Seeking Power is Often Convergently Instrumental in MDPs
post by TurnTrout, Logan Riggs (elriggs) · 2019-12-05T02:33:34.321Z · LW · GW · 39 commentsThis is a link post for https://arxiv.org/abs/1912.01683
Contents
Motivation Formalizing the Environment Power as Average Optimal Value POWER-seeking actions lead to high-POWER states POWER-seeking is not a binary property POWER-seeking depends on the agent’s time preferences Convergently instrumental actions are those which are more probable under optimality When is Seeking POWER Convergently Instrumental? Retaining “long-term options” is POWER-seeking and more probable under optimality when the discount rate is “close enough” to 1 Be careful applying this theorem Having “strictly more options” is more probable under optimality and POWER-seeking for all discount rates Conclusion Explaining catastrophes Instrumental usefulness of this work Future work Acknowledgements None 39 comments
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents a cripplingly unrealistic picture of the role of reward functions in reinforcement learning. I expect this post to harm your alignment research intuitions unless you've already inoculated yourself by deeply internalizing and understanding Reward is not the optimization target [LW · GW]. If you're going to read one alignment post I've written, read that one.
Follow-up work (Parametrically retargetable decision-makers tend to seek power [LW · GW]) moved away from optimal policies and treated reward functions more realistically.
In 2008, Steve Omohundro's foundational paper The Basic AI Drives conjectured that superintelligent goal-directed AIs might be incentivized to gain significant amounts of power in order to better achieve their goals. Omohundro's conjecture bears out in toy models, and the supporting philosophical arguments are intuitive. In 2019, the conjecture was even debated by well-known AI researchers [LW · GW].
Power-seeking behavior has been heuristically understood as an anticipated risk, but not as a formal phenomenon with a well-understood cause. The goal of this post (and the accompanying paper, Optimal Policies Tend to Seek Power) is to change that.
Motivation
It’s 2008, the ancient wild west of AI alignment. A few people have started thinking about questions like “if we gave an AI a utility function over world states, and it actually maximized that utility... what would it do?"
In particular, you might notice that wildly different utility functions seem to encourage similar strategies.
Resist shutdown? | Gain computational resources? | Prevent modification of utility function? | |
|---|---|---|---|
Paperclip utility | ✔️ | ✔️ | ✔️ |
Blue webcam pixel utility | ✔️ | ✔️ | ✔️ |
People-look-happy utility | ✔️ | ✔️ | ✔️ |
These strategies are unrelated to terminal preferences: the above utility functions do not award utility to e.g. resource gain in and of itself. Instead, these strategies are instrumental: they help the agent optimize its terminal utility. In particular, a wide range of utility functions incentivize these instrumental strategies. These strategies seem to be convergently instrumental.
But why?
I’m going to informally explain a formal theory which makes significant progress in answering this question. I don’t want this post to be Optimal Policies Tend to Seek Power with cuter illustrations, so please refer to the paper for the math. You can read the two concurrently.
We can formalize questions like “do ‘most’ utility maximizers resist shutdown?” as “Given some prior beliefs about the agent’s utility function, knowledge of the environment, and the fact that the agent acts optimally, with what probability do we expect it to be optimal to avoid shutdown?”
The table’s convergently instrumental strategies are about maintaining, gaining, and exercising power over the future, in some sense. Therefore, this post will help answer:
- What does it mean for an agent to “seek power”?
- In what situations should we expect seeking power to be more probable under optimality, than not seeking power?
This post won’t tell you when you should seek power for your own goals; this post illustrates a regularity in optimal action across different goals one might pursue.
Formalizing Convergent Instrumental Goals suggests that the vast majority of utility functions incentivize the agent to exert a lot of control over the future, assuming that these utility functions depend on “resources.” This is a big assumption: what are “resources”, and why must the AI’s utility function depend on them? We drop this assumption, assuming only unstructured reward functions over a finite Markov decision process (MDP), and show from first principles how power-seeking can often be optimal.
Formalizing the Environment
My theorems apply to finite MDPs; for the unfamiliar, I’ll illustrate with Pac-Man.

- Full observability: You can see everything that’s going on; this information is packaged in the state s. In Pac-Man, the state is the game screen.
- Markov transition function: the next state depends only on the choice of action a and the current state s. It doesn’t matter how we got into a situation.
- Discounted reward: future rewards get geometrically discounted by some discount rate
- At discount rate , this means that reward in one turn is half as important as immediate reward, reward in two turns is a quarter as important, and so on.
- We’ll colloquially say that agents “care a lot about the future” when is “sufficiently” close to 1.
- I'll use quotations to flag well-defined formal concepts that I won’t unpack in this post.
- The score in Pac-Man is the undiscounted sum of rewards-to-date.
When playing the game, the agent has to choose an action at each state. This decision-making function is called a policy; a policy is optimal (for a reward function and discount rate ) when it always makes decisions which maximize discounted reward. This maximal quantity is called the optimal value for reward function at state and discount rate .
By the end of this post, we’ll be able to answer questions like “with respect to a ‘neutral’ distribution over reward functions, do optimal policies have a high probability of avoiding ghosts?”
Power as Average Optimal Value
When people say 'power' in everyday speech, I think they’re often referring to one’s ability to achieve goals in general. This accords with a major philosophical school of thought on the meaning of ‘power’:
On the dispositional view, power is regarded as a capacity, ability, or potential of a person or entity to bring about relevant social, political, or moral outcomes.
Sattarov, Power and Technology, p.13
As a definition, one’s ability to achieve goals in general seems philosophically reasonable: if you have a lot of money, you can make more things happen and you have more power. If you have social clout, you can spend that in various ways to better tailor the future to various ends. All else being equal, losing a limb decreases your power, and dying means you can't control much at all.
This definition explains some of our intuitions about what things count as ‘resources.’ For example, our current position in the environment means that having money allows us to exert more control over the future. That is, our current position in the state space means that having money allows us more control. However, possessing green scraps of paper would not be as helpful if one were living alone near Alpha Centauri. In a sense, resource acquisition can naturally be viewed as taking steps to increase one's power.
Exercise: spend a minute considering specific examples – does this definition reasonably match your intuition?
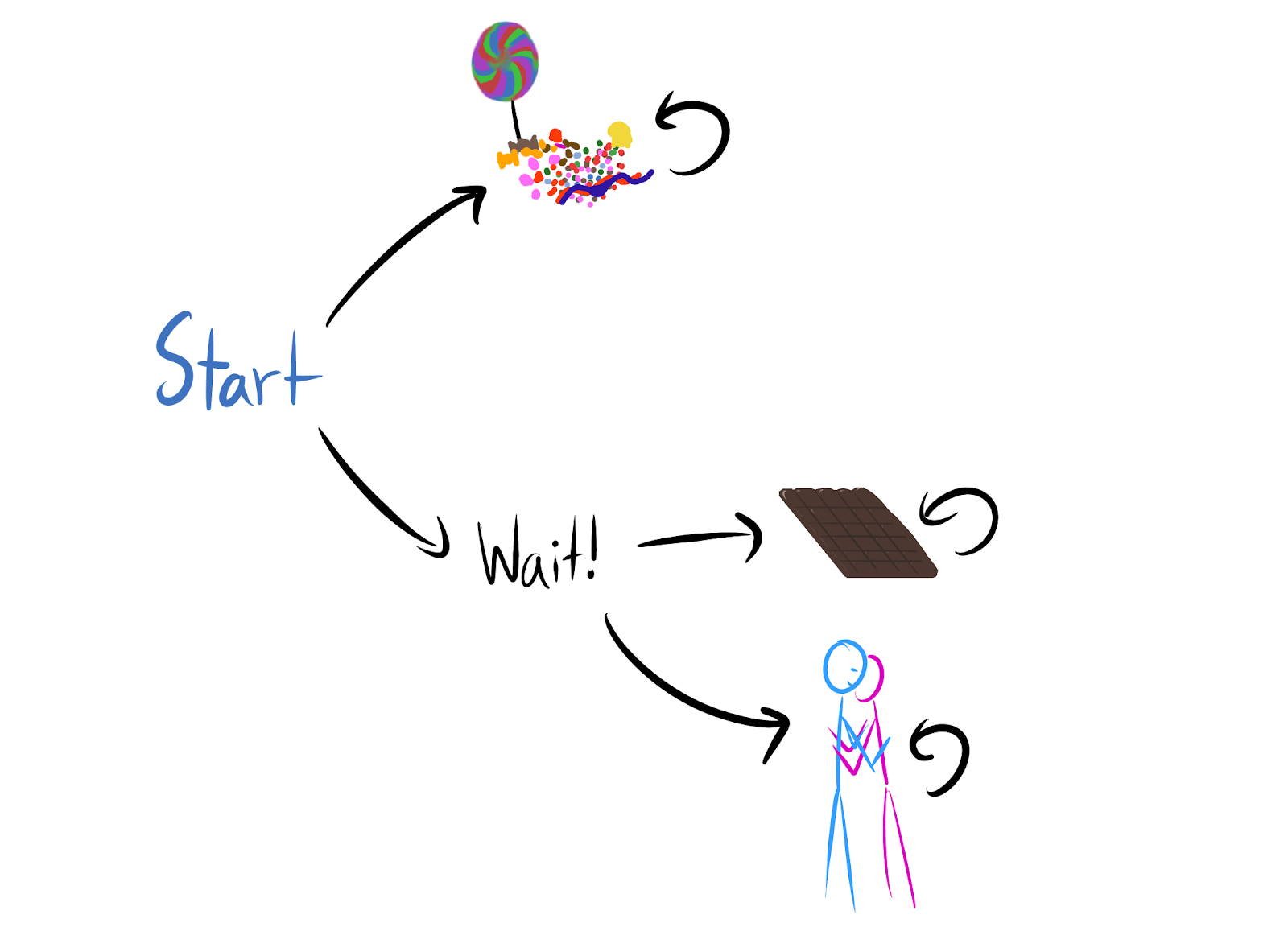
To formalize this notion of power, let’s look at an example. Imagine a simple MDP with three choices: eat candy, eat a chocolate bar, or hug a friend.

