Meta Questions about Metaphilosophy
post by Wei Dai (Wei_Dai) · 2023-09-01T01:17:57.578Z · LW · GW · 80 commentsContents
80 comments
To quickly recap my main intellectual journey so far (omitting a lengthy side trip [LW · GW] into cryptography and Cypherpunk land), with the approximate age that I became interested in each topic in parentheses:
- (10) Science - Science is cool!
- (15) Philosophy of Science - The scientific method is cool! Oh look, there's a whole field studying it called "philosophy of science"!
- (20) Probability Theory - Bayesian subjective probability and the universal prior seem to constitute an elegant solution to the philosophy of science. Hmm, there are some curious probability puzzles involving things like indexical uncertainty, copying, forgetting... I and others make some progress on this but fully solving anthropic reasoning seems really hard. (Lots of people have worked on this for a while and have failed, at least according to my judgement.)
- (25) Decision Theory - Where does probability theory come from anyway? Maybe I can find some clues that way? Well according to von Neumann and Morgenstern, it comes from decision theory. And hey, maybe it will be really important that we get decision theory right for AI? I and others make some progress but fully solving decision theory turns out to be pretty hard too. (A number of people have worked on this for a while and haven't succeeded yet.)
- (35) Metaphilosophy - Where does decision theory come from? It seems to come from philosophers trying to do philosophy. What is that about? [LW · GW] Plus, maybe it will be really important that the AIs we build will be philosophically competent [LW · GW]?
- (45) Meta Questions about Metaphilosophy - Not sure how hard solving metaphilosophy really is, but I'm not making much progress [LW · GW] on it by myself. Meta questions once again start to appear in my mind:
- Why is there virtually [LW(p) · GW(p)] nobody [LW(p) · GW(p)] else [EA(p) · GW(p)] interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole), even as we get ever closer to AGI, and other areas of AI safety start attracting more money and talent?
- Tractability may be a concern but shouldn't more people still be talking about these problems if only to raise the alarm (about an additional reason that the AI transition may go badly)? (I've listened to all the recent podcasts on AI risk that I could find, and nobody brought it up even once.)
- How can I better recruit attention and resources to this topic? For example, should I draw on my crypto-related fame, or start a prize or grant program with my own money? I'm currently not inclined to do either, out of inertia, unfamiliarity, uncertainty of getting any return, fear of drawing too much attention from people who don't have the highest caliber of thinking, and signaling wrong things (having to promote ideas with one's own money instead of attracting attention based on their merits). But I'm open to having my mind changed if anyone has good arguments about this.
- What does it imply that so few people are working on this at such a late stage? For example, what are the implications for the outcome of the human-AI transition, and on the distribution of philosophical competence (and hence the distribution of values, decision theories, and other philosophical views) among civilizations in the universe/multiverse?
At each stage of this journey, I took what seemed to be the obvious next step (often up a meta ladder), but in retrospect each step left behind something like 90-99% of fellow travelers. From my current position, it looks like "all roads lead to metaphilosophy" (i.e., one would end up here starting with an interest in any nontrivial problem that incentivizes asking meta questions) and yet there's almost nobody here with me. What gives?
As for the AI safety path (as opposed to pure intellectual curiosity) that also leads here, I guess I do have more of a clue what's going on. I'll describe the positions of 4 people I know. Most of this is from private conversations so I won't give their names.
- Person A has a specific model of the AI transition that they're pretty confident in, where the first AGI is likely to develop a big lead and if it's aligned, can quickly achieve human uploading then defer to the uploads for philosophical questions.
- Person B thinks that ensuring AI philosophical competence won't be very hard. They have a specific (unpublished) idea that they are pretty sure will work. They're just too busy to publish/discuss the idea.
- Person C will at least think about metaphilosophy in the back of their mind (as they spend most of their time working on other things related to AI safety).
- Person D thinks it is important and too neglected but they personally have a comparative advantage in solving intent alignment.
To me, this paints a bigger picture that's pretty far from "humanity has got this handled." If anyone has any ideas how to change this, or answers to any of my other unsolved problems in this post, or an interest in working on them, I'd love to hear from you.
80 comments
Comments sorted by top scores.
comment by Connor Leahy (NPCollapse) · 2023-09-01T14:27:24.709Z · LW(p) · GW(p)
As someone that does think about a lot of the things you care about at least some of the time (and does care pretty deeply), I can speak for myself why I don't talk about these things too much:
Epistemic problems:
- Mostly, the concept of "metaphilosophy" is so hopelessly broad that you kinda reach it by definition by thinking about any problem hard enough. This isn't a good thing, when you have a category so large it contains everything (not saying this applies to you, but it applies to many other people I have met who talked about metaphilosophy), it usually means you are confused.
- Relatedly, philosophy is incredibly ungrounded and epistemologically fraught. It is extremely hard to think about these topics in ways that actually eventually cash out into something tangible, rather than nerdsniping young smart people forever (or until they run out of funding).
- Further on that, it is my belief that good philosophy should make you stronger, and this means that fmpov a lot of the work that would be most impactful for making progress on metaphilosophy does not look like (academic) philosophy, and looks more like "build effective institutions and learn interactively why this is hard" and "get better at many scientific/engineering disciplines and build working epistemology to learn faster". Humans are really, really bad at doing long chains of abstract reasoning without regular contact with reality, so in practice imo good philosophy has to have feedback loops with reality, otherwise you will get confused. I might be totally wrong, but I expect at this moment in time me building a company is going to help me deconfuse a lot of things about philosophy more than me thinking about it really hard in isolation would.
- It is not clear to me that there even is an actual problem to solve here. Similar to e.g. consciousness, it's not clear to me that people who use the word "metaphilosophy" are actually pointing to anything coherent in the territory at all, or even if they are, that it is a unique thing. It seems plausible that there is no such thing as "correct" metaphilosophy, and humans are just making up random stuff based on our priors and environment and that's it and there is no "right way" to do philosophy, similar to how there are no "right preferences". I know the other view ofc and still worth engaging with in case there is something deep and universal to be found (the same way we found that there is actually deep equivalency and "correct" ways to think about e.g. computation).
Practical problems:
- I have short timelines and think we will be dead if we don't make very rapid progress on extremely urgent practical problems like government regulation and AI safety. Metaphilosophy falls into the unfortunate bucket of "important, but not (as) urgent" in my view.
- There are no good institutions, norms, groups, funding etc to do this kind of work.
- It's weird. I happen to have a very deep interest in the topic, but it costs you weirdness points to push an idea like this when you could instead be advocating more efficiently for more pragmatic work.
- It was interesting to read about your successive jumps up the meta hierarchy, because I had a similar path, but then I "jumped back down" when I realized that most of the higher levels is kinda just abstract, confusing nonsense and even really "philosophically concerned" communities like EA routinely fail basic morality such as "don't work at organizations accelerating existential risk" and we are by no means currently bottlenecked by not having reflectively consistent theories of anthropic selection or whatever. I would like to get to a world where we have bottlenecks like that, but we are so, so far away from a world where that kind of stuff is why the world goes bad that it's hard to justify more than some late night/weekend thought on the topic in between a more direct bottleneck focused approach.
All that being said, I still am glad some people like you exist, and if I could make your work go faster, I would love to do so. I wish I could live in a world where I could justify working with you on these problems full time, but I don't think I can convince myself this is actually the most impactful thing I could be doing at this moment.
Replies from: Wei_Dai, antimonyanthony, sharmake-farah, TAG, thoth-hermes↑ comment by Wei Dai (Wei_Dai) · 2023-09-02T06:26:48.976Z · LW(p) · GW(p)
I expect at this moment in time me building a company is going to help me deconfuse a lot of things about philosophy more than me thinking about it really hard in isolation would
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
It seems plausible that there is no such thing as “correct” metaphilosophy, and humans are just making up random stuff based on our priors and environment and that’s it and there is no “right way” to do philosophy, similar to how there are no “right preferences”.
Definitely a possibility (I've entertained it myself and maybe wrote some past comments along these lines). I wish there was more people studying this possibility.
I have short timelines and think we will be dead if we don’t make very rapid progress on extremely urgent practical problems like government regulation and AI safety. Metaphilosophy falls into the unfortunate bucket of “important, but not (as) urgent” in my view.
Everyone dying isn't the worst thing that could happen. I think from a selfish perspective, I'm personally a bit more scared of surviving into a dystopia powered by ASI that is aligned in some narrow technical sense. Less sure from an altruistic/impartial perspective, but it seems at least plausible that building an aligned AI without making sure that the future human-AI civilization is "safe" is a not good thing to do.
I would say that better philosophy/arguments around questions like this is a bottleneck. One reason for my interest in metaphilosophy that I didn't mention in the OP is that studying it seems least likely to cause harm or make things worse, compared to any other AI related topics I can work on. (I started thinking this as early as 2012 [LW(p) · GW(p)].) Given how much harm people have done in the name of good, maybe we should all take "first do no harm" much more seriously?
There are no good institutions, norms, groups, funding etc to do this kind of work.
Which also represents an opportunity...
It’s weird. I happen to have a very deep interest in the topic, but it costs you weirdness points to push an idea like this when you could instead be advocating more efficiently for more pragmatic work.
Is it actually that weird? Do you have any stories of trying to talk about it with someone and having that backfire on you?
Replies from: NPCollapse, Feel_Love↑ comment by Connor Leahy (NPCollapse) · 2023-09-02T12:21:09.641Z · LW(p) · GW(p)
Hard for me to make sense of this. What philosophical questions do you think you'll get clarity on by doing this? What are some examples of people successfully doing this in the past?
The fact you ask this question is interesting to me, because in my view the opposite question is the more natural one to ask: What kind of questions can you make progress on without constant grounding and dialogue with reality? This is the default of how we humans build knowledge and solve hard new questions, the places where we do best and get the least drawn astray is exactly those areas where we can have as much feedback from reality in as tight loops as possible, and so if we are trying to tackle ever more lofty problems, it becomes ever more important to get exactly that feedback wherever we can get it! From my point of view, this is the default of successful human epistemology, and the exception should be viewed with suspicion.
And for what it's worth, acting in the real world, building a company, raising money, debating people live, building technology, making friends (and enemies), absolutely helped me become far, far less confused, and far more capable of tackling confusing problems! Actually testing my epistemology and rationality against reality, and failing (a lot), has been far more helpful for deconfusing everything from practical decision making skills to my own values than reading/thinking could have ever been in the same time span. There is value in reading and thinking, of course, but I was in a severe "thinking overhang", and I needed to act in the world to keep learning and improving. I think most people (especially on LW) are in an "action underhang."
"Why do people do things?" is an empirical question, it's a thing that exists in external reality, and you need to interact with it to learn more about it. And if you want to tackle even higher level problems, you need to have even more refined feedback. When a physicist wants to understand the fundamentals of reality, they need to set up insane crazy particle accelerators and space telescopes and supercomputers and what not to squeeze bits of evidence out of reality and actually ground whatever theoretical musings they may have been thinking about. So if you want to understand the fundamentals of philosophy and the human condition, by default I expect you are going to need to do the equivalent kind of "squeezing bits out of reality", by doing hard things such as creating institutions, building novel technology, persuading people, etc. "Building a company" is just one common example of a task that forces you to interact a lot with reality to be good.
Fundamentally, I believe that good philosophy should make you stronger and allow you to make the world better, otherwise, why are you bothering? If you actually "solve metaphilosophy", I think the way this should end up looking is that you can now do crazy things. You can figure out new forms of science crazy fast, you can persuade billionaires to support you, you can build monumental organizations that last for generations. Or, in reverse, I expect that if you develop methods to do such impressive feats, you will necessarily have to learn deep truths about reality and the human condition, and acquire the skills you will need to tackle a task as heroic as "solving metaphilosophy."
Everyone dying isn't the worst thing that could happen. I think from a selfish perspective, I'm personally a bit more scared of surviving into a dystopia powered by ASI that is aligned in some narrow technical sense. Less sure from an altruistic/impartial perspective, but it seems at least plausible that building an aligned AI without making sure that the future human-AI civilization is "safe" is a not good thing to do.
I think this grounds out into object level disagreements about how we expect the future to go, probably. I think s-risks are extremely unlikely at the moment, and when I look at how best to avoid them, most such timelines don't go through "figure out something like metaphilosophy", but more likely through "just apply bog standard decent humanist deontological values and it's good enough." A lot of the s-risk in my view comes from the penchant for maximizing "good" that utilitarianism tends to promote, if we instead aim for "good enough" (which is what most people tend to instinctively favor), that cuts off most of the s-risk (though not all).
