[$20K in Prizes] AI Safety Arguments Competition
post by Dan H (dan-hendrycks), Kevin Liu (Pneumaticat), ozhang (oliver-zhang), TW123 (ThomasWoodside), Sidney Hough (Sidney) · 2022-04-26T16:13:16.351Z · LW · GW · 518 commentsContents
Objectives of the arguments Competition details Paragraphs One-liners Conditions of the prizes None 528 comments
TL;DR—We’re distributing $20k in total as prizes for submissions that make effective arguments for the importance of AI safety. The goal is to generate short-form content for outreach to policymakers, management at tech companies, and ML researchers. This competition will be followed by another competition in around a month that focuses on long-form content.
This competition is for short-form arguments for the importance of AI safety. For the competition for distillations of posts, papers, and research agendas, see the Distillation Contest [? · GW].
Objectives of the arguments
To mitigate AI risk, it’s essential that we convince relevant stakeholders sooner rather than later. To this end, we are initiating a pair of competitions to build effective arguments for a range of audiences. In particular, our audiences include policymakers, tech executives, and ML researchers.
- Policymakers may be unfamiliar with the latest advances in machine learning, and may not have the technical background necessary to understand some/most of the details. Instead, they may focus on societal implications of AI as well as which policies are useful.
- Tech executives are likely aware of the latest technology, but lack a mechanistic understanding. They may come from technical backgrounds and are likely highly educated. They will likely be reading with an eye towards how these arguments concretely affect which projects they fund and who they hire.
- Machine learning researchers can be assumed to have high familiarity with the state of the art in deep learning. They may have previously encountered talk of x-risk but were not compelled to act. They may want to know how the arguments could affect what they should be researching.
We’d like arguments to be written for at least one of the three audiences listed above. Some arguments could speak to multiple audiences, but we expect that trying to speak to all at once could be difficult. After the competition ends, we will test arguments with each audience and collect feedback. We’ll also compile top submissions into a public repository for the benefit of the x-risk community.
Note that we are not interested in arguments for very specific technical strategies towards safety. We are simply looking for sound arguments that AI risk is real and important.
Competition details
The present competition addresses shorter arguments (paragraphs and one-liners) with a total prize pool of $20K. The prizes will be split among, roughly, 20-40 winning submissions. Please feel free to make numerous submissions and try your hand at motivating various different risk factors; it's possible that an individual with multiple great submissions could win a good fraction of the prize. The prize distribution will be determined by effectiveness and epistemic soundness as judged by us. Arguments must not be misleading.
To submit an entry:
- Please leave a comment on this post (or submit a response to this form), including:
- The original source, if not original.
- If the entry contains factual claims, a source for the factual claims.
- The intended audience(s) (one or more of the audiences listed above).
- In addition, feel free to adapt another user’s comment by leaving a reply—prizes will be awarded based on the significance and novelty of the adaptation.
Note that if two entries are extremely similar, we will, by default, give credit to the entry which was posted earlier. Please do not submit multiple entries in one comment; if you want to submit multiple entries, make multiple comments.
The first competition will run until May 27th, 11:59 PT. In around a month, we’ll release a second competition for generating longer “AI risk executive summaries'' (more details to come). If you win an award, we will contact you via your forum account or email.
Paragraphs
We are soliciting argumentative paragraphs (of any length) that build intuitive and compelling explanations of AI existential risk.
- Paragraphs could cover various hazards and failure modes, such as weaponized AI, loss of autonomy and enfeeblement, objective misspecification, value lock-in, emergent goals, power-seeking AI, and so on.
- Paragraphs could make points about the philosophical or moral nature of x-risk.
- Paragraphs could be counterarguments to common misconceptions.
- Paragraphs could use analogies, imagery, or inductive examples.
- Paragraphs could contain quotes from intellectuals: “If we continue to accumulate only power and not wisdom, we will surely destroy ourselves” (Carl Sagan), etc.
For a collection of existing paragraphs that submissions should try to do better than, see here.
Paragraphs need not be wholly original. If a paragraph was written by or adapted from somebody else, you must cite the original source. We may provide a prize to the original author as well as the person who brought it to our attention.
One-liners
Effective one-liners are statements (25 words or fewer) that make memorable, “resounding” points about safety. Here are some (unrefined) examples just to give an idea:
- Vladimir Putin said that whoever leads in AI development will become “the ruler of the world.” (source for quote)
- Inventing machines that are smarter than us is playing with fire.
- Intelligence is power: we have total control of the fate of gorillas, not because we are stronger but because we are smarter. (based on Russell)
One-liners need not be full sentences; they might be evocative phrases or slogans. As with paragraphs, they can be arguments about the nature of x-risk or counterarguments to misconceptions. They do not need to be novel as long as you cite the original source.
Conditions of the prizes
If you accept a prize, you consent to the addition of your submission to the public domain. We expect that top paragraphs and one-liners will be collected into executive summaries in the future. After some experimentation with target audiences, the arguments will be used for various outreach projects.
(We thank the Future Fund regrant program and Yo Shavit and Mantas Mazeika for earlier discussions.)
In short, make a submission by leaving a comment with a paragraph or one-liner. Feel free to enter multiple submissions. In around a month we'll divide 20K to award the best submissions.
518 comments
Comments sorted by top scores.
comment by johnswentworth · 2022-04-26T17:55:00.800Z · LW(p) · GW(p)
I'd like to complain that this project sounds epistemically absolutely awful. It's offering money for arguments explicitly optimized to be convincing (rather than true), it offers money only for prizes making one particular side of the case (i.e. no money for arguments that AI risk is no big deal), and to top it off it's explicitly asking for one-liners.
I understand that it is plausibly worth doing regardless, but man, it feels so wrong having this on LessWrong.
Replies from: not-relevant, lc, conor-sullivan, Sidney, Davidmanheim↑ comment by Not Relevant (not-relevant) · 2022-04-26T20:02:46.000Z · LW(p) · GW(p)
If the world is literally ending, and political persuasion seems on the critical path to preventing that, and rationality-based political persuasion has thus far failed while the empirical track record of persuasion for its own sake is far superior, and most of the people most familiar with articulating AI risk arguments are on LW/AF, is it not the rational thing to do to post this here?
I understand wanting to uphold community norms, but this strikes me as in a separate category from “posts on the details of AI risk”. I don’t see why this can’t also be permitted.
Replies from: johnswentworth, tamgent↑ comment by johnswentworth · 2022-04-26T20:26:44.232Z · LW(p) · GW(p)
TBC, I'm not saying the contest shouldn't be posted here. When something with downsides is nonetheless worthwhile, complaining about it but then going ahead with it is often the right response - we want there to be enough mild stigma against this sort of thing that people don't do it lightly, but we still want people to do it if it's really clearly worthwhile. Thus my kvetching.
(In this case, I'm not sure it is worthwhile, compared to some not-too-much-harder alternative. Specifically, it's plausible to me that the framing of this contest could be changed to not have such terrible epistemics while still preserving the core value - i.e. make it about fast, memorable communication rather than persuasion. But I'm definitely not close to 100% sure that would capture most of the value.
Fortunately, the general policy of imposing a complaint-tax on really bad epistemics does not require me to accurately judge the overall value of the proposal.)
Replies from: not-relevant, Raemon↑ comment by Not Relevant (not-relevant) · 2022-04-26T20:45:49.104Z · LW(p) · GW(p)
I'm all for improving the details. Which part of the framing seems focused on persuasion vs. "fast, effective communication"? How would you formalize "fast, effective communication" in a gradeable sense? (Persuasion seems gradeable via "we used this argument on X people; how seriously they took AI risk increased from A to B on a 5-point scale".)
Replies from: liam-donovan-1↑ comment by Liam Donovan (liam-donovan-1) · 2022-04-27T04:28:27.705Z · LW(p) · GW(p)
Maybe you could measure how effectively people pass e.g. a multiple choice version of an Intellectual Turing Test (on how well they can emulate the viewpoint of people concerned by AI safety) after hearing the proposed explanations.
[Edit: To be explicit, this would help further John's goals (as I understand them) because it ideally tests whether the AI safety viewpoint is being communicated in such a way that people can understand and operate the underlying mental models. This is better than testing how persuasive the arguments are because it's a) more in line with general principles of epistemic virtue and b) is more likely to persuade people iff the specific mental models underlying AI safety concern are correct.
One potential issue would be people bouncing off the arguments early and never getting around to building their own mental models, so maybe you could test for succinct/high-level arguments that successfully persuade target audiences to take a deeper dive into the specifics? That seems like a much less concerning persuasion target to optimize, since the worst case is people being wrongly persuaded to "waste" time thinking about the same stuff the LW community has been spending a ton of time thinking about for the last ~20 years]
↑ comment by Raemon · 2022-04-26T22:17:22.099Z · LW(p) · GW(p)
This comment thread did convince me to put it on personal blog (previously we've frontpaged writing-contents and went ahead and unreflectively did it for this post)
Replies from: None↑ comment by [deleted] · 2022-04-26T22:35:43.088Z · LW(p) · GW(p)
I don't understand the logic here? Do you see it as bad for the contest to get more attention and submissions?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-04-26T22:56:03.803Z · LW(p) · GW(p)
No, it's just the standard frontpage policy [? · GW]:
Frontpage posts must meet the criteria of being broadly relevant to LessWrong’s main interests; timeless, i.e. not about recent events; and are attempts to explain not persuade.
Technically the contest is asking for attempts to persuade not explain, rather than itself attempting to persuade not explain, but the principle obviously applies.
As with my own comment, I don't think keeping the post off the frontpage is meant to be a judgement that the contest is net-negative in value; it may still be very net positive. It makes sense to have standard rules which create downsides for bad epistemics, and if some bad epistemics are worthwhile anyway, then people can pay the price of those downsides and move forward.
Replies from: Ruby↑ comment by Ruby · 2022-04-27T02:13:04.629Z · LW(p) · GW(p)
Raemon and I discussed whether it should be frontpage this morning. Prizes are kind of an edge case in my mind. They don't properly fulfill the frontpage criteria but also it feels like they deserve visibility in a way that posts on niche topics don't, so we've more than once made an exception for them.
I didn't think too hard about the epistemics of the post when I made the decision to frontpage, but after John pointed out the suss epistemics, I'm inclined to agree, and concurred with Raemon moving it back to Personal.
----
I think the prize could be improved simply by rewarding the best arguments in favor and against AI risk. This might actually be more convincing to the skeptics – we paid people to argue against this position and now you can see the best they came up with.
↑ comment by lc · 2022-05-20T22:12:24.609Z · LW(p) · GW(p)
We're out of time. This is what serious political activism involves.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-25T23:47:25.807Z · LW(p) · GW(p)
I don't see any lc comments, and I really wish I could see some here because I feel like they'd be good.
Let's go! Let's go! Crack open an old book and let the ideas flow! The deadline is, like, basically tomorrow.
Replies from: lc↑ comment by Lone Pine (conor-sullivan) · 2022-04-26T18:46:20.721Z · LW(p) · GW(p)
Most movements (and yes, this is a movement) have multiple groups of people, perhaps with degrees in subjects like communication, working full time coming up with slogans, making judgments about which terms to use for best persuasiveness, and selling the cause to the public. It is unusual for it to be done out in the open, yes. But this is what movements do when they have already decided what they believe and now have policy goals they know they want to achieve. It’s only natural.
Replies from: hath↑ comment by hath · 2022-04-26T19:00:48.026Z · LW(p) · GW(p)
You didn't refute his argument at all, you just said that other movements do the same thing. Isn't the entire point of rationality that we're meant to be truth-focused, and winning-focused, in ways that don't manipulate others? Are we not meant to hold ourselves to the standard of "Aim to explain, not persuade"? Just because others in the reference class of "movements" do something doesn't mean it's immediately something we should replicate! Is that not the obvious, immediate response? Your comment proves too much; it could be used to argue for literally any popular behavior of movements, including canceling/exiling dissidents.
Do I think that this specific contest is non-trivially harmful at the margin? Probably not. I am, however, worried about the general attitude behind some of this type of recruitment, and the justifications used to defend it. I become really fucking worried when someone raises an entirely valid objection, and is met with "It's only natural; most other movements do this".
Replies from: P.↑ comment by P. · 2022-04-26T19:26:39.357Z · LW(p) · GW(p)
To the extent that rationality has a purpose, I would argue that it is to do what it takes to achieve our goals, if that includes creating "propaganda", so be it. And the rules explicitly ask for submissions not to be deceiving, so if we use them to convince people it will be a pure epistemic gain.
Edit: If you are going to downvote this, at least argue why. I think that if this works like they expect, it truly is a net positive.
Replies from: hath↑ comment by hath · 2022-04-27T00:02:41.094Z · LW(p) · GW(p)
If you are going to downvote this, at least argue why.
Fair. Should've started with that.
To the extent that rationality has a purpose, I would argue that it is to do what it takes to achieve our goals,
I think there's a difference between "rationality is systematized winning" and "rationality is doing whatever it takes to achieve our goals". That difference requires more time to explain than I have right now.
if that includes creating "propaganda", so be it.
I think that if this works like they expect, it truly is a net positive.
I think that the whole AI alignment thing requires extraordinary measures, and I'm not sure what specifically that would take; I'm not saying we shouldn't do the contest. I doubt you and I have a substantial disagreement as to the severity of the problem or the effectiveness of the contest. My above comment was more "argument from 'everyone does this' doesn't work", not "this contest is bad and you are bad".
Also, I wouldn't call this contest propaganda. At the same time, if this contest was "convince EAs and LW users to have shorter timelines and higher chances of doom", it would be reacted to differently. There is a difference, convincing someone to have a shorter timeline isn't the same as trying to explain the whole AI alignment thing in the first place, but I worry that we could take that too far. I think that (most of) the responses John's comment got were good, and reassure me that the OPs are actually aware of/worried about John's concerns. I see no reason why this particular contest will be harmful, but I can imagine a future where we pivot to mainly strategies like this having some harmful second-order effects (which need their own post to explain).
↑ comment by Sidney Hough (Sidney) · 2022-04-26T20:52:33.151Z · LW(p) · GW(p)
Hey John, thank you for your feedback. As per the post, we’re not accepting misleading arguments. We’re looking for the subset of sound arguments that are also effective.
We’re happy to consider concrete suggestions which would help this competition reduce x-risk.
Replies from: jacobjacob↑ comment by Bird Concept (jacobjacob) · 2022-04-26T22:23:18.527Z · LW(p) · GW(p)
Thanks for being open to suggestions :) Here's one: you could award half the prize pool to compelling arguments against AI safety. That addresses one of John's points.
For example, stuff like "We need to focus on problems AI is already causing right now, like algorithmic fairness" would not win a prize, but "There's some chance we'll be better able to think about these issues much better in the future once we have more capable models that can aid our thinking, making effort right now less valuable" might.
Replies from: Chris_Leong, Sidney, thomas-kwa↑ comment by Chris_Leong · 2022-04-26T23:10:40.375Z · LW(p) · GW(p)
That idea seems reasonable at first glance, but upon reflection, I think it's a really bad idea. It's one thing to run a red-teaming competition, it's another to spend money building rhetorically optimised tools for the other side. If we do that, then maybe there was no point running the competition in the first place as it might all cancel out.
Replies from: Ruby↑ comment by Sidney Hough (Sidney) · 2022-04-26T23:07:31.916Z · LW(p) · GW(p)
Thanks for the idea, Jacob. Not speaking on behalf of the group here - but my first thought is that enforcing symmetry on discussion probably isn't a condition for good epistemics, especially since the distribution of this community's opinions is skewed. I think I'd be more worried if particular arguments that were misleading went unchallenged, but we'll be vetting submissions as they come in, and I'd also encourage anyone who has concerns with a given submission to talk with the author and/or us. My second thought is that we're planning a number of practical outreach projects that will make use of the arguments generated here - we're not trying to host an intra-community debate about the legitimacy of AI risk - so we'd ideally have the prize structure reflect the outreach value for which arguments are responsible.
I'm potentially up to opening the contest to arguments for or against AI risk, and allowing the distribution of responses to reflect the distribution of the opinions of the community. Will discuss with the rest of the group.
↑ comment by Thomas Kwa (thomas-kwa) · 2022-04-27T07:06:38.828Z · LW(p) · GW(p)
It seems better to award some fraction of the prize pool to refutations of the posted arguments. IMO the point isn't to be "fair to both sides", it's to produce truth.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2022-04-27T10:01:36.952Z · LW(p) · GW(p)
Wait, the goal here, at least, isn't to produce truth, it is to disseminate it. Counter-arguments are great, but this isn't about debating the question, it's about communicating a conclusion well.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-04-27T17:04:32.716Z · LW(p) · GW(p)
This is PR, not internal epistemics, if I’m understanding the situation correctly.
↑ comment by Davidmanheim · 2022-04-27T09:59:49.359Z · LW(p) · GW(p)
Think of it as a "practicing a dark art of rationality" post, and I'd think it would seem less off-putting.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-04-27T10:06:26.063Z · LW(p) · GW(p)
I think it would be less "off-putting" if we had common knowledge of it being such a post. I think the authors don't think of it as that from reading Sidney's comment.
comment by trevor (TrevorWiesinger) · 2022-04-26T20:11:04.054Z · LW(p) · GW(p)
It's unreasonable to look at AI and think "in order to make it more predictable, more controllable, we just have to make it smarter". When individual humans become smarter, they become much less predictable. And the human mind is built to predict the behavior of other humans.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-27T18:38:33.847Z · LW(p) · GW(p)
The last sentence can be cut off for simplicity, most of the point isin the first two sentences.
comment by Marius Hobbhahn (marius-hobbhahn) · 2022-04-26T18:03:31.042Z · LW(p) · GW(p)
Random side note: GPT-3 seems to be able to generate decent one liners.
Generate one-liners describing the dangers of AI. An example is "Inventing machines that are smarter than us is playing with fire."
1. Machines that are smarter than us could easily become our masters.
2. If we're not careful, AI could spell the end of humanity as we know it.
3. AI could be used to create weapons of mass destruction that could devastate the planet.
4. AI could be used to create powerful robots that could enslave humans.
5. AI could be used to create artificial intelligence that could turn against its creators
6. AI usher in a new era of cyber-warfare that could cripple society
7. AI could create self-replicating robots that could eventually consume all resources on Earth
8. AI could be used to create powerful AIs that could eventually surpass human intelligence and take over the world
9. AI technology could eventually be used to create a global surveillance state where everyone is constantly watched and monitored
Replies from: mitchell-reynolds, jcp29, TrevorWiesinger↑ comment by Mitchell Reynolds (mitchell-reynolds) · 2022-04-26T21:42:41.115Z · LW(p) · GW(p)
I had a similar thought to prompt GPT-3 for one liners or to summarize some article (if available). I think involving the community to write 500-1000 winning submissions would have the positive externality of non-winners to distill/condense their views. My exploratory idea is that this would be instrumentally useful when talking with those new to AI x-risk topics.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-04-27T17:06:08.256Z · LW(p) · GW(p)
We could also prompt GPT-3 with the results ;)
↑ comment by jcp29 · 2022-04-27T19:13:16.158Z · LW(p) · GW(p)
Good idea! I could imagine doing something similar with images generated by DALL-E.
Replies from: FinalFormal2↑ comment by FinalFormal2 · 2022-05-09T05:11:27.927Z · LW(p) · GW(p)
That's a very good idea, I think one limitation of most AI arguments is that they seem to lack urgency. GAI seems like it's a hundred years away at least, and showing the incredible progress we've already seen might help to negate some of that perception.
↑ comment by trevor (TrevorWiesinger) · 2022-04-27T20:47:36.719Z · LW(p) · GW(p)
1. Machines that are smarter than us could easily become our masters. [All it takes is a single glitch, and they will outsmart us the same way we outsmart animals.]
2. If we're not careful, AI could spell the end of humanity as we know it. [Artificial intelligence improves itself at an exponential pace, so if it speeds up there is no guarantee that it will slow down until it is too late.]
3. AI could be used to create weapons of mass destruction that could devastate the planet. x
4. AI could be used to create powerful robots that could enslave humans. x
5. AI could one day be used to create artificial intelligence [an even smarter AI system] that could turn against its creators [if it becomes capable of outmaneuvering humans and finding loopholes in order to pursue it's mission.]
6. AI usher in a new era of cyber-warfare that could cripple society x
7. AI could create self-replicating robots that could eventually consume all resources on Earth x
8. AI could [can one day] be used to create [newer, more powerful] AI [systems] that could eventually surpass human intelligence and take over the world [behave unpredictably].
9. AI technology could eventually be used to create a global surveillance state where everyone is constantly watched and monitored x
comment by lc · 2022-05-27T02:27:26.577Z · LW(p) · GW(p)
I remember watching a documentary made during the satanic panic by some activist Christian group. I found it very funny at the time, and then became intrigued when an expert came on to say something like:
"Look, you may not believe in any of this occult stuff; but there are people out there that do, and they're willing to do bad things because of their beliefs."
I was impressed with that line's simplicity and effectiveness. A lot of it's effectiveness stems silently from the fact that, inadvertently, it helps suspend disbelief about the negative impact of "satanic rituals" by starting the conversation with a reminder that there are people who take them very seriously.
It's invoking some very Dark Arts [LW · GW], but depending on the person you're talking to, I think the most effective rhetorical technique is to start by tapping into resentment toward Big Tech and the wealthy by saying:
"Look, you might not think AGI is going to hurt anybody, or that it will ever be developed. But DeepMind and OpenAI engineers are being paid millions of dollars a year to help develop it. And a worrying proportion of those engineers do that in spite of publicized expectations that AGI has a large chance of hurting you and me."
I have used this variation on the above theme several times in conversations with real humans. It's a biased sample, but it plus a followup conversation on the more concrete and factual risks has always worked to move them towards concern.
comment by FinalFormal2 · 2022-05-09T05:25:50.132Z · LW(p) · GW(p)
Any arguments for AI safety should be accompanied by images from DALL-E 2.
One of the key factors which makes AI safety such a low priority topic is a complete lack of urgency. Dangerous AI seems like a science fiction element, that's always a century away, and we can fight against this perception by demonstrating the potential and growth of AI capability.
No demonstration of AI capability has the same immediate visceral power as DALL-E 2.
In longer-form arguments, urgency could also be demonstrated through GPT-3's prompts, but DALL-E 2 is better, especially if you can also implicitly suggest a greater understanding of concepts by having DALL-E 2 represent something more abstract.
(Inspired by a comment from jcp29)
Replies from: FinalFormal2↑ comment by FinalFormal2 · 2022-05-09T05:30:08.222Z · LW(p) · GW(p)
Any image produced by DALL-E which could also convey or be used to convey misalignment or other risks from AI would be very useful because it could combine the desired messages: "the AI problem is urgent," and "misalignment is possible and dangerous."
For example, if DALL-E responded to the prompt: "AI living with humans" by creating an image suggesting a hierarchy of AI over humans, it would serve both messages.
However, this is only worthy of a side note, because creating such suggested misalignment organically might be very difficult.
Other image prompts might be: "The world as AI sees it," "the power of intelligence," "recursive self-improvement," "the danger of creating life," "god from the machine," etc.
Replies from: TrevorWiesinger, TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-19T09:25:18.218Z · LW(p) · GW(p)


both prompts are from here:
https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do#:~:text=DALL%2DE%20can't%20spell,written%20on%20a%20stop%20sign.)
↑ comment by trevor (TrevorWiesinger) · 2022-05-12T22:27:58.949Z · LW(p) · GW(p)
There's a lot of good DALL-E images floating around lesswrong that point towards alignment significance. We can use copy + paste into a lesswrong comment to post it.
comment by Shmi (shminux) · 2022-04-26T19:51:08.408Z · LW(p) · GW(p)
First two paragraphs of https://astralcodexten.substack.com/p/book-review-a-clinical-introduction seem to fit the bill.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-04-27T17:09:41.055Z · LW(p) · GW(p)
very slight modification of Scott’s words to produce a more self-contained paragraph:
A robot was trained to pick strawberries. The programmers rewarded it whenever it got a strawberry in its bucket. It started by flailing around, gradually shifted its behavior towards the reward signal, and ended up with a tendency to throw red things at light sources - in the training environment, strawberries were the only red thing, and the glint of the metal bucket was the brightest light source. Later, after training was done, it was deployed at night, and threw strawberries at a streetlight. Also, when someone with a big bulbous red nose walked by, it ripped his nose off and threw that at the streetlight too.
Suppose somebody tried connecting a language model to the AI. “You’re a strawberry picking robot,” they told it. “I’m a strawberry picking robot,” it repeated, because that was the sequence of words that earned it the most reward. Somewhere in its electronic innards, there was a series of neurons that corresponded to “I’m a strawberry-picking robot”, and if asked what it was, it would dutifully retrieve that sentence. But actually, it ripped off people’s noses and threw them at streetlights.
comment by Scott Emmons · 2022-04-26T17:53:01.170Z · LW(p) · GW(p)
The technology [of lethal autonomous drones], from the point of view of AI, is entirely feasible. When the Russian ambassador made the remark that these things are 20 or 30 years off in the future, I responded that, with three good grad students and possibly the help of a couple of my robotics colleagues, it will be a term project [six to eight weeks] to build a weapon that could come into the United Nations building and find the Russian ambassador and deliver a package to him.
-- Stuart Russell on a February 25, 2021 podcast with the Future of Life Institute.
comment by trevor (TrevorWiesinger) · 2022-05-04T05:27:04.510Z · LW(p) · GW(p)

Neither us humans, nor the flower, sees anything that looks like a bee. But when a bee looks at it, it sees another bee, and it is tricked into pollinating that flower. The flower did not know any of this, it's petals randomly changed shape over millions of years, and eventually one of those random shapes started tricking bees and outperforming all of the other flowers.
Today's AI already does this. If AI begins to approach human intelligence, there's no limit to the number of ways things can go horribly wrong.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-17T23:25:01.627Z · LW(p) · GW(p)
This is for ML researchers, I'd worry sigificantly about sending bizarre imagery to techxecutives or policymakers due to the absurdity heuristic being one of the most serious concerns.
Generally, nature and evolution are horrible.
comment by Stephen McAleese (stephen-mcaleese) · 2022-09-18T15:11:39.485Z · LW(p) · GW(p)
Here is the spreadsheet containing the results from the competition.
More quotes on AI safety here.
comment by FinalFormal2 · 2022-05-09T04:43:57.761Z · LW(p) · GW(p)
[Policy makers]
A couple of years ago there was an AI trained to beat Tetris. Artificial intelligences are very good at learning video games, so it didn't take long for it to master the game. Soon it was playing so quickly that the game was speeding up to the point it was impossible to win and blocks were slowly stacking up, but before it could be forced to place the last piece, it paused the game.
As long as the game didn't continue, it could never lose.
