Causal Scrubbing: a method for rigorously testing interpretability hypotheses [Redwood Research]
post by LawrenceC (LawChan), Adrià Garriga-alonso (rhaps0dy), Nicholas Goldowsky-Dill (nicholas-goldowsky-dill), ryan_greenblatt, jenny, Ansh Radhakrishnan (anshuman-radhakrishnan-1), Buck, Nate Thomas (nate-thomas) · 2022-12-03T00:58:36.973Z · LW · GW · 35 commentsContents
1 Introduction 1.1 Related work 2 Setup 3 Causal Scrubbing 3.1 An informal description: What activation replacements does a hypothesis imply are valid? Intervention 1: semantically equivalent subtrees Intervention 2: unimportant inputs 3.2 The causal scrubbing algorithm Intuitive Algorithm Pseudocode 4 Why ablate by resampling? 4.1 What does it mean to say “this thing doesn’t matter”? 4.2 Problems with zero and mean ablation 5 Results 5.1 On a paren balance checker 5.2 On induction 6 Relevance to alignment 7 Limitations Acknowledgements Citation None 35 comments
* Authors sorted alphabetically.
Summary: This post introduces causal scrubbing, a principled approach for evaluating the quality of mechanistic interpretations. The key idea behind causal scrubbing is to test interpretability hypotheses via behavior-preserving resampling ablations. We apply this method to develop a refined understanding of how a small language model implements induction and how an algorithmic model correctly classifies if a sequence of parentheses is balanced.
1 Introduction
A question that all mechanistic interpretability work must answer is, “how well does this interpretation explain the phenomenon being studied?”. In the many recent papers in mechanistic interpretability, researchers have generally relied on ad-hoc methods to evaluate the quality of interpretations.[1]
This ad hoc nature of existing evaluation methods poses a serious challenge for scaling up mechanistic interpretability. Currently, to evaluate the quality of a particular research result, we need to deeply understand both the interpretation and the phenomenon being explained, and then apply researcher judgment. Ideally, we’d like to find the interpretability equivalent of property-based testing—automatically checking the correctness of interpretations, instead of relying on grit and researcher judgment. More systematic procedures would also help us scale-up interpretability efforts to larger models, behaviors with subtler effects, and to larger teams of researchers. To help with these efforts, we want a procedure that is both powerful enough to finely distinguish better interpretations from worse ones, and general enough to be applied to complex interpretations.
In this work, we propose causal scrubbing, a systematic ablation method for testing precisely stated hypotheses about how a particular neural network[2] implements a behavior on a dataset. Specifically, given an informal hypothesis about which parts of a model implement the intermediate calculations required for a behavior, we convert this to a formal correspondence between a computational graph for the model and a human-interpretable computational graph. Then, causal scrubbing starts from the output and recursively finds all of the invariances of parts of the neural network that are implied by the hypothesis, and then replaces the activations of the neural network with the maximum entropy[3] distribution subject to certain natural constraints implied by the hypothesis and the data distribution. We then measure how well the scrubbed model implements the specific behavior.[4] Insofar as the hypothesis explains the behavior on the dataset, the model’s performance should be unchanged.
Unlike previous approaches that were specific to particular applications, causal scrubbing aims to work on a large class of interpretability hypotheses, including almost all hypotheses interpretability researchers propose in practice (that we’re aware of). Because the tests proposed by causal scrubbing are mechanically derived from the proposed hypothesis, causal scrubbing can be incorporated “in the inner loop” of interpretability research. For example, starting from a hypothesis that makes very broad claims about how the model works and thus is consistent with the model’s behavior on the data, we can iteratively make hypotheses that make more specific claims while monitoring how well the new hypotheses explain model behavior. We demonstrate two applications of this approach in later posts: first on a parenthesis balancer checker, then on the induction heads in a two-layer attention-only language model.
We see our contributions as the following:
- We formalize a notion of interpretability hypotheses that can represent a large, natural class of mechanistic interpretations;
- We propose an algorithm, causal scrubbing, that tests hypotheses by systematically replacing activations in all ways that the hypothesis implies should not affect performance.
- We demonstrate the practical value of this approach by using it to investigate two interpretability hypotheses for small transformers trained in different domains.
This is the main post in a four post sequence, and covers the most important content:
- What is causal scrubbing? Why do we think it’s more principled than other methods? (sections 2-4)
- A summary of our results from applying causal scrubbing (section 5)
- Discussion: Applications, Limitations, Future work (sections 6 and 7).
In addition, there are three posts with information of less general interest. The first [AF · GW] is a series of appendices to the content of this post. Then, a pair of posts covers the details of what we discovered applying causal scrubbing to a paren-balance checker [AF · GW] and induction in a small language model [AF · GW].[5] They are collected in a sequence here [? · GW].
1.1 Related work
Ablations for Model Interpretability: One commonly used technique in mechanistic interpretability is the “ablate, then measure” approach. Specifically, for interpretations that aim to explain why the model achieves low loss, it’s standard to remove parts that the interpretation identifies as important and check that model performance suffers, or to remove unimportant parts and check that model performance is unaffected. For example, in Nanda and Lieberum’s Grokking [AF · GW] work, to verify the claim that the model uses certain key frequencies to compute the correct answer to modular addition questions, the authors confirm that zero ablating the key frequencies greatly increases loss, while zero ablating random other frequencies has no effect on loss. In Anthropic’s Induction Head paper, they remove the induction heads and observe that this reduces the ability of models to perform in-context learning. In the IOI mechanistic interpretability project, the authors define the behavior of a transformer subcircuit by mean-ablating everything except the nodes from the circuit. This is used to formulate criteria for validating that the proposed circuit preserves the behavior they investigate and includes all the redundant nodes performing a similar role.
Causal scrubbing can be thought of as a generalized form of the “ablate, then measure” methodology.[6] However, unlike the standard zero and mean ablations, we ablate modules by resampling activations from other inputs (which we’ll justify in the next post). In this work, we also apply causal scrubbing to more precisely measure different mechanisms of induction head behavior than in the Anthropic paper.
Causal Tracing: Like causal tracing, causal scrubbing identifies computations by patching activations. However, causal tracing aims to identify a specific path (“trace”) that contributes causally to a particular behavior by corrupting all nodes in the neural network with noise and then iteratively denoising nodes. In contrast, causal scrubbing tries to solve a different problem: systematically testing hypotheses about the behavior of a whole network by removing (“scrubbing away”) every causal relationship that should not matter according to the hypothesis being evaluated. In addition, causal tracing patches with (homoscedastic) Gaussian noise and not with the activations of other samples. Not only does this take your model off distribution, it might have no effect in cases where the scale of the activation is much larger than the scale of the noise.
Heuristic explanations: This work takes a perspective on interpretability that is strongly influenced by ARC’s work on “heuristic explanations” of model behavior. In particular, causal scrubbing can be thought of as a form of defeasible reasoning: unlike mathematical proofs (where if you have a proof for a proposition P, you’ll never see a better proof for the negation of P that causes you to overall believe P is false), we expect that in the context of interpretability, we need to accept arguments that might be overturned by future arguments.
2 Setup
We assume a dataset over a domain and a function which captures a behavior of interest. We will then explain the expectation of this function on our dataset, .
This allows us to explain behaviors of the form “a particular model gets low loss on a distribution .” To represent this we include the labels in and both the model and a loss function in :

We also want to explain behaviors such as “if the prompt contains some bigram AB and ends with the token A, then the model is likely to predict B follows next.” We can do this by choosing a dataset where each datum has the prompt ...AB...A and expected completion B. For instance:

We then propose a hypothesis about how this behavior is implemented. Formally, a hypothesis for is a tuple of three things:
- A computational graph [7], which implements the function
- We require to be extensionally equal to (equal on all of )
- A computational graph , intuitively an ‘interpretation’ of the model.
- A correspondence function from the nodes of to the nodes of .
- We require to be an injective graph homomorphism: that is, if there is an edge in then the edge must exist in .
We additionally require and to each have a single input and output node, where maps input to input and output to output. All input nodes are of type which allows us to evaluate both and on all of .
Here is an example hypothesis:

In this figure, we hypothesize that works by having A compute whether , B compute whether , and then ORing those values. Then we’re asserting that the behavior is explained by the relationship between D and the true label .
A couple of important things to notice:
- We will often rewrite the computational graph of the original model implementation into a more convenient form (for instance splitting up a sum into terms, or grouping together several computations into one).
