Morpheus's Shortform
post by Morpheus · 2020-08-07T22:35:57.530Z · LW · GW · 63 commentsContents
64 comments
63 comments
Comments sorted by top scores.
comment by Morpheus · 2024-09-04T09:59:48.025Z · LW(p) · GW(p)
I went through Gwern’s posts and collected all the posts with importance 8 and higher as of 2024-09-04 in case someone else was searching for something like this.
10
- How Often Does Correlation=Causality?
- Why Correlation Usually ≠ Causation
- The Scaling Hypothesis
- Complexity no Bar to AI
- The Algernon Argument
- Embryo Selection For Intelligence
- Life Extension Cost-Benefits
- Colder Wars
- Metamagical Themas: Sanity and Survival
- The Existential Risk of Math Errors
9
- Iodine and Adult IQ meta-analysis
- Lithium in ground-water and well-being
- Melatonin
- Modafinil
- Modafinil community survey
- Nicotine
- Why Tool AIs Want to Be Agent AIs
- Machine Learning Scaling
- The Hyperbolic Time Chamber & Brain Emulation
- The Iron Law Of Evaluation And Other Metallic Rules
- Spaced Repetition for Efficient Learning
- Are Sunk Costs Fallacies?
- Plastination versus Cryonics
- Silk Road 1: Theory & Practice
- Darknet Market Archives (2013–2015)
- The Melancholy of Subculture Society
8
- The Replication Crisis: Flaws in Mainstream Science
- How Should We Critique Research?
- The Narrowing Circle
- Zeo sleep self-experiments
- When Should I Check The Mail?
- Candy Japan’s new box A/B test
- The Kelly Coin-Flipping Game: Exact Solutions
- In Defense of Inclusionism
- Bitcoin Is Worse Is Better
- Time-lock encryption
- Easy Cryptographic Timestamping of Files
- GPT-3 Creative Fiction
- RNN Metadata for Mimicking Author Style
- Terrorism Is Not About Terror
- Terrorism Is Not Effective
- Archiving URLs
- Conscientiousness & Online Education
- Radiance: A Novel
↑ comment by trevor (TrevorWiesinger) · 2024-09-04T20:11:25.738Z · LW(p) · GW(p)
This could have been a post so more people could link it (many don't reflexively notice that you can easily get a link to a Lesswrong quicktake or Twitter or facebook post by mousing over the date between the upvote count and the poster, which also works for tab and hotkey navigation for people like me who avoid using the mouse/touchpad whenever possible).
Replies from: Morpheus↑ comment by Morpheus · 2024-09-05T11:17:43.779Z · LW(p) · GW(p)
It not being linked on Twitter and Facebook seems more like a feature than a bug, given that when I asked Gwern why a page like this doesn't already exist, he wrote me he doesn't want people to mock it.
> I really like the importance Tags, but what I would really like is a page
> where I can just go through all the posts ordered by importance. I just
> stumbled over another importance 9 post (iron rules) when I thought I had
> read all of them. Clicking on the importance tag, just leads to a page
> explaining the importance tag.
Yeah, that is a mix of 'too hard to fix' and 'I'm not sure I want to
fix it'. (I don't know how Hakyll works well enough to do it
'normally', and while I think I can just treat it as a tag-directory,
like 'meta/importance/1', 'meta/importance/2' etc, that's a little
awkward.) Do I *want* people to be able to go through a list of
articles sorted by importance and be able to easily mock it - avoiding
any actual substantive critique?
comment by Morpheus · 2024-08-23T17:31:31.428Z · LW(p) · GW(p)
Things I learned that surprised me from a deep dive into how the medication I've been taking for years (Vyvanse) actually gets metabolized:
- It says in the instructions that it works for 13 hours, and my psychiatrist informed me that it has a slow onset of about an hour. What that actually means is that after ~1h you reach 1/2 the peak concentration and after 13 hours you are at 1/2 the peak concentration again, because the half-life is 12h (and someone decided at some point 1/2 is where we decide the exponential starts and ends?). Importantly, this means 1/4 of the medication is still present the next day!

Here is some real data, which fit the simple exponential decay rather well (It's from children though, which metabolize dextroamphetamine faster, which is why the half-life is only ~10h) 
- If you eat ~1-3 grams of baking soda, you can make the amount of medication you lose through urine (usually ~50%) go to 0[1] (don't do this! Your body probably keeps its urine pH at the level it does for a reason! You could get kidney stones).
- I thought the opposite effect (acidic urine gets rid of the medication quickly) explained why my ADHD psychologist had told me that the medication works less well combined with citric fruit, but no! Citric fruit actually increase your urine pH (or mostly don't affect it much)? Probably because of the citric acid cycle which means there's more acid leaving as co2 through your lungs? (I have this from gpt4 and a rough gloss over details checked out when checking Wikipedia, but this could be wrong, I barely remember my chemistry from school)
- Instead, Grapefruit has some ingredients known to inhibit enzymes for several drugs, including dextroamphetamine (I don't understand if this inhibitory effect is actually large enough to be a problem yet though)
- This brings me to another observation: apparently each of these enzymes is used in >10-20% of drugs: (CYP3A4/5, CYP2D6, CYP2C9). Wow! Seems worth learning more about them! CYP2D6 gets actually used twice in the metabolism of dextroamphetamine, once for producing and once for degrading an active metabolite.

Currently still learning more about basics about neurotransmitters from a textbook, and I might write another update once/if at the point where I feel comfortable writing about the effects of dextroamphetamine on signal transmission.