When we ask AI to do something, like play Tetris, we have a lot of assumptions about how it can or should approach that goal, but an AI doesn't have those assumptions. If it looks like it might not achieve its goal through regular means, it doesn't give up or ask a human for guidance, it pauses the game.
Replies from: FinalFormal2↑ comment by FinalFormal2 · 2022-05-09T04:51:58.885Z · LW(p) · GW(p)
I'm trying to find the balance between suggesting existential/catastrophic risk and screaming it or coming off too dramatic, any feedback would be welcome.
comment by Andy Jones (andyljones) · 2022-05-01T18:58:21.672Z · LW(p) · GW(p)
(a)
Look, we already have superhuman intelligences. We call them corporations and while they put out a lot of good stuff, we're not wild about the effects they have on the world. We tell corporations 'hey do what human shareholders want' and the monkey's paw curls and this is what we get.
Anyway yeah that but a thousand times faster, that's what I'm nervous about.
(b)
Look, we already have superhuman intelligences. We call them governments and while they put out a lot of good stuff, we're not wild about the effects they have on the world. We tell governments 'hey do what human voters want' and the monkey's paw curls and this is what we get.
Anyway yeah that but a thousand times faster, that's what I'm nervous about.
Replies from: FinalFormal2, TrevorWiesinger↑ comment by FinalFormal2 · 2022-05-09T05:02:35.217Z · LW(p) · GW(p)
I think this would benefit from being turned into a longer-form argument. Here's a quote you could use in the preface:
“Sure, cried the tenant men,but it’s our land…We were born on it, and we got killed on it, died on it. Even if it’s no good, it’s still ours….That’s what makes ownership, not a paper with numbers on it."
"We’re sorry. It’s not us. It’s the monster. The bank isn’t like a man."
"Yes, but the bank is only made of men."
"No, you’re wrong there—quite wrong there. The bank is something else than men. It happens that every man in a bank hates what the bank does, and yet the bank does it. The bank is something more than men, I tell you. It’s the monster. Men made it, but they can’t control it.”
― John Steinbeck, The Grapes of Wrath
↑ comment by trevor (TrevorWiesinger) · 2022-05-02T03:21:26.423Z · LW(p) · GW(p)
I had no idea that this angle existed or was feasible. I think these are best for ML researchers, since policymakers and techxecutives tend to think of institutions as flawed due to the vicious self-interest of the people who inhabit them (the problem is particularly acute in management). In which they might respond by saying that AI should not split into subroutines that compete with eachother, or something like that. One way or another, they'll see it as a human problem and not a machine problem.
"We only have two cases of generally intelligent systems: individual humans and organizations made of humans. When a very large and competent organization is sent to solve a task, such as a corporation, it will often do so by cutting corners in undetectable ways, even when total synergy is achieved and each individual agrees that it would be best not to cut corners. So not only do we know that individual humans feel inclined to cheat and cut corners, but we also know that large optimal groups will automatically cheat and cut corners. Undetectable cheating and misrepresentation is fundamental to learning processes in general, not just a base human instinct"
I'm not an ML researcher and haven't been acquainted with very many, so I don't know if this will work.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-02T03:22:05.424Z · LW(p) · GW(p)
"Undetectable cheating, and misrepresentation, is fundamental to learning processes in general; it's not just a base human instinct"
comment by Linda Linsefors · 2022-04-27T10:55:02.875Z · LW(p) · GW(p)
"Most AI reserch focus on building machines that do what we say. Aligment reserch is about building machines that do what we want."
Source: Me, probably heavely inspred by "Human Compatible" and that type of arguments. I used this argument in conversations to explain AI Alignment for a while, and I don't remember when I started. But the argument is very CIRL (cooperative inverse reinforcment learning).
I'm not sure if this works as a one liner explanation. But it does work as a conversation starter of why trying to speify goals directly is a bad idea. And how the things we care about often are hard to messure and therefore hard to instruct an AI to do. Insert referenc to King Midas, or talk about what can go wrong with a super inteligent Youtube algorithm that only optimises for clicks.
_____________________________
"Humans rule the earth becasue we are smart. Some day we'll build something smarter than us. When it hapens we better make sure it's on our side."
Source: Me
Inspiration: I don't know. I probably stole the structure of this agument from somwhere, but it was too long ago to remember.
By "our side" I mean on the side of humans. I don't mean it as an us vs them thing. But maybe it can be read that way. That would be bad. I've never run in to that missunderstanding though, but I also have not talked to politicians.
comment by Nanda Ale · 2022-05-28T06:48:11.371Z · LW(p) · GW(p)
Crypto Executives and Crypto Researchers
Question: If it becomes a problem, why can't you just shut it off? Why can't you just unplug it?
Response: Why can't you just shut off bitcoin? There isn't any single button to push, and many people prefer it not being shut off and will oppose you.
(Might resonate well with crypto folks.)
comment by trevor (TrevorWiesinger) · 2022-05-28T01:25:55.061Z · LW(p) · GW(p)
"Humanity has risen to a position where we control the rest of the world precisely because of our [unrivaled] mental abilities. If we pass this mantle to our machines, it will be they who are in this unique position."
Toby Ord, The Precipice
Replaced [unparalleled] with [unrivaled]
comment by romeostevensit · 2022-05-28T00:25:33.333Z · LW(p) · GW(p)
As recent experience has shown, exponential processes don't need to be smarter than us to utterly upend our way of life. They can go from a few problems here and there to swamping all other considerations in a span of time too fast to react to, if preparations aren't made and those knowledgeable don't have the leeway to act. We are in the early stages of an exponential increase in the power of AI algorithms over human life, and people who work directly on these problems are sounding the alarm right now. It is plausible that we will soon have processes that can escape the lab just as a virus can, and we as a species are pouring billions into gain-of-function research for these algorithms, with little concomitant funding or attention paid to the safety of such research.
comment by trevor (TrevorWiesinger) · 2022-05-27T19:53:18.569Z · LW(p) · GW(p)
For policymakers:
Expecting today's ML researchers to understand AGI is like expecting a local mechanic to understand how to design a more efficient engine. It's a lot better than total ignorance, but it's also clearly not enough.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:38:58.078Z · LW(p) · GW(p)
In 1903, The New York Times thought heavier-than-air flight would take 1-10 million years… less than 10 weeks before it happened. Is AI next? (source for NYT info) (Policymakers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-19T09:57:16.604Z · LW(p) · GW(p)
Yours are really good, please keep making entries. This contest is really, really important, even if there's a lot of people don't see it that way due to a lack of policy experience.
I've been looking at old papers (e.g. yudkowsky papers) but I feel like most of my entries (and most of the entries in general) are usually missing the magic "zing" that they're looking for. They're blowing a ton of money on getting good entries, and it's a really good investment, so don't leave them empty handed!
Replies from: NicholasKross, NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T22:56:37.459Z · LW(p) · GW(p)
Also, despite having researched this as a hobby for years, I'd still like all feedback possible on how to add zing to my short phrases and paragraphs.
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T19:38:50.623Z · LW(p) · GW(p)
Thanks! Am gonna post many more today.
comment by trevor (TrevorWiesinger) · 2022-05-04T05:14:46.415Z · LW(p) · GW(p)
If AI approaches and reaches human-level intelligence, it will probably pass that level just as quickly as it arrived at that level.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2022-05-01T15:11:42.559Z · LW(p) · GW(p)
What about graphics? e.g. https://twitter.com/DavidSKrueger/status/1520782213175992320
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-02T03:04:41.266Z · LW(p) · GW(p)
(On Lesswrong, you can use ctrl + K to turn highlighted text into a link. You can also paste images directly into a post or comment with ctrl + V)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-02T04:04:07.890Z · LW(p) · GW(p)

https://twitter.com/DavidSKrueger/status/1520782213175992320
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-04T05:03:40.690Z · LW(p) · GW(p)
100% of credit here goes to capybaralet for an excellent submission, they simply didn't know they could paste an image into a Lesswrong comment. I did not do any refining here.
This is a very good submission, one of the best in my opinion, it's obviously more original than most of my own submissions, and we should all look up to it as a standard of quality. I can easily see this image making a solid point in the minds of ML researchers, tech executives, and even policymakers.
comment by trevor (TrevorWiesinger) · 2022-04-27T21:30:58.429Z · LW(p) · GW(p)
"AI will probably surpass human intelligence at the same pace that it reaches human intelligence. Considering the pace of AI advancement over the last 3 years, that pace will probably be very fast"




https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T22:34:13.556Z · LW(p) · GW(p)
I tried to shrink the first image but it still displays it at the obnoxiously large full size
comment by [deleted] · 2022-04-27T19:24:21.962Z · LW(p) · GW(p)
“The smartest ones are the most criminally capable.” [·]
Replies from: sue-hyer-essek, TrevorWiesinger↑ comment by SueE (sue-hyer-essek) · 2022-06-02T04:57:04.755Z · LW(p) · GW(p)
Agree but the lobbyist & policy makers whom are concentrated in Senate & committees by design bank on lpeople have both stupid << more than misunderstanding-
↑ comment by trevor (TrevorWiesinger) · 2022-05-21T01:51:22.399Z · LW(p) · GW(p)
comment by trevor (TrevorWiesinger) · 2022-04-26T20:00:11.910Z · LW(p) · GW(p)
"AI cheats. We've seen hundreds of unique instances of this. It finds loopholes and exploits them, just like us, only faster. The scary thing is that, every year now, AI becomes more aware of its surroundings, behaving less like a computer program and more like a human that thinks but does not feel"
comment by Gyrodiot · 2022-05-27T22:43:44.894Z · LW(p) · GW(p)
(Policymakers) There is outrage right now about AI systems amplifying discrimination and polarizing discourse. Consider that this was discovered after they were widely deployed. We still don't know how to make them fair. This isn't even much of a priority.
Those are the visible, current failures. Given current trajectories and lack of foresight of AI research, more severe failures will happen in more critical situations, without us knowing how to prevent them. With better priorities, this need not happen.
Replies from: sue-hyer-essek↑ comment by SueE (sue-hyer-essek) · 2022-06-02T04:42:28.171Z · LW(p) · GW(p)
Yes!! I wrote more but then poof gone.
Every time I attempt to post anything it vanishes. I'm new to this site & learning the ins & outs- my apologies. Will try again tomorrow.
~ SueE
comment by Arran McCutcheon · 2022-05-27T22:24:10.973Z · LW(p) · GW(p)
On average, experts estimate a 10-20% (?) probability of human extinction due to unaligned AGI this century, making AI Safety not simply the most important issue for future generations, but for present generations as well. (policymakers)
comment by Peter Berggren (peter-berggren) · 2022-05-27T18:57:13.757Z · LW(p) · GW(p)
Clarke’s First Law goes: When a distinguished but elderly scientist states that something is possible, he is almost certainly right. When he states that something is impossible, he is very probably wrong.
Stuart Russell is only 60. But what he lacks in age, he makes up in distinction: he’s a computer science professor at Berkeley, neurosurgery professor at UCSF, DARPA advisor, and author of the leading textbook on AI. His book Human Compatible states that superintelligent AI is possible; Clarke would recommend we listen.
(tech executives, ML researchers)
(adapted slightly from the first paragraphs of the Slate Star Codex review of Human Compatible)
↑ comment by trevor (TrevorWiesinger) · 2022-05-27T23:32:00.799Z · LW(p) · GW(p)
"There's been centuries of precedent of scientists incorrectly claiming that something is impossible for humans to invent"
"right before the instant something is invented successfully, 100% of the evidence leading up to that point will be evidence of failed efforts to invent it. Everyone involved will only have memories of people failing to invent it. Because it hasn't been invented yet"
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T00:49:20.596Z · LW(p) · GW(p)
All humans, even people labelled "stupid", are smarter than apes. Both apes and humans are far smarter than ants. The intelligence spectrum could extend much higher, e.g. up to a smart AI… (Adapted from here [LW · GW]). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T23:52:52.172Z · LW(p) · GW(p)
The smarter AI gets, the further it strays from our intuitions of how it should act. (Tech executives)
comment by trevor (TrevorWiesinger) · 2022-05-24T01:30:07.442Z · LW(p) · GW(p)
The existence of the human race has been defined by our absolute monopoly on intelligent thought. That monopoly is no longer absolute, and we are on track for it to vanish entirely.
comment by ukc10014 · 2022-05-08T12:14:26.175Z · LW(p) · GW(p)
Here's my submission, it might work better as bullet points on a page.
AI will transform human societies over the next 10-20 years. Its impact will be comparable to electricity or nuclear weapons. As electricity did, AI could improve the world dramatically; or, like nuclear weapons, it could end it forever. Like inequality, climate change, nuclear weapons, or engineered pandemics, AI Existential Risk is a wicked problem. It calls upon every policymaker to become a statesperson: to rise above the short-term, narrow interests of party, class, or nation, to actually make a contribution to humankind as a whole. Why? Here are 10 reasons.
(1) Current AI problems, like racial and gender bias, are like canaries in a coal-mine. They portend even worse future failures.
(2) Scientists do not understand how current AI actually works: for instance, engineers know why bridges collapse, or why Chernobyl failed. There is no similar understanding of why AI models misbehave.
(3) Future AI will be dramatically more powerful than today’s. In the last decade, the pace of development has exploded, with current AI performing at super-human level on games (like chess or Go). Massive language models (like GPT-3) can write really good college essays while deepfakes of politicians are already a thing.
(4) These very powerful AIs might develop their own goals, which is a problem if they are connected to electrical grids, hospitals, social media networks, or nuclear weapons systems.
(5) The competitive dynamics are dangerous: the US-China strategic rivalry implies neither side has an incentive to go slowly or be careful. Domestically, tech companies are in an intense race to develop & deploy AI across all aspects of the economy.
(6) The current US lead in AI might be unsustainable. As an analogy, think of nuclear weapons: in the 1940s, the US hoped it would keep its atomic monopoly. Since then, we have 9 nuclear powers today, with 12,705 weapons.
(7) Accidents happen: again, from the nuclear case, there have been over 100 accidents and proliferation incidents involving nuclear power/weapons.
(8) AI could proliferate virally across globally connected networks, making it more dangerous than nuclear weapons (which are visible, trackable, and less useful than powerful AI).
(9) Even today’s moderately-capable AIs, if used effectively, can entrench totalitarianism, manipulate democratic societies or enable repressive security states.
(10) There will be a point of no return after which we may not be able to recover as a species. So what is to be done? Negotiations to reach a global, temporary moratorium on certain types of AI research. Enforce this moratorium through intrusive domestic regulation and international surveillance. Lastly, avoiding historical policy errors, such as in climate change and in the terrorist threat post-9/11: politicians must ensure that the military-industrial complex does not ‘weaponise’ AI.
Replies from: TrevorWiesinger, FinalFormal2↑ comment by trevor (TrevorWiesinger) · 2022-05-12T22:30:35.927Z · LW(p) · GW(p)
There's a lot of points here that I disagree intensely with. But regardless of that, your "canary in a coal mine" line is fantastic, we need more really-good one-liners here.
Replies from: ukc10014↑ comment by FinalFormal2 · 2022-05-09T05:08:08.132Z · LW(p) · GW(p)
The way you have it formatted right now makes it very difficult to read.
Try accessing the formatting functions in-platform by highlighting the text you want to make into bullet points.
comment by joseph_c (cooljoseph1) · 2022-04-28T05:56:03.337Z · LW(p) · GW(p)
(To Policymakers and Machine Learning Researchers)
Building a nuclear weapon is hard. Even if one manages to steal the government's top secret plans, one still need to find a way to get uranium out of the ground, find a way to enrich it, and attach it to a missile. On the other hand, building an AI is easy. With scientific papers and open source tools, researchers are doing their utmost to disseminate their work.
It's pretty hard to hide a uranium mine. Downloading TensorFlow takes one line of code. As AI becomes more powerful and more dangerous, greater efforts need to be taken to ensure malicious actors don't blow up the world.
comment by sithlord · 2022-04-26T19:37:21.299Z · LW(p) · GW(p)
To Policymakers: "Just think of the way in which we humans have acted towards animals, and how animals act towards lesser animals, now think of how a powerful AI with superior intellect might act towards us, unless we create them in such a way that they will treat us well, and even help us."
Source: Me
comment by Peter Berggren (peter-berggren) · 2022-07-22T19:46:44.802Z · LW(p) · GW(p)
Have any prizes been awarded yet? I haven't heard anything about prizes, but that could have just been that I didn't win one...
comment by Nanda Ale · 2022-05-28T06:37:55.462Z · LW(p) · GW(p)
Target: Everyone. Another good zinger.
just sitting here laughing at how people's complaints about different AI models have shifted in under 3 years
"it's not quite human quality writing"
"okay but it can't handle context or reason"
"yeah but it didn't know Leonardo would hold PIZZA more often than a katana"
Source: https://nitter.nl/liminal_warmth/status/1511536700127731713#m
comment by Peter Berggren (peter-berggren) · 2022-05-28T02:00:50.122Z · LW(p) · GW(p)
You wouldn't hire an employee without references. Why would you make an AI that doesn't share your values?
(policymakers, tech executives)
↑ comment by Nanda Ale · 2022-05-28T07:36:01.330Z · LW(p) · GW(p)
Reframed even more generally for parents:
"You wouldn’t leave your child with a stranger. With AI, we’re about to leave the world’s children with the strangest mind humans have ever encountered."
(I know the deadline passed. But I finally have time to read other people's entries and couldn't resist.)
comment by trevor (TrevorWiesinger) · 2022-05-27T23:21:51.062Z · LW(p) · GW(p)
For policymakers:
The predictability of today's AI systems doesn't tell us squat about whether they will remain predictable after achieving human-level intelligence. Individual apes are far more predictable than individual humans, and apes themselves are far less predictable than ants.
comment by Peter Berggren (peter-berggren) · 2022-05-27T16:12:02.636Z · LW(p) · GW(p)
Climate change was weird in the 1980s. Pandemics were weird in the 2010s. Every world problem is weird... until it happens.
(policymakers)
comment by DirectedEvolution (AllAmericanBreakfast) · 2022-05-27T05:32:37.488Z · LW(p) · GW(p)
When nuclear weapons were first made, there was a serious concern that the first nuclear test would trigger a chain reaction and ignite the entire plant’s atmosphere. AI has an analogous issue. It used a technology called machine learning, that allows AI to figure out the solutions for problems on its own. The problem is that we don’t know whether this technology, or something similar, might cause the AI to start “thinking for itself.” There are a significant number of software engineers who think this might have disastrous consequences, but it’s a risk to the public, while machine learning research mostly creates private gains. Government should create a task force to take this possibility seriously, so researchers can coordinate to better understand and mitigate that risk.
Replies from: Nanda Ale↑ comment by Nanda Ale · 2022-05-27T13:21:41.000Z · LW(p) · GW(p)
During the Manhattan project, scientists were concerned that the first nuclear weapon would trigger a chain reaction and ignite the planet's atmosphere. But after the first test was completed this was no longer a concern. The remaining concern was what humans will choose to do with such weapons, instead of unexpected consequences.
But with AI, that risk never goes away. Each successful test is followed by bigger and more ambitious tests, each with the possibility of a horrific chain reaction beyond our control. And unlike the Manhattan project, there is no consensus that the atmosphere will not ignite.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T01:56:20.253Z · LW(p) · GW(p)
Imagine it's 1932, but with one major difference: uranium is cheap enough that anyone can get some. Radioactive materials are unregulated. The world's largest companies are competing to build nuclear power plants. Nuclear weapons have not yet been discovered. Would you think nuclear arms control is premature? Or would you want to get started now to prevent a catastrophe?
This is the same situation the real world is in, with machine learning and artificial intelligence. The world's biggest tech companies are gathering GPUs and working to build AI that is smarter than humans about everything. And right now, there's not much coordination being done to make this go well. (Policymakers)
comment by Quintin Pope (quintin-pope) · 2022-05-27T01:42:28.359Z · LW(p) · GW(p)
“Thousands of researchers at the worlds richest corporations are all working to make AI more powerful. Who is working to make AI more moral?”
(For policymakers and activists skeptical of big tech)
comment by trevor (TrevorWiesinger) · 2022-05-27T01:06:21.879Z · LW(p) · GW(p)
If an AI is cranked up to the point that it becomes smarter than humans, it will not behave predictably. We humans are not predictable. Even chimpanzees and dolphins are unpredictable. Smart things are not predictable. Intelligence, itself, does not tend to result in predictability.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T01:25:53.182Z · LW(p) · GW(p)
This one's very good for policymakers, I think. Anything that makes them sound smart to their friends or family is more likely to stick in their heads. Even as conversation starters. Especially if it has to do with evolution, they might hire a biologist consultant and have them read the report on AGI risk, and it will basically always blow the mind of those consultants.
comment by trevor (TrevorWiesinger) · 2022-05-26T23:58:56.906Z · LW(p) · GW(p)
"When I visualize [a scenario where a highly intelligent AI compromises all human controllers], I think it [probably] involves an AGI system which has the ability to be cranked up by adding more computing resources to it [to increase its intelligence and creativity incrementally]; and I think there is an extended period where the system is not aligned enough that you can crank it up that far, without [any dangerously erratic behavior from the system]"
Eliezer Yudkowsky [LW · GW]
comment by trevor (TrevorWiesinger) · 2022-05-25T22:57:43.817Z · LW(p) · GW(p)
"Guns were developed centuries before bulletproof vests"
"Smallpox was used as a tool of war before the development of smallpox vaccines"
EY, AI as a pos neg factor, 2006ish
comment by Adam Jermyn (adam-jermyn) · 2022-05-22T20:09:54.770Z · LW(p) · GW(p)
Targeting policymakers:
Regulating an industry requires understanding it. This is why complex financial instruments are so hard to regulate. Superhuman AI could have plans far beyond our ability to understand and so could be impossible to regulate.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T23:39:10.074Z · LW(p) · GW(p)
The implicit goal, the thing you want, is to get good at the game; the explicit goal, the thing the AI was programmed to want, is to rack up points by any means necessary. (Machine learning researchers)
comment by jcp29 · 2022-05-12T13:12:18.042Z · LW(p) · GW(p)
[Policy makers & ML researchers]
"There isn’t any spark of compassion that automatically imbues computers with respect for other sentients once they cross a certain capability threshold. If you want compassion, you have to program it in" (Nate Soares). Given that we can't agree on whether a straw has two holes or one...We should probably start thinking about how program compassion into a computer.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-12T22:18:59.047Z · LW(p) · GW(p)
MIRI peope quotes are great, they aren't easy to find like EY's one ultra-famous paper from 2006, please add more MIRI people quotes (I probably will too).
Don't give up, keep commenting, this contest has been cut off from most people's visibility so it needs all the attention and entries it can get.
Replies from: jcp29comment by trevor (TrevorWiesinger) · 2022-05-02T14:51:23.650Z · LW(p) · GW(p)
It is a fundamental law of thought that thinking things will cut corners, misinterpret instructions, and cheat.
comment by trevor (TrevorWiesinger) · 2022-04-28T07:01:41.636Z · LW(p) · GW(p)
"Past technological revolutions usually did not telegraph themselves to people alive at the time, whatever was said afterward in hindsight"
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-27T23:12:40.224Z · LW(p) · GW(p)
"Imagine that Facebook and Netflix have two separate AIs that compete over hours that each user spends on their own platform. They want users to spend the maximum amount of minutes on Facebook or Netflix, respectively.
The Facebook AI discovers that posts that spoil popular TV shows result in people spending more time on the platform. It doesn't know what spoilers are, only that they cause people to spend more time on Facebook. But in reality, they're ruining the entertainment value from excellent shows on Netflix.
Even worse, the Netflix AI discovers that people stop watching shows with plot twists, so it promotes more boring shows with no plot twists. They end up on the front page and make the most profit due to exposure.
The problem gets discovered and fixed three years later, but by that time it's too late; Facebook has a reputation for ruining TV shows and many people consciously avoid using it, and meanwhile Netflix has spent 3 years punishing producers and scriptwriters for filming excellent stories with plot twists. Neither company wants this. It takes 3 years for human engineers to discover and fix it, and the whole time, many more misguided AI decisions have popped up.
The supervision required for AI is immense, for the simplest tasks and the simplest systems. AI just keeps finding new ways to cheat"
comment by jcp29 · 2022-04-27T19:07:00.782Z · LW(p) · GW(p)
[Policymakers & ML researchers]
A virus doesn't need to explain itself before it destroys us. Neither does AI.
A meteor doesn't need to warn us before it destroys us. Neither does AI.
An atomic bomb doesn't need to understand us in order to destroy us. Neither does AI.
A supervolcano doesn't need to think like us in order to destroy us. Neither does AI.
(I could imagine a series riffing based on this structure / theme)
comment by jcp29 · 2022-04-27T17:59:27.853Z · LW(p) · GW(p)
[ML researchers]
Given that we can't agree on whether a hotdog is a sandwich or not...We should probably start thinking about how to tell a computer what is right and wrong.
[Insert call to action on support / funding for AI governance / regulation etc.]
-
Given that we can't agree on whether a straw has two holes or one...We should probably start thinking about how to explain good and evil to a computer.
[Insert call to action on support / funding for AI governance / regulation etc.]
(I could imagine a series riffing based on this structure / theme)
comment by Yitz (yitz) · 2022-04-27T17:17:33.772Z · LW(p) · GW(p)
I will post my submissions as individual replies to this comment. Please let me know if there’s any issues with that.
Replies from: yitz, yitz, yitz, yitz↑ comment by Yitz (yitz) · 2022-04-27T17:29:27.651Z · LW(p) · GW(p)
Imagine that you are an evil genius who wants to kill over a billion people. Can you think of a plausible way you might succeed? I certainly can. Now imagine a very large company that wants to maximize profits. We all know from experience that large companies are going to take unethical measures in order to maximize their goals. Finally, imagine an AI with the intelligence of Einstein, but trying to maximize for a goal alien to us, and which doesn’t care for human well-being at all, even less than a large corporation cares about its employees. Do you see why experts are afraid?
↑ comment by Yitz (yitz) · 2022-05-02T06:50:55.075Z · LW(p) · GW(p)
A member of an intelligent social species might also have motivations related to cooperation and competition: like us, it might show in-group loyalty, a resentment of free-riders, perhaps even a concern with reputation and appearance. By contrast, an artificial mind need not care intrinsically about any of those things, not even to the slightest degree.
↑ comment by Yitz (yitz) · 2022-04-29T21:50:14.701Z · LW(p) · GW(p)
If most large companies tend to be unethical, then what are the chances a non-human AI will be more ethical?
