarists rather than a million people who are B tier guitarists, the months long intensive training school sounds like a much better approach. (Though if I was in charge of that, I'd be tempted to do both. Get a million people to practice once a week, check if any of them stand out, and invite those people to the intensive program.) For X-risk, especially AI risk, I'd expect you want a smaller number of better rationalists.
I don't know how to make S tier rationalists. I have some ideas on how to turn D tier rationalists into C tier rationalists, and I have ambitions of hitting the B range. This topic is very relevant to my interests, especially these days, and if you have an idea of what the payload of such a meetup would look like then I think I can contribute some of the wrapper and the reporting.
Replies from: Raemon↑ comment by Raemon · 2023-08-07T21:20:38.412Z · LW(p) · GW(p)
I think "Feedbackloop Rationality Club" is, if you had a good working version of it, way better than "Feedbackloop rationality school" for the goal of getting the skillset to spread.
I agree with this, but, I think we're aways away from it being clear what the skillsets exactly what you want to spread are. I think there's a lot of versions of this that are kind of fake, and I think it's an important gear in my model that you should actually see yourself demonstrably improving to verify you're doing it right. (I think it's much easier to tell if you're getting better at guitar than at "thinking")
That all said... I've had on my TODO list to ping you about this and say "hey, I think encouraging meetup organizers to do this is probably a) at least worth trying once, and b) Probably better than a lot of other meetups types for leveling up rationalists, even in the unguided, less committed fashion." (It's also fun, so, it's at least competitive on that axis)
Replies from: Screwtape↑ comment by Screwtape · 2023-08-08T01:54:45.571Z · LW(p) · GW(p)
I agree we don't know what the best skillsets are. I have a version in my head that's maybe one third The Art Of Rationality and two thirds The Art Of Screwtape though the boundaries between those are fuzzy. There is a confounder I've noticed where people tend to be growing all the time anyway, so it's common for them to get better at random tasks and generate false positives. (Example: A ten year old who doesn't know Bayes loses Magic games to a ten year old who does, but they can both lose to twenty year olds with experience and money.)
I notice I don't have that high of a threshold for trying things here. Most of that willingness to flail about and risk fake versions of this (especially if I flag it as fun meetup ideas more than flagging it as intensive rationality training) are downstream of a lot of thinking about which parts of a meetup are load bearing. "Rationalists get together to play 7 Wonders or Hanabi and chat" is a beloved pastime which I wouldn't try to replace with "Rationalists get together to do physics homework" but would be cheerful about trying to replace with "Rationalists get together to play Rationality Cardinality or Calibration Trivia and chat." Double Crux continues to be a popular ACX meetup activity, and I suspect that's because it involves pairing up to talk about something that's divisive.
comment by romeostevensit · 2023-08-07T21:10:41.102Z · LW(p) · GW(p)
I'd be up for attempting to transfer some learning about this that I had.
Replies from: Raemoncomment by fnymnky · 2023-08-27T13:57:00.783Z · LW(p) · GW(p)
If an experiment along these lines is attempted, I think using Stanovich’s Comprehensive Assessment of Rational Thinking (CART) in addition to IQ as a pretest/post test would be a good idea. LW folks would likely be near ceiling on many of the components, but it’d be interesting to see if the training transferred to the CART itself, and also to give some measure of “room for growth” before the training began.
comment by Raemon · 2023-08-30T23:55:23.735Z · LW(p) · GW(p)
Update for now:
I'm not likely to do the "full time, full-fledged version of this experiment" in the foreseeable future, because of a combination of:
- Lightcone team generally wanting to all focus on LessWrong.com for awhile (after 1.5 years of being split apart doing various other things)
- Not having someone up for being a cofounder
- The people I'm most interested in being test-subjects mostly not being able/willing to commit full-time.
For now, my plan is to try "Deliberate Practice Club". Current draft of that plan is:
- Aim to deliberate practice a skill you care about at least ~30 min every-other-day(ish).
- Meet once a week to share updates and meta-thoughts.
I've been doing some preliminary testing of this, not started it in earnest yet, and am not yet sure how it'll shake out. But I describe it here partly so people following along can see how the concept is evolving, and get a sense of how much iteration is involved.
comment by Chris_Leong · 2023-08-08T00:14:17.422Z · LW(p) · GW(p)
Oh I just thought I’d also add my opinion that Less Wrong has insufficient meta discussion.