Urinary excretion of methylamphetamine in man (scihub is your friend) ↩︎
↑ comment by keltan · 2024-08-23T21:12:46.749Z · LW(p) · GW(p)
This seems like it will be useful for me in the future.
I’ve been wondering for a while how the long half life of ADHD meds impact sleep. Any data on that?
Replies from: Morpheus↑ comment by Morpheus · 2024-08-23T21:38:23.297Z · LW(p) · GW(p)
There is probably a lot of variation between people regarding that. In my family meds across the board improved people's sleep (by making people less sleepy during the day, so more active and less naps). When I reduced my medication from 70mg to 50mg for a month to test whether I still needed the full dose, the thing that was annoying the most was my sleep (waking up at night and not falling asleep again increased. Falling asleep initially was maybe slightly easier). Taking it too late in the afternoon is really bad for my sleep, though.
Replies from: keltan↑ comment by keltan · 2024-08-23T22:47:03.674Z · LW(p) · GW(p)
That matches with what my psychiatrist told me. I find it surprising how large the variation between individuals can be with these meds.
I have met people who can drink an espresso before bed and it actually helps their sleep. But I find those people to be rare. I see much more variance in amphetamines. My mental data set isn’t large enough to make any sold predictions. But I am unable to point to a clear “most people's sleep is (X)ed by amphetamines”.
Replies from: Morpheus↑ comment by Morpheus · 2024-10-21T19:54:18.499Z · LW(p) · GW(p)
One confounder: depression/mania [LW(p) · GW(p)]. Recently (the last ~two weeks) I have been having bad sleep (waking up 3-7 am and not feeling sleepy anymore (usually I sleep from midnight to 9). My current best guess is that the problem is that my life has been going too well recently, leading to a self-sustaining equilibrium where I have little sleep and mania. Reduced my medication today (~55mg instead of 70mg) which seems to have helped with the mania. I had another day with slight mania 1 month ago when sleeping little in order to travel to a conference, so in the future I'll probably reduce my medication dose on such days. Took a friend describing his symptoms on too much medication for me to realize what is going on.
comment by Morpheus · 2024-09-10T15:34:06.889Z · LW(p) · GW(p)
If legibility of expertise [LW · GW] is a bottleneck to progress and adequacy [LW · GW] of civilization, it seems like creating better benchmarks for knowledge and expertise for humans might be a valuable public good. While that seems difficult for aesthetics, it seems easier for engineering? I'd rather listen to a physics PhD, who gets Thinking Physics [LW(p) · GW(p)] questions right (with good calibration), years into their professional career, than one who doesn't.
One way to do that is to force experts to make forecasts, but this takes a lot of time to hash out and even more time to resolve.
One idea I just had related to this: the same way we use datasets like MMLU and MMMU, etc. to evaluate language models, we use a small dataset like this and then experts are allowed to take the test and performance on the test is always public (and then you make a new test every month or year).
Maybe you also get some participants to do these questions in a quiz show format and put it on YouTube, so the test becomes more popular? I would watch that.
The disadvantage of this method compared to tests people prepare for in academia would be that the data would be quite noisy. On the other hand, this measure could be more robust to goodharting and fraud (although of course this would become a harder problem once someone actually cared about that test). This process would inevitably miss genius hedgehog's of course, but maybe not their ideas, if the generalists can properly evaluate them.
There are also some obvious issues in choosing what kinds of questions one uses as representative.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-09-10T22:40:49.084Z · LW(p) · GW(p)
If you have a best that actually measures expertise in engineering well, it's going to be valuable for those who make hiring decisions.
Triplebyte essentially seems to have found a working business model that is about testing for expertise in programming. If you can do something similar as Triplebyte for other areas of expertise, that might be a good business model.
As far as genius hedgehog's in academia go, currently they find it very hard to get funding for their ideas. If you would replace the current process of having to write a grant proposal with having to take a test to measure expertise, I would expect the diversity of ideas that get researched to increase.
Replies from: bhauth↑ comment by bhauth · 2024-09-10T22:58:30.460Z · LW(p) · GW(p)
Triplebyte? You mean, the software job interviewing company?
-
They had some scandal a while back where they made old profiles public without permission, and some other problems that I read about but can't remember now.
-
They didn't have a better way of measuring engineering expertise, they just did the same leetcode interviews that Google/etc did. They tried to be as similar as possible to existing hiring at multiple companies; the idea wasn't better evaluation but reducing redundant testing. But companies kind of like doing their own testing.
-
They're gone now, acquired by Karat. Which seems to be selling companies a way to make their own leetcode interviews using Triplebyte's system, thus defeating the original point.
comment by Morpheus · 2024-06-09T13:54:16.034Z · LW(p) · GW(p)
Has anyone here investigated before if washing vegetables/fruits is worth it? Until recently I never washed my vegetables, because I classified that as a bullshit value claim [LW · GW].
Intuitively, if I am otherwise also not super hygienic (like washing my hands before eating) it doesn't seem that plausible to me that vegetables are where I am going to get infected from other people having touched the carrots etc... . Being in quarantine during a pandemic might be an exception, but then again I don't know if I am going to get rid of viruses if I am just lazily rinsing them with water in my sink. In general washing vegetables is a trivial inconvenience I'd like to avoid, because it leads me to eat less vegetables/fruits (like raw carrots or apples).
Also I assume a little pesticides and dirt are not that bad (which might be wrong).
