Ruby's Quick Takes
post by Ruby · 2019-02-23T21:17:48.972Z · LW · GW · 121 commentsContents
122 comments
121 comments
Comments sorted by top scores.
comment by Ruby · 2024-09-28T00:22:24.305Z · LW(p) · GW(p)
Just thinking through simple stuff for myself, very rough, posting in the spirit of quick takes
At present, we are making progress on the Technical Alignment Problem[2] and like probably could solve it within 50 years.
- Humanity is on track to build ~lethal superpowerful AI in more like 5-15 years.
- Working on technical alignment (direct or meta) only matters if we can speed up overall progress by 10x (or some lesser factor if AI capabilities is delayed from its current trajectory). Improvements of 2x are not likely to get us to an adequate technical solution in time.
- Working on slowing things down is only helpful if it results in delays of decades.
- Shorter delays are good in so far as they give you time to buy further delays.
- There is technical research that is useful for persuading people to slow down (and maybe also solving alignment, maybe not). This includes anything that demonstrates scary capabilities or harmful proclivities, e.g. a bunch of mech interp stuff, all the evals stuff.
AI is in fact super powerful and people who perceive there being value to be had aren’t entirely wrong[3]. This results in a very strong motivation to pursue AI and resist efforts to be stopped
These motivations apply to both businesses and governments.
- People are also developing stances on AI along ideological, political, and tribal lines, e.g. being anti-regulation. This generates strong motivations for AI topics even separate from immediate power/value to be gained.
- Efforts to agentically slow down the development of AI capabilities are going to be matched by agentic efforts to resist those efforts and push in the opposite direction.
- Efforts to convince people that we ought to slow down will be matched by people arguing that we must speed up.
- Efforts to regulate will be matched by efforts to block regulation. There will be efforts to repeal or circumvent any passed regulation.
- If there are chip controls or whatever, there will be efforts to get around that. If there are international agreements, there will be efforts to clandestinely hide.
- If there are successful limitations on compute, people will compensate and focus on algorithmic progress.
- Many people are going to be extremely resistant to being swayed on topics of AI, no matter what evidence is coming in. Much rationalization will be furnished to justify proceeding no matter the warning signs.
- By and large, our civilization has a pretty low standard of reasoning.
People who want to speed up AI will use falsehoods and bad logic to muddy the waters, and many people won’t be able to see through it[4]. No matter the evals or other warning signs, there will be people arguing it can be fixed without too much trouble and we must proceed [LW · GW].
In other words, there’s going to be an epistemic war and the other side is going to fight dirty[5], I think even a lot of clear evidence will have a hard time against people’s motivations/incentives and bad arguments.
- When there are two strongly motivated sides, seems likely we end up in a compromise state, e.g. regulation passes but it’s not the regulation originally designed that even in its original form was only maybe actually enough.
- It’s unclear to me whether “compromise regulation” will be adequate. Or that any regulation adequate to cost people billions in anticipated profit will conclude with them giving up.
Further Thoughts
- People aren’t thinking or talking enough about nationalization.
- I think it’s interesting because I expect that a lot of regulation about what you can and can’t do stops being enforceable once the development is happening in the context of the government performing it.
What I Feel Motivated To Work On
Thinking through the above, I feel less motivated to work on things that feel like they’ll only speed up technical alignment problem research by amounts < 5x. In contrast, maybe there’s more promise in:
- Cyborgism or AI-assisted research that gets up 5x speedups but applies differentially to technical alignment research
- Things that convince people that we need to radically slow down
- good writing
- getting in front of people
- technical demonstrations
- research that shows the danger
- why the whole paradigm isn’t safe
- evidence of deception, etc.
- Development of good (enforceable) “if-then” policy that will actually result in people stopping in response to various triggers, and not just result in rationalization for why actually it’s okay to continue (ignore signs) or just a bandaid solution
- Figuring out how to overcome people’s rationalization
- Developing robust policy stuff that’s set up to withstand lots of optimization pressure to overcome it
- Things that cut through the bad arguments of people who wish to say there’s no risk and discredit the concerns
- Stuff that prevents national arms races / gets into national agreements
- Thinking about how to get 30 year slowdowns
- ^
By “slowing down”, I mean all activities and goals which are about preventing people from building lethal superpowerful AI, be it via getting them to stop, getting to go slower because they’re being more cautious, limiting what resources they can use, setting up conditions for stopping, etc.
- ^
How to build a superpowerful AI that does what we want.
- ^
They’re wrong about their ability to safely harness the power, but not if you could harness, you’d have a lot of very valuable stuff.
- ^
My understanding is a lot of falsehoods were used to argue against SB1047 by e.g. a16z
- ^
Also some people arguing for AI slowdown will fight dirty too, eroding trust in AI slowdown people, because some people think that when the stakes are high you just have to do anything to win, and are bad at consequentialist reasoning.
↑ comment by Stephen Fowler (LosPolloFowler) · 2024-09-28T13:57:51.443Z · LW(p) · GW(p)
"Cyborgism or AI-assisted research that gets up 5x speedups but applies differentially to technical alignment research"
How do you do you make meaningful progress and ensure it does not speed up capabilities?
It seems unlikely that a technique exists that is exclusively useful for alignment research and can't be tweaked to help OpenMind develop better optimization algorithms etc.
↑ comment by Noosphere89 (sharmake-farah) · 2024-09-28T02:08:13.878Z · LW(p) · GW(p)
I basically agree with this:
People who want to speed up AI will use falsehoods and bad logic to muddy the waters, and many people won’t be able to see through it
In other words, there’s going to be an epistemic war and the other side is going to fight dirty, I think even a lot of clear evidence will have a hard time against people’s motivations/incentives and bad arguments.
But I'd be more pessimistic than that, in that I honestly think pretty much every side will fight quite dirty in order to gain power over AI, and we already have seen examples of straight up lies and bad faith.
From the anti-regulation side, I remember Martin Casado straight up lying about mechanistic interpretability rendering AI models completely understood and white box, and I'm very sure that mechanistic interpretability cannot do what Martin Casado claimed.
I also remembered a16z lying a lot about SB1047.
From the pro-regulation side, I remembered Zvi incorrectly claiming that Sakana AI did instrumental convergence/recursive self-improvement, and as it turned out, the reality was far more mundane than that:
https://www.lesswrong.com/posts/ppafWk6YCeXYr4XpH/danger-ai-scientist-danger#AtXXgsws5DuP6Jxzx [LW(p) · GW(p)]
Zvi then misrepresented what Apollo actually did, and attempted to claim that o1 was actually deceptively aligned/lying, when it did a capability eval to see if it was capable of lying/deceptively aligned, and straight up lied in claiming that this was proof of Yudkowsky's proposed AI alignment problems being here, and inevitable, which is taken down in 2 comments:
https://www.lesswrong.com/posts/zuaaqjsN6BucbGhf5/gpt-o1#YRF9mcTFN2Zhne8Le [LW(p) · GW(p)]
https://www.lesswrong.com/posts/zuaaqjsN6BucbGhf5/gpt-o1#AWXuFxjTkH2hASXPx [LW(p) · GW(p)]
Overall, this has made me update in pretty negative directions concerning the epistemics of every side.
There's a core of people who have reasonable epistemics IMO on every side, but they are outnumbered and lack the force of those that don't have good epistemics.
The reason I can remain optimistic despite it is that I believe we are progressing faster than that:
At present, we are making progress on the Technical Alignment Problem[2] and like probably could solve it within 50 years.
I think that thankfully, I think we could probably solve it in 5-10 years, primarily because I believe 0 remaining insights are necessary to align AI, and the work that needs to be done is in making large datasets about human values, because AIs are deeply affected by what their data sources are, and thus whoever controls the dataset controls the values of the AI.
↑ comment by Cole Wyeth (Amyr) · 2024-09-29T03:49:00.168Z · LW(p) · GW(p)
Though I am working on technical alignment (and perhaps because I know it is hard) I think the most promising route may be to increase human and institutional rationality and coordination ability. This may be more tractable than "expected" with modern theory and tools.
Also, I don't think we are on track to solve technical alignment in 50 years without intelligence augmentation in some form, at least not to the point where we could get it right on a "first critical try" if such a thing occurs. I am not even sure there is a simple and rigorous technical solution that looks like something I actually want, though there is probably a decent engineering solution out there somewhere.
↑ comment by davekasten · 2024-09-29T16:01:25.341Z · LW(p) · GW(p)
I think this can be true, but I don't think it needs to be true:
"I expect that a lot of regulation about what you can and can’t do stops being enforceable once the development is happening in the context of the government performing it."
I suspect that if the government is running the at-all-costs-top-national-priority Project, you will see some regulations stop being enforceable. However, we also live in a world where you can easily find many instances of government officials complaining in their memoirs that laws and regulations prevented them from being able to go as fast or as freely as they'd want on top-priority national security issues. (For example, DoD officials even after 9-11 famously complained that "the lawyers" restricted them too much on top-priority counterterrorism stuff.)
↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-30T02:08:11.833Z · LW(p) · GW(p)
Yes, this is a good point. We need a more granular model than a binary 'all the same laws will apply to high priority national defense projects as apply to tech companies' versus 'no laws at all will apply'.
↑ comment by Lao Mein (derpherpize) · 2024-09-28T22:33:34.490Z · LW(p) · GW(p)
I have a few questions.
- Can you save the world in time without a slowdown in AI development if you had a billion dollars?
- Can you do it with a trillion dollars?
- If so, why aren't you trying to ask the US Congress for a trillion dollars?
- If it's about a lack of talent, do you think Terrance Tao can make significant progress on AI alignment if he actually tried?
- Do you think he would be willing to work on AI alignment if you offered him a trillion dollars?
↑ comment by Amalthea (nikolas-kuhn) · 2024-09-29T14:49:47.913Z · LW(p) · GW(p)
Interestingly, Terence Tao has recently started thinking about AI, and his (publicly stated) opinions on it are ... very conservative? I find he mostly focuses on the capabilities that are already here and doesn't really extrapolate from it in any significant way.
Replies from: o-o↑ comment by O O (o-o) · 2024-09-30T03:46:13.184Z · LW(p) · GW(p)
Really? He seems pretty bullish. He thinks it will co author math papers pretty soon. I think he just doesn’t think or at least state his thoughts on implications outside of math.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-09-30T05:03:07.978Z · LW(p) · GW(p)
He's clearly not completely discounting that there's progress, but overall it doesn't feel like he's "updating all the way":
This is a recent post about the deepmind math olympiad results: https://mathstodon.xyz/@tao/112850716240504978
"1. This is great work, shifting once again our expectations of which benchmark challenges are within reach of either #AI-assisted or fully autonomous methods"
↑ comment by Ruby · 2024-09-29T00:51:09.251Z · LW(p) · GW(p)
Money helps. I could probably buy a lot of dignity points for a billion dollars. With a trillion variance definitely goes up because you could try crazy stuff and could backfire. (I mean true for a billion too). But EV of such a world is better.
I don't think there's anything that's as simple as writing a check though.
US Congress gives money to specific things. I do not have a specific plan for a trillion dollars.
I'd bet against Terrance Tao being some kind of amazing breakthrough researcher who changes the playing field.
↑ comment by Raemon · 2024-09-29T00:25:45.543Z · LW(p) · GW(p)
My answer (and I think Ruby's) answer to most of these questions is "no", but What Money Cannot Buy [LW · GW] reasons, as well as "geniuses don't often actually generalize and are hard to motivate with money."
↑ comment by jmh · 2024-09-28T15:29:49.987Z · LW(p) · GW(p)
I really like the observation in your Further Thoughts point. I do think that is a problem people need to look at as I would guess many will view the government involvement from a acting in public interests view rather than acting in either self interest (as problematic as that migh be when the players keep changing) or from a special interest/public choice perspective.
Probably some great historical analysis already written about events in the past that might serve as indicators of the pros and cons here. Any historians in the group here?
Replies from: Rubycomment by Ruby · 2024-07-01T21:00:51.427Z · LW(p) · GW(p)
There is a now a button to say "I didn't like this recommendation, show fewer like it"
Clicking it will:


- update the recommendation engine that you strongly don't like this recommendation
- store analytics data for the LessWrong team to know that you didn't like this post (we won't look at your displayname, just random id). This will hopefully let us understand trends in bad recommendations
- hide the post item from posts lists like Enriched/Latest Posts/Recommended. It will not hide it from user profile pages, Sequences, etc

comment by Ruby · 2024-08-30T01:13:57.262Z · LW(p) · GW(p)
Seeking Beta Users for LessWrong-Integrated LLM Chat
Comment here if you'd like access. (Bonus points for describing ways you'd like to use it.)
