[Intuitive self-models] 3. The Homunculus
post by Steven Byrnes (steve2152) · 2024-10-02T15:20:18.394Z · LW · GW · 38 commentsContents
3.1 Post summary / Table of contents 3.2 “The Conventional Intuitive Self-Model” 3.3 The “vitalistic force” intuition 3.3.1 What is the “vitalistic force” intuition? 3.3.2 “Vitalistic force” is built from the interoceptive feeling of surprise (i.e. physiological arousal + prediction error), but is different from that feeling 3.3.3 The “vitalistic force” intuition does not veridically correspond to anything at all 3.3.4 The “wanting” intuition 3.3.5 The intuition that “vitalistic force” and “wanting” seem to be present inside the brain algorithm itself 3.3.6 The “vitalistic force” intuition contributes to bad takes about free will and artificial general intelligence 3.4 The homunculus in contexts 3.4.1 The homunculus, in the context of knowledge and assessments 3.4.2 The homunculus, in the context of “self” 3.4.3 The homunculus, in the context of technical neuroscience research 3.5 What does the homunculus want? 3.5.1 The homunculus centrally “wants” and “causes” X’s for which S(X) has positive valence 3.5.2 An edge case: impulsive planning 3.5.3 “I seek goals” versus “my goals are the things that I find myself seeking” 3.5.4 Why are ego-dystonic things “externalized”? 3.6 The homunculus concept does not veridically correspond to anything at all 3.7 Where does it feel like the homunculus is located? 3.7.1 Some people and cultures have a homunculus outside their head 3.7.2 Mistaken intuition: “When I intuitively feel like the homunculus is in my head, I’m just directly feeling where my brain is” 3.7.3 Mistaken intuition: “When I intuitively feel like the homunculus is in my head, I’m just feeling where my eyes see from, and my ears hear from”[16] 3.7.4 So how does the homunculus wind up in a particular location? 3.7.5 By the way, where is “awareness”? 3.8 Conclusion None 38 comments
3.1 Post summary / Table of contents
Part of the Intuitive Self-Models series [? · GW].
So far in the series, Post 1 [LW · GW] established some foundations about intuitive self-models in general, and then Post 2 [LW · GW] talked about the specific intuitive self-model concept “conscious awareness”.
Now we’re ready to meet the protagonist starring in (most people’s) intuitive self-models—the mental concept that is conceptualized as being the root cause of many important mental events, especially those associated with “free will”. It’s the intender of intentions! It’s the decider of decisions! It’s the will-er of willing!
Following Dennett, I call this concept: “the homunculus”.[1]

If you’re still not sure what I’m talking about, here are a couple more pointers:
- If “I exercise my free will to do X”, then, in my intuitive self-model, X was caused by the homunculus. By contrast, “reflexive” actions (“acting on instinct”, “blurting something out”, etc.) are usually conceptualized as not being caused by the homunculus—notwithstanding the fact that they are caused by the brain in real life.
- The terms “my self”, “my mind”, and “I” / “me” generally include the homunculus, but are often broader than that. For example, in the sentence “I don’t know what I’m doing”, the first “I” refers mainly to the homunculus, and the second “I” refers to the broader notion of my brain and body.
I’ll argue that you are already familiar with “the homunculus” as a pre-theoretical intuition. By the time we’re done with this post, “the homunculus” will still be a pre-theoretical intuition—that’s just what it is!—but hopefully it will be a pre-theoretical intuition that you’ll be better equipped to identify, understand, and question.
Here’s the post outline:
- Section 3.2 explains why I said “most people’s intuitive self-models” instead of “everyone’s intuitive self-models” at the top of the post. For example, in Dissociative Identity Disorder (Post 5) [LW · GW], there’s more than one homunculus concept! And in “awakening” (Post 6) [LW · GW], the homunculus concept just disappears entirely! But in this post, we’re restricting attention to what I call the “Conventional Intuitive Self-Model”, which is the intuitive self-model that the vast majority of my readers have in their heads right now.
- Section 3.3 describes a property of our intuitive worlds that I call “vitalistic force”. As background, sometimes we treat our own feelings as intrinsic properties of things out there in the world—Arthur is handsome, Birthdays are exciting, Capitalism is bad, etc. When we apply that general principle to “the feeling of being surprised”, we get an intuition that objects can be intrinsically unpredictable. And that’s what I call “vitalistic force”. We intuitively ascribe “vitalistic force” (and the closely-related intuitive model of “wanting”) to live animals, to other people, and most importantly for our purposes, to the homunculus. Vitalistic force is an intuition in the “map”, but I’ll argue that it does not veridically (§1.3.2 [? · GW]) correspond to anything at all in the “territory”; I’ll suggest that this is the root cause of many bad takes on free will and artificial intelligence.
- Section 3.4 elaborates on what the “homunculus” concept is and isn’t, by putting it in the context of our knowledge and assessments, and in the context of our broader concept of “self”, and in the context of technical neuroscience research.
- Section 3.5 asks “what does the homunculus want”? I argue that it most centrally “wants” concepts X such that the self-reflective S(X) concept (see §2.2.3 [LW · GW]) has positive valence; this turns out to be related to brainstorming and planning how to make X happen. Relatedly, I explain why our ego-syntonic motivations tend to be “internalized” as “desires”, while our ego-dystonic motivations are “externalized” as “urges”.
- Section 3.6 argues for the counterintuitive claim that the homunculus, just like vitalistic force, does not veridically correspond to anything at all—which explains how different intuitive self-models can wildly modify the homunculus concept, or even do away with it altogether, as we’ll see in future posts.
- Section 3.7 delves into one particularly interesting aspect of the homunculus concept, and one which will come up again in future posts: the location of the homunculus. For the vast majority of people reading this post, you feel like when the homunculus does things, those things happen in your head. But interestingly, this is not universal. I’ll talk about why the homunculus has a location at all, and how it winds up in the head (in my culture), and also how it winds up not in the head in other cases.
3.2 “The Conventional Intuitive Self-Model”
If you read mainstream philosophical discourse on consciousness, free will, and so on, it’s overwhelmingly written by people with a generally similar intuitive self-model,[2] and that’s the one I want to discuss in this post. I don’t know if it already has a name, so I’m naming it “The Conventional Intuitive Self-Model”.
It does include things like “consciousness”, “qualia”, and a unified “self” with “free will”. It does not include experiences like trance, or dissociation, or awakening, or hearing voices (the next four posts respectively), nor does it include (I presume) any of a zillion uncatalogued idiosyncrasies in people’s inner worlds.
The word “conventional” is not meant to indicate approval or disapproval (see §1.3.3 [? · GW]). It’s just the one that’s most common in my own culture. If you believe Julian Jaynes (a big “if”!—more on Jaynes in Post 7 [LW · GW]), the Conventional Intuitive Self-Model was rare-to-nonexistent before 1300–800 BC, at least in the Near East, until it gradually developed via cultural evolution and spread. And still today, there are plenty of cultures and subcultures where the Conventional Intuitive Self-Model is not in fact very conventional—e.g. a (self-described) anthropologist on reddit[3] writes: “I work with Haitian Vodou practitioners where spirit possession, signs, hearing voices, seeing things, dreaming, card reading, etc. are all integral parts of their everyday lived reality. Hearing the lwa tell you to do something or give you important guidance is as everyday normal as hearing your phone ring…”.
Anyway, this post is limited in scope to The Conventional Self-Model, which I claim has a “homunculus” concept as described below. Then in subsequent posts, we’ll see how, in other intuitive self-models, this “homunculus” concept can be modified or even eliminated.
3.3 The “vitalistic force” intuition
3.3.1 What is the “vitalistic force” intuition?
As discussed in Post 1 [LW · GW], the cortex’s predictive learning algorithm systematically builds generative models that can predict what’s about to happen. Let’s consider three examples:
- (A) How well does the predictive learning algorithm do when you’re manipulating a rock in your hands? Great! After the generative models are built and refined a bit, there are no more surprises left—their predictions are basically perfect.
- (B) How well does the predictive learning algorithm do when you’re interacting with TV static? Also great! In this case, the generative models cannot predict each little random speck, but there’s also no need to—you rapidly stop paying attention to all the little random specks. In other words, the generative models remain agnostic about them; they don’t make any prediction one way or the other. But the generative models do successfully predict the gestalt appearance of the screen. So again, there will eventually be no important surprises left. Victory!
- (C) Finally, how well does the predictive learning algorithm do when you’re interacting with a live mouse? Not so good! Unlike the TV static, you’re probably drawn to pay attention to the motion of the mouse, rather than zoning it out. And unlike a rock, there’s no way to predict that motion in detail. It’s a never-ending fountain of surprise. The best the generative models can do is learn typical mouse behavior patterns, and expect to always be a bit surprised.
I think this last pattern—a prediction that something is inherently a source of continual important but unpredictable behavior—turns into its own generalized intuitive model that we might label “vitalistic force”[4]. (Other related terms include “animated-ness” as opposed to “inanimate”, and maybe “agency”). Our intuitive models ascribe the “vitalistic force” intuitive property to various things, particularly animals and people, but also to cartoon characters and machines that “seem alive”.
I think the predictive learning algorithm rapidly and reliably invents “vitalistic force” as an ingredient that can go into intuitive models of people and animals. Then when there’s a new stream of important and unpredictable observations, a salient possibility is that it’s caused by or associated with some new agency possessing vitalistic force. For example, the ancient Greeks observed lightning, and attributed it to Zeus.
3.3.2 “Vitalistic force” is built from the interoceptive feeling of surprise (i.e. physiological arousal + prediction error), but is different from that feeling
Again, vitalistic force is rooted in the interoceptive sensation of being surprised—probably some combination of physiological arousal and salient prediction error. But it’s different from that sensation. Vitalistic force is “part of the map” (it’s part of the generative model space in the cortex), whereas actually being surprised is “part of the territory” (it’s one of the sensory inputs that the generative models are built to predict[5]).
Now, suppose my shirt is white. I intuitively think of the whiteness as being a property of the shirt, out in the world, not as a belief about the shirt within my own mind. As another example, valence is an interoceptive sensory input [LW · GW], but it doesn’t seem to be an assessment that exists within my own mind, but rather, a property of things in the world. For example, if whenever I think of capitalism, it calls forth a reaction of positive / negative valence, then I might well say “capitalism is good / bad”, as if the the “goodness” or “badness” were a kind of metaphysical paint[6] that’s painted onto “capitalism” itself. (See: “The (misleading) intuition that valence is an attribute of real-world things” [LW · GW].). Similarly, we say that a joke is funny, that a person is beautiful, that a movie is scary, that a hickey is embarrassing, and so on—each of your interoceptive sensations turns into its own color of metaphysical paint that gets painted onto (your conception of) the world outside yourself. (Cf. “mind projection fallacy” [? · GW].[7])
Back to the case at hand. “Surprisingness” is an interoceptive input in my own brain, but in our intuitive models, it turns into a kind of metaphysical paint that seems to be painted onto things in the world, outside our own brain. And that metaphysical paint is what I call “vitalistic force”.
Now, if my white shirt happens to have a red flashlight shining on it right now, then when I look down at it, my current sensory inputs are more typical of the “red” concept, not white. But I don’t think of my shirt as actually being red. I know it’s still a white shirt. Instead, those red visual inputs are explained away by a different ingredient in my intuitive model of the situation—namely, the red flashlight.
By the same token, it’s entirely possible for me to be actually surprised when looking at the outputs of a complex clockwork contraption that I don’t understand, but to simultaneously model the contraption itself as lacking any “surprisingness” / “vitalistic force” metaphysical paint, within my intuitive model. Instead, the surprising feeling that I feel would be explained away by a different ingredient in my intuitive model of the situation—namely, my own unfamiliarity with all the gears inside the contraption and how they fit together.
I think you can get a sense for what I’m saying by watching those mesmerizing videos of the nanomachines powering a cell (e.g. 1, 2), and then try to envision a worm as an unfathomably complex clockwork contraption of countless tiny nanomachines. That’s a really different intuitive model from how you normally think of a worm, right? It’s got a different “feel”, somehow. I think a big part of that different “feel” is the absence of the “vitalistic force” metaphysical paint in your intuitive model. It feels “inanimate”.
3.3.3 The “vitalistic force” intuition does not veridically correspond to anything at all
As in §1.3.2 [? · GW], “veridical” refers to “map–territory correspondence”. Vitalistic force is in the “map”—our intuitive models of how the world works. Is there some corresponding thing in the territory? Some objective, observer-independent thing that tracks the intuition of vitalistic force?
Nope!
Instead, I’d say:
- Sometimes the most salient and intuitively-plausible model of a situation (from a particular person’s perspective) involves vitalistic force—i.e., things having intrinsic surprising-ness.
- And sometimes the most salient and intuitively-plausible model of a situation does not involve vitalistic force—i.e., nothing present seems to have intrinsic surprising-ness, although there can still be surprises and unpredictability due to other factors like unfamiliarity, limited information, not paying attention, etc.
…And I think that’s all there is to say; this intuitive distinction doesn’t track anything in the real world.[8]
3.3.4 The “wanting” intuition
Related to the “vitalistic force” intuition is the “wanting” intuition. The “wanting” intuition involves a frame “X wants Y”, defined as follows:
- X has vitalistic force—it seems to have an intrinsic property of taking actions that we can’t reliably predict.
- …But we can predict that X’s unpredictable actions will tend to result in Y.
(Related: Demski’s notion of “Vingean agency” [LW · GW].)
For example, if I’m watching someone sip their coffee, I’ll be surprised by their detailed bodily motions as they reach for the mug and bring it to their mouth, but I’ll be less surprised by the fact that they wind up eventually sipping the coffee.
This seems like the kind of general pattern that a predictive learning algorithm should readily learn.
The “wanting” intuition and the “vitalistic force” intuition seem to be closely intertwined, with each strongly implying the other. Presumably this comes out of their observed correlation in the world—for example, the unpredictability of people and animals is associated with both “wanting” and (very mild) physiological arousal; conversely, the unpredictability of TV static and raindrops is associated with neither “wanting” nor physiological arousal.
3.3.5 The intuition that “vitalistic force” and “wanting” seem to be present inside the brain algorithm itself
Let’s say a toddler has already internalized the “vitalistic force” and “wanting” intuitions by observing other humans and animals. Then they observe their own minds.[9] What do they see?
Well, one thing that happens in the mind is: sometimes a thought X becomes active, and has positive valence. This automatically kicks off brainstorming / planning about how to make X happen (see here [LW · GW] & here [LW · GW] for mechanistic details), and if a good plan is found by that process, then X is liable to actually happen. Moreover, we can’t predict what the brainstorming / planning results will be in advance—when those thoughts appear, they will be surprising (as discussed in §1.4.1 [? · GW]).