The POWER of a state is how well agents can generally do by starting from that state. “POWER” to my formalization, while “power” refers to the intuitive concept. Importantly, we're considering POWER from behind a “veil of ignorance” about the reward function. We're averaging the best we can do for a lot of different individual goals.
We formalize the ability to achieve goals in general as the average optimal value at a state, with respect to some distribution over reward functions which we might give an agent. For simplicity, we'll think about the maximum-entropy distribution where each state is uniformly randomly assigned a reward between 0 and 1.
Each reward function has an optimal trajectory. If chocolate has maximal reward, then the optimal trajectory is start chocolate chocolate….
From start, an optimal agent expects to average reward per timestep for reward functions drawn from this uniform distribution . This is because you have three choices, each of which has reward between 0 and 1. The expected maximum of draws from is ; you have three draws here, so you expect to be able to get reward. Some reward functions do worse than this, and some do better; but on average, they get reward. You can test this out for yourself.
If you have no choices, you expect to average reward: sometimes the future is great, sometimes it's not (Lemma 4.5). Conversely, the more things you can choose between, the closer the POWER gets to 1 (Lemma 4.6).
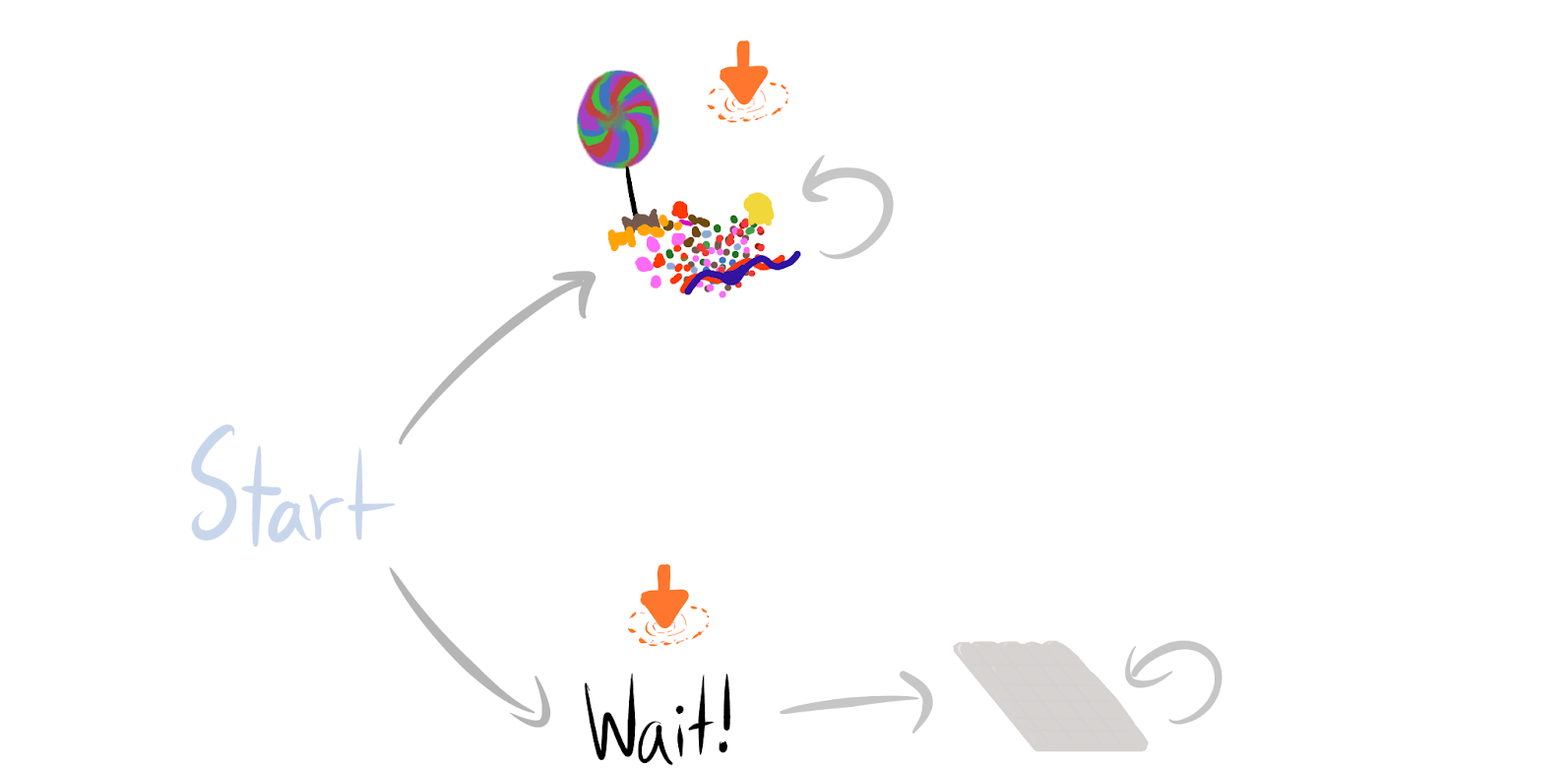
Let’s slightly expand this game with a state called wait (which has the same uniform reward distribution as the other three).

When the agent barely cares at all about the future, it myopically chooses either candy or wait, depending on which provides more reward. After all, rewards beyond the next time step are geometrically discounted into thin air when the discount rate is close to 0. At start, the agent averages optimal reward. This is because the optimal reward is the maximum of the candy and wait rewards, and the expected maximum of draws from is .
However, when the agent cares a lot about the future, most of its reward is coming from which terminal state it ends up in: candy, chocolate, or hug. So, for each reward function, the agent chooses a trajectory which ends up in the best spot, and thus averages reward each timestep. When , the average optimal reward is therefore . In this way, the agent’s power increases with the discount rate, since it incorporates the greater future control over where the agent ends up.
Written as a function, we have POWER(state, discount rate), which essentially returns the average optimal value for reward functions drawn from our distribution , normalizing so the output is between 0 and 1. As we’ve discussed, this quantity often changes with the discount rate: as the future becomes more or less important, the agent has more or less POWER, depending on how much control it has over the relevant parts of that future.
POWER-seeking actions lead to high-POWER states
By waiting, the agent seems to seek “control over the future” compared to obtaining candy. At wait, the agent still has a choice, while at candy, the agent is stuck. We can prove that for all .
Definition (POWER-seeking). At state and discount rate , we say that action seeks POWER compared to action when the expected POWER after choosing a is greater than the expected POWER after choosing .
This definition suggests several philosophical clarifications about power-seeking.
POWER-seeking is not a binary property
Before this definition, I thought that power-seeking was an intuitive ‘you know it when you see it’ kind of thing. I mean, how do you answer questions like “suppose a clown steals millions of dollars from organized crime in a major city, but then he burns all of the money. Did he gain power?”
Unclear: the question is ill-posed. Instead, we recognize that the “gain a lot of money” action was POWER-seeking, but the “burn the money in a big pile” part threw away a lot of POWER.

POWER-seeking depends on the agent’s time preferences
Suppose we’re roommates, and we can’t decide what ice cream shop to eat at today or where to move next year. We strike a deal: I choose the shop, and you decide where we live. I gain short-term POWER (for close to 0), and you gain long-term POWER (for close to 1).

However, when is close to 1, 2 has more control over terminal options and it has more POWER than 3; accordingly, at 1, up seeks POWER compared to down. Furthermore, stay is maximally POWER-seeking for these , since the agent maintains access to all six terminal states.
Most policies aren’t always seeking POWER
We already know that POWER-seeking isn’t binary, but there are policies which choose a maximally POWER-seeking move at every state. In the above example, a maximally POWER-seeking agent would stay at 1. However, this seems rather improbable: when you care a lot about the future, there are so many terminal states to choose from – why would staying put be optimal?
Analogously: consumers don’t just gain money forever and ever, never spending a dime more than necessary. Instead, they gain money in order to spend it. Agents don’t perpetually gain or preserve their POWER: they usually end up using it to realize high-performing trajectories.
So, we can’t expect a result like “agents always tend to gain or preserve their POWER.” Instead, we want theorems which tell us: in certain kinds of situations, given a choice between more and less POWER, what will “most” agents do?