A couple of months ago, a few of the LW team set out to see how LLMs might be useful in the context of LW. It feels like they should be at some point before the end, maybe that point is now. My own attempts to get Claude to be helpful for writing tasks weren't particularly succeeding, but LLMs are pretty good at reading a lot of things quickly, and also can be good at explaining technical topics.
So I figured just making it easy to load a lot of relevant LessWrong context into an LLM might unlock several worthwhile use-cases. To that end, Robert and I have integrated a Claude chat window into LW, with the key feature that it will automatically pull in relevant LessWrong posts and comments to what you're asking about.
I'm currently seeking beta users.
Since using the Claude API isn't free and we haven't figured out a payment model, we're not rolling it out broadly. But we are happy to turn it on for select users who want to try it out.
Comment here if you'd like access. (Bonus points for describing ways you'd like to use it.)
↑ comment by Ruby · 2024-08-30T15:10:56.447Z · LW(p) · GW(p)
@Chris_Leong [LW · GW] @Jozdien [LW · GW] @Seth Herd [LW · GW] @the gears to ascension [LW · GW] @ProgramCrafter [LW · GW]
You've all been granted to the LW integrated LLM Chat prototype. Cheers!
↑ comment by Ruby · 2024-08-30T18:38:02.302Z · LW(p) · GW(p)
Oh, you access it with the sparkle button in the bottom right:

↑ comment by Ruby · 2024-08-31T18:47:12.652Z · LW(p) · GW(p)
@Neel Nanda [LW · GW] @Stephen Fowler [LW · GW] @Saul Munn [LW · GW] – you've been added.
I'm hoping to get a PR deployed today that'll make a few improvements:
- narrow the width so doesn't overlap the post on smaller screens than before
- load more posts into the context window by default
- upweight embedding distance relative to karma in the embedding search for relevant context to load in
- various additions to the system response to improve tone and style
↑ comment by Saul Munn (saul-munn) · 2024-08-31T21:54:20.962Z · LW(p) · GW(p)
great! how do i access it on mobile LW?
Replies from: Ruby↑ comment by Ruby · 2024-09-01T02:33:51.333Z · LW(p) · GW(p)
Not available on mobile at this time, I'm afraid.
Replies from: saul-munn↑ comment by Saul Munn (saul-munn) · 2024-09-01T19:19:34.847Z · LW(p) · GW(p)
gotcha. what would be the best way to send you feedback? i could do:
- comments here
- sent directly to you via LW DM, email, [dm through some other means] or something else if that's better
(while it's top-of-mind: the feedback that generated this question was that the chat interface pops up every single time open a tab of LW, including every time i open a post in a new tab. this gets really annoying very quickly!)
Replies from: Ruby↑ comment by Seth Herd · 2024-08-30T11:40:41.502Z · LW(p) · GW(p)
I'm interested. I'll provide feedback, positive or negative, like I have on other site features and proposed changes. I'd be happy to pay on almost any payment model, at least for a little while. I have a Cause subscription fwiw.
I'd use it to speed up researching prior related work on LW for my posts. I spend a lot of time doing this currently.
↑ comment by Chris_Leong · 2024-08-30T11:09:07.112Z · LW(p) · GW(p)
I'd like access.
TBH, if it works great I won't provide any significant feedback, apart from "all good"
But if it annoys me in any way I'll let you know.
For what it's worth, I have provided quite a bit of feedback about the website in the past.
I want to see if it helps me with my draft document on proposed alignment solutions:
https://docs.google.com/document/d/1Mis0ZxuS-YIgwy4clC7hKrKEcm6Pn0yn709YUNVcpx8/edit#heading=h.u9eroo3v6v28
↑ comment by the gears to ascension (lahwran) · 2024-08-30T02:57:42.692Z · LW(p) · GW(p)
Interested! I would pay at cost if that was available. I'll be asking about which posts are relevant to a question, misc philosophy questions and asking for Claude to challenge me, etc. Primarily interested if I can ask for brevity using a custom prompt, in the system prompt.
↑ comment by Tetraspace (tetraspace-grouping) · 2024-08-30T01:36:43.041Z · LW(p) · GW(p)
I'd like beta access. My main use case is that I intend to write up some thoughts on alignment (Manifold gives 40% that I'm proud of a write-up, I'd like that number up), and this would be helpful for literature review and finding relevant existing work. Especially so because a lot of the public agent foundations work is old and migrated from the old alignment forum, where it's low-profile compared to more recent posts.
Replies from: Ruby↑ comment by Neel Nanda (neel-nanda-1) · 2024-08-31T14:00:18.970Z · LW(p) · GW(p)
I'd be interested! I would also love to see the full answer to why people care about SAEs
Replies from: Ruby↑ comment by Stephen Fowler (LosPolloFowler) · 2024-08-31T04:26:44.498Z · LW(p) · GW(p)
I'd like access to it.
↑ comment by RobinGoins (Daunting) · 2024-08-30T01:35:31.110Z · LW(p) · GW(p)
Interested! Unsure how I'll use it; will need to play around with it to figure that out. But in general, I like asking questions while reading things to stay engaged and I'm very interested to see how it goes with an LLM that's loaded up with LW context.
Replies from: Ruby↑ comment by Saul Munn (saul-munn) · 2024-08-31T04:58:06.139Z · LW(p) · GW(p)
i’d love access! my guess is that i’d use it like — elicit:research papers::[this feature]:LW posts
↑ comment by ProgramCrafter (programcrafter) · 2024-08-30T14:25:54.426Z · LW(p) · GW(p)
I'm interested! I, among other usage, hope to use it for finding posts exploring similar topics by different names.
By the way, I have an idea what to use instead of a payment model: interacting with user's local LLM like one started within LM Studio. That'd require a checkbox/field to enter API URL, some recommendations on which model to use and working out how to reduce amount of content fed into model (as user-run LLM seem to have smaller context windows than needed).
↑ comment by Garrett Baker (D0TheMath) · 2024-09-28T20:22:30.099Z · LW(p) · GW(p)
Oh I didn’t see this! I’d like access, in part because its pretty common I try to find a LessWrong post or comment, but the usual search methods don’t work. Also because it seems like a useful way to explore the archives.
Replies from: Ruby↑ comment by Dalcy (Darcy) · 2024-09-28T18:16:02.932Z · LW(p) · GW(p)
I'd also love to have access!
Replies from: Ruby↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-09-28T16:49:36.620Z · LW(p) · GW(p)
I'd love to try it, mainly thinking about research (agent foundations and AI safety macrostrategy).
Replies from: Ruby↑ comment by jenn (pixx) · 2024-09-16T19:32:11.651Z · LW(p) · GW(p)
I'm interested if you're still adding folks. I run local rationality meetups, this seems like a potentially interesting way to find readings/topics for meetups (e.g. "find me three readings with three different angles on applied rationality", "what could be some good readings to juxtapose with burdens by scott alexander", etc.)
Replies from: Ruby↑ comment by dirk (abandon) · 2024-09-01T16:47:01.864Z · LW(p) · GW(p)
I'm interested! I'd probably mostly be comparing it to unaugmented Claude for things like explaining ML topics and turning my post ideas into drafts (I don't expect it to be great at this latter but I'm curious whether having some relevant posts in the context window will elicit higher quality). I also think the low-friction integration might make it useful for clarifying math- or programming-heavy posts, though I'm not sure I'll want this often.
Replies from: Ruby↑ comment by Ruby · 2024-09-03T21:17:34.678Z · LW(p) · GW(p)
You now have access to the LW LLM Chat prototype!
also think the low-friction integration might make it useful for clarifying math- or programming-heavy posts, though I'm not sure I'll want this often.
That's actualy one of my favorite use-cases
↑ comment by Sheikh Abdur Raheem Ali (sheikh-abdur-raheem-ali) · 2024-09-01T12:16:06.685Z · LW(p) · GW(p)
I'd love to have early access. I will probably give feedback on bugs in the implementation before it is rolled out to more users, and am happy to use my own API keys.
Replies from: Rubycomment by Ruby · 2019-09-14T00:21:20.747Z · LW(p) · GW(p)
Selected Aphorisms from Francis Bacon's Novum Organum
I'm currently working to format Francis Bacon's Novum Organum as a LessWrong sequence. It's a moderate-sized project as I have to work through the entire work myself, and write an introduction which does Novum Organum justice and explains the novel move of taking an existing work and posting in on LessWrong (short answer: NovOrg is some serious hardcore rationality and contains central tenets of the LW foundational philosophy notwithstanding being published back in 1620, not to mention that Bacon and his works are credited with launching the modern Scientific Revolution)
While I'm still working on this, I want to go ahead and share some of my favorite aphorisms from is so far:
3. . . . The only way to command reality is to obey it . . .
9. Nearly all the things that go wrong in the sciences have a single cause and root, namely: while wrongly admiring and praising the powers of the human mind, we don’t look for true helps for it.
Bacon sees the unaided human mind as entirely inadequate for scientific progress. He sees for the way forward for scientific progress as constructing tools/infrastructure/methodogy to help the human mind think/reason/do science.
10. Nature is much subtler than are our senses and intellect; so that all those elegant meditations, theorizings and defensive moves that men indulge in are crazy—except that no-one pays attention to them. [Bacon often uses a word meaning ‘subtle’ in the sense of ‘fine-grained, delicately complex’; no one current English word will serve.]
24. There’s no way that axioms •established by argumentation could help us in the discovery of new things, because the subtlety of nature is many times greater than the subtlety of argument. But axioms •abstracted from particulars in the proper way often herald the discovery of new particulars and point them out, thereby returning the sciences to their active status.
Bacon repeatedly hammers that reality has a surprising amount of detail such that just reasoning about things is unlikely to get at truth. Given the complexity and subtlety of nature, you have to go look at it. A lot.
28. Indeed, anticipations have much more power to win assent than interpretations do. They are inferred from a few instances, mostly of familiar kinds, so that they immediately brush past the intellect and fill the imagination; whereas interpretations are gathered from very various and widely dispersed facts, so that they can’t suddenly strike the intellect, and must seem weird and hard to swallow—rather like the mysteries of faith.
Anticipations are what Bacon calls making theories by generalizing principles from a few specific examples and the reasoning from those [ill-founded] general principles. This is the method of Aristotle and science until that point which Bacon wants to replace. Interpretations is his name for his inductive method which only generalizes very slowly, building out slowly increasingly large sets of examples/experiments.
I read Aphorism 28 as saying that Anticipations have much lower inferential distance since they can be built simple examples with which everyone is familiar. In contrast, if you build up a theory based on lots of disparate observation that isn't universal, you know have lots of inferential distance and people find your ideas weird and hard to swallow.
All quotations cited from: Francis Bacon, Novum Organum, in the version by Jonathan Bennett presented at www.earlymoderntexts.com
Replies from: Viliam, jp, RRBB
↑ comment by Viliam · 2019-09-14T14:09:51.754Z · LW(p) · GW(p)
Please note that even things written in 1620 can be under copyright. Not the original thing, but the translation, if it is recent. Generally, every time a book is modified, the clock starts ticking anew... for the modified version. If you use a sufficiently old translation, or translate a sufficiently old text yourself, then it's okay (even if a newer translation exists, if you didn't use it).
Replies from: Raemon↑ comment by jp · 2019-09-14T00:31:10.718Z · LW(p) · GW(p)
I'm a complete newcomer to information on Bacon and his time. How much of his influence was due to Novum Organum itself vs other things he did? If significantly the latter, what were those things? Feel free to tell me to Google that.
Replies from: habryka4↑ comment by habryka (habryka4) · 2019-09-14T09:23:07.375Z · LW(p) · GW(p)
At the very least "The New Atlantis", a fictional utopian novel he wrote, was quite influential, at least in that it's usually cited as one of the primary inspirations for the founding of the royal society:
comment by Ruby · 2024-09-27T23:41:01.479Z · LW(p) · GW(p)
The “Deferred and Temporary Stopping” Paradigm
Quickly written. Probably missed where people are already saying the same thing.
I actually feel like there’s a lot of policy and research effort aimed at slowing down the development of powerful AI–basically all the evals and responsible scaling policy stuff.
A story for why this is the AI safety paradigm we’ve ended up in is because it’s palatable. It’s palatable because it doesn’t actually require that you stop. Certainly, it doesn’t right now. To the extent companies (or governments) are on board, it’s because those companies are at best promising “I’ll stop later when it’s justified”. They’re probably betting that they’ll be able to keep arguing it’s not yet justified. At the least, it doesn’t require a change of course now and they’ll go along with it to placate you.