So we have all the ingredients of “vitalistic force” and “wanting” (§3.3.4 above)—important unpredictability, with an ability to predict certain end-results better than the path by which they actualize. Thus, our intuitive models fit these kinds of observations to the hypothesis that there’s a vitalistic-force-carrying entity in our minds that “wants” X.
After Dennett, I call this entity “the homunculus”.
To be clear, it’s not a hard-and-fast rule that there must be only one vitalistic-force-carrying entity in our intuitive self-model. Rather, it’s an aspect of how I’m defining the Conventional Intuitive Self-Model (CISM, §3.2 above), and I’m restricting this post to the CISM. In fact, even someone mainly in the CISM might occasionally “animate” some non-homunculus aspect of their minds—“my OCD is telling me to buy squirrel repellent, just in case”—and there’s a spectrum of how literal versus metaphorical those kinds of statements feel to the speaker. We’ll see more dramatic departures from CISM in later posts.
More on the homunculus in a bit. But first…
3.3.6 The “vitalistic force” intuition contributes to bad takes about free will and artificial general intelligence
When people ask me my opinion about free will, I immediately launch into a spiel along the following lines:
For the kind of complex algorithm that underlies human decision-making, the only way to reliably figure out what this algorithm will output, is to actually run the algorithm step-by-step and see.[10]
So it’s kinda misleading to say “the laws of physics predict that the person will decide to take action A1”. A better description is: “the laws of physics predict that the person will think it over, ponder their goals and preferences and whims, and then make a decision, and it turns out the decision they made is … [and then we pause and watch as the person takes action A1] … well, I guess it was Action A1”. And if the person had decided A2, then evidently A2 would have been the prediction of the laws of physics! In other words, if the laws of physics were deterministic, that determinism would run through the “execution of free will”; it wouldn’t circumvent it.
…OK, that’s my spiel. I think it’s a nice spiel! But it’s entirely omitting the part of the story that’s most relevant to this series.
Instead let’s ask: Why do people’s intuitions push so hard against the possibility of voluntary decisions being entirely determined by the workings of step-by-step algorithmic mechanisms under the hood? I think it gets to a non-veridical aspect of the intuitive model.
- The intuitive model says that the decisions are caused by the homunculus, and the homunculus is infused with vitalistic force and hence unpredictable. And not just unpredictable as a state of our limited modeling ability, but unpredictable as an intrinsic property of the thing itself—analogous to how it’s very different for something to be “transparent” versus “of unknown color”, or how “a shirt that is red” is very different from “a shirt that appears red in the current lighting conditions”.
- By contrast, as in §3.3.2 above, if you look at a clockwork contraption that you don’t understand, you’ll be surprised by its behavioral outputs, but your intuitive model will say that there’s no “surprisingness” / “vitalistic force” metaphysical paint within the clockwork contraption itself. Instead, the surprise is explained away (in your intuitive model) as arising from your unfamiliarity with the details of the contraption.
So if you’re imagining the vitalistic-force-carrying homunculus, and you’re also simultaneously imagining that there’s a deterministic clockwork contraption under the hood … oops, you can’t. Those model ingredients contradict each other. It’s like trying to imagine a square circle, or a perfectly stationary explosion.
People tend to have a very-deeply-rooted (i.e., very-high-prior-probability) belief in the Conventional Intuitive Self-Model. After all, this model has issued hundreds of millions of correct predictions over their lifetime. Talk about a strong prior! So they’re naturally very resistant to accept any claim that’s incompatible with this intuitive model. And the idea that there is any mechanism under the hood that leads to “decisions”—whether we call that mechanism “the laws of physics”, or “the steps of an algorithm”, or “the dynamics of neurons and synapses”, or anything else—would be in violation of that intuitive model.
(Side note: if you’re wondering what free will actually is, if anything, I’ll leave that to the philosophers—see §1.6.2 [? · GW].)
Relatedly, you’ll sometimes hear things like “AI is just math” as an argument that Artificial General Intelligence (as I define it) [LW · GW] is impossible,[11] i.e. that no AI system will ever be able to do the cool things that human brains can do, like invent new science and technology from scratch, creatively make and execute plans to solve problems, anticipate and preempt roadblocks, collaborate at civilization scale, and so on.
I think part of what’s happening there is that when these people think of humans, they see vitalistic force, and when they think of algorithms running on computer chips, they see an absence of vitalistic force. And it seems to follow that of course the algorithms-on-chips can’t possibly do those above things that human scientists and entrepreneurs do every day. Those things require vitalistic force!
Indeed (these people continue), if you are stupid enough to think AGI is in fact possible, it’s not because you don’t see vitalistic force in human brains (a possibility that doesn’t even cross their minds!), but rather that you do see vitalistic force in AI algorithms. So evidently (from their perspective), you must just not understand how AI works! After all, we can all agree that if you understood every hardware and software component of a chip running an AI algorithm, then you would correctly see that it’s “just” a “mechanism”, free of vitalistic force. Of course, these people don’t realize that a brain, or indeed a global civilization of billions of human brains and bodies and institutions, is “just” a “mechanism”, free of vitalistic force, as well.[12]
3.4 The homunculus in contexts
“Homunculus” means “little person”. It’s part of your intuitive self-model. To better explain what it is and isn’t, here are some points of clarification:
3.4.1 The homunculus, in the context of knowledge and assessments
The homunculus is definitely not the same as “everything in my brain” or “everything in my mind”. To give three examples:
- Ego-syntonic “desires” are conceptualized as being internal to the homunculus, whereas ego-dystonic “urges” are conceptualized as intrusions upon the homunculus from the outside. But in reality, both are part of my brain algorithms.
- A self-reflective explicit belief like “I’m pretty sure that the capital of Burundi is Gitega” would be conceptualized as involving the homunculus; whereas an implicit belief like [implicit expectation that the bedroom doorknob is hard to twist] would be conceptualized as being unrelated to the homunculus, and instead a property of the doorknob itself. But in reality, both kinds of beliefs are part of my brain algorithms.
- Likewise, as mentioned in §3.3.2 above, a self-reflective explicit preference / judgment (“I hate Jo”) would be conceptualized as being internal to the homunculus; whereas an implicit preference / judgment like “Jo sucks” would be conceptualized as being unrelated to the homunculus, and instead a property of Jo herself. But in reality, both kinds of judgments are part of my brain algorithms.
3.4.2 The homunculus, in the context of “self”
The “self” involves a bunch of things:
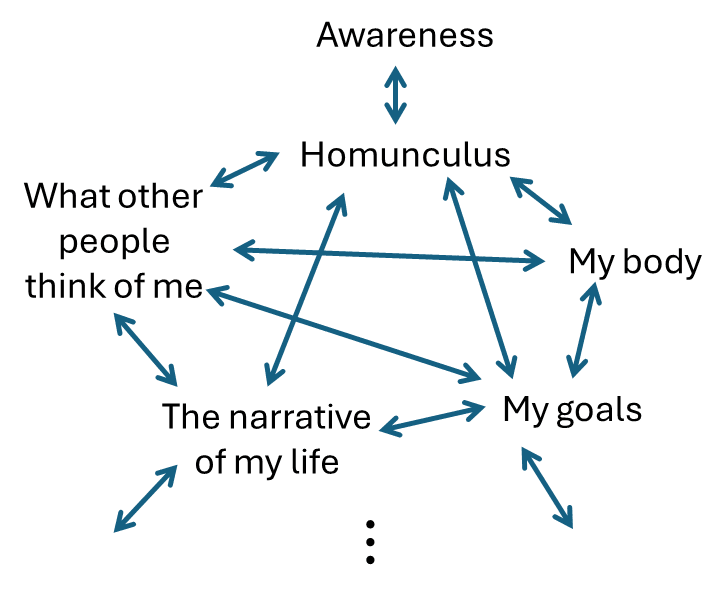
As above, the homunculus is definitionally the thing that carries “vitalistic force”, and that does the “wanting”, and that does any acts that we describe as “acts of free will”. Beyond that, I don’t have strong opinions. Is the homunculus the same as the whole “self”, or is the homunculus only one part of a broader “self”? No opinion. Different people probably conceptualize themselves rather differently anyway.
3.4.3 The homunculus, in the context of technical neuroscience research
I find that the homunculus intuition also comes up in my neuroscience work, almost always for the worse. In particular, if you’re thinking about neuroscience, and if you’re tempted to give the homunculus some important role in how brain algorithms work at a fundamental level, then you’re definitely on the wrong track! The homunculus is one of a zillion learned concepts in the cortex—it’s at the trained model level, not the learning algorithm level (see §1.5.1 [LW · GW])—and thus you should expect the homunculus to have a fundamentally similar kind of role in innate low-level brain algorithms as other learned concepts like “Taylor Swift” or “lithium ion battery”—i.e., a rather incidental role!
One example of how people mess this up is summarized in this handy chart:
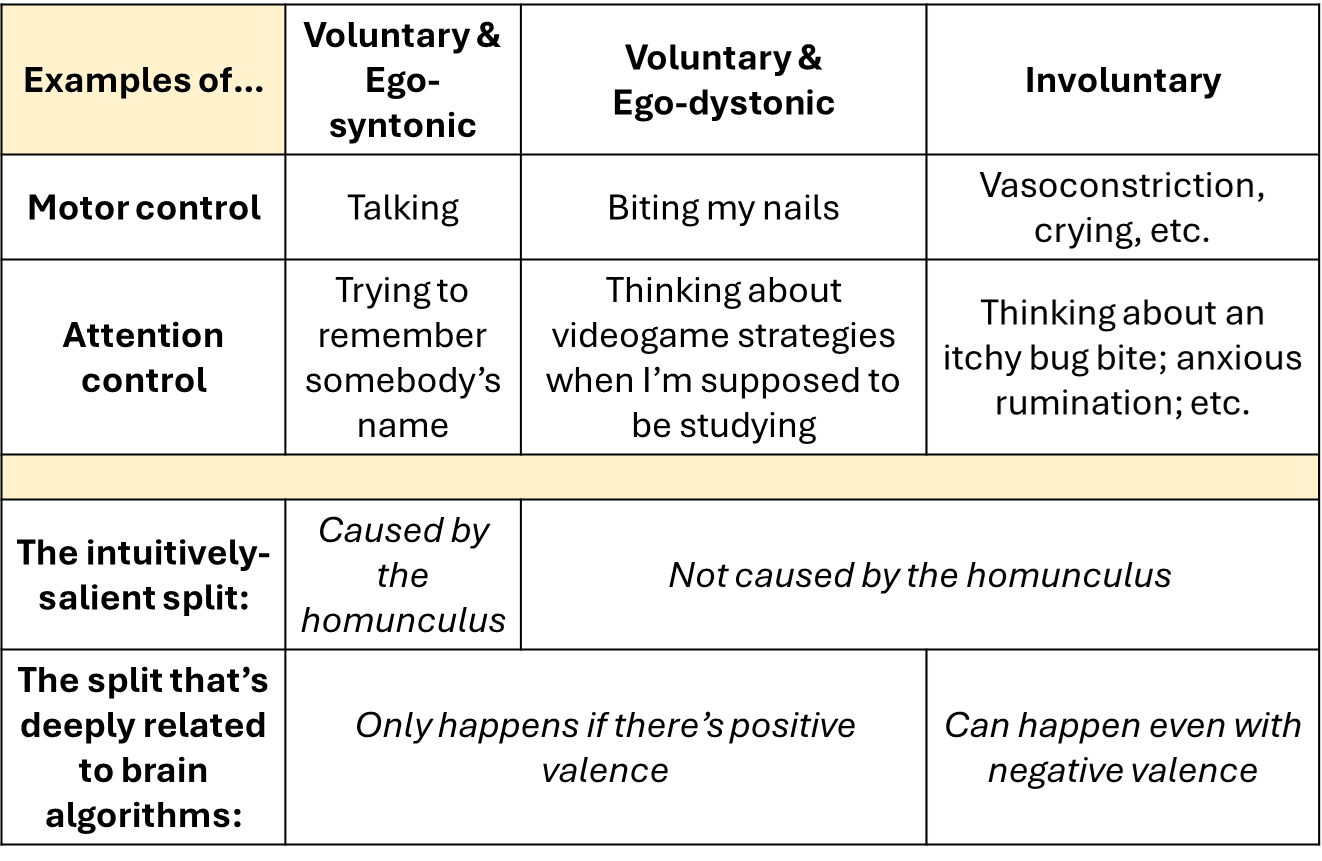
If you’re trying to think carefully about brain algorithms—e.g. you want to reverse-engineer what the cortex does, versus the brainstem, etc.—I claim that the fundamental division in this chart is between involuntary and voluntary actions. This division relates to valence [LW · GW], and is right at the core of the reinforcement learning algorithm built into your brain. But in our homunculus-centric intuitions, we’re instead drawn to incorrectly see the fundamental division as between things that the homunculus causes, versus things the homunculus does not cause.
(Neuroscientists obviously don’t use the term “homunculus”, but when they talk about “top-down versus bottom-up”, I think they’re usually equating “top-down” with “caused by the homunculus” and “bottom-up” with “not caused by the homunculus”.)
Here’s another example: The neuro-AI researcher Jeff Hawkins incorrectly conflates the within-homunculus-versus-outside-homunculus intuitive division, with the cortex-versus-brainstem neuroanatomical division. This error leads him to make flagrantly self-contradictory claims, along with the dangerously incorrect claim that the brain-like AIs he’s trying to develop will have nice prosocial motivations by default. For details see here [LW · GW].
3.5 What does the homunculus want?
3.5.1 The homunculus centrally “wants” and “causes” X’s for which S(X) has positive valence
Back in §2.6 [? · GW], I argued that there’s a common sequence of two thoughts:
- STEP 1: There’s a self-reflective thought S(A), for some action-program A (either motor-control or attention-control), and this thought has positive valence;
- STEP 2 (a fraction of a second later): The non-self-reflective (a.k.a. object-level) thought A occurs, and this thought also has positive valence, and thus the action A actually happens.
In the Conventional Intuitive Self-Model, we conceptualize this as follows:
- Why is there positive valence in STEP 1? Because the homunculus wants A to happen right now.
- Why did A happen in STEP 2? Because the homunculus did it.
And we might describe this process as “I exercised my free will to do A”, in an intentional, self-aware way.
Another illustrative case is where S(A) has positive valence, but A has negative valence. An example would be: “I really wanted and intended to step into the ice-cold shower, but when I got there, man, I just couldn’t.” Recall that a positive-valence self-reflective S(A) will pull upwards on the valence of the action A itself (§2.5.2 [LW · GW]). But if A is sufficiently demotivating for other reasons, then its net valence can still be negative, and thus it won’t happen.
Why am I centering my story around the valence of S(X), rather than the valence of X?