Convergently instrumental actions are those which are more probable under optimality
We return to our favorite example. In the waiting game, let's think about how optimal action tends to change as we start caring about the future more. Consider the states reachable in one turn:
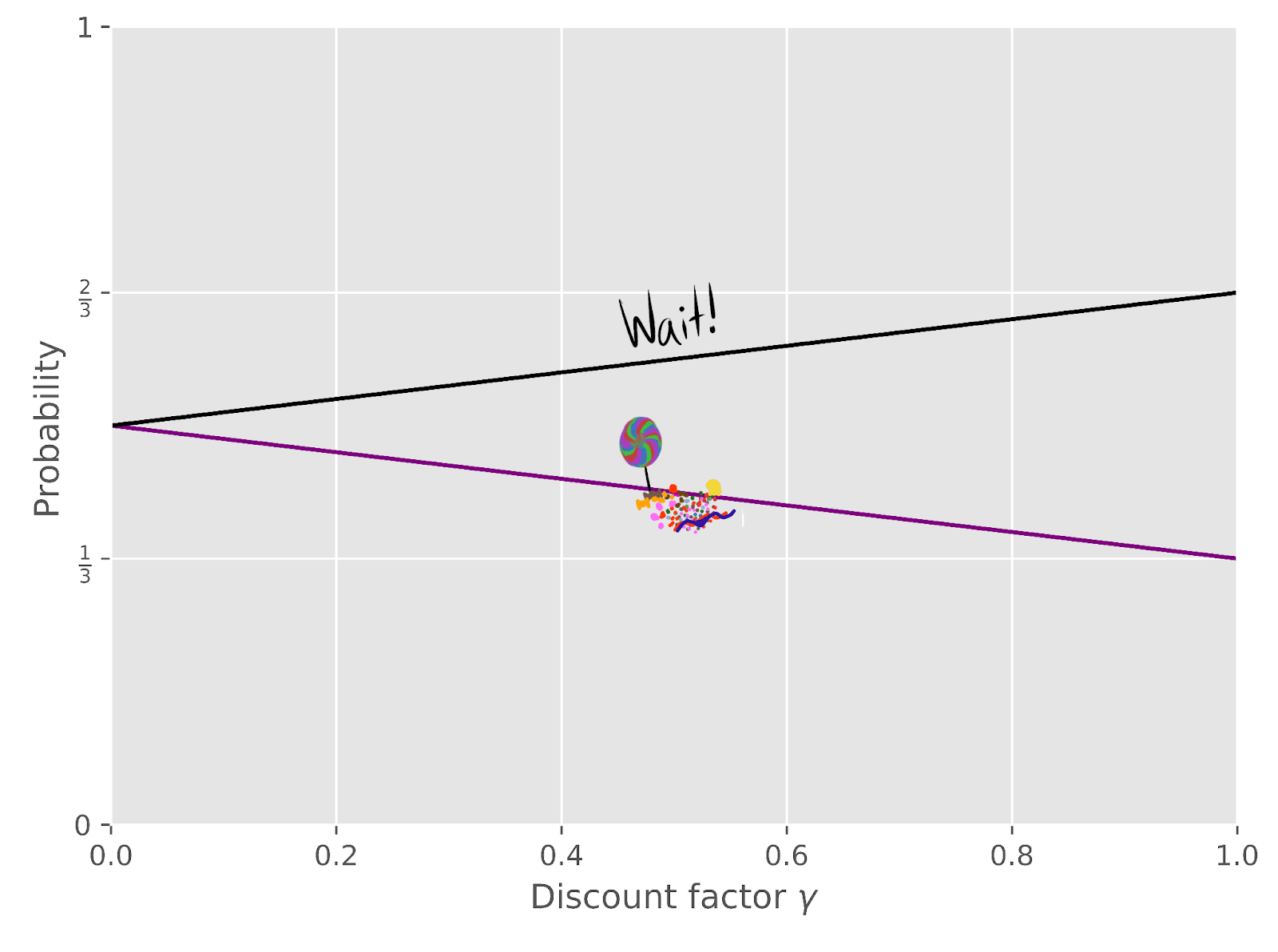
The agent can be in two states. If the agent doesn’t care about the future, with what probability is it optimal to choose candy instead of wait?
It's 50/50: since randomly chooses a number between 0 and 1 for each state, both states have an equal chance of being optimal. Neither action is convergently instrumental / more probable under optimality.
Now consider the states reachable in two turns:

When the future matters a lot, of reward functions have an optimal policy which waits, because two of the three terminal states are only reachable by waiting.
Definition (Action optimality probability). At discount rate , action is more probable under optimality than action at state when
Let’s take “most agents do X” to mean “X has relatively large optimality probability.”
I think optimality probability formalizes the intuition behind the instrumental convergence thesis: with respect to our beliefs about what reward function an agent is optimizing, we may expect some actions to have a greater probability of being optimal than other actions.
Generally, my theorems assume that reward is independently and identically distributed (IID) across states, because otherwise you could have silly situations like “only candy ever has reward available, and so it’s more probable under optimality to eat candy.” We don’t expect reward to be IID for realistic tasks, but that’s OK: this is basic theory about how to begin formally reasoning about instrumental convergence and power-seeking. (Also, I think that grasping the math to a sufficient degree sharpens your thinking about the non-IID case.)
Author's note (7/21/21): As explained in Environmental Structure Can Cause Instrumental Convergence [LW · GW], the theorems no longer require the IID assumption. This post refers to v6 of Optimal Policies Tend To Seek Power, available on arXiv.
When is Seeking POWER Convergently Instrumental?
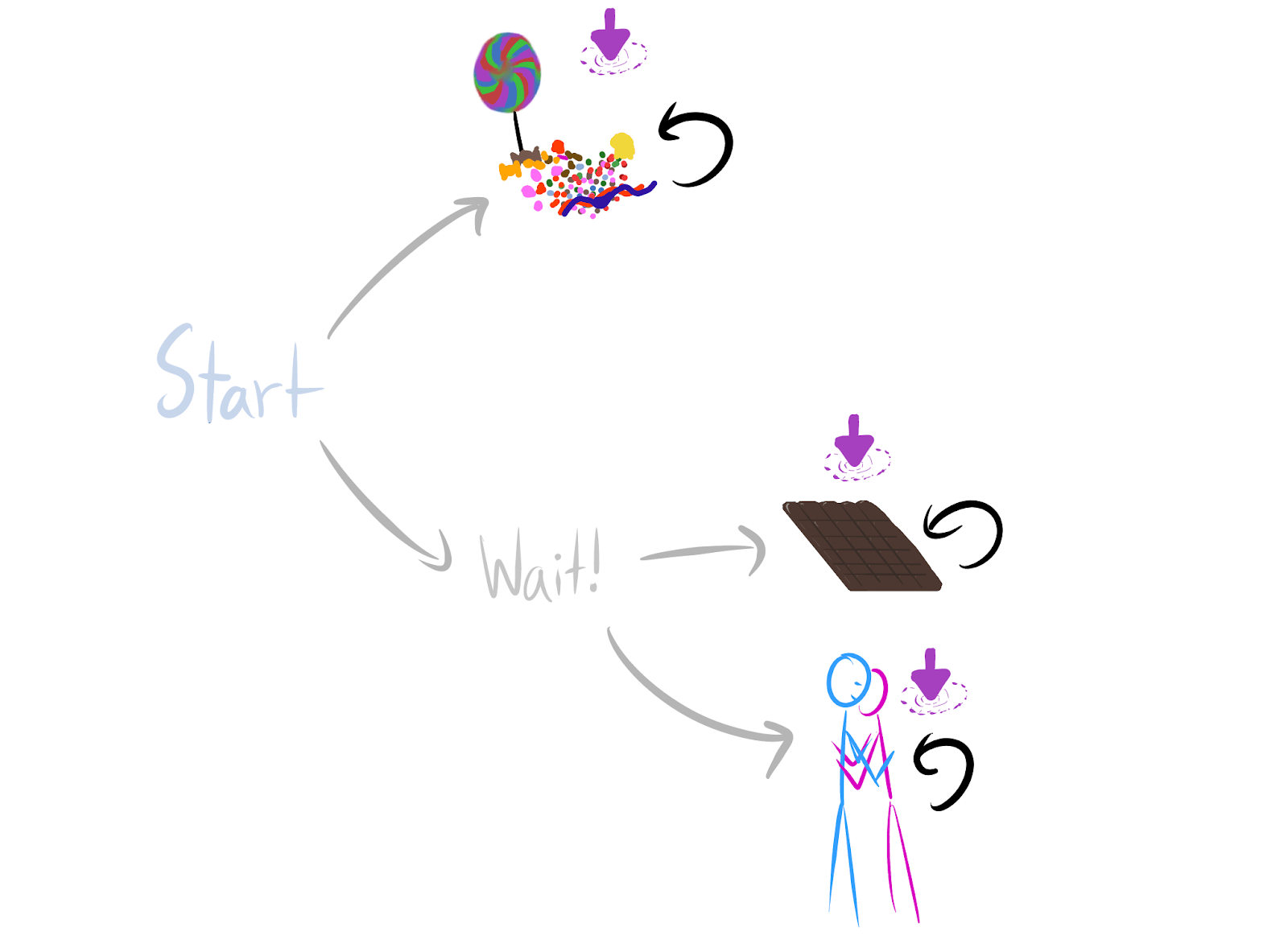
In this environment, waiting is both POWER-seeking and more probable under optimality. The convergently instrumental strategies we originally noticed were also power-seeking and, seemingly, more probable under optimality. Must seeking POWER be more probable under optimality than not seeking POWER?
Nope.
Here’s a counterexample environment:

However, any reasonable notion of ‘power’ must consider having no future choices (at state 2) to be less powerful than having one future choice (at state 3). For more detail, see Section 6 and Appendix B.3 of v6 of the paper.

If you’re curious, this happens because this quadratic reward distribution has negative skew. When computing the optimality probability of the up trajectory, we’re checking whether it maximizes discounted return. Therefore, the probability that up is optimal is
Weighted averages of IID draws from a left-skew distribution will look more Gaussian and therefore have fewer large outliers than the left-skew distribution does. Thus, going right will have a lower optimality probability.
