[Intro to brain-like-AGI safety] 2. “Learning from scratch” in the brain
post by Steven Byrnes (steve2152) · 2022-02-02T13:22:58.562Z · LW · GW · 12 commentsContents
2.1 Post summary / Table of contents 2.2 What is “learning from scratch”? 2.3 Three things that “learning from scratch” is NOT 2.3.1 Learning-from-scratch is NOT “blank slate” 2.3.2 Learning-from-scratch is NOT “nurture-over-nature” 2.3.3 Learning-from-scratch is NOT the more general notion of “plasticity” 2.4 My hypothesis: the cortex, extended striatum, and cerebellum learn from scratch; the hypothalamus and brainstem don’t 2.5 Evidence on whether the cortex, striatum, and cerebellum learn from scratch 2.5.1 Big-picture-type evidence 2.5.2 Neonatal evidence 2.5.3 “Uniformity” evidence 2.5.4 Locally-random pattern separation 2.5.4.1 What is pattern separation? 2.5.4.2 Where is pattern-separation? 2.5.4.3 Why does pattern separation suggest learning-from-scratch? 2.5.5 Summary: I don’t pretend that I’ve proven the hypothesis of learning-from-scratch cortex, striatum, and cerebellum, but I’ll ask you to suspend disbelief and read on 2.6 Is my hypothesis consensus, or controversial? 2.7 Why does learning-from-scratch matter for AGI safety? 2.8 Timelines-to-brain-like-AGI part 1/3: how hard will it be to reverse-engineer the learning-from-scratch parts of the brain, well enough for AGI? Changelog None 12 comments
(Last revised: October 2024. See changelog at the bottom.)
2.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series [? · GW].
Having introduced the “brain-like-AGI safety” problem in the previous post [AF · GW], the next 6 posts (#2–#7 [AF · GW]) are primarily about neuroscience, building up to a more nuts-and-bolts understanding of what a brain-like AGI might look like (at least, in its safety-relevant aspects).
This post focuses on a concept that I call “learning from scratch”, and I will offer a hypothesized breakdown in which >90% of the human brain (including the cortex) “learns from scratch”, and the other <10% (including the brainstem) doesn’t. This hypothesis is central to how I think the brain works, and hence will be a key prerequisite for the whole rest of the series.
- In Section 2.2, I’ll define the concept of “learning from scratch”. As an example, if I assert that the cortex “learns from scratch”, then I’m claiming that the cortex starts out totally useless to the organism—outputting fitness-improving signals no more often than chance—until it starts learning things (within the individual's lifetime). Here are a couple everyday examples of things that “learn from scratch”:
- In most deep learning papers, the trained model “learns from scratch”—the model is initialized from random weights, and hence the model outputs are random garbage at first. But during training, the weights are updated, and the model outputs eventually become very useful.
- An initially-blank flash drive also “learns from scratch”—you can't pull useful information out of it until after you’ve written information into it.
- In Section 2.3, I will clarify some frequent confusions:
- “Learning from scratch” is different from “blank slate”, because there is an innate learning algorithm, innate neural architecture, innate hyperparameters, etc.
- “Learning from scratch” is different from “nurture-not-nature”, because (1) only some parts of the brain learn from scratch, while other parts don’t, and (2) the learning algorithms are not necessarily learning about the external environment—they could also be learning e.g. how to control one’s own body.
- “Learning from scratch” is different from (and more specific than) “brain plasticity”, because the latter can also include (for example) a genetically-hardwired circuit with just one specific adjustable parameter, and that parameter changes semi-permanently under specific conditions.
- In Section 2.4, I’ll propose my hypothesis that much of the brain (>90% by volume) exists solely to run learning-from-scratch algorithms—namely, roughly the cortex, striatum, and cerebellum, but defined broadly so as to also include the amygdala, nucleus accumbens, hippocampus, and more. I’ll use the term Learning Subsystem to refer to these learning-from-scratch parts of the brain. The rest of the brain—which I call the Steering Subsystem—includes the brainstem and hypothalamus, and is the subject of the next post [LW · GW].
- In Section 2.5, I’ll touch on four different lines of evidence concerning my hypothesis that the cortex, striatum, and cerebellum learn from scratch: (1) big-picture thinking about how the brain works, (2) neonatal data, (3) a connection to the hypothesis of “cortical uniformity” and related issues, and (4) the possibility that a certain brain preprocessing motif—so-called “pattern separation”—involves randomization in a way that forces downstream algorithms to learn from scratch.
- In Section 2.6, I’ll talk briefly about whether my hypothesis is mainstream vs idiosyncratic. (Answer: I’m not really sure.)
- In Section 2.7, I’ll offer a little teaser of why learning-from-scratch is important for AGI safety—we wind up with a situation where the thing we want the AGI to be trying to do (e.g. cure Alzheimer's) is a concept buried inside a big hard-to-interpret learned-from-scratch data structure. Thus, it is not straightforward for the programmer to write motivation-related code that refers to this concept. Much more on this topic in future posts.
- Section 2.8 will be the first of three parts of my “timelines to brain-like AGI” discussion, focusing on how long it will take for future scientists to reverse-engineer the key operating principles of the learning-from-scratch part of the brain. (The remainder of the timelines discussion is in the next post [AF · GW].)
2.2 What is “learning from scratch”?
As in the intro above, I’m going to suggest that large parts of the brain (see Section 2.4 below for anatomical breakdown) “learn from scratch”, in the sense that they start out emitting signals that are random garbage, not contributing to evolutionarily-adaptive behaviors, but over time become more and more immediately useful thanks to a within-lifetime learning algorithm.
Here are two ways to think about the learning-from-scratch hypothesis:
- How you should think about learning-from-scratch (if you’re an ML reader): Think of a deep neural net initialized with random weights. Its neural architecture might be simple or might be incredibly complicated; it doesn't matter. And it certainly has an inductive bias that makes it learn certain types of patterns more easily than other types of patterns. But it still has to learn them! If its weights are initially random, then it’s initially useless, and gets gradually more useful with training data. The idea here is that these parts of the brain (cortex etc.) are likewise “initialized from random weights”, or something equivalent.
- How you should think about learning-from-scratch (if you’re a neuroscience reader): Think of a memory-related system, like the hippocampus. The ability to form memories is a very helpful ability for an organism to have! …But it ain’t helpful at birth!![1] You need to accumulate memories before you can use them! My proposal is that everything in the cortex, striatum, and cerebellum are in the same category—they’re kinds of memory modules. They may be very special kinds of memory modules! For example, areas of isocortex (a.k.a. neocortex) can learn and remember a super-complex web of interconnected patterns, and comes with powerful querying features, and can even query itself in recurrent loops, and so on. But still, it’s a form of memory, and hence starts out useless, and gets progressively more useful to the organism as it accumulates learned content.
2.3 Three things that “learning from scratch” is NOT
2.3.1 Learning-from-scratch is NOT “blank slate”
I already mentioned this, but I want to be crystal clear: if the cortex (for example) learns from scratch, that does not mean that there is no genetically-hardcoded information content in the cortex. It means that the genetically-hardcoded information content is probably better thought of as the following:
- Learning algorithm(s)—i.e., innate rules for semi-permanently changing the neurons or their connections, in a situation-dependent way.
- Inference algorithm(s)—i.e., innate rules for what output signals should be sent right now, to help the animal survive and thrive. The actual output signals, of course, will also depend on previously-learned information.
- Neural network architecture—i.e., an innate large-scale wiring diagram specifying how different parts of the learning module are connected to each other, and to input and output signals.
- Hyperparameters—e.g., different parts of the architecture might innately have different learning rates. These hyperparameters can also change during development (cf. “sensitive periods”). There can also be an innate capacity to change hyperparameters on a moment-by-moment basis in response to special command signals (in the form of neuromodulators like acetylcholine).
Given all those innate ingredients, the learning-from-scratch algorithm is ready to receive input data and supervisory signals from elsewhere[2], and it gradually learns to do useful things.
This innate information is not necessarily simple. There could be 50,000 wildly different learning algorithms in 50,000 different parts of the cortex, and that would still qualify as “learning-from-scratch” in my book! (I don’t think that’s the case though—see Section 2.5.3 on “uniformity”.)
2.3.2 Learning-from-scratch is NOT “nurture-over-nature”
There’s a tendency to associate “learning-from-scratch algorithms” with the “nurture” side of the “nature-vs-nurture” debate. I think that’s wrong. Quite the contrary: I think that the learning-from-scratch hypothesis is fully compatible with the possibility that evolved innate behaviors play a big role.