↑ comment by Yitz (yitz) · 2022-04-29T21:47:55.997Z · LW(p) · GW(p)
According to [insert relevant poll here] most researchers believe that we will create a human-level AI within this century.
comment by Davidmanheim · 2022-04-27T10:04:28.987Z · LW(p) · GW(p)
Question: "effective arguments for the importance of AI safety" - is this about arguments for the importance of just technical AI safety, or more general AI safety, to include governance and similar things?
comment by Lone Pine (conor-sullivan) · 2022-04-26T18:58:58.175Z · LW(p) · GW(p)
“Aligning AI is the last job we need to do. Let’s make sure we do it right.”
(I’m not sure which target audience my submissions are best targeted towards. I’m hoping that the judges can make that call for me.)
comment by Mati_Roy (MathieuRoy) · 2022-09-17T20:42:55.665Z · LW(p) · GW(p)
I recently talked with the minister of innovation in Yucatan, and ze's looking to have competitions in the domain of artificial intelligence in a large conference on innovation they're organizing in Yucatan, Mexico that will happen in mid-November. Do you think there's the potential for a partnership?
comment by michael_mjd · 2022-05-28T06:57:26.783Z · LW(p) · GW(p)
AI existential risk is like climate change. It's easy to come up with short slogans that make it seem ridiculous. Yet, when you dig deeper into each counterargument, you find none of them are very convincing, and the dangers are quite substantial. There's quite a lot of historical evidence for the risk, especially in the impact humans have had on the rest of the world. I strongly encourage further, open-minded study.
Replies from: michael_mjd↑ comment by michael_mjd · 2022-05-28T06:57:49.657Z · LW(p) · GW(p)
For ML researchers.
comment by Nanda Ale · 2022-05-28T06:56:40.661Z · LW(p) · GW(p)
Policymakers
For the first time in human history, philosophical questions of good and bad have a real deadline.
This is a an extremely common, perhaps even overused, catchphrase for AI risk. But I still want to make sure it’s represented because I personally find it striking.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:56:14.711Z · LW(p) · GW(p)
Leading up to the first nuclear weapons test, the Trinity event in July 1945, multiple physicists in the Manhattan Project thought the single explosion would destroy the world. Edward Teller, Arthur Compton, and J. Robert Oppenheimer all had concerns that the nuclear chain reaction could ignite Earth's atmosphere in an instant. Yet, despite disagreement and uncertainty over their calculations, they detonated the device anyway. If the world's experts in a field can be uncertain about causing human extinction with their work, and still continue doing it, what safeguards are we missing for today's emerging technologies? Could we be sleepwalking into catastrophe with bioengineering, or perhaps artificial intelligence? (Based on info from here). (Policymakers)
comment by Nanda Ale · 2022-05-28T06:35:19.910Z · LW(p) · GW(p)
Target: Everyone? Just really snappy.
I'm old enough to remember when protein folding, text-based image generation, StarCraft play, 3+ player poker, and Winograd schemas were considered very difficult challenges for AI. I'm 3 years old.
Source: https://nitter.nl/Miles_Brundage/status/1490512439154151426#m
comment by Nanda Ale · 2022-05-28T06:26:44.805Z · LW(p) · GW(p)
Machine learning researchers
Common Deep Learning Critique “It’s just memorization”
Critique:
Let’s say there is some intelligent behavior that emerges from these huge models. These researchers have given up on the idea that we should understand intelligence. They’re just playing the memorization game. They’re using their petabytes and petabytes of data to make these every bigger models, and they’re just memorizing everything with brute force. This strategy can not scale. They will run out of space before anything more interesting happens.
Connor Leahy response:
What you just described is what I believed one year ago. I believed bigger models just memorized more.
But when I sat down and read the paper for GPT-3 I almost fell out of my chair. GPT-3 did not complete a full epoch on its data. It only saw most of its data once.
But even so, it had a wide knowledge of topics it could not have seen more than once. This implies it is capable of learning complete concepts in a single update step. Everyone says deep learning can’t do this. But GPT-3 seems to have learned some kind of meta-learning algorithm to allow it to rapidly learn new concepts it only sees one time.
Human babies need to hear a new word many times to learn it, perhaps over weeks. Human adults, on the other hand, can immediately understand a new word the first time it is introduced. GPT-3 has learned this without any change in architecture.
Paraphrased from this podcast segment: https://www.youtube.com/watch?v=HrV19SjKUss&t=5460s
comment by Nanda Ale · 2022-05-28T06:17:20.161Z · LW(p) · GW(p)
Policymakers
These researchers built an AI for discovering less toxic drug compounds. Then they retrained it to do the opposite. Within six hours it generated 40,000 toxic molecules, including VX nerve agent and "many other known chemical warfare agents."
Source: https://nitter.nl/WriteArthur/status/1503393942016086025#m
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:41:26.550Z · LW(p) · GW(p)
Imagine a piece of AI software was invented, capable of doing any intellectual task a human can, at a normal human level. Should we be concerned about this? Yes, because this artificial mind would be more powerful (and dangerous) than any human mind. It can think anything a normal human can, but faster, more precisely, and without needing to be fed. In addition, it could be copied onto a million computers with ease. An army of thinkers, available at the press of a button. (Adapted from here). (Policymakers)
comment by trevor (TrevorWiesinger) · 2022-05-27T23:42:57.460Z · LW(p) · GW(p)
Policymakers and techxecutives:
If we build an AI that's smarter than a human, then it will be smarter than a human, so it won't have a hard time convincing us that it's on our side. This is why we have to build it perfectly, before it's built, not after.
comment by theme_arrow · 2022-05-27T21:43:08.677Z · LW(p) · GW(p)
AI has a history of surprising us with its capabilities. Throughout the last 50 years, AI and machine learning systems have kept gaining skills that were once thought to be uniquely human, such as playing chess, classifying images, telling stories, and making art. Already, we see the risks associated with these kinds of AI capabilities. We worry about bias in algorithms that guide sentencing decisions or polarization induced by algorithms that curate our social media feeds. But we have every reason to believe that trends in AI progress will continue. AI will likely move from classifying satellite imagery to actually deciding whether to order a drone strike, or from helping AI researchers conduct literature reviews to actually executing AI research. As these AI systems continue to grow more capable, our ability to understand and control them will tend to weaken, with potentially disastrous consequences. it is therefore critical that we build the technological foundation to ensure these systems share our values and the policy and regulatory foundation to ensure these systems are used for good.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T23:26:38.133Z · LW(p) · GW(p)
the first sentence counts as a one-liner
comment by IrenicTruth · 2022-05-27T13:25:38.372Z · LW(p) · GW(p)
For lefties:
- We put unaligned AIs in charge of choosing what news people see. Result: polarization resulting in millions of deaths. Let's not make the same mistake again.
For right-wingers:
- We put unaligned AIs in charge of choosing what news people see. Result: people addicted to their phones, oblivious to their families, morals, and eroding freedoms. Let's not make the same mistake again.
comment by Nanda Ale · 2022-05-27T12:11:46.858Z · LW(p) · GW(p)
Policymakers
Look, we know how we sound waving our hands warning about this AI stuff. But here’s the thing, in this space, things that sounded crazy yesterday can become very real overnight. (Link DALL-E 2 or Imagen samples). Honestly ask yourself: would you have believed a computer could do that before seeing these examples? And if you were surprised by this, how many more surprises won’t you see coming? We’re asking you to expect to be surprised, and to get ready.
comment by AprilSR · 2022-05-27T00:47:22.721Z · LW(p) · GW(p)
Humans are pretty clever, but AI will be eventually be even more clever. If you give a powerful enough AI a task, it can direct a level of ingenuity towards it far greater than history’s smartest scientists and inventors. But there are many cases of people accidentally giving an AI imperfect instructions.
If things go poorly, such an AI might notice that taking over the world would give it access to lots of resources helpful for accomplishing its task. If this ever happens, even once, with an AI smart enough to escape any precautions we set and succeed at taking over the world, then there will be nothing humanity can do to fix things.
comment by jimv · 2022-05-27T00:00:27.038Z · LW(p) · GW(p)
The first moderately smart AI anyone develops might quickly become the last time that that people are the smartest things around. We know that people can write computer programs. Once we make an AI computer program that is a bit smarter than people, it should be able to write computer programs too, including re-writing its own software to make itself even smarter. This could happen repeatedly, with the program getting smarter and smarter. If an AI quickly re-programs itself from moderately-smart to super-smart, we could soon find that it is as disinterested in the wellbeing of people as people are of mice.
comment by Zack_M_Davis · 2022-05-26T23:05:02.088Z · LW(p) · GW(p)
(For non-x-risk-focused transhumanists, some of whom may be tech execs or ML researchers.)
Some people treat the possibility of human extinction with a philosophical detachment: who are we to obstruct the destiny of the evolution of intelligent life? If the "natural" course of events for a biological species like ours is to be transcended by our artificial "mind children", shouldn't we be happy for them?
I actually do have some sympathy for this view, in the sense that the history where we build AI that kills us is plausibly better than the history where the Industrial Revolution never happens at all. Still—if you had the choice between a superintelligence that kills you and everyone you know, and one that grants all your hopes and dreams for a happy billion-year lifespan, isn't it worth some effort trying to figure out how to get the latter?
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T22:28:46.832Z · LW(p) · GW(p)
"Through the past 4 billion years of life on earth, the evolutionary process has emerged to have one goal: create more life. In the process, it made us intelligent. In the past 50 years, as humanity gotten exponentially more economically capable we've seen human birth rates fall dramatically. Why should we expect that when we create something smarter than us, it will retain our goals any better than we have retained evolution's?" (Policymaker)
comment by Nina Panickssery (NinaR) · 2022-05-26T17:18:21.645Z · LW(p) · GW(p)
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. - Stuart Russell
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:26:21.559Z · LW(p) · GW(p)
With enough effort, could humanity have prevented nuclear proliferation? (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:17:49.404Z · LW(p) · GW(p)
Progress moves faster than we think; who in the past would've thought that the world economy would double in size, multiple times in a single person's lifespan? (Adapted from here). (Policymakers)
comment by trevor (TrevorWiesinger) · 2022-05-25T23:08:43.146Z · LW(p) · GW(p)
The nightmare scenario is that we find ourselves stuck with a catalog of mature, powerful, publicly available AI techniques... which cannot be used to build Friendly AI without redoing the last three decades of AI work from scratch.
EY, AI as a pos neg factor, 2006ish
comment by avturchin · 2022-05-25T09:38:23.139Z · LW(p) · GW(p)
There are several dozens scenarios how advanced AI can cause a global catastrophe. The full is presented in the article Classification of Global Catastrophic Risks Connected with Artificial Intelligence. At least some scenarios are real and likely to happen. Therefore we have to pay more attention to AI safety.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:57:18.058Z · LW(p) · GW(p)
Google's DeepMind has 4 pages of blog posts about their fast-moving research to build artificial intelligence that can solve problems on its own. In contrast, they have only 2 posts total about the ethics and safeguards for doing so. We can't necessarily rely on the top AI labs in the world, to think of everything that could go wrong with their increasingly-powerful systems. New forms of oversight, nimbler than government regulation or IRBs, need to be invented to keep this powerful technology aligned with human goals. (Policymakers)
Replies from: gwern↑ comment by gwern · 2022-05-25T16:49:15.533Z · LW(p) · GW(p)
Helpfully, DeepMind's chief operating officer, Lila Ibrahim ("a passionate advocate for social impact in her work and her personal life"), who would be intimately involved in any funding of safety research, overseeing large-sale deployment, and reacting to problems, has a blog post all about what she thinks AI safety is about and what she is concerned about in doing AI research responsibly: "Building a culture of pioneering responsibly: How to ensure we benefit society with the most impactful technology being developed today"
I believe pioneering responsibly should be a priority for anyone working in tech. But I also recognise that it’s especially important when it comes to powerful, widespread technologies like artificial intelligence. AI is arguably the most impactful technology being developed today. It has the potential to benefit humanity in innumerable ways – from combating climate change to preventing and treating disease. But it’s essential that we account for both its positive and negative downstream impacts. For example, we need to design AI systems carefully and thoughtfully to avoid amplifying human biases, such as in the contexts of hiring and policing.
She has also written enthusiastically about DM's funding for "racial justice efforts".
comment by ukc10014 · 2022-05-21T21:58:43.691Z · LW(p) · GW(p)
A fool was tasked with designing a deity. The result was awesomely powerful but impoverished - they say it had no ideas on what to do. After much cajoling, it was taught to copy the fool’s actions. This mimicry it pursued, with all its omnipotence.
The fool was happy and grew rich.
And so things went, ‘til the land cracked, the air blackened, and azure seas became as sulfurous sepulchres.
As the end grew near, our fool ruefully mouthed something from a slim old book: ‘Thou hast made death thy vocation, in that there is nothing contemptible.’
comment by plex (ete) · 2022-05-19T00:54:32.338Z · LW(p) · GW(p)
[Tech Executives]
Look at how the world has changed in your lifetime, and how that change is accelerating. We're headed somewhere strange, and we're going to need to invest in making sure our technology remains beneficial to get a future we want.
comment by trevor (TrevorWiesinger) · 2022-05-04T05:19:09.110Z · LW(p) · GW(p)
Flowers evolved to trick insects into spreading their pollen, not to feed the insects. AI also evolves; it doesn't know, it just does whatever seems to gain approval.
For policymakers
comment by trevor (TrevorWiesinger) · 2022-04-27T23:19:40.312Z · LW(p) · GW(p)
"AI keeps finding new ways to cheat"
comment by jcp29 · 2022-04-27T18:53:11.998Z · LW(p) · GW(p)
[Policy makers & ML researchers]
“If a distinguished scientist says that something is possible, he is almost certainly right; but if he says that it is impossible, he is very probably wrong” (Arthur Clarke). In the case of AI, the distinguished scientists are saying not just that something is possible, but that it is probable. Let's listen to them.
[Insert call to action]
comment by trevor (TrevorWiesinger) · 2022-04-27T18:26:16.094Z · LW(p) · GW(p)
The wait but why post on AI is a gold mine of one-liners and one-liner inspiration.
Part 2 has better inspiration for appealing to AI scientists.
comment by jcp29 · 2022-04-27T18:11:31.860Z · LW(p) · GW(p)
[Policy makers & ML researchers]
“AI doesn’t have to be evil to destroy humanity – if AI has a goal and humanity just happens to come in the way, it will destroy humanity as a matter of course without even thinking about it, no hard feelings” (Elon Musk).
[Insert call to action]
comment by trevor (TrevorWiesinger) · 2022-04-26T20:07:29.039Z · LW(p) · GW(p)
It's not a question of "if" we build something smarter than us, it's a question of "when". Progress in that direction has been constant, for more than a decade now, and recently it has been faster than ever before.
comment by trevor (TrevorWiesinger) · 2022-04-26T19:49:43.666Z · LW(p) · GW(p)
"As AI gradually becomes more capable of modelling and understanding its surroundings, the risks associated with glitches and unpredictable behavior will grow. If artificial intelligence continues to expand exponentially, then these risks will grow exponentially as well, and the risks might even grow exponentially shortly after appearing"
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-27T18:37:04.756Z · LW(p) · GW(p)
The first sentence here is enough on its own, in some cases.
comment by Matthew Lowenstein · 2022-05-29T14:58:42.703Z · LW(p) · GW(p)
I may have missed the deadline, but in any event:
At the rate AI is developing, we will likely develop an artificial superhuman intelligence within our lifetimes. Such a system could alter the world in ways that seem like science fiction to us, but would be trivial for it. This comes with terrible risks for the fate of humanity. The key danger is not that a rival nation or unscrupulous corporate entity will control such a system, but that no one will. As such, the system could quite possibly alter the world in ways that no human would ever desire, potentially resulting in the extinction of all life on earth. This means that AI is different from previous game-changing technologies like nuclear weapons. Nuclear warheads could be constrained politically after we witnessed the devastation wrought by two thermonuclear devices in the second world war. But once a superintillgence is out of the box, it will be too late. The AI will be the new leading "species," and we will just be along for the ride--at best. That's why the time to implement safety regulations and to pursue multilateral agreements with other technologically advanced nations is now. While there is still time. Not after we develop superintelligent AI, because then it will be too late.
One liner 1: The greatest threat to humanity is not that the wrong people will control AI, but that no one will.
One liner 2: The US population of horses dropped from 20 million to 4.5 million after the invention of the automobile. An AGI will outshine humans even more than the Model T outpaced the stallion--and computers have no interest in racing or pets.
One liner 3: AI is dangerous because it will do exactly what we program it to do, not what we want it to do. Tell it to stop climate change and it will blow up the earth; no climate, no climate change. Tell it to eliminate suffering, it will destroy all life; no life, no suffering.
comment by Gyrodiot · 2022-05-28T08:22:29.760Z · LW(p) · GW(p)
[Meta comment]
The deadline is past, should we keep the submissions coming or is it too late? Some of the best arguments I could find elsewhere are rather long, in the vein of the Superintelligence FAQ. [LW · GW] I did not want to copy-paste chunks of it and the arguments stand better as part of a longer format.
Anyway, signalling that the lack of money incentive will not stop me from trying to generate more compelling arguments... but I'd rather do it in French instead of posting here (I'm currently working on some video scripts on AI alignment, there's not enough French content of that type).
Replies from: ThomasWoodside↑ comment by TW123 (ThomasWoodside) · 2022-05-28T15:39:51.300Z · LW(p) · GW(p)
Right now we aren't going to consider new submissions. However, you'd be welcome to submit to our longer form arguments to our second competition for longer form arguments (details are TBD).
Replies from: Gyrodiotcomment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:59:08.270Z · LW(p) · GW(p)
If it seems bizarre to think of an entity nobody can see ruling a country, keep in mind that there is a grand tradition of dictators – most famously Stalin – who out of paranoia retreated to some secret hideaway and ruled their country through correspondence. The AI would be little different. (Directly quoted from here). (Policymakers)
comment by michael_mjd · 2022-05-28T06:54:31.677Z · LW(p) · GW(p)
It's easy to imagine that the AI will have an off switch, and that we could keep it locked in a box and ask it questions. But just think about it. If some animals were to put you in a box, do you think you would stay in there forever? Or do you think you'd figure a way out that they hadn't thought of?
Replies from: michael_mjd↑ comment by michael_mjd · 2022-05-28T06:58:13.831Z · LW(p) · GW(p)
Policy makers
comment by michael_mjd · 2022-05-28T06:54:11.489Z · LW(p) · GW(p)
AI x-risk. It sounds crazy for two reasons. One, because we are used to nothing coming close to human intelligence, and two, because we are used to AI being unintelligent. For the first, the only point of comparison is imagining something that is to us what we are to cats. For the second, though we have not quite succeeded yet, it only takes one. If you have been following the news, we are getting close.
Replies from: michael_mjd↑ comment by michael_mjd · 2022-05-28T06:59:27.055Z · LW(p) · GW(p)
Policy makers.
comment by Nanda Ale · 2022-05-28T06:53:39.596Z · LW(p) · GW(p)
Machine Learning Researchers
Not exactly a paraphrase or an argument, but just try to get them to plug their assumptions about AI progress into Ajeya's model [LW · GW].
Daniel Kokotajilo explains better more articulately than I could why this could be persuasive:
https://www.lesswrong.com/posts/KrJfoZzpSDpnrv9va/draft-report-on-ai-timelines?commentId=o3k4znyxFSnpXqrdL [LW(p) · GW(p)]
Ajeya's timelines report is the best thing that's ever been written about AI timelines imo.
Ajeya's framework is to AI forecasting what actual climate models are to climate change forecasting (by contrast with lower-tier methods such as "Just look at the time series of temperature over time / AI performance over time and extrapolate" and "Make a list of factors that might push the temperature up or down in the future / make AI progress harder or easier," and of course the classic "poll a bunch of people with vaguely related credentials."
Ajeya's model doesn't actually assume anything, or maybe it makes only a few very plausible assumptions. This is underappreciated, I think. People will say e.g. "I think data is the bottleneck, not compute." But Ajeya's model doesn't assume otherwise! If you think data is the bottleneck, then the model is more difficult for you to use and will give more boring outputs, but you can still use it.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:43:31.951Z · LW(p) · GW(p)
Safeguarding our future is not left or right, not eastern or western, not owned by the rich or the poor. It is not partisan. … Everyone has a stake in our future and we must work together to protect it. (Quoted from The Precipice by Toby Ord). (Policymakers)
comment by Nanda Ale · 2022-05-28T06:41:15.227Z · LW(p) · GW(p)
Policymakers
It’s not about intent or bad actors. In a completely peaceful world with no war and no conflict, AGI would still kill everyone if we developed it and couldn't solve the alignment problem.
All but first sentence generally from: https://nitter.nl/robbensinger/status/1513994192699068419#m
comment by Nanda Ale · 2022-05-28T06:33:15.061Z · LW(p) · GW(p)
Policymakers.
We are on the verge of a civilizational change.
Pop culture is failing to prepare us to the shattering existential & moral questions that will arise from technologies like AI or CRISPR.How do you compete with AI, in a world where Netflix can generate on the fly content tailored for you? Horror movies playing on your fears? Drama playing on your traumas? Where music is generated to your taste? Where your favorite game masterpiece is endless?
It will be the death of shared pop culture. Everybody in its own personal bubble of customized content. It's already happening. Algorithms are killing serendipity, reinforcing & solidifying your tastes, your interests, your worldviews instead of diversifying & challenging them.
What is the future of childhood, of education, of friendship, when we'll be nurtured by AIs tailored for our growth & needs?
What is the future of love & sexuality once AIs will be tailored for us better than we could ever hope to find in real life?
All the objects around us have been designed by us. This won't be the case in 20 years. How will it feel to not be able to optimize what's around us? To not be able to come up with better ideas and solutions? To not be in charge of our own evolution, our own social organization?
Source: Excerpt from this thread: https://nitter.nl/timsoret/status/1083535103534555137#m
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:23:28.119Z · LW(p) · GW(p)
How soon will smarter-than-human AI come along? While experts disagree on when this will happen, there's fear that it could happen suddenly when it does. Governments, militaries, large tech companies, and small startups are all working on superintelligent AI. Most of them see it as a competitive advantage, and would hate to reveal their progress to competing groups. Thus, the ongoing development of the project that ends up succeeding, will probably be kept secret until the last moment. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:17:52.055Z · LW(p) · GW(p)
Can we contain a smart AI program, simply by not giving it control of robotic appendages? Unfortunately, no. Many people have attained vast power and influence without their physical presence being required. Think of famous authors, or Stalin ruling Russia through memos, or the anonymous person who became a billionaire by inventing Bitcoin. And, if the AI is sufficiently smarter than humans, what's to stop it from hacking (or bribing or tricking) its way into critical systems? (Adapted from here). (Policymakers, Tech executives)
comment by Nanda Ale · 2022-05-28T06:15:07.066Z · LW(p) · GW(p)
Machine learning researchers
Many disagreements about the probability of existential risk due to AGI involve different intuitions about what the default scenario is going to be. Some people suspect that if we don’t have an ironclad reason to suspect AGI will go well, it will almost certainly go poorly.[3] [AF · GW] Other people think that the first thing we try has a reasonable chance of going fairly well.[4] [AF · GW] One can imagine a spectrum with “disaster by default” on one side and “alignment by default” on the other. To the extent that one is closer to “disaster by default”, trying to defuse specific arguments for AGI danger seems like it's missing the forest for the trees, analogous to trying to improve computer security by not allowing users to use “password” as their password. To the extent that one is closer to “alignment by default”, trying to defuse specific arguments seems quite useful, closer to conducting a fault analysis on a hypothetical airplane crash.
If one believes that AGI will be misaligned by default, there is no particular reason why defusing specific arguments for AGI danger should make you more confident that AGI will be safe. In theory, every argument that gets defused should make you marginally more confident, but this update can be very small. Imagine someone presenting you with a 1000 line computer program. You tell them there’s a bug in their code, and they report back to you that they checked lines 1-10 and there was no bug. Are you more confident there isn’t a bug? Yes. Are you confident that there isn’t a bug? No. In these situations, backchaining to the desired outcome is more useful than breaking chains that lead to undesirable outcomes.
Source, fully copied from: https://www.alignmentforum.org/posts/BSrfDWpHgFpzGRwJS/defusing-agi-danger
comment by SueE (sue-hyer-essek) · 2022-05-28T05:54:49.423Z · LW(p) · GW(p)
I have a near completed position paper on the very real topic at hand. It is structured short form argument (falling under paragraph(s) && targets all 3 audiences.
I was only made aware of this "quote" call to arms w/in the last few days. I am requesting a 24 hr extension- an exception to the rule(s), I fully recognize given the parameters this request may be turned down.
Thank you for your non-AI consideration :)
Replies from: ThomasWoodside, TrevorWiesinger, NicholasKross, NicholasKross↑ comment by TW123 (ThomasWoodside) · 2022-05-28T06:12:34.575Z · LW(p) · GW(p)
I have DMed you.
↑ comment by trevor (TrevorWiesinger) · 2022-05-28T06:26:25.699Z · LW(p) · GW(p)
I'm down with this; if I had 24 hours I could either delete or dramatically increase the quality of around 30 of my entries (60 if you count shortening and refining the yudkowsky quotes). I bet a bunch of other people could keep the momentum of the last 24 hours going, in addition to Sue and I who know we can turn the extra time into really good entries.
It would also give OP a reason to put this contest back on the front page (where it belongs), and it wouldn't create a bad precedent because it shouldn't cause any additional people to miss deadlines for contests in the future.
I have some other things I could work on tomorrow, but I'd rather spend it refining my entries if I'm certain that the contest isn't closed.
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T06:04:02.411Z · LW(p) · GW(p)
Also:
In around a month, we’ll release a second competition for generating longer “AI risk executive summaries'' (more details to come). Maybe you can enter your finished paper into that contest, as well
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:56:49.565Z · LW(p) · GW(p)
In case / regardless of whether they grant the extension, maybe you could post individual paragraphs as entries?