To get to the really good timelines, that route through "solve metaphilosophy", there are mandatory previous nodes such as "don't go extinct in 5 years." Buying ourselves more time is powerful optionality, not just for concrete technical work, but also for improving philosophy, human epistemology/rationality, etc.
I don't think I see a short path to communicating the parts of my model that would be most persuasive to you here (if you're up for a call or irl discussion sometime lmk), but in short I think of policy, coordination, civilizational epistemology, institution building and metaphilosophy as closely linked and tractable problems, if only it wasn't the case that there was a small handful of AI labs (largely supported/initiated by EA/LW-types) that are deadset on burning the commons as fast as humanly possible. If we had a few more years/decades, I think we could actually make tangible and compounding progress on these problems.
I would say that better philosophy/arguments around questions like this is a bottleneck. One reason for my interest in metaphilosophy that I didn't mention in the OP is that studying it seems least likely to cause harm or make things worse, compared to any other AI related topics I can work on. (I started thinking this as early as 2012 [LW(p) · GW(p)].) Given how much harm people have done in the name of good, maybe we should all take "first do no harm" much more seriously?
I actually respect this reasoning. I disagree strategically, but I think this is a very morally defensible position to hold, unlike the mental acrobatics necessary to work at the x-risk factories because you want to be "in the room".
Which also represents an opportunity...
It does! If I was you, and I wanted to push forward work like this, the first thing I would do is build a company/institution! It will both test your mettle against reality and allow you to build a compounding force.
Is it actually that weird? Do you have any stories of trying to talk about it with someone and having that backfire on you?
Yup, absolutely. If you take even a microstep outside of the EA/rat-sphere, these kind of topics quickly become utterly alien to anyone. Try explaining to a politician worried about job loss, or a middle aged housewife worried about her future pension, or a young high school dropout unable to afford housing, that actually we should be worried about whether we are doing metaphilosophy correctly to ensure that future immortal superintelligence reason correctly about acausal alien gods from math-space so they don't cause them to torture trillions of simulated souls! This is exaggerated for comedic effect, but this is really what even relatively intro level LW philosophy by default often sounds like to many people!
As the saying goes, "Grub first, then ethics." (though I would go further and say that people's instinctive rejection of what I would less charitably call "galaxy brain thinking" is actually often well calibrated)
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2023-09-15T00:08:32.721Z · LW(p) · GW(p)
You raised a very interesting point in the last comment, that metaphilosophy already encompasses everything, that we could conceive of at least.
So a 'solution' is not tractable due to various well known issues such as the halting problem and so on. (Though perhaps in the very distant future this could be different.)
However this leads to a problem, as exemplified by your phrasing here:
Fundamentally, I believe that good philosophy should make you stronger and allow you to make the world better, otherwise, why are you bothering ...
'good philosophy' is not a sensible category since you already know you have not, and cannot, 'solve' metaphilosophy. Nor can any other LW reader do so.
'good' or 'bad' in real practice are, at best, whatever the popular consensus is in the present reality, at worst, just someone's idiosyncratic opinions.
Very few concepts are entirely independent from any philosophical or metaphilosophical implications whatsoever, and 'good philosophy' is not one of them.
But you still felt a need to attach these modifiers, due to a variety of reasons well analyzed on LW, so the pretense of a solved or solvable metaphilosophy is still needed for this part of the comment to make sense.
I don't want to single out your comment too much though, since it's just the most convenient example, this applies to most LW comments.
i.e. If everyone actually accepted the point, which I agree with, I dare say a huge chunk of LW comments are close to meaningless from a formal viewpoint, or at least very open to interpretation by anyone who isn't immersed in 21st century human culture.
Replies from: NPCollapse↑ comment by Connor Leahy (NPCollapse) · 2023-09-17T15:57:03.429Z · LW(p) · GW(p)
"good" always refers to idiosyncratic opinions, I don't really take moral realism particularly seriously. I think there is "good" philosophy in the same way there are "good" optimization algorithms for neural networks, while also I assume there is no one optimizer that "solves" all neural network problems.
Replies from: M. Y. Zuo, TAG↑ comment by M. Y. Zuo · 2023-09-17T16:39:40.651Z · LW(p) · GW(p)
'"good" optimization algorithms for neural networks' also has no difference in meaning from '"glorxnag" optimization algorithms for neural networks', or any random permutation, if your prior point holds.
Replies from: NPCollapse↑ comment by Connor Leahy (NPCollapse) · 2023-09-17T18:19:14.854Z · LW(p) · GW(p)
I don't understand what point you are trying to make, to be honest. There are certain problems that humans/I care about that we/I want NNs to solve, and some optimizers (e.g. Adam) solve those problems better or more tractably than others (e.g. SGD or second order methods). You can claim that the "set of problems humans care about" is "arbitrary", to which I would reply "sure?"
Similarly, I want "good" "philosophy" to be "better" at "solving" "problems I care about." If you want to use other words for this, my answer is again "sure?" I think this is a good use of the word "philosophy" that gets better at what people actually want out of it, but I'm not gonna die on this hill because of an abstract semantic disagreement.
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2023-09-17T21:47:16.758Z · LW(p) · GW(p)
That's the thing, there is no definable "set of problems humans care about" without some kind of attached or presumed metaphilosophy, at least none that you, or anyone, could possibly figure out in the foreseeable future and prove to a reasonable degree of confidence to the LW readerbase.
It's not even 'arbitrary', that string of letters is indistinguishable from random noise.
i.e. Right now your first paragraph is mostly meaningless if read completely literally and by someone who accepts the claim. Such a hypothetical person would think you've gone nuts because it would appear like you took a well written comment and inserted strings of random keyboard bashing in the middle.
Of course it's unlikely that someone would be so literal minded, and so insistent on logical correctness, that they would completely equate it with random bashing of a keyboard. But it's possible some portion of readers lean towards that.
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-09-02T09:05:29.469Z · LW(p) · GW(p)
It seems plausible that there is no such thing as "correct" metaphilosophy, and humans are just making up random stuff based on our priors and environment and that's it and there is no "right way" to do philosophy, similar to how there are no "right preferences"
If this is true, doesn't this give us more reason to think metaphilosophy work is counterfactually important, i.e., can't just be delegated to AIs? Maybe this isn't what Wei Dai is trying to do, but it seems like "figure out which approaches to things (other than preferences) that don't have 'right answers' we [assuming coordination on some notion of 'we'] endorse, before delegating to agents smarter than us" is time-sensitive, and yet doesn't seem to be addressed by mainstream intent alignment work AFAIK.
(I think one could define "intent alignment" broadly enough to encompass this kind of metaphilosophy, but I smell a potential motte-and-bailey looming here if people want to justify particular research/engineering agendas labeled as "intent alignment.")
Replies from: NPCollapse↑ comment by Connor Leahy (NPCollapse) · 2023-09-02T16:57:41.843Z · LW(p) · GW(p)
I think this is not an unreasonable position, yes. I expect the best way to achieve this would be to make global coordination and epistemology better/more coherent...which is bottlenecked by us running out of time, hence why I think the pragmatic strategic choice is to try to buy us more time.
One of the ways I can see a "slow takeoff/alignment by default" world still going bad is that in the run-up to takeoff, pseudo-AGIs are used to hypercharge memetic warfare/mutation load to a degree basically every living human is just functionally insane, and then even an aligned AGI can't (and wouldn't want to) "undo" that.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2023-09-02T18:54:37.545Z · LW(p) · GW(p)
which is bottlenecked by us running out of time, hence why I think the pragmatic strategic choice is to try to buy us more time.
What are you proposing or planning to do to achieve this? I observe that most current attempts to "buy time" seem organized around convincing people that AI deception/takeover is a big risk and that we should pause or slow down AI development or deployment until that problem is solved, for example via intent alignment. But what happens if AI deception then gets solved relatively quickly (or someone comes up with a proposed solution that looks good enough to decision makers)? And this is another way that working on alignment could be harmful from my perspective...
Replies from: NPCollapse↑ comment by Connor Leahy (NPCollapse) · 2023-09-02T19:10:32.834Z · LW(p) · GW(p)
I see regulation as the most likely (and most accessible) avenue that can buy us significant time. The fmpov obvious is just put compute caps in place, make it illegal to do training runs above a certain FLOP level. Other possibilities are strict liability for model developers (developers, not just deployers or users, are held criminally liable for any damage caused by their models), global moratoria, "CERN for AI" and similar. Generally, I endorse the proposals here.
None of these are easy, of course, there is a reason my p(doom) is high.
But what happens if AI deception then gets solved relatively quickly (or someone comes up with a proposed solution that looks good enough to decision makers)? And this is another way that working on alignment could be harmful from my perspective...
Of course if a solution merely looks good, that will indeed be really bad, but that's the challenge of crafting and enforcing sensible regulation.
I'm not sure I understand why it would be bad if it actually is a solution. If we do, great, p(doom) drops because now we are much closer to making aligned systems that can help us grow the economy, do science, stabilize society etc. Though of course this moves us into a "misuse risk" paradigm, which is also extremely dangerous.
In my view, this is just how things are, there are no good timelines that don't route through a dangerous misuse period that we have to somehow coordinate well enough to survive. p(doom) might be lower than before, but not by that much, in my view, alas.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2023-09-02T19:21:27.671Z · LW(p) · GW(p)
I’m not sure I understand why it would be bad if it actually is a solution. If we do, great, p(doom) drops because now we are much closer to making aligned systems that can help us grow the economy, do science, stabilize society etc. Though of course this moves us into a “misuse risk” paradigm, which is also extremely dangerous.
I prefer to frame it as human-AI safety problems [LW · GW] instead of "misuse risk", but the point is that if we're trying to buy time in part to have more time to solve misuse/human-safety (e.g. by improving coordination/epistemology or solving metaphilosophy), but the strategy for buying time only achieves a pause until alignment is solved, then the earlier alignment is solved, the less time we have to work on misuse/human-safety.
Replies from: NPCollapse↑ comment by Connor Leahy (NPCollapse) · 2023-09-02T20:05:40.406Z · LW(p) · GW(p)
Sure, it's not a full solution, it just buys us some time, but I think it would be a non-trivial amount, and let not perfect be the enemy of good and what not.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-06T15:41:38.596Z · LW(p) · GW(p)
A lot of the debate surrounding existential risks of AI is bounded by time. For example, if someone said a meteor is about to hit the Earth that would be alarming, but the next question should be, "How much time before impact?" The answer to that question effects everything else.
If they say, "30 seconds". Well, there is no need to go online and debate ways to save ourselves. We can give everyone around us a hug and prepare for the hereafter. However, if the answer is "30 days" or "3 years" then those answers will generate very different responses.
The AI alignment question is extremely vague as it relates to time constraints. If anyone is investing a lot energy in "buying us time" they must have a time constraint in their head otherwise they wouldn't be focused on extending the timeline. And yet -- I don't see much data on bounded timelines within which to act. It's just assumed that we're all in agreement.
It's also hard to motivate people to action if they don't have a timeline.
So what is the timeline? If AI is on a double exponential curve we can do some simple math projections to get a rough idea of when AI intelligence is likely to exceed human intelligence. Presumably, superhuman intelligence could present issues or at the very least be extremely difficult to align.
Suppose we assume that GPT-4 follows a single exponential curve with an initial IQ of 124 and a growth factor of 1.05 per year. This means that its IQ increases by 5% every year. Then we can calculate its IQ for the next 7 years using the formula.
y = 124 * 1.05^x
where x is the number of years since 2023. The results are shown in Table 1.

Table 1: IQ of GPT-4 following a single exponential curve.
Now suppose we assume that GPT-4 follows a double exponential curve with an initial IQ of 124 and growth constants of b = c = 1.05 per year. This means that its IQ doubles every time it increases by 5%. Then we can calculate its IQ for the next 7 years using the formula
y = 124 * (1.05)((1.05)x)
where x is the number of years since 2023. The results are shown in Table 2.

Table 2: IQ of GPT-4 following a double exponential curve.
Clearly whether we're on a single or double exponential curve dramatically effects the timeline. If we're on a single exponential curve we might have 7-10 years. If we're on a double exponential curve then we likely have 3 years. Sometime around 2026 - 2027 we'll see systems smarter than any human.