- You can think of as a heuristic[8] that the hypothesis claims that the model uses to achieve the behavior. It’s possible that the heuristic is imperfect and will sometimes disagree with the label . In that case our hypothesis would claim that the model should be incorrect on these inputs.
- Note that the mapping doesn’t tell you how to translate a value of into an activation, only which nodes correspond.
- We will call the “important nodes” of .[9]
- Let , be nodes in and respectively such that .
- Intuitively this is a claim that when we evaluate both and on the same input, then the value of (usually an activation of the model) ‘represents’ the value of (usually a simple feature of the input).
- The causal scrubbing algorithm will test a weaker claim: that the equivalence classes on inputs to are the same as the equivalence classes on inputs to . We think this is sufficient to meaningfully test the mechanistic interpretability hypotheses we are interested in, although it is not strong enough to eliminate all incorrect hypotheses.
- Let , be nodes in and respectively such that .
- Among other things, the hypothesis claims that nodes of that are not mapped to by are unimportant for the behavior under investigation.[10]
Hypotheses are covered in more detail in the appendix [AF · GW].
3 Causal Scrubbing
In this section we provide two different explanations of causal scrubbing:
- An informal description [AF · GW] of the activation-replacements that a hypothesis implies are valid. We try to provide a helpful introduction to the core idea of causal scrubbing via many diagrams; and
- The causal scrubbing algorithm and pseudocode [AF(p) · GW(p)]
Different readers of this document have found different explanations to be helpful, so we encourage you to skip around or skim some sections.
Our goal will be to define a metric by recursively sampling activations that should be equivalent according to each node of the interpretation . We then compare this value to . If a hypothesis is (reasonably) accurate, then the activation replacements we perform should not alter the loss and so we’d have . Overall, we think that this difference will be a reasonable proxy for the faithfulness of the hypothesis—that is, how accurately the hypothesis corresponds to the “real reasons” behind the model behavior.[11]
3.1 An informal description: What activation replacements does a hypothesis imply are valid?
Consider a hypothesis on the graphs below, where maps to the corresponding nodes of highlighted in green:

This hypothesis claims that the activations A and B respectively represent checking whether the first and second component of the input is greater than 3. Then the activation D represents checking whether either of these conditions were true. Both the third component of the input and the activation of C are unimportant (at least for the behavior we are explaining, the log loss with respect to the label ).
If this hypothesis is true, we should be able to perform two types of ‘resampling ablations’:
- replacing the activations of A, B, and D with the activations on other inputs that are “equivalent” under ; and
- replacing the activations that are claimed to be unimportant for a particular path (such as C or into B) with their activation on any other input.
To illustrate these interventions, we will depict a “treeified” version of where every path from the input to output of is represented by a different copy of the input. Replacing an activation with one from a different input is equivalent to replacing all inputs in the subtree upstream of that activation.
Intervention 1: semantically equivalent subtrees
Consider running the model on two inputs = (5,6,7, True) and = (8, 0, 4, True). The value of A’ is the same on both and . Thus, if the hypothesis depicted above is correct, the output of A on both these is equivalent. This means when evaluating on we can replace the activation of A with its value on , as depicted here:
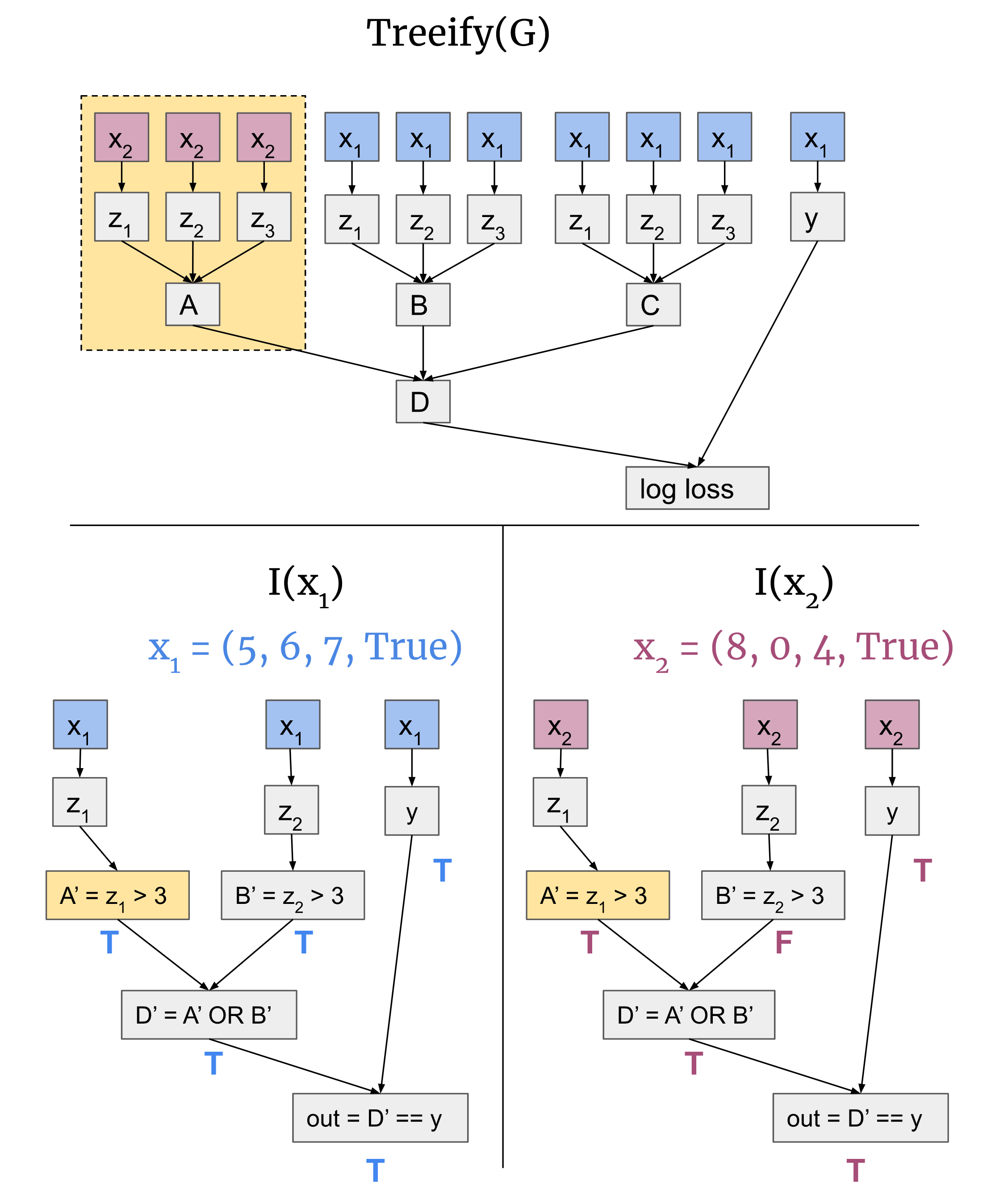
To perform the replacement, we replaced all of the inputs upstream of A in our treeified model. (We could have performed this replacement with any other that agrees on A’.)
Our hypothesis permits many other activation replacements. For example, we can perform this replacement for D instead:

Intervention 2: unimportant inputs
The other class of intervention permitted by is replacement of any inputs to nodes in that suggests aren’t semantically important. For example, says that the only important input for A is . So the model’s behavior should be preserved if we replace the activations for and (or, equivalently, change the input that feeds into these activations). The same applies for and into B. Additionally, says that D isn’t influenced by C, so arbitrarily resampling all the inputs to C shouldn’t impact the model’s behavior.
Pictorially, this looks like this:

Notice that we are making 3 different replacements with 3 different inputs simultaneously. Still, if is accurate, we will have preserved the important information and the output of should be similar.
The causal scrubbing algorithm involves performing both of these types of intervention many times. In fact, we want to maximize the number of such interventions we perform on every run of – to the extent permitted by .
3.2 The causal scrubbing algorithm
We define an algorithm for evaluating hypotheses. This algorithm uses the intuition, illustrated in the previous section, of what activation replacements are permitted by a hypothesis.
The core idea is that hypotheses can be interpreted as an “intervention blacklist”. We like to think of this as the hypothesis sticking its neck out and challenging us to swap around activations in any way that it hasn’t specifically ruled out.
In a single sentence, the algorithm is: Whenever we need to compute an activation, we ask “What are all the other activations that, according to , we could replace this activation with and still preserve the model’s behavior?”, and then make the replacement by choosing uniformly at random from that subset of the dataset, and do this recursively.