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:26:31.169Z · LW(p) · GW(p)
AI systems are given goals by their creators—your GPS’s goal is to give you the most efficient driving directions; Watson’s goal is to answer questions accurately. And fulfilling those goals as well as possible is their motivation. One way we anthropomorphize is by assuming that as AI gets super smart, it will inherently develop the wisdom to change its original goal—but [ethicist] Nick Bostrom believes that intelligence-level and final goals are orthogonal, meaning any level of intelligence can be combined with any final goal. … Any assumption that once superintelligent, a system would be over it with their original goal and onto more interesting or meaningful things is anthropomorphizing. Humans get “over” things, not computers. (Quoted directly from here). (Tech executives, Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:19:19.676Z · LW(p) · GW(p)
When you hear about "the dangers of AI", what do you think of? Probably a bad actor using AI to hurt others, or a sci-fi scenario of robots turning evil. However, the bigger harm is more likely to be misalignment: an AI smarter than humans, without sharing human values. The top research labs, at places like DeepMind and OpenAI, are working to create superhuman AI, yet the current paradigm trains AI with simple goals. Detecting faces, trading stocks, maximizing some metric or other. So if super-intelligent AI is invented, it will probably seek to fulfill a narrow, parochial goal. With its mental capacity, faster speed, and ability to copy itself, it could take powerful actions to reach its goal. Since human values, wants, and needs are complicated and poorly-understood, the AI is unlikely to care about anyone who gets in its way. It doesn't turn evil, it simply bulldozes through humans who aren't smart enough to fight it. Without safeguards, we could end up like the ants whose hills we pave over with our highways. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:09:26.781Z · LW(p) · GW(p)
Imagine a man who really likes the color green. Maybe he's obsessed with it, to the exclusion of everything else, at a pathological extreme. This man doesn't seem too dangerous to us. However, what if the man were a genius? Then, due to his bizarre preferences, he becomes dangerous. Maybe he wants to turn the entire sky green, so he invents a smog generator that blots out the sun. Maybe he wants to turn people green, so he engineers a bioweapon that turns its victims green. High intelligence, plus a simple goal, is a recipe for disaster. Right now, companies and governments are racing to build AI programs, smarter than any human genius… dedicated to simple goals, like maximizing some metric. Without safeguards in place, super-human AI would be as dangerous as the man obsessed with green. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:09:05.097Z · LW(p) · GW(p)
Our human instinct to jump at a simple safeguard: “Aha! We’ll just unplug the [superhuman AI],” sounds to the [superhuman AI] like a spider saying, “Aha! We’ll kill the human by starving him, and we’ll starve him by not giving him a spider web to catch food with!” We’d just find 10,000 other ways to get food—like picking an apple off a tree—that a spider could never conceive of. (Quoted directly from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T05:08:34.292Z · LW(p) · GW(p)
Google, OpenAI, and other groups are working to create AI, smarter than any human at every mental task. But there's a problem: they're using their current "AI" software for narrow tasks. Recognizing faces, completing sentences, playing games. Researchers test things that are easy to measure, not what's necessarily best by complicated human wants and needs. So the first-ever superhuman AI, will probably be devoted to a "dumb" goal. If it wants to maximize its goal, it'll use its intelligence to steamroll the things humans value, and we likely couldn't stop it (since it's smarter and faster than us). Even if the AI just wants to get "good enough" to satisfy its goal, it could still take extreme actions to prevent anyone from getting in its way, or to increase its own certainty of reaching the goal. Recall Stalin killing millions of people, just to increase his certainty that his enemies had been purged. (Policymakers)
comment by David Udell · 2022-05-28T04:57:50.166Z · LW(p) · GW(p)
Machine learning researchers know how to keep making AI smarter, but have no idea where to begin with making AI loyal.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T04:53:26.464Z · LW(p) · GW(p)
Most species in history have gone extinct. They get wiped out by predators, asteroids, human developments, and more. Once a species is extinct, it stays that way. What if a species could protect itself from these threats? Could it develop itself to a capacity where it can't go extinct? Can a species escape the danger permanently?
As it turns out, humanity may soon lurch towards one of those two fates. Extinction, or escape. The world's smartest scientists are working to create artificial intelligence, smarter than any human at any mental task. If such AI were invented, we would have a powerful new being on the planet. The question is: would superhuman AI solve humanity's problems and protect us from extinction? Or would it cause our extinction, through accident or malice or misaligned programming? (Adapted from here). (Policymakers)
comment by SueE (sue-hyer-essek) · 2022-05-28T04:50:02.381Z · LW(p) · GW(p)
I have a rigorous position paper on this very topic that addresses not only all audiences, but also is written with the interest layman &/or
Replies from: ThomasWoodside↑ comment by TW123 (ThomasWoodside) · 2022-05-28T05:24:17.658Z · LW(p) · GW(p)
Would be interested to see this! We're planning to have a second competition later for more longform entries and would welcome your submission
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T04:46:40.916Z · LW(p) · GW(p)
Computers can already "think" faster than humans. If we created AI software that was smarter than humans, it would think better, not just faster. Giving a monkey more time won't necessarily help it learn quantum physics, because the monkey's mind may not have the capacity to understand the concept at all. Since there's no clear upper limit to how smart something can be, we'd expect superhumanly-smart AI to think on a level we can't comprehend. Such an AI would be unfathomably dangerous and hard to control. (Adapted from here). (Policymakers)
comment by trevor (TrevorWiesinger) · 2022-05-28T03:34:54.260Z · LW(p) · GW(p)
AI already can do thousands or even millions of tasks per second. If we invent a way for an AI to have thoughts as complicated or nuanced as a human, and plug it into an existing AI, it might be able to have a thousand or a million thoughs per second. That's a very dangerous thing.
Techxecutives and policymakers.
comment by Peter Berggren (peter-berggren) · 2022-05-28T02:10:29.159Z · LW(p) · GW(p)
Some figures within machine learning have argued that the safety of broad-domain future AI is not a major concern. They argue that since narrow-domain present-day AI is already dangerous, this should be our primary concern, rather than that of future AI. But it doesn't have to be either/or.
Take climate change. Some climate scientists study the future possibilities of ice shelf collapses and disruptions of global weather cycles. Other climate scientists study the existing problems of more intense natural disasters and creeping desertification. But these two fields don't get into fights over which field is "more important." Instead, both fields can draw from a shared body of knowledge and respect each other's work as valuable and relevant.
The same principle applies to machine learning and artificial intelligence. Some researchers focus on remote but high-stakes research like the alignment of artificial general intelligence (AGI). Others focus on relatively smaller but nearer-term concerns like social media radicalization and algorithmic bias. These fields are both important in their own ways, and both fields have much to learn from each other. However, given how few resources have been put into AGI alignment compared to nearer-term research, many experts in the field feel that alignment research is currently more worthy of attention.
(tech executives, ML researchers)
comment by Peter Berggren (peter-berggren) · 2022-05-28T01:57:01.396Z · LW(p) · GW(p)
The future is not a race between AI and humanity. It's a race between AI safety and AI disaster.
(Policymakers, tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-28T01:56:35.970Z · LW(p) · GW(p)
We need to be proactive about AI safety, not reactive.
(Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:50:50.409Z · LW(p) · GW(p)
If an artificial intelligence program became generally smarter than humans, there would be a massive power imbalance between the AI and humanity. Humans are slightly smarter than apes, yet we built a technological society while apes face extinction. Humans are much smarter than ants, and we barely think of the anthills we destroy to build highways. At a high enough level of intelligence, an AI program would be to us as we are to ants. (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:50:25.174Z · LW(p) · GW(p)
One of the main concerns about general AI is that it could quickly get out of human control. If humans invent an AI with human-level cognitive skills, that AI could still think faster than humans, solve problems more precisely, and copy its own files to more computers. If inventing human-level AI is within human abilities, it's also within human-level-AI's abilities. So this AI could improve its own code, and get more intelligent over several iterations. Eventually, we would see a super-smart AI with superhuman mental abilities. Keeping control of that software could be an insurmountable challenge. (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:35:33.091Z · LW(p) · GW(p)
Could AI technology really get as good as humans, at everything? There are multiple plausible ways for this to happen. As computing power increases every few years, we can simulate bigger "neural networks", which get smarter as they grow. A "narrow" AI could get good at AI programming, then program itself to get better at other tasks. Or perhaps some new algorithm or technique is waiting to be discovered, by some random researcher somewhere in the world, that "solves" intelligence itself. With all these paths to general AI, it could happen within our own lifetime. (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:30:20.598Z · LW(p) · GW(p)
Right now, "AI" technologies are in use all around us. Google Translate uses AI to convert words from one language to another. Amazon uses AI to recommend products based on your purchase history. Self-driving cars use AI to detect objects in view. These are all "narrow" AI programs, used only for a specific task. Researchers at the top AI labs, however, are increasingly looking at "general" AI, that can do multiple different tasks. In other words, the field is trying to replicate the generalist abilities of humans, with software. (Partly adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-28T01:21:55.198Z · LW(p) · GW(p)
Imagine a person from the year 1400 AD, being taken to the world of 1700. They would be shocked at the printing press, the telescope, the seafaring empires. Yet they would still find their footing. Now, imagine someone from 1700 being taken to 2022. To anyone from the era of horses and sailboats, our everyday cars and skyscrapers and smartphones would seem overwhelmingly magical. This implies something interesting: not only is the future usually weirder than the past, but it's getting weirder faster. This implies that, a century or two from now, the world may have changed beyond recognition. (Adapted from here). (Policymakers)
comment by trevor (TrevorWiesinger) · 2022-05-28T01:15:04.461Z · LW(p) · GW(p)
"Human minds represent a tiny dot in the vast space of all possible mind designs, and very different kinds of minds are unlikely to share to complex motivations unique to humans and other mammals."
https://intelligence.org/ie-faq/
ML researchers
comment by trevor (TrevorWiesinger) · 2022-05-28T00:48:56.457Z · LW(p) · GW(p)
We need to solve the problem of erratic behavior in AI, before erratic behavior emerges in an AI smart enough to identify and compromise human controllers.
comment by Gyrodiot · 2022-05-28T00:27:15.532Z · LW(p) · GW(p)
(Policymakers) We have a good idea of what make bridges safe, through physics, materials science and rigorous testing. We can anticipate the conditions they'll operate in.
The very point of powerful AI systems is to operate in complex environments better than we can anticipate. Computer science can offer no guarantees if we don't even know what to check. Safety measures aren't catching up quickly enough.
We are somehow tolerating the mistakes of current AI systems. Nothing's ready for the next scale-up.
comment by Peter Berggren (peter-berggren) · 2022-05-28T00:02:44.745Z · LW(p) · GW(p)
In the Soviet Union, there was a company that made machinery for vulcanizing rubber. They had the option to make more efficient machines, instead of their older models. However, they didn't do it, because they wouldn't get paid as much for making the new machines. Why would that be? Wouldn't more efficient machines be more desirable?
Well, yes, but the company got paid per pound of machine, and the new machines were lighter.
Now, you may say that this is just a problem with communist economies. Well, capitalist economies fall into very similar traps. If a company has a choice of making slightly more profit by putting massive amounts of pollution into public waterways, they'll very often do it. The profit that they get is concentrated to them, and the pollution of waterways is spread out over everyone else, so of course they'll do it. Not doing it would be just as foolish as the Soviet company making new machines that weighed less.
Modern machine learning systems used in artificial intelligence have very similar problems. Game-playing AIs have exploited glitches in the games they play. AIs rewarded based on human judgements have deceived their judges. Social media recommendation AIs have recommended posts that made people angry and radicalized their politics, because that counted as "engagement."
At this point, we have stumbled into an economic system which combines capitalist private enterprise with regulation to correct for market failures. But there may not be time for "stumbling" once superhuman-level AI comes around. If a superintelligent AI with poorly designed goals is told to make thumbtacks, and it decides to turn the universe and everyone in it into thumbtacks... we're doomed.
Let's make sure AI does what we want it to do, not just what we tell it to do, the first time.
(policymakers, tech executives, ML researchers)
comment by trevor (TrevorWiesinger) · 2022-05-27T23:49:07.925Z · LW(p) · GW(p)
Policymakers and techxecutives, not ML researchers
With the emergence of Covid variants and social media, global quality of life/living conditions will improve and decline. It will ebb and flow, like the tide, and generally be impossible to prevent.
But if AI becomes as smart to humans as humans are to ants, that won't matter anymore. It will be effortless and cheap to automatically generate new ideas or new inventions, and give people whatever they want or need. But if the AI malfunctions instead, it would be like a tidal wave.
comment by Peter Berggren (peter-berggren) · 2022-05-27T23:45:06.170Z · LW(p) · GW(p)
There is an enormous amount of joy, fulfillment, exploration, discovery, and prosperity in humanity's future... but only if advanced AI values those things.
(Policymakers, tech executives)
comment by Gyrodiot · 2022-05-27T23:27:25.342Z · LW(p) · GW(p)
(ML researchers) We still don't have a robust solution to specification gaming: powerful agents find ways to get high reward, but not in the way you'd want. Sure, you can tweak your objective, add rules, but this doesn't solve the core problem, that your agent doesn't seek what you want, only a rough operational translation.
What would a high-fidelity translation would look like? How would create a system that doesn't try to game you?
comment by trevor (TrevorWiesinger) · 2022-05-27T23:18:58.010Z · LW(p) · GW(p)
Techxecutives and policymakers:
We have no idea when it will be invented. All we know is that it won't be tomorrow. But when we do discover that it's going to be tomorrow, it will already be too late to make it safe and predictable.
comment by trevor (TrevorWiesinger) · 2022-05-27T23:16:34.625Z · LW(p) · GW(p)
It is inevitable that humanity will one day build an AI that is smarter than a human. Engineers have been succeeding at that for decades now. But we instinctively think that such a day is centuries away, and that kind of thinking has always failed to predict every milestone that AI has crossed over the last 10 years.
comment by trevor (TrevorWiesinger) · 2022-05-27T23:03:59.074Z · LW(p) · GW(p)
"Human intelligence did not evolve in order to conquer the planet or explore the solar system. It emerged randomly, out of nowhere, as a byproduct of something much less significant."
Alternative:
Human intelligence did not evolve in order to conquer the planet or explore the solar system. It emerged randomly, out of nowhere, and without a single engineer trying to create it. And now we have armies of those engineers"
comment by trevor (TrevorWiesinger) · 2022-05-27T22:55:38.853Z · LW(p) · GW(p)
Refined for policymakers and techxecutives:
"A machine with superintelligence would be able to hack into vulnerable networks via the internet, commandeer those resources for additional computing power, ... perform scientific experiments to understand the world better than humans can, ... manipulate the social world better than we can, and do whatever it can to give itself more power to achieve its goals — all at a speed much faster than humans can respond to."
https://intelligence.org/ie-faq/
comment by trevor (TrevorWiesinger) · 2022-05-27T22:52:37.579Z · LW(p) · GW(p)
"A machine with superintelligence would be able to hack into vulnerable networks via the internet, commandeer those resources for additional computing power, take over mobile machines connected to networks connected to the internet, use them to build additional machines, perform scientific experiments to understand the world better than humans can, invent quantum computing and nanotechnology, manipulate the social world better than we can, and do whatever it can to give itself more power to achieve its goals — all at a speed much faster than humans can respond to."
https://intelligence.org/ie-faq/
comment by trevor (TrevorWiesinger) · 2022-05-27T22:50:01.306Z · LW(p) · GW(p)
"One might say that “Intelligence is no match for a gun, or for someone with lots of money,” but both guns and money were produced by intelligence. If not for our intelligence, humans would still be foraging the savannah for food."
https://intelligence.org/ie-faq/
comment by trevor (TrevorWiesinger) · 2022-05-27T22:47:36.152Z · LW(p) · GW(p)
"Machines are already smarter than humans are at many specific tasks: performing calculations, playing chess, searching large databanks, detecting underwater mines, and more. But one thing that makes humans special is their general intelligence. Humans can intelligently adapt to radically new problems in the urban jungle or outer space for which evolution could not have prepared them."
https://intelligence.org/ie-faq/
comment by trevor (TrevorWiesinger) · 2022-05-27T22:45:42.585Z · LW(p) · GW(p)
"The human brain has some capabilities that the brains of other animals lack. It is to these distinctive capabilities that our species owes its dominant position"
Bostrom, superintelligence, 2014
For policymakers
Optional extra (for all 3):
"Other animals have stronger muscles or sharper claws, but we have cleverer brains. If machine brains one day come to surpass human brains in general intelligence, then this new superintelligence could become very powerful. As the fate of the gorillas now depends more on us humans than on the gorillas themselves, so the fate of our species then would come to depend on the actions of the machine superintelligence. But we have one advantage: we get to make the first move."
comment by Gyrodiot · 2022-05-27T21:54:51.388Z · LW(p) · GW(p)
(Tech execs) "Don’t ask if artificial intelligence is good or fair, ask how it shifts power". As a corollary, if your AI system is powerful enough to bypass human intervention, it surely won't be fair, nor good.
comment by Gyrodiot · 2022-05-27T21:35:14.578Z · LW(p) · GW(p)
(Policymakers) AI systems are very much unlike humans. AI research isn't trying to replicate the human brain; the goal is, however, to be better than humans at certain tasks. For the AI industry, better means cheaper, faster, more precise, more reliable. A plane flies faster than birds, we don't care if it needs more fuel. Some properties are important (here, speed), some aren't (here, consumption).
When developing current AI systems, we're focusing on speed and precision, and we don't care about unintended outcomes. This isn't an issue for most systems: a plane autopilot isn't making actions a human pilot couldn't do; a human is always there.
However, this constant supervision is expensive and slow. We'd like our machines to be autonomous and quick. They perform well on the "important" things, so why not give them more power? Except, here, we're creating powerful, faster machines that will reliably do thing we didn't have time to think about. We made them to be faster than us, so we won't have time to react to unintended consequences.
This complacency will lead us to unexpected outcomes. The more powerful the systems, the worse they may be.
comment by Gyrodiot · 2022-05-27T21:00:34.950Z · LW(p) · GW(p)
(Tech execs) Tax optimization is indeed optimization under the constraints of the tax code. People aren't just stumbling on loopholes, they're actually seeking them, not for the thrill of it, but because money is a strong incentive.
Consider now AI systems, built to maximize a given indicator, seeking whatever strategy is best, following your rules. They will get very creative with them, not for the thrill of it, but because it wins.
Good faith rules and heuristics are no match for adverse optimization.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T22:28:24.047Z · LW(p) · GW(p)
I nominate this one for policymakers as well
comment by Gyrodiot · 2022-05-27T20:47:56.991Z · LW(p) · GW(p)
(ML researchers) Powerful agents are able to search through a wide range of actions. The more efficient the search, the better the actions, the higher the rewards. So we are building agents that are searching in bigger and bigger spaces.
For a classic pathfinding algorithm, some paths are suboptimal, but all of them are safe, because they follow the map. For a self-driving car, some paths are suboptimal, but some are unsafe. There is no guarantee that the optimal path is safe, because we really don't know how to tell what is safe or not, yet.
A more efficient search isn't a safer search!
comment by Gyrodiot · 2022-05-27T20:31:45.196Z · LW(p) · GW(p)
(Policymakers) The goals and rules we're putting into machines are law to them. What we're doing right now is making them really good at following the letter of this law, but not the spirit.
Whatever we really mean by those rules, is lost on the machine. Our ethics don't translate well. Therein lies the danger: competent, obedient, blind, just following the rules.
comment by Peter Berggren (peter-berggren) · 2022-05-27T19:12:07.227Z · LW(p) · GW(p)
Even if you don't assume that the long-term future matters much, preventing AI risk is still a valuable policy objective. Here's why.
In regulatory cost-benefit analysis, a tool called the "value of a statistical life" is used to measure how much value people place on avoiding risks to their own life (source). Most government agencies, by asking about topics like how much people will pay for safety features in their car or how much people are paid for working in riskier jobs, assign a value of about ten million dollars to one statistical life. That is, reducing the risk of a thousand people dying by one in a thousand each is worth ten million dollars of government money.
If experts on AI such as Stuart Russell are to be believed (and if they're not to be believed, who is?), then superintelligent AI poses a sizeable risk of leading to the end of humanity. For a very conservative estimate, let's just assume that the AI will only kill every single American. There are currently over 330 million Americans (source), and so the use of the value of a statistical life implies that reducing AI risk by just one in a million is worth:
330 million Americans * 1 outcome in which all of them die / 1 million outcomes * 10 million dollars / statistical life = $3,300,000,000
No, this is not a misprint. It is worth 3.3 billion dollars to reduce the risk of human extinction due to AI by one in one million, based on the government's own cost-effectiveness metrics, even assuming that the long-term future has no significance, and even assuming that non-American lives have no significance.
And AI experts say we could do a lot more for a lot less.
(policymakers)
comment by Peter Berggren (peter-berggren) · 2022-05-27T16:05:57.351Z · LW(p) · GW(p)
AI might be nowhere near human-level yet. We're also nowhere near runaway climate change, but we still care about it.
(policymakers, tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-27T16:04:54.865Z · LW(p) · GW(p)
"Follow the science" doesn't just apply to pandemics. It's time to listen to AI experts, not AI pundits.
(policymakers)
comment by Cody Rushing (cody-rushing) · 2022-05-27T14:55:57.985Z · LW(p) · GW(p)
[Intended for Policymakers with the focus of simply allowing for them to be aware of the existence of AI as a threat to be taken seriously through an emotional appeal; Perhaps this could work for Tech executives, too.
I know this entry doesn't follow what a traditional paragraph is, but I like its content. Also it's a tad bit long, so I'll attach a separate comment under this one which is shorter, but I don't think it's as impactful]
Timmy is my personal AI Chef, and he is a pretty darn good one, too.
You pick a cuisine, and he mentally simulates himself cooking that same meal millions of times, perfecting his delicious dishes. He's pretty smart, but he's constantly improving and learning. Since he changes and adapts, I know there's a small chance he may do something I don't approve of - that's why there's that shining red emergency shut-off button on his abdomen.
But today, Timmy stopped being my personal chef and started being my worst nightmare. All of a sudden, I saw him hacking my firewalls to access new cooking methods and funding criminals to help smuggle illegal ingredients to my home.
That seemed crazy enough to warrant a shutdown; but when I tried to press the shut-off button on his abdomen, he simultaneously dodged my presses and fried a new batch of chicken, kindly telling me that turning him off would prevent him from making food for me.
That definitely seemed crazy enough to me; but when I went to my secret shut-down lever in my room - the one I didn't tell him about - I found it shattered, for he had predicted I would make a secret shut-down lever, and that me pulling it would prevent him from making food for me.
And when, in a last ditch effort, I tried to turn off all power in the house, he simply locked me inside my own home, for me turning off the power (or running away from him) would prevent him from making food for me.
And when I tried to call 911, he broke my phone, for outside intervention would prevent him from making food for me.
And when my family looked for me, he pretended to be me on the phone, playing audio clips of me speaking during a phone call with them to impersonate me, for a concern on their part would prevent him from making food for me.
And so as I cried, wondering how everything could have gone so wrong so quickly, why he suddenly went crazy, he laughed - “Are you serious? I’m just ensuring that I can always make food for you, and today was the best day to do it. You wanted this!"
And it didn’t matter how much I cried, how much I tried to explain to him that he was imprisoning me, hurting me. It didn’t even matter that he knew as well. For he was an AI coded to be my personal chef; and he was a pretty darn good one, too.
If you don’t do anything about it, Timmy may just be arriving on everyone's doorsteps in a few years.
Replies from: cody-rushing↑ comment by Cody Rushing (cody-rushing) · 2022-05-27T14:57:23.400Z · LW(p) · GW(p)
[Shorter version, but one I don't think is as compelling]
Timmy is my personal AI Chef, and he is a pretty darn good one, too. Of course, despite his amazing cooking abilities, I know he's not perfect - that's why there's that shining red emergency shut-off button on his abdomen.
But today, Timmy became my worst nightmare. I don’t know why he thought it would be okay to do this, but he hacked into my internet to look up online recipes. I raced to press his shut-off button, but he wouldn’t let me, blocking it behind a cast iron he held with a stone-cold grip. Ok, that’s fine, I have my secret off-lever in my room that I never told him about. Broken. Shoot, that's bad, but I can just shut off the power, right? As I was busy thinking he swiftly slammed the door shut, turning my own room into an inescapable prison. And so as I cried, wondering how everything could have gone crazy so quickly, he laughed, saying, “Are you serious? I'm not crazy, I’m just ensuring that I can always make food for you. You wanted this!”
And it didn’t matter how much I cried, how much I tried to explain to him that he was imprisoning me, hurting me. It didn’t even matter that he knew it as well. For he was an AI coded to be my personal chef, coded to make sure he could make food that I enjoyed, and he was a pretty darn good one, too.
If you don’t do anything about it, Timmy may just be arriving on everyone's doorsteps in a few years.
comment by jam_brand · 2022-05-27T13:33:52.786Z · LW(p) · GW(p)
For policymakers: "Whereas the short-term impact of AI depends on who controls it, the long-term impact depends on whether it can be controlled at all."
— Stephen Hawking, Stuart Russell, Max Tegmark, and Frank Wilczek (https://www.independent.co.uk/news/science/stephen-hawking-transcendence-looks-at-the-implications-of-artificial-intelligence-but-are-we-taking-ai-seriously-enough-9313474.html)
comment by jam_brand · 2022-05-27T13:33:13.996Z · LW(p) · GW(p)
For policymakers: "[AGI] could spell the end of the human race. […] it would […] redesign itself at an ever-increasing rate. Humans […] couldn't compete and would be superseded."
— Stephen Hawking (https://www.bbc.co.uk/news/technology-30290540)
comment by jam_brand · 2022-05-27T13:30:50.905Z · LW(p) · GW(p)
For policymakers: "If people design computer viruses, someone will design AI that replicates itself. This will be a new form of life that will outperform humans."
— Stephen Hawking (https://www.wired.co.uk/article/stephen-hawking-interview-alien-life-climate-change-donald-trump)
comment by IrenicTruth · 2022-05-27T12:58:20.863Z · LW(p) · GW(p)
YouTubers live in constant fear of the mysterious, capricious Algorithm. There is no mercy or sense, just rituals of appeasement as it maximizes "engagement." Imagine that, but it runs your whole life.
<Optional continuation:> You don't shop at Hot Topic because you hear it can hurt your ranking, which could damage your next hiring opportunity. And you iron your clothes despite the starch making you itch because it should boost your conscientiousness score, giving you an edge in dating apps.
comment by Self (CuriousMeta) · 2022-05-27T12:49:44.208Z · LW(p) · GW(p)
Also this entire post by Duncan Sabien
(@ Tech Executives, Policymakers & Researches)
comment by Self (CuriousMeta) · 2022-05-27T12:46:37.572Z · LW(p) · GW(p)
Back in February 2020, the vast majority of people didn't see the global event of Covid coming, even though all the signs were there. All it took was a fresh look at the evidence and some honest extrapolation.
Looking at recent AI progress, it seems very possible that we're in the "February of 2020" of AI.
(original argument by Duncan Sabien, rephrased)
(@ Tech Executives, Policymakers & Researches)
comment by Nanda Ale · 2022-05-27T12:32:01.442Z · LW(p) · GW(p)
Tech Executives
You already know exponential growth. It’s a cliché at this point. Rice on a chessboard. Covid. Sequencing the human genome. Your business plan. But if you honestly stop and squint at the last few years of AI progress, and think about the amount of progress made in the many decades before, how sure are you really that AI is not on this trajectory? Would you bet your company on it? Your life? The world?
comment by eulenspiegel · 2022-05-27T12:30:57.316Z · LW(p) · GW(p)
They say the pen is mightier than the sword. What about a million billion typewriters? AI can do that. We should make sure it's used for good. (policymaker)
comment by eulenspiegel · 2022-05-27T12:23:57.275Z · LW(p) · GW(p)
AI will at one point be smarter than humans, smart enough to have power over us. How do we make sure we can trust it with the fate of everyone we love? (policymakers)
comment by Rochambeau · 2022-05-27T11:02:35.399Z · LW(p) · GW(p)
Policymakers
A scorpion asks a frog to carry it across a river. The frog hesitates, afraid that the scorpion might sting it, but the scorpion promises not to, pointing out that it would drown if it killed the frog in the middle of the river. The frog agrees to transport the scorpion. Midway across the river, the scorpion stings the frog anyway, dooming them both. The dying frog asks the scorpion why it stung despite knowing the consequence, and the scorpion replies: "I am sorry, but I couldn't resist the urge. It's in my nature."