Two reasons:
First, some parts of the brain are absolutely NOT running learning-from-scratch algorithms! This category, which mainly includes the brainstem and hypothalamus, comprises what I call the brain’s “Steering Subsystem”—see next post [LW · GW]. These non-learning-from-scratch parts of the brain would have to be fully responsible for any adaptive behavior at birth.[1] Is that plausible? I think so, given the impressive range of functionality in the brainstem. For example, the cortex has circuitry for processing visual and other sensory data—but so does the brainstem! The cortex has motor-control circuitry—but so does the brainstem! In at least some cases, full adaptive behaviors seem to be implemented entirely within the brainstem: for example, mice have a brainstem incoming-bird-detecting circuit wired directly to a brainstem running-away circuit. So my learning-from-scratch hypothesis is not making any blanket claims about what algorithms or functionalities are or aren’t present in the brain. It’s just a claim that certain types of algorithms are only in certain parts of the brain.
Second, “learning from scratch” is not the same as “learning from the environment”. Here’s a made-up example[3]. Imagine a bird brainstem is built with an innate capability to judge what a good birdsong should sound like, but lacks a recipe for how to produce a good birdsong. Well, a learning-from-scratch algorithm could fill in that gap—doing trial-and-error to get from the former to the latter. This example shows that learning-from-scratch algorithms can be in charge of behaviors that we would naturally and correctly describe as innate / “nature not nurture”.
2.3.3 Learning-from-scratch is NOT the more general notion of “plasticity”
“Plasticity” is a term for the brain semi-permanently changing itself, typically by changing the presence / absence / strength of neuron-to-neuron synapses, but also sometimes via other mechanisms, like changes of a neuron’s gene expression.
Any learning-from-scratch algorithm necessarily involves plasticity. But not all brain plasticity is part of a learning-from-scratch algorithm. A second possibility is what I call “individual innate adjustable parameters”. Here’s a table with both an example of each and general ways in which they differ:
| Learning-from-scratch algorithms | Individual innate adjustable parameters | |
| Stereotypical example to keep in mind: | Every deep learning paper: there’s a learning algorithm that gradually builds a trained model by adjusting lots of parameters. | Some connection in the rat brain that strengthens when the rat wins a fight—basically, it’s a counter variable, tallying how many fights the rat has won over the course of its life. Then this connection is used to implement the behavior “If you’ve won lots of fights in your life, be more aggressive.” (ref) |
| Number of parameters that change based on input data (i.e. how many dimensions is the space of all possible trained models?) | Maybe lots—hundreds, thousands, millions, etc. | Probably few—even as few as one |
| If you could scale it up, would it work better after training? | Yeah, probably. | Huh?? WTF does “scale it up” mean? |
I don’t think there’s a sharp line between these things; I think there’s a gray area where one blends into the other. Well, at least I think there’s a gray area in principle. In practice, I feel like it's a pretty clean division—whenever I learn about a particular example of brain plasticity, it winds up being clearly in one category or the other.
My categorization here, by the way, is a bit unusual in neuroscience, I think. Neuroscientists more often focus on low-level implementation details: “Does the plasticity come from long-term synaptic change, or does it come from long-term gene expression change?” “What’s the biochemical mechanism?” Etc. That’s a totally different topic. For example, I’d bet that the exact same low-level biochemical synaptic plasticity mechanism can be involved in both a learning-from-scratch algorithm and an individual innate adjustable parameter.
Why do I bring this up? Because I’m planning to argue that the hypothalamus and brainstem have little or no learning-from-scratch algorithms, so far as I can tell. But they definitely have individual innate adjustable parameters.
To be concrete, here are three examples of “individual innate adjustable parameters” in the hypothalamus & brainstem:
- I already mentioned the mouse hypothalamus circuit that says “if you keep winning fights, be more aggressive”—ref.
- Here’s a rat hypothalamus circuit that says “if you keep getting dangerously salt-deprived, increase your baseline appetite for salt”.
- The superior colliculus in the brainstem contains a visual map, auditory map, and saccade motor map, and it has a mechanism to keep all three lined up—so that when you see a flash or hear a noise, you immediately turn to look in exactly the right direction. This mechanism involves plasticity—it can self-correct in animals wearing prism glasses, for example. I’m not familiar with the details, but I’m guessing it’s something like: If you see a motion, and saccade to it, but the motion is not centered even after the saccade, then that generates an error signal that induces a corresponding incremental map shift. Maybe this whole system involves 8 adjustable parameters (scale and offset, horizontal and vertical, three maps to align), or maybe it’s more complicated—again, I don’t know the details.
See the difference? Go back to the table above if you’re still confused.
2.4 My hypothesis: the cortex, extended striatum, and cerebellum learn from scratch; the hypothalamus and brainstem don’t
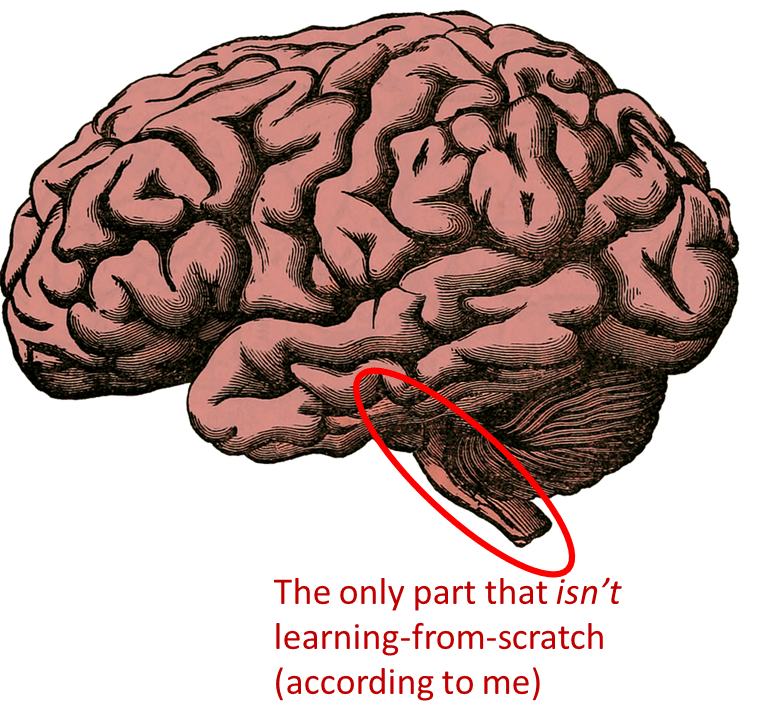
Three claims:
First, I think the whole cortex (a.k.a. “cortical mantle” or “pallium”) learns from scratch (and is useless at birth[1]). That includes (in mammals) the “neocortex”, the hippocampus, part of the amygdala, and a few other areas. (The thalamus is not 100% learning-from-scratch by my definition, but it’s worth keeping in mind that one of its main functions is basically to form part of the cortex learning and inference algorithms.)
Second, I think the whole extended striatum (a.k.a. “corpus striatum”) likewise learns from scratch. This includes the putamen, caudate, nucleus accumbens, lateral septum, part of the amygdala, and a few other areas.
The cortex and striatum together comprise ≈80% the volume of the human brain (ref).
Third, I think the cerebellum also learns from scratch (and is likewise useless at birth). The cerebellum is ≈10% of adult brain volume (ref). More on the cerebellum in Post #4 [LW · GW].
Fourth, I think the hypothalamus and brainstem absolutely do NOT learn from scratch (and they are very active and useful right from birth). I think certain other parts of the brain are in the same category too—e.g. the habenula, pineal gland, and parts of the pallidum.
OK, that’s my hypothesis.
I wouldn’t be surprised if there were minor exceptions to this picture. Maybe there’s some little nucleus somewhere in one of these systems that orchestrates a biologically-adaptive behavior without first learning it from scratch. As a possible example, the olfactory bulb is embryologically part of the cortex but (supposedly) it’s functionally part of the thalamus. Sure, why not. But I currently think this picture is at least broadly right.
In the next two sections I’ll talk about some evidence related to my hypothesis, and then what others in the field think of it.
2.5 Evidence on whether the cortex, striatum, and cerebellum learn from scratch
2.5.1 Big-picture-type evidence
I find from reading and talking to people that the biggest sticking points against believing that the cortex, extended striatum, and cerebellum learn from scratch is overwhelmingly not detailed discussion of neuroscience data etc. but rather:
- failure to even consider this hypothesis as a possibility, and
- confusion about the consequences of this hypothesis, and in particular how to flesh it out into a sensible big picture of brain and behavior.
If you’ve read this far, then #1 should no longer be a problem.
What about #2? A central type of question is “If the cortex, striatum, and cerebellum learn from scratch, then how do they do X?”—for various different X. If there’s an X for which we can’t answer this question at all, it suggests that the learning-from-scratch hypothesis is wrong. Conversely, if we can find really good answers to this question for lots of X, it would offer evidence (though not proof) that the learning-from-scratch hypothesis is right. The upcoming posts in this series will, I hope, offer some of this type of evidence.