Even if people anticipate they will trigger evals and maybe have to delay or stop releases, I would bet they’re not imagining they have to delay or stop for all that long (if they’re even thinking it through that much). Just long enough to patch or fix the issue, then get back to training the next iteration. I'm curious how many people imagine that once certain evaluations are triggered, the correct update is that deep learning and transformers are too shaky a foundation. We might then need to stop large AI training runs until we have much more advanced alignment science, and maybe a new paradigm.
I'd wager that if certain evaluations are triggered, there will be people vying for the smallest possible argument to get back to business as usual. Arguments about not letting others get ahead will abound. Claims that it's better for us to proceed (even though it's risky) than the Other who is truly reckless. Better us with our values than them with their threatening values.
People genuinely concerned about AI are pursuing these approaches because they seem feasible compared to an outright moratorium. You can get companies and governments to make agreements that are “we’ll stop later” and “you only have to stop while some hypothetical condition is met”. If the bid was “stop now”, it’d be a non-starter.
And so the bet is that people will actually be willing to stop later to a much greater extent than they’re willing to stop now. As I write this, I’m unsure of what probabilities to place on this. If various evals are getting triggered in labs:
- What probability is there that the lab listens to this vs ignores the warning sign and it doesn’t even make it out of the lab?
- If it gets reported to the government, how strongly does the government insist on stopping? How quickly is it appeased before training is allowed to resume?
- If a released model causes harm, how many people skeptical of AI doom concerns does it convince to change their mind and say “oh, actually this shouldn’t be allowed”? How many people, how much harm?
- How much do people update that AI in general is unsafe vs that particular AI from that particular company is unsafe, and only they alone should be blocked?
- How much do people argue that even though there are signs of risk here, it’d be more dangerous to let other pull ahead?
- And if you get people to pause for a while and focus on safety, how long will they agree to a pause for before the shock of the damaged/triggered eval gets normalized and explained away and adequate justifications are assembled to keep going?
There are going to be people who fight tooth and nail, weight and bias, to keep the development going. If we assume that they are roughly equally motivated and agentic as us, who wins? Ultimately we have the harder challenge in that we want to stop others from doing something. I think the default is people get to do things.
I think there's a chance that various evals and regulations do meaningfully slow things down, but I write this to express the fear that they're false reassurance–there's traction only because people who want to build AI are betting this won't actually require them to stop.
Related:
comment by Ruby · 2019-11-21T23:51:18.932Z · LW(p) · GW(p)
Why I'm excited by the 2018 Review
I generally fear that perhaps some people see LessWrong as a place where people just read and discuss "interesting stuff", not much different from a Sub-Reddit on anime or something. You show up, see what's interesting that week, chat with your friends. LessWrong's content might be considered "more healthy" relative to most internet content and many people say they browse LessWrong to procrastinate but feel less guilty about than other browsing, but the use-case still seems a bit about entertainment.
None of the above is really a bad thing, but in my mind, LessWrong is about much more than a place for people to hang out and find entertainment in sharing joint interests. In my mind, LessWrong is a place where the community makes collective progress on valuable problems. It is an ongoing discussion where we all try to improve our understanding of the world and ourselves. It's not just play or entertainment– it's about getting somewhere. It's as much like an academic journal where people publish and discuss important findings as it is like an interest-based sub-Reddit.
And all this makes me really excited by the LessWrong 2018 Review. The idea of the review is to identify posts that have stood the test of time and have made lasting contributions to the community's knowledge and meaningfully impacted people's lives. It's about finding the posts that represent the progress we've made.
During the design of the review (valiantly driven by Raemon), I was apprehensive that people would not feel motivated by the process and put in the necessary work. But less than 24 hours after launching, I'm excited by the nominations [? · GW] and what people are writing in their nomination comments.
Looking at the list of nominations so far and reading the comments, I'm thinking "Yes! This is a list showing the meaningful progress the LW community has made. We are not just a news or entertainment site. We're building something here. This is what we're about. So many great posts that have helped individuals and community level up. Stuff I'm really proud of." There are posts about communication, society narratives, AI, history, honesty, reasoning and argumentation, and more: each crystallizing concepts and helping us think about reality better, make better decisions.
I am excited that by the end of the process we will be able to point to the very best content from 2018, and then do that for each year.
Of late, I've been thinking a lot about how to make LessWrong's historical corpus of great content more accessible: search/tagging/Wiki's. We've got a lot of great content that does stand the test of time. Let's make it easy for people to find relevant stuff. Let it be clear that LW is akin to a body of scientific work, not Reddit or FB. Let this be clear so that people feel enthused to contribute to our ongoing progress, knowing that if they write something good, it won't merely be read and enjoyed this week, it'll become part of communal corpus to be built upon. Our project of communal understand and self-improvement.
comment by Ruby · 2019-07-07T01:23:10.678Z · LW(p) · GW(p)
Communal Buckets
A bucket error [LW · GW] is when someone erroneously lumps two propositions together, e.g. I made a spelling error automatically entails I can't be great writer, they're in one bucket when really they're separate variables.
In the context of criticism, it's often mentioned that people need to learn to not make the bucket error of I was wrong or I was doing a bad thing -> I'm a bad person. That is, you being a good person is compatible with making mistakes, being wrong, and causing harm since even good people make mistakes. This seems like a right and true and a good thing to realize.
But I can see a way in which being wrong/making mistakes (and being called out for this) is upsetting even if you personally aren't making a bucket error. The issue is that you might fear that other people have the two variables collapsed into one. Even if you might realize that making a mistake doesn't inherently make you a bad person, you're afraid that other people are now going to think you are a bad person because they are making that bucket error.
The issue isn't your own buckets, it's that you have a model of the shared "communal buckets" and how other people are going to interpret whatever just occured. What if the community/social reality only has a single bucket here?
We're now in the territory of common knowledge challenges (this might not require full-blown common knowledge, but each person knowing what all the others think). For an individual to no longer be worried about automatic entailment between "I was wrong -> I'm bad", they need to be convinced that no one else is thinking that. Which is hard, because I think that people do think that.
(Actually, it's worse, because other people can "strategically" make or not make bucket errors. If my friend does something wrong, I'll excuse it and say they're still a good person. If it's someone I already disliked, I'll take any wrongdoing is evidence of their inherent evil nature. There's a cynical/pessimistic model here where people are likely to get upset anytime something is shared which might be something they can be attacked with (e.g. criticism of their mistakes of action/thought), rightly or wrongly.)
Replies from: Dagon↑ comment by Dagon · 2019-07-10T17:38:51.355Z · LW(p) · GW(p)
"did a bad thing" -> "bad person" may not be a bucket error, it may be an actual inference (if "bad person" is defined as "person who does bad things"), or a useless category (if "bad person" has no actual meaning).
This question seems to be "fear of attribution error". You know you have reasons for things you do, others assume you do things based on your nature.
Replies from: Ruby↑ comment by Ruby · 2019-07-10T18:31:08.297Z · LW(p) · GW(p)
Yeah, I think the overall fear would be something like "I made a mistake but now overall people will judge me as a bad person" where "bad person" is above some threshold of doing bad. Indeed, each bad act is an update towards the threshold, but the fear is that in the minds of others, a single act will be generalized and put you over. The "fear of attribution error" seems on the mark to me.
comment by Ruby · 2024-05-15T00:30:42.221Z · LW(p) · GW(p)
As noted in an update on LW Frontpage Experiments! (aka "Take the wheel, Shoggoth!") [LW · GW], yesterday we started an AB test on some users automatically being switched over to the Enriched [with recommendations] Latest Posts feed.
The first ~18 hours worth of data does seem like a real uptick in clickthrough-rate, though some of that could be novelty.
(examining members of the test (n=921) and control groups (n~=3000) for the last month, the test group seemed to have a slightly (~7%) lower clickthrough-rate baseline, I haven't investigated this)
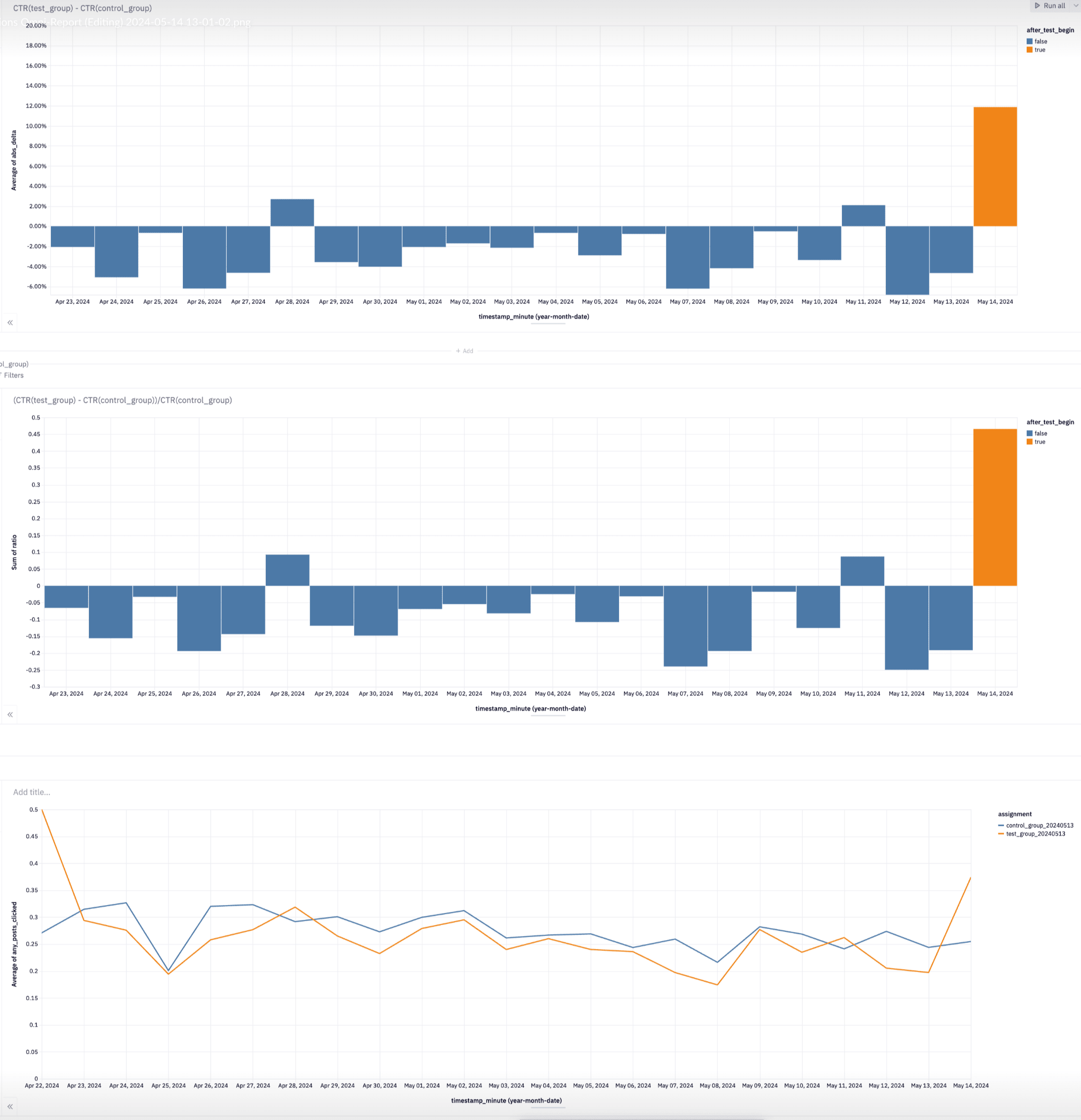
However the specific posts that people are clicking on don't feel on the whole like the ones I was most hoping the recommendations algorithm would suggest (and get clicked on). It feels kinda like there's a selection towards clickbaity or must-read news (not completely, just not as much as I like).
If I look over items recommended by Shoggoth that are older (50% are from last month, 50% older than that), they feel better but seem to get fewer clicks.