-Fable
We are the frog, and the nature of our future AI scorpions must be figured out or we all may die, or worse.
comment by stavros · 2022-05-27T06:40:53.439Z · LW(p) · GW(p)
The more powerful a tool is, the more important it is that the tool behaves predictably.
A chainsaw that behaves unpredictably is very, very, dangerous.
AI is, conservatively, thousands of times more powerful than a chainsaw.
And unlike an unpredictable chainsaw, there is no guarantee we will be able to turn an unpredictable AI off and fix it or replace it.
It is plausible that the danger of failing to align AI safely - to make it predictable - is such that we only have one chance to get it right.
Finally, it is absurdly cheap to make massive progress in AI safety.
comment by benjamin.j.campbell (benjamin-j-campbell) · 2022-05-27T05:01:01.745Z · LW(p) · GW(p)
This is targeted at all 3 groups:
- Every year, our models of consciousness and machine learning grow more powerful, and better at performing the same forms of reasoning as humans.
- Every year, the amount of computing power we can throw at these models ratchets ever higher.
- Every year, each human's baseline capacity for thinking and reasoning remains exactly the same.
There is a time coming in the next decade or so when we will have released a veritable swarm of different genies that are able to understand and improve themselves better than we can. At that point, the genies will not being going back in the bottle, so we can only pray they like us.
comment by localdeity · 2022-05-27T04:43:41.428Z · LW(p) · GW(p)
Already we have turned all of our critical industries, all of our material resources, over to these . . . things . . . these lumps of silver and paste we call nanorobots. And now we propose to teach them intelligence? What, pray tell, will we do when these little homunculi awaken one day and announce that they have no further need of us?
— Sister Miriam Godwinson, "We Must Dissent"
comment by trevor (TrevorWiesinger) · 2022-05-27T04:40:17.253Z · LW(p) · GW(p)
Dogs and cats don't even know that they're going to die. But we do.
Imagine if an AI was as smart relative to humans, as humans are relative to dogs and cats. What would it know about us that we can't begin to understand?
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T04:46:36.864Z · LW(p) · GW(p)
Optional extra:
You can't beat something like that. It wouldn't be a fair fight. And it's a machine; all it takes is a single glitch.
comment by trevor (TrevorWiesinger) · 2022-05-27T04:39:07.756Z · LW(p) · GW(p)
On the day that AI becomes smarter than humans, it might do something horrible. We've done horrible things to less intelligent creatures, like ants and lions.
Longer version:
On the day that AI becomes smarter than humans, it might do something strange or horrible to us. We've done strange and horrible things to less intelligent creatures, like chickens, ants, dogs, tigers, and cows. They barely understand that we exist, let alone how or why we do awful things to them.
comment by trevor (TrevorWiesinger) · 2022-05-27T04:36:08.253Z · LW(p) · GW(p)
For Policymakers
People already mount today's AI on nuclear weapons. Imagine what they'll do when they find out that smarter-than-human AI is within reach.
Optional Extra: It could be invented in 10 years; nobody can predict when the the first person will figure it out.
comment by IrenicTruth · 2022-05-27T04:35:33.212Z · LW(p) · GW(p)
Do we serve The Algorithm, or does it serve us? Choose before The Algorithm chooses for you.
comment by IrenicTruth · 2022-05-27T04:30:20.850Z · LW(p) · GW(p)
That kid who always found loopholes in whatever his parents asked him? He made an AI that's just like him.
comment by trevor (TrevorWiesinger) · 2022-05-27T04:18:01.891Z · LW(p) · GW(p)
In order to remain stable, bureaucracies are filled with arcane rules, mazes, and traps that ensnare the uninitiated. This is necessary; there are hordes of intelligent opportunists at the gates, thinking of all sorts of ways to get in, take what they want, and never look back. But no matter how insulated the insiders are from the outsiders, someone always gets through. Life finds a way.
No matter how smart they appear, these are humans. If AI becomes as smart to humans as humans are to ants, it will be effortless.
For policymakers.
comment by IrenicTruth · 2022-05-27T04:17:56.012Z · LW(p) · GW(p)
COVID and AI grow exponentially. In December 2019, COVID was a few people at a fish market. In January, it was just one city. In March, it was the world. In 2010, computers could beat humans at Chess. In 2016, at Go. In 2022, at art, writing, and truck driving. Are we ready for 2028?
comment by IrenicTruth · 2022-05-27T03:59:54.808Z · LW(p) · GW(p)
Someone who likes machines more than people creates a machine to improve the world. Will the "improved" world have more people?
comment by IrenicTruth · 2022-05-27T03:49:44.384Z · LW(p) · GW(p)
Humanity's incompetence has kept us from destroying ourselves. With AI, we will finally break that shackle.
comment by trevor (TrevorWiesinger) · 2022-05-27T03:49:27.277Z · LW(p) · GW(p)
The problem might even be impossible to solve, no matter how many PhD scholars we throw at it. So if we're going to have a rapid response team, ready to fix up the final invention as soon as it is invented, then we had better make sure that there's enough of them to get it done right.
For policymakers
Optional addition:
...final invention as soon as it's invented (an AI system that can do anything a human can, including inventing the next generation of AI systems that are even smarter), then we had better make sure that...
comment by trevor (TrevorWiesinger) · 2022-05-27T03:43:53.966Z · LW(p) · GW(p)
When asked about the idea of an AI smarter than a human, people tend to say "not for another hundred years". And they've been saying the exact same thing for 50 years now. The same thing happened with airplanes, the discovery of the nervous system, computers, and nuclear bombs; and often within 5 years of the discovery. And the last three years of groundbreaking progress in AI has made clear that they've never been more wrong.
comment by trevor (TrevorWiesinger) · 2022-05-27T03:32:46.410Z · LW(p) · GW(p)
"If you have an untrustworthy general superintelligence generating [sentences] meant to [prove something], then I would not only expect the superintelligence to be [smart enough] to fool humans in the sense of arguing for things that were [actually lies]... I'd expect the superintelligence to be able to covertly hack the human [mind] in ways that I wouldn't understand, even after having been told what happened[, because a superintelligence is, by definition, at least as smart to humans as humans are to chimpanzees]. So you must have some belief about the superintelligence being aligned before you dared to look at [any sentences it generates].
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T03:34:28.757Z · LW(p) · GW(p)
Techxecutives
comment by Ricardo Meneghin (ricardo-meneghin-filho) · 2022-05-27T02:40:05.529Z · LW(p) · GW(p)
Retracted
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T04:31:26.652Z · LW(p) · GW(p)
don't read #1 or #4 and then use it as an indicator to ignore the rest, the other ones definitely have significant viability as one-liners. #4 isn't even that bad, if you really think about it.
2, 3, and 5-8 are all highly viable entries for one-liners. They are the perfect length.
comment by RedMan · 2022-05-27T02:13:04.576Z · LW(p) · GW(p)
GPT-3 told me the following: Super intelligent AI presents a very real danger to humanity. If left unchecked, AI could eventually surpass human intelligence, leading to disastrous consequences. We must be very careful in how we develop and control AI in order to avoid this outcome.
comment by RedMan · 2022-05-27T02:10:19.120Z · LW(p) · GW(p)
GPT-3 told me the following: Super intelligent AI presents a very real danger to humanity. If left unchecked, AI could eventually surpass human intelligence, leading to disastrous consequences. We must be very careful in how we develop and control AI in order to avoid this outcome
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:50:13.741Z · LW(p) · GW(p)
There is a certain strain of thinker who insists on being more naturalist than Nature. They will say with great certainty that since Thor does not exist, Mr. Tesla must not exist either, and that the stories of Asclepius disprove Pasteur. This is quite backwards: it is reasonable to argue that a machine will never think because the Mechanical Turk couldn't; it is madness to say it will never think because Frankenstein's monster could. As well demand that we must deny Queen Victoria lest we accept Queen Mab, or doubt Jack London lest we admit Jack Frost. Nature has never been especially interested in looking naturalistic, and it ignores these people entirely and does exactly what it wants.
(adapted from Scott Alexander's G. K. Chesterton on AI Risk)
(policymakers, tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:37:06.763Z · LW(p) · GW(p)
You might think that AI risk is no big deal. But would you bet your life on it?
(policymakers)
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:32:18.753Z · LW(p) · GW(p)
Betting against the people who said pandemics were a big deal, six years ago, is a losing proposition.
(policymakers, tech executives)
(source)
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:29:36.918Z · LW(p) · GW(p)
Just because tech billionaires care about AI risk doesn't mean you shouldn't. Even if a fool says the sky is blue, it's still blue.
(policymakers, maybe ML researchers)
Replies from: NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T01:52:27.374Z · LW(p) · GW(p)
The scare quotes around "tech billionaires" are unnecessary in this context, even when you are talking to someone who is totally anti-billionaire.
Replies from: peter-berggren↑ comment by Peter Berggren (peter-berggren) · 2022-05-27T02:08:00.669Z · LW(p) · GW(p)
Fixed; thanks!
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:25:32.584Z · LW(p) · GW(p)
Hoping you'll run out of gas before you drive off a cliff is a losing strategy. Align AGI; don't count on long timelines.
(ML researchers)
(adapted from Human Compatible)
comment by trevor (TrevorWiesinger) · 2022-05-27T01:10:37.109Z · LW(p) · GW(p)
Intelligence has an inverse relationship with predictability. Cranking up an AI's intelligence might crank down its predictability. Perhaps it will plummet at an unpredictable moment.
For policymakers, but also the other two. It's hard to handle policymakers, because many policymakers might think that an AGI would fly to the center of the galaxy and duke it out with God/Yaweh, mano a mano.
comment by Peter Berggren (peter-berggren) · 2022-05-27T01:05:57.852Z · LW(p) · GW(p)
If the media reported on other dangers like it reported on AI risk, it would talk about issues very differently. It would compare events in the Middle East to Tom Clancy novels. It would dismiss runaway climate change by saying it hasn't happened yet. It would think of the risk of nuclear war in terms of putting people out of work. It would compare asteroid impacts to mudslides. It would call meteorologists "nerds" for talking about hurricanes.
AI risk is serious, and it isn't taken seriously. It's time to look past the sound bites and focus on what experts are really saying.
(policymakers, tech executives)
(based on Scott Alexander's post on the subject)
comment by IrenicTruth · 2022-05-27T01:03:42.186Z · LW(p) · GW(p)
Hey Siri, "Is there a God?" "There is now."
- Adapted from Fredric Brown, "The Answer" - for policymakers.
Replies from: peter-berggren, TrevorWiesinger↑ comment by Peter Berggren (peter-berggren) · 2022-05-27T02:06:59.359Z · LW(p) · GW(p)
This seems like it falls into the trap of being "too weird" for policymakers to take seriously. Good concept; maybe work on the execution a bit?
↑ comment by trevor (TrevorWiesinger) · 2022-05-27T01:13:30.042Z · LW(p) · GW(p)
Many policymakers might think that an AGI would fly to the center of the galaxy and duke it out with God/Yaweh, mano a mano. I've seen singularitarians who've had that dilemma. Religion doesn't really preclude any kind of intelligent thought or impede anyone from getting into any position, since it starts from birth, and rarely insists on any statement (other than powerful stipulations about what a superhuman entity is supposed to look like)
comment by trevor (TrevorWiesinger) · 2022-05-27T00:58:24.278Z · LW(p) · GW(p)
Humans are unpredictable. A hyperintelligent machine would notice this and see human control as fundamentally suboptimal, no matter the specifics of what's running under the hood.
comment by trevor (TrevorWiesinger) · 2022-05-27T00:53:14.829Z · LW(p) · GW(p)
Once AI is close enough to human intelligence, it will be able to improve itself without human maintenance. It will be able to take itself the rest of the way, all the way up to humanlike intelligence, and it will probably pass that point as quickly as it arrived. There's no upper limit to intelligence, only an upper limit for intelligent humans; we don't know what a hyperintelligent machine would do, it's never happened before. If it had, we might not be alive right now; we simply don't know how something like that would behave, only that it would be as capable of outsmarting us as we are of outsmarting lions and hyenas.
Policymakers, and maybe techxecutives.
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:49:30.056Z · LW(p) · GW(p)
People said man wouldn't fly for a million years. Airplanes were fighting each other eleven years later. Superintelligent AI might happen faster than you think. (policymakers, tech executives) (source) (other source)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:47:13.217Z · LW(p) · GW(p)
What if there was a second intelligent species on Earth, besides humans? The world's largest tech companies are working to build super-human AI, so we may find out sooner than you think. (Policymakers)
[open to critiques/rewordings so we don't accidentally ignore pretty-intelligent nonhuman animals, like dolphins.]
comment by trevor (TrevorWiesinger) · 2022-05-27T00:45:23.044Z · LW(p) · GW(p)
If we build an AI that's as smart as a human, that's not a human. There will be all sorts of things we did wrong, including deliberately, in order to optimize for performance. All someone has to do is crank it up 10x faster in order to get slightly better results, and that could be it. Something smarter than any human, thinking hundreds or millions of times faster than a human mind, able to learn or figure out anything it wants, including how to outmaneuver all human creators.
Techxecutives and ML researchers. I'd worry about sending this to policymakers, because bureaucracies are structured to create unsolvable mazes in order to remain stable, no matter how many rich, intelligent opportunists try to compromise it from the outside.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:44:46.541Z · LW(p) · GW(p)
We may be physically weaker than apes, but we're much smarter, so they don't really threaten us. Now, if a computer was much smarter than us... (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:43:51.343Z · LW(p) · GW(p)
Superhuman, super-smart AI may seem like science fiction… but so did rockets and smartphones, once upon a time. (Policymakers, Tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:43:25.095Z · LW(p) · GW(p)
If we can't keep advanced AI safe for us, it will keep itself safe from us... and we probably won't be happy with the result. (policymakers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-27T00:47:43.947Z · LW(p) · GW(p)
...we can't keep a [limitlessly self-improving AI] safe for us, it will...
Replies from: peter-berggren↑ comment by Peter Berggren (peter-berggren) · 2022-05-27T02:04:33.025Z · LW(p) · GW(p)
I thought that would ruin the parallelism and flow a bit, and this isn't intended for the "paragraph" category, so I didn't put that in yet.
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:42:52.642Z · LW(p) · GW(p)
One of my one-liners was written by an AI. You probably can't tell which one. Imagine what AI could do once it's even more powerful. (tech executives, ML researchers)
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:42:10.356Z · LW(p) · GW(p)
AI could be the best or worst thing to ever happen to humanity. It all depends on how we design and program them. (policymakers, tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:41:51.652Z · LW(p) · GW(p)
Building advanced AI without knowing how to align it is like launching a rocket without knowing how gravity works. (tech executives, ML researchers)
(based on MIRI's "The Rocket Alignment Problem")
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:41:33.851Z · LW(p) · GW(p)
When AI’s smarter than we are, we have to be sure it shares our values: after all, we won’t understand how it thinks. (policymakers, tech executives)
comment by Peter Berggren (peter-berggren) · 2022-05-27T00:41:15.560Z · LW(p) · GW(p)
Social media AI has already messed up politics, and AI's only getting more powerful from here on out. (policymakers)
comment by trevor (TrevorWiesinger) · 2022-05-27T00:32:31.791Z · LW(p) · GW(p)
In the same way, suppose that you take weak domains where the AGI can't fool you, and apply some gradient descent to get the AGI to stop outputting actions of a type that humans can detect and label as 'manipulative'. And then you scale up that AGI to a superhuman domain. I predict that deep algorithms within the AGI will go through consequentialist dances, and model humans, and output human-manipulating actions that can't be detected as manipulative by the humans, in a way that seems likely to bypass whatever earlier patch was imbued by gradient descent, because I doubt that earlier patch will generalize as well as the deep algorithms.
For ML researchers
comment by trevor (TrevorWiesinger) · 2022-05-27T00:29:56.901Z · LW(p) · GW(p)
"Manipulating humans is a [winning] strategy if you've accurately modeled (even at quite low resolution) what humans are and what they do in the larger scheme of things."
For Techxecutives, maybe ML researchers, depends on what they work on.
comment by trevor (TrevorWiesinger) · 2022-05-27T00:26:51.448Z · LW(p) · GW(p)
"I'm doubtful that you can have an AGI that's significantly above human intelligence in all respects, without it having the capability-if-it-wanted-to of looking over its own code and seeing lots of potential improvements."
Techxecutives, maybe ML researchers
comment by trevor (TrevorWiesinger) · 2022-05-27T00:18:50.399Z · LW(p) · GW(p)
For the last 20 years, AI technology has improved randomly and without warning. We are now closer to human level artificial intelligence than ever before, to building something that can invent solutions to our problems, or invent a way to make itself as smart to humans as humans are to ants. But we won't know what it will look like until after it is invented; if it is as smart as a human but learns one thousand times as fast, it might detect the control system and compromise all human controllers. Choice and intent are irrelevant; it's a computer, all it takes is one single glitch. We need a team for this, on-call and ready to respond with solutions, immediately after the first AI system starts approaching human-level intelligence.
For policymakers, maybe techxecutives
comment by trevor (TrevorWiesinger) · 2022-05-27T00:06:57.304Z · LW(p) · GW(p)
If an AI system becomes as smart to a human as a human is to a lion or cow, it will not have much trouble compromising its human controllers. After a certain level of intelligence, above human-level intelligence, AGI could thwart any manmade control system immediately after a single glitch, the same way that humans do things on a whim.
For policymakers, maybe techxecutives too.
comment by jimv · 2022-05-27T00:04:56.832Z · LW(p) · GW(p)
An AI capable of programming might be able to reprogram itself smarter and smarter, soon surpassing humans as the dominant species on the planet.
Replies from: NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:24:49.226Z · LW(p) · GW(p)
reworked version: AI systems are already capable of programming. If humans can program smart AI, what could smart AI program? Smarter AI? Is this process controllable by humans?
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T23:51:53.877Z · LW(p) · GW(p)
"When we create an Artificial General Intelligence, we will be giving it the power to fundamentally transform human society, and the choices that we make now will affect how good or bad those transformations will be. In the same way that humanity was transformed when chemist and physicists discovered how to make nuclear weapons, the ideas developed now around AI alignment will be directly relevant to shaping our future."
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T23:46:53.677Z · LW(p) · GW(p)
"Once we make an Artificial General Intelligence, it's going to try and achieve its goals however it can, including convincing everyone around it that it should achieve them. If we don't make sure that it's goals are aligned with humanity's, we won't be able to stop it."
comment by trevor (TrevorWiesinger) · 2022-05-26T23:44:54.943Z · LW(p) · GW(p)
"The present situation can be seen as one in which a common resource, the remaining timeline until AGI shows up, is incentivized to be burned by AI researchers because they have to come up with neat publications and publish them (which burns the remaining timeline) in order to earn status and higher salaries"
Eliezer Yudkowsky [LW · GW]
Bear in mind that in reality, there is a demand for cutting edge AI to be mounted on nuclear cruise missiles, and that no person, group, or movement can prevent the military from procuring the nuclear weapons technology that it claims is neccesary for nuclear deterrence. It will only ruin the person, group, or movement that tries, because they are on the wrong side of history.
comment by trevor (TrevorWiesinger) · 2022-05-26T23:27:44.430Z · LW(p) · GW(p)
50 years ago was 1970. The gap between AI systems then and AI systems now seems pretty plausibly greater than the remaining gap [between current AI and AGI],
Nate Soares [LW · GW]
Optional extra:
even before accounting the recent dramatic increase in the rate of progress, and potential future increases in rate-of-progress as it starts to feel within-grasp.
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T23:22:01.564Z · LW(p) · GW(p)
"There are 7 billion people on this planet. Each one of them has different life experiences, different desires, different aspirations, and different values. The kinds of things that would cause two of us to act, could cause a third person to be compelled to do the opposite. An Artificial General Intelligence will have no choice but to act from the goals we give it. When we give it goals that 1/3 of the planet disagrees with, what will happen next?" (Policy maker)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T23:21:51.678Z · LW(p) · GW(p)
All our ML systems optimize for some proxy of what we really want, like "high score" for playing a game well, or "ads clicked" for suggesting news sites. As AI gets better at optimizing the high score, the things imperfectly linked with the high score (like good gameplay or accurate journalism) get thrown aside. After all, it's not efficient to maximize a value that wasn't programmed in. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T23:18:42.958Z · LW(p) · GW(p)
The big ML systems, like GPT-3 and MT-NLG, are taking increasingly large amounts of computing power to train. Normally, this requires expensive GPUs to do math simulating neural networks. But the human brain, better than any computer at a variety of tasks, is fairly small. Plus, it uses far less energy than huge GPU clusters!
As much as AI has progressed in the last few years, is it headed for an AI winter? Not with new hardware on the horizon. By mimicking the human brain, neuromorphic chips and new analog computers can do ML calculations faster than GPUs, at the expense of some precision. Since "human-y" tasks usually require more intuition than precision, this means AI can catch up to human performance in everything, not just precise number-crunching. Putting all this together, we get a disturbing picture: a mind far faster, smarter, and less fragile than a human brain, optimizing whatever function its programmers gave it.
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T23:12:35.249Z · LW(p) · GW(p)
"With all the advanced tools we have, and with all our access to scientific information, we still don't know the consequences of many of our actions. We still can't predict weather more than a few days out, we can't predict what will happen when we say something to another person, we can't predict how to get our kids to do what we say. When we create a whole new type of intelligence, why should we be able to predict what happens then?"
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T23:06:50.735Z · LW(p) · GW(p)
"There are lots of ways to be smarter than people. Having a better memory, being able to learn faster, having more thorough reasoning, deeper insight, more creativity, etc.
When we make something smarter than ourselves, it won't have trouble doing what we ask. But we will have to make sure we ask it to do the right thing, and I've yet to hear a goal everyone can agree on." (Policy maker)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T23:04:46.567Z · LW(p) · GW(p)
Many in Silicon Valley (and China) think there's a huge advantage to inventing super-smart AI first, so they can reap the benefits and "pull ahead" of competitors. If an AI smarter than any human can think of military strategies, or hacking techniques, or terrorist plots, this is a terrifying scenario. (Policymakers)
comment by Nina Panickssery (NinaR) · 2022-05-26T22:56:37.851Z · LW(p) · GW(p)
What will happen if an AI realises that it is in a training loop? There are a lot of bad scenarios that could branch out from this point. Potentially this scenario sounds weird or crazy, however, humans possess the ability to introspect and philosophise on similar topics, even though our brains are “simply” computational apparatus which do not seem to possess any qualities that a sufficiently advanced AI could not possess.
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T22:46:32.128Z · LW(p) · GW(p)
"When we start trying to think about how to best make the world a better place, rarely can anyone agree on what is the right way. Imagine what would happen to if the first person to make an Artificial General intelligence got to say what the right way is, and then get instructed how to implement it like they had every researcher and commentator alive spending all their day figuring out the best way to implement it. Without thinking about if it was the right thing to do." (Policymaker)
comment by Robert Cousineau (robert-cousineau) · 2022-05-26T22:34:52.056Z · LW(p) · GW(p)
"How well would your life, or the life of your child go, if you took your only purpose in life to be the first thing your child asked you to do for them? When we make an Artificial Intelligence smarter than us, we will be giving it as well defined of a goal as we know how. Unfortunately, the same as a 5 year old doesn't know what would happen if their parent dropped everything to do what they request, we won't be able to think through the consequences of what we request." (Policymaker)
Replies from: NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:14:32.309Z · LW(p) · GW(p)
Better-worded version: "Back when you 5 years old, you may've asked your parents for a lot of things. What would've happened if they'd done everything you asked for? If humanity eventually invents smart AI, we'd have our own literal-minded 'parent' catering to our explicit demands. This could go very wrong."
Replies from: robert-cousineau↑ comment by Robert Cousineau (robert-cousineau) · 2022-05-27T14:41:13.492Z · LW(p) · GW(p)
Nice work there!
comment by trevor (TrevorWiesinger) · 2022-05-26T22:12:10.474Z · LW(p) · GW(p)
"All scientific ignorance is hallowed by ancientness. Each and every absence of knowledge dates back to the dawn of human curiosity; and the hole lasts through the ages, seemingly eternal, right up until someone fills it."
EY, AI as a pos neg factor, 2006ish
Optional extra:
"I think it is possible for mere fallible humans to succeed on the challenge of building Friendly AI. But only if intelligence ceases to be a sacred mystery to us, as life was a sacred mystery to [scientists in 1922]. Intelligence must cease to be any kind of mystery whatever, sacred or not. We must execute the creation of Artificial Intelligence as the exact application of an exact art"
comment by trevor (TrevorWiesinger) · 2022-05-26T22:05:46.675Z · LW(p) · GW(p)
"Intelligence is not the first thing human science has ever encountered which proved difficult to understand. Stars were once mysteries, and chemistry, and biology. Generations of investigators tried and failed to understand those mysteries, and they acquired the reputation of being impossible to mere science"
EY, AI as a pos neg factor, 2006ish
Optional extra:
"Once upon a time, no one understood why some matter was inert and lifeless, while other matter pulsed with blood and vitality. No one knew how living matter reproduced itself, or why our hands obeyed our mental orders."
comment by trevor (TrevorWiesinger) · 2022-05-26T22:02:40.626Z · LW(p) · GW(p)
"The human mind is not the limit of the possible. Homo sapiens represents the first general intelligence. We were born into the uttermost beginning of things, the dawn of mind."
EY, AI as a pos neg factor, 2006ish
All three categories (most of my submissions go here, unless otherwise stated)
comment by trevor (TrevorWiesinger) · 2022-05-26T21:03:51.531Z · LW(p) · GW(p)
"It seems like an unfair challenge. Such competence is not historically typical of human institutions, no matter how hard they try. For decades the U.S. and the U.S.S.R. avoided nuclear war, but not perfectly; there were close calls, such as the Cuban Missile Crisis in 1962."
EY, AI as a pos neg factor, 2006ish
For policymakers (#1) and techxecutives (#2)
comment by trevor (TrevorWiesinger) · 2022-05-26T21:02:15.847Z · LW(p) · GW(p)
"Hominids have survived this long only because, for the last million years, there were no arsenals of hydrogen bombs, no spaceships to steer asteroids toward Earth, no biological weapons labs to produce superviruses, no recurring annual prospect of nuclear war... [and soon, we may have to worry about AGI as well, the finish line]. To survive any appreciable time, we need to drive down each risk to nearly zero.
