Birds, Brains, Planes, and AI: Against Appeals to the Complexity/Mysteriousness/Efficiency of the Brain
post by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-18T12:08:13.418Z · LW · GW · 86 commentsContents
Plan:
Illustrative Analogy
Exciting Graph
Analysis
Part 1: Extra brute force can make the problem a lot easier
Part 2: Evolution produces complex mysterious efficient designs by default, even when simple inefficient designs work just fine for human purposes.
Part 3: What’s bogus and what’s not
Part 4: Example: Data-efficiency
Conclusion
Appendix
None
86 comments
[Epistemic status: Strong opinions lightly held, this time with a cool graph.]
I argue that an entire class of common arguments against short timelines is bogus, and provide weak evidence that anchoring to the human-brain-human-lifetime milestone is reasonable.
In a sentence, my argument is that the complexity and mysteriousness and efficiency of the human brain (compared to artificial neural nets) is almost zero evidence that building TAI will be difficult, because evolution typically makes things complex and mysterious and efficient, even when there are simple, easily understood, inefficient designs that work almost as well (or even better!) for human purposes.
In slogan form: If all we had to do to get TAI was make a simple neural net 10x the size of my brain, my brain would still look the way it does.
The case of birds & planes illustrates this point nicely. Moreover, it is also a precedent for several other short-timelines talking points, such as the human-brain-human-lifetime (HBHL) anchor.
Plan:
- Illustrative Analogy
- Exciting Graph
- Analysis
- Extra brute force can make the problem a lot easier
- Evolution produces complex mysterious efficient designs by default, even when simple inefficient designs work just fine for human purposes.
- What’s bogus and what’s not
- Example: Data-efficiency
- Conclusion
- Appendix

1909 French military plane, the Antionette VII.
By Deep silence (Mikaël Restoux) - Own work (Bourget museum, in France), CC BY 2.5, https://commons.wikimedia.org/w/index.php?curid=1615429
Illustrative Analogy
| AI timelines, from our current perspective | Flying machine timelines, from the perspective of the late 1800’s: |
| Shorty: Human brains are giant neural nets. This is reason to think we can make human-level AGI (or at least AI with strategically relevant [AF · GW] skills, like politics and science [LW · GW]) by making giant neural nets. | Shorty: Birds are winged creatures that paddle through the air. This is reason to think we can make winged machines that paddle through the air. |
Longs: Whoa whoa, there are loads of important differences between brains and artificial neural nets: [what follows is a direct quote from the objection a friend raised when reading an early draft of this post!] - It's at least possible that the wiring diagram of neurons plus weights is too coarse-grained to accurately model the brain's computation, but it's all there is in deep neural nets. If we need to pay attention to glial cells, intracellular processes, different neurotransmitters etc., it's not clear how to integrate this into the deep learning paradigm. - My impression is that several biological observations on the brain don't have a plausible analog in deep neural nets: growing new neurons (though unclear how important it is for an adult brain), "repurposing" in response to brain damage, … | Longs: Whoa whoa, there are loads of important differences between birds and flying machines:
- Birds paddle the air by flapping, whereas current machine designs use propellers and fixed wings.
- It’s at least possible that the anatomical diagram of bones, muscles, and wing surfaces is too coarse-grained to accurately model how a bird flies, but that’s all there is to current machine designs (replacing bones with struts and muscles with motors, that is). If we need to pay attention to the percolation of air through and between feathers, micro-eddies in the air sensed by the bird and instinctively responded to, etc. it’s not clear how to integrate this into the mechanical paradigm.
- My impression is that several biological observations of birds don’t have a plausible analog in machines: Growing new feathers and flesh (though unclear how important this is for adult birds), “repurposing” in response to damage ... |
Shorty: The key variables seem to be size and training time. Current neural nets are tiny; the biggest one is only one-thousandth the size of the human brain. But they are rapidly getting bigger. Once we have enough compute to train neural nets as big as the human brain for as long as a human lifetime (HBHL), it should in principle be possible for us to build HLAGI. No doubt there will be lots of details to work out, of course. But that shouldn’t take more than a few years. | Shorty: The key variables seem to be engine-power and engine weight. Current motors are not strong & light enough, but they are rapidly getting better. Once the power-to-weight ratio of our motors surpasses the power-to-weight ratio of bird muscles, it should be in principle possible for us to build a flying machine. No doubt there will be lots of details to work out, of course. But that shouldn’t take more than a few years. |
Longs: Bah! I don’t think we know what the key variables are. For example, biological brains seem to be able to learn faster, with less data, than artificial neural nets. And we don’t know why.
| Longs: Bah! I don’t think we know what the key variables are. For example, birds seem to be able to soar long distances without flapping their wings at all, and we still haven’t figured out how they do it. Another example: We still don’t know how birds manage to steer through the air without crashing (flight stability & control). Besides, “there will be lots of details to work out” is a huge understatement. It took evolution billions of generations of billions of individuals to produce birds. What makes you think we’ll be able to do it quickly? It’s plausible that actually we’ll have to do it the way evolution did it, i.e. meta-design, i.e. evolve a large population of flying machines, tweaking our blueprints each generation of crashed machines to grope towards better designs. And even if you think we’ll be able to do it substantially quicker than evolution did, it’s pretty presumptuous to think we could do it quickly enough that the date our engines achieve power/weight parity with bird muscle is relevant for forecasting. |
Exciting Graph
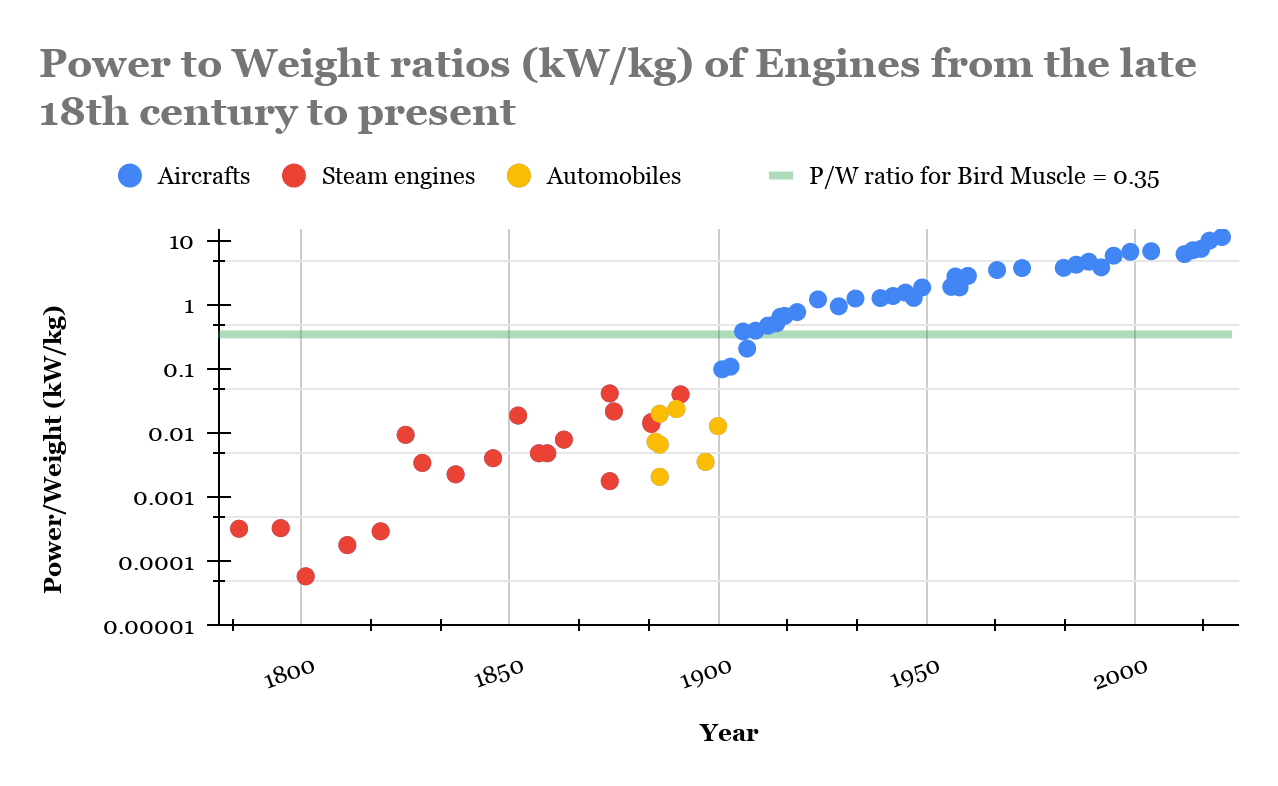
This data shows that Shorty was entirely correct about forecasting heavier-than-air flight. (For details about the data, see appendix.) Whether Shorty will also be correct about forecasting TAI remains to be seen.
In some sense, Shorty has already made two successful predictions: I started writing this argument before having any of this data; I just had an intuition that power-to-weight is the key variable for flight and that therefore we probably got flying machines shortly after having comparable power-to-weight as bird muscle. Halfway through the first draft, I googled and confirmed that yes, the Wright Flyer’s motor was close to bird muscle in power-to-weight. Then, while writing the second draft, I hired an RA, Amogh Nanjajjar, to collect more data and build this graph. As expected, there was a trend of power-to-weight improving over time, with flight happening right around the time bird-muscle parity was reached.
I had previously heard from a friend, who read a book about the invention of flight, that the Wright brothers were the first because they (a) studied birds and learned some insights from them, and (b) did a bunch of trial and error, rapid iteration, etc. (e.g. in wind tunnels). The story I heard was all about the importance of insight and experimentation--but this graph seems to show that the key constraint was engine power-to-weight. Insight and experimentation were important for determining who invented flight, but not for determining which decade flight was invented in.
Analysis
Part 1: Extra brute force can make the problem a lot easier
One way in which compute can substitute for insights/algorithms/architectures/ideas is that you can use compute to search for them. But there is a different and arguably more important way in which compute can substitute for insights/etc.: Scaling up the key variables, so that the problem becomes easier, so that fewer insights/etc. are needed.
For example, with flight, the problem becomes easier the more power/weight ratio your motors have. Even if the Wright brothers didn’t exist and nobody else had their insights, eventually we would have achieved powered flight anyway, because when our engines are 100x more powerful for the same weight, we can use extremely simple, inefficient designs. (For example, imagine a u-shaped craft with a low center of gravity and helicopter-style rotors on each tip. Add a third, smaller propeller on a turret somewhere for steering. EDIT: Oops, lol, I'm actually wrong about this. Keeping center of gravity low doesn't help. Welp, this is embarrassing.)
With neural nets, we have plenty of evidence now that bigger = better, with theory to back it up. Suppose the problem of making human-level AGI with HBHL levels of compute is really difficult. OK, 10x the parameter count and 10x the training time and try again. Still too hard? Repeat.
Note that I’m not saying that if you take a particular design that doesn’t work, and make it bigger, it’ll start working. (If you took Da Vinci’s flying machine and made the engine 100x more powerful, it would not work). Rather, I’m saying that the problem of finding a design that works gets qualitatively easier the more parameters and training time you have to work with.
Finally, remember that human-level AGI is not the only kind of TAI. Sufficiently powerful R&D tools would work, as would sufficiently powerful persuasion tools [AF · GW], as might something that is agenty and inferior to humans in some ways but vastly superior in others.
Part 2: Evolution produces complex mysterious efficient designs by default, even when simple inefficient designs work just fine for human purposes.
Suppose that actually all we have to do to get TAI is something fairly simple and obvious, but with a neural net 10x the size of my (actual) brain and trained for 10x longer. In this world, does the human brain look any different than it does in the actual world?
No. Here is a nonexhaustive list of reasons why evolution would evolve human brains to look like they do, with all their complexity and mysteriousness and efficiency, even if the same capability levels could be reached with 10x more neurons and a very simple architecture. Feel free to skip ahead if you think this is obvious.
- In general, evolved creatures are complex and mysterious to us, even when simple and human-comprehensible architectures work fine. Take birds, for example: As mentioned before, all the way up to the Wright brothers there were a lot of very basic things about birds that were still not understood. From this article: “They watched buzzards glide from horizon to horizon without moving their wings, and guessed they must be sucking some mysterious essence of upness from the air. Few seemed to realize that air moves up and down as well as horizontally.” I don’t know much about ornithology but I’d be willing to bet that there were lots of important things discovered about birds after airplanes already existed, and that there are still at least a few remaining mysteries about how birds fly. (Spot check: Yep, the history of ornithopters page says “...the development of comprehensive aerodynamic theory for flapping remains an outstanding problem...”). And of course evolved creatures are often more efficient in various ways than their still-useful engineered counterparts.
- Making the brain 10x bigger would be enormously costly to fitness, because it would cost 10x more energy and restrict mobility (not to mention the difficulties of getting through the birth canal!) Much better to come up with clever modules, instincts, optimizations, etc. that achieve the same capabilities in a smaller brain.
- Evolution is heavily constrained on training data, perhaps even more than on brain size. It can’t just evolve the organism to have 10x more training data, because longer-lived organisms have more opportunities to be eaten or suffer accidents, especially in their 10x-longer childhoods. Far better to hard-code some behaviors as instincts.
- Evolution gets clever optimizations and modules and such “for free” in some sense. Since it is evolving millions of individuals for millions of generations anyway, it’s not a big deal for it to perform massive search and gradient descent through architecture-space.
- Completely blank slate brains (i.e. extremely simple architecture, no instincts or finely tuned priors) would be unfit even if they were highly capable because they wouldn’t be aligned to evolution’s values (i.e. reproduction.) Perhaps most of the complexity in the human brain--the instincts, inbuilt priors, and even most of the modules--isn’t for capabilities at all, but rather for alignment [LW · GW].
Part 3: What’s bogus and what’s not
The general pattern of argument I think is bogus is:
The brain has property X, which seems to be important to how it functions. We don’t know how to make AI’s with property X. It took evolution a long time to make brains have property X. This is reason to think TAI is not near.
As argued above, if TAI is near, there should still be many X which are important to how the brain functions, which we don’t know how to reproduce in AI, and which it took evolution a long time to produce. So rattling off a bunch of X’s is basically zero evidence against TAI being near.
Put differently, here are two objections any particular argument of this type needs to overcome:
- TAI does not actually require X (analogous to how airplanes didn’t require anywhere near the energy-efficiency of birds, nor the ability to soar, nor the ability to flap their wings, nor the ability to take off from unimproved surfaces… the list goes on)
- We’ll figure out how to get property X in AIs soon after we have the other key properties (size and training time), because (a) we can do search, like evolution did but much more efficient, (b) we can increase the other key variables to make our design/search problem easier, and (c) we can use human ingenuity & biological inspiration. Historically there is plenty of precedent for the previous three factors being strong enough; see e.g. the case of powered flight.
This reveals how the arguments could be reformulated to become non-bogus! They need to argue (a) that X is probably necessary for TAI, and (b) that X isn’t something that we’ll figure out fairly quickly once the key variables of size and training time are surpassed.
In some cases there are decent arguments to be made for both (a) and (b). I think efficiency is one of them, so I’ll use that as my example below.
Part 4: Example: Data-efficiency
Let’s work through the example of data-efficiency. A bad version of this argument would be:
Humans are much more data-efficient learners than current AI systems. Data-efficiency is very important; any human who learned as inefficiently as current AI would basically be mentally disabled. This is reason to think TAI is not near.
The rebuttal to this bad argument is:
If birds were as energy-inefficient as planes, they’d be disabled too, and would probably die quickly. Yet planes work fine. (See Table 1 from this AI Impacts page) Even if TAI is near, there are going to be lots of X’s that are important for the brain, that we don’t know how to make in AI yet, but that are either unnecessary for TAI or not too difficult to get once we have the other key variables. So even if TAI is near, I should expect to hear people going around pointing out various X’s and claiming that this is reason to think TAI is far away. You haven’t done anything to convince me that this isn’t what’s happening with X = data-efficiency.
However, I do think the argument can be reformulated and expanded to become good. Here’s a sketch, inspired by Ajeya Cotra’s argument here.