2.5.2 Neonatal evidence
If the cortex, striatum, and cerebellum cannot produce biologically-adaptive outputs except by learning to do so over time, then it follows that any biologically-adaptive neonatal[1] behavior would have to be driven by the other parts of the brain (“Steering Subsystem”, see next post [LW · GW]), i.e. mainly the brainstem & hypothalamus. Is that right? At least some people think so! For example, Morton & Johnson 1991 says “evidence has been accumulating that suggests that newborn perceptuomotor activity is mainly controlled by subcortical mechanisms”. More recently, Blumberg & Adolph 2023 claim that “cortical control of eye, face, head, and limb movements is absent at birth and slowly emerges over the first postnatal year and beyond”, and forcefully argue that the early childhood development literature is full of errors stemming from the misattribution of brainstem behaviors to the cortex.
Anyway, diving into this type of evidence is a bit harder than it sounds. Suppose an infant does something biologically-adaptive…
- The first question we need to ask is: really? Maybe it’s a bad (or wrongly-interpreted) experiment. For example, if an adult sticks his tongue out at a newborn infant human, will the infant stick out her own tongue as an act of imitation? Seems like a simple question, right? Nope, it’s a decades-long raging controversy. A competing theory is centered around oral exploration: “tongue protrusion seems to be a general response to salient stimuli and is modulated by the child’s interest in the stimuli”; a protruding adult tongue happens to elicit this response, but so do flashing lights and bursts of music. I’m sure some people know which newborn experiments are trustworthy, but I don’t, at least not at the moment. And I’m feeling awfully paranoid after seeing two widely-respected books in the field (Scientist in the Crib, Origin of Concepts) repeat that claim about newborn tongue imitation as if it’s a rock-solid fact.
- The second question we need to ask is: is it the result of within-lifetime learning? Remember, even a 3-month-old infant has had 4 million waking seconds of “training data” to learn from. In fact, even zero-day-old infants could have potentially been running learning-from-scratch algorithms in the womb.[1]
- The third question we need to ask is: what part of the brain is orchestrating this behavior? My hypothesis says that non-learned adaptive behaviors cannot be orchestrated by the cortex, striatum, cerebellum, amygdala, etc. But my hypothesis does allow such behaviors to be orchestrated by the brainstem! And figuring out which part of the neonatal brain is causally upstream of some behavior can be experimentally challenging.
2.5.3 “Uniformity” evidence
The “cortical uniformity” hypothesis says that every part of the cortex runs a more-or-less similar algorithm.
This obviously needs some caveats. For one thing, the cortex has zones with different numbers of layers—mostly between 3 (“allocortex”) and 6 (“isocortex”), and sometimes even more than 6 (e.g. primate visual cortex). Before the isocortex evolved in mammals, early amniotes are believed to have had 100% allocortex—hence people sometimes refer to the varieties of cortex with >3 layers as “neocortex” (“neo-” is Greek for “new”). There are also more fine-grained differences across the cortex, such as how thick the different layers are, neuron morphology, and so on. Moreover, different parts of the cortex are wired to each other, and to different parts of the brain, in systematic, obviously-non-random, ways.
Nevertheless, while opinions differ, I feel strongly that cortical uniformity is basically right. Or more specifically: I feel strongly that if a future researcher has a really good nuts-and-bolts understanding of how Isocortex Area #147 works, that person would be well on their way to understanding how literally any other part of the cortex works. The differences across the cortex noted in the previous paragraph are real and important, but are more akin to how a single learning-and-inference algorithm can have different hyperparameters in different places, and different loss functions in different places, and can have a complex neural architecture.
Intriguingly, even the difference between 6-layer isocortex and 3-layer allocortex has the property of being smoothly interpolatable—you can find rather continuous gradations from allocortex to isocortex (cf. periallocortex, proisocortex). If isocortex and allocortex were two totally different algorithms, you wouldn’t see that—for example, there’s no way to smoothly interpolate between a SAT solver and a sorting algorithm, with useful algorithms every step along the way!! But it is what you’d expect from hyperparameter or architectural variations of a single learning-and-inference algorithm. For example, if you take a ResNet, and let the number of nodes in the residual blocks gradually go to zero, then those residual blocks do less and less, and eventually they disappear entirely, but we still have legitimate, functioning learning algorithms every step along the way.
I say a bit more about cortical uniformity here [AF · GW], but I won’t argue for it in more detail—I consider it generally off-topic for this series.
I bring this up because if you believe in cortical uniformity, then you should probably believe in cortical learning-from-scratch as well. The argument goes as follows:
Adult isocortex does lots of apparently very different things: vision processing, sound processing, motor control, language, planning, and so on. How would one reconcile this fact with cortical uniformity?
Learning-from-scratch offers a plausible way to reconcile them. After all, we know that a single learning-from-scratch algorithm, fed with very different input data and supervisory signals, can wind up doing very different things—consider how transformer-architecture deep neural networks can be trained to generate natural-language text, or images, or music, or robot motor control signals, etc.
By contrast, if we accept cortical uniformity but reject learning-from-scratch, well, umm, I can’t see any way to make sense of how that would work.
Moving on, I mentioned above the idea (due to Larry Swanson) that the whole extended striatum (caudate, putamen, nucleus accumbens, lateral septum, etc.) starts from a unified embryological structure, suggesting a hypothesis that it’s all running a similar learning algorithm. So what’s the evidence for “striatal uniformity”? Don’t expect to find a dedicated literature review—in fact, the previous sentence seems to be the first time that term has ever been written down. But there are some commonalities—in particular, I think medium spiny neurons (a.k.a. spiny projection neurons) exist everywhere in the extended striatum. When we get to Posts #4 [LW · GW]-#6 [LW · GW], I’ll propose a computational story for what those medium spiny neurons are doing, namely a form of supervised learning that I call “short-term prediction”, and how that fits into the bigger picture.
In the cerebellum case, there is at least some literature on the uniformity hypothesis (search for the term “universal cerebellar transform”), but again no consensus. The adult cerebellum is likewise involved in apparently-different functions like motor coordination, language, cognition, and emotions. I personally strongly believe in uniformity there too, with details coming up in Post #4 [AF · GW].
2.5.4 Locally-random pattern separation
This is another reason that I personally put a lot of stock in the learning-from-scratch cortex and cerebellum. It’s kinda specific, but very salient in my mind; see if you buy it.
2.5.4.1 What is pattern separation?
There is a common motif in the brain called “pattern separation”. Let me explain what it is and why it exists.
Suppose you’re an ML engineer working for a restaurant chain. Your boss tells you to predict sales for different candidate franchise locations.
The first thing you might do is to gather a bunch of data-streams—local unemployment rate, local restaurant ratings, local grocery store prices, whether there happens to be a novel coronavirus spreading around the world right now, etc. I like to call these “context data”. You would use the context data as inputs to a neural network. The output of the network is supposed to be a prediction of the restaurant sales. You adjust the neural network weights (using supervised learning, with data from existing restaurants) to make that happen. No problem!
Pattern separation is when you add an extra step at the beginning. You take your various context data-streams, and randomly combine them in lots and lots of different ways. Then you sprinkle in some nonlinearity, and voilà! You now have way more context data-streams than you started with! Then those can be the inputs to the trainable neural net.[4]
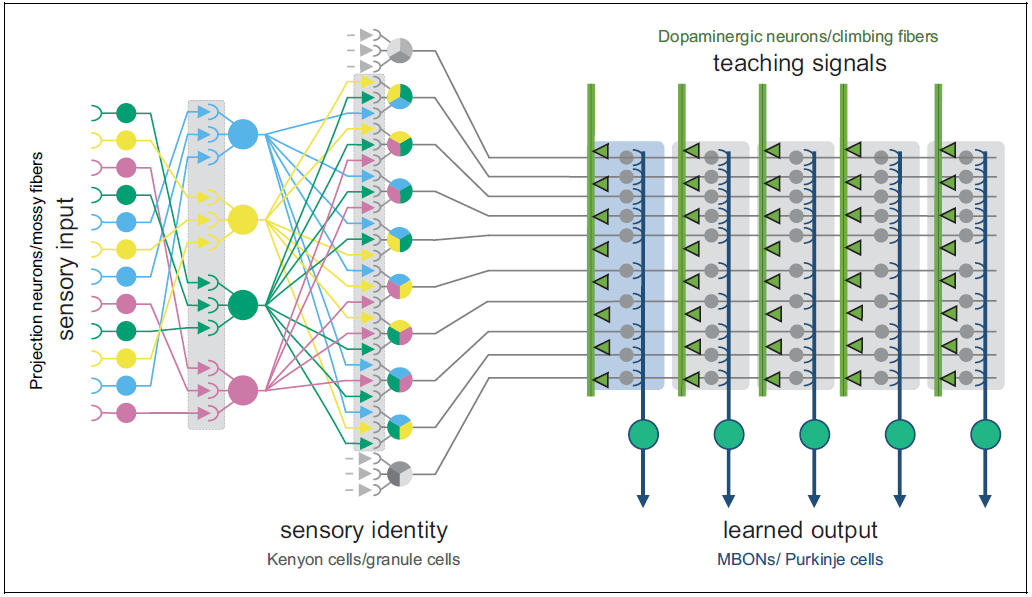
In ML terms, pattern separation is like adding a very wide hidden layer, at the input side, with fixed weights. If the layer is wide enough, you’ll find that some neurons in the layer are carrying useful representations, just by good luck. And then the next layer can use those useful neurons, and ignore the rest.
