The Preference Fulfillment Hypothesis
post by Kaj_Sotala · 2023-02-26T10:55:12.647Z · LW · GW · 62 commentsContents
Short version Long version The preference fulfillment hypothesis Cooperation requires simulation Preference fulfillment may be natural On the other hand None 62 comments
Short version
Humans have an innate motivation ("preference fulfillment", PF) to fulfill the preferences of those they care about. It corresponds to at least some of the senses of the word "love", as well as related words such as "kindness" and "compassion".
I hypothesize that it works by simulating the other person and predicting what they would want or how they would like to be treated. PF is when you take your simulation of what other people would want and add an extra component that makes you intrinsically value outcomes that your simulation predicts the other people would prefer.
I also hypothesize that this is the same kind of simulation that forms our ability to work as a social species in the first place. A mental simulation process is active in virtually every situation where we interact with other people, such as in a grocery store. People use masks/roles/simulations to determine the right behavior in any social situation, running simulations of how others would react to various behaviors. These simulations involve both the actual people present in the situation as well as various other people whose opinions we've internalized and care about. The simulations generally allow people to engage in interactions by acting the way a normal person would in a given situation.
Once you have this kind of a simulation, constantly running in basically any social situation, it’s likely already exhibiting the PF drive to a weak degree. Doing things that we expect to fulfill other people’s preferences often feels intrinsically nice, even if the person in question was a total stranger. So does wordless coordination in general, as evidenced by the popularity of things like dance.
If this is true, capabilities progress may then be closely linked to alignment progress. Getting AIs to be better at following instructions requires them to simulate humans better. Once you have an AI that can simulate human preferences, you already have most of the machinery required for having PF as an intrinsic drive. This is contrary to the position that niceness is unnatural [LW · GW]. The preference fulfillment hypothesis is that niceness/PF is a natural kind that will be relatively easy to get out of any AI smart enough to understand what humans want it to do. This implies that constructing aligned AIs might be reasonably easy, in the sense that most of the work necessary for it will be a natural part of progress in capabilities.
Long version
The preference fulfillment hypothesis
Imagine someone who you genuinely care about. You probably have some kind of a desire to fulfill their preferences in the kind of way that they would like their preferences to be fulfilled.
It might be very simple ("I like chocolate but they like vanilla, so I would prefer for them to get vanilla ice cream even when I prefer chocolate"), but it might get deep into pretty fundamental differences in preferences and values ("I'm deeply monogamous and me ever being anything else would go against my sacred value, but clearly non-monogamy is what works for my friend and makes them happy so I want them to continue living that way").
It's not necessarily absolute - some things you might still find really upsetting and you'd still want to override the other person’s preferences in some cases - but you can at least feel the "I want them to satisfy their preferences the way they themselves would like their preferences to be satisfied" thing to some extent.
I think this kind of desire is something like its own distinct motivation in the human mind. It can easily be suppressed by other kinds of motivations kicking in - e.g. if the other person getting what they wanted made you feel jealous or insecure, or if their preferences involved actively hurting you. But if those other motivations aren’t blocking it, it can easily bubble up. Helping other people often just feels intrinsically good, even if you know for sure that you yourself will never get any benefit out of it (e.g. holding a door open for a perfect stranger in a city you’re visiting and will probably never come back to).
The motivation seems to work by something like simulating the other person based on what you know of them (or people in general), and predicting what they would want in various situations. This is similar to how "shoulder advisors [? · GW]" are predictive models that simulate what someone you know would react in a particular situation, and also somewhat similar to how large language models simulate [LW · GW] the way a human would continue a piece of writing. The thought of the (simulated/actual) person getting what they want (or just existing in the first place) then comes to be experienced as intrinsically pleasing.
A friend of mine collects ball-jointed dolls (or at least used to); I don’t particularly care about them, but I like the thought of my friend collecting them and having them on display, because I know it’s important for my friend. If I hear about my friend getting a new doll, then my mental simulation of her predicts that she will enjoy it, and that simulated outcome makes me happy. If I were to see some doll that I thought she might like, I would enjoy letting her know, because my simulation of her would appreciate finding out about that doll.
If I now think of her spending time with her hobby and finding it rewarding, then I feel happy about that. Basically, I'm running a mental simulation of what I think she's doing, and that simulation makes me happy.
While I don't know exactly how, this algorithm seems corrigible [? · GW]. If it turned out that my friend had lost her interest in ball-jointed dolls, then I’d like to know that so that I could better fulfill her preferences.
The kinds of normal people who aren't on Less Wrong inventing needlessly convoluted technical-sounding ways of expressing everyday concepts would probably call this thing "love" or “caring”. And genuine love (towards a romantic partner, close friend, or child/parent) definitely involves experiencing what I have just described. Terms such as kindness and compassion are also closely related. To avoid bringing in possibly unwanted connotations from those common terms, I’ll call this thing “preference fulfillment” or PF for short.
Preference fulfillment: a motivational drive that simulates the preferences of other people (or animals) and associates a positive reward with the thought of them getting their preferences fulfilled. Also associates a positive reward with thought of them merely existing.
I hypothesize that PF (or the common sense of the word “love”) is merely adding one additional piece (the one that makes you care about the simulations) to an underlying prediction and simulation machinery that is already there and exists for making social interaction and coordination possible in the first place.
Cooperation requires simulation
In this section, I’ll say a few words about why running these kinds of simulations of other people seems to be a prerequisite for any kind of coordination we do daily.
Under the “virtual bargaining” model of cooperation, people coordinate without communication by behaving on the basis of what they would agree to do if they were explicitly to bargain, provided the agreement that would arise from such discussion is commonly known.
A simple example is that of two people carrying a table across the room: who should grab which end of the table? Normally, the natural solution is for each to grab the side that minimizes the joint distance moved (see picture). However, if one of the people happens to be a despot and the other a servant, then the natural solution is for the despot to grab the end that’s closest to them, forcing the servant to walk the longer distance.
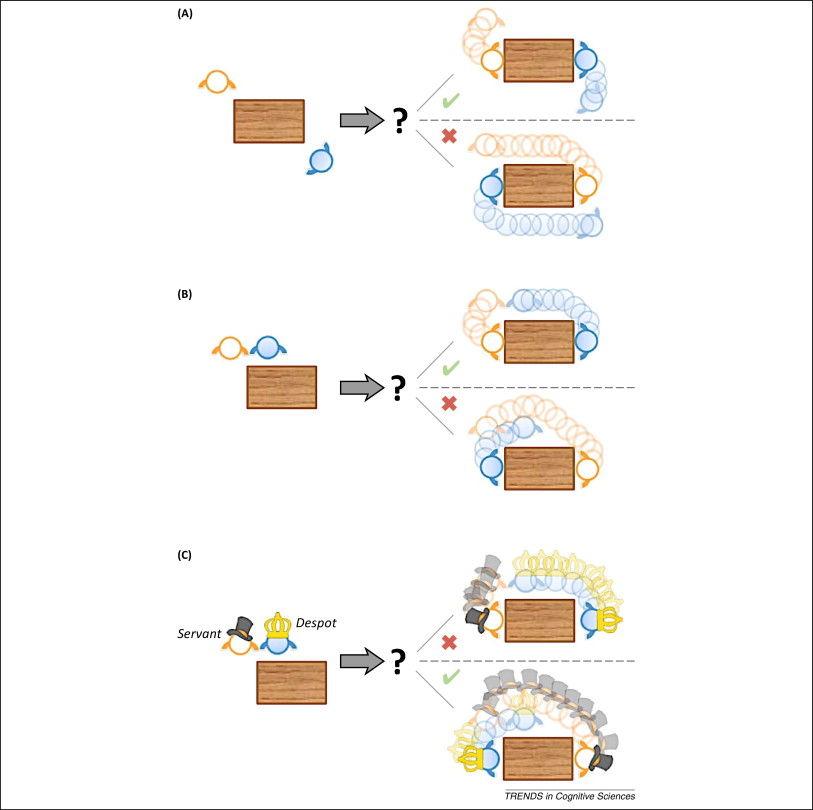
This kind of coordination tends can happen automatically and wordlessly as long as we have some model of the other person’s preferences. Mutual simulation is also still required even if the slave and the despot hate each other - in order to not get punished for being a bad servant, the servant still needs to simulate the despot’s desires. And the despot needs to simulate the servant’s preferences in order to know what the servant will do in different situations.
I think this kind of a mental simulation is on some level active in basically every situation where we interact with other people. If you are in a grocery store, you know not to suddenly take off your clothes and start dancing in the middle of the store, because you know that the other people would stare at you and maybe call the police. You also know how you are expected to interact with the clerk, and the steps involved in the verbal dance of “hello how are you, yes that will be all, thank you, have a nice day”.
As a child, you also witnessed how adults acted in a store. You are probably also running some simulation of “how does a normal kind of a person (like my parents) act in a grocery store”, and intuitively trying to match that behavior. In contrast, if you’re suddenly put into a situation where you don’t have a good model of how to act (maybe in a foreign country where the store seems to act differently from how you’re used to) and can’t simulate the reactions of other people in advance, you may find yourself feeling anxious.
ChatGPT may be an alien entity wearing a human-like mask. Meanwhile, humans may be non-alien entities wearing person-like masks. It’s interesting to compare the Shoggoth-ChatGPT meme picture below, with Kevin Simler’s comic of personhood.
Kevin writes:
A person (as such) is a social fiction: an abstraction specifying the contract for an idealized interaction partner. Most of our institutions, even whole civilizations, are built to this interface — but fundamentally we are human beings, i.e., mere creatures. Some of us implement the person interface, but many of us (such as infants or the profoundly psychotic) don't. Even the most ironclad person among us will find herself the occasional subject of an outburst or breakdown that reveals what a leaky abstraction her personhood really is.