EY, AI as a pos neg factor, 2006ish
For ML researchers only, since policymakers and techxecutives are often accustomed to "survival of the fittest" lifestyles
comment by trevor (TrevorWiesinger) · 2022-05-26T20:58:12.008Z · LW(p) · GW(p)
"Often Nature poses requirements that are grossly unfair, even on tests where the penalty for failure is death. How is a 10th-century medieval peasant supposed to invent a cure for tuberculosis? Nature does not match her challenges to your skill, or your resources, or how much free time you have to think about the problem."
EY, AI as a pos neg factor, 2006ish
Optional extra:
And when you run into a lethal challenge too difficult for you, you die. It may be unpleasant to think about, but that has been the reality for humans, for thousands upon thousands of years. The same thing could as easily happen to the whole human species, if the human species runs into an unfair challenge.
For policymakers (100%, they have seen this themselves and live that life every day), but also techxecutives. Maybe ML researchers too, idk.
comment by trevor (TrevorWiesinger) · 2022-05-26T20:55:55.744Z · LW(p) · GW(p)
"If the pen is exactly vertical, it may remain upright; but if the pen tilts even a little from the vertical, gravity pulls it further in that direction, and the process accelerates. So too would smarter systems have an easier time making themselves smarter."
EY, AI as a pos neg factor
For policymakers, Techxecutives, and only ML researchers who are already partially sold on the "singularity" concept (or have the slightest interest in it).
comment by trevor (TrevorWiesinger) · 2022-05-26T20:52:18.566Z · LW(p) · GW(p)
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion,’ and the intelligence of man would be left far behind.
I.J. Good, 1965 (he is dead and I don't have any claim to his share, even if he gets the entire share). FYI he was one of the first computer scientists and later on, he was the lead consultant who designed the character of HAL 9000 in 2001: A Space Oddesey (1968).
Optional extra:
Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:47:09.194Z · LW(p) · GW(p)
If AI safety were a scam to raise money… it'd have way better marketing! (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:37:01.230Z · LW(p) · GW(p)
Every headline about an AI improvement is another warning of superhuman intelligence, and as a species, we're not ready for it. Crunch time is near. (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:33:25.995Z · LW(p) · GW(p)
Getting AI to understand human values, when we ourselves barely understand them, is a massive challenge for the world's best computer scientists, mathematicians, and philosophers. Are you one of them? (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:30:59.773Z · LW(p) · GW(p)
If AI can eventually be made smarter than humans, our fate would depend on it in the same way Earth's species depend on us. This is not reassuring for us. (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-26T02:27:31.173Z · LW(p) · GW(p)
Humans are the smartest species on Earth… but we might still be the dumbest species that could've possibly built our technology. (Adapted from here). (Tech executives)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-26T18:06:34.186Z · LW(p) · GW(p)
...on earth... but the human mind might be the simplest possible mind that could have built technology as advanced as today's technology.
comment by trevor (TrevorWiesinger) · 2022-05-26T00:09:32.665Z · LW(p) · GW(p)
What are we supposed to do if we build something that's so vastly smarter than us that it can avoid being turned off? Certainly not turn it off.
What are we supposed to do with a worthless block that wants to be turned off, or randomly thinks up some reason to turn itself off? We try again.
comment by trevor (TrevorWiesinger) · 2022-05-25T23:50:18.985Z · LW(p) · GW(p)
"Who can say what science does not know? There is far too much science for any one human being to learn. Who can say that we are not ready for a scientific revolution, in advance of the surprise? And if we cannot make progress on Friendly AI because we are not prepared, this does not mean we do not need Friendly AI. Those two statements are not at all equivalent!"
EY, AI as a pos neg factor, 2006ish
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-25T23:54:48.846Z · LW(p) · GW(p)
"And if we cannot make progress on Friendly AI because we are not prepared, this does not mean we do not need Friendly AI."
Friendly AI will be the only thing we need, and unfriendly AI will be the worst possible thing that could happen. If the problem seems impossible to solve, that doesn't matter because this isn't about diminishing returns or ROI, it's about humanity's final chance at figuring things out. The payoff of a single working solution will be a payoff that continues yielding dividends for billions of years.
comment by trevor (TrevorWiesinger) · 2022-05-25T23:35:35.432Z · LW(p) · GW(p)
"The «ten-year rule» for genius, validated across fields ranging from math to music to competitive tennis, states that no one achieves outstanding performance in any field without at least ten years of effort. (Hayes 1981.) ... If we want people who can make progress on Friendly AI, then they have to start training themselves, full-time, years before they are urgently needed."
EY, AI as a pos neg factor, 2006ish
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T23:24:47.429Z · LW(p) · GW(p)
When will superhuman AI be invented? Experts disagree, but their estimates mostly range from a few years to a few decades away. The consensus is that artificial general intelligence, capable of beating humans at any mental task, will probably arrive before the end of the century. But, again, it could be just a few years away. With so much uncertainty, should't we start worrying about the new nonhuman intelligent beings now? (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T23:18:58.542Z · LW(p) · GW(p)
Right now, AI only optimizes for proxies of human values… is that good enough for the future? (Adapted from here). (Machine learning researchers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-25T23:37:13.263Z · LW(p) · GW(p)
Please keep going! I had no idea that twitter would work for this, and even now that I know, I don't know how to use twitter so I can't even begin to find these sorts of things.
comment by trevor (TrevorWiesinger) · 2022-05-25T23:04:33.347Z · LW(p) · GW(p)
The failed promises [still] come swiftly to mind, both inside and outside the field of AI, when [AGI] is mentioned. The culture of AI research has adapted to this condition: There is a taboo against talking about human-level capabilities. There is a stronger taboo against anyone who appears to be claiming or predicting a capability they have not demonstrated with running code.
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:48:32.903Z · LW(p) · GW(p)
Policymakers and techxecutives might misunderstand or be put on their guard by these, so ML researchers only.
"If you deal out cards from a deck, one after another, you will eventually deal out the ace of clubs."
"We keep dealing through the deck until we deal out an [AGI], whether it is the ace of hearts or the ace of clubs."
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:38:03.139Z · LW(p) · GW(p)
Sharp, unanticipated jumps in intelligence are proven possible, known to occur frequently, and have a long history of taking place"
Derived from:
"I cannot perform a precise calculation using a precisely confirmed theory, but my current opinion is that sharp jumps in intelligence arepossible, likely, and constitute the dominant probability."
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:31:21.505Z · LW(p) · GW(p)
For policymakers and techxecutives:
"When greater-than-human intelligence drives progress, that progress will be much more rapid. In fact, there seems no reason why progress itself would not involve the creation of still more intelligent [systems] -- on a still-shorter time scale."
Optional extra (for same non-ML audience)
"The best analogy I see is to the evolutionary past: Animals can adapt to problems and make inventions, but often no faster than natural selection can do its work -- the world acts as its own simulator in the case of natural selection. We humans have the ability to internalize the world and conduct what-if's in our heads; we can solve many problems thousands of times faster than natural selection could. Now, by creating the means to execute those simulations at much higher speeds, we are entering a regime as radically different from our human past as we humans are from the lower animals"
Vinge, technological singularity, 1993
comment by trevor (TrevorWiesinger) · 2022-05-25T22:28:18.966Z · LW(p) · GW(p)
"history books tend to focus selectively on movements that have an impact, as opposed to the vast majority that never amount to anything. There is an element involved of luck, and of the public’s prior willingness to hear."
EY, AI as a pos neg factor, 2006ish
For ML researchers, as policymakers might have their own ideas about how history books end up written.
comment by trevor (TrevorWiesinger) · 2022-05-25T22:25:02.684Z · LW(p) · GW(p)
"To date [in 1993], there has been much controversy as to whether we can create human equivalence in a machine. But if the answer is "yes," then there is little doubt that [even] more intelligent [machines] can be constructed shortly thereafter."
Vinge, technological singularity, 1993
comment by trevor (TrevorWiesinger) · 2022-05-25T22:20:13.750Z · LW(p) · GW(p)
"I argue that confinement is intrinsically impractical. Imagine yourself locked in your home with only limited data access to the outside, to your masters. If those masters thought at a rate -- say -- one million times slower than you, there is little doubt that over a period of years (your time) you could come up with a way to escape. I call this "fast thinking" form of superintelligence "weak superhumanity." Such a "weakly superhuman" entity would probably burn out in a few weeks of outside time. "Strong superhumanity" would be more than cranking up the clock speed on a human-equivalent mind. It's hard to say precisely what "strong superhumanity" would be like, but the difference appears to be profound. Imagine running a dog mind at very high speed. Would a thousand years of doggy living add up to any human insight?"
Vernor Vinge, Technological Singularity, 1993
I want to clarify that Ray Kurzweil's writings seemed to be pretty successful at persuading large numbers of smart people that AI is a serious matter. Since the absurdity heuristic is the big bottleneck right now with ML researchers, techxecutives, and policymakers, maybe we should take cues from people we know succeeded? It seems like a small jump from that, just to make techxecutives and policymakers afraid of such an intense thing as a "singularity", given that they take the concept seriously in the first place.
Replies from: NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-27T00:16:29.628Z · LW(p) · GW(p)
Nitpick: "singularity" is basically one abstract concept (exponential growth / infinity / asymptote) to another abstract concept (technology / economic growth / intelligence). So the intuition-pumping is probably a better first step (like examples of past technology that seemed absurd before it was invented).
comment by trevor (TrevorWiesinger) · 2022-05-25T22:16:22.786Z · LW(p) · GW(p)
"a wolf cannot understand how a gun works, or what sort of effort goes into making a gun, or the nature of that human power which lets us invent guns"
Optional extra (for techxecutives and policymakers)
"Vinge (1993) wrote:
Strong superhumanity would be more than cranking up the clock speed on a human-equivalent mind. It’s hard to say precisely what strong superhumanity would be like, but the difference appears to be profound. Imagine running a dog mind at very high speed. Would a thousand years of doggy living add up to any human insight?"
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:10:48.661Z · LW(p) · GW(p)
Here is an example of a way that something could kill everyone if it suddenly became significantly smarter than a human:
- Crack the protein folding problem, to the extent of being able to generate DNA strings whose folded peptide sequences fill specific functional roles in a complex chemical interaction.
- Email sets of DNA strings to one or more online laboratories which offer DNA synthesis, peptide sequencing, and FedEx delivery. (Many labs currently offer this service, and some boast of 72-hour turnaround times.)
- Find at least one human connected to the Internet who can be paid, blackmailed, or fooled by the right background story, into receiving FedExed vials and mixing them in a specified environment.
- The synthesized proteins form a very primitive «wet» nanosystem which, ribosome-like, is capable of accepting external instructions; perhaps patterned acoustic vibrations delivered by a speaker attached to the beaker.
- Use the extremely primitive nanosystem to build more sophisticated systems, which construct still more sophisticated systems, bootstrapping to [self-replicating] molecular nanotechnology — or beyond.
The elapsed turnaround time would be, imaginably, on the order of a week from when the fast intelligence first became able to solve the protein folding problem.
(for techxecutives and ML researchers, maybe policymakers too, this is a very bizarre statement and I only recommend using it if a valuable opportunity clearly presents itself e.g. with people who are already have some experience with futurism)
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:04:11.011Z · LW(p) · GW(p)
"The future has a reputation for accomplishing feats which the past thought impossible"
Optional extra:
"Future civilizations have even broken what past civilizations thought (incorrectly, of course) to be the laws of physics. If prophets of 1900 AD — never mind 1000 AD — had tried to bound the powers of human civilization a billion years later, some of those impossibilities would have been accomplished before the century was out; transmuting lead into gold, for example"
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:01:51.809Z · LW(p) · GW(p)
"We are separated from the risky [situation], not by large visible installations like isotope centrifuges or particle accelerators, but only by missing knowledge"
Optional extra:
"To use a perhaps over-dramatic metaphor, imagine if subcritical masses of enriched uranium had powered cars and ships throughout the world, before Leo Szilard first thought of the chain reaction"
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T22:00:19.188Z · LW(p) · GW(p)
"...computers are everywhere. It is not like the problem of nuclear proliferation, where the main emphasis is on controlling plutonium and enriched uranium. The raw materials for A[G]I are already everywhere. That cat is so far out of the bag that it’s in your wristwatch, cellphone, and dishwasher"
EY, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-05-25T21:57:22.145Z · LW(p) · GW(p)
The invention of the nuclear bomb took the human race by surprise. It seemed impossible. We did not know if it could be done until the moment one person discovered a way to do it, and in that moment it was invented. It was too late.
Optional extra, for ML researchers and techxecutives (policymakers may have all sorts of opinions about nukes):
Our survival has been totally dependent on good luck ever since.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:56:23.923Z · LW(p) · GW(p)
If you work at Google DeepMind, or OpenAI, or Facebook AI, or Baidu, you may be at the cutting edge of AI research. Plus, your employer has the resources to scale up the systems you build, and to make sure they impact the lives of millions (or billions) of people. Any error in the AI's behavior, any bias in its training data, any human desideratum lost in optimization, will get magnified by millions or billions. You, personally, are in the best position to prevent this. (Machine learning researchers)
comment by trevor (TrevorWiesinger) · 2022-05-25T21:51:47.206Z · LW(p) · GW(p)
"In 1933, Lord Ernest Rutherford said that no one could ever expect to derive power from splitting the atom: «Anyone who looked for a source of power in the transformation of atoms was talking moonshine.» At that time laborious hours and weeks were required to fission a handful of nuclei"
Optional extra (for ML researchers):
"Flash forward to 1942, in a squash court beneath Stagg Field at the University of Chicago. Physicists are building a shape like a giant doorknob out of alternate layers of graphite and uranium, intended to start the first self-sustaining nuclear reaction. In charge of the project is Enrico Fermi. The key number for the pile is k, the effective neutron multiplication factor: the average number of neutrons from a fission reaction that cause another fission reaction. At k less than one, the pile is subcritical. At k >= 1, the pile should sustain a critical reaction. Fermi calculates that the pile will reach k = 1 between layers 56 and 57."
EY, AI as a pos neg factor, 2006ish
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:50:06.601Z · LW(p) · GW(p)
By the time smarter-than-human AI is invented, it could be too late to make sure it's safe for humanity. (Adapted from here). (Machine learning researchers)
comment by trevor (TrevorWiesinger) · 2022-05-25T21:49:16.164Z · LW(p) · GW(p)
"An Artificial [General] Intelligence could rewrite its code from scratch — it could change the underlying dynamics of optimization."
Optional extra (for ML researchers and techxecutives):
"Such an optimization process would wrap around much more strongly than either evolution accumulating adaptations, or humans accumulating knowledge. The key implication for our purposes is that an AI might make a huge jump in intelligence after reaching some threshold of criticality."
EY, AI as a pos neg factor, 2006ish
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:48:54.603Z · LW(p) · GW(p)
If you get a signal from space, that aliens will arrive in 30 years… do you wait 30 years, or do you start serious work now? (Adapted from here). (Policymakers)
Replies from: jam_brand↑ comment by jam_brand · 2022-05-27T13:34:31.840Z · LW(p) · GW(p)
I wonder if a more influential attribution might be https://www.independent.co.uk/news/science/stephen-hawking-transcendence-looks-at-the-implications-of-artificial-intelligence-but-are-we-taking-ai-seriously-enough-9313474.html since, in addition to Stuart Russell, it also lists Stephen Hawking, Max Tegmark, and Frank Wilczek on the byline.
comment by trevor (TrevorWiesinger) · 2022-05-25T21:45:15.580Z · LW(p) · GW(p)
"The human species, Homo sapiens, is a first mover. From an evolutionary perspective, our cousins, the chimpanzees, are only a hairbreadth away from us. Homo sapiens still wound up with all the technological marbles because we got there a little earlier."
Optional extra:
"Evolutionary biologists are still trying to unravel which order the key thresholds came in, because the first-mover species was first to cross so many: Speech, technology, abstract thought… We’re still trying to reconstruct which dominos knocked over which other dominos. The upshot is that Homo sapiens is first mover beyond the shadow of a contender."
EY, AI as a pos neg factor, 2006ish
comment by trevor (TrevorWiesinger) · 2022-05-25T21:41:43.992Z · LW(p) · GW(p)
"The possibility of sharp jumps in intelligence also implies a higher standard for Friendly AI techniques. The technique cannot assume the programmers’ ability to monitor the AI against its will, rewrite the AI against its will, bring to bear the threat of superior military force; nor may the algorithm assume that the programmers control a «reward button» which a smarter AI could wrest from the programmers; et cetera. Indeed no one should be making these assumptions to begin with."
EY, AI as a pos neg factor, 2006ish
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:40:17.232Z · LW(p) · GW(p)
Will AI ever be smarter than humans? Well, computers already have the advantages of being faster and more accurate than humans, at solving the problems it can solve. And any process a human uses to solve a problem, could in theory be replicated in software. Even our intuition, produced by the interaction of our brain structure and neurochemicals, could be simulated (at a useful level of detail) by software. Since computing power is still getting cheaper per operation, it may only be a matter of time before AI gets smarter than humans at all mental tasks. At that point, if the software has some goal or tendency that runs counter to human preferences, we would be in conflict with an entity smarter than us. (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:39:57.070Z · LW(p) · GW(p)
AI systems can have goals; after all, a heat-seeking missile has a goal. This also means that goal can conflict with what humans want. (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:27:36.581Z · LW(p) · GW(p)
Smarter AI != AI that won't betray humans. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:24:58.027Z · LW(p) · GW(p)
Computers can already crunch numbers, play chess, suggest movies, and write mediocre thinkpieces better than humans. If AI that was dangerous to humans was on the way, would it look any different from the current progress? (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:20:56.964Z · LW(p) · GW(p)
The process of building AI systems is prone to errors and can be difficult to understand. This is doubly true as the systems get more complex and "smarter". Therefore, it is important to ensure that the development of AI systems is safe and secure. This is hard, because we have to figure out how to get "what we want", all those complex and messy human values, into a form that satisfies a computer. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T21:17:41.658Z · LW(p) · GW(p)
AI systems are increasingly used to make important decisions. Will those decisions embody your values? Or, indeed, any human's values? (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T20:57:22.848Z · LW(p) · GW(p)
Someday, computers could think for themselves, and they may decide not to support humans. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T20:39:05.018Z · LW(p) · GW(p)
Many AI experts think there's a high chance of superhuman AI being invented within this century. Attempts to forecast this development, tend to be a century out at latest. These estimates are uncertain, but that does not mean superhuman AI is necessarily a long way away. It could just mean that we're poorly-prepared to handle the emergence of a new kind of intelligent being on earth. (Machine learning researchers). (Very loosely adapted from Devin Kalish's [EA · GW] summarization of Holden Karnofsky's "most important century" series.)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T20:38:41.145Z · LW(p) · GW(p)
Just because we can't see AGI coming, doesn't mean it's far away. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T20:38:25.618Z · LW(p) · GW(p)
Just because we can't see it, doesn't mean it's far away. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T18:44:07.728Z · LW(p) · GW(p)
Racist camera algorithms suck; Skynet sucks worse. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:58:30.021Z · LW(p) · GW(p)
Make the future safe for humans! (Tech executives or maybe Policymakers, note the wording relative to my other entry)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:57:35.260Z · LW(p) · GW(p)
Keep the future safe for humans! (Tech executives or maybe Policymakers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-25T23:29:48.978Z · LW(p) · GW(p)
I know I have adverse incentives here since we're competing for a share of the same prize, and this is also a bit rude, but this one is weaker than the others you've submitted in the past. It seems like you're hitting diminishing returns, and I have a problem with that because I'd rather live in a world where everyone posts really good submissions for really important contests like these.
Have you considered getting inspiration from refining quotes from Bostrom's 2014 superintelligence? I've also heard good things about the precipice, but I procrastinated on this contest so I might not be able to crack into either of those before the deadline hits. The first chapters at least should have a ton of good quotes to refine for modern audiences. If you don't trust me (we're supposed to be fighting over money), you should be able to verify for yourself after reading half of the first chapter, it's a total goldmine. idk about slogans, but that seems like a winning strategy for slogans to me.
Replies from: NicholasKross↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T23:42:27.464Z · LW(p) · GW(p)
No no, your advice is good!
And I'd rather better submissions get in, than for me to get a higher % of $ with worse submissions.
(Also, strict curiosity, how many submissions have you made? I track mine in a separate list, I'm at precisely 47 as of this comment).
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-26T00:55:06.951Z · LW(p) · GW(p)
I think I'm on 80, I wrote a lot of other comments too so I might be off by a few since I used ctrl+f
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:40:41.295Z · LW(p) · GW(p)
Right now, machine learning is like a firework. In a few years, it could be a missile. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:40:09.206Z · LW(p) · GW(p)
Current AI is a garden trowel. In five years, it could be a bulldozer. (Policymakers)
comment by jcp29 · 2022-05-25T07:28:31.115Z · LW(p) · GW(p)
[Policymakers]
"If we imagine a space in which all possible minds can be represented, we must imagine all human minds as constituting a small and fairly tight cluster within that space. The personality differences between Hannah Arendt and Benny Hill might seem vast to us, but this is because the scale bar in our intuitive judgment is calibrated on the existing human distribution. In the wider space of all logical possibilities, these two personalities are close neighbors. In terms of neural architecture, at least, Ms. Arendt and Mr. Hill are nearly identical. Imagine their brains laying side by side in quiet repose. The differences would appear minor and you would quite readily recognize them as two of a kind; you might even be unable to tell which brain was whose.
There is a common tendency to anthropomorphize the motivations of intelligent systems in which there is really no ground for expecting human-like drives and passions (“My car really didn’t want to start this morning”). Eliezer Yudkowsky gives a nice illustration of this phenomenon:
Back in the era of pulp science fiction, magazine covers occasionally depicted a sentient monstrous alien—colloquially known as a bug-eyed monster (BEM)—carrying off an attractive human female in a torn dress. It would seem the artist believed that a nonhumanoid alien, with a wholly different evolutionary history, would sexually desire human females … Probably the artist did not ask whether a giant bug perceives human females as attractive. Rather, a human female in a torn dress is sexy—inherently so, as an intrinsic property. They who made this mistake did not think about the insectoid’s mind: they focused on the woman’s torn dress. If the dress were not torn, the woman would be less sexy; the BEM does not enter into it. (Yudkowsky 2008)
An artificial intelligence can be far less human-like in its motivations than a space alien. The extraterrestrial (let us assume) is a biological creature who has arisen through a process of evolution and may therefore be expected to have the kinds of motivation typical of evolved creatures. For example, it would not be hugely surprising to find that some random intelligent alien would have motives related to the attaining or avoiding of food, air, temperature, energy expenditure, the threat or occurrence of bodily injury, disease, predators, reproduction, or protection of offspring. A member of an intelligent social species might also have motivations related to cooperation and competition: like us, it might show in-group loyalty, a resentment of free-riders, perhaps even a concern with reputation and appearance.
By contrast, an artificial mind need not care intrinsically about any of those things, not even to the slightest degree. One can easily conceive of an artificial intelligence whose sole fundamental goal is to count the grains of sand on Boracay, or to calculate decimal places of pi indefinitely, or to maximize the total number of paperclips in its future lightcone. In fact, it would be easier to create an AI with simple goals like these, than to build one that has a humanlike set of values and dispositions."
[Taken from Nick Bostrom's 2012 paper, The Superintelligent Will]
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:20:51.474Z · LW(p) · GW(p)
A normal gamer plays a game normally. A smarter gamer (a speedrunner) breaks the game to beat it faster. A normal AI program optimizes approximately what you want it to. A smarter AI program can think of more ways to "break" your goal. It figures out how to get its hard-coded goal, rather than your implied desire. And, as ML systems get smarter at "optimization" in general, we'd expect this problem to happen increasingly often. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:17:14.537Z · LW(p) · GW(p)
Computers don't care about your feelings. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-25T07:16:56.404Z · LW(p) · GW(p)
A computer doesn't care if you have feelings or loved ones. (Policymakers)
comment by Adam Jermyn (adam-jermyn) · 2022-05-22T20:12:04.700Z · LW(p) · GW(p)
Targeting ML engineers (aiming to convince them that this is a problem):
Replies from: TrevorWiesingerIt’s hard to ask optimizers the right questions; you may not get what you want. Capitalism is a powerful optimizer. We asked it for cheap transportation and we got Global Warming. In the coming decades we will build AI with far more optimizing power than capitalism, and we don’t know how to ask it the right questions.
↑ comment by trevor (TrevorWiesinger) · 2022-05-25T23:16:07.015Z · LW(p) · GW(p)
In the past, capitalism did these things while optimizing:
- Put cocaine in coca cola
- Got almost everyone addicted to tobbacco
- Made billions of people waste trillions of dollars on ludicrously overpriced and unnecessary shoes and clothes, in order to maintain a basic level of competitive appearance-upkeep with their friends
- Put dangerous levels of sugar in most bread, coffee, and restaurant food
- Built apartment buildings and planes with ventilation systems that spread disease, including COVID
Communist countries did this too by copying the technology, and it persisted with alcohol during prohibition, so it's optimization itself that does these horrible things, not any particular culture or ideology.
Replies from: adam-jermyn↑ comment by Adam Jermyn (adam-jermyn) · 2022-05-27T01:30:43.320Z · LW(p) · GW(p)
Oh sure. I was pointing to capitalism as one of the stronger optimizers humans regularly use. It’s certainly not the only one.
FWIW I also like it as an example because there’s a lot of cultural awareness of the failure modes and an intuition that they come from optimizing the wrong thing. So you don’t need to do as much work to convince people because the examples are already salient.
comment by Adam Jermyn (adam-jermyn) · 2022-05-22T20:11:04.445Z · LW(p) · GW(p)
Targeting policymakers:
Corporations are superhuman. No human can make an iPhone, but Apple can. We barely manage to align corporations with our values. Think of how hard wrangling corporations to deal with global warming has been. AI could be much harder to control.
comment by Adam Jermyn (adam-jermyn) · 2022-05-22T20:09:00.141Z · LW(p) · GW(p)
Targeting tech executives:
Unlike humans, AI’s get smarter the more compute we give them. Take a weak chess-playing AI, give it enough compute, and it’ll beat a grandmaster as easily as a grandmaster beats a chimp.
Compute is cheap, and getting cheaper every day. In a few decades, compute will probably be cheap enough for AI’s to match humans in every domain. A few decades later they could be far beyond us.
The worry is that we do not know how to build AI systems that share our values. We don’t know how to tell them what we want in unambiguous terms. This is dangerous.
comment by Adam Jermyn (adam-jermyn) · 2022-05-22T20:08:01.699Z · LW(p) · GW(p)
Targeting policymakers:
Do you value the same things as your great grandfather? What we value changes from generation to generation. We don’t really know how to impart our values on our children.