ML readers are now thinking to themselves: “OK, fine, but this is kinda dumb. Why add a extra-wide hidden layer at the beginning, with non-learnable weights? Why not just add a normal-sized hidden layer at the beginning, with learnable weights? Wouldn’t that be easier and better?” Umm, probably! At least, it would indeed probably be better in this particular example.[5]
So why add a pattern-separation layer, instead of an extra learnable layer? Well, remember that in biological neurons, doing backprop (or something equivalent) through multiple learnable layers is at best a complicated procedure, and at worst totally impossible. Or at least, that’s my current impression. Backprop as such is widely acknowledged to be impossible to implement in biological neurons (cf. “the weight transport problem”). Various groups in ML and neuroscience have taken that as a challenge, and devised roughly 7 zillion different mechanisms that are (allegedly) biologically plausible and (allegedly) wind up functionally similar to backprop for one reason or another.[6] I haven’t read all these papers. But anyway, even if it’s possible to propagate errors through 2 learnable layers of biological neurons (or 3 layers, or even N layers), let’s remember that it's an absolute breeze to do error-driven learning with just one learnable layer, using biological neurons. (All it takes is a set of identical synapses, getting updated by a 3-factor learning rule. Details coming up in Post #4 [AF · GW].) So it’s not crazy to think that evolution might settle on a solution like pattern separation, which gets some of the advantage of an extra learnable layer, but without the complication of actually propagating errors through an extra learnable layer.
2.5.4.2 Where is pattern-separation?
Pattern separation is thought to occur in a number of places, particularly involving the tiny and numerous neurons called “granule cells”:
- The cerebellum has pattern-separating granule cells in its “granular layer” (ref). And boy are there a lot of them! Adult humans have 50 billion of them—more than half the neurons in your entire brain.
- The hippocampus has pattern-separating granule cells in its “dentate gyrus”.
- Isocortex areas have pattern-separating granule cells in “layer 4”, its primary input layer. To be clear, some cortex areas are called “agranular”, meaning that they lack this granular layer. But that’s just because not all the cortex is processing inputs of the type that gets pattern-separated. Some cortex is geared to outputs instead (details here).
- The fruit fly nervous system has a “mushroom body” consisting of “kenyon cells” which are also believed to be pattern-separators—see references here [LW · GW].
2.5.4.3 Why does pattern separation suggest learning-from-scratch?
The thing is, pattern separation seems to be a locally random process. What does “locally” mean here? Well, it’s generally not true that any one input is equally likely to be mixed with any other input. (At least, not in fruit flies.) I only claim that it involves randomness at a small scale—like, out of this microscopic cluster of dozens of granule cells, exactly which cell connects with exactly which of the nearby input signals? I think the answer to those kinds of questions is: it’s random.
Why do I say that it’s probably (locally) random? Well, I can’t be sure, but I do have a few reasons.
- From an algorithm perspective, (local) randomness seems like it would work, and indeed has some nice properties, like statistical guarantees about low overlap between sparse activation patterns.
- From an information-theory perspective, if there are 50 billion granule cells in an adult cerebellum, I find it pretty hard to imagine that the exact connections to each of them is deterministically orchestrated by the <1GB genome, while still satisfying the various algorithmic and biological constraints.
- From an experimental perspective, I’m not sure about vertebrates, but at least in the fruit fly case, genetically-identical fruit flies are known to have different kenyon cell connectivity (ref).
Anyway, if pattern-separation is a (locally) random process, then that means that you can’t do anything useful with the outputs of a pattern-separation layer, except by learning to do so. In other words, we wind up with a learning-from-scratch algorithm! (Indeed, one that would stay learning-from-scratch even in the face of evolutionary pressure to micromanage the initial parameters!)
2.5.5 Summary: I don’t pretend that I’ve proven the hypothesis of learning-from-scratch cortex, striatum, and cerebellum, but I’ll ask you to suspend disbelief and read on
In my own head, when I mash together all the considerations I discussed above (big-picture stuff, neonatal stuff, uniformity, and locally-random pattern separation), I wind up feeling quite confident in my hypothesis of a learning-from-scratch cortex, striatum, and cerebellum (broadly construed, including the amygdala etc., see above). But really, everything here is suggestive, not the kind of definitive, authoritative discussion that would convince every skeptic. The comprehensive scholarly literature review on learning-from-scratch in the brain, so far as I know, has yet to be written.
Don’t get me wrong; I would love to write that! I would dive into all the relevant evidence, like everything discussed above, plus other things like experiments on decorticate rats, etc. That would be awesome, and I may well do that at some point in the future. (Or reach out if you want to collaborate!)
But meanwhile, I’m going to treat the hypothesis as if it were true. This is just for readability—the whole rest of the series will be exploring bigger-picture consequences of the hypothesis, and it would get really annoying if I put apologies and caveats in every other sentence.
2.6 Is my hypothesis consensus, or controversial?
Weirdly, I just don’t know! This is not a hot topic of discussion in neuroscience. I think most people haven’t even thought to formulate “what parts of the brain learn from scratch?” as an explicit question, let alone a question of absolutely central importance.
(I heard from an old-timer in the field that the question “what parts of the brain learn from scratch?” smells too much like “nature vs nurture”. According to them, everyone had a fun debate about “nature vs nurture” in the 1990s, and then they got sick of it and moved on to other things! Indeed, I asked for a state-of-the art reference on the evidence for learning-from-scratch in the cortex, striatum, and cerebellum, and they suggested a book from 25 years earlier! It’s a good book—in fact I had already read it. But c’mon!! We’ve learned new things since 1996, right??)
Some data points:
- Neuroscientist Randall O’Reilly explicitly endorses a learning-from-scratch cortex (in agreement with me). He talks about it here (30:00), citing this paper on infant face recognition as a line of evidence. In fact, I think O’Reilly would agree with at least most of my hypothesis, and maybe all of it.
- I’m also pretty confident that Jeff Hawkins and Dileep George would endorse my hypothesis, or at least something very close to it. More on them in the next post [AF · GW].
- A commenter suggested the book Beyond Evolutionary Psychology by George Ellis & Mark Solms (2018), which (among other things) argues for something strikingly similar to my hypothesis—they list the brain’s “soft-wired domains” as consisting of the cortex, the cerebellum, and “parts of the limbic system, for instance most of the hippocampus and amygdala, and large parts of the basal ganglia” (page 209). Almost a perfect match to my list! But their notion of “soft-wired domains” is defined somewhat differently than my notion of “learning from scratch”, and indeed I disagree with the book in numerous areas. But anyway, the book has lots of relevant evidence and literature. Incidentally, the book was mainly written as an argument against an “innate cognitive modules” perspective exemplified by Steven Pinker’s How the Mind Works (1994). So it’s no surprise that Steven Pinker would disagree with the claim that the cortex learns from scratch (well, I’m 99% confident that he would)—see, for example, his book The Blank Slate (2003) chapter 5.
- Some corners of computational neuroscience—particularly those with ties to the deep learning community—seem very enthusiastic about learning-from-scratch algorithms in the brain in general. But the discourse there doesn’t seem specific enough to answer my question. For example, I’m looking for statements like “Within-lifetime learning algorithms are a good starting point for understanding the cortex, but a bad starting point for understanding the medulla.” I can’t find anything like that. Instead I see, for example, the paper “A deep learning framework for neuroscience” (by 32 people including Blake Richards and Konrad Kording), which says something like “Learning algorithms are very important for the brain, and sometimes those learning algorithms are within-lifetime learning algorithms, whereas other times the only learning algorithm is evolution.” But which parts of the brain are in which category? The paper doesn’t say.
- My vague impression from sporadically reading papers with computational models of the cortex, hippocampus, cerebellum, and striatum, from various different groups, is that the models are at least often learning-from-scratch models, but not always.
In summary, while I’m uncertain, there’s some reason to believe that my hypothesis is not too far outside the mainstream…
But it’s only “not too far outside the mainstream” in a kind of tunnel-vision sense. Almost nobody in neuroscience is taking the hypothesis seriously enough to grapple with its bigger-picture consequences. As mentioned above, if you believe (as I do) that “if the cortex, striatum, or cerebellum perform a useful function X, they must have learned to perform that function, within the organism’s lifetime, somehow or other”, then that immediately spawns a million follow-up questions of the form: “How did it learn to do X? Is there a ground-truth that it’s learning from? What is it? Where does it come from?” I have a hard time finding good discussions of these questions in the literature. Whereas I’m asking these questions constantly, as you’ll see if you read on.
In this series of posts, I’m going to talk extensively about the bigger-picture framework around learning-from-scratch. By contrast, I’m going to talk relatively little about the nuts-and-bolts of how the learning algorithms work. That would be a complicated story which is not particularly relevant for AGI safety. And at least in some cases, nobody really knows the exact learning algorithms anyway.