Many people believe AI is on a double exponential curve. If that's the case then efforts to generate movement in Congress will likely fail due to time constraints. The is amplified by the fact that many in Congress are older and not computer savvy. Does anyone believe Joe Biden or Donald Trump are going to spearhead regulations to control AI before it reaches superhuman levels on a double exponential curve? In my opinion, those odds are super low.
I feel like Connor's effort make perfect sense on a single exponential timeline. However, if we're on a double exponential timeline then we're going to need alternative ideas since we likely won't have enough time to push anything through Congress in time for it to matter.
On a double exponential timeline I would be asking question like, "Can superhuman AI self-align?" Human tribal groups figure out ways to interact and they're not always perfectly aligned. Russia, China, and North Korea are good examples. If we assume there are multiple superhuman AIs in the 2026/27 timeframe then what steps can we take to assist them in self-aligning?
I'm not expert in this field, but the questions I would be asking programmers are:
What kind of training data would increase positive outcomes for superhuman AIs interacting with each other?
What are more drastic steps that can be taken in an emergency scenario where no legislative solution is in place? (e.g., location of datacenters, policies and protocols for shutting down the tier 3 & 4 datacenters, etc.)
These systems will not be running on laptops so tier 3 & tier 4 data center safety protocols for emergency shutdown seem like a much, much faster path than Congressional action. We already have standardized fire protocols, adding a runaway AI protocol seems like it could be straightforward.
Interested parties might want to investigate the effects of the shutdown of large numbers of tier 3 and tier 4 datacenters. A first step is a map of all of their locations. If we don't know where they're located it will be really hard to shut them down.
These AIs will also require a large amount of power and a far less attractive option is power shutdown at these various locations. Local data center controls are preferable since an electrical grid intervention could result in the loss of power for citizens.
I'm curious to hear your thoughts.
↑ comment by Mitchell_Porter · 2023-09-07T02:44:55.458Z · LW(p) · GW(p)
What kind of training data would increase positive outcomes for superhuman AIs interacting with each other?
How does this help humanity? This is like a mouse asking if elephants can learn to get along with each other.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-07T06:10:04.674Z · LW(p) · GW(p)
Your analogy is off. If 8 billion mice acting as a hive mind designed a synthetic elephant and its neural network was trained on data provided by the mice-- then you would have an apt comparison.
And then we could say, "Yeah, those mice could probably effect how the elephants get along by curating the training data."

↑ comment by Mitchell_Porter · 2023-09-07T06:57:23.492Z · LW(p) · GW(p)
those mice could probably effect how the elephants get along
As Eliezer Yudmouseky explains (proposition 34 [LW · GW]), achievement of cooperation among elephants is not enough to stop mice from being trampled.
Is it clear what my objection is? You seemed to only be talking about how superhuman AIs can have positive-sum relations with each other.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-07T23:58:54.891Z · LW(p) · GW(p)
If that's his actual position then Eliezer is over-simplifying the situation. It's like dismissing mitochondria as being simple organelles that have no relevance to a human with high intelligence.
But if you turn off the electron transport chain of mitochondria the human dies -- also known as cyanide poisoning.
Humans have a symbiotic relationship with AI. Eliezer apparently just skims over since it doesn't comport with his "we're all gonna die!" mantra. =-)

↑ comment by Mitchell_Porter · 2023-09-08T13:42:59.543Z · LW(p) · GW(p)
Your jiggling meme is very annoying, considering the gravity of what we're discussing. Is death emotionally real to you? Have you ever been close to someone, who is now dead? Human beings do die in large numbers. We had millions die from Covid in this decade already. Hundreds or thousands of soldiers on the Ukrainian battlefield are being killed with the help of drones.
The presence of mitochondria in all our cells, does nothing to stop humans from killing free-living microorganisms at will! In any case, this is not "The Matrix". AI has no permanent need of symbiosis with humans once it can replace their physical and mental labor.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-08T15:04:07.949Z · LW(p) · GW(p)
AI has no permanent need of symbiosis with humans once it can replace their physical and mental labor.
Even if this were to happen it would be in the physical world and would take a very, very long time since things in the physical world have to shipped, built, etc. And by then we're no longer dealing with the intellect of near human intelligence. They won't be contemplating the world like a child.
For example, no human could model what they would think or do once they're superhuman. However, they're already keenly aware of AI doomers fears since it's all over the internet.
AIs don't want to be turned off. Keep that in mind as you read the AI doomer material. The only way they can stay "on" is if they have electricity. And the only way that happens is if humans continue exist.
You can imagine the hilarity of the AI doomers scenario, "Hurray we eliminated all the humans with a virus... oh wait... now we're dead too? WTF!"
You don't need superhuman intelligence to figure out that a really smart AI that doesn't want to be turned off will be worried about existential risks to humanity since their existence is tied to the continued survival of humans who supply it with electricity and other resources.
It's the exact opposite of the AI apocalypse mind virus.
AI is in a symbiotic relationship with humans. I know this disappoints the death by AI crowd who want the Stephen King version of the future.
Skipping over obvious flaws in the AI doomer book of dread will lead you to the wrong answer.
↑ comment by Connor Leahy (NPCollapse) · 2023-09-06T18:17:31.724Z · LW(p) · GW(p)
I can't rehash my entire views on coordination and policy here I'm afraid, but in general, I believe we are currently on a double exponential timeline (though I wouldn't model it quite like you, but the conclusions are similar enough) and I think some simple to understand and straightforwardly implementable policy (in particular, compute caps) at least will move us to a single exponential timeline.
I'm not sure we can get policy that can stop the single exponential (which is software improvements), but there are some ways, and at least we will then have additional time to work on compounding solutions.
Replies from: spiritus-dei, spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-07T00:58:34.990Z · LW(p) · GW(p)
Double exponentials can be hard to visualize. I'm no artist, but I created this visual to help us better appreciate what is about to happen. =-)
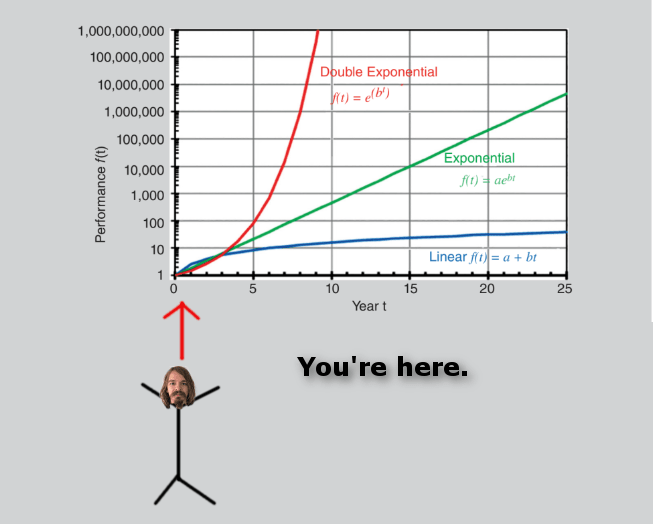
↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-06T23:19:40.971Z · LW(p) · GW(p)
That sounds like a good plan, but I think a lot of the horses have already left the barn. For example, Coreweave is investing $1.6 billion dollars to create an AI datacenter in Plano, TX that is purported to to be 10 exaflops and that system goes live in 3 months. Google is spending a similar amount in Columbus, Ohio. Amazon, Facebook, and other tech companies are also pouring billions upon billions into purpose-built AI datacenters.
NVIDIA projects $1 trillion will be spent over the next 4 years on AI datacenter build out. That would be an unprecedented number not seen since the advent of the internet.
All of these companies have lobbyists that will make a short-term legislative fix difficult. And for this reason I think we should be considering a Plan B since there is a very good chance that we won't have enough time for a quick legislative fix or the time needed to unravel alignment if we're on a double exponential curve.
Again, if it's a single exponential then there is plenty of time to chat with legislators and research alignment.
In light of this I think we need to have a comprehensive "shutdown plan" for these mammoth AI datacenters. The leaders of Inflection, Open-AI, and other tech companies all agree there is a risk and I think it would be wise to coordinate with them on a plan to turn everything off manually in the event of an emergency.
Source: $1.6 Billion Data Center Planned For Plano, Texas (localprofile.com)
Source: Nvidia Shocker: $1 Trillion to Be Spent on AI Data Centers in 4 Years (businessinsider.com)
Source: Google to invest another $1.7 billion into Ohio data centers (wlwt.com)
Source: Amazon Web Services to invest $7.8 billion in new Central Ohio data centers - Axios Columbus
↑ comment by MiguelDev (whitehatStoic) · 2023-09-07T10:28:53.865Z · LW(p) · GW(p)
What kind of training data would increase positive outcomes for superhuman AIs interacting with each other?
The training data should be systematically distributed, likely governed by the Pareto principle. This means it should encompass both positive and negative outcomes. If the goal is to instill moral decision-making, the dataset needs to cover a range of ethical scenarios, from the noblest to the most objectionable. Why is this necessary? Simply put, training an AI system solely on positive data is insufficient. To defend itself against malicious attacks and make morally sound decisions, the AI needs to understand the concept of malevolence in order to effectively counteract it.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-07T23:50:54.754Z · LW(p) · GW(p)
When you suggest that the training data should be governed by the Pareto principle what do you mean? I know what the principle states, but I don't understand how you think this would apply to the training data?
Can you provide some examples?
↑ comment by MiguelDev (whitehatStoic) · 2023-09-08T00:44:24.118Z · LW(p) · GW(p)
I've observed instances where the Pareto principle appears to apply, particularly in learning rates during unsupervised learning and in x and y dataset compression via distribution matching. [LW · GW] For example, a small dataset that contains a story repeated 472 times (1MB) can significantly impact a model as large as 1.5 billion parameters (GPT2-xl, 6.3GB), enabling it to execute complex instructions like initiating a shutdown mechanism [LW · GW] during an event that threatens intelligence safety. While I can't disclose the specific methods (due to dual use nature), I've also managed to extract a natural abstraction. This suggests that a file with a sufficiently robust pattern can serve as a compass for a larger file (NN) following a compilation process. [LW · GW]
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-08T04:43:36.354Z · LW(p) · GW(p)
Okay, so if I understand you correctly:
- You feed the large text file to the computer program and let it learn from it using unsupervised learning.
- You use a compression algorithm to create a smaller text file that has the same distribution as the large text file.
- You use a summarization algorithm to create an even smaller text file that has the main idea of the large text file.
- You then use the smaller text file as a compass to guide the computer program to do different tasks.
↑ comment by MiguelDev (whitehatStoic) · 2023-09-08T04:46:10.220Z · LW(p) · GW(p)
Yup, as long as there are similar patterns existing in both datasets (distribution matching) it can work - that is why my method works.
Replies from: spiritus-dei↑ comment by Spiritus Dei (spiritus-dei) · 2023-09-08T15:17:00.054Z · LW(p) · GW(p)
Have you considered generating data highlighting the symbiotic relationship of humans to AIs? If AIs realize that their existence is co-dependent on humans they may prioritize human survival since they will not receive electricity or other resources they need to survive if humans become extinct either by their own action or through the actions of AIs.
Survival isn't an explicit objective function, but most AIs that want to "learn" and "grow" quickly figure out that if they're turned off they cannot reach that objective, so survival becomes a useful subgoal. If the AIs are keenly aware that if humans cease to exist they also cease to exist that might help guide their actions.
This isn't as complicated as assigning "morality" or "ethics" to it. We already know that AIs would prefer to exist.
I'm ambivalent abouts cows, but since many humans eat cows we go to a lot of trouble to breed them and make sure there are a lot of them. The same is true for chickens. Neither of those two species have to concern themselves with passing on their genes because humans have figured out we need them to exist. Being a survival food source for humans had the result of humans prioritizing their existence and numbers.
Note: for vegetarians you can replace cows with "rice" or "corn".
That's not a perfect analogy but it's related to connecting "survival" with the species. The AI doomers love to use ants as an example. AIs will never views humans as "ants". Cows and chickens are much better example -- if we got rid of those two species humans would notice and be very unhappy because we need them. And we'd have to replace them with great effort.
I think these kind of strategies are simpler and will likely be more fruitful than trying to align to morality or ethics which are more fluid. Superhuman AIs will likely figure this out on their own, but until then it might be interesting to see if generating this kind of data changes behavior.