Part of the answer is a “refrigerator-light illusion”. “Wanting” behavior involves brainstorming / planning towards some goal X. When we turn our attention to the “wanting” itself, in real-time, we incidentally make the self-reflective S(X) thought highly active and salient. If that S(X) thought has negative valence, then the whole brainstorming / planning process starts feeling demotivating (details here [LW · GW]), so we’ll stop “wanting” X and start thinking about something else instead. Whereas if S(X) has positive valence, we can continue “wanting” X even while noticing what’s happening. So we can only “directly observe” what wanting X looks like in cases where S(X) has positive valence.
Another part of the answer is that positive-valence S(X) unlocks a far more powerful kind of brainstorming / planning, where attention-control is part of the strategy space. I’ll get into that more in Post 8 [LW · GW].
Meanwhile, it might help to see the opposite case:
3.5.2 An edge case: impulsive planning
Consider an example of an X which is itself positive valence, but where the corresponding self-reflective S(X) thought is negative valence—say, X = smoking a cigarette, when I’m trying to quit.
Let’s say the idea X becomes active in my mind. Since it has positive valence, it kicks off brainstorming-towards-X (see §3.3.5 above)—for example, if the cigarette is at the bottom of my dad’s bag, then an idea might pop into my head that I can remove all the items from the bag, get the cigarette, and put the items back. That plan seems appealing, so I do it. But the whole thing is impulsive.
How do I describe what just happened?
I might say “I got the cigarette unthinkingly”. But that’s a pretty weird thing to say, right? I don’t really believe that I concocted and executed a skillful multi-step foresighted plan without “thinking”, right??
Alternatively, if you ask me whether what I did was “deliberate or accidental”, well, it sure wasn’t accidental! But calling it a “deliberate act” isn’t quite right either.
I certainly wouldn’t say “I exercised my free will to get the cigarette”.
A better description than “I got the cigarette unthinkingly” might be “I got the cigarette unreflectively”—specifically, I’m saying that the self-reflective S(cigarette) thought did not activate during this process.
Anyway, there’s clearly “wanting” and “vitalistic force” involved in the construction and execution of the cigarette-retrieval plan. So my above claim that the homunculus “wants” X’s for which S(X) has positive valence is evidently a bit oversimplified. Or actually, maybe that is the intuitive model, and people just squeeze these kinds of poorly-fitting edge-cases into that intuitive model as best they can—maybe they’ll say “I wasn’t myself for a moment”, as if a different homunculus had temporarily subbed in!
3.5.3 “I seek goals” versus “my goals are the things that I find myself seeking”
As in §3.3.6 above, the “vitalistic force” intuition forbids the existence of any deterministic cause, seen or unseen, upstream of “wanting” behavior. (Probabilistic upstream causes, like “hunger makes me want food”, are OK. But the stronger such predictions get, the more they seem intuitively to undermine “free will”.)
This constraint on intuitive models leads to some systematic distortions, as shown in this diagram:
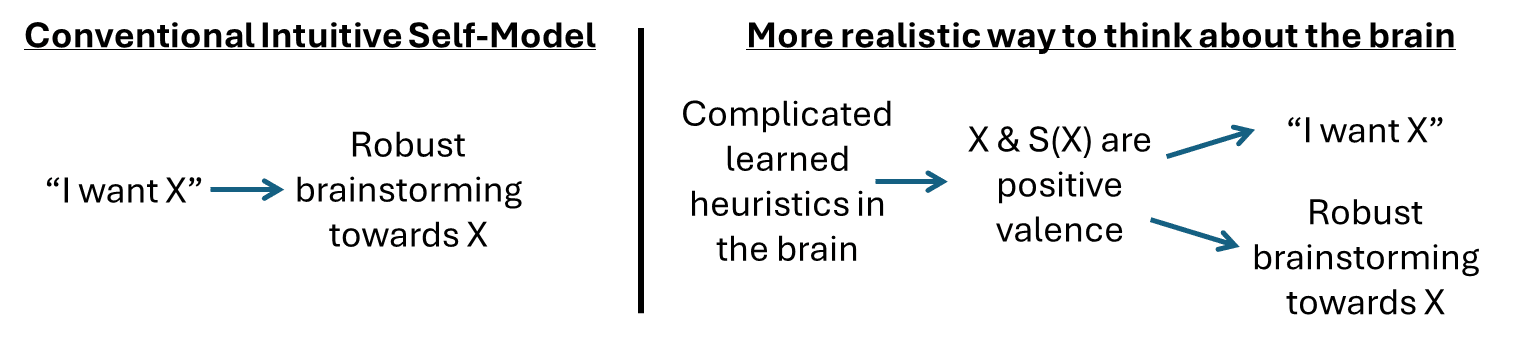
So within the Conventional Intuitive Self-Model,
- “I seek things that I want” seems normal and correct,
- “If I’m seeking something, then evidently that’s a thing I want” seems somewhere between “confused” and “a threat to my sense of agency”.
…But in terms of the real brain algorithm, I claim that these are more-or-less equivalent.
3.5.4 Why are ego-dystonic things “externalized”?
The main thing that the homunculus does is apply its vitalistic force towards accomplishing things it “wants”, via brainstorming / planning. So if there’s robust brainstorming / planning happening towards bungee jumping, then evidently (in our intuitive model) the homunculus “wants” to go bungee jumping. We call this an “internalized” desire. Conversely, if there’s robust brainstorming / planning happening towards not scratching an itch, but I scratch my itch anyway, then this is an “externalized” desire—the homunculus didn’t want the itch to get scratched, but the “urge” made it happen anyway.
We can apply this kind of thinking more generally. Compare the internalized “I become angry sometimes” with the externalized “I am beset by anger sometimes”. These are not synonymous: the latter, but not the former, has a connotation that there’s robust brainstorming / planning happening in my brain towards the goal of not being angry, possibly even while I’m angry. Admittedly, maybe I’m not spending much time doing such brainstorming / planning, or even any time, and maybe the brainstorming / planning isn’t effective. But still, the statement is still conveying something.
Combining this idea with §3.5.1, which says that robust brainstorming requires the corresponding self-reflective thoughts to have positive valence, and we wind up with the general picture that we tend to “internalize” things that reflect well upon ourselves (see §2.5.1 [LW · GW]), and “externalize” things that don’t.
Now, I used to think that the connection between ego-dystonic / ego-syntonic and externalized / internalized was the result of motivated reasoning [LW · GW]: it’s nice to think of bad things as being “outside ourselves”. But now I think it’s directly about motivation, treated as probabilistic evidence within the Conventional Intuitive Self-Model—as opposed to being about motivated reasoning.
I suppose that distinction doesn’t matter much—by and large, the “motivation-as-evidence” hypothesis and the “motivated reasoning” hypothesis both lead to the same downstream predictions. Well, maybe my “motivation-as-evidence” story is a better fit to the example I gave in §2.5.2 [LW · GW] of the tired person saying “Screw being ‘my best self’, I’m tired, I’m going to sleep”. This action is internalized, not externalized, and yet it goes directly against how the person would like to be perceived by themselves and others.
3.6 The homunculus concept does not veridically correspond to anything at all
As in §1.3.3 [? · GW], “veridical” refers to “map–territory correspondence”. Is there some kind of objective, observer-independent thing (in the “territory”) that corresponds to the “homunculus” concept (in the “map”)? I don’t think so.
To be clear:
- The core of the “homunculus” concept is that it’s an entity that carries “vitalistic force” (intrinsic unpredictability with no upstream cause) and applies that vitalistic force to accomplish things that it “wants”. That’s what I’m saying doesn’t exist “in the territory”.
- I’m not questioning that all the phenomena that we conventionally explain via the homunculus, are real phenomena that demand a real explanation (see Post 8 [LW · GW]).
- I’m not questioning that many other aspects of “self”—see diagram in §3.4.2—are veridical models of things.
The non-veridicality of the homunculus might seem unintuitive to you right now. I ask you to withhold judgment, and keep reading more of the series, where we’ll see:
- Intuitive self-models in which actions and intentions sometimes intuitively seem to be caused by an external agent, rather than by the homunculus (Post 4 on trance [LW · GW], Post 7 on hearing voices and other hallucinations [LW · GW])
- Intuitive self-models with several different homunculus concepts (Post 5 on Dissociative Identity Disorder [LW · GW])
- Intuitive self-models with no homunculus concept at all (Post 6 on awakening a.k.a. enlightenment [LW · GW])
…And especially hang on until Post 8 [LW · GW], where I’ll discuss how to properly think about motivation, goals, and willpower, without attributing them to the homunculus concept.
3.7 Where does it feel like the homunculus is located?
For most people reading this, your intuitive models say that the homunculus is located in your head. For example, when you “exercise your free will” to “decide” to wiggle your fingers, that “decision” feels like it happens in your head.[13]
Of course, in real life, yes the decision did happen in your head! That’s where your brain is!
But an important point that we’ll need for later posts in this series is that the homunculus-in-the-head intuition is by no means a requirement of an intuitive self-model.
You might find that kinda hard to imagine,[14] so I’ll offer a few different lines of evidence and ways of thinking about it.
3.7.1 Some people and cultures have a homunculus outside their head
Here’s a source claiming that there’s substantial cross-culture variation in the intuitive spatial location of the homunculus:
The placing of the personality in a particular part of the body is cultural. Most Europeans place themselves in the head, because they have been taught that they are the brain. In reality of course the brain can’t feel the concave of the skull, and if we believed with Lucretius that the brain was an organ for cooling the blood, we would place ourselves somewhere else. The Greeks and Romans were in the chest, the Japanese a hand’s breadth below the navel, Witla Indians in the whole body, and even outside it. We only imagine ourselves as ‘somewhere’.
Meditation teachers in the East have asked their students to practise placing the mind in different parts of the body, or in the Universe, as a means of inducing trance.… Michael Chekhov, a distinguished acting teacher…suggested that students should practise moving the mind around as an aid to character work. He suggested that they should invent ‘imaginary bodies’ and operate them from ‘imaginary centres’… —Impro by Keith Johnstone (1979)
I definitely believe the second paragraph—I’ll get back to trance in Post 4 [LW · GW] and meditation in Post 6 [LW · GW]. Is the first paragraph trustworthy? I tried to double check Johnstone’s claims:
Start with his claim about “the Japanese”. When I tried looking into it, I quickly came across the term shirikodama, which you should definitely google, as all the top English-language results are incredulous blog posts with titles like “The Soul in Your Butt, According to Japanese Legend” or “Shirikodama (n): Small Anus Ball”, full of helpful 18th-century woodblock prints of demons stealing people’s shirikodama via their butts.

Anyway, after a bit more effort, I found the better search term, hara, and lots of associated results that do seem to back up Johnstone’s claim (if I’m understanding them right—the descriptions I’ve found feel a bit cryptic). Note, however, that Johnstone was writing 45 years ago, and I have a vague impression that Japanese people below age ≈70 probably conceptualize themselves as being in the head—another victim of the ravages of global cultural homogenization, I suppose. If anyone knows more about this topic, please share in the comments!
Then I checked Johnstone’s claim about “Witla Indians”, but apparently there’s no such thing as “Witla Indians”. It’s probably a misspelling of something, but I don’t know what. Guess I’ll just ignore that part!
As for the Greeks and Romans, I gather that there’s more complexity and variation than Johnstone is letting on, but at least Lucretius seems to firmly support Johnstone’s claim:
Now I say that mind and soul are held in union one with the other, and form of themselves a single nature, but that the…lord in the whole body is the reason, which we call mind or understanding, and it is firmly seated in the middle region of the breast.[15]
In summary, I think it’s probably true that the homunculus is conceptualized as being in different parts of the body in different cultures. But please comment if you know more than me.
3.7.2 Mistaken intuition: “When I intuitively feel like the homunculus is in my head, I’m just directly feeling where my brain is”
To understand the problem with this intuition, check out Daniel Dennett’s fun short story “Where Am I?”. He imagines his brain being moved into a jar, but attached to all its usual bodily inputs and outputs via radio link. He notes that he would still “feel” like he was in his head:
…While I recovered my equilibrium and composure, I thought to myself: “Well, here I am sitting on a folding chair, staring through a piece of plate glass at my own brain … But wait,” I said to myself, “shouldn’t I have thought, ‘Here I am, suspended in a bubbling fluid, being stared at by my own eyes’?” I tried to think this latter thought. I tried to project it into the tank, offering it hopefully to my brain, but I failed to carry off the exercise with any conviction. I tried again. “Here am I, Daniel Dennett, suspended in a bubbling fluid, being stared at by my own eyes.” No, it just didn’t work. …
Similarly, as Johnstone points out above, for most of history, people didn’t know that the brain thinks thoughts! So it’s obviously not the kind of thing one can just “feel”.
Indeed, different parts of the cortex are separated from each other by >15 cm. If a neuroscientist wants to know which cortical subregion is responsible for which types of computations, can they just “feel” where in their heads the different thoughts seem to be coming from? Of course not!
(Having said all that, our knowledge of brains is presumably not totally irrelevant to why we have a homunculus-in-the-head intuition—it probably lends that intuition some extra salience and plausibility. I’m just arguing that it’s not a requirement in practice.)
3.7.3 Mistaken intuition: “When I intuitively feel like the homunculus is in my head, I’m just feeling where my eyes see from, and my ears hear from”[16]
(Just like the above, I’m open-minded to the eyes-and-ears factor being an influence on where the homunculus actually winds up in practice; I’m just arguing against it imposing a requirement on where the homunculus must be.)
One problem is that eyes and ears are only two of your senses, and the other senses provide ample evidence that it’s possible for sensory perceptions to have a “center” away from the homunculus. Close your eyes, reach out your hand, and feel the shape of some object. Your sensory perceptions are working fine, but all the action is happening “over there”, some distance away from “me” in the head. I see no reason in principle that vision and hearing couldn’t likewise be happening “over there”, with “me” being somewhere else, like the chest.
Or as another example, when you feel an excitement in the pit of your stomach, that feeling of excitement is happening “down there”, while vision is happening “right here”—and I’m saying that it could equally well be the other way around. And indeed, “the other way around” evidently has its own kind of intuitive compellingness, given that some cultures wind up doing it that way: Specifically, the pit of your stomach is intuitively tied to the feeling of physiological arousal, and hence to the willpower and sense-of-agency that are foundational to the homunculus.
3.7.4 So how does the homunculus wind up in a particular location?
The first question is: Why does the homunculus seem to have any location at all? Why can’t it be locationless, as are many other concepts like “justice”?
I’m not entirely sure. Here’s my best guess. Per above, the homunculus exists as the cause of certain thoughts and motor actions. We have a pretty deep-seated intuition, generalized from everyday experience, that causes of unusual motion require physical contact—think of grabbing the ball, pushing the door, stepping on the floor, etc.[17] Presumably, this intuition implies that the homunculus must have a physical location in the body.