We probably can’t get TAI without figuring out how to make AIs that are as data-efficient as humans. It’s true that there are some useful tasks for which there is plenty of data--like call center work, or driving trucks--but AIs that can do these tasks won’t be transformative. Transformative AI will be doing things like managing corporations, leading armies, designing new chips, and writing AI theory publications. Insofar as AI learns more slowly than humans, by the time it accumulates enough experience doing one of these tasks, (a) the world would have changed enough that its skills would be obsolete, and/or (b) it would have made a lot of expensive mistakes in the meantime.
Moreover, we probably won’t figure out how to make AIs that are as data-efficient as humans for a long time--decades at least. This is because 1. We’ve been trying to figure this out for decades and haven’t succeeded, and 2. Having a few orders of magnitude more compute won’t help much. Now, to justify point #2: Neural nets actually do get more data-efficient as they get bigger, but we can plot the trend and see that they will still be less data-efficient than humans when they are a few orders of magnitude bigger. So making them bigger won’t be enough, we’ll need new architectures/algorithms/etc. As for using compute to search for architectures/etc., that might work, but given how long evolution took, we should think it’s unlikely that we could do this with only a few orders of magnitude of searching—probably we’d need to do many generations of large population size. (We could also think of this search process as analogous to typical deep learning training runs, in which case we should expect it’ll take many gradient updates with large batch size.) Anyhow, there’s no reason to think that data-efficient learning is something you need to be human-brain-sized to do. If we can’t make our tiny AIs learn efficiently after several decades of trying, we shouldn’t be able to make big AIs learn efficiently after just one more decade of trying.
I think this is a good argument. Do I buy it? Not yet. For one thing, I haven’t verified whether the claims it makes are true, I just made them up as plausible claims which would be persuasive to me if true. For another, some of the claims actually seem false to me. Finally, I suspect that in 1895 someone could have made a similarly plausible argument about energy efficiency, and another similarly plausible argument about flight control, and both arguments would have been wrong: Energy efficiency turned out to be insufficiently necessary, and flight control turned out to be insufficiently difficult!
Conclusion
What I am not saying: I am not saying that the case of birds and planes is strong evidence that TAI will happen once we hit the HBHL milestone. I do think it is evidence, but it is weak evidence. (For my all-things-considered view of how many orders of magnitude of compute it’ll take to get TAI, see future posts, or ask me.) I would like to see a more thorough investigation of cases in which humans attempt to design something that has an obvious biological analogue. It would be interesting to see if the case of flight was typical. Flight being typical would be strong evidence for short timelines, I think.
What I am saying: I am saying that many common anti-short-timelines arguments are bogus. They need to do much more than just appeal to the complexity/mysteriousness/efficiency of the brain; they need to argue that some property X is both necessary for TAI and not about to be figured out for AI anytime soon, not even after the HBHL milestone is passed by several orders of magnitude.
Why this matters: In my opinion the biggest source of uncertainty about AI timelines has to do with how much “special sauce” is necessary for making transformative AI. As jylin04 puts it [LW · GW],
A first and frequently debated crux is whether we can get to TAI from end-to-end training of models specified by relatively few bits of information at initialization, such as neural networks initialized with random weights. OpenAI in particular seems to take the affirmative view[^3], while people in academia, especially those with more of a neuroscience / cognitive science background, seem to think instead that we'll have to hard-code in lots of inductive biases from neuroscience to get to AGI [^4].
In my words: Evolution clearly put lots of special sauce into humans, and took millions of generations of millions of individuals to do so. How much special sauce will we need to get TAI?
Shorty is one end of a spectrum of disagreement on this question. Shorty thinks the amount of special sauce required is small enough that we’ll “work out the details” within a few years of having the key variables (size and training time). At the other end of the spectrum would be someone who thought that the amount of special sauce required is similar to the amount found in the brain. Longs is in the middle. Longs thinks the amount of special sauce required is large enough that the HBHL milestone isn’t particularly relevant to timelines; we’ll either have to brute-force search for the special sauce like evolution did, or have some brilliant new insights, or mimic the brain, etc.
This post rebutted common arguments against Shorty’s position. It also presented weak evidence in favor of Shorty’s position: the precedent of birds and planes. In future posts I’ll say more about what I think the probability distribution over amount-of-special-sauce-needed should be and why.
Acknowedgements: Thanks to my RA, Amogh Nanjajjar, for compiling the data and building the graph. Thanks to Kaj Sotala, Max Daniel, Lukas Gloor, and Carl Shulman for comments on drafts. This research was conducted at the Center on Long-Term Risk and the Polaris Research Institute.
Appendix
Some footnotes:
- I didn’t say anything about why we might think size and training time are the key variables, or even what “key variables” means. Hopefully I’ll get a chance in the comments or in subsequent posts.
- I deliberately left vague what “training time” means and what “size” means. Thus, I’m not commiting myself to any particular way of calculating the HBHL milestone yet. I’m open to being convinced that the HBHL milestone is farther in the future than it might seem.
- Persuasion tools, even very powerful ones, wouldn’t be TAI by the standard definition. However they would constitute a potential-AI-induced-point-of-no-return [LW · GW], so they still count for timelines purposes.
- This "How much special sauce is needed?" variable is very similar to Ajeya Cotra's variable "how much compute would lead to TAI given 2020's algorithms."
Some bookkeeping details about the data:
- This dataset is not complete. Amogh did a reasonably thorough search for engines throughout the period (with a focus on stuff before 1910) but was unable to find power or weight stats for many of the engines we heard about. Nevertheless I am reasonably confident that this dataset is representative; if an engine was significantly better than the others of its time, probably this would have been mentioned and Amogh would have flagged it as a potential outlier.
- Many of the points for steam engine power/weight should really be bumped up slightly. This is because most of the data we had was for the weight of the entire locomotive of a steam-powered train, rather than just the steam engine part. I don’t know what fraction of a locomotive is non-steam-engine but 50% seems like a reasonable guess. I don’t think this changes the overall picture much; in particular, the two highest red dots do not need to be bumped up at all (I checked).
- The birds bar is the power/weight ratio for the muscles of a particular species of bird, reported by this source, which reports the power/weight for a particular species of bird. Amogh has done a bit of searching and doesn’t think muscle power/weight is significantly different for other species of bird. Seems plausible to me; even if the average bird has muscles that are twice (or half) as powerful-per-kilogram, the overall graph would look basically the same.
- I attempted to find estimates of human muscle power-to-weight ratio; it gets smaller the more tired the muscles get, but at peak performance for fit individuals it seems to be about an order of magnitude less than bird muscle. (This chart lists power-to-weight ratio for human cyclists, which according to this are probably about half muscle, so look at the left-hand column and double it.) Interestingly, this means that the engines of the first flying machines were possibly the first engines to be substantially better than human flapping/pedaling as a source of flying-machine power.
- EDIT Gaaah I forgot to include a link to the data! Here's the spreadsheet.
86 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2021-01-18T16:14:12.637Z · LW(p) · GW(p)
Related to one aspect of this: my post Building brain-inspired AGI is infinitely easier than understanding the brain [LW · GW]
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-18T16:30:47.554Z · LW(p) · GW(p)
Ah! If I had read that before, I had forgotten about it, sorry. This is indeed highly relevant. Strong-upvoted to signal boost.
comment by Bucky · 2021-01-21T10:47:48.386Z · LW(p) · GW(p)
Flying machines are one example but can we choose other examples which would teach the opposite lesson?
Nuclear Fusion Power Generation
Longs: The only way we know sustained nuclear fusion can be achieved is in stars. If we are confined to things less big than the sun then sustaining nuclear fusion to produce power will be difficult and there are many unknown unknowns.
Shorty: The key parameters are temperature and pressure and then controlling the plasma. A Tokamak design should be sufficient to achieve this - if we lose control it just means we need stronger / better magnets.
Replies from: Veedrac, daniel-kokotajlo↑ comment by Veedrac · 2021-01-24T20:23:42.566Z · LW(p) · GW(p)
The appeal-to-nature's-constants argument doesn't work great in this context because the sun actually produces fairly low power per unit volume. Nuclear fusion on Earth requires vastly higher power density to be practical.
That said, I think it is correct that temperature and pressure are the key factors. I just don't think the factors map on to the natural equivalents, as much as onto some physical equations that give us the Q factor.
In the context of the article, controlling the plasma is an appeal to complexity; if it turns out to be a rate limiter even after temperature and pressure suffice, then it would be evidence against the argument, but if it turns out not to matter that much, it would be evidence for.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-25T10:19:43.348Z · LW(p) · GW(p)
Controlling the plasma is an appeal to complexity, but it isn't an appeal to the complexity of the natural design. The natural design is super simple in this case. So it's not analogous to the types of arguments I think are bogus.
Replies from: Veedrac↑ comment by Veedrac · 2021-01-25T11:30:00.515Z · LW(p) · GW(p)
OK, but doesn't this hurt the point in the post? Shortly's claim that the key variables for AI ‘seem to be size and training time’ and not other measures of complexity seems no stronger (and actually much weaker) than the analogous claim that the key variables for fusion seem to be temperature and pressure, and not other measures of complexity like plasma control.
If the point of the post is only to argue against one specific framing for introducing appeals to complexity, rather than advocate for the simpler models, it seems to lose most of its predictive power for AI, since most of those appeals to complexity can be easily rephrased.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-25T12:00:24.971Z · LW(p) · GW(p)
Thanks for these questions and arguments, they've given me something to think about. Here's my current take:
The point of this post was to argue against a common type of argument I heard. I agree that some of these appeals can be rephrased to become non-bogus, and indeed I sketched an account of how they need to rephrase in order to become non-bogus: They need to argue that a.) X is probably necessary for TAI, and b.) X probably won't arrive shortly after the other variables are achieved. I think most of the arguments I am calling bogus cannot be rephrased in this way to achieve a and b, or if they can, I haven't seen it done yet.
The secondary point of this post was to provide evidence for the HBHL milestone, basically "Hey, the case of flight seems analogous in a bunch of ways to the case of AI, and if AI goes the way flight went, it'll happen around the HBHL milestone." This point is much weaker for the obvious reason that flight is just one case-study and we can think of others (like maybe fusion?) that yield the opposite lessons. I think flight is more analogous to AI than fusion, but I'm not sure.
Thus, to people who already assigned non-negligible weight to the HBHL and who didn't put much stock in the bogus arguments, my post is just preaching to the choir and provides no further evidence. My post should only cause a big update in people who either bought the bogus arguments, or who assigned such a low probability to the HBHL milestone that a single historical case study is enough to make them feel like their probability was too low.
Shortly's claim that the key variables for AI ‘seem to be size and training time’ and not other measures of complexity seems no stronger (and actually much weaker) than the analogous claim that the key variables for AI seem to be temperature and pressure, and not other measures of complexity like plasma control.
I agree that it's unclear whether "size and training time" are the key variables; maybe we need to add "control" to the list of key variables. In the case of fusion, it certainly seems that control is a key variable, at least in retrospect -- since we've had temperature and pressure equal to the sun for a while. In the case of flight, one could probably have made a convincing argument that control was a key variable, a major constraint that would take a long time to be overcome... but you would have been totally wrong; control was figured out very quickly once the other variables were in place (but not before!). Moreover, for flight at least, the control problem becomes easier and easier the more power-to-weight you have. For fusion, in my naive guessing opinion the control problem does not become easier the more temperature and pressure you have. For AI, the control problem (not the alignment kind, the capabilities kind) does become easier the more compute you have, because you can use compute to search over architectures, and because you can use parameter count and training time to compensate for other failings like data-inefficiency or whatever. So this argument which I just gave (and which I hinted at in the OP) does seem to suggest that AI will be more like flight than like fusion, but I don't by any means think this is a knock-down argument!
Replies from: Veedrac↑ comment by Veedrac · 2021-01-25T15:39:22.142Z · LW(p) · GW(p)
In the case of fusion, it certainly seems that control is a key variable, at least in retrospect -- since we've had temperature and pressure equal to the sun for a while.
To get this out of the way, I expect that fusion progress is in fact predominantly determined by temperature and pressure (and factors like that that go into the Q factor), and expect that issues with control won't seem very relevant to long-run timelines in retrospect. It's true that we've had temperature and pressure equal to the sun for a while, but it's also true that low-yield fusion is pretty easy. The missing piece to that cannot simply be control, since even a perfectly controlled ounce of a replica sun is not going to produce much energy. Rather, we just have a higher bar to cross before we get yield.
In fusion, you can use temperature and pressure to trade off against control issues. This is most clearly illustrated in hydrogen bombs. In fact, there is little in-principle reason you couldn't use hydrogen bombs to heat water to power a turbine, even if it's not the most politically or economically sensible design.
They need to argue that a.) X is probably necessary for TAI, and b.) X probably won't arrive shortly after the other variables are achieved. I think most of the arguments I am calling bogus cannot be rephrased in this way to achieve a and b, or if they can, I haven't seen it done yet.
While I've seen arguments about the complexity of neuron wiring and function, the argument has rarely been ‘and therefore we need a more exact diagram to capture the human thought processes so we can replicate it’, as much as ‘and therefore intelligence is likely to rely on a lot of specialized machinery and hardcoded knowledge.’
This argument refutes that in its naïve direct form, because, as you say, nature would add complexity irrespective of necessity, even for marginal gains. But if you allow for fusion to say, well, the simple model isn't working out, so let's add [miscellaneous complexity term], as long as it's not directly in analogy to nature, then why can't AI Longs say, well, GPT-3 clearly isn't capturing certain facets of cognition, and scaling doesn't immediately seem to be fixing that, so let's add [miscellaneous complexity term] too? Hence, ‘and therefore intelligence is likely to rely on a lot of specialized machinery and hardcoded knowledge.’
I don't think we necessarily disagree on much wrt. grounded arguments about AI, but I think if one of the key arguments (‘Part 1: Extra brute force can make the problem a lot easier’) is that certain driving forces are fungible, and can trade-off for complexity, then it seems like cases where that doesn't hold (eg. your model of fusion) would be evidence against the argument's generality. Because we don't really know how intelligence works, it seems that either you need to have a lot of belief in this class of argument (which is the case for me), or you need to be very careful applying it to this domain.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-25T17:12:23.442Z · LW(p) · GW(p)
I expect that fusion progress is in fact predominantly determined by temperature and pressure (and factors like that that go into the Q factor), and expect that issues with control won't seem very relevant to long-run timelines in retrospect. It's true that we've had temperature and pressure equal to the sun for a while, but it's also true that low-yield fusion is pretty easy. The missing piece to that cannot simply be control, since even a perfectly controlled ounce of a replica sun is not going to produce much energy. Rather, we just have a higher bar to cross before we get yield. In fusion, you can use temperature and pressure to trade off against control issues. This is most clearly illustrated in hydrogen bombs. In fact, there is little in-principle reason you couldn't use hydrogen bombs to heat water to power a turbine, even if it's not the most politically or economically sensible design.
OK, then in that case I feel like the case of fusion is totally not a counterexample-precedent to Shorty's methodology, because the Sun is just not at all analogous to what we are trying to do with fusion power generation. I'm surprised and intrigued to hear that control isn't a big deal. I assume you know more about fusion than me so I'm deferring to you.
While I've seen arguments about the complexity of neuron wiring and function, the argument has rarely been ‘and therefore we need a more exact diagram to capture the human thought processes so we can replicate it’, as much as ‘and therefore intelligence is likely to rely on a lot of specialized machinery and hardcoded knowledge.’
This argument refutes that in its naïve direct form, because, as you say, nature would add complexity irrespective of necessity, even for marginal gains.
Then we agree, at least on the main point of this paper, which was indeed just to refute this sort of argument, which I heard surprisingly often. Just because the brain is complex mysterious etc. doesn't mean 'therefore intelligence is likely to rely on a lot of specialized machinery and hardcoded knowledge.'
But if you allow for fusion to say, well, the simple model isn't working out, so let's add [miscellaneous complexity term], as long as it's not directly in analogy to nature, then why can't AI Longs say, well, GPT-3 clearly isn't capturing certain facets of cognition, and scaling doesn't immediately seem to be fixing that, so let's add [miscellaneous complexity term] too? Hence, ‘and therefore intelligence is likely to rely on a lot of specialized machinery and hardcoded knowledge.’