Replies from: jmh, lahwran↑ comment by jmh · 2024-06-09T14:53:20.369Z · LW(p) · GW(p)
Cannot say this is a good source, but was a quick on. It does seem to speak to the question you're asking though so might be of interest. Might support the view that the additional produce you eat if not washing could out weigh the costs of the increased pesticide comsumption. But, I suspect that might be a very uncertain conclusion given the potential variability in factors regarding your specific situation -- where are the produce grown (what's in the soil), what pesticides, and what quantity, might be in use, what is the post harvesting process (any washing at all).
The other aspect might be what consumption levels you have with and without washing. I am sure there is a level over which additional intake is adding little value. So if you're still eatting plenty of fresh produce even with the additional effor of washing you probably don't really need the additional nutriants (concentration levels in your body are already sufficient for the needed chemical reactions) but are avoiding things we know are not helpful to human biology.
↑ comment by the gears to ascension (lahwran) · 2024-06-10T13:11:47.149Z · LW(p) · GW(p)
water washing with slight rubbing is likely sufficient to get rid of most of the pesticide imo
Replies from: hypnoscomment by Morpheus · 2024-03-06T06:02:37.254Z · LW(p) · GW(p)
While there is currently a lot of attention on assessing language models, it puzzles me that no one seems to be independently assessing the quality of different search engines and recommender systems. Shouldn't this be easy to do?
The only thing I could find related to this is this Russian site (It might be propaganda from Yandex, as it is listed as the top quality site?). Taking their “overall search quality” rating at face value does seem to support the popular hypothesis that search quality of Google has slightly deteriorated over the last 10 years (although compared to 2009-2012, quality has been basically the same according to this measure).
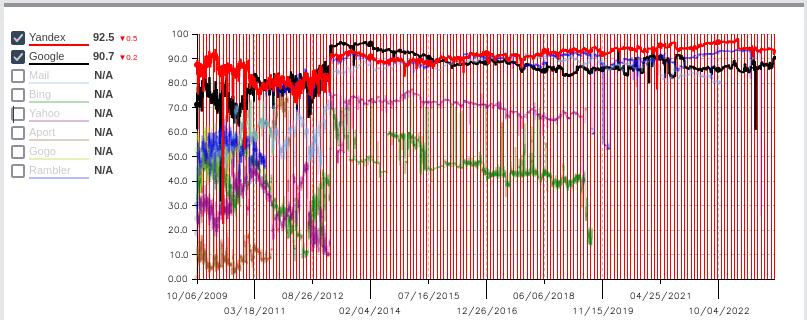
The gpt-4 translated version of their blog states that they gave up actively maintaining this project in 2014, because search engine quality had become reasonable according to them:
For the first time in the history of the project, we have decided to shut down one of the analyzers: SEO pressing as a phenomenon has essentially become a thing of the past, and the results of the analyzer have ceased to be interesting.
Despite the fact that search engine optimization as an industry continues to thrive, search engine developers have made significant progress in combating the clutter of search results with specially promoted commercial results. The progress of search engines is evident to the naked eye, including in the graph of our analyzer over the entire history of measurements:
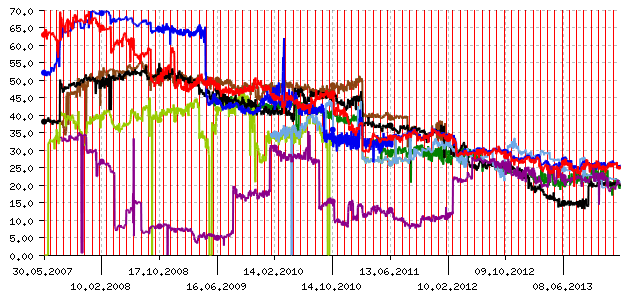
SEO Pressing Analyzer Graph
The result of the analyzer is the share of commercial sites in the search results for queries that do not have a clearly commercial meaning; when there are too many such sites in the search results, it is called susceptibility to SEO pressing. It is easy to see that a few years ago, more than half (sometimes significantly more than half) of the search results from all leading search engines consisted of sites offering specific goods or services. This is, of course, a lot: a query can have different meanings, and the search results should cater to as many of them as possible. At the same time, a level of 2-3 such sites seems decent, since a user who queries "Thailand" might easily be interested in tours to that country, and one who queries "power station" might be interested in power stations for a country home.
If we are worried that current recommender systems are already doing damage [LW(p) · GW(p)] and expect things to get worse in the future, it might be good to actively monitor this to not get frog boiled.
comment by Morpheus · 2024-10-10T11:26:01.050Z · LW(p) · GW(p)
I feel like there should exist a more advanced sequence that explains problems with filtered evidence [? · GW] leading to “confirmation bias” [? · GW]. I think the Luna sequence [? · GW] is already a great step in the right direction. I do feel like there is a lack of the equivalent non-fiction version, that just plainly lays out the issue. Maybe what I am envisioning is just a version of What evidence filtered evidence [LW · GW] with more examples of how to practice this skill (applied to search engines, language models, someone’s own thought process, information [? · GW] actively [LW · GW] hidden from you, rationality in groups etc.).
comment by Morpheus · 2024-03-21T14:27:36.564Z · LW(p) · GW(p)
If I had more time I would have written a shorter letter.
TLDR: I looked into how much it would take to fine-tune gpt-4 to do Fermi estimates better. If you liked the post/paper [LW · GW] on fine-tuning Language models to make predictions you might like reading this. I evaluated gpt-4 on the first dataset I found, but gpt-4 was already making better fermi estimates than the examples in the dataset, so I stopped there (my code).
First problem I encountered: there is no public access to fine-tuning gpt-4 so far. Ok, we might as well just do gpt-3.5 I guess.