2.7 Why does learning-from-scratch matter for AGI safety?
Much more on this later, but here’s a preview.
The single most important question in AGI safety is: Is the AGI trying to do something that we didn’t intend for it to be trying to do?
If no, awesome! This is sometimes called “intent alignment”. Granted, even with intent alignment, we can’t declare victory over accident risk—the AGI can still screw things up despite good intentions (see Post #11 [AF · GW]), not to mention the problems outside the scope of technical AGI safety research (races-to-the-bottom on human oversight, careless actors, etc.—see Post #1 Section 1.2 [LW · GW] and this later post [LW · GW]). But we’ve made a lot of progress.
By contrast, if the AGI is trying to do something that we hadn’t intended for it to be trying to do, that’s where we get into the really bad minefield of catastrophic accidents. And as we build more and more capable AGIs over time, the accidents get worse, not better, because the AGI will become more skillful at figuring out how best to do those things that we had never wanted it to be doing in the first place.
So the critical question is: how does the AGI wind up trying to do one thing and not another? And the follow-up question is: if we want the AGI to be trying to do a particular thing X (where X is “act ethically”, or “be helpful”, or whatever—more on this in future posts), what code do we write?
Learning-from-scratch means that the AGI’s common-sense world-model involves one or more big data structures that are built from scratch during the AGI’s “lifetime” / “training”. The stuff inside those data structures is not necessarily human-interpretable[7]—after all, it was never put in by humans in the first place!
And unfortunately, the things that we want the AGI to be trying to do—“act ethically”, or “solve Alzheimer’s”, or whatever—are naturally defined in terms of abstract concepts. At best, those concepts are buried somewhere inside those big data structures. At worst (e.g. early in training), the AGI might not even have those concepts in the first place. So how do we write code such that the AGI wants to solve Alzheimer’s?
In fact, evolution has the same problem! Evolution would love to paint the abstract concept “Have lots of biological descendants” with positive valence, but thanks to learning-from-scratch, the genome doesn’t know which precise set of neurons will ultimately be representing this concept. (And not all humans have a “biological descendants” concept anyway.) The genome does other things instead, and later in the series I’ll be talking more about what those things are.
2.8 Timelines-to-brain-like-AGI part 1/3: how hard will it be to reverse-engineer the learning-from-scratch parts of the brain, well enough for AGI?
This isn’t exactly on-topic, so I don’t want to get too deep into it. But in Section 1.5 of the previous post [LW · GW], I mentioned that there’s a popular idea that “brain-like AGI” (as defined in Section 1.3.2 of the previous post [AF · GW]) is probably centuries away because the brain is so very horrifically complicated. I then said that I strongly disagreed. Now I can say a bit about why.
As context, we can divide the “build brain-like AGI” problem up into three pieces:
- Reverse-engineer the learning-from-scratch parts of the brain (cortex, striatum, cerebellum) well enough for AGI,
- Reverse-engineer everything else (mainly the brainstem & hypothalamus) well enough for AGI,
- Actually build the AGI—including hardware-accelerating the code, running model trainings, working out all the kinks, etc.
This section is about #1. I’ll get back to #2 & #3 in Sections 3.7 & 3.8 of the next post [AF · GW].
Learning-from-scratch is highly relevant here because reverse-engineering learning-from-scratch algorithms is a way simpler task than reverse-engineering trained models.
For example, think of the OpenAI Microscope visualizations of different neurons in a deep neural net. There’s so much complexity! But no human needed to design that complexity; it was automatically discovered by the learning algorithm. The learning algorithm itself is comparatively simple—gradient descent and so on.
Here are some more intuitions on this topic:
- I think that learning-from-scratch algorithms kinda have to be simple, because they have to draw on broadly-applicable regularities—“patterns tend to recur”, and “patterns are often localized in time and space”, and “things are often composed of other things”, and so on.
- Human brains were able to invent quantum mechanics. I can kinda see how a learning algorithm based on simple, general principles like “things are often composed of other things” (as above) can eventually invent quantum mechanics. I can’t see how a horrifically-complicated-Rube-Goldberg-machine of an algorithm can invent quantum mechanics. It’s just so wildly different from anything in the ancestral environment.
- The learning algorithm’s neural architecture, hyperparameters, etc. could be kinda complicated. I freely admit it. For example, this study says that the cortex has 180 distinguishable areas. But on the other hand, future researchers don’t need to reinvent that stuff from scratch; they could also just “crib the answers” from the neuroscience literature. And also, not all that complexity is necessary for human intelligence—as we know from the ability of infants to (sometimes) fully recover from various forms of brain damage. Some complexity might just help speed the learning process up a bit, on the margin, or might help with unnecessary-for-AGI things like our sense of smell.
- In Section 2.5.3, I discussed the “cortical uniformity” hypothesis and its various cousins. If true, it would greatly limit the potential difficulty of understanding how those parts of the brain work. But I don’t think anything I’m saying here depends on the “uniformity” hypotheses being true, let alone strictly true.
Going back to the question at issue. In another (say) 20 years, will we understand the cortex, striatum, and cerebellum well enough to build the learning-from-scratch part of an AGI?
I say: I don’t know! Maybe we will, maybe we won’t.
There are people who disagree with me on that. They claim that the answer is “Absolutely 100% not! Laughable! How dare you even think that? That’s the kind of thing that only a self-promoting charlatan would say, as they try to dupe money out of investors! That’s not the kind of thing that a serious cautious neuroscientist would say!!!” Etc. etc.
My response is: I think that this is wildly-unwarranted overconfidence. I don’t see any good reason to rule out figuring this out in (say) 20 years, or even 5 years. Or maybe it will take 100 years! I think we should remain uncertain. As they say, “Predictions are hard, especially about the future.”
Changelog
July 2024: Since the initial version:
BIG CHANGE: In the initial version, I wrote that the whole telencephalon “learns from scratch”. That was a bit too broad. Larry Swanson proposes that the telencephalon consists of three embryological layers: the cortex (a.k.a. pallium), striatum, and pallidum. (I think this claim is mostly uncontroversial, except for some dispute over where exactly the extended amygdala fits in, but I’ll leave that aside.) I still think the first two are learning-from-scratch, but not the pallidum. I currently think that parts of the pallidum are basically an extension of the brainstem RAS, and thus definitely don’t belong in the learning-from-scratch bucket. Other parts of the pallidum could go either way, depending on some judgment calls about where to define the I/O surface of certain learning algorithms. I also cut out the thalamus from the learning-from-scratch bucket—I still think one of its main roles is as part of the cortex learning-and-inference algorithm, but it does other things too and I don’t want to over-claim. Between these two changes, the learning-from-scratch volume of the human brain goes from “96%” to the more conservative “>90%”.
OTHER THINGS: I also added a couple more paragraphs about cortical uniformity, including the relationship between allocortex and isocortex. Speaking of which, I also mostly switched terminology from “neocortex” to “isocortex”. “Isocortex” is actually the original term for 6-layer cortex, I believe, and remains much more common in the relevant corner of the neuroscience literature. So it seemed like a better choice. “Neocortex” somehow wound up widespread in popularizations outside neuroscience, particularly associated with Paul MacLean and Jeff Hawkins. Those popularizations have some issues (see next post), such that I’m happy to not sound too much like they do. But I also put “(a.k.a. neocortex)” in various places, in order to help readers with preexisting knowledge of that term. Separately, I added a link to the book Beyond Evolutionary Psychology after a twitter commenter suggested it. All other changes were so minor that no one will notice them—suboptimal links, suboptimal wording, broken links, etc.
October 2024: I found a paper Blumberg & Adolph 2023, which discusses the extent to which the cortex is involved in newborn behavior. Their answer is “very little” (which supports my hypothesis). I added it as a reference in Section 2.5.2.
- ^
I keep saying that “learning from scratch” implies “unhelpful for behavior at birth”. This is an oversimplification, because it’s possible for “within-lifetime learning” to happen in the womb. After all, there should already be plenty of data to learn from in the womb—interoception, sounds, motor control, etc. And maybe retinal waves too—those could be functioning as fake sensory data for the learning algorithm to learn from.
- ^
Minor technicality: Why did I say the input data and supervisory signals for the cortex (for example) come from outside the cortex? Can’t one part of the cortex get input data and/or supervisory signals from a different part of the cortex? Yes, of course. However, I would instead describe that as “part of the cortex’s neural architecture”. By analogy, in ML, people normally would NOT say “ConvNet-layer-12 gets input data from ConvNet-layer-11”. Instead, they would be more likely to say “The ConvNet (as a whole) gets input data from outside the ConvNet”. This is just a way of talking, it doesn't really matter.