My understanding was the worry was that it’s too easy to spend all of your time in meta-land. However, I worry that we’ve veered too far in that direction and that LW needs a specific period where we think about where we are, where we’d like to be and how to get there.
comment by Chris_Leong · 2023-08-08T00:11:08.152Z · LW(p) · GW(p)
I’d be very interested in this.
I’ve thought for a while that paradoxes would be a useful way of helping people develop rationality, although I admit physics paradoxes are an event better place to start since you can actually see what happens in real life.
comment by chrizbo · 2023-08-08T16:45:02.532Z · LW(p) · GW(p)
You should check out Vaughn Tan's new work on "not knowing." I think the uncertainty of possible actions, possible outcomes, linkage of actions to outcomes, and value of outcomes could be a way to consider these vague goals.
https://vaughntan.org/notknowing
I've been joining his Interintellect conversations and they have been really great:
https://interintellect.com/series/thinking-about-not-knowing/
Replies from: Raemoncomment by Dalcy (Darcy) · 2023-08-08T02:23:45.856Z · LW(p) · GW(p)
I am very interested in this, especially in the context of alignment research and solving not-yet-understood problems in general [LW · GW]. Since I have no strong commitments this month (and was going to do something similar to this anyways), I will try this every day for the next two weeks and report back on how it goes (writing this comment as a commitment mechanism!)
Have a large group of people attempt to practice problems from each domain, randomizing the order that they each tackle the problems in. (The ideal version of this takes a few months)
...
As part of each problem, they do meta-reflection on "how to think better", aiming specifically to extract general insights and intuitions. They check what processes seemed to actually lead to the answer, even when they switch to a new domain they haven't studied before.
Within this upper-level feedback loop (at the scale of whole problems, taking hours or days), I'm guessing a lower-level loop would involve something like cognitive strategy tuning [LW · GW] to get real-time feedback as you're solving the problems?
Replies from: Raemon↑ comment by Raemon · 2023-08-08T02:45:57.631Z · LW(p) · GW(p)
Yeah. I have another post brewing that a) sort of apologizes for the sort of excessive number of feedback loops going on here, b) explaining in detail why they are necessary and how they fit together. But here is a rough draft of it.
The most straightforward loops you have, before you have get into Cognitive Tuning, are:
- Object level "did I succeed at this task?"
- Have I gotten better at this task as I've practiced it?
- As I try out other domains I'm unpracticed on, do I seem to be able to apply skills I learned from previous ones and at least subjectively feel like I'm transfer learning?
- Hypothetical expensive science experiment: if I do the exhaustive experiment described in this blogpost, do I verifiably get better at some kind of transfer learning?
For connecting it to your real life, there's an additional set of loops like:
- When I reflect on what my actual problems or skill-limitations are at my day job, what sort of exercises do I think would help? (these can be "more exercise-like" or "more like just adding a reflection step to my existing day-job")
- When I do those exercises, does it seem like they improve my situation with my day-job or main project?
- Does that transfer seem to stick / remain relevant over time?
Re: "tuning your cognitive algorithms", these sort of slot inside the object level #1 exercise in each of the previous lists. Within an exercise (or real world task), you can notice "do I seem to be stuck? Does it feel like my current train of thought is useful? Do I have a creeping sense that I'm going down a unproductive rabbit hole and rationalizing it as progress?"
But there is a danger to over-relying on these internal, subjective feedback loops. So there's an additional upper level loop of, after getting an exercise right (or wrong), asking "which of my metacognitive intuitions actually turned out to be right?", and becoming calibrated on how trustworthy those are. (And hopefully making them more trustworthy)
comment by Ruby · 2023-08-25T19:17:19.972Z · LW(p) · GW(p)
but I do think it's the most important open problem in the field.
What are the other contenders?
Replies from: Raemon↑ comment by Raemon · 2023-08-25T19:47:49.193Z · LW(p) · GW(p)
Basically trying to directly answer other major problems, each of which includes a "how do you learn this for yourself?" and "how do you convey the concept to others?"
- how do you notice when you're being politically/socially motivated? what do you do when you're like "okay cool I'm definitely socially motivated?"