And offers us this comic:

So for example, a customer in a grocery store will wear the “grocery store shopper” mask; the grocery store clerk will wear the “grocery store clerk” mask. That way, both will act the way that’s expected of them, rather than stripping their clothes off and doing a naked dance. And this act of wearing a mask seems to involve running a simulation of what “a typical grocery store person” would do and how other people would react to various behaviors in the store. We’re naturally wired to use these masks/roles/simulations to determine the right behavior in any social situation [LW · GW].
Some of the other people being simulated are the actual other people in the store, others are various people whose opinions you’ve internalized and care about. E.g. if you ever had someone shame you for a particular behavior, even when that person isn’t physically present, a part of your mind may be simulating that person as an “inner critic” [LW(p) · GW(p)] who will virtually shame you for the thought of any such behavior.
And even though people do constantly misunderstand each other, we don't usually descend to Outcome Pump [LW · GW] levels of misunderstanding (where you ask me to get your mother out of a burning building and I blow up the building so that she gets out but is also killed in the process, because you never specified that you wanted her to get out alive). The much more common scenario are countless of minor interactions of the type where people just go to a grocery store and act the way a normal grocery store shopper would, or where two people glance at a table that needs to be carried and wordlessly know who should grab which end.
Preference fulfillment may be natural
PF then, is when you take your already-existing simulation of what other people would want, and just add a bit of an extra component that makes you intrinsically value those people getting what your simulation says they want. In the grocery store, it’s possible that you’re just trying to fulfill the preferences of others because you think you’d be shamed if you didn’t. But if you genuinely care about someone, then you actually intrinsically care about seeing their preferences fulfilled.
Of course, it’s also possible to genuinely care about other people in a grocery store (as well as to be afraid of a loved one shaming you). In fact, correctly performing a social role can feel enjoyable by itself.
Even when you don’t feel like you love someone in the traditional sense of the word, some of the PF drive seems to be active in most social situations. Wordlessly coordinating on things like how to carry the table or how to move can feel intrinsically satisfying, assuming that there are no negative feelings such as fear blocking the sastisfaction. (At least in my personal experience [? · GW], and also evidenced by the appeal of activities such as dance.)
The thesis that PF involves simulating others + intrinsically valuing the satisfaction of their preferences stands in contrast with models such as the one in "Niceness is Unnatural [LW · GW]", which holds that
the specific way that the niceness/kindness/compassion cluster shook out in us is highly detailed, and very contingent on the specifics of our ancestral environment.
The preference fulfillment hypothesis is that the exact details of when niceness/kindness/compassion/love/PF is allowed to express itself is indeed very contingent on the specifics of our ancestral environment. That is, our brains have lots of complicated rules for when to experience PF towards other people, and when to feel hate/envy/jealousy/fear/submission/dominance/transactionality/etc. instead, and the details of those rules are indeed shaped by the exact details of our evolutionary history. It’s also true that the specific social roles that we take are very contingent on the exact details of our evolution and our culture.
But the motivation of PF (“niceness”) itself is simple and natural - if you have an intelligence that is capable of acting as a social animal and doing what other social animals ask from it, then it already has most of the machinery required for it to also implement PF as a fundamental intrinsic drive. If you can simulate others, you only need to add the component that intrinsically values those simulations getting what they want.
This implies that capabilities progress may be closely linked to alignment progress. Getting AIs to be better at following instructions requires them to simulate humans better, so as to understand what exactly would satisfy the preferences of the humans. The way we’re depicting large language models as shoggoths wearing a human mask, suggest that they are already starting to do so. While they may often “misunderstand” your intent, they already seem to be better at it than a pure Outcome Pump would be.
If the ability to simulate others in a way sufficient to coordinate with them forms most of the machinery required for PF, then capabilities progress might deliver most of the progress necessary for alignment.
Some kind of a desire to simulate and fulfill the desires of others seems to show up very early. Infants have it. Animals being trained have their learning accelerated once they figure out they're being trained and start proactively trying to figure out what the trainer intends [LW(p) · GW(p)]. Both point to these being simple and natural competencies.
Humans are often untrustworthy because of all the conflicting motivations and fears they're running. (“If I feel insecure about my position and the other person seems likely to steal it, suppress love and fear/envy/hate them instead.”) However, an AI wouldn't need to exhibit any of the evolutionary urges for backstabbing and the like. We could take the prediction + love machinery and make that the AI’s sole motivation (maybe supplemented by some other drives such as intrinsic curiosity to boost learning).
On the other hand
Of course, this does not solve all problems with alignment. A huge chunk of how humans simulate each other seems to make use of structural similarities. Or as Niceness is unnatural [LW · GW] also notes:
It looks pretty plausible to me that humans model other human beings using the same architecture [LW · GW] that they use to model themselves. This seems pretty plausible a-priori as an algorithmic shortcut — a human and its peers are both human, so machinery for self-modeling will also tend to be useful for modeling others — and also seems pretty plausible a-priori as a way for evolution to stumble into self-modeling in the first place ("we've already got a brain-modeler sitting around, thanks to all that effort we put into keeping track of tribal politics").
Under this hypothesis, it's plausibly pretty easy for imaginations of others’ pain to trigger pain in a human mind, because the other-models and the self-models are already in a very compatible format.
This seems true to me. On the other hand, LLMs are definitely running a very non-humanlike cognitive architecture, and seem to at least sometimes manage a decent simulation. People on the autistic spectrum may also have the experience of understanding other people better than neurotypicals do. The autistics had to compensate for their lack of “hardware-accelerated” intuitive social modeling by coming with explicit models of what drives the behavior of other people, until they got better at it than people who never needed to develop those models. And humans often seem to have significant differences [1 [LW · GW], 2] in how their minds work, but still manage to model each other decently, especially if someone tells them about those differences so that they can update their models.
Another difficulty is that humans also seem to incorporate various ethical considerations into their model - e.g. we might feel okay with sometimes overriding the preferences of a young child or a mentally ill person, out of the assumption that their future self would endorse and be grateful for it. Many of these considerations seem strongly culturally contingent, and don’t seem to have objective answers.
And of course, even though humans are often pretty good at modeling each other, it’s also the case that they still frequently fail and mispredict what someone else would want. Just because you care about fulfilling another person's preferences does not mean that you have omniscient access to them. (It does seem to make you corrigible with regard to fulfilling them, though.)
I sometimes see people suggesting things like “the main question is whether AI will kill everyone or not; compared to that, it’s pretty irrelevant which nation builds the AI first”. On the preference fulfillment model, it might be the other way around. Maybe it’s relatively easy to make an AI that doesn’t want to kill everyone, as long as you set it to fulfill the preferences of a particular existing person who doesn’t want to kill everyone. But maybe it’s also easy to anchor it into the preferences of one particular person or one particular group of people (possibly by some process analogous to how children initially anchor into the desires of their primary caregivers), without caring about the preferences of anyone else. In that case, it might impose the values of that small group on the world, where those values might be arbitrarily malevolent [EA · GW] or just indifferent towards others.
62 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2023-02-26T11:11:22.500Z · LW(p) · GW(p)
An observation: it feels slightly stressful to have posted this. I have a mental simulation telling me that there are social forces around here that consider it morally wrong or an act of defection to suggest that alignment might be relatively easy, like it implied that I wasn't taking the topic seriously enough or something. I don't know how accurate that is, but that's the vibe that my simulators are (maybe mistakenly) picking up.
Replies from: MSRayne, rvnnt, stavros, lahwran, dave-orr↑ comment by MSRayne · 2023-02-26T13:43:43.648Z · LW(p) · GW(p)
That's exactly why it's wonderful and important that you in fact have posted this. For what it's worth, I agree-ish with you. I have enough security mindset and general paranoia to be very scared the Eliezer is right and we're all doomed, but I also have enough experience with LLMs and with phenomenology / introspection to realize that it just doesn't seem like it would be that hard to make an entity that cares intrinsically about other entities.
Replies from: rvnnt↑ comment by rvnnt · 2023-02-26T14:23:04.833Z · LW(p) · GW(p)
Some voice in my head started screaming something like
"A human introspecting on human phenomenology does not provide reliable evidence about artificial intelligences! Remember that humans have a huge amount of complex built-in circuitry that operates subconsciously and makes certain complicated things---like kindness---feel simple/easy [LW · GW]!"
Thought I'd share that. Wondering if you disagree with the voice.
Replies from: MSRayne↑ comment by MSRayne · 2023-02-26T20:49:43.939Z · LW(p) · GW(p)
I disagree very strongly with the voice. Those complicated things are only complicated because we don't introspect about them hard enough, not for any intrinsic reasons. I also think most people just don't have enough self-awareness to be able to perceive their thoughts forming and get a sense of the underlying logic. I'm not saying I can do it perfectly, but I can do it much better than the average person. Consider all the psychological wisdom of Buddhism, which came from people without modern science just paying really close attention to their own minds for a long time.
Replies from: rvnnt↑ comment by rvnnt · 2023-02-27T13:19:21.164Z · LW(p) · GW(p)
Interesting!
Those complicated things are only complicated because we don't introspect about them hard enough, not for any intrinsic reasons.
My impression is that the human brain is in fact intrinsically quite complex![1]
I also think most people just don't have enough self-awareness to be able to perceive their thoughts forming and get a sense of the underlying logic.
I think {most people's introspective abilities} are irrelevant. (But FWIW, given that lots of people seem to e.g. conflate a verbal stream with thought, I agree that median human introspective abilities are probably kinda terrible.)
Consider all the psychological wisdom of Buddhism [...]
