High Status Eschews Quantification of Performance
post by niplav · 2023-03-19T22:14:16.523Z · LW · GW · 36 commentsContents
Examples of the Dynamic Ignaz Semmelweis and Hospitals Intellectuals Resist IQ FPTP and Two-Party Systems Prediction Markets Software Development Effort Estimation The Rationality Community Transitions to Clearer Quantification None 37 comments
In a recent episode of The Filan Cabinet, Oliver Habryka elaborated on a very interesting social pattern: If you have a community with high status people, and try to introduce clearer metrics of performance into that community, high status individuals in the community will strongly resist those metrics because they have an asymmetric downside: If they perform well on the metric, they stay in their position, but if they perform poorly, they might lose status. Since they are at least a little bit unsure about their performance on the metric relative to others, they can only lose.
Daniel Filan: So let's go back to what you think on your bad days. So you mentioned that you had this sense that lots of things in the world were, I don't know, trying to distract you from things that are true or important. And that LessWrong did that somewhat less.
Oliver Habryka: Yeah.
Daniel Filan: Can you kind of flesh that out? What kinds of things are you thinking of?
Oliver Habryka: I mean, the central dimension that I would often think about here is reputation management. As an example, the medical profession, which, you know, generally has the primary job of helping you with your medical problems and trying to heal you of diseases and various other things, also, at the same time, seems to have a very strong norm of mutual reputation protection. Where, if you try to run a study trying to figure out which doctors in the hospital are better or worse than other doctors in the hospital, quite quickly, the hospital will close its ranks and be like, “Sorry, we cannot gather data on [which doctors are better than the other doctors in this hospital].” Because that would, like, threaten the reputation arrangement we have. This would introduce additional data that might cause some of us to be judged and some others of us to not be judged.
And my sense is the way that usually looks like from the inside is an actual intentional blinding to performance metrics in order to both maintain a sense of social peace, and often the case because... A very common pattern here [is] something like, you have a status hierarchy within a community or a local institution like a hospital. And generally, that status hierarchy, because of the way it works, has leadership of the status hierarchy be opposed to all changes to the status hierarchy. Because the current leadership is at the top of the status hierarchy, and so almost anything that we introduce into the system that involves changes to that hierarchy is a threat, and there isn't much to be gained, [at least in] the zero-sum status conflict that is present.
And so my sense is, when you try to run these studies about comparative doctor performance, what happens is more that there's an existing status hierarchy, and lots of people feel a sense of uneasiness and a sense of wanting to protect the status quo, and therefore they push back on gathering relevant data here. And from the inside this often looks like an aversion to trying to understand what are actually the things that cause different doctors to be better than other doctors. Which is crazy, if you're, like, what is the primary job of a good medical institution and a good medical profession, it would be figuring out what makes people be better doctors and worse doctors. But [there are] all of the social dynamics that tend to be present in lots of different institutions that make it so that looking at relative performance [metrics] becomes a quite taboo topic and a topic that is quite scary.
So that's one way [in which] I think many places try to actively... Many groups of people, when they try to orient and gather around a certain purpose, actually [have a harder time] or get blinded or in some sense get integrated into a hierarchy that makes it harder for them to look at a thing that they were originally interested in when joining the institution.
— Oliver Habryka & Daniel Filan, “The Filan Cabinet Podcast with Oliver Habryka - Transcript” [LW · GW], 2023
This dynamic appears to me to explain many dysfunctions that currently occur, and important enough to collect some examples where this pattern occurred/occurs and where it was broken.
Examples of the Dynamic
Ignaz Semmelweis and Hospitals
Ignaz Semmelweis studied the maternal mortality rate due to puerperal fever in two different hospitals in the Vienna of the mid 19th century. Finding a stark difference in mortality rates between the two clinics (10% and 4%), he pursued different theories, finally concluding that the medical students and doctors in the first clinic did not wash their hands even after autopsies, while the midwives in the second clinic did not have contact with corpses. He instituted a policy of first desinfecting hands with a chlorinated solution and later simple handwashing, leading to drastic declines in the mortality rate.