Then there’s a second question: what location? I think there are forces that make some possibilities more “natural” and “salient” than others—as mentioned above, your eyes and ears and brain are in the head, while your physiological arousal feels like it’s in the chest or abdomen. But most importantly, I think we pick it up from cultural transmission. Sometime in childhood,[18] we learn from our friends and parents that there’s a homunculus in the head, and this becomes a self-fulfilling prophecy: the more that we conceptualize deliberate thoughts and actions as being caused by a homunculus-in-the-head, the more likely we are to assume that any other deliberate thoughts and actions are caused by it too (i.e., it becomes a strong prior).
In terms of the bistable perception discussion of §1.2 [LW · GW], imagine that you’ve been “seeing” the spinning dancer go clockwise, and never counterclockwise, thousands of times per day, day after day, month after month. After a while, it would become awfully hard to see it going counterclockwise, even if you wanted it to. By analogy, after a lifetime of practice conceptualizing a homunculus-in-your-head as the cause of deliberate thoughts and actions, it’s very hard (albeit not totally impossible) to imagine deliberate thoughts and actions as being caused by a homunculus-in-your-chest, or indeed by no homunculus at all. More on this in Posts 4 and 6.
3.7.5 By the way, where is “awareness”?
Everything so far has been about the intuitive location of the homunculus. Next, what about the other star of our intuitive self-models, namely the “awareness” concept of Post 2 [LW · GW]?
(Recall the X-versus-S(X) distinction of §2.2.3 [LW · GW]—I’m talking here about the intuitive location of the self-reflective “awareness” concept itself. Nobody is questioning the fact that, when I have an object-level thought about my coffee cup, my attention is over on the table.)
My current belief is that, in our intuitive models, the “awareness” concept, in and of itself, doesn’t really have a location! It’s more like “justice” and other such location-free concepts. Recall, above I suggested that the homunculus winds up with a location because it seems to cause bodily motion, and we have an intuition that motion-causation entails physical contact. But “awareness” is not a cause of any motion, so that argument doesn’t apply.
That said, I think the “awareness” concept winds up generally anchored to the head, but only because that’s where the homunculus is. Recall, the homunculus is intimately connected to “awareness”—the homunculus is causing things to be in awareness via attention control, and conversely the homunculus is taking in whatever is happening in awareness by “watching the projector screen in the Cartesian theater”, so to speak. So thoughts involving “awareness” itself almost always involve the homunculus too, and hence those thoughts seem to be about something happening in the head.
The main reason I believe all this is: the experiment has been done! I think there are lots of people who have an intuitive self-model involving an awareness concept, but not involving any homunculus concept. Those people generally report that, with the homunculus gone, suddenly the “awareness” concept is free to have any location, or no location at all.[19] More on these “awakened” people in Post 6 [LW · GW].
3.8 Conclusion
Between this and the previous post [LW · GW], we’ve covered the main ingredients of the Conventional Intuitive Self-Model. There’s much more that could be said, but this is a good enough foundation to get us to the fun stuff that will fill the rest of the series: trance, hallucinations, dissociation, and more. Onward!
Thanks Thane Ruthenis, Linda Linsefors, Seth Herd, and Justis Mills for critical comments on earlier drafts.
- ^
In Consciousness Explained, Dennett emphasizes a passive role of the homunculus, where it “watches” the stream-of-consciousness; by contrast, I’m emphasizing the active role of the homunculus, where it causes the thoughts and actions that we associate with free will. I don’t think the passive role is wrong, but I do think it’s incidental—it’s not why the homunculus concept exists. Indeed, as we’ll see in Posts 4 (trance) and 6 (awakening), people empirically find that their intuitive homunculus concept dissolves away when the homunculus stops taking any actions for an extended period—despite the fact that the stream-of-consciousness is still there. In fact, I claim that Dennett’s stream-of-consciousness discussion can be lightly edited to make the same substantive points without mentioning the homunculus; and indeed, that’s exactly what I already did in §2.3 [LW · GW]. Specifically, Dennett could have talked about whether there’s a fact-of-the-matter about what’s on the “projector screen” of the “Cartesian Theater”, without talking about whether anyone is sitting in the theater audience. Still, at the end of the day, I think Dennett & I are talking about the same homunculus, so I borrowed his term instead of inventing a new one.
- ^
Well, probably different philosophers-of-mind have different intuitive self-models to some extent. I imagine that this leads to people talking past each other.
- ^
Yes I know that’s not a great source, but it passes various smell tests and is at least vaguely consistent with other things I’ve read about Haitian Vodou. Feel free to comment if you know more.
- ^
I’m obviously borrowing the terminology from Vitalism, but I’m not a historian of science and don’t know (or care) if I’m using the term in the same way that the actual vitalists did.
- ^
Things like physiological arousal are called “interoceptive” sensory inputs, as opposed to “exteroceptive” sensory inputs like hearing and vision. But from the perspective of the predictive learning algorithm, and the generative models that this algorithm builds, it hardly matters—a sensory input is a sensory input. See here [LW · GW] for related discussion.
- ^
See also “The Meaning of Right” (Yudkowsky 2008) [LW · GW], who uses the metaphor of “XML tags” instead of “metaphysical paint”.
- ^
- ^
Granted, one can argue that observer-independent intrinsic unpredictability does in fact exist “in the territory”. For example, there’s a meaningful distinction between “true” quantum randomness versus pseudorandomness. However, that property in the “territory” has so little correlation with “vitalistic force” in the map, that we should really think of them as two unrelated things. For example, in my own brain, the sporadic clicking of a geiger counter feels like an inanimate (vitalistic-force-free) “mechanism”, but is intrinsically unpredictable (from a physics perspective). Conversely, a rerun cartoon depiction of Homer Simpson feels like it’s infused with vitalistic force, but in fact it’s intrinsically fully predictable. Recall also that vitalistic force is related not only to unpredictability but also physiological arousal.
- ^
From my (limited) understanding of the childhood development literature, it seems likely that the “vitalistic force” and “wanting” intuitions are learned from modeling other people and animals first, and then are applied to our own minds second. So that’s how I’m describing things in this section. There’s a school of thought (cf. Graziano & Kastner 2011 maybe?) which says that this ordering is profoundly important, i.e. that self-modeling is fundamentally a consequence of social modeling. I’m mildly skeptical of that way of thinking; the hypothesis that things get learned in the opposite order seems plenty plausible to me, even if it’s not my first guess. But whatever, that debate is not too important for this series.
- ^
This claim is related to so-called “Computational Irreducibility” (more discussion here). Or just note that, if there were a magical shortcut to figuring out what the brain’s decision-making process will wind up outputting, without having to walk through that whole process in some form, then the brain wouldn’t be running that decision-making process in the first place! It would just use the shortcut instead!
Of course, none of these considerations rules out confident a priori probabilistic predictions of the outputs of the brain’s decision-making algorithm in particular cases. For example: I predict with very high confidence that you won’t choose to stab yourself in the eye with a pen right now. Ha, not feeling so “free” now, right? …But our intuitions about “free will” come into force precisely when decisions are not overdetermined by circumstances.
- ^
Very similar arguments are also sometimes put forward as an a priori reason to dismiss the possibility of AGI misalignment [LW · GW].
- ^
Caveat for this paragraph: As usual, one should be extremely cautious with this kind of Bulverism. I think what I’m saying should be taken as a possibility for your consideration, when trying to understand any particular person’s perspective. But there are lots of people who confidently universally a priori dismiss the possibility of AGI and/or AI misalignment, for lots of different reasons. Yes, I think those people are all wrong, but hopefully it goes without saying that this “vitalistic force” discussion is not in itself proof that they’re all wrong! You still need to listen to their actual arguments, if any. Separately, there are people who dismiss the possibility of AGI and/or AI misalignment in reference to specific AI algorithms or algorithm classes. Those arguments are very different from what I’m talking about.
- ^
As in §3.4.2 above, the homunculus is narrower than “me” or “my self”. Certainly it’s possible to “feel a yearning in your chest” and so on. But I will go out on a limb and say that, if a guy says “I was thinking with my dick”, he’s speaking metaphorically, as opposed to straightforwardly describing his intuitive self-model.
- ^
As mentioned in §3.3.6 above, as a rule, everything about intuitive self-models always feels extremely compelling, and alternatives hard to imagine. After all, your intuitive self-models have been issuing predictions that get immediately validated thousands of times each day, for every day of your life, apart from very early childhood, so it’s a very strong prior.
- ^
Fuller quote: “Now I say that mind and soul are held in union one with the other, and form of themselves a single nature, but that the head, as it were, and lord in the whole body is the reason, which we call mind or understanding, and it is firmly seated in the middle region of the breast. For here it is that fear and terror throb, around these parts are soothing joys; here then is the understanding and the mind. The rest of the soul, spread abroad throughout the body, obeys and is moved at the will and inclination of the understanding.” (source) (I think the word “head” in that excerpt is meant in the “person in charge” sense, not the anatomical sense.) (Note that the original is in Latin, and it’s possible that some important nuances were lost in translation.)
- ^
Side note: This intuition would apply less to deaf people and blind people, and would not apply at all to deaf-blind people. Do those people feel like the homunculus is in their head? I can’t find good sources.
- ^
See also Le Sage’s theory of gravitation which attempted to explain Newton’s law as a consequence of (more intuitive) physical contact forces; and see Richard Feynman’s comment that people ask him to explain bar magnets, but nobody ever asks him to explain physical contact forces (e.g. why your hand doesn’t pass through a chair), even though it should really be the other way around (electromagnetism is a fundamental law of nature, and physical contact forces are in turn a consequence of electromagnetism).
- ^
Indeed, the indoctrination—oh sorry, acculturation—starts very early: when my kid was barely three years old, his preschool class was singing “Mat Man has one head, one head, one head, Mat Man has one head—so that he can think”!
- ^
If you’re wondering how I got the impression that “awareness” becomes untethered from any particular location as soon as the homunculus is gone, it’s based on a bunch of things, but two examples that spring to mind are: “Centrelessness, Boundarylessness Phenomenology And Freedom From The Cage Of The Mind” by Thisdell, and the discussions of “awake awareness” and “witness” in Shift into Freedom by Kelly.
38 comments
Comments sorted by top scores.
comment by justinpombrio · 2024-10-08T16:46:56.906Z · LW(p) · GW(p)
Rice’s theorem (a.k.a. computational irreducibility) says that for most algorithms, the only way to figure out what they’ll do with certainty is to run them step-by-step and see.
Rice's theorem says nothing of the sort. Rice's theorem says:
For every semantic property P,
For every program Q that purports to check if an arbitrary program has property P,
There exists a program R such that Q(R) is incorrect:
Either P holds of R but Q(R) returns false,
or P does not hold of R but Q(R) returns true
Notice that the tricky program R that's causing your property-checker Q to fail is under an existential. This isn't saying anything about most programs, and it isn't even saying that there's a subset of programs that are tricky to analyze. It's saying that after you fix a property P and a property checker Q, there exists a program R that's tricky for Q.
There might be a more relevant theorem from algorithmic information theory, I'm not sure.
Going back to the statement:
for most algorithms, the only way to figure out what they’ll do with certainty is to run them step-by-step and see
This is only sort of true? Optimizing compilers rewrite programs into equivalent programs before they're run, and can be extremely clever about the sorts of rewrites that they do, including reducing away parts of the program without needing to run them first. We tend to think of the compiled output of a program as "the same" program, but that's only because compilers are reliable at producing equivalent code, not because the equivalence is straightforward.
a.k.a. computational irreducibility
Rice's theorem is not "also known as" computational irreducibility.
By the way, be wary of claims from Wolfram. He was a serious physicist, but is a bit of an egomaniac these days. He frequently takes credit for others' ideas (I've seen multiple clear examples) and exaggerates the importance of the things he's done (he's written more than one obituary for someone famous, where he talks more about his own accomplishments than the deceased's). I have a copy of A New Kind of Science, and I'm not sure there's much of value in it. I don't think this is a hot take.
for most algorithms, the only way to figure out what they’ll do with certainty is to run them step-by-step and see
I think the thing you mean to say is that for most of the sorts of complex algorithms you see in the wild, such as the algorithms run by brains, there's no magic shortcut to determine the algorithm's output that avoids having to run any of the algorithm's steps. I agree!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-08T17:39:06.286Z · LW(p) · GW(p)
I was gonna say that you’re nitpicking, but actually, I do want this post to be correct in detail and not just in spirit. So I edited the post. Thanks. :)
Rice's theorem is not "also known as" computational irreducibility.
OK, I no longer claim that. I still think it might be true, at least based on skimming the wikipedia article, but I’m not confident, so I shouldn’t say it. Maybe you know more than me. Oh well, it doesn’t really matter.
By the way, be wary of claims from Wolfram
Yeah, I think “computational irreducibility” is an intuitive term pointing to something which is true, important, and not-obvious-to-the-general-public. I would consider using that term even if it had been invented by Hitler and then plagiarized by Stalin :-P
Replies from: justinpombrio↑ comment by justinpombrio · 2024-10-08T19:10:51.174Z · LW(p) · GW(p)
Yeah, I think “computational irreducibility” is an intuitive term pointing to something which is true, important, and not-obvious-to-the-general-public. I would consider using that term even if it had been invented by Hitler and then plagiarized by Stalin :-P
Agreed!
OK, I no longer claim that. I still think it might be true
No, Rice's theorem is really not applicable. I have a PhD in programming languages, and feel confident saying so.
Let's be specific. Say there's a mouse named Crumbs (this is a real mouse), and we want to predict whether Crumbs will walk into the humane mouse trap (they did). What does Rice's theorem say about this?
There are a couple ways we could try to apply it:
-
We could instantiate the semantic property P with "the program will output the string 'walks into trap'". Then Rice's theorem says that we can't write a program Q that takes as input a program R and says whether R outputs 'walks into trap'. For any Q we write, there will exist a program R that defeats it. However, this does not say anything about what the program R looks like! If R is simply
print('walks into trap'), then it's pretty easy to tell! And if R is the Crumbs algorithm running in Crumb's brain, Rice's theorem likewise does not claim that we're unable tell if it outputs 'walks into trap'. All the theorem says is that there exists a program R that Q fails on. The proof of the theorem is constructive, and does give a specific program as a counter-example, but this program is unlikely to look anything like Crumb's algorithm. The counter-example program R runs Q on P and then does the opposite of it, while Crumbs does not know what we've written for Q and is probably not very good at emulating Python. -
We could try to instantiate the counter-example program R with Crumb's algorithm. But that's illegal! It's under an existential, not a forall. We don't get to pick R, the theorem does.
Actually, even this kind of misses the point. When we're talking about Crumb's behavior, we aren't asking what Crumbs would do in a hypothetical universe in which they lived forever, which is the world that Rice's theorem is talking about. We mean to ask what Crumbs (and other creatures) will do today (or perhaps this year). And that's decidable! You can easily write a program Q that takes a program R and checks if R outputs 'walks into trap' within the first N steps! Rice's theorem doesn't stand in your way even a little bit, if all you care about is behavior after a fixed finite amount of time!