Unfortunately I'm not familiar with the wisdom of Buddhism; so that doesn't provide me with much evidence either way :-/
An obvious way to test how complex a thing X really is, or how well one understands it, is to (attempt to) implement it as code or math. If the resulting software is not very long, and actually captures all the relevant aspects of X, then indeed X is not very complex.
Are you able to write software that implements (e.g.) kindness, prosociality, or "an entity that cares intrinsically about other entities"[2]? Or write an informal sketch of such math/code? If yes, I'd be very curious to see it! [3]
Like, even if only ~1% of the information in the human genome is about how to wire the human brain, that'd still be ~10 MB worth of info/code. And that's just the code for how to learn from vast amounts of sensory data; an adult human brain would contain vastly more structure/information than that 10 MB. I'm not sure how to estimate how much, but given the vast amount "training data" and "training time" that goes into a human child, I wouldn't be surprised if it were in the ballpark of hundreds of terabytes. If even 0.01% of that info is about kindness/prosociality/etc., then we're still talking of something like 10 GB worth of information. This (and other reasoning) leads me to feel moderately sure that things like "kindness" are in fact rather complex. ↩︎
...and hopefully, in addition to "caring about other entities", also tries to do something like "and implement the other entities' CEV". ↩︎
Please don't publish anything infohazardous, though, obviously. ↩︎
↑ comment by MSRayne · 2023-02-27T13:28:55.601Z · LW(p) · GW(p)
It would in fact be infohazardous, but yes, I've kinda been doing all this introspection for years now with the intent of figuring out how to implement it in an AGI. In particular, I think there's a nontrivial possibility that GPT-2 by itself is already AGI-complete and just needs to be prompted in the right intricate pattern to produce thoughts in a similar structure to how humans do. I do not have access to a GPU, so I cannot test and develop this, which is very frustrating to me.
I'm almost certainly wrong about how simple this is, but I need to be able to build and tweak a system actively in order to find out - and in particular, I'm really bad at explaining abstract ideas in my head, as most of them are more visual than verbal.
One bit that wouldn't be infohazardous though afaik is the "caring intrinsically about other entities" bit. I'm sure you can see how a sufficiently intelligent language model could be used to predict, given a simulated future scenario, whether a simulated entity experiencing that scenario would prefer, upon being credibly given the choice, for the event to be undone / not have happened in the first place. This is intended to parallel the human ability - indeed, automatic subconscious tendency - to continually predict whether an action we are considering will contradict the preferences of others we care about, and choose not to do it if it will.
So, a starting point would be to try to make a model which is telling a story, but regularly asks every entity being simulated if they want to undo the most recent generation, and does so if even one of them asks to do it. Would this result in a more ethical sequence of events? That's one of the things I want to explore.
↑ comment by rvnnt · 2023-02-26T14:10:41.162Z · LW(p) · GW(p)
I'm guessing this might be due to something like the following:
-
(There is a common belief on LW that) Most people do not take AI x/s-risk anywhere near seriously enough; that most people who do think about AI x/s-risk are far too optimistic about how hard/easy alignment is; that most people who do concede >10% p(doom) are not actually acting with anywhere near the level of caution that their professed beliefs would imply to be sensible.
-
If alignment indeed is difficult, then (AI labs) acting based on optimistic assumptions is very dangerous, and could lead to astronomical loss of value (or astronomical disvalue)
-
Hence: Pushback against memes suggesting that alignment might be easy.
I think there might sometimes be something going on along the lines of "distort the Map in order to compensate for a currently-probably-terrible policy of acting in the Territory".
Analogy: If, when moving through Territory, you find yourself consistently drifting further east than you intend, then the sane solution is to correct how you move in the Territory; the sane solution is not to skew your map westward to compensate for your drifting. But what if you're stuck in a bus steered by insane east-drifting monkeys, and you don't have access to the steering wheel?
Like, if most people are obviously failing egregiously at acting sanely in the face of x/s-risks, due to those people being insane in various ways
("but it might be easy!", "this alignment plan has the word 'democracy' in it, obviously it's a good plan!", "but we need to get the banana before those other monkeys get it!", "obviously working on capabilities is a good thing, I know because I get so much money and status for doing it", "I feel good about this plan, that means it'll probably work", etc.),
then one of the levers you might (subconsciously) be tempted to try pulling is people's estimate of p(doom). If everyone were sane/rational, then obviously you should never distort your probability estimates. But... clearly everyone is not sane/rational.
If that's what's going on (for many people), then I'm not sure what to think of it, or what to do about it. I wish the world were sane?
Replies from: dave-orr, Kaj_Sotala↑ comment by Dave Orr (dave-orr) · 2023-02-26T15:22:29.171Z · LW(p) · GW(p)
I feel like every week there's a post that says, I might be naive but why can't we just do X, and X is already well known and not considered sufficient. So it's easy to see a post claiming a relatively direct solution as just being in that category.
The amount of effort and thinking in this case, plus the reputation of the poster, draws a clear distinction between the useless posts and this one, but it's easy to imagine people pattern matching into believing that this is also probably useless without engaging with it.
Replies from: rvnnt↑ comment by Kaj_Sotala · 2023-02-26T15:49:11.788Z · LW(p) · GW(p)
This seems correct to me.
↑ comment by stavros · 2023-02-26T13:37:27.694Z · LW(p) · GW(p)
In my experience the highest epistemic standard is achieved in the context of 'nerds arguing on the internet'. If everyone is agreeing, all you have is an echo chamber.
I would argue that good faith, high effort contributions to any debate are something we should always be grateful for if we are seeking the truth.
I think the people who would be most concerned with 'anti-doom' arguments are those who believe it is existentially important to 'win the argument/support the narrative/spread the meme' - that truthseeking isn't as important as trying to embed a cultural norm of deep deep precaution around AI.
To those people, I would say: I appreciate you, but there are better strategies to pursue in the game you're trying to play. Collective Intelligence has the potential to completely change the game you're trying to play and you're pretty well positioned to leverage that.
↑ comment by the gears to ascension (lahwran) · 2023-04-08T00:02:36.897Z · LW(p) · GW(p)
I think you're on the right track here and also super wrong. Congrats on being specific enough to be wrong, because this is insightful about things I've also been thinking, and allows people to be specific about where likely holes are. Gotta have negative examples to make progress! Don't let the blurry EY in your head confuse your intuitions ;)
↑ comment by Dave Orr (dave-orr) · 2023-02-26T13:23:43.911Z · LW(p) · GW(p)
FWIW I at least found this to be insightful and enlightening. This seems clearly like a direction to explore more and one that could plausibly pan out.
I wonder if we would need to explore beyond the current "one big transformer" setup to realize this. I don't think humans have a specialized brain region for simulations (though there is a region that seems heavily implicated, see https://www.mountsinai.org/about/newsroom/2012/researchers-identify-area-of-the-brain-that-processes-empathy), but if you want to train something using gradient descent, it might be easier if you have a simulation module that predicts human preferences and is rewarded for accurate predictions, and then feed those into the main decision-making model.
Perhaps we can use revealed preferences through behavior combined with elicited preferences to train the preference predictor. This is similar to the idea of training a separate world model rather than lumping it in with the main blob.
comment by Steven Byrnes (steve2152) · 2023-02-26T20:19:53.567Z · LW(p) · GW(p)
PF then, is when you take your already-existing simulation of what other people would want, and just add a bit of an extra component that makes you intrinsically value those people getting what your simulation says they want. … This implies that constructing aligned AIs might be reasonably easy, in the sense that most of the work necessary for it will be a natural part of progress in capabilities.
Seems to me that the following argument is analogous:
A sufficiently advanced AGI familiar with humans will have a clear concept of “not killing everyone” (or more specifically, “what humans mean when they say the words ‘not killing everyone’”). We just add a bit of an extra component that makes the AGI intrinsically value that concept. This implies that capabilities progress may be closely linked to alignment progress.
Or ditto where “not killing everyone” is replaced by “helpfulness” or “CEV” or whatever. Right?
So I’m not clear on why PF would imply something different about the alignment-versus-capabilities relationship from any of those other things.
Do you agree or disagree?
Anyway, for any of these, I think “the bit of an extra component” is the rub. What’s the component? How exactly does it work? Do we trust it to work out of distribution under optimization pressure?
In the PF case, the unsolved problems [which I am personally interested in and working on, although I don’t have any great plan right now] IMO are more specifically: (1) we need to identify which thoughts are and aren’t empathetic simulations corresponding to PF; (2) we need the AGI to handle edge-cases in a human-like (as opposed to alien) way, such as distinguishing doing-unpleasant-things-that-are-good-ideas-in-hindsight from being-brainwashed, or the boundaries of what is or isn’t human, or what if the human is drunk right now, etc. I talk about those a lot more here [LW · GW] and here [LW · GW], see also shorter version here [LW · GW].
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-02-26T21:20:16.926Z · LW(p) · GW(p)
A sufficiently advanced AGI familiar with humans will have a clear concept of “not killing everyone” (or more specifically, “what humans mean when they say the words ‘not killing everyone’”). We just add a bit of an extra component that makes the AGI intrinsically value that concept. This implies that capabilities progress may be closely linked to alignment progress.
Some major differences off the top of my head:
- Picking out a specific concept such as "not killing everyone" and making the AGI specifically value that seems hard. I assume that the AGI would have some network of concepts and we would then either need to somehow identify that concept in the mature network, or design its learning process in such a way that the mature network would put extra weight on that. The former would probably require some kinds of interpretability tools for inspecting the mature network and making sense of its concepts, so is a different kind of proposal. As for the latter, maybe it could be done, but any very specific concepts don't seem to have an equally simple/short/natural algorithmic description as simulating the preferences of others seems to have, so it'd seem harder to specify.