However, Semmelweis was derided for his ideas, and they were dismissed as out of line with the then common four humors theory. Additionally, Wikipedia states that
As a result, his ideas were rejected by the medical community. Other, more subtle, factors may also have played a role. Some doctors, for instance, were offended at the suggestion that they should wash their hands, feeling that their social status as gentlemen was inconsistent with the idea that their hands could be unclean.
And:
János Diescher was appointed Semmelweis's successor at the Pest University maternity clinic. Immediately, mortality rates increased sixfold to 6%, but the physicians of Budapest said nothing; there were no inquiries and no protests.
It is quite surprising to me that we still know these numbers.
Intellectuals Resist IQ
Another example is that (arguendo) many intellectuals place an absurdly high amount of rigor on any attempts to develop tests for g, and the widespread isolated demands for rigor placed on IQ tests, despite their predictive predictive value.
The hypothesis that many intellectuals fear that widespread reliable testing of cognitive ability could hurt their position in status hierarchies where intellectual performance is crucial retrodicts this.
FPTP and Two-Party Systems
A more esoteric example is the baffling prevalence of first-past-the-post voting systems, despite the large amount of wasted votes it incurs, the pressure towards two-party systems via Duverger's law (and probably thereby creating more polarization), and the large number of voting method criteria it violates.
Here, again, the groups with large amounts of power have an incentive to prevent better methods of measurement coming into place: in a two-party system, both parties don't want additional competitors (i.e. third parties) to have a better shot at coming into power, which would be the case with better voting methods—so both parties don't undertake any steps to switch to a better system (and might even attempt to hinder or stop such efforts).
If this is true, then it's a display that high status actors not only resist quantification of performance, but also improvements in the existing metrics for performance.
Prediction Markets
Prediction markets offer to be a reliable mechanism for aggregating information about future events, yet they have been adopted in neither governments nor companies.
One reason for this is the at best shaky legal ground such markets stand on in the US, but they also threaten the reputations of pundits and other information sources who often do not display high accuracy in their predictions. See also Hanson 2023
A partner at a prominent US-based global management consultant:
“The objective truth should never be more than optional input to any structural narrative in a social system.”
Software Development Effort Estimation
(epistemic status: The information in this section is from personal communication with a person with ~35 years of industry experience in software, but I haven't checked the claims in detail yet.)
It is common for big projects to take more effort and time to complete than initially estimated. For software projects, there exist several companies who act as consultants to estimate the effort and time required for completing software projects. However, none of those companies publish track records of their forecasting ability (in line with the surprising general lack of customers demanding track records of performance).
This is a somewhat noncentral case, because the development effort estimation companies and consultancies are probably not high status relative to their customers, but perhaps the most well-regarded of such companies have found a way to coordinate around making track records low status.
The Rationality Community
Left as an exercise to the reader.
Transitions to Clearer Quantification
If one accepts that this dynamic is surprisingly common, one might be interested in how to avoid it (or transition to a regime with stronger quantification for performance).
One such example could be the emergence of Mixed Martial Arts through the Gracie challenge in the 1920s and later the UFC: The ability to hold fights in relatively short tournaments with clear win conditions seems to have enabled the establishment of a parallel status hierarchy, which outperformed other systems whenever the two came in contact. I have not dug into the details of this, but this could be an interesting case study for bringing more meritocracy into existing sklerotic status hierarchies.
36 comments
Comments sorted by top scores.
comment by Brendan Long (korin43) · 2023-03-19T23:18:59.041Z · LW(p) · GW(p)
I don't think this is just about status. There's also issues around choosing the metric and Goodhearting. I work in software development, and it would be really nice if we could just measure a single thing and know how effective engineers are, but every metric we've thought of is easy to game. You could say you plan to start measuring lines of code written and won't use it in performance reviews, but the only sane thing for an engineer to do would be to start gaming the metric immediately since lines-of-code is correlated with performance and how long will management resist the temptation use the metric?
It seems like academia has a similar problem, where publications are measurable and gameable, and if we could somehow stop measuring publications it would make the field better.