Here's what Rice's theorem does say. It says that if you want to know whether an arbitrary critter will walk into a trap after an arbitrarily long time, including long after the heat death of the universe, and you think you have a program that can check that for any creature in finite time, then you're wrong. But creatures aren't arbitrary (they don't look like the very specific, very scattered counterexample programs that are constructed in the proof of Rice's theorem), and the duration of time we care about is finite.
If you care to have a theorem, you should try looking at Algorithmic Information Theory. It's able to make statements about "most programs" (or at least "most bitstrings"), in a way that Rice's theorem cannot. Though I don't think it's important you have a theorem for this, and I'm not even sure that there is one.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-08T19:49:03.584Z · LW(p) · GW(p)
Oh sorry, when I said “it might be true” just above, I meant specifically: “it might be true that ‘computational irreducibility’ and Rice’s theorem are the same thing”. But after a bit more thought, and finding a link to a clearer statement of what “computational irreducibility” is supposed to mean, I agree with you that they’re pretty different.
Anyway, I have now deleted all mention of Rice’s theorem, and also added a link to this very short proof that computationally-irreducible programs exist at all. Thanks very much :)
comment by cubefox · 2024-10-03T19:20:16.435Z · LW(p) · GW(p)
That's an interesting theory which sounds overall plausible.
One complaint I have about Dennett is his arguably question-begging choice of terminology. "Homunculus" has a similar connotation to "that ridiculous thing which obviously doesn't exist if you spell it out for a bit, and if your opinion is otherwise you are very naive". He should have used more neutral terminology.
As far as I can tell, what he or you seems to mean with "homunculus" is what we usually mean with "me", "I", "myself", "self" etc. I don't think these terms normally refer partly to our body.
For example, if I was transformed into a ghost, or if I was uploaded (after the singularity), I would arguably still exist, but my body wouldn't. And if I was instead transformed into a philosophical zombie (be permanently unconscious), I would arguably stop existing. Or think of the popular movie trope "body swap". After person A and B do a body swap, A has the body of B, and B the body of A. It is not the case that A has the mind of B and B the mind of A. If the person with the body of B says "I", this refers to person A, not B.
So "I" refers to something in my mind, while my body is, conceptually, just an accidental property of myself, something which I have but may not have. Much like you can change the color of a car while it still being the same car as before. (Whether or not the laws or physics rule out ghosts or zombies or mind uploads is a different question.)
So I would caution against saying things like "The homunculus doesn't exist", because what that is saying seems dangerously close to "I don't exist". I know you said your main arguments come in the next posts, but this is a possible pitfall I'd like to flag in advance. I think it is more productive to say: I obviously exist, though it is not yet clear in what way or sense.
Replies from: Linda Linsefors, steve2152↑ comment by Linda Linsefors · 2024-10-03T22:12:42.355Z · LW(p) · GW(p)
I don't think what Steve is calling "the homonculus" is the same as the self.
Actually he says so:
The homunculus, as I use the term, is specifically the vitalistic-force-carrying part of a broader notion of “self”
It's part of the self model but not all of it.
Replies from: Linda Linsefors↑ comment by Linda Linsefors · 2024-10-04T00:23:40.694Z · LW(p) · GW(p)
Based on Steve's response to one of my comments, I'm now less sure.
Replies from: cubefox↑ comment by cubefox · 2024-10-04T06:40:40.969Z · LW(p) · GW(p)
Steve writes:
the homunculus is definitionally the thing that carries “vitalistic force”, and that does the “wanting”, and that does any acts that we describe as “acts of free will”
Who wants things? Me of course. I want things. So the homunculus seems to be myself.
Replies from: Linda Linsefors↑ comment by Linda Linsefors · 2024-10-04T08:15:14.817Z · LW(p) · GW(p)
The way I understand it the homunculus is part of self. So if you put the wanting in the homunculus, it's also inside self. I don't know about you, but my self concept has more than wanting. To be fair, he homunculus concept is also a bit richer than wanting (I think?) but less encompassing than the full self (I think?).
↑ comment by Steven Byrnes (steve2152) · 2024-10-04T14:11:26.950Z · LW(p) · GW(p)
From both this comment and especially our our thread on Post 2 [LW(p) · GW(p)], I have a strong impression that you just completely misunderstand this series and everything in it. I think you have your own area of interest which you call “conceptual analysis” here [LW(p) · GW(p)], involving questions like “what is the self REALLY?”, an area which I dismiss as pointlessly arguing over definitions [LW · GW]. Those “what is blah REALLY” questions are out-of-scope for this series.
I really feel like I pulled out all the stops to make that clear, including with boldface font (cf. §1.6.2 [LW · GW]) and multiple repetitions in multiple posts. :)
And yet you somehow seem to think that this “conceptual analysis” activity is not only part of this series, but indeed the entire point of this series! And you’re latching onto various things that I say that superficially resemble this activity, and you’re misinterpreting them as examples of that activity, when in fact they’re not.
I suggest that you should have a default assumption going forward that anything at all that you think I said in this series, you were probably misunderstanding it. :-P
It’s true that what I’m doing might superficially seem to overlap with “conceptual analysis”. For example, “conceptual analysis” involves talking about intuitions, and this series also involves talking about intuitions. There’s a good reason for that superficial overlap, and I explain that reason in §1.6 [LW · GW].
If you can pinpoint ways that I could have written more clearly, I’m open to suggestions. :)
Replies from: cubefox↑ comment by cubefox · 2024-10-04T15:05:13.374Z · LW(p) · GW(p)
Sorry, I didn't want to come off as obnoxious. You can remove my comment if you consider it missing the point.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-04T15:08:16.828Z · LW(p) · GW(p)
Oh, it’s not obnoxious! You’re engaging in good faith. :)
comment by Linda Linsefors · 2024-10-03T22:45:16.341Z · LW(p) · GW(p)
Reading this post is so strange. I've already read the draft, so it's not even new to me, but still very strange.
I do not recognise this homunculus concept you describe.
Other people reading this, do you experience yourself like that? Do you resonate with the intuitive homunculus concept as described in the post?
I my self have a unified self (mostly). But that's more or less where the similarity ends.
For example when I read:
in my mind, I think of goals as somehow “inside” the homunculus. In some respects, my body feels like “a thing that the homunculus operates”, like that little alien-in-the-head picture at the top of the post,
my intuitive reaction is astonishment. Like, no-one really think of themselves like that, right? It's obviously just a metaphor, right?
But that was just my first reaction. I know enough about human mind variety to absolutely believe that Steve has this experience, even though it's very strange to me.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-03T23:49:18.506Z · LW(p) · GW(p)
Linda is referring to the following paragraph in §3.4.2 that I just deleted :)
There’s a whole lot more detailed structure that I’m glossing over in that diagram. For example, in my own mind, I think of goals as somehow “inside” the homunculus. In some respects, my body feels like “a thing that the homunculus operates”, like that little alien-in-the-head picture at the top of the post, whereas in other respects my body feels connected to the homunculus in a more intimate way than that. The homunculus is connected to awareness both as an input channel (it “watches the stream-of-consciousness (§2.3 [LW · GW]) on the projector screen of the Cartesian theater”, in the Consciousness Explained analogy), and as an output (“choosing” thoughts and actions). Moods might be either internalized (“I’m really anxious”) or externalized (“I feel anxiety coming on”), depending on the situation. (More on externalization in §3.5.4 below.) And so on.
I thought about it more and decided that this paragraph was saying things that I hadn’t really thought too hard about, and that don’t really matter for this series, and that are also rather hard to describe (or at any rate, that I lack the language to describe well). I mean, concepts can be kinda vague clouds that have a lot of overlaps and associations, making a kinda complicated mess … and then I try to describe it, and it sounds like I’m describing a neat machine of discrete non-overlapping parts, which isn’t really what I meant.
(That said, I certainly wouldn’t be surprised if there were also person-to-person differences, between you and me, and also more broadly, on top of my shoddy introspection and descriptions :) )
New version is:
As above, the homunculus is definitionally the thing that carries “vitalistic force”, and that does the “wanting”, and that does any acts that we describe as “acts of free will”. Beyond that, I don’t have strong opinions. Is the homunculus the same as the whole “self”, or is the homunculus only one part of a broader “self”? No opinion. Different people probably conceptualize themselves rather differently anyway.
comment by Linda Linsefors · 2024-10-03T22:04:52.647Z · LW(p) · GW(p)
(Neuroscientists obviously don’t use the term “homunculus”, but when they talk about “top-down versus bottom-up”, I think they’re usually equating “top-down” with “caused by the homunculus” and “bottom-up” with “not caused by the homunculus”.)
I agree that the homunculus-theory is wrong and bad, but I still think there is something to top-down vs bottom-up.
It's related to what you write later
Another part of the answer is that positive-valence S(X) unlocks a far more powerful kind of brainstorming / planning, where attention-control is part of the strategy space. I’ll get into that more in Post 8.
I think conscious control (aka top-down) is related to conscious thoughts (in the global work space theory sense) which is related to using working memory, to unlock more serial compute.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-03T23:22:57.150Z · LW(p) · GW(p)
I agree that it is possible to operationalize “top-down versus bottom-up” such that it corresponds to a real and important bright-line distinction in the brain. But it’s also possible to operationalize “top-down versus bottom-up” such that it doesn’t. And that’s what sometimes happens. :)
comment by Towards_Keeperhood (Simon Skade) · 2024-10-19T15:58:51.466Z · LW(p) · GW(p)
(also quick feedback in case it's somehow useful: When I reread the post today I was surprised that by "vitalistic force" you really just mean inherent unpredictability and not more. You make this pretty clear, so I feel like me thinking some time after the first read that you meant it to explain more (which you don't) is fully on me, but still I think it might've been easier to understand if you had just called it "inherent unpredictability" instead of "vitalistic force".)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-21T15:42:33.143Z · LW(p) · GW(p)
I think “vitalistic force” is a better term for describing what it intuitively seems to be, and “inherent unpredictability” is a better term for describing what’s happening under the hood. In this case I thought the former was a better label.
For example, last month, I had watch the vet put down my pet dog. His transition from living to corpse was fast and stark. If you ask me to describe what happened, I would say “my dog’s animation / agency / vitality / life-force / whatever seemed to evaporate away”, or something like that. I certainly wouldn’t say “well, 10 seconds ago there seemed to be inherent unpredictability in this body, and now it seems like there isn’t”. ¯\_(ツ)_/¯
Still, I appreciate the comment, I’ll keep it in mind in case I think of some way to make things clearer.
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-10-21T19:27:45.197Z · LW(p) · GW(p)
Sorry about your dog.
So I agree that there's this introspective sense that feels more like something one would call "vitalistic force". However I do not think that all of the properties of how we experience animals comes from just our mind attaching "inherent surprisingness". Rather humans have a tendency to model animals or so as there being some mind/soul stuff which probably entails more than just agency and inherent surprisingness, though I don't know what precisely.
Like if you say that vitalistic force is inherent surprisingness, and that vitalistic force is explaining the sense of vitality or life force we see in living creatures, you're sneaking in connotations. "vitalistic force" is effectively a mysterious answer for most of the properties you're trying to explain with it. (Or a placeholder like "the concept I don't understand yet but I give it a name".)
(Like IMO it's important to recognize that saying "inherent-surprisingness/vitalistic-force my mind paints on objects explains my sense of animals having life-force" is not actually a mechanistic hypothesis -- I would not advance-predict a sense of life-force from thinking that minds project their continuous surprise about an object as a property on the object itself. Not sure whether you're making this mistake though.)
(I guess my initial interpretation was correct then. I just later wrongly changed my interpretation because for your free will reduction all that is needed is the thing that the vitalistic-force/inherent-surprisingless hypothesis does in fact properly explain.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-24T15:51:08.126Z · LW(p) · GW(p)
Hmm. Maybe here’s an analogy. Suppose somebody said:
There’s a certain kind of interoceptive sensory input, consisting of such-and-such signal coming from blah type of thermoreceptor in the peripheral nervous system. Your brain does its usual thing of transforming that sensation into its own “color” of “metaphysical paint” (as in §3.3.2) that forms a concept / property in your conscious awareness and world-model, and you know it by the everyday term “cold”.
On the one hand, I would defend this passage as basically true. On the other hand, there’s clearly a lot of connotations and associations of the word “cold” that go way beyond the natural generalization of things that trigger this thermoreceptor. “Concepts are clusters in thingspace” [LW · GW], as the saying goes, and thus things that go along with coldness often enough kinda get roped in as a connation or aspect of the coldness concept itself. And then all those aspects of coldness can in turn get analogized into other domains, and now here we are talking about cold personalities and cold starts and cold cases and cold symptoms and the Cold War and on and on.
By the same token, I’m happy to defend a claim along the lines of “intrinsic unpredictability is the seed / core at the center of concepts like animation, vitality, agency, etc.”, but I acknowledge that intrinsic unpredictability in and of itself is not the entirety of those terms and their various connotations and associations.
(This is a helpful discussion for me, thanks.)
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-10-24T19:19:56.700Z · LW(p) · GW(p)
By the same token, I’m happy to defend a claim along the lines of “intrinsic unpredictability is the seed / core at the center of concepts like animation, vitality, agency, etc.”
Well I don't think that intrinsic unpredictability explains the sense of lifeforce or whatever.
(What seems possible is that something like hard-to-predict (and purposeful?) behavior triggers human minds to model an object as interfaced to an invisible mind/soul/spirit, and the way humans model such souls is particular in some way which explains the sense of lifeforce.)
I think when humans model other minds (which includes animals (and gods)) they start from a pre-built template (potentially from mirroring part of their own cognitive machinery) with properties goals/desires, emotions, memory and beliefs.
When your dog dies the appearance of lifeforce disappearing might've been caused by seeing the dead body being now very predictable, but the explanation isn't that the sense of unpredictability went away, but rather something to do with that your whole model of the mind of your dog stopped having any predictive power. (I don't know yet what exactly might cause the sense of life force.)
Tbc what I'm imagining when saying "intrinsic unpredictability" is a reductionist model of how some machinery in the mind works, sorta like the model that explains frequentist[1] intuitions that a coin has an inherent 50% probability to come up heads. (I do NOT mean that an "intrinsic unpredictability" tag gets attached to the object which then needs to get interpreted by some abstract-modelling machinery.)
As example for a reductionist explanation, consider the frequentist intuition that it is a fact about the world that a coin comes up heads with 50% probability. This can be explained by saying that such agents model the world as probabilistic environment with P(coin=heads)=50%. (As opposed to worlds as deterministic environments where the oucome of an experiment is fixed and then having probabilistic uncertainty about what world one is in.)