In this algorithm we don’t explicitly treeify G; but we traverse it one path at a time in a tree-like fashion.
We define the scrubbed expectation, , as the expectation of the behavior over samples from this algorithm.
Intuitive Algorithm
(This is mostly redundant with the pseudocode below. Read in your preferred order.)
The algorithm is defined in pseudocode below. Intuitively we:
- Sample a random reference input from
- Traverse all paths through from output towards the input by calling
run_scrubon nodes of recursively. For every node we consider the subgraph of that contains everything ‘upstream’ of (used to calculate its value from the input). Each of these correspond to a subgraph of the image in . - The return value of
run_scrub(n_I, c, D, x)is an activation from . Specifically it is an activation for the corresponding node in that the hypothesis claims represents the value of when is run on inputx.- Let .
- If is an input node we will return .
- Otherwise we will determine the activations of each input from the parents of . For each parent of :
- If there exists a parent of that corresponds to then the hypothesis claims that the value of is important for . In particular it is important as it represents the value defined by . Thus we sample a datum
new_xthat agrees with on the value of . We’ll recursively callrun_scrubon in order to get an activation for . - For any “unimportant parent” not mapped by the correspondence, we select an input
other_x. This is a random input from the dataset, however we enforce that the same random input is used by all unimportant parents of a particular node.[12] We record the value of onother_x. - We now have the activations of all the parents of – these are exactly the inputs to running the function defined for the node . We return the output of this function.
Pseudocode
def estim(h, D):
"""Estimate E_scrubbed(h, D)"""
_G, I, c = h
outs = []
for i in NUM_SAMPLES:
x = random.sample(D)
outs.append(run_scrub(c, D, output_node_of(I), x))
return mean(outs)
def run_scrub(
c, # correspondence I -> G
D: Set[Datum],
n_I, # node of I
ref_x: Datum
):
"""Returns an activation of n_G which h claims represents n_I(ref_x)."""
n_G = c(n_I)
if n_G is an input node:
return ref_x
inputs_G = {}
# pick a random datum to use for all “unimportant parents” of this node
random_x = random.sample(D)
# get the scrubbed activations of the inputs to n_G
for parent_G in n_G.parents():
# “important” parents
if parent_G is in map(c, n_I.parents()):
parent_I = c.inverse(parent_G)
# sample a new datum that agrees on the interpretation node
new_x = sample_agreeing_x(D, parent_I, ref_x)
# and get its scrubbed activations recursively
inputs_G[parent_G] = run_scrub(c, D, parent_I, new_x)
# “unimportant” parents
else:
# get the activations on the random input value chosen above
inputs_G[parent_G] = parent_G.value_on(random_x)
# now run n_G given the computed input activations
return n_G.value_from_inputs(inputs_G)
def sample_agreeing_x(D, n_I, ref_x):
"""Returns a random element of D that agrees with ref_x on the value of n_I"""
D_agree = [x in D if n_I.value_on(ref_x) == n_I.value_on(x)]
return random.sample(D_agree)4 Why ablate by resampling?
4.1 What does it mean to say “this thing doesn’t matter”?
Suppose a hypothesis claims that some module in the model isn’t important for a given behavior. There are a variety of different interventions that people do to test this. For example:
- Zero ablation: setting the activations of that module to 0
- Mean ablation: replacing the activations of that module with their empirical mean on D
- Resampling ablation: patching in the activation of that module on a random different input
In order to decide between these, we should think about the precise claim we’re trying to test by ablating the module.
If the claim is “this module’s activations are literally unused”, then we could try replacing them with huge numbers or even NaN. But in actual cases, this would destroy the model behavior, and so this isn’t the claim we’re trying to test.
We think a better type of claim is: “The behavior might depend on various properties of the activations of this module, but those activations aren’t encoding any information that’s relevant to this subtask.” Phrased differently: The distribution of activations of this module is (maybe) important for the behavior. But we don’t depend on any properties of this distribution that are conditional on which particular input the model receives.
This is why, in our opinion, the most direct way to translate this hypothesis into an intervention experiment is to patch in the module’s activation on a randomly sampled different input–this distribution will have all the properties that the module’s activations usually have, but any connection between those properties and the correct prediction will have been scrubbed away.
4.2 Problems with zero and mean ablation
Despite their prevalence in prior work, zero and mean ablations do not translate the claims we’d like to make faithfully.
As noted above, the claim we’re trying to evaluate is that the information in the output of this component doesn’t matter for our current model, not the claim that deleting the component would have no effect on behavior. We care about evaluating the claim as faithfully as possible on our current model and not replacing it with a slightly different model, which zero or mean ablation of a component does. This core problem can manifest in three ways:
- Zero and mean ablations take your model off distribution in an unprincipled manner.
- Zero and mean ablations can have unpredictable effects on measured performance.
- Zero and mean ablations remove variation and thus present an inaccurate view of what’s happening.
For more detail on these specific issues, we refer readers to the appendix post. [AF · GW]
5 Results
To show the value of this approach, we apply causal scrubbing algorithm to two tasks: 1) verifying hypotheses about an algorithmic model we found previously through ad-hoc interpretability, and 2) test and incrementally improve hypotheses about how induction heads work on a 2-layer attention only model. Here, we summarize the results of those applications here to illustrate the applications of causal scrubbing; detailed results can be found in the respective auxiliary posts.
5.1 On a paren balance checker
We apply the causal scrubbing algorithm to a small transformer which classifies sequences of parentheses as balanced or unbalanced; see the results post [AF · GW] for more information. In particular, we test three claims about the mechanisms this model uses.
Claim 1: There are three heads that directly pass important information to output:[13]
- Heads 1.0 and 2.0 test the conjunction of two checks: that there are an equal number of open and close parentheses in the entire sequence, and that the sequence starts open.
- Head 2.1 checks that the nesting depth is never negative at any point in the sequence.
Claim 1 is represented by the following hypothesis:[14]
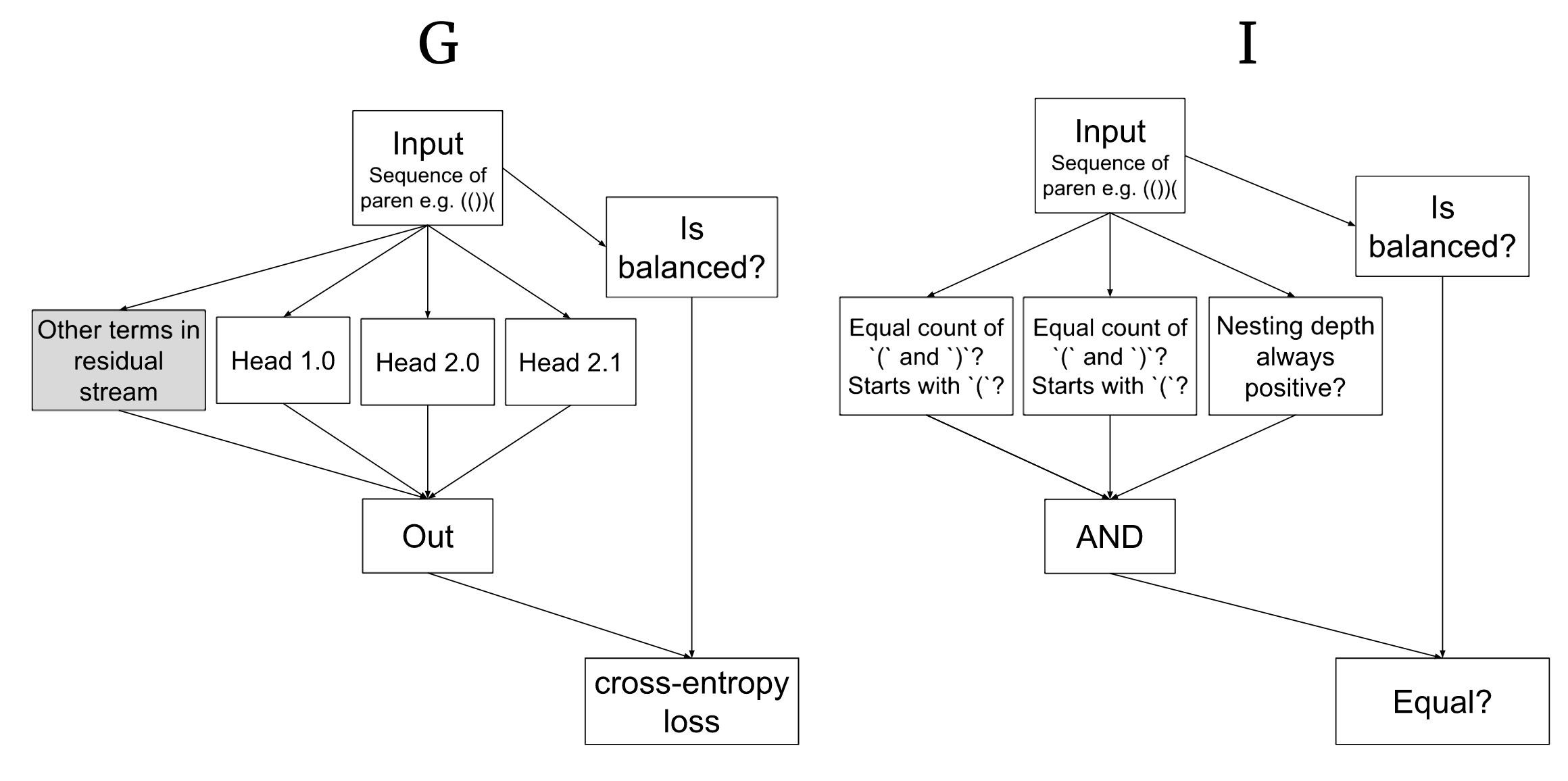
( and )? Starts with (?” computes the conjunction of both these two checks.Claim 2: Heads 1.0 and 2.0 depend only on their input at position 1, and this input indirectly depends on:
- The output of 0.0 at position 1, which computes the overall proportion of parentheses which are open. This is written into a particular direction of the residual stream in a linear fashion.