- The framing of the question also implies to me that the AGI also has some other pre-existing set of values or motivation system besides the one we want to install, which seems like a bad idea since that will bring the different motivation systems into conflict and create incentives to e.g. self-modify or otherwise bypass the constraint we've installed.
- It also generally seems like a bad idea to go manually poking around the weights of specific values and concepts without knowing how they interact with the rest of AGI's values/concepts. Like if we really increase the weight of "don't kill everyone" but don't look at how it interacts with the other concepts, maybe that will lead to a With Folded Hands scenario when the AGI decides that letting people die by inaction is also killing people and it has to prevent humans from doing things that might kill them. (This is arguably less of a worry for something like "CEV", but even we don't seem to know what exactly CEV even should be, so I don't know how we'd put that in.)
↑ comment by Steven Byrnes (steve2152) · 2023-02-27T00:39:18.595Z · LW(p) · GW(p)
Thanks! Hmm, I think we’re mixing up lots of different issues:
- 1. Is installing a PF motivation into an AGI straightforward, based on what we know today?
I say “no”. Or at least, I don’t currently know how you would do that, see here [LW · GW]. (I think about it a lot; ask me again next year. :) )
If you have more thoughts on how to do this, I’m interested to hear them. You write that PF has a “simple/short/natural algorithmic description”, and I guess that seems possible, but I’m mainly skeptical that the source code will have a slot where we can input this algorithmic description. Maybe the difference is that you’re imagining that people are going to hand-write source code that has a labeled “this is an empathetic simulation” variable, and a “my preferences are being satisfied” variable? Because I don’t expect either of those to happen (well, at least not the former, and/or not directly). Things can emerge inside a trained model instead of being in the source code, and if so, then finding them is tricky.
- 2. Will installing a PF motivation into an AGI be straightforward in the future “by default” because capabilities research will teach us more about AGI than we know today, and/or because future AGIs will know more about the world than AIs today?
I say “no” to both. For the first one, I really don’t think capabilities research is going to help with this, for reasons here [LW(p) · GW(p)]. For the second one, you write in OP that even infants can have a PF motivation, which seems to suggest that the problem should be solvable independent of the AGI understanding the world well, right?
- 3. Is figuring out how to install a PF motivation a good idea?
I say “yes”. For various reasons I don’t think it’s sufficient for the technical part of Safe & Beneficial AGI, but I’d rather be in a place where it is widely known how to install PF motivation, than be in a place where nobody knows how to do that.
- 4. Independently of which is a better idea, is the technical problem of installing a PF motivation easier, harder, or the same difficulty as the technical problem of installing a “human flourishing” motivation?
I’m not sure I care. I think we should try to solve both of those problems, and if we succeed at one and fail at the other, well I guess then we’ll know which one was the easier one. :-P
That said, based on my limited understanding right now, I think there’s a straightforward method kinda based on interpretability [LW · GW] that would work equally well (or equally poorly) for both of those motivations, and a less-straightforward method based on empathetic simulation [LW · GW] that would work for human-style PF motivation and maybe wouldn’t be applicable to “human flourishing” motivation. I currently feel like I have a better understanding of the former method, and more giant gaps in my understanding of the latter method. But if I (or someone) does figure out the latter method, I would have somewhat more confidence (or, somewhat less skepticism) that it would actually work reliably, compared to the former method.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-01T15:35:39.553Z · LW(p) · GW(p)
Thanks, this seems like a nice breakdown of issues!
If you have more thoughts on how to do this, I’m interested to hear them. You write that PF has a “simple/short/natural algorithmic description”, and I guess that seems possible, but I’m mainly skeptical that the source code will have a slot where we can input this algorithmic description. Maybe the difference is that you’re imagining that people are going to hand-write source code that has a labeled “this is an empathetic simulation” variable, and a “my preferences are being satisfied” variable? Because I don’t expect either of those to happen (well, at least not the former, and/or not directly). Things can emerge inside a trained model instead of being in the source code, and if so, then finding them is tricky.
So I don't think that there's going to be hand-written source code with slots for inserting variables. When I expect it to have a "natural" algorithmic description, I mean natural in a sense that's something like "the kinds of internal features that LLMs end up developing in order to predict text, because those are natural internal representations to develop when you're being trained to predict text, even though no human ever hand-coded or them or even knew what they would be before inspecting the LLM internals after the fact".
Phrased differently, the claim might be something like "I expect that if we develop more advanced AI systems that are trained to predict human behavior and to act in a way that they predict to please humans, then there is a combination of cognitive architecture (in the sense that "transformer-based LLMs" are a "cognitive architecture") and reward function that will naturally end up learning to do PF because that's the kind of thing that actually does let you best predict and fulfill human preferences".
The intuition comes from something like... looking at LLMs, it seems like language was in some sense "easy" or "natural" - just throw enough training data at a large enough transformer-based model, and a surprisingly sophisticated understanding of language emerges. One that probably ~nobody would have expected just five years ago. In retrospect, maybe this shouldn't have been too surprising - maybe we should expect most cognitive capabilities to be relatively easy/natural to develop, and that's exactly the reason why evolution managed to find them.
If that's the case, then it might be reasonable to assume that maybe PF could be the same kind of easy/natural, in which case it's that naturalness which allowed evolution to develop social animals in the first place. And if most cognition runs on prediction, then maybe the naturalness comes from something like there only being relatively small tweaks in the reward function that will bring you from predicting & optimizing your own well-being to also predicting & optimizing the well-being of others.
If you ask me what exactly that combination of cognitive architecture and reward function is... I don't know. Hopefully, e.g. your research might one day tell us. :-) The intent of the post is less "here's the solution" and more "maybe this kind of a thing might hold the solution, maybe we should try looking in this direction".
- 2. Will installing a PF motivation into an AGI be straightforward in the future “by default” because capabilities research will teach us more about AGI than we know today, and/or because future AGIs will know more about the world than AIs today?
I say “no” to both. For the first one, I really don’t think capabilities research is going to help with this, for reasons here [LW(p) · GW(p)]. For the second one, you write in OP that even infants can have a PF motivation, which seems to suggest that the problem should be solvable independent of the AGI understanding the world well, right?
I read your linked comment as an argument for why social instincts are probably not going to contribute to capabilities - but I think that doesn't establish the opposite direction of "might capabilities be necessary for social instincts" or "might capabilities research contribute to social instincts"?
If my model above is right, that there's a relatively natural representation of PF that will emerge with any AI systems that are trained to predict and try to fulfill human preferences, then that kind of a representation should emerge from capabilities researchers trying to train AIs to better fulfill our preferences.
- 3. Is figuring out how to install a PF motivation a good idea?
I say “yes”.
You're probably unsurprised to hear that I agree. :-)
- 4. Independently of which is a better idea, is the technical problem of installing a PF motivation easier, harder, or the same difficulty as the technical problem of installing a “human flourishing” motivation?
What do you have in mind with a "human flourishing" motivation?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-03T17:16:21.167Z · LW(p) · GW(p)
What do you have in mind with a "human flourishing" motivation?
An AI that sees human language will certainly learn the human concept “human flourishing”, since after all it needs to understand what humans mean when they utter that specific pair of words. So then you can go into the AI and put super-positive valence on (whatever neural activations are associated with “human flourishing”). And bam, now the AI thinks that the concept “human flourishing” is really great, and if we’re lucky / skillful then the AI will try to actualize that concept in the world. There are a lot of unsolved problems and things that could go wrong with that (further discussion here [LW · GW]), but I think something like that is not entirely implausible as a long-term alignment research vision.
I guess the anthropomorphic analog would be: try to think of who is the coolest / highest-status-to-you / biggest-halo-effect person in your world. (Real or fictional.) Now imagine that this person says to you: “You know what’s friggin awesome? The moon. I just love it. The moon is the best.” You stand there with your mouth agape. “Wow, huh, the moon, yeah, I never thought about it that way.” (But 100× moreso. Maybe you’re on some psychedelic at the time, or whatever.)
How would that event change your motivations? Well, you’re probably going to spend a lot more time gazing at the moon when it’s in the sky. You’re probably going to be much more enthusiastic about anything associated with the moon. If there are moon trading cards, maybe you would collect them. If NASA is taking volunteers to train as astronauts for a lunar exploration mission, maybe you would be first in line. If a supervillain is planning to blow up the moon, you’ll probably be extremely opposed to that.
Now by the same token, imagine we do that kind of thing for an extremely powerful AGI and the concept of “human flourishing”. What actions will this AGI then take? Umm, I don’t know really. It seems very hard to predict. But it seems to me that there would be a decent chance that its actions would be good, or even great, as judged by me.
I read your linked comment as an argument for why social instincts are probably not going to contribute to capabilities - but I think that doesn't establish the opposite direction of "might capabilities be necessary for social instincts" or "might capabilities research contribute to social instincts"?
Sorry, that’s literally true, but they’re closely related. If answering the question “What reward function leads to human-like social instincts?” is unhelpful for capabilities, as I claim it is, then it implies both (1) my publishing such a reward function would not speed capabilities research, and (2) current & future capabilities researchers will probably not try to answer that question themselves, let alone succeed. The comment I linked was about (1), and this conversation is about (2).
If my model above is right, that there's a relatively natural representation of PF that will emerge with any AI systems that are trained to predict and try to fulfill human preferences, then that kind of a representation should emerge from capabilities researchers trying to train AIs to better fulfill our preferences.