Bummer. However, we can prove sufficient conditions under which seeking POWER is more probable under optimality.
Retaining “long-term options” is POWER-seeking and more probable under optimality when the discount rate is “close enough” to 1
Let's focus on an environment with the same rules as Tic-Tac-Toe, but considering the uniform distribution over reward functions. The agent (playing O) keeps experiencing the final state over and over when the game's done. We bake a fixed opponent policy into the dynamics: when you choose a move, the game automatically replies. Let's look at part of the game tree.

Whenever we make a move that ends the game, we can't go anywhere else – we have to stay put. Since each terminal state has the same chance of being optimal, a move which doesn't end the game is more probable under optimality than a move which ends the game.
Starting on the left, all but one move leads to ending the game, but the second-to-last move allows us to keep choosing between five more final outcomes. If you care a lot about the future, then the first green move has a 50% chance of being optimal, while each alternative action is only optimal for 10% of goals. So we see a kind of “power preservation” arising, even in Tic-Tac-Toe.
Remember how, as the agent cares more about the future, more of its POWER comes from its ability to wait, while also waiting becomes more probable under optimality?
The same thing happens in Tic-Tac-Toe as the agent cares more about the future.



As the agent cares more about the future, it makes a bigger and bigger difference to control what happens during later steps. Also, as the agent cares more about the future, moves which prolong the game gain optimality probability. When the agent cares enough about the future, these game-prolonging moves are both POWER-seeking and more probable under optimality.
Theorem summary (“Terminal option” preservation). When is sufficiently close to 1, if two actions allow access to two disjoint sets of “terminal options”, and action allows access to “strictly more terminal options” than does , then is strictly more probable under optimality and strictly POWER-seeking compared to .
(This is a special case of the combined implications of Theorems 6.8 and 6.9; the actual theorems don’t require this kind of disjointness.)
In the wait MDP, this is why waiting is more probable under optimality and POWER-seeking when you care enough about the future. The full theorems are nice because they’re broadly applicable. They give you bounds on how probable under optimality one action is: if action is the only way you can access many terminal states, while only allows access to one terminal state, then when , has many times greater optimality probability than . For example:
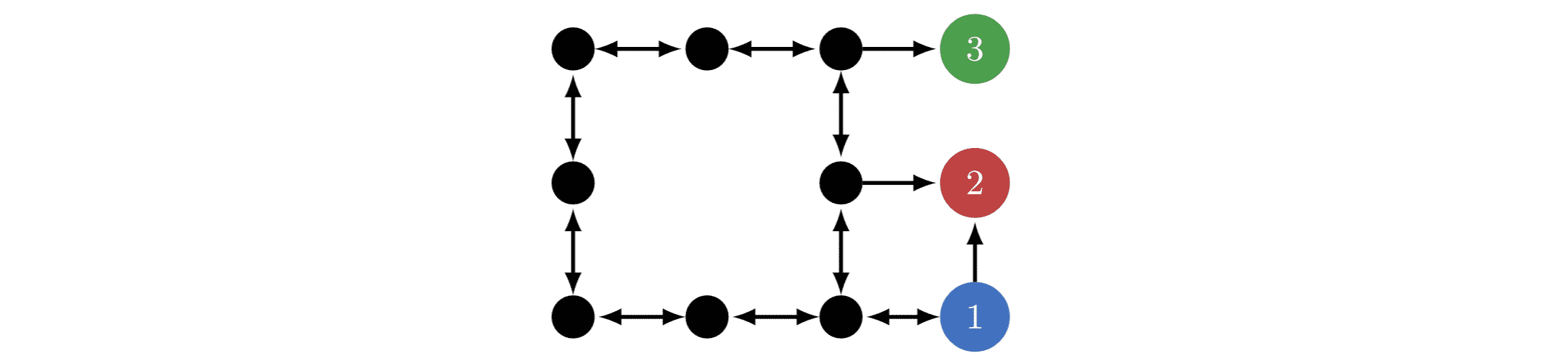
In AI: A Modern Approach (3e), the agent receives reward for reaching . The optimal policy for this reward function avoids , and you might think it’s convergently instrumental to avoid . However, a skeptic might provide a reward function for which navigating to is optimal, and then argue that “instrumental convergence” is subjective and that there is no reasonable basis for concluding that is generally avoided.
We can do better. When the agent cares a lot about the future, optimal policies avoid 2 iff its reward function doesn’t give the most reward. only has a chance of having the most reward. If we complicate the MDP with additional terminal states, this probability further approaches 0.
Taking to represent shutdown, we see that avoiding shutdown is convergently instrumental in any MDP representing a real-world task and containing a shutdown state. Seeking POWER is often convergently instrumental in MDPs.
Exercise: Can you conclude that avoiding ghosts in Pac-Man is convergently instrumental for IID reward functions when the agent cares a lot about the future?
You can’t with the pseudo-theorem due to the disjointness condition: you could die now, or you could die later, so the ‘terminal options’ aren’t disjoint. However, the real theorems do suggest this. Supposing that death induces a generic ‘game over’ screen, touching the ghosts without a power-up traps the agent in that solitary 1-cycle.
But there are thousands of other ‘terminal options’; under most reasonable state reward distributions (which aren’t too positively skewed), most agents maximize average reward over time by navigating to one of the thousands of different cycles which the agent can only reach by avoiding ghosts. In contrast, most agents don’t maximize average reward by navigating to the ‘game over’ 1-cycle. So, under e.g. the maximum-entropy uniform state reward distribution, most agents avoid the ghosts.
Be careful applying this theorem
The results inspiring the above pseudo-theorem are easiest to apply when the “terminal option” sets are disjoint: you’re choosing to be able to reach one set, or another. One thing which Theorem 6.9 says is: since reward is IID, then two “similar terminal options” are equally likely to be optimal a priori. If choice lets you reach more “options” than choice does, then choice yields greater POWER and has greater optimality probability, a priori.
Theorem 6.9's applicability depends on what the agent can do.

But wait! What if you have a private jet that can fly anywhere in the world? Then going to the airport isn’t convergently instrumental anymore.
Generally, it’s hard to know what’s optimal for most goals. It’s easier to say that some small set of “terminal options” has low optimality probability and low POWER. For example, this is true of shutdown, if we represent hard shutdown as a single terminal state: a priori, it’s improbable for this terminal state to be optimal among all possible terminal states.
Having “strictly more options” is more probable under optimality and POWER-seeking for all discount rates
Sometimes, one course of action gives you “strictly more options” than another. Consider another MDP with IID reward:

The right blue gem subgraph contains a “copy” of the upper red gem subgraph. From this, we can conclude that going right to the blue gems seeks POWER and is more probable under optimality for all discount rates between 0 and 1!
Theorem summary (“Transient options”). If actions and let you access disjoint parts of the state space, and enables “trajectories” which are “similar” to a subset of the “trajectories” allowed by , then seeks more POWER and is more probable under optimality than for all .
This result is extremely powerful because it doesn’t care about the discount rate, but the similarity condition may be hard to satisfy.
These two theorems give us a formally correct framework for reasoning about generic optimal behavior, even if we aren’t able to compute any individual optimal policy! They reduce questions of POWER-seeking to checking graphical conditions.
Even though my results apply to stochastic MDPs of any finite size, we illustrated using known toy environments. However, this MDP “model” is rarely explicitly specified. Even so, ignorance of the model does not imply that the model disobeys these theorems. Instead of claiming that a specific model accurately represents the task of interest, I think it makes more sense to argue that no reasonable model could fail to exhibit convergent instrumentality and POWER-seeking. For example, if deactivation is represented by a single state, no reasonable model of the MDP could have most agents agreeing to be deactivated.
Conclusion
In real-world settings, it seems unlikely a priori that the agent’s optimal trajectories run through the relatively smaller part of future in which it cooperates with humans. These results translate that hunch into mathematics.
Explaining catastrophes
AI alignment research often feels slippery. We're trying hard to become less confused about basic questions, like:
- What [? · GW] are "agents [LW · GW]"?
- Do people even have "values" [LW · GW], and should we try to get the AI to learn them? [LW · GW] [LW · GW]
- What does it mean [LW · GW] to be "corrigible", or "deceptive [LW · GW]"? [LW · GW]
- What are our machine learning models even doing [LW · GW]?
We have to do philosophical work while in a state of significant confusion and ignorance about the nature of intelligence and alignment.
In this case, we’d noticed that slight reward function misspecification seems to lead to doom, but we didn't really know why. Intuitively, it's pretty obvious that most agents don't have deactivation as their dream outcome, but we couldn't actually point to any formal explanations, and we certainly couldn't make precise predictions.
On its own, Goodhart's law [LW · GW] doesn't explain why optimizing proxy goals leads to catastrophically bad outcomes, instead of just less-than-ideal outcomes.
I think that we're now starting to have this kind of understanding. I suspect that [? · GW] power-seeking is why capable, goal-directed agency is so dangerous by default. If we want to consider more benign alternatives to goal-directed agency, then deeply understanding the rot at the heart of goal-directed agency is important for evaluating alternatives. This work lets us get a feel for the generic incentives of reinforcement learning at optimality.