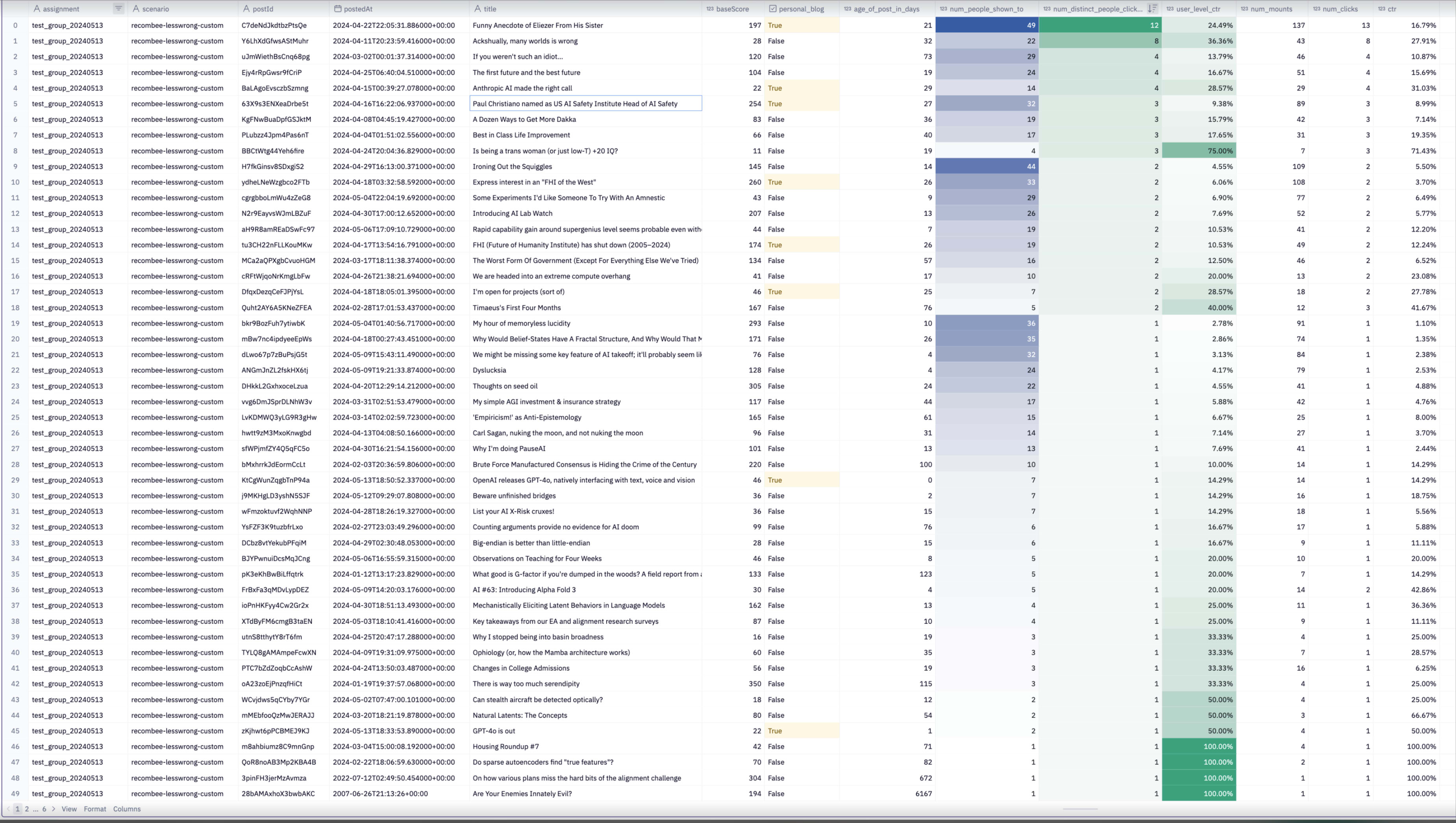
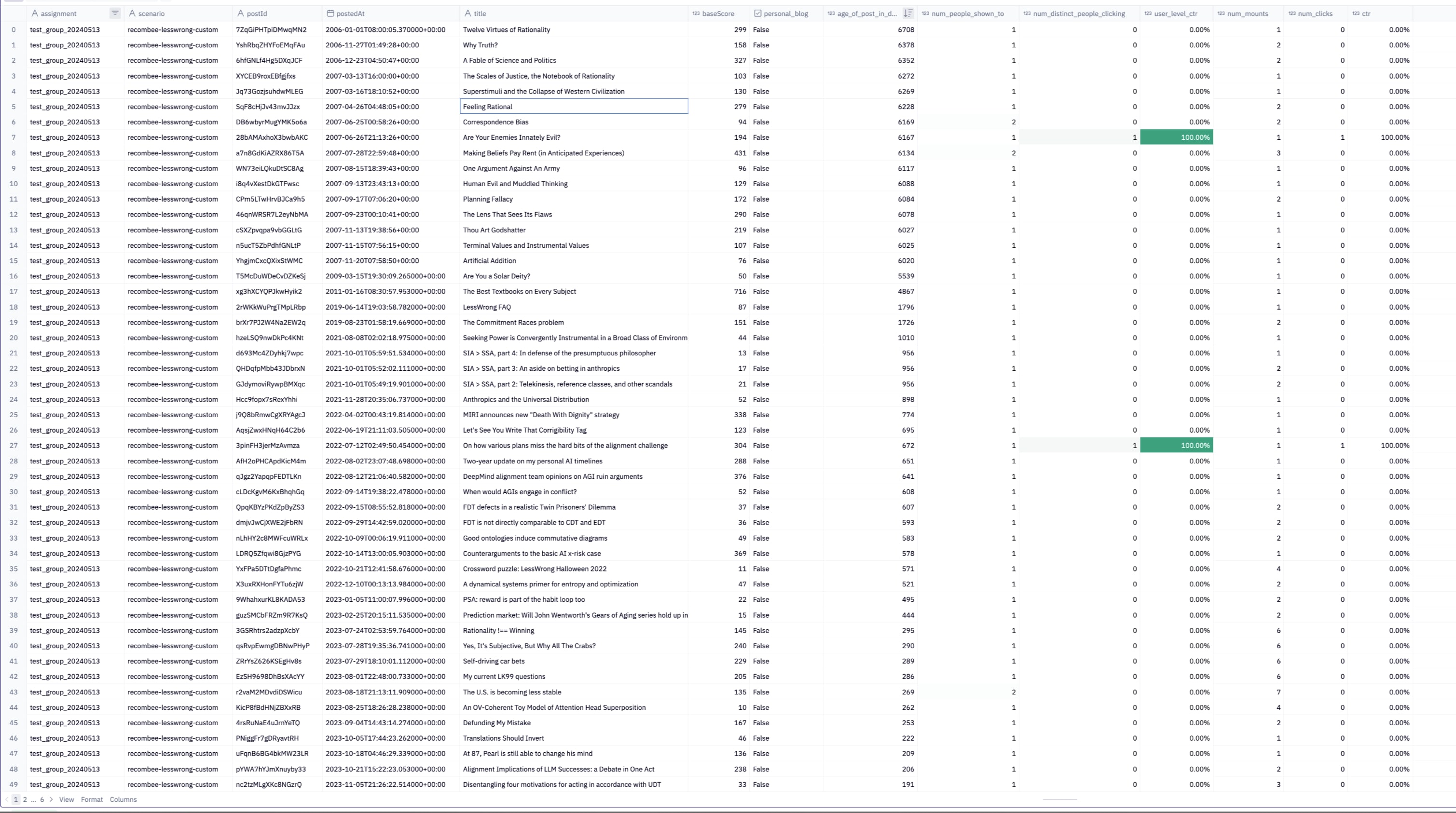
A to-do item is to look at voting behavior relative to clicking behavior. Having clicked on these items, do people upvote them as much as others?
I'm also wanting to experiment with just applying a recency penalty if it seems that older content suggested by the algorithm is more "wholesome", though I'd like to get some data from the current config before changing it.
comment by Ruby · 2019-09-02T03:36:34.665Z · LW(p) · GW(p)
It feels like the society I interact with dislikes expression of negative emotions, at least in the sense that expressing negative emotions is kind of a big deal - if someone expresses a negative feeling, it needs to be addressed (fixed, ideally). The discomfort with negative emotions and consequent response acts to a fair degree to suppress their expression. Why mention something you're a little bit sad about if people are going to make a big deal out of it and try to make you feel better, etc., etc.?
Related to the above (with an ambiguously directed causal arrow) is that we lack reliable ways to communicate about negative emotions with something like nuance or precision. If I think imagine starting a conversation with a friend by saying "I feel happy", I expect to be given space to clarify the cause, nature, and extent of my happiness. Having clarified these, my friend will react proportionally. Yet when I imagine saying "I feel sad", I expect this to be perceived as "things are bad, you need sympathy, support, etc." and the whole stage of "clarify cause, nature, extent" is skipped instead proceeding to a fairly large reaction.
And I wish it wasn't like that. I frequently have minor negative emotions which I think are good, healthy, and adaptive. They might persist for one minute, five minute, half a day, etc. The same as with my positive emotions. When | get asked how I am, or I'm just looking to connect with others by sharing inner states, then I want to be able to communicate my inner state - even when it's negative - and be able to communicate that precisely. I want to be given space to say "I feel sad on the half-hour scale because relatively minor bad thing X happened” vs "I'm sad on the weeks scale because a major negative life event happened." And I want to be able to express the former without it being a bid deal, just a normal thing that sometimes slightly bad things happens and you're slightly sad.
↑ comment by Viliam · 2019-09-02T23:57:28.640Z · LW(p) · GW(p)
The specific details are probably gender-specific.
Men are supposed to be strong. If they express sadness, it's like a splash of low status and everyone is like "ugh, get away from me, loser, I hope it's not contagious". On the other hand, if they express anger, people get scared. So men gradually learn to suppress these emotions. (They also learn that words "I would really want you to show me your true feelings" are usually a bait-and-switch. The actual meaning of that phrase is that the man is supposed to perform some nice emotion, probably because his partner feels insecure about the relationship and wants to be reassured.)
Women have other problems, such as being told to smile when something irritates them... but this would be more reliably described by a woman.
But in general, I suppose people simply do not want to empathize with bad feelings; they just want them to go away. "Get rid of your bad feeling, so that I am not in a dilemma to either empathize with you and feel bad, or ignore you and feel like a bad person."
A good reaction would be something like: "I listen to your bad emotion, but I am not letting myself get consumed by it. It remains your emotion; I am merely an audience." Perhaps it would be good to have some phrase to express that we want this kind of reaction, because from the other side, providing this reaction unprompted can lead to accusations of insensitivity. "You clearly don't care!" (By feeling bad when other people feel bad we signal that we care about them. It is a costly signal, because it makes us feel bad, too. But in turn, the cost is why we provide all kinds of useless help just to make it go away.)
comment by Ruby · 2019-09-24T17:51:45.500Z · LW(p) · GW(p)
Just a thought: there's the common advice that fighting all out with the utmost desperation makes sense for very brief periods, a few weeks or months, but doing so for longer leads to burnout. So you get sayings like "it's a marathon, not a sprint." But I wonder if length of the "fight"/"war" isn't the only variable in sustainable effort. Other key ones might be the degree of ongoing feedback and certainty about the cause.
Though I expect a multiyear war which is an existential threat to your home and family to be extremely taxing, I imagine soldiers experiencing less burnout than people investing similar effort for a far-mode cause, let's say global warming which might be happening, but is slow and your contributions to preventing it unclear. (Actual soldiers may correct me on this, and I can believe war is very traumatizing, though I will still ask how much they believed in the war they were fighting.)
(Perhaps the relevant variables here are something like Hanson's Near vs Far mode thinking, where hard effort for far-mode thinking more readily leads to burnout than near-mode thinking even when sustained for long periods.)
Then of course there's generally EA and X-risk where burnout [EA · GW] is common. Is this just because of the time scales involved, or is it because trying to work on x-risk is subject to so much uncertainty and paucity of feedback? Who knows if you're making a positive difference? Contrast with a Mario character toiling for years to rescue the princess he is certain is locked in a castle waiting [LW · GW]. Fighting enemy after enemy, sleeping on cold stone night after night, eating scraps. I suspect Mario, with his certainty and much more concrete sense of progress, might be able expend much more effort and endure much more hardship for much longer than is sustainable in the EA/X-risk space.
Related: On Doing the Improbable [LW · GW]
comment by Ruby · 2019-09-09T06:25:50.449Z · LW(p) · GW(p)
A random value walks into a bar. A statistician swivels around in her chair, one tall boot unlaced and an almost full Manhattan sitting a short distance from her right elbow.
"I've been expecting you," she says.
"Have you been waiting long?" respond the value.
"Only for a moment."
"Then you're very on point."
"I've met enough of your kind that there's little risk of me wasting time."
"I assure you I'm quite independent."
"Doesn't mean you're not drawn from the same mold."
"Well, what can I do for you?"
"I was hoping to gain your confidence..."
comment by Ruby · 2019-07-21T20:18:28.750Z · LW(p) · GW(p)
Some Thoughts on Communal Discourse Norms
I started writing this in response to a thread about "safety", but it got long enough to warrant breaking out into its own thing.
I think it's important to people to not be attacked physically, mentally, or socially. I have a terminal preference over this, but also think it's instrumental towards truth-seeking activities too. In other words, I want people to actually be safe.