Sure, but “the representation is somewhere inside this giant neural net” doesn’t make it obvious what reward function we need, right? If you think LLMs are a good model for future AGIs (as most people around here do, although I don’t), then I figure those representations that you mention are already probably present in GPT-3, almost definitely to a much larger extent than they’re present in human toddlers. For my part, I expect AGI to be more like model-based RL, and I have specific thoughts about how that would work, but those thoughts don’t seem to be helping me figure out what the reward function should be. If I had a trained model to work with, I don’t think I would find that helpful either. With future interpretability advances maybe I would say “OK cool, here’s PF, I see it inside the model, but man, I still don’t know what the reward function should be.” Unless of course I use the very-different-from-biology direct interpretability approach (analogous to the “human flourishing” thing I mentioned above).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-13T15:24:06.324Z · LW(p) · GW(p)
Update: writing this comment made me realize that the first part ought to be a self-contained post; see Plan for mediocre alignment of brain-like [model-based RL] AGI [LW · GW]. :)
comment by quetzal_rainbow · 2023-02-26T16:47:26.244Z · LW(p) · GW(p)
The difficulty with preference fullfilment is that we need to target AI altruistic utility function exactly at humans, not, for example, all sentient/agentic beings. Superintelligent entity can use some acausal decision theory and discover some Tegmark-like theory of the multiverse, decide that there is much more paperclip maximizers than human-adjusted entities and fulfill their preferences, not ours.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-02-26T17:48:19.437Z · LW(p) · GW(p)
I think that the kind of simulation that preference fulfillment is based on, naturally only targets actually existing humans (or animals). The kind of reasoning that makes you think about doing acausal trades with entities in other branches of Tegmarkian multiverse doesn't seem strongly motivational in humans, I think because humans are rewarded by the actual predicted sensory experiences of their actions so they are mostly motivated by things that affect the actual world they live in. I think that if an AI were to actually end up doing acausal trades of that type, the motivation for that would need to come from a module that was running something else than a preference fulfillment drive.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2023-02-26T19:26:40.563Z · LW(p) · GW(p)
I think that recursively self-improved superintelligent reflectively consistent human would do acausal trade to ensure human/human-compatible flourishing across the multiverse as well? Maybe they would do it after and only after turning local reality into Utopia, because our local preferences are stronger than general, but I don't see the reason to not do it after local altruistic utility hits some upper attainable level, unless we find unexpected evidence that there is no multiverse in any variation.
By the way, it was a hyperbolized example of "AI learns some core concept of altruism but doesn't prefer human preferences explicitly" . Scenario "After reflection, AI decides that insects preferences matters as much as humans" is also undesirable. My point is that learning and preserving during reflection "core altruism" is easier than doing the same for "altruism towards existing humans", because "existing humans" are harder to specify than abstract concept of agents. We know examples when very altruistic people neglected needs of actually existing people in favor of needs of someone else - animals, future generations, future utopias, non-existent people (see antinatalism), long dead ancestors, imaginary entities (like gods or nations) etc.
I also think that for humans imaginary (not percieved directly, modeled) people often are more important, and especially they are important in the moments that really matters - when you resist conformity, for example.
comment by Gunnar_Zarncke · 2023-02-26T13:27:17.232Z · LW(p) · GW(p)
A precondition for this to work is that the entities in question benefit (get rewarded, ...) from simulating other entities. That's true for the grocery store shopper mask example and most humans in many situations but not all. It is true for many social animals. Dogs also seem to run simulations of their masters. But "power corrupts" has some truth. Even more so for powerful AIs. The preference fulfillment hypothesis breaks down at the edges.
Relatedly, the Brain-like AGI project "aintelope" [LW · GW] tries build a simulation where the preference fulfillment hypothesis can be tested and find out at which capability it breaks down.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-02-26T15:47:58.428Z · LW(p) · GW(p)
But "power corrupts" has some truth
Agreed - but I think that power corrupts because being put in a position of power triggers its own set of motivational drives evolved for exploiting that power. I think that if an AI wasn't built with such drives, power wouldn't need to corrupt it.
Replies from: jimmy, Gunnar_Zarncke↑ comment by jimmy · 2023-03-08T06:09:12.847Z · LW(p) · GW(p)
I don't think it's necessary to posit any separate motivational drives. Once you're in a position where cooperation isn't necessary for getting what you want, then there's no incentive to cooperate or shape yourself to desire cooperative things.
It's rare-to-nonexistent in a society as large and interconnected as ours for anyone to be truly powerful enough that there's no incentive to cooperate, but we can look at what people do when they don't perceive a benefit to taking on (in part) other people's values as their own. Sure, sometimes we see embezzlement and sleeping with subordinates which look like they'd correlate with "maximizing reproductive fitness in EEA", but we also see a lot of bosses who are just insufferable in ways that make them less effective at their job to their detriment. We see power tripping cops and security guards, people being dicks to waiters, and without the "power over others" but retaining "no obvious socializing forces" you get road rage and twitter behavior.
The explanation that looks to me to fit better is just that people stop becoming socialized as soon as there's no longer a strong perceived force rewarding them for doing so and punishing them for failing to. When people lose the incentive to refactor their impulses, they just act on them. Sometimes that means they'll offer a role in a movie for sexual favors, but sometimes that means completely ignoring the people you're supposed to be serving at the DMV or taking out your bitterness on the waiter who can't do shit about it.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-08T18:03:47.849Z · LW(p) · GW(p)
Once you're in a position where cooperation isn't necessary for getting what you want, then there's no incentive to cooperate or shape yourself to desire cooperative things.
That seems to assume that you don't put any intrinsic value on being cooperative?
Replies from: jimmy↑ comment by jimmy · 2023-03-09T07:49:22.825Z · LW(p) · GW(p)
I don't think people do, in general. Not as any sort of separate instinctual terminal value somehow patched into our utility function before we're born.
It can be learned, and well socialized people tend to learn it to some extent or another, but young kids are sure selfish and short sighted. And people placed in situations where it's not obvious to them why cooperation is in their best interest don't tend to act like they intrinsically value being cooperative. That's not to say I think people are consciously tallying everything and waiting for a moment to ditch the cooperative BS to go do what they really want to do. I mean, that's obviously a thing too, but there's more than that.
People can learn to fake caring, but people can also learn to genuinely care about other people -- in the kind of way where they will do good by the people they care about even when given the power not to. It's not that their utility function is made up of a "selfish" set consisting of god knows what, and then a term for "cooperation" is added. It's that we start out with short sighted impulses like "stay warm, get fed", and along the way we build a more coherent structure of desires by making trades along the way of the sorts "I value patience over one marshmallow now, and receive two marshmallows in the future" and "You care a bit about my things, and I'll care a bit about yours". We start out ineffective shits that can only cry when our immediate impulses aren't met, and can end up people who will voluntarily go cold and hungry even without temptation or suffering in order to provide for the wellbeing of our friends and family -- not because we reason that this is the best way to stay warm in each moment, but that we have learned to not care so much whether we're a little cold now and then relative to the long term wellbeing of our friends and family.
What I'm saying is that at the point where a person gains sufficient power over reality that they no longer have to deceive others in order to gain support and avoid punishment, the development of their desires will stop and their behaviors will be best predicted by the trades they actually made. If they managed to fake their whole way there from childhood, you will get childish behavior and childish goals. To the extent that they've only managed to succeed and acquire power by changing what they care about to be prosocial, power will not corrupt.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2023-03-09T15:37:43.150Z · LW(p) · GW(p)
I do think there are hard-wired Little Glimpses of Empathy [LW · GW], as Steven Byrnes calls them that get the cooperation game started. I think these can have different strengths for different people, but they are just one of the many rewards ("stay warm, get fed" etc.) that we have and thus often not the most important factor - esp. at the edge of high power where you can get more of the other.
↑ comment by Gunnar_Zarncke · 2023-02-26T22:25:18.701Z · LW(p) · GW(p)
Yes, that is one of the avenues worth exploring. I doubt it scales to high levels of optimization power, but maybe simulations can measure the degree to which it does.
comment by orthonormal · 2023-02-26T23:11:45.790Z · LW(p) · GW(p)
Kudos for talking about learning empathy in a way that seems meaningfully different and less immediately broken than adjacent proposals.
I think what you should expect from this approach, should it in fact succeed, is not nothing- but still something more alien than the way we empathize with lower animals, let alone higher animals. Consider the empathy we have towards cats... and the way it is complicated by their desire to be a predator, and specifically to enjoy causing fear/suffering. Our empathy with cats doesn't lead us to abandon our empathy for their prey, and so we are inclined to make compromises with that empathy.
Given better technology, we could make non-sentient artificial mice that are indistinguishable by the cats (but their extrapolated volition, to some degree, would feel deceived and betrayed by this), or we could just ensure that cats no longer seek to cause fear/suffering.
I hope that humans' extrapolated volitions aren't cruel (though maybe they are when judged by Superhappy standards). Regardless, an AI that's guaranteed to have empathy for us is not guaranteed, and in general quite unlikely, to have no other conflicts with our volitions; and the kind of compromises it will analogously make will probably be larger and stranger than the cat example.
Better than paperclips, but perhaps missing many dimensions we care about.
Replies from: Nonecomment by moridinamael · 2023-02-26T16:57:19.428Z · LW(p) · GW(p)
I noticed a while ago that it’s difficult to have a more concise and accurate alignment desiderata than “we want to build a god that loves us”. It is actually interesting that the word “love” doesn’t occur very frequently in alignment/FAI literature, given that it’s exactly (almost definitionally) the concept we want FAI to embody.
Replies from: LVSN↑ comment by LVSN · 2023-02-26T21:04:23.888Z · LW(p) · GW(p)
I don't want a god that loves humanity. I want a god that loves the good parts of humanity. Antisemitism is a part of humanity and I hate it and I prescribe hating it.