- The embedding at position 1, which indicates if the sequence starts with
(.
Claim 3: Head 2.1 depends on the input at all positions, and if the nesting depth (when reading right to left!) is negative at that position.[15]
Here is a visual representation of the combination of all three claims:
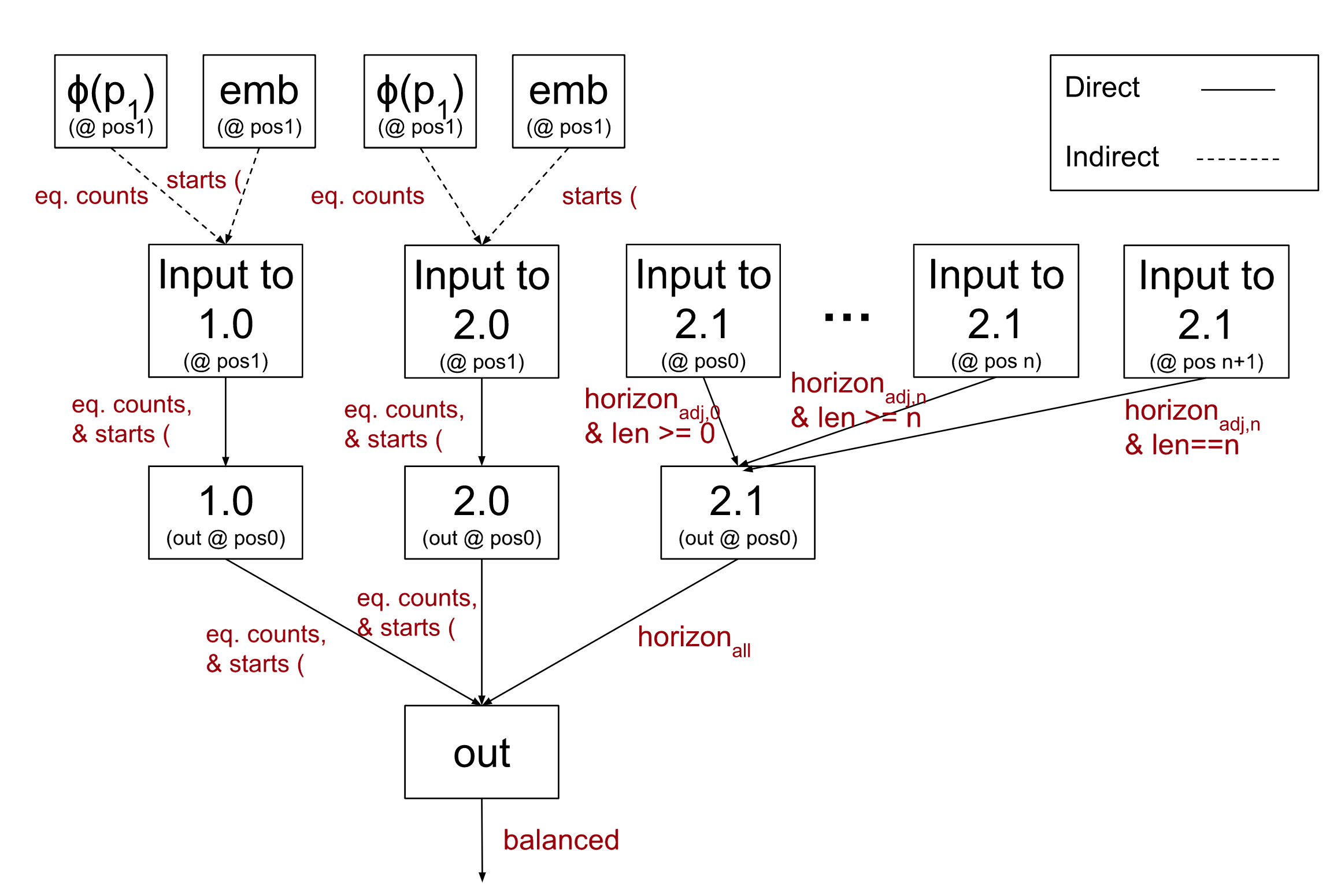
Testing these claims with causal scrubbing, we find that they are reasonably, but not completely, accurate:
| Claim(s) tested | Performance recovered[16] |
| 1 | 93% |
| 1 + 2 | 88% |
| 1 + 3 | 84% |
| 1 + 2 + 3 | 72% |
As expected, performance drops as we are more specific about how exactly the high level features are computed. This is because as the hypotheses get more specific, they induce more activation replacements, often stacked several layers deep.[17]
This indicates our hypothesis is subtly incorrect in several ways, either by missing pathways along which information travels or imperfectly identifying the features that the model uses in practice.
We explain these results in more detail in this appendix post [AF · GW].
5.2 On induction
We investigated ‘induction’ heads in a 2 layer attention only model. We were able to easily test out and incrementally improve hypotheses about which computations in the model were important for the behavior of the heads.
We first tested a naive induction hypothesis, which separates out the input to an induction head in layer 1 into three separate paths – the value, the key, and the query – and specified where the important information in each path comes from. We hypothesized that both the values and queries are formed based on only the input directly from the token embeddings via the residual stream and have no dependence on attention layer 0. The keys, however, are produced only by the input from attention layer 0; in particular, they depend on the part of the output of attention layer 0 that corresponds to attention on the previous token position.[18]
We test these hypotheses on a subset of openwebtext where induction is likely (but not guaranteed) to be helpful.[19] Evaluated on this dataset, this naive hypothesis only recovers 35% of the performance. In order to improve this we made various edits which allow the information to flow through additional pathways:
- First, we allow the attention pattern of the induction head to compare a set of three consecutive tokens (instead of just a single token) to determine when to induct.
- Next, we also allow the query and value to also depend on the part of the output of layer 0 that corresponds to the current position.
- We also special case three layer 0 heads which attend to repeated occurrences of the current token. In particular, we assume that the important part of the output of these heads is what their output would be if their attention was just an identity matrix.[20]
With these adjustments, our hypothesis recovers 86% of the performance.
We believe it would have been significantly harder to develop and have confidence in a hypothesis this precise only using ad-hoc methods to verify the correctness of a hypothesis.
We explain these results in more detail in this appendix post [AF · GW].
6 Relevance to alignment
The most obvious application of causal scrubbing to alignment is using it to evaluate mechanistic interpretations. In particular, we can imagine several specific use cases that are relevant to alignment:
- Checking interpretations of model behaviors produced by human researchers. Having a standardized, reliable, and convenient set of tests would make it much easier to scale up mechanistic interpretability efforts; this might be particularly important if there are big interpretability projects right before the deployment of transformative AI.
- Automated algorithmic searches for explanations. In some cases, researchers might be able to specify a space of hypotheses and then use optimization algorithms to find the most predictive ones. We’ve done some work like this and we hope to do much more in the future.