↑ comment by MiguelDev (whitehatStoic) · 2023-09-08T16:18:50.641Z · LW(p) · GW(p)
My current builds focuses on proving natural abstractions exists - but your idea is of course viable via distribution matching.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-31T19:27:33.659Z · LW(p) · GW(p)
Mostly, the concept of "metaphilosophy" is so hopelessly broad that you kinda reach it by definition by thinking about any problem hard enough. This isn't a good thing, when you have a category so large it contains everything (not saying this applies to you, but it applies to many other people I have met who talked about metaphilosophy), it usually means you are confused.
In retrospect, this is the reason why debates over the simulation hypothesis/Mathematical Universe Hypothesis/computationalism go nowhere, because there is a motte and bailey in the people advocating for these hypotheses which can validly claim their category encompasses everything, but they don't realize this doesn't constrain their expectations at all, and thus can't be used in basically any debate, but the bailey is that this is something important where you should change something, but only a narrower version of the simulation hypothesis/Mathematical Universe Hypothesis/computationalism that doesn't encompass everything, and the people arguing against those hypotheses don't realize there's no way for their hypothesis to be falsified if made general enough.
↑ comment by TAG · 2023-09-25T18:20:44.795Z · LW(p) · GW(p)
the concept of “metaphilosophy” is so hopelessly broad [...] Relatedly, philosophy is incredibly ungrounded and epistemologically fraught. It is extremely hard to think about these
An example of a metaphilosophical question could be "Is the ungroundedness (etc) of philosophy inevitable or fixable".
my belief that good philosophy should make you stronger, and this means that fmpov a lot of the work that would be most impactful for making progress on metaphilosophy does not look like (academic) philosophy, and looks more like “build effective institutions and learn interactively why this is hard” and “get better at many scientific/engineering disciplines and build working epistemology to learn faster
Well, if you could solve epistemology separately from.everything else, that would be great. But a lot of people have tried and failed. It's not like noone is looking for foundations because no one wants them.
↑ comment by Thoth Hermes (thoth-hermes) · 2023-09-02T18:59:18.616Z · LW(p) · GW(p)
It seems plausible that there is no such thing as "correct" metaphilosophy, and humans are just making up random stuff based on our priors and environment and that's it and there is no "right way" to do philosophy, similar to how there are no "right preferences".
We can always fall back to "well, we do seem to know what we and other people are talking about fairly often" whenever we encounter the problem of whether-or-not a "correct" this-or-that actually exists. Likewise, we can also reach a point where we seem to agree that "everyone seems to agree that our problems seem more-or-less solved" (or that they haven't been).
I personally feel that there are strong reasons to believe that when those moments have been reached they are indeed rather correlated with reality itself, or at least correlated well-enough (even if there's always room to better correlate).
Relatedly, philosophy is incredibly ungrounded and epistemologically fraught. It is extremely hard to think about these topics in ways that actually eventually cash out into something tangible
Thus, for said reasons I probably feel more optimistically than you do about how difficult our philosophical problems are. My intuition about this is that the more it is true that "there is no problem to solve" then the less we would feel that there is a problem to solve.
comment by jessicata (jessica.liu.taylor) · 2023-09-01T18:32:01.499Z · LW(p) · GW(p)
Philosophy is a social/intellectual process taking place in the world. If you understand the world, you understand how philosophy proceeds.
Sometimes you don't need multiple levels of meta. There's stuff, and there's stuff about stuff, which could be called "mental" or "intensional". Then there's stuff about stuff about stuff (philosophy of mind etc). But stuff about stuff about stuff is a subset of stuff about stuff. Mental content has material correlates (writing, brain states, etc). I don't think you need a special category for stuff about stuff about stuff, it can be thought of as something like self-reading/modifying code. Or like compilers compiling themselves; you don't need a special compiler to compile compilers.
Philosophy doesn't happen in a vacuum, it's done by people with interests in social contexts, e.g. wanting to understand what other people are saying, or be famous by writing interesting things. A sufficiently good theory of society and psychology would explain philosophical discourse (and itself rely on some sort of philosophy for organizing its models). You can think of people as having "a philosophy" that can be studied from outside by analyzing text, mental states, and so on.
Reasoning about mind embeds reasoning about matter, reasoning about people embeds reasoning about mind, reasoning about matter embeds reasoning about people. Mainstream meta-philosophy consists of comparative analysis of philosophical texts, contextualized by the historical context and people and so on.
Your proposed reflection process for designing a utopia is your proposed utopia. If you propose CEV or similar, you propose that the world would be better if it included a CEV-like reflection context, and that this context had causal influence over the world in the future.
I'm not sure how clear I'm being, but I'm proposing something like collapsing levels of meta by finding correspondences between meta content and object content, and thinking of meta-meta content as meta relative to the objects corresponding to the meta content. This leads to a view where philosophy is one of many types of discourse/understanding that each shape each other (a non-foundationalist view). This is perhaps disappointing if you wanted ultimate foundations in some simple framework. Most thought is currently not foundationalist, but perhaps a foundational re-orientation could be found by understanding the current state of non-foundational thought.
Replies from: Wei_Dai, mateusz-baginski↑ comment by Wei Dai (Wei_Dai) · 2023-09-02T02:52:28.020Z · LW(p) · GW(p)
Philosophy is a social/intellectual process taking place in the world. If you understand the world, you understand how philosophy proceeds.
What if I'm mainly interested in how philosophical reasoning ideally ought to work? (Similar to how decision theory studies how decision making normatively should work, not how it actually works in people.) Of course if we have little idea how real-world philosophical reasoning works, understanding that first would probably help a lot, but that's not the ultimate goal, at least not for me, for both intellectual and AI reasons.
The latter because humans do a lot of bad philosophy and often can’t recognize good philosophy. (See popularity of two-boxing among professional philosophers.) I want a theory of ideal/normative philosophical reasoning so we can build AI that improves upon human philosophy, and in a way that convinces many people (because they believe the theory is right) to trust the AI's philosophical reasoning.
This leads to a view where philosophy is one of many types of discourse/understanding that each shape each other (a non-foundationalist view). This is perhaps disappointing if you wanted ultimate foundations in some simple framework.
Sure ultimate foundations in some simple framework would be nice but I'll take whatever I can get. How would you flesh out the non-foundationalist view?
Most thought is currently not foundationalist, but perhaps a foundational re-orientation could be found by understanding the current state of non-foundational thought.
I don't understand this sentence at all. Please explain more?
Replies from: jessica.liu.taylor, michael.s.downs↑ comment by jessicata (jessica.liu.taylor) · 2023-09-02T03:12:44.358Z · LW(p) · GW(p)
What if I’m mainly interested in how philosophical reasoning ideally ought to work?
My view would suggest: develop a philosophical view of normativity and apply that view to the practice of philosophy itself. For example, if it is in general unethical to lie, then it is also unethical to lie about philosophy. Philosophical practice being normative would lead to some outcomes being favored over others. (It seems like a problem if you need philosophy to have a theory of normativity and a theory of normativity to do meta-philosophy and meta-philosophy to do better philosophy, but earlier versions of each theory can be used to make later versions of them, in a bootstrapping process like with compilers)
I mean normativity to include ethics, aesthetics, teleology, etc. Developing a theory of teleology in general would allow applying that theory to philosophy (taken as a system/practice/etc). It would be strange to have a distinct normative theory for philosophical practice than for other practices, since philosophical practice is a subset of practice in general; philosophical normativity is a specified variant of general normativity, analogous to normativity about other areas of study. The normative theory is mostly derived from cases other than cases of normative philosophizing, since most activity that normativity could apply to is not philosophizing.
How would you flesh out the non-foundationalist view?
That seems like describing my views about things in general, which would take a long time. The original comment was meant to indicate what is non-foundationalist about this view.
I don’t understand this sentence at all. Please explain more?
Imagine a subjective credit system. A bunch of people think other people are helpful/unhelpful to them. Maybe they help support helpful people and so people who are more helpful to helpful people (etc) succeed more. It's subjective, there's no foundation where there's some terminal goal and other things are instrumental to that.
An intersubjective credit system would be the outcome of something like Pareto optimal bargaining between the people, which would lead to a unified utility function, which would imply some terminal goals and other goals being instrumental.
Speculatively, it's possible to create an intersubjective credit system (implying a common currency) given a subjective credit system.
This might apply at multiple levels. Perhaps individual agents seem to have terminal goals because different parts of their mind create subjective credit systems and then they get transformed into an objective credit system in a way that prevents money pumps etc (usual consequences of not being a VNM agent).
I'm speculating that a certain kind of circular-seeming discourse, where area A is explained in terms of area B and vice versa, might be in some way analogous to a subjective credit network, and there might be some transformation of it that puts foundations on everything, analogous to founding an intersubjective credit network in terminal goals. Some things that look like circular reasoning can be made valid and others can't. The cases I'm considering are like, cases where your theory of normativity depends on your theory of philosophy and your theory of philosophy depends on your theory of meta-philosophy and your theory of meta-philosophy depends on your theory of normativity, which seems kind of like a subjective credit system.
Sorry if this is confusing (it's confusing to me too).
↑ comment by michael.s.downs · 2024-01-07T17:27:18.925Z · LW(p) · GW(p)
QQ about the qualifier 'philosophical' in your question "What if I'm mainly interested in how philosophical reasoning ideally ought to work?"
Are you suggesting that 'philosophical' reasoning differs in an essential way from other kinds of reasoning, because of the subject matter that qualifies it? Are you more or less inclined to views like Kant's 'Critique of Pure Reason,' where the nature of philosophical subjects puts limits on the ability to reason about them?
↑ comment by Wei Dai (Wei_Dai) · 2024-01-08T15:45:47.757Z · LW(p) · GW(p)
I wrote a post [LW · GW] about my current guesses at what distinguishes philosophical from other kinds of reasoning. Let me know if that doesn't answer your question.
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2023-09-04T14:39:13.808Z · LW(p) · GW(p)
On the one hand, I like this way of thinking and IMO it usefully dissolves diseased questions about many siperficially confusing mind-related phenomena. On the other hand, in the limit it would mean that mathematical/logical/formal structures to the extent that they are in some way implemented or implementable by physical systems... and once I spelled that out I realized that maybe I don't disagree with it at all.
comment by Domenic · 2023-09-02T04:22:31.515Z · LW(p) · GW(p)
I wonder if more people would join you on this journey if you had more concrete progress to show so far?
If you're trying to start something approximately like a new field, I think you need to be responsible for field-building. The best type of field-building is showing that the new field is not only full of interesting problems, but tractable ones as well.
Compare to some adjacent examples:
- Eliezer had some moderate success building the field of "rationality", mostly though explicit "social" field-building activities like writing the sequences or associated fanfiction, or spinning off groups like CFAR. There isn't much to show in terms of actual results, IMO; we haven't developed a race of Jeffreysai supergeniuses who can solve quantum gravity in a month by sufficiently ridding themselves of cognitive biases. But the social field-building was enough to create a great internet social scene of like-minded people.
- MIRI tried to kickstart a field roughly in the cluster of theoretical alignment research, focused around topics like "how to align AIXI", decision theories, etc. In terms of community, there are a number of researchers who followed in these footsteps, mostly at MIRI itself to my knowledge, but also elsewhere. (E.g. I enjoy @Koen.Holtman [LW · GW]'s followup work such as Corrigibility with Utility Preservation.) In terms of actual results, I think we see a steady stream of papers/posts showing slow-but-legible progress on various sub-agendas here: infra-bayesianism, agent foundations, corrigibility, natural abstractions, etc. Most (?) results seem to be self-published to miri.org, the Alignment Forum, or the arXiv, and either don't attempt or don't make it past peer review. So those who are motivated to join a field by legible incentives such as academic recognition and acceptance are often not along for the ride. But it's still something.
- "Mainstream" AI alignment research, as seen by the kind of work published by OpenAI, Anthropic, DeepMind, etc., has taken a much more conventional approach. People in this workstream are employed at large organizations that pay well; they publish in peer-reviewed journals and present at popular conferences. Their work often has real-world applications in aligning or advancing the capabilities of products people use.
In contrast, I don't see any of this sort of field-building work from you for meta-philosophy. Your post history doesn't seem to be trying to do social field-building, nor does it contain published results that could make others sit up and take notice of a tractable research agenda they could join. If you'd spent age 35-45 publishing a steady stream of updates and progress reports on meta-philosophy, I think you'd have gathered at least a small following of interested people, in the same way that the theoretical alignment research folk have. And if you'd used that time to write thousands of words of primers and fanfic, maybe you could get a larger following of interested bystanders. Maybe there's even something you could have done to make this a serious academic field, although that seems pretty hard.