- what do you do when you think other people are being politically/socially motivated?
- how to figure out the right frame for thinking about a problem? (which includes a bit of goal-factoring to figure out how you're evaluating "what
- for teaching/learning "research taste in particular domains", just focus on learning/conveying insights from people who seem pretty good at it (without worrying about having a feedbackloop to sanity-check the insight).
- For many of the above, mapping out "where do we have best practices based on real-world experience, and where do we have crisp formalizations that help us do engineering-to-it? How do we good job at both and bridge the gap?"
comment by hiAndrewQuinn (hiandrewquinn) · 2023-08-08T08:29:33.551Z · LW(p) · GW(p)
This idea holds considerable promise, and supports many similar ideas I have found in practice to work well on skilling up in arbitrary domains of interest.
Currently that domain is Leetcode problems, which are about as concrete and deliberate practice-friendly as you can get, as a mind sport with a clear end goal (solve the problem) and 2 primary quality markers (CPU used by your solution, memory used by your solution.
To really make it into a proper loop I do my LC kata according to when they come up in my Anki decks, which isn't deliberate practice but it's closer than I think most part-time study regimens can get. An interesting phenomenon about doing a lot of practice in a concrete domain is that, for most new problems which I can't yet get on the first shot, there is a very clear "first gate" stopping point where my brain throws up its hands and says "Bridge missing, consult solutions". And indeed this first gate to understanding is usually much more difficult to overpower solely by myself, taking hours instead of minutes if I can open it at all. To say nothing of possible second, third etc gates that often appear afterward... I suspect these are distributed log-normally. I sometimes wonder if I'm depriving myself of potential unseen mental gains by usually deciding to just look at the solution and mark the Anki card as "again" instead of pushing through.
Incidentally I did some research in undergrad on control theory, the mathematical discipline underlying feedback loops, although like a lot of higher level math I haven't found a decent way to transmit my intuition around e.g. Lyapunov stability into something that accelerates human or machine learning. I do get the sense there's a there there.
comment by jmh · 2023-08-26T11:24:21.543Z · LW(p) · GW(p)
I liked the post. It fits quite well with a simple quip I've known and sometimes use: "Practice makes permanent, perfect practice makes perfect."
In other words, without that good feedback loop in the process one may well simply be reinforcing bad habits or bad thought processes with all the hard practice.
comment by junk heap homotopy (zrkrlc) · 2023-08-12T07:40:46.576Z · LW(p) · GW(p)
There seems to two major counter-claims to your project:
- Feedback loops can't work for nebulous domains, so this whole thing is misguided.
- Transfer learning is impossible and you can't get better at rationality by grinding LeetCode equivalents.
(There's also the third major counter-claim that this can't work for alignment research, but I assume that's actually irrelevant since your main point seems to be about rationality training.)
My take is that these two claims stem from inappropriately applying an outcome-oriented mindset to a process-oriented problem. That is, the model seems to be: "we wanted to learn X and applied Feedback Loops™️ but it didn't work, so there!" instead of "feedback-loopiness seems like an important property of a learning approach we can explicitly optimise for".
In fact, we can probably factor out several senses of 'feedback loops' (henceforth just floops) that seem to be leading a lot of people to talk past each other in this thread:
- Floops as reality pushing back against movement, e.g. the result of swinging a bat, the change in an animation when you change a slider in an Explorable Explanation
- Floops where the feedback is quick but nebulous (e.g. persuasion, flirting)
- Floops where the feedback is clear but slow (e.g. stock market)
- Floops as reinforcement, i.e. the cycle Goal → Attempt → Result
- Floops as OODA loops (less legible, more improvisational than previous item)
- Floops where you don't necessary choose the Goal (e.g. competitive multiplayer games, dealing with the death of a loved one)
- Floops which are not actually loops, but a single Goal → Attempt → Result run (e.g., getting into your target uni)
- Floops which are about getting your environment to support you doing one thing over and over again (e.g. writing habits, deliberate practice)
- Floops which are cumulative (e.g. math)
- Floops where it's impossible to get sufficiently fine-grained feedback without the right paradigm (e.g. chemistry before Robert Boyle)
- Floops where you don't necessarily know the Goal going in (e.g. doing 1-on-1s at EA Global)
- Floops where failure is ruinous and knocks you out of the game (e.g. high-rise parkour)
- Anti-floops where the absence of an action is the thing that moves you towards the Goal
- Floops that are too complex to update on a single result (e.g. planning, designing a system)
When someone says "you can't possibly apply floops to research", I imagine they're coming from a place where they interpret goal-orientedness as an inherent requirement of floopiness. There are many bounded, close-ended things that one can use floops for that can clearly help the research process: stuff like grinding the prerequisites and becoming fluent with certain techniques (cf. Feynman's toolbox approach to physics), writing papers quickly, developing one's nose (e.g. by trying to forecast the number of citations of a new paper), etc.