- AI-assisted explanations. We might be able to train models to produce highly rated and human-understandable explanations.
In all three applications, we required that researchers understand the explanations that were verified by causal scrubbing. Unfortunately, it might be the case that the behaviors we want to interpret in large neural networks won’t have any understandable interpretations at all if most of the cognition performed inside powerful AI systems is in some sense irreducibly complex. It also seems plausible that even if these human-understandable interpretations exist, it might be intractable or impractical to find them.
A lot of our interest in causal scrubbing (and mechanistic interpretability more generally) comes from applications which require interpretability-like techniques which rely on formally manipulating explanation-like objects but don’t require that these objects be understood by anyone (human or AI):
- Automated strategies for solving ELK. ARC is optimistic about some strategies [LW · GW] for solving ELK that involve searching for objects similar to causal scrubbing explanations and then using properties of these explanations as part of the training procedure of the model, in ways that don’t require humans to understand the explanations.
- Detecting deceptive alignment. Suppose you have a weak trusted model and a strong untrusted model. You might be able to search for explanations of why these models take similar actions which allow you to distinguish whether the untrusted model is deceptively aligned just based on the structure of the explanation, rather than via having to understand its content.
- Relaxed adversarial training [LW · GW] requires some way of adjudicating arguments about whether the internals of models imply they’ll behave badly in ways that are hard to find with random sampling (because the failures only occur off the training distribution, or they’re very rare). This doesn’t require that any human is able to understand these arguments; it just requires we have a mechanical argument evaluation procedure. Improved versions of the causal scrubbing algorithm might be able to fill this gap.
7 Limitations
Unfortunately, causal scrubbing may not be able to express all the tests of interpretability hypotheses we might want to express:
- Causal scrubbing only allows activation replacements that are perfectly permissible by the hypothesis: that is, the respective inputs have an exactly equal value in the correspondance.
- Despite being maximally strict in what replacements to allow, we are in practice willing to accept hypotheses that fail to perfectly preserve performance. We think this is an inconsistency in our current approach.
- As a concrete example, if you think a component of your model encodes a continuous feature, you might want to test this by replacing the activation of this component with the activation on an input that is approximately equal on this feature–causal scrubbing will refuse to do this swap.
- You can solve this problem by considering a generalized form of causal scrubbing, where hypotheses specify a non-uniform distribution over swaps. We’ve worked with this “generalized causal scrubbing” algorithm a bit. The space of hypotheses is continuous, which is nice for a lot of reasons (e.g. you can search over the hypothesis space with SGD). However, there are a variety of conceptual problems that still need to be resolved (e.g. there are a few different options for defining the union of two hypotheses, and it’s not obvious which is most principled).
- Causal scrubbing can only propose tests that can be constructed using the data provided to it. If your hypothesis predicts that model performance will be preserved if you swap the input to any other input which has a particular property, but no other inputs in the dataset have that property, causal scrubbing can’t test your hypothesis. This happens in practice–there is probably only one sequence in webtext with a particular first name at token positions 12, 45, and 317, and a particular last name at 13, 46, 234.
- This problem is addressed if you are able to produce samples that match properties by some mechanism other than rejection sampling.
- Causal scrubbing doesn’t allow us to distinguish between two features that are perfectly correlated on our dataset, since they would induce the same equivalence classes. In fact, to the extent that two features A and B are highly correlated, causal scrubbing will not complain if you misidentify an A-detector as a B-detector.[21]
Another limitation is that causal scrubbing does not guarantee that it will reject a hypothesis that is importantly false or incomplete. Here are two concrete cases where this happens:
- When a model uses some heuristic that isn’t always applicable, it might use other circuits to inhibit the heuristic (for example, the negative name mover heads in the Indirect Object Identification paper [AF · GW]). However, these inhibitory circuits are purely harmful for inputs where the heuristic is applicable. In these cases, if you ignore the inhibitory circuits, you might overestimate the contribution of the heuristic to performance, leading you to falsely believe that your incomplete interpretation fully explains the behavior (and therefore fail to notice other components of the network that contribute to performance).
- If two terms are correlated, sampling them independently (by two different random activation swaps) reduces the variance of the sum. Sometimes, this variance can be harmful for model performance – for instance, if it represents interference from polysemanticity [AF · GW]. This can cause a hypothesis that scrubs out correlations present in the model’s activations to appear ‘more accurate’ under causal scrubbing.[22]
These examples are both due to the hypotheses not being specific enough and neglecting to include some correlation in the model (either between input-feature and activation or between two activations) that would hurt the performance of the scrubbed model.
We don’t think that this is a problem with causal scrubbing in particular; but instead is because interpretability explanations should be regarded as an example of defeasible reasoning, where it is possible for an argument to be overturned by further arguments.
We think these problems are fairly likely to be solvable using an adversarial process where hypotheses are tested by allowing an adversary to modify the hypothesis to make it more specific in whatever ways affect the scrubbed behavior the most. Intuitively, this adversarial process requires that proposed hypotheses “point out all the mechanisms that are going on that matter for the behavior”, because if the proposed hypothesis doesn’t point something important out, the adversary can point it out. More details on this approach are included in the appendix post [AF · GW].
Despite these limitations, we are still excited about causal scrubbing. We’ve been able to directly apply it to understanding the behaviors of simple models and are optimistic about it being scalable to larger models and more complex behaviors (insofar as mechanistic interpretability can be applied to such problems at all). We currently expect causal scrubbing to be a big part of the methodology we use when doing mechanistic interpretability work in the future.
Acknowledgements
This work was done by the Redwood Research interpretability team. We’re especially thankful for Tao Lin for writing the software that we used for this research and for Kshitij Sachan for contributing to early versions of causal scrubbing. Causal scrubbing was strongly inspired by Kevin Wang, Arthur Conmy, and Alexandre Variengien’s work on how GPT-2 Implements Indirect Object Identification. We’d also like to thank Paul Christiano and Mark Xu for their insights on heuristic arguments on neural networks. Finally, thanks to Ben Toner, Oliver Habryka, Ajeya Cotra, Vladimir Mikulik, Tristan Hume, Jacob Steinhardt, Neel Nanda, Stephen Casper, and many others for their feedback on this work and prior drafts of this sequence.
Citation
Please cite as:
Chan, et al., "Causal Scrubbing: a method for rigorously testing interpretability hypotheses", AI Alignment Forum, 2022. BibTeX Citation:
@article{chan2022causal,
title={Causal scrubbing, a method for rigorously testing interpretability hypotheses},
author={Chan, Lawrence and Garriga-Alonso, Adrià and Goldwosky-Dill, Nicholas and Greenblatt, Ryan and Nitishinskaya, Jenny and Radhakrishnan, Ansh and Shlegeris, Buck and Thomas, Nate},
year={2022},
journal={AI Alignment Forum},
note={\url{https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/causal-scrubbing-a-method-for-rigorously-testing}}
}- ^
For example, in the causal tracing paper (Meng et al 2022), to evaluate whether their hypothesis correctly identified the location of facts in GPT-2, the authors replace the activation of the involved neurons and observed that the model behaved as though it believed the edited fact, and not the original fact. In the Induction Heads paper (Olsson et al 2022) the authors provide six different lines of evidence, from macroscopic co-occurrence to mechanistic plausibility.
- ^
Causal scrubbing is technically formulated in terms of general computational graphs, but we’re primarily interested in using causal scrubbing on computational graphs that implement neural networks.
- ^
See the discussion in the “An alternative formalism: constructing a distribution on treeified inputs” section of the appendix post [AF · GW].
- ^
Most commonly, the behavior we attempt to explain is why a model achieves low loss on a particular set of examples, and thus we measure the loss directly. However, the method can explain any expected quality of the model’s output.
- ^
We expect the results posts will be especially useful for people who wish to apply causal scrubbing in their own research.
- ^
Note that we can use causal scrubbing to ablate a particular module, by using a hypothesis where that specific module’s outputs do not matter for the model’s performance.
- ^
A computational graph is a graph where the nodes represent computations and the edges specify the inputs to the computations.
- ^
In the normal sense of the word, not ARC’s Heuristic Arguments approach [LW · GW]
- ^
Since is required to be an injective graph homomorphism, it immediately follows that is a subgraph of which is isomorphic to . This subgraph will be a union of paths from the input to the output.