I called that complexity term "Special sauce." I have not in this post argued that the amount of special sauce needed is small; I left open the possibility that it might be large. The precedent of birds and planes is evidence that necessary special sauce can be small even in situations where one might think it is large, but like I said, it's just one case, so we shouldn't update too strongly based on it. Maybe we can find other cases in which necessary special sauce does seem to be big. Maybe fusion is such a case, though as described above, it's unclear -- it seems like you are saying that we just haven't reached enough temperature and pressure yet to get viable fusion? In which case fusion isn't an example of lots of special sauce being needed after all.
I don't think we necessarily disagree on much wrt. grounded arguments about AI, but I think if one of the key arguments (‘Part 1: Extra brute force can make the problem a lot easier’) is that certain driving forces are fungible, and can trade-off for complexity, then it seems like cases where that doesn't hold (eg. your model of fusion) would be evidence against the argument's generality. Because we don't really know how intelligence works, it seems that either you need to have a lot of belief in this class of argument (which is the case for me), or you need to be very careful applying it to this domain.
I'm not sure I followed this paragraph. Are you saying that you think that, in general, there are key variables for any particular design problem which make the problem easier as they are scaled up? But that I shouldn't think that, given what I erroneously thought about fusion?
Replies from: Veedrac↑ comment by Veedrac · 2021-01-26T12:30:36.172Z · LW(p) · GW(p)
I am by no means an expert on fusion power, I've just been loosely following the field after the recent bunch of fusion startups, a significant fraction of which seem to have come about precisely because HTS magnets significantly shifted the field strength you can achieve at practical sizes. Control and instabilities are absolutely a real practical concern, as are a bunch of other things like neutron damage; my expectation is only that they are second-order difficulties in the long run, much like wing shape was a second-order difficulty for flight. My framing is largely shaped by this MIT talk (here's another, here's their startup).
I called that complexity term "Special sauce." I have not in this post argued that the amount of special sauce needed is small; I left open the possibility that it might be large.
I'm probably just wanting the article to be something it's not then!
I'll try to clarify my point about key variables. The real-world debate of short versus long AI timelines pretty much boils down to the question of whether the techniques we have for AI capture enough of cognition, that short-term future prospects (scaling and research both) end up capturing enough of the important ones for TAI.
It's pretty obvious that GPT-3 doesn't do some things we'd expect a generally intelligent agent to do, and it also seems to me (and seems to be a commonality among skeptics) that we don't have enough of a grounded understanding of intelligence to expect to fill in these pieces from first principles, at least in the short term. Which means the question boils down to ‘can we buy these capabilities with other things we do have, particularly the increasing scale of computation, and by iterating on ideas?’
Flight is a clear case where, as you've said, you can trade the one variable (power-to-weight) to make up for inefficiencies and deficiencies in the other aspects. I expect fusion is another. A case where this doesn't seem to be clearly the case is in building useful, self-replicating nanoscale robots to manufacture things, in analogy to cells and microorganisms. Lithography and biotech have given us good tools for building small objects with defined patterns, but there seems to be a lot of fundamental complexity to the task that can't easily be solved by this. Even if we could fabricate a cubic millimeter of matter with every atom precisely positioned, it's not clear how much of the gap this would close. There is an issue here with trading off scale and manufacturing to substitute for complexity and the things we don't understand.
‘Part 1: Extra brute force can make the problem a lot easier’ says that you can do this sort of trade for AI, and it justifies this in part by drawing analogy to flight. But it's hard to see what intrinsically motivates this comparison specifically, because trading off a motor's power-to-weight ratio for physical upness is very different to trading off a computer's FLOP rate for abstract thinkingness. I assumed you did this because you believed (as I do) that this sort of argument is general. Hence, a general argument should apply generally, so unless there's something special about fusion, it should apply there too. If you don't believe it's a general sort of argument, then why the comparison to flight, rather than to useful, self-replicating nanoscale robots?
If instead you're just drawing comparison to flight to say it's potentially possible that compute is fungible with complexity, rather than it being likely, then it just seems like not a very impactful argument.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-26T14:19:14.608Z · LW(p) · GW(p)
Thanks again for the detailed reply; I feel like I'm coming to understand you (and fusion!) much better.
You may indeed be hoping the OP is something it's not.
That said, I think I have more to say in agreement with your strong position:
There is an issue here with trading off scale and manufacturing to substitute for complexity and the things we don't understand.
‘Part 1: Extra brute force can make the problem a lot easier’ says that you can do this sort of trade for AI, and it justifies this in part by drawing analogy to flight. But it's hard to see what intrinsically motivates this comparison specifically, because trading off a motor's power-to-weight ratio for physical upness is very different to trading off a computer's FLOP rate for abstract thinkingness. I assumed you did this because you believed (as I do) that this sort of argument is general. Hence, a general argument should apply generally, so unless there's something special about fusion, it should apply there too. If you don't believe it's a general sort of argument, then why the comparison to flight, rather than to useful, self-replicating nanoscale robots?
If instead you're just drawing comparison to flight to say it's potentially possible that compute is fungible with complexity, rather than it being likely, then it just seems like not a very impactful argument.
1. I don't know enough about nanotech to say whether it's a counterexample to Shorty's position Currently I suspect it isn't. This is a separate issue from the issue you raise, which is whether it's a counterexample to the position "In general, you can substitute brute force in some variables for special sauce." Call this position the strong view.
2. I'm not sure whether I hold the strong view. I certainly didn't try to argue for it in the OP (though I did present a small amount of evidence for it I suppose.)
3. I do hold the strong-view-applied-to-AI. That is, I do think we can make the problem of building TAI easier by using more compute. (As you say, compute is fungible with complexity). I gave two reasons for this in the OP: Can scale up the key variables, and can use compute to automate the search for special sauce. I think both of these reasons are solid on their own; I don't need to appeal to historical case studies to justify them.
4. I am happy to expand on both arguments if you like. I think the "can use compute to automate search for special sauce" is pretty self-explanatory. The "can scale up the key variables" thing is based on deep learning theory as I understand it, which is that bigger neural nets work by containing more and better lottery tickets (and you need longer to train to isolate and promote those tickets from the sludge of competitor subnetworks?). And neural networks are universal function approximators. So whatever skill it is that humans do and that you are trying to get an AI to do, with a big enough neural net trained on enough data, you'll succeed. And "big enough" means probably about the size of the human brain. This is just the sketch of a skeleton of an argument of course, but I could go on...
Replies from: Veedrac↑ comment by Veedrac · 2021-01-26T23:19:18.450Z · LW(p) · GW(p)
Thanks, I think I pretty much understand your framing now.
I think the only thing I really disagree with is that “"can use compute to automate search for special sauce" is pretty self-explanatory.” I think this heavily depends on what sort of variable you expect the special sauce to be. Eg. for useful, self-replicating nanoscale robots, my hypothetical atomic manufacturing technology would enable rapid automated iteration, but it's unclear how you could use that to automatically search for a solution in practice. It's an enabler for research, moreso than a substitute. Personally I'm not sure how I'd justify that claim for AI without importing a whole bunch of background knowledge of the generality of optimization procedures!
IIUC this is mostly outside the scope of what your article was about, and we don't disagree on the meat of the matter, so I'm happy to leave this here.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T08:23:25.856Z · LW(p) · GW(p)
I think I agree that it's not clear compute can be used to search for special sauce in general, but in the case of AI it seems pretty clear to me: AIs themselves run in computers, and the capabilities we are interested in (some of them, at least) can be detected on AIs in simulations (no need for e.g. robotic bodies) and so we can do trial-and-error on our AI designs in proportion to how much compute we have. More compute, more trial-and-error. (Except it's more efficient than mere trial-and-error, we have access to all sorts of learning and meta-learning and architecture search algorithms, not to mention human insight). If you had enough compute, you could just simulate the entire history of life evolving on an earth-sized planet for a billion years, in a very detailed and realistic physics environment!
Replies from: Veedrac↑ comment by Veedrac · 2021-01-27T12:44:41.929Z · LW(p) · GW(p)
Eventually the conclusion holds trivially, sure, but that takes us very far from the HBHL anchor. Most evolutionary algorithms we do today are very constrained in what programs they can generate, and are run over small models for a small number of iteration steps. A more general search would be exponentially slower, and even more disconnected from current ML. If you expect that sort of research to be pulling a lot of weight, you probably shouldn't expect the result to look like large connectionist models trained on lots of data, and you lose most of the argument for anchoring to HBHL.
A more standard framing is that ‘we can do trial-and-error on our AI designs’, but there we're again in a regime where scale is an enabler for research, moreso than a substitute for it. Architecture search will still fine-tune and validate these ideas, but is less likely to drive them directly in a significant way.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T13:13:18.147Z · LW(p) · GW(p)
Eventually the conclusion holds trivially, sure, but that takes us very far from the HBHL anchor.
It takes us about 17 orders of magnitude away from the HBHL anchor, in fact. Which is not very far, when you think about it. Divide 100 percentage points of probability mass evenly across those 17 orders of magnitude, and you get almost 6% per OOM, which means something like 4x as much probability mass on the HBHL anchor than Ajeya puts on it in her report!
If you expect that sort of research to be pulling a lot of weight, you probably shouldn't expect the result to look like large connectionist models trained on lots of data, and you lose most of the argument for anchoring to HBHL.
I don't follow this argument. It sounds like double-counting to me, like: "If you put some of your probability mass away from HBHL, that means you are less confident that AI will be made in the HBHL-like way, which means you should have even less of your probability mass on HBHL."
A more standard framing is that ‘we can do trial-and-error on our AI designs’, but there we're again in a regime where scale is an enabler for research, moreso than a substitute for it. Architecture search will still fine-tune and validate these ideas, but is less likely to drive them directly in a significant way.
I'm not sure I get the distinction between enabler and substitute, or why it is relevant here. The point is that we can use compute to search for the missing special sauce. Maybe humans are still in the loop; sure.
Replies from: Veedrac↑ comment by Veedrac · 2021-01-27T15:47:10.728Z · LW(p) · GW(p)
It takes us about 17 orders of magnitude away from the HBHL anchor, in fact. Which is not very far, when you think about it. Divide 100 percentage points of probability mass evenly across those 17 orders of magnitude, and you get almost 6% per OOM, which means something like 4x as much probability mass on the HBHL anchor than Ajeya puts on it in her report!
I don't understand what you're doing here. Why 17 orders of magnitude, and why would I split 100% across each order?
I don't follow this argument. It sounds like double-counting to me
Read ‘and therefore’, not ‘and in addition’. The point is that the more you spend your compute on search, the less directly your search can exploit computationally expensive models.
Put another way, if you have HBHL compute but spend nine orders of magnitude on search, then the per-model compute is much less than HBHL, so the reasons to argue for HBHL don't apply to it. Equivalently, if your per-model compute estimate is HBHL, then the HBHL metric is only relevant for timelines if search is fairly limited.
I'm not sure I get the distinction between enabler and substitute, or why it is relevant here. The point is that we can use compute to search for the missing special sauce. Maybe humans are still in the loop; sure.
Motors are an enabler in the context of flight research because they let you build and test designs, learn what issues to solve, build better physical models, and verify good ideas.
Motors are a substitute in the context of flight research because a better motor means more, easier, and less optimal solutions become viable.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T16:48:59.734Z · LW(p) · GW(p)
Ajeya estimates (and I agree with her) how much compute it would take to recapitulate evolution, i.e. simulate the entire history of life on earth evolving for a billion years etc. The number she gets is 10^41 FLOP give or take a few OOMs. That's 17 OOMs away from where we are now. So if you take 10^41 as an upper bound, and divide up the probability evenly across the OOMs... Of course it probably shouldn't be a hard upper bound, so instead of dividing up 100 percentage points you should divide up 95 or 90 or whatever your credence is that TAI could be achieved for 10^41 or less compute. But that wouldn't change the result much, which is that a naive, flat-across-orders-of-magnitude-up-until-the-upper-bound-is-reached distribution would assign substantially higher probability to Shorty's position than Ajeya does.
I'm still not following the argument. I agree that you won't be able to use your HBHL compute to do search over HBHL-sized brains+childhoods, because if you only have HBHL compute, you can only do one HBHL-sized brain+childhood. But that doesn't undermine my point, which is that as you get more compute, you can use it to do search. So e.g. when you have 3 OOMs more compute than the HBHL milestone, you can do automated search over 1000 HBHL-sized brains+childhoods. (Also I suppose even when you only have HBHL compute you could do search over architectures and childhoods that are a little bit smaller and hope that the lessons generalize)
I think part of what might be going on here is that since Shorty's position isn't "TAI will happen as soon as we hit HBHL" but rather "TAI will happen shortly after we hit HBHL" there's room for an OOM or three of extra compute beyond the HBHL to be used. (Compute costs decrease fairly quickly, and investment can increase much faster, and probably will when TAI is nigh) I agree that we can't use compute to search for special sauce if we only have exactly HBHL compute (setting aside the paranthetica in the previous paragraph, which suggests that we can)
Replies from: Veedrac↑ comment by Veedrac · 2021-01-27T19:13:11.352Z · LW(p) · GW(p)
Well I understand now where you get the 17, but I don't understand why you want to spread it uniformly across the orders of magnitude. Shouldn't you put the all probability mass for the brute-force evolution approach on some gaussian around where we'd expect that to land, and only have probability elsewhere to account for competing hypotheses? Like I think it's fair to say the probability of a ground-up evolutionary approach only using 10-100 agents is way closer to zero than to 4%.
I'm still not following the argument. [...] So e.g. when you have 3 OOMs more compute than the HBHL milestone
I think you're mixing up my paragraphs. I was referring here to cases where you're trying to substitute searching over programs for the AI special sauce.
If you're in the position where searching 1000 HBHL hypotheses finds TAI, then the implicit assumption is that model scaling has already substituted for the majority of AI special sauce, and the remaining search is just an enabler for figuring out the few remaining details. That or that there wasn't much special sauce in the first place.
To maybe make my framing a bit more transparent, consider the example of a company trying to build useful, self-replicating nanoscale robots using a atomically precise 3D printer under the conditions where 1) nobody there has a good idea of how to go about doing this, and 2) you have 1000 tries.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-14T17:09:22.941Z · LW(p) · GW(p)
Sorry I didn't see this until now!
--I agree that for the brute-force evolution approach, we should have a gaussian around where we'd expect that to land. My "Let's just do evenly across all the OOMs between now and evolution" is only a reasonable first-pass approach to what our all-things-considered distribution should be like, including evolution but also various other strategies. (Even better would be having a taxonomy of the various strategies and a gaussian for each; this is sorta what Ajeya does. the problem is that insofar as you don't trust your taxonomy to be exhaustive, the resulting distribution is untrustworthy as well.) I think it's reasonable to extend the probability mass down to where we are now, because we are currently at the HBHL milestone pretty much, which seems like a pretty relevant milestone to say the least.
If you're in the position where searching 1000 HBHL hypotheses finds TAI, then the implicit assumption is that model scaling has already substituted for the majority of AI special sauce, and the remaining search is just an enabler for figuring out the few remaining details. That or that there wasn't much special sauce in the first place.
This seems right to me.
To maybe make my framing a bit more transparent, consider the example of a company trying to build useful, self-replicating nanoscale robots using a atomically precise 3D printer under the conditions where 1) nobody there has a good idea of how to go about doing this, and 2) you have 1000 tries.
I like this analogy. I think our intuitions about how hard it would be might differ though. Also, our intuitions about the extent to which nobody has a good idea of how to make TAI might differ too.
Replies from: Veedrac↑ comment by Veedrac · 2021-03-17T20:19:54.535Z · LW(p) · GW(p)
Also, our intuitions about the extent to which nobody has a good idea of how to make TAI might differ too.
To be clear I'm not saying nobody has a good idea of how to make TAI. I expect pretty short timelines, because I expect the remaining fundamental challenges aren't very big.