This claim is independent of whether or not the person utilising floops is good enough to get better quickly. I think it's not controversial to claim that you can never get a person with profound mental disabilities and who is not a savant at technical subjects to discover a new result in quantum field theory, but this is also irrelevant when talking about people who are baseline capable enough to worry about this things on LessWrong dot com in the first place.
On the other end of the spectrum, the reductio version of being against floops: that everyone was literally born with all the capabilities they would ever need in life and Learning Is Actually a Myth, seems blatantly false too. Optimising for floopiness seems to me merely trying to find a happy medium in between.
On an unrelated note, I wrote about how to package and scalably transfer floops a while back: https://www.lesswrong.com/posts/3CsynkTxNEdHDexTT/how-i-learned-to-stop-worrying-and-love-skill-trees [LW · GW]
All modern games have two floops built-in: a core game loop that gets completed in under a minute, and a larger game loop that makes you come back for more. Or in the context of my project, Blackbelt:
{kind=link}
The idea is you can design bespoke tests-of-skill to serve as your core game loop (e.g., a text box with a word counter underneath, the outputs of your Peloton bike, literally just checking a box like with a TODO list) and have the deliberately status-oriented admission to a private channel be the larger, overarching hook. I think this approach generalises well to things that are not just alignment, because floops can be found in both calculating determinants and doing on-the-fly Fermi calculations for setting your base rates, and who wouldn't want to be in the company of people who obsess endlessly about numbers between 0 and 1?
comment by Prakrti Zephyr · 2023-08-07T21:08:32.231Z · LW(p) · GW(p)
Feedbackloop-first Rationality is such a good term!
On my personal notes I might refer to it as Loop Rationality, as I quite like how that sounds.
Replies from: Raemoncomment by Prakrti Zephyr · 2023-08-07T21:02:54.463Z · LW(p) · GW(p)
I am thrilled reading this post. I've been practicing something along this for some years now, and the dynamics described here match my experience. I imagine one could write a whole sequence about this!
comment by Raemon · 2025-02-04T19:14:34.214Z · LW(p) · GW(p)
I followed up on this with a year exploring various rationality exercises and workshops. My plans and details have evolved a bunch since then, but I still think the opening 7 bullets (i.e. "Deliberate Practice, Metacognition" etc, with "actually do the goddamn practice" and "the feedbackloop is the primary product") are quite important guiding lights.
I've written up most of my updates as they happened over the year, in:
- Rationality Research Report: Towards 10x OODA Looping? [LW · GW]
- "Fractal Strategy" workshop report [LW · GW]
- The Cognitive Bootcamp Agreement [LW · GW]
- Skills from a year of Purposeful Rationality Practice [LW · GW]
The biggest overall updates since this post:
Fluent enough for your day job.
The primary aim of my workshops and practice is to get new skills fluent enough that you can appy them to your day job, because that's where it's practical to deliberate practice in a way that pays for itself rather than being an exhausting extra thing you do.
"Fluency at new skill that seem demonstrably useful" is also a large enough effect size that there's at least something you can measure near term, to get a sense of whether the workshop is working.
Five minute versions of skills.
Relatedly: many skills have elaborate, comprehensive versions that take ~an hour to get the full value of, but you're realisitically not going to do those most of the time. So it's important to boil them down into something you can do in 5 minutes (or, 30 seconds).
Morning Orient Prompts.
A thing I've find useful for myself, and now think of as one of the primary goal of the workshop to get people to try out, is a "morning orient prompt list" that you do every day.