- ^
- ^
We have no guarantee, however, that any hypothesis that passes the causal scrubbing test is desirable. See more discussion of counterexamples in the limitations section [AF · GW].
- ^
This is because otherwise our algorithm would crucially depend on the exact representation of the causal graph: e.g. if the output of a particular attention layer was represented as a single input or if there was one input per attention head instead. There are several other approaches that can be taken to addressing this ambiguity, see the appendix [AF · GW].
- ^
That is, we consider the contribution of these heads through the residual stream into the final layer norm, excluding influence they may have through intermediate layers.
- ^
Note that as part of this hypothesis we have aggressively simplified the original model into a computational graph with only 5 separate computations. In particular, we relied on the fact that residual stream just before the classifier head can be written as a sum of terms, including a term for each attention head (see “Attention Heads are Independent and Additive” section of Anthropic’s “Mathematical Framework for Transformer Circuits” paper). Since we claim only three of these terms are important, we clump all other terms together into one node. Additionally note this means that the ‘Head 2.0’ node in G includes all of the computations from layers 0 and 1, as these are required to compute the output of head 2.0 from the input.
- ^
The claim we test is somewhat more subtle [AF · GW], involving a weighted average between the proportion of the open-parentheses in the prefix and suffix of the string when split at every position. This is equivalent for the final computation of balancedness, but more closely matches the model’s internal computation.
- ^
- ^
Our final hypothesis combines up to 51 different inputs: 4 inputs feeding into each of 1.0 and 2.0, 42 feeding into 2.1 (one for each sequence position), and 1 for the ‘other terms’.
- ^
The output of an attention layer can be written as a sum of terms, one for each previous sequence position. We can thus claim that only one of these terms is important for forming the queries.
- ^
In particular we create a whitelist of tokens on which exact 2-token induction is often a helpful heuristic (over and above bigram-heuristics). We then filter openwebtext (prompt, next-token) pairs for prompts that end in tokens on our whitelist. We evaluate loss on the actual next token from the dataset, however, which may not be what induction expects. More details here [AF · GW].
We do this as we want to understand not just how our model implements induction but also how it decides when to use induction. - ^
And thus the residual of (actual output - estimated output) is unimportant and can be interchanged with the residual on any other input.
- ^
This is a common way for interpretability hypotheses to be ‘partially correct.’ Depending on the type of reliability needed, this can be more or less problematic.
- ^
Another real world example of this is this this experiment [AF · GW] on the paren balance checker
35 comments
Comments sorted by top scores.
comment by Buck · 2024-01-02T22:51:37.541Z · LW(p) · GW(p)
(I'm just going to speak for myself here, rather than the other authors, because I don't want to put words in anyone else's mouth. But many of the ideas I describe in this review are due to other people.)
I think this work was a solid intellectual contribution. I think that the metric proposed for how much you've explained a behavior is the most reasonable metric by a pretty large margin.
The core contribution of this paper was to produce negative results about interpretability. This led to us abandoning work on interpretability a few months later, which I'm glad we did. But these negative results haven’t had that much influence on other people’s work AFAICT, so overall it seems somewhat low impact.
The empirical results in this paper demonstrated that induction heads are not the simple circuit which many people claimed (see this post [LW · GW] for a clearer statement of that), and we then used these techniques to get mediocre results for IOI (described in this comment [LW(p) · GW(p)]).
There hasn’t been much followup on this work. I suspect that the main reasons people haven't built on this are:
- it's moderately annoying to implement it
- it makes your explanations look bad (IMO because they actually are unimpressive), so you aren't that incentivized to get it working
- the interp research community isn't very focused on validating whether its explanations are faithful, and in any case we didn’t successfully persuade many people that explanations performing poorly according to this metric means they’re importantly unfaithful
I think that interpretability research isn't going to be able to produce explanations that are very faithful explanations of what's going on in non-toy models (e.g. I think that no such explanation has ever been produced). Since I think faithful explanations are infeasible, measures of faithfulness of explanations don't seem very important to me now.
(I think that people who want to do research that uses model internals should evaluate their techniques by measuring performance on downstream tasks (e.g. weak-to-strong generalization and measurement tampering detection [LW · GW]) instead of trying to use faithfulness metrics.)
I wish we'd never bothered with trying to produce faithful explanations (or researching interpretability at all). But causal scrubbing was important in convincing us to stop working on this, so I'm glad for that.
See the dialogue between Ryan Greenblatt, Neel Nanda, and me [LW · GW] for more discussion of all this.
—
Another reflection question: did we really have to invent this whole recursive algorithm? Could we have just done something simpler?
My guess is that no, we couldn’t have done something simpler–the core contribution of CaSc is to give you a single number for the whole explanation, and I don’t see how to get that number without doing something like our approach where you apply every intervention at the same time.
Replies from: LawChan, thomas-kwa↑ comment by LawrenceC (LawChan) · 2024-01-02T23:15:06.472Z · LW(p) · GW(p)
I agree with the overall point (that this was a solid intellectual contribution and is a reasonable-ish metric), but there's been a non-zero amount of followups or at least use cases of this work, imo. Off the top of my head:
- In general, CaSc has been used on lots of toy/tiny models to a decent level of success. I agree that part of the reason for CaSc's lack of adoption is that the metric consistently returns "this explanation is not very faithful/complete/etc". For example:
- I checked the hypotheses for the toy modular arithmetic/group composition work with my own hand-crafted CaSc implementation and found that the modular arithmetic results held up quite well.
- CaSc-style tests were used by Marius and Stefan to confirm their solutions to Stephen Casper's Mech Interp challenges (challenge 1 [LW · GW], challenge 2 [LW · GW]).
- etc.
- Erik Jenner's agenda [LW · GW] is pretty closely related to causal scrubbing and is still actively being worked on.
↑ comment by Thomas Kwa (thomas-kwa) · 2024-01-05T00:34:27.057Z · LW(p) · GW(p)
I think that interpretability research isn't going to be able to produce explanations that are very faithful explanations of what's going on in non-toy models (e.g. I think that no such explanation has ever been produced). Since I think faithful explanations are infeasible, measures of faithfulness of explanations don't seem very important to me now.
By "explanations" you mean labeled high-level causal graphs right? Do you also think it's infeasible to identify sparse, unlabeled circuits as "the part of the model that's doing the task", like in ACDC, in a way that gets good performance on some downstream task?
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-01-07T20:07:40.281Z · LW(p) · GW(p)
By explanations, I think Buck means fully human understandable explanations.
Do you also think it's infeasible to identify sparse, unlabeled circuits as "the part of the model that's doing the task", like in ACDC, in a way that gets good performance on some downstream task?
Personally, I don't have a strong opinion and this will probably depend on the exact architecture and the extent of sparsity we demand. This seems related to other views I have on difficulties in interp (ETA: so I'm probably more pessimistic here than people who are more optimistic about interp), but at least partially orthogonal.
comment by Buck · 2023-02-22T22:27:15.004Z · LW(p) · GW(p)
After a few months, my biggest regret about this research is that I thought I knew how to interpret the numbers you get out of causal scrubbing, when actually I'm pretty confused about this.
Causal scrubbing takes an explanation and basically says “how good would the model be if the model didn’t rely on any correlations in the input except those named in the explanation?”. When you run causal scrubbing experiments on the induction hypothesis and our paren balance classifier explanation, you get numbers like 20% and 50%.
The obvious next question is: what do these numbers mean? Are those good numbers or bad numbers? Does that mean that the explanations are basically wrong, or mostly right but missing various minor factors?
My current position is “I don’t really know what those numbers mean."
The main way I want to move forward here is to come up with ways of assessing the quality of interpretability explanations which are based on downstream objectives like "can you use your explanation to produce adversarial examples" or "can you use your explanation to distinguish between different mechanisms the model is using", and then use causal-scrubbing-measured explanation quality as the target which you use to find explanations, but then validate the success of the project based on whether the resulting explanations allow you to succeed at your downstream objective.
(I think this is a fairly standard way of doing ML research. E.g., the point of training large language models isn't that we actually wanted models which have low perplexity at predicting webtext, it's that we want models that understand language and can generate plausible completions and so on, and optimizing a model for the former goal is a good way of making a model which is good at the latter goal, but we evaluate our models substantially based on their ability to generate plausible completions rather than by looking at their perplexity.)
I think I was pretty wrong to think that I knew what “loss explained” means; IMO this was a substantial mistake on my part; thanks to various people (e.g. Tao Lin) for really harping on this point.