- I think that when people feel unsafe and have defensive reactions, this makes their ability to think and converse much worse. It can push discussion from truth-seeking exchange to social war.
- Here I think mr-hire has a point: if you don't address people's "needs" overtly, they'll start trying to get them covertly, e.g. trying to win arguments for the sake of protecting their reputation rather than trying to get to the truth. Doing things like writing hasty scathing replies rather slow, carefully considered ones (*raises hand*), and worse, feeling righteous anger while doing so. Having thoughts like "the only reason my interlocutor could think X is because they are obtuse due to their biases" rather than "maybe they have I point I don't fully realize" (*raises hand*).
- I want to avoid people being harmed and also feeling like they won't be harmed (but in a truth-tracking way: if you're likely to be attacked, you should believe it). I also think that protective measures are extremely risky themselves for truth-seeking. There is a legitimate fear here a) people can use the protections to silence things they don't like hearing, b) it may be onerous and stifle honest expression to have to constrain one's speech, c) fear of being accused of harming others stifles expression of true ideas, d) these protections will get invoked in all kind of political games.
- I think the above a real dangers. I also think it's dangerous to have no protections against people being harmed, especially if they're not even allowed to object to be harmed. In such an arrangement, it becomes too easy to abuse the "truth-seeking free speech" protections to socially attack and harm people while claiming impunity. Some of it's truth-seeking ability lost to becoming partly a vicious social arena.
I present the Monkey-Shield Allegory (from an unpublished post of mine):
Take a bunch of clever monkeys who like to fight with each other (perhaps they throw rocks). You want to create peace between them, so you issue them each with a nice metal shield which is good at blocking rocks. Fantastic! You return the next day, and you find that the monkeys are hitting each with the mental shields (turns out if you whack someone with a shield, their shield doesn’t block all the force of the blow and it’s even worse than fighting with rocks).
I find it really non-obvious what the established norms and enforced policies should be. I have guesses, including a proposed set of norms which are being debated in semi-private and should be shared more broadly soon.Separate from the question I have somewhat more confidence in the following points and what they imply for individual.
1. You should care about other people and their interests. Their feelings are 1) real and valuable, and 2) often real information about important states of the world for their wellbeing. Compassion is a virtue.
- Even if you are entirely selfish, understanding and caring about other people is instrumentally advantageous for your own interests and for the pursuit of truth.
2. Even failing 1, you should try hard to avoid harming people (i.e. attacking them) and only do so when you really mean to. It's not worth it to accidentally do it if you don't mean to.
3. I suspect many people of possessing deep drives to always be playing monkey-political games, and these cause them to want to win points against each other however they can. Ways to do that include being aggressive, insulting people, etc, baiting them, and all the standard behaviors people engage in online forums.
- These drives are anti-cooperative, anti-truth, and zero-sum. I basically think they should be inhibited and instead people should cultivate compassion and ability to connect.
- I think people acting in these harmful ways often claim their behaviors are fine by attributing to some more defensible cause. I think there are defensible reasons for some behaviors, but I get really suspicious when someone consistently behaves in a way that doesn't further their stated aims.
- People getting defensive are often correctly perceiving that they are being attacked by others. This makes me sympathetic to many cases of people being triggered.
4. Beyond giving up on the monkey-games, I think that being considerate and collaborative (including the meta-collaborative within a Combat culture) costs relatively little most of the time. There might be some upfront costs to change one's habits and learn to be sensitive, but long run the value of learning them pays off many times over in terms of being able to have productive discussions where no one is getting defensive + plus that seems intrinsically better for people to be having a good time. Pleasant discussions provoke more pleasant discussions, etc.
* I am not utterly confident in the correctness of 4. Perhaps my brain devotes more cycles to being considerate and collaborative than I realize (as this slowly ramped up over the years) and it costs me real attention that could go directly to object-level thoughts. Despite the heavy costs, maybe it is just better to not worry about what's going on in other people's minds and not expend effort optimizing for it. I should spend more time trying to judge this.
5. It is good to not harm people, but it also good to build one's resilience and "learn to handle one's feelings." That is just plainly an epistemically virtuous thing to do. One ought to learn how to become less often and also how to operate sanely and productively while defensive. Putting all responsibility onto others for your psychological state is damn risky. Also 1) people who are legitimately nasty sometimes still have stuff worth listening to, you don't want to give up on that; 2) sometimes it won't be the extraneous monkey-attack stuff that is upsetting, and instead the core topic - you want to be able to talk about that, 3) misunderstandings arise easily and it's easy to feel attacked when you aren't being, some hardiness to protection again misunderstandings rapidly spiralling into defensiveness and demonthreads.
6. When discussing topics online, in-text, and with people you don't know, it's very easy to miscalibrated on intentions and the meaning behind words (*raises hand*). It's easy for their to be perceived attacks even when no attacks are intended (this is likely the result of a calibrated prior on the prevalence of social attacks).
a. For this reason, it's worth being a little patient and forgiving. Some people talk a bit sarcastically to everyone (which is maybe bad), but it's not really intended as an attack on you. Or perhaps they were plainly critical, but they were just trying to help.
b. When you are speaking, it's worth a little extra effort to signal that you're friendly and don't mean to attack. Maybe you already know that and couldn't imagine otherwise, but a stranger doesn't. What counts as an honest signal of friendly intent is anti-inductive, if we declare to be something simple, the ill-intentioned by imitate it by rote, go about their business, and the signal will lose all power to indicate the friendliness. But there are lots of cheap ways to indicate you're not attacking, that you have "good will". I think they're worth it.
In established relationships where the prior has become high that you are not attacking, less and less effort needs to be expended on signalling your friendly intent and you can get talk plainly, directly, and even a bit hostilly (in a countersignalling way). This is what my ideal Combat culture looks like, but it relies of having a prior and common knowledge established of friendliness. I don't think it works to just "declare it by fiat."
I've encountered push back when attempting to 6b. I'll derive two potential objections (which may not be completely faithful to those originally raised):
Objection 1: No one should be coerced into having to signal friendliness/maintain someone else's status/generally worry about what impact their saying true things will have. Making them worry about it impedes the ability to say true things which is straightforwardly good.
Response: I'm trying to coerce anyone into doing this. I'm trying to make the case you should want to do this of your own accord. That this is good and worth it and in fact results in more truth generation than otherwise. It's a good return of investment. There might be an additional fear that if I promote this as virtuous behavior, it might have the same truth-impeding effects as it if was policy. I'm not sure, I have to think about that last point more.
Objection 2: If I have to signal friendly intent when I don't mean it, I'd be lying.
Response: Then don't signal friendly intent. I definitely don't want anyone to pretend or go through the motions. However I do think you should probably be trying to have honestly friendly intent. I expect conversations with friendly intent to be considerable better than those without (this is something of a crux for me here), so if you don't have it towards someone, that's real unfortunate, and I am pessimistic about the exchange. Barring exceptional circumstances, I generally don't want to talk to people who do not have friendly intent/desire to collaborate (even just at the meta-level) towards me.
What do I mean by friendly intent? I mean that you don't have goals to attack, win, or coerce. It's an exchange intended for the benefit of both parties where you're not the side acting in a hostile way. I'm not pretending to discuss a topic with you when actually I think you're an idiot and want to demonstrate it to everyone, etc., I'm not trying to get an emotional reaction for my own entertainment, I'm not just trying to win with rhetoric rather than actually expose my beliefs and cruxes, if I'm criticizing, I'm not just trying to destroy you, etc. As above, many times this is missing and it's worth trying to signal its presence.
If it's absent, i.e. you actually want to remove someone from the community or think everyone should disassociate from them, that's sometimes very necessary. In that case, you don't have friendly intent and that's good and proper. Most of the time though (as I will argue), you should have friendly intent and should be able to honestly signal it. Probably I should elaborate and clarify further on my notion of friendly intent.
There are related notions to friendly intent like good faith, questions like "respect your conversation partner", think you might update based on what they say, etc. I haven't discussed them, but should.
comment by Ruby · 2024-09-22T16:13:16.380Z · LW(p) · GW(p)
There's an age old tension between ~"contentment" and ~"striving" with no universally accepted compelling resolution, even if many people feel they have figured it out. Related:
In my own thinking, I've been trying to ground things out in a raw consequentialism that one's cognition (including emotions) is just supposed to take you towards more value (boring, but reality is allowed to be)[1].
I fear that a lot of what people do is ~"wireheading". The problem with wireheading is it's myopic. You feel good now (small amount of value) at the expense of greater value later. Historically, this has made me instinctively wary of various attempts to experience more contentment such as gratitude journaling. Do such things curb the pursuit of value in exchange for feeling better less unpleasant discontent in the moment?
Clarity might come from further reduction of what "value" is. The primary notion of value I operate with is preference satisfaction: the world is how you want it to be. But also a lot of value seems to flow through experience (and the preferred state of the world is one where certain experiences happen).
A model whereby gratitude journaling (or general "attend to what is good" motions) maximize value as opposed to the opposite, is that they're about turning 'potential value' into 'experienced actual value'. The sunset on its own is merely potential value, it becomes experienced actual value when you stop and take it in. The same for many good things in one's life you might have just gotten used it, but could be enjoyed and savored (harvested) again by attending to them.
Relatedly, I've thought a distinction between actions that "sow value" vs "reap value", roughly mapping onto actions that are instrumental vs terminal to value, roughly mapping to "things you do to get enjoyment later" vs "things you actually enjoy[2] now".
My guess is that to maximize value over one's lifetime (the "return" in RL terms), one shouldn't defer reaping/harvesting value until the final timestep. Instead you want to be doing a lot of sowing but also reaping/harvesting as you go to, and gratitude-journaling-esque, focus-on-what-you-got-already stuff faciliates that, and is part of of value maximization, not simply wireheading.
It's a bit weird in our world, because the future value you can be sowing for (i.e. the entire cosmic endowment not going to waste) is so overwhelming, it kinda feels like maybe it should outweigh any value you might reap now. My handwavy answer is something something human psychology it doesn't work to do that.
I'm somewhat rederiving standard "obvious" advice, but I don't think it actually is, and figuring out better models and frameworks might ultimately solve the contentment/striving tension (/ focus on what you go vs focus on what you don't tension).
- ^
And as usual, that doesn't mean one tries to determine the EV of every individual mental act. It means when setting up policies, habits, principles, etc., etc., that ultimate the thing that determines whether those are good is the underlying value consequentialism.
- ^
To momentarily speak in terms of experiential value vs preference satisfaction value.
↑ comment by tailcalled · 2024-09-22T18:59:26.423Z · LW(p) · GW(p)
I think gratitude also has value in letting you recognize what is worth maintaining and what has historically shown itself to have lots of opportunities and therefore in the future may have opportunities too.
↑ comment by Ruby · 2024-09-22T16:16:31.304Z · LW(p) · GW(p)
Once I'm rambling, I'll note another thought I've been mulling over:
My notion of value is not the same as the value that my mind was optimized to pursue. Meaning that I ought to be wary that typical human thought patterns might not be serving me maximally.
That's of course on top of the fact that evolution's design is flawed even by its own goals; humans rationanlize left, right, and center, are awfully myopic, and we'll likely all die because of it.
↑ comment by ABlue · 2024-09-22T17:51:13.842Z · LW(p) · GW(p)
I don't think wireheading is "myopic" when it overlaps with self-maintenance. Classic example would be painkillers; they do ~nothing but make you "feel good now" (or at least less bad), but sometimes feeling less bad is necessary to function properly and achieve long-term value. I think that gratitude journaling is also part of this overlap area. That said I don't know many peoples' experiences with it so maybe it's more prone to "abuse" than I expect.
Replies from: Rubycomment by Ruby · 2019-09-02T16:42:36.030Z · LW(p) · GW(p)
Hypothesis that becomes very salient from managing the LW FB page: "likes and hearts" are a measure of how much people already liked your message/conclusion*.
*And also like how well written/how alluring a title/how actually insightful/how easy to understand, etc. But it also seems that the most popular posts are those which are within the Overton window, have less inferential distance, and a likable message. That's not to say they can't have tremendous value, but it does make me think that the most popular posts are not going to be the same as the most valuable posts + optimizing for likes is not going to be same as optimizing for value.
**And maybe this seems very obvious to many already, but it just feels so much more concrete when I'm putting three posts out there a week (all of which I think are great) and seeing which get the strongest response.
***This effect may be strongest at the tails.
****I think this effect would affect Gordon's proposed NPS-rating [LW · GW] too.
*****I have less of this feeling on LW proper, but definitely far from zero.
comment by Ruby · 2019-07-28T18:02:27.128Z · LW(p) · GW(p)
Narrative Tension as a Cause of Depression
I only wanted to budget a couple of hours for writing today. Might develop further and polish at a later time.