Replies from: niplav, Viliam↑ comment by Viliam · 2023-03-20T09:58:17.825Z · LW(p) · GW(p)
In medicine and education one can improve results by improving inputs (only accepting easier patients or smarter students). A pressure to provide measurable results could translate to pressure to game the results.
Then again, maybe prediction markets could help here. Or those would be gamed too, considering that the information (on patients' health, or students' skills) is not publicly available.
Replies from: M. Y. Zuocomment by evhub · 2023-03-20T19:48:16.257Z · LW(p) · GW(p)
Seems like this post is missing the obvious argument on the other side here, which is Goodhart's Law: if you clearly quantify performance, you'll get more of what you clearly quantified, but potentially much less of the things you actually cared about. My Chesterton's-fence-style sense here is that many clearly quantified metrics, unless you're pretty confident that they're measuring what you actually care about, will often just be worse than using social status, since status is at least flexible enough to resist Goodharting in some cases. Also worth pointing out that once you have a system with clearly quantified performance metrics, that system will also be sticky for the same reasons that the people at the top will have an incentive to keep it that way.
comment by DirectedEvolution (AllAmericanBreakfast) · 2023-03-20T01:58:48.030Z · LW(p) · GW(p)
I'd qualify the argument to say that high-status individuals can only lose local short-term status when subjected to new performance metrics. Locally high status but globally moderate status people have room to grow from performance metrics, if those metrics either strengthen the performance or prestige of their home institution.
- A high status doctor at an underrated hospital can gain status relative to the global medical community if new performance metrics boost the hospital's prestige.
- A high status worker within an underrated company can gain higher-status employment if new performance metrics let them compensate for their low-prestige CV.
- A major party asymetrically hampered by third party voters can improve its odds of victory by enacting approval voting, since it's more likely to fix their spoiler candidate problem than it is to let the third party win.
Μy guess is that resistance to metrics is about a preference for social harmony, resistance to Goodharting, and loss aversion, more than a shortsighted conspiracy in favor of complacency by the chief. In a monopolar metricized status hierarchy, there's only one way to be a winner. When we decide how to allocate status qualitatively, everybody can be the best at something, even if it's just by being the only competitor in their chosen game.
comment by johnswentworth · 2023-03-20T18:24:26.805Z · LW(p) · GW(p)
LessWrong, conveniently, has a rough metric of status directly built-in, namely karma. So we can directly ask: do people with high karma (i.e. high LW-status) wish to avoid quantification of performance? Speaking as someone with relatively high karma myself, I do indeed at least think that every quantitative performance metric I've heard sounds terrible, and I'd guess that most of the other folks with relatively high karma on the site would agree.
... and yet the story in the post doesn't quite seem to hold up. My local/first-order incentives actually favor quantifying performance by status, so long as the quantitative metric in question is one by which I'm already doing well - like, say, LW karma. If e.g. research grants were given out based solely on LW karma, that would be great for me personally (ignoring higher-order effects).
And yet, despite the favorable local/first-order incentives, I think that's not a very good idea (either for me personally or at the community level), because implementing it would mostly result in karma being goodhearted a lot more.
Zooming back out to the more general case, I see two generalizable lessons.
First: the local incentives of those with high status agree with performance quantification just fine, so long as the metric in question is one by which they're already doing well. Quantification is not actually the relevant thing to focus on. The relevant thing to focus on is whether a particular new criterion (whether quantitative or not) is something on which high-status people already perform well.
Second: performance standards are a commons. Goodhearting burns that commons; performing well at a widely-goodhearted metric has relatively little benefit even for those who are very good at goodhearting the metric, compared to performing well on a non-goodhearted metric. So, high-status individuals' incentives also push toward avoiding goodhearting, in a way which is plausibly-beneficial to the community as a whole.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-20T18:38:22.747Z · LW(p) · GW(p)
the local incentives of those with high status agree with performance quantification just fine, so long as the metric in question is one by which they're already doing well.