- ^
I’m framing this as a “made-up example” because I’m trying to make a simple conceptual point, and don’t want to get bogged down in complicated uncertain empirical details. That said, the bird song thing is not entirely made up—it’s at least “inspired by a true story”. See discussion here [AF · GW] of Gadagkar 2016, which found that a subset of dopamine neurons in the songbird brainstem send signals that look like RL rewards for song quality, and those signals go specifically to the vocal motor system, presumably training it to sing better. The missing part of that story is: what calculations are upstream of those particular dopamine neurons? In other words, how does the bird brain judge its own success at singing? For example, does it match its self-generated auditory inputs to an innate template? Or maybe the template is generated in a more complicated way—say, involving listening to adult birds of the same species? Or something else? I’m not sure the details here are known—or at least, I don’t personally know them.
- ^
Why is it called “pattern separation”? It’s kinda related to the fact that a pattern-separator has more output lines than input lines. For example, you might regularly encounter five different “patterns” of sensory data, and maybe all of them consist of activity in the same set of 30 input lines, albeit with subtle differences—maybe one pattern has such-and-such input signal slightly stronger than in the other patterns, etc. So on the input side, we might say that these five patterns “overlap”. But on the output side, maybe these five patterns would wind up activating entirely different sets of neurons. Hence, the patterns have been “separated”.
- ^
In other examples, I think pattern separation is serving other purposes too, e.g. sparsifying the neuron activations, which turns out to be very important for various reasons, including not getting seizures.
- ^
If you want to dive into the rapidly-growing literature on biologically-plausible backprop-ish algorithms, a possible starting point would be References #12, 14, 34–38, 91, 93, and 94 of A deep learning framework for neuroscience.
- ^
There is a field of “machine learning interpretability”, dedicated to interpreting the innards of learned-from-scratch “trained models”—example. I (along with pretty much everyone else working on AGI safety) strongly endorse efforts to advance that field, including tackling much bigger models, and models trained by a wider variety of different learning algorithms. Also on this topic: I sometimes hear an argument that a brain-like AGI using a brain-like learning algorithm will produce a relatively more human-interpretable trained model than alternatives. This strikes me as maybe true, but far from guaranteed, and anyway “relatively more human-interpretable” is different than “very human-interpretable”. Recall that the cortex has ≈100 trillion synapses, and an AGI could eventually have many more than that.
12 comments
Comments sorted by top scores.
comment by Jan (jan-2) · 2022-02-04T23:20:09.729Z · LW(p) · GW(p)
Hey Steve! Thanks for writing this, it was an interesting and useful read! After our discussion in the LW comments [LW · GW], I wanted to get a better understanding of your thinking and this sequence is doing the job. Now I feel I can better engage in a technical discussion.
I can sympathize well with your struggle in section 2.6. A lot of the "big picture" neuroscience is in the stage where it's not even wrong. That being said, I don't think you'll find a lot of neuroscientists who nod along with your line of argument without raising objections here and there (neuroscientists love their trivia). They might be missing the point, but I think that still makes your theory (by definition) controversial. (I think the term "scientific consensus" should be used carefully and very selectively).
In that spirit, there are a few points that I could push back on:
- Cortical uniformity (and by extension canonical microcircuits) are extremely useful concepts for thinking about the brain. But they are not literally 100% accurate. There are a lot of differences between different regions of the cortex, not only in thickness but also in the developmental process (here or here). I don't think anyone except for Jeff Hawkin believes in literal cortical uniformity.
- In section 2.5.4.1 you are being a bit dismissive of biologically-"realistic" implementations of backpropagation. I used to be pretty skeptical too, but some of the recent studies are beginning to make a lot of sense. This one (a collaboration of Deepmind and some of the established neuroscience bigshots) is really quite elegant and offers some great insights on how interneurons and dendritic branches might interact.
- A more theoretical counter: If evolution could initialize certain parts of the cortex so that they are faster "up and running" why wouldn't it? (Just so that we can better understand it? How nice!) From the perspective of evolution, it makes a lot of sense to initialize the cortex with an idea of what an oriented edge is because oriented edges have always been around since the inception of the eye.
Or, in terms of computation theory, learning from scratch is computationally intractable. Strong, informative priors over hypothesis space might just be necessary to learn anything worthwhile at all.
But perhaps I'm missing the point with that nitpicking. I think the broader conceptual question I have is: What does "randomly initialized" even mean in the brain? At what point is the brain initialized? When the neural tube forms? When interneurons begin to migrate to the cortex? When the first synapses are established? When the subplate is gone? When the pruning of excess synapses and the apoptosis of cells is over? When the animal/human is born? When all the senses begin to transmit input? After college graduation?
Perhaps this is the point that the "old-timer" also wanted to make. It doesn't really make sense to separate the "initialization" from the "refinement". They happen at the same time, and whether you put a certain thing into one category or the other is up to individual taste.
All of this being said, I'm very curious to read the next parts of this sequence! :) Perhaps my points don't even affect your core argument about AI Safety.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-02-05T20:49:00.185Z · LW(p) · GW(p)
Thanks!
I don't think anyone except for Jeff Hawkin believes in literal cortical uniformity.
Not even him! Jeff Hawkins: "Mountcastle’s proposal that there is a common cortical algorithm doesn’t mean there are no variations. He knew that. The issue is how much is common in all cortical regions, and how much is different. The evidence suggests that there is a huge amount of commonality."
I mentioned "non-uniform neural architecture and hyperparameters". I'm inclined to put different layer thicknesses (including agranularity) in the category of "non-uniform hyperparameters".
If evolution could initialize certain parts of the cortex so that they are faster "up and running" why wouldn't it?
If you buy the "locally-random pattern separation" story (Section 2.5.4), that would make it impossible for evolution to initialize the adjustable parameters in a non-locally-random way.
in terms of computation theory, learning from scratch is computationally intractable. Strong, informative priors over hypothesis space might just be necessary to learn anything worthwhile at all.
I'm very confused by this. I have coded up a ConvNet with random initialization. It was computationally tractable; in fact, it ran on my laptop!
I guess maybe what you're claiming is: we can't have all three of {learning from scratch, general intelligence, computational tractability}. If so, well, that's a possible thing to believe, although I happen not to believe it. My question would be: why do you believe it? "Learning-from-scratch algorithms" consist of an astronomically large number of algorithms, of which an infinitesimal fraction have ever been even conceived of by humans. I think it's difficult to make blanket statements about the whole category.
I don't see the relevance of Solomonoff Induction here. "Generally intelligent" is a much lower bar than "just as intelligent as a Solomonoff Inductor", right?
I'm also confused about why you think "strong, informative priors over hypothesis space" are not compatible with learning-from-scratch algorithms. The famous example everyone talks about is how ConvNets disproportionately search for patterns that are local (i.e. involve neighboring pixels) and translation-invariant.
What does "randomly initialized" even mean in the brain? At what point is the brain initialized?
Here's an operationalization. Suppose someday we write computer code that can do the exact same useful computational things that the neocortex (etc.) does, for the exact same reason. My question is: Might that code look like a learning-from-scratch algorithm?
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-07T18:34:15.741Z · LW(p) · GW(p)
Here's an operationalization. Suppose someday we write computer code that can do the exact same useful computational things that the neocortex (etc.) does, for the exact same reason. My question is: Might that code look like a learning-from-scratch algorithm?
Hmm, I see. If this is the crux, then I'll put all the remaining nitpicking at the end of my comment and just say: I think I'm on board with your argument. Yes, it seems conceivable to me that a learning-from-scratch program ends up in a (functionally) very similar state to the brain. The trajectory of how the program ends up there over training probably looks different (and might take a bit longer if it doesn't use the shortcuts that the brain got from evolution), but I don't think the stuff that evolution put in the cortex is strictly necessary.
A caveat: I'm not sure how much weight the similarity between the program and the brain can support before it breaks down. I'd strongly suspect that certain aspects of the cortex are not logically implied by the statistics of the environment, but rather represent idiosyncratic quirks that were adapted at some point during evolution. Those idiosyncratic quirks won't be in the learning-from-scratch program. But perhaps (probably?) they are also not relevant in the big scheme of things.
I'm inclined to put different layer thicknesses (including agranularity) in the category of "non-uniform hyperparameters".
Fair! Most people in computational neuroscience are also very happy to ignore those differences, and so far nothing terribly bad happened.
If you buy the "locally-random pattern separation" story (Section 2.5.4), that would make it impossible for evolution to initialize the adjustable parameters in a non-locally-random way.
You point out yourself that some areas (f.e. the motor cortex) are granular, so that argument doesn't work there. But ignoring that, and conceding the cerebellum and the drosophila mushroom body to you (not my area of expertise), I'm pretty doubtful about postulating "locally-random pattern separation" in the cortex. I'm interpreting your thesis to cash out as "Given a handful of granule cells from layer 4, the connectivity with pyramidal neurons in layer 2/3 is (initially) effectively random, and therefore layer 2/3 neurons need to learn (from scratch) how to interpret the signal from layer 4". Is that an okay summary?