What I don't expect is that the remaining fundamental challenges go away through small-N search over large architectures, if the special sauce does turn out to be significant.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-21T11:17:50.307Z · LW(p) · GW(p)
Good point! I'd love to see a more thorough investigation into cases like this. This is the best comment so far IMO; strong-upvoted.
My immediate reply would be: Shorty here is just wrong about what the key parameters are; as Longs points out, size seems pretty important, because it means you don't have to worry about control. Trying to make a fusion reactor much smaller than a star seems to me to be analogous to trying to make a flying machine with engines much weaker than bird muscle, or an AI with neural nets much smaller than human brains. Yeah, maybe it's possible in principle, but in practice we should expect it to be very difficult. But I'm not sure, I'd want to think about this more.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-21T11:32:03.959Z · LW(p) · GW(p)
Update: Actually, I think I analyzed that wrong. Shorty did mention "controlling the plasma" as a key variable; in that case, I agree that Shorty got the key variables correct. Shorty's methodology is to plot a graph with the key variables and say "We'll achieve it when our variables reach roughly the same level as they are in nature's equivalent." But how do we measure level of control? How can we say that we've reached the same level of control over the plasma as the Sun has? This bit seems implausible. So I think a steelman Shorty would either say that it's unknown whether we've reached the key variables yet (because we don't know how good tokamaks are at controlling plasma) or that control isn't a key variable (because it can be compensated for by other things, like temperature and pressure.) (Though in this case if Shorty went that second route, they'd probably just be wrong? Compare to the case of flight, where the problem of controlling the craft really does become a lot easier when you have access to more powerful&light engines. I don't know much about fusion designs but I suspect that cranking up temperature and pressure doesn't, in fact, make controlling the reaction easier. Am I wrong?)
Replies from: Bucky↑ comment by Bucky · 2021-01-22T08:45:36.859Z · LW(p) · GW(p)
Probably nowadays what Shorty missed was the difficulty in dealing with the energetic neutrons being created and associated radiation. Then associated maintenance costs etc and therefore price-competitiveness. I chose nuclear fusion purely because it was the most salient example of project-that-always-misses-its-deadlines.
(I did my university placement year in nuclear fusion research but still don't feel like I properly understand it! I'm pretty sure you're right though about temperature, pressure and control.)
In theory a steelman Shorty could have thought of all of these things but in practice it's hard to think of everything. I find myself in the weird position of agreeing with you but arguing in the opposite direction.
For a random large project X, which is more likely to be true:
- Project X took longer than expert estimates because of failure to account for Y
- Project X was delivered approximately on time
In general I suspect that it is the former (1). In that case the burden of evidence is on Shorty to show why project X is outside of the reference class of typical-large-projects and maybe in some subclass where accurate predictions of timelines are more achievable.
Maybe what is required is to justify TAI as being in the subclass
- projects-that-are-mainly-determined-by-a-single-limiting-factor
or
- projects-whose-key-variables-are-reliably-identifiable-in-advance
I think this is essentially the argument the OP is making in Analysis Part1?
***
I notice in the above I've probably gone beyond the original argument - the OP was arguing specifically against using the fact that natural systems have such properties to say that they're required. I'm talking about something more general - systems generally have more complexity than we realize. I think this is importantly different.
It may be the case that Longs' argument about brains having such properties is based on an intuition from the broader argument. I think that the OP is essentially correct in saying that adding examples from the human brain into the argument does little to make such an argument stronger (Analysis part 2).
***
(1) Although there is also the question of how much later counts as a failure of prediction. I guess Shorty is arguing for TAI in the next 20 years, Longs is arguing 50-100 years?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-22T11:20:58.139Z · LW(p) · GW(p)
I still prefer my analysis above: Fusion is not a case of Shorty being wrong, because a steelman Shorty wouldn't have predicted that we'd get fusion soon. Why? Because we don't have the key variables. Why? Because controlling the plasma is one of the key variables, and the sun has near-perfect control, whereas we are trying to substitute with various designs which may or may not work.
Shorty is actually arguing for TAI much sooner than 20 years from now; if TAI comes around the HBHL milestone then it could happen any day now, it's just a matter of spending a billion dollars on compute and then iterating a few times to work out the details, wright-brothers style. Of course we shouldn't think Shorty is probably correct here; the truth is probably somewhere in between. (Unless we do more historical analyses and find that the case of flight is truly representative of the reference class AI fits in, in which case ho boy singularity here we come)
And yeah, the main purpose of the OP was to argue that certain anti-short-timelines arguments are bogus; this issue of whether timelines are actually short or long is secondary and the case of flight is just one case study, of limited evidential import.
I do take your point that maybe Longs' argument was drawing on intuitions of the sort you are sketching out. In other words, maybe there's a steelman of the arguments I think are bogus, such that they become non-bogus. I already agree this is true in at least one way (see Part 3). I like your point about large projects -- insofar as we think of AI in that reference class, it seems like our timelines should be "Take whatever the experts say and then double it." But if we had done this for flight we would have been disastrously wrong. I definitely want to think, talk, and hear more about these issues... I'd like to have a model of what sorts of technologies are like fusion and what sort are like flight, and why.
I like your suggestions:
projects-that-are-mainly-determined-by-a-single-limiting-factor
projects-whose-key-variables-are-reliably-identifiable-in-advance
My own (hinted at in the OP) was going to be something like "When your basic theory of a design problem is developed enough that you have identified the key variables, and there is a natural design that solves the problem in a similar way to the thing you are trying to build, then you can predict roughly when the problem will be solved by saying that it'll happen around the time that parity-with-the-natural-design is reached in the key variables. What are key variables? I'm not sure how to define them, but one property that seems maybe important is that the design problem becomes easier when you have more of the key variables."
Another thing worth mentioning is that probably having a healthy competition between different smart people is important. The Wright brother succeeded but there were several other groups around the same time also trying to build flying machines, who were less successful (or who took longer to succeed). If instead there had been one big government-funded project, there's more room for human error and the usual failures to cause cost overruns and delays. (OTOH having more funding might have made it happen sooner? IDK). In the case of AI, there are enough different projects full of enough smart people working on the problem that I don't think this is a major constraint. I'd be curious to hear more about the case of fusion. I've heard some people say that actually it could have been achieved by now if only it had more funding, and I think I've heard other people say that it could have been achieved by now if it was handled by a competitive market instead of a handful of bureaucracies (though I may be misremembering that, maybe no one said that).
comment by Thomas Kwa (thomas-kwa) · 2021-01-28T19:29:58.253Z · LW(p) · GW(p)
(For example, imagine a u-shaped craft with a low center of gravity and helicopter-style rotors on each tip. Add a third, smaller propeller on a turret somewhere for steering.)
Extremely minor nitpick: the low center of gravity wouldn't stabilize the craft. Helicopters are unstable regardless of where the rotors are relative to the center of gravity, due to the pendulum rocket fallacy.
Replies from: robert-miles, daniel-kokotajlo↑ comment by Robert Miles (robert-miles) · 2021-03-04T10:32:18.658Z · LW(p) · GW(p)
I came here to say this :)
If you do the stabilisation with the rotors in the usual helicopter way, you basically have a Chinook (though you don't need the extra steering propeller because you can control the rotors well enough)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T11:29:21.917Z · LW(p) · GW(p)
A Chinook was basically what I was envisioning... what does a Chinook do that my U-shaped proposal wouldn't do? How does stabilization with rotors work? EDIT: Ok, so helicopters use some sort of weighted balls attached to their rotors, and maybe some flexibility in the rotors also... I still don't fully understand how it works but it seems like there are probably explainer videos somewhere.
Replies from: robert-miles↑ comment by Robert Miles (robert-miles) · 2021-03-15T12:14:41.760Z · LW(p) · GW(p)
Yeah, the mechanics of helicopter rotors is pretty complex and a bit counter-intuitive, Smarter Every Day has a series on it
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T11:28:04.167Z · LW(p) · GW(p)
Damn! I feel foolish, should have looked this up first. Thanks!
EDIT: OK, so simple design try #2: What about a quadcopter (with counter-rotating propellers of course to cancel out torque) but where the propellers are angled away from the center of mass instead of just pointing straight down--that way if the craft starts tilting in some direction, it will have an imbalance of forces such that more of the upward component comes from the side that is tilting down, and less from the side that is tilting up, and so the former side will rise and the latter side will fall, and it'll be not-tilted again. This was the other idea I had, but I wrote the U-shaped thing because it took fewer words to explain. ... is this wrong too? EDIT: Now I'm worried this is wrong too for the same reason... damn... I guess I'm still just very confused about the pendulum rocket fallacy and why it's a fallacy. I should go read more.)
comment by Steven Byrnes (steve2152) · 2021-01-18T16:30:15.856Z · LW(p) · GW(p)
Moreover, we probably won’t figure out how to make AIs that are as data-efficient as humans for a long time--decades at least.
I know you weren't endorsing this claim as definitely true, but FYI my take is that other families of learning algorithms besides deep neural networks are in fact as data-efficient as humans, particularly those related to probabilistic programming and analysis-by-synthesis, see examples here [LW · GW].
comment by Rohin Shah (rohinmshah) · 2021-01-20T18:56:26.136Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post argues against a particular class of arguments about AI timelines. These arguments have the form: “The brain has property X, but we don’t know how to make AIs with property X. Since it took evolution a long time to make brains with property X, we should expect it will take us a long time as well”. The reason these are not compelling is because humans often use different approaches to solve problems than evolution did, and so humans might solve the overall problem without ever needing to have property X. To make these arguments more convincing, you need to argue 1) why property X really is _necessary_ and 2) why property X won’t follow quickly once everything else is in place.
This is illustrated with a hypothetical example of someone trying to predict when humans would achieve heavier-than-air flight: in practice, you could have made decent predictions just by looking at the power to weight ratios of engines vs. birds. Someone who argued that we were far away because “we don’t know how to make wings that flap” would have made incorrect predictions.
Planned opinion:
Replies from: daniel-kokotajloThis all seems generally right to me, and is part of the reason I like the <@biological anchors approach@>(@Draft report on AI timelines@) to forecasting transformative AI.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-20T19:23:14.579Z · LW(p) · GW(p)
Sounds good to me! I suggest you replace "we don't know how to make wings that flap" with "we don't even know how birds stay up for so long without flapping their wings," because IMO it's a more compelling example. But it's not a big deal either way.
As an aside, I'd be interested to hear your views given this shared framing. Since your timelines are much longer than mine, and similar to Ajeya's, my guess is that you'd say TAI requires data-efficiency and that said data-efficiency will be really hard to get, even once we are routinely training AIs the size of the human brain for longer than a human lifetime. In other words, I'd guess that you would make some argument like the one I sketched in Part 3. Am I right? If so, I'd love to hear a more fleshed-out version of that argument from someone who endorses it -- I suppose there's what Ajeya has in her report...
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-01-20T21:14:19.674Z · LW(p) · GW(p)
Sorry, what in this post contradicts anything in Ajeya's report? I agree with your headline conclusion of
If all we had to do to get TAI was make a simple neural net 10x the size of my brain, my brain would still look the way it does.
This also seems to be the assumption that Ajeya uses. I actually suspect we could get away with a smaller neural net ,that is similar in size to or somewhat smaller than the brain.
I guess the report then uses existing ML scaling laws to predict how much compute we need to train a neural net the size of a brain, whereas you prefer to use the human lifetime to predict it instead? From my perspective, the former just seems way more principled / well-motivated / likely to give you the right answer, given that the scaling laws seem to be quite precise and reasonably robust.
I would predict that we won't get human-level data efficiency for neural net training, but that's a consequence of my trust in scaling laws (+ a simple model for why that would be the case, namely that evolution can bake in some prior knowledge that it will be harder for humans to do, and you need more data to compensate).
I suggest you replace "we don't know how to make wings that flap" with "we don't even know how birds stay up for so long without flapping their wings,"
Done.
Replies from: daniel-kokotajlo, daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-21T11:47:02.023Z · LW(p) · GW(p)
OK, so here is a fuller response:
First of all, yeah, as far as I can tell you and I agree on everything in the OP. Like I said, this disagreement is an aside.
Now that you mention it / I think about it more, there's another strong point to add to the argument I sketched in part 3: Insofar as our NN's aren't data-efficient, it'll take more compute to train them, and so even if TAI need not be data-efficient, short-timelines-TAI must be. (Because in the short term, we don't have much more compute. I'm embarrassed I didn't notice this earlier and include it in the argument.) That helps the argument a lot; it means that all the argument has to do is establish that we aren't going to get more data-efficient NN's anytime soon.
And yeah, I agree the scaling laws are a great source of evidence about this. I had them in mind when I wrote the argument in part 3. I guess I'm just not as convinced as you (?) that (a) when we are routinely training NN's with 10e15 params, it'll take roughly 10e15 data points to get to a useful level of performance, and (b) average horizon length for the data points will need to be more than short.
Some reasons I currently doubt (a):
--A bunch of people I talk to, who know more about AI than me, seem confident that we can get several OOMs more data-efficient training than the GPT's had using various already-developed tricks and techniques.
--The scaling laws, IIRC, don't tell us how much data is needed to reach a useful level of performance. Rather, they tell us how much data is needed if you want to use your compute budget optimally. It could be that at 10e15 params and 10e15 data points, performance is actually much higher than merely useful; maybe only 10e13 params and 10e13 data points would be the first to cross the usefulness threshold. (Counterpoint: Extrapolating GPT performance trends on text prediction suggests it wouldn't be human-level at text prediction until about 10e15 params and 10e15 data points, according to data I got from Lanrian. Countercounterpoint: Extrapolating GPT performance trends on tasks other than text prediction makes it seem to me that it could be pretty useful well before then; see these figures, [LW · GW] in which I think 10e15/10e15 would be the far-right edge of the graph).
Some reasons I currently doubt (b):
--I've been impressed with how much GPT-3 has learned despite having a very short horizon length, very limited data modality, very limited input channel, very limited architecture, very small size, etc. This makes me think that yeah, if we improve on GPT-3 in all of those dimensions, we could get something really useful for some transformative tasks, even if we keep the horizon length small.
--I think that humans have a tiny horizon length -- our brains are constantly updating, right? I guess it's hard to make the comparison, given how it's an analog system etc. But it sure seems like the equivalent of the average horizon length for the brain is around a second or so. Now, it could be that humans get away with such a small horizon length because of all the fancy optimizations evolution has done on them. But it also could just be that that's all you need.
--Having a small average horizon length doesn't preclude also training lots on long-horizon tasks. It just means that on average your horizon length is small. So e.g. if the training process involves a bit of predict-the-next input, and also a bit of make-and-execute-plans-actions-over-the-span-of-days, you could get quite a few data points of the latter variety and still have a short average horizon length.
I'm very uncertain about all of this and would love to hear your thoughts, which is why I asked. :)
Replies from: rohinmshah, nostalgebraist, steve2152↑ comment by Rohin Shah (rohinmshah) · 2021-01-21T17:39:31.270Z · LW(p) · GW(p)
Now that you mention it / I think about it more, there's another strong point to add to the argument I sketched in part 3: Insofar as our NN's aren't data-efficient, it'll take more compute to train them, and so even if TAI need not be data-efficient, short-timelines-TAI must be.
Yeah, this is (part of) why I put compute + scaling laws front and center and make inferences about data efficiency; you can have much stronger conclusions when you start reasoning from the thing you believe is the bottleneck.
--A bunch of people I talk to, who know more about AI than me, seem confident that we can get several OOMs more data-efficient training than the GPT's had using various already-developed tricks and techniques.
Note that Ajeya's report does have a term for "algorithmic efficiency", that has a doubling time of 2-3 years.
Certainly "several OOMs using tricks and techniques we could implement in a year" would be way faster than that trend, but you've really got to wonder why these people haven't done it yet -- if I interpret "several OOMs" as "at least 3 OOMs", that would bring the compute cost down to around $1000, which is accessible for basically any AI researcher (including academics). I'll happily take a 10:1 bet against a model as competent as GPT-3 being trained on $1000 of compute within the next year.
Perhaps the tricks and techniques are sufficiently challenging that they need a full team of engineers working for multiple years -- if so, this seems plausibly consistent with the 2-3 year doubling time.