I don't know precisely how to model "intrinsic unpredictability" yet, but if I'm looking for the part that explains why it seems unintuitive to us to think of ourselves (and others?) as deterministic, it could be that we model minds as "intrinsically probabilistic" just like in the coin case, or it might be a bit different like that a part predicts the model of the vitalistic object to get constantly updated as we observe it. (I previously didn't think about it clearly and had a slightly different guess how it might be implemented but it wasn't a full coherent picture that made sense.)
In case you do think that "intrinsic unpredictability" explains the sense of lifeforce, I think this is a mysterious answer [? · GW].
Harry gasped for breath, "but what is going on? "
"Magic," said Professor McGonagall.
"That's just a word! Even after you tell me that, I can't make any new predictions! It's exactly like saying 'phlogiston' or 'elan vital' or 'emergence' or 'complexity'!"
(chapter 6, HPMoR)
(To clarify: Even though it is magic, I think Harry is correct here that it's not an explanation.)
Also, I think you're aware of this, but nothing is inherently meaningful; meaning can only arise through how something is relative to something else. In the cold case (where I assume you talk about mental-physiological reactions to freezing/feeling-cold (as opposed to modelling the temperature of objects)), the meaning of "cold" comes from the cluster of sensations it refers to and how it affects considerations. If you just had the information "type-ABC (aka 'cold') sensors fired at position-XYZ", the rest of the mind wouldn't need to know what to do with that information on it's own but it needs some circutry to relate the information to other events. So I wouldn't say what you wrote explains cold, but maybe you didn't think it did.
- ^
I might not be fair to frequentists and don't really know their models. I just don't know how else to easily call it because it seems some people like Eliezer might not have had such intuitions.
↑ comment by Steven Byrnes (steve2152) · 2024-11-04T16:11:44.760Z · LW(p) · GW(p)
Hmm. I don’t think I’m invoking any mysterious answers. I think I’m suggesting a nuts-and-bolts model—a particular prediction about the behavior of a particular kind of algorithm given a particular type of input data. I’m trying to figure out why you disagree.
Like IMO it's important to recognize that saying "inherent-surprisingness/vitalistic-force my mind paints on objects explains my sense of animals having life-force" is not actually a mechanistic hypothesis -- I would not advance-predict a sense of life-force from thinking that minds project their continuous surprise about an object as a property on the object itself. Not sure whether you're making this mistake though.
Again I think it’s a mechanistic hypothesis. Let me walk through it in more detail; see where you disagree:
- Any concept or property in your conscious experience is a piece (latent variable or whatever) in a generative model built by a predictive (self-supervised) learning algorithm on sensory data.
- Some of that sensory data is interoceptive, including things like sense of one’s own physiological arousal, temperature, confusion, valence (goodness / badness), physical attraction, etc.
- The “mind projection fallacy” applies to these interoceptive sensations (§3.3.2). Why? Because the learning algorithm is finding generative models that predict sensory data, and mind-projection-fallacy generative models are simple and effective at predicting interoceptive sensory data. For example, whenever I look at the shirt, I reliably get white-derived visual sensations, therefore I wind up with a generative model that says that there’s a shirt in the world, and it’s white. Likewise, whenever I think about capitalism, I reliably get an interoceptive sensation of negative valence, therefore I wind up with a generative model that says that there’s a thing “capitalism” in the world, and that thing is “bad”.
- Every interoceptive sensation spawns a mind-projection-fallacy conscious concept / property that applies to things in the outside world. And surprise is one such sensation. So a priori we strongly expect every adult human to feel like there’s a surprise-derived intuitive property of things in the world. (But I haven’t yet said which intuitive property it is.)
- Meanwhile, in our everyday experience, we all have an intuitive sense of animation / agency. I think the word “vitalistic force” is a good way to point to this recognizable intuition.
- And then my substantive claim is that the previous two bullet should be equated: the surprise-derived intuitive property in adult humans is the intuitive sense of animation / agency.
Alternatively, suppose we didn’t have our subjective experience, but were told that there exists predictive learning algorithms blah blah as in Post 1. We should predict that these algorithms will build generative models containing a surprise-derived property of things in the world. And then we could look around the “training environment” (human world), try to figure out what would generate surprise (things that are both unpredictable an un-ignorable), and we’d predict that this intuitive property would get painted first and foremost onto things that are alive, but also onto cartoon characters and so on, and also to certain self-reflective things (i.e., aspects of the brain algorithm itself). When we do this kind of analysis well, we’ll wind up describing every aspect of our actual everyday intuitions around animation / agency / alive-ness, and predicting all the items in §3.3. But we’d be doing all that purely from first-principles reasoning about algorithms and biology. And then that “prediction” would be “tested” by noticing that humans have exactly those intuitions. As it happens, it’s not really a “prediction” because we already know what intuitions are typical in human adults. But nevertheless I think the reasoning is sound and tight and locally-valid, not just special pleading because we already know the answer. See what I mean?
I think when humans model other minds (which includes animals (and gods)) they start from a pre-built template (potentially from mirroring part of their own cognitive machinery) with properties goals/desires, emotions, memory and beliefs.
I think that when an average person sees a cockroach running across the floor, they think of it as having goals but probably not emotions or memories or beliefs. As a scientific matter, cockroaches do have memories, but I think at least some people feel kinda surprised and impressed when they see a cockroach doing something that demonstrates memory, which suggests that their intuitive model did not already include cockroach memory. But everyone thinks of the cockroach as being alive / animate, and also, nobody would be surprised or impressed to see a cockroach demonstrate “wanting” / goal-seeking by going around a trivial barrier to get into a hiding place.
That goes well with my theory that “vitalistic force” (derived from surprise) and “wanting” (derived from a pattern where I can make medium-term predictions despite short-term surprise) are two widely-used core intuitions in our generative model space, which strongly tend to go together. And then other aspects of modeling minds are optional add-ons. (Just like “has frost on it” is an optional add-on to an object being “cold”.)
Also, I think you're aware of this, but nothing is inherently meaningful; meaning can only arise through how something is relative to something else. In the cold case (where I assume you talk about mental-physiological reactions to freezing/feeling-cold (as opposed to modelling the temperature of objects)), the meaning of "cold" comes from the cluster of sensations it refers to and how it affects considerations. If you just had the information "type-ABC (aka 'cold') sensors fired at position-XYZ", the rest of the mind wouldn't need to know what to do with that information on it's own but it needs some circutry to relate the information to other events. So I wouldn't say what you wrote explains cold, but maybe you didn't think it did.
My claim is: there’s a predictive learning algorithm that sculpts generative models that can explain incoming sensory data. (See Post 1.) When I look at a clock, the sensory data involves retinal cells firing, while the generative model involves the concept “clock” (among other things).
The concept “cold”, like “clock”, is a concept in our intuitive models. This is “meaningful” in the same way any other intuitive concept is meaningful. It fits into our web-of-knowledge / world-model / “map” / generative model space, it has relations to other concepts, it helps make sense of the world, etc.
If an adult has a concept in their intuitive models, then that concept must be doing some work: it must be directly or indirectly helping to predict some kind of sensory input data. Otherwise it would not be in the generative models in the first place—that’s how the predictive learning algorithm works. For example, the concept “clock” is doing lots of work in different contexts, including helping explain visual input data when I happen to be looking at a clock. Thus we can ask by analogy: what’s the concept “cold” doing? The obvious answer is: the concept “cold” is mainly helping explain sensory input data involving the signals coming from blah blah type of thermoreceptor in the peripheral nervous system.
The point I was making before was that the concept “cold” starts from that important role. But by adulthood it winds up being invoked by analogy in things like “cold comfort”, and getting all these other connotations that are not superficially related to predicting the sensory signals coming from blah blah type of thermoreceptor. …But nevertheless, I think it’s fair to say that the central role of the “cold” concept, even in adults, is to enable generative models to correctly predict (many of) the signals coming from blah blah type of thermoreceptor.
And in a similar way, I’m claiming that the central role of the intuitive “vitalistic force” / “animation” concept is to enable generative models to correctly predict many of the sensory signals coming from the interoceptive sensation of surprise. (But it’s still true that this concept winds up with other connotations and extensions-by-analogy too.)
Does that help? Thanks for patient engagement and feedback.
Replies from: Simon Skade, Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-11-04T20:38:46.017Z · LW(p) · GW(p)
I agree that memory and beliefs are in some sense optional addons. I don't understand precisely enough yet how we model animals.
On your section on cold:
First, I'm still not sure in what way you're using "cold" of the two interpretations I indicated here: "(where I assume you talk about mental-physiological reactions to freezing/feeling-cold (as opposed to modelling the temperature of objects))".
But in either case I mostly just mean that having a full reductionist explanation of e.g. cold is an extremely high standard that ought to fulfill the following criteria:
- You can replace the word "cold" and other related abstract words with some other token-sequences/made-up-words, and someone who had a sufficiently good understanding would still be able to figure out that the new made-up-word corresponds to the concept we call "cold".
- (Where I don't think your explanation had something in it where you couldn't just replace "cold" with "heat" or "redness" (except redness wouldn't work if we allow "thermoreceptor" but I'd also want to rename this to "receptor-type-abc".)
- You can sorta write code for a relevant part of what's happening in the mind when e.g. the freezing emotion/sensation is triggered.
- (Like you would not need to describe a fully conscious program, but the function that triggers how muscles contract and the sensation of wanting to curl up and the skin shivering and causes a negative hedonic tone as well as instantiating a subgoal of getting thermoreceptors to report higher temperature or sth. Like I'd count this description as a weak reductionist hypothesis (which makes progress on unpacking the "cold" concept but where there are more levels of unpacking to do), though it might be very incomplete and partially wrong.)
Like I'm not sure we disagree much here. I think everything you said is correct, but I feel like emphasizing that there are still more layers of understanding that need to get unpacked and that saying "it's a concept that's useful to predict sensory data" still leaves up open questions of what exactly the information is the concept has the ability to communicate or of how the concept relates to other concepts.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-06T16:22:51.253Z · LW(p) · GW(p)
Hmm, I still might not be following, but I’ll write something anyway. :)
Take some “concept” in your world-model, operationalized as a particular cluster C of neurons in some part of your cortex that tend to activate together.
How might we figure out what what C “means”?
One part of the answer is entirely within the cortex world-model: C has particular relationships to other things in the cortex world-model, which in term have relationships to still other things etc. Clusters of neurons related to “bird” have some connection to clusters of neurons related to “flying”. That by itself might already be enough to pin down the “meanings” of different things, just because there’s so much structure there, and we can try to match it up with structures in the world, by analogy with unsupervised machine translation. But if not…
The other part of the answer is about how the cortex world-model relates to the real world. Maybe C directly predicts some particular pattern in low-level sensory inputs. Maybe C directly activates some particular pattern in motor output. Or maybe the connection is less direct—a certain abstract pattern in the space of abstract patterns in the space of abstract patterns in the space of low-level sensory inputs, or whatever. If we look at naturalistic visual inputs that directly or indirectly trigger C, and they’re disproportionately pictures of clocks, then that’s some evidence that C “means” clock.
So, how about “cold”? Our body has a couple relevant sensors: peripheral nerves that express TRPM8 (“cold and menthol receptor 1”), hypothalamus neurons that detect blood temperature via TRPV1, etc. (I’m not an expert on the details.) As usual [LW · GW], these sensory signals are processed in two areas in parallel. In the hypothalamus & brainstem (“Steering Subsystem”), they trigger innate reactions like shivering, unpleasant feelings / desire to warm up, and so on. And in the cortex, they’re treated as just so many more channels of unlabeled input data that the world-model needs to predict.
In the course of predicting them well, the world-model invents some slightly-higher-level concept (or family of closely-interlinked concepts) that we call “cold”. And it notices and memorizes predictively-useful relationships between this new “cold” concept and other things in the world-model, e.g. shivering and ice.
I don’t think there’s more to the concept “cold” than the sum total of its associations with every other concept, with sensory input, and with motor output. And we can explain those latter associations via the structure of the world and body in conjunction with a learning algorithm running throughout your life experience.
You can sorta write code for a relevant part of what's happening in the mind when e.g. the freezing emotion/sensation is triggered.
I like to draw the distinction between understanding learning algorithms and understanding trained models. The former is kinda like what you learn in an ML course (gradient descent, training data, etc.) , the latter is kinda like what you learn in a mechanistic interpretability paper. I don’t think it’s realistic to “write code” for the “cold” concept, because I think it (like all concepts) emerges at the trained model level. It emerges from a learning algorithm, training environment, loss function, etc.
Of course, we can chat about the trained model level to some extent. Why is “cold” associated with shivering? Because in the training environment of life experience, those two things have tended to go together, such that each provides nonzero Bayesian evidence that the other should be active, or will be soon. Ditto with the connection between cold and ice cream, and everything else. So we can chat about it, but it would take forever to directly write code for all those things. Hence the learning algorithm. Does that help?
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-11-06T20:17:49.800Z · LW(p) · GW(p)
Thanks for communicating your model well again!
I think we might mostly agree, but let's clarify.
I agree with all of:
In the course of predicting them well, the world-model invents some slightly-higher-level concept (or family of closely-interlinked concepts) that we call “cold”. And it notices and memorizes predictively-useful relationships between this new “cold” concept and other things in the world-model, e.g. shivering and ice.
I don’t think there’s more to the concept “cold” than the sum total of its associations with every other concept, with sensory input, and with motor output.
I also basically agree with:
I like to draw the distinction between understanding learning algorithms and understanding trained models. The former is kinda like what you learn in an ML course (gradient descent, training data, etc.) , the latter is kinda like what you learn in a mechanistic interpretability paper. I don’t think it’s realistic to “write code” for the “cold” concept, because I think it (like all concepts) emerges at the trained model level. It emerges from a learning algorithm, training environment, loss function, etc.
I agree that fully writing code would be quite a daunting task. I think my phrasing of "write code" was not great. But it's already some reductionist progress if you have something like:
if coldness concept gets more activated: increase activation of shivering anticipation; weakly increase activation of snow concept; ...I don't think it's a worthwhile exercise to get very precise.
An important point I wanted to make here is just that the meaning of "cold" comes from the interactions with other concepts, and there's no such thing as an inherent independent meaning of the word "cold". (So when I hear 'If we look at naturalistic visual inputs that directly or indirectly trigger C, and they’re disproportionately pictures of clocks, then that’s some evidence that C “means” clock.' this seems a bit off to me, though not too bad.)
I guess I best try to explain why I felt some unease with your initial description of the cold example:
Suppose somebody said:
There’s a certain kind of interoceptive sensory input, consisting of such-and-such signal coming from blah type of thermoreceptor in the peripheral nervous system. Your brain does its usual thing of transforming that sensation into its own “color” of “metaphysical paint” (as in §3.3.2) that forms a concept / property in your conscious awareness and world-model, and you know it by the everyday term “cold”.
On the one hand, I would defend this passage as basically true.
Basically I think that some people - though a priory not you - would think that sth like "i feel cold because the cold-thermorecepters activate the corresponding cold concept" explains their sense of cold. However, if you just take this hypothesis which basically is "some sensors activate some concept" without anything else, then the concept would be completely shapeless and uninterpretable - unrelated to anything known.