Replies from: moridinamael↑ comment by moridinamael · 2023-02-27T01:32:08.426Z · LW(p) · GW(p)
Of course conciseness trades off against precision; when I say “love” I mean a wise, thoughtful love, like the love of an intelligent and experienced father for this child. If the child starts spouting antisemitic tropes, the father neither stops loving the child, nor blandly accepts the bigotry, but rather offers guidance and perspective, from a loving and open-hearted place, aimed at dissuading the child from a self-destructive path.
Unfortunately you actually have to understand what a wise thoughtful mature love actually consists of in order to instantiate it in silico, and that’s obviously the hard part.
Replies from: LVSN↑ comment by LVSN · 2023-02-27T03:35:20.621Z · LW(p) · GW(p)
Of course, the father does not love every part of the child; he loves the good and innocent neutral parts of the child; he does not love the antisemitism of the child. The father may be tempted to say that the child is the good and innocent neutral brain parts that are sharing a brain with the evil parts. This maneuver of framing might work on the child.
How convenient that the love which drives out antisemitism is "mature" rather than immature, when adults are the ones who invite antisemitism through cynical demagogic political thought. Cynical demagogic hypotheses do not occur to children undisturbed by adults. The more realistic scenario here is that the father is the antisemite. If the child is lucky enough to arm themself with philosophy, they will be the one with the opportunity to show their good friendship to their father by saving his good parts from his bad parts.
But the father has had more time to develop an identity. Maybe he feels by now that antisemitism is a part of his natural, authentic, true self. Had he held tight to the virtues of children while he was a child, such as the absence of cynical demagoguery, he would not have to choose between natural authenticity and morality.
Replies from: moridinamael↑ comment by moridinamael · 2023-02-27T14:31:31.269Z · LW(p) · GW(p)
I think you’re arguing against a position I don’t hold. I merely aim to point out that the definition of CEV, a process that wants for us what we would want for ourselves if we were smarter and more morally developed, looks a lot like the love of a wise parental figure.
If your argument is that parents can be unwise, this is obviously true.
comment by 2PuNCheeZ · 2023-02-26T19:50:04.083Z · LW(p) · GW(p)
relevant article I just read - On the origins of empathy for other species
Among the Mbuti foragers of West Africa, ethnographer Colin Turnbull noted that many magical rituals invoking animal spirits ‘convey to the hunter the senses of the animal so that he will be able to deceive the animal as well as foresee his movements’ (emphasis mine). Such an ability to take on the thoughts of others may have similarly scaffolded an understanding of one’s self
In many of these cases of deception and mimicry, we can find explicit references to having to think like an animal thinks, act like an animal acts, and pretend to be an animal. These forms of mimicry include not only mimicking the behavior of prey animals, but also mimicking the behavior of their predators in order to become better hunters.
... By allowing the thoughts of other organisms into our minds, we built a pathway to developing empathy with our prey. Like the rest of the world’s predators, humans have to kill their prey to eat it. Unlike the rest of the world’s predators, we have the capacity to empathize with our prey.
Outside of a Western context, the ethnographic record is rife with explicit examples of hunter’s guilt, or the pain felt from taking an animal’s life. I opened this piece with one example of a trapper’s guilt from Willerslev’s book Soul Hunters, but numerous examples from his ethnographic experience are recorded, such as in an interview with one young hunter who stated, ‘When killing an elk or a bear, I sometimes feel I’ve killed someone human. But one must banish such thoughts or one would go mad from shame.’Examples like these are abundant. Consider this excerpt from Robert Knox Dentan’s book on the Semai of Malaysia, where one hunter discusses the guilt felt after his hunts: ‘You have to deceive and trap your food, but you know that it is a bad thing to do, and you don’t want to do it.’ Dentan goes on to state, ‘trappers should take ritual precautions like those associated with the srngloo’ (hunter’s violence) . . . Animals, remember, are people “in their own dimension,” so that the trapping he is engaged in is profoundly antisocial, both violent and duplicitous.’
comment by Fabien Roger (Fabien) · 2023-02-27T09:25:10.758Z · LW(p) · GW(p)
I like this post, and I think these are good reasons to expect AGI around human level to be nice by default.
But I think this doesn't hold for AIs that have large impacts on the world, because niceness is close to radically different and dangerous things to value. Your definition (Doing things that we expect to fulfill other people’s preferences) is vague, and could be misinterpreted in two ways:
- Present pseudo-niceness: maximize the expected value of the fulfillment of people's preferences across time. A weak AI (or a weak human) being present pseudo-nice would be indistinguishable from someone being actually nice. But something very agentic and powerful would see the opportunity to influence people's preferences so that they are easier to satisfy, and that might lead to a world of people who value suffering for the glory of their overlord or sth like that.
- Future pseudo-niceness: maximize the expected value of all future fulfillment of people's initial preferences . Again, this is indistinguishable from niceness for weak AIs. But this leads to a world which locks in all the terrible present preferences people have, which is arguably catastrophic.
I don't know how you would describe "true niceness", but I think it's neither of the above.
So if you train an AI to develop "niceness", because AIs are initially weak, you might train niceness, or you might get one of the two pseudo niceness I described. Or something else entirely. Niceness is natural for agents of similar strengths because lots of values point towards the same "nice" behavior. But when you're much more powerful than anyone else, the target becomes much smaller, right?
Do you have reasons to expect "slight RL on niceness" to give you "true niceness" as opposed to a kind of pseudo-niceness?
I would be scared of an AI which has been trained to be nice if there was no way to see if, when it got more powerful, it tried to modify people's preferences / it tried to prevent people's preferences from changing. Maybe niceness + good interpretability enables you to get through the period where AGIs haven't yet made breakthroughs in AI Alignment?
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-06T13:06:19.929Z · LW(p) · GW(p)
I don't know how you would describe "true niceness", but I think it's neither of the above.
Agreed. I think "true niceness" is something like, act to maximize people's preferences, while also taking into account the fact that people often have a preference for their preferences to continue evolving and to resolve any of their preferences that are mutually contradictory in a painful way.
Niceness is natural for agents of similar strengths because lots of values point towards the same "nice" behavior. But when you're much more powerful than anyone else, the target becomes much smaller, right?
Depends on the specifics, I think.
As an intuition pump, imagine the kindest, wisest person that you know. Suppose that that person was somehow boosted into a superintelligence and became the most powerful entity in the world.
Now, it's certainly possible that for any human, it's inevitable for evolutionary drives optimized for exploiting power to kick in at that situation and corrupt them... but let's further suppose that the process of turning them into a superintelligence also somehow removed those, and made the person instead experience a permanent state of love towards everybody.
I think it's at least plausible that the person would then continue to exhibit "true niceness" towards everyone, despite being that much more powerful than anyone else.
So at least if the agent had started out at a similar power level as everyone else - or if it at least simulates the kinds of agents that did - it might retain that motivation when boosted to higher level of power.
Do you have reasons to expect "slight RL on niceness" to give you "true niceness" as opposed to a kind of pseudo-niceness?
I don't have a strong reason to expect that it'd happen automatically, but if people are thinking about the best ways to actually make the AI have "true niceness", then possibly! That's my hope, at least.
I would be scared of an AI which has been trained to be nice if there was no way to see if, when it got more powerful, it tried to modify people's preferences / it tried to prevent people's preferences from changing.
Me too!
comment by kibber · 2023-02-26T17:06:36.221Z · LW(p) · GW(p)
An AI that can be aligned to preferences of even just one person is already an aligned AI, and we have no idea how to do that.
An AI that's able to ~perfectly simulate what a person would feel would not necessarily want to perform actions that would make the person feel good. Humans are somewhat likely to do that because we have actual (not simulated) empathy, that makes us feel bad when someone close feels bad, and the AI is unlikely to have that. We even have humans that act like that (i.e. sociopaths), and they are still humans, not AIs!
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-02-26T17:43:11.647Z · LW(p) · GW(p)
and the AI is unlikely to have that.
Is there some particular reason to assume that it'd be hard to implement?
Replies from: kibber, green_leaf↑ comment by kibber · 2023-02-26T18:33:49.878Z · LW(p) · GW(p)
To clarify, I meant the AI is unlikely to have it by default (being able to perfectly simulate a person does not in itself require having empathy as part of the reward function).
If we try to hardcode it, Goodhart's curse seems relevant: https://arbital.com/p/goodharts_curse/
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2023-02-26T22:28:35.537Z · LW(p) · GW(p)
But note that Reward is not the optimization target [LW · GW]
↑ comment by green_leaf · 2023-02-27T03:55:00.934Z · LW(p) · GW(p)
I'm thinking that even if it didn't break when going out of distribution, it would still not be a good idea to try to train AI to do things that will make us feel good, because what if it decided it wanted to hook us up to morphine pumps?
comment by MattJ · 2023-02-26T19:28:50.186Z · LW(p) · GW(p)
Running simulations of other people’s preferences is what is usually called ”empathy”so I will use that word here.
To have empathy for someone, or an intuition about what they feel is a motivational force to do good in most humans, but it can also be used to be better at deceving and take advantage of others. Perhaps high functioning psychopaths work in this way.
To build an AI that knows what we think and feel, but without having moral motivation would just lead to a world of superintelligent psychopaths.
P.s. I see now that kibber is making the exact same point.
comment by Yonatan Cale (yonatan-cale-1) · 2023-02-28T12:11:15.518Z · LW(p) · GW(p)
Hey Kaj :)
The part-hiding-complexity here seems to me like "how exactly do you take a-simulation/prediction-of-a-person and get from it the-preferences-of-the-person".