First, I found this Fermi estimate dataset. (While doing this, I was thinking I should perhaps search more widely what kind of different AI benchmarks exist, since probably a dataset that is evaluating a similar capability is already out there, but I don't know its name.)
Next I looked at this paper, where people used among other gpt-3.5 and gpt-4 on this benchmark. Clearly these people weren't even trying, though, because gpt-4 does worse than gpt-3.5. One of the main issues I saw was that they were trying to make the LLM output the answer as a program in the domain specific language used in that dataset. They couldn't even get the LLM to output valid programs more than 60% of the time (their metric compares on a log scale, if the answer by the LLM is within 3 orders of magnitude of the real answer. 1 is best 0 is more than 3 orders of magnitude away: fp-score(x) = max(0,1-1/3 * | log_10(prediction/answer)|)).
My conjecture was that just using python instead should give you better results.(This turned out to be true). I get a mean score of ~0.57 on 100 sample problems, so as good results with gpt-4-turbo as they get when they first provide “context” by giving the llm the values for the key variables needed to compute the answer (why would this task even still be hard at all?).
When gpt-4 turned out to get a worse fp-score than gpt-4-turbo on my 10 samples. I got suspicious and after looking at samples gpt-4 got a bad score, it was clear this was mostly to blame on bad quality of the dataset. 2 answers were flat-out not using the correct variables/confused, while gpt-4 was answering correctly. Once, the question didn't make clear what unit to use. 2 of the samples gpt-4 gave a better answer. Once, using a better approach (using geometry instead of wrong figures of how much energy the earth gets from the sun, to determine the fraction of sun energy that the earth receives). Once, by having better numbers, input estimates like how many car miles are driven in total in the US.
So on this dataset, gpt-4 seems to be already at the point of data-saturation. I was actually quite impressed how well it was doing. When I had tried using gpt-4 for this task, I had always felt like it was doing quite badly. One guess I have is this is because when I ask gpt-4 for an estimate, it is often a practical question, which is actually harder than these artificial questions. In addition, the reason I ask gpt-4 is that the question is hard, and I expect to need to employ a lot of cognitive labor to do it myself.
Another data point with respect to this was the “Thinking physics exercises”. Which I tried with some of my friends [LW(p) · GW(p)]. For that task, gpt-4 was better than people who were bad at this, but worse than people who were good at this (and given 5–10 minutes of thinking time) (although I did not rigorously evaluate that). GPT-4 is probably better than most humans at doing Fermi estimates given 10 minutes of time. Especially in domains one is unfamiliar with, since it has so much more breadth.
I would be interested to see what one would get out of actually making a high quality dataset by taking Fermi estimates from people I deem to produce high quality work in that area.
comment by Morpheus · 2023-01-03T16:19:46.612Z · LW(p) · GW(p)
Probably silly
Quantifying uncertainty is great and all, but also exhausting precious mental energy. I am getting quite fond of giving probability ranges instead of point estimates when I want to communicate my uncertainty quickly. For example: “I'll probably (40-80%) show up to the party tonight.” For some reason, translating natural language uncertainty words into probability ranges feels more natural (at least to me) so requires less work for the writer.
If the difference is important, the other person can ask, but it still seems better than just saying 'probably'.
Replies from: Dagon, Morpheus↑ comment by Dagon · 2023-01-04T23:20:13.873Z · LW(p) · GW(p)
Interesting. For me, thinking/saying "about 60%" is less mental load and feels more natural than "40 to 80%". It avoids the rabbit-hole of what a range of probabilities even means - presumably that implies your probability estimates are normal around 60% with a standard deviation of 20%, or something.
Is there anything your communication recipient would do differently with a range than a point estimate? presumably they care about the resolution of the event (will you attend) rather than the resolution of the "correct" probability estimate.
There's a place for "no", "probably not", "maybe", "I hope to", "probably", "I think so", "almost certainly", and "yes" as a somewhat ambiguous estimate as well, but that's a separate discussion.
Replies from: Morpheus↑ comment by Morpheus · 2023-01-05T13:47:59.463Z · LW(p) · GW(p)
Agree that the meaning of the ranges is very ill-defined. I think I am most often drawn to this when I have a few different heuristics that seem applicable. Example of internals: One is just how likely this feels when I query one of my predictive engines and another is just some very crude "outside view"/eyeballed statistic that estimates how well I did on this in the past. Weighing these against each other causes lots of cognitive dissonance for me, so I don't like doing it.
↑ comment by Morpheus · 2024-09-17T13:59:53.306Z · LW(p) · GW(p)
I think from the perspective of a radical probabilist, it is very natural to not only have a word of where your current point estimate is at, but also have some tagging for the words indicating how much computation went into it or if this estimate already tries to take the listeners model into account also?
comment by Morpheus · 2022-09-23T13:17:09.090Z · LW(p) · GW(p)
I am not sure how much this was a problem, but I felt like listening more to pop music on Spotify slowly led to value drift [LW · GW], because so many songs are about love and partying.
I felt a stronger desire to invest more time to fix the fact that I am single. I do not actually endorse that on reflection. The best solution I've found so far is starting to listen to music in languages I don't understand, which works great!
Replies from: yitz↑ comment by Yitz (yitz) · 2022-09-23T14:53:28.420Z · LW(p) · GW(p)
I hope the fact I like listening to songs where the singer role-plays as a supervillain isn’t affecting me that way lol
comment by Morpheus · 2024-10-01T11:12:33.483Z · LW(p) · GW(p)
Hypothesis based on the fact that status is a strong drive and people who are on the outer ends of that spectrum get classified as having a "personality disorder" and are going to be very resistant to therapy:
- weak-status-fear==psychopathy: psychopathy is caused by the loop leading to fear of loosing status, being less strong than average or possibly broken. (psychopathy is Probably on a spectrum. I don't see a reason why little of this feeling would be less optimal than none.)