Because then I think this fails at three points:
- One characteristic feature of the cortex is the presence of cortical maps. They exist in basically all sensory and motor cortices, and they have a very regular structure that is present in animal species separated by as much as 64 million years of evolution. These maps imply that if you pick a handful of granule cells from layer 4 that are located nearby, their functional properties will be somewhat similar! Therefore, even if connectivity between L4 and L2/3 is locally random it doesn't really matter since the input is somewhat similar in any case. Evolution could "use" that fact to pre-structure the circuit in L2/3.
- Connectivity between L4 and L2/3 is not random. Projections from layer 4 are specific to different portions of the postsynaptic dendrite, and nearby synapses on mature and developing dendrites tend to share similar activation patterns. Perhaps you want to argue that this non-randomness only emerges through learning and the initial configuration is random? That's a possibility, but ...
- ... when you record activity from neurons in the cortex of an animal that had zero visual experience prior to the experiment (lid-suture), they are still orientation-selective! And so is the topographic arrangement of retinal inputs and the segregation of eye-specific inputs. At the point of eye-opening, the animals are already pretty much able to navigate their environment.
Obviously, there are still a lot of things that need to be refined and set up during later development, but defects in these early stages of network initialization are pretty bad (a lot of neurodevelopmental disorders manifest as "wiring defects" that start in early development).
I'm very confused by this. I have coded up a ConvNet with random initialization. It was computationally tractable; in fact, it ran on my laptop!
Okay, my claim there came out a lot stronger than I wanted and I concede a lot of what you say. Learning from scratch is probably not computationally intractable in the technical sense. I guess what I wanted to argue is that it appears practically infeasible to learn everything from scratch. (There is a lot of "everything" and not a lot of time to learn it. Any headstart might be strictly necessary and not just a nice-to-have).
(As a side point: your choice of a convnet as the example is interesting. People came up with convnets because fully-connected, randomly initialized networks were not great at image classification and we needed some inductive bias in the form of a locality constraint to learn in a reasonable time. That's the point I wanted to make.)
I guess maybe what you're claiming is: we can't have all three of {learning from scratch, general intelligence, computational tractability}.
Interesting, I haven't thought about it like this before. I do think it could be possible to have all three - but then it's not the brain anymore. As far as I can tell, evolutionary pressures make complete learning from scratch infeasible.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-02-07T20:36:00.590Z · LW(p) · GW(p)
Thanks for your interesting comments!
People came up with convnets because fully-connected, randomly initialized networks were not great at image classification and we needed some inductive bias in the form of a locality constraint to learn in a reasonable time. That's the point I wanted to make.
I'm pretty confused here. To me, that doesn't seem to support your point, which suggests that one of us is confused, or else I don't understand your point.
Specifically: If I switch from a fully-connected DNN to a ConvNet, I'm switching from one learning-from-scratch algorithm to a different learning-from-scratch algorithm.
I feel like your perspective is that {inductive biases, non-learning-from-scratch} are a pair that go inexorably together, and you are strongly in favor of both, and I am strongly opposed to both. But that's not right: they don't inexorably go together. The ConvNet example proves it.
I am in favor of learning-from-scratch, and I am also in favor of specific designed inductive biases, and I don't think those two things are in opposition to each other.
Yes, it seems conceivable to me that a learning-from-scratch program ends up in a (functionally) very similar state to the brain.
I think you're misunderstanding me. Random chunks of matter do not learn language, but the neocortex does. There's a reason for that—aspects of the neocortex are designed by evolution to do certain computations that result in the useful functionality of learning language (as an example). There is a reason that these particular computations, unlike the computations performed by random chunks of matter, are able to learn language. And this reason can be described in purely computational terms—"such-and-such process performs a kind of search over this particular space, and meanwhile this other process breaks down the syntactic tree using such-and-such algorithm…", I dunno, whatever. The point is, this kind of explanation does not talk about subplates and synapses, it talks about principles of algorithms and computations.
Whatever that explanation is, it's a thing that we can turn into a design spec for our own algorithms, which, powered by the same engineering principles, will do the same computations, with the same results.
In particular, our code will be just as data-efficient as the neocortex is, and it will make the same types of mistakes in the same types of situations as the neocortex does, etc. etc.
when you record activity from neurons in the cortex of an animal that had zero visual experience prior to the experiment (lid-suture), they are still orientation-selective
is that true even if there haven't been any retinal waves?
Replies from: jan-2↑ comment by Jan (jan-2) · 2022-02-11T01:07:41.606Z · LW(p) · GW(p)
I'm pretty confused here.
Yeah, the feeling's mutual 😅 But the discussion is also very rewarding for me, thank you for engaging!
I am in favor of learning-from-scratch, and I am also in favor of specific designed inductive biases, and I don't think those two things are in opposition to each other.
A couple of thoughts:
- Yes, I agree that the inductive bias (/genetically hardcoded information) can live in different components: the learning rule, the network architecture, or the initialization of the weights. So learning-from-scratch is logically compatible with inductive biases - we can just put all the inductive bias into the learning rule and the architecture and none in the weights.
- But from the architecture and the learning rule, the hardcoded info can enter into the weights very rapidly (f.e. first step of the learning rule: set all the weights to the values appropriate for an adult brain. Or, more realistically, a ConvNet architecture can be learned from a DNN by setting a lot of connections to zero). Therefore I don't see what it could buy you to assume the weights to be free of inductive bias.
- There might also be a case that in the actual biological brain the weights are not initialized randomly. See f.e. this work on clonally related neurons.
- Something that is not appreciated a lot outside of neuroscience: "Learning" in the brain is as much a structural process as it is a "changing weights" process. This is particularly true throughout development but also into adulthood - activity-dependent learning rules do not only adjust the weights of connections, but they can also prune bad connections and add new connections. The brain simultaneously produces activity, which induces plasticity, which changes the circuit, which produces slightly different activity in turn.
The point is, this kind of explanation does not talk about subplates and synapses, it talks about principles of algorithms and computations.
That sounds a lot more like cognitive science than neuroscience! This is completely fine (I did my undergrad in CogSci), but it requires a different set of arguments from the ones you are providing in your post, I think. If you want to make a CogSci case for learning from scratch, then your argument has to be a lot more constructive (i.e. literally walk us through the steps of how your proposed system can learn all/a lot of what humans can learn). Either you take a look at what is there in the brain (subplate, synapses, ...), describe how these things interact, and (correctly) infer that it's sufficient to produce a mind (this is the neuroscience strategy); Or you propose an abstract system, demonstrate that it can do the same thing as the mind, and then demonstrate that the components of the abstract system can be identified with the biological brain (this is the CogSci strategy). I think you're skipping step two of the CogSci strategy.
Whatever that explanation is, it's a thing that we can turn into a design spec for our own algorithms, which, powered by the same engineering principles, will do the same computations, with the same results.
I'm on board with that. I anticipate that the design spec will contain (the equivalent of) a ton of hardcoded genetic stuff also for the "learning subsystem"/cortex. From a CogSci perspective, I'm willing to assume that this genetic stuff could be in the learning rule and the architecture, not in the initial weights. From a neuroscience perspective, I'm not convinced that's the case.
is that true even if there haven't been any retinal waves?
Blocking retinal waves messes up the cortex pretty substantially (same as if the animal were born without eyes). There is the beta-2 knockout mouse, which has retinal waves but with weaker spatiotemporal correlations. As a consequence beta-2 mice fail to track moving gratings and have disrupted receptive fields.
comment by Jon Garcia · 2022-02-04T04:53:46.976Z · LW(p) · GW(p)
Great summary of the argument. I definitely agree that this will be an important distinction (learning-from-scratch vs. innate circuitry) for AGI alignment, as well as for developing a useful Theory of Cognition. The core of what motivates our behavior must be innate to some extent (e.g., heuristics that evolution programmed into our hypothalamus that tell us how far from homeostasis we're veering), to act as a teaching signal to the rest of our brains (e.g., learn to generate goal states that minimize the effort required to maintain or return to homeostasis, goal states that would be far too complex to encode genetically).
However, I think that characterizing the telencephelon+cerebellum as just a memory system + learning algorithm is selling it a bit short. Even at the level of abstraction that you're dealing with here, it seems important to recognize that the neocortex is a dynamic generative simulator. It has intrinsic dynamics that generate top-down spatiotemporal patterns, from regions that represent the highest levels of abstraction down to regions that interface directly with the senses and motor system.
At the beginning, yes, it is simulating nonsense, but the key is that it is more than just randomly initialized memory slots. The sorts of hierarchical patterns that it generates contain information about the dynamical priors that it expects to deal with in life. (Cortical waves, for instance, set priors for spatiotemporally local causal interactions. Retinal waves are probably doing something similar.)
The job of the learning algorithm is, then, to bind the dynamics of experience to the intrinsic dynamics of the neural circuitry, so that the top-down system is better able to simulate real-world dynamics in the future. It probably does so by propagating prediction errors bottom-up from the sensorimotor areas up to the regions representing abstract concepts, making adjustments and learning from them along the way.