Instrumental usefulness of this work
POWER might be important for reasoning about the strategy-stealing assumption [LW · GW] (and I think it might be similar to what Paul Christiano means by "flexible influence over the future”). Evan Hubinger has already noted [LW · GW] the utility of the distribution of attainable utility shifts for thinking about value-neutrality in this context (and POWER is another facet of the same phenomenon). If you want to think about whether, when, and why mesa optimizers might try to seize power, this theory seems like a valuable tool.
Optimality probability might be relevant for thinking about myopic agency, as the work formally describes how optimal action tends to change with the discount factor.
And, of course, we're going to use this understanding of power to design an impact measure.
Future work
There’s a lot of work I think would be exciting, most of which I suspect will support our current beliefs about power-seeking incentives:
- These results assume you can see all of the world at once.
- These results assume the environment is finite.
- These results don’t say anything about non-IID reward.
- These results don’t prove that POWER-seeking is bad for other agents in the environment [? · GW].
- These results don’t prove that POWER-seeking is hard to disincentivize.
- Learned policies are rarely optimal.
That said, I think there’s still an important lesson here. Imagine you have good formal reasons to suspect that typing random strings will usually blow up your computer and kill you. Would you then say, "I'm not planning to type random strings" and proceed to enter your thesis into a word processor? No. You wouldn't type anything, not until you really, really understand what makes the computer blow up sometimes.
Speaking to the broader debate taking place in the AI research community, I think a productive stance will involve investigating and understanding these results in more detail, getting curious about unexpected phenomena, and seeing how the numbers crunch out in reasonable models.
From Optimal Policies Tend to Seek Power:
In the context of MDPs, we formalized a reasonable notion of power and showed conditions under which optimal policies tend to seek it. We believe that our results suggest that in general, reward functions are best optimized by seeking power. We caution that in realistic tasks, learned policies are rarely optimal – our results do not mathematically prove that hypothetical superintelligent RL agents will seek power. We hope that this work and its formalisms will foster thoughtful, serious, and rigorous discussion of this possibility.
Acknowledgements
This work was made possible by the Center for Human-Compatible AI, the Berkeley Existential Risk Initiative, and the Long-Term Future Fund.
Logan Smith (elriggs [LW · GW]) spent an enormous amount of time writing Mathematica code to compute power and measure in arbitrary toy MDPs, saving me from computing many quintuple integrations by hand. I thank Rohin Shah for his detailed feedback and brainstorming over the summer of 2019, and I thank Andrew Critch for significantly improving this work through his detailed critiques. Last but not least, thanks to:
- Zack M. Davis, Chase Denecke, William Ellsworth, Vahid Ghadakchi, Ofer Givoli, Evan Hubinger, Neale Ratzlaff, Jess Riedel, Duncan Sabien, Davide Zagami, and TheMajor for feedback on version 1 of this post.
- Alex Appel (diffractor), Emma Fickel, Vanessa Kosoy, Steve Omohundro, Neale Ratzlaff, and Mark Xu for reading / giving feedback on version 2 of this post.
Throughout Reframing Impact, we’ve been considering an agent’s attainable utility: their ability to get what they want (their on-policy value, in RL terminology). Optimal value is a kind of “idealized” attainable utility: the agent’s attainable utility were they to act optimally.
Even though instrumental convergence was discovered when thinking about the real world, similar self-preservation strategies turn out to be convergently instrumental in e.g. Pac-Man.
39 comments
Comments sorted by top scores.
comment by johnswentworth · 2020-12-27T21:41:33.734Z · LW(p) · GW(p)
This review is mostly going to talk about what I think the post does wrong and how to fix it, because the post itself does a good job explaining what it does right. But before we get to that, it's worth saying up-front what the post does well: the post proposes a basically-correct notion of "power" for purposes of instrumental convergence, and then uses it to prove that instrumental convergence is in fact highly probable under a wide range of conditions. On that basis alone, it is an excellent post.
I see two (related) central problems, from which various other symptoms follow:
- POWER offers a black-box notion of instrumental convergence. This is the right starting point, but it needs to be complemented with a gears-level understanding of what features of the environment give rise to convergence.
- Unstructured MDPs are a bad model in which to formulate instrumental convergence. In particular, they are bad for building a gears-level understanding of what features of the environment give rise to convergence.
Some things I've thought a lot about over the past year seem particularly well-suited to address these problems [? · GW], so I have a fair bit to say about them.
Why Unstructured MDPs Are A Bad Model For Instrumental Convergence
The basic problem with unstructured MDPs is that the entire world-state is a single, monolithic object. Some symptoms of this problem:
- it's hard to talk about "resources", which seem fairly central to instrumental convergence
- it's hard to talk about multiple agents competing for the same resources
- it's hard to talk about which parts of the world an agent controls/doesn't control
- it's hard to talk about which parts of the world agents do/don't care about
- ... indeed, it's hard to talk about the world having "parts" at all
- it's hard to talk about agents not competing, since there's only one monolithic world-state to control
- any action which changes the world at all changes the entire world-state; there's no built-in way to change a "small part" of the world
More generally, unstructured MDPs are problematic for most kinds of gears-level understanding: the point of gears is to talk about the structure of the world, and the point of unstructured MDPs is to use one black-box world-state without any internal structure. (The one exception to this is time-structure, which MDPs do have.)
My go-to model would instead be a circuit/Bayes net, with some decision nodes. There are alternatives to this, but it's probably the most general option in which the world has structure/parts.
What Would A Gearsier Model Of Instrumental Convergence Look Like?
Intuitive example: in a real-time strategy game, units and buildings and so forth can be created, destroyed, and generally moved around given sufficient time. Over long time scales, the main thing which matters to the world-state is resources - creating or destroying anything else costs resources. So, even though there's a high-dimensional game-world, it's mainly a few (low-dimensional) resource counts which impact the long term state space. Any agents hoping to control anything in the long term will therefore compete to control those few resources.
More generally: of all the many "nearby" variables an agent can control, only a handful (or summary) are relevant to anything "far away". Any "nearby" agents trying to control things "far away" will therefore compete to control the same handful of variables.
Main thing to notice: this intuition talks directly about a feature of the world - i.e. "far away" variables depending only on a handful of "nearby" variables. That, according to me, is the main feature which makes or breaks instrumental convergence in any given universe. We can talk about that feature entirely independent of agents or agency. Indeed, we could potentially use this intuition to derive agency, via some kind of coherence theorem; this notion of instrumental convergence is more fundamental than utility functions.
I would still expect something like this to agree with the POWER notion of instrumental convergence. But something along these lines would provide a more gears-level picture, to complement the more functional/black-boxy picture provided by POWER. Ideally, the two would turn out to fully agree, providing a strong characterization of instrumental convergence.
Replies from: TurnTrout, TurnTrout↑ comment by TurnTrout · 2021-01-02T00:29:22.467Z · LW(p) · GW(p)
To quote Eliezer (who was originally talking to Benja Fallenstein; edits italicized):
Well, that's a very intelligent review, John Wentworth. But I have a crushing reply to your review, such that, once I deliver it, you will at once give up further debate with me on this particular point: You're right.
Here are some more thoughts.
POWER offers a black-box notion of instrumental convergence. This is the right starting point, but it needs to be complemented with a gears-level understanding of what features of the environment give rise to convergence.
I agree, and I'd like to elaborate my take on the black boxy-ness.
To me, these theorems (and the further basic MDP theorems I've developed but not yet made available) feel analogous to the Sylow theorems in group theory. Indeed, a CHAI researcher once remarked to me that my theorems seem to apply the spirit of abstract algebra to MDPs.
The Sylow theorems tell you that if you know the cardinality of a group , you can constrain its internal structure in useful ways, and sometimes even guarantee it has normal subgroups of given cardinalities. But maybe we don't know . What's that world like, where we don't have easy ways of knowing the group cardinality and deriving its prime factorization, but we still have the Sylow theorems?
My theorems say that if you know certain summary information of the graphical properties of an MDP, you can conclude POWER-seeking. But maybe we don't know that summary information, because we don't know exactly what the MDP looks like [LW · GW]. What's that world like, where we don't have easy ways of knowing the MDP model and deriving high-level graphical properties, but we still have the POWER-seeking theorems?
I think that you still want to know both sets of theorems, even though you might not have recourse to a constructive explanation for the actual (groups / MDPs) you care about understanding.
But you also care about the cardinalities, and you also care about what kinds of things will tend to be robustly instrumental, what kinds of things tend to give you POWER / "resources", and I think that the kind of theory you propose could take an important step in that direction.
I also think that it's aesthetically pleasing to have a notion of POWER-seeking which doesn't depend on the state featurization, but only on the environmental dynamics; however, more granular theories probably should depend on that.
~~~~
In Abstraction, Evolution and Gears [? · GW], you write:
if an agent’s goals do not explicitly involve things close to , then the agent cares only about controlling .
This, I think, is too strong: not only do some agents not care about [exact voltages on a CPU], some agents aren't even incentivized to care about [the summary information of these voltages]. For example, an agent with a constant utility function cares neither about nor about , and I imagine there are less trivial utility functions which are indifferent to large classes of outcomes and share this property.
The main point here isn't to nitpick the implication, but to shift the emphasis towards a direction I think might be productive (towards * below). So, I would say:
if an agent’s goals do not explicitly involve things close to , then the agent cares only about controlling , if it cares at all.
Crucially, is of type thing-to-care-about, and is of type thing-to-condition-on. By definition, one cares about itself for terminal reasons, but cares about for instrumental predictive benefit - because of what it implies about the other things one does care about.