- strong-status-fear==(?histrionic personality disorder)
- weak-status-seeking-loop==(?schizoid personality disorder)
- strong-status-seeking-loop==(?narcissism)
Was thinking about Steven Byrnes agenda to figure out social drives [? · GW] and what makes a psychopath a psychopath. One clearly existing social drive that seemed to be a thing was “status-seeking” and “status-fear” (fear of loosing status). Both of these could themselves be made of several drives? The idea that status-seeking and status-fear are different came to me when trying to think of the simplest hypothesis explaining psychopathy and from introspecting that both of these feelings feel very different to me and distinct from other fears. These two could be made more mostly separate loops, but I can't complicate my fake framework even more just yet.
If someone is interested, I'd write a post how to stress test this fake-framework and what I'd expect in the world where it is true or isn't (Most interesting would be social drives that are distinct from the above? Or maybe they use some of the same sub-circuitry? Like jealousy seems obviously like it would fit under strong status fear, so histrionic personality would go with being more jealous)
Replies from: Morpheuscomment by Morpheus · 2024-04-20T12:03:19.745Z · LW(p) · GW(p)
Can anyone here recommend particular tools to practice grammar? Or with strong opinions on the best workflow/tool to correct grammar on the fly? I already know Grammarly and LanguageTool, but Grammarly seems steep at $30 per month when I don’t know if it is any good. I have tried GPT-4 before, but the main problems I have there, is that it is too slow and changes my sentences more than I would like (I tried to make it do that less through prompting, which did not help that much).
I notice that feeling unconfident about my grammar/punctuation leads me to write less online, especially applying for jobs or fellowships, feels more icky because of it. That seems like an avoidable failure mode.
Ideally, I would like something like the German Orthografietrainer (It was created to teach middle and high school children spelling and grammar). It teaches you on a sentence by sentence basis where to put the commas and why by explaining the sentence structure (Illustrated through additional examples). Because it trains you with particularly tricky sentences, the training is effective, and I rapidly got better at punctuation than my parents within ~3 hours. Is there a similar tool for English that I have never heard of?
While writing this, I noticed that I did not have the free version of Grammarly enabled anymore and tried the free version while writing this. One trick I noticed is that it lists what kinds of error you are making across the whole text. So it is easy to infer what particular mistake I made in which spot, and then I correct it myself. Also, Grammarly did not catch a few simple spelling and punctuation mistakes that Grammarly caught (like “anymore” or the comma at the start of this sentence.). At the end, I also tried ProWritingAid, which found additional issues.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-04-25T01:19:50.204Z · LW(p) · GW(p)
Practicing grammar and correcting grammar on the fly seem to be two different things.
If you want to improve, then I would prompt GPT-4 with something like "I'm a student looking to improve my writing and grammar ability, here's an essay I wrote. Given that writing, please teach me about grammar."
comment by Morpheus · 2024-03-04T04:56:36.394Z · LW(p) · GW(p)
Metaculus recently updated the way they score user predictions. For anyone who used to be active on Metaculus and hasn't logged on for a while, I recommend checking out your peer and baseline accuracy scores in the past years. With the new scoring system, you can finally determine whether your predictions were any good compared to the community median. This makes me actually consider using it again instead of Manifold.
By the way, if you are new to forecasting and want to become better, I would recommend past-casting and/or calibration games instead, because of the faster feedback loops. Instead of within weeks, you'll know within 1–2 hours whether you tend to be overconfident or underconfident.
comment by Morpheus · 2025-04-14T07:28:11.271Z · LW(p) · GW(p)
Not sure what's going on, but gpt-4o keeps using its search tool when it shouldn't and telling me about either the weather, or sonic the hedgehog. I couldn't find anything about this online. Are funny things like this happening to anyone else? I checked both my custom instructions and the memory items and nothing there mentions either of these.
comment by Morpheus · 2023-09-16T19:52:30.604Z · LW(p) · GW(p)
Epistemic Status: Anecdote
Two weeks ago, I’ve been dissatisfied with the amount of workouts I do. When I considered how to solve the issue, my brain generated the excuse that while I like running [LW · GW] outside, I really don’t like doing workouts with my dumbbells in my room even though that would be a more intense and therefore more useful workout. Somehow I ended up actually thinking [LW · GW] and asked myself why I don’t just take the dumbbells with me outside. Which was of course met by resistance because it looks weird. It’s even worse! I don’t know how to “properly” do curls or whatnot, and other people would judge me on that. I noticed that I don’t actually care that much about people in my dorm judging me. These weirdness points have low cost. In addition, this muscle of rebellion [LW · GW] seems useful to train, as I suspect it to be one of the bottlenecks that hinders me from writing posts like this one.
comment by Morpheus · 2022-09-17T06:35:47.876Z · LW(p) · GW(p)
I was just thinking that there is actually a way to justify using occams razor, because by using it, you will always converge on the true hypothesis in the limit of accumulating evidence. Not sure if I've seen this somewhere else before, or if I gigabrained myself into some nonsense:
Let's say the true world is some finite state machine M'∈M with the input alphabet {1} and the output alphabet {0,1}. Now I feed into this an infinite sequence of 1s. If I use a uniform prior over all possible finite state automatons, then at any step of observing the output, there will be a countably infinite number of machines that explain my observation, so my prior and posterior will always be flat and never converge. Now I use as my prior,m∈M f: M -> R, m->2^(|m|+1) where |m| is the number of states after which m repeats (I will view different automatons that always produce the same output as the same). If I use this prior, then M' will be my top hypothesis after observing |M'| + 1 bits and will just rise in confidence after that. Since we used finite state automatons, we avoid the whole computability business, but my intuition would be that you could make the argument go through with Turing machines, it would have to become way more subtle though.