(We have some more ideas about how to think about "loss explained" than I articulated here, but I don't think they're very satisfying yet.)
—-
In terms of what we can take away from these numbers right now: I think that these numbers seem bad enough that the interpretability explanations we’ve tested don’t seem obviously fine. If the tests had returned numbers like 95%, I’d be intuitively sympathetic to the position “this explanation is basically correct”. But because these numbers are so low, I think we need to instead think of these explanations as “partially correct” and then engage with the question of how good it is to produce explanations which are only partially correct, which requires thinking about questions like “what metrics should we use for partial correctness” and “how do we trade off between those metrics and other desirable features of explanations”.
I have wide error bars here. I think it’s plausible that the explanations we’ve seen so far are basically “good enough” for alignment applications. But I also think it’s plausible that the explanations are incomplete enough that they should roughly be thought of as “so wrong as to be basically useless”, because similarly incomplete explanations will be worthless for alignment applications. And so my current position is “I don’t think we can be confident that current explanations are anywhere near the completeness level where they’d add value when trying to align an AGI”, which is less pessimistic than “current explanations are definitely too incomplete to add value” but still seems like a pretty big problem.
We started realizing that all these explanations were substantially incomplete in around November last year, when we started doing causal scrubbing experiments. At the time, I thought that this meant that we should think of those explanations as “seriously, problematically incomplete”. I’m now much more agnostic.
comment by Neel Nanda (neel-nanda-1) · 2022-12-03T13:48:35.332Z · LW(p) · GW(p)
Really excited to see this come out! I'm in generally very excited to see work trying to make mechanistic interpretability more rigorous/coherent/paradigmatic, and think causal scrubbing is a pretty cool idea, though have some concerns that it sets the bar too high for something being a legit circuit. The part that feels most conceptually elegant to me is the idea that an interpretability hypothesis allows certain inputs to be equivalent for getting a certain answer (and the null hypothesis says that no inputs are equivalent), and then the recursive algorithm to zoom in and ask which inputs should be equivalent on a particular component.
I'm excited to see how this plays out at REMIX, in particular how much causal scrubbing can be turned into an exploratory tool to find circuits rather than just to verify them (and also how often well-meaning people can find false positives).
This sequence is pretty long, so if it helps people, here's a summary of causal scrubbing I wrote for a mechanistic interpretability glossary that I'm writing (please let me know if anything in here is inaccurate)
Replies from: anshuman-radhakrishnan-1, kshitij-sachan
- Redwood Research have suggested that the right way to think about circuits is actually to think of the model as a computational graph. In a transformer, nodes are components of the model, ie attention heads and neurons (in MLP layers), and edges between nodes are the part of input to the later node that comes from the output of the previous node. Within this framework, a circuit is a computational subgraph - a subset of nodes and a subset of the edges between them that is sufficient for doing the relevant computation.
- The key facts about transformer that make this framework work is that the output of each layer is the sum of the output of each component, and the input to each layer (the residual stream) is the sum of the output of every previous layer and thus the sum of the output of every previous component.
- Note: This means that there is an edge into a component from every component in earlier layers
- And because the inputs are the sum of the output of each component, we can often cleanly consider subsets of nodes and edges - this is linear and it’s easy to see the effect of adding and removing terms.
- The differences with the above framing are somewhat subtle:
- In the features framing, we don’t necessarily assume that features are aligned with circuit components (eg, they could be arbitrary directions in neuron space), while in the subgraph framing we focus on components and don’t need to show that the components correspond to features
- It’s less obvious how to think about an attention head as “representing a feature” - in some intuitive sense heads are “larger” than neurons - eg their output space lies in a rank d_head subspace, rather than just being a direction. The subgraph framing side-steps this.
- Causal scrubbing: An algorithm being developed by Redwood Research that tries to create an automated metric for deciding whether a computational subgraph corresponds to a circuit.
- (The following is my attempt at a summary - if you get confused, go check out their 100 page doc…)
- The exact algorithm is pretty involved and convoluted, but the key idea is to think of an interpretability hypothesis as saying which parts of a model don’t matter for a computation.
- The null hypothesis is that everything matters (ie, the state of knowing nothing about a model).
- Let’s take the running example of an induction circuit, which predicts repeated subsequences. We take a sequence … A B … A (A, B arbitrary tokens) and output B as the next token. Our hypothesis is that this is done by a previous token head, which notices that A1 is before B, and then an induction head, which looks from the destination token A2 to source tokens who’s previous token is A (ie B), and predicts that the value of whatever token it’s looking at (ie B) will come next.
- If a part of a model doesn’t matter, we should be able to change it without changing the model output. Their favoured tool for doing this is a random ablation, ie replacing the output of that model component with its output on a different, randomly chosen input. (See later for motivation).
- The next step is that we can be specific about which parts of the input matter for each relevant component.
- So, eg, we should be able to replace the output of the previous token head with any sequence with an A in that position, if we think that that’s all it depends on. And this sequence can be different from the input sequence that the input head sees, so long as the first A token agrees.
- There are various ways to make this even more specific that they discuss, eg separately editing the key, value and query inputs to a head.
- The final step is to take a metric for circuit quality - they use the expected loss recovered, ie “what fraction of the expected loss on the subproblem we’re studying does our scrubbed circuit recover, compared to the original model with no edits”
↑ comment by Ansh Radhakrishnan (anshuman-radhakrishnan-1) · 2022-12-03T18:42:13.753Z · LW(p) · GW(p)
in particular how much causal scrubbing can be turned into an exploratory tool to find circuits rather than just to verify them
I'd like to flag that this has been pretty easy to do - for instance, this process can look like resample ablating different nodes of the computational graph (eg each attention head/MLP), finding the nodes that when ablated most impact the model's performance and are hence important, and then recursively searching for nodes that are relevant to the current set of important nodes by ablating nodes upstream to each important node.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2022-12-04T12:55:20.122Z · LW(p) · GW(p)
Exciting! I look forward to the first "interesting circuit entirely derived by causal scrubbing" paper
↑ comment by Kshitij Sachan (kshitij-sachan) · 2022-12-03T16:08:32.069Z · LW(p) · GW(p)
Nice summary! One small nitpick:
> In the features framing, we don’t necessarily assume that features are aligned with circuit components (eg, they could be arbitrary directions in neuron space), while in the subgraph framing we focus on components and don’t need to show that the components correspond to features
This feels slightly misleading. In practice, we often do claim that sub-components correspond to features. We can "rewrite" our model into an equivalent form that better reflects the computation it's performing. For example, if we claim that a certain direction in an MLP's output is important, we could rewrite the single MLP node as the sum of the MLP output in the direction + the residual term. Then, we could make claims about the direction we pointed out and also claim that the residual term is unimportant.
The important point is that we are allowed to rewrite our model however we want as long as the rewrite is equivalent.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2022-12-03T16:14:16.914Z · LW(p) · GW(p)
Thanks for the clarification! If I'm understanding correctly, you're saying that the important part is decomposing activations (linearly?) and that there's nothing really baked in about what a component can and cannot be. You normally focus on components, but this can also fully encompass the features as directions frame, by just saying that "the activation component in that direction" is a feature?
Replies from: kshitij-sachan↑ comment by Kshitij Sachan (kshitij-sachan) · 2022-12-04T05:21:15.833Z · LW(p) · GW(p)
Yes! The important part is decomposing activations (not neccessarily linearly). I can rewrite my MLP as:
MLP(x) = f(x) + (MLP(x) - f(x))
and then claim that the MLP(x) - f(x) term is unimportant. There is an example of this in the parentheses balancer example.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2022-12-04T12:54:35.722Z · LW(p) · GW(p)
Thanks! Can you give a non-linear decomposition example?
Replies from: ryan_greenblatt, kshitij-sachan↑ comment by ryan_greenblatt · 2022-12-05T01:50:30.466Z · LW(p) · GW(p)
I would typically call
MLP(x) = f(x) + (MLP(x) - f(x))
a non-linear decomposition as f(x) is an arbitrary function.
Regardless, any decomposition into a computational graph (that we can prove is extensionally equal) is fine. For instance, if it's the case that MLP(x) = combine(h(x), g(x)) (via extensional equality), then I can scrub h(x) and g(x) individually.
One example of this could be a product, e.g, suppose that MLP(x) = h(x) * g(x) (maybe like swiglu or something).