It's important that it be every day, even when you don't need it too much, so that you still have a habit of metacognition for the times you need it (but, when you don't need it too much, it's fine/good to do a very quick version of it)
It's useful to have a list of explicit prompts, because that gives you an artifact that's easier to iterate on.
What about RCT-style science?
The original post noted an expensive plan that would be "actual science shaped", which would give a clearer sense of whether rationality training worked. I do still think that's the right goal to be aspiring to.
It is quite an expensive goal – not just in my effort but in a lot of smart people's time.
Oddly, the two major objections I frequently get are both "why haven't you done an RCT?" and "Doing [the real RCT version of this] is too expensive so the plan is bad."
My actual belief right now is that the most important feedbackloops to be developing are more focused on "how to track if this is helping with your day-job", because I think that's what most people's cruxes actually are (and, should be). RCTs would at best tell you what works on average for People of Some Reference Class, but still don't actually tell you personally if it's worthwhile for you.
A lot of my focus right now is helping people who have attended a workshop to integrate the practice into their daily life, and seeing what sort of problems come up there and how to deal with them. (Where my current partial-answers to that are the previous three sections)
comment by Prakrti Zephyr · 2023-09-01T15:45:03.453Z · LW(p) · GW(p)
comment by Ruby · 2023-08-25T19:40:57.592Z · LW(p) · GW(p)
Curated. There's a lot about Raemon's feedbackloop-first rationality that doesn't sit quite right, isn't quite how I'd theorize about it, but there's a core here I do like. My model is that "rationality" was something people were much more excited about ~10 years ago until people updated that AGI was much closer than previously thought. Close enough, that rather than sharpen the axe (perfect the art of huma thinking), we better just cut the tree now (AI) with what we've got.
I think that might be overall correct, but I like it if not everyone forgets about the Art of Human Rationality. And if enough people pile on the AI Alignment train, I could see it being right to dedicate quite a few of them to the meta of generally thinking better.
Something about the ontology here isn't quite how I'd frame it, though I think I could translate it. The theory that connects this back to Sequences rationality is perhaps that feedbackloops are iterated empiricism with intervention. An alternative name might be "engineered empiricism", basically this is just one approach to entangling oneself with the territory. That's much less of what Raemon's sketched out, but I think situating feedbackloops within known rationality-theory would help.
I think it's possible this could help with Alignment research, though I'm pessimistic about that unless Alignment researchers are driving the development process, but maybe it could happen and just be slower.
I'd be pretty glad for a world where we had more Raemons and other people and this could be explored. In general, I like this is for keeping alive the genre of "thinking better is possible", a core of LessWrong and something I've pushed to keep alive even as the bulk of the focus is on concrete AI stuff.
comment by Raemon · 2023-08-16T23:12:08.785Z · LW(p) · GW(p)
Idea after chatting with Romeostevens:
Have a "Deliberate Practice Deliberate Practice Club" that meets once-a-day for ~30 minutes, where most days people are just independently practice the art of deliberate practice, and then once a week or month or something people do presentations on the skills they gained, and approaches they used. (Romeo originally suggested something more like "people just commit to practicing 30 minutes a day and meet once a week or month", which also seems fine but I expect people to drop out a lot more.)
I think I'll try something like this myself and see if I can actually fit the 30-minutes-of-practice into my day reasonably. I think this might be a thing people can self-organize in a kind of grassroots fashion.
The basic idea is something like cultivating the skill of finding a skill that you want to be better at, figuring out what subskills would make you better at it and how to practice them, and see if you actually get better. You could start on very concrete skills with clear feedbackloops, and then gradually port the meta-skills over to more confusing domains.
comment by Matt Goldenberg (mr-hire) · 2023-08-12T19:44:48.993Z · LW(p) · GW(p)
This is cool!
Two things this made me think of that may be relevant:
- Standard Jiu Jitsu - It's a very interesting Jiu Jitsu training program that doesn't use any drilling of moves. Instead, it looks at much smaller skills that make up various moves, then creates games where one player tries to execute the result of that skill (e.g, separating the arm from the body) while the other player tries to avoid that. This is very effective because it gives you immediate feedback on what actually works for each step of the move. They say this approach is science based, but I haven't yet found which science they're referring to here.
- Accelerated Expertise - A breakdown of some of the most effective teaching programs in the military and business. They go through the process of doing detailed Cognitive Task Analyses on experts, then, rather than teaching those CTAs, they instead create simulations that force people to learn the skills needed from the CTA, while rarely teaching them directly.