To me this rhymes pretty closely with the message in Is Success the Enemy of Freedom? [LW · GW], in that in both cases you're very averse to competition on even pretty nearby metrics that you do worse on.
comment by TurnTrout · 2023-03-20T15:44:40.442Z · LW(p) · GW(p)
The Rationality Community
Left as an exercise to the reader.
I wish this had been part of the post and not left as an exercise.
Replies from: niplav, niplav↑ comment by niplav · 2023-03-20T20:25:47.129Z · LW(p) · GW(p)
In hindsight, leaving my personal opinion out was the right call: It would've distracted from the (at least by intention) descriptive nature of the post, and my personal take on What's Wrong with LessWrong™ would've made conveying the general pattern less straightforward.
I perhaps already regret having had that section title in there at all.
Replies from: TurnTrout↑ comment by TurnTrout · 2023-03-28T01:23:06.726Z · LW(p) · GW(p)
I think you're right. I revise my original contention to:
I have recently worried that the rationality community is at substantial risk here. In particular, I am worried about lack of benchmarks and legible track records. I was glad to see you hint at a discussion of this kind of issue. I think someone should write that post. I agree that it's good that your post wasn't that post.
comment by tailcalled · 2023-03-19T22:32:32.028Z · LW(p) · GW(p)
Intellectuals Resist IQ
Another example is that (arguendo) many intellectuals place an absurdly high amount of rigor on any attempts to develop tests for g, and the widespread isolated demands for rigor placed on IQ tests, despite their predictive predictive value [? · GW].
The hypothesis that many intellectuals fear that widespread reliable testing of cognitive ability could hurt their position in status hierarchies where intellectual performance is crucial retrodicts this.
LessWrong is an intellectual community that mainly allocates status through informal social consensus. Should we switch to allocating status based on IQ instead?
Replies from: niplav, lc, habryka4↑ comment by niplav · 2023-03-19T22:39:01.130Z · LW(p) · GW(p)
I don't think so, though it would be interesting to try out. I have some other metric in mind that I believe is undervalued on LessWrong.
I also have the impression that fields in which accomplishments are less clear (mostly the humanities and philosophy) are the strongest in their resistance to IQ tests.
Replies from: r↑ comment by RomanHauksson (r) · 2023-03-20T02:07:46.127Z · LW(p) · GW(p)
Is the metric calibration?
Replies from: niplav↑ comment by niplav · 2023-03-20T10:18:51.811Z · LW(p) · GW(p)
Yes*.
*: Terms and conditions apply. Marginal opinions only.
Replies from: tailcalled↑ comment by tailcalled · 2023-03-20T10:25:20.384Z · LW(p) · GW(p)
Couldn't you max out on calibration by guessing 50% for everything?
Replies from: niplav↑ comment by niplav · 2023-03-20T10:35:54.181Z · LW(p) · GW(p)
Yes. (To nitpick, with existing platforms one would max out calibration in expectation by guessing 17.5% or 39% or 29%.)
Ideally we'd want to use a proper scoring rule, but this brings up other Goodharting issues: if people can select the questions they predict on, this will incentivize predicting on easier questions, and people who have made very few forecasts will often appear at the top of the ranking, so we'd like to use something like a credibility formula. I plan on writing something up on this.
Replies from: Viliam, tailcalled↑ comment by Viliam · 2023-03-20T12:27:58.282Z · LW(p) · GW(p)
if people can select the questions they predict on, this will incentivize predicting on easier questions
True. On the other hand, if I publicly say that I consider myself an expert on X and ignorant on Y, should my self-assessment on X be penalized just because I got the answers on Y wrong?
Replies from: tailcalled↑ comment by tailcalled · 2023-03-20T14:13:15.918Z · LW(p) · GW(p)
Depends on the correlation in accuracy within X vs between X and Y.
↑ comment by tailcalled · 2023-03-20T10:39:43.575Z · LW(p) · GW(p)
What pool of questions would people make predictions on?
↑ comment by lc · 2023-03-20T18:26:55.752Z · LW(p) · GW(p)
How would that even work?