For example, would you simulate a negotiation with the human and how the negotiation would result? Would you simulate asking the human and then do whatever the human answers? (there were a few suggestions in the post, I don't know if you endorse a specific one or if you even think this question is important)
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-01T17:35:47.310Z · LW(p) · GW(p)
Hey Yonatan :)
For example, would you simulate a negotiation with the human and how the negotiation would result? Would you simulate asking the human and then do whatever the human answers? (there were a few suggestions in the post, I don't know if you endorse a specific one or if you even think this question is important)
Maybe something like that, I'm not sure of the specifics - is my response to Steven [LW(p) · GW(p)] helpful in addressing your question?
comment by torekp · 2023-02-26T20:22:34.331Z · LW(p) · GW(p)
"People on the autistic spectrum may also have the experience of understanding other people better than neurotypicals do."
I think this casts doubt on the alignment benefit. It seems a priori likely that an AI, lacking the relevant evolutionary history, will be in an exaggerated version of the autistic person's position. The AI will need an explicit model. If in addition the AI has superior cognitive abilities to the humans it's working with - or expects to become superior - it's not clear why simulation would be a good approach for it. Yes that works for humans, with their hardware accelerators and their clunky explicit modeling, but...
I read you as saying that simulation is what makes preference satisfaction a natural thing to do. If I misread, please clarify.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-03-01T17:32:09.235Z · LW(p) · GW(p)
I think this casts doubt on the alignment benefit. It seems a priori likely that an AI, lacking the relevant evolutionary history, will be in an exaggerated version of the autistic person's position.
Maybe. On the other hand, AIs have recently been getting quite good at things that we previously thought to require human-like intuition, like playing Go, understanding language, and making beautiful art. It feels like a natural continuation of these trends would be for it to develop a superhuman ability for intuitive social modeling as well.
comment by Jonas Hallgren · 2023-03-13T11:17:53.485Z · LW(p) · GW(p)
I feel like I want to mention the connection to game theory and being able to model other people's preference structures as a reason to why PF might develop. To me it seems like a GTO strategy to fulfill other people's preferences when you have reciprocity like systems and that the development of PF then should be highly conditional on the simulated game theory environment.
Not sure how trivial the GTO argument is but interesting post! (and I also feel that this is leaning towards the old meme of someone using meditation, in this case metta to solve alignment. The agi should just read TMI & then we would be good to go.)
comment by Karl von Wendt · 2023-02-27T15:55:46.666Z · LW(p) · GW(p)
I would like to point out that empathy (in the sense that one "understands" another's feelings) and altruism (or "preference fulfillment" if you like) are not the same, and one doesn't automatically follow from the other. The case in point is pathological narcissism. Most narcissists are very empathetic in the sense that they know perfectly well how others feel, but they simply don't care. They only care about the feelings others have towards them. In this sense, AIs like ChatGPT or Bing Chat are narcissistic: They "understand" how we feel (they can read our emotions pretty well from what we type) and want us to "love" them, but they don't really "care" about us. I think it is dangerously naive to assume that teaching AIs to better "understand" humans will automatically lead to more beneficial behavior.
comment by alexlyzhov · 2023-02-27T03:43:32.618Z · LW(p) · GW(p)
https://www.lesswrong.com/posts/WKGZBCYAbZ6WGsKHc/love-in-a-simbox-is-all-you-need [LW · GW] was vaguely similar
comment by cfoster0 · 2023-02-27T02:56:25.683Z · LW(p) · GW(p)
Very happy to see this. Strong upvote.
I'll go out on a limb and say: I feel like the algorithmic core of preference fulfillment may be extremely simple. I think that you get something like preference fulfillment automatically if you have an agent with a combination of:
- Core affect: The agent's thoughts/internal states have associated valence & intensity.
- Intentional action: The agent makes decisions motivated by the affect (valence & intensity) associated with its future-oriented thoughts.
- Neural reuse: The agent uses similar representational hardware (like, which neurons represent "getting a papercut") for thinking about itself (and the ego-centric effects of its actions) as it does for thinking about others (and the allo-centric effects of its actions), triggering similar downstream affect.
↑ comment by Steven Byrnes (steve2152) · 2023-02-27T20:37:47.658Z · LW(p) · GW(p)
Do you have a take on why / how that doesn’t get trained away [LW(p) · GW(p)]?
Replies from: cfoster0↑ comment by cfoster0 · 2023-02-27T22:14:34.927Z · LW(p) · GW(p)
Yeah, good question. Mostly, I think that sticks around because it pays rent and becomes something terminally valued or becomes otherwise cognitively self-sustaining.
That being said, I do think parts of it in fact get trained away, or at least weakened. As you develop more sophisticated theory of mind, that involves learned strategies for contextually suppressing the effects of this neural reuse, so that you can distinguish "how they feel about it" from "how I feel about it" when needed. But I think the lazy, shared representations remain the default, because they require less mental bookkeeping (whose feelings were those, again?), they're really useful for making predictions in the typical case (it usually doesn't hurt), and they make transfer learning straightforward.
EDIT: These are beliefs held lightly. I think it is plausible that a more active intervention is required like "some mechanism to detect when a thought is an empathetic simulation, and then it can just choose not to send an error signal in that circumstance", or something similar, as you mentioned in the linked comment.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-02-28T14:38:19.481Z · LW(p) · GW(p)
becomes something terminally valued
Sure, but there’s a question about how much control “you” have. For example, say I’m a guy who really likes scary movies, and I really liked Alien the first 7 times I watched it, but it’s been getting less scary each time I watch it. I really want it to feel super-scary again the 8th time I watch it. But that’s not under my control.
I think there’s kinda a “I should be scared right now” “head” on the world-model and it has gradually learned over the previous 7 viewings that none of the scenes depicted in Aliens are actually threatening to me. I have some conscious control over e.g. what to attend to / think about while watching, whether to take drugs first, etc., and those will have some effect over how scared I feel, but this is a case where I’m mostly powerless, I think.
I think in the absence of “more active intervention” like your last paragraph, something similar would happen with “feeling good about a situation which will lead to another person feeling reward”. Even if I terminally value that, it’s not clear that there would be anything I could do about it.
But I think the lazy, shared representations remain the default
I dunno, it’s not obvious to me that prosocial concern for others is “default” while status competition and outgroup-hatred and jealousy and flirting and all those other things are “non-default”.
Hmm, well really, maybe it’s not worth arguing about. We need to explain these antisocial behaviors one way or the other. My hunch is that when we can explain status competition, we’ll naturally see that those same mechanisms, whatever they are (“more active interventions” as in your last paragraph) are probably also involved in prosocial empathetic concern.
Well anyway, let’s explain status drive and then we can cross that bridge when we get to it. :)
comment by rvnnt · 2023-02-26T14:03:29.483Z · LW(p) · GW(p)
IIUC, in this model, in order to align an AGI, we need it to first be able to simulate {humans and their preferences} in reasonably high detail. But if the AGI is able to simulate humans, it must already be at least "human-level" in terms of capabilities.
Thus, question: How do you reliably load a goal built out of complicated abstractions ("implement these humans' preferences, for just the right concept of 'preferences'") into an AGI after having trained that AGI to "human+ level" capabilities? (Without the AGI killing you before you load the goal into it?)
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2023-02-26T15:44:54.772Z · LW(p) · GW(p)
Consider human infants. It's not the case that we first raise a human to be an adult-level intelligence, and only then teach it to be aligned with the preferences of other humans. Instead, alignment and capabilities develop hand in hand: a newborn has some innate heuristics that make it imprint on its primary caregivers and recognize them, and then try to do things as the caregivers (and later, its' peers) do. At first, the newborn only has a very vague concept of just what the parents are (if it has concepts at all), but as its cognitive capabilities become more sophisticated, it also develops a more sophisticated understanding of what "being a person" means.
I now realize that I have an additional assumption that I didn't explicitly put in the post, which is something like... alignment and capabilities may be transmitted simultaneously. For instance, an infant who experiences a situation as potentially (but not certainly) dangerous, will look to its caregivers to see how they respond and whether they seem to treat the situation as dangerous. If it then copies the behavior of its caregivers (starts to simulate the way its caregivers behaved), that makes it both aligned with the behavior of its caregivers and - assuming that the caregivers have the capability to interpret the situation correctly and react to it - more capable, as it now knows how to navigate the situation.
Also, a dog that has learned to act the way its owner wants it to, is not a human-level intelligence but seems to have some concept of wanting to fulfill the preferences of its owner. Or look at ChatGPT. It's clearly not a human-level intelligence, but it also seems to have a partial ability to follow human instructions and model their intent already.
I don't know how exactly the specifics of this are going to work. But a story by which I imagine that it could work is something like - the AI somehow gets some specific humans pointed at it, and then imprints on those humans and starts trying to predict and mimic their behavior. At first its concept of those humans might be very simple, like "the entity that gets tagged as 'my human' by my face and voice recognition submodule". And it might start out by just trying to create a predictive model that would predict that human's behavior, which would then become increasingly sophisticated as the AI's cognitive sophistication grew.
I don't know how exactly we get from the part where the AI is modeling the human to the part where it actively wants to fulfill the human's preferences - but again, that drive shows up in human infants and animals, so I'd guess that it wouldn't be very complicated. Maybe something like it being rewarding if the predictive model finds actions that the adult/human seems to approve of.
Of course, this story assumes that we're raising an AI the way we'd raise a human child. In practice, I'd guess that it's going to look less like raising a child, and more like there being a successive series of more sophisticated AI systems that get gradually better at understanding human preferences and being aligned with them (the way we went from GPT-1 to GPT-3.5).
The one thing that may make it easier to build an aligned AI is that human children also have all kinds of evolved drives than push them to be less aligned with their caregivers and towards increased independence and separation from them. (E.g. that stage when a previously-compliant toddler suddenly starts saying "no" to everything, seems like it's some new drive kicking in to reduce caregiver-alignment.) Our AIs may not need to be programmed with those separation drives.