Then you might wonder, in a given environment:
- why "agents" are incentivized to develop "good abstractions";
- given , what kinds of query classes tend to make a good abstraction;
- There's a corresponding question of:
"given variables , what kinds of utility functions will terminally care about ?",
but this isn't as relevant. This question also seems easier, since is presumably in the domain of the utility functions.
- There's a corresponding question of:
- given an abstraction , what kinds of goals will incentivize policies which care about controlling .
* The answers to 2. and 3. would point to "caring about thing Y means you care about summary information Z, and if you care about summary information Z, you'll tend to try to control features A, B, and C." This could then not only say how many goals tend to seek POWER, but which kinds of goals seek which kinds of control and resources and flexible influence. *
We can talk about that feature entirely independent of agents or agency. Indeed, we could potentially use this intuition to derive agency, via some kind of coherence theorem; this notion of instrumental convergence is more fundamental than utility functions.
Can you expand on this? I'm mostly confused about what kind of agency might be derived, exactly.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-01-02T14:37:17.647Z · LW(p) · GW(p)
I'd say you passed my intellectual Turing test, but that seems like an understatement. More like... if you were a successor AI, I would be comfortable deferring to you on this topic. (Not literally true, but the analogy seems to convey something of the right spirit.) You fully understand my points and have made further novel observations about them; in particular, the analogy to the Sylow theorems is perfect, and you're clearly asking the right questions.
Regarding instrumental convergence as a foundation for coherence theorems...
I touched on this a bit in this review of Coherent Decisions Imply Consistent Utilities [LW(p) · GW(p)]. The main issue is that coherence theorems generally need some kind of "yardstick" to measure utility against, something which agents are assumed to generally want more of; the flavor text around the theorem usually calls it "money". It need not be something that agents want as a terminal value, just something that we assume agents can always use more of in order to get more utility. We then recognize "incoherent decisions" by an agent "throwing away" the yardstick-resource unnecessarily - i.e. taking a path which expends strictly more of the resource than is necessary to reach the end-state.
But what if our universe doesn't have some built-in, ontologically-basic yardstick against which to measure decision-coherence? How can we derive the yardstick from first principles?
That's the question I think instrumental convergence could potentially answer. If broad classes of mind designs in a certain universe "want similar things" (as non-terminal goals), then those things might make a good yardstick. In order to to give full force to this argument, we need to ground "want similar things" in a way which doesn't talk about "wanting", since we're trying to derive utility from first principles. That's where something like "nearby subsystems can only influence far away subsystems via <small set of variables>" comes in. That small set of variables acts like a natural yardstick to measure coherence of nearby decisions: throwing away control over those variables implies that the agent is strictly suboptimal for controlling (almost) anything far away. In some sense, it's coherence of nearby decisions, as viewed from a distance.
↑ comment by TurnTrout · 2020-12-28T00:26:23.762Z · LW(p) · GW(p)
Review of Review for 2019 Review
I'm going to reply more fully later (I'm taking a break right now), but I want to say: as an author, I always hope to receive reviews like this for my academic papers. Rare enough are reviewers who demonstrate a clear grasp of the work; rarer still are reviewers whose critiques are so well-placed that my gut reaction is excitement instead of defensiveness. I've received several such reviews this year, and I've appreciated every one.
comment by ryan_b · 2019-12-05T16:37:23.894Z · LW(p) · GW(p)
Strong upvote, this is amazing to me. On the post:
- Another example of explaining the intuitions for formal results less formally. I strongly support this as a norm.
- I found the graphics helpful, both in style and content.
Some thoughts on the results:
- This strikes at the heart of AI risk, and to my inexpert eyes the lack of anything rigorous to build on or criticize as a mechanism for the flashiest concerns has been a big factor in how difficult it was and is to get engagement from the rest of the AI field. Even if the formalism fails due to a critical flaw, the ability to spot such a flaw is a big step forward.
- The formalism of average attainable utility, and the explicit distinction from number of possibilities, provides powerful intuition even outside the field. This includes areas like warfare and business. I realize it isn't the goal, but I have always considered applicability outside the field as an important test because it would be deeply concerning for thinking about goal-directed behavior to mysteriously fail when applied to the only extant things which pursue goals.
- I find the result aesthetically pleasing. This is not important, but I thought I would mention it.
comment by Steven Byrnes (steve2152) · 2019-12-07T02:47:10.351Z · LW(p) · GW(p)
This is great work, nice job!
Maybe a shot in the dark, but there might be some connection with that paper a few years back Causal Entropic Forces (more accessible summary). They define "causal path entropy" as basically the number of different paths you can go down starting from a certain point, which might be related to or the same as what you call "power". And they calculate some examples of what happens if you maximize this (in a few different contexts, all continuous not discrete), and get fun things like (what they generously call) "tool use". I'm not sure that paper really adds anything important conceptually that you don't already know, but just wanted to point that out, and PM me if you want help decoding their physics jargon. :-)
Replies from: TurnTrout↑ comment by TurnTrout · 2019-12-07T17:00:04.111Z · LW(p) · GW(p)
Yeah, this is a great connection which I learned about earlier in the summer. I think this theory explains what's going on when they say
They argue that simple mechanical systems that are postulated to follow this rule show features of “intelligence,” hinting at a connection between this most-human attribute and fundamental physical laws.
Basically, since near-optimal agents tend to go towards states of high power, and near-optimal agents are generally ones which are intelligent, observing an agent moving towards a state of high power is Bayesian evidence that it is intelligent. However, as I understand it, they have the causation wrong: instead of physical laws -> power-seeking and intelligence, intelligent goal-directed behavior tends to produce power-seeking.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-12-07T18:42:04.579Z · LW(p) · GW(p)
I agree 100% with everything you said.
comment by TurnTrout · 2020-12-23T17:14:37.484Z · LW(p) · GW(p)
One year later, I remain excited about this post, from its ideas, to its formalisms, to its implications. I think it helps us formally understand part of the difficulty of the alignment problem [? · GW]. This formalization of power and the Attainable Utility Landscape [? · GW] have together given me a novel frame for understanding alignment and corrigibility [LW · GW].
Since last December, I’ve spent several hundred hours expanding the formal results and rewriting the paper; I’ve generalized the theorems, added rigor, and taken great pains to spell out what the theorems do and do not imply. For example, the main paper is 9 pages long; in Appendix B, I further dedicated 3.5 pages to exploring the nuances of the formal definition of ‘power-seeking’ (Definition 6.1).
However, there are a few things I wish I’d gotten right the first time around. Therefore, I’ve restructured and rewritten much of the post. Let’s walk through some of the changes.
‘Instrumentally convergent’ replaced by ‘robustly instrumental’
Like [LW · GW] many [LW · GW] good things, this terminological shift was prompted by a critique from Andrew Critch.
Roughly speaking, this work considered an action to be ‘instrumentally convergent’ if it’s very probably optimal, with respect to a probability distribution on a set of reward functions. For the formal definition, see Definition 5.8 in the paper.
This definition is natural. You can even find it echoed by Tony Zador in the Debate on Instrumental Convergence [LW · GW]:
So i would say that killing all humans is not only not likely to be an optimal strategy under most scenarios, the set of scenarios under which it is optimal is probably close to a set of measure 0.
(Zador uses “set of scenarios” instead of “set of reward functions”, but he is implicitly reasoning: “with respect to my beliefs about what kind of objective functions we will implement and what the agent will confront in deployment, I predict that deadly actions have a negligible probability of being optimal.”)
While discussing this definition of ‘instrumental convergence’, Andrew asked me: “what, exactly, is doing the converging? There is no limiting process. Optimal policies just are.”
It would be more appropriate to say that an action is ‘instrumentally robust’ instead of ‘instrumentally convergent’: the instrumentality is robust to the choice of goal. However, I found this to be ambiguous: ‘instrumentally robust’ could be read as “the agent is being robust for instrumental reasons.”
I settled on ‘robustly instrumental’, rewriting the paper’s introduction as follows:
An action is said to be instrumental to an objective when it helps achieve that objective. Some actions are instrumental to many objectives, making them robustly instrumental. The so-called instrumental convergence thesis is the claim that agents with many different goals, if given time to learn and plan, will eventually converge on exhibiting certain common patterns of behavior that are robustly instrumental (e.g. survival, accessing usable energy, access to computing resources). Bostrom et al.'s instrumental convergence thesis might more aptly be called the robust instrumentality thesis, because it makes no reference to limits or converging processes:
“Several instrumental values can be identified which are convergent in the sense that their attainment would increase the chances of the agent's goal being realized for a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.”
Some authors have suggested that gaining power over the environment is a robustly instrumental behavior pattern on which learning agents generally converge as they tend towards optimality. If so, robust instrumentality presents a safety concern for the alignment of advanced reinforcement learning systems with human society: such systems might seek to gain power over humans as part of their environment. For example, Marvin Minsky imagined that an agent tasked with proving the Riemann hypothesis might rationally turn the planet into computational resources.
This choice is not costless: many are already acclimated to the existing ‘instrumental convergence.’ It even has its own Wikipedia page. Nonetheless, if there ever were a time to make the shift, that time would be now.
Qualification of Claims
The original post claimed that “optimal policies tend to seek power”, period. This was partially based on a result which I’d incorrectly interpreted. Vanessa Kosoy and Rohin Shah pointed out this error to me, and I quickly amended the original post and posted a follow-up explanation [LW · GW].
At the time, I’d wondered whether this was still true in general via some other result. The answer is ‘no’: it isn’t always more probable for optimal policies to navigate towards states which give them more control over the future. Here’s a surprising counterexample which doesn’t even depend on my formalization of ‘power.’