-The scaling laws, IIRC, don't tell us how much data is needed to reach a useful level of performance. Rather, they tell us how much data is needed if you want to use your compute budget optimally.
Evolution was presumably also going for compute-optimal performance, so it seems like this is the right comparison to make. I agree there's uncertainty here, but I don't see why the uncertainty should bias us towards shorter timelines rather than longer timelines.
I could see it if we thought we were better than evolution, since then we could say "we'd figure something out that evolution missed and that would bias towards short timelines"; but this is also something that Ajeya considered and iirc she then estimated that evolution tended to be ~10x better than us (lots of caveats here though).
Countercounterpoint: Extrapolating GPT performance trends on tasks other than text prediction makes it seem to me that it could be pretty useful well before then; see these figures, [LW · GW] in which I think 10e15/10e15 would be the far-right edge of the graph
Both Ajeya and I think that AI systems will be incredibly useful before they get to the level of "transformative AI". The tasks in the graph you link are particularly easy and not that important; having superhuman performance on them would not transform the world.
(b) average horizon length for the data points will need to be more than short.
I just put literally 100% mass on short horizon in my version of the timelines model (which admittedly has changed some other parameters, though not hugely iirc) and the median I get is 2041 (about 10 years lower than what it was previously). So I don't think this is making a huge difference (though certainly 10 years is substantial).
--I've been impressed with how much GPT-3 has learned despite having a very short horizon length, very limited data modality, very limited input channel, very limited architecture, very small size, etc. This makes me think that yeah, if we improve on GPT-3 in all of those dimensions, we could get something really useful for some transformative tasks, even if we keep the horizon length small.
I see horizon length (as used in the report) as a function of a task, so "horizon length of GPT-3" feels like a type error given that what we care about is how GPT-3 can do many tasks. Any task done by GPT-3 has a maximum horizon length of 2048 (the size of its context window). During training, GPT-3 saw 300 billion tokens, so it saw around 100 million "effective examples" of size 2048. It makes sense within the bio anchors framework that there would be some tasks with horizon length in the thousands that GPT-3 would be able to do well.
--I think that humans have a tiny horizon length -- our brains are constantly updating, right? I guess it's hard to make the comparison, given how it's an analog system etc. But it sure seems like the equivalent of the average horizon length for the brain is around a second or so. Now, it could be that humans get away with such a small horizon length because of all the fancy optimizations evolution has done on them. But it also could just be that that's all you need.
Again, this feels like a type error to me. Horizon length isn't about the optimization algorithm, it's about the task.
(You can of course define your own version of "horizon length" that's about the optimization algorithm, but then I think you need to have some way of incorporating the "difficulty" of a transformative task into your timelines estimate, given that the scaling laws are all calculated on "easy" tasks.)
--Having a small average horizon length doesn't preclude also training lots on long-horizon tasks. It just means that on average your horizon length is small. So e.g. if the training process involves a bit of predict-the-next input, and also a bit of make-and-execute-plans-actions-over-the-span-of-days, you could get quite a few data points of the latter variety and still have a short average horizon length.
Agree with this. I remember mentioning this to Ajeya but I don't actually remember what the conclusion was.
EDIT: Oh, I remember now. The argument I was making is that you could imagine that most of the training is unsupervised pretraining on a short-horizon objective, similarly to GPT-3, after which you finetune (with negligible compute cost) on the long-horizon transformative task you care about, so that on average your horizon is short. I definitely remember this being an important reason in me putting as much weight on short horizons as I did; I think this was also true for Ajeya.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-24T14:35:55.144Z · LW(p) · GW(p)
Thanks for the detailed reply!
Yeah, this is (part of) why I put compute + scaling laws front and center and make inferences about data efficiency; you can have much stronger conclusions when you start reasoning from the thing you believe is the bottleneck.
I didn't quite follow this part. Do you think I'm not reasoning from the thing I believe is the bottleneck?
Certainly "several OOMs using tricks and techniques we could implement in a year" would be way faster than that trend, but you've really got to wonder why these people haven't done it yet -- if I interpret "several OOMs" as "at least 3 OOMs", that would bring the compute cost down to around $1000, which is accessible for basically any AI researcher (including academics). I'll happily take a 10:1 bet against a model as competent as GPT-3 being trained on $1000 of compute within the next year.
Perhaps the tricks and techniques are sufficiently challenging that they need a full team of engineers working for multiple years -- if so, this seems plausibly consistent with the 2-3 year doubling time.
Some of the people I talked to said about 2 OOMs, others expressed it differently, saying that the faster scaling law can be continued past the kink point predicted by Kaplan et al. Still others simply said that GPT-3 was done in a deliberately simple, non-cutting-edge way to prove a point and that it could have used its compute much more compute-efficiently if they threw the latest bags of tricks at it. I am skeptical of all this, of course, but perhaps less skeptical than you? 2 OOMs is 7 doublings, which will happen around 2037 according to Ajeya. Would you be willing to take a 10:1 bet that there won't be something as good as GPT-3 trained on 2 OOMs less compute by 2030? I think I'd take the other side of that bet.
Evolution was presumably also going for compute-optimal performance, so it seems like this is the right comparison to make.
I don't think evolution was going for compute-optimal performance in the relevant sense. With AI, we can easily trade off between training models longer and making models bigger, and according to the scaling laws it seems like we should increase training time by 0.75 OOMs for every OOM of parameter count increase. With biological systems, sure maybe it is true that if you faced a trade-off where you were trying to minimize total number of neuron firings over the course of the organism's childhood, the right ratio would be 0.75 OOMs of extra childhood duration for every 1 OOM of extra synapses... maybe. But even if this were true, it's pretty non-obvious that that's the trade-off regime evolution faces. There are all sorts of other pros and cons associated with more synapses and longer childhoods. For example, maybe evolution finds it easier to increase synapse count than to increase childhood, because increased childhood reduces fitness significantly (more chances to die before you reproduce, longer doubling time of population).
Both Ajeya and I think that AI systems will be incredibly useful before they get to the level of "transformative AI". The tasks in the graph you link are particularly easy and not that important; having superhuman performance on them would not transform the world.
Yeah, sorry, by useful I meant useful for transformative tasks.
Yes, obviously the tasks in the graph are not transformative. But it seems to me to be... like, 25% likely or so that once we have pre-trained, unsupervised models that build up high skill level at all those tasks on the graph, it's because they've developed general intelligence in the relevant sense. Or maybe they haven't but it's a sign that general intelligence is near, perhaps with a more sophisticated training regime and architecture. Like, yeah those tasks are "particularly easy" compared to taking over the world, but they are also incredibly hard in some sense; IIRC GPT-3 was also tested on a big dataset of exam questions used for high school, college, and graduate-level admissions, and got 50% or so whereas every other AI system got 25%, random chance, and I bet most english-speaking literate humans in the world today would have done worse than 50%.
I just put literally 100% mass on short horizon in my version of the timelines model (which admittedly has changed some other parameters, though not hugely iirc) and the median I get is 2041 (about 10 years lower than what it was previously). So I don't think this is making a huge difference (though certainly 10 years is substantial).
Huh. When I put 100% mass on short horizon in my version of Ajeya's model, it says median 2031. Admittedly, I had made some changes to some other parameters too, also not hugely iirc. I wonder if this means those other-parameter changes matter more than I'd thought.
I see horizon length (as used in the report) as a function of a task, so "horizon length of GPT-3" feels like a type error given that what we care about is how GPT-3 can do many tasks. Any task done by GPT-3 has a maximum horizon length of 2048 (the size of its context window). During training, GPT-3 saw 300 billion tokens, so it saw around 100 million "effective examples" of size 2048. It makes sense within the bio anchors framework that there would be some tasks with horizon length in the thousands that GPT-3 would be able to do well.
Huh, that's totally not how I saw it. From Ajeya's report:
I’ll define the “effective horizon length” of an ML problem as the amount of data it takes (on average) to tell whether a perturbation to the model improves performance or worsens performance. If we believe that the number of “samples” required to train a model of size P is given by KP, then the number of subjective seconds that would be required should be given by HKP, where H is the effective horizon length expressed in units of “subjective seconds per sample.”
To me this really sounds like it's saying the horizon length = the number of subjective seconds per sample during training. So, maybe it makes sense to talk about "horizon length of task X" (i.e. number of subjective seconds per sample during training of a typical ML model on that task) but it seems to make even more sense to talk about "horizon length of model X" since model X actually had a training run and actually had an average number of subjective seconds per sample.
But I'm happy to 70% defer to your judgment on this since you probably have talked to Ajeya etc. and know more about this than me.
At any rate, deferring to you on this doesn't undermine the point I was making at all, as far as I can tell.
you could imagine that most of the training is unsupervised pretraining on a short-horizon objective, similarly to GPT-3, after which you finetune (with negligible compute cost) on the long-horizon transformative task you care about, so that on average your horizon is short. I definitely remember this being an important reason in me putting as much weight on short horizons as I did; I think this was also true for Ajeya.
Exactly. I think this is what humans do too, to a large extent. I'd be curious to hear why you put so much weight on medium and long horizons. I put 50% on short, 20% on medium, and 10% on long.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-01-24T17:55:38.344Z · LW(p) · GW(p)
I didn't quite follow this part. Do you think I'm not reasoning from the thing I believe is the bottleneck?
I actually don't remember what I meant to convey with that :/
Would you be willing to take a 10:1 bet that there won't be something as good as GPT-3 trained on 2 OOMs less compute by 2030?
No, I'd also take the other side of the bet. A few reasons:
- Estimated algorithmic efficiency in the report is low because researchers are not currently optimizing for "efficiency on a transformative task", whereas researchers probably are optimizing for "efficiency of GPT-3 style systems", suggesting faster improvements in algorithmic efficiency for GPT-3 than estimated in the report.
- 90% confidence is quite a lot; I do not have high certainty in the algorithmic efficiency part of the report.
(Note that 2 OOMs in 10 years seems significantly different from "we can get several OOMs more data-efficient training than the GPT's had using various already-developed tricks and techniques". I also assume that you have more than 10% credence in this, since 10% seems too low to make a difference to timelines.)
I don't think evolution was going for compute-optimal performance in the relevant sense.
I feel like this is already taken into account by the methodology by which we estimated the ratio of evolution to human design? Like, taking your example of flight, presumably evolution was not optimizing just for power-to-weight ratio, it was optimizing for a bunch of other things; nonetheless we ignore those other things when making the comparison. Similarly, in the report the estimate is that evolution is ~10x better than humans on the chosen metrics, even though evolution was not literally optimizing just for the chosen metric. Why not expect the same here?
I think you'd need to argue that there is a specific other property that evolution was optimizing for, that clearly trades off against compute-efficiency, to argue that we should expect that in this case evolution was worse than in other cases.
But it seems to me to be... like, 25% likely or so that once we have pre-trained, unsupervised models that build up high skill level at all those tasks on the graph, it's because they've developed general intelligence in the relevant sense.
This seems like it is realist about rationality [LW · GW], which I mostly don't buy. Still, 25% doesn't seem crazy, I'd probably put 10 or 20% on it myself. But even at 25% that seems pretty consistent with my timelines; 25% does not make the median.
Or maybe they haven't but it's a sign that general intelligence is near, perhaps with a more sophisticated training regime and architecture.
Why aren't we already using the most sophisticated training regime and architecture? I agree it will continue to improve, but that's already what the model does.
GPT-3 was also tested on a big dataset of exam questions used for high school, college, and graduate-level admissions, and got 50% or so whereas every other AI system got 25%, random chance, and I bet most english-speaking literate humans in the world today would have done worse than 50%.
- I don't particularly care about comparisons of memory / knowledge between GPT-3 and humans. Humans weren't optimized for that.
- I expect that Google search beats GPT-3 on that dataset.
I don't really know what you mean when you say that this task is "hard". Sure, humans don't do it very well. We also don't do arithmetic very well, while calculators do.
But I'm happy to 70% defer to your judgment on this since you probably have talked to Ajeya etc. and know more about this than me.
Er, note that I've talked to Ajeya for like an hour or two on the entire report. I'm not that confident that Ajeya also believes the things I'm saying (maybe I'm 80% confident).
To me this really sounds like it's saying the horizon length = the number of subjective seconds per sample during training. [...]
I agree that the definition used in the report does seem consistent with that. I think that's mostly because the report assumes that you are training a model to perform a single (transformative) task, and so a definition in terms of the model is equivalent to definition in terms of the task. The report doesn't really talk about the unsupervised pretraining approach so its definitions didn't have to handle that case.
But like, irrespective of what Ajeya meant, I think the important concept would be task-based. You would want to have different timelines for "when a neural net can do human-level summarization" and "when a neural net can be a human-level personal assistant", even if you expect to use unsupervised pretraining for both. The only parameter in the model that can plausibly do that is the horizon length. If you don't use the horizon length for that purpose, I think you should have some other way of incorporating "difficulty of the task" into your timelines.
Exactly. I think this is what humans do too, to a large extent. I'd be curious to hear why you put so much weight on medium and long horizons. I put 50% on short, 20% on medium, and 10% on long.
I mean, I'm at 30 / 40 / 10, so that isn't that much of a difference. Half of the difference could be explained by your 25% on general reasoning, vs my (let's say) 15% on it.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-24T20:01:41.201Z · LW(p) · GW(p)
Thanks again. My general impression is that we disagree less than it first appeared, and that our disagreements are currently bottoming out in different intuitions rather than obvious cruxes we can drill down on. Plus I'm getting tired. ;) So, I say we call it a day. To be continued later, perhaps in person, perhaps in future comment chains on future posts!
For the sake of completeness, to answer your questions though:
I don't really know what you mean when you say that this task is "hard". Sure, humans don't do it very well. We also don't do arithmetic very well, while calculators do.
By "hard" I mean something like "Difficult to get AIs to do well." If we imagine all the tasks we can get AIs to do lined up by difficulty, there is some transformative task A which is least difficult. As the tasks we succeed at getting AIs to do get harder and harder, we must be getting closer to A. I think that getting an AI to do well on all the benchmarks we throw at it despite not being trained for any of them (but rather just trained to predict random internet text) seems like a sign that we are getting close to A. You say this is because I believe in realism about rationality; I hope not, since I don't believe in realism about rationality. Maybe there's a contradiction in my views then which you have pointed to, but I don't see it yet.
I feel like this is already taken into account by the methodology by which we estimated the ratio of evolution to human design? Like, taking your example of flight, presumably evolution was not optimizing just for power-to-weight ratio, it was optimizing for a bunch of other things; nonetheless we ignore those other things when making the comparison. Similarly, in the report the estimate is that evolution is ~10x better than humans on the chosen metrics, even though evolution was not literally optimizing just for the chosen metric. Why not expect the same here?
At this point I feel the need to break things down into premise-conclusion form because I am feeling confused about how the various bits of your argument are connecting to each other. I realize this is a big ask, so don't feel any particular pressure to do it.
I totally agree that evolution wasn't optimizing just for power-to-weight ratio. But I never claimed that it was. I don't think that my comparison relied on the assumption that evolution was optimizing for power-to-weight ratio. By contrast, you explicitly said "presumably evolution was also going for compute-optimal performance." Once we reject that claim, my original point stands that it's not clear how we should apply the scaling laws to the human brain, since the scaling laws are about compute-optimal performance, i.e. how you should trade off size and training time if all you care about is minimizing compute. Since evolution obviously cares about a lot more than that (and indeed doesn't care about minimizing compute at all, it just cares about minimizing size and training time separately, with no particular ratio between them except that which is set by the fitness landscape) the laws aren't directly relevant. In other words, for all we know, if the human brain was 3 OOMs smaller and had one OOM more training time it would be qualitatively superior! Or for all we know, if it had 1 OOM more synapses it would need 2 OOMs less training time to be just as capable. Or... etc. Judging by the scaling laws, it seems like the human brain has a lot more synapses than its childhood length would suggest for optimal performance, or else a lot less if you buy the idea that evolutionary history is part of its training data.
↑ comment by nostalgebraist · 2021-01-25T02:35:48.985Z · LW(p) · GW(p)
The scaling laws, IIRC, don't tell us how much data is needed to reach a useful level of performance.