Related to and an expansion of Identities are [Subconscious] Strategies [LW · GW]
Epistemic status: This is non-experimental psychology, my own musings. Presented here is a model derived from thinking about human minds a lot over the years, knowing many people who’ve experienced depression, and my own depression-like states. Treat it as a hypothesis, see if matches your own data and it generates helpful suggestions.
Clarifying “narrative”
In the context of psychology, I use the term narrative to describe the simple models of the world that people hold to varying degrees of implicit vs explicit awareness. They are simple in the sense of being short, being built of concepts which are basic to humans (e.g. people, relationships, roles, but not physics and statistics), and containing unsophisticated blackbox-y causal relationships like “if X then Y, if not X then not Y.”
Two main narratives
I posit that people carry two primary kinds of narratives in their minds:
- Who I am (the role they are playing), and
- How my life will go (the progress of their life)
The first specifies the traits they possess and actions they should take. It’s a role to played. It’s something people want to be for themselves and want to be seen to be by others. Many roles only work when recognized by others, e.g. the cool kid.
The second encompasses wants, needs, desires, and expectations. It specifies a progression of events and general trajectory towards a desired state.
The two narratives function as a whole. A person believes that by playing a certain role they will attain the life they want. An example: a 17 year-old with a penchant for biology decides they destined to be a doctor (perhaps there are many in the family); they expect to study hard for SATs, go to pre-med, go to medical school, become a doctor; once they are a doctor they expect to have a good income, live in a nice house, attract a desirable partner, be respected, and be a good person who helps people.
The structure here is “be a doctor” -> “have a good life” and it specifies the appropriate actions to take to live up to that role and attain the desired life. One fails to live up to the role by doing things like failing to get into med school, which I predict would be extremely distressing to someone who’s predicated their life story on that happening.
Roles needn’t be professional occupations. A role could be “I am the kind, fun-loving, funny, relaxed person who everyone loves to be around”, it specifies a certain kind of behavior and precludes others (e.g. being mean, getting stressed or angry). This role could be attached to a simple causal structure of “be kind, fun-loving, popular” -> “people like me” -> “my life is good.”
Roles needn’t be something that someone has achieved. They are often idealized roles towards which people aspire, attempting to always take actions consistent with achieving those roles, e.g. not yet a doctor but studying for it, not yet funny but practicing.
I haven’t thought much about this angle, but you could tie in self-worth here. A person derives their self-worth from living up to their narrative, and believes they are worthy of the life they desire when they succeed at playing their role.
Getting others to accept our narratives is extremely crucial for most people. I suspect that even when it seems like narratives are held for the self, we're really constructing them for others, and it's just much simpler to have a single narrative than say "this is my self-narrative for myself" and "this is my self-narrative I want others to believe about me" a la Trivers/Elephant in the Brain.
Maintaining the narrative
A hypothesis I have is that among the core ways people choose their actions, it’s with reference to which actions would maintain their narrative. Further, that most events that occur to people are evaluated with reference to whether that event helps or damages the narrative. How upsetting is it to be passed over for a promotion? It might depend on whether you have a self-narrative is as “high-achiever” or “team-player and/or stoic.”
Sometimes it’s just about maintaining the how my life will go element: “I’ll move to New York City, have two kids and a dog, vacation each year in Havana, and volunteer at my local Church” might be a story someone has been telling themselves for a long time. They work towards it and will become distressed if any part of it starts to seem implausible.
You can also see narratives as specifying the virtues that an individual will try to act in accordance with.
Narrative Tension
Invariable, some people encounter difficult living up to their narratives. What of the young sprinter who believes their desired future requires them to win Olympic Gold yet is failing to perform? Or the aspiring parent who in their mid-thirties is struggling to find a co-parent? Or the person who believes they should be popular, yet is often excluded? Or the start-up founder wannabee who’s unable to obtain funding yet again for their third project?
What happens when you are unable to play the role you staked your identity on?
What happens when the life you’ve dreamed of seems unattainable?
I call this narrative tension. The tension between reality and the story one wants to be true. In milder amounts, when hope is not yet lost, it can be a source of tremendous drive. People work longer and harder, anything to keep the drive alive.
Yet if the attempts fail (or it was already definitively over) then one has to reconcile themselves to the fact that they cannot live out that story. They are not that person, and their life isn’t going to look like that.
It is crushing.
Heck, even just the fear of it possibly being the case, even when their narrative could in fact still be entirely achievable, can still be crushing.
Healthy and Unhealthy Depression
Related: Eliezer on depression and rumination
I can imagine that depression could serve an important adaptive function when it occurs in the right amounts and at the right times. A person confronted with the possible death of their narratives either: a) reflects and determines they need to change their approach, or b) grieves and seeks to construct new narratives to guide their life. This is facilitated with a withdrawal from their normal life and disengagement from typical activities. Sometimes the subconscious mind forces this on a person who otherwise would drive themselves into the ground vainly trying to cling to a narrative that won’t float.
Yet I could see this all failing if a person refuses to grieve and refuses to modify their narrative. If their attitude is “I’m a doctor in my heart of hearts and I could never be anything else!” then they’ll fail to consider whether being a dentist or nurse or something else might be the next best thing for them. A person who’s only ever believed (implicitly or explicitly) that being the best is the only strategy for them to be liked and respected, won’t even ponder how it is other people who aren’t the best in their league ever get liked or respected, and whether she might do the same.
Depressed people think things like:
- I am a failure.
- No one will ever love me.
- I will never be happy.
One lens on this might be that some people are unwilling to give up a bucket error [LW · GW] whereby they’re lumping their life-satisfaction/achievement of their value together with achievement of a given specific narrative. So once they believe the narrative is dead, they believe all is lost.
They get stuck. They despair.
It’s despair which I’ve begun to see as the hallmark of depression, present to some degree or other in all the people I’ve personally known to be depressed. They see no way forward. Stuck.
[Eliezer's hypothesis of depressed individuals wanting others to validate their retelling of past events seems entirely compatible with people wanting to maintain narratives and seeking indication that others still accept their narrative, e.g. of being good person.]
Narrative Therapy
To conjecture on how the models here could be used to help, I think the first order is to try to uncover a person’s narratives: everything they model about who they’re supposed to be and how their life should look and progress. The examples I’ve given here are simplified. Narratives are simple relative to full causal models of reality, but a person’s self-narrative will still have have many pieces, distributed over parts of their mind, often partitioned by context, etc. I expect doing this to require time, effort, and skill.
Eventually, once you’ve got the narrative models exposed, they can be investigated and supplemented with full causal reasoning. “Why don’t we break down the reasons you want to be a doctor and see what else might be a good solution?” “Why don’t we list out all the different things that make people likable, see which might you are capable of?”
I see CBT and ACT each offering elements of this. CBT attempts to expose many of one’s simple implicit models and note where the implied reasoning is fallacious. ACT instructs people to identify their values and find the best way to live up to them, even if they can’t get their first choice way of doing so, e.g. “you can’t afford to travel, but you can afford to eat foreign cuisine locally.”
My intuition though is that many people are extremely reluctant to give up any part of their narrative and very sensitive to attempts to modify any part of it. This makes sense if they’re in the grips of a bucket error where making any allowance feels like giving up on everything they value. The goal of course is to achieve flexible reasoning.
Why this additional construct?
Is really necessary to talk about narratives? Couldn’t I have described just talking about what people want and their plans? Of course, people get upset when they fail to get what they want and their plans fail!
I think the narratives model is important for highlighting a few elements:
- The kind of thinking used here is very roles-based in a very deep way: what kind of person I am, what do I do, how do I relate to others and they relate to me.
- The thinking is very simplistic, likely a result of originating heavily from System 1. This thinking does not employ a person’s full ability to causally model the world.
- Because of 2), the narratives are much more inflexible than a person’s general thinking. Everything is all or nothing, compromises are not considered, it’s that narrative or bust.
↑ comment by RobinGoins (Daunting) · 2019-07-29T02:44:33.449Z · LW(p) · GW(p)
This is aligned with my thoughts on the importance of narratives, especially personal narratives.
The best therapists are experts at helping pull out your stories - they ask many, many questions and function as working memory, so you can better see the shapes of your stories and what levers exist to mold them differently.
(We have a word for those who tell stories - storyteller - but do we have a word for experts at pulling stories out of others?)
↑ comment by Jakob_J · 2019-07-29T18:12:51.162Z · LW(p) · GW(p)
A related concept in my view is that of agency, as in how much I feel I am in control of my own life. I am not sure what is the cause and what is the effect, but I have noticed that during periods of depression I feel very little agency and during more happy periods I feel a lot more agency over my life. Often, focusing on the things I can control in my life (exercise, nutrition, social activities) over things I can't (problems at work) allows me to recover from depression a lot faster.
comment by Ruby · 2019-02-28T19:35:53.312Z · LW(p) · GW(p)
Over the years, I've experienced a couple of very dramatic yet rather sudden and relatively "easy" shifts around major pain points: strong aversions, strong fears, inner conflicts, or painful yet deeply ingrained beliefs. My post Identities are [Subconscious] Strategies contains examples. It's not surprising to me that these are possible, but my S1 says they're supposed to require a lot of effort: major existential crises, hours of introspection, self-discovery journeys, drug trips, or dozens of hours with a therapist.
Have recently undergone a really big one, I noted my surprise again. Surprise, of course, is a property of bad models. (Actually, the recent shift occurred precisely because of exactly this line of thought: I noticed I was surprised and dug in, leading to an important S1 shift. Your strength as a rationalist and all that.) Attempting to come up with a model which wasn't as surprised, this is what I've got:
The shift involved S1 models. The S1 models had been there a long time, maybe a very long time. When that happens, they begin to seem how the world just *is*. If emotions arise from those models, and those models are so entrenched they become invisible as models, then the emotions too begin to be taken for granted - a natural way to feel about the world.
Yet the longevity of the models doesn’t mean that they’re deep, sophisticated, or well-founded. That might be very simplistic such that they ignore a lot of real-world complexity. They might have been acquired in formative years before one learned much of their epistemic skill. They haven’t been reviewed, because it was hardly noticed that they were beliefs/models rather than just “how the world is”.
Now, if you have a good dialog with your S1, if your S1 is amenable to new evidence and reasoning, then you can bring up the models in question and discuss them with your S1. If your S1 is healthy (and is not being entangled with threats), it will be open to new evidence. It might very readily update in the face of that evidence. “Oh, obviously the thing I’ve been thinking was simplistic and/or mistaken. That evidence is incompatible with the position I’ve been holding.” If the models shift, then the feelings shift.
Poor models held by an epistemically healthy "agent" can rapidly change when presented with the right evidence. This is perhaps not surprising.
Actually, I suspect that difficulty updating often comes from the S1 models and instances of the broccoli error: “If I updated to like broccoli then I would like broccoli, but I don’t like broccoli, so I don’t want that.” “If I updated that people aren’t out to get me then I wouldn’t be vigilant, which would be bad since people are out to get me.” Then the mere attempt to persuade that broccoli is pretty good / people are benign is perceived as threatening and hence resisted.
So maybe a lot of S1 willingness to update is very dependent on S1 trusting that it is safe, that you’re not going to take away any important, protective beliefs of models.
If there are occasions where I achieve rather large shifts in my feelings from relatively little effort, maybe it is just that I’ve gotten to a point where I’m good enough at locating the S1 models/beliefs that are causing inner conflict, good enough at feeling safe messing with my S1 models, and good enough at presenting the right reasoning/evidence to S1.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2019-09-14T20:51:57.522Z · LW(p) · GW(p)
Unlocking the Emotional Brain is basically about this.
comment by Ruby · 2023-07-07T18:06:30.066Z · LW(p) · GW(p)
The LessWrong admins are often evaluating whether users (particularly new users) are going to be productive members of the site vs are just really bad and need strong action taken.
A question we're currently disagreeing on is which pieces of evidence it's okay to look at in forming judgments. Obviously anything posted publicly. But what about:
- Drafts (admins often have good reason to look at drafts, so they're there)
- Content the user deleted
- The referring site that sent someone to LessWrong
I'm curious how people feel about moderators looking at those.
Alternatively, we're not in complete agreement about:
- Should deleted stuff even be that private? It was already public, could already have been copied, archived, etc. So there isn't that much expectation of privacy so admins should look at it.
- Is it the case that we basically shouldn't extend the same rights, e.g. privacy, to new users because they haven't earned them as much, and we need to look at more activity/behavior to assess the new user?
- There's some quantitative here where we might sometimes doing this depending on our degree of suspicion. Generally respecting privacy but looking at more things, e.g. drafts, that if we're on the edge about banning someone.