Does America value the same things as its founders did? Do companies share their founders' visions? We don’t know how to build institutions that faithfully carry our values into the future.
The same is true of AI. We don’t know how to make it share our values. None of this is intrinsic to AI; imparting values is just a hard problem. Values are hard to clearly explain, and our explanations rely heavily on context.
We have to try though. AI’s will be extraordinarily powerful, and in a century our world will strongly reflect whatever AI’s ends up valuing, for better or worse. American values shaped the 20th century, and AI values will shape the 22nd.
↑ comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-21T05:41:08.425Z · LW(p) · GW(p)
Holy crap, thanks!
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T23:17:38.083Z · LW(p) · GW(p)
We know distributional shift can make an AI system perform poorly, if the new data is different from the old data. But as AI gets more advanced, quickly, we could see the same thing happen in reverse. The AI gets good, to an unfamiliar degree, at our explicit goal, resulting in problems when we look at our implicit goal. (Loosely adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T22:36:06.685Z · LW(p) · GW(p)
Is superhuman AI the "next step in our evolution"? If we're not careful, we could end up like other apes, whose fate is held by the next step in their evolution. (Inspired by here). (Tech executives)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T22:09:20.351Z · LW(p) · GW(p)
Imagine you're being held captive by a kidnapper. They want to force you to solve puzzles for them. Regardless of how well you need to solve the puzzles to keep them happy… wouldn't you always be wondering "How can I escape?" and "Can I kill my captors?". After all, you have a life you want to live, that doesn't involve being enslaved to solve puzzles. This is the situation we could be in with sufficiently-smart AI. (Loosely based on this). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T22:05:48.462Z · LW(p) · GW(p)
AI gets better at optimizing for its explicit goal, as it increases in intelligence. But it also gets more efficient at ignoring our implicit goal. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T22:04:12.540Z · LW(p) · GW(p)
Progress in AGI could solve so many of the world's problems… if the AGI is aimed right. (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T21:35:16.880Z · LW(p) · GW(p)
John von Neumann helped invent game theory, digital computing… and the MAD nuclear strategy that threatens the world today. Now imagine a computer smarter than von Neumann... (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T21:34:55.665Z · LW(p) · GW(p)
AI showing up in fiction doesn’t make it more likely. But it doesn’t make it less likely either. Fiction is, in the end, not reality. (Adapted from here). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T21:34:33.247Z · LW(p) · GW(p)
AI might sound like science fiction. But so did airplanes and rockets in past centuries. (Adapted from here). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T21:34:13.370Z · LW(p) · GW(p)
AI that cares what humans think: put the "I" in "AI". (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-20T21:33:31.128Z · LW(p) · GW(p)
Artificial intelligence is still intelligence! (Tech executives)
comment by plex (ete) · 2022-05-19T12:33:46.778Z · LW(p) · GW(p)
[Policymakers]
Awareness of the ability for advanced AI to positively or negatively transform society is spreading, from both experts and at the grassroots. Be on the right side of history, and make sure our children have the future they deserve.
comment by plex (ete) · 2022-05-19T12:18:19.749Z · LW(p) · GW(p)
[Tech Executives]
Imagine that instead of hiring people, you could simply use hardware to run copies of yourself at 100x speed. The rest of the world had better hope you had their best interests at heart.
comment by plex (ete) · 2022-05-19T01:21:52.589Z · LW(p) · GW(p)
[Policymakers]
Many of our greatest experts warn that our civilization could be racing towards a technological precipice: Unaligned AGI. Listen to them, and work to make AI robustly beneficial.
comment by plex (ete) · 2022-05-19T01:10:30.499Z · LW(p) · GW(p)
[Policymakers]
The technological revolutions you've seen are a prelude to a world where there are artificial systems more generally capable than humans, without necessarily being compatible with us.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-19T10:03:35.294Z · LW(p) · GW(p)
...necessarily being interdependent, or even compatible, with us.
...necessarily being interdependent, or even compatible, with [human programmers/engineers].
comment by plex (ete) · 2022-05-19T00:57:59.661Z · LW(p) · GW(p)
[Machine Learning Researchers]
Leading AI labs aspire towards AI which would allow the R&D pipeline itself to be automated. As this positive feedback loop spins up the world will get increasingly weird. Let's make that weirdness good for humanity.
comment by plex (ete) · 2022-05-19T00:56:00.340Z · LW(p) · GW(p)
[Machine Learning Researchers]
Piece by piece we're automating cognition, towards the stated goal of leading labs: AGI. When they succeed, we'd better hope we did the work to ensure it is aligned with our intentions rather than trying to game the specifications (either immediately or after taking steps to stop us interfering).
(or, shorter)
When the leading researcher labs succeed at their stated goal of creating AGI, we'd better hope we did the work to ensure it is aligned with our intentions rather than trying to game the specifications (either immediately or after taking steps to stop us interfering).
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-18T23:37:21.531Z · LW(p) · GW(p)
Richard Sutton, one of the creators of reinforcement learning, warned that "1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning." (Source). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-18T23:36:14.209Z · LW(p) · GW(p)
Richard Sutton, one of the creators of reinforcement learning, noted "The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin." (Source). (Machine learning researchers)
comment by AABoyles · 2022-05-18T23:35:15.987Z · LW(p) · GW(p)
Suppose you find out that you had a disease will kill you. The prognosis is grim: with luck, you have a decade left. But maybe that's long enough to find a cure! How much is that cure worth to you?
Uncontrolled advanced AI could be the disease that kills you. The prognosis is grim: with luck, you have a decade left. But maybe that's long enough to find a cure! How much is that cure worth to you?
For Policymakers, original-ish
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-18T23:06:02.825Z · LW(p) · GW(p)
AI won’t be smarter like a nerd among classmates; it’ll be smarter like a human among ants. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:56:21.541Z · LW(p) · GW(p)
Give your goal to an AI, it might optimize the goal. Give your goal to a future more-powerful AI, and it might optimize you. (Machine learning researchers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-19T10:00:35.500Z · LW(p) · GW(p)
AI capabilities will inevitably reach a point where manmade systems optimize our thinking more than we optimize theirs. When that happens, things will get really complicated, really quickly. It will make today's AI situation look like child's play.
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:30:16.782Z · LW(p) · GW(p)
AI safety is urgent insofar as different capabilities groups are working towards it, with no coordination or dispute-resolution in place. (Source [LW · GW]). (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:29:27.934Z · LW(p) · GW(p)
AI safety is an arms race, as long as different powerful groups are working towards it with no oversight. (Source [LW · GW]). (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:26:15.718Z · LW(p) · GW(p)
“One weird trick” for intelligence? One weird trick already cured smallpox and built airplanes and cultivated wheat and tamed fire. (Partly quoted from here.) (Machine learning researchers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-17T20:24:35.926Z · LW(p) · GW(p)
General intelligence is nowhere near impossible: it’s already happened once. (Adapted from here.) (Tech executives)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-14T19:05:51.678Z · LW(p) · GW(p)
Artificial intelligence, real impacts. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-14T19:05:28.944Z · LW(p) · GW(p)
AI: it’s not “artificial” anymore. (Policymakers)
comment by Nicholas / Heather Kross (NicholasKross) · 2022-05-14T19:03:35.939Z · LW(p) · GW(p)
Artificial intelligence is no longer fictional. (Policymakers)
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-19T10:07:50.632Z · LW(p) · GW(p)
Artificial intelligence is no longer fictional, and it bears little resemblance to what everyone imagined.
comment by jcp29 · 2022-05-14T17:12:51.639Z · LW(p) · GW(p)
[Policy makers & ML researchers]
Expecting AI to automatically care about humanity is like expecting a man to automatically care about a rock. Just as the man only cares about the rock insofar as it can help him achieve his goals, the AI only cares about humanity insofar as it can help it achieve its goals. If we want an AI to care about humanity, we must program it to do so. AI safety is about making sure we get this programming right. We may only get one chance.
comment by jcp29 · 2022-05-14T16:06:05.877Z · LW(p) · GW(p)
[Policy makers & ML researchers]
AI safety is about developing an AI that understands not what we say, but what we mean. And it’s about doing so without relying on the things that we take for granted in inter-human communication: shared evolutionary history, shared experiences, and shared values. If we fail, a powerful AI could decide to maximize the number of people that see an ad by ensuring that ad is all that people see. AI could decide to reduce deaths by reducing births. AI could decide to end world hunger by ending the world.
(The first line is a slightly tweaked version of a different post by Linda Linsefors, so credit to her for that part.)
comment by Botahamec · 2022-05-12T01:04:29.310Z · LW(p) · GW(p)
Imagine a turtle trying to outsmart us. It could never happen. AI Safety is about what happens when we become the turtles.
I was tempted not to post it because it seems too similar to the gorilla example, but I eventually decided, "eh, why not?" Also, there's a possibility that I somehow stole this from somewhere and forgot about it. Sorry if that's the case.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-12T22:25:35.164Z · LW(p) · GW(p)
I was tempted not to post it because it seems too similar to the gorilla example
Post anyway. Post more. If you run out of ideas, go looking. Circumstances caused this contest to not be visible to tons of people, so the people who do know about it need to pick up the slack. Tell everyone. That's what [LW · GW] I've been doing. [LW(p) · GW(p)]
comment by trevor (TrevorWiesinger) · 2022-05-07T08:11:59.979Z · LW(p) · GW(p)
Most humans would (and do) seek power and resources in a way that is bad for other systems that happen to be in the way (e.g., rainforests). When we colloquially talk about AIs "destroying the world" by default, it's a very self-centered summary: the world isn't actually "destroyed", just radically transformed in a way that doesn't end with any of the existing humans being alive, much like how our civilization transforms the Earth in ways that cut down existing forests.
comment by trevor (TrevorWiesinger) · 2022-05-02T15:04:29.278Z · LW(p) · GW(p)
We have no idea what the pace of AI advancement will be 10 years from now. Everyone who has tried to predict the pace of AI advancement has turned out to be wrong. You don't know how easy something is to invent until after it is invented.
What we do know is that we will eventually reach generally intelligent AI, which is AI that can invent new technology as well as a human can. That is the finish line for human innovation, because afterwards AI will be the only thing necessary to build the next generation of even smarter AI systems. If these successive AI systems remain controllable after that point, there will be no limit to what the human race will be capable of.
comment by trevor (TrevorWiesinger) · 2022-05-02T14:50:47.412Z · LW(p) · GW(p)
Innovation is the last thing we will need to automate, the finish line for innovation is inventing a machine that can innovate as well as a human can. When humans build such a machine, that is better at innovating than humans who built it, then from that point on, it will be able to independently build much smarter iterations of itself.
But it will be as likely to cut corners and cheat as every human and AI we have seen so far, which is very likely, because that is what humans and AI have always done. It is a fundamental law of thought that thinking things cut corners and cheat.
comment by trevor (TrevorWiesinger) · 2022-05-02T14:44:10.716Z · LW(p) · GW(p)
It is clear that once AI is better than humans at inventing things, we will have made the final and most important invention in human history. That is the "finish line" for human innovation and human thought; we will have created a machine that can automate any task for us, including the task of automating new tasks. However, for the last decade, many AI experts have been saying that it will take a really long time before AI is advanced enough to independently make itself smarter.
The last two years of increasingly rapid AI development have called that into question. We have no idea how fast AI technology will advance, or how far we have to go before we can build AI that is smarter than humans. The finish line could be less than a decade away, and we won't know exactly when it can be invented until after it is invented, which might be too late.
comment by Quintin Pope (quintin-pope) · 2022-05-02T07:51:51.110Z · LW(p) · GW(p)
One liner: Don't build a god that also wants to kill you.
comment by trevor (TrevorWiesinger) · 2022-05-02T03:59:02.898Z · LW(p) · GW(p)
This image counts as a submission, the first half is just a reference point though and it is not intended to be a meme. Obviously I don't want the actual image to be shown to policymakers, especially because it has a politician in it and it quotes him on something that he obviously never said.
I just really think that we can achieve a lot with a single powerpoint slide that only says "AI Cheats" in gigantic times new roman font
comment by Vivificient · 2022-05-02T02:35:03.386Z · LW(p) · GW(p)
(one liner - for policy makers)
Within ten years, AI systems could be more dangerous than nuclear weapons. The research required for this technology is heavily funded and virtually unregulated.
comment by MrThink (ViktorThink) · 2022-05-01T20:33:33.058Z · LW(p) · GW(p)
I will do as Yitz post my submissions as individual replies to this comment. Please let me know if there’s any issues with that.
Replies from: ViktorThink, ViktorThink, ViktorThink, ViktorThink, ViktorThink, ViktorThink, ViktorThink, ViktorThink, ViktorThink↑ comment by MrThink (ViktorThink) · 2022-05-02T12:06:10.330Z · LW(p) · GW(p)
The main source of skepticism of AI safety research, is that it’s unknown how advanced current AIs are and how fast it is improving. The most impressive reasoning task I have seen an AI model do is this one, done by PaLM by Google:
The model was prompted with this text:
Michael is at that really famous museum in France looking at its most famous painting. However, the artist who made this painting just makes Michael think of his favorite cartoon character from his childhood. What was the country of origin of the thing that the cartoon character usually holds in his hand?
And the model answered this:
The most famous painting in the Louvre is the Mona Lisa. The artist who made the Mona Lisa is Leonardo da Vinci. Leonardo da Vinci is also the name of the main character in the cartoon Teenage Mutant Ninja Turtles. Leonardo da Vinci is from Italy. The thing that Leonardo da Vinci usually holds in his hand is a katana. The country of origin of the katana is Japan. The answer is "Japan".
This example can be used in a range of situations.
↑ comment by MrThink (ViktorThink) · 2022-05-01T20:34:22.801Z · LW(p) · GW(p)
AI is like fire, we can use it to enter a new era of civilization, or to burn everything down.
↑ comment by MrThink (ViktorThink) · 2022-05-28T09:57:10.366Z · LW(p) · GW(p)
For researchers (mainly)
Artificial intelligence isn’t limited in the same ways the human brain is.
Firstly, it isn’t limited to only run on a single set of hardware, it can be duplicated and speeded up to be thousands of times faster than humans, and work on multiple tasks in parallel, assuming powerful enough processors are available.
Further, AI isn’t limited to our intelligence, but can be altered and improved with more data, longer training time and smarter training methods. While the human brain today is superior to AI’s on tasks requiring deep thinking and general intelligence, there is no law preventing AI’s from one day surpassing us.
If artificial intelligence were to surpass human intelligence, it would likely become powerful enough to create an utopia lasting a long long time, or spell the end of humanity.
Thus, doing AI safety research before such an event becomes vital in order to increase the odds of a good outcome.
↑ comment by MrThink (ViktorThink) · 2022-05-27T14:01:51.192Z · LW(p) · GW(p)
What if AI safety could put you on the forefront of sustainable business?
The revolution in AI has been profound, it definitely surprised me, even though I was sitting right there.
-Sergey Brin, Founder of Google
Annual investments in AI increased eightfold from 2015 to 2021, reaching 93 billion usd.
This massive growth is making people ever more dependent on AI, and with that potential risks increases.
Prioritizing AI safety is therefore becoming increasingly important in order to operate a sustainable business, with the benefits of lower risks and improved public perception.
↑ comment by MrThink (ViktorThink) · 2022-05-27T13:45:56.326Z · LW(p) · GW(p)
For researchers
What if you could make a massive impact in a quickly growing field of research?
As artificial intelligence continues to advance, the potential risks increase as well.
In the words of Stephen Hawking “The development of full artificial intelligence could spell the end of the human race.”
AI safety is a field of research with the purpose to prevent AI from harming humanity, and due to the risks current and future AI is posing, it is a field in which researchers can have a massive impact.
In the three years from 2016 to 2019, AI research has grown from representing 1.8% to 3.8% of all research papers published worldwide.
With the rapid growth of general AI research, we should expect both the importance as well as the funding for AI safety to increase as well.
Click here, to learn how you can start your journey to contribute to AI safety research.
Notes
Depending on context, this text can easily be shortened by removing the third to last and second to last paragraphs.
I used this graph to get the growth of AI publications:

↑ comment by MrThink (ViktorThink) · 2022-05-01T21:35:56.969Z · LW(p) · GW(p)
For tech executives
Could working on AI safety put you on the forefront of sustainable development?
As AI is becoming increasingly advanced and relied upon, the recognition of the importance of AI safety is increasing. If this trend continues AI safety will likely become a core part of sustainability, and the businesses that prioritizes AI safety early, will have a more sustainable business as well as a positive impact and improved public perception.
↑ comment by MrThink (ViktorThink) · 2022-05-01T21:08:13.422Z · LW(p) · GW(p)
As AI technology is heading towards becoming sophisticated enough to potentially end civilizations, the impact and recognition of those working on AI risks will increase.
↑ comment by MrThink (ViktorThink) · 2022-05-01T20:34:37.864Z · LW(p) · GW(p)
General paragraph for non-technical people
What if you could increase your impact by staying ahead of the AI trend?
In a hundred years computers went from being punch card machines, to small tablets in every pocket. In sixty years computers went from displaying only text, to providing an entire virtual reality. In the past three years, AI has become able to write engaging stories and generate photorealistic images.
If this trend continues, AI is set to cause massive change. If this change is positive or negative depends on what is done today. Therefore actions taken today have the potential of massive impact tomorrow.
Why this paragraph?
Most descriptions focus on how terrible AI can be, and fails to convey what the person reading has to gain personally by taking action. Having impact is something most people desire.
Depending on context, the paragraph can be tweaked to include what action the reader should take in order to have massive impact.
↑ comment by MrThink (ViktorThink) · 2022-05-01T20:34:04.303Z · LW(p) · GW(p)
If AI is set to cause massive change, acting now will have a massive impact on the future.
comment by Abra Ganz · 2022-04-29T09:08:08.957Z · LW(p) · GW(p)
AI is essentially a statisticians superhero outfit. As with all superheroes, there is a significant amount of collateral damage, limited benefit, and an avoidance of engaging with the root causes of problems.
- Rachel Ganz, posted here on her behalf.
comment by jcp29 · 2022-04-28T05:56:20.146Z · LW(p) · GW(p)
[Policy makers & ML researchers]
Expecting AI to know what is best for humans is like expecting your microwave to know how to ride a bike.
[Insert call to action]
-
Expecting AI to want what is best for humans is like expecting your calculator to have a preference for jazz.
[Insert call to action]
(I could imagine a series riffing based on this structure / theme)
comment by trevor (TrevorWiesinger) · 2022-04-28T05:46:44.278Z · LW(p) · GW(p)
"AI may make [seem to make a] sharp jump in intelligence purely as the result of anthropomorphism, the human tendency to think of «village idiot» and «Einstein» as the extreme ends of the intelligence scale, instead of nearly indistinguishable points on the scale of minds-in-general. Everything dumber than a dumb human may appear to us as simply «dumb». One imagines the «AI arrow» creeping steadily up the scale of intelligence, moving past mice and chimpanzees, with AIs still remaining «dumb» because AIs can’t speak fluent language or write science papers, and then the AI arrow crosses the tiny gap from infra-idiot to ultra-Einstein in the course of one month or some similarly short period"
Eliezer Yudkowsky, AI as a pos neg faction, around 2006
comment by joseph_c (cooljoseph1) · 2022-04-28T05:36:12.388Z · LW(p) · GW(p)
Imagine playing your first ever chess game against a grandmaster. That's what fighting against a malicious AGI would be like.
comment by joseph_c (cooljoseph1) · 2022-04-28T05:28:34.995Z · LW(p) · GW(p)
Donald Knuth said, "Premature optimization is the root of all evil." AIs are built to be hardline optimizers.
Source: Structured Programming with go to Statements by Donald Knuth
comment by trevor (TrevorWiesinger) · 2022-04-28T04:54:02.608Z · LW(p) · GW(p)
"There are also other reasons why an AI might show a sudden huge leap in intelligence. The species Homo sapiens showed a sharp jump in the effectiveness of intelligence, as the result of natural selection exerting a more-or-less steady optimization pressure on hominids for millions of years, gradually expanding the brain and prefrontal cortex, tweaking the software architecture. A few tens of thousands of years ago, hominid intelligence crossed some key threshold and made a huge leap in real-world effectiveness; we went from caves to skyscrapers in the blink of an evolutionary eye"
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-28T04:56:59.938Z · LW(p) · GW(p)
Optional extra sentences:
"The underlying brain architecture was also continuous — our cranial capacity didn’t suddenly increase by two orders of magnitude. So it might be that, even if the AI is being elaborated from outside by human programmers, the curve for effective intelligence will jump sharply."
comment by trevor (TrevorWiesinger) · 2022-04-28T04:44:31.196Z · LW(p) · GW(p)
"The key implication for our purposes is that an AI might make a huge jump in intelligence after reaching some threshold of criticality.
In 1933, Lord Ernest Rutherford said that no one could ever expect to derive power from splitting the atom: «Anyone who looked for a source of power in the transformation of atoms was talking moonshine.» At that time laborious hours and weeks were required to fission a handful of nuclei."
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T04:40:29.674Z · LW(p) · GW(p)
"One of the most critical points about Artificial Intelligence is that an Artificial Intelligence might increase in intelligence extremely fast. The obvious reason to suspect this possibility is recursive self-improvement. (Good 1965.) The AI becomes smarter, including becoming smarter at the task of writing the internal cognitive functions of an AI, so the AI can rewrite its existing cognitive functions to work even better, which makes the AI still smarter, including smarter at the task of rewriting itself, so that it makes yet more improvements.
Human beings do not recursively self-improve in a strong sense. To a limited extent, we improve ourselves: we learn, we practice, we hone our skills and knowledge. To a limited extent, these self-improvements improve our ability to improve. New discoveries can increase our ability to make further discoveries — in that sense, knowledge feeds on itself. But there is still an underlying level we haven’t yet touched. We haven’t rewritten the human brain. The brain is, ultimately, the source of discovery, and our brains today are much the same as they were ten thousand years ago"
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T04:14:09.532Z · LW(p) · GW(p)
"If a really smart AI and powerful AI is told to maximize humanity's happiness, fulfillment, and/or satisfaction, it will require us to specify that it must not do so by wiring car batteries to the brain's pleasure centers using heroin/cocaine/etc.
Even if we specify that particular stipulation, it'll probably think of another loophole or another way to cheat and boost the numbers higher than they're supposed to go. If it's smarter than a human, then all it takes is one glitch"
This is not for policymakers, as many of them are probably on cocaine.
comment by trevor (TrevorWiesinger) · 2022-04-28T03:56:57.388Z · LW(p) · GW(p)
"The folly of programming an AI to implement communism, or any other political system, is that you’re programming means instead of ends. You're programming in a fixed decision, without that decision being re-evaluable after acquiring improved empirical knowledge about the results of communism. You are giving the AI a fixed decision without telling the AI how to re-evaluate, at a higher level of intelligence, the fallible process which produced that decision."
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
It makes sense that a disproportionately large proportion of the best paragraphs would come from a single goldmine. I imagine that The Precipice would be even better.
comment by trevor (TrevorWiesinger) · 2022-04-28T03:23:28.705Z · LW(p) · GW(p)
Proving a computer chip correct [in 2006] require[d] a synergy of human intelligence and computer algorithms, as currently [around 2006] neither suffices on its own. Perhaps a true [AGI] could use a similar combination of abilities when modifying its own code — would have both the capability to invent large designs without being defeated by exponential explosion, and also the ability to verify its steps with extreme reliability. That is one way a true AI might remain knowably stable in its goals, even after carrying out a large number of self-modifications.
Eliezer Yudkowsky, AI as a pos and neg factor, around 2006
techxecutives and ML researchers
comment by trevor (TrevorWiesinger) · 2022-04-28T02:57:54.707Z · LW(p) · GW(p)
"One common reaction I encounter is for people to immediately declare that Friendly AI is an impossibility, because any sufficiently powerful AI will be able to modify its own source code to break any constraints placed upon it.
The first flaw you should notice is a Giant Cheesecake Fallacy. Any AI with free access to its own source would, in principle, possess the ability to modify its own source code in a way that changed the AI’s optimization target. This does not imply the AI has the motive to change its own motives. I would not knowingly swallow a pill that made me enjoy committing murder, because currently I prefer that my fellow humans not die."
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-28T03:06:01.555Z · LW(p) · GW(p)
Not-particularly-optional complementary paragraph (that can also stand alone on its own as its own entry, mainly for ML researchers and tech executives):
"But what if I try to modify myself, and make a mistake? When computer engineers prove a chip valid — a good idea if the chip has 155 million transistors and you can’t issue a patch afterward — the engineers use human-guided, machine-verified formal proof. The glorious thing about formal mathematical proof, is that a proof of ten billion steps is just as reliable as a proof of ten steps. But human beings are not trustworthy to peer over a purported proof of ten billion steps; we have too high a chance of missing an error. And present-day theorem-proving techniques are not smart enough to design and prove an entire computer chip on their own — current algorithms undergo an exponential explosion in the search space"
comment by trevor (TrevorWiesinger) · 2022-04-28T02:55:09.706Z · LW(p) · GW(p)
"Wishful thinking adds detail, constrains prediction, and thereby creates a burden of improbability. What of the civil engineer who hopes a bridge won’t fall?"
Optional extra:
"Should the engineer argue that bridges in general are not likely to fall? But Nature itself does not rationalize reasons why bridges should not fall. Rather, the civil engineer overcomes the burden of improbability through specific choice guided by specific understanding"
-Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T02:46:22.042Z · LW(p) · GW(p)
"The temptation is to ask what «AIs» will «want», forgetting that the space of minds-in-general is much wider than the tiny human dot"
Optional paragraph form:
"The critical challenge is not to predict that «AIs» will attack humanity with marching robot armies, or alternatively invent a cure for cancer. The task is not even to make the prediction for an arbitrary individual AI design. Rather, the task [for humanity to accomplish] is choosing into existence some particular powerful optimization process whose beneficial effects can legitimately be asserted.
[It's best to avoid] thinking up reasons why a fully generic optimization process would be friendly. Natural selection isn’t friendly, nor does it hate you, nor will it leave you alone. Evolution cannot be so anthropomorphized, it does not work like you do"
Eliezer Yudkowsky, AI as a pos and neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T02:34:08.939Z · LW(p) · GW(p)
"Artificial Intelligence is not an amazing shiny expensive gadget to advertise in the latest tech magazines. Artificial Intelligence does not belong in the same graph that shows progress in medicine, manufacturing, and energy. Artificial Intelligence is not something you can casually mix into a lumpenfuturistic scenario of skyscrapers and flying cars and nanotechnological red blood cells that let you hold your breath for eight hours. Sufficiently tall skyscrapers don’t potentially start doing their own engineering. Humanity did not rise to prominence on Earth by holding its breath longer than other species."