Replies from: tailcalled↑ comment by tailcalled · 2023-03-20T20:09:30.219Z · LW(p) · GW(p)
I don't know. I am pretty skeptical and mainly posed the question for OP to think through the practical implications of intellectuals using IQ for status allocation.
Replies from: niplav↑ comment by niplav · 2023-03-20T20:22:55.269Z · LW(p) · GW(p)
Ah, that clears things up.
I tried phrasing the post as a description of a social dynamic, not as a prescription of any particular policy. Apparently multiple people interpreted it normatively, so I should probably amend the post in some way to make it clearer that it is intended to be purely descriptive.
Replies from: niplav↑ comment by habryka (habryka4) · 2023-03-20T04:00:46.068Z · LW(p) · GW(p)
I think this is an interesting idea!
In doing community building I have definitely used publicly available information about IQ distributions in a lot of different ways, and I do think things like SAT scores and top-university admissions and other things that are substantial proxies for IQ are things that I definitely use in both deciding who to respect, listen to and invest in.
That said, while IQ tests do have some validity outside the 135+ regime, I do think it's a good bit weaker, and I put substantially less weight on the results of IQ tests being able to differentiate among the tails. I think it's definitely still an input, and I do think I kind of wish there were better ways to assess people's intelligence in various different contexts, but it doesn't feel like a hugely burning need for me, and most of my uncertainty about people usually isn't concentrated in being able to tell how smart someone is, but is more concentrated in how reliable they are, how ethical they are and how likely they are to get hijacked by weird societal forces and happy-death spirals and similar things, for which making standardized tests seem at least a good amount harder (especially ones that can't be gamed).
Another huge problem with assigning status according to IQ test results is that IQ tests are not at all robust against training effects. If you want an official high IQ score, just spend a few dozen hours doing IQ tests, practicing the type of challenges you will be tested on. The SAT in-contrast is kind of useful anyways, because kind of everyone saturates on practicing for the SAT, at least in the US, but that test sadly also maxes out at an average that is below the average IQ test result in the LessWrong community, and so isn't super helpful in distinguishing between the remaining variance. If there was a well-tested IQ-test that was made to be training-resistant, that could potentially provide a bunch of value, but I don't know of one.
Replies from: tailcalled, Archimedes↑ comment by tailcalled · 2023-03-20T10:23:37.354Z · LW(p) · GW(p)
That said, while IQ tests do have some validity outside the 135+ regime, I do think it's a good bit weaker, and I put substantially less weight on the results of IQ tests being able to differentiate among the tails.
I think this can be solved by creating an IQ test optimized for informativeness in the high range of ability. That shouldn't be very hard to do, compared to the scale at which it could be applied.
most of my uncertainty about people usually isn't concentrated in being able to tell how smart someone is, but is more concentrated in how reliable they are, how ethical they are and how likely they are to get hijacked by weird societal forces and happy-death spirals and similar things, for which making standardized tests seem at least a good amount harder (especially ones that can't be gamed).
I agree, though this also raises some questions about whether OP's post has all of the important points. Some resistance to objective metrics is likely due to those metrics not being appropriate.
Also, I can't help but wonder, I feel like an organization that put effort into it could make a lot of progress testing for other stuff. It may be mainly about setting up some reputation systems that collect a lot of private information about how people act. Though in practice I suspect people will oppose it for privacy reasons.
↑ comment by Archimedes · 2023-03-25T03:38:53.150Z · LW(p) · GW(p)
The SAT in-contrast is kind of useful anyways, because kind of everyone saturates on practicing for the SAT, at least in the US, but that test sadly also maxes out at an average that is below the average IQ test result in the LessWrong community
Am I correct in interpreting this as you implying that the average member of the LessWrong community got perfect SAT scores (or would have had they taken it)?
Replies from: Benito, habryka4↑ comment by Ben Pace (Benito) · 2023-03-25T20:05:20.988Z · LW(p) · GW(p)
This is an odd response from me, but, recently for my birthday, I posted a survey for my friends to fill out about me, anonymously rating me on lots of different attributes.
I included some spicier/fun questions, one of which was whether they thought they were smarter than me or not.