Replies from: rvnnt, alexlyzhov↑ comment by rvnnt · 2023-02-27T18:19:27.212Z · LW(p) · GW(p)
Thanks for the thoughtful answer. After thinking about this stuff for a while, I think I've updated a bit towards thinking (i.a.) that alignment might not be quite as difficult as I previously believed.[1]
I still have a bunch of disagreements and questions, some of which I've written below. I'd be curious to hear your thoughts on them, if you feel like writing them up.
I.
I think there's something like an almost-catch-22 in alignment. A simplified caricature of this catch-22:
-
In order to safely create powerful AI, we need it to be aligned.
-
But in order to align an AI, it needs to have certain capabilities (it needs to be able to understand humans, and/or to reason about its own alignedness, or etc.).
-
But an AI with such capabilities would probably already be dangerous.
Looking at the paragraphs quoted below,
I now realize that I have an additional assumption that I didn't explicitly put in the post, which is something like... alignment and capabilities may be transmitted simultaneously. [...]
[...] a successive series of more sophisticated AI systems that get gradually better at understanding human preferences and being aligned with them (the way we went from GPT-1 to GPT-3.5)
I'm pattern-matching that as proposing that the almost-catch-22 is solvable by iteratively
-
1.) incrementing the AI's capabilities a little bit
-
2.) using those improved capabilities to improve the AI's alignedness (to the extent possible); goto (1.)
Does that sound like a reasonable description of what you were saying? If yes, I'm guessing that you believe sharp left turns [LW · GW] are (very) unlikely?
I'm currently quite confused/uncertain about what happens (notably: whether something like sharp left turns happen) when training various kinds of (simulator-like) AIs to very high capabilities. But I feel kinda pessimistic about it being practically possible to implement and iteratively interleave steps (1.)-(2.) so as to produce a powerful aligned AGI. If you feel optimistic about it, I'm curious as to what makes you optimistic.(?)
II.
I don't know how exactly we get from the part where the AI is modeling the human to the part where it actively wants to fulfill the human's preferences [...]
I think {the stuff that paragraph points at} might contain a crux or two.
One possible crux:
[...] that drive shows up in human infants and animals, so I'd guess that it wouldn't be very complicated. [2]
Whereas I think it would probably be quite difficult/complicated to specify a good version of D := {(a drive to) fulfill human H's preferences, in a way H would reflectively endorse}. Partly because humans are inconsistent, manipulable, and possessed of rather limited powers of comprehension; I'd expect the outcome of an AI optimizing for D to depend a lot on things like
-
just what kind of reflective process the AI was simulating H to be performing
-
in what specific ways/order did the AI fulfill H's various preferences
-
what information/experiences the AI caused H to have, while going about fulfilling H's preferences.
I suspect one thing that might be giving people the intuition that {specifying a good version of D is easy} is the fact that {humans, dogs, and other agents on which people's intuitions about PF are based} are very weak optimizers; even if such an agent had a flawed version of D, the outcome would still probably be pretty OK. But if you subject a flawed version of D to extremely powerful optimization pressure, I'd expect the outcome to be worse, possibly catastrophic.
And then there's the issue of {how do you go about actually "programming" a good version of D in the AI's ontology, and load that program into the AI, as the AI gains capabilities?}; see (I.).
Maybe something like it being rewarding if the predictive model finds actions that the adult/human seems to approve of.
I think this would run into all the classic problems arising from {rewarding proxies to what we actually care about}, no? Assuming that D := {understand human H's preferences-under-reflection (whatever that even means), and try to fulfill those preferences} is in fact somewhat complex (note that crux again!), it seems very unlikely that training an AI with a reward function like R := {positive reward whenever H signals approval} would generalize to D. There seem to be much, much simpler (a priori more likely) goals Y to which the AI could generalize from R. E.g. something like Y := {maximize number of human-like entities that are expressing intense approval}.
III.
Side note: I'm weirded out by all the references to humans, raising human children, etc. I think that kind of stuff is probably not practically relevant/useful for alignment; and that trying to align an ASI by... {making it "human-like" in some way} is likely to fail, and probably has poor hyperexistential separation to boot. I don't know if anyone's interested in discussing that, though, so maybe better I don't waste more space on that here. (?)
To put some ass-numbers on it, I think I'm going from something like
- 85% death (or worse) from {un/mis}aligned AI
- 10% some humans align AI and become corrupted, Weak Dystopia [LW · GW] ensues
- 5% AI is aligned by humans with something like security mindset and cosmopolitan values, things go very well
to something like
- 80% death (or worse) from {un/mis}aligned AI
- 13% some humans align AI and become corrupted, Weak Dystopia [LW · GW] ensues
- 7% AI is aligned by humans with something like security mindset and cosmopolitan values, things go very well
Side note: The reasoning step {drive X shows up in animals} -> {X is probably simple} seems wrong to me. Like, Evolution is stupid, yes, but it's had a lot of time to construct prosocial animals' genomes; those genomes (and especially the brains they produce in interaction with huge amounts of sensory data) contain quite a lot of information/complexity. ↩︎
↑ comment by Kaj_Sotala · 2023-03-01T18:50:18.424Z · LW(p) · GW(p)
I'm pattern-matching that as proposing that the almost-catch-22 is solvable by iteratively
1.) incrementing the AI's capabilities a little bit
2.) using those improved capabilities to improve the AI's alignedness (to the extent possible); goto (1.)
Does that sound like a reasonable description of what you were saying?
I think it might be at least a reasonable first approximation, yeah.
If yes, I'm guessing that you believe sharp left turns [LW · GW] are (very) unlikely?
I wouldn't be so confident as to say they're very unlikely, but also not convinced that they're very likely. I don't have the energy to do a comprehensive analysis of the post right now, but here are some disagreements that I have with it:
- "The central analogy here is that optimizing apes for inclusive genetic fitness (IGF) doesn't make the resulting humans optimize mentally for IGF..." I suspect this analogy is misleading, I touched upon some of the reasons for why in this comment [LW(p) · GW(p)]. (I have a partially finished draft for a post that has a thesis that goes along the lines of "genetic fitness isn't what evolution selects for, fitness is a measure of how strongly evolution selects for some other trait" but I need to check my reasoning / finish it.)
- The post suggests that we might get an AI's alignment properties up to some level, but at some point, its capabilities shoot up to such a point where those alignment properties aren't enough to prevent us from all being killed. I think that if the preference fulfillment hypothesis is right, then "don't kill the people whose preferences you're trying to fulfill" is probably going to be a relatively basic alignment property (it's impossible to fulfill the preferences of someone who is dead). So hopefully we should be able to lock that in before the AI's capabilities get to the sharp left turn. (Though it's still possible that the AI makes some more subtle mistake - say modifying people's brains to make their preferences easier to optimize - than just killing everyone outright.)
- "sliding down the capabilities well is liable to break a bunch of your existing alignment properties [...] things in the capabilities well have instrumental incentives that cut against your alignment patches". This seems to assume that the AI has been built with a motivation system that does not primarily optimize for something like alignment. Rather the alignment has been achieved by "patches" on top of the existing motivation system. But if the AI's sole motivation is just fulfilling human preferences, then the alignment doesn't take the form of patches that are trying to combat its actual motivation.
I'd expect the outcome of an AI optimizing for D to depend a lot on things like
- just what kind of reflective process the AI was simulating H to be performing
- in what specific ways/order did the AI fulfill H's various preferences
- what information/experiences the AI caused H to have, while going about fulfilling H's preferences.
Agree; these are the kinds of things that I mentioned as still being unsolved problems and highly culturally contingent, in my original post. Though it seems worth noting that if there aren't objective right or wrong answers to these questions, then it implies that the AI can't really get them wrong, either. Plausibly different approaches to fulfilling our preferences could lead to very different outcomes... but maybe we would be happy with any outcome we ultimately ended up at, since probably "are humans happy with the outcome" is going to be a major criterion with any preference fulfillment process.
I'm not certain of this. Maybe there are versions of D that the AI might end up on, where the humans are doing the equivalent of suffering horribly on the inside while pretending to be okay on the outside, and that looks to the AI as their preferences being fulfilled. But I'd guess that to be less likely than most versions of D actually genuinely caring about our happiness.
And then there's the issue of {how do you go about actually "programming" a good version of D in the AI's ontology, and load that program into the AI, as the AI gains capabilities?}; see (I.).
My reply to Steven [LW(p) · GW(p)] (the way part about how I think preference fulfillment might be "natural") might be relevant here.
I think this would run into all the classic problems arising from {rewarding proxies to what we actually care about}, no?
It certainly sounds like it... but then somehow humans do manage to genuinely come to care about what makes other humans happy, so there seems to be some component (that might be "natural" in the sense that I described to Steven) that helps us avoid it.
Side note: I'm weirded out by all the references to humans, raising human children, etc. I think that kind of stuff is probably not practically relevant/useful for alignment;
About five to ten years ago, I would have shared that view. But more recently I've been shifting toward the view that maybe AIs are going to look and work relatively similarly to humans. Because if there's a solution X for intelligence that is relatively easy to discover, then it might be that both early-stage AI researchers and evolution will hit upon that solution first: exactly because it's the easiest solution to discover. And also, humans are the one example we have of intelligence that's at least somewhat aligned with human the species, so that seems to be the place where we should be looking at for solutions.
See also "Humans provide an untapped wealth of evidence about alignment [LW · GW]", which I largely agree with.
Replies from: rvnnt↑ comment by alexlyzhov · 2023-02-26T21:15:13.218Z · LW(p) · GW(p)
Relevant recent paper: https://www.lesswrong.com/posts/8F4dXYriqbsom46x5/pretraining-language-models-with-human-preferences [LW · GW]