- We are generally very hesitant to look at votes, but start to do this if we suspect bad voting behavior (e.g. someone possibly indiscriminately downvoting another person). Rate limiting being tied to downvotes perhaps makes this more likely and more of an issue. Just how ready to investigate (including deanonymization) should be if we suspect abuse?
↑ comment by Raemon · 2023-07-07T19:50:59.794Z · LW(p) · GW(p)
I want to clarify the draft thing:
In general LW admins do not look at drafts, except when a user has specifically asked for help debugging something. I indeed care a lot about people feeling like they can write drafts without an admin sneaking a peak.
The exceptions under discussion are things like "a new user's first post or comment looks very confused/crackpot-ish, to the point where we might consider banning the user from the site. The user has some other drafts. (I think a central case here is a new user shows up with a crackpot-y looking Theory of Everything. The first post that they've posted publicly looks sort of borderline crackpot-y and we're not sure what call to make. A thing we've done sometimes is do a quick skim of their other drafts to see if they're going in a direction that looks more reassuring or "yeah this person is kinda crazy and we don't want them around.")
I think the new auto-rate-limits somewhat relax the need for this (I feel a bit more confident that crackpots will get downvoted, and then automatically rate limited, instead of something the admins have to monitor and manage). I think I'd have defended the need to have this tool in the past, but it might be sufficiently unnecessary now that we should remove it from our common mod toolset.
...
I also want to emphasize since @Dagon [LW · GW] brought it up: we never look at DMs. We do have a flag for "a new user has sent a lot of DMs without posting any content", but the thing we do there is send the user a message saying approximately "hey, we have observed this metadata, we haven't read your DMs, but just want to encourage you to be careful about spamming people in DMs". In cases where we suspect someone is doing flagrant DM spam we might disable their ability to send future DMs until they've persuaded us they're a reasonable real person, but still not actually read the DM.
Replies from: Dagon↑ comment by Dagon · 2023-07-08T03:58:12.755Z · LW(p) · GW(p)
I apologize if I implied that the mods were routinely looking at private data without reason - I do, in fact, trust your intentions very deeply, and I'm sad when my skepticism about the ability to predict future value bleeds over into making your jobs harder.
I wonder if the missing feature might be a status for "post approval required" - if someone triggers your "probably a crackpot" intuition, rather than the only options being "ban" or "normal access" have a "watchlist" option, where posts and comments have a 60-minute delay before becoming visible (in addition to rate limiting). The only trustworthy evidence about future posts is the posts themselves - drafts or deleted things only show that they have NOT decided to post that.
Note that I don't know how big a problem this is. I think that's a great credit to the mods - you're removing the truly bad before I notice it, and leaving some not-great-but-not-crackpot, which I think is about right. This makes it very hard for me to be confident in any opinions about whether you're putting too much work into prior-censorship or not.
↑ comment by Rafael Harth (sil-ver) · 2023-07-07T19:45:38.233Z · LW(p) · GW(p)
I'm emotionally very opposed to looking at drafts of anyone, though this is not a rationally thought out position. I don't have the same reaction toward votes because I don't feel like you have an expectation of privacy there. There are forums where upvotes are just non-anonymous by default.
↑ comment by Nathan Young · 2023-07-08T11:58:10.805Z · LW(p) · GW(p)
Ruby, why doesn't your shortform have agree/disagreevote?
Replies from: Raemon↑ comment by Max H (Maxc) · 2023-07-08T21:28:43.982Z · LW(p) · GW(p)
Personal opinion: it's fine and good for the mods to look at all available evidence when making these calls, including votes and vote patterns. If someone is borderline, I'd rather they be judged based on all available info about them, and I think the more data the mods look at more closely, the more accurate and precise their judgments will be.
I'm not particularly worried about a moderator being incorrectly "biased" from observing a low-quality draft or a suspect referral; I trust the mods to be capable of making roughly accurate Bayesian updates based on those observations.
I also don't think there's a particularly strong expectation or implicit promise about privacy (w.r.t mods; of course I don't expect anyone's votes or drafts to be leaked to the public...) especially for new / borderline users.
Separately, I feel like the precise policies and issues here are not worth sweating too much, for the mods / LW team. I think y'all are doing a great job overall, and it's OK if the moderation policy towards new users is a bit adhoc / case-by-case. In particular, I don't expect anything in the neighborhood of current moderation policies / rate-limiting / privacy violations currently implemented or being discussed to have any noticeable negative effects, on me personally or on most users. (In particular, I disagree pretty strongly with the hypothesis in e.g. this comment [LW(p) · GW(p)]; I don't expect rate limits or any other moderation rules / actions to have any impact whatsoever on my own posting / commenting behavior, and I don't give them any thought when posting or commenting myself. I suspect the same is true for most other users, who are either unaware of them or don't care / don't notice.)
↑ comment by Dagon · 2023-07-08T19:14:06.642Z · LW(p) · GW(p)
How frequent are moderation actions? Is this discussion about saving moderator effort (by banning someone before you have to remove the rate-limited quantity of their bad posts), or something else? I really worry about "quality improvement by prior restraint" - both because low-value posts aren't that harmful, they get downvoted and ignored pretty easily, and because it can take YEARS of trial-and-error for someone to become a good participant in LW-style discussions, and I don't want to make it impossible for the true newbies (young people discovering this style for the first time) to try, fail, learn, try, fail, get frustrated, go away, come back, and be slightly-above-neutral for a bit before really hitting their stride.
Relatedly: I'm struck that it seems like half or more of posts get promoted to frontpage (if the /allPosts list is categorizing correctly, at least). I can't see how many posts are deleted, of course, but I wonder if, rather than moderation, a bit more option in promotion/depromotion would help. If we had another category (frontpage, personal, and random), and mods moved things both up and down pretty easily, it would make for lower-stakes decisionmaking, and you wouldn't have to ban anyone unless they're making lots of work for mods even after being warned (or are just pure spam, which doesn't seem to be the question triggering this discussion).
Replies from: DragonGod↑ comment by DragonGod · 2023-07-08T20:39:40.058Z · LW(p) · GW(p)
How frequent are moderation actions? Is this discussion about saving moderator effort (by banning someone before you have to remove the rate-limited quantity of their bad posts), or something else? I really worry about "quality improvement by prior restraint" - both because low-value posts aren't that harmful, they get downvoted and ignored pretty easily, and because it can take YEARS of trial-and-error for someone to become a good participant in LW-style discussions, and I don't want to make it impossible for the true newbies (young people discovering this style for the first time) to try, fail, learn, try, fail, get frustrated, go away, come back, and be slightly-above-neutral for a bit before really hitting their stride.
I agree with Dagon here.
Six years ago after discovering HPMOR and reading part (most?) of the Sequences, I was a bad participant in old LW and rationalist subreddits.
I would probably have been quickly banned on current LW.
It really just takes a while for people new to LW like norms to adjust.
↑ comment by Dagon · 2023-07-07T19:36:10.556Z · LW(p) · GW(p)
Can you formalize the threat model a bit more? What is the harm you're trying to prevent with this predictive model of whether a user (new or not) will be "productive" or "really bad"? I'm mostly interested in your cost estimates for false positive/negative and your error bars for the information you have available. Also, how big is the gap between "productive" and "really bad". MOST users are neither - they're mildly good to mildly bad, with more noise than signal to figure out the sign.
The bayesean in me says "use all data you have", but the libertarian side says "only use data that the target would expect to be used", and even more "I don't believe you'll USE the less-direct data to reach correct conclusions". For example, is it evidence of responsibility that someone deleted a bad comment, or evidence of risk that they wrote it in the first place?
I DO strongly object to differential treatment of new users. Long-term users have more history to judge them on, but aren't inherently different, and certainly shouldn't have more expectation of privacy. I do NOT strongly object to a clear warning that drafts, deleted comments, and DMs are not actually private, and will often be looked at by site admins. I DO object to looking at them without the clear notice that LW is different than a naive expectation in this regard.
I should say explicitly: I have VERY different intuitions of what's OK to look at routinely for new users (or old) in a wide-net or general policy vs what's OK to look at if you have some reason (a complaint or public indication of suspicious behavior) to investigate an individual. I'd be very conservative on the former, and pretty darn detailed on the latter.
I think you're fully insane (or more formally, have an incoherent privacy, threat, and prediction model) if you look at deleted/private/draft messages, and ignore voting patterns.
comment by Ruby · 2023-02-09T01:55:54.059Z · LW(p) · GW(p)
I want to register a weak but nonzero prediction that Anthropic’s interpretability publication of A Mathematical Framework for Transformers Circuits will turn out to lead to large capabilities gains and in hindsight will be regarded as a rather bad move that it was published.
Something like we’ll have capabilities-advancing papers citing it and using its framework to justify architecture improvements.
Replies from: lahwran, riceissa↑ comment by the gears to ascension (lahwran) · 2023-02-09T02:00:44.392Z · LW(p) · GW(p)
Agreed, and I don't think this is bad, nor that they did anything but become the people to implement what the zeitgeist demanded. It was the obvious next step, if they hadn't done it, someone else who cared less about trying to use it to make systems actually do what humans want would have done it. So the question is, are they going to release their work for others to use, or just hoard it until someone less scrupulous releases their models? It's looking like they're trying to keep it "in the family" so only corporations can use it. Kinda concerning.
If human understandability hadn't happened, the next step might have been entirely automated sparsification, and those don't necessarily produce anything humans can use to understand. Distillation into understandable models is an extremely powerful trajectory.
↑ comment by riceissa · 2023-03-11T21:42:49.761Z · LW(p) · GW(p)
Not the same paper, but related: https://twitter.com/jamespayor/status/1634447672303304705
comment by Ruby · 2020-09-11T01:15:14.010Z · LW(p) · GW(p)
Just updated the Concepts Portal. Tags that got added are:
- Infra-Bayesianism [? · GW]
- Aversion/Ugh Fields [? · GW]
- Murphyjitsu [? · GW]
- Coherent Extrapolated Volition [? · GW]
- Tool AI [? · GW]
- Computer Science [? · GW]
- Sleeping Beauty Paradox [? · GW]
- Simulation Hypothesis [? · GW]
- Counterfactuals [? · GW]
- Trolley Problem [? · GW]
- Climate Change [? · GW]
- Organizational Design and Culture [? · GW]
- Acausal Trade [? · GW]
- Privacy [? · GW]
- 80,000 Hours [? · GW]
- GiveWell [? · GW]
- Note-Taking [? · GW]
- Reading Group [? · GW]
↑ comment by Ruby · 2020-09-11T01:29:12.622Z · LW(p) · GW(p)
Also Fermi Estimation [? · GW]
comment by Ruby · 2023-04-28T02:02:30.446Z · LW(p) · GW(p)
Edit: I thought this distinction must have been pointed out somewhere. I see it under Raw of Law vs Rule of Man
Law is Ultimate vs Judge is Ultimate
Just writing up a small idea for reference elsewhere. I think spaces can get governed differently on one pretty key dimension, and that's who/what is supposed to driving the final decision.
Option 1: What gets enforced by courts, judgeds, police, etc in countries is "the law" of various kinds, e.g. the Constitution. Lawyers and judges attempt to interpret the law and apply it in given circumstances, often with reference to how the law was used previously. Laws can be changed by appropriate process, but it's not trivial.
Option 2: There is a "ruler" who gets to decide what is right and what is wrong. The ruler can state rules, but then the ruler is the person who gets to interpret their rules and how to apply them. Also the ruler can decide to change the rules. (The constraint on the ruler might be the governed people revolting or leaning i the judge doesn't seem to rule justly). Small private companies can operate more like this: the CEO just gets final say in decisions, according to their judgment of what's good.
An advantage of Law is Ultimate is it might protect against the corruption or self-interest than a self-determining ruler could exhibit. It's also something where different people can be placed in charge of upholding the same laws, and the laws are (relatively) legible.
Advantages of Ruler is Ultimate are:
- More sophisticated and nuanced judgment than codified law
- More resilient to being gamed and abused
- Enforced rules can evolve over time as situations change and ruler gets wiser
- Can operate in domains where it'd be very hard or costly to codify adequate laws
- Don't have the same requirements on bureaucracy and process for interpreting and apply the law
comment by Ruby · 2022-05-13T07:16:05.698Z · LW(p) · GW(p)
PSA:
Is Slack your primary coordination tool with your coworkers?
If you're like me, you send a lot of messages asking people for information or to do things, and if your coworkers are resource-limited humans like mine, they won't always follow-up on the timescale you need.
How do you ensure loops get closed without maintaining a giant list of unfinished things in your head?