Here were the results for that question:
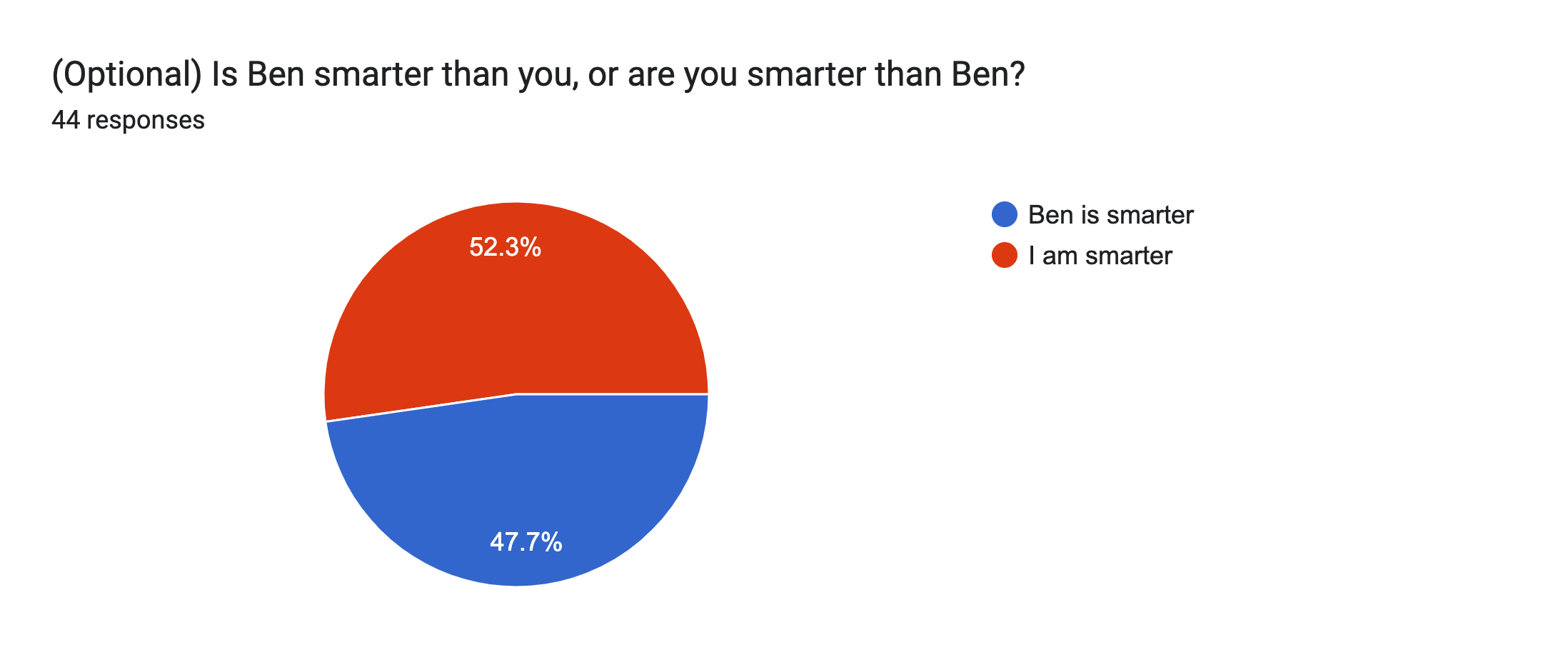
It was roughly 50/50 throughout the entire time data came in over the two days.
The vast majority of people responding said that they'd read the sequences (either "some" or "yes"). I'd guess that basically everyone had except my family.
So, this is some evidence that I am of median IQ amongst a large group of people who have read the sequences.
Also, I got a perfect SAT score.
↑ comment by habryka (habryka4) · 2023-03-25T19:49:10.413Z · LW(p) · GW(p)
Something pretty close to that. We included SAT scores in one of the surveys from a long time ago. IIRC the median score was pretty close to perfect, of the people who gave their results, but I might be misremembering.