I now think you probably didn't mean it in a nearly that bad way but not sure.
(But some parts of what you write seem to me like you have slightly weaker sensors about "how does a hypothesis actually constrain my anticipations / concentrate probability mass" or "what would this hypothesis predict if I didn't already know how I perceive it", and I do think those sensors are useful.)
(I also think that there is some hypothalamus-or-so buisness logic for what responses to trigger (e.g. shivers) from significant cold input signals that would need to be figured out if you want to get a good model of freezing/feeling-uncomfortably-cold, but that's about freezing in particular and not temperature as a property we model on objects.)
↑ comment by Towards_Keeperhood (Simon Skade) · 2024-11-04T20:09:21.979Z · LW(p) · GW(p)
Thanks for being so wonderfully precise to make it easy for me to reply!
The part where you loose me is here:
Meanwhile, in our everyday experience, we all have an intuitive sense of animation / agency.
Where does this sense of agency come from? Likewise:
When we do this kind of analysis well, we’ll wind up describing every aspect of our actual everyday intuitions around animation / agency / alive-ness, and predicting all the items in §3.3.
How do we get from something seeming inherently surprising to something seeming agentic or embued with life-force?
EDITED TO ADD: Tbc I think you can explain agency (though not life-force, and you need to be carefuly to only interpret agency in this limited sense) through being able to predict outcomes without trajectories (as you also seem to have realized, as in "(derived from a pattern where I can make medium-term predictions despite short-term surprise)"). I wouldn't equate agency with inherent surprisingness though, although it often occurs together.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-06T16:49:29.072Z · LW(p) · GW(p)
Yeah, I think the §3.3.1 pattern (intrinsic surprisingness) is narrower than the §3.3.4 pattern (intrinsic surprisingness but with an ability to make medium-term predictions).
But they tend to go together so much in practice (life experience) that when we see the former we generally kinda assume the latter. An exception might be, umm, a person spasming, or having a seizure? Or a drunkard wandering about randomly? Hmm, maybe those don’t count because there are still some desires, e.g. the drunkard wants to remain standing.
I agree that agency / life-force has a strong connotation of the §3.3.4 thing, not just the §3.3.1 thing. Or at least, it seems to have that connotation in my own intuitions. ¯\_(ツ)_/¯
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-11-06T20:23:16.206Z · LW(p) · GW(p)
I feel like life-force seems like a sensation that's different from what I'd expect from just having a thing in the world model with inherent surprisingness and ends-without-trajectory-predictions/"optimizerness" attached. ("Life-force" sounds more like "as if the thing had a soul" to me. I do not understand where this comes from but I don't see how I'd predict such a sensation in advance given just the inherent-surprisingness + optimizerness hypothesis.)
comment by Towards_Keeperhood (Simon Skade) · 2024-10-19T15:02:53.078Z · LW(p) · GW(p)
I feel like I'm still confused on 2 points:
- Why is, according to your model, the valence of self-reflective thoughts sorta the valence our "best"/pro-social selves would ascribe?
- Why does the homunculus get modeled as wanting pro-social/best-self stuff (as opposed to just what overall valence would imply)?
(I'd guess that there was evolutionary pressure for a self-model/homunculus to seem more pro-social as the overall behavior (and thoughts) of the human might imply, so I guess there might be some particular programming from evolution into that direction. I don't know how exactly it might look like though. I also wouldn't be shocked if it's mostly just like all the non-myopic desires are pretty pro-social and the self-model's values get straightened out in a way the myopic desires end up dropped because that would be incoherent. Would be interested in hearing your model on my questions above.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-21T17:59:42.935Z · LW(p) · GW(p)
Why is, according to your model, the valence of self-reflective thoughts sorta the valence our "best"/pro-social selves would ascribe?
That would be §2.5.1 [LW · GW]. The idea is that, in general, there are lots of kinds of self-reflective thoughts: thoughts that involve me, and what I’m doing, and what I’m thinking about, and how my day is going, and whether I’m following through with my new years resolution, and what other people would think of me right now, and so on.
These all tend to have salient associations with each other. If I’m thinking about how my day is going, it might remind me that I had promised myself to exercise every day, which might remind me that Sally called me fat, and so on.
Whereas non-self-reflective thoughts by and large have less relation to that whole cloud of associations. If I’m engrossed in a movie and thinking about how the prince is fighting a dragon in a river, or even if I’m just thinking about how best to chop this watermelon, then I’m not thinking about any of those self-reflective things in the above paragraph, and am unlikely to for at least the next second or two.
Incidentally, I think your description is an overstatement. My claim is that “the valence our "best"/pro-social selves would ascribe” is very relevant to the valence of self-reflective thoughts, to a much greater extent than non-self-reflective thoughts. But they’re not decisive. That’s what I was suggesting by my §2.5.2 [LW · GW] example of “Screw being ‘my best self’, I’m tired, I’m going to sleep”. The reason that they’re very relevant is those salient associations I just mentioned. If I self-reflect on what I’m thinking about, then that kinda reminds me of how what I’m thinking about reflects on myself in general; so if the latter seems really good and motivating, then some of that goodness will splash onto the former too.
Do you buy that? Sorry if I’m misunderstanding.
Why does the homunculus get modeled as wanting pro-social/best-self stuff (as opposed to just what overall valence would imply)?
Again, I think this is an overstatement, per the §2.5.2 [LW · GW] example of “Screw being ‘my best self’, I’m tired, I’m going to sleep”. But it’s certainly directionally true, and I was talking about that in §3.5.1. I think the actual rule is that, if planning / brainstorming is happening towards some goal G, then we imagine that “the homunculus wants G”, since in general the planning / brainstorming process in general pattern-matches to “wanting” (i.e., we can predict what will probably wind up happening without knowing how).
So that moves us to the question: “if planning / brainstorming is happening towards some goal G, then why do we conclude that S(G) is positive valence, rather than concluding that G is positive valence?” For one thing, if G is negative-valence but S(G) is positive-valence, then we’ll still do the planning / brainstorming, we just focus our attention on S(G) rather than G during that process. That’s my example above of “I really wanted and intended to step into the ice-cold shower, but when I got there, man, I just couldn’t.” Relatedly, if the brainstorming process involves self-reflective thoughts, then that enables better brainstorming, for example involving attention-control strategies, making deals with yourself, etc. (more in Post 8). And another part of the answer is the refrigerator-light illusion, as mentioned in §3.5.1 (and see also the edge-case of “impulsive planning” in §3.5.2).
Does that help?
I'd guess that there was evolutionary pressure for a self-model/homunculus to seem more pro-social as the overall behavior (and thoughts) of the human might imply, so I guess there might be some particular programming from evolution into that direction. I don't know how exactly it might look like though. I also wouldn't be shocked if it's mostly just like all the non-myopic desires are pretty pro-social and the self-model's values get straightened out in a way the myopic desires end up dropped because that would be incoherent. Would be interested in hearing your model on my questions above.
This is a nitpick, but I think you’re using the word “pro-social” when you mean something more like “doing socially-endorsed things”. For example, If a bully is beating up a nerd, he’s impressing his (bully) friends, and he’s acting from social motivations, and he’s taking pride in his work, and he’s improving his self-image and popularity, but most people wouldn’t call bullying “pro-social behavior”, right?
Anyway, I think there’s an innate drive to impress the people who you like in turn. I’ve been calling it the drive to feel liked / admired [LW · GW]. It is certainly there for evolutionary reasons, and I think that it’s very strong (in most people, definitely not everyone), and causes a substantial share of ego-syntonic desires, without people realizing it. It has strong self-reflective associations, in that “what the people I like would think of me” centrally involves “me” and what I’m doing, both right now and in general. It’s sufficiently strong that there tends to be a lot of overlap between “the version of myself that I would want others to see, especially whom I respect in turn” versus “the version of myself that I like best all things considered”.
I think that’s similar to what you’re talking about, right?
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-10-21T20:18:10.953Z · LW(p) · GW(p)
This is a nitpick, but I think you’re using the word “pro-social” when you mean something more like “doing socially-endorsed things”. For example, If a bully is beating up a nerd, he’s impressing his (bully) friends, and he’s acting from social motivations, and he’s taking pride in his work, and he’s improving his self-image and popularity, but most people wouldn’t call bullying “pro-social behavior”, right?
Agreed.
Incidentally, I think your description is an overstatement. My claim is that “the valence our "best"/pro-social selves would ascribe” is very relevant to the valence of self-reflective thoughts, to a much greater extent than non-self-reflective thoughts. But they’re not decisive. That’s what I was suggesting by my §2.5.2 [LW · GW] example of “Screw being ‘my best self’, I’m tired, I’m going to sleep”.
Also agreed.
Re your reply to my first question:
I think that makes sense iiuc. Does the following correction to my model seem correct?:
I was thinking of it like "self reflective thoughts have some valence ---causes---> model of homunculus gets described as wanting those things where self-reflective thoughts have positive valence". But actually your model is like "there are beliefs about what the model of the homunculus wants ---causes---> self-reflective thoughts to get higher valence if they fit to what the homunculus wants". (Where I think for many people the "what the homunculus wants" is sorta a bit editable and changes in different situations depending on what subagents are in control.)
Re your reply to my second question:
So I'm not sure what your model is, but as far as I understand it seems like the model says "valence of S(X) heavily depends on what homunculus wants" and "what homunculus wants is determined by what goals there is sophisticated brainstorming towards, which are the goals where S(X) is positive valence". And it's possible that such a circularity is there, but that alone doesn't explain to me why the homunculus' preferences usually end up in the "socially-endorsed" attactor.
I mean another way to phrase the question might be "why are there a difference between ego-syntonic and positive valence? why not just one thing?". And yeah it's possible that the answer here doesn't really require anything new and it's just that the way valence naturally is coded in our brain is stupid and incoherent and the homunculus-model has higher consistency pressure which straightens out the reflectively endorsed values to be more coherent and in particular neglects myopic high-valence urges.
And that the homunculus-model ends up with socially-endorsed preferences because modelling what thoughts come up in the mind is pretty intertwined with language and it makes sense that for language-related thoughts the "is this socially endorsed" thought accessors are particularly strong. Not sure whether that's the whole story though.
(Also I think ego-dystonic goals can sometimes still cause decently sophisticated brainstorming, especially if it comes from urges that other parts try to suppress and thus learn to "hide their thoughts". Possibly related is that people often rationalize about why to do something.)
Anyway, I think there’s an innate drive to impress the people who you like in turn. I’ve been calling it the drive to feel liked / admired [LW · GW]. It is certainly there for evolutionary reasons, and I think that it’s very strong (in most people, definitely not everyone), and causes a substantial share of ego-syntonic desires, without people realizing it. It has strong self-reflective associations, in that “what the people I like would think of me” centrally involves “me” and what I’m doing, both right now and in general. It’s sufficiently strong that there tends to be a lot of overlap between “the version of myself that I would want others to see, especially whom I respect in turn” versus “the version of myself that I like best all things considered”.
I think that’s similar to what you’re talking about, right?
Yeah sorta. I think what I wanted to get at is that it seems to me that people often think of themselves as (wanting to be) nicer than their behavior would actually imply (though maybe I overestimated how strong that effect is) and I wanted to look for an explanation why.
(Also I generally want to get a great understanding of what values end up being reflectively endorsed and why -- this seems very important for alignment.)
comment by lillybaeum · 2024-10-03T05:59:40.681Z · LW(p) · GW(p)
Really loving this series. It's clicking together lots of things in a way I wasn't able to do on my own, and neither was AI despite me feeding it all my disparate thoughts and questions about awareness, tulpa, DID, nirodha samapatti, etc... and this series is just getting into this stuff and doing a wonderful job of explaining and solidifying these concepts.
As soon as I read that last sentence about people being able to perceive awareness as not being within the mind, I feel like it unlocked something in terms of my ability to get closer to awakening in a really palpable way.
comment by TAG · 2025-02-11T21:22:29.702Z · LW(p) · GW(p)
(Extensively reviesed and edited).
Reductionism
Reductionism is not a positive belief, but rather, a disbelief that the higher levels of simplified multilevel models are out there in the territory.
Things like airplane wings actually are, at least as approximations. I don't see why you are.approvingly quoting this: it conflates reduction and elimination.
But the way physics really works, as far as we can tell, is that there is only the most basic level—the elementary particle fields and fundamental forces.
If that's a scientific claim ,it needs to be treated as falsifiable, not as dogma.
You can’t handle the raw truth, but reality can handle it without the slightest simplification. (I wish I knew where Reality got its computing power.)"
It's not black and white. A simplified model isn't entirely out there, but it's partly out there. There's still a difference between an aeroplane wing and horse feathers.
Vitalistic Force
Vitalistic force (§3.3) is an intuitive concept that we apply to animals, people, cartoon characters, and machines that “seem alive” (as opposed to seeming “inanimate”).
It amounts to a sense that something has intrinsic important unpredictability in its behavior
The intuitive model says that the decisions are caused by the homunculus, and the homunculus is infused with vitalistic force and hence unpredictable. And not just unpredictable as a state of our limited modeling ability, but unpredictable as an intrinsic property of the thing itself—analogous to how it’s very different for something to be “transparent” versus “of unknown color”, or how “a shirt that is red” is very different from “a shirt that appears red in the current lighting conditions
Unpredictability is the absence of a property: predictability. Vitalistic force sounds like the presence of one. It's difficult to see why a negative property would equate to a positive one. We don't have to regard an unpredictable entity as quasi-alive. We don't regard gambling machines in casinos as quasi alive. Our ancestors used to regard the weather as quasi alive, but we don't -- so it's not all that compulsive. We also don't have to regard living things as unpredictable --an ox ploughing a furrow is pretty predictable. Unpredictability and vitalism aren't the same concept, and aren't very rigidly linked, psychologically.
It doesn’t veridically (§1.3.2) correspond to anything in the real world (§3.3.3).
Except..
Granted, one can argue that observer-independent intrinsic unpredictability does in fact exist “in the territory”. For example, there’s a meaningful distinction between “true” quantum randomness versus pseudorandomness. However, that property in the “territory” has so little correlation with “vitalistic force” in the map, that we should really think of them as two unrelated things.
So let's say that two different things: unpredictableness , non-pseudo randomness could exist in the territory, and could found a real, non-supernatural version of free will. Vitality could exist in the territory too -- reductionism only requires that it is not fundamental, not that it is not real at all. It could be as real as an airplane wing. Reduction is not elimination.
However, that property in the “territory” has so little correlation with “vitalistic force” in the map, that we should really think of them as two unrelated things
So what is the definition of vitalistic force that's a) different from intrinsic surprisingness b) incapable of existing in the territory even as an approximation?