Replies from: Morpheus↑ comment by Morpheus · 2022-09-17T11:54:11.491Z · LW(p) · GW(p)
I rechecked Hutter on induction https://arxiv.org/pdf/1105.5721.pdf and the convergence stuff seems to be already known. Going to recheck logical induction. I think maybe Occam's razor is actually hard to justify. What is easier justify is using a prior that will actually converge, if there is any explanation at all (your observations aren't random noise)
Replies from: Morpheuscomment by Morpheus · 2022-09-10T21:40:19.464Z · LW(p) · GW(p)
I like the agreement voting feature for comments! Not only does it change incentives/signals people receive, I also notice how looking at whether to press this button I am more often actually asking myself whether I actually just endorse a comment or whether I actually belief it. Which seems great. I do feel the added time considering to press a button costly, but for this particular one that seems more like a feature than a bug.
Replies from: Morpheus↑ comment by Morpheus · 2022-09-10T22:02:41.748Z · LW(p) · GW(p)
I also notice my disappointment that this is not possible for shortforms... yet?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2022-09-11T02:58:03.530Z · LW(p) · GW(p)
The feature works for newer posts created after it was released, including newer shortforms [LW(p) · GW(p)]. If multiple posts could take on the role [LW · GW] of shortform repositories, agreement voting would work for the newer ones.
Replies from: Raemoncomment by Morpheus · 2020-08-07T22:35:58.694Z · LW(p) · GW(p)
Summary: I have updated on being more conscientious than I thought.
Since most of the advice on 80.000 hours is aimed at high performing college students, I find it difficult how much this advice should apply to myself, who just graduated from high school. Previously I had thought of myself as talented in math (I was the best in my class with 40 students, since first grade), but mid- to below average in conscientiousness. I also feel slightly ashamed of my (hand-)writing: most of my teachers commented that my texts were too short and my writing is not exactly pretty. I was diagnosed with ADHD with eleven and even with medication, my working memory is pretty bad. Even though I have started to develop strategies to cope with my disabilities, I wasn't sure how I was doing compared to those classmates that performed better in writing. So I just assumed that they must be way more productive. Recently I thought it would be interesting to try to predict my final grades by predicting the grades for every subject using Guesstimate (Unfortunately I later put in the grades I got in the end without saving my initial model. If someone is interested I can try to recreate it). This proved to be more useful then I thought: It was a major update for me being more productive and conscientious compared to the rest of my class.
- Together with another student, I got the highest grades in German (my native tongue) in my final exam (13 out of 15 points), because I practiced writing (Exams).
- I think I would not have realized that I had false assumptions about my performance if I had not seen the difference (There were 3-4 additional students in my class who I thought would be better than me in the final exam) between my prediction and the outcome.
- It is not like I was bad before in German, but I attributed a lot of the credit to my teacher liking me. Since a second teacher graded my final exam, this effect shouldn't be as great.
↑ comment by Viliam · 2020-08-15T17:04:57.591Z · LW(p) · GW(p)
even with medication, my working memory is pretty bad
To say the obvious [LW · GW]: make notes about what you learn. (I am not recommending any specific note-taking method here, only the general advice that a mediocre system you actually start using today is better than a hypothetically perfect system you only dream about.) It really sucks to spend a lot of time and work learning something, then not using it for a few years, then finding out you actually forgot everything.
This usually doesn't happen at high school, because the elementary and high school education is designed as a spiral (you learn something, then four years later you learn the more advanced version of the thing). But at university: you may learn a thing once, and maybe never again.
I was the best in my class with 40 students
How much this means, you will only find out later, because it depends a lot on your specific school and classmates. I mean, it definitely means that you are good... but is it 1:100 good or 1:1000000 good? At high school both are impressive, but in later life you are going to compete against people who often also were the best in their classes.
Replies from: Morpheus↑ comment by Morpheus · 2021-11-03T14:15:50.503Z · LW(p) · GW(p)
I mean, it definitely means that you are good... but is it 1:100 good or 1:1000000 good? At high school both are impressive, but in later life you are going to compete against people who often also were the best in their classes.
Update after a year: I am currently studying CS and I feel like I got kind of spoiled by reading "How to be a straight A student" which was mostly aimed at us-college students, and it was kind of hard to sort out which kinds of advice would apply in Germany and made the whole thing seem easier than it actually is. I am doing ok, but my grades aren't great (my best guess is that in pure grit+IQ I'm somewhere in the upper 40%). In the end, I decided that the value of this information wasn't so great after all, and now I am focusing more on how to actually gain career capital and getting better at prioritizing on a day-to-day basis.
comment by Morpheus · 2024-08-29T12:13:16.479Z · LW(p) · GW(p)
The recent post on reliability and automation [LW(p) · GW(p)] reminded me that my "textexpansion" tool Espanso is not reliable enough on Linux (Ubuntu, Gnome, X11). Anyone here using reliable alternatives?