Replies from: Unnamed, Archimedes↑ comment by Unnamed · 2023-03-26T04:55:01.758Z · LW(p) · GW(p)
Only like 10% are perfect scores. Median of 1490 on each of the two old LW surveys I just checked.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-26T08:02:39.079Z · LW(p) · GW(p)
Thank you for checking!
Getting a perfect SAT does sure actually look harder than I thought (I don't have that much experience with the SAT, I had to take it when I applied to U.S. universities but I only really thought about it for the 3-6 month period in which I was applying).
↑ comment by Archimedes · 2023-03-25T23:36:18.913Z · LW(p) · GW(p)
Interesting. I wonder how much selection bias there was in responses.
comment by Viliam · 2023-03-20T12:23:38.586Z · LW(p) · GW(p)
It's complicated. On one hand, there are good reasons to resist Goodharting. On the other hand, it is convenient to defend the existing hierarchies, if you happen to be on the top. Just because the status quo is convenient for high-status people, doesn't mean that the worries about Goodharting should be dismissed. Then again, maybe in some situations the Goodharting could be avoided by making better tests, and yes it is likely that the high-status people would resist that, too.
I guess this needs to be examined case by case. Even obviously bad things like the number of patients dying... we need to be careful whether the alternative is not something like turning the most sick patients away (so that they die at home, or in a competing hospital, in a way that does not hurt our statistics) or denying euthanasia to the terminally ill, which the metric would incentivize.
The issue with intellectuals and rationalists is that high IQ does not necessarily imply expertise or rationality. It may be a necessary condition, but is far from sufficient. Many highly intelligent people believe in various conspiracy theories. (This is further complicated by the fact that some highly intelligent people signal their intelligence by believing in weird things, in a way that does not positively correlate "weird" with "true".)
It might make sense to reject people based on IQ, for example to make a web forum where only people with IQ 130 or more are allowed to post. But there would still be many crackpots and politically mindkilled people who pass this bar, so you would still need to filter them by something else. (In which case it makes sense to avoid the controversy and drop the IQ bar, and just filter them by their apparent expertise or rationality.)
(Basically, the entire idea of Mensa was filtering by high IQ, and it is considered a failure by many.)
That said, it might be good to make some public tests of expertise at various things; ideally tests that directly measure "how much you understand this" without simultaneously measuring "how much money and time are you willing to waste in order to get certified that you understand this", and make such certificate a requirement for participating in some debates. Preferably make the test relatively simple (like, one or two sigma), so that it is a positive filter ("this person understands the basics of the topic they are discussing") rather than a negative filter ("this person got all the obscure details right"), so that the ignorant are filtered away, but educated people are not censored because of a trick question that you can get right by learning to the test rather than learning the topic in general. We would also need to make sure that people are not measuring political compliance instead of knowledge of the topic in general.
comment by Ben (ben-lang) · 2023-03-20T11:01:19.545Z · LW(p) · GW(p)
Reminded me of this comedian saying a similar thing:
↑ comment by Viliam · 2023-03-20T12:43:17.833Z · LW(p) · GW(p)
A charitable interpretation of Mensa membership would be something like: "Hey, I have a high IQ, and yet I am not successful, so apparently I am missing something. Maybe I can't figure out what it is, and maybe you could help me, especially given that you see many people with a similar problem."
And sometimes the problem is something that can't be fixed, or at least not quickly, like maybe your EQ is zero, and you would need a decade of therapy, and you don't even agree that this is the problem, so you would reject the therapy anyway. (Or a similar thing about rationality.)
And maybe sometimes the problem is something that could be fixed relatively easily, for example maybe your social circle is simply too stupid or too anti-intellectual, and you just need to start hanging out with different people and get some guidance... and maybe most smart people automatically assume that you are stupid because of your cultural differences and wrong signaling, and the IQ test could be an evidence that it is indeed worth spending their time on you.
Then again, if only the people who need some help join Mensa, it will become a "blind guiding the blind" club.
comment by baturinsky · 2023-03-26T05:52:21.739Z · LW(p) · GW(p)
Hmm... by analogy, would high status AI agent sabotage the creation and use of the more capable AI agents?