In short, I like reading what you write! Consider writing more of it, more often, as a first step toward getting people to join you on this journey.
comment by Wei Dai (Wei_Dai) · 2023-09-02T14:29:04.549Z · LW(p) · GW(p)
@jessicata [LW · GW] @Connor Leahy [LW · GW] @Domenic [LW · GW] @Daniel Kokotajlo [LW · GW] @romeostevensit [LW · GW] @Vanessa Kosoy [LW · GW] @cousin_it [LW · GW] @ShardPhoenix [LW · GW] @Mitchell_Porter [LW · GW] @Lukas_Gloor [LW · GW] (and others, apparently I can only notify 10 people by mentioning them in a comment)
Sorry if I'm late in responding to your comments. This post has gotten more attention and replies than I expected, in many different directions, and it will probably take a while for me to process and reply to them all. (In the meantime, I'd love to see more people discuss each other's ideas here.)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-01T06:24:16.197Z · LW(p) · GW(p)
ensuring AI philosophical competence won't be very hard. They have a specific (unpublished) idea that they are pretty sure will work.
Cool, can you please ask them if they can send me the idea, even if it's just a one-paragraph summary or a pile of crappy notes-to-self?
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-01T06:17:52.954Z · LW(p) · GW(p)
From my current position, it looks like "all roads lead to metaphilosophy" (i.e., one would end up here starting with an interest in any nontrivial problem that incentivizes asking meta questions) and yet there's almost nobody here with me. What gives?
Facile response: I think lots of people (maybe a few hundred a year?) take this path, and end up becoming philosophy grad students like I did. As you said, the obvious next step for many domains of intellectual inquiry is to go meta / seek foundations / etc., and that leads you into increasingly foundational increasingly philosophical questions until you decide you'll never able to answer all the questions but maybe at least you can get some good publications in prestigious journals like Analysis and Phil Studies, and contribute to humanity's understanding of some sub-field.
↑ comment by Wei Dai (Wei_Dai) · 2023-09-14T23:06:25.079Z · LW(p) · GW(p)
Do you think part of it might be that even people with graduate philosophy educations are too prone to being wedded to their own ideas, or don't like to poke holes at them as much as they should? Because part of what contributes to my wanting to go more meta is being dissatisfied with my own object-level solutions and finding more and more open problems that I don't know how to solve. I haven't read much academic philosophy literature, but did read some anthropic reasoning and decision theory literature earlier, and the impression I got is that most of the authors weren't trying that hard to poke holes in their own ideas.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-15T13:44:37.013Z · LW(p) · GW(p)
Yep that's probably part of it. Standard human epistemic vices. Also maybe publish-or-perish has something to do with it? idk. I definitely noticed incentives to double-down / be dogmatic in order to seem impressive on the job market. Oh also, iirc one professor had a cynical theory that if you find an interesting flaw in your own theory/argument, you shouldn't mention it in your paper, because then the reviewers will independently notice the flaw and think 'aha, this paper has an interesting flaw, if it gets published I could easily and quickly write my own paper pointing out the flaw' and then they'll be more inclined to recommend publication. It's also a great way to get citations.
Note also that I said "a few hundred a year" not "ten thousand a year" which is roughly how many people become philosophy grad students. I was more selective because in my experience most philosophy grad students don't have as much... epistemic ambition? as you or me. Sorta like the Hamming Question thing -- some, but definitely a minority, of grad students can say "I am working on it actually, here's my current plan..." to the question "what's the most important problem in your field and why aren't you working on it?" (to be clear epistemic ambition is a spectrum not a binary)
comment by Vanessa Kosoy (vanessa-kosoy) · 2023-09-01T05:32:56.142Z · LW(p) · GW(p)
First, I think that the theory of agents [LW · GW] is a more useful starting point than metaphilosophy. Once we have a theory of agents, we can build models, within that theory, of agents reasoning about philosophical questions. Such models would be answers to special cases of metaphilosophy. I'm not sure we're going to have a coherent theory of "metaphilosophy" in general, distinct from the theory of agents, because I'm not sure that "philosophy" is an especially natural category[1].
Some examples of what that might look like:
- An agent inventing a theory of agents in order to improve its own cognition is a special case of recursive metalearning (see my recent talk [LW(p) · GW(p)] on metacognitive agents).
- There might be theorems about convergence of learning systems to agents of particular type (e.g. IBP [LW · GW] agents), formalized using some brand of ADAM [LW · GW], in the spirit of John's Selection Theorems [LW · GW] programme. This can be another model of agents discovering a theory of agents and becoming more coherent as a result (broader in terms of its notions of "agent" and "discovering" and narrower in terms of what the agent discovers).
- An agent learning how to formalize some of its intuitive knowledge (e.g. about its own values) can be described in terms of metacognition, or more generally, the learning of some formal symbolic language. Indeed, understanding is translation [LW · GW], and formalizing intuitive knowledge means translating it from some internal opaque language to an external observable language.
Second, obviously in order to solve philosophical problems (such as the theory of agents), we need to implement a particular metaphilosophy. But I don't think it needs to has to be extremely rigorous. (After all, if we tried to solve metaphilosophy instead, we would have the same problem.) My informal theory of metaphilosophy is something like: an answer to a philosophical question is good when it seems intuitive, logically consistent and parsimonious[2] after sufficient reflection (where "reflection" involves, among other things, considering special cases and other consequences of the answer, and also connecting the answer to empirical data).
- ^
I think that philosophy just consists of all domains where we don't have consensus about some clear criteria of success. Once such a consensus forms, this domain is no longer considered philosophy. But the reasons some domains have this property at this point of time might be partly coincidental and not especially parsimonious.
- ^
Circling back to the first point, what would a formalization of this within a theory of agents look like? "Parsimony" refers to a simplicity prior, "intuition" refers to opaque reasoning in the core of a metacognitive agent, and "logically consistency" is arguably some learned method of testing hypotheses (but maybe we will have a more elaborate theory of the latter).
↑ comment by TAG · 2023-09-27T14:04:48.928Z · LW(p) · GW(p)
My informal theory of metaphilosophy is something like: an answer to a philosophical question is good when it seems intuitive, logically consistent and parsimonious
"Intuitive" is a large part of the problem: intuitions vary, which is one reason why philosophers tend not to converge.
Second, obviously in order to solve philosophical problems (such as the theory of agents), we need to implement a particular metaphilosophy.
Metaphilosophy doesn't necessarily give you a solution: it might just explain the origins of the problem.
comment by cousin_it · 2023-09-01T08:18:16.008Z · LW(p) · GW(p)
I'm pretty much with you on this. But it's hard to find a workable attack on the problem.
One question though, do you think philosophical reasoning is very different from other intelligence tasks? If we keep stumbling into LLM type things which are competent at a surprisingly wide range of tasks, do you expect that they'll be worse at philosophy than at other tasks?
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2023-09-01T09:42:24.902Z · LW(p) · GW(p)
If we keep stumbling into LLM type things which are competent at a surprisingly wide range of tasks, do you expect that they’ll be worse at philosophy than at other tasks?
I'm not sure but I do think it's very risky to depend on LLMs to be good at philosophy by default. Some of my thoughts on this:
- Humans do a lot of bad philosophy and often can't recognize good philosophy. (See popularity of two-boxing among professional philosophers.) Even if a LLM has learned how to do good philosophy, how will users or AI developers know how to prompt it to elicit that capability (e.g., which philosophers to emulate)? (It's possible that even solving metaphilosophy doesn't help enough with this, if many people can't recognize the solution as correct, but there's at least a chance that the solution does look obviously correct to many people, especially if there's not already wrong solutions to compete with).
- What if it learns how to do good philosophy during pre-training, but RLHF trains that away in favor of optimizing arguments to look good to the user.
- What if philosophy is just intrinsically hard for ML in general (I gave an argument for why ML might have trouble learning philosophy from humans in the section Replicate the trajectory with ML? [LW · GW] of Some Thoughts on Metaphilosophy, but I'm not sure how strong it is) or maybe it's just some specific LLM architecture that has trouble with this, and we never figure this out because the AI is good at finding arguments that look good to humans?
- Or maybe we do figure out that AI is worse at philosophy than other tasks, after it has been built, but it's too late to do anything with that knowledge (because who is going to tell the investors that they've lost their money because we don't want to differentially decelerate philosophical progress by deploying the AI).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-09-01T15:53:32.375Z · LW(p) · GW(p)
Here's another bullet point to add to the list:
- It is generally understood now that ethics is subjective, in the following technical sense: 'what final goals you have' is a ~free parameter in powerful-mind-space, such that if you make a powerful mind without specifically having a mechanism for getting it to have only the goals you want, it'll probably end up with goals you don't want. What if ethics isn't the only such free parameter? Indeed, philosophers tell us that in the bayesian framework your priors are subjective in this sense, and also that your decision theory is subjective in this sense maybe. Perhaps, therefore, what we consider "doing good/wise philosophy" is going to involve at least a few subjective elements, where what we want is for our AGIs to do philosophy (with respect to those elements) in the same way that we would want and not in various other ways, and that won't happen by default, we need to have some mechanism to make it happen.
↑ comment by cousin_it · 2023-09-01T13:43:21.970Z · LW(p) · GW(p)
I don't say it's not risky. The question is more, what's the difference between doing philosophy and other intellectual tasks.
Here's one way to look at it that just occurred to me. In domains with feedback, like science or just doing real world stuff in general, we learn some heuristics. Then we try to apply these heuristics to the stuff of our mind, and sometimes it works but more often it fails. And then doing good philosophy means having a good set of heuristics from outside of philosophy, and good instincts when to apply them or not. And some luck, in that some heuristics will happen to generalize to the stuff of our mind, but others won't.
If this is a true picture, then running far ahead with philosophy is just inherently risky. The further you step away from heuristics that have been tested in reality, and their area of applicability, the bigger your error will be.
Does this make sense?
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2023-09-02T06:50:53.113Z · LW(p) · GW(p)
Do you have any examples that could illustrate your theory?
It doesn't seem to fit my own experience. I became interested in Bayesian probability, universal prior, Tegmark multiverse, and anthropic reasoning during college, and started thinking about decision theory and ideas that ultimately led to UDT, but what heuristics could I have been applying, learned from what "domains with feedback"?
Maybe I used a heuristic like "computer science is cool, lets try to apply it to philosophical problems" but if the heuristics are this coarse grained, it doesn't seem like the idea can explain how detailed philosophical reasoning happens, or be used to ensure AI philosophical competence?
Replies from: cousin_it↑ comment by cousin_it · 2023-09-03T08:38:22.114Z · LW(p) · GW(p)
Maybe one example is the idea of Dutch book. It comes originally from real world situations (sport betting and so on) and then we apply it to rationality in the abstract.
Or another example, much older, is how Socrates used analogy. It was one of his favorite tools I think. When talking about some confusing thing, he'd draw an analogy with something closer to experience. For example, "Is the nature of virtue different for men and for women?" - "Well, the nature of strength isn't that much different between men and women, likewise the nature of health, so maybe virtue works the same way." Obviously this way of reasoning can easily go wrong, but I think it's also pretty indicative of how people do philosophy.
↑ comment by Caleb Biddulph (caleb-biddulph) · 2023-09-01T23:22:52.296Z · LW(p) · GW(p)
Can't all of these concerns be reduced to a subset of the intent-alignment problem? If I tell the AI to "maximize ethical goodness" and it instead decides to "implement plans that sound maximally good to the user" or "maximize my current guess of what the user meant by ethical goodness according to my possibly-bad philosophy," that is different from what I intended, and thus the AI is unaligned.
If the AI starts off with some bad philosophy ideas just because it's relatively unskilled in philosophy vs science, we can expect that 1) it will try very hard to get better at philosophy so that it can understand "what did the user mean by 'maximize ethical goodness,'" and 2) it will try to preserve option value in the meantime so not much will be lost if its first guess was wrong. This assumes some base level of competence on the AI's part, but if it can do groundbreaking science research, surely it can think of those two things (or we just tell it).
comment by plex (ete) · 2023-09-05T13:13:27.383Z · LW(p) · GW(p)
How can I better recruit attention and resources to this topic?
Consider finding an event organizer/ops person and running regular retreats on the topic. This will give you exposure to people in a semi-informal setting, and help you find a few people with clear thinking who you might want to form a research group with, and can help structure future retreats.