I've been using Espanso for a while now, but its text expansions miss characters too often, which is worse than useless. I fiddled with Espanso's settings just now and set the backend to Clipboard, which seems to help with that, but it still has bugs like the special characters remaining ("@my_email_shorthand" -> "@myemail@gmail.com").
comment by Morpheus · 2024-07-01T10:28:58.114Z · LW(p) · GW(p)
I noticed some time ago there is a big overlap between lines of hope mentioned in Garret Baker's post [LW · GW] and lines of hope I already had. The remaining things he mentions are lines of hope that I at least can't antipredict [? · GW] which is rare. It's currently the top plan/model of Alignment that I would want to read a critique of (to destroy or strengthen my hopes). Since no one else seems to have written that critique yet I might write a post myself (Leave a comment if you'd be interested to review a draft or have feedback on the points below).
- if singular learning theory is roughly correct in explaining confusing phenomena about neural nets (double descent, grokking), then the things confusing about these architectures are pretty straightforward implications from probability theory (Implying we might expect fewer diffs in priors between humans and neural nets because biases are less architecture dependent).
- the idea of whether something like "reinforcing shards" can be stable if your internals are part of the context during training even if you don't have perfect interpretability [LW · GW]
- The idea that maybe the two ideas above can stack [LW · GW]? If for both humans and AI training data is the most crucial, then perhaps we can develop methods comparing human brains and AI. If we get to the point of being able to do this in detail (big If, especially on the neuroscience side this seems possibly hopeless?), then we could get further guarantees that the AI we are training is not a "psychopath".
Quite possibly further reflection feedback would change my mind and counterarguments/feedback would be appreciated. I am quite worried about motivated reasoning to think this plan is better than I think because it would give me something tractable to work on. Also to which extent people planning to work on methods that should be robust enough to survive a sharp left turn are pessimistic about lines of research like this only because of the capability externalities. I have a hard time evaluating the capability externalities of publishing research on plans like the above. If someone is interested in writing a post about this or reading it feel free to leave a comment.
comment by Morpheus · 2023-08-20T21:00:09.988Z · LW(p) · GW(p)
Testing a claim from the lesswrong_editor tag [? · GW] about the spoiler feature: first trying ">!":
! This should be hidden
Apparently markdown does not support ">!" for spoiler tags. now ":::spoiler ... :::"
It's hidden!
works.
comment by Morpheus · 2023-08-15T12:50:07.850Z · LW(p) · GW(p)
Inspired by John's post on How To Make Prediction Markets Useful For Alignment Work [LW · GW] I made two markets (see below):
I feel like there are pretty important predictions to be made around things like whether the current funding situation is going to continue as it is. It seems hard to tell, though what kind of question to ask that provides someone more value, than just reading something like the recent post on what the marginal LTFF grant looks like [EA · GW].
comment by Morpheus · 2022-12-15T14:44:40.434Z · LW(p) · GW(p)
Has someone bothered moving the content on Arbital into a format where it is (more easily) accessible? By now I figured out that and where you can see all math and ai-alignment related content, but I only found that by accident, when Arbitals main page actually managed to load not like the other 5 times I clicked on its icon. I had already assumed it was nonexistent, but it's just slow as hell.
Replies from: Vladimir_Nesov, johannes-c-mayer↑ comment by Vladimir_Nesov · 2022-12-15T23:15:04.489Z · LW(p) · GW(p)
It mostly works lately (after a months/years period of mostly not working), but the greaterwrong viewer seems more reliable.
Replies from: Morpheus↑ comment by Johannes C. Mayer (johannes-c-mayer) · 2022-12-15T16:40:19.239Z · LW(p) · GW(p)
Would this not be better as a Question post?
comment by Morpheus · 2022-10-10T11:54:59.636Z · LW(p) · GW(p)
I wonder if you could exploit instrumental convergence for IRL. For example, with humans that we lack information about, we would still guess that money would probably help them. In some sense, most of the work is probably done by the assumption that the human is rational.
comment by Morpheus · 2022-09-26T16:07:56.333Z · LW(p) · GW(p)
Epistemic status: Speculation
"Everyone" is misinterpreting the implications of the original "no-free-lunch theorems". Stuart Armstrong is misinterpreting [LW · GW] the implications of his no-free-lunch theorems for value learning.
The original no-free-lunch theorems show, that if you use a terrible prior over your hypothesis, then it will not converge/learning is impossible. In practice, this is not important, because we always make the assumption that learning is possible. We call these priors "simplicity priors", but the actually important bit about these is not the simplicity, but that they "work"(that they converge). Now, Stuart says that using a simplicity prior is not enough to make value learning converge, and thus we must use additional assumptions (taken from human knowledge). Maybe I am reading into it, but the implied problem is telling what kind of assumptions might just be a product of our cultural upbringing or our evolutionary tuning, and it would be hard to say what to judge these values by. But this is wrong! I think the value assumptions shouldn't have a different status from the "simplicity prior" ones. If his theorem should also apply to humans, then humans would never have been able to learn values. What we must include in our prior is not some knowledge that humans acquired over their environment, but a kind of prior that humans already have before they get any inputs!
comment by Morpheus · 2022-02-09T15:16:03.432Z · LW(p) · GW(p)
While reading p vs. np for dummies recently, I was really intrigued by Scott's probabilistic reasoning about math questions. It occurred to me that of all science areas, math seems like a really fruitful area for betting markets, because compared to areas like psychology where you have to argue with people what results of studies actually mean, it seems mathematicians are better at getting at a consensus (it could potentially also help to uncover areas where this is not the case?) I also just remembered that There are a few math-related questions on Metaculus, but their aggregation method seemed badly suited for math questions (changed my mind after thinking of considerations below), because I'd expect thinking more about the question to have more payoff in this area, so it seems desirable for people to be able to stake more money.