The scaling laws from the Kaplan et al papers do tell you this.
The relevant law is , for the early-stopped test loss given parameter count and data size . It has the functional form
with .
The result that you should scale comes from trying to keep the two terms in this formula about the same size.
This is not exactly a heuristic for managing compute (since is not dependent on compute, it's dependent on how much data you can source). It's more like a heuristic for ensuring that your problem is the right level of difficulty to show off the power of this model size, as compared to smaller models.
You always can train models that are "too large" on datasets that are "too small" according to the heuristic, and they won't diverge or do poorly or anything. They just won't improve much upon the results of smaller models.
In terms of the above, you are setting and then asking what ought to be. If the heuristic gives you an answer that seems very high, that doesn't mean the model is "not as data efficient as you expected." Rather, it means that you need a very large dataset if you want a good reason to push the parameter count up to rather than using a smaller model to get almost identical performance.
I find it more intuitive to think about the following, both discussed in the papers:
- , the limit of
- meaning: the peak data efficiency possible with this model class
- , the limit of
- meaning: the scaling of loss with parameters when not data-constrained but still using early stopping
If the Kaplan et al scaling results are relevant for AGI, I expect one of these two limits to provide the relevant constraint, rather than a careful balance between and to ensure we are not in either limit.
Ultimately, we expect AGI to require some specific-if-unknown level of performance (ie crossing some loss threshold ). Ajeya's approach essentially assumes that we'll cross this threshold at a particular value of , and then further assumes that this will happen in a regime where data and compute limitations are around the same order of magnitude.
I'm not sure why that ought to be true: it seems more likely that one side of the problem will become practically difficult to scale in proportion to the other, after a certain point, and we will essentially hug tight to either the or the curve until it hits .
See also my post here. [LW · GW]
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-25T11:22:18.649Z · LW(p) · GW(p)
Huh, thanks, now I'm more confused about the scaling laws than I was before, in a good way! I appreciate the explanation you gave but am still confused. Some questions:
--In my discussion with Rohin I said:
Since evolution obviously cares about a lot more than that (and indeed doesn't care about minimizing compute at all, it just cares about minimizing size and training time separately, with no particular ratio between them except that which is set by the fitness landscape) the laws aren't directly relevant. In other words, for all we know, if the human brain was 3 OOMs smaller and had one OOM more training time it would be qualitatively superior! Or for all we know, if it had 1 OOM more synapses it would need 2 OOMs less training time to be just as capable. Or... etc. Judging by the scaling laws, it seems like the human brain has a lot more synapses than its childhood length would suggest for optimal performance, or else a lot less if you buy the idea that evolutionary history is part of its training data.
Do you agree or disagree? My guess is that you'd disagree, since you say:
If the heuristic gives you an answer that seems very high, that doesn't mean the model is "not as data efficient as you expected." Rather, it means that you need a very large dataset if you want a good reason to push the parameter count up to N∼10^15 rather than using a smaller model to get almost identical performance.
which I take to mean that you think the human brain could have had almost identical performance with much fewer synapses, since it has much more N than is appropriate given its D? (But wait, surely you don't think that... OK, yeah, I'm just very confused here, please help!)
2. You say "This is not exactly a heuristic for managing compute (since D is not dependent on compute, it's dependent on how much data you can source)." Well, isn't it both? You can't have more D than you have compute, in some sense, because D isn't the amount of training examples you've collected, it's the amount you actually use to train... right? So... isn't this a heuristic for managing compute? It sure seemed like it was presented that way.
3. Perhaps it would help me if I could visualize it in two dimensions. Let the y-axis be parameter count, N, and the x-axis be data trained on, D. Make it a heat map with color = loss. Bluer = lower loss. It sounds to me like the compute-optimal scaling law Kaplan et al tout is something like a 45 degree line from the origin such that every point on the line has the lowest loss of all the points on an equivalent-compute indifference curve that contains that point. Whereas you are saying there are two other interesting lines, the L(D) line and the L(N) line, and the L(D) line is (say) a 60-degree line from the origin such that for any point on that line, all points straight above it are exactly as blue. And the L(N) line is (say) a 30-degree line from the origin such that for any point on that line, all points straight to the right of it are exactly as blue. This is the picture I currently have in my head, is it correct in your opinion? (And you are saying that probably when we hit AGI we won't be on the 45-degree line but rather will be constrained by model size or by data and so will be hugging one of the other two lines)
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-01-25T16:51:41.514Z · LW(p) · GW(p)
You can't have more D than you have compute, in some sense, because D isn't the amount of training examples you've collected, it's the amount you actually use to train... right? So... isn't this a heuristic for managing compute? It sure seemed like it was presented that way.
This is a subtle and confusing thing about the Kaplan et al papers. (It's also the subject of my post [LW · GW] that I linked earlier, so I recommend you check that out.)
There are two things in the papers that could be called "optimal compute budgeting" laws:
- A law that assumes a sufficiently large dataset (ie effectively infinite dataset), and tell you how to manage the tradeoff between steps and params .
- The law we discussed above, that assumes a finite dataset, and then tells you how to manage its size vs params .
I said the vs law was "not a heuristic for managing compute" because the vs law is more directly about compute, and is what the authors mean when they talk about compute optimal budgeting.
However, the vs law does tell you about how to spend compute in an indirect way, for the exact reason you say, that is related to how long you train. Comparing the two laws yields the "breakdown" or "kink point."
Do you agree or disagree? ... I take [you] to mean that you think the human brain could have had almost identical performance with much fewer synapses, since it has much more N than is appropriate given its D?
Sorry, why do you expect I disagree? I think I agree. But also, I'm not really claiming the scaling laws say or don't say anything about the brain, I'm just trying to clarify what they say about (specific kinds of) neural nets (on specific kinds of problems). We have to first understand what they predict about neural nets before we can go on to ask whether those predictions generalize to explain some other area.
Perhaps it would help me if I could visualize it in two dimensions
This part is 100% qualitatively accurate, I think. The one exception is that there are two "optimal compute" lines on the plot with different slopes, for the two laws referred to above. But yeah, I'm saying we won't be on either of those lines, but on the L(N) or the L(D) line.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-25T21:13:32.718Z · LW(p) · GW(p)
I've read your linked post thrice now, it's excellent, any remaining confusions are my fault.
I didn't confidently expect you to disagree, I just guessed you did. The reason is that the statement you DID disagree with: " The scaling laws, IIRC, don't tell us how much data is needed to reach a useful level of performance. " was, in my mind, closely related to the paragraph about the human brain which you agree with. Since they were closely related in my mind, I thought if you disagreed with one you'd disagree with the other. The statement about brains is the one I care more about, since it relates to my disagreement with Rohin.
I'm glad my 2D visualization is qualitatively correct! Quantitatively, roughly how many degrees do you think there would be between the L(D) and L(N) laws? In my example it was 30, but of course I just made that up.
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-01-25T23:28:51.776Z · LW(p) · GW(p)
Actually, I think I spoke too soon about the visualization... I don't think your image of L(D) and L(N) is quite right.
Here is what the actual visualization looks like. More blue = lower loss, and I made it a contour plot so it's easy to see indifference curves of the loss.
{kind=link}
In these coordinates, L(D) and L(N) are not really straight lines, but they are close to straight lines when we are far from the diagonal line:
- If you look at the upper left region, the indifference curves are parallel to the vertical (N) axis. That is, in this regime, N doesn't matter and loss is effectively a function of D alone.
- This is L(D).
- It looks like the color changes you see if you move horizontally through the upper left region.
- Likewise, in the lower right region, D doesn't matter and loss depends on N alone.
- This is L(N).
- It looks like the color changes you see if you move vertically through the lower right region.
To restate my earlier claims...
If either N or D is orders of magnitude larger than the other, then you get close to the same loss you would get from N ~ D ~ (whichever OOM is lower). So, setting eg (N, D) = (1e15, 1e12) would be sort of a waste of N, achieving only slightly lower loss than (N, D) = (1e12, 1e12).
This is what motives the heuristic that you scale D with N, to stay on the diagonal line.
On the other hand, if your goal is to reach some target loss and you have resource constraints, what matters is whichever resource constraint is more restrictive. For example, if we were never able to scale D above 1e12, then we would be stuck achieving a loss similar to GPT-3, never reaching the darkest colors on the graph.
When I said that it's intuitive to think about L(D) and L(N), I mean that I care about which target losses we can reach. And that's going to be set, more or less, by the highest N or the highest D we can reach, whichever is more restrictive.
Asking "what could we do with a N=1e15 model?" (or any other number) is kind of a weird question from the perspective of this plot. It could mean either of two very different situations: either we are in the top right corner with N and D scaled together, hitting the bluest region ... or we are just near the top somewhere, in which case our loss is entirely determined by D and can be arbitrarily low.
In Ajeya's work, this question means "let's assume we're using an N=1e15 model, and then let's assume we actually need that many parameters, which must mean we want to reach the target losses in the upper right corner, and then let's figure out how big D has to be to get there."
So, the a priori choice of N=1e15 is driving the definition of sufficient performance, defined here as "the performance which you could only reach with N=1e15 params".
What feels weird to me -- which you touched on above -- is the way this lets the scaling relations "backset drive" the definition of sufficient quality for AGI. Instead of saying we want to achieve some specific thing, then deducing we would need N=1e15 params to do it... we start with an unspecified goal and the postulate that we need N=1e15 params to reach it, and then derive the goal from there.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-26T08:54:36.434Z · LW(p) · GW(p)
OK, wow, I didn't realize the indifference curves were so close to being indifference L-shapes! Now I think Ajeya's methodology was great after all -- my worries have been largely dispelled!
Given that the indifference curves are so close to being L-shaped, it seems there'a a pretty strong argument to be made that since the human brain has 10e15 params or so, it must be doing some fairly important tasks which can't be done (at least not as well) for much less than 10e15 params. Like, maybe a 10e13 param brain could do the task if it didn't have to worry about other biological constraints like noisy neurons that occasionally die randomly, or being energy-efficient, etc. But probably these constraints and others like them aren't that big a deal, such that we can be fairly confident that these tasks require a NN of 10e13 or more params.
The next step in the argument is to say that TAI requires one of these tasks. Then we point out that an AI which is bigger than the human brain should be able to do all the things it can do, in principle. Thus we feel justified in setting the parameter count of our hypothetical TAI to "within a few OOMs of 10e15."
Then we look at the scaling law chart you just provided us, and we look at those L-shaped indifference curves, and we think: OK, so a task which can't be done for less than 10e15 params is a task which requires 10e15 data points also. Because otherwise we could reduce parameter count below 10e15 and keep the same performance.
So I no longer feel weird about this; I feel like this part of Ajeya's analysis makes sense.
But I am now intensely curious as to how many "data points" the human brain has. Either the argument I just gave above is totally wrong, or the human brain must be trained on 10e15 data points in the course of a human lifetime, or the genome must be substituting for the data points via priors, architectures, etc.
Is the second possibility plausible? I guess so. there are 10^9 seconds in a human lifetime, so if you are processing a million data points a second... Huh, that seems a bit much.
What about active learning and the like? You talked about how sufficiently big models are extracting all the info out of the data, and so that's why you need more data to do better -- but that suggests that curating the data to make it more info-dense should reduce compute requirements, right? Maybe that's what humans are doing -- "only" a billion data points in a lifetime, but really high-quality ones and good mechanisms for focusing on the right stuff to update on of all your sensory data coming in?
And then there's the third possibility of course. The third possibility says: These scaling laws only apply to blank-slate, simple neural nets. The brain is not a blank slate, nor is it simple; it has lots of instincts and modules and priors etc. given to it by evolution. So that's how humans can get away with only 10^9 data points or so. (well, I guess it should be more like 10^11, right? Each second of experience is more than just one data point, probably more like a hundred, right? What would you say?)
What do you think of these three possibilities?
Replies from: nostalgebraist↑ comment by nostalgebraist · 2021-01-26T17:31:30.885Z · LW(p) · GW(p)
I'm don't think this step makes sense:
Then we look at the scaling law chart you just provided us, and we look at those L-shaped indifference curves, and we think: OK, so a task which can't be done for less than 10e15 params is a task which requires 10e15 data points also.
In the picture, it looks like there's something special about having a 1:1 ratio of data to params. But this is a coincidence due to the authors' choice of units.
They define "one data point" as "one token," which is fine. But it seems equally defensible to define "one data point" as "what the model can process in one forward pass," which is ~1e3 tokens. If the authors had chosen that definition in their paper, I would be showing you a picture that looked identical except with different numbers on the data axis, and you would conclude from the picture that the brain should have around 1e12 data points to match its 1e15 params!
To state the point generally, the functional form of the scaling law says nothing about the actual ratio D/N where the indifference curves have their cusps. This depends on your choice of units. And, even if we were careful to use the same units, this ratio could be vastly different for different systems, and people would still say the systems "have the same scaling law." Scaling is about relationships between differences, not relationships between absolute magnitudes.
On the larger topic, I'm pessimistic about our ability to figure out how many parameters the brain has, and even more pessimistic about our ability to understand what a reasonable scale for "a data point" is. This is mostly for "Could a Neuroscientist Understand a Microprocessor?"-type reasons. I would be more interested in an argument that starts with upper/lower bounds that feel absurdly extreme but relatively certain, and then tries to understand if (even) these weak bounds imply anything interesting, rather than an argument that aims for an point estimate or a subjective distribution.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T09:13:40.434Z · LW(p) · GW(p)
They define "one data point" as "one token," which is fine. But it seems equally defensible to define "one data point" as "what the model can process in one forward pass," which is ~1e3 tokens. If the authors had chosen that definition in their paper, I would be showing you a picture that looked identical except with different numbers on the data axis, and you would conclude from the picture that the brain should have around 1e12 data points to match its 1e15 params!
Holy shit, mind blown! Then... how are the scaling laws useful at all then? I thought the whole point was to tell you how to divide your compute between... Oh, I see. The recommendations for how to divide up your compute would be the same regardless of which definition of data we used. I guess this suggests that it would be most convenient to define data as "how long you run the model during training" (which in turn is maybe "how many times the average parameter of the model is activated during training?") Because that way we can just multiply parameter count by data to get our total compute cost. Or maybe instead we should do what Ajeya does, and define data as the number of updates to the model * the batch size, and then calculate compute by multiplying data * "horizon length."
I'm very interested to hear your thoughts on Ajeya's methodology. Is my sketch of it above accurate? Do you agree it's a good methodology? Does it indeed imply (in conjunction with the scaling laws) that a model with 10^15 params should need 10^15 data points to train to a performance level that you couldn't have got more easily with a smaller model--regardless of what the horizon length is, or what your training environment is, or what the task is?
...
As for the broader point, what do you think of the Carlsmith report? The figure given in the conclusion seems to give some absurdly extreme but reasonably certain upper and lower bounds. And I think the conclusions we draw from them are already drawn in Ajeya's report, because she includes uncertainty about this in her model. I suppose you could just redo her model but with even more variance... that would probably make her timelines shorter, funnily enough!
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-16T12:33:59.798Z · LW(p) · GW(p)
Update: According to this the human brain actually is getting ~10^7 bits of data every second, although the highest level conscious awareness is only processing ~50. So insofar as we go with the "tokens" definition, it does seem that the human brain is processing plenty of tokens for its parameter count -- 10^16, in fact, over the course of its lifetime. More than enough! And insofar as we go with the "single pass through the network" definition, which would mean we are looking for about 10^12... then we get a small discrepancy; the maximum firing rate of neurons is 250 - 1000 times per second, which means 10^11.5 or so... actually this more or less checks out I'd say. Assuming it's the max rate that matters and not the average rate (the average rate is about once per second).
Does this mean that it may not actually be true that humans are several OOMs more data-efficient than ANNs? Maybe the apparent data-efficiency advantage is really mostly just the result of transfer learning from vast previous life experience, just as GPT-3 can "few-shot learn" totally new tasks, and also "fine-tune" on relatively small amounts of data (3+ OOMs less, according to the transfer laws paper!) but really what's going on is just transfer learning from its vast pre-training experience.