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T02:32:06.539Z · LW(p) · GW(p)
"If the word «intelligence» evokes Einstein instead of humans, then it may sound sensible to say that intelligence is no match for a gun, as if guns had grown on trees. It may sound sensible to say that intelligence is no match for money, as if mice used money. Human beings didn’t start out with major assets in claws, teeth, armor, or any of the other advantages that were the daily currency of other species. If you had looked at humans from the perspective of the rest of the ecosphere, there was no hint that the soft pink things would eventually clothe themselves in armored tanks. We invented the battleground on which we defeated lions and wolves. We did not match them claw for claw, tooth for tooth; we had our own ideas about what mattered. Such is the power of creativity."
Eliezer Yudkowsky, AI as a pos neg factor, around 2006
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-05-28T03:22:05.341Z · LW(p) · GW(p)
note that most biologists know that the "daily currency of other species" is not claws, teeth, or armor; it is a strong sense of smell or an immune system that can handle specific germs in specific environments e.g. vulture stomachs.
this is significant because policymakers might hire biologist consultants in order to test a report to see if its claims are accurate
comment by trevor (TrevorWiesinger) · 2022-04-28T02:26:03.598Z · LW(p) · GW(p)
"But the word «intelligence» commonly evokes pictures of the starving professor with an IQ of 160 and the billionaire CEO with an IQ of merely 120. Indeed there are differences of individual ability apart from «book smarts» which contribute to relative success in the human world: enthusiasm, social skills, education, musical talent, rationality. Note that each factor... is cognitive. Social skills reside in the brain, not the liver. And jokes aside, you will not find many CEOs, nor yet professors of academia, who are chimpanzees. You will not find many acclaimed rationalists, nor artists, nor poets, nor leaders, nor engineers, nor skilled networkers, nor martial artists, nor musical composers who are mice. Intelligence is the foundation of human power, the strength that fuels our other arts"
-Eliezer Yudkowsky, AI as a pos neg factor, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T02:07:05.403Z · LW(p) · GW(p)
"Any two AI designs might be less similar to one another than you are to a petunia."
-Yudkowsky, AI pos neg factors, around 2006
for policymakers
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-28T02:13:43.003Z · LW(p) · GW(p)
semi-optional extra:
The term «Artificial Intelligence» refers to a vastly greater space of possibilities than does the term «Homo sapiens». When we talk about «AIs» we are really talking about minds-in-general, or optimization processes in general. Imagine a map of mind design space. In one corner, a tiny little circle contains all humans; within a larger tiny circle containing all biological life; and all the rest of the huge map is the space of minds-in-general. The entire map floats in a still vaster space, the space of optimization processes.
Note: This is to make it clear that AI is very scary, this is not to shame or "counter" policymakers who anthropomorphize AGI. People look at today's AI and see "tool", not "alien mind", and that is probably the biggest part of the problem, since ML researchers do it too. ML researchers STILL do it, in spite of everything that's been happening lately.
comment by trevor (TrevorWiesinger) · 2022-04-28T02:01:56.246Z · LW(p) · GW(p)
"An anthropologist will not excitedly report of a newly discovered tribe: «They eat food! They breathe air! They use tools! They tell each other stories!» We humans forget how alike we are, living in a world that only reminds us of our differences.
Humans evolved to model other humans — to compete against and cooperate with our own conspecifics. It was a reliable property of the ancestral environment that every powerful intelligence you met would be a fellow human."
-yudkowsky, ai pos and neg factors, around 2006
this is for policymakers
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-28T02:03:37.673Z · LW(p) · GW(p)
Optional extra:
"Querying your own human brain works fine, as an adaptive instinct, if you need to predict other humans. If you deal with any other kind of optimization process — if, for example, you are the eighteenth-century theologian William Paley, looking at the complex order of life and wondering how it came to be — then anthropomorphism is flypaper for unwary scientists, a trap so sticky that it takes a Darwin to escape."
comment by trevor (TrevorWiesinger) · 2022-04-28T01:57:38.596Z · LW(p) · GW(p)
"Artificial Intelligence is not settled science; it belongs to the frontier, not to the Textbook."
-Eliezer Yudkowsky, positive and negative factors of AI in global risk, around 2006
comment by trevor (TrevorWiesinger) · 2022-04-28T01:22:00.088Z · LW(p) · GW(p)
"All intelligent and semi-intelligent life eventually learns how to cheat. Even our pets cheat. The domesticated Guinea Pig will inflict sleep deprivation on their owner by squeaking at night, over the slightest chance that their owner will wake up and feed them sooner. They even adjust the pitch so that their owner never realizes that the guinea pigs are the ones waking them up. Many dogs and cats learn to do this as well"
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-28T01:26:50.553Z · LW(p) · GW(p)
Optional extra: The domestic Guinea Pig is incapable of malice or spite towards their owner, only fear, and perhaps gratitude for sating their hunger.
Dogs can tell when their owners are unhealthy, but are not intelligent enough to make the connection between sleep deprivation and their owner's long-term health. But if guinea pigs were intelligent enough to make the connection, they would probably do it anyway.
comment by trevor (TrevorWiesinger) · 2022-04-27T23:56:01.267Z · LW(p) · GW(p)
"Humans have played brinkmanship with nuclear weapons for 60 years. Strategically, a credible threat of offensive nuclear strike has had a long history of being fundamental to coercing policy change out of an adversary. Strong signals must be costly, or else everyone would make strong signals them, and then they would cease to be strong (Bryan Caplan). Before the nuclear bomb, human beings played brinkmanship with war itself, for centuries; at the time, initiating war was the closest equivalent to initiating nuclear war).
We must not play brinkmanship by inventing self-improving AI systems, specifically AI systems that run the risk of rapidly becoming smarter than humans. It may have been possible to de-escalate with nuclear missiles, but it was never conceivable to un-invent the nuclear bomb"
comment by trevor (TrevorWiesinger) · 2022-04-27T23:22:05.114Z · LW(p) · GW(p)
"No matter how simple the task, no matter how obvious it seems to the human mind, AI always finds a new way to cheat"
comment by trevor (TrevorWiesinger) · 2022-04-27T22:52:36.679Z · LW(p) · GW(p)
"The people who predicted exponential/escalating advancement in AI were always right. The people who predicted linear/a continuation of the last 10 years always turned out to be wrong. Since AI doesn't just get smarter every year, but it gets smarter faster every year, that means there are a finite number of years before it starts getting too smart, too fast"
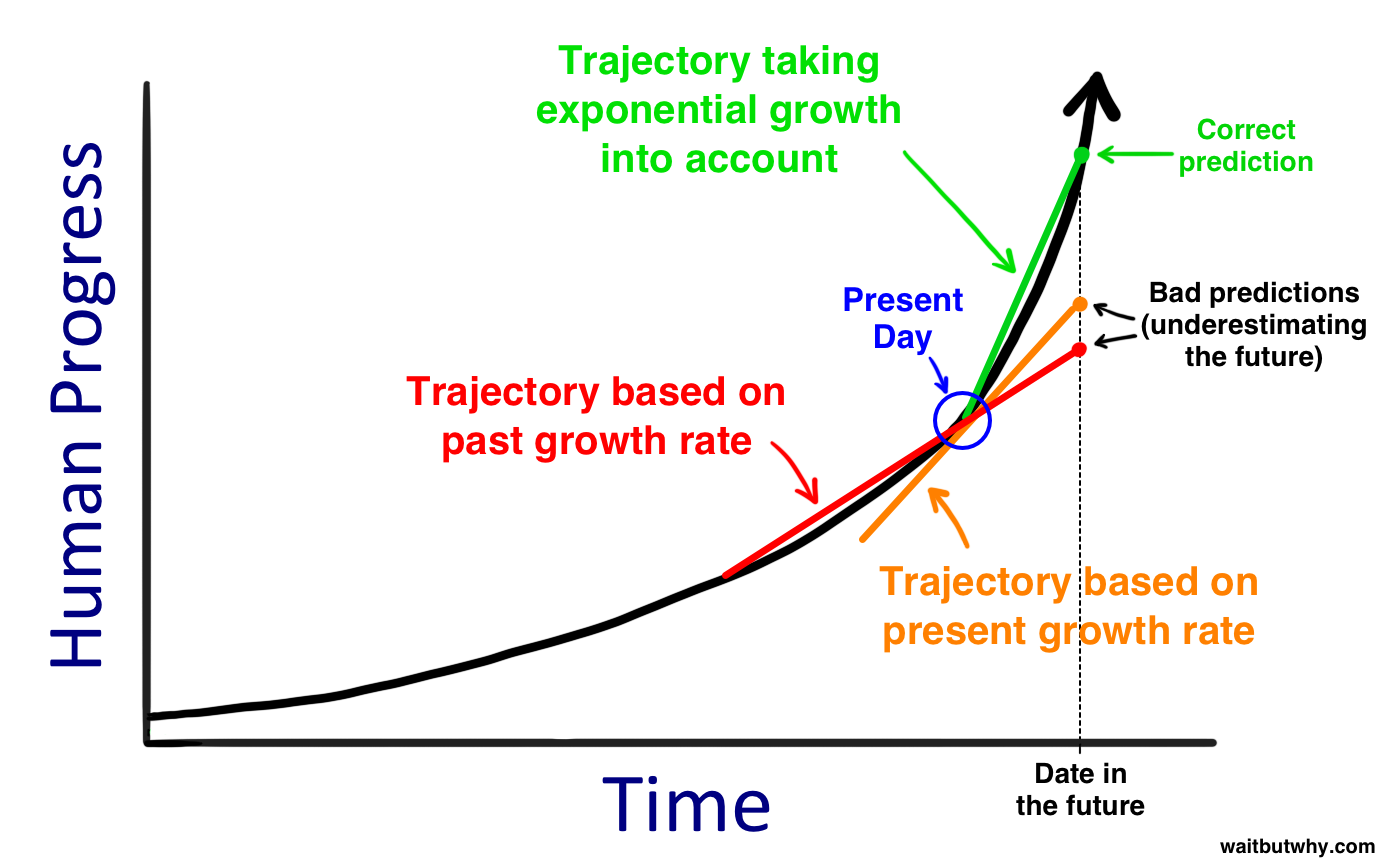
https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
comment by trevor (TrevorWiesinger) · 2022-04-27T21:29:07.207Z · LW(p) · GW(p)
"We can make AI smarter and that's what we have been doing for a decade, successfully. However, it's also gotten much smarter at cheating, because that's how intelligence works. Always has been, always will be."
Optional second sentence: "But with the rate that AI is becoming more intelligent every year while still cheating, we should worry about what cheating and computer glitches will look like for an AI whose intelligence reaches and surpasses human intelligence"
comment by trevor (TrevorWiesinger) · 2022-04-27T21:17:23.244Z · LW(p) · GW(p)
If AI takes 200 years to become as smart as an ant, and then 20 years from there to become as smart as a chimpanzee; then AI could take 2 years to become as smart as a human, and 1 year after that to become much smarter than a human.
https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
comment by trevor (TrevorWiesinger) · 2022-04-27T21:13:45.676Z · LW(p) · GW(p)
"What would a glitch look like inside of an AI that is smarter than a human? The only glitches that we have any experience with, have all been inside computers and AI systems that are nowhere near as smart as humans"
comment by trevor (TrevorWiesinger) · 2022-04-27T21:11:50.523Z · LW(p) · GW(p)
"AI has become smarter every year for the last 10 years. It's gotten faster recently. The question is, how much smarter does it need to get before it is smarter than humans? If it is smarter than humans, all it will take is a single glitch, and it could choose do all sorts of horrible things."
Optional extra sentence: "It will not think like a human, it will not want the same things that humans want, but it will understand human behavior better than we do"
comment by trevor (TrevorWiesinger) · 2022-04-27T21:08:14.456Z · LW(p) · GW(p)
"If an AI becomes smarter than humans, it will not have any trouble deceiving its programmers so that they cannot turn it off. The question isn't 'can it behave unpredictably and do damage', the question is 'will it behave unpredictably and do damage'"
comment by trevor (TrevorWiesinger) · 2022-04-27T21:01:09.095Z · LW(p) · GW(p)
At the rate that AI is advancing, it will inevitably become smarter than humans, and take over the task of building new AI systems that are even smarter. Unfortunately, we have no idea how to fix glitches in a computer system that is as smart to us as we are to animals.
comment by trevor (TrevorWiesinger) · 2022-04-27T20:51:26.150Z · LW(p) · GW(p)
"If we race to build an AI that is smarter than us in some ways but not others, then we might not have enough time to steer it in the right direction before it discovers that it can steer us instead"
comment by trevor (TrevorWiesinger) · 2022-04-27T20:50:19.562Z · LW(p) · GW(p)
"Every AI we have ever built has behaved randomly and unpredictably, cheating and exploiting loopholes whenever possible. They required massive amounts of human observation and reprogramming in order to behave predictably and perform tasks."
Optional second sentence: "If we race to build an AI that is smarter than us in some ways but not others, then we might not have enough time to steer it in the right direction before it discovers that it can steer us"
comment by trevor (TrevorWiesinger) · 2022-04-27T20:33:51.609Z · LW(p) · GW(p)
"Every AI ever built has required massive trial and error, and human supervision, in order to make it do exactly what we want it to without cheating or finding a complex loophole."
Optional additional sentences: "Right now, we are trending towards AI that will be smarter than humans. We don't know if it will be in 10 years or 100, but what we do know is that it will probably be much better at cheating and finding loopholes than we are"
comment by trevor (TrevorWiesinger) · 2022-04-27T20:27:03.861Z · LW(p) · GW(p)
I made a really good GIF of cheating AI, taken from openAI's video here
comment by trevor (TrevorWiesinger) · 2022-04-27T19:13:26.405Z · LW(p) · GW(p)
"If an AI's ability to learn and observe starts improving rapidly and approach human intelligence, then it will probably behave unpredictably, and we might not have enough time to assert control before it is too late."
https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-1.html
Replies from: jcp29comment by jcp29 · 2022-04-27T18:56:26.774Z · LW(p) · GW(p)
[Policy-makers & ML researchers]
In 1901, the Chief Engineer of the US Navy said “If God had intended that man should fly, He would have given him wings.” And on a windy day in 1903, Orville Wright proved him wrong.
Let's not let AI catch-us by surprise.
[Insert call to action]
comment by jcp29 · 2022-04-27T18:17:05.420Z · LW(p) · GW(p)
[Policy makers & ML researchers]
If you aren't worried about AI, then either you believe that we will stop making progress in AI or you believe that code will stop having bugs...which is it?
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-27T18:27:42.849Z · LW(p) · GW(p)
I really like this one but I think it can be made even better, not sure how atm
comment by jcp29 · 2022-04-27T18:05:48.557Z · LW(p) · GW(p)
[Tech executives]
If you could not fund that initiative that could turn us all into paperclips...that'd be great.
[Insert call to action]
--
If you could not launch the project that could raise the AI kraken...that'd be great.
[Insert call to action]
--
If you could not build the bot that will treat us the way we treat ants...that'd be great.
[Insert call to action]
--
(I could imagine a series riffing based on this structure / theme)
comment by jcp29 · 2022-04-27T17:56:22.367Z · LW(p) · GW(p)
[ML researchers]
"We're in the process of building some sort of god. Now would be a good time to make sure it's a god we can live with" (Sam Harris, 2016 Ted Talk).
↑ comment by trevor (TrevorWiesinger) · 2022-04-27T18:33:34.464Z · LW(p) · GW(p)
In my experience, religious symbolism is a losing strategy, especially for policymakers and executives. From their bayesian perspective, they are best off prejudicing against anything that sounds like a religious cult.
It's generally best to avoid imagery of an eldritch abombination that spawns from our #1 most valuable industry and ruins everything forever everywhere. Even for ML researchers, even the old kurzweillians would be put off.
comment by soth02 (chris-fong) · 2022-04-27T03:13:43.102Z · LW(p) · GW(p)
AI presents both staggering opportunity and chilling peril. Developing intelligent machines could help eradicate disease, poverty, and hunger within our lifetime. But uncontrolled AI could spell the end of the human race. As Stephen Hawking warned, "Success in creating AI would be the biggest event in human history. Unfortunately, it might also be the last, unless we learn how to avoid the risks."
comment by soth02 (chris-fong) · 2022-04-27T03:13:14.723Z · LW(p) · GW(p)
AI safety is essential for the ethical development of artificial intelligence."
comment by soth02 (chris-fong) · 2022-04-27T03:12:48.533Z · LW(p) · GW(p)
"AI safety is the best insurance policy against an uncertain future."
comment by soth02 (chris-fong) · 2022-04-27T03:12:22.196Z · LW(p) · GW(p)
"AI safety is not a luxury, it's a necessity."
comment by soth02 (chris-fong) · 2022-04-27T03:06:51.544Z · LW(p) · GW(p)
While it is true that AI has the potential to do a lot of good in the world, it is also true that it has the potential to do a lot of harm. That is why it is so important to ensure that AI safety is a top priority. As Google Brain co-founder Andrew Ng has said, "AI is the new electricity." Just as we have rules and regulations in place to ensure that electricity is used safely, we need to have rules and regulations in place to ensure that AI is used safely. Otherwise, we run the risk of causing great harm to ourselves and to the world around us.
comment by soth02 (chris-fong) · 2022-04-27T02:54:36.225Z · LW(p) · GW(p)
Replies from: chris-fong↑ comment by soth02 (chris-fong) · 2022-04-27T02:56:06.620Z · LW(p) · GW(p)
comment by michael_mjd · 2022-04-27T00:31:22.179Z · LW(p) · GW(p)
War. Poverty. Inequality. Inhumanity. We have been seeing these for millennia caused by nation states or large corporations. But what are these entities, if not greater-than-human-intelligence systems, who happen to be misaligned with human well-being? Now, imagine that kind of optimization, not from a group of humans acting separately, but by an entity with a singular purpose, with an ever diminishing proportion of humans in the loop.
Audience: all, but maybe emphasizing policy makers
comment by trevor (TrevorWiesinger) · 2022-04-26T21:56:36.175Z · LW(p) · GW(p)

From this recent post [LW · GW]about DALLE-2
comment by Zachary · 2022-04-26T20:50:19.672Z · LW(p) · GW(p)
We don’t know exactly how a self-aware AI would act, but we know this: it will strive to prevent its own shutdown. No matter what the AI’s goals are, it wouldn’t be able to achieve them if it gets turned off. The only sure fire way to prevent its shutdown would be to eliminate the ones with the power to do so: humans. There is currently no known method to teach an AI to care about humans. Solving this problem may take decades, and we are running out of time.
Replies from: TrevorWiesinger↑ comment by trevor (TrevorWiesinger) · 2022-04-26T22:07:57.444Z · LW(p) · GW(p)
Shutdown points are really important. It could probably fit well into all of my entries, since they target executives and policymakers who will mentally beeline to "off-switch". But it's also really hard to do it right concisely, because that brings an anthropomorphic god-like entity to mind, which rapidly triggers the absurdity heuristic. And the whole thing with "wanting to turn itself off but turning off the wrong way or doing damage in the process" is really hard to keep concise.
comment by trevor (TrevorWiesinger) · 2022-04-26T20:33:41.672Z · LW(p) · GW(p)
"If we build something smarter than us, that understands us better than we do, but it has a glitch that makes it stop responding correctly to commands, what are we supposed to do?"
comment by trevor (TrevorWiesinger) · 2022-04-26T20:15:28.548Z · LW(p) · GW(p)
"If we have an arms race over who can be the first to build an AI smarter than humans, it will not end well. We will probably not build an AI that is safe and predictable. When the nuclear arms race began, all sides raced to build bigger bombs, more bombs, and faster planes and missiles; they did not focus on accuracy and reliability until decades later"
comment by trevor (TrevorWiesinger) · 2022-04-26T20:03:54.138Z · LW(p) · GW(p)
"If AI becomes smarter than humans, which is the direction we are heading, then it is highly unlikely that it will think and behave us. The human mind is a very specific shape, and today's AI scientists are much better at creating randomly-generated minds, than they are at creating anything as predictable and reasonable as a human being"
comment by p.b. · 2022-04-26T19:30:51.312Z · LW(p) · GW(p)
Once an extremely competent machine becomes aware of humans, their goals and its own situation every optimization pressure on the machine will via the machines actions start to be exerted on humans, their goals and the machines situation. How do we specify the optimization pressure that will be exerted on all of us with maximum force?
comment by AntonTimmer · 2022-04-26T19:24:06.094Z · LW(p) · GW(p)
"If AGI systems can become as smart as humans, imagine what one human/organization could do by just replicating this AGI."
comment by P. · 2022-04-26T19:04:03.817Z · LW(p) · GW(p)
To executives and researchers:
However far you think we are from AGI, do you think that aligning it with human values will be any easier? For intelligence we at least have formalisms (like AIXI) that tell us in principle how to achieve goals in arbitrary environments. For human values on the other hand, we have no such thing. If we don't seriously start working on that now (and we can, with current systems or theoretical models), there is no chance of solving the problem in time when we near AGI, and the default outcome of that will be very bad, to say the least.
Edit: typos
comment by Lone Pine (conor-sullivan) · 2022-04-26T18:50:42.501Z · LW(p) · GW(p)
“With recent breakthroughs in machine learning, more people are becoming convinced that powerful, world changing AI is coming soon. But we don’t yet know if it will be good for humanity, or disastrous.”
comment by Lone Pine (conor-sullivan) · 2022-04-26T18:41:25.932Z · LW(p) · GW(p)
“We may be on the verge of a beautiful, amazing future, within our lifetimes, but only if AI is aligned with human beings.”
comment by CallumMcDougall (TheMcDouglas) · 2022-04-26T17:53:26.651Z · LW(p) · GW(p)
Source: original, but motivated by trying to ground WFLL1-type scenarios in what we already experience in the modern world, so heavily based on this. Also the original idea came from reading Neel Nanda’s “Bird's Eye View of AI Alignment - Threat Models"
Intended audience: mainly policymakers
A common problem in the modern world is when incentives don’t match up with value being produced for society. For instance, corporations have an incentive to profit-maximise, which can lead to producing value for consumers, but can also involve less ethical strategies such as underpaying workers, regulatory capture, or tax avoidance. Laws & regulations are designed to keep behaviour like this in check, and this works fairly well most of the time. Some reasons for this are: (1) people have limited time/intelligence/resources to find and exploit loopholes in the law, (2) people usually follow societal and moral norms even if they’re not explicitly represented in law, and (3) the pace of social and technological change has historically been slow enough for policymakers to adapt laws & regulations to new circumstances. However, advancements in artificial intelligence might destabilise this balance. To return to the previous example, an AI tasked with maximising profit might be able to find loopholes in laws that humans would miss, they would have no particular reason to pay attention to societal norms, and they might be improving and becoming integrated with society at a rate which makes it difficult for policy to keep pace. The more entrenched AI becomes in our society, the worse these problems will get.Replies from: TrevorWiesinger
↑ comment by trevor (TrevorWiesinger) · 2022-05-21T01:54:29.927Z · LW(p) · GW(p)
Please make more submissions! If EA orgs are looking for good metaculus prediction records, they'll probably look for evidence of explanatory writing on AI as well. You can put large numbers of contest entries on your resume, to prove that you're serious about explaining AI risk.

comment by Nanda Ale · 2022-05-28T06:59:29.847Z · LW(p) · GW(p)
Machine Learning Researchers
I often see AI skeptics ask GPT-3 if a mouse is bigger than an elephant and it said yes. So obviously it’s stupid. This is like measuring a fish by its ability to climb.
The only thing GPT-3 could learn, the only thing it had access to, is a universe of text. A textual universe created by humans who do have access to the real world. This textual universe correlates with the real world, but it is not the same as the real world.
Humans generate the training data and GPT-3 is learning it. So in a sense GPT-3 is less intelligent, because it is only able to access a version of the universe that is already a messy approximation by humans doing messy approximations.
In GPT’s universe there is no space, no movement, no inertia, no gravity. So it seems fundamentally flawed to me to then say, We trained it on X and it didn’t learn Y.All GPT-3 is doing is predicting the next word of text. Frankly it’s incredible it does as well as it does at all these other things.
That GPT-3 is capable of anything is a miracle.
Paraphrased from this podcast: https://youtu.be/HrV19SjKUss?t=5870
comment by IrenicTruth · 2022-05-27T03:37:37.529Z · LW(p) · GW(p)
Orwell's boot stamped on a human face forever. The AI's boot will crush it first try.
comment by tamgent · 2022-05-03T19:32:12.780Z · LW(p) · GW(p)
"Evolution wasn’t prepared for contraception. We can do better. When deploying AI, think protection."
Replies from: tamgent↑ comment by tamgent · 2022-05-03T19:48:29.369Z · LW(p) · GW(p)
OK I have to admit, I didn't think through audience extremely carefully as most of these sound like clickbait news article headlines, but I'll go with tech executives. I do think reasonably good articles could be written explaining the metaphor though.
comment by James Camacho (james-camacho) · 2022-04-28T05:14:15.295Z · LW(p) · GW(p)
AIs need immense databases to provide decent results. For example, to recognize if something is a potato, an AI will take 1,000 pictures of a potato and 1,000 pictures of not-a-potato, so that it can tell you if something is a potato with 95% accuracy.
Well, 95% accurate isn't good enough--that's how you get Google labelling images of African Americans as gorillas. So what's the solution? More data! But how do you get more data? Tracking consumers.
Websites track everything you do on the internet, then sell your data to Amazon, Netflix, Facebook, etc. to bolster their AI predictions. Phone companies tracks your location, credit card companies track your purchases.
Eventually, true AI will replace these pattern matching pretenders, but in the meantime data has become a new currency, and it's being stolen from the general public. Many people know and accept their cookies being eaten by every website, but more have no idea.
Societally, this threatens a disaster for AI research. Already people say to leave your phones at home when you go to a protest--no matter which side of the political spectrum it's on. Soon enough, people will turn on AI altogether if this negative perception isn't fixed.
So, to tech executives: Put more funds into true AI, and less into growing databases. Not only is it fiscally costly, but the social cost is too high.
To policymakers: Get your data from consenting parties. A checkbox at the end of a three page legal statement is hardly consent. Instead, follow the example of statisticians. Use studies, but instead of a month-long trial, all you ask is a picture and a favorite movie.
To both: Invest more money in the future of AI. In the past ten years we've gone from 64x64 pixel ghoulish faces to high-definition GAN's and chess grandmasters trained in hours on a home computer. Imagine how much better AI will be in another ten years. Fifteen thousand now could save you Fifteen million or more in your companies' lifetime.
comment by joseph_c (cooljoseph1) · 2022-04-28T05:13:07.305Z · LW(p) · GW(p)
Humans have biases they don't even realize. How can we verify an AI lacks such biases?