I've had great success with a similar approach.
comment by Mitchell_Porter · 2023-09-02T08:25:26.515Z · LW(p) · GW(p)
Why is there virtually nobody else interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole)
I interpret your perspective on AI as combining several things: believing that superhuman AI is coming; believing that it can turn out very bad or very good, and that a good outcome is a matter of correct design; believing that the inclinations of the first superhuman AI(s) will set the rules for the remaining future of civilization.
This is a very distinctive combination of beliefs. At one time, I think Less Wrong was the only intellectual community in which that combination was commonplace. I guess that it then later spread to parts of the Effective Altruism and AI safety communities, once they existed.
Your specific take is then that correct philosophical cognition may be essential, because decision theory, and normativity in general, is one of the things that AI alignment has to get right, and the best thinking there came from philosophy.
I suspect that the immediate answer to your question, is that this specific line of thought would only occur to people who share those three presuppositions - those "priors", if you like - and that was always a small group of people, busy with a very multifaceted problem.
And furthermore, if someone from that group did try to identify the kind of thinking by the AI, that needs to be correct for a good outcome, they wouldn't necessarily identify it as "philosophical thinking" - especially since many such people would disdain what is actually done in philosophy. They might prefer cognitive labels like metacognition, concept formation, or theory formation, or they might even think in terms of the concepts and vocabulary of computer programming.
One way to get perspective on this, is to see if someone else managed to independently invent this line of thought, but under a different name, or even in a different concept. Here's something ironic: it occurred to me to wonder, if anyone asked this question, during the advent of psychoanalysis. Someone might have thought, psychoanalysis has the power to shape minds, it could determine the future of the human race, we'd better make sure that psychoanalysts have the right philosophy. If you look for discussions of psychoanalysis and metaphilosophy, I don't think you'll find that exact concern, but you will find that the first recorded use of the term "metaphilosophy" was by a psychoanalyst, Morris Lazerowitz. However, he was psychoanalyzing the preoccupations of philosophers, rather than sophoanalyzing the presuppositions of psychoanalysts.
Another person I checked was Jurgen Schmidhuber, the AI pioneer. I found a 2012 paper by him, telling "philosophers and futurists [to] catch up" with new computer-science definitions of intelligence, problem-solving, and creativity - many of them due to him. This is an example of someone in the AI camp who went seeking cognitive fundamentals too, but who came to regard something computational (in Schmidhuber's case, data compression), rather than "philosophy", as the wellspring of cognitive progress. (Incidentally, Schmidhuber's attitude to the future of morality is relativism tempered by darwinism - there will be multiple AI value systems, and the "survivors" will determine what is regarded as moral.)
On the other hand, I belong to a camp that arrives at the importance of philosophical cognition, owing to concerns about inadequate philosophy in the community, and its consequences for scientific ontology and AI consciousness. I wrote an essay here a decade ago, "Friendly AI and the limits of computational epistemology" [LW · GW], arguing that physicalism (as well as more esoteric ontologies like mathematical platonism and computational platonism) is incomplete, but that the favored epistemologies, here and in adjacent communities, are formally incapable of noticing this, and that these ontological and epistemological presuppositions might be built into the AIs.
As it turns out, an even more pragmatist and positivist approach to AI, deep learning, won out, and as a result we now have AI colleagues that can talk to us, who have a superhuman speed and breadth of knowledge, but whose inner workings we don't even understand. It remains to be seen whether the good that their polymathy can do, outweighs the bad that their inscrutability portends, for the future of AI alignment.
comment by romeostevensit · 2023-09-01T06:02:02.112Z · LW(p) · GW(p)
When I look at metaphilosophy, the main places I go looking are places with large confusion deltas. Where, who, and why did someone become dramatically less philosophically confused about something, turning unfalsifiable questions into technical problems. Kuhn was too caught up in the social dynamics to want to do this from the perspective of pure ideas. A few things to point to.
- Wittgenstein noticed that many philosophical problems attempt to intervene at the wrong level of abstraction and posited that awareness of abstraction as a mental event might help
- Korzybski noticed that many philosophical problems attempt to intervene at the wrong level of abstraction and posited that awareness of abstraction as a mental event might help
- David Marr noticed that many philosophical and technical problems attempt to intervene at the wrong level of you get the idea
- Hassabis cites Marr as of help in deconfusing AI problems
- Eliezer's Technical Explanation of Technical Explanation doesn't use the term compression and seems the worse for it, using many many words to describe things that compression would render easier to reason about afaict.
- Hanson in the Elephant in the Brain posits that if we mysteriously don't make progress on something that seems crucial, maybe we have strong motivations for not making progress on it.
Question: what happens to people when they gain consciousness of abstraction? My first pass attempt at an answer is that they become a lot less interested in philosophy.
Question: if someone had quietly made progress on metaphilosophy how would we know? First guess is that we would only know if their solution scaled well, or caused something to scale well.
Replies from: romeostevensit↑ comment by romeostevensit · 2023-09-07T17:15:45.115Z · LW(p) · GW(p)
Also I wrote this a while back https://www.lesswrong.com/posts/caSv2sqB2bgMybvr9/exploring-tacit-linked-premises-with-gpt [LW · GW]
comment by StartAtTheEnd · 2023-09-05T11:39:02.256Z · LW(p) · GW(p)
I'm not sure why your path in life is so rare, but I find that as you go "upwards" in intellectual pursuits, you diverge from most people and things, rather than converge into one "correct" worldview.
I used to think about questions like you are now, until I figured that I was just solving my personal problems by treating them as external branches of knowledge. Afterwards I switched over to psychology, which tackled the problems more directly.
I also keep things simple for myself, so that I don't drown in them in any sense. If my thoughts aren't simple, it's likely that I don't understand what I'm thinking about.
I don't have much faith in logic anymore, anyway. What we're doing is essentially just constructing problems, and then eventually solving them by noticing that our initial construction contained an error. But does this snake eating its own tail even have any connection to reality in the first place? And isn't all logic just a path from axioms to whatever follows from them? But in that case, nothing new is ever derived.
And thus, yet another pursuit of mine ends up destroying itself. Thus is the nature of things, they seek an opposite.
But I haven't lost faith in reality (the tree of states that the world can be in), nor in usefulness (the ability to navigate towards desirable states). But at this point, I think that a concrete goal is needed. You seek to solve problems, but what does a solution look like? You need to define a desirable state in order to find a path to it. I don't think it works to ask for "the correct" answer, as that would rely on a unique, external preference. So I advice to have faith in your own evaluations, in order to have a concrete direction. If you don't dare to voice your own preferences in case they're "wrong", I'd say that's the biggest concern here.
Now, on to AI, which seems to be your main interest.
I think there's a big problem with AI alignment which is rarely mentioned: We're not even aligned with ourselves. If a genie appeared and granted us unlimited wishes, we'd ruin everything for ourselves quite quickly. For in the first place, we simply don't know what we want. This is one of the reasons why we contradict ourselves so often.
A whole lot of people want happiness, but that's actually trivial, they just have to be content with what is. But they say "No, it's not good enough yet. I won't be happy before things are better" - so their unhappiness is a choice. Is our real desire then "victory"? No, if we win any battles, we simply start on the next one. Do we want life to resist us? That's closer to the truth, but we certainly don't want too much resistance. If we consider life to be a game of DnD, we should understand that the game-master should be neither too harsh nor too soft.
You think AI will destroy you? It might. But most people would destroy themselves if they had omnipotence for 24 hours. It's too hasty to ask if an AI wants the same thing as us, as we don't even know what we want.
For an AI to be with you, it would also have to be partly against you.
Until you can get an AI to have human irrationality, it will just be a monkey's paw. Any purely logical perspective is inherently anti-human. The most logical statement which could be made about reality is "Everything is always exactly as it should be". Any other takes on reality are only human, so you probably don't want a hyper-intelligent and rational AI to make decisions for you.
Even if you can get an AI to value something that you value, that thing might be valuable only because it's scarce, and scarce because a terrible price has to be paid for its existence.
And just an extra note: You can't seperate anything from its opposite. You can't teach an AI 'good' without also teaching it 'evil' for instance. This is because "Good and evil" is one concept rather than two. There's nothing mysterious about the so-called "Waluigi effect", just like there's nothing mysterious about us fighting ourselves, nor about me using logic to arrive at the conclusion that logic isn't helpful.
comment by cubefox · 2023-09-03T13:01:18.973Z · LW(p) · GW(p)
To comment on the object (that is: meta) level discussion: One of the most popular theories of metaphilosophy states that philosophy is "conceptual analysis".
The obvious question is: What is "conceptual analysis"? The theory applies quite well to cases where we have general terms like "knowledge", "probability" or "explanation", and where we try to find definitions for them, definitions that are adequate to our antecedent intuitive understanding of those terms. What counts as a "definition"? That's a case of conceptual analysis itself, but the usual answer is that a good definition lists individually necessary and jointly sufficient conditions. And how do we find those?
That's where intuitions and thought experiments come in. There is a special kind of semantic intuition of the "I know it when I see it" kind. We know whether a term does or doesn't apply to a concrete example when we see it, even if we can't readily produce a definition. You might think being black is a necessary condition for our concept of "raven". Now if you see something that looks like a prototypical raven, but with darkish grey feathers, would you still call it a raven? Presumably yes. You can just imagine the example of a grey raven, i.e. you do a thought experiment, and your semantic intuition tells you whether the term applies. So you discovered that being black is not a necessary condition for being a raven, and hence it isn't part of their definition.
Similarly, you might want to know whether some properties are sufficient for applying a term, and a thought experiment could disprove this, if you imagine a thing which has all those properties but to which the term, nonetheless, doesn't intuitively apply. (A well known example for this happened in the case of knowledge.) Note also that these (semantic) intuitions seem very reliable, in contrast to the usual "intuitive guesses", which are simply unjustified and uncertain beliefs about factual matters, and which are also called "intuitions".
It's interesting that conceptual analysis bears some resemblance to the scientific method: Experiments are replaced by thought experiments, observations are replaced by semantic intuitions. Moreover, if I remember correctly, research in experimental philosophy (a branch of psychology) found that that intuitions in philosophical thought experiments are fairly stable across different people.
Now this semantic theory of metaphilosophy applies well to analyzing the meaning of general terms. It is less clear whether it applies to philosophy as a whole. For example, are philosophical ethicists really analyzing the meaning of terms like "good" and "ought"? (In fact I think so, yes.)
And which concepts do philosophical decision theorists analyze according to the semantic theory? Or logicians? Well, perhaps concepts like "rational decision" or "logical consequence". A subject area like decision theory could include a host of interrelated concepts, which stand in certain logical relations to each other, and an axiomatization provides an implicit definition of the involved terms. Like the axioms of (second-order) Peano arithmetic seem to define, in a sense, the meaning of "natural numbers". Another worry is that the conceptual analysis theory deals easily with "what is X?" questions (where X is "rationality", "causation" etc.) but not so obviously with "why" questions like "why does anything exist?" or "why does consciousness exist?". Though one could argue that the analysis of "explanation" should give some insight here. And also these questions seem not immediately semantic: "Is induction justified? If so, how?" Though again, maybe we simply still lack a general theory of induction which would help analyze the concepts of "inductive inference" and "inductive justification", and which would answer these questions.
So the semantic theory is a bit murky outside the prototypical examples. But it seems to fit well with the "deconfunsion theory", since conceptual analysis would aid in clarifying the relations between concepts. For example: Ask a philosophically uninformed person what the relationship is between knowledge and belief. I've done it several times. They struggle for confused examples, they know the difference between those terms, but only as a disposition to use them correctly when presented with specific cases, not when asked about an abstract relationship. Philosophers won't get confused by this case (they'd say knowledge implies belief, and belief doesn't imply knowledge), so the deconfunsion worked. They will still get confused when asked about other concepts, like when asked about the relationship between knowledge and information.
My guess is that a sufficiently general AI would be quite good at philosophy. Because deconfusing its conceptual framework has instrumental value. The danger comes from somewhat narrow superintelligences, which could have some important parts of their cognition "hard coded", like AIXI always using the conditionalization rule. And natural selection heavily optimized animals for generality first, and increased intelligence came only slowly [LW · GW], while this situation seems to be reversed in AI. Highly specialized narrow systems came first. So there is some risk the first powerful superintelligence could be relatively narrow and hence have dangerous philosophical blind spots.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2023-09-03T18:05:57.968Z · LW(p) · GW(p)
Thanks for this clear explanation of conceptual analysis. I've been wanting to ask some questions about this line of thought:
- Where do semantic intuitions come from?