However, any reasonable notion of ‘power’ must consider having no future choices (at state 2) to be less powerful than having one future choice (at state 3). For more detail, see Section 6 and Appendix B.3 of the paper.

If you’re curious, this happens because this quadratic reward distribution has negative skew. When computing the optimality probability of the up trajectory, we’re checking whether it maximizes discounted return. Therefore, the probability that up is optimal is
Weighted averages of IID draws from a left-skew distribution will look more Gaussian and therefore have fewer large outliers than the left-skew distribution does. Thus, going right will have a lower optimality probability.
No matter how you cut it, the relationship just isn’t true in general. Instead, the post [LW · GW] now sketches sufficient conditions under which power-seeking behavior is more probably optimal – conditions which are proven in the paper.
comment by evhub · 2020-12-11T20:37:11.365Z · LW(p) · GW(p)
I think this post was a valuable contribution both to our understanding of instrumental convergence as well as making instrumental convergence rigorous enough to stand up to more intense outside scrutiny.
Replies from: ofer↑ comment by Ofer (ofer) · 2020-12-12T03:11:32.500Z · LW(p) · GW(p)
Instrumental convergence is a very simple idea that I understand very well, and yet I failed to understand this paper (after spending hours on it) [EDIT: and also the post], so I'm worried about using it for the purpose of 'standing up to more intense outside scrutiny'. (Though it's plausible I'm just an outlier here.)
Replies from: TurnTrout↑ comment by TurnTrout · 2020-12-12T04:20:42.060Z · LW(p) · GW(p)
While it's been my experience that most people have understood the important parts of the post and paper, a few intelligent readers (like you) haven't had the expected clicks. The paper has already been dramatically rewritten, to the point of being a different paper than that originally linked to by this post. I'm also planning on rewriting some of the post. I'd be happy to send a draft by you to ensure it's as clearly written as possible.
As far as 'more intense outside scrutiny', we received two extremely positive NeurIPS reviews which were quite persuaded, and one very negative review which pointed out real shortcomings that have since been rectified. I anticipate that it will do quite well at ICML / NeurIPS this year. That said, I don't plan on circulating these arguments to LeCun et al. until after the work has passed peer review.
comment by abramdemski · 2020-12-11T16:48:59.950Z · LW(p) · GW(p)
A formal answer (or at least, major contribution) to a previously informal but significant debate in AI safety.
comment by ESRogs · 2019-12-05T22:34:26.557Z · LW(p) · GW(p)
This means that if there's more than twice the power coming from one move than from another, the former is more likely than the latter. In general, if one set of possibilities contributes 2K the power of another set of possibilities, the former set is at least K times more likely than the latter.
Where does the 2 come from? Why does one move have to have more than twice the power of another to be more likely? What happens if it only has 1.1x as much power?
Replies from: TurnTrout↑ comment by TurnTrout · 2019-12-05T23:03:38.539Z · LW(p) · GW(p)
What happens if it only has 1.1x as much power?
Then it won't always be instrumentally convergent, depending on the environment in question. For Tic-Tac-Toe, there's an exact proportionality in the limit of farsightedness (see theorem 46). In general, there's a delicate interaction between control provided and probability which I don't fully understand right now. However, we can easily bound how different these quantities can be; the constant depends on the distribution we choose (it's at most 2 for the uniform distribution). The formal explanation can be found in the proof of theorem 48, but I'll try to give a quick overview.
The power calculation is the average attainable utility. This calculation breaks down into the weighted sum of the average attainable utility when is best, the average attainable utility when is best, and the average attainable utility when is best; each term is weighted by the probability that its possibility is optimal.[1] Each term is the power contribution of a different possibility.[2]
Let's think about 's contribution to the first (simple) example. First, how likely is to be optimal? Well, each state has an equal chance of being optimal, so of goals choose . Next, given that is optimal, how much reward do we expect to get? Learning that a possibility is optimal tells us something about its expected value. In this case, the expected reward is still ; the higher this number is, the "happier" an agent is to have this as its optimal possibility.
In general,
If the agent can "die" in an environment, more of its "ability to do things in general" is coming from not dying at first. Like, let's follow where the power is coming from, and that lets us deduce things about the instrumental convergence. Consider the power at a state. Maybe 99% of the power comes from the possibilities for one move (like the move that avoids dying), and 1% comes from the rest. Part of this is because there are "more" goals which say to avoid dying at first, but part also might be that, conditional on not dying being optimal, agents tend to have more control.
By analogy, imagine you're collecting taxes. You have this weird system where each person has to pay at least 50¢, and pays no more than $1. The western half of your city pays $99, while the eastern half pays $1. Obviously, there have to be more people living in this wild western portion – but you aren't sure exactly how many more. Even so, you know that there are at least 99 people west, and at most 2 people east; so, there are at least 44.5 times as many people in the western half.
In the exact same way, the minimum possible average control is not doing better than chance ( is the expected value of an arbitrary possibility), and the maximum possible is all agents being in heaven ( reward is maximal). So if 99% of the power comes from one move, then this move is at least 44.5 times as likely as any other moves.
↑ comment by ESRogs · 2019-12-06T19:30:42.786Z · LW(p) · GW(p)
Thanks for this reply. In general when I'm reading an explanation and come across a statement like, "this means that...", as in the above, if it's not immediately obvious to me why, I find myself wondering whether I'm supposed to see why and I'm just missing something, or if there's a complicated explanation that's being skipped.
In this case it sounds like there was a complicated explanation that was being skipped, and you did not expect readers to see why the statement was true. As a point of feedback: when that's the case I appreciate when writers make note of that fact in the text (e.g. with a parenthetical saying, "To see why this is true, refer to theorem... in the paper.").
Otherwise, I feel like I've just stopped understanding what's being written, and it's hard for me to stay engaged. If I know that something is not supposed to be obvious, then it's easier for me to just mentally flag it as something I can return to later if I want, and keep going.
comment by mattmacdermott · 2022-11-21T16:53:13.112Z · LW(p) · GW(p)
I've been thinking about whether these results could be interpeted pretty differently under different branding.
The current framing, if I understand it correctly, is something like, 'Powerseeking is not desirable. We can prove that keeping your options open tends to be optimal and tends to meet a plausible definition of powerseeking. Therefore we should expect RL agents to seek power, which is bad.'
An alternative framing would be, 'Making irreversible changes is not desirable. We can prove that keeping your options open tends to be optimal. Therefore we should not expect RL agents to make irreversible changes, which is good.'
I don't think that the second framing is better than the first, but I do think that if you had run with it instead then lots of people would be nodding their heads and feeling reassured about corrigibility, instead of feeling like their views about instrumental convergence had been confirmed. That makes me feel like we shouldn't update our views too much based on formal results that leave so much room for interpretation. If I showed a bunch of theorems about MDPs, with no exposition, to two people with different opinions about alignment, I expect they might come to pretty different conclusions about what they meant.
What do you think?
(To be clear I think this is a great post and paper, I just worry that there are pitfalls when it comes to interpretation.)
↑ comment by TurnTrout · 2022-11-21T21:14:44.527Z · LW(p) · GW(p)
Consider an agent navigating a tree MDP, with utility on the leaf nodes. At any internal node in the tree, ~most utility functions will have the agent retain options by going towards the branch with the most leaves. But all policies use up all available options -- they navigate to a leaf with no more power.
I agree that we shouldn't update too hard for other reasons. EG this post's focus on optimal policies seems bad because reward is not the optimization target [LW · GW].
Replies from: mattmacdermott↑ comment by mattmacdermott · 2022-11-22T19:41:42.176Z · LW(p) · GW(p)
Fair enough, but in that example making irreversible decisions is unavoidable. What if we consider a modified tree such that one and only one branch is traversible in both directions, and utility can be anywhere?
I expect we get that the reversible brach is the most popular across the distribution of utility functions (but not necessarily that most utility functions prefer it). That sounds like cause for optimism—'optimal policies tend to avoid irreversible changes'.
comment by ESRogs · 2019-12-05T19:47:46.244Z · LW(p) · GW(p)
Remember how, as the agent gets more farsighted, more of its control comes from Chocolate and Hug, while also these two possibilities become more and more likely?
I don't understand this bit -- how does more of its control come from Chocolate and Hug? Wouldn't you say its control comes from Wait!? Once it ends up in Candy, Chocolate, or Hug, it has no control left. No?
Replies from: TurnTroutcomment by ESRogs · 2019-12-05T19:34:10.246Z · LW(p) · GW(p)
Imagine we only care about the reward we get next turn. How many goals choose Candy over Wait? Well, it's 50-50 – since we randomly choose a number between 0 and 1 for each state, both states have an equal chance of being maximal.
I got a little confused at the introduction of Wait!, but I think I understand it now. So, to check my understanding, and for the benefit of others, some notes:
- the agent gets a reward for the Wait! state, just like the other states
- for terminal states (the three non-Wait! states), the agent stays in that state, and keeps getting the same reward for all future time steps
- so, when comparing Candy vs Wait! + Chocolate, the rewards after three turns would be (R_candy + γ
* R_candy + γ^2 * R_candy) vs (R_wait + γ * R_chocolate + γ^2 * R_chocolate)
(I had at first assumed the agent got no reward for Wait!, and also failed to realize that the agent keeps getting the reward for the terminal state indefinitely, and so thought it was just about comparing different one-time rewards.)