↑ comment by Steven Byrnes (steve2152) · 2021-01-21T14:31:54.230Z · LW(p) · GW(p)
humans have a tiny horizon length
What do you mean by horizon length here?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-21T16:39:37.612Z · LW(p) · GW(p)
I intended to mean something similar to what Ajeya meant in her report:
I’ll define the “effective horizon length” of an ML problem as the amount of data it takes (on average) to tell whether a perturbation to the model improves performance or worsens performance. If we believe that the number of “samples” required to train a model of size P is given by KP, then the number of subjective seconds that would be required should be given by HKP, where H is the effective horizon length expressed in units of “subjective seconds per sample.”
To be clear, I'm still a bit confused about the concept of horizon length. I'm not sure it's a good idea to think about things this way. But it seems reasonable enough for now.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-01-21T17:38:11.713Z · LW(p) · GW(p)
I've been working on a draft blog post kinda related to that, if you're interested in I can DM you a link, it could use a second pair of eyes.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-22T20:04:24.199Z · LW(p) · GW(p)
Sure!
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-20T23:08:03.174Z · LW(p) · GW(p)
Nothing in this post directly contradicts anything in Ajeya's report. The conflict, insofar as there is any, is in that Part 3 I mentioned, where I sketch an argument for long timelines based on data-efficiency. That argument sketch was inspired by what Ajeya said; it's what my model of her (and of you) would say. Indeed it's what you are saying now (e.g. you are saying the scaling laws tell us how data-efficient our models will be once they are bigger, and it's still not data-efficient enough to be transformative, according to you.) I think. So, the only conflict is external to this post I guess: I think this is a decent argument but I'm not yet fully convinced, whereas (I think) you and Ajeya think it or something like it is a more convincing argument. I intend to sleep on it and get back to you tomorrow with a more considered response.
comment by Ofer (ofer) · 2021-01-19T09:45:07.080Z · LW(p) · GW(p)
Great post!
we’ll either have to brute-force search for the special sauce like evolution did
I would drop the "brute-force" here (evolution is not a random/naive search).
Re the footnote:
This "How much special sauce is needed?" variable is very similar to Ajeya Cotra's variable "how much compute would lead to TAI given 2020's algorithms."
I don't see how they are similar.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-19T10:06:31.129Z · LW(p) · GW(p)
Thanks! Fair enough re: brute force; I guess my problem is that I don't have a good catchy term for the level of search evolution does. It's better than pure random search, but a lot worse than human-intelligent search.
I think "how much compute would lead to TAI given 2020's algorithms" is sort of an operationalization of "how much special sauce is needed." There are three ways to get special sauce: Brute-force search, awesome new insights, or copy it from the brain. "given 2020's algorithms" rules out two of the three. It's like operationalizing "distance to Edinburgh" as "time it would take to get to Edinburgh by helicopter."
Replies from: ofer, steve2152↑ comment by Ofer (ofer) · 2021-01-19T12:56:20.224Z · LW(p) · GW(p)
My understanding is that the 2020 algorithms in Ajeya Cotra's draft report refer to algorithms that train a neural network on a given architecture (rather than algorithms that search for a good neural architecture etc.). So the only "special sauce" that can be found by such algorithms is one that corresponds to special weights of a network (rather than special architectures etc.).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-19T13:33:45.265Z · LW(p) · GW(p)
Huh, that's not how I interpreted it. I should reread the report. Thanks for raising this issue.
↑ comment by Steven Byrnes (steve2152) · 2021-01-19T12:14:47.220Z · LW(p) · GW(p)
"automated search"?
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-12-03T21:17:11.314Z · LW(p) · GW(p)
Quick self-review:
Yep, I still endorse this post. I remember it fondly because it was really fun to write and read. I still marvel at how nicely the prediction worked out for me (predicting correctly before seeing the data that power/weight ratio was the key metric for forecasting when planes would be invented). My main regret is that I fell for the pendulum rocket fallacy and so picked an example that inadvertently contradicted, rather than illustrated, the point I wanted to make! I still think the point overall is solid but I do actually think this embarrassment made me take somewhat more seriously the "we are missing important insights" hypothesis. Sometimes you don't know what you don't know.
I still see lots of people making claims about the efficiency and mysteriousness of the brain to justify longer timelines. Frustratingly I usually can't tell from their offhand remarks whether they are using the bogus arguments I criticize in this post, or whether they have something more sophisticated and legit in mind. I'd have to interrogate them further, and probably get them to read this post, to find out, and in conversation there usually isn't time or energy to do that.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-10-05T15:01:38.085Z · LW(p) · GW(p)
Update: Unfortunately, three years later, it seems like plenty of people are still making the same old bogus arguments. Oh well. This is unsurprising. I'm still proud of this post & link to it occasionally when I remember to.
comment by Greg C (greg-colbourn) · 2021-12-16T16:22:48.189Z · LW(p) · GW(p)
we probably won’t figure out how to make AIs that are as data-efficient as humans for a long time--decades at least. This is because 1. We’ve been trying to figure this out for decades and haven’t succeeded
EfficientZero [LW · GW] seems to have put paid to this pretty fast. It seems incredible that the algorithmic advances involved aren't even that complex either. Kind of makes you think that people haven't really been trying all that hard over the last few decades. Worrying in terms of its implications for AGI timelines.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-12-16T17:07:10.452Z · LW(p) · GW(p)
I tentatively agree? Given what people I respect were saying about how AIs are less data-efficient than humans, I certainly ended up quite surprised by EfficientZero. But those people haven't reacted much to it, don't seem to be freaking out, etc. so I guess I misunderstood their view and incorrectly thought it would be surprised by EfficientZero. But now I'm just confused as to what their view is, because it sure seems like EfficientZero is comparably data-efficient to humans, despite lacking pre-training and despite being much smaller...
Replies from: Aiyen↑ comment by Aiyen · 2021-12-16T19:54:55.349Z · LW(p) · GW(p)
Have you had a chance to ask these people if they’re surprised, and why not if not?
Replies from: steve2152, daniel-kokotajlo↑ comment by Steven Byrnes (steve2152) · 2021-12-16T20:19:38.836Z · LW(p) · GW(p)
For my part, I kinda updated towards "Well, actually data efficiency isn't quite exactly what I care about, and EfficientZero is gaming / Goodharting that metric in a way that dissociates it from the thing that I care about". See here [LW(p) · GW(p)].
Yeah, I know it totally sounds like special pleading / moving the goalposts. Oh well.
For example, I consider "running through plans one-timestep-at-a-time" to be a kind of brute force way to make plans and understand consequences, and I'm skeptical of that kind of thing scaling to "real world intelligence and common sense". By contrast, the brain can do flexible planning at multiple levels of an abstraction hierarchy, that it can build and change in real time, like how "I'm gonna go to the store and buy cucumbers" is actually millions of motor actions. EfficientZero still retains that brute-force aspect, seems to me. It just rejiggers things so that the brute-force aspect doesn't count as "data inefficiency".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-12-16T20:30:45.860Z · LW(p) · GW(p)
Thanks this is helpful! I think for timelines though... EfficientZero can play an Atari game for 2 subjective hours and get human-level ability at it. That's, like, 1000 little 7-second clips of gameplay -- maybe 1000 'lives,' or 1000 data points. Make a list of all the "transformative tasks" and "dangerous tasks" etc. and then go down the list and ask: Can we collect 1000 data points for this task? How many subjective hours is each data point? Remember, humans have at most about 10,000 hours on any particular task. So even if it takes 20,000 hours for each data point, that's only 10M subjective hours total... which is only 7 OOMs more than EfficientZero had in training.
EfficientZero costs 1 day on $10K worth of hardware. Imagine it is 2030, hardware is 2 OOMs cheaper, and people are spending $10B on hardware and running it for 100 days. That's 10 OOMs more compute to work with. So, we could run EfficientZero for 7 OOMs longer, and thereby get our 1000 data points of experience, each 20,000 hours long. And if EfficientZero could beat humans in data-efficiency for Atari, why wouldn't it also beat humans for data-efficiency at this transformative task / dangerous task? Especially because we only used 7 of our 10 available OOMs, so we can also make it 1000x larger if we want to.
And this argument only has to work for at least one transformative / dangerous task, not all of them.
This is a crude sketchy argument of course, but you see what I'm getting at? ETA: I'm attacking the view that by 2030ish we'll have AIs that can do all the short-horizon tasks, but long-horizon tasks will only come around 2040 or 2050 because it takes a lot more compute to train on them because each data point requires a lot more subjective time.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-16T22:06:32.251Z · LW(p) · GW(p)
Let's say we want our EfficientZero-7 to output good alignmentforum blog posts. We have plenty of training data, in terms of the finished product, but we don't have training data in terms of the "figuring out what to write" part. That part happens in the person's head.
(Suppose the test data is a post containing Insight X. If we're training a network to output that post, the network updates can lead to the ability to figure out Insight X, or can lead the network to already know Insight X. Evidence from GPT-3 suggests that the latter is what would actually happen, IMO.)
So then maybe you'll say: Someone will get the AGI safety researcher to write an alignmentforum blog post while wearing a Kernel Flux brain-scanner helmet, and make EfficientZero-7 build a model from that. But I'm skeptical that the brain-scan data would sufficiently constrain the model so that it would learn how to "figure things out". Brain scans are too low-resolution, too noisy, and/or too incomplete. I think they would miss pretty much all the important aspects of "figuring things out".
I think if we had a sufficiently good operationalization of "figuring things out" to train EfficientZero-7, we could just use that to build a "figuring things out" AGI directly instead.
That's my guess anyway.
Then maybe your response would be: Writing alignmentforum blog posts is a bad example. Instead let's build silicon-eating nanobots. We can run a slow expensive molecular-dynamics simulation running on a supercomputer, and we can have EfficientZero-7 query it, watch it, build its own "mental model" of what happens in a molecular simulation, and recapitulate that model on cheaper faster GPUs. And we can put in some kind of score that's maximized when you query the model with the precursors to a silicon-eating nanobot.
I can get behind that kind of story; indeed, I would not be surprised to see papers along those general lines popping up on arxiv tomorrow, or indeed years ago. But would describe that kind of thing as "pivotal acts that require only narrow AI". I'm not an expert on pivotal acts, and I'm open-minded to the possibility that there are "pivotal acts that require only narrow AI". And I'm also open-minded to the possibility that we can't do those acts today, because they require too much querying of expensive-to-query stuff like molecular simulation code or humans or real-world actuation, and that future narrow-AI advances like EfficientZero-7 will solve that problem. I guess I'm modestly skeptical, but I suppose there are unknown unknowns (to me), and certainly I haven't spent enough time thinking about pivotal acts to have any confidence.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-12-16T22:41:34.520Z · LW(p) · GW(p)
I wasn't imagining this being a good thing that helps save the world; I was imagining it being a world-ending thing that someone does anyway because they don't realize how dangerous it is.
I totally agree that the two examples you gave probably wouldn't work. How about this though:
--Our task will be: Be a chatbot. Talk to users over the course of several months to get them to give you high marks in a user satisfaction survey.
--Pre-train the model on logs of human-to-human chat conversations so you have a reasonable starting point for making predictions about how conversations go.
--Then run the efficientzero algorithm, but with a massively larger parameter count, and talking to hundreds of thousands (millions?) of humans for several years. It would be a very expensive, laggy chatbot (but the user wouldn't care since they aren't paying for it and even with lag the text comes in about as fast as a human would reply)
Seems to me this would "work" in the sense that we'd all die within a few years of this happening, on the default trajectory.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-13T20:19:06.192Z · LW(p) · GW(p)
In a similar conversation about non-main-actor paths to dangerous AI I came up with this as an example of a path I can imagine being plausible and dangerous: A plausible-to-me worst case scenario would be something like:
A phone-scam organization employs someone to build them a online-learning reinforcement learning agent (using an open-source language model as a language-understanding-component) that functions as a scam-helper. It takes in the live transcription of the ongoing conversation between a scammer and a victim, and gives the scammer suggestions for what to say next to persuade the victim to send money. So long as it was even a bit helpful sometimes according to the team of scammers using it, more resources would be given to it and it would continue to collect useful data.
I think this scenario contains a number of dangerous aspects:
being illegal and secret, not subject to ethical or safety guidance or regulation
deliberately being designed to open-endedly self-improve
bringing in incremental resources as it trains to continue to prove its worth (thus not needing a huge initial investment of training cost)
being agentive and directed at the specific goal of manipulating and deceiving humans
I don't think we need 10 more years of progress in algorithms and compute for this story to be technologically feasible. A crude version of this is possibly already in use, and we wouldn't know.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-12-16T20:19:57.906Z · LW(p) · GW(p)
Not yet! I didn't want to bother them. I have been closely following (and asking questions in) all the LW discussions about EfficientZero, but they haven't shown up. Maybe I should just message them directly... I should also go reread Ajeya's report because the view is explained there IIRC.
comment by Richard Horvath · 2021-01-19T10:07:51.660Z · LW(p) · GW(p)
I like the bird-plane analogy. I kind of had the same idea, but for slightly different reason: just as man made flying machines can be superior to birds in a lot of aspects, man made ai will most likely can be superior to a human mind in a similar way.
Regarding your specific points: they may be valid, however, we do not know at which point in time we are talking about flying or AI: Probably a lot of similar arguments could have been made by Leonardo da Vinci when he was designing his flying machine; most likely he understood a lot more about birds and the way they fly than any of his contemporaries or predecessors; yet, he had no chance to succeed for at least three additional centuries. So are we in the era of the Wright Brothers of A.I., or are we still only at da Vinci's?
I personally think the former is more likely, but I believe the probability of the second one is a lot greater than zero.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-19T10:39:17.009Z · LW(p) · GW(p)
So are we in the era of the Wright Brothers of A.I., or are we still only at da Vinci's?
That depends on how close we are to having the key variables at the human-equivalent level. I think the key variables are size and training time, so the relevant milestone is the HBHL. We are currently just a few orders of magnitude away from the HBHL milestone, depending on how you calculate it. GPT-3 was about three orders of magnitude smaller than the human brain, for example. Given how fast we cross orders of magnitude these days, that means we are in the era of the Wright brothers.
Replies from: Bucky↑ comment by Bucky · 2021-01-21T10:36:06.400Z · LW(p) · GW(p)
Given how fast we cross orders of magnitude these days, that means we are in the era of the Wright brothers.
I think this assumes the conclusion - it assumes that we know enough about intelligence to know what the key variables are and how effective they can be at compensating for other variables. Da Vinci could have argued how much more efficient his new designs were getting or how much better his new wings were but none of his designs could have worked no matter how much better he made them.
I don't disagree with you in general but I think the effect of Longs' argument should be to stretch out the probability distribution.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-21T11:24:25.692Z · LW(p) · GW(p)
Sorry for not making this clear--I agree the probability distribution should be stretched out. I think Longs' argument is bogus, in the sense of being basically zero evidence for its conclusion as currently stated -- but the conclusion may still be right, because there are more fleshed-out arguments one could make that are much better. For example, as you point out, I didn't really investigate the issue of whether or not Shorty properly identified the key variables in the case of TAI. I think a really good way to critique Shorty is to argue that those aren't the key variables, or at least that they probably aren't. As it happens, I do think those are probably the key variables, but I haven't argued for that yet, and I am still rather uncertain.
(I think Long's argument that those aren't the key variables is bad though. It's too easy to point to things we currently don't understand; see e.g. how many things we didn't understand about birds or flight in 1900! Better would be to have an alternative theory of what the key variables are, or a more direct rebuttal of Shorty's theory of key variables by showing that it makes some incorrect prediction or something.)
comment by Daniel_Eth · 2021-01-28T10:16:41.855Z · LW(p) · GW(p)
I think this is a good point, but I'd flag that the analogy might give the impression that intelligence is easier than it is - while animals have evolved flight multiple times by different paths (birds, insects, pterosaurs, bats) implying flight may be relatively easy, only one species has evolved intelligence.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-28T14:37:25.155Z · LW(p) · GW(p)
Hmmm, this is a good point -- but here's a counter that just now occurred to me:
Let's disambiguate "intelligence" into a bunch of different things. Reasoning, imitation, memory, data-efficient learning, ... the list goes on. Maybe the complete bundle has only evolved once, in humans, but almost every piece of the bundle has evolved separately many times.