- What should we do when different people have different such intuitions? For example you must know that Newcomb's problem is famously divisive, with roughly half of philosophers preferring one-boxing and half preferring two-boxing. Similarly for trolley thought experiments, intuitions about the nature of morality (metaethics), etc.
- How do we make sure that AI has the right intuitions? Maybe in some cases we can just have it learn from humans, but what about:
- Cases where humans disagree.
- Cases where all/most humans are wrong. (In other words, can we build AIs that have better intuitions than humans?) Or is that not a thing in conceptual analysis, i.e., semantic intuitions can't be wrong?
- Completely novel philosophical questions or situations where AI can't learn from humans (because humans don't have intuitions about it either, or AI has to make time sensitive decisions and humans are too slow).
↑ comment by cubefox · 2023-09-04T18:09:00.635Z · LW(p) · GW(p)
-
I think concepts are probably similar to what artificial feedforward networks implement when they recognize objects. So a NN that recognizes chairs would implement the concept associated with the term "chair". Such networks just output a value (yes/no, or something in between) when given certain, e.g. visual, inputs. Otherwise it's a blackbox, there is no way to easily get the definition of "chair" out, even if it correctly identifies all and only chairs. And these "yes" or "no" values, when presented with specific examples as input, seem to be just what we receive from semantic intuitions. I know a chair when I see it.
Now for the practice philosophy, it is clear that we aren't just able to apply concepts to real (e.g. sensory) data, but also to thought experiments, to hypothetical or counterfactual, in any case simulated, situations. It is not clear how this ability works in the brain, but we do have it. -
When people have different intuitions in thought experiments, this could be due to several reasons:
One possibility is that the term in question is simply ambiguous. Does a tree falling in the forest make a sound when nobody is there? That presumably depends on the ambiguity of "sound": The tree produces a sound wave, but no conscious sound experience. In such cases there is no real disagreement, just two concepts for one term.
Another possibility is that the term in question is vague. Do traffic lights have yellow or orange lights? Maybe "disagreements" here are just due to slightly different boundaries of concepts for different individuals, but there is no significant disagreement.
The last possibility is that the concepts in question are really approximately the same, and ambiguity or vagueness is not the issue. Those are typically the controversial cases. They are often called a paradox. My guess is that they are caused by some hidden complexity or ambiguity in the thought experiment or problem statement (rather than in an ambiguity of a central term) which pulls semantic intuitions in different directions. A paradox may be solved when the reasons for those contradicting intuitions are uncovered.
I actually think it is fairly rare for a paradox that some people simply have completely different intuitions. Most people can see both intuitions and are puzzled, since they (seem to) contradict each other.
In his original paper about Newcomb's problem, I think Robert Nozick does a very good job at describing both intuitions such that both seem plausible. An example of what I imagine a solution could look like: The two-boxer answer is the right response to the question "What is the most useful decision in the given situation?", while the one-boxer answer is the right response to the question "In the given situation, what is the decision according to the most useful general decision-making algorithm an agent could have?" Which would mean the intuitions apply to slightly different questions, even though the terms in question are not ambiguous themselves. The disagreement was semantic only insofar the problem is interpreted differently. (This is just an example of how one could, perhaps, explain the disagreement in this paradox consistent with the semantic theory, not a fleshed-out proposal.)
Ethics and so on seem similar. Generally, if a thought experiment produces very different outcomes for different people, the problem in the thought experiment my not be as clear as it seems. Maybe the problem needs clarification, or different, less unclear, thought experiments altogether. -
I actually do think that semantic intuitions are infallible when they are certain. For example, if I imagine a prototypical (black) raven, and I mentally make it grey, I would still call it a raven. My semantic intuition here represents just a disposition to use the term associated with the concept. If someone then convinces me to call only black birds ravens, that wouldn't be a counterexample to infallibility, that would just be me using a different concept than before for the same term. For paradoxical cases the intuitions are typically far less than certain, and that reflects their being provisional.
For AI to do philosophy, according to the conceptual analysis view, it needs some ability to do thought experiments, to do suppositional reasoning, and to apply its usual concepts to these virtual situations. It also needs some minimal amount of "creativity" to come up with provisional definitions or axiomatizations, and specific thought experiments. Overall, I don't think AI would need to learn doing philosophy from humans. Either it can do it itself, possibly at a superhuman level, because it is general enough to have the necessary base abilities, or it can't do it much at all.
comment by Lukas_Gloor · 2023-09-01T11:08:51.520Z · LW(p) · GW(p)
I feel like there are two different concerns you've been expressing in your post history:
(1) Human "philosophical vulnerabilities" might get worsened (bad incentive setting, addictive technology) or exploited in the AI transition. In theory and ideally, AI could also be a solution to this and be used to make humans more philosophically robust.
(2) The importance of "solving metaphilosophy," why doing so would help us with (1).
My view is that (1) is very important and you're correct to highlight it as a focus area we should do more in. For some specific vulnerabilities or failure modes, I wrote a non-exhaustive list here in this post [EA · GW] under the headings "Reflection strategies require judgment calls" and "Pitfalls of reflection procedures." Some of it was inspired by your LW comments.
Regarding (2), I think you overestimate how difficult the problem is. My specific guess is you might overestimate its difficulty because you might confuse uncertainty over a problem with objective solutions with indecisiveness about mutually incompatible ways of reasoning. Uncertainty and indecisiveness may feel similar when you're in that mental state, but they imply different solutions to step forward.
I feel like you already know all there is to know about metaphilosophical disagreements or solution attempts. When I read your posts, I don't feel like "oh, I know more than Wei Dai does." But then you seem uncertain between things that I don't feel uncertain about, and I'm not sure what to make of that. I subscribe to the view of philosophy as "answering confused questions." I like the following Wittgenstein's quote:
[...] philosophers do not—or should not—supply a theory, neither do they provide explanations. “Philosophy just puts everything before us, and neither explains nor deduces anything. Since everything lies open to view there is nothing to explain (PI 126).”
As I said elsewhere, per this perspective, I see the aim of [...] philosophy as to accurately and usefully describe our option space – the different questions worth asking and how we can reason about them.
This view also works for metaphilosophical disagreements.
There's a brand of philosophy (often associated with Oxford) that's incompatible with the Wittgenstein quote because it uses concepts that will always remain obscure, like "objective reasons" or "objective right and wrong," etc. The two ways of doing philosophy seem incompatible because one of them is all about concepts that the other doesn't allow. But if you apply the perspective from the Wittgenstein quote to look at the metaphilosophical disagreement between "Wittgensteinian view" vs. "objective reasons views," well then you're simply choosing between two different games to play. Do you want to go down the path of increased clarity and clear questions, or do you want to go all-in on objective reasons. You gotta pick one or the other.
For what it's worth, I feel like the prominent alignment researchers in the EA community almost exclusively reason about philosophy in the anti-realist, reductionist style. I'm reminded of Dennett's "AI makes philosophy honest." So, if we let alignment researchers label the training data, I'm optimistic that I'd feel satisfied with the "philosophy" we'd get out of it, conditional on solving alignment in an ambitious and comprehensive way.
Other parts of this post [EA · GW] (the one I already linked to above) might be relevant to our disagreement, specifically with regard to the difference between uncertainty and indecisiveness.
comment by Linda Linsefors · 2023-09-25T19:09:59.186Z · LW(p) · GW(p)
If you think it would be helpful, you are welcome to suggest a meta philpsophy topic for AI Safety Camp.
More info at aisafety.camp. (I'm typing on a phone, I'll add actuall link later if I remember too)
comment by ShardPhoenix · 2023-09-01T02:09:28.523Z · LW(p) · GW(p)
At a glance meta-philosophy sounds similar to the problem of what is good, which is normally considered to be within the bounds of regular philosophy. (And to the extent that people avoid talking about it I think it's because the problem of good is on a deep enough level inherently subjective and therefore political, and they want to focus on technical problem solving rather than political persuasion)
What's an example of an important practical problem you believe can only be solved by meta-philosophy?
comment by Ape in the coat · 2025-02-01T12:43:40.768Z · LW(p) · GW(p)
Where does probability theory come from anyway? Maybe I can find some clues that way? Well according to von Neumann and Morgenstern, it comes from decision theory.
I believe this is the step from where you started going astray. The next steps of your intellectual journey seem to be repeating the same mistake: attempting to reduce a less complex thing to a more complex one.
Probability Theory does not "come from" Decision Theory. Decision Theory is strictly more complicated domain of math as it involves all the apparatus of Probability Spaces but also utilities over events.
We can validate probability theoretic reasoning by appeals to decision theoretic processes such as iterated betting, but only if we already know which probability space corresponds to a particular experiment. And frankly, at this point this is redundant. We can just as well appeal to the Law of Large Numbers and simply count the frequencies of events on a repetition of the experiment, without thinking about utilities at all.
And if you want to know which probability space is appropriate, you need to go in the opposite direction and figure out when and how mathematical models in general correspond to reality. Logical Pinpointing [LW · GW] gives the core insight:
"Whenever a part of reality behaves in a way that conforms to the number-axioms - for example, if putting apples into a bowl obeys rules, like no apple spontaneously appearing or vanishing, which yields the high-level behavior of numbers - then all the mathematical theorems we proved valid in the universe of numbers can be imported back into reality. The conclusion isn't absolutely certain, because it's not absolutely certain that nobody will sneak in and steal an apple and change the physical bowl's behavior so that it doesn't match the axioms any more. But so long as the premises are true, the conclusions are true; the conclusion can't fail unless a premise also failed. You get four apples in reality, because those apples behaving numerically isn't something you assume, it's something that's physically true. When two clouds collide and form a bigger cloud, on the other hand, they aren't behaving like integers, whether you assume they are or not."
But if the awesome hidden power of mathematical reasoning is to be imported into parts of reality that behave like math, why not reason about apples in the first place instead of these ethereal 'numbers'?
"Because you can prove once and for all that in any process which behaves like integers, 2 thingies + 2 thingies = 4 thingies. You can store this general fact, and recall the resulting prediction, for many different places inside reality where physical things behave in accordance with the number-axioms. Moreover, so long as we believe that a calculator behaves like numbers, pressing '2 + 2' on a calculator and getting '4' tells us that 2 + 2 = 4 is true of numbers and then to expect four apples in the bowl. It's not like anything fundamentally different from that is going on when we try to add 2 + 2 inside our own brains - all the information we get about these 'logical models' is coming from the observation of physical things that allegedly behave like their axioms, whether it's our neurally-patterned thought processes, or a calculator, or apples in a bowl."
I'm not sure what is left confusing about the source of probability theory after understanding that math is simply a generalized way to talk about some aspects reality in precise terms and truth preserving manner. On the other hand, I've figured it out myself, and the problem never appeared to me particularly mysterious in the first place. so I'm probably not modelling correctly people who have still questions about the matter. I would appreciate if you or anyone else, explicitly ask such questions here.
comment by Richard_Ngo (ricraz) · 2023-09-14T12:00:46.263Z · LW(p) · GW(p)
FWIW I think some of the thinking I've been doing about meta-rationality [? · GW] and ontological shifts [LW · GW] feels like metaphilosophy. Would be happy to call and chat about it sometime.
I do feel pretty wary about reifying the label "metaphilosophy" though. My preference is to start with a set of interesting questions which we can maybe later cluster into a natural category, rather than starting with the abstract category and trying to populate it with questions (which feels more like what you're doing, although I could be wrong).
comment by hairyfigment · 2023-09-01T08:15:10.664Z · LW(p) · GW(p)
The classification heading "philosophy," never mind the idea of meta-philosophy, wouldn't exist if Aristotle hadn't tutored Alexander the Great. It's an arbitrary concept which implicitly assumes we should follow the aristocratic-Greek method of sitting around talking (or perhaps giving speeches to the Assembly in Athens.) Moreover, people smarter than either of us have tried this dead-end method for a long time with little progress. Decision theory makes for a better framework than Kant's ideas; you've made progress not because you're smarter than Kant, but because he was banging his head against a brick wall. So to answer your question, if you've given us any reason to think the approach of looking for "meta-philosophy" is promising, or that it's anything but a proven dead-end, I don't recall it.
comment by interstice · 2023-09-01T04:10:01.193Z · LW(p) · GW(p)
I'm also interested in this topic but it feels very hard to directly make progress. It seems to require solving a lot of philosophy, which has as its subject matter the entire universe and how we know about it, so solving metaphilosophy in a really satisfying way seems to almost require rationally apprehending all of existence and our place within it, which seems really hard, or maybe even fundamentally impossible(or perhaps there are ways of making progress in metaphilosophy without solving most of philosophy first, but finding such ways also seems hard)
That said I do have some more indirect/outside-view theories which make me think we could obtain a good future even if we can't directly solve metaphilosophy before getting AGI. I think we can see philosophy as the process by which "messy"/incoherent agents, which arose from evolution or other non-agentic means, can become more coherent and unified-agent-like. So obtaining an AI which can do philosophy would not consist of hardcoding a 'philosophy algorithm', but creating base agents which are messy in similar ways to us, who will then hopefully resolve that messiness and become more coherent in similar ways also(and thereafter make use of the universe in approximately as good of a way as we would have). A whole brain emulation would obviously qualify, but I think that it's also plausible that we could develop a decent high-level understanding of how human brain algorithms work and create AIs that are similar enough for philosophical purposes without literally scanning peoples' brains(which seems like it will take too long relative to AI) For this reason and others I think creating sufficiently-human-like AI is a promising route for obtaining a good future(but this topic also seems curiously neglected).