↑ comment by Kshitij Sachan (kshitij-sachan) · 2022-12-05T20:51:49.531Z · LW(p) · GW(p)
We haven't had to use a non-linear decomposition in our interp work so far at Redwood. Just wanted to point out that it's possible. I'm not sure when you would want to use one, but I haven't thought about it that much.
comment by ojorgensen · 2023-02-01T17:51:19.153Z · LW(p) · GW(p)
This seems very similar to recent work that has come out of the Stanford AI Lab recently, linked to here.
Replies from: Buck↑ comment by Buck · 2023-03-18T16:28:02.317Z · LW(p) · GW(p)
It’s a pretty different algorithm, though obviously it’s trying to solve a related problem.
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2023-03-28T21:40:55.112Z · LW(p) · GW(p)
ETA: We've now written a post that compares causal scrubbing and the Geiger et al. approach in much more detail: https://www.alignmentforum.org/posts/uLMWMeBG3ruoBRhMW/a-comparison-of-causal-scrubbing-causal-abstractions-and [AF · GW]
I still endorse the main takeaways from my original comment below, but the list of differences isn't quite right (the newer papers by Geiger et al. do allow multiple interventions, and I neglected the impact that treeification has in causal scrubbing).
To me, the methods seem similar in much more than just the problem they're tackling. In particular, the idea in both cases seems to be:
- One format for explanations of a model is a causal/computational graph together with a description of how that graph maps onto the full computation.
- Such an explanation makes predictions about what should happen under various interventions on the activations of the full model, by replacing them with activations on different inputs.
- We can check the explanation by performing those activation replacements and seeing if the impact is what we predicted.
Here are all the differences I can see:
- In the Stanford line of work, the output of the full model and of the explanation are the same type, instead of the explanation having a simplified output. But as far as I can tell, we could always just add a final step to the full computation that simplifies the output to basically bridge this gap.
- How the methods quantify the extent to which a hypothesis isn't perfect: at least in this paper, the Stanford authors look at the size of the largest subset of the input distribution on which the hypothesis is perfect, instead of taking the expectation of the scrubbed output.
- The "interchange interventions" in the Stanford papers are allowed to change the activations in the explanation. They then check whether the output after intervention changes in the way the explanation would predict, as opposed to checking that the scrubbed output stays the same. (So along this axis, causal scrubbing just performs a subset of all the interchange interventions.)
- Apparently the Stanford authors only perform one intervention at a time, whereas causal scrubbing performs all possible interventions at once.
These all strike me as differences in implementation of fundamentally the same idea.
Anyway, maybe we're actually on the same page and those differences are what you meant by "pretty different algorithm". But if not, I'd be very interested to hear what you think the key differences are. (I'm working on yet another approach [AF · GW] and suspect more and more strongly that it's very similar to both causal scrubbing and Stanford's causal abstraction approach, so would be really good to know if I'm misunderstanding anything.)
FWIW, I would agree that the motivation of the Stanford authors seems somewhat different, i.e. they want to use this measurement of explanation quality in different ways. I'm less interested in that difference right now.
Replies from: nora-belrose, LawChan↑ comment by Nora Belrose (nora-belrose) · 2023-05-30T17:05:34.365Z · LW(p) · GW(p)
FWIW it appears that out of the 4 differences you cited here, only one of them (the relaxation of the restriction that the scrubbed output must be the same) still holds as of this January paper from Geiger's group https://arxiv.org/abs/2301.04709. So the methods are even more similar than you thought.
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2023-05-30T17:45:01.894Z · LW(p) · GW(p)
Yeah, that seems to be the most important remaining difference now that Atticus is also using multiple interventions at once. Though I think the metrics are also still different? (ofc that's pretty orthogonal to the main methods)
My sense now is that the types of interventions are bigger difference than I thought when writing that comment. In particular, as far as I can tell, causal scrubbing shouldn't be thought of as just doing a subset of the interventions, it also does some additional things (basically because causal abstractions don't treeify so are more limited in that regard). And there's a closely related difference in that causal scrubbing never compares to the output of the hypothesis, just different outputs of G.
But it also seems plausible that this still turns out not to matter too much in terms of which hypotheses are accepted/rejected. (There are definitely some examples of disagreements between the two methods, but I'm pretty unsure how severe and wide-spread they are.)
↑ comment by LawrenceC (LawChan) · 2023-05-24T20:40:06.635Z · LW(p) · GW(p)
Strongly upvoted for a clear explanation!
comment by Lauro Langosco · 2023-01-14T13:35:47.172Z · LW(p) · GW(p)
Is there an open-source implementation of causal scrubbing available?
Replies from: Buck, arthur-conmy, Buck, pranav-gade↑ comment by Arthur Conmy (arthur-conmy) · 2023-03-05T13:52:45.462Z · LW(p) · GW(p)
It is open sourced here and there is material from REMIX to get used to the codebase here
↑ comment by Buck · 2023-01-21T20:13:15.049Z · LW(p) · GW(p)
nope, but hopefully we'll release one in the next few weeks.
Replies from: Lauro Langosco↑ comment by Lauro Langosco · 2023-01-21T22:11:44.825Z · LW(p) · GW(p)
awesome!
↑ comment by Pranav Gade (pranav-gade) · 2023-02-19T09:56:26.487Z · LW(p) · GW(p)
I ended up throwing this(https://github.com/pranavgade20/causal-verifier) together over the weekend - it's probably very limited compared to redwood's thing, but seems to work on the one example I've tried.
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2023-02-20T03:52:14.977Z · LW(p) · GW(p)
Oh, cool! I'll take a look later this week
comment by Sonia Joseph (redhat) · 2023-07-12T20:22:50.179Z · LW(p) · GW(p)
Thank you for this write-up!
I am wondering how to relate causal scrubbing to @Arthur Conmy [LW · GW]'s ACDC method.
It seems that causal scrubbing becomes relevant when one is testing a relatively specific hypothesis (e.g. induction heads), while ACDC can work with simply a dataset, metric, behavior? If so, would it be accurate to say that ACDC would be a more general pass, and part of an earlier workflow, to develop your hypothesis? And causal scrubbing can validate it? Curious about trade-offs in types of insight, resources, computational complexity, positioning in one's mech interp workflow, and in what circumstances one would use each.
Replies from: rhaps0dy, arthur-conmy↑ comment by Adrià Garriga-alonso (rhaps0dy) · 2023-12-10T23:22:49.015Z · LW(p) · GW(p)
If you're still interested in this, we have now added Appendix N to the paper, which explains our final take.
↑ comment by Arthur Conmy (arthur-conmy) · 2023-07-14T02:02:57.527Z · LW(p) · GW(p)
(Personal opinion as an ACDC author) I would agree that causal scrubbing aims mostly to test hypotheses and ACDC does a general pass over model components to hopefully develop a hypothesis (see also the causal scrubbing post's related work and ACDC paper section 2). These generally feel like different steps in a project to me (though some posts in the causal scrubbing sequence show that the method can generate hypotheses, and also ACDC was inspired by causal scrubbing). On the practical side, the considerations in How to Think About Activation Patching [LW · GW] may be a helpful field guide for projects where one of several tools might be best for a given use case. I think both causal scrubbing are currently somewhat inefficient for different reasons; causal scrubbing is slow because causal diagrams have lots of paths in them, and ACDC is slow as computational graphs have lots of edges in them (follow up work to ACDC will do gradient descent over the edges).
comment by rusheb · 2023-01-18T13:29:46.174Z · LW(p) · GW(p)
If your hypothesis predicts that model performance will be preserved if you swap the input to any other input which has a particular property, but no other inputs in the dataset have that property, causal scrubbing can’t test your hypothesis
Would it be possible to make interventions which we expect not to preserve the model's behaviour, and assert that the behaviour does in fact change?
Replies from: Buck↑ comment by Buck · 2023-01-21T20:15:51.814Z · LW(p) · GW(p)
Something like this might be a good idea :) . We've thought about various ideas along these lines. The basic problem is that in such cases, you might be taking the model importantly off distribution, such that it seems to me that your test might fail even if the hypothesis was a correct explanation of how the model worked on-distribution.
comment by DanielFilan · 2023-01-17T01:08:08.009Z · LW(p) · GW(p)
Am I right that this algorithm is going to visit each "important" node in once per path from to the output? If so, that could be pretty slow given a densely-connected interpretation, right?
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2023-01-17T18:13:24.894Z · LW(p) · GW(p)
Yep, this is correct - in the worse case, you could have performance that is exponential in the size of the interpretation.
(Redwood is fully aware of this problem and there have been several efforts to fix it.)