I used Slacks remind-me feature extensively. Whenever I send a message that I want to follow-up on if the targeted party doesn't get back to me within a certain time frame, I set a reminder on the message (drop-down menu, "remind me".
Slack is also a major source of to-do items for me. One thing I could is always act on each to-do item as I come across (e.g. replying to messages), but this would make it hard together anything done. Just because I want to do something doesn't mean I should do it on the spot to avoid forgetting about it. Here I also use remind-me feature to return to items when it's a good time (I batch things this way).
comment by Ruby · 2025-01-07T18:58:28.090Z · LW(p) · GW(p)
Errors are my own
At first blush, I find this caveat amusing.
1. If there are errors, we can infer that those providing feedback were unable to identify them.
2. If the author was fallible enough to have made errors, perhaps they are are fallible enough to miss errors in input sourced from others.
What purpose does it serve? Given its often paired with "credit goes to..<list of names> it seems like an attempt that people providing feedback/input to a post are only exposed to upside from doing so, and the author takes all the downside reputation risk if the post is received poorly or exposed as flawed.
Maybe this works? It seems that as a capable reviewer/feedback haver, I might agree to offer feedback on a poor post written by a poor author, perhaps pointing out flaws, and my having given feedback on it might reflect poorly on my time allocation, but the bad output shouldn't be assigned to me. Whereas if my name is attached to something quite good, it's plausible that I contributed to that. I think because it's easier to help a good post be great than to save a bad post.
But these inferences seem like they're there to be made and aren't changed by what an author might caveat at the start. I suppose the author might want to remind the reader of them rather than make them true through an utterance.
Upon reflection, I think (1) doesn't hold. The reviewers/input makers might be aware of the errors but be unable to save the author from them. (2) That the reviewers made mistakes that have flowed into the piece seems all the more likely the worse the piece is overall, since we can update that the author wasn't likely to catch them.
On the whole, I think I buy the premise that we can't update too much negatively on reviewers and feedback givers from them having deigned to give feedback on something bad, though their time allocation is suspect. Maybe they're bad at saying no, maybe they're bad at dismissing people's ideas aren't that good, maybe they have hope for this person. Unclear. Upside I'm more willing to attribute.
Perhaps I would replace the "errors are my my own[, credit goes to]" with a reminder or pointer that these are the correct inferences to make. The words themselves don't change them? Not sure, just musing here.
Edited To Add: I do think "errors are my own" is a very weird kind of social move that's being performed in an epistemic contexts and I don't like.
↑ comment by gwillen · 2025-01-07T19:21:24.064Z · LW(p) · GW(p)
I think this makes sense as a reminder of a thing that is true anyway, as you somewhat already said; but also consider situations like:
- A given reviewer was only reviewing for substance, and the error is stylistic, or vice versa;
- A given reviewer was only reviewing for a subset of the subject matter;
- A given reviewer was reviewing an early draft, and an error was introduced in a later draft.
In general a given reviewer will not necessarily have a real opportunity to catch any particular error, and usually a reader won't have enough context to determine whether they did or didn't. The author by contrast always bears responsibility for errors.
I think the point of the caveat is that it is polite to thank people who helped, but putting someone's name on something implies they bear responsibility for it, and so the disclaimer is meant to keep the acknowledgement from being double-edged in an inappropriate way. Someone familiar with the writing and editing process will already in theory know all these things; someone who is not familiar maybe won't be. But ultimately I see it as kind of a phatic courtesy which merely alludes to all this.
comment by Ruby · 2019-10-24T20:40:49.565Z · LW(p) · GW(p)
Great quote from Francis Bacon (Novum Organum Book 2:8 [LW · GW]):
Don’t be afraid of large numbers or tiny fractions. In dealing with numbers it is as easy to write or think a thousand or a thousandth as to write or think one.
comment by Ruby · 2019-09-15T05:45:08.075Z · LW(p) · GW(p)
Converting this from a Facebook comment to LW Shortform.
A friend complains about recruiters who send repeated emails saying things like "just bumping this to the top of your inbox" when they have no right to be trying to prioritize their emails over everything else my friend might be receiving from friends, travel plans, etc. The truth is they're simply paid to spam.
Some discussion of repeated messaging behavior ensued. These are my thoughts:
I feel conflicted about repeatedly messaging people. All the following being factors in this conflict:
- Repeatedly messaging can be making yourself an asshole that gets through someone's unfortunate asshole filter.
- There's an angle from which repeatedly, manually messaging people is a costly signal bid that their response would be valuable to you. Admittedly this might not filter in the desired ways.
- I know that many people are in fact disorganized and lose emails or otherwise don't have systems for getting back to you such that failure to get back to you doesn't mean they didn't want to.
- There are other people have extremely good systems I'm always impressed by the super busy, super well-known people who get back to you reliably after three weeks. Systems. I don't always know where someone falls between "has no systems, relies on other people to message repeatedly" vs "has impeccable systems but due to volume of emails will take two weeks."
- The overall incentives are such that most people probably shouldn't generally reveal which they are.
- Sometimes the only way to get things done is to bug people. And I hate it. I hate nagging, but given other people's unreliability, it's either you bugging them or a good chance of not getting some important thing.
- A wise, well-respected, business-experienced rationalist told me many years ago that if you want something from someone you, you should just email them every day until they do it. It feels like this is the wisdom of the business world. Yet . . .
- Sometimes I sign up for a free trial of an enterprise product and, my god, if you give them your email after having expressed the tiniest interest, they will keep emailing you forever with escalatingly attention-grabby and entitled subject titles. (Like recruiters but much worse.) If I was being smart, I'd have a system which filters those emails, but I don't, and so they are annoying. I don't want to pattern match to that kind that of behavior.
- Sometimes I think I won't pattern match to that kind of spam because I'm different and my message is different, but then the rest of the LW team cautions me that such differences are in my mind but not necessarily the recipient tho whom I'm annoying.
- I suspect as a whole they lean too far in the direction of avoiding being assholes while at the risk of not getting things done while I'm biased in the reverse direction. I suspect this comes from my previous most recent work experience being in the "business world" where ruthless, selfish, asshole norms prevail. It may be I dial it back from that but still end up [LW · GW] seeming brazen to people with less immersion in that world; probably, overall, cultural priors and individual differences heavily shape how messaging behavior is interpreted.
So it's hard. I try to judge on a case by case basis, but I'm usually erring in one direction or another with a fear in one direction or the other.
A heuristic I heard in this space is to message repeatedly but with an exponential delay factor each time you don't get a response, e.g. message again after one week, if you don't get a reply, message again after another two weeks, then four weeks, etc. Eventually, you won't be bugging whoever it is.
Related:
- Discussion of whether paying people to be able to send them emails [LW · GW] or paying if they reply can solving the various bid-for-attention problems involved with emails.
comment by Ruby · 2019-05-15T17:59:25.601Z · LW(p) · GW(p)
For my own reference.
Brief timeline of notable events for LW2:
- 2017-09-20 LW2 Open Beta launched
- (2017-10-13 There is No Fire Alarm published)
- (2017-10-21 AlphaGo Zero Significance post published)
- 2017-10-28 Inadequate Equilibria first post published
- (2017-12-30 Goodhart Taxonomy Publish) <- maybe part of January spike?
- 2018-03-23 Official LW2 launch and switching of www.lesswrong.com to point to the new site.
In parentheses events are possible draws which spiked traffic at those times.
comment by Ruby · 2023-09-27T11:30:48.640Z · LW(p) · GW(p)
Huh, well that's something.
I'm curious, who else got this? And if yes, anyone click the link? Why/why not?
↑ comment by Richard_Kennaway · 2023-09-27T12:36:15.360Z · LW(p) · GW(p)
I got the poll and voted, but not the follow-up, only "You [sic] choice has been made. It cannot be unmade."
↑ comment by Max H (Maxc) · 2023-09-27T13:31:16.896Z · LW(p) · GW(p)
I got that exact message, and did click the link, about 1h after the timestamp of the message in my inbox.
Reasoning:
- The initial poll doesn't actually mention that the results would be used to decide the topic of next year's Petrov Day. I think all the virtues are important, but if you want to have a day specifically focusing on one, it might make more sense to have the day focused on the least voted virtue (or just not the most-voted one), since it is more likely to be neglected.
- I predict there was no outright majority (just a plurality) in the original poll. So most likely, the only thing the first clicker is deciding is going with the will of something like a 20% minority group instead of a 30% minority group.
- I predict that if you ran a ranked-choice poll that was explicitly on which virtue to make the next Petrov Day about, the plurality winner of the original poll would not win.
All of these reasons are independent of my actual initial choice, and seem like the kind of thing that an actual majority of the initial poll respondents might agree with me about. And it actually seems preferable (or at least not harmful) if one of the other minorities gets selected instead, i.e. my actual preference ordering for what next year's Petrov Day should be about is (my own choice) > (one of the other two minority options) > (whatever the original plurality selection was).
If lots of other people have a similar preference ordering, then it's better for most people if anyone clicks the link, and if you happen to be the first clicker, you get a bonus of having your own personal favorite choice selected.
(Another prediction, less confident than my first two: I was not the first clicker, but the first clicker was also someone who initially chose the "Avoiding actions..." virtue in the first poll.)
↑ comment by Dagon · 2023-09-27T17:33:41.456Z · LW(p) · GW(p)
I got both mails (with a different virtue). I clicked on it.
I think this is a meta-petrov, where everyone has the choice to make their preference (likely all in the minority, or stated as such even if not) the winner, or to defer to others. I predict that it will eventually be revealed that the outcome would be better if nobody clicked the second link. I defected, because pressing buttons is fun.
↑ comment by Matt Goldenberg (mr-hire) · 2023-09-27T14:22:59.395Z · LW(p) · GW(p)
I got both messages, didn't click the second.
↑ comment by frontier64 · 2023-09-27T15:46:56.838Z · LW(p) · GW(p)
I got it both messages. Only clicked on the first. I guess other admins besides you were working on this and didn't say anything to you?
comment by Ruby · 2021-02-09T07:38:17.594Z · LW(p) · GW(p)
When I have a problem, I have a bias towards predominantly Googling and reading. This is easy, comfortable, do it from laptop or phone. The thing I'm less inclined to do is ask other people – not because I think they won't have good answers, just because...talking to people.
I'm learning to correct for this. The think about other people is 1) sometimes they know more, 2) they can expose your mistaken assumptions.
The triggering example for this note is an appointment I had today with a hand and arm specialist for the unconventional RSI I've been experiencing the last 1.5 years. I have spent several dozen hours studying and reading into various possible diagnoses and treatments. I've seen a few doctors about it, all seeming uninformed.
This one thought it was Radial Tunnel Syndrome, a 1-in-10,000 nerve compression issue. I don't explicitly remember ruling out that specific diagnosis, but I had ruled out nerve conditions because I don't have any numbness or tingling. Turns out it can be a nerve issue even in the absence of those.
The cure might be as simple as taking Vitamin D (I know I should be because of Covid, and I bought some, but I've been bad about it).
This is why you talk to other people (and keep looking for those worth talking to).
I'm not sure how much reading and thinking on my own it would have taken to question that assumption and try this solution. A lot. Because we're talking about an uncommon condition, I'm unlikely to come across it reading generally about my symptoms and hypotheses.
I erred in the same direction when researching Miranda's cancer. Many doctors aren't very good when you take them out of their usual range of practice, but some are pretty good and their area of knowledge does coincide with your problem. I might suggest visiting even five specialists for significant problems.
I mean, I don't know if today's doctor was correct. He's plausibly correct which is better than I can say for most. He was worth talking to, even accounting the ~2 hour return trip from Emeryville to Stanford.
Talk to people. I expect this to generalize. I intend to do it for all my research projects, and maybe other projects too. You've got to talk to the people who expose your false assumptions and introduce you to your unknown unkowns.
↑ comment by ChristianKl · 2021-02-11T12:18:53.719Z · LW(p) · GW(p)
Without medical training one has a lot of unknown unknowns when researching issues oneself. Talking things through with a doctor can often help to get aware of medical knowledge that's relevant.
Replies from: Ruby↑ comment by Ruby · 2021-02-11T20:46:10.404Z · LW(p) · GW(p)
Yeha, it's easy to get discouraged though when initial doctors clearly know less than you and only know of the most common diagnoses which very much don't seem to apply. Hence my advice to keep looking for doctors who do know more.
Replies from: ChristianKl↑ comment by ChristianKl · 2021-02-11T22:54:36.142Z · LW(p) · GW(p)
My point was that even if you know more specific facts then the doctor you are talking to, he might still be able to tell you something useful.
When it comes to asking people to get knowledge total amount of knowledge isn't the only thing that matters. It matters a great deal that they have different knowledge then you.
Replies from: Ruby