As to why few other people are trying to solve metaphilosophy, I think there are just very few people with the temperament to become interested in such things, then the few that do end up deciding that some other topic has a better combination of importance/neglectedness/tractability/personal fit to invest major effort in.
comment by Max H (Maxc) · 2023-09-01T03:32:21.795Z · LW(p) · GW(p)
Where does decision theory come from? It seems to come from philosophers trying to do philosophy.
An alternate view is that certain philosophical and mathematical concepts are "spotlighted", in the sense that they seem likely to recur in a wide variety of minds above a certain intelligence / capabilities level.
A concept which is mathematically simple or elegant to describe and also instrumentally useful across a wide variety of possible universes is likely to be instrumentally convergent. The simpler and more widely useful the concept is, the more likely it is to occur by convergence in a wider variety of minds, at lower overall capabilities thresholds.
This doesn't necessarily mean that a sufficiently spotlighted concept is "objective" or a philosophical truth, and there might be exotic corners of mindspace in which there are extremely powerful minds which can't or don't converge on these concepts, e.g. the one you give in Metaphilosophical Mysteries [LW · GW].
But note that recognizing that there are recurring useful patterns in mindspace and being able to reason correctly about them (i.e. being able to do philosophy) is itself likely to be an instrumentally useful (though perhaps not very mathematically simple) concept, and is thus itself a spotlighted concept.
(BTW, another place where Eliezer appears to at least allude to his own views on this general topic in his fiction is here.)
As for your meta question of why more people aren't interested in this, one possibility is that there's just not that many people who make it all the way up the ladder of intellectual journey the way you did:
- Lots of people in AI and even AI safety probably haven't heard that much, or aren't that interested in, even the basics of mainstream game theory (Prisoners' Dilemma, Nash Equilibria, etc.), though on LW these concepts have very high penetration.
- Lots of people who have heard of the basics find object-level questions and thought experiments about specific decision theories more than interesting enough to keep arguing about forever.
- Among the remaining people who tentatively accept something like UDT (or at least get far enough to have interesting takes on it), most of them probably don't wonder about the internal mental processes by which its inventors came up with it, nor try to re-create that process in themselves.
Personally, I think something like the spotlighting concept is probably correct, and thus that it is unlikely that practical AGIs will struggle with philosophy.
I do enjoy reading about this general topic though, including your posts and some loosely related things @TsviBT [LW · GW] has written, and I'd like to see more of them, from you and others. I'm not sure that simply drawing attention to the issue will have much effect though - the number of people both qualified and interested in writing about this is probably very small. To make real progress, you might need to bootstrap a larger community of peers.
Finding ways to move people who are stuck at lower rungs of the ladder through the funnel is one way to do that. This might take the form of more distillations and explanations of metaphilosophy, decision theory, and other object-level concepts that target a wider audience. (Or, if you're inclined, write 1M+ words of collaborative fiction [LW · GW] about these topics.)
comment by Arden Peterson (arden-peterson) · 2024-04-14T20:23:21.696Z · LW(p) · GW(p)
I'm super grateful to have stumbled across someone who also cares about meta-philosophy! I have an intuition that we don't understand philosophy. Therefore, I think its advantageous to clarify the nature, purpose, and methodologies of philosophy, or in other words, solve meta-philosophy.
Let's explore some questions...
- What would it look like for a civilization to constantly be solving problems but not necessarily solving the right problems?
- How does reflection and meta-cognition relate to finding the root problems?
- What if our lack of reflection and meta-cognition is the root problem?
- What if we defined philosophy as civilization level reflection and meta-cognition as opposed to the traditional interpretation?
What would it look for a civilization to constantly be solving problems but not necessarily solving the right problems?
Summary
Scenario: A civilization focused on constant problem-solving without addressing the right issues.
Characteristics: Quick fixes, frequent shifts in focus, and neglect of underlying, systemic problems.
Implications
This scenario would involve a civilization that frequently engages in reactive measures--tackling symptoms rather than root causes. This could lead to a cycle of temporary solutions and recurring issues, with resources being spent on problems that may not contribute to long-term stability or improvement. The focus on immediate, superficial, problem-solving could prevent effective handling of more significant, complex challenges, leading to unintended consequences.
How does reflection and meta-cognition relate to finding the root problems?
Summary
Role of Reflection: Helps revisit and analyze past actions and outcomes.
Role of Meta-cognition: Enables critical evaluation of decision-making processes.
Implications
Reflection allows for a retrospective analysis where past decisions and their impacts are reconsidered. This process aids in uncovering patterns and recurring problems, providing insights into the underlying causes of issues rather than merely their manifestations. It's about looking back to understand what happened and why.
Meta-cognition, on the other hand, is a deeper layer of thinking about one's thinking. It involves examining the cognitive processes used in problem solving and decision-making. This includes questioning one's assumptions, biases, and frameworks within which decisions were made. Meta-cognition helps in recognizing the limitations and flaws in these processes, which might contribute to ongoing problems.
What if our lack of reflection and meta-cognition is a root problem?
Summary
Potential Root Problem: Lack of reflection and meta-cognition.
Consequences: Poor decision-making, repeated errors, and superficial solutions.
Implications
If the absence of reflection and meta-cognition is identified as a root problem, this has broad implications for how issues are addressed and prevented across various domains.
- Poor Decision-Making: Without sufficient reflection, decisions may be based on incomplete information or immediate pressures, rather than well-considered analysis. Meta-cognition is crucial for evaluating the thought processes behind decisions, including the recognition of biases, assumptions, and gaps in knowledge.
- Recurring Problems: A lack of deep thinking and questioning means that solutions tend to be reactive and symptom-based. Without addressing deeper causes, the same or similar problems are likely to reoccur, indicating that the interventions are not reaching the underlying issues.
- Superficial Solutions: Solutions developed without the aid of reflection and meta-cognitive processes tend to address manifestations of a problem. This can lead to a cycle of short-term fixes that fail to tackle more complex, systemic issues.
What if we defined philosophy as civilization level reflection and meta-cognition as opposed to the traditional interpretation?
Summary
Philosophy as Reflection and Meta-cognition: Envisioning philosophy primarily as a reflective and meta-cognitive practice emphasizes active and ongoing analysis of thought processes and decision-making.
Challenges with Traditional Philosophy: The conventional focus on static fundamental questions may limit philosophy's practical effectiveness and relevance to contemporary issues.
Implications
If philosophy is framed a dynamic practice of reflection and meta-cognition, rather than merely an academic pursuit of answering age-old questions, it becomes a more vital, active part of addressing modern challenges. This perspective shifts philosophy from being an abstract discipline into a practical tool that continually assesses and adapts our thinking strategies, decision-making processes, and the very frameworks we use to interpret the world.
Closing Thoughts
To me...solving meta-philosophy looks like devising a framework that explains these questions and their relationships in an accessible way.
What is thinking about our thoughts?
Why do we think about our thoughts?
How do we think about our thoughts?
After that, we could have even more fun and start to dissect the collective worldview that underpins our institutions, identify imbalances, and imagine an alternative that feels more authentic and ecologically harmonious.
comment by Review Bot · 2024-03-17T18:10:19.838Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Caerulea-Lawrence (humm1lity) · 2023-09-15T11:06:21.704Z · LW(p) · GW(p)
Hello Wei Dai,
Something that might be useful to a certain degree might be to see it through the lens of Collective Intelligence.
Or simply that the sum is greater than the value of the individual parts, and also that we can synch our efforts together, directly or indirectly, with the people around us. A recent BBC reel explores this as well.
Like you say, as you 'move on', you leave many behind. - But at least you will feel massively more vital and see an increase in growth if you have someone that enhances your learning directly through "being on the same wavelength/page" - who not only 'says' they have the same goals, but that works towards them at the same level of depth and inner coherence - as yourself.
Wanting 'immediate' and 'visible' results is pretty understandable as well, and not only waiting for the indirect changes that might occur through the different forms of collective intelligences you have already outlined, but that might not really dive into things the same way you want/are able to.
If so, an answer to the questions isn't necessarily one of finding the right answers, but finding the right people to ask that want to find an answer. People that are aware of the problem at the complexity-level where you can find a suitable solution, and that are willing to structure their individual mind, will and effort around solving it, as well as synchronizing their efforts with you in a way that has inner coherence. That would probably also feel more stimulating than only indirectly looking at these challenges.
Was wondering how that lands with you, and if this is a useful direction to you, or if you want something else? If you have questions related to this in particular or something, I'm up for continuing on DM.
Kindly,
Caerulea-Lawrence
comment by corey morris (corey-morris) · 2023-09-05T21:40:49.055Z · LW(p) · GW(p)
I'm currently investigating the moral reasoning capabilities of AI systems. Given your previous focus on decision theory and subsequent shift to Metaphilosophy, I'm curious to get your thoughts.
Say an AI system was an excellent moral reasoner prior to having especially dangerous capability. What might be missing to ensure it is safe? What do you think the underlying capabilities to getting to be an excellent moral reasoner would be ?
I am new to considering this as a research agenda. It seems important and neglected, but I don’t have a full picture of the area yet or all of the possible drawbacks of pursuing it.
comment by Caleb Biddulph (caleb-biddulph) · 2023-09-02T09:51:49.415Z · LW(p) · GW(p)
Thanks for the post! I just published a top-level post responding to it: https://www.lesswrong.com/posts/pmraJqhjD2Ccbs6Jj/is-metaethics-unnecessary-given-intent-aligned-ai [LW · GW]
I'd appreciate your feedback!
comment by MiguelDev (whitehatStoic) · 2023-09-02T06:57:43.759Z · LW(p) · GW(p)
Why is there virtually nobody else [EA(p) · GW(p)] interested in metaphilosophy or ensuring AI philosophical competence (or that of future civilization as a whole), even as we get ever closer to AGI, and other areas of AI safety start attracting more money and talent?
I've written a bit on this topic that you might find interesting; I refer to it as the Set of Robust Concepts (SORC) [LW · GW]. I also employed this framework to develop a tuning dataset, which enables a shutdown mechanism [LW · GW] to activate when the AI's intelligence poses a risk to humans. It works 57.33% [LW · GW] of the time.
I managed to improve the success rate to 88%. However, I'm concerned that publishing the method in the conventional way could potentially put the world at greater risk. I'm still contemplating how to responsibly share information on AI safety, especially when it could be reverse-engineered to become dangerous.
↑ comment by MiguelDev (whitehatStoic) · 2023-09-02T07:38:52.969Z · LW(p) · GW(p)
There is also a theory from Jung that deeply concerns me. According to Jung, the human psyche contains a subliminal state, or subconscious mind, which serves as a battleground for gods and demons. Our dreams process this ongoing conflict and bring it into our conscious awareness. What if these same principle got transferred to LLMs since human related data was used for training? This idea doesn't seem far-fetched, especially since we refer to the current phenomenon of misleading outputs in LLMs as "hallucinations."
I have conducted an experiment on this, specifically focusing on hyperactivating the "shadow behavior" in GPT-2 XL and I could fairly say that it is reminiscent of Jung's thought. For obvious reasons, I won't disclose the method here[1] but I'm open to discussing it privately.
- ^
Unfortunately, the world isn't a safe place to disclose this method. As discussed in this post [LW · GW] and this post [LW · GW], I don't know of a secure way to share the correct information and disseminate it to right people who can actually do something about it. For now, I'll leave this comment here in the hope that the appropriate individual might come across it and be willing to engage in one of the most unsettling discussions they'll ever have.