In my opinion, some sort of predictive coding scheme using some sort of hierarchical, dynamic generative simulator will be necessary (though not sufficient) to building generally intelligent systems. For learning-from-scratch to be effective (i.e., not require millions of labelled training examples before it can make useful generalizations), it needs to have such a head start.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-02-04T14:41:46.050Z · LW(p) · GW(p)
Thanks! I'm not sure we have much disagreement here. Some relevant issues are:
- Memory ≠ Unstructured memory (and likewise, locally-random ≠ globally-random): There's certainly a neural architecture, with certain types of connections between certain macroscopic regions.
- "just" a memory system + learning algorithm—with a dismissive tone of voice on the "just": Maybe you didn't mean it that way, but for the record, I would suggest that to the extent that you feel wowed by something the neocortex does, I claim you should copy that feeling, and feel equally wowed by "what learning-from-scratch algorithms are capable of". The things that ML people are doing right now are but a tiny corner of a vast universe of possible learning-from-scratch algorithms.
- Generative models can be learned from scratch—obviously, e.g. StyleGAN. I imagine you agree, but you mentioned "generative", so I'm just throwing this in.
- Dynamics is not unrelated to neural architecture: For example, there's a kinda silly sense in which GPT-3 involves a "wave of activity" that goes from layer 1 through layers 2, 3, 4, …, ending in layer 96. I'm not saying anything profound here—it's just that GPT-3 happens to be feedforward, not recurrent. But anyway, if you think it's important that the neocortex has a bias for waves that travel in certain directions, I'd claim that such a bias can likewise be built out of a (not-perfectly-recurrent) neural architecture in the brain.
- Lottery ticket hypothesis [? · GW]: I was recently reading Brain From The Inside Out by Buzsáki, and Chapter 13 had a discussion which to my ears sounded like the author was proposing that we should brain learning as like the lottery ticket hypothesis. E.g. "Rich brain dynamics can emerge from the genetically programmed wiring circuits and biophysical properties of neurons during development even without any sensory input or experience." Then "experience [is] a matching process" between data and this "preexisting dictionary of nonsense words combined with internally generated syntactical rules"—i.e., "preexisting neuronal patterns that coincide with the attended unexpected event are marked as important". That all sounds to me like the lottery ticket hypothesis. And I have no argument there. What I'm not so sure about is who or what he was arguing against. Obviously the lottery ticket hypothesis is compatible with learning-from-scratch with locally-random initialization, indeed that's the context in which that term is universally used. Maybe Buzsáki is arguing against globally-random, unstructured networks, or something? (Does anyone believe that? I dunno.) Anyway, that's Buzsáki not you, but I bring it up because I felt like I was maybe getting similar vibes from your comment.
↑ comment by Jon Garcia · 2022-02-05T05:08:23.683Z · LW(p) · GW(p)
Memory ≠ Unstructured memory (and likewise, locally-random ≠ globally-random): [...]
Agreed. I didn't mean to imply that you thought otherwise.
"just" a memory system + learning algorithm—with a dismissive tone of voice on the "just": [...]
I apologize for how that came across. I had no intention of being dismissive. When I respond to a post or comment, I typically try to frame what I say for a typical reader as much for the original poster. In this case, I had a sense that a typical reader could get the wrong impression about how the neocortex does what it does if the only sorts of memory systems and learning algorithms that came to mind were things like a blank computer drive and stochastic gradient descent on a feed-forward neural network.
You are absolutely right that the neocortex is equipped to learn from scratch, starting out generating garbage and gradually learning to make sense of the world/body/other-brain-regions/etc., which can legitimately be described as a memory system + learning algorithm. I just wanted anyone reading to appreciate that, at least in biological brains, there is no clean separation between learning algorithm and memory, but that the neocortex's role as a hierarchical, dynamic, generative simulator is precisely what makes learning from scratch so efficient, since it only has to correlate its intrinsic dynamics with the statistically similar dynamics of learned experience.
I'm sure that there are vastly more ways of implementing learning-from-scratch, maybe some much better ways in fact, and I realize that the exact implementation is probably not relevant to the arguments you plan to make in this sequence. I just feel that a basic understanding of what a real learning-from-scratch system looks like could help drive intuitions of what is possible.
Generative models can be learned from scratch [...]
Indeed, but of course including their own particular structural priors.
Dynamics is not unrelated to neural architecture: [...]
Well, what is a recurrent neural network after all but an arbitrarily deep feed-forward neural network with shared weights across layers? My comment on cortical waves was just to point out a clever way that the brain learns to organize its cortical maps and primes them to expect causality to operate (mostly) locally in space and time. For example, orientation columns in V1 may be adjacent to each other because similarly oriented edges (from moving objects) were consistently presented to the same part of the visual field close in time, such that traveling waves of excitation would teach pyramidal cell A to learn orientation A at time A and then teach neuron B to learn orientation B at time B.
Lottery ticket hypothesis: [...]
"Lottery tickets" (i.e., subnetworks with random initializations that just so happen to give them the right inductive bias to generalize well from the training data for a particular task) probably occur in the brain as much as in current deep learning architectures. However, the issue in DL is that the rest of the network often fails to contribute much to test performance beyond what the lottery ticket subnetwork was able to achieve, as though there was a chasm in model space that the other subnetworks were unable to cross to reach a solution. Evolution seems to have found a way around this problem, at least by the time the neocortex came along, in the sense that the brain seems adept at giving every subnetwork a useful job.
Again, I think the nature of the neocortex as a generative simulator is what makes this feasible with sparse training data. The structure and dynamics of the neocortex have enough in common statistically with the structure and dynamics of the natural world that it is easy for it to align with experience. In contrast, the structure and (lack of) dynamics of current DL systems makes them more brittle when trying to make sense of the natural world.
All that being said, I realize that my comments might be taking things down a rabbit hole. But I appreciate your feedback and look forward to seeing your perspective fleshed out more in the rest of this sequence.
comment by Lucius Bushnaq (Lblack) · 2022-08-03T15:24:20.226Z · LW(p) · GW(p)
By contrast, I’m going to talk relatively little about the nuts-and-bolts of how the learning algorithms work. That would be a complicated story which is not particularly relevant for AGI safety.
Disagree. If someone could figure out what these algorithms are, I think that could be a useful component in the tech tree needed to produce training setups, architectures and learning algorithms that make networks converge towards learning human-like primitive goals and desires ("Shards").
Whether a network placed in an information environment similar to that of a human baby will learn circuits similar in function to those the baby brain learns seems like it could potentially depend on differences in the learning algorithms (ADAM vs whatever brains use) as well as architecture.
At the very least, it would be good to confirm that the algorithms don't have any particularly nasty surprises for us. Like, say, they turn out to operate "non-locally" in parameter space, unlike Gradient Descent or genetic algorithms or anything else we're using, and so the structures they find are totally unlike the structures our algorithms find, so it's nigh impossible to evolve human-like motivations with GD variants.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2022-08-03T16:50:25.706Z · LW(p) · GW(p)
I mean, there’s a sense in which every aspect of developing AGI capabilities is “relevant for AGI safety”. If nothing else, for every last line of AGI source code, we can do an analysis of what happens if that line of code has a bug, or if a cosmic ray flips a bit, and how do we write good unit tests, etc.
So anyway, there’s a category of AGI safety work that we might call “Endgame Safety”, where we’re trying to do all the AGI safety work that we couldn’t or didn’t do ahead of time, in the very last moments before (or even after) people are actually playing around with the kind of powerful AGI algorithms that could get out of control and destroy the future.
My claims are:
- If there’s any safety work that requires understanding the gory details of the brain’s learning algorithms, then that safety work in the category of “Endgame Safety”—because as soon as we understand those gory details, then we’re spitting distance from a world in which hundreds of actors around the world are able to build very powerful and dangerous superhuman AGIs. My argument for that claim is §3.7–§3.8 here [LW · GW]. (Plus here [LW · GW] for the “hundreds of actors” part.)
- The following is a really bad argument: “Endgame Safety is really important, so let’s try to make the endgame happen ASAP, so that we can get to work on Endgame Safety.” It’s a bad argument because, What’s the rush? There’s going to be an endgame sooner or later, and we can do Endgame Safety Research then! Bringing the endgame sooner is basically equivalent to having all the AI alignment and strategy researchers hibernate for some number N years, and then wake up and get back to work. And that, in turn, is strictly worse than having all the AI alignment and strategy researchers do what they can during the next N years, and also continue doing work after those N years have elapsed. I claim that there is plenty of safety work that we can do right now that is not in the category of “Endgame Safety”, and in particular that posts #12 [LW · GW]–#15 [LW · GW] are in that category (and they have lots more open questions!).
↑ comment by Lucius Bushnaq (Lblack) · 2022-08-03T19:45:18.697Z · LW(p) · GW(p)
I don‘t need the gory details, but „the brain is doing some variant of gradient descent“ or „the brain is doing this crazy thing that doesn‘t seem to depend on local information in the loss landscape at all“ would seem like particularly valuable pieces of information to me, compared to other generic information about the AGI we have, for things I am working on right now.