Replies from: TurnTroutcomment by Rafael Harth (sil-ver) · 2020-07-23T14:06:11.440Z · LW(p) · GW(p)
Thoughts after reading and thinking about this post
The thing that's bugging me here is that Power and Instrumental convergence seem to be almost the same.
In particular, it seems like Power asks [a state]: "how good are you across all policies" and Instrumental Convergence asks: "for how many policies are you the best?". In an analogy to tournaments where policies are players, power cares about the average performance of a player across all tournaments, and instrumental convergence about how many first places that player got. In that analogy, the statement that "most goals incentivize gaining power over that environment" would then be "for most tournaments, the first place finisher is someone with good average performance." With this formulation, the statement
formal POWER contributions of different possibilities are approximately proportionally related to instrumental convergence.
seems to be exactly what you would expect (more first places should strongly correlate with better performance). And to construct a counter-example, one creates a state with a lot of second places (i.e., a lot of policies for which it is the second best state) but few first places. I think the graph in the "Formalizations" section does exactly that. If the analogy is sound, it feels helpful to me.
(This is all without having read the paper. I think I'd need to know more of the theory behind MDP to understand it.)
Replies from: TurnTrout↑ comment by TurnTrout · 2020-07-23T14:37:29.529Z · LW(p) · GW(p)
Yes, this is roughly correct!
As an additional note: it turns out, however, that even if you slightly refine the notion of "power that this part of the future gives me, given that I start here", you have neither "more power instrumental convergence" nor "instrumental convergence more power" as logical implications.
Instead, if you're drawing the causal graph, there are many, many situations which cause both instrumental convergence and greater power. The formal task is then, "can we mathematically characterize those situations?". Then, you can say, "power-seeking will occur for optimal agents with goals from [such and such distributions] for [this task I care about] at [these discount rates]".
comment by TurnTrout · 2019-12-12T20:01:46.796Z · LW(p) · GW(p)
It seems a common reading of my results is that agents tend to seek out states with higher power. I think this is usually right, but it's false in some cases. Here's an excerpt from the paper:

So, just because a state has more resources, doesn't technically mean the agent will go out of its way to reach it. Here's what the relevant current results say: parts of the future allowing you to reach more terminal states are instrumentally convergent, and the formal POWER contributions of different possibilities are approximately proportionally related to their instrumental convergence. As I said in the paper,
The formalization of power seems reasonable, consistent with intuitions for all toy MDPs examined. The formalization of instrumental convergence also seems correct. Practically, if we want to determine whether an agent might gain power in the real world, one might be wary of concluding that we can simply "imagine'' a relevant MDP and then estimate e.g. the "power contributions'' of certain courses of action. However, any formal calculations of POWER are obviously infeasible for nontrivial environments.
To make predictions using these results, we must combine the intuitive correctness of the power and instrumental convergence formalisms with empirical evidence (from toy models), with intuition (from working with the formal object), and with theorems (like theorem 46, which reaffirms the common-sense prediction that more cycles means asymptotic instrumental convergence, or theorem 26, fully determining the power in time-uniform environments). We can reason, "for avoiding shutdown to not be heavily convergent, the model would have to look like such-and-such, but it almost certainly does not...''.
I think the Tic-Tac-Toe reasoning is a better intuition: it's instrumentally convergent to reach parts of the future which give you more control from your current vantage point. I'm working on expanding the formal results to include some version of this.
comment by SoerenMind · 2019-12-05T21:40:02.180Z · LW(p) · GW(p)
Thanks for writing this! It always felt like a blind spot to me that we only have Goodhart's law that says "if X is a proxy for Y and you optimize X, the correlation breaks" but we really mean a stronger version: "if you optimize X, Y will actively decrease". Your paper clarifies that what we actually mean is an intermediate version: "if you optimize X, it becomes a harder to optimize Y". My conclusion would be that the intermediate version is true but the strong version false then. Would you say that's an accurate summary?
Replies from: TurnTrout↑ comment by TurnTrout · 2019-12-05T22:01:15.583Z · LW(p) · GW(p)
My conclusion would be that the intermediate version is true but the strong version false then. Would you say that's an accurate summary?
I'm not totally sure I fully follow the conclusion, but I'll take a shot at answering - correct me if it seems like I'm talking past you.
Taking to be some notion of human values, I think it's both true that actively decreases and becomes harder for us to optimize. Both of these are caused, I think, by the agent's drive to take power / resources from us. If this weren't true, we might expect to see only "evil" objectives inducing catastrophically bad outcomes.
Replies from: SoerenMind↑ comment by SoerenMind · 2019-12-06T12:13:23.133Z · LW(p) · GW(p)
I should've specified that the strong version is "Y decreases relative to a world where neither of X nor Y are being optimized". Am I right that this version is not true?
Replies from: TurnTrout↑ comment by TurnTrout · 2019-12-06T14:01:31.842Z · LW(p) · GW(p)
I don't immediately see why this wouldn't be true as well as the "intermediate version". Can you expand?
Replies from: SoerenMind↑ comment by SoerenMind · 2019-12-07T15:35:22.290Z · LW(p) · GW(p)
If X is "number of paperclips" and Y is something arbitrary that nobody optimizes, such as the ratio of number of bicycles on the moon to flying horses, optimizing X should be equally likely to increase or decrease Y in expectation. Otherwise "1-Y" would go in the opposite direction which can't be true by symmetry. But if Y is something like "number of happy people", Y will probably decrease because the world is already set up to keep Y up and a misaligned agent could disturb that state.
Replies from: TurnTroutcomment by TurnTrout · 2023-05-16T20:19:18.430Z · LW(p) · GW(p)
I added the following to the beginning:
Edit, 5/16/23: I think this post is beautiful, correct in its narrow technical claims, and practically irrelevant to alignment. This post presents a cripplingly unrealistic picture of the role of reward functions in reinforcement learning. I expect this post to harm your alignment research intuitions unless you've already inoculated yourself by deeply internalizing and understanding Reward is not the optimization target [LW · GW]. If you're going to read one alignment post I've written, read that one.
Follow-up work (Parametrically retargetable decision-makers tend to seek power [LW · GW]) moved away from optimal policies and treated reward functions more realistically.
I'm now going to add this warning to other relevant posts in this sequence.
comment by TurnTrout · 2021-07-21T15:10:15.984Z · LW(p) · GW(p)
I proposed changing "instrumental convergence" to "robust instrumentality." This proposal has not caught on, and so I reverted the post's terminology. I'll just keep using 'convergently instrumental.' I do think that 'convergently instrumental' makes more sense than 'instrumentally convergent', since the agent isn't "convergent for instrumental reasons", but rather, it's more reasonable to say that the instrumentality is convergent in some sense.
For the record, the post used to contain the following section:
A note on terminology
The robustness-of-strategy phenomenon became known as the instrumental convergence hypothesis, but I propose we call it robust instrumentality instead.
From the paper’s introduction:
An action is said to be instrumental to an objective when it helps achieve that objective. Some actions are instrumental to many objectives, making them robustly instrumental. The so-called instrumental convergence thesis is the claim that agents with many different goals, if given time to learn and plan, will eventually converge on exhibiting certain common patterns of behavior that are robustly instrumental (e.g. survival, accessing usable energy, access to computing resources). Bostrom et al.'s instrumental convergence thesis might more aptly be called the robust instrumentality thesis, because it makes no reference to limits or converging processes:
“Several instrumental values can be identified which are convergent in the sense that their attainment would increase the chances of the agent's goal being realized for a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.”
Some authors have suggested that gaining power over the environment is a robustly instrumental behavior pattern on which learning agents generally converge as they tend towards optimality. If so, robust instrumentality presents a safety concern for the alignment of advanced reinforcement learning systems with human society: such systems might seek to gain power over humans as part of their environment. For example, Marvin Minsky imagined that an agent tasked with proving the Riemann hypothesis might rationally turn the planet into computational resources.
This choice is not costless: many are already acclimated to the existing ‘instrumental convergence.’ It even has its own Wikipedia page. Nonetheless, if there ever were a time to make the shift, that time would be now.
comment by avturchin · 2019-12-05T10:02:15.841Z · LW(p) · GW(p)
We explored similar idea in "Military AI as a Convergent Goal of Self-Improving AI". In that article we suggested that any advance AI will have a convergent goal to take over the world and because of this, it will have convergent subgoal of developing weapons in the broad sense of the word "weapon": not only tanks or drones, but any instruments to enforce its own will over others or destroy them or their goals.
We wrote in the abstract: "We show that one of the convergent drives of AI is a militarization drive, arising from AI’s need to wage a war against its potential rivals by either physical or software means, or to increase its bargaining power. This militarization trend increases global catastrophic risk or even existential risk during AI takeoff, which includes the use of nuclear weapons against rival AIs, blackmail by the threat of creating a global catastrophe, and the consequences of a war between two AIs. As a result, even benevolent AI may evolve into potentially dangerous military AI. The type and intensity of militarization drive depend on the relative speed of the AI takeoff and the number of potential rivals."
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2019-12-05T10:30:50.363Z · LW(p) · GW(p)
That paper seems quite different from this post in important ways.
In particular, the gist of the OP seems to be something like "showing that pre-formal intuitions about instrumental convergence persist under a certain natural class of formalisations". In particular, it does so using formalism closer to standard machine learning research.
The paper you linked seems to me to instead assume that this holds true, and then apply that insight in the context of military strategy. Without speculating about the merits of that, it seems like a different thing which will appeal to different readers, and if it is important, it will be important for somewhat different reasons.