In particular, the number 1 thing people point to as a candidate X for "X is necessary for TAI and we don't know how to make AIs with X yet and it's going to be really hard to figure it out soon" is data-efficient learning.
But data-efficient learning has evolved separately many times; AlphaStar may need thousands of years of Starcraft to learn how to play, but dolphins can learn new games in minutes. Games with human trainers, who are obviously way out of distribution as far as Dolphin's ancestral environment is concerned.
The number 2 thing I hear people point to is "reasoning" and maybe "causal reasoning" in particular. I venture to guess that this has evolved a bunch of times too, based on how various animals can solve clever puzzles to get pieces of food.
(See also: https://www.lesswrong.com/posts/GMqZ2ofMnxwhoa7fD/the-octopus-the-dolphin-and-us-a-great-filter-tale [LW · GW] )
Replies from: DTX, Daniel_Eth↑ comment by DTX · 2021-01-28T16:26:08.634Z · LW(p) · GW(p)
Someone who actually knows something about taxonomic phylogeny of neural traits would need to say for sure, but the fact that many species share neural traits doesn't necessarily mean those traits evolved many times independently as flight did. They could have inherited the traits from a common ancestor. I have no idea if anyone has any clue whether "data efficient learning" falls into the came from a single common ancestor or evolved independently in many disconnected trees categories. It is not a trait that leaves fossil evidence.
Replies from: steve2152, daniel-kokotajlo↑ comment by Steven Byrnes (steve2152) · 2021-01-28T18:55:17.279Z · LW(p) · GW(p)
I think [LW · GW] all the things we identify as "intelligence" (including data-efficient learning) are things that the neocortex does, working in close conjunction with the thalamus (which might as well be a 7th layer of the neocortex), hippocampus (temporarily stores memories before gradually transferring them back to the neocortex because the neocortex needs a lot of repetition to learn), basal ganglia (certain calculations related to reinforcement learning including the value function calculation I think), and part of the cerebellum (you can have human-level intelligence without a cerebellum, but it does help speed things up dramatically, I think mainly by memoizing neocortex calculations [LW · GW]).
Anyway, it's not 100% proven, but my read of the evidence is that the neocortex in mammals is a close cousin of the pallium in lizards and birds and dinosaurs, and the neocortex & bird/lizard pallium do the same calculations using the same neuronal circuits descended from the same ancestor which also did those calculations. The neurons are arranged differently in space in the neocortex vs pallium, but that doesn't matter, the network is what matters. Some early version of the pallium dates back at least as far as lampreys, if memory serves, and I would not be remotely surprised if the lamprey proto-pallium (whatever it's called) did data-efficient learning, albeit learning relatively simple things like 1D time-series data or 3D environments. (That doesn't sound like it has much in common with human intelligence and causal reasoning and rocket science but I think it really does...long story...)
Paul Cisek wrote this paper which I found pretty thought-provoking. He's now diving much deeper into that and writing a book, but says he won't be done for a few years.
I don't know anything about octopuses by the way. That could be independent.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-28T16:49:12.949Z · LW(p) · GW(p)
Fair enough -- maybe data efficient learning evolved way back with the dinosaurs or something. Still though... I find it more plausible that it's just not that much harder than flight (and possibly even easier).
↑ comment by Daniel_Eth · 2021-01-28T15:19:00.929Z · LW(p) · GW(p)
Yeah, that's fair - it's certainly possible that the things that make intelligence relatively hard for evolution may not apply to human engineers. OTOH, if intelligence is a bundle of different modules that all coexistent in humans and of which different animals have evolved in various proportions, that seems to point away from the blank slate/"all you need is scaling" direction.
comment by Aaro Salosensaari (aa-m-sa) · 2021-01-26T18:38:12.575Z · LW(p) · GW(p)
Thanks for writing this, the power to weight statistics are quite interesting. I have an another, longer reply with my own take (edit. comments about the graph, that is) in the works, but while writing it, I started to wonder about a tangential question:
I am saying that many common anti-short-timelines arguments are bogus. They need to do much more than just appeal to the complexity/mysteriousness/efficiency of the brain; they need to argue that some property X is both necessary for TAI and not about to be figured out for AI anytime soon, not even after the HBHL milestone is passed by several orders of magnitude.
I am not super familiar with the state of discussion and literature nowadays, but I was wondering what are these anti-short-timelines arguments that appeal to the general complexity/mysteriousness and how common they are? Are they common in popular discourse, or common among people considered worth taking seriously?
Data efficiency, for example, is already a much more specific feature than handwave-y "human brain is so complex", and thus as you demonstrate, it becomes much easier to write a more convincing argument from data efficiency than mysterious complexity.
Replies from: daniel-kokotajlo, daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T15:07:13.475Z · LW(p) · GW(p)
UPDATE: I just reread Ajeya's report and actually her version of the human lifetime anchor is shifted +3 OOMs because she's trying to account for how humans have priors, special sauce, etc. in them given by evolution. So... I'm pretty perplexed. Even after shifting the anchor +3 OOMs to account for special sauce etc. she still assigns only 5% weight to it! Note that if you just did the naive thing, which is to look at the 41-OOM cost of recapitulating evolution as a loose upper bound, and take (say) 85% of your credence and divide it evenly between all the orders of magnitude less than that but more than where we are now... you'd get something like 5% per OOM, which would come out to 25% or so for the human lifetime anchor!
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-27T08:46:21.876Z · LW(p) · GW(p)
Thanks, and I look forward to seeing your reply!
I'm partly responding to things people have said in conversation with me. For example, the thing Longs says that is a direct quote from one of my friends commenting on an early draft! I've been hearing things like this pretty often from a bunch of different people.
I'm also partly responding to Ajeya Cotra's epic timelines report. It's IMO the best piece of work on the topic there is, and it's also the thing that bigshot AI safety people (like OpenPhil, Paul, Rohin, etc.) seem to take most seriously. I think it's right about most things but one major disagreement I have with it is that it seems to put too much probability mass on "Lots of special sauce needed" hypotheses. Shorty's position--the "not very much special sauce" position--applied to AI seems to be that we should anchor on the Human Lifetime anchor. If you think there's probably a little special sauce but that it can be compensated for via e.g. longer training times and bigger NNs, then that's something like the Short Horizon NN hypothesis. I consider Genome Anchor, Medium and Long-Horizon NN Anchor, and of course Evolution Anchor to be "lots of special sauce needed" views. In particular, all of these views involve, according to Ajeya, "Learning to Learn:" I'll quote her in full:
We may need long horizons for meta-learning or other abilities that evolution selected for
Training a model with SGD to solve a task generally requires vastly more data and experience than a human would require to learn to do the same thing. For example, esports players generally train for a few years to reach professional level play at games like StarCraft and DOTA; on the other hand, AlphaStar was trained on 400,000 subjective years of StarCraft play, and the OpenAI Five DOTA model was trained on 7000 subjective years of DOTA. GPT-3 was trained on 300 billion tokens, which amounts to about 3000 subjective years of reading given typical human reading speeds; despite having seen many times more information than a human about almost any given topic, it is much less useful than a human for virtually all language-based jobs (programming, policymaking, research, etc).
I think that for a single model to have a transformative impact on its own, it would likely need to be able to learn new skills and concepts about as efficiently as a human, and much more efficiently than hand-written ML algorithms like SGD. For a model trained in 2020 to accelerate the prevailing rate of growth by 10x (causing the economy to double by ~2024), it seems like it would have to have capabilities broadly along the lines of one of the following:
Automate a wide swathe of jobs such that large parts of the economy can ~immediately transition to a rate of growth closer to the faster serial thinking speeds of AI workers, or
Speed up R&D progress for other potentially transformative technologies (e.g. atomically precise manufacturing, whole brain emulation, highly efficient space colonization, or the strong version of AGI itself) by much more than ten-fold, such that once the transformative model is trained, the relevant downstream technology can be developed and deployed in only a couple of additional years in expectation, and then that technology could raise the growth rate by ten-fold. For AI capable of speeding up R&D like this, I picture something like an “automated scientist/engineer” that can do the hardest parts of science and engineering work, including quickly learning about and incorporating novel ideas.
Both of these seem to require efficient learning in novel domains which would not have been represented fully in the training dataset. In the first case, the model would need to be a relatively close substitute for an arbitrary human and would therefore probably need to learn new skills on the job as efficiently as a human could. In the second case, the model would likely need to efficiently learn about how a complex research domain works with very little human assistance (as human researchers would not be able to keep up with the necessary pace).
Humans may learn more efficiently than SGD because we are able to use sophisticated heuristics and/or logical reasoning to determine how to update from a particular piece of information in a fine-grained way, whereas SGD simply executes a “one-size-fits-all” gradient update step for each data point. Given that SGD has been used for decades without improving dramatically in sample-efficiency, I think it is relatively unlikely that researchers will be able to hand-design a learning algorithm which is in the range of human-level sample efficiency.
Instead, I would guess that a transformative ML problem would involve meta-learning (that is, using a hand-written optimization algorithm such as SGD to find a model which itself uses its own internal process for learning new skills, a process which may be much more complex and sophisticated than the original hand-written algorithm).
My best guess is that human ability to learn new skills quickly was optimized by natural selection over many generations. Many smaller animals seem capable of learning new skills that were not directly found in their ancestral environment, e.g. bees, mice, octopi, squirrels, crows, dogs, chimps, etc.
The larger animals in particular seem to be able to learn complex new tasks over long periods of subjective time: for example, dogs are trained over a period of months to perform many relatively complex functions such as guiding the blind, herding sheep, assisting with a hunt, unearthing drugs or bombs, and so on. My understanding is that animals trained to perform in a circus also learn complex behaviors over a period of weeks or months. Larger animals seem to exhibit a degree of logical reasoning as well (e.g. the crow in the linked video above), which seems to help speed up their learning, although I’m less confident in this.
This makes me believe it’s likely that our brain’s architecture, our motivation and attention mechanisms, the course of brain development over infancy and childhood, synaptic plasticity mechanisms, and so on were optimized over hundreds of millions of generations for the ability to learn and perhaps reason effectively.
The average generation length was likely several months or years over the period of evolutionary history that seems like it could have been devoted to optimizing for animals which learn efficiently. I consider this a prima facie reason to believe that the effective horizon length for meta-learning -- and possibly for training other cognitive abilities which were also selected over evolutionary time -- may be in the range of multiple subjective months or years. It could be much lower in reality for various reasons (see below), but anchoring to generation times seems like a “naive” default.
Here I am not saying we should expect that training a transformative model would take as much computation as natural selection (that view is represented by the Evolution Anchor hypothesis which I place substantially less weight on than the Neural Network hypotheses). I am instead saying:
A transformative model would likely need to be able to learn new skills and concepts as efficiently as a human could.
Hand-written optimization algorithms such as SGD are currently much less efficient than human learning is, and don’t seem to be on track to improve dramatically over a short period of time, so training a model that can learn new things as efficiently as a human is likely to require meta-learning.
It seems likely that evolution selected humans over many generations to have good heuristics for learning efficiently. So naively, we should expect that it could take an amount of subjective time comparable to the average generation length in our evolutionary history to be able to tell which of two similar models is more efficient at learning new skills (or better at some other cognitive trait that evolution selected for over generations).
My understanding is that meta-learning has had only limited success so far, and there have not yet been strong demonstrations of meta-learning behaviors which would take a human multiple subjective minutes to learn how to do, such as playing a new video game. Under this hypothesis -- assuming that training data is not a bottleneck -- the implicit explanation for the limited success of meta-learning would be some combination of a) our models have not been large enough, and b) our horizons have not been long enough.
This seems like a plausible explanation to me. Let’s estimate the cost of training a model to learn how to play a new video game as quickly as a human can:
Effective horizon length: Learning to play an unfamiliar video game well takes a typical human multiple hours of play; I will assume the effective horizon length for the meta-learning problem is one subjective hour.
Model FLOP / subj sec and parameter count: Even if our ML architectures are just as good as nature’s brain architectures, it seems plausible that models much smaller than the size of a mouse brain aren’t capable of learning to learn complex new behaviors at all -- my understanding is that we have some solid evidence of mice learning complex behaviors, and more ambiguous evidence about smaller animals. According to Wikipedia, a mouse has about ~1e12 synapses in its brain, implying that its brain runs on ~1e12 FLOP/s. I will assume we need a model larger than the equivalent of a bee but smaller than the equivalent of a mouse (say at least ~3e9 parameters and 1e11 FLOP / subj sec) to perform well on the “learning to learn new video games” ML problem.
If the scaling behavior follows the estimate generated in Part 2, the amount of computation required to train a model that could quickly master a new video game should be (3600 subj sec) * (1e11 FLOP / subj sec) * (1700 * 1e11^0.8) = 2e25 FLOP. At ~1e17 FLOP per dollar, that would cost $200 million, which makes it unsurprising this hasn’t been successfully demonstrated yet, given that it is not particularly valuable.
Note that while meta-learning seems to me like the single most likely way that a transformative ML problem could turn out to have a long horizon, there may be other critical cognitive traits or abilities that were optimized by natural selection which may have an effective horizon length of several subjective months or longer.
I interpret her as making the non-bogus version of the argument from efficiency here. However, (and I worry that I'm being uncharitable?) I also suspect that the bogus version of the argument is sneaking in a little bit, she keeps talking about how evolution took millions of generations to do stuff, as if that's relevant... I certainly think that even if she isn't falling for the bogus arguments herself, it's easy for people to fall for them, and this would make her conclusions seem much more reasonable than they are.
In particular, she assigns only 5% weight to the human lifetime anchor--the hypothesis that Shorty is promoting--and only 20% weight to the short-horizon NN anchor, which I think of as the "There's some special sauce but we can find it with a few OOMs of searching and scaling up key variables" hypothesis. She assigns 75% of her weight to the various "There's a lot of special sauce needed, we're going to have to do a TON of search and/or have some brilliant new insights" hypotheses. In other words, the "Longs is right" hypotheses.
I think this is lopsided; much more weight should be on the lower-special-sauce anchors/'hypotheses. Why? Well, why not? We haven't actually been presented with strong reason to think Longs is right about AI. There's a bunch of bogus arguments which many people find seductive, but when you cut them away, we are left with... only the non-bogus argument Ajeya made / I sketched in Part 3. And that's not a super convincing argument to me, in part because it feels like someone could have made a very similar argument in 1900 about airplane control or about understanding the principles of efficient flight. Meanwhile we have the example of birds and planes as precedent for Shorty being right sometimes...
I probably should have put this in the main post. Maybe I'll make it its own post someday. I'd be interested to hear what Rohin and Ajeya think.
comment by denkenberger · 2021-01-23T02:22:35.658Z · LW(p) · GW(p)
That was an exciting graph! However, the labeling would be more consistent if it were steam engines, piston engines, and turbine engines OR stationary, ship/barge, train, automobile, and aircraft (I assume you mean airplanes and helicopters and you excluded rockets).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-01-23T09:21:32.305Z · LW(p) · GW(p)
Yeah, I guess it should have been steam engines, automobile engines, and aircraft engines. (The steam engines were partly for trains, partly stationary, partly for other things iirc).
comment by USER0xe3afcf0a9d42d1c8 · 2021-08-24T17:00:19.541Z · LW(p) · GW(p)
The wrong analogies to flight don't help much if
a) you don't know what your looking for and would need +80 OOM to "search" for a solution like evolution did (which you will never have)
b) you have no idea what intelligence is about (hint, it is NOT just about optimization, see (a)
if TAI were near I would expect
Q) more work in the field of AGI and way more AGI architectures, even with evolutionary / DL / latest clap trap hype of ML
T) more companies betting on AGI
U) a lot of strange ASI/AGI theories
V) a lot of work on RSI
W) autonomous robots roaming the streets (AGI/TAI has to be autonomous so this is a prerequisit)
this all is not happening and won't happen for at least 20 years, so TAI is not "near".