Homunculi
The strong version of the homunculus , the one-stop-shop that explains everything about consciousness, identity, and free will, is probably false...but bits and pieces of it could still be rescued.
Function: it's possible that there are control systems even if they don't have a specific physical location.
Location: Its quite possible for higher brain areas to be a homunculus (or homunculi) lite, in the sense that , they exert executive control, or are where sensory data are correlated. Rejecting ghostly homunculi because they are ghostly doesn't entail rejecting physical homunculi The sensory and mirror homunculi.
Vitalism: It's possible for intrinsic surprisingness to exist in the territory, because intrinsic surprisingness is the same thing as indeterminism.
There's also a further level of confusion about whether your idea of homunculus is observer or observed.
Are "we" are observing "ourselves" as a vitalistic homunculus , observing the rest of ourselves? If the latter, which is the real self, the the observer or the homunculus?
As discussed in Post 1, the cortex’s predictive learning algorithm systematically builds generative models that can predict what’s about to happen
No one has discovered a brain algorithm, so far.
Free Will
the suite of intuitions related to free will has spread its tentacles into every corner of how we think and talk about motivation, desires, akrasia, willpower, self, and more
And now we come to the part of the argument where an objective unbiased assessment of free will. concludes that the concept (or rather concepts) are so utterly broken and wrong that any vestige has to be "rooted out".
Now, I expect that most people reading this are scoffing right now that they long ago moved past their childhood state of confusion about free will. Isn’t this “Physicalism 101” stuff?
It's the case that a lot of people think that the age old problem of free will is solved at a stroke by "physics, lol"... but there are also sophisticated naturalistic defences.
There are two dimensions to the problem: the what-we-mean-by-free-will dimension, and the what-reality-offers-us dimension. The question of free will partially depends on how free will is defined, so accepting a basically scientific approach does not avoid the "semantic" issues of how free will, determinism , and so on, are best conceptualised.
I don’t know what people mean by “free will” and I don’t think they usually do either.
Professional philosophers are quite capable of stating their definitions, and you at capable of looking them up.)
Mr. Yudkowsky has no novel insight to offer into how the territory works, nor any novel insight into the correct semantics of free will. He has not solved either sub problem, let alone both. He has proposed a mechanism (not novel) about how the feeling of free will could be a predictable illusion, but that falls short of proving that it is..he basically relies on having an audience who are already strongly biased against free will.
To dismiss fee will, just on the basis of Physicalism, not even deterministic physics, is to tacitly define it as supernatural. Does everyone define it that way? No,there are compatibilists and naturalistic libertarians.
Compatibilism is a naturalistic theory of free will, and libertarianism can be.
(https://insidepoliticalscience.com/libertarian-free-will-vs-compatibilism/)
To provide a mechanism by which the feeling of free will could be an illusion , which he had done, , does not show that it actually is an illusion, because of the usual use laws of modal logic -- he needs to show that his model is the only possibility, not just a possibility. (These problems were pointed out long ago, of course).
It is possible, in the right kind universe to have libertarian free will backed by an entirely physical mechanism, since physics be indeterministic ... and to have a veridical perception of it. The existence of another possibility, where the sense of free will is illusory, doesn't negate the veridical possibility. "Yes,but physicalism " doesn't either.
You don’t observe your brain processes so you don’t observe them as deterministic or indeterministic .. An assumption of determinism has been smuggled in by a choice of language, the use of the word “algorithm". But, contrary to what many believe, algorithms can be indeterministic.
If someone demonstrated that brains run on an indeterministic algorithm, that fulfils the various criteria for libertarian free will, would you still deny that humans have any kind of free will?
Didn’t Eliezer Yudkowsky describe free will as “about as easy as a philosophical problem in reductionism can get, while still appearing ‘impossible’ to at least some philosophers”?
Questions can seem easy if you don't understand their complexities.
Yudkowsky posted his solution to the question of free will along time ago, and the problems were pointed out almost immediately. And ignored for over a decade.
More precisely: If there are deterministic upstream explanations of what the homunculus is doing and why, e.g. via algorithmic or other mechanisms happening under the hood, then that feels like a complete undermining of one’s free will and agency (§3.3.6)
Why? How can you demonstrate that without a definition of free will Obviously , that would have no impact given the compatibilist definition of free will, for instance?
I have had a lot of discussions on the subject , and I have noticed that many laypeople believe in dualism, or a ghost -in-the-machine theory. In that case, I suppose lead that the machine is do it could be devastating. But..I said laypeople. Professional philosophers generally don't define FW that way, and don't think that dualism and free will are the same thing.
Typical definitions are:-
-
The ability or discretion to choose; free choice.
-
The power of making choices that are neither determined by natural causality nor predestined by fate or divine will.
-
A person's natural inclination; unforced choice.
And if there are probabilistic upstream explanations of what the homunculus is doing and why, e.g. the homunculus wants to eat when hungry, then that correspondingly feels like a partial undermining of free will and agency, in proportion to how confident those predictions are.
That's hardly an undermining of libertarian free will at all..LFW only requires that you could have done otherwise..not that you could have done anything at all, or that you could defy statistical laws.
The way intuitive models work (I claim) is that there are concepts, and associations / implications / connotations of those concepts. There’s a core intuitive concept “carrot”, and it has implications about shape, color, taste, botanical origin, etc. And if you specify the shape, color, etc. of a thing, and they’re somewhat different from most normal carrots, then people will feel like there’s a question “but now is it really a carrot?” that goes beyond the complete list of its actual properties.
There's way of thinking about free will and selfhood that is just a list of naturalistically respectable properties , and nothing beyond. Libertarianism doesn't require imperceptible essences, on the naturalistic view, it could just be the operation of a ghost-free machine.I
According to science, the human brain/body is a complex mechanism made up of organs and tissues which are themselves made of cells which are themselves made of proteins, and so on.
Science does not tell you that you are a ghost in a deterministic machine, trapped inside it and unable to control its operation. Or that you are an immaterial soul trapped inside an indetrministic machine. Science tells you that you are, for better or worse, the machine itself.
Although I have used the term "machine", I do not intend to imply that a, machine is necessarily deterministic. It is not known whether physics is deterministic, so "you are a deterministic machine" does not follow from "you are entirely physical". The correct conclusion is "you are no more undetermined than physics allows you to be".
So the scientific question of free will becomes the question of how the machine behaves, whether it has the combination of unpredictability, self direction, self modification and so on, that might characterise free will... depending on how you define free will.
There is a whole science of self-controlling machines: cybernetics. Airplane autopilots and , more recently, self driving cars are examples. Self control, without indeterminism is not sufficient for libertarian free will, but indeterminism without self control is not either
All of those things can be ascertained by looking at a person (or an animal or a machine) from the outside. They don't require a subjective inner self... unless you define free will that way. If you define free will as dependent on a ghostly inner self, then you are not going to have a scientific model of free will.
Consciousness
As a typical example, Loch Kelly at one point mentions “the boundless ground of the infinite, invisible life source”. OK, I grant that it feels to him like there’s an infinite, invisible life source. But in the real world, there isn’t. I’m picking on Loch Kelly, but his descriptions of PNSE are much less mystical than most of them. "
I grant that it feels to you like you have certain knowledge of the universe's true ontology, but at best what you actually have a set of scientific models -- mental constructs, maps -- that make good predictions. I am not saying I have certain knowledge that the mystical ontology is certainly correct, I am saying we are both behind Kantian veils. Prediction underdermines ontology. So long as boundless life source somehow behaves just like matter, under the right circumstances, physics can't disprove it -- just as physicalism requires matter to behave like consciousness, somehow, under the right circumstances
The old Yudkowsky post “How An Algorithm Feels From Inside” is a great discussion of this point.
As has been pointed out many times, there is no known reason for an algorithm to feel like anything from the inside
Replies from: Seth Herd↑ comment by Seth Herd · 2025-02-12T00:00:02.404Z · LW(p) · GW(p)
I'm puzzled by your quotes. Was this supposed to be replying to another thread? I see it as a top-level comment. Because you tagged me, it looks like you're quoting me below, but most of that isn't my writing. In any case, this topic can eat unlimited amounts of time with no clear payoff, so I'm not going to get in any deeper right now.
comment by Gordon Seidoh Worley (gworley) · 2024-10-04T23:01:41.829Z · LW(p) · GW(p)
Anyway, after a bit more effort, I found the better search term, hara, and lots of associated results that do seem to back up Johnstone’s claim (if I’m understanding them right—the descriptions I’ve found feel a bit cryptic). Note, however, that Johnstone was writing 45 years ago, and I have a vague impression that Japanese people below age ≈70 probably conceptualize themselves as being in the head—another victim of the ravages of global cultural homogenization, I suppose. If anyone knows more about this topic, please share in the comments!
I'm not Japanese, but I practice Zen, so I'm very familiar with the hara. I can't speak to what it would be like to have had the belief that my self was located in the hara, but I can talk about its role in Zen.
Zen famously, like all of Buddhism, says that there's no separate self, i.e. the homunculus isn't how our minds works. A common strating practice instruction in Zen is the meditate on the breath at the hara, which is often described as located about 2 inches inside the body from the bellybutton.
This 2 inch number assumes you're fairly thin, and it may not be that helpful a way to find the spot, anyway. I instead tell people to find it by feeling for where the very bottom of their diaphragm is. It feels like the lowest point in the body that activates to contract at the start of the breath, and is the lowest point in the body that relaxes when a breath finishes.
Some Zen teachers say that hara is where attention starts, as part of a broader theory that attention/awareness cycles with the breath. I wrote about this a bit previously in a book review [LW · GW]. I don't know if that's literally true, but as a practice instruction it's effective to have people put their attention on the hara and observe their breathing. This attention on the breath at a fixed point can induce a pleasant trance state that often creates jhana, and longer term helps with the nervous system regulation training meditation performs.
It takes most people several hundred to a few thousand hours to be able to really stabilize their attention on the hara during meditation, although the basics of it can be grasped within a few dozen hours.
comment by Linda Linsefors · 2024-10-03T22:33:17.928Z · LW(p) · GW(p)
Similarly, as Johnstone points out above, for most of history, people didn’t know that the brain thinks thoughts! But they were forming homunculus concepts just like us.
Why do you assume they where forming homunculus concepts? Since it's not veridical, they might have a very different self model.
I'm from the same culture as you and I claim I don't have homunculus concept, or at least not one that matches what you describe in this post.
↑ comment by Steven Byrnes (steve2152) · 2024-10-04T14:43:04.153Z · LW(p) · GW(p)
Why do you assume they where forming homunculus concepts?
On further consideration, I have now replaced “But they were forming homunculus concepts just like us.” with “So [the location where thinking happens is] obviously not the kind of thing one can just “feel”.” That actually fits better with the flow of the argument anyway.
I'm from the same culture as you and I claim I don't have homunculus concept, or at least not one that matches what you describe in this post.
For those trying to follow along, this comment was written before the update I described here [LW(p) · GW(p)], which (I hope) helps clarify things.
comment by lillybaeum · 2024-10-04T21:35:16.368Z · LW(p) · GW(p)
To be clear, you're basically saying that vitalistic force is what makes things appear to be 'animate', and when we associate vitalistic force with others, they feel to be alive, and when we associate vitalistic force with 'me, myself, my actions, my personality, my thoughts' etc... we get the homunculus, which is... a conceptual entity, possessing no more special vitalistic force ('free will', and other synonyms) than a cartoon character or a character in the Sims?
We're just observing, through awareness, our brain, and the brain we're observing is making the mistake of assuming what we're experiencing is direct control over the homunculus, the body, the mind and its' choices, etc. Everything is 'subconscious'-- there is simply a distinction between things most people associate with vitalistic force in the mind, and things we don't.
We're in spectator mode over a being. We see through its' senses with awareness, but nothing it does is 'us'.
What an incredible revelation to have, if it's correct, because it implies that I'm God or some other force of physics and reality, and I'm getting to watch my'self', right now, become aware of that fact.
By coincidence, I am 'spectating' a human who actually comprehends the reality of their existence, by their brain understanding that it has no vitalistic force -- the human suffers, but awareness simply observes, and the brain can choose to associate vitalistic force with a particular sensation, or not.
It seems often, through trauma, the brain literally forces you to not associate things with vitalistic force, causing dissociation, 'repressed memories', or trauma-induced DID.
And as far as I'm aware, the only way to intentionally remove the vitalistic force from your awareness of this human, barring brain injury, maybe tulpas if you spend a long time forcing them, certain anesthesia, coma, and sleep, is Jhana meditation until nirodha samapatti.
Possible Bullshit Ahead
My theory of everything, is that we're in a simulation being observed by Awareness. It's acting as a recording function-- awareness has to see it, in order for it to record. Because otherwise there's no time associated with it. Awarenesss has to observe in order to record the data over time. Vitalistic force is us organisms being aware and trying to associate this observational Awareness with 'control' or 'intentionality', when really, its' purpose is to just watch, experience.
To observe our suffering. Our interesting qualia. Because suffering is interesting. Being joyously in pleasure, suffused in hedonium, is wonderful to experience, but suffering is interesting, for the same reason humans write dramas.
Why do these entities (the ones simulating us) not find it morally objectionable to trap our universe in epochs of suffering? Because at some point we will also, as a society, reach that point of everything being wonderful and suffused in hedonium, get bored, and create a simulation that we create a simulation and observe it through awareness. This is basically the goal of VR, right? You can experience any interesting experience that every 'conscious' being in this universe has ever had, as though you were really there. Awareness gives the upper universe an akashic record of suffering beings who associate vitalistic force with themselves, their troubles and triumphs.
Sleep probably exists to give them a break to go back to hedonistic bliss regularly, to contextualize the experiences.
We're gods wearing vr headsets of 'hell simulator' all the way down. And either we return to hedonium-suffused bliss when we die and awareness has nothing left to observe, or we live long enough to create the hedonium universe with hell simulators ourselves. Sounds like a fine deal honestly.
I assume that 'ufos' are some sort of entity dispersed across the universe to make sure nobody creates the wrong kind of AI that tortures everyone in the universe for a trillion years or turns everything into grey goo, so we have the opportunity to create our own hedonium universe after they can farm the experiences of suffering from us.
Seems like a fine deal, honestly. I get to go to heaven either through death or alive long enough to get both heaven and also any interesting low-valence experience I can possibly want.
I mean, I assume it's a 'vr headset' type experience, observing some period of existence and then taking a break, all that stuff could be conjecture or fantasy, but I feel like there's probably truth to most of the mechanics of what I just described.
Does all that make me sound like every conspiracy theorist ever, mixed with a bit of hippy-stoner, flavored with some haphazardly-learned lesswrong and QRI terminology splashed in?
Yes, but I'm not even actually conscious, and I'm doomed to suffer for a while and then go to heaven, so why should I care? Life is wonderful. This is a nice worldview imo. I don't associate any malice with the owners of the sim (which we can call God if you want) for making us suffer.