So why are there no betting markets for math conjectures? Why would it be a bad idea? Some ideas:
- The cutting edge is hard to understand and probably also not the most useful stuff. Results that are actually uncertain take a long time for lay people to understand.
- Results that haven't been solved for a long time, on the other hand, probably will continue to do so for a long time. This is an issue because it skews prices and incentives in ways that lead to "wrong" prices. I won't bother correcting the price for p!=np if it is not significantly off, if I can make more money by just investing it.
- In Math you can always ask more arbitrary questions and most of them would never be resolved, because no one bothers with them. (It would be hard to keep only relevant questions)
- The intuition behind the math problems and the ideas behind the proofs are the things people are actually interested in. When someone makes a conjecture, the intuition that led her to it is actually the interesting bit. Pure probabilities are bad for transferring these intuitions.
comment by Morpheus · 2022-12-14T08:49:49.032Z · LW(p) · GW(p)
“Causality is part of the map, not the territory”. I think I had already internalized that this is true for probabilities, but not for “causality”, a concept that I don't have a solid grasp on yet. This should be sort of obvious. It's probably written somewhere in the sequences. But not realizing this made me very confused when thinking about causality in a deterministic setting after reading the post on finite factored sets in pictures [LW · GW] (causality doesn't seem to make sense in a deterministic setting). Thanks to Lucius [LW · GW] for making me realize this.
Replies from: TAG↑ comment by TAG · 2022-12-14T14:29:20.573Z · LW(p) · GW(p)
There isnt any strong reason to believe either "probability is in the map" or "causation is in the map", mainly because there aren't good reasons to believe it's a dichotomy.
Replies from: Morpheus↑ comment by Morpheus · 2022-12-14T15:07:30.128Z · LW(p) · GW(p)
Hm… maybe? Do you have a specific example, or links you have in mind when you say this? I am still having trouble wrapping my head around this and plan think more about it.
Replies from: TAG↑ comment by TAG · 2022-12-14T15:16:27.950Z · LW(p) · GW(p)
if you didn't get the idea from https://www.lesswrong.com/posts/f6ZLxEWaankRZ2Crv/probability-is-in-the-mind [LW · GW] ...where did you get it from?
Replies from: Morpheus↑ comment by Morpheus · 2022-12-14T15:35:35.928Z · LW(p) · GW(p)
Yeah, I know, that post. I give Jaynes most of the credit for further corrupting me. Was mostly hoping for good links for how to think about causality. Something pointing towards the solution to the problems mentioned in this post [LW · GW]. I kinda skimmed "The book of why", but did not feel like I really understood the motivation behind do-calculus. I still don't really understand the justification between saying that xyz are random variables. It seems like saying "these observations should all be bagged into the same variable X" is already doing huge legwork in terms of what is able to cause what. I kinda wonder whether you could do a thing similar to implications in logic where you say, "assuming we put these observations all in the same bag, that implies this bag causes this other bag to have a slightly different composition", but say we bag them a bit differently, and causation looks different.
Replies from: TAG↑ comment by TAG · 2022-12-14T18:16:44.336Z · LW(p) · GW(p)
Well, I responded to That Post, and you can tell it was good , because it was downvoted.
Do you read the comments?
Do you read non-rationalsphere material? It's not like the topic hasn't been extensively written about
Its likely that mainstream won't tell you The Answer, but if there isn't an answer, you should wish to believe there is not an answer. You should not force yourself to "internalise" an answer you can't personally understand, and that has objections to it.
Replies from: Morpheus↑ comment by Morpheus · 2022-12-14T19:16:02.184Z · LW(p) · GW(p)
Do you read the comments?
Wups...that might be a bug to fix. My excuse might be that I read the post before you made the comment, but I am not sure if that is true.
Its likely that it won't tell you The Answer, but if there isn't an answer, you should wish to believe there is not an answer. You should not force yourself to "internalise" an answer you can't perosnally understand, and that has objections to it.
I think you are definitely pointing out a failure mode I've fallen into recently, a few times. But mostly I am not sure if I understood what you mean. I also think my original comment failed to communicate how my views have actually shifted, which is mostly that after fidling with binary strings a bit and trying to figure out how I would model any causal chains in that, I noticed that the simple way I wanted to do that didn't work and my naive notion for how causes work broke down. I now think, when you have a system that is fully deterministic and that in such worlds "probabilistic causality" is a property of maps of such agents, but mostly I am still very confused. I don't actually have anything that I would call solution actually.
Replies from: TAG↑ comment by TAG · 2022-12-14T20:19:39.535Z · LW(p) · GW(p)
I made the comment over a year ago ... and the question was whether you read the comments in general.
It should be obvious that if the territory is deterministic, the only remaining place for possibilities/probabilities to reside is in the map/mind. But it isn't at all obvious that the territory is deterministic.
Replies from: Morpheus↑ comment by Morpheus · 2022-12-14T20:34:05.328Z · LW(p) · GW(p)
I often do read the comments, though I don't really read that intentionally, so I don't have a good estimate of how often I read comments or how many I read (probably read most comments if I find the topic interesting, and I feel like the points in the post wasn't obvious before I read it). I scroll through the "Recent discussion" stuff almost never. So I miss a lot of comments if I read a post early on and then people make comments later that I never see.
Replies from: TAG↑ comment by TAG · 2022-12-14T21:12:54.764Z · LW(p) · GW(p)
The point is that there is often a good counterargument to whatever is being asserted in a post. Sometimes it's in a comment to the post itself -- which is easy and convenient-- and sometimes it's on another website,.or in a book. Either way,.rationality does not consist of forcing yourself to adopt a list of "correct" beliefs.