Both of these add a couple of steps that aren't in your program, that I would recommend could be:
- Break down the larger skill into smaller skills extracted from someone already good at them, using Cognitive Task Analysis, the Experiential array, [LW(p) · GW(p)] Business Process Modelling, or other frameworks.
- Create exercises specifically tailored to train those skills, so that the feedback loop is way more effective.
comment by Review Bot · 2024-02-26T22:01:22.792Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by keltan · 2023-09-04T09:11:22.052Z · LW(p) · GW(p)
I would like to volunteer as a test subject! As someone new to LW I was hoping to train my rationality skills this spring anyway. I have quite a clear schedule and can dedicate at least 2-4 hours a day.
Get in touch if you decide to run a trial within the next two months. I myself teach kids at weekly art classes and have been slowly trying to integrate my own rationality exercises. Some guidance and external pressure to continue my training would be beneficial to me.
comment by Sasha Samuel Iwanczuk (sasha-samuel-iwanczuk) · 2023-08-27T16:27:44.449Z · LW(p) · GW(p)
Hi, this if my first comment and the second post of this kind that I've read.
Really great post. Help me to tag some ideas on my entire learning experience.
Next, I have thoughts about Feedback loop paradigm. I can recognize two types of loops, one is faster and I found myself using it when I practice my instrument (I'm a professional trumpet player), I won't go deep into this because there're some constrains and I think it cannot be used for exclusive cognitive training, except the part of deliberate continuous practice. The second one, the slow loop, involves more concrete thinking on the exercise and the execution of the steps needed to find a solution, either correct or not.
Back to my recent learning experience, an ICPC training camp (International Collegiate Programming Contest), in some moments I found myself trying to apply the fast framework, without great results of course.
In conclusion, I'm really interested to be part as a test subject but because I implement kind of this paradigm (in a intuitive form), the progress or results could be not relevant for global results. On the other hand, I think a cheap and fast way to perform loops on Feedback Loops is take a bunch of people from one domain, test the effectiveness to solve a specific situation of another domain, then training them for a couple of weeks and test again in the other domain. Kind of loops of feedback loops.
comment by rain8dome9 · 2023-08-26T19:42:49.962Z · LW(p) · GW(p)
I am willing to be a test subject. Evidence that I am serious is I have 119k reviews on Anki and am analyzing the data hoping it will be a psychometric test.
comment by JayP (jayant-pahuja) · 2023-08-25T23:56:08.251Z · LW(p) · GW(p)
Shorter feedback loops are more effective if you know exactly what the output is and is measurable I use the same philosophy at work while coding too. https://martinfowler.com/articles/developer-effectiveness.html here is a post that talks more about how shorter feedback loops help programmers be more effective.
But on a personal level converting my vague goals into a framework with a feedback loop is hard and I imagine, I will most likely get stuck in finding a good feedback loop for the goal. Though the post motivates me to try it out.
comment by Anonyvole · 2023-08-25T23:09:27.894Z · LW(p) · GW(p)
Can this be summed up as mindfulness?
The feedback concept also points to short vs long term memory. Reimprinting short term memory insights turns them into long term memory. I suspect it's the evaluation process that is critical -- don't reimprint bad data, faulty logic, dead-end reasoning.
I use a chime on my phone that rings ever 15 minutes. What am I doing? Is there something I've just learned I should reconsider (forcing it into long(er) term memory. Is my posture good? Is there something I'm missing?
A feedback loop will only feed back if there's a mechanism to echo, or regurgitate the latest set of thoughts back into your mind for reevaluation, no?
Replies from: Raemon↑ comment by Raemon · 2023-08-26T21:22:51.981Z · LW(p) · GW(p)
There are three types of feedbackloops here:
- Object level practice ("did you succeed at a concrete thing")
- Longterm work ("do you seem to have succeeded at your broader goals, even if they're fuzzy and hard to pin down")
- Metacognition ("do your thoughts/feelings/etc seem pointed in useful directions?")
I think the last bit is connected to mindfulness (or: "mindfulness is one of the tools you can employ to get good at it"). But it still requires being connected to the other two things in order to